Embed Size (px)
Citation preview

UNIVERSIDADE PAULISTA – UNIP
PROGRAMA DE DOUTORADO EM ENGENHARIA DE PRODUÇÃO
PROPOSTA DE UM MODELO DE AVALIAÇÃO DE
DESEMPENHO DE ALUNOS DE UMA IES
UTILIZANDO A INTELIGÊNCIA COMPUTACIONAL
Tese apresentada ao Programa de Pós-Graduação, em Engenharia de Produção da Universidade Paulista – UNIP para a obtenção do título de Doutor em Engenharia de Produção.
FERNANDO JOSÉ ALHO GOTTI
SÃO PAULO 2013

UNIVERSIDADE PAULISTA – UNIP
PROGRAMA DE DOUTORADO EM ENGENHARIA DE PRODUÇÃO
PROPOSTA DE UM MODELO DE AVALIAÇÃO DE
DESEMPENHO DE ALUNOS DE UMA IES
UTILIZANDO A INTELIGÊNCIA COMPUTACIONAL
Tese apresentada ao Programa de Pós-Graduação, em Engenharia de Produção da Universidade Paulista – UNIP para a obtenção do título de Doutor em Engenharia de Produção.
Orientador: Prof. Dr. Ivanir Costa
Área de Concentração: Redes de Empresas e Planejamento da Produção.
FERNANDO JOSÉ ALHO GOTTI
SÃO PAULO
2013

Gotti, Fernando José Alho. Proposta de um modelo de avaliação de desempenho de alunos de uma IES
utilizando a inteligência computacional /Fernando José Alho Gotti - 2013. 109 f. : il. color. + CD-ROM.
Tese de doutorado apresentada ao Programa de Pós Graduação em Engenharia de Produção da Universidade Paulista, São Paulo, 2013.
Área de Concentração: Redes de Empresas e Planejamento da
Produção.
Orientador: Prof. Dr. Ivanir Costa.
1. Gestão acadêmica. 2. Inteligência computacional. 3. Redes neurais,
artificiais. 4. Algoritmos genéticos. I. Título. II. Costa, Ivanir (orientador).

FERNANDO JOSÉ ALHO GOTTI
PROPOSTA DE UM MODELO DE AVALIAÇÃO DE
DESEMPENHO DE ALUNOS DE UMA IES
UTILIZANDO A INTELIGÊNCIA COMPUTACIONAL
Tese apresentada ao Programa de Pós-Graduação, em Engenharia de Produção da Universidade Paulista – UNIP para a obtenção do título de Doutor em Engenharia de Produção.
Aprovado em:
BANCA EXAMINADORA
_______________________/__/___ Prof. Dr Ivanir Costa - Orientador
Universidade Paulista – UNIP
_______________________/__/___ Prof. Dr Mario Mollo Neto
Universidade Paulista – UNIP
_______________________/__/___ Prof. Dr Rodrigo Franco
Universidade Paulista – UNIP
_______________________/__/___ Prof. Dr Elcio Hideiti Shiguemori
Instituto de Estudos Avançados – IEAv/CTA
_______________________/__/___ Prof. Dr Paulo Tadeu de Melo Lourenção
Universidade do Vale do Paraíba - UNIVAP

DEDICATÓRIA
A meus familiares:
Meu pai Nivaldo Gotti,
À minha mãe Maria Dulce – (in memorian),
À minha esposa Júnia e à minha filha Mariana, pois, sem o seu apoio, paciência,
dedicação e amor incondicionais, não seria possível chegar até aqui, pois, muitas
vezes foram privados da minha presença, ao longo desta jornada.

AGRADECIMENTOS
Agradeço a Deus, pois com ELE tudo é possível.
Ao Professor Dr. Ivanir Costa, pela amizade, dedicação e a paciência, com
que conduziu o processo de orientação e aprendizagem.
Ao Professor Dr. Oduvaldo Vendrameto, pela humildade e simpatia
conseguindo cativar a todos que o conhecem.
Ao amigo Elcio Hideiti Shiguemori, pela enorme contribuição e dedicação
neste desafio.
Ao bolsista do CNPQ/PIBIC André Matias, que soube a partir de uma ideia
fazê-la tornar-se realidade, despendendo grande parte do seu precioso tempo.
Aos Professores do Programa de Pós Graduação, pela contribuição que
deram direta ou indiretamente.
Aos funcionários do programa, pela dedicação no pronto atendimento às
questões extra-classe.
E a todos os colegas e pessoas que direta ou indiretamente, participaram
desta fase do meu aprendizado.

RESUMO
A Gestão Acadêmica das Instituições de Ensino Superior no Brasil tem um grande
desafio, que é a obtenção de dados através da execução de processos manuais,
apesar da utilização de vários tipos de sistemas de controle acadêmico, que contam
com um grande volume de investimentos em Tecnologia da Informação. Existem
muitos indicadores disponíveis, tais como os indicadores disponibilizados pelo INEP
do Ministério da Educação referente o Exame Nacional de Cursos, ou então coletam
dados de diversas fontes, internas ou externas, com o intuito de subsidiar as
tomadas de decisões. Para que se possam verificar informações como, por exemplo:
desempenho de alunos por curso, turno ou ainda entre as diversas Instituições de
Ensino Superior. A verificação dessas informações torna-se importante para
identificar informações específicas referentes ao negócio. Em um sistema
informatizado, aplicando-se a Inteligência Computacional, encontram-se subsídios
que possam apontar o melhor caminho para essa análise dos resultados. Foi
desenvolvido um software para os testes chamado SCIAAD, que através da
aplicação de técnicas de uma Rede Neural Artificial, Perceptron de Múltiplas
Camadas, pela sua própria característica e quantidade dos dados disponíveis,
permite que se aprenda com o treinamento, gerando uma fonte mais confiável de
resultados. Nesse ponto os resultados foram testados a fim de validá-los de acordo
com o Ministério da Educação. Logo após a validação, são utilizados os Algoritmos
Genéticos para buscar dentre uma amostra com várias soluções, a melhor
combinação ou as melhores segundo esse processo. Ao final do estudo será gerado
um modelo que poderá ser aplicado a problemas semelhantes, permitindo uma
rápida tomada de decisões.
Palavras-chave: Gestão Acadêmica, Inteligência Computacional, Redes Neurais
Artificiais e Algoritmos Genéticos.

ABSTRACT
The academic management of institutions of higher education in Brazil has a big
challenge, which is to obtain data by performing full manual processes, while using
various types of academic control systems and have a large volume of investments
in information tecnology. There are many indicators available, such as the indicators
provided by the Ministry of Education, or collect data from various sources, internal or
external in order to support decision making. But often they only have aggregate data
on complex reports, analyzes where only individual data and analyze individual data
and eletronic spreadsheet. After that they can check information such as students
performance by course, between various institutions (benchmark). The analises of
this information becomes important to identify the specific relating business
information. In a computerized system such as Computational Intelligence, we intend
to obtain subsidies that could point out the best way for analysis of the results. A
software tool called SCIAAD – Computing Intelligence System applied to a Decision
Making, are developed to realize that, using a Artificial Neural Network, with
Multilayer Perceptron was chosen because of the characteristics and a amount of
available data. Allowing the learning from the training net, and creating a more
reliable source of income data. The tests, of the entered data acts in order to validate
the results according to Ministry of Education evaluators. After this validation, there
are used a Genethic Algorithm to search among a sample of several solutions, to
classify the best or more than one process. At the end of the study it will generate a
model that can be applied to similar problems.
Key-words: Academic Management, Computing Intelligence, Artificial Neural
Network and Genethic Algorithm.

LISTA DE ILUSTRAÇÕES
Figura 1 – Aplicação da IC em uma IES. .................................................................. 16
Figura 2 – IC nas avaliações das IES. ...................................................................... 16
Figura 3 – A representação de um Neurônio Humano. ............................................. 27
Figura 4 – Representação de uma rede PMC. .......................................................... 28
Figura 5 – Arquitetura perceptron de múltiplas camadas com duas camadas
ocultas. ...................................................................................................................... 29
Figura 6 – Fluxo de processamento do algoritmo de retropropagação do erro. ........ 30
Figura 7 – Gráficos das funções de ativação; (a) Função de limiar; (b) Função
linear. (c) Função Sigmóide. .................................................................................... 34
Figura 7 – Fluxograma de uma GA. .......................................................................... 37
Figura 9 – Rede Neural em avaliação. ...................................................................... 50
Figura 10 – Exemplo do erro de treinamento. ........................................................... 52
Figura 11 – Comparação dos resultados obtidos pela Rede Neural, com o resultado
dos Avaliadores. ....................................................................................................... 52
Figura 12 – Comparação dos resultados obtidos pela Rede Neural e os dos
Avaliadores. ............................................................................................................... 54
Figura 13 – Teste de Generalização da rede neural. ................................................ 57
Figura 14 – Tela de Introdução com as opções do SCIAAD. .................................... 59
Figura 15 – Tela da opção Treinar RNA. ................................................................... 59
Figura 16 – Tela para seleção do arquivo de exemplo a ser treinado. ...................... 60
Figura 17 – Tela para escolha da planilha a ser utilizada no treinamento. ................ 60
Figura 18 – Tela que identifica a planilha a ser utilizada. .......................................... 61
Figura 19 – Tela que solicita a escolha das características a serem treinadas. ........ 61
Figura 20 – Caixa de diálogo para confirmação da seleção dos dados a serem
utilizados. .................................................................................................................. 62
Figura 21 – Exemplo de Tabela ENADE a ser utilizado. ........................................... 62

Figura 22 – Tela com a seleção dos dados para a entrada e a saída. ...................... 63
Figura 23 – Tela exemplo do conjunto de validação. ................................................ 63
Figura 24 – Tela que apresenta os limites encontrados no conjunto de dados
escolhidos. ................................................................................................................ 64
Figura 25 – Parâmetros utilizados no treinamento. ................................................... 65
Figura 26 – Resultado obtido no treinamento da rede neural. .................................. 65
Figura 27 – Tela de ativação da RNA. ...................................................................... 66
Figura 28 – Exemplo de Tela com a seleção já feita e a resposta apresentada
segundo o aprendizado realizado. ............................................................................ 66
Figura 29 – Limites operacionais existentes na planilha escolhida. .......................... 67
Figura 30 – Parâmetros de otimização. ..................................................................... 68
Figura 31 – Dados a serem otimizados. .................................................................... 68
Figura 32 – Resultados da otimização. ..................................................................... 69

LISTA DE TABELAS
Tabela 1 – As principais tarefas que as RNAs podem executar e alguns exemplos de
aplicação. .................................................................................................................. 25
Tabela 2 – Dados de exemplo do ENADE ................................................................ 41
Tabela 3 – Características avaliadas pelo ENADE. .................................................. 49
Tabela 4 – Características avaliadas pelo Enade, continuação. ............................... 49
Tabela 5 – Conjunto de Treinamento da Rede Neural. ............................................. 50
Tabela 6 – Conjunto de Validação da Rede Neural. ................................................. 50
Tabela 7 – Conjunto de Generalização da Rede Neural. .......................................... 50
Tabela 8 – Erros obtidos nos testes de validação. .................................................... 52
Tabela 9 – Influência das características nas avaliações. ......................................... 53
Tabela 10 – Erros obtidos nos testes de validação. .................................................. 54
Tabela 11 – Dados ENADE de 16 Instituições. ......................................................... 55
Tabela 12 – Dados utilizados na validação cruzada. ................................................ 56
Tabela 13 – Dados utilizados nos testes de generalização. ...................................... 56
Tabela 14 – Erros obtidos nos testes de validação. .................................................. 56
Tabela 15 – Pesos da rede neural. ........................................................................... 57
Tabela 16 – Erros obtidos na generalização. ............................................................ 57
Tabela 17 – Tabela comparativa entre número de neurônios na camada escondida X
erro. ........................................................................................................................... 71
Tabela 18 – Dados a serem otimizados. ................................................................... 72
Tabela 19 – Classificação dos melhores resultados. ................................................ 73
Tabela 20 – Características que mais influenciaram a rede. ..................................... 74

LISTAS DE SIGLAS
eMEC – Portal do Ministério da Educação e Cultura que permite o preenchimento de
documentos eletrônicos;
EAD – Ensino a Distância;
ENADE - Exame Nacional de Desempenho dos Estudantes;
GA – Genetic Algorithm;
GUI – Graphics Users Interface (Interface gráfica do usuário);
IA – Inteligência Artificial;
IC – Inteligência Computacional;
IES – Instituição de Ensino Superior;
INEP – Instituto Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira;
KEA! – Software emulador multi terminal desenvolvido pela Attachmate Corporation;
LDB – Lei de Diretrizes e Bases da Educação;
MatLab – Matrix Laboratory (Software matemático para programação e execução de
operações com matrizes);
MEC – Ministério da Educação e Cultura;
PMC – Perceptron de Múltiplas Camadas;
RNA – Redes Neurais Artificiais;
SAD – Sistema de Apoio à Decisão;
SCIAAD – Sistema Computacional Inteligente de Avaliação e Apoio à Decisão;
SE – Sistemas Especialistas;
SINAES - Sistema Nacional de Avaliação da Educação Superior;
SISUN – Sistema Universitário (software de gestão acadêmica);
TI – Tecnologia da Informação;

SUMÁRIO
1 INTRODUÇÃO ................................................................................................... 13
1.1 Objetivos do Trabalho ..................................................................................... 17
1.2 Delimitação da Pesquisa ................................................................................ 17
1.3 Metodologia de Pesquisa Utilizada ................................................................. 17
1.4 Resultados Esperados .................................................................................... 18
1.5 Estrutura do Trabalho ..................................................................................... 18
2 FUNDAMENTAÇÃO TEÓRICA ......................................................................... 20
2.1 Modelo Proposto ............................................................................................. 23
2.2 As Redes Neurais Artificiais (RNAs) ............................................................... 24
2.2.1 Redes Perceptron de Múltiplas Camadas (PMC) ..................................... 28
2.2.2 Métodos de tratamento de erros............................................................... 30
2.2.3 Função de Ativação .................................................................................. 33
2.3 Algoritmos Genéticos (GAs) ........................................................................... 34
2.3.1 Histórico ................................................................................................... 35
2.3.2 População ................................................................................................ 36
2.3.3 Aptidão ..................................................................................................... 36
2.3.4 Crossover (Cruzamento) .......................................................................... 37
2.3.5 Mutação .................................................................................................... 37
3 METODOLOGIA ................................................................................................. 39
3.1 Obtenção e tratamento dos dados iniciais ...................................................... 40
3.1.1 Preparação dos dados para o treinamento da RNA ................................. 41
3.1.2 Características da RNA ............................................................................ 42
3.1.3 Treinamento da RNA ................................................................................ 42
3.1.4 Característica do Algoritmo Genético ....................................................... 43
3.1.5 Método utilizado para os testes do algoritmo ........................................... 45
4 ESTUDO DE CASO............................................................................................ 47
4.1 1º Conjunto de treinamento ............................................................................ 48
4.2 2º Conjunto de treinamento ............................................................................ 54
4.3 3º Conjunto de treinamento ............................................................................ 58

5 CONCLUSÃO ..................................................................................................... 75
REFERÊNCIAS ......................................................................................................... 77
ANEXOS ................................................................................................................... 81
Anexo A – Tabela Enade 2011_103 x 23 ............................................................... 81
Anexo B – Tabela dos resultados calculados ........................................................ 85
Anexo C - Arquivos do SCIAAD ............................................................................. 89
Anexo D – Conjunto de treinamento da RNA ......................................................... 90
Anexo E – Dados totais de treinamento ................................................................. 92
Anexo F - Aplicação de redes neurais na avaliação de bens ................................. 93
Anexo G - Aplicação de redes neurais na análise e na concessão de crédito ao
consumidor ............................................................................................................ 94
Anexo H – Descrição das variáveis do sistema ..................................................... 95
Anexo I - Aceite Congresso Internacional - VII ICECE 2011 .................................. 97
Anexo J – Comprovante de publicação no XVIII ICIEOM 2012 ............................. 98
Anexo I – Comprovante ICPR 22 ........................................................................... 99
Anexo K – Revista Tema ..................................................................................... 102
Anexo L – Tabela com a evolução das características avaliadas ........................ 103

13
1 INTRODUÇÃO
Com a globalização, as transformações significativas ocorrem nas
organizações, para sua sobrevivência. A necessidade da alta administração de uma
Instituição de Ensino Superior (IES) não difere muito de uma organização ou
empresa comum, possuindo as mesmas prerrogativas quanto às condições de
gestão e tomada de decisões.
Algumas empresas brasileiras possuem em seus sistemas administrativos,
execuções de processos manuais, apesar de apresentarem um grande índice de
automação, com vários tipos de processos e sistemas de controle, culminando com
grandes investimentos em Tecnologia da Informação (TI) em sua Gestão, Meireles
(2011). As IES não diferem muito dessa realidade, pois possuem um grande número
de indicadores disponíveis em seus sistemas ou têm grande possibilidade de coletar
os dados de diversas fontes, com o intuito de subsidiar as tomadas de decisões,
Silva (2009).
Muitas vezes essas fontes somente disponibilizam dados globais, em
relatórios complexos, em que análises individualizadas e o planilhamento dos dados
possibilitam apresentar as informações, tais como se apresentam, como no exemplo:
desempenho de alunos por turma, turno ou uma combinação dessas, em
comparação entre as diversas IES (benchmark) como, por exemplo, desempenho de
alunos de um determinado curso das diversas IES de uma região ou cidade. A
verificação e análise destas informações tornam-se importantes para a identificação
das principais e as específicas, mais voltadas às características do negócio, Braga,
(2011).
Com a necessidade de processamento de grandes quantidades de dados
para extração de informações e tomada de decisão, o uso de técnicas de
Inteligência Computacional (IC), surge como uma ótima estratégia para
desempenhar esse papel. Em um sistema informatizado, a IC busca imitar o
comportamento humano, inspirando-se em técnicas naturais. A IC ou Inteligência
Artificial (IA) envolve a utilização de métodos baseados no comportamento
inteligente de humanos e outros animais para solucionar problemas complexos,
Braga (2011).

