Embed Size (px)
Citation preview

Definindo melhor alguns conceitos
Processamento Paralelo: processamento de informação concorrente que pertencem a um ou mais processos que resolvem um único problema.
Processamento Distribuído: processamento de informações em um sistema cujos recursos estão sendo compartilhados por vários programas
Computador Paralelo: computador de múltiplos processadores capaz de realizar processamento paralelo
Supercomputador: computador de propósito geral capaz de resolver problemas em alta velocidade, comparando com outras máquinas da mesma época.

A vazão de um dispositivo é o número de resultados produzidos por unidade de tempo. (throughtput)
Speedup (aceleração): razão entre o tempo de execução necessário para o algoritmo seqüencial mais eficiente e o tempo necessário para se realizar a mesma computação numa máquina paralela
Existem diversas definições de speedup:
– speedup absoluto(n)= T(melhor alg. seq. )/ T( prog // c/ n proc.)
– speedup aproximado(n)= T(prog.// c/1 proc.)/T( prog // c/ n proc.)
– speedup relativo (n)= T(prog. // c/(n-1) proc.)/T(prog.// c/ n proc.)
Terminologia
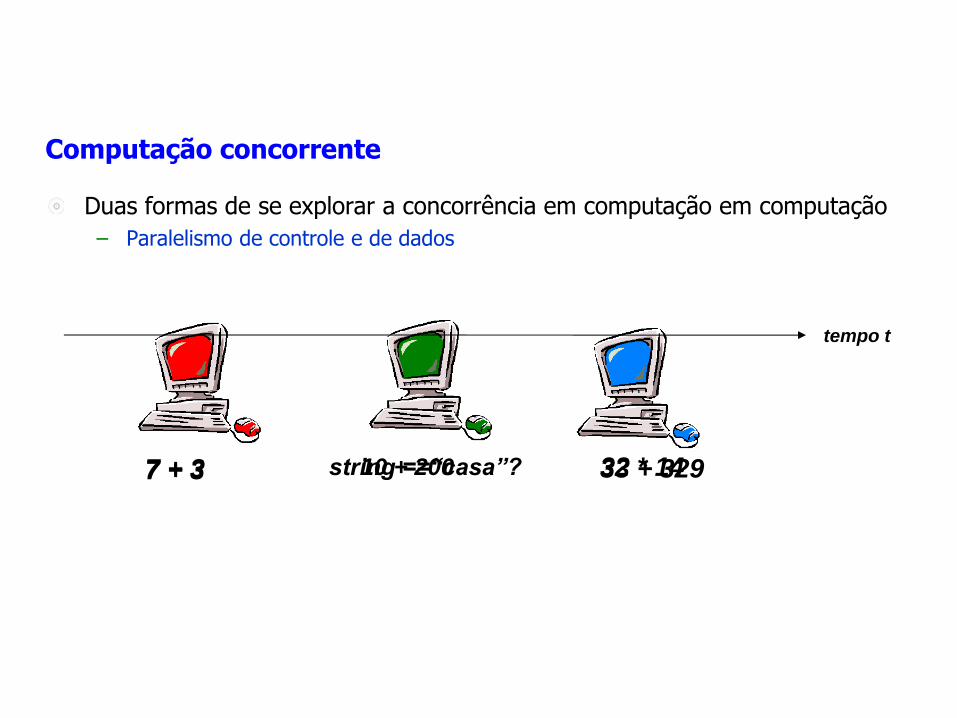
Computação concorrente
Duas formas de se explorar a concorrência em computação em computação
– Paralelismo de controle e de dados
tempo t
7 + 3 string ==“casa”? 32 * 14 7 + 3 10 + 200 33 + 329

Paralelismo de Controle
aplicando-se operações diferentes a diferentes dados simultaneamente.
– fluxo de dados entre processos pode ser arbitrariamente complexo
Exemplo:
– Pipelining: cada estágio trabalha em velocidade plena sobre uma parte particular da computação. A saída de um estágio é a entrada do estágio seguinte
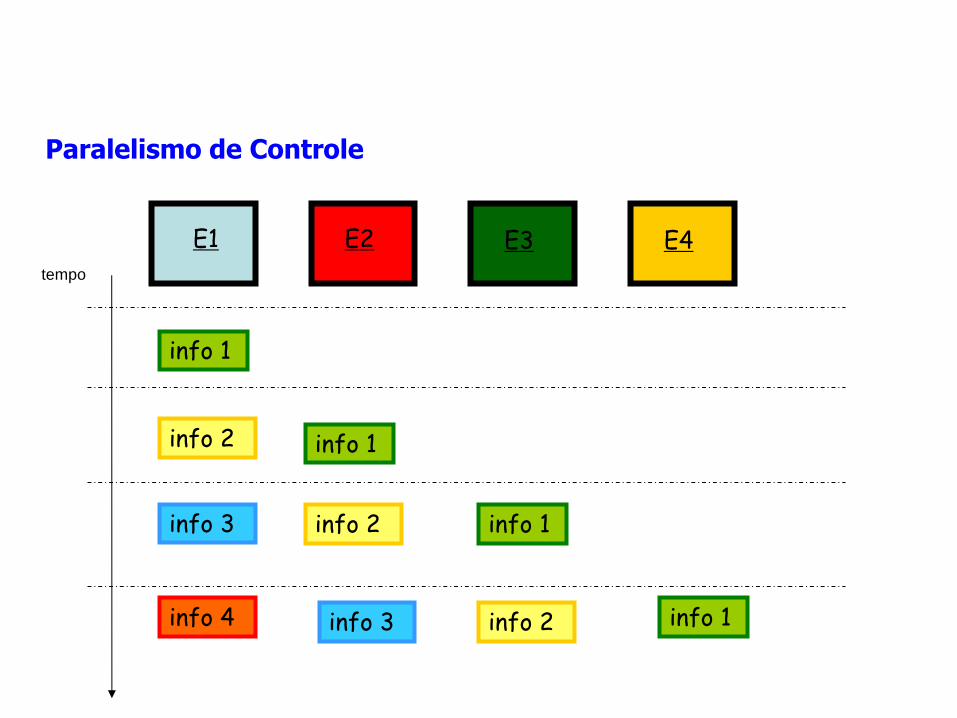
Paralelismo de Controle
tempo
info 1
E4 E1 E2 E3
info 2 info 1
info 3 info 1 info 2
info 3 info 4 info 1 info 2
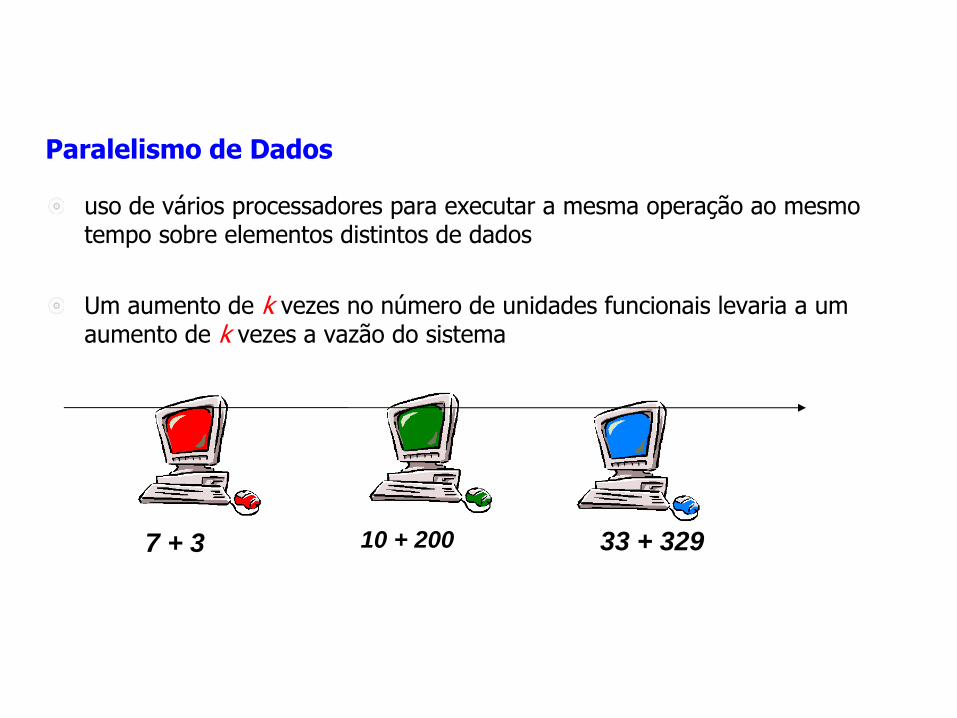
Paralelismo de Dados
uso de vários processadores para executar a mesma operação ao mesmo tempo sobre elementos distintos de dados
Um aumento de k vezes no número de unidades funcionais levaria a um aumento de k vezes a vazão do sistema
7 + 3 10 + 200 33 + 329

Aplicações
Aplicações ou programas podem ser executados mais rapidamente, considerando duas formas de paralelismo
– tratar o programa seqüencial como uma série de tarefas
– cada tarefa = uma instrução ou blocos de instruções
OU
– especificar um programa paralelo, que resolve o problema através da especificação de tarefas ou processos concorrentes

Exploração de paralelismo
Particionamento
– identificar em um programa, as tarefas que possam ser executadas em paralelo (simultaneamente em mais de um processador)
• caso extremo: cada linha do programa correspondendo a uma tarefa
um bom desempenho só é alcançado se um número máximo de comandos são executados simultaneamente
É preciso considerar dependências de dados
problema: se quase todos os comandos são dependentes

Exemplo: programa seqüencial paralelismo de instruções
program nothing(){
input (A,B,C);
if A>B then {
C=A-B;
output (C);
} else {
C = B-A;
output (A,B,C)
}
A=0; B=1;
for i=1 to 3 {
input(C);
A=A+C;
B=B*C;
}
output (A,B,C);
}

