Embed Size (px)
Citation preview

FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO
Deteção de Fraudes emTelecomunicações com Recurso a
Técnicas de Data Mining
João Vítor Cepêda de Sousa
PREPARAÇÃO DA DISSERTAÇÃO
PREPARAÇÃO DA DISSERTAÇÃO
Orientador: Prof. Dr. Carlos Manuel Milheiro de Oliveira Pinto Soares
Co-orientador: Prof. Dr. Luís Fernando Rainho Alves Torgo
16 de Fevereiro de 2014

c© João Cepêda, 2014

Deteção de Fraudes em Telecomunicações com Recurso aTécnicas de Data Mining
João Vítor Cepêda de Sousa
PREPARAÇÃO DA DISSERTAÇÃO
16 de Fevereiro de 2014


Resumo
O presente documento foi redigido no âmbito de relatório final da unidade curricular de "Pre-paração da Dissertação"do 5o ano do curso de Mestrado Integrado em Engenharia Eletrotécnica ede Computadores. Tem como objetivo a apresentação do tema de dissertação "Deteção de Fraudeem Telecomunicações com Técnicas de Data Mining"cujo orientador é o Prof. Dr. Carlos ManuelMilheiro de Oliveira Pinto Soares. São apresentados os motivos que requerem a necessidade de de-senvolver conhecimento neste tema e os objetivos do projeto. É ainda apresentado uma recolha deinformação sobre este tema e projetos do mesmo âmbito produzidos anteriormente. Na conclusãodeste documento será apresentado o planeamento e calendário definido para o desenvolvimentodo projeto.
i

ii

Abstract
This document is the final report of the course of "Preparação de Dissertação"of the 5th gradeof the Masters in Electrical and Computers Engineering. It has the objetive of presenting the theses"Detection of Fraud in Telecommunication with Data Mining Techniques"oriented by Prof. Dr.Carlos Manuel Milheiro de Oliveira Pinto Soares. The context and motivation that created theneed of this development of the project are presented. There is also ilustrated some of the previouswork done on this theme and some information that is important for the project. In the conclusionsection, the planning and schedule of the work steps are announced.
iii

iv

“Prediction is very difficult, especially if it’s about the future.”
Niels Bohr
v

vi

Conteúdo
1 Introdução 11.1 Motivação e Contexto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Apresentação do Problema e Requisitos . . . . . . . . . . . . . . . . . . . . . . 21.3 Objetivos do Projeto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Estado da Arte 52.1 Fraude em Telecomunicações . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Prespetiva Histórica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.1.2 Métodos Fraudulentos . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Deteção de Anomalia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2.1 Tipos de Anomalia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.2 Rotulagem de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.3 Técnicas Baseadas em Clustering . . . . . . . . . . . . . . . . . . . . . 112.2.4 Técnicas Baseadas em Vizinho Mais Próximo . . . . . . . . . . . . . . . 122.2.5 Técnicas Estatiticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.6 Técnicas Baseadas em Classificação . . . . . . . . . . . . . . . . . . . . 142.2.7 Árvores de Decisão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 Data Mining Aplicado à Deteção de Fraude . . . . . . . . . . . . . . . . . . . . 162.3.1 Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.3.2 User Profiling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.3.3 Aplicações Baseadas em Regras . . . . . . . . . . . . . . . . . . . . . 182.3.4 Aplicações Baseadas em Redes Neuronais . . . . . . . . . . . . . . . . . 182.3.5 Híbrido . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3.6 Melhorias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3 Plano do Projeto 213.1 Planeamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Referências 23
vii

viii CONTEÚDO

Lista de Figuras
2.1 Dispositivo Blue Box. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 Estatística sobre Metodos Fraudulentos Detetados em 2013. . . . . . . . . . . . 92.3 Exemplos de anomalias num conjunto de dados bidimensional. . . . . . . . . . 10
3.1 Planeamento do projeto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
ix

x LISTA DE FIGURAS

Lista de Tabelas
1.1 Perdas de receita anual a nivel global. . . . . . . . . . . . . . . . . . . . . . . . 1
2.1 Relação Digito-Frequência para MF Pulsing do Operador Breen e Dahlbom (1960) 6
xi

xii LISTA DE TABELAS

Abreviaturas e Símbolos
ASPeCT Advanced Security for Personal Communications TechnologiesCDR Call Details RecordCFCA Communications Fraud Control AssociationCRISP-DM Cross Industry Standard Process for Data MiningDC-1 Detector ConstructorLDA Latent Dirichlet AllocationMF Multiple-FrequenciesSMS Short Message SystemSOM Self-Organizing MapsSVM Support Vector Machine
xiii


Capítulo 1
Introdução
O objetivo deste documento é a apresentação da dissertação "Deteção de Fraude em Telecomu-
nicações com Técnicas de Data Mining"cujo orientador é o Prof. Dr. Carlos Manuel Milheiro de
Oliveira Pinto Soares. O tema desta dissertação surge através de um desafio lançado pela empresa
WeDo Technologies.
Este documento encontrasse dividido em três capitulos: Introdução, estado da arte e traba-
lho futuro. Na introdução será apresentado o tema desta dissertação, a motivação e o contexto,
o problema e requisitos e os objetivos finais. No estado da arte será avaliado o conhecimento
produzido anteriormente sobre os temas de fraude em telecomunicações, deteção de anomalias, e
data mining na deteção de fraudes. O último capitulo servirá para fazer uma breve apresetnação
do planeamento do trabalho futuro.
1.1 Motivação e Contexto
A fraude em telecomunicações tem graves impactos nas indústrias que oferecem estes serviços
tanto a nível a financeiro (Rosas e Analide, 2009; Becker et al., 2010) como a nível de infraes-
truturas. Estas podem resumir-se em perdas de receita (Estévez et al., 2006), são usados recursos
sem serem devidamente cobrados, perda da confiança dos clientes, devido ao aparecimento de
comportamentos fraudulentos dentro da sua operadora, e perda clientes, devido à oferta disponí-
vel de mercado e facilidade contratual os clientes (ou possíveis novos clientes) optam por assinar
contrato com uma operadora que não tenha problemas com fraudes. Hollmén e Tresp (1999)
2005 2008 2011 2013Receita Global Estimada (USD) 1.2 Biliões 1.7 Biliões 2.1 Biliões 2.2 Biliões
Receita Perdida em Fraude (USD) 61.3 Mil Milhões 60.1 Mil Milhões 40.1 Mil Milhões 46.3 Mil Milhões% Representativa 5.11% 3.54% 1.88%
Tabela 1.1: Perdas de receita anual a nivel global.
Observando a tabela 1.1 é possível observar a dimensão financeira da indústria das telecomu-
nicações. Também é possível observar o impacto direto que a fraude tem sobre a receita anual das
operadoras. CFCA (2013)
1