14
Dentro dessa área, há várias técnicas inspiradas na natureza como: a Rede
Neural Artificial (RNA), (Haykin, 2008; Coppin, 2010), a Lógica Fuzzy (Fuzzy),
Coppin (2010), os Sistemas Especialistas (SE), (Coppin, 2010; Meireles, 2012) e os
Algoritmos Genéticos (GA) (Linden, 2011; Coppin, (2010).
As Redes Neurais Artificiais (RNAs) ou rede neuronal artificial é uma rede de
nós de processamento simples, moldada, aproximadamente, como o cérebro
humano. O cérebro humano é um dispositivo computacional paralelo, que atinge seu
poder pela enorme conectividade entre seus neurônios. RNAs consistem em um
número de nós, podendo cada um ser considerado representante de um neurônio.
Os neurônios são organizados em camadas e os neurônios de uma camada são
conectados aos neurônios de duas camadas em cada um de seus lados. A rede é
organizada de modo que uma camada seja a de entrada, a ser classificada.
As entradas provocam a ativação de alguns neurônios na camada de entrada
e os neurônios, por sua vez, enviam sinais àqueles que estão conectados, alguns
dos quais também ativam as ligações e assim por diante. Um padrão complexo de
ativações é organizado pela rede, resultando na ativação de alguns neurônios na
camada de saída. As conexões entre os neurônios são ponderadas e, ao modificar
seus pesos, a rede neural pode ser organizada para realizar tarefas de classificação
extremamente complexas, (Coppin, 2010; Haykin, 2008).
A Lógica Fuzzy ou lógica nebulosa é uma forma de lógica aplicada a variáveis
nebulosas. Lógica é a ciência que tem como objetivo o estudo das leis do raciocínio.
A lógica fuzzy tem por finalidade estudar os princípios formais do raciocínio. Por
tanto, um conjunto da lógica nebulosa é não monotônica, no sentido de que se um
novo fato nebuloso for adicionado a uma base de dados, esse fato poderá
contradizer conclusões previamente derivadas da base de dados, (Coppin,
2010;Oliveira Junior, 2007).
Os Sistemas Especialistas (SE) são projetados para modelar o
comportamento de um especialista em alguma área, como medicina ou geologia. Os
SE, são baseados em regras, e projetados para serem capazes de usar as mesmas
regras que os especialistas usariam para chegar a conclusões, a partir de um
conjunto de fatos apresentados ao sistema (Coppin, 2010; Meireles, 2012).

15
Os GAs visam encontrar soluções para problemas complexos, utilizando um
método baseado no processo de evolução que há na natureza. Da mesma forma
que a natureza evolui, há criaturas mais capacitadas para ajustar-se ao ambiente,
pela seleção de características (a sobrevivência do mais adaptado), os algoritmos
genéticos funcionam por combinar soluções potenciais a um problema, de modo que
produza melhores soluções ao longo de gerações sucessivas. Essa é a forma de
otimização local, em que mutação e cruzamento são utilizados para tentar evitar
máximos locais. Eles são usados para identificar soluções ótimas para problemas
complexos, (Coppin, 2010; Linden, 2011).
Este trabalho é baseado na aplicação das técnicas das RNAs e nas técnicas
das GAs. As RNAs são empregadas para extração de informações de grande
quantidade de dados, após aprender com exemplos, comportando-se como
avaliadores, (Braga, 2011; Haykin, 2008; Zhang, 2000). Os algoritmos genéticos são
usados na busca por soluções que melhorem o desempenho para a solução de um
problema, (Braga, 2011; Haykin, 2008; Linden, 2011; Zhang, 2000).
Serão usados para organizar, avaliar e classificar as avaliações para gestão
acadêmica, para atender às necessidades de tomadas de decisões. Neste trabalho,
será utilizada a aplicação das RNAs do tipo Perceptron de Múltiplas Camadas (PMC)
treinada com algoritmo de retropropagação do erro.
A natureza do treinamento da RNA supervisionado da rede PMC requer que o
conjunto de treinamento seja composto de um conjunto de entrada e uma saída
desejada. As entradas são os dados referentes às características das instituições e
as saídas são as notas dadas por profissionais avaliadores e as referentes às
avaliações dos alunos da IES.
A utilização dos GAs, são algoritmos de otimização e busca baseados nos
mecanismos de seleção natural e genética que fará a validação final do método,
(Braga, 2011; Haykin, 2008; Linden, 2011).
De acordo com as necessidades de uma IES em buscar a melhora da
qualidade, a escolha das informações disponíveis no INEP/MEC permite a escolha e
o planilhamento das informações gerando um repositório de informações, a partir do
qual se pode utilizar o Sistema de Apoio à Decisão (SAD), permitindo ao gestor da

16
IES aplicar medidas corretivas, para garantir a qualidade, Meireles (2012). A Figura
1 ilustra esse processo.
Figura 1 – Aplicação da IC em uma IES.
Propõe-se a utilização da IC para a análise, através um software para
processamento dos dados chamado Sistema Computacional Inteligente para
Avaliação e Apoio à Decisão (SCIAAD) apresentado a lista dos arquivos no Anexo
C, a extração automática de informações e simulação de melhorias, como uma
interface gráfica, para a avaliação de IES, como apresentado na Figura 2.
Diferentes técnicas de IC têm sido aplicadas em avaliações, dentre elas as
técnicas de IA aqui apresentadas. Serão utilizadas para aprender com uso de dados
de avaliações anteriores, e prever as possíveis melhorias de desempenho com
variações dos parâmetros de entrada. Na próxima seção é apresentada uma breve
introdução sobre a IC, conforme a literatura dos seguintes autores, (Braga, 2011;
Haykin, 2008; Linden, 2011).
Figura 2 – IC nas avaliações das IES.

17
1.1 Objetivos do Trabalho
O presente trabalho visa auxiliar na Gestão Acadêmica de uma IES, com foco
na IC, aplicando-se uma RNA treinada a fim de testar os dados tabelados. Na
sequência será usado um Algoritmo Genético para a validação e consolidação dos
resultados. Para que isso possa ocorrer, é necessário o conhecimento da IES, e a
técnica a ser utilizada para que se possa objetivar a visualização adequada dos
resultados. Os dados são retirados do repositório do INEP/MEC, com disponibilidade
das tabelas referentes a um determinado ano e a cursos que se quer pesquisar,
MEC (2012). Com base nesses dados e após a utilização das ferramentas
necessárias, faz-se a análise dos resultados para que seja possível uma tomada de
decisão.
1.2 Delimitação da Pesquisa
Há várias formas de se avaliar dados pesquisados, mas a simulação,
operação e apresentação dos dados fazem parte da maior dificuldade das
organizações. Quando se trata de aplicações da TI para se obter uma vantagem
competitiva, a apresentação dos resultados é fundamental. Para se chegar a uma
informação de qualidade, é necessário que ela seja certa, no tempo, no lugar e na
forma que se deseja, Meireles (2012).
Através de um estudo de caso será feita a análise de dados disponíveis, de
diversas IES, mas que ainda necessitam ser organizados e comparados, ou seja,
trabalhados para que se obtenham as informações necessárias para utilizá-los nas
tomada de decisões.
1.3 Metodologia de Pesquisa Utilizada
A proposta deste trabalho está baseada em um estudo de caso, e a partir de
dados coletados pelo ENADE (Exame Nacional de Desempenho dos Estudantes),
parte das diretivas do SINAES (Sistema Nacional de Avaliação da Educação
Superior) do MEC, permite que as organizações IES tenham condições de avaliar
melhor o processo de ensino aprendizagem, Souza (2001).

18
O estudo de caso é um método bastante indicado para contexto em que o
investigador tem pouco controle sobre os eventos, pesquisados, sendo tais eventos
fenômenos contemporâneos e reais, Yin (1994).
1.4 Resultados Esperados
Serão geradas informações através de gráficos e tabelas comparativas, que
possam ser utilizadas para indicar aos gestores a real condição dos cursos (parte
pedagógica), infraestrutura, corpo docente e a avaliação dos alunos. Com a
aplicação de ferramentas de IC do modelo proposto, busca-se a solução para a
definição do número de variáveis a serem definidas e utilizadas no estudo. A
montagem de um banco de dados com a análise desses resultados permite a
tomada de decisão.
1.5 Estrutura do Trabalho
O trabalho está estruturado da seguinte forma:
Capítulo 2. Fundamentação Teórica - é apresentada uma revisão da
literatura conceitual para o entendimento do modelo proposto e das IES e
a necessidade da Gestão Estratégica; esse aspecto é relevante, e
utilizado para orientar e nortear as ações de apoio à decisão. Serão
apresentadas as técnicas das Redes Neurais Artificiais e Algoritmos
Genéticos. O estudo engloba as principais características, vantagens de
utilização das RNAs, processos de aprendizagem e enfatizando as redes
do tipo PMC e o algoritmo de aprendizado por retropropagação de erros e
nos GA são definidas suas características e também a aptidão, o
cruzamento e a mutação, visando a validação dos resultados.
Capítulo 3. Metodologia - aborda os aspectos estruturais da pesquisa
envolvidos neste trabalho. Foi adotado um estudo de caso, pois o objetivo
é apoiar a pesquisa nos dados colhidos e analisados previamente, sem
compromisso com a necessidade de coletá-los nas IES. Apresentando-se
o tipo de problema abordado, o modelo utilizado e a partir daí,

19
descrevem-se todas as etapas efetuadas durante o desenvolvimento
prático do trabalho, o levantamento dos dados, o pré-processamento dos
dados, a divisão dos conjuntos para treinamento e os testes, treinamento,
validação e avaliação dos resultados.
Capítulo 4. Estudo de Caso - descreve qualitativa e quantitativamente o
uso dos dados analisados e aplicados, segundo o uso das ferramentas de
IC adotadas, com a apresentação dos resultados obtidos e as discussões.
Para validação e teste do modelo, foi utilizado um software desenvolvido
no MatLab para treinamento, validação e otimização. As etapas do
processamento são: o treinamento da rede e seus resultados com seus
tratamentos apresentados juntamente com a avaliação da configuração
da RNA escolhida por apresentar a menor taxa de erro. Em seguida
apresenta-se uma validação do modelo proposto. E finalizam-se os
processos de avaliação utilizando-se uma GAs para otimização dos
resultados, sendo apresentados os resultados e as respectivas tabelas.
Os resultados são comparados e apresentados graficamente, e
analisados da seguinte forma: primeiramente com base no treinamento
realizado, a aprendizagem e após com base na ativação da rede, a
verificação da aprendizagem (se ela está coerente com o resultado
esperado) e por fim, com base nos dados do aprendizado, serão
otimizados, a partir das informações extraídas do software (SCIAAD),
possibilitando a tomada de decisão.
Capítulo 5. Conclusão - serão apresentadas as avaliações obtidas a
partir dos resultados apresentados, com a pesquisa e a aplicação do
modelo proposto, com o uso do software SCIAAD. Serão avaliados vários
estudos de caso com as contribuições relevantes e permitindo a tomada
de decisão. Propondo sugestões para novas pesquisas.

20
2 FUNDAMENTAÇÃO TEÓRICA
Várias transformações que vem ocorrendo nas organizações, na última
década, são marcantes. Em especial no Ensino Superior Privado Brasileiro, que por
conta de vários fatores, estão atrelados a elas, tais como: a profissionalização do
setor, o avanço tecnológico, a internacionalização, as fusões, incorporações e
cisões, as mudanças de comportamento do consumidor, o desemprego entre outros
temas, têm resultado em mudanças no ambiente desse segmento, e a partir do
enfrentamento inicial do excesso de oferta com demanda reprimida, vê-se em
processo de consolidação, forçando as IES a se reestruturarem ou mesmo até
redefinirem seu próprio negócio, Silva (2009).
As estratégias competitivas nas organizações é fator de sobrevivência, sendo
que o conceito básico de estratégia está relacionado à ligação da empresa e seu
ambiente. As organizações procuram definir e operacionalizar estratégias que
maximizem os resultados da interação estabelecida, Silva (2009).
Numa empresa, a estratégia está relacionada à arte de utilizar
adequadamente os recursos físicos, financeiros e humanos, tendo em vista a
minimização dos problemas e a maximização das oportunidades, Oliveira apud Silva
(2009).
Como exemplos de aplicação da IC em outras empresas, como estratégia de
avaliação e análise são apresentados a seguir.
1º - A aplicação de redes neurais na avaliação de bens, segundo Guedes
(2005), os resultados confirmaram com um caso prático o que a teoria afirmava a
priori: que as predições através das redes neurais deveriam ser melhores do que
aquelas obtidas com a análise de regressão linear. No caso em estudo, o erro
quadrático médio obtido via rede neural foi mais de 30% menor do que aquele
gerado pela análise de regressão múltipla. Isto se deve, fundamentalmente, ao fato
de os fenômenos sociais e relações do mundo real, expressos por variáveis, não
serem necessariamente lineares.
Mesmo quando se lineariza a função, transformando-se as variáveis para
melhor captar essa relação não retilínea, continua havendo a possibilidade de existir
um melhor estimador não linear.

21
Ao final os resultados para comparação, verifica-se que a rede neural
respondeu melhor que o modelo de regressão em 28 vezes das 48 possíveis,
Guedes (2005). Como pode ser verificado no memorial de cálculos, no Anexo F, a
modelagem revelou que os imóveis no Micro-centro apresentam menores valores
quando comparados com os das regiões recém desenvolvidas, Guedes (2005).
2º - A aplicação de redes neurais na análise e na concessão de crédito ao
consumidor, segundo Lima (2008), tem como objetivo a construção de um modelo
de análise de risco de crédito para consumidores, baseado em redes neurais
artificiais. A partir de uma base de dados real, fornecida por uma importante
empresa varejista brasileira, identificou-se que o algoritmo baseado em uma rede
neural multilayer perceptron, conduziu a resultados satisfatórios na predição de perfil
de pagadores, Lima (2008).
Os resultados mostraram que o modelo criado consegue identificar
corretamente mais de 75% dos clientes que pagam a primeira prestação em dia de
seus financiamentos, e capta pouco mais de 72% dos clientes que não pagam nem
a primeira prestação do empréstimo. O foco no pagamento da primeira parcela foi
influenciado pelo interesse, demonstrado pelos participantes do mercado, em tentar
desenvolver mecanismos que proporcionem a identificação de indivíduos que nem
sequer pagam a primeira parcela, conforme apresentado no Anexo G, Lima (2008).
Como o foco da nossa pesquisa é uma IES, apresenta-se a seguir a sua
característica e motivação para a aplicação da IC.
A gestão eficiente de uma IES é de grande complexidade. A criação de valor
para alunos, professores, funcionários e sociedade está fundamentada no
gerenciamento equilibrado dos ativos intangíveis (conhecimento, processos,
sistemas e informação) e no planejamento e controle dos recursos financeiros que
se traduzirão em excelência na prestação de serviços educacionais e na perenidade
financeira do negócio, Silva (2009). Para se acompanhar o desempenho de uma IES
é necessária a utilização de um conjunto extenso de indicadores qualitativos, além
dos tradicionais indicadores financeiros de qualquer negócio, Silva (2009).
A caracterização das IES permite o entendimento do grau de dificuldade e da
autonomia que cada uma tem. De acordo como o MEC, as instituições de ensino

22
são divididas em: Faculdades, que não possuem autonomia, não podendo criar
novos cursos, para isso dependem de solicitação e autorização do MEC; os Centros
Universitários que, por sua vez, possuem autonomia para criação, mas desde que
autorizados posteriormente, e também com vários cursos oferecidos e também
devem ser autorizados, Silva (2009).
Por último, as Universidades que, possuem autonomia para a criação de
novos cursos, sem necessidade prévia de autorização e é uma instituição de ensino
superior correspondendo a um conjunto de faculdades ou escolas para
especialização profissional e científica, e tem por função precípua garantir a
conservação e o progresso nos diversos ramos do conhecimento, pelo ensino e pela
pesquisa, MEC (2012).
Este trabalho está baseado em um Estudo de Caso, a partir de dados
coletados pelo Exame Nacional de Desempenho dos Estudantes (ENADE), parte
das diretivas do Sistema Nacional de Avaliação da Educação Superior (SINAES) do
Ministério da Educação (MEC), permitindo que as organizações IES tenham
condições de avaliar melhor o processo de ensino aprendizagem. Esse processo faz
parte da nova Lei de Diretrizes e Bases da Educação Nacional – LDB 9.394/96,
segundo Souza (2001) através do SINAES, realizando o ENADE todo o ano, para
cursos predeterminados, obtém-se assim os seus indicadores da qualidade. Em
conjunto com as análises feitas pelas visitas in-loco e as informações coletadas no
portal e-Mec, geram o Índice Geral do Curso para uma IES, classificando as notas
de uma IES como, Boa (4 e 5), Média (3) ou Ruím (1 e 2). Acarretam ações por
parte do MEC se a avaliação for Ruim, tais como; visitas em loco para atestar ou não
essa condição, descredenciamento do curso em determinada IES que receber uma
nota Ruim por mais de 2 processos de avaliação (ENADE) consecutivos, Souza
(2001).
As informações obtidas com o uso da metodologia de estudo de caso podem
ser utilizadas na gestão acadêmica de uma IES. Neste trabalho, são utilizadas para
avaliar o desempenho da IES com base nas informações apresentadas pelo modelo
proposto, segundo as análises feitas pelas RNA e GA.