Exemplo
Tarefa T1
input (A,B,C);
if A>B then{
C=A-B;
output (C);
}else{
C = B-A;
output (A,B,C)
}
Tarefa T3
B=1;
Tarefa T4
for i=1 to 3 {
input(C);
A=A+C;
B=B*C;
}
output (A,B,C)
Tarefa T2
A = 0;
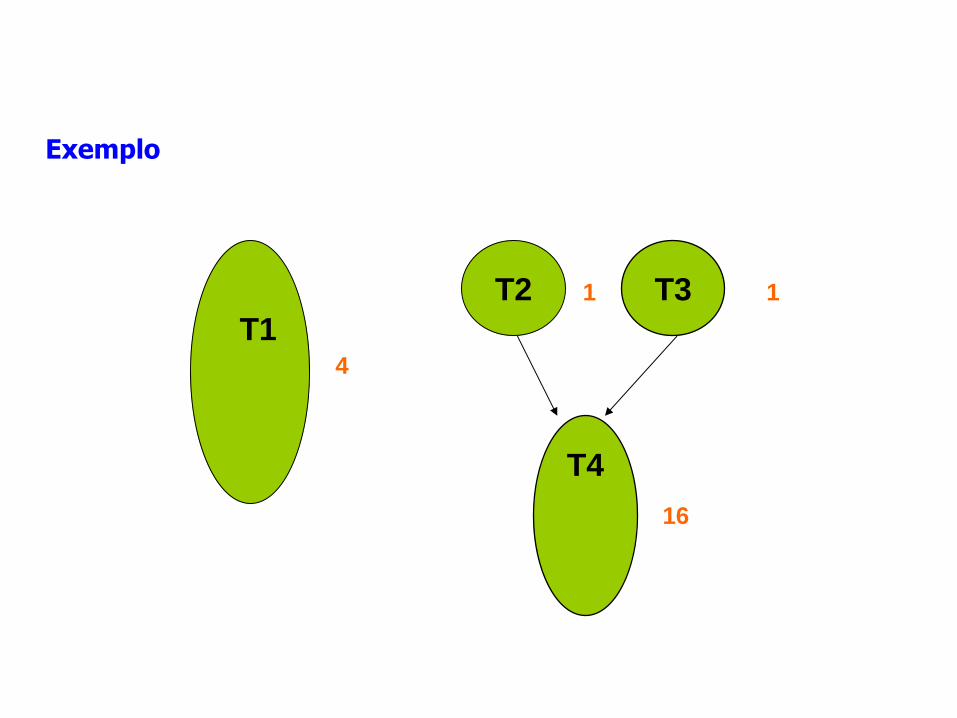
Exemplo
T1
T3 T2
T4
16
1 1
4

Exemplo: Soma n números
Problema: somar n números quaisquer
Programa seqüencial:
read (n, vetor);
soma = 0;
for (i = 0; i < n; i++)
soma = soma + vetor[i];
Como paralelizar o problema?
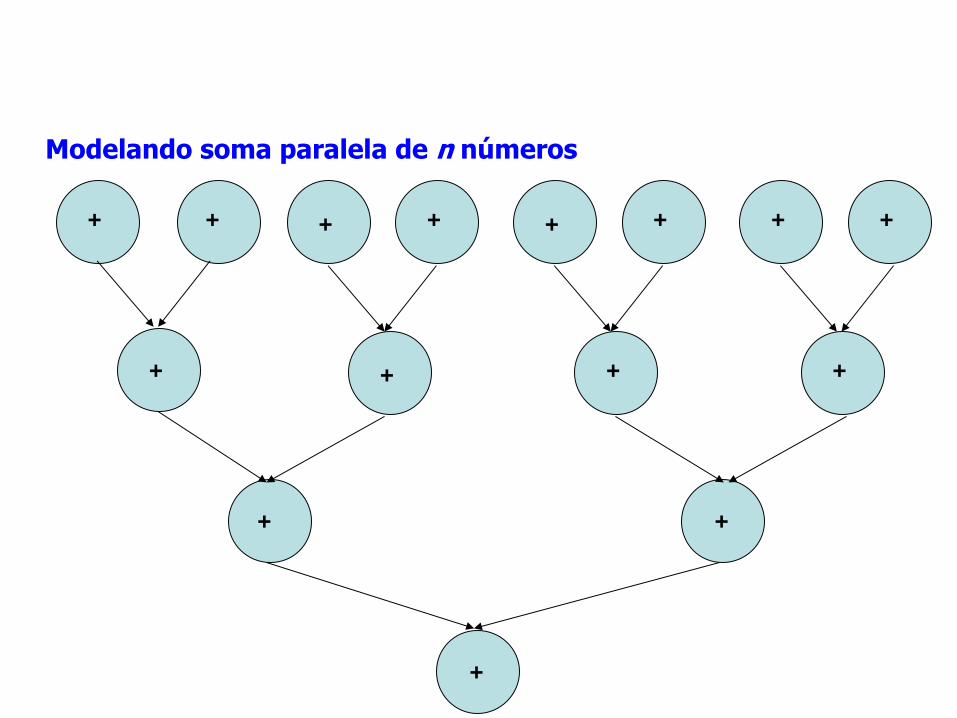
Modelando soma paralela de n números
+
+ + + + + + + +
+ + + +
+ +

1a.14
Speedup Factor
where ts is execution time on a single processor and tp is
execution time on a multiprocessor.
S(p) gives increase in speed by using multiprocessor.
Typically use best sequential algorithm with single
processor system. Underlying algorithm for parallel
implementation might be (and is usually) different.
S(p) = Execution time using one processor (best sequential algorithm)
Execution time using a multiprocessor with p processors
ts
tp =

1a.15
Speedup factor can also be cast in terms
of computational steps:
S(p) = Number of computational steps using one processor
Number of parallel computational steps with p processors
Speedup Factor

1a.16
Maximum Speedup Maximum speedup usually p with p processors (linear
speedup).
Ex.: Ts = 15
Speedup(5) >= 3
One can think that the best that we can get is the sequential time
devided by p
Possible to get superlinear speedup (greater than p) but
usually a specific reason such as:
– Extra memory in multiprocessor system
– Nondeterministic algorithm
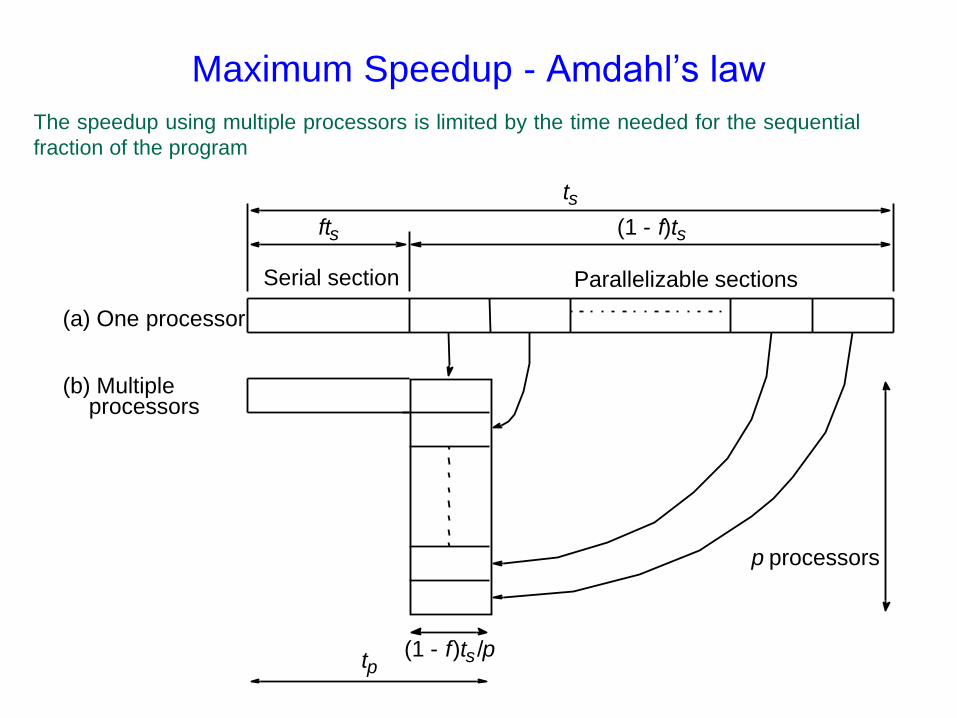
1a.17
Maximum Speedup - Amdahl’s law
Serial section Parallelizable sections
(a) One processor
(b) Multiple processors
ft s (1 - f ) t s
t s
(1 - f ) t s / p t p
p processors
The speedup using multiple processors is limited by the time needed for the sequential
fraction of the program

1a.18
Let
• f = proportion of a program that can be totally
parallelized
– (1 − f) is the proportion that remains serial
• Then the maximum speedup that can be achieved by
using P processors is
• Amdahl used this argument to support the design of ultra-
high speed single processor systems in the 1960s.
(reflete monoprocessadores)
1
(1-f)+ f/P
Amdahl’s law
Sp (P) =

Gustafson’s law
Gustafon’s Law - 1988
Tipicamente, o grande interesse não é executar um problema no
menor período de tempo (o que advoga Amdahl), mas resolver
problema de grandes dimensões em um tempo razoável
A parte não paralelizável não deve ser fixa, mas um
percentual de acordo com a dimensão do problema. Se
essa parte paralelizável cresce pouco com o aumento da
instância, é possível escalar o speedup com o aumento de
processadores.
1a.19

Gustafson’s law
f ’ = fraction computed sequentially
1 – f ’ = parallel fraction
Gustafson’s so-called scaled speedup fraction
1a.20
S’(p) = p + (1 – p) f ’

Para pensar/pesquisar
Dê exemplo e discuta as reais diferenças entre
Amdahl’s e Gustafson’s Law
• O que cada uma quer realmente representar?