2 Introdução
Um dos problemas da deteção que impulsiona a prática de fraudes em telecomunicações é a
dificuldade em localizar o infrator. O processo de localização é dispendioso a nível financeiro
e temporal, de tal forma que se torna impraticável. Outro problema é o da exigência tecnoló-
gica. Para cometer algumas fraudes nesta área, um fraudador não necessita de um equipamento
particularmente sofisticado Hilas e Sahalos (2007).
Todos estes aspetos geram a necessidade de detetar comportamentos fraudulentos o mais efi-
cazmente possível para evitar futuros danos na indústria.
A aplicação de técnicas de data mining surge como opção mais vantajosa, pois permite identi-
ficar atividades fraudulentas com um grau de certeza associado e funciona especialmente bem em
grandes quantidades de dados, característica da área de telecomunicações.
1.2 Apresentação do Problema e Requisitos
As operadoras de telecomunicações armazenam uma grande quantidade de registos referentes
á atividade dos seus clientes na sua infraestrutura. Alguns desses registos são de atividades frau-
dulentas. Neste caso o nùmero de registos fraudulentos é muito inferior a registo de actividades
legais. O problema surge quando se tenta detetar esses registos de forma automática e sem falhas.
Esta dissertação tenta avaliar o desempenho de técnicas de classificação da área de deteção
de anómalias em data mining, mais concretamente, técnicas de extração de regras com recurso
a algoritmos de árvores de decisão. As regras resultantes representam os valores extremos nos
quais um registo é considerado normal. Se um registo não respeitar estas regras então este será
considerado fraudulento.
A implementação dos algoritmos será feita sobre registos reais de chamadas entre utilizadores
de uma operadora de telecomunicações, disponibilizados pela empresa WeDo Techonologies. Os
requisitos que avaliarão os algoritmos estudados e desenvolvidos serão:
• A precisão – os valores obtidos descrevem na perfeição os limites no qual uma chamada é
considerada normal. Isto reflete-se num número reduzido de resultados falsos (chamadas
normais avaliadas como fraudulentas e vice-versa);
• A velocidade – a determinação destes valores necessita de ser em tempo real permitindo
ao sistema uma maior rapidez na deteção da fraude. Isto permitirá uma intervenção mais
rápida sobre o infrator.
1.3 Objetivos do Projeto
Esta dissertação têm como objetivo o estudo dos algoritmos de árvores de decisão para a
extração de regras em fraude de telecomunicações.
Para a realização do projeto dividiu-se os objetivos foram dividos em duas etápas:
I Estudo do desempenho de algoritmos de árvores de decisão já desenvolvidos no problema de
deteção de fraudes;

1.3 Objetivos do Projeto 3
II Desenvolver uma nova variante do algoritmo que melhor se adapte aos dados disponibiliza-
dos;

4 Introdução

Capítulo 2
Estado da Arte
Neste capítulo é ilustrado o estado da arte sobre a deteção de fraudes em telecomunicações.
Eset está dividido em três temas que definem este problema: a fraude em telecomunicações, os
modelos de deteção de outlier e a aplicação de data mining na deteção de fraude.
2.1 Fraude em Telecomunicações
O ato de fraude pode ser descrito como um ato de enganar os outros para ganhos pessoais
Becker et al. (2010). Em telecomunicações, a fraude consiste na utilização de recursos oferecidos
por uma operadora de telecomunicações sem a intensão de os pagar. Nesta situação poderão existir
duas vítimas:
• Operadora — como estão a ser utilizados recursos sem a devida cobrança isto reflete-se
num desperdício de capacidade de operação e numa diminuição do lucro;
• Cliente — quando são vitimas de uma ataque fraudulento, a sua deteção não é tão sim-
plificada como no caso da operadora. Assim, os danos causados resumem-se em perda de
confiança na operadora e perda de dinheiro
A prática de fraude está normalmente relacionada com razões monetárias, no entanto exis-
tem outras razões que estimulam o a sua prática como motivos políticos, prestígio pessoal e auto
preservação. Becker et al. (2010)
2.1.1 Prespetiva Histórica
O dano causado pela atividade fraudulenta em telecomunicações nunca foi constante. Inicial-
mente, os casos de fraude infligiam grandes perdas financeiras nas companhias de telecomunica-
ções, pois o custo relacionado com o estabelecimento de uma chamada na infraestrutura primordial
era relativamente elevado.
Hoje em dia, esse custo foi reduzido graças á evolução tecnológica dos equipamentos na área
das telecomunicações. Apesar do custo do estabelecimento de uma chamada ter vindo a diminuir
5

6 Estado da Arte
Figura 2.1: Dispositivo Blue Box.
ao longo dos anos, a atividade fraudulenta cresceu exponencialmente. O que fez com que os custos
associados à fraude não diminuíssem.
Um dos primeiros tipos de fraude que foi registado em telecomunicações foi em 1957 na rede
telefónica da AT&T e foi atribuido o nome de phreaking (phone + freak). Este tipo de fraude
surgiu quando foram instalados os primeiros PBX’s em que para estabelecer o roteamento das
chamadas ou aceder a outras propriedades do sistema, eram emitidos na linha telefónica, junta-
mente com os sinais de voz, sinais sonoros de múltipla frequência (MF) na ordem dos 2400Hz,
Joe Engressia, também conhecido com Joybubbles foi o pioneiro em phreaking. Ele percebeu
que se assobia-se em certas frequências conseguia aceder aos comandos do operador da rede e
efetuar certas tarefas como estabelecer chamadas entre dois terminais sem custos associados.
Mais tarde John Darper descobriu que um apito oferecido nos cereais Captain Crunch, tinha
a capacidade de emitir um tom perfeito à frequência de 2600Hz, o que poderia ser utilizado para
phreaking. Esta descoberta valeu-lhe o apelido de Cpt. Crunch.
Entre os anos 60 e 70, Steve Wozniak, co-fundador da Apple, utilizou o trabalho feito por
John Darper, e inventou a Blue Box. Este dispositivo conseguia gerar tons à frequência necessária
para configurar a central telefónica como se fosseum operador. Pode-se observar a conversão dos
dígitos dos operadores para os pares de frequência na tabela 2.1.
A invenção da BlueBox foi insere-se âmbito académico e nunca elaborado sobre a intenção de
o utilizar para cometer atividades fraudulentas. No entanto, isto não impediu que outros indivíduos
700 900 1100 1300 1500 1700700 1 2 4 7900 3 5 81100 6 9 #1300 01500 *
Tabela 2.1: Relação Digito-Frequência para MF Pulsing do Operador Breen e Dahlbom (1960)