23
2.1 Modelo Proposto
O modelo em estudo tem por finalidade permitir que dirigentes e gestores
possam avaliar melhor os dados de um determinado problema. Com base em
informações extraídas destes dados, com uso do modelo computacional inteligente,
é permitida a realização de simulações automatizadas para uma rápida tomada de
decisão. Este modelo faz uso da rede neural artificial Perceptron de Múltiplas
Camadas e Algoritmos Genéticos.
Os dados são subdivididos em 3 grupos, que resultam nos subconjuntos de
treinamento, validação e generalização. Os dois primeiros subconjuntos são
empregados na fase de treinamento. Para isso, com base no estudo de (Sun, 2012;
Hongmei, 2013; Webber, 2009) seleciona-se aproximadamente 50% dos dados
disponíveis para o subconjunto de treinamento e aproximadamente 40% dos dados
para o subconjunto de validação. Por último é selecionado o restante do conjunto
para os testes de generalização.
Na fase de treinamento os pesos e limiares da rede neural são ajustados até
que seja verificado se o comportamento da RNA é equivalente ao dos avaliadores.
Para isso, os dados de entrada são apresentados à rede neural com certo número
de neurônios na camada escondida. Nesta fase, busca-se utilizar taxas de
aprendizado e funções de ativação adequadas. Após uma das condições de parada
ser atingida, o treinamento é finalizado Haykin, (2008).
A fase de ativação da RNA consiste em utilizar os pesos e limiares obtidos na
fase de treinamento no modelo computacional. Nesta etapa é possível testar se a
rede neural treinada possui comportamento semelhante ao dos avaliadores mesmo
com dados novos Linden, (2011).
Na fase de otimização, as técnicas de algoritmos genéticos fazem uso da
RNA treinada de modo que sejam encontrados parâmetros para maximizar uma
função custo, que apontem indicadores para melhoria do problema em estudo
Linden, (2011).

24
2.2 As Redes Neurais Artificiais (RNAs)
A busca por se aprimorar as capacidades cognitivas de um ser humano tem
sido uma área de pesquisa amplamente investigada, Oliveira Junior (2007),
projetando-se máquinas capazes de exibir um comportamento inteligente, como se
fossem próximos das reações humanas. A inteligência humana é a mais avançada
dentro do universo das criaturas na Terra.
Essa inteligência, dentro do corpo humano, situa-se no cérebro. O mecanismo
base para que isso ocorra, são os neurônios, interconectados em redes permitindo a
troca de informação entre eles, criando-se a inteligência biológica. Uma tentativa
óbvia de se chegar a ela, surge às observações estruturais computacionais na
tentativa de se copiar a estrutura e o funcionamento do cérebro dentro de um
ambiente automatizado Artero (2009).
Isso significa que os pesquisadores tentam entender o funcionamento da
inteligência residente nos neurônios e traduzem para uma estrutura artificial, por
exemplo, uma combinação de aplicação de hardware e de software, transformando
as redes neurais biológicas em redes neurais artificiais, Coppin (2010).
Uma RNA é composta de técnicas computacionais, que apresentam um
modelo matemático inspirado na estrutura neural de organismos inteligentes e
adquirem conhecimento através da experiência, Haykin (2008). Na Tabela 1,
verificam-se as principais tarefas que as RNAs podem executar e alguns exemplos
de aplicação, Braga (2011).
A grande abrangência e especialização das RNAs estão dentro dessas
tarefas e a previsão com a aplicação da modelagem de sistemas dinâmicos é a que
melhor se enquadra no sistema proposto no estudo.

25
Tabela 1 – As principais tarefas que as RNAs podem executar e alguns exemplos de aplicação.
Tarefas Algumas aplicações
Classificação Reconhecimento de caracteres
Reconhecimento de imagens
Detecção de falhas
Análise de risco de crédito
Detecção de fraudes
Categorização Agrupamento de sequências de DNA
Mineração de dados
Análise de expressão gênica
Agrupamentos de clientes
Previsão Previsão do tempo
Previsão financeira (câmbio, bolsa, etc)
Modelagem de sistemas dinâmicos
Fonte: Adaptado de Braga (2011).
Nos últimos anos, as aplicações que utilizam modelos com redes neurais
artificiais são bastante significativas. As redes neurais artificiais são uma das formas
mais apropriadas para resolver problemas cognitivos complexos, Braga (2011).
As redes neurais têm uma gama de aplicações de sucesso como, a solução
de problemas de reconhecimentos de padrões, otimização combinacional,
modelagem de sistemas, representação de conhecimento, aproximação de funções,
diagnóstico e classificação, monitoramento e controle, processamento de voz e de
imagem, recuperação de informações, previsão, diagnósticos médicos, composição
musical, entre outros, (Haykin, 2008; Braga, 2011; Coppin, 2010; Oliveira Junior,
2007).
Na tentativa de se buscar as características mais importantes do cérebro
humano, prepara-se para um comportamento inteligente, e é atrativa de serem
simuladas em uma rede neural artificial, que podem ser resumidas a seguir
conforme, Braga (2011).
• Robustez e tolerância a falhas: Com a eliminação de alguns neurônios
não afetará a funcionalidade global.
• Capacidade de aprendizagem: O cérebro é capaz de aprender novas
tarefas que nunca foram executadas antes.

26
• Processamento de informação incerta: Mesmo que a informação
fornecida esteja incompleta, afetada por um problema ou parcialmente
corrompida, um raciocínio correto é possível.
• Paralelismo: Pode-se utilizar um imenso número de neurônios, ativos ao
mesmo tempo. Não existe a restrição de um ou mais processadores que
trabalhe uma instrução após a outra.
O sistema nervoso é formado por um conjunto bastante complexo de células,
que são os neurônios. Esses neurônios possuem um papel essencial na
determinação do funcionamento e comportamento do corpo humano e do raciocínio,
Haykin (2008).
O processamento local de informação no cérebro efetua-se em cerca de 100
bilhões de unidades (os neurônios) com uma estrutura relativamente simples. O
neurônio é uma célula com núcleo e corpo celular, em que as reações químicas e
elétricas representam o processamento de informação. A saída da informação do
corpo celular é realizada por impulsos elétricos, que se propagam através do axônio.
No final do axônio existem inúmeras ramificações que distribuem a informação para
outros neurônios vizinhos (Haykin, 2008; Braga, 2011).
A ligação com os outros neurônios é realizada através de sinapses, que estão
conectadas a um dendrito do neurônio receptor. A sinapse dispara uma substância
química quando excitada pelo impulso do axônio. A substância se transmite entre
sinapse e dendrito realizando a conexão entre dois neurônios vizinhos. Conforme as
excitações (ou inibições) que células vizinhas transmitem para a célula em
consideração, ela processa a informação novamente e a transmite via seu axônio
(Haykin, 2008; Braga, 2011).
Uma rede neural artificial é um mecanismo implementado em hardware e/ou
software, que emula o modo como o cérebro realiza uma tarefa particular ou função
de interesse, Haykin (2008). A rede neural artificial assemelha-se às funções
realizadas no cérebro em dois aspectos: o conhecimento é adquirido pela rede,
através de um processo de treinamento ou aprendizado; e as conexões entre os
neurônios, conhecidos como pesos sinápticos são utilizados para armazenar o
conhecimento, Braga (2011).

27
Na Figura 3 apresenta-se o modelo simplificado de um único neurônio
biológico e as partes que o compõem. Vários tipos de neurônios têm sido
identificados, cada qual se distingue dos demais pela forma do corpo celular.
Figura 3 – A representação de um Neurônio Humano.
Fonte: - Adaptado de Braga (2011).
As RNAs exploram o intrínseco do processamento paralelo e são tolerantes a
falhas, propriedades que as tornam apropriadas para aplicação em reconhecimento
de padrões, processamento de sinais, processamento de imagens, mercados
financeiros, visão computacional, engenharia, entre outros segundos os autores,
(Haykin, 2008; Braga, 2011).
As redes neurais artificiais têm dois estágios em sua aplicação. Durante a
fase de treinamento há a aprendizagem, em que os pesos e bias da rede
correspondente a cada conexão são ajustados. Para a ativação, a saída é obtida
baseada nos pesos e limiares da fase de treinamento.
RNAs são compostas de elementos simples de processamento (neurônios).
Um modelo de neurônio artificial consiste de uma combinação linear seguida de uma
função de ativação, dado pela equação 1:
n
j
kjkjk bxwy1
(1)
Onde:
wkj são os pesos sinápticos, bk o limiar, xj é o vetor de entrada e yk a saída no
k-ésimo neurônio e )( é a função de ativação do neurônio.

28
A RNA irá resolver problemas não lineares, se forem utilizadas funções de
ativação não lineares nas camadas ocultas e/ou de saída. Dentre as várias funções,
a sigmoide e a tangente hiperbólica são as mais utilizadas, Braga (2011).
2.2.1 Redes Perceptron de Múltiplas Camadas (PMC)
De acordo com o trabalho original de McCulloch e Pitts, foi enfocada a
modelagem de um neurônio biológico e sua capacidade computacional por meio da
apresentação de vários exemplos de topologias de rede com capacidade de
execução de funções booleanas, segundo Braga (2011). Mas foi Frank Rosemblatt
em 1958, que introduziu o conceito de aprendizado em uma RNAs. O modelo
apresentado por Rosemblatt, conhecido como perceptron era composto por
estruturas de rede, tendo como base neurônios e por uma regra de aprendizado.
Somente alguns anos mais tarde é que foi demonstrado por Rosemblatt o teorema
de convergência do perceptron, Haykin (2008). Como representado na Figura 4.
Existem diferentes arquiteturas das RNAs, dependentes da estratégia de
aprendizagem adotada.
Figura 4 – Representação de uma rede PMC.
Fonte: Haykin, (2008).
A rede PMC com algoritmo de retropropagação do erro possui uma
aprendizagem supervisionada, que requer pelo menos um par de entradas e a saída
desejada.
Tais pares permitem o cálculo do erro da rede como a diferença entre a saída
desejada e a saída calculada. Os pesos são ajustados através da retropropagação

29
do erro, que é uma rede alimentada para frente composta por uma camada de
entrada, uma camada de saída e uma ou mais camadas escondidas, e governados
pela regra de ajuste e os pesos são ajustados por um erro proporcional ao erro
quadrático. Mais detalhes podem ser encontrados em Haykin (2008).
Existem diferentes modelos de RNA, cada um indicado para aplicação em
uma classe de problemas. A Rede Percetron é uma rede bastante conhecida, no
entanto, não reconhece padrões complexos, sendo mais indicada para o
reconhecimento de caracteres. Outra rede neural muito utilizada é a Kohonen, que
tem a vantagem de não ser supervisionada, mas em certas aplicações é pouco
eficiente e tem sido utilizada com sucesso no reconhecimento de padrões. A Rede
Memória Associativa Bidirecional (BAM) tem a vantagem de ser estável, no entanto,
é pouco eficiente e tem sido aplicada no reconhecimento de padrões. A Rede de
Hopfield tem sido implementada em alta escala, não tem aprendizado e tem sido
empregada na recuperação de dados e fragmentos de imagens (Artero, 2008). No
presente trabalho foi utilizada a rede Perceptron de Múltiplas Camadas (PMC)
treinada com algoritmo de retropropação do erro, cujo objetivo é extrair estatísticas
de alta ordem de seus dados de entrada, exemplificado na Figura 5. Esta rede
neural tem a vantagem de possuir um grau maior de complexidade e alta eficiência,
utilizado na solução de problemas não lineares, exigir um treinamento
supervisionado com muitos registros e classificação supervisionada, sendo a mais
indicada para esta aplicação (Artero, 2008).
Figura 5 – Arquitetura perceptron de múltiplas camadas com duas camadas ocultas.
Fonte: Haykin (2008).

30
2.2.2 Métodos de tratamento de erros
O algoritmo de retropropagação do erro é um algoritmo supervisionado que
utilizam pares (entrada, saída desejada) para, por meio de um mecanismo de
correção de erros, ajustar os pesos da rede, Braga (2011).
O processo de aprendizagem por retropropagação do erro atua em duas
etapas através das camadas da rede. Essas duas etapas são chamadas de
propagação, do inglês forward e retropropagação, do inglês backward, Haykin
(2008). Na primeira etapa é obtida a resposta da rede produzida pela camada de
saída, a partir de um padrão de dados apresentado a camada de entrada. Na
segunda etapa, é feita a comparação da saída desejada com a saída obtida pela
rede neural, caso a resposta não esteja correta, o erro é calculado. Esse erro é
propagado a partir da camada de saída para a camada de entrada, e durante a
retropropagação do erro são feitos os ajustes dos pesos sinápticos, Linden (2012).
Observa-se, na Figura 6, a direção dos dois fluxos básicos de sinais em uma
rede PMC com o algoritmo de retropropagação do erro.
Figura 6 – Fluxo de processamento do algoritmo de retropropagação do erro.
Fonte: Braga (2011).

31
Conforme as abordagens encontradas em (Braga, 2011; Haykin, 2008), nas
linhas seguintes descreve-se o algoritmo de retropropagação do erro.
1. Inicialização
Definir os pesos das conexões aleatoriamente.
2. Apresentação dos Exemplos de Treinamento
Ordenar o conjunto de treinamento aleatoriamente.
Apresentar a rede um padrão de treinamento.
Para todo o conjunto de treinamento, efetuar os passos 3 e 4.
3. Computação para frente (Propagação)
Calcular os sinais de saída dos neurônios através da equação 2:
Onde:
j = nó que representa a camada de entrada da rede ou um neurônio da
camada oculta;
w = representa os pesos das conexões.
Calcular a função de ativação, definida pela equação 3:
Onde:
a = parâmetro de inclinação da função, ou seja, quanto maior o valor de a,
mais inclinada se torna a curva.
Calcular o sinal de erro pela equação 4:
Onde:
d = saída desejada pela rede;
y = saída apresentada pelo neurônio.
(2)
(3)
(4)

32
Calcular o valor instantâneo da energia total do erro, definido pela equação 5:
Onde:
= valor instantâneo da soma dos erros quadráticos.
4. Computação para trás (Retropropagação)
Calcular os gradientes locais, definido pelas equações 6 e 7:
)
Onde:
h = saída encontrada para o neurônio j.
Calcular os deltas através das equações 8 e 9:
Onde:
= taxa de aprendizado;
= gradiente local.
Fazer os ajustes dos pesos sinápticos, definido pela equação 10:
5. Iteração
Executar os passos dos pontos 3 e 4 apresentando novas épocas de
exemplos de treinamento calculando a média do erro até que a rede encontre
o valor mínimo ou o número máximo de épocas de treinamento.
(5)
(6)
(7)
(8)
(9)
(10)