Terminologias
Um algoritmo é escalável se o nível de paralelismo aumenta no mínimo linearmente com o tamanho do problema.
Uma arquitetura é dita escalável se continua a alcançar o mesmo desempenho por processador, mesmo para problemas maiores, com o aumento de processadores.
– Se aplicável, o usuário pode resolver problemas maiores no mesmo intervalo de
tempo através da compra de uma máquina paralela com maiores dimensões
Algoritmos paralelos-de-dados são mais escaláveis do que algoritmos com paralelismo de controle – o nível de paralelismo de controle é geralmente constante, independente do
tamanho do problema, enquanto o nível do paralelismo de dados é uma função crescente do tamanho do problema

Convergência entre Computação Paralela & Distribuída
Existia uma grande dificuldade de manter máquinas paralelas a frente aos projetos de chip-único
– Computadores paralelos se tornaram mais difíceis de se construir e se usar do que se esperava.
Motivo desta dificuldade:
software
Paralelizar e gerenciar algoritmos paralelos não é uma tarefa fácil

Programação Paralela
No início dos anos 90: processamento paralelo foi retomado.
O problema de programação paralela seria bem mais difícil de atacar do que se imaginava.
Pesquisa na área de programação em paralelo tem sido um tópico importante.
Mas ao mesmo tempo....

Internet
Enquanto muitos estudavam processamento paralelo associado processadores ligados internamente em uma máquina, um outro grupo se concentrava em paralelismo externo através de redes de computadores
a internet possibilitou a especificação de um tipo de paralelismo através de uma conexões entre processadores

Sistema Paralelo e Distribuído
processamento distribuído renasceu como uma forma de paralelismo mais lenta
computação distribuída e paralela são dois extremos num espectro de computação concorrente
Sistema paralelo e distribuído é uma coleção de componentes de hardware e software que otimizam o desempenho por problema, vazão de múltiplos problemas e confiabilidade, ou uma combinação destes

Sistema Paralelo e Distribuído
Problemas: a aglomeração de muitos processadores através de canais de comunicação: o desempenho pode cair muito.
Para alcançar o máximo dos sistemas paralelos e distribuídos: projetistas e desenvolvedores de software precisam compreender a interação entre hardware e software

Sistema Paralelo e Distribuído
computação distribuída é mais abrangente e universal do que computação paralela
Paralelismo - forma restrita de computação distribuída
sistema paralelo : voltado à solução de um problema único no menor tempo possível (otimização)
Computação distribuída é mais geral e reúne outras formas de otimização...

Paralelismo é interessante ?
Na natureza, os eventos ocorrem em paralelo
programação seqüencial ordena eventos paralelos
essa ordenação dificulta a trabalho do compilador
mas, maior desempenho com o uso de paralelismo
– no entanto, não é trivial atingir alto desempenho em computadores paralelos
aplicações como os Grandes Desafios são limitados computacionalmente

Investindo em paralelismo
Dificuldades encontradas
pensar em paralelo é difícil
conhecimento em paralelismo é recente
pouco conhecimento sobre representações abstratas de computações paralelas

Investindo em paralelismo
Em relação a características da máquina
Relação entre a velocidade do processador
– Elementos de processamento heterogêneos
Desempenho da interconexão de comunicação
– Latência de comunicação
– Congestionamento
– Topologia da rede
Hierarquia de memória
Tendência hoje:
– memória compartilhada distribuída
– superprocessadores distribuídos

Quais características importantes das aplicações ?
Processos/tarefas
existe comunicação entre essas tarefas
– pode ser vantajoso executar várias tarefas em um só processador
– a tarefa perde o processador quando precisa de um dado a ser comunicado
paralelismo virtual X real
– Por exemplo: existem 100 processadores disponíveis
– cada processador pode estar executando vários processos: virtualmente existem um total de 300 processos

Quais características importantes das aplicações ?
difícil definir processos/tarefas totalmente independentes
– comunicação entre processos pode gerar um tráfego de mensagens pesado
comunicação entre processos:
– troca de mensagens: considera a topologia da rede de interconexão
– memória compartilhada: utilização de semáforos para proteção de regiões críticas
– direct remote-memory access: existência de processadores dedicados à comunicação

Modelos de Computação Paralela
interface - uma máquina abstrata
a abstração se faz necessária para facilitar a programação sem se preocupar com detalhes da máquina
– um modelo deve ser estável para ser um padrão
um modelo contém os aspectos importantes tanto para os projetistas de software quanto para os da máquina
as decisões de implementações são feitas para cada máquina destino, não havendo necessidade de se refazer programas

Aspectos Explorados pelo Modelo
Independência da arquitetura
Fácil entendimento

Aspectos Explorados pelo Modelo
Facilidade de programação
O programador não deve se preocupar com detalhes da máquina destino
– modelos abstratos: programação mais fácil
O compilador é que deve traduzir para uma estrutura do programa em execução considerando o sistema computacional destino
– tarefa do compilador: mais árdua
nível de abstração
nível de máquina

Exercício
Capitulo I do Livro disponibilizado por Ian Foster – um resumo
Exercícios – 1, 2 e 3

Aspectos Explorados pelo Modelo
O modelo deve ser capaz de oferecer facilidades tais que seja fácil:
Decompor o programa em tarefas paralelas
Mapear as tarefas nos processadores físicos
– custo de comunicação
– heterogeneidade dos processadores
Sincronização entre tarefas: é preciso ter conhecimento do estado global da estrutura de execução do programa (quando é necessário sincronizar?)

Abstraindo para Programar
Maior facilidade de programação: o esforço intelectual é reduzido quando nos concentrarmos em "uma coisa de cada vez”
duas dimensões:
– dimensão espacial
– dimensão temporal

Dimensão Espacial
A cada momento, conjuntos de tarefas independentes são implementadas
– cada tarefa ou processador não sabe o que acontecerá "a seguir"
detalhamento de informações globais levam a uma programação difícil
Dimensão Temporal
programas são composições de ações seqüenciais que preenchem o sistema computacional como um todo:
pode-se definir com maior conhecimento o que vai acontecer a seguir

Níveis de Paralelismo
Dependendo do nível considerado, a exploração do paralelismo é diferente
nível de aplicações ou fases de aplicações
a nível de tarefas
a nível de instruções - a execução da instrução necessita da busca, análise e execução propriamente dita
dentro dos circuitos aritméticos

Algoritmos
Quando queremos resolver um problema computacionalmente, temos que analisar a complexidade deste. No domínio seqüencial, se procura definir um algoritmo que resolva o problema em tempo mínimo.
Mas quando se tratando de algoritmos paralelos, mais um parâmetro
– número de processadores
– operações independentes devem ser executadas em paralelo.
qual o tamanho dos processos? noção de granulosidade (granularity)
– a razão entre o tempo de computação necessário para executar uma tarefa e a sobrecarga de comunicação durante essa computação.

Modelos de Computação
Modelo de Computação Seqüencial: von Neumann
plataforma base para que usuários e projetistas
– complexidade de tempo do pior caso: tempo máximo que o algoritmo pode levar para executar qualquer entrada com n elementos
– complexidade de tempo esperado: complexidade média
– critério de custo uniforme: qualquer instrução RAM leva uma unidade de tempo para ser executada e também o acesso a registradores
Modelo de Computação Paralela
O desempenho do programa paralelo depende de certos fatores dependentes da máquina:
– grau de concorrência;
– escalonamento e alocação de processadores;
– comunicação e sincronização.

Modelo PRAM – modelo ideal
conjunto de p processadores operando sincronamente sob o controle de um único relógio, compartilhando um espaço global de memória
algoritmos desenvolvidos para este modelo geralmente são do tipo SIMD
– todos os processadores executam o mesmo conjunto de instruções, e ainda a cada unidade de tempo, todos os processadores estão executando a mesma instrução mas usando dados diferentes.

Modelo PRAM – modelo ideal
propriedades chaves:
– execução síncrona sem nenhum custo adicional para a sincronização
– comunicação realizada em uma unidade de tempo, qualquer que seja a célula de memória acessada
– comunicação é feita usando a memória global

Passo do algoritmo PRAM
fase de leitura: os processadores acessam simultaneamente locais de memória para leitura. Cada processador acessa no máximo uma posição de memória e armazena o dado lido em sua memória local
fase de computação: os processadores executam operações aritméticas básicas com seus dados locais
fase de gravação: os processadores acessam simultaneamente locais de memória global para escrita. Cada processador acessa no máximo uma posição de memória e grava um certo dado que está armazenado localmente

Modelo PRAM
análise e estudo de algoritmos paralelos
definição de paradigma de programação paralela
avaliação do desempenho desses algoritmos independentemente das máquinas paralelas
se o desempenho de um algoritmo paralelo para o modelo PRAM não é satisfatório, então não tem sentido implementá-lo em qualquer que seja a máquina paralela
se eficiente, no entanto, podemos simulá-lo em uma máquina real : simulação deve ser eficiente

Padrões de Acesso no Modelo PRAM
Exclusive Read (ER): vários processadores não podem ler ao mesmo tempo no mesmo local
Exclusive Write (EW): vários processadores não pode escrever no mesmo local de memória
Concurrent Read (CR): vários processadores podem ler ao mesmo tempo o mesmo local de memória
Concurrent Write (CW): vários processadores podem escrever no mesmo local de memória ao mesmo tempo
Combinações são usadas para formar as variantes do PRAM:
EREW, CREW, ERCW e CRCW