2.1 Fraude em Telecomunicações 7
conseguissem reproduzir o dispositivo e o utilizassem para fins ilegais.
Mais recentemente, nos anos 90 e 2000, as preocupações de fraude em telecomunicações,
estenderam-se a outra dimensão devido á entrada em cena da Internet e de uma panóplia de servi-
ços novos. Novos tipos de fraudes surgiram e menos controlo se passou a ter sobre a infraestrutura,
o que resulta numa dificuldade acrescida prevenção deste problema.
Ao longo dos anos não foram apenas as infraestruturas e as medidas de segurança para evi-
tar fraudes que evoluíram, também as técnicas usadas nas atividades fraudulentas conseguiram
acompanhar esta tendência, o que se traduz muitas das vezes no surgimento de um novo tipo de
fraude.
Atualmente, existe um constante braço-de-ferro entre os operadores e os fraudadores. Os
operadores tentam ficar á frente dos infratores, desenvolvendo métodos para evitar que os seus sis-
temas sejam vulneráveis a ataques. Os fraudadores pelo contrário, tentam contornar esses métodos
de forma a explorarem os serviços da operadora.
2.1.2 Métodos Fraudulentos
A área de telecomunicações é muito vasta, pois é composta por muitas componentes como
a internet, telefones, satélites, etc. A fraude neste tema tem de ser analisado ao nível de cada
uma dessas componentes. Existem fraudes que são características de um serviço apenas, como a
de clonagem do cartão SIM no caso do serviço de telefone móvel, e existem outras que podem
ocorrer em mais do que um serviço, como a fraude contratual. De seguida irão ser ilustrados
alguns do métodos que revelam maior preocupação.
2.1.2.1 Fraude de Superimposição
Este método de fraude ocorre quando o infrator ganha acesso não autorizado á conta de um
utilizador. Em telecomunicações, é também designado por clonagem do cartão SIM que consiste
na cópia da informação do cartão SIM de utilizador legítimo para um outro cartão para uso ile-
gítimo. Assim, as atividades fraudulentas ocorrem em paralelo com as atividades legítimas da
vítima. Apesar de não ser o método de fraude com mais incidências nos últimos anos, este foi o
método fraudulento mais praticado desde a sua deteção e o que mais atenção recebeu. Fawcett e
Provost (1997)
2.1.2.2 Fraude de Subscrição
Ocorre quando um utilizado subscreve a um serviço (como por exemplo a internet) e não tem
intensões de o pagar. Este é o tipo de fraude com maior número de ocorrências em 2013 2.2

8 Estado da Arte
2.1.2.3 Fraudes Técnicas
Ocorre quando são exploradas as deficiências técnicas de uma infraestrutura. A deteção destas
deficiências por parte do fraudador são normalmente feitas por tentativa-erro ou através da indi-
cação direta de um trabalhador que cometa fraude interna. A ocorrência de fraude técnica tem
maior ocorrência em serviços novos, pois são estes que maioritariamente apresentam algumas fa-
lhas de conceção, muitas vezes só detetadas mais tarde. Esta fraude engloba todas as definições
de hacking a um sistema.
2.1.2.4 Fraude Interna
Ocorre quando os trabalhadores de uma operadora de telecomunicações utilizam os conheci-
mentos que têm sobre a infraestrutura para benefícios próprios ou outros.
2.1.2.5 Engenharia Social
Em vez de tentar descobrir uma deficiência na infraestrutura, como em fraude técnica, o frau-
dador utiliza a interação humana para descobrir mais informação sobre o sistema e assim estudar
o melhor método para aplicar. As informações podem ser obtidas por trabalhadores da operadora
sem que estes estejam cientes do objetivo do fraudador. Noutro caso, poderá existir uma relação
entre este método e o de fraude interna, pois o fraudador poderá utilizar as suas competências
sociais para convencer algum trabalhador da indústria a cometer a fraude interna.
Na figura 2.2 está representada uma distribuição dos métodos fraudulentos detetados no ano
de 2013 a nível mundial.
2.2 Deteção de Anomalia
A deteção de anomalias é uma das áreas da aplicação do data mining e consiste em técnicas
de análises de dados que permitem identificar os dados que não apresentam semelhanças com os
restantes. Uma anomalia (ou outlier) é então definida como uma instância de um conjunto de
dados que não apresenta uma relação com as restantes. Assim, as instâncias que pertencem e
definem o padrão são consideradas normais e as que não pertencem são consideradas anómalas.
Existem casos em que as instâncias são avaliadas como normais e anómalas ao mesmo tempo.
Isto significa que a esta instância foi atribuido um score de anomalia ou seja, a instância tem
a sí associado um valor percentual de anomalia que define o nível de incerteza na avaliação da
instância. Estas avaliação têm especial importância pois, a deteção de uma anomalia num conjunto
de dados, representa um problema no sistema que originou esse conjunto de dados.
Existem aplicações de deteção de anómalias em áreas como:
• Deteção de fraudes;
• Deteção de intrusões;

2.2 Deteção de Anomalia 9
Figura 2.2: Estatística sobre Metodos Fraudulentos Detetados em 2013.
• Diagonóstico de redes;
• Análise de Imagem;
• Deteção de falhas;
• Outras;
Uma característica interessante na maioria destas técnicas é a capacidade de detetar anomalias
que não estavam previstas na projeção do sistema de deteção. Isto devesse aos sistemas que são
projetados para apenas identificas as instâncias que são consideradas normais, sendos as restante
consideradas anomalas. Um defeito que estas técnicas apresentam é complexidade computacional.
Já foram feitos estudos de soluções que fazem a análise dos dados de forma paralela, de forma a
reduzir depêndencia. Hung e Cheung (1999)
O processo de construção de um sistema de deteção consiste normalmente em duas fases, a
fase de treino e a fase de teste. A primeira fase é utilizada para a contrução do modelo de deteção.
A segunda é para a validação desse mesmo modelo Patcha e Park (2007). É portanto normal que
os dados sejam inicialmente divididos em duas porções, uma de treino e outra de teste.
Numa análise empírica detetar anómalias num conjunto de objetos não seria complicado. O
problema surge quando a quantidade de objetos nesse conjunto cresce exponencialmente e o mé-
todo de análise empirico deixa de ser fiável, pois quem efetua a análise sofre mais desgaste do que
um sistema computacional. Na figura 2.3 podemos observar dois padrões no conjunto de dados
N1 e N2, uma anomalia o1 e um conjunto de anomalias O1.

10 Estado da Arte
2N
1N
1o
1O
Y
X
Figura 2.3: Exemplos de anomalias num conjunto de dados bidimensional.
Nesta secção serão ilustrados os tipos de anomalia, a rotulagem dos dados, e algumas técnicas
baseadas em métodos de data mining. No fim, será feita uma análise aos algoritmos de árvores de
decisão devido à importância que têm para este projeto. A organização e apresentação deste tópi-
cos é semelhante a alguns artigos que contêm vários estudos sobre deteção de anomalias Hodge e
Austin (2004); Patcha e Park (2007); Chandola et al. (2009).
2.2.1 Tipos de Anomalia
Ao fazer um sistema de deteção de anomalia é necessário especifica o tipo de anomalia que se
está a detetar. Estas podem ser do tipo:
• Pontual — Uma amostra é considerada um anomalia pontual quando se desvia do padrão
definido pelas restantes. Este é o tipo de anomalia mais simples. Na figura 2.3 a amostra
anómala o1 é do tipo pontual. Um exemplo em telecomunicações é quando o utilizador tem
um custo médio de chamada X e surge uma chamada com o valor de Y em que Y » X. Esse
chamada é considerada uma anomalia pois o valor da chamada não apresenta uma relação
com a média das restantes.
• Contextual — Neste caso, uma amostra é apenas considerada uma anomalia dependendo
do contexto. Num dado contexto uma amostra pode ser considerada uma anomalia, num
entanto, para um contexto diferente a mesma amostra poderá não o ser. A definição do
contexto pertence á formulação do problema. Um exemplo de anomalia contextual é o caso
em que se compara o número de chamadas efetuadas ao dia por um utilizador que apenas
utiliza o telefone no contexto pessoal e outro no contexto empresarial. O primeiro tem
tendência a efetuar menos chamadas do que o segundo pelo que, um número elevado de
chamadas será considerado anómalo no caso do primeiro utilizador e normal no caso do
segundo.