33
Dada pela equação 11.
Onde:
N = representa o número total de padrões de entrada apresentados à rede em
uma época de treinamento;
2.2.3 Função de Ativação
O processamento gerado por um neurônio para se obter o sinal de saída é
composto de duas etapas: na primeira, tem-se a soma ponderada de cada entrada e
na segunda, tem-se a aplicação da função de ativação sobre a soma.
A função de ativação tem por finalidade limitar a amplitude do intervalo do
sinal de saída do neurônio para valores normalizados no intervalo [0,1] ou [-1,1] e
são apresentados na Figura 7.
Os tipos básicos das funções de ativação, segundo Haykin (2008) são:
a) Função de bias ou Função Degrau, dada pelas equações 12, 13 e 14.
b) Função Linear
c) Função Sigmoide
O gráfico de cada função é representado dentro do intervalo proposto e pode
ser observado na Figura 7.
(11)
(12)
(13)
(14)
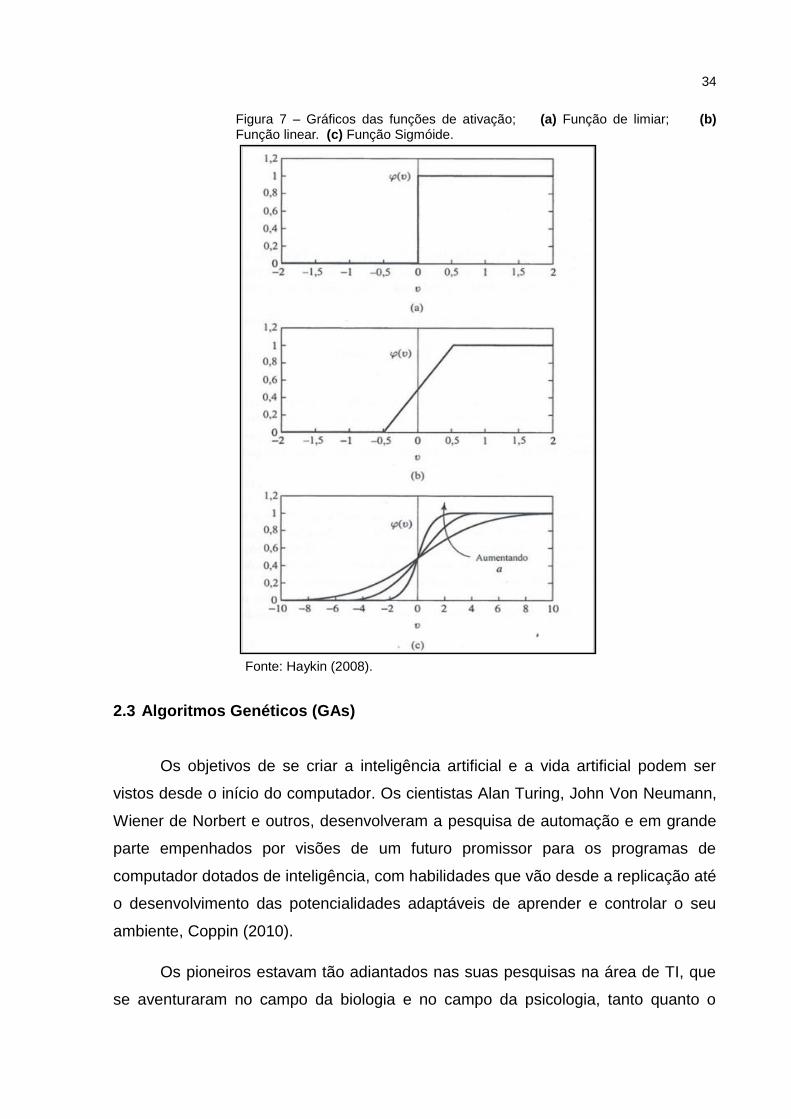
34
Figura 7 – Gráficos das funções de ativação; (a) Função de limiar; (b) Função linear. (c) Função Sigmóide.
Fonte: Haykin (2008).
2.3 Algoritmos Genéticos (GAs)
Os objetivos de se criar a inteligência artificial e a vida artificial podem ser
vistos desde o início do computador. Os cientistas Alan Turing, John Von Neumann,
Wiener de Norbert e outros, desenvolveram a pesquisa de automação e em grande
parte empenhados por visões de um futuro promissor para os programas de
computador dotados de inteligência, com habilidades que vão desde a replicação até
o desenvolvimento das potencialidades adaptáveis de aprender e controlar o seu
ambiente, Coppin (2010).
Os pioneiros estavam tão adiantados nas suas pesquisas na área de TI, que
se aventuraram no campo da biologia e no campo da psicologia, tanto quanto o

35
campo da eletrônica, e olharam os sistemas naturais como metáforas, que os
guiaram para seguir o caminho necessário das suas visões, Coppin (2010).
Não deve ser nenhuma surpresa, que os computadores mais modernos são
aplicados, não somente nas trajetórias dos mísseis balísticos, com seus códigos
militares, mas também no cálculo da órbita dos satélites espiões. Também são
capazes de modelar o cérebro, e a imitar a aprendizagem humana, tentando simular
a evolução biológica. Essas atividades da computação biológica foram motivadas
pelas pesquisas desde os anos 1980. A primeira cresceu no campo das redes
neurais, a segunda na aprendizagem de máquina, e na terceira que é chamado
agora de “computação evolucionária” de que os algoritmos genéticos são o exemplo
mais proeminente, Coppin (2010).
2.3.1 Histórico
Nos anos de 1950 e 1960, diversos cientistas da computação estudaram
independentemente, os sistemas evolucionários com a ideia de que a evolução
poderia ser usada como uma ferramenta de otimização para solucionar problemas
complexos. A ideia em todos esses sistemas era evoluir um conjunto de dados,
chamado de população, para soluções do candidato a um problema dado, usando
os operadores inspirados pela variação genética natural e pela seleção natural
Linden (2012). Nos anos 1960, foram introduzidas as “estratégias da evolução”, um
método utilizando parâmetros do valor real otimizados para dispositivos, como as
superfícies de sustentação (aerofólio).
O campo de estratégias da evolução remanesceu numa área de pesquisa
ativa, tornando-se na maior parte do tempo independente do campo dos algoritmos
genéticos. Fogel, Owens, e Walsh, em 1966, desenvolveram “a programação
evolucionária,” uma técnica em que duas tarefas dadas, geram as soluções. Foram
representadas como o estado finito da máquina, que foi evoluindo com uma mutação
aleatória e seus diagramas de estado e de transição visando selecionar o mais apto.
Uma formulação um tanto mais larga da programação evolucionária
remanesce também numa área de pesquisa ativa. Junto, as estratégias da evolução,
a programação evolucionária, e os algoritmos genéticos dão forma à espinha dorsal
do campo da computação evolucionária, Linden (2012).

36
Os GAs foram inventados por John Holland nos anos 1960 e desenvolvidos
na Universidade de Michigan entre os anos 1960 e 1970. No contraste com outras
estratégias, a da evolução e da programação evolucionária, o objetivo original de
Holland não era projetar algoritmos para resolver problemas específicos, mas sim
estudar a fundo o fenômeno da adaptação porque ocorre na natureza e para
desenvolver as maneiras em que os mecanismos da adaptação natural pudessem
ser implementados nos sistemas computadorizados, Linden (2012).
Na adaptação do livro de Holland de 1975, os sistemas naturais e artificiais
apresentaram o algoritmo genético como uma evolução biológica e deu uma
estrutura teórica para a adaptação do GA. O GA de Holland é um método para
mover-se de uma população de “cromossomos” (por exemplo, linhas de uns e zeros)
para uma população nova usando um tipo “de seleção natural” junto com operadores
genéticos do cruzamento, da mutação, e da inversão. Cada cromossomo consiste
em “genes”, cada gene é um exemplo de um “alelo em particular” (por exemplo, 0 ou
1), Linden (2012).
O operador da seleção escolhe aqueles cromossomos na população que será
permitido reproduzir, e na média o produto dos mais aptos dos cromossomos. O
cruzamento troca as subpartes de dois cromossomos, imitando aproximadamente
uma recombinação biológica entre dois “haploides”; nos organismos de
cromossomos simples, a mutação muda aleatoriamente os valores dos alelos de
algumas posições no cromossomo; e a troca inverte a ordem de uma seção contígua
do cromossomo, assim rearranjando a ordem em que os genes são postos. O
fluxograma de um GA é apresentado na Figura 8. A introdução feita por Holland em
que na base da população, o algoritmo com cruzamento, inversão, e o de mutação
era uma inovação, Linden (2012).
2.3.2 População
É o número inicial de indivíduos que participam da amostra a ser otimizada.
2.3.3 Aptidão
Nos GAs tradicionais, é necessária uma métrica pela qual a aptidão de um
cromossomo possa ser determinada objetivamente. Uma medida mais sofisticada de

37
aptidão poderia ser obtida calculando quanto cada número localizado incorretamente
está distante de seu local correto, Coppin (2012). Nos espaços de busca o
movimento irá para baixo na aptidão. Do mesmo modo, no GAs os operadores do
cruzamento e o de mutação podem ser vistos como maneiras de mover uma
população ao redor é definida pela função da aptidão, Linden (2012).
Figura 8 – Fluxograma de uma GA.
Fonte: Linden (2012).
2.3.4 Crossover (Cruzamento)
O operador escolhe aleatoriamente um local e troca os subsequentes antes e
depois desse local. Entre dois cromosomos para criar a prole dois.
Por exemplo, as cordas, que são as sequências genéticas, 10000100 e
11111111 que podiam ser cruzadas, após o terceiro gene em cada um para produzir
dois, a prole 10011111 e 11100100. O operador do cruzamento imita
aproximadamente uma recombinação biológica entre dois organismos “haploide”,
que possui apenas um cromossoma livre, no cromossoma simples, Linden (2012).
2.3.5 Mutação
Este operador lança aleatoriamente alguns elementos em um cromossomo.
Por exemplo, a linha 00000100 pode ser mutada em sua segunda posição

38
01000100. A mutação pode ocorrer em cada posição de uma corda com alguma
probabilidade de repetição, geralmente muito pequena (por exemplo, 0.001), Linden
(2012).
Aos pesquisadores do campo da computação evolutiva, utilizam os
mecanismos da evolução, que parecem bem apropriados para solucionar os
problemas computacionais em muitos campos. Muitos problemas computacionais
requerem a busca por um número enorme de possibilidades de soluções.
Um exemplo é o problema da engenharia computacional da proteína, em que
um algoritmo é utilizado para procurar entre um número vasto de sequências
possíveis do aminoácido, por uma de proteína com propriedades especificadas.
Outro exemplo é a procura por um jogo de réguas ou as equações que farão a
previsão de um mercado financeiro, como a avaliação da moeda corrente
estrangeira. Tais problemas da busca podem frequentemente beneficiar-se de um
uso eficaz do paralelismo, em que muitas possibilidades diferentes são exploradas
simultaneamente de uma maneira eficiente, Coppin (2010).

39
3 METODOLOGIA
Para o desenvolvimento deste trabalho, foi definido o tipo de pesquisa
segundo as necessidades do Estudo de Caso. Há uma divisão dessa estratégia de
pesquisa, em um estudo de caso único e um estudo de casos múltiplos, Yin (1994).
A estratégia a ser utilizada, realiza um estudo de casos múltiplos, mas por se tratar
de uma única base de dados, a base de dados do MEC, e ser um assunto muito
abrangente, são analisados vários indicadores dessa avaliação.
Os dados a serem coletados estão disponibilizados no site do Instituto
Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira (INEP), que faz parte
do Ministério da Educação e Cultura (MEC). Como os dados estão disponíveis para
consulta, são escolhidos os principais indicadores apresentados nos diversos anos
de avaliações lá disponibilizados, e por área (Exatas, humanas e biológicas) ou por
cursos: Engenharia, Computação, Administração, Psicologia, Fisioterapia entre
outros.
No estudo de caso, a coleta dos dados é, através do resultado da (as) IES
nas avaliações dos alunos em um exame do ENADE, realizada em um determinado
ano. Devem-se escolher os dados a serem utilizados para que o teste seja feito da
melhor maneira possível.
No decorrer da pesquisa, são identificadas várias possibilidades de ação, com
as quais se pretende levar à melhoria do processo de Ensino x Aprendizagem, e
consequentemente à qualidade da IES. O estudo de caso deste trabalho segue a
abordagem qualitativa, quantitativa e exploratória, ou seja, são analisados os dados
do levantamento anual do MEC, que é o escopo do trabalho e sendo o foco da
análise.
A partir do levantamento dados e da tabulação desses resultados, é utilizada
uma ferramenta de software desenvolvida para testar as informações utilizando-se
as técnicas de IC, como também para a obtenção das respostas para apresentação
em ferramentas gráficas.

40
Para este estudo de caso foi desenvolvido um software em MatLab, cujos
arquivos são apresentados no Anexo C e D, para treinamento, validação e
otimização, dos dados coletados, sendo apresentado a seguir:
“Dados das IES brasileiras” significa importar os dados do ENADE.
“Processamento dos dados com IA” significa a utilização de técnicas
para simular o comportamento dos avaliadores e efetuar combinações
que possam alcançar uma solução para o problema proposto.
“Informações para a Gestão Acadêmica” significa a resposta do
programa, com a indicação de uma ou mais características e seus
respectivos valores para auxiliar na tomada de decisão.
Seguem abaixo os passos a serem seguidos na aplicação das técnicas de IC,
será o seguinte:
3.1 Obtenção e tratamento dos dados iniciais
Preparação dos dados para o treinamento no formato numérico
compatível com os formatos de entrada aceitos pelo software Matlab. Os
dados devem estar em uma planilha Excel para que possa ser lida pelo
software.
Realizar a transposição da tabela do Matlab para a correta posição dos
dados e características apresentadas nas tabelas do ENADE. As colunas
são as características e as linhas são os valores.
Conforme o exemplo de uma tabela com dados retirados do ENADE
representada abaixo na Tabela 2, que apresentam as características e são assim
classificadas: IES – Instituição de Ensino Superior; Part – número de alunos
ingressantes no curso; Conc – número de alunos concluintes, Enade – valor
calculado do Enade; e Con_Enade – Conceito associado aos valores calculados.

41
Tabela 2 – Dados de exemplo do ENADE
IES Part Conc Enade Con_Enade A 62 93 2.13 3
B 38 141 3.93 4
C 41 41 3.08 4
D 129 24 2.24 3
E 81 15 2.41 3
F 192 77 2.62 3
G 317 214 1.66 2
H 15 39 2.78 3
I 177 230 2.01 3
J 63 51 2.09 3
N 60 73 1.98 3
M 66 117 1.99 3
Fonte: Gotti (2011a).
3.1.1 Preparação dos dados para o treinamento da RNA
Mesclar os exemplos: esse passo tem por objetivo remover uma possível
ordem estabelecida, fazendo com que o aprendizado da RNA seja o mais
amplo possível. O comando utilizado no MatLab é o randperm.
Intervalo: Verificar quais os valores de máximo e mínimo admissíveis de
cada característica. Por exemplo, o “conceito” varia de 1 a 5, não sendo
admissível outro valor nesse campo.
Normalizar: transformar de cada característica entre os valores entre zero
e um, respeitando a proporção entre o dado original. Essa fase é
necessária devido à função de ativação da RNA ser a sigmoide.
Definir o conjunto de dados para o treinamento da RNA: separam-se entre
40% e 70% dos dados do conjunto inicial.
Identificar no conjunto de dados para treinamento, quais são os valores
de entrada (x1, x2, ... , xn) que serão apresentados a RNA.
Identificar no conjunto de dados para treinamento, quais são os valores
de saída desejados (y), para que a RNA tenha o parâmetro para sua
aprendizagem.
Definir o conjunto de dados para a validação. Esses dados serão usados
para verificar o grau de acerto da RNA e efetuar a condição de parada no
treinamento. Separam-se entre 20% e 40% dos dados do conjunto inicial.

42
Separar no conjunto de dados para a validação, os valores de entrada e
saída da RNA.
Definir o conjunto de dados para verificação da generalização. Esses
dados serão utilizados para testar a capacidade da RNA de não ficar
extremamente especializada nos dados do conjunto de treinamento,
servindo também como critério de parada no treinamento. Separam-se
entre 10% e 20% restantes do conjunto inicial, preferencialmente que
sejam compostos de notas 1 até 5.
Separar no conjunto de dados para generalização os valores de entrada e
saída.
3.1.2 Características da RNA
Definir a arquitetura da RNA e os parâmetros para o algoritmo de
treinamento: A arquitetura da RNA é do tipo Perceptron de Múltiplas
Camadas (PMC) com algoritmo de treinamento backpropagation. Neste
passo são definidas as seguintes variáveis do modelo:
a) A quantidade de exemplos mostrados para a RNA;
b) A quantidade de padrões utilizados para a validação;
c) A quantidade de características do conjunto;
d) A quantidade de neurônios na camada escondida;
e) A taxa de aprendizado;
f) A erro desejado, para critério de parada;
g) Número máximo de épocas de treinamento.
3.1.3 Treinamento da RNA
Treinar RNA: executa-se o algoritmo de treinamento com os parâmetros
definidos.
Salvar dados de pesos e bias: são salvos os parâmetros (pesos e bias) da
interconexão dos neurônios obtidos na etapa de treinamento.

43
3.1.4 Característica do Algoritmo Genético
Há a necessidade da indicação do dado real a ser otimizado: são mostradas
as características, seus valores atuais, a meta e a restrição da evolução.
Por exemplo: um curso que tem 10 características, e obtém nota 3, deseja
obter nota máxima aplicável (5), pode-se alterar apenas 2 dessas características.
São definidos os seguintes parâmetros do comportamento do GA:
a) Definir o intervalo (mínimo e máximo) aceitável de cada característica, por
exemplo, pode ser inviável para uma pequena IES que tem apenas 10
docentes num curso, elevar seu número para 1.000 em curto prazo.
Dessa forma, a otimização pode limitar-se à realidade;
b) Número de indivíduos da população;
c) Taxa de cruzamento;
d) Taxa de mutação;
e) Os critérios de parada: quando o GA termina sua atividade estabelecida
por ordem de prioridade:
A partir do objetivo proposto, quando atingir a meta estabelecida através
dos seguintes critérios.
Por exemplo: “para se atingir a nota 4 na avaliação”;
Critério de parada local: verifica se ocorre evolução no conjunto de
variáveis escolhidas, caso não seja suficiente, o GA apaga toda a
população, voltando ao passo da geração da população, dessa vez com
novas características. Esse passo possibilitou um uso particular do GA,
diferente do uso convencional, para aplicação no problema proposto;
Pela quantidade de gerações sem alteração: quando ocorre estabilização
do melhor resultado no decorrer das gerações. Por exemplo: passaram
300 gerações sem melhoria do resultado;
Quantidade máxima de gerações.