Prioridades do CRCW
Para resolver conflitos no caso de vários processadores tentarem escrever ao mesmo tempo no mesmo local de memória global:
Comum - vários processadores concorrem a escrita no mesmo local de memória global durante o mesmo instante de relógio - todos devem escrever o mesmo valor;
Arbitrário - dentre os vários processadores, um é selecionado arbitrariamente e seu valor armazenado no local de memória disputado;
Prioridade - dentre os vários processadores, aquele com o menor índice é escolhido para escrever o seu valor no local concorrido.
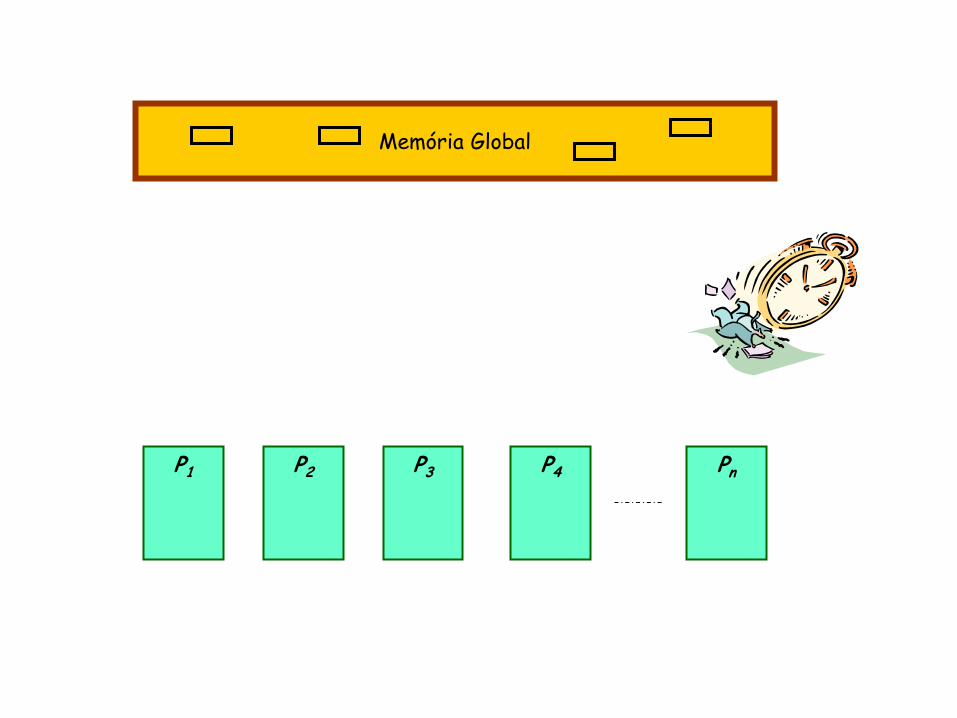
Memória Global
P1 P2 P3 P4 Pn

Comunicação em uma máquina PRAM
Comunicação através da memória global: Pi quer passar x para Pj
– Pi escreve x em um local de memória global em um determinado passo
– Pj pode acessar o dado naquele local no próximo passo
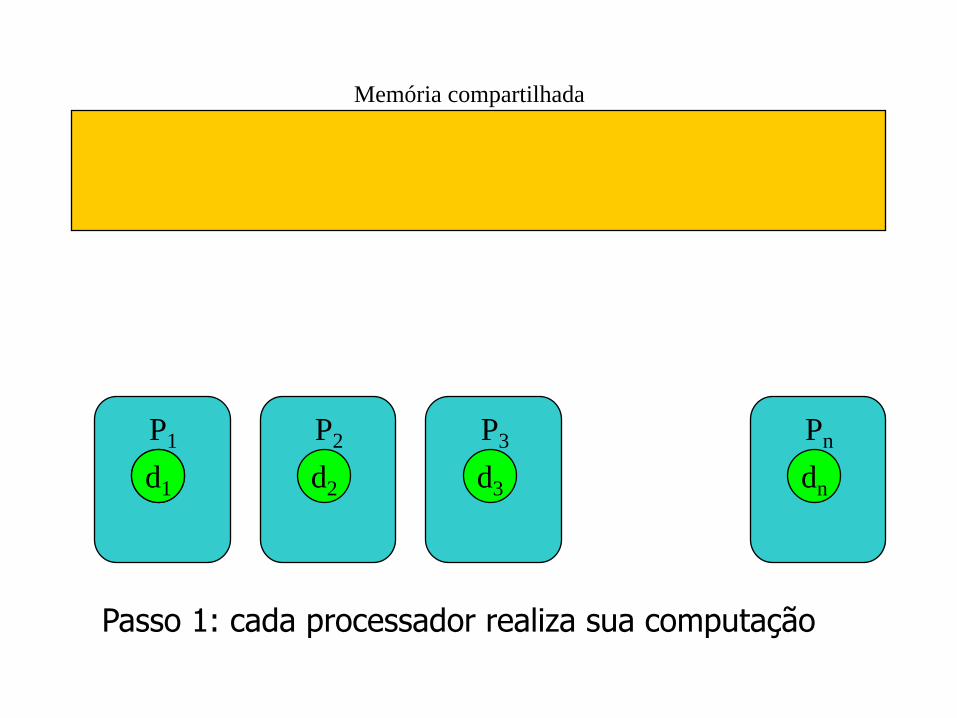
d1 d1
Memória compartilhada
P1 P2
d2
P3
d3
Pn
dn
Passo 1: cada processador realiza sua computação
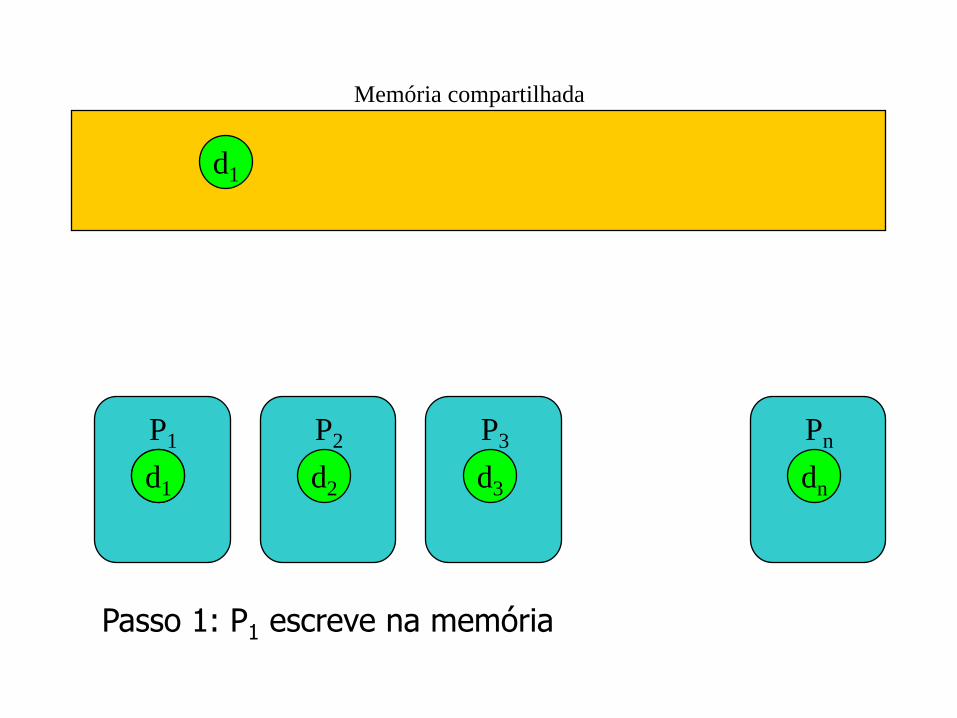
d1 d1
Memória compartilhada
P1 P2
d2
P3
d3
Pn
dn
Passo 1: P1 escreve na memória
d1

Observações
os processadores operam sincronamente: a cada passo, todas os processadores executam a mesma instrução sobre dados distintos
uma instrução pode ser simplesmente uma operação aritmética ou uma comparação de dois números
processadores ativos: somente um subconjunto de processadores executem uma instrução e processadores restantes ficam ociosos/inativos

Exemplo
V vetor com n elementos.
x um dado valor
Problema: x V ?
Ambiente: P processadores tipo EREW PRAM
Analisando o problema:
todos os processadores tem que saber o valor de x
não podem acessar a célula de x simultaneamente
depois, cada processador tem que olhar os elementos de V
sinalização da localização do valor x no vetor V

Solução
todos os processadores devem saber sobre x: broadcasting ou difusão
Pior caso deste procedimento log2 P passos
– P1 acessa a memória global:
– P2 comunica com P1 ou seja, de alguma forma, P1 informa x para P2
– P1 e P2 informam x para P3 e P4
– assim por diante
processadores não têm permissão de acesso simultâneo gravam x em lugares distintos: Mi é um dos P locais de memória global
Um vetor M auxiliar é utilizado

Solução do broadcasting (leitura)
P1 lê x
P1 escreve x em M1
P2 lê M1
P2 escreve em M2
P3 e P4 lêem M1 e M2
P3 e P4 escrevem em M3 e M4
P5, P6, P7 e P8 lêem M1, M2, M3 e M4
P5, P6, P7 e P8 escrevem M5, M6, M7 e M8
e assim por diante
a cada passo: duas vezes o número de processadores ativos do passo anterior podem ler e escrever log P passos

broadcasting
P1 lê de x;
P1 escreve em M[1];
Para h:= 1 até log P faça {
se 2h-1 < i ≤ 2h então {
Pi lê de M[i - 2h-1];
Pi escreve em M[i];
}
}
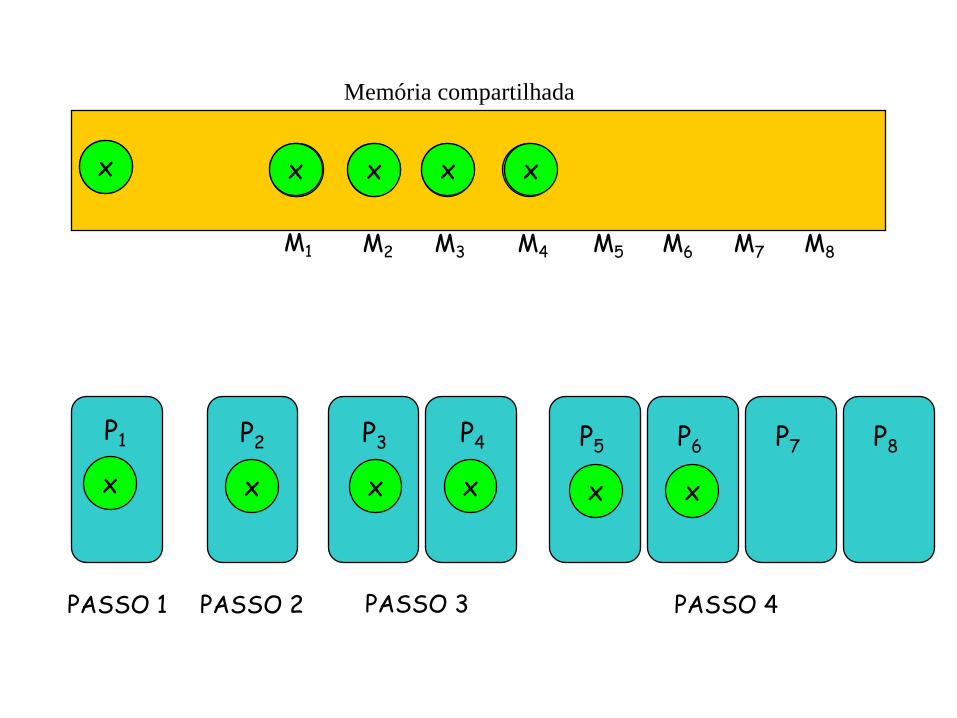
x x x
Memória compartilhada
P1
x
PASSO 1
x
P2
x
x
x
x
x
P3
x
P4
x x
P5 P6 P7 P8
x x
x x
PASSO 2 PASSO 3 PASSO 4
M1 M2 M3 M4 M5 M6 M7 M8

A Procura
o vetor V é divido em P pedaços: S1, S2, …, SP
– Pi procura por x em Si
– pior caso: n/P passos
Total: log P + n/P passos, no pior caso
Como o algoritmo poderia ser melhorado??
– Definição de uma variável Achou
Com computador mais poderoso algoritmo mais rápido.