2.2 Deteção de Anomalia 11
• Coletiva –Uma anomalia coletiva representa um subconjunto de dados que são consideradas
anomalias pelo desvio que juntos apresentam do padrão definido pelos restantes. Neste caso
o subconjunto dos dados pode ser considerado anómalo, mas individualmente cada amostra
poderá não o ser.
2.2.2 Rotulagem de Dados
A rotulagem de dados é o processo de identificar dados anomolos ou normais. O processo
é muitas das vezes feito por um humano o que muitas vezes se reflete em escassez de dados
rotulados, ou mesmo mal rotulado.Hilas (2009)
Ao aplicar uma técnicas de deteção de anomalias, os dados podem ter vários tipos de rotula-
gem. Assim, as técnicas existentes são do tipo:
• Supervisionadas — Na deteção de anomalias supervisionada, para construção do modelo
foram utilizadas instâncias já rotuladas. Este tipo de dado são úteis em modelos de previsão.
Qualquer amostra que não esteja rotulada terá de passar pelo modelo desenhado para a sua
rotulagem.O problemas deste tipo de rotulagem devem-se: à quantidade de dados anómalos
nas amostras de treino é muito reduzida comparativamente aos normais; para obter rótu-
los precisos para dados anómalos é necessária a intervenção humana, o que pode ser um
trabalho esgotante;
• Semi-Supervisionas — Na deteção de anomalias semi-supervisionada assume-se que ape-
nas as amostras normais estão rotuladas. Neste caso é normal usar as amostras rotuladas
para contruir o modelo, e utilizar as não rotuladas para validar o modelo.
• Não Supervisionadas — Na deteção de anomalia não supervisionada as amostras não estão
rotuladas. Estes modelos funciona sob o princípio de que a quantidade de instâncias normais
é muito superior às anómalas.
2.2.3 Técnicas Baseadas em Clustering
O clustering é utilizado para juntar instâncias de dados que sejam semelhantes num grupo.
Esses grupos são chamados de clusters. Normalmente o primeiro passo nesta técnica passa pela
aplicação de um algoritmo de clustering para agrupar os dados em clusters e depois é feita avalia-
ção segundo as seguintes principios:
• Instâncias normais pertencem a um cluster e anomalias não — neste caso é recomendado
que o algoritmo de clustering utilizado não force todas as instâncias a pertencer a um cluster;
• Instâncias normais estão mais perto do centroid do cluster e anomalias mais longe —
é calculada a distância de um instância ao centroid do cluster e é atribuído um score á
anomalia ;

12 Estado da Arte
• Instâncias normais pertencem a clusters mais densos, enquanto que instâncias anoma-las são inseridas em clusters menos densos — para definir um cluster como anómalo ou
normal é utilizado um valor de threshold que determina o valor no qual a densidade de um
passa de um valor normal para um anómalo;
As vantagens desta abordagem são:
• Não requer dados rotulado ou seja, sem supervisão;
• Funciona com vários tipos de dados;
• As clusters podem ser consideradas um resumo dos dados;
• Após obter as clusters, o processo de deteção é uma simples comparação entre os objetos e
a cluster;
As desvantagens:
• Técnicas de clustering podem ser bastante demorados e dispendiosos computacionalmente;
• Dependem de um bom resultado no processo de clustering;
• Existem métodos que forçam todas as instâncias a pertencerem a uma cluster;
2.2.4 Técnicas Baseadas em Vizinho Mais Próximo
As técnicas de vizinho mais próximo funcionam sobre o principio de que "As instâncias nor-
mais aparecem em vizinhanças mais próximas e as anomalias em vizinhanças mais distantes". O
conceito de vizinhança é definido como a distância que se observa entre os dados. A distância
está relacionada com a semelhança entre os dados. Quanto menor a distância, maior a semelhança
entre duas instâncias. Os dois métodos utilizados por esta técnica para medir o score da anomalia
são:
• A distância ao Kth vizinho mais próximo — Quando se aplica este método, a compo-
nente que define o score da anomalia é a distância ao Kth vizinho mais próximo. Instâncias
mais distantes dos seus vizinhos mais próximos, comparativamente a outras, são candida-
tas à classificação de anómalas. Existem algumas variantes deste processo que não serão
relevantes para este estudo.
• A densidade relativa de cada instância — Neste caso, a variável que define o score da
anomalia é a densidade relativa calculada entre a instância e as suas vizinhas. Instâncias que
estão em vizinhanças menos densas são candidatas à classificação de anómalas;
As vantagens desta abordagem são:
• Tal como as técnicas de clustering, também estas não requerem dados rotulados ou seja, não
supervisionadas;

2.2 Deteção de Anomalia 13
• Técnicas semi-supervisionadas funcionam melhor do que não supervisionadas, pois a pro-
babilidade de um anomalia formar uma vizinhança é muito reduzida necessitando de dados
que permitam a associção;
• Permite a adaptação a outro tipo de dados, alterando apenas a forma como é medida a
distância;
As desvantagens são:
• Em técnicas não supervisionadas, as instâncias normais com poucos vizinhos ou anómalas
com muitos vizinhos serão mal classificadas;
• Em técnicas semi-supervisionadas, se uma instância normal não tiver outras instâncias se-
melhantes, então o resultado obterá uma taxa alta de falso positivos;
• Complexidade computacional é elevada e depende do algoritmo utilizado para medir a dis-
tância;
2.2.5 Técnicas Estatiticas
Nestas técnicas, para deteção de anomalia é utilizada uma abordagem estatística. Assume-se
que a probabilidade de uma instância ser normal, ocorre na região de grande probabilidade do
modelo estocástico, enquanto as instâncias anómalas encontram-se na zona de baixa probabili-
dade. Assim, é desenhado um modelo estatístico dimensionado para os dados a analisar. Depois
efetua-se testes de inferência estatística sobre instâncias ainda não analisadas para verificar se es-
tas pertence ao modelo ou não. Instâncias com baixa probabilidade de pertencerem a este modelo
serão consideradas anómalas.
A distribuição de probabilidades pode ser de dois tipos:
• Paramétricas — Assume-se que os dados normais são gerados por uma distribuição para-
métrica. Este inclui distribuição gaussiana, modelos de regressão, distribuição exponencial
etc. Também é possível utilizar vários modelos de distribuição paramétrica como duas dis-
tribuições gaussianas com valor médio diferente.
• Não-Paramétricas — Neste caso o modelo estatístico não é construído a priori, mas sim
construído a partir dos dados. Existem aplicações deste modelo com dados baseados em
histogramas e funções de kernel.
As vantagens desta abordagem são:
• O score da anomalia para cada objeto obtido com esta técnica está associado a um intervalo
de confiança;
• Se na etapa de estimativa da distribuição a distribuição for robusta relativamente aos dados
de teste, então esse modelo está apto para operar de forma não supervisionada;