44
Verificar se o intervalo aceitável proposto está entre os valores de máximo
e mínimo admissíveis de cada característica. Caso extrapole, não será
possível continuar os demais passos.
Normalizar os dados reais da mesma forma que foram feitos os dados de
exemplo.
Ativar a RNA: nesse passo, a RNA não aprenderá, mas sim, avaliará com
base nos parâmetros obtidos no processo de aprendizagem (pesos e
biases).
Gera-se a população inicial:
Copia-se o dado real para ser o indivíduo-mestre;
Escolher aleatoriamente um conjunto contendo de um até o número
máximo de características indicadas na “restrição da evolução”, para
serem alteradas;
Gerar aleatoriamente, dentro do intervalo aceitável proposto, valores
para compor tais características em todos os indivíduos da população.
Avaliar a população: cada indivíduo da população será avaliado pela RNA
que retornará, com base nos valores das características, um valor, que é
chamado de “aptidão”.
Ordenar a população na ordem da melhor aptidão para a pior aptidão.
Elitismo: O melhor indivíduo, ou seja, com a melhor aptidão, será
guardado e não poderá ser modificado até que um novo, com melhor
aptidão, seja encontrado.
Para isso, ele é o primeiro elemento da matriz da população, e para a
seleção, as seguintes formas de seleção são adotadas:
Line Breeding (linhagem): escolhe os melhores indivíduos da população.
Essa técnica sugere que a escolha da combinação dos melhores
indivíduos, pode gerar um novo indivíduo, melhor adaptado.

45
Stochastic Universal Sampling (SUS): escolha aleatória entre os
indivíduos.
Cruzamento: as formas de cruzamento são por média e por troca de
posição entre os genes dos indivíduos. Para isso, é observada a taxa de
cruzamento.
Mutação: observando a taxa de mutação, são aplicados valores
aleatórios na característica observada, respeitando os valores máximo
e mínimo.
Esse passo tem por objetivo obter diversidade de características na
população, isto é, uma nova característica poderá surgir e ser de relevada
importância para resolver o problema.
Atualização da população: os novos indivíduos são inseridos no final da
matriz população.
Avaliação: a avaliação da aptidão é realizada pela RNA.
Ordenar a população na ordem da melhor para a pior aptidão.
Verifica os critérios de parada. Verifica-se o melhor resultado e confere
com os critérios de parada, enquanto não atingir algum critério, volta para
a fase de seleção. Caso os critérios foram atingidos, o GA encerra as
atividades e apresenta o resultado.
Apresentação do resultado: ocorre a desnormalização (retira da escala
entre zero e um e identifica o real valor), identifica a característica e o seu
respectivo valor para atingir a meta proposta. Caso não encontrado,
mostra o critério de parada utilizado.
3.1.5 Método utilizado para os testes do algoritmo
A forma de avaliação da eficácia do algoritmo desenvolvido se dá pelo erro
quadrático médio, descrito pela equação 18, em que o valor esperado é o valor
provado matematicamente e o valor obtido é o valor que o resultado obtido pelo

46
algoritmo. Quanto menor o erro, melhor será o conjunto calculado.
(15)

47
4 ESTUDO DE CASO
Na Gestão de uma IES, as tarefas do dia a dia tem um papel preponderante
no seu correto funcionamento. Para que sejam adequadamente executadas, são
necessários investimentos em TI, para que se possa acompanhar o ritmo de
crescimento do setor, e há uma grande separação, um distanciamento dos
interesses entre o Pedagógico e o Administrativo. Ao focar-se apenas uma IES
como exemplo, há três sistemas disponíveis e todos estão disponíveis a todos os
usuários.
O primeiro, e mais antigo sistema é confiável e utiliza-se de equipamentos de
grande porte, totalmente centralizado e exigindo uma maior infraestrutura de TI para
o seu correto funcionamento. Esse sistema chama-se KEA! e foi desenvolvido pela
Attachmate Corporation, que é um emulador de terminais e usa como base um
sistema multiterminal, possui uma interface sóbria e não é muito amigável, está
disponível a todos os usuários cadastrados.
O segundo sistema é uma solução interna, pois se trata de um software
desenvolvido na própria empresa, de acordo com as próprias necessidades e é
baseado na Internet, estando disponível na Intranet da empresa e chama-se SISUN
(Sistema Universitário). Este software é baseado nas plataformas PC existente nas
diversas unidades, com o sistema operacional Windows XP ou NT e depende do
acesso à Intranet para seu correto funcionamento, possuindo uma interface muito
mais amigável para o usuário, disponível a um grande número de usuários
cadastrados, uma vez que a maioria dos usuários do KEA!, também acessam o
SISUN.
O terceiro sistema disponível é o Lyceum desenvolvido pela Techne Sistemas
que é composto por um software de Gestão Acadêmica, disponível apenas para a
área de Pós Graduação (Lato e Stricto Senso), não sendo disponibilizado para todos
os usuários.
De qualquer forma, o acesso possível aos sistemas é fácil, mas é totalmente
centralizado, o que dificulta a tarefa do gestor, exigindo que se utilizem outras
formas de consulta ou de avaliação dos dados, através de planilhas individualizadas
e montadas em cada uma das unidades independentemente. Ao final de cada
semestre, tem-se a necessidade de montar toda uma estrutura novamente, que

48
comporão os dados, gerando muita demora na obtenção dos resultados para que se
possa atingir uma tomada de decisão.
Com a proposta deste trabalho, espera-se que esse tipo de demora na
obtenção dos resultados não exista, fazendo com que se tenha mais rapidez na
tomada de decisão. Para exemplificar a proposta, são estudados três casos: o
primeiro com dados do ENADE 2008, considerando 12 IES e 8 características; o
segundo com dados do ENADE 2009, de 16 IES e 10 características; e o terceiro
com dados do ENADE 2011, de 103 IES e 22 características, fundamentais para que
se possa avaliar desempenho dos cursos em diferentes situações.
4.1 1º Conjunto de treinamento
Esses conjuntos serviram como base para a apresentação de 2 artigos
científicos – 1) no ICECE 2011 em Guimarães em Portugal, com o Título
“Inteligência Computacional aplicada às avaliações da gestão acadêmica em
uma Instituição de Ensino Superior”, apresentado em Setembro de 2011 e o 2) no
IV SIDEPRO 2011 em São Paulo/SP, com o Título “Proposta de uma metodologia
para a avaliação da gestão acadêmica em uma IES utilizando a inteligência
computacional”, apresentado em Novembro/2011. Estes dois artigos são
apresentados nos Anexos I, J, K, L.
Como as redes neurais são utilizadas para avaliação de uma IES com base
nas informações do ENADE, foram selecionados dados de 12 IES escolhidas para o
exemplo 8 características, que são apresentados nas Tabelas 3 e 4, ou seja, as
características foram divididas em duas Tabelas. Nesse caso, foram escolhidas
somente 12 IES, ou específicamente as unidades universitárias de uma IES que
possuem um determinado curso. Quanto às características definimos 8 por serem as
principais para serem testadas.
A seguir descreve-se cada uma dascaracterísticas: C1: Part – total de
participantes, C2: Conc – número de alunos concluintes, C3: Enade – valor
calculado do Enade por IES, C4: Con_Enade – conceito do Enade de cada IES, C5:
Not_enade – nota do Enade para cada IES, C6: Idd – indicador de diferença entre o
desempenho observado e esperado dos alunos, C7: Cpc – conceito preliminar de
curso e C8: Cpc_fx – conceito preliminar de curso padronizado. A Figura 9 ilustra a
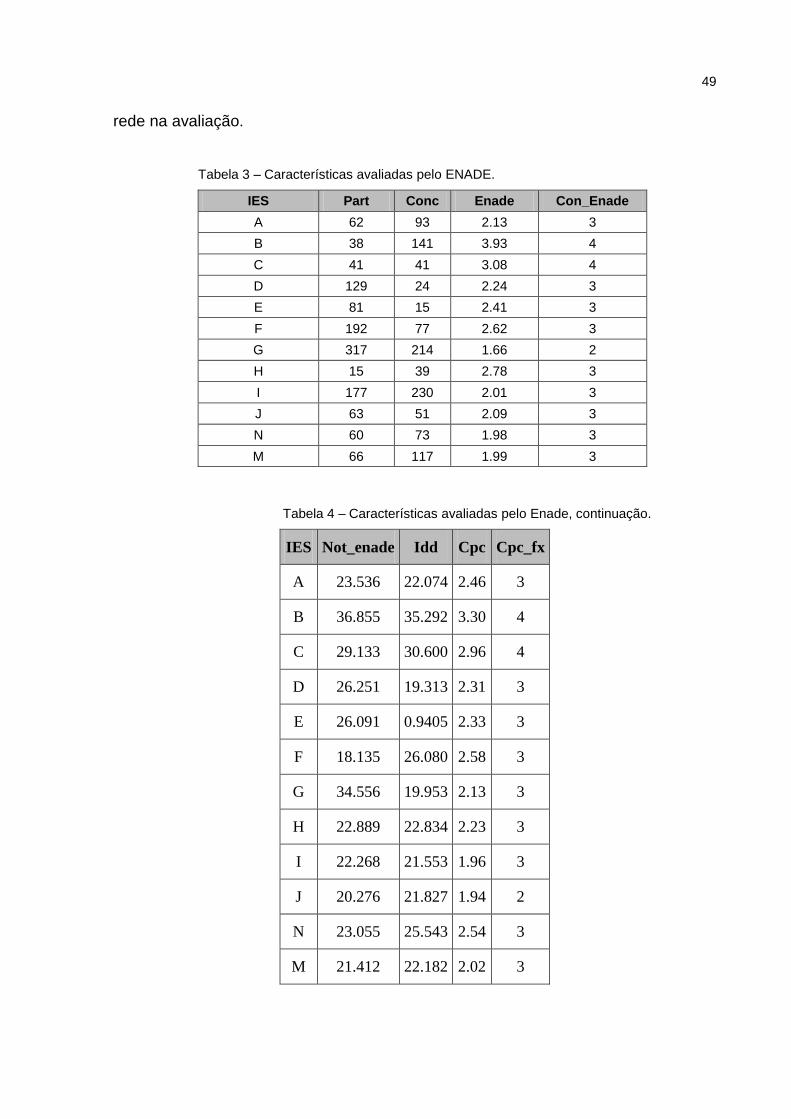
49
rede na avaliação.
Tabela 3 – Características avaliadas pelo ENADE.
IES Part Conc Enade Con_Enade
A 62 93 2.13 3
B 38 141 3.93 4
C 41 41 3.08 4
D 129 24 2.24 3
E 81 15 2.41 3
F 192 77 2.62 3
G 317 214 1.66 2
H 15 39 2.78 3
I 177 230 2.01 3
J 63 51 2.09 3
N 60 73 1.98 3
M 66 117 1.99 3
Tabela 4 – Características avaliadas pelo Enade, continuação.
IES Not_enade Idd Cpc Cpc_fx
A 23.536 22.074 2.46 3
B 36.855 35.292 3.30 4
C 29.133 30.600 2.96 4
D 26.251 19.313 2.31 3
E 26.091 0.9405 2.33 3
F 18.135 26.080 2.58 3
G 34.556 19.953 2.13 3
H 22.889 22.834 2.23 3
I 22.268 21.553 1.96 3
J 20.276 21.827 1.94 2
N 23.055 25.543 2.54 3
M 21.412 22.182 2.02 3
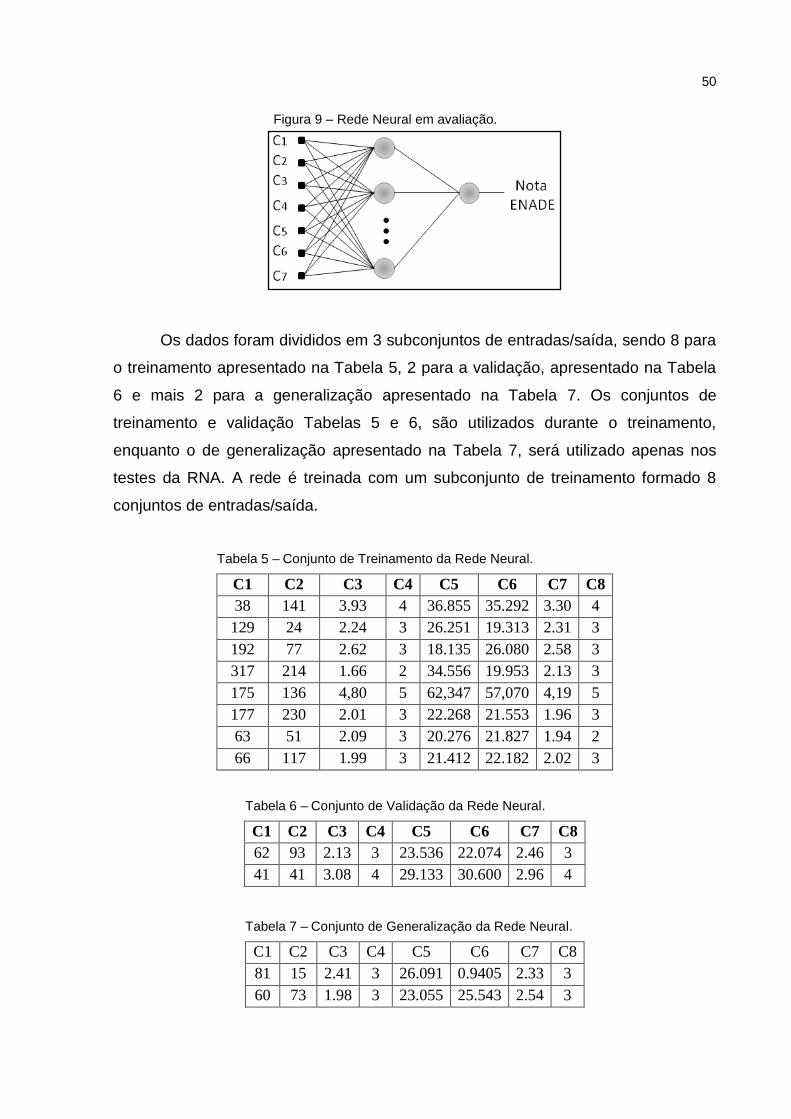
50
Figura 9 – Rede Neural em avaliação.
Os dados foram divididos em 3 subconjuntos de entradas/saída, sendo 8 para
o treinamento apresentado na Tabela 5, 2 para a validação, apresentado na Tabela
6 e mais 2 para a generalização apresentado na Tabela 7. Os conjuntos de
treinamento e validação Tabelas 5 e 6, são utilizados durante o treinamento,
enquanto o de generalização apresentado na Tabela 7, será utilizado apenas nos
testes da RNA. A rede é treinada com um subconjunto de treinamento formado 8
conjuntos de entradas/saída.
Tabela 5 – Conjunto de Treinamento da Rede Neural.
C1 C2 C3 C4 C5 C6 C7 C8
38 141 3.93 4 36.855 35.292 3.30 4
129 24 2.24 3 26.251 19.313 2.31 3
192 77 2.62 3 18.135 26.080 2.58 3
317 214 1.66 2 34.556 19.953 2.13 3
175 136 4,80 5 62,347 57,070 4,19 5
177 230 2.01 3 22.268 21.553 1.96 3
63 51 2.09 3 20.276 21.827 1.94 2
66 117 1.99 3 21.412 22.182 2.02 3
Tabela 6 – Conjunto de Validação da Rede Neural.
C1 C2 C3 C4 C5 C6 C7 C8
62 93 2.13 3 23.536 22.074 2.46 3
41 41 3.08 4 29.133 30.600 2.96 4
Tabela 7 – Conjunto de Generalização da Rede Neural.
C1 C2 C3 C4 C5 C6 C7 C8
81 15 2.41 3 26.091 0.9405 2.33 3
60 73 1.98 3 23.055 25.543 2.54 3