PRAM mais poderoso: CREW PRAM
para achar x, o algoritmo executa n/P passos
leituras concorrentes são permitidas
– todos os processadores podem acessar x em um passo
– todos os processadores podem consultar Achou em um passo
– mas ao encontrar, o processador tem que atualizar Achou
Quantos passos nas seguintes situações?
– somente um dos elementos tem valor x
– x pode ser um valor repetido em V
• mais de um processador pode atualizar Achou simultaneamente.

Relações entre Modelos
EREW PRAM mais fraco
CREW PRAM pode executar EREW na mesma quantidade de tempo
– simplesmente leituras concorrentes não são feitas
CRCW PRAM pode executar EREW na mesma quantidade de tempo
– simplesmente leituras concorrentes não são feitas

Simulando Múltiplos Acessos em EREW
um só processador pode acessar a um local de memória a em um determinado instante
o modelo é bastante flexível
– pode ser executado em qualquer outra PRAM
– permite a simulação de múltiplos acessos mesmo que o espaço de armazenamento aumente ou o tempo de execução aumente

Simulando Múltiplos Acessos em EREW
Por que a simulação? O simulação pode ser necessária caso uma das razões aconteça:
– se os computadores paralelos disponíveis são do tipo EREW - então executar algoritmos tipo: CREW e CRCW através de simulação
– para computadores paralelos com um grande número de processadores:
• o número de processadores que podem acessar a um mesmo local de memória simultaneamente é limitado

Simulando CW comum em um EREW
N acessos simultâneos por um EREW PRAM por N processos no mesmo local
– leituras simultâneas: valor difundido, conforme já descrito: log N passos
– escritas simultâneas: procedimento simétrico à difusão
CW comum:
todos processadores podem escrever no mesmo local de memória global se o valor for o mesmo.
Suponha que Pi queira escrever o valor ai (1 i N)
variável auxiliar para cada processador Pi : bi

Simulando CW comum em um EREW
Dividindo a série ai em dois grupos
compare ai com ai+(N/2)
se forem iguais, Pi seta bi para verdadeiro (1)
Dividindo a série ai em quatro grupos
compare ai com ai+(N/4) e bi com bi i+(N/4)
se forem iguais, Pi seta bi para verdadeiro (1)

Modelos Fortes e Fracos
O que quer dizer mais forte? Se um algoritmo é simulado em um modelo mais fraco, o número de passos pode aumentar
CR N leituras podem ser feitas concorrentemente
ER uma leitura é feita por mais de uma passo
[EcKstein,1979][Vishkin,1983] p processadores CRCW com prioridade, é simulado por um EREW PRAM com complexidade de tempo aumentado por um fator (log p).
em um CRCW com prioridade, os acessos simultâneos seria imediatos, mas não no EREW

Exercícios – Capítulo I do livro de Jájá Algoritmos em diferentes Modelos de Memória
• Os tópicos abaixo são classificados em dois tipos de modelo: algoritmos sob o modelo de memória compartilhada e algoritmos que seguem o modelo de rede. Cada apresentação deve resumir o modelo que está sendo abordado, discutir o algoritmo.
matrix and vector multiplication on the shared memory model
matrix multiplication on PRAM
matrix vector product on a ring
• Capitulo I do Jájá
exercícios 1.5 e 1.8

Algoritmos PRAM
para um problema: se um algoritmo PRAM tem complexidade de tempo menor que a do algoritmo seqüencial ótimo, então o paralelismo pode ser usado
Como iniciar um algoritmo PRAM: ativar os P processadores que farão parte da computação
– os processadores serem ativados um a um
– através do algoritmo de difusão: log P passos
depois da ativação, o algoritmo paralelo pode ser executado

Identificando Paralelismo
paradigmas de computação paralela
algoritmos aqui falados consideram o modelo PRAM. Exemplos:
Árvore Binária: o fluxo de dados (e controle) se dá da raiz até as folhas
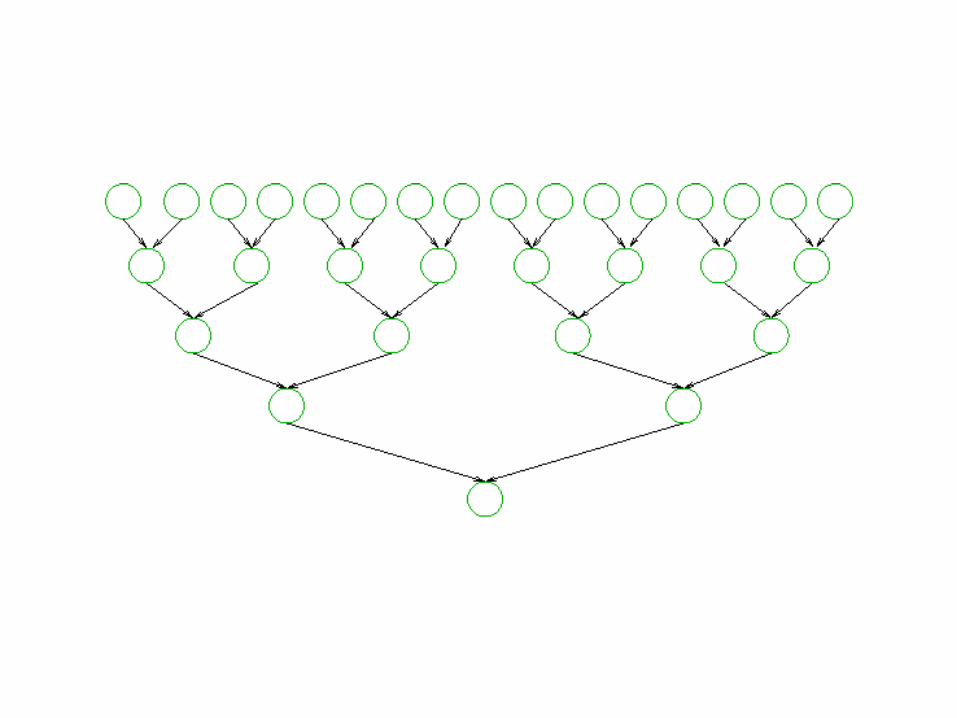
– Difusão: a partir de um processador, o fluxo (controle ou dados) passa para dois processadores e assim, dobrando a cada iteração.
– Divisão e Conquista: um problema é subdividido em subproblemas cada vez menores
ou contrário, das folhas até a raíz:
– Redução: dado n valores, a operação X é uma binária associativa

Redução: Soma
soma de n elementos: A = < 4, 3, 8, 2, 9, 1, 0, 5, 6, 3, 10, 2, 4, 7, 11, 3>
Soma_PRAM_Pi (){
Para ( 1 h log n ) faça
se ( i n/2h ) faça
A[i] := A[2i] + A[2i -1];
}
A[i] := A[2i] + A[2i -1]; leitura: A[2i] e A[2i -1];
computa: A[2i] + A[2i -1];
escreve: A[i]
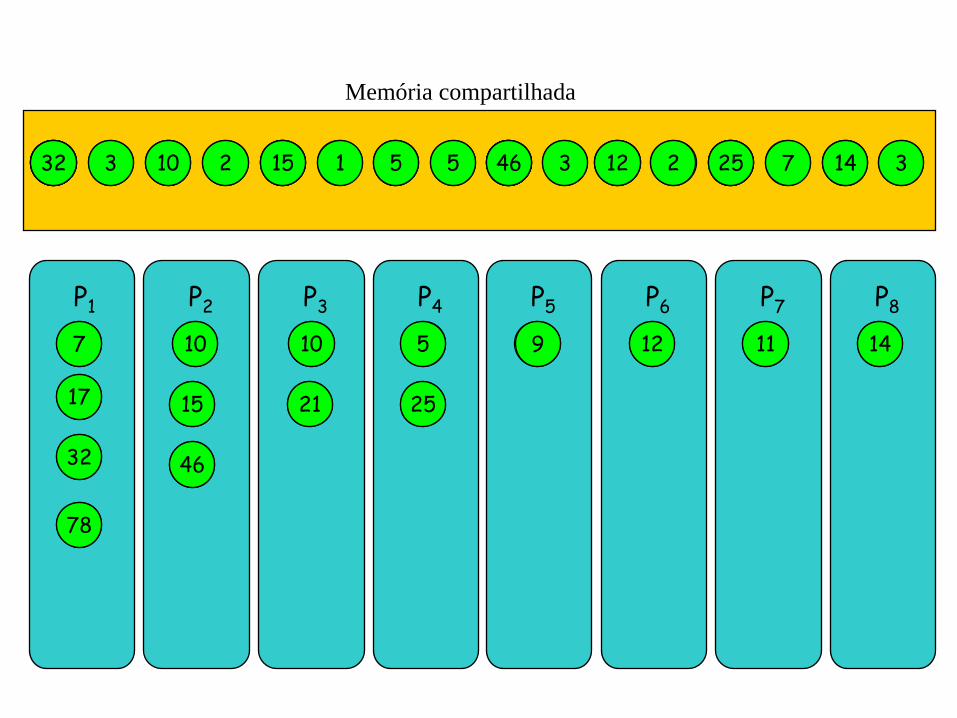
3 4
P1 P2 P3 P4 P5 P6 P7 P8
4 3 8 2 9 1 0 5 6 3 10 2 4 7 11 3
Memória compartilhada
8 2 9 1 0 5
7 7 10 10
6 3 10 2 4 7 11 3 9
10 10 5 5 9 9 12 12 11 11 14 14
7 10 10 5
25
12 11 14
17 15 21 17 15 21 25
17 15 21 25
32 46 32 46
32 46
78 78