14 Estado da Arte
As desvantagens são:
• Assume que os dados estão sobre uma distribuição probabilística específica, ou conjunto de
distribuições;
• Apesar da facilidade em implementar técnicas não paramétricas baseadas em histogramas,
estas não conseguem interpretar relações entre variáveis;
2.2.6 Técnicas Baseadas em Classificação
Nas técnicas de classificação, a deteção de anomalias é feita pela aplicação de um modelo
de classificação. Utiliza-se o conjunto de dados de treino supervisionados para a construção de
um modelo deteção de anomalias e posteriormente, testa-se o modelo a um conjunto de dados
de teste, também supervisionados, verificando assim a validade desse do modelo. Um modelo é
considerado válido se conseguir colocar os dados na classe correta.
As classes estão divididas em duas categorias:
• Uni-classe — As instâncias normais pertencem a apenas uma classe;
• Multi-classe — As instâncias normais pertencem a várias classes;
As técnicas de classificação são podem ser dos seguintes tipos:
• Redes Neuronais — modelo computacional que tem a capacidade de "aprender"padrões
através de treino. Para este modelo ter a capacidade de detetar anomalias, primeiro treina-se
a rede com os dados de treino para esta aprender as diferentes classes normais, ou classe (no
caso de uni-classe). Depois aplica-se os dados de teste e verifica-se se o modelo consegue
separar as instâncias anómalas das normais;
• Redes de Bayes — detetam anomalias com recurso á estimativa de probabilidade de obser-
var uma classe, de um conjunto de classes normais ou anómalas, a partir de uma instância
de teste. A classe com maior probabilidade de ser escolhida é considerada a classe teste;
• SVM — esta metodologia utiliza os dados de treino para detetar os limites que definem a
zona da classe normal. Depois, aplicam análise de regressão não probabilistica para clas-
sificar cada instância colocada à sua entrada. Uma instância é considerada anómala se não
estiver nessa zona;
• Regras — um modelo baseado em regras é desenhado para que as regras aprendidas consi-
gam identificar o comportamento normal do sistema. Para extração dessas regras, utiliza-se
um algoritmo como árvores de decisão sobre os dados de teste. Ao aplicar o modelo, se uma
instância não estiver dentro dessas regras, então, é considerada anómala. Esta técnica tem
aplicações em classe da categoria uni-classe.
As vantagens desta abordagem são:

2.2 Deteção de Anomalia 15
• Técnicas de Classificação podem utilizar algoritmos muito flexíveis e poderosos, especial-
mente, quando aplicados a mutli-classes;
• A fase de teste é bastante rápida pois apenas tem de se comparar cada instância a um modelo;
As desvantagens são;
• Como é uma técnica supervisionada esta dependem de uma rotulagem eficaz;
2.2.7 Árvores de Decisão
Os algoritmos de árvores de decisão são utilizados para a extração de regras no âmbito das
técnicas de classificação. No caso da deteção de fraude, são utilizados para definir os valores
críticos que separam comportamentos normais de fraudulentos.
Estes algoritmos utilizam uma metodologia de divide-and-conquer, isto significa que os dados
são divididos constantemente e em cada iteração o algoritmo tenta maximizar o ganho de infor-
mação. Cada nó na árvore é um teste a um atríbuto dos dados. O teste consiste na comparação do
atributo com uma constante ou com outro atributo. Assim, os objetos (instâncias) são associados
aos nós de acordo com o valor dos seus atributos. Se todos os objetos pertencerem á mesma classe,
então o processo termina e é gerada uma folha (nó terminal). O objetivo deste processo é obter
folhas mais puras possíveis ou seja, a folha define de forma precisa os objetos a sí associados.
Este processo pode resultar em árvores de dimensão muito grande e complexa. Como con-
sequência a árvore tem tendência a perder a sua capacidade de generalizar dados similares. Um
processo para reduzir o tamanho e a complexidade da árvore é uma técnica denominada por poda.
Este processo é iterativo e têm como objetivo a substituição de algumas subárvores por folhas
mantendo-se a eficácia da àrvore. Outro processo é o cross-validation onde o conjunto de dados
de treino é divido em N porções de tamanho igual. O algoritmo é então testado N vezes, sendo que
em cada iteração é retirada uma das N porções e é feita a construção da árvore com os restantes
dados do conjunto. A porção retirada é depois utilizada para testar a árvore. No fim das itera-
ções foram geradas N árvores das quais é escolhida a que maior precisão ofereceu durante todo o
processo.
O desempenho da árvore é avaliado pelo número de classificações verdadeiras e falsas. Os
dois parâmetros que são utilizados normalmente são o recall e a precision. O recall é a numero de
verdadeiro-positivas (VP). A precision denominada pelo numero de classifcações corretas sobre o
numero total de classificações (VP/(VP+FP), em que FP significa a taxa falso-positivas ). O valor
da performance é então dado por:
per f ormance =2∗ recall ∗ precision
recall + precision(2.1)
O autor Hilas e Sahalos (2007) estudou a aplicação de árvores de decisão para a extração
de regras em fraude de telecomunicações. Para a construção da árvore foi utilizado o algoritmo
C4.5. Para a etapa experimental o autor construiu 4 árvores distintas a análise semanal de 3 para

16 Estado da Arte
a análise diária. Na etapa de classificação foram analisadas 20.000 onde a análise das 4 primeiras
resultaram numa média de 85% de classificações corretas e a 3 seguintes 65%.
2.3 Data Mining Aplicado à Deteção de Fraude
Os dados gerados pelas operadoras de telecomunicações são os mais interessantes para apli-
cações de data mining devido á sua grande quantidade.Farvaresh e Sepehri (2011).
Data mining é o um processo que permite obter extrair conhecimento não explicito de dados
Phua et al. (2010). O seu processo convencional consiste em 5 passos: Han et al. (2006)
• Limpeza e Integração dos Dados - combinação dos dados de múltiplas fontes e remoção
de ruído e dados considerados redundantes e inúteis;
• Seleção e Transformação dos Dados - selecionar os dados que são relevantes para a tarefa,
e preparação dos dados para o modelo de data mining. Podem ainda ser feitas operações
sobre dados para gerar novos atríbutos;
• Data Mining - processo utilizado para extrair novo conhecimento dos dados. Neste mó-
dulo são utilizados as técnicas referênciadas anteriormente para remover padrões ou outras
informações dos dados;
• Avaliação - analisa os resultados do processo de data mining e verfica se estão de acordo os
objetivos definidos no início do processo;
• Apresentação de Conhecimento - apresenta os resultados ao utilizador. A apresentação
depende da estrutura e pode ser do tipo visual ou na forma de novos dados para um novo
processo de data mining;
Existem ainda outras derivações do método convencional. Um exemplo muito interessante é
o CRISP-DM Chapman et al. (2000). CRISP-DM é tentativa de formalizar o processo de data
mining a nível empresarial. Este processo é composto por 6 passos:
• Compreensão do Negócio - definição dos objetivos numa perspetiva empresarial. Conver-
são desses objetivos para um problema de data mining;
• Compreensão dos Dados - familiarização inicial com os dados, determinar a qualidade dos
dados, descobrir possíveis subconjuntos e formular hipóteses aplicáveis sobre dados;
• Tratamento dos Dados - preparação do conjunto de dados que serão utilizado no passo de
"Modulação". Inclui limpeza, seleção, integração e transformação dos dados;
• Modulação - aplicação das técnicas de modulação aos dados para atingir os objetivos espe-
cificados;
• Avaliação - avalia e revê todos os passos efetuados anteriormente. Além disso, verificação
se os objetivos definidos no inicio do processo estão a ser atingidos;