51
Durante a fase de treinamento, a rede neural deve ser treinada de modo que
aprenda o suficiente com base no conjunto de treinamento, e seja capaz de
generalizar com novos dados. Uma ferramenta para evitar que a rede não se
especialize nos dados treinados é a validação cruzada, que consiste em apresentar
o subconjunto de validação e parar antes da especialização, Haykin (2008).
O erro quadrático da avaliação é obtido pela equação 16:
2Neural RedeAvaliador
2
1Erro NN (16)
Onde:
NAvalidador é a nota apresentada pelo avaliador e NRede Neural é a nota estimada
pela rede neural.
No treinamento da rede da rede neural foram utilizados os subconjuntos de
treinamento contendo 8 avaliações e o de validação contendo 2 pares de
entrada/saída. Foi variado o número de neurônios na camada escondida com o
objetivo de encontrar uma melhor arquitetura de rede neural, esse processo é
necessário para um melhor desempenho da classificação. Na Tabela 8 apresenta-se
a média dos Erros obtidos e a variação do número de neurônios na camada
escondida dessas avaliações.
A Figura 10 ilustra um exemplo de avaliação do treinamento da rede neural, e
o critério de parada utilizado no treinamento foi o critério de validação cruzada,
Haykin (2008).
Na Tabela 8 mostra-se o número de neurônios na camada escondida para a
rede neural e variou entre 1 e 6 e o melhor resultado foi obtido com os dados
apresentados com 4 neurônios, menos que isso não há informações suficientes para
o treinamento e mais que 4 inicia-se o processo de saturação da rede neural.
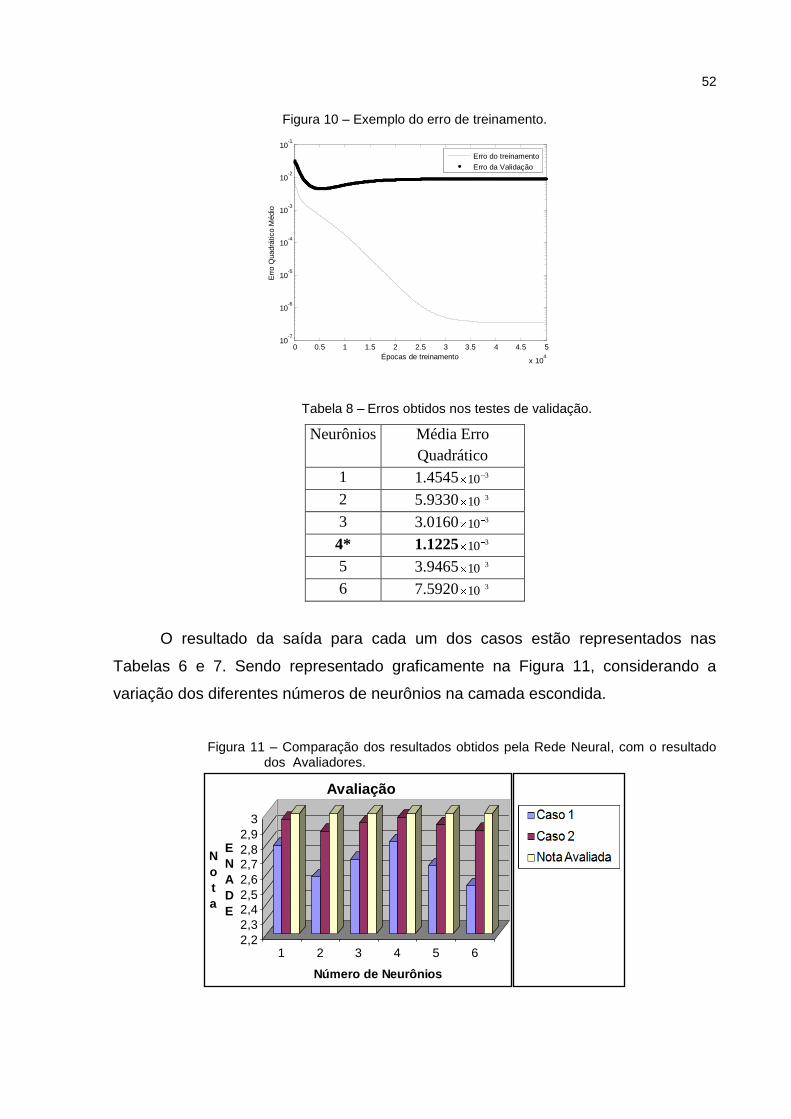
52
Figura 10 – Exemplo do erro de treinamento.
Tabela 8 – Erros obtidos nos testes de validação.
Neurônios Média Erro
Quadrático
1 1.4545 310
2 5.9330 310
3 3.0160 310
4* 1.1225 310
5 3.9465 310
6 7.5920 310
O resultado da saída para cada um dos casos estão representados nas
Tabelas 6 e 7. Sendo representado graficamente na Figura 11, considerando a
variação dos diferentes números de neurônios na camada escondida.
Figura 11 – Comparação dos resultados obtidos pela Rede Neural, com o resultado dos Avaliadores.
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
x 104
10-7
10-6
10-5
10-4
10-3
10-2
10-1
Épocas de treinamento
Err
o Q
uadrá
tico M
édio
Erro do treinamento
Erro da Validação
2,2
2,3
2,4
2,5
2,6
2,7
2,8
2,9
3
N
o
t
a
E
N
A
D
E
1 2 3 4 5 6
Número de Neurônios
Avaliação Caso 1
Caso 2
Nota Avaliada

53
Portanto é possível para a gestão acadêmica, extrair informações de quais
são as características que mais influenciaram na avaliação com o uso de
informações e dos pesos da rede neural. Esses pesos são apresentados na Tabela
9.
De acordo com os cálculos efetuados pela RNA, são apresentadas na Tabela
9, as características que mais influenciam nos resultados são: C2: número de alunos
concluintes, C3: Enade, C5: Not_Enade e C7: Cpc. Com essa identificação foi
possível fazer simulações para a melhoria das características, tornando as
avaliações de desempenho pela IES, mais próximas da realidade.
Tabela 9 – Influência das características nas avaliações.
1 2 3 4 5 6
C1 0.43 0.35 0.66 0.96 0.81 0.51
C2 0.84 1.10 1.52 1.96 2.06 2.22
C3 1.76 1.87 3.24 3.97 4.40 4.26
C4 0.06 0.11 0.33 0.84 0.70 0.96
C5 1.29 1.43 2.49 3.22 3.50 3.32
C6 0.15 0.78 0.58 0.31 1.00 1.88
C7 2.02 1.53 3.40 4.85 4.47 3.60
Baseando-se nesses dados, novos experimentos foram realizados com uso
das 4 características destacadas pela rede neural. Foram utilizadas 4 entradas e 1
saída, sendo as entradas: C2: número de alunos concluintes, C3: Enade, C5:
Not_Enade e C7: Cpc e a saída desejada era a nota definida pelos avaliadores.
Novamente, variou-se a quantidade de neurônios na camada escondida. A Tabela
10 apresenta os resultados obtidos na validação da rede neural.
Para essa configuração, a rede neural apresentou notas mais próximas às
dos avaliadores utilizando 5 neurônios na camada escondida, quando comparada
com o experimento anterior apresentada na Tabela 10. O teste de generalização
também mostrou que a rede neural apresenta notas mais próximas às dos
avaliadores, como é apresentado na Figura 12, com uso de 5 neurônios na camada
escondida.
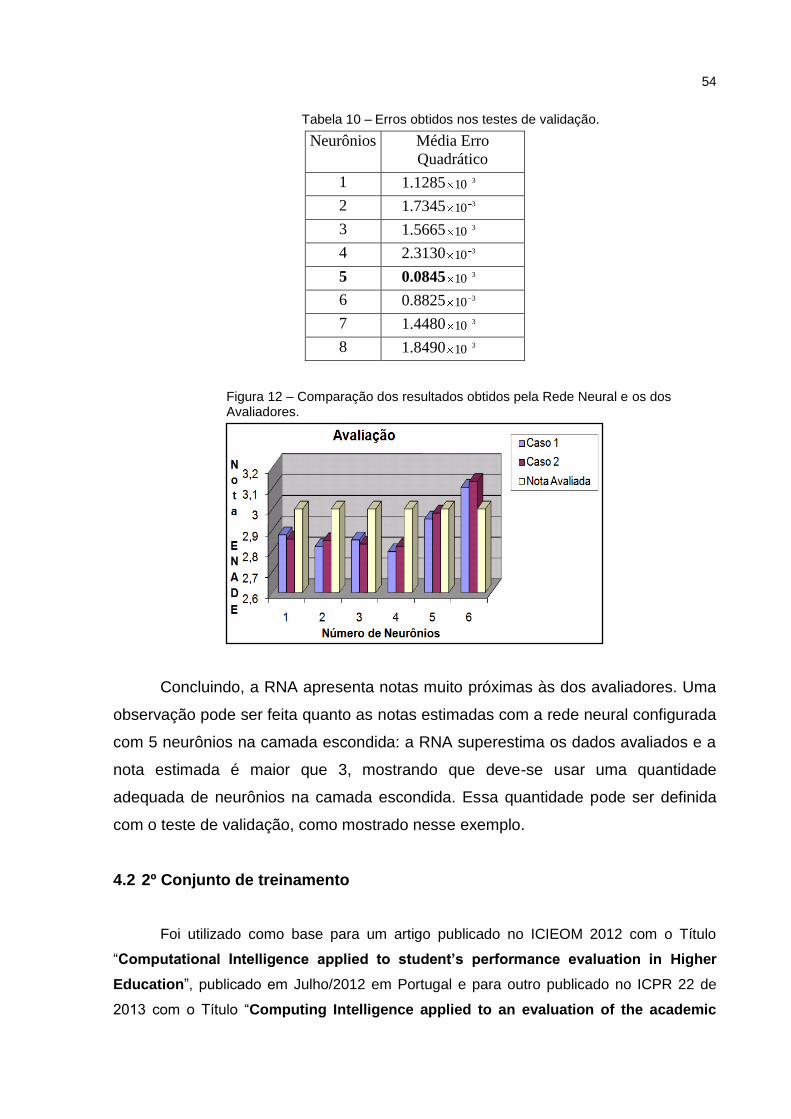
54
Tabela 10 – Erros obtidos nos testes de validação.
Neurônios Média Erro
Quadrático
1 1.1285 310
2 1.7345 310
3 1.5665 310
4 2.3130 310
5 0.0845 310
6 0.8825 310
7 1.4480 310
8 1.8490 310
Figura 12 – Comparação dos resultados obtidos pela Rede Neural e os dos Avaliadores.
Concluindo, a RNA apresenta notas muito próximas às dos avaliadores. Uma
observação pode ser feita quanto as notas estimadas com a rede neural configurada
com 5 neurônios na camada escondida: a RNA superestima os dados avaliados e a
nota estimada é maior que 3, mostrando que deve-se usar uma quantidade
adequada de neurônios na camada escondida. Essa quantidade pode ser definida
com o teste de validação, como mostrado nesse exemplo.
4.2 2º Conjunto de treinamento
Foi utilizado como base para um artigo publicado no ICIEOM 2012 com o Título
“Computational Intelligence applied to student’s performance evaluation in Higher
Education”, publicado em Julho/2012 em Portugal e para outro publicado no ICPR 22 de
2013 com o Título “Computing Intelligence applied to an evaluation of the academic

55
management”, publicado em Julho/2013. Estes artigos são apresentados nos Anexos I, J,
K, L.
Com base no banco de dados do ENADE 2009, foram selecionados dados de
16 IES de diferentes cursos e foram selecionadas 10 características como as
apresentadas a seguir na Tabela 11 e as características escolhidas são: Conc – total
de participantes; Enade – Conceito calculado de cada IES representados em
percentual; Med_Conc_FG – média calculada do Enade para os alunos concluintes
em formação geral; Med_Conc_FE – média calculada no Enade para os alunos
concluintes em formação específica; Con_Enade – conceito do Enade de cada IES;
Med_Ing_FG – média dos alunos ingressantes em formação geral; Med_Ing_FE –
média dos alunos ingressantes em formação específica; Idd – indicador de
diferença entre o desempenho observado e esperado dos alunos; Cpc – conceito
preliminar de curso e Cpc_fx – conceito preliminar de curso padronizado.
Tabela 11 – Dados ENADE de 16 Instituições.
Conc Enade Med_Conc_FG Med_Conc_FE Con_Enade Med_Ing_FG Med_Ing_FE Idd Cpc Cpc_fx
136 4,8 62,3471 57,0699 5 55,3086 44,0691 3,6196 4,19 5
29 2,24 45,4897 36,8897 3 45,1400 28,4000 2,4414 2,19 3
52 3,29 47,6077 46,2577 4 39,8129 31,5620 2,7001 3,02 4
262 1,93 37,2847 35,8794 2 37,5515 28,8235 2,2998 1,81 2
28 2,89 58,4750 40,0679 3 53,4600 32,1244 3,1203 2,64 3
40 3,87 56,0725 49,8100 4 48,9753 33,4188 3,1672 3,47 4
51 3,08 51,4235 43,4549 4 48,8485 33,7303 3,2029 2,90 3
47 4,09 58,6702 51,2128 5 45,0055 32,0534 4,9076 3,30 4
60 3,38 61,6067 43,9483 4 50,4652 36,4011 3,5782 3,14 4
106 3,49 57,5623 45,8953 4 50,0300 34,0362 3,2714 3,24 4
158 4,02 61,1601 49,9861 5 64,8894 41,5816 2,5559 3,53 4
30 4,03 61,2667 50,0667 5 31,4727 29,4273 2,2195 3,38 4
78 2,09 45,6103 35,4808 3 42,6586 30,0186 2,0131 2,24 3
36 4,46 60,3194 54,3667 5 60,0611 41,9000 4,5116 3,62 4
141 3,93 57,4801 50,0447 4 55,7974 36,1658 3,6855 3,30 4
506 3,41 53,2630 46,0658 4 38,1419 29,7941 2,4363 3,43 4
Para o teste da validação cruzada foram utilizados dados de 3 IES,
apresentados na Tabela 12. Foram selecionadas instituições com notas 3 e 4.
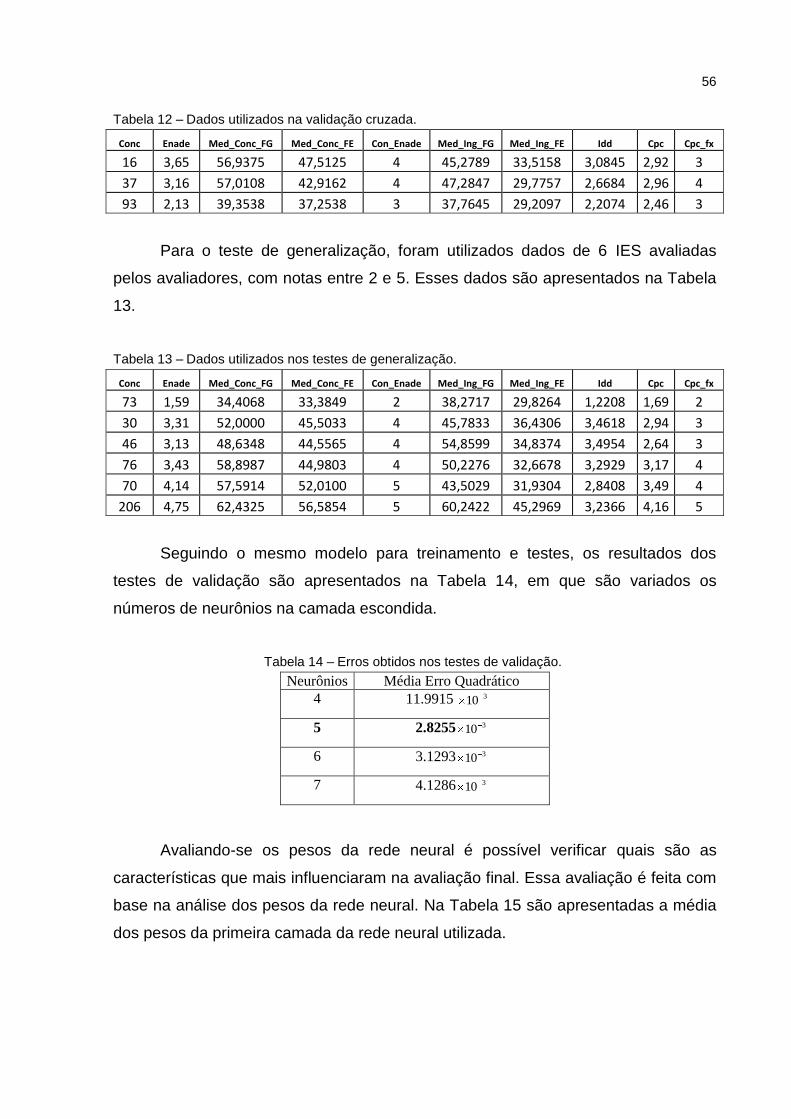
56
Tabela 12 – Dados utilizados na validação cruzada.
Conc Enade Med_Conc_FG Med_Conc_FE Con_Enade Med_Ing_FG Med_Ing_FE Idd Cpc Cpc_fx
16 3,65 56,9375 47,5125 4 45,2789 33,5158 3,0845 2,92 3
37 3,16 57,0108 42,9162 4 47,2847 29,7757 2,6684 2,96 4
93 2,13 39,3538 37,2538 3 37,7645 29,2097 2,2074 2,46 3
Para o teste de generalização, foram utilizados dados de 6 IES avaliadas
pelos avaliadores, com notas entre 2 e 5. Esses dados são apresentados na Tabela
13.
Tabela 13 – Dados utilizados nos testes de generalização.
Conc Enade Med_Conc_FG Med_Conc_FE Con_Enade Med_Ing_FG Med_Ing_FE Idd Cpc Cpc_fx
73 1,59 34,4068 33,3849 2 38,2717 29,8264 1,2208 1,69 2
30 3,31 52,0000 45,5033 4 45,7833 36,4306 3,4618 2,94 3
46 3,13 48,6348 44,5565 4 54,8599 34,8374 3,4954 2,64 3
76 3,43 58,8987 44,9803 4 50,2276 32,6678 3,2929 3,17 4
70 4,14 57,5914 52,0100 5 43,5029 31,9304 2,8408 3,49 4
206 4,75 62,4325 56,5854 5 60,2422 45,2969 3,2366 4,16 5
Seguindo o mesmo modelo para treinamento e testes, os resultados dos
testes de validação são apresentados na Tabela 14, em que são variados os
números de neurônios na camada escondida.
Tabela 14 – Erros obtidos nos testes de validação.
Neurônios Média Erro Quadrático
4 11.9915 310
5 2.8255 310
6 3.1293 310
7 4.1286 310
Avaliando-se os pesos da rede neural é possível verificar quais são as
características que mais influenciaram na avaliação final. Essa avaliação é feita com
base na análise dos pesos da rede neural. Na Tabela 15 são apresentadas a média
dos pesos da primeira camada da rede neural utilizada.
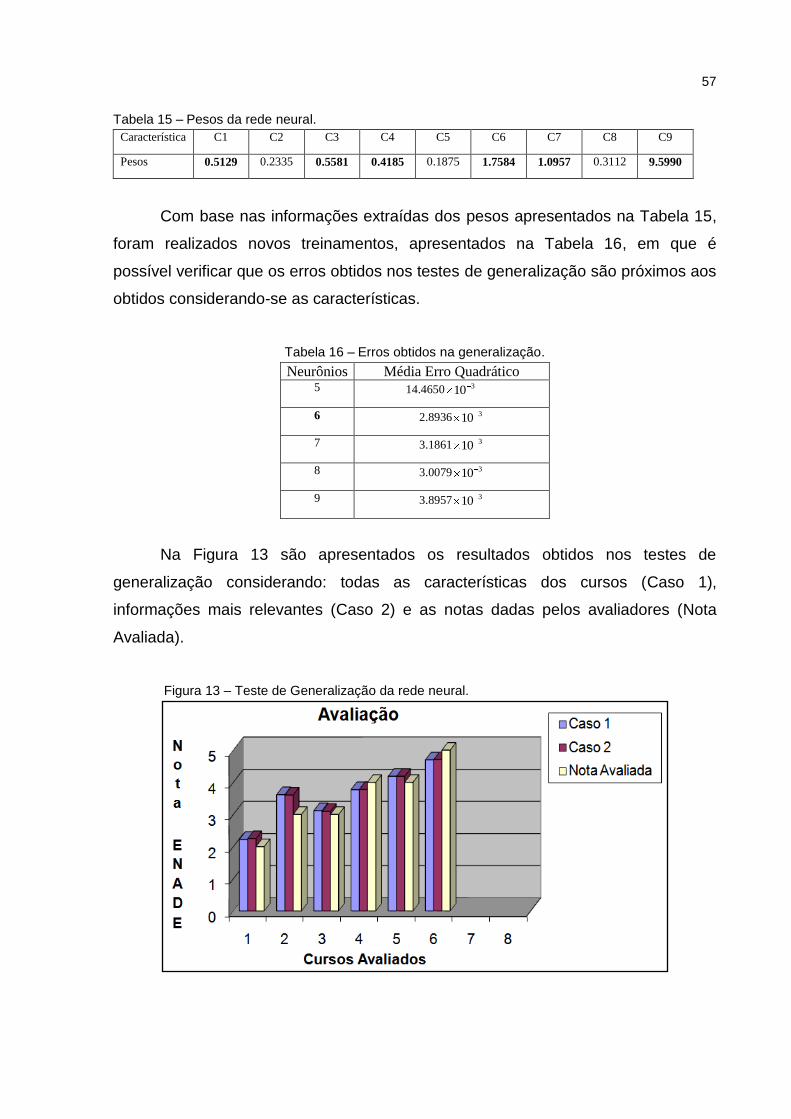
57
Tabela 15 – Pesos da rede neural. Característica C1 C2 C3 C4 C5 C6 C7 C8 C9
Pesos 0.5129 0.2335 0.5581 0.4185 0.1875 1.7584 1.0957 0.3112 9.5990
Com base nas informações extraídas dos pesos apresentados na Tabela 15,
foram realizados novos treinamentos, apresentados na Tabela 16, em que é
possível verificar que os erros obtidos nos testes de generalização são próximos aos
obtidos considerando-se as características.
Tabela 16 – Erros obtidos na generalização.
Neurônios Média Erro Quadrático 5 14.4650 310
6 2.8936 310
7 3.1861 310
8 3.0079 310
9 3.8957 310
Na Figura 13 são apresentados os resultados obtidos nos testes de
generalização considerando: todas as características dos cursos (Caso 1),
informações mais relevantes (Caso 2) e as notas dadas pelos avaliadores (Nota
Avaliada).
Figura 13 – Teste de Generalização da rede neural.