Redução: Soma
primeiro loop: não há necessidade de mais do que n/2 processadores
processadores acessam dois locais de memória simultaneamente, mas distintos
processadores escrevem em um local de memória (cada) simultaneamente, mas distintos
para somar, log n iterações são necessárias, cada uma tem tempo constante
Complexidade do Algoritmo: O ( log n) com O ( n/2 ) processadores

Noções de Complexidade
Existem algoritmos PRAM cuja complexidade de tempo é menor do que o algoritmo correspondente seqüencial ótimo, mas podem desempenhar mais operações do que o seqüencial
Complexidade de tempo do pior caso em função do tamanho da entrada. Cada passo corresponde:
– uma fase de computação
– uma fase de comunicação
é importante especificar
– o número máximo de processadores usados, como função da entrada
– o modelo arquitetural sendo usado

Noções de Complexidade
Paralelismo Limitado
algoritmo p-paralelo se implementado em um modelo com p processadores, fixo
T(n) e P(n): o tempo de execução e a quantidade de processadores do algoritmo paralelo
se o número de passos é T(n) considerando p processadores, então esse algoritmo é p computável neste tempo
se T(n) é polinomial e p é limitado superiormente por polinômio, então o número de processadores é limitado polinomialmente, senão, ilimitado

Algumas Definições
Custo do Algoritmo Paralelo
produto tempo-processador T(n) P(n)
– ignora ociosidade de processador
Algoritmo paralelo de custo ótimo: Ts = T(n) P(n)
– Ts o tempo de execução do melhor algoritmo seqüencial
p < P(n) processadores: cada processador executa sequencialmente o que P(n)/ p processadores executam
– T(n) P(n)/p unidades de tempo
A - algoritmo paralelo n - o tamanho da entrada

Algumas Definições
Speedup , dado o número de processadores p
Se o S(A(n),p) é linear então todos os processadores são efetivamente utilizados
– difícil de ser alcançado devido a natureza dos algoritmos e do ambiente computacional paralelo
– difícil decompor o algoritmo em tarefas completamente independentes, onde cada tarefa leva Ts /p unidades de tempo para ser executada

Algumas Definições
Eficiência do algoritmo paralelo
razão entre S(A(n),p) e o número de processadores p
E(A(n),p) = S(A(n),p)/p
– mostra como os processadores são efetivamente utilizados: quanto maior, melhor a utilização de cada processador
se E(A(n),p) = 1 o algoritmo paralelo é de custo ótimo (por que?)

Algumas Definições
Trabalho de um Algoritmo Paralelo
um algoritmo é descrito como uma seqüência de unidades de tempo, onde em cada unidade um conjunto de instruções concorrentes
trabalho de um algoritmo paralelo é o número total de operações executadas, não incluindo os tempos ociosos de certos processadores
são somadas, a cada unidade de tempo, o número de operações concorrentes podem estar sendo executadas

Exemplo: soma de n elementos
T(n) e P(n): n/2 processadores executam em O(log n) unidades de tempo
Custo de O(n log n) em O(log n) unidades de tempo
Usando p < P(n) processadores: O(n log n/p)
• 1a unidade de tempo - n/2 operações (somas em paralelo)
• 2a unidade de tempo - n/4 operações (somas em paralelo)
• 3a unidade de tempo - n/8 operações (somas em paralelo)
• j-ésima unidade de tempo - n/2j operações
Total de operações: O(log n) n/2j = O(n)
..............
Reduzindo o número de processadores
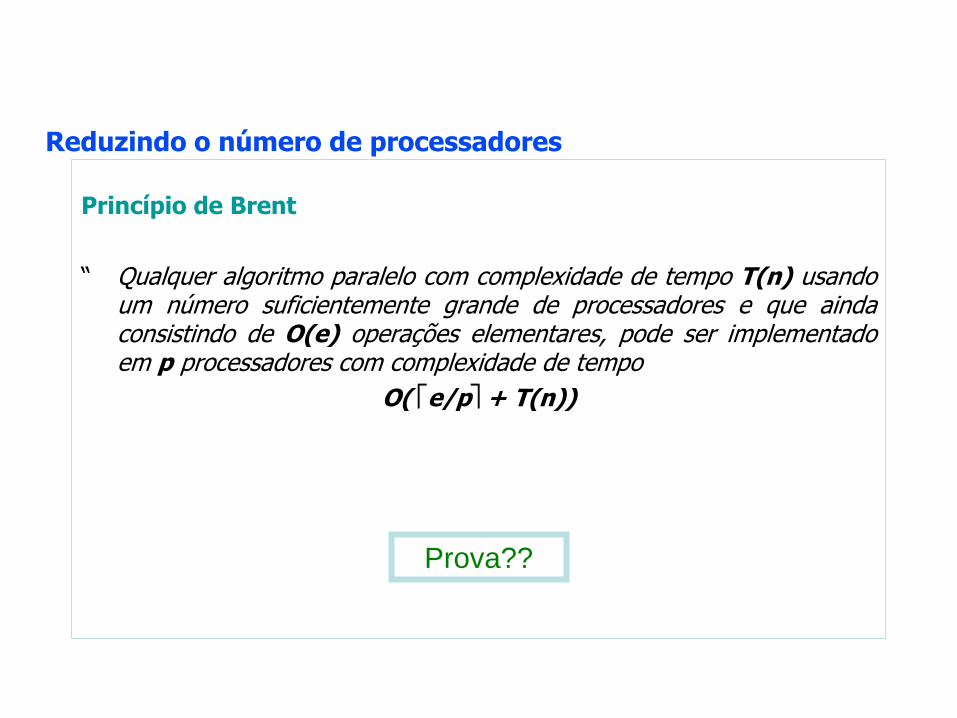
Princípio de Brent
“ Qualquer algoritmo paralelo com complexidade de tempo T(n) usando um número suficientemente grande de processadores e que ainda consistindo de O(e) operações elementares, pode ser implementado em p processadores com complexidade de tempo
O( e/p + T(n))
Prova??
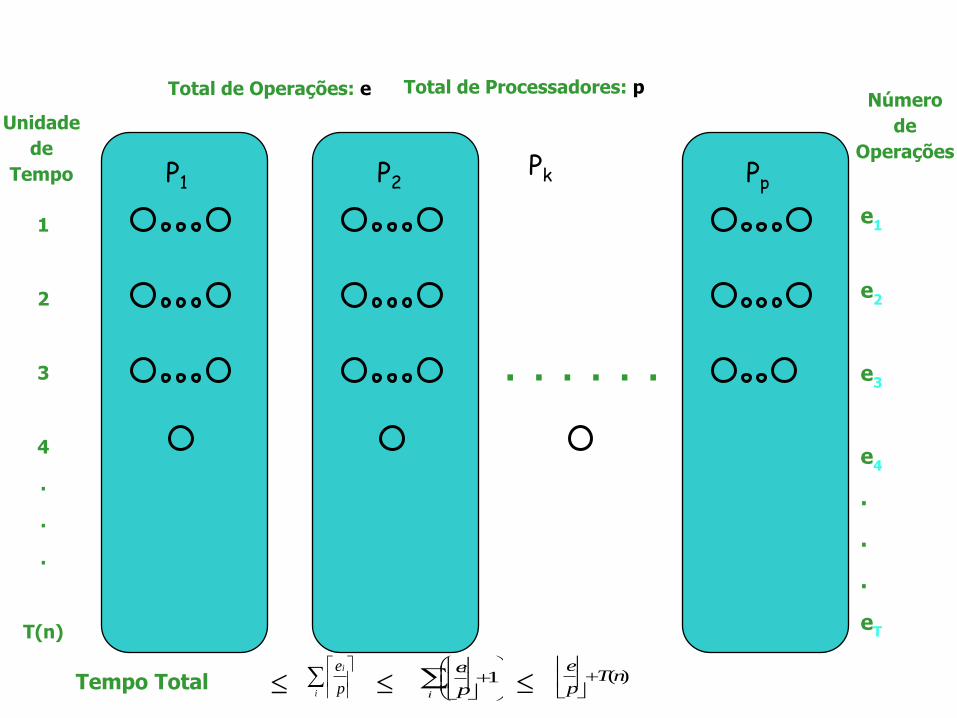
P2 Pp P1
. . . . . .
Total de Operações: e Total de Processadores: p
Unidade
de
Tempo
1
2
3
4
.
.
.
T(n)
Número
de
Operações
e1
e2
e3
e4
.
.
.
eT
Pk
Tempo Total
i
i
p
e
i
i
p
e1 )(nT
p
e