2.3 Data Mining Aplicado à Deteção de Fraude 17
• Lançamento - fase final do processo. Organização do conhecimento gerado de forma a
que o utilizador consiga utilizá-lo. O lançamento poderá ser um simples relatório ou um
conjunto de dados que alimentarão outro processo de data mining;
Apesar dos passos apresentarem uma ordem bem definida é por vezes necessário retroceder
ou repetir vários passos para atingir o resultado mais satisfatório.
Na maioria dos trabalhos de data mining aplicado à deteção de fraudes em telecomunicações, o
objetivo é a deteção de fraude de superimposição Fawcett e Provost (1997)Hilas (2009) ou fraude
subscrição Estévez et al. (2006)Farvaresh e Sepehri (2011), pois são estes que mais dano têm
causado às operadoras de telecomunicações.
2.3.1 Dados
A realização de estudos nesta àrea nem sempre é facil, pois uma operadora não pode livremente
disponibilizar dados sobre os seus utilizadores devido a acordos de privacidade entre a operadora
e os seus clientes. Os dados que são utilizados normalmente como objeto de estudo são os CDR
(Call Details Record) Kou e Lu (2004); Rosas e Analide (2009); Estévez et al. (2006); Hilas e
Sahalos (2007); Hilas (2009); Farvaresh e Sepehri (2011); Augustin et al. (2012). Estes dados são
registos que as operadores efetua sempre que os utilizadores terminam a utilização de um serviço
da operadora. A estrutura destes dados é basicamente a seguinte:
• Identificação do chamador (emissor) e chamado (recetor);
• Data e Hora;
• Tipo interação (Chamada de Voz, SMS, etc...) ;
• Duração da Interação;
• Identificação dos Nós de acesso á rede;
• Outros;
Pode-se observar que estes dados não comprometem a identidade ou os conteúdos trocados
entre utilizadores,não violando assim nenhum acordo de privacidader. Este fator também dificulta
a trabalho de user profiling, que iremos discutir mais à frente.
2.3.2 User Profiling
Na maioria das técnicas de deteção de fraude desenvolvidas, os autores optam por usar mode-
los de user profiling para a descrever o comportamento dos utilizadores Fawcett e Provost (1996);
Kou e Lu (2004); Hilas e Sahalos (2007); Rosas e Analide (2009). User profiling, consiste em
observar os dados de um utilizador e desenvolver um modelo de representação do seu comporta-
mento. Posteriormente, utiliza-se este modelo em técnicas de deteção de anomalia.

18 Estado da Arte
Este modelos necessitam de uma capacidade adaptativa para poderem manter todo o seu po-
tencial Fawcett e Provost (1997). Isto significa que o modelo tem de ser constantemente atualizado
à medida que novos comportamentos são avaliados, pois o utilizador que esta modelado não terá
sempre os mesmo comportamentos.
A precisão desta solução é dependente da qualidade dos dados utilizados para o profiling. Os
CDR’s, descritos anteriormente, são bastante uteis para a construção de modelos comportamentais.
No entanto, para aumentar a precisão do modelo era bastante útil obter mais informações sobre os
utilizadores, o que é notoriamente difícil.
2.3.3 Aplicações Baseadas em Regras
Os autores Fawcett e Provost (1997), apresentam um método de deteção de fraude de supe-
rimposição baseado em regras. Os autores utilizam um conjunto de regras adaptativas para obter
indicadores de comportamento fraudulento dos dados. Esses indicadores são utilizados para a
construção de monitores. Os monitores definem perfis de utilizadores fraudulentos e são utiliza-
dos na entrada de um módulo de análise, o deteto rFawcett e Provost (1996). O detetor combina
os vários monitores com os dados gerados ao longo de um dia por um utilizador, e gera alarmes
de alta confiança.
Augustin et al. (2012) desenvolveram um sistema de deteção de fraude para redes de nova
geração. O sistema é composto por dois módulos, um de interpretação e um de classificação. No
módulo interpretação os CDR’s são analisados e convertidos em objetos de CDRs que servirão
para alimentar o módulo de classificação. O módulo de classificação analisa os objetos CDR atra-
vés da aplicação de filtros, os quais eram compostos por regras em que os tresholds associados
foram obtidos pela avaliação de casos de fraudulento. Na eventualidade de um objeto não respeitar
as regras presentes num dos filtros, era gerado um alarme. O autor não disponibilizou a percenta-
gem de deteção de fraude conseguida no entanto, a taxa de deteções falso-positivas era cerca de
4% .
2.3.4 Aplicações Baseadas em Redes Neuronais
No sistema desenvolvido pelos autores Michiaki Taniguchi, Michael Haft, Jaakko Hollmén
(1998) são usadas técnicas de redes neuronais supervisionadas, estimativas de densidade não su-
pervisionadas e redes de bayes. As redes neuronais são utilizadas para fazer uma classificação
dos utilizadores através de valores estatísticos. As estimativas de densidade são utilizadas para
a previsão da evolução dos comportamentos. Para tal é utilizada Gaussian-mixture density para
modelar o comportamento passado dos utilizadores de forma a que a probabilidade de um com-
portamento atual possa ser calculado, isto também possibilita a deteção de anomalias vindas de
comportamentos passados. No fim, as redes de bayes descrevem as estatísticas de um utilizador e
as estatísticas de diferentes casos de fraude, possibilitando obter a probabilidade de fraude dado
o comportamento de um utilizador. Segundo o autor este sistema foi capaz de detetar 85% dos
fraudadores num caso de estudo sem nenhum falso alarme.