58
Concluindo, a RNA apresenta novamente as notas muito próximas às dos
avaliadores. Podemos observar mais uma vez, que as notas estimadas com a rede
neural configurada com 6 neurônios na camada escondida, superestima os dados
avaliados e a nota é maior do que 4. Mostrando que se deve usar uma quantidade
adequada de neurônios na camada escondida. Essa quantidade pode ser verificada
com o teste de validação, como os apresentados nesse exemplo.
4.3 3º Conjunto de treinamento
Foi utilizado como base para este trabalho um conjunto mais amplo de IES com 103
e com 22 características, onde o conjunto total é apresentado no Anexo D. Neste
treinamento foi utilizada uma ferramenta composta por um sistema computadorizado para
simulação, avaliação, testes e apresentação dos resultados, chamado “Sistema
Computacional Inteligente de Avaliação e Apoio à Decisão – SCIAAD”. Esse software foi
enviado para patente no INPI, pelo diferencial contributivo que apresenta, conforme a
documentação e informações nos Anexos D, E e H.
Apresentação do Software SCIAAD.
Foi desenvolvido em MatLAb, com base em um programa desenvolvido em
Fortran para execução dos cálculos e apresenta as seguintes características:
Facilidade de operação;
Rapidez, dependendo do número a ser utilizados (épocas, gerações e
outros);
Confiabilidade;
Interface de fácil visualização, GUI.
Na Figura 14, é apresentada a interface GUI, na tela inicial do software
SCIAAD.

59
Figura 14 – Tela de Introdução com as opções do SCIAAD.
Há três opções, etapas de avaliações: Treinamento; Ativação da RNA; e a
Otimização do GA. Ao escolher a opção Treinar RNA, a Figura 15 é apresentada,
com um breve comentário sobre a operação a ser executada.
Figura 15 – Tela da opção Treinar RNA.
Clicando-se na opção avançar, entra-se na opção de importação do exemplo
dos dados a serem calculados, tabelados em EXCEL, para o treinamento da RNA,
apresentado na Figura 16.
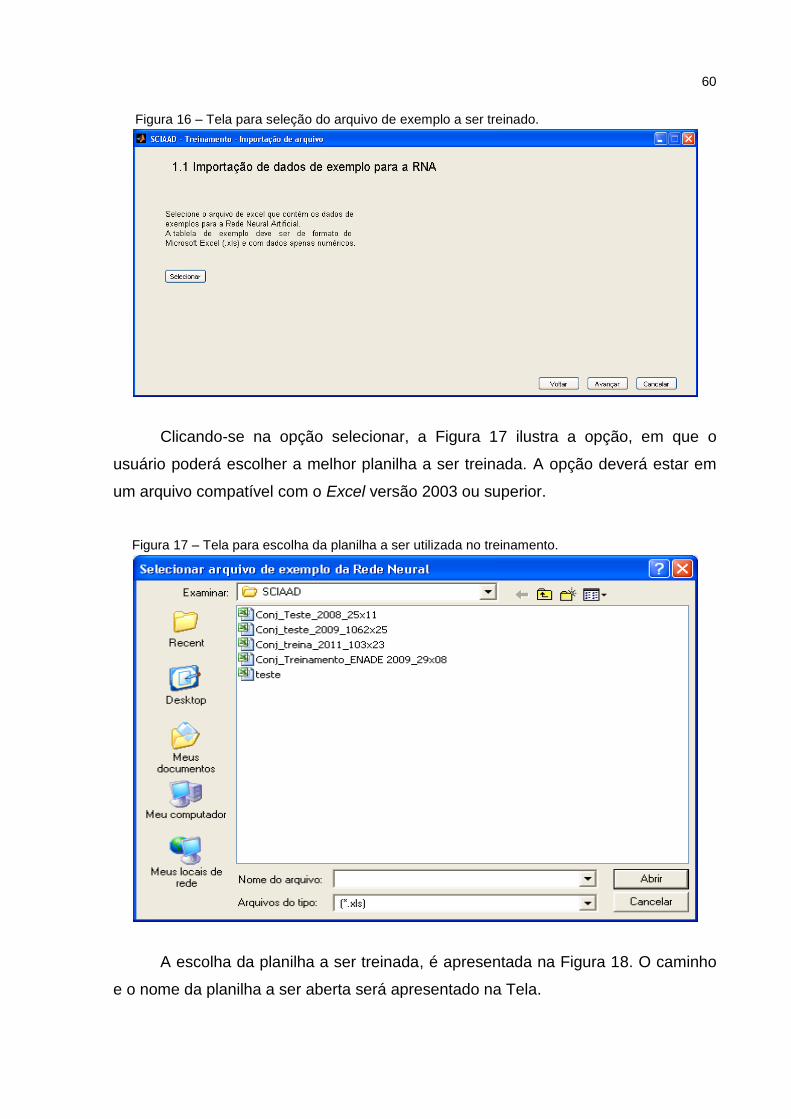
60
Figura 16 – Tela para seleção do arquivo de exemplo a ser treinado.
Clicando-se na opção selecionar, a Figura 17 ilustra a opção, em que o
usuário poderá escolher a melhor planilha a ser treinada. A opção deverá estar em
um arquivo compatível com o Excel versão 2003 ou superior.
Figura 17 – Tela para escolha da planilha a ser utilizada no treinamento.
A escolha da planilha a ser treinada, é apresentada na Figura 18. O caminho
e o nome da planilha a ser aberta será apresentado na Tela.
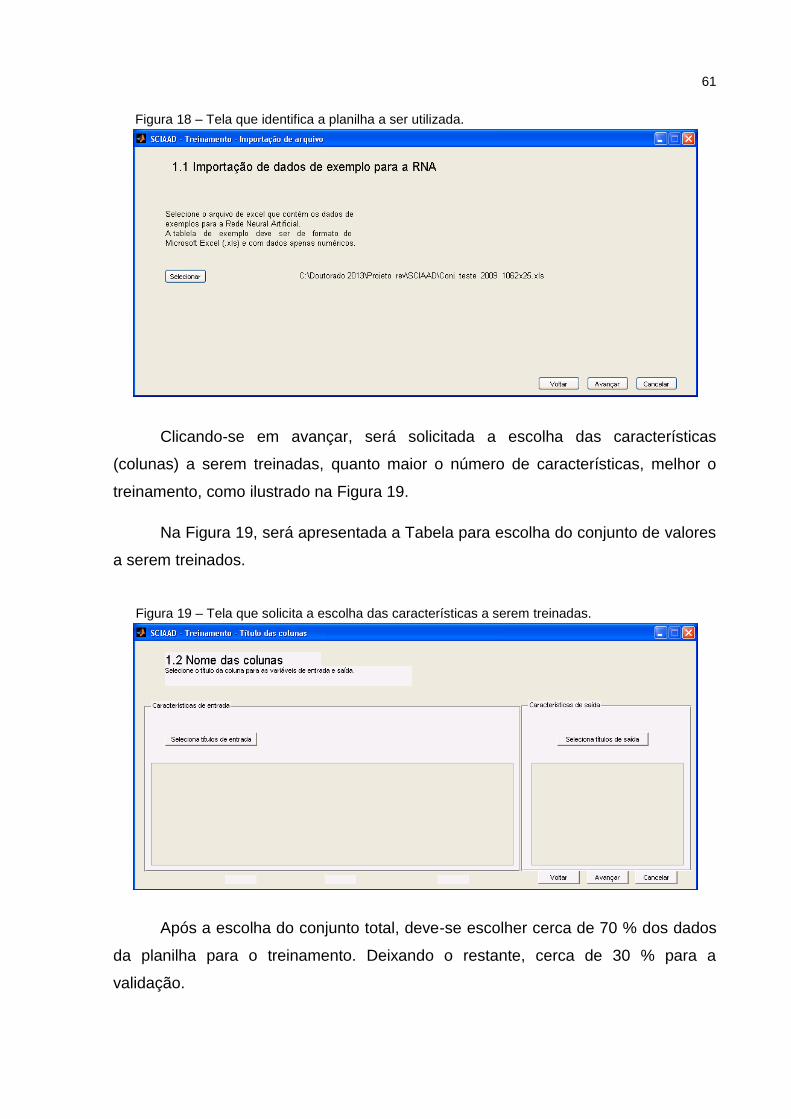
61
Figura 18 – Tela que identifica a planilha a ser utilizada.
Clicando-se em avançar, será solicitada a escolha das características
(colunas) a serem treinadas, quanto maior o número de características, melhor o
treinamento, como ilustrado na Figura 19.
Na Figura 19, será apresentada a Tabela para escolha do conjunto de valores
a serem treinados.
Figura 19 – Tela que solicita a escolha das características a serem treinadas.
Após a escolha do conjunto total, deve-se escolher cerca de 70 % dos dados
da planilha para o treinamento. Deixando o restante, cerca de 30 % para a
validação.

62
A Figura 20 ilustra a caixa de validação, após a escolha dos elementos para
utilização no conteúdo.
Figura 20 – Caixa de diálogo para confirmação da seleção dos dados a serem utilizados.
Na Figura 21, é apresentado o exemplo selecionado, o texto da tela alerta o
usuário para a quantidade a ser selecionada.
Figura 21 – Exemplo de Tabela ENADE a ser utilizado.

63
Será copiado o conteúdo da planilha para o software MatLab para seja
executado o treinamento. A seguir, a Figura 22 mostra o conjunto de validação que é
solicitado, baseado na planilha escolhida. Novamente, há uma informação no texto
da tela para o usuário se ater aos totais, nesse momento, 30 % deve ser
selecionado.
Figura 22 – Tela com a seleção dos dados para a entrada e a saída.
Logo após as escolhas dos conjuntos de entrada e saída e ao se clicar em
avançar, serão apresentados os limites encontrados no conjunto de dados
escolhido, tanto na entrada quanto na saída, essa tela é apresentada na Figura 23.
Figura 23 – Tela exemplo do conjunto de validação.

64
Com base nos dados escolhidos e treinados, foram obtidos os seguintes
resultados, apresentados na Figura 24, que apresenta a Tela 1.5, mostrando as
informações sobre os valores máximos e mínimos encontrados na amostra. Tanto
para os dados de entrada quanto para os dados de saída.
Figura 24 – Tela que apresenta os limites encontrados no conjunto de dados escolhidos.
Com base nos dados escolhidos e treinados, foram obtidos os seguintes
resultados, apresentados na Figura 25, que apresenta a Tela 1.6. Ela mostra as
informações sobre os parâmetros de treinamento utilizados, para este caso, num
total de 50.000 épocas de treinamento, com 5 neurônios na camada escondida, taxa
de aprendizado de 0,3 e um erro desejado de 0,0001.
Possuindo um total de características de entrada iguais a 21, e de saída igual
a 1 e tendo ainda o número de exemplos de treinamento igual a 321 e o número de
exemplos para validação igual a 130, os dados do treinamento estão nos Anexos D,
E e H.