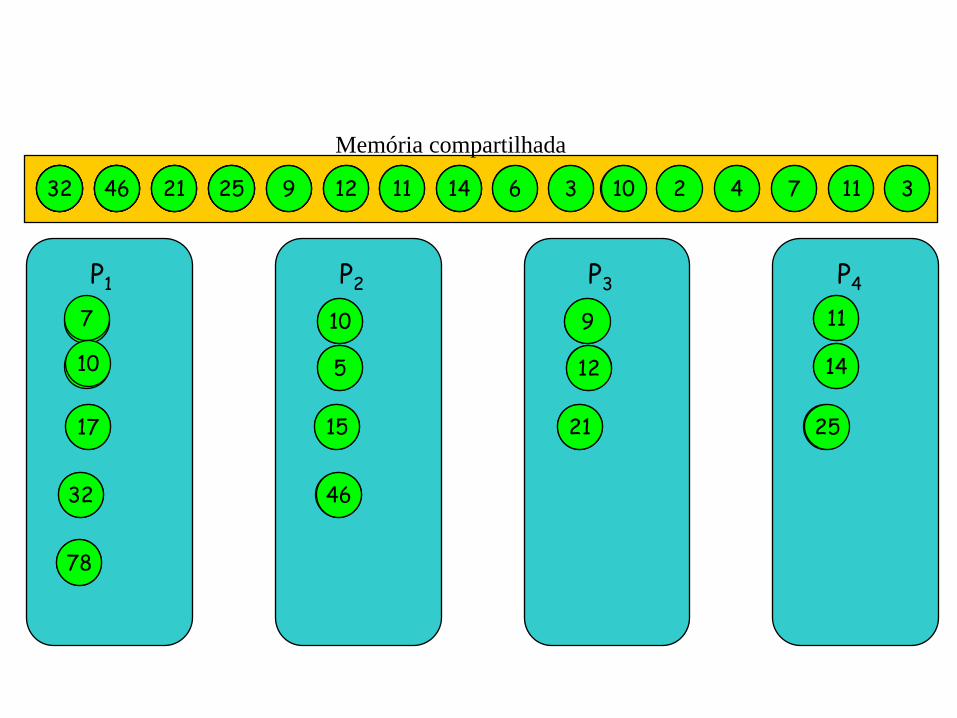
Fixando o número de processadores: soma de n elementos
Seja um modelo PRAM com p = 2q n = 2k processadores: P1,..., Pp
proponha um algoritmo paralelo para p processadores

Fixando o número de processadores: soma de n elementos
Seja um modelo PRAM com p = 2q n = 2k processadores: P1,..., Pp
Seja l = n/p = 2s é responsável por A[l(s - 1) + 1] , …. , A[ls]
cada elemento é um vértice de uma árvore binária
o número de computações concorrentes corresponde ao número de vértices em cada nível dividido pelos processadores disponíveis
Análise do Algoritmo
Seja o algoritmo em que n elementos são somados usando p processadores (Obs.: O algoritmo só considera o trabalho de um dado processador Ps:
primeiro passo: O(n/p) unidades de tempo
segundo passo?

Soma de n Elementos (JáJá)
Soma_Paralela_Ps ( A, p ){
for j =1 to l do /* l = n/p */
B(l(s - 1) + j): =A(l(s - 1) + j);
for h = 1 to log n do
if (k - h - q 0) then
for j = 2k-h-q(s - 1) + 1 to 2k-h-q s do
B(j): = B(2j - 1) + B(2j);
else if (s 2k-h) then
B(s): = B(2s - 1) + B(2s);
if (s = l) then S: = B(1);
}
P3 P2
0
P4
0 11
11
P1
Memória compartilhada
3 2 1 5 3 2 7 3 8 10 11 9 4 4 6 4 3 8 2 9 1 5 6 3 10 2 4 7 11 3
7
10
10
5
9
12
11
14
7
10
10
5
9
12 14
7 10 10 5 9 12 14
17 15 21 25 17 15 21 25
17 15 21 25
32 46
32 46
32 46
78 78

Modelando soma paralela de n números
+
+ + + + + + + +
+ + + +
+ +

Perguntas:
qual o número de operações?
qual o trabalho?
qual o custo
complexidade?
tipo do PRAM?
teria alguma outra versão com um menor de trabalho ou custo?
qual o número de comunicações?
1 Responda as perguntas considerando as duas versões discutidas na sala de aula
2 especificar o pseudo-algoritmo da segunda versão discutida.

Implementação I – soma de n números
através de threads, implementar a soma de n números
- em um número qualquer de processadores
- em um número fixo de processadores
vantagens e desvantagens?

Pointer Jumping
T = (V,E) : árvore direcionada
odg(v) e idg(v): graus de saída e entrada do vértice v V
um vértice r tal que
v V-{r}, odg(v) = 1, odg(r)=0
v V-{r}, um caminho de v a r
O vértice r é dita raíz de T
Pointer Jumping é uma técnica usada para processamento de dados
armazenados em forma de um conjunto de árvores direcionadas enraizadas

Pointer Jumping - árvore direcionada

Problema F : floresta de árvores direcionadas enraizadas
especificação: através de um vetor F de n elementos onde
– F(i) = j se (i,j) E (é um arco) j é o pai ou predecessor imediato de i
– F(i) = i se i é a raiz
Problema: determinar a raiz S(j) da árvore contendo o vértice j
Solução Seqüencial - resolve o problema em tempo linear:
identificação das raízes: achar todos os vértices v tal que F(v) = v em O(n)
reversão dos arcos: pois estamos considerando que se (i,j) E então j é pai de i em O(n)
execução de uma busca em profundidade ou largura: nesta busca, podemos saber a partir da raiz r quem são seus descendentes

Solução Paralela
Um algoritmo eficiente foi proposto, sendo um esquema totalmente diferente do esquema seqüencial
inicialmente: i V, S(i) é o pai de i
a técnica pointer jumping consiste em atualizar o sucessor de cada
vértice pelo sucessor do sucessor
– percorrendo desta maneira, corresponde a cada iteração chegar mais e mais próximo doa raiz da árvore
– a cada iteração, a distância entre o vértice i e seu sucessor S(i) dobra
– o ponto de parada: quando S(i) é a raiz procurada;

Pointer Jumping
início : S[1] = 2 S[2] = 3 S[3] = 4 S[4] = 5 S[5] = 5
1o passo: S[1] = 3 S[2] = 4 S[3] = 5 S[4] = 5 S[5] = 5
2o passo: S[1] = 4 S[2] = 5 S[3] = 5 S[4] = 5 S[5] = 5
3o passo: S[1] = 5 S[2] = 5 S[3] = 5 S[4] = 5 S[5] = 5
……..
k-ésimo passo: S[1] = raiz d(1, S[1]) = 2k (término do Algoritmo)

Pointer Jumping
1 2 3 4 5 R

Pointer Jumping
PointerJumping_Pp (){
S[p] = F[p];
While (S[p] != S[S[p]]{
S[p] := S[S[p]];
}
}
ler S[p], S[S[p]] em variáveis locais pai e avô
Comparar as duas informações;
Escrever avô em S[p];

Complexidade e Corretude do Algoritmo
como podemos provar que o algoritmo está correto?
simplesmente definimos um algoritmo e o executamos?
– seja h a altura máxima de uma árvore qualquer na floresta de árvores enraizadas direcionadas
– por indução em h
Temos que analisar tal algoritmo, considerando a altura da maior árvore dentre as da floresta: domina o tempo de execução do algoritmo
– cada passo j, definição de distância entre i e S[i]
dj(i,S[j]) = 2dj-1(i,S[i])
– por indução em k: supondo verdade que dk-1(i,S[i]) = 2k-1

Complexidade e Corretude do Algoritmo
– assim, no passo k
dk(i,S[j]) = 2 dk -1(i,S[i]) = 2* 2k-1
– logo, por definição da distância máxima, tem-se h = 2k e assim, o número máximo de iterações é k = O(log h)
em cada iteração, o tempo paralelo é O(1). Temos um total de O(log h) iterações. Ainda, o número de processadores é n
o algoritmo paralelo não tem custo ótimo. Por que?
é um algoritmo CREW PRAM

Soma de Prefixos
si = x1 x2 …. xi
saída: n elementos : s1, s2, …., sn
Aplicações: concatenação de strings, soma, multiplicação, etc
Algoritmo Seqüencial
Soma_Prefixos_Sequencial( x){
s1 := x1 ;
Para i = 2, …., n
si = si-1 xi ;
}
Complexidade: O(n)

Soma de Prefixos
Definição
Seja X = { x1, x2, …., xn } e uma operação binária e
a operação é fechada sobre X ou seja, se xi e xj são elementos de X então xi xj também é
a operação é associativa

Soma de Prefixos - pointer jumping
representação dos elementos é feita através de uma árvore direcionada enraizada
– cada vértice i da árvore tem um peso associado xi
– pointer jumping é usado, armazenando as somas intermediárias a cada iteração
– como várias árvores podem ser percorridas ao mesmo tempo, várias seqüências podem ser resolvidas ao mesmo tempo
algoritmo para soma de prefixos: temos a informação de quem é pai do vértice i, ou seja, F[i]
– em seqüência de n elementos F[i] = i+ 1, i = 1,…., n-1
– a árvore seria uma lista linear

Soma de Prefixos - pointer jumping
5 4 3 2 1 0
5+4 4+3 3+2 2+1
5+4+3+2 4+3+2+1 3+2+1
5+4+3+2+1

Soma de Prefixos - pointer jumping
Soma_Prefixo_PJ_Pp (){
S[p] = F[p];
sp[i] = x[i];
While (S[p] != S[S[p]]{
sp[p] = sp[p] + sp[S[p]];
S[p] := S[S[p]];
}
}
Implementação II – pointer junping
através de threads, implementar a soma de prefixos de n números através da técnica do pointer jumping
- em um número qualquer de processadores
algum cuidado especial a ser tomado?