2.3 Data Mining Aplicado à Deteção de Fraude 19
2.3.5 Híbrido
O trabalho desenvolvido pelos autores Moreau et al. (1996); Burge et al. (1997) no âmbito de
um projeto para Comissão Europeia, ASPeCT, estuda a possibilidade de detetar comportamento
fraudulento através de regras e redes neuronais, ambas de forma supervisionada e não supervisio-
nada. Os dados utilizados são provenientes de um servidor de emissão de tickets de uma operadora.
O objetivo deste estudo era desenvolver um sistema que fosse concretizável.
Um exemplo de uma aplicação que utiliza ambas as técnicas (Regras e Redes Neuronais)
é o modelo desenvolvido para a previsão de fraude de subscrição pelos autores Estévez et al.
(2006). Este modelo é composto por 2 módulos, um de classificação e outro de previsão. No
módulo de classificação são utilizadas regras (neste caso árvores de decisão) para a análise dados
de utilizadores, atribuído a cada um uma de quatro possíveis classificações: fraudulento, outrora
fraudulento, insolvente e normal. No módulo de previsão é utilizado um uma rede neuronal de
múltiplas camadas que têm como o objetivo identificar se um novo pedido para instalação de um
linha telefónica corresponde a uma fraude ou não. No resultados o módulo de classificação teve
uma taxa sucesso de 100% e o módulo de previsão identificou 56.2% dos verdadeiros fraudadores.
Outro exemplo é o sistema desenvolvido por Farvaresh e Sepehri (2011) para a deteção de
fraude de subscrição. Este sistema é composto por 3 módulos: pré-processamento de dados, clus-
tering e classificação. No pré-processamento de dados é feita a interpretação e limpeza dos dados,
equivalente aos dois primeiros passos de data mining descritos anteriormente. Após o tratamento,
os dados não rotulados, são transferidos para o módulo de clustering. No clustering são aplicados
os algoritmos de clustering SOM e k.means de forma a agrupar os dados em clusters. Após o pro-
cesso de clustering os Clusters muito distantes de outros clusters, clusters com instâncias muito
divergentes e clusters de anomalias serão removidos com o objetivo de não comprometer a eficácia
da classificação. É também após o processo de clustering que os dados são rotulados. Na classifi-
cação, os dados são analisados por classificadores de árvores de decisão (Regras - algoritmo C4.5),
redes neuronais e SVM. Os classificadores apresentam vários esquemas de construção como: bag-
ging, boosting, stacking, majority and consensus voting. No fim da fase de classificação, é avaliada
a performance entres classificadores em cada construção. Num caso experimental, o autor testou
o modelo com os dados de 8 períodos de 2 meses, de 25.000 clientes. Os resultados variaram
de acordo com os esquemas de construção dos classificadores ou com a omissão de passos no
processo, no entanto a média dos resultados foi superior a 90% de deteção.
2.3.5.1 Outras aplicações
Os autores Cox et al. (1997) afirmam que as técnicas de visualização baseadas em reconhe-
cimento de padrões humanos, podem oferecer uma grande vantagem na deteção de fraude com-
parativamente ao algoritmos computacionais, isto porque, os sistemas de visualização humano
têm maior dinamismo e adaptabilidade, conseguindo acompanhar de forma natural a evolução dos
comportamentos fraudulentos. Estes sistemas baseia-se na apresentação gráfica dos dados para
posteriormente análise humana.

20 Estado da Arte
Hollmén e Tresp (1999) apresentam uma solução de deteção de fraude em tempo real baseada
em chamadas. Este sistema baseia-se num modelo de mudança de regime hierárquico. Na fase
de treino é utilizado o algoritmo EM e as regras de inferência são derivadas de algoritmos de
árvores de junção não supervisionados Hollmén (1999). Para refinar os resultados, é utilizado
uma técnica de discriminação baseada em gradientes supervisionada. Para o modo online esta
aplicação obteve probabilidades de deteção de 97.4% e 92.8% para os dados de treino e dados
de teste, respetivamente. A probabilidade de falso-positivas definida no início do processo foi de
0.3% para o treino e 2% para o teste.
2.3.6 Melhorias
Os autores Rosas e Analide (2009) desenvolveram um método baseado em profiling e KDD
num ambiente multi-agent para obter melhor desempenho de um sistema de deteção de fraude.
Este método utiliza os resultados de um sistema já implementado e tenta descobrir novos tipos de
fraude.
Os autores Hilas (2009) desenvolveram uma metodologia para a construção de um sistema de
deteção de fraude de superimposição dentro da rede de uma empresa. Para tal são utilizados os
conhecimentos do administradores da rede e métodos de data mining já desenvolvidos.

Capítulo 3
Plano do Projeto
Neste capitulo são ilustradas tarefas que são necessárias para a concretização deste projeto.
3.1 Planeamento
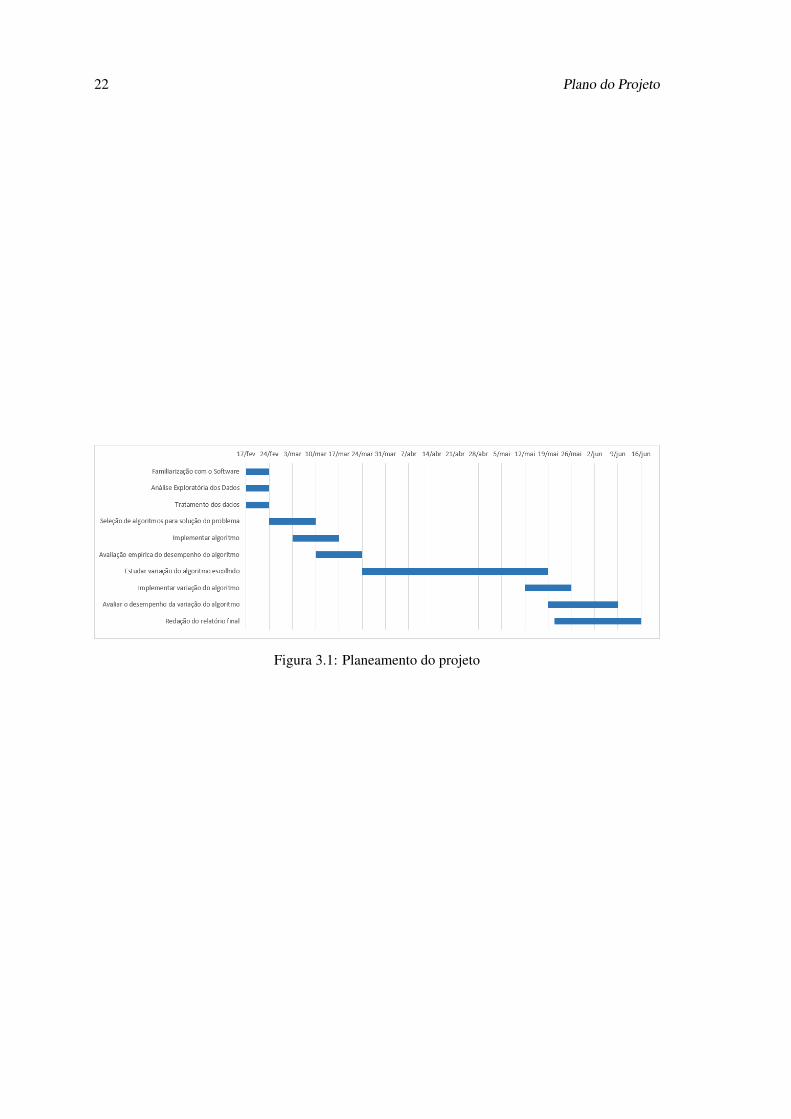
Como se pode observar na figura 3.1, o planeamento encontra-se dividido em dez tarefas
distintas que são:
• A Familiarização com o software utilizado para a implementação dos algoritmos, visualiza-
ção de resultado e outras;
• A análise exploratória dos dados que serão disponibilizados para a concretização deste ta-
balho;
• O tratamento dos dados, como produzir novos dados dos já existentes e eliminar dados
redundantes e insignificativos para o problema;
• Seleção de algoritmos para a solução do problema;
• Implementar o algoritmo;
• Avaliação empírica do desempenho do algoritmo;
• Propor variação do algoritmo escolhido, ou seja, descobrir uma forma de optimizar o algo-
ritmo para este problema;
• Implementar a variação do algoritmo;
• Avaliar o desempenho da variação do algoritmo;
• Redação do documento final;
21
22 Plano do Projeto
Figura 3.1: Planeamento do projeto