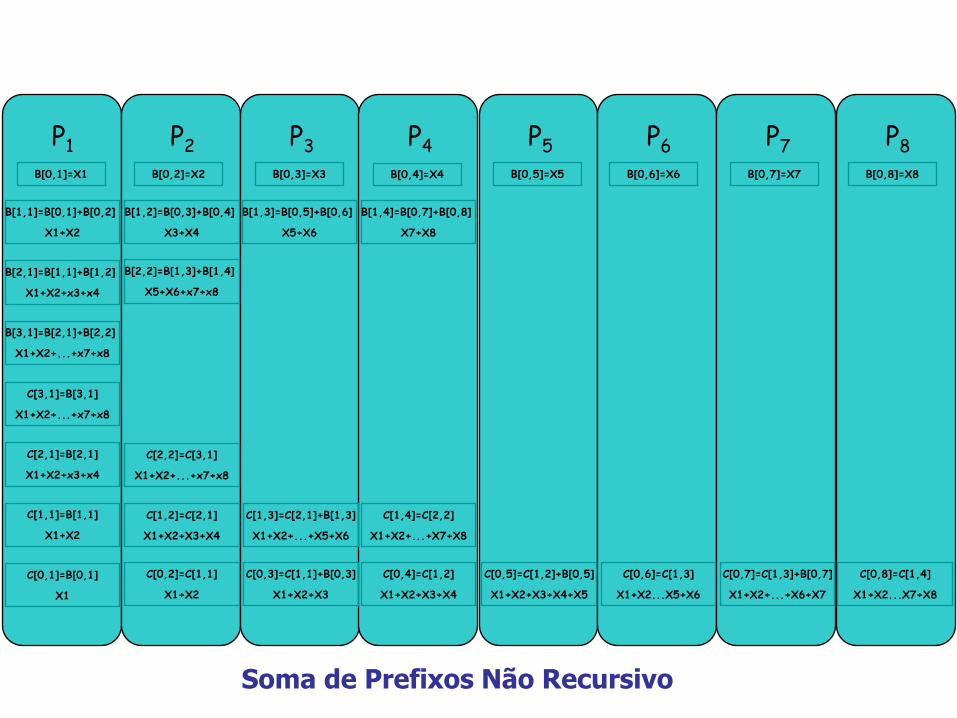
Soma de Prefixo – outro paradigma
si = x1 x2 …. xi
saída: n elementos : s1, s2, …., sn
Paradigma: árvores binárias
A[i] = xi
B[h,j] e C[h,j] onde 1 j n/2h (1 h log n especifica o nível)
ao final: sj = C[0,j]
P1 P2 P3 P4 P5 P6 P7 P8
B[0,1]=X1 B[0,2]=X2 B[0,3]=X3 B[0,4]=X4 B[0,5]=X5 B[0,6]=X6 B[0,7]=X7 B[0,8]=X8
B[1,1]=B[0,1]+B[0,2]
X1+X2
B[1,2]=B[0,3]+B[0,4]
X3+X4
B[1,3]=B[0,5]+B[0,6]
X5+X6
B[1,4]=B[0,7]+B[0,8]
X7+X8
B[2,1]=B[1,1]+B[1,2]
X1+X2+x3+x4
B[2,2]=B[1,3]+B[1,4]
X5+X6+x7+x8
B[3,1]=B[2,1]+B[2,2]
X1+X2+...+x7+x8
C[3,1]=B[3,1]
X1+X2+...+x7+x8
C[2,1]=B[2,1]
X1+X2+x3+x4
C[2,2]=C[3,1]
X1+X2+...+x7+x8
C[1,1]=B[1,1]
X1+X2
C[1,2]=C[2,1]
X1+X2+X3+X4
C[1,3]=C[2,1]+B[1,3]
X1+X2+...+X5+X6
C[1,4]=C[2,2]
X1+X2+...+X7+X8
C[0,1]=B[0,1]
X1
C[0,2]=C[1,1]
X1+X2
C[0,3]=C[1,1]+B[0,3]
X1+X2+X3
C[0,4]=C[1,2]
X1+X2+X3+X4
C[0,5]=C[1,2]+B[0,5]
X1+X2+X3+X4+X5
C[0,6]=C[1,3]
X1+X2...X5+X6
C[0,8]=C[1,4]
X1+X2...X7+X8
C[0,7]=C[1,3]+B[0,7]
X1+X2+...+X6+X7
Soma de Prefixos Não Recursivo

Algoritmo Paralelo não Recursivo
Soma_Prefixos_Paralela_nRecursivo( A ){
1. Para 1 i n faça em // : B[0,j] := A[j];
2. Para 1 h log n faça
2.1 Para 1 j n/2h faça em //
2.1.1 B[h,j] := B[h - 1, 2j-1] * B[h - 1, 2j];
3. Para h = log n … 0 faça
3.1 Para 1 j n/2h faça em //
3.1.1 se j é par, então C[h,j] := C[h + 1,j/2];
3.1.2 se j == 1, então C[h,1] := B[h,1];
3.1.3 se j é ímpar, então C[h,j] := C[h + 1,(j-1)/2] * B[h,j];
}

Princípio de Brent tempo de execução do algoritmo // A para P(n) processadores: T(n)
w operações do algoritmo A
tempo paralelo do algoritmo considerando p processadores de acordo com o princípio de Brent:
Tp(n) = w/p + T
Aplicação do Princípio
necessário saber quantas operações são executadas a cada passo
algoritmo de soma de prefixos com n = 2k - número de passos:
2log n + 2 2k+2
– qual o número de operações?
– qual o custo?

Princípio de Brent
w1,1 : número de operações no passo 1 considerando o único loop
w2,m : número de operações executadas no passo 2 na m-ésima iteração
w3,m : número de operações executadas no passo 3 na m-ésima iteração
Então:
w1,1 = n
w2,m = n/2m = 2k /2m para 1 m k
w3,m = 2m para 0 m k
Assim:
w = w1,1 + w2,m + w3,m
w = n + n/2m + 2m
w = n + n(1-1/n) + 2n-1 = 4n-2
w = O(n)

Divisão e Conquista
usada quando identificamos problemas que podem ser particionados em subproblemas menores, que são mais simples de serem resolvidos
– divisão da entrada em partições menores de mesmo tamanho (ou quase)
– resolução recursiva de cada subproblema definido por cada partição
– combinação das soluções de cada subproblema, produzindo a solução do
problema como um todo
tende a ser eficiente se a decisão e resolução podem ser feitas recursivamente
eficiente no mundo seqüencial
natural na exploração de paralelismo

Divisão e Conquista
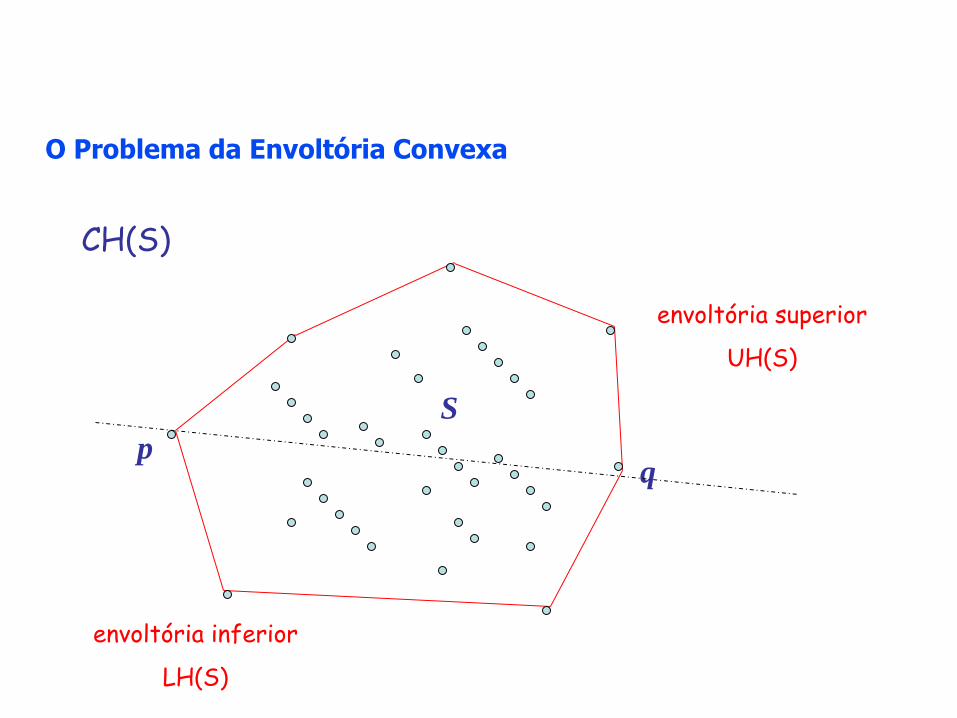
Problema da Envoltória Convexa
Seja S = { p1 , p2
, …. , pn } um conjunto de n pontos em um plano, cada um
representado por suas coordenadas (xi, yi). A envoltória convexa planar de S é o menor polígono convexo que contém todos os pontos de S
observação: um polígono é convexo quando, para qualquer dois pontos, (xi, yi) (xj, yj), a reta [(xi, yi),(xj, yj)] está dentro do polígono.
o problema: determinar a lista ordenada de pontos S que formam o polígono convexo. Essa lista será denotada por CH(S) (convex hull).

Divisão e Conquista
Problema da Envoltória Convexa
é um problema muito importante em geometria planar:
– estatística
– processamento de imagem
– reconhecimento de padrões
– computação gráfica
– problemas geométricos
resolvido sequencialmente através de divisão e conquista O(n log n)
– o algoritmo de ordenação de pontos resolve esse problema mais eficientemente

Divisão e Conquista Paralelo
Dado um conjunto S de n pontos, sejam:
p S o ponto com o menor xi
q S o ponto com o maior xj
ordenação paralela: em O(log n) em uma PRAM EREW com O(n log n ) operações
particionam CH(S) em:
envoltório superior UH(S) = < todos os pontos de p a q pertencentes a CH(S) seguindo o sentido horário >
envoltório inferior LH(S) = < todos os pontos de q a p pertencentes a CH(S) seguindo o sentido horário >
O Problema da Envoltória Convexa
p q
CH(S)
S
envoltória inferior
LH(S)
envoltória superior
UH(S)

Divisão e Conquista Paralelo
p q

p q
Merging de duas envoltórias superiores

Merging de duas envoltórias superiores
p q
Tangente Comum Superior
• sequencial – O(log n) • busca binária

Entrada: n pontos ordenados tais que x(p1) < x(p2) < .... <
x(pn)
Saída: UH(S)
1) Se n <= 4 então ache UH(S) por força bruta e retorne
2) S1 = (p1, ..., pn/2) e S2 = (pn/2+1, pn). Compute UH(S1)
e UH(S2) em paralelo, recursivamente
3) Ache a tangente comum superior entre UH(S1) e UH(S2) e
defina UH(S)
1) O(1)
2) T(n/2)
3) TCS(UH(S1), UH(S2)) em O (log n)
Combinar as duas curvas dada a tangente produzindo S
– em O(1) com n processadores leituras concorrentes
serão realizadas.
Algoritmo

Implementação III – divisão e conquinta
implementar o problema da envoltória convexa
(coletar na internet um algorithmo da tangente comum superior
Explicar:
– ComplexidadeT(n) = O(log2 n) com O(n) processadores
Qual o número de operações?

Exercícios
Capítulo II
2.3, 2.7, 2.13

Apresentação
Partitioning
Pipeline
Symetry Breaking





