Referências
Simon Augustin, Carmen Gaiß er, Julian Knauer, Michael Massoth, Katrin Piejko, David Rihme Torsten Wiens. Telephony Fraud Detection in Next Generation Networks. In AICT 2012,The Eighth Advanced International Conference on Telecommunications, páginas 203–207,Maio 2012. ISBN 978-1-61208-199-1. URL http://www.thinkmind.org/index.php?view=article&articleid=aict_2012_8_50_10226.
Richard a. Becker, Chris Volinsky e Allan R. Wilks. Fraud Detection in Telecommunications:History and Lessons Learned. Technometrics, 52(1):20–33, Fevereiro 2010. ISSN 0040-1706.doi: 10.1198/TECH.2009.08136. URL http://www.tandfonline.com/doi/abs/10.1198/TECH.2009.08136.
C Breen e CA Dahlbom. Signaling systems for control of telephone switching. Bell SystemTechnical Journal, (September), 1960. URL http://onlinelibrary.wiley.com/doi/10.1002/j.1538-7305.1960.tb01611.x/abstract.
P Burge, J Shawe-Taylor e C Cooke. Fraud detection and management in mobile telecommu-nications networks. 1997. URL http://digital-library.theiet.org/content/conferences/10.1049/cp_19970429.
CFCA. Communications Fraud Control Association 2013 Global Fraud Loss Survey. 2013.
V Chandola, A Banerjee e V Kumar. Anomaly detection: A survey. ACM Computing Surveys(CSUR), 2009. URL http://dl.acm.org/citation.cfm?id=1541882.
P Chapman, J Clinton e R Kerber. CRISP-DM 1.0. CRISP-DM . . . , 2000. URLftp://ftp.software.ibm.com/software/analytics/spss/support/Modeler/Documentation/14/UserManual/CRISP-DM.pdf.
KC Cox, SG Eick, GJ Wills e RJ Brachman. Brief application description; visual data mining:Recognizing telephone calling fraud. Data Mining and Knowledge . . . , páginas 1–6, 1997. URLhttp://link.springer.com/article/10.1023/A:1009740009307.
PA Estévez, CM Held e CA Perez. Subscription fraud prevention in telecommunications usingfuzzy rules and neural networks. Expert Systems with Applications, 2006. URL http://www.sciencedirect.com/science/article/pii/S0957417405002204.
Hamid Farvaresh e Mohammad Mehdi Sepehri. A data mining framework for detecting subscrip-tion fraud in telecommunication. Engineering Applications of Artificial Intelligence, 24(1):182–194, 2011. URL http://www.sciencedirect.com/science/article/pii/S0952197610001144.
23

24 REFERÊNCIAS
T Fawcett e F Provost. Adaptive fraud detection. Data mining and knowledge disco-very, 316:291–316, 1997. URL http://link.springer.com/article/10.1023/A:1009700419189.
Tom Fawcett e FJ Provost. Combining Data Mining and Machine Learning for Effective UserProfiling. KDD, 1996. URL http://www.aaai.org/Papers/KDD/1996/KDD96-002.pdf.
J Han, M Kamber e J Pei. Data mining: concepts and techniques. 2006. ISBN 9781558609013.URL http://books.google.com/books?hl=en&lr=&id=AfL0t-YzOrEC&oi=fnd&pg=PP2&dq=Data+Mining+Concepts+and+Techniques&ots=Uv-SwNfly7&sig=QLl8mafRBS2Djnd8Px4eLUNItdk.
Constantinos Hilas e John Sahalos. An application of decision trees forrule extraction towards telecommunications fraud detection. 2007. URLhttp://sfx.fe.up.pt/feup?sid=EI:Compendex&issn=0302-9743&date=2007&volume=4693&issue=2&spage=1112&epage=1121&title=LectureNotesinComputerScience(includingsubseriesLectureNotesinArtificialIntelligenceandLectureNotesinBioinformatics)&atitle=Anapplicationofdecisiontreesforruleextractiontowardstelecommunicationsfrauddetection&aulast=Hilas&aufirst=ConstantinosS.
Constantinos S. Hilas. Designing an expert system for fraud detection in private telecom-munications networks. Expert Systems with Applications, 36(9):11559–11569, 2009. URLhttp://www.sciencedirect.com/science/article/pii/S095741740900284X.
VJ Hodge e Jim Austin. A survey of outlier detection methodologies. Artificial IntelligenceReview, 22:85–126, 2004. URL http://link.springer.com/article/10.1007/s10462-004-4304-y.
J Hollmén. Probabilistic approaches to fraud detection. Licentiate’s Thesis, Helsinki University ofTechnology, . . . , 1999. URL http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.33.1130&rep=rep1&type=pdf.
Jaakko Hollmén e V Tresp. Call-Based Fraud Detection in Mobile Communication NetworksUsing a Hierarchical Regime-Switching Model. Advances in Neural Information Proces-sing . . . , 1999. URL http://pdf.aminer.org/000/515/763/call_based_fraud_detection_in_mobile_communication_networks_using_a.pdf.
Edward Hung e DW Cheung. Parallel algorithm for mining outliers in large database. Proc. 9thInternational Database Conference (IDC’ . . . , 1999. URL http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.117.1575&rep=rep1&type=pdf.
Yufeng Kou e CT Lu. Survey of fraud detection techniques. . . . , sensing and control, . . . ,páginas 749–754, 2004. URL http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1297040.
Volker Tresp Michiaki Taniguchi, Michael Haft, Jaakko Hollmén. Fraud detection in communica-tions networks using neural and probabilistic methods. In In Proceedings of IEEE InternationalCon- ference in Acoustics, Speech and Signal Processing Vol. 2. IEEE Computer Society, vo-lume II, páginas 1241–1244. 1998.

REFERÊNCIAS 25
Yves Moreau, PBJ Shawe-taylor e C Stoermann. Novel techniques for fraud detection in mobiletelecommunication networks. 1996. URL http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.48.1207.
Animesh Patcha e Jung-Min Park. An overview of anomaly detection techniques: Existingsolutions and latest technological trends. Computer Networks, 51(12):3448–3470, Agosto2007. ISSN 13891286. doi: 10.1016/j.comnet.2007.02.001. URL http://linkinghub.elsevier.com/retrieve/pii/S138912860700062X.
Clifton Phua, Vincent Lee, Kate Smith e Ross Gayler. A comprehensive survey of data mining-based fraud detection research. arXiv preprint arXiv:1009.6119, 2010. URL http://arxiv.org/abs/1009.6119.
E Rosas e Cesar Analide. Telecommunications Fraud: Problem Analysis-an Agent-basedKDD Perspective. epia2009.web.ua.pt, 2009. URL http://epia2009.web.ua.pt/onlineEdition/402.pdf.





