65
Figura 25 – Parâmetros utilizados no treinamento.
Após o treinamento, conforme o exemplo da tela apresentada na Figura 26,
Tela 1.7, o erro obtido no treinamento é o 0,0195568, pode ser verificando através
do gráfico, onde as duas curvas, a do erro de validação e do erro do treinamento são
apresentadas.
Tornando-se assim, fácil a identificação desses resultados, pois ainda há as
opções de impressão do gráfico, movimentação do resultado, identificação dos
resultados (eixo X e Y), zoom in e zoom out, para que se possam visualizar melhor
os resultados.
Figura 26 – Resultado obtido no treinamento da rede neural.
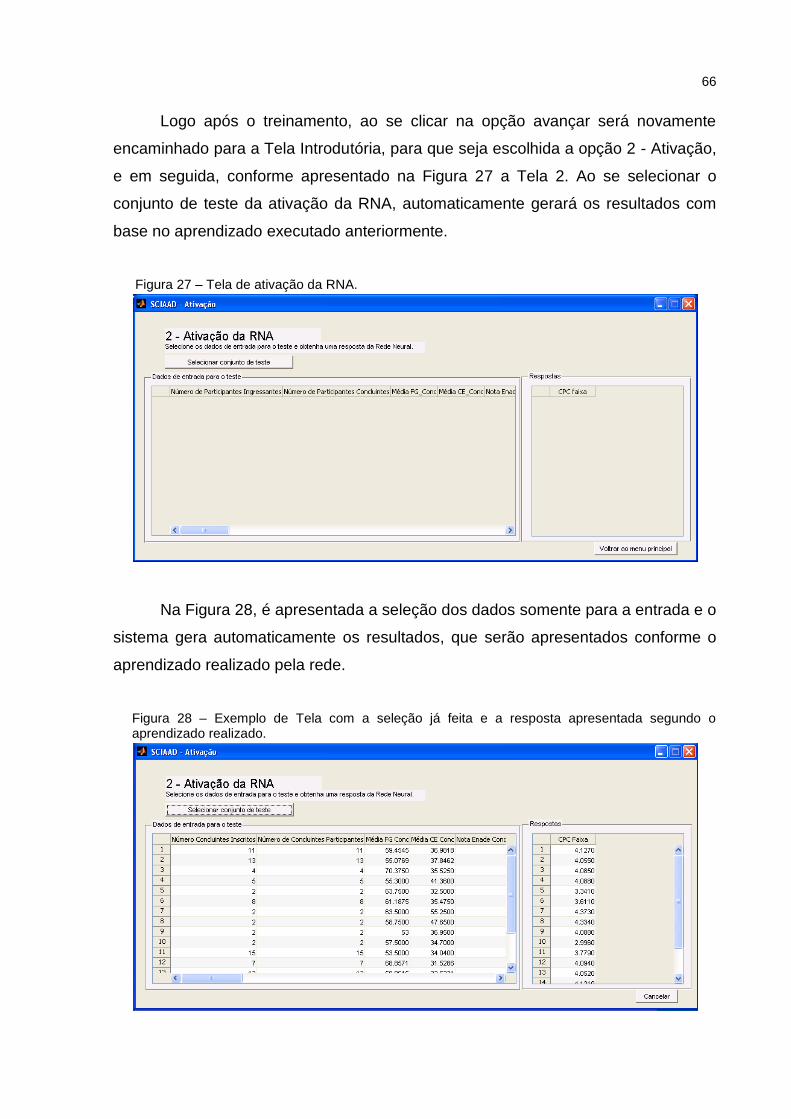
66
Logo após o treinamento, ao se clicar na opção avançar será novamente
encaminhado para a Tela Introdutória, para que seja escolhida a opção 2 - Ativação,
e em seguida, conforme apresentado na Figura 27 a Tela 2. Ao se selecionar o
conjunto de teste da ativação da RNA, automaticamente gerará os resultados com
base no aprendizado executado anteriormente.
Figura 27 – Tela de ativação da RNA.
Na Figura 28, é apresentada a seleção dos dados somente para a entrada e o
sistema gera automaticamente os resultados, que serão apresentados conforme o
aprendizado realizado pela rede.
Figura 28 – Exemplo de Tela com a seleção já feita e a resposta apresentada segundo o aprendizado realizado.
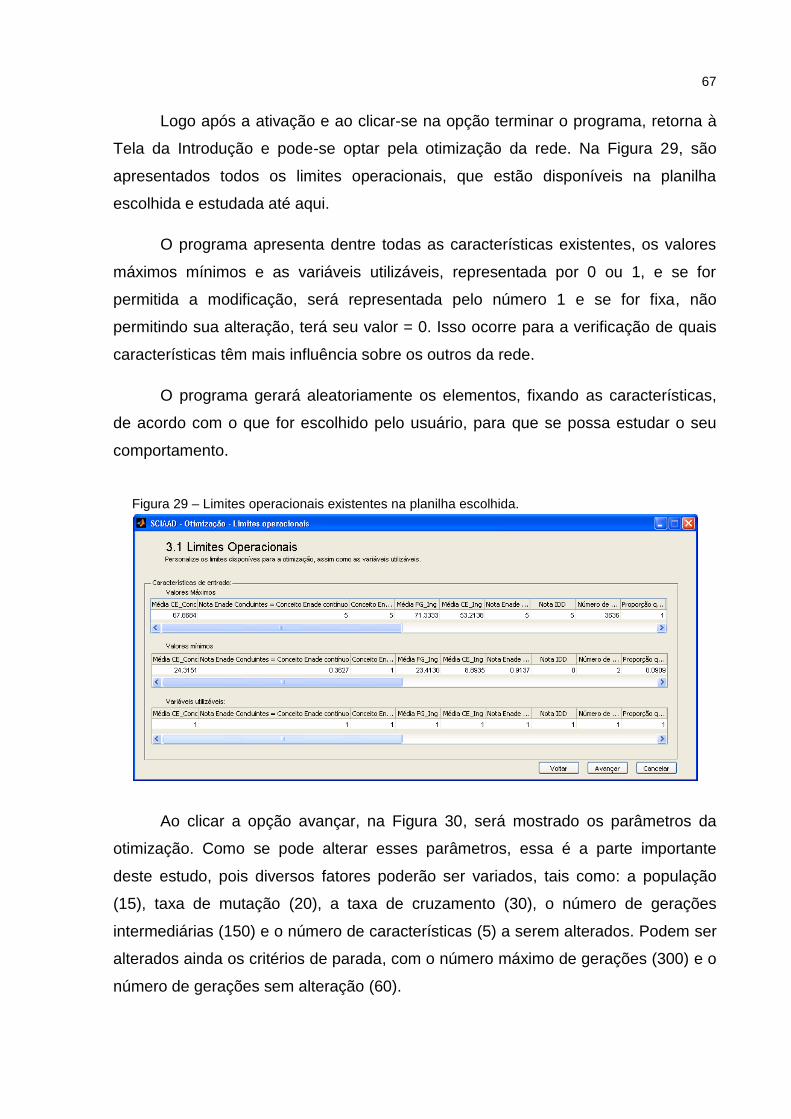
67
Logo após a ativação e ao clicar-se na opção terminar o programa, retorna à
Tela da Introdução e pode-se optar pela otimização da rede. Na Figura 29, são
apresentados todos os limites operacionais, que estão disponíveis na planilha
escolhida e estudada até aqui.
O programa apresenta dentre todas as características existentes, os valores
máximos mínimos e as variáveis utilizáveis, representada por 0 ou 1, e se for
permitida a modificação, será representada pelo número 1 e se for fixa, não
permitindo sua alteração, terá seu valor = 0. Isso ocorre para a verificação de quais
características têm mais influência sobre os outros da rede.
O programa gerará aleatoriamente os elementos, fixando as características,
de acordo com o que for escolhido pelo usuário, para que se possa estudar o seu
comportamento.
Figura 29 – Limites operacionais existentes na planilha escolhida.
Ao clicar a opção avançar, na Figura 30, será mostrado os parâmetros da
otimização. Como se pode alterar esses parâmetros, essa é a parte importante
deste estudo, pois diversos fatores poderão ser variados, tais como: a população
(15), taxa de mutação (20), a taxa de cruzamento (30), o número de gerações
intermediárias (150) e o número de características (5) a serem alterados. Podem ser
alterados ainda os critérios de parada, com o número máximo de gerações (300) e o
número de gerações sem alteração (60).
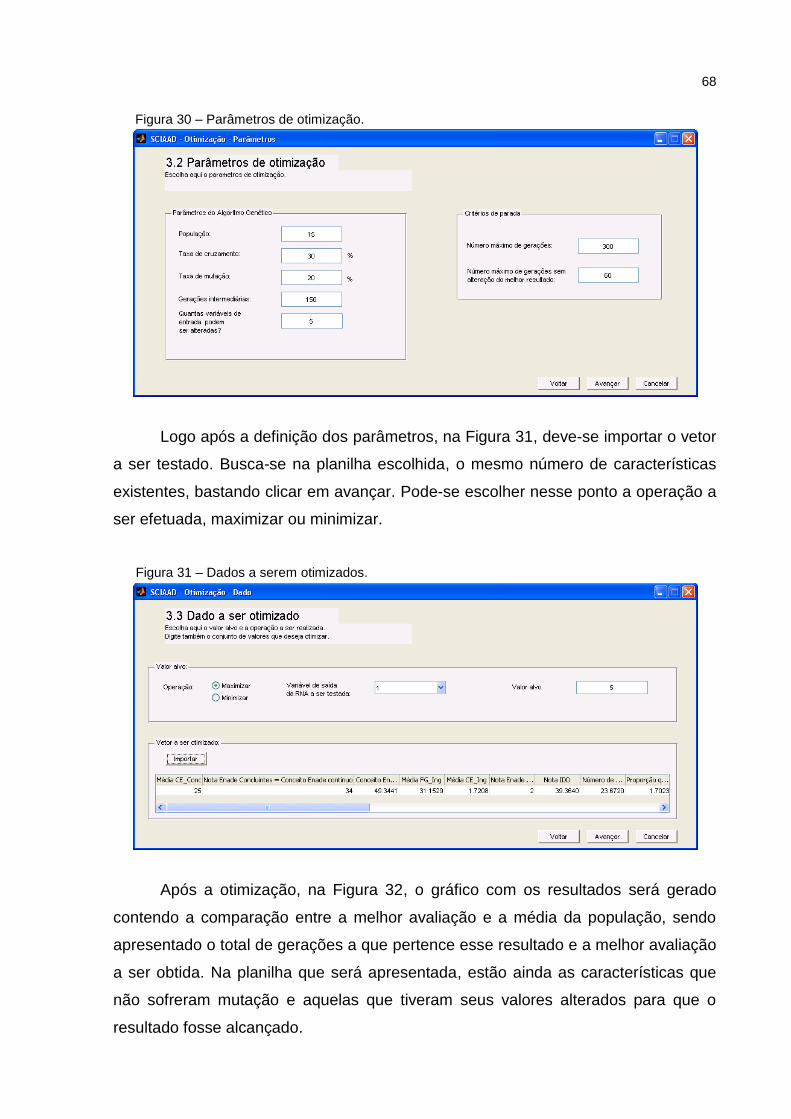
68
Figura 30 – Parâmetros de otimização.
Logo após a definição dos parâmetros, na Figura 31, deve-se importar o vetor
a ser testado. Busca-se na planilha escolhida, o mesmo número de características
existentes, bastando clicar em avançar. Pode-se escolher nesse ponto a operação a
ser efetuada, maximizar ou minimizar.
Figura 31 – Dados a serem otimizados.
Após a otimização, na Figura 32, o gráfico com os resultados será gerado
contendo a comparação entre a melhor avaliação e a média da população, sendo
apresentado o total de gerações a que pertence esse resultado e a melhor avaliação
a ser obtida. Na planilha que será apresentada, estão ainda as características que
não sofreram mutação e aquelas que tiveram seus valores alterados para que o
resultado fosse alcançado.

69
Figura 32 – Resultados da otimização.
De acordo com os resultados obtidos, podemos concluir que o software
cumpriu o seu papel de automação do modelo proposto, permitindo-se assim a
tomada de decisão.
Com esses resultados, é apresentada a melhor simulação encontrada,
verificando-se que alterando as seguintes características: Nota_Enade,
Prop_queavalb, Docentes_minmestres, Nota_doutor e Prop_doctempoparc., a Nota
da IES que era de 1 passará para 3,359.
Será realizada uma análise complementar, de todas as etapas estudadas..
Foram realizados um conjunto de testes para identificar o melhor conjunto de
características da arquitetura da RNA para se obter o menor erro.
Para realizar os testes, foi utilizada uma planilha composta de 102 amostras e
23 características abaixo descritas,que contém os dados do Enade do ano de 2011
e os dados na íntegra encontra-se no ANEXO A.
São as características de entrada:
Número Concluintes Inscritos;
Número de Concluintes Participantes;
Média FG Conc;
Média CE Conc;

70
Nota Enade Concluintes;
Conceito Enade Faixa;
Número Ingressantes Inscritos;
Número Ingressantes Participantes noEnem;
Nota Enem Ingressantes;
Nota IDD;
Proporção de respostas sobre infraestrutura;
Nota de Infraestrutura;
Proporção de respostas sobre plano ensino;
Nota de Organização Pedagógica;
Número docentes;
Proporção Docentes Mestres;
Nota Mestrado;
Proporção Docentes Doutores;
Nota Doutorado;
Proporção Docentes Parc Integral;
Nota Regime;
CPC Contínuo.
E a característica de saída:
CPC Faixa.
Os resultados são mostrados na Tabela 17. Na coluna „Neuronio na camada
escondida‟ refere-se a arquitetura da RNA, a coluna “taxa de aprendizado” refere-se
ao parâmetro de treinamento dado. As colunas “erro de treinamento” e “erro de
validação” mostram a eficácia do treinamento. A escala com as cores Verde –
Amarelo – Vermelho e suas tonalidades representa o valor da célula onde verde é o
melhor resultado obtido e vermelho o pior.
Foram feitas várias avaliações na RNA partindo-se de zero (0) até dez (10)
neurônios na camada escondida. Utilizando-se para o conjunto de treinamento, das
linhas de 02 até 61 resultando 60 amostras; para validação, as linhas de 62 até 85 e
para teste as linhas 86 até 103. Foram ainda escolhidas 50.000 épocas de
treinamento.

71
Tabela 17 – Tabela comparativa entre número de neurônios na camada escondida X erro.

72
Os testes realizados com nenhum neurônio na camada escondida obtiveram
o maior índice de erro encontrado. O que indica que o problema não pode ser
linearmente separável, Haykin (2008).
O melhor arranjo para o conjunto de treinamento encontrado se fez com 3
neurônios na camada escondida e com taxa de aprendizado de 0,1.
Não há melhora no desempenho da RNA com o acréscimo de neurônios na
camada escondida. Com o melhor arranjo encontrado, foram efetuados testes na
etapa de otimização.
Foi escolhido para o estudo de otimização, o curso com a pior avaliação, e
cujas características estão na Tabela 18.
Tabela 18 – Dados a serem otimizados.

73
Este conjunto resultou com avaliação CPC faixa 2, como o pior resultado
Enade do ano de 2011 no extrato contido no ANEXO A.
Foram executados 46 testes, com variação dos parâmetros de otimização:
tais como taxa de cruzamento e mutação, com 2.000 gerações e população de 40
indivíduos.
Os melhores resultados obtidos são apresentados na Tabela 19, sendo
disponibilizado na íntegra, no ANEXO B.
Tabela 19 – Classificação dos melhores resultados.
A melhor nota obtida foi 3,905 para a taxa de cruzamento de 40%, taxa de
mutação de 25%, com alteração das 3 características listadas abaixo:
Nota Enade Concluintes = 4,9938;
Conceito Enade Faixa = 4,9331;
Nota IDD = 4,4194.
A característica que mais influenciou nos testes foi a „Nota Enade
Concluintes‟, sua influência ocorreu 20 vezes. A Tabela 20, mostra em ordem
decrescente o grau de influência.

74
Tabela 20 – Características que mais influenciaram a rede.
Característica Nº vezes que foi utilizada
Nota Enade Concluintes 20
CPC Contínuo 12
Nota IDD 7
Número de docentes 7
Nota Prof. c/ Doutorado 6
Número de concluintes inscritos 5
Nota infraestrutura 4
Nota CE concluintes 3
Nota Enem Ingressantes 3
Nota regime trab. 3
Conceito Enade faixa 2
Proporção doc. Parc./Integ. 2
Número de Conc. Participantes 1
Média FG Conc. 1
Número de ingressantes inscritos 1
Número ingressantes part. Enem 1
Prop. de resp. sobre planos de ensino
1
Nota organiz. Pedag. 1
Prop. docentes mestres 1
Nota prof. c/ mestrado 1
Prop. docentes doutore 1
Prop. de respostas sobre infra estrut.
0
Conforme a análise feita para esta amostra, confirmou-se que a Nota Enade
Concluintes é a mais utilizada, 20 utilizações nos arranjos, em segundo o CPC
Contínuo com 12 utlizações e em terceiro lugar, o IDD e o número de docentes de
um determinado curso da IES, com 7 utilizações.
Com base nos resultados obtidos e apresentados nesse software e no estudo
feito, há a convicção de que se pode alavancar os objetivos de qualidade de uma
IES, com base na avaliação dos dados existentes e também indicar novos caminhos
para aquelas que pretendem melhorar a qualidade com base em dados oferecidos
pelo ENADE.
Para o Gestor, essas informações são de suma importância, pois demandará
uma decisão no que tange a fomentar as mudanças para a melhoria da qualidade do
ensino em uma IES.

75
5 CONCLUSÃO
Neste trabalho foi apresentada uma proposta para auxiliar na gestão de uma
Instituição de Ensino Superior Brasileira com foco na dificuldade de se avaliar e
apresentar análises e melhorias na gestão acadêmica. Visou-se apresentar uma
abordagem para automatizar o processo de avaliação da IES e indicar pontos fortes
e fracos com o objetivo de contribuir para a tomada de decisão na instituição com o
uso de sistemas de Inteligência Computacional.
Confirmou-se que com a extração de informações e com o uso de uma RNA,
que aprende a avaliar as características de cada IES, o processo proposto no
trabalho, atuou como se fosse um avaliador do MEC. Em seguida técnicas de
Algoritmos Genéticos foram usadas com sucesso para encontrar melhorias nas IES,
permitindo-se assim aumentar o índice de avaliação da IES e possibilitando aos
gestores uma rápida tomada de decisão.
Nos três conjuntos de testes em que foram utilizadas informações de
diferentes anos de realização do ENADE e diferentes características das IES
indicam que o modelo proposto é adequado. O mais importante passo dessa análise
é o de que após a execução dos procedimentos, o sistema indica adequadamente o
conjunto de características que melhore o desempenho da IES.
Os resultados obtidos mostram que o modelo escolhido é indicado para atingir
os objetivos que foram propostos. Para trabalhos futuros, espera-se que se abram
várias frentes para utilização da IC em sistemas de avaliações, como projetos de
pesquisa e também uma avaliação de custos.
Ainda como sugestão indica-se novas avaliações, utilizando-se otimização
multiobjetivo, onde serão analisados mais de um critério, como por exemplo: impacto
financeiro para a contratação e manutenção de novos docentes; Estimativa de prazo
para a realização das melhoras apontadas pelos indicadores; E a aplicação desse
modelo em outras áreas.
O aceite e a publicação da proposta em três congressos internacionais, um
congresso nacional e a submissão de um artigo para a Revista Tema, comprovantes
nos Anexos I, J, K e L. Será também submetido mais um artigo para uma revista

76
qualificada, bem como já foi solicitado o pedido de registro do software SCIAAD no
INPI, comprovante em Anexo I, J, K e L, o que indica a relevância do tema.

77
REFERÊNCIAS
AGUIAR, Juliana. HERMOSILLA, Lígia. Aplicações da Inteligência artificial na educação. Labienópolis, 2007. Disponível em:<www.revista.inf.br/sistemas06/ artigos/edic6anoIVfev2007-artigo04.pdf> Acesso em:13/11/2012.
ARTERO, A. O. Inteligência Artificial: Teórica e Prática. São Paulo: Ed. Livraria da Física, 2009.
BARBOSA, Andréa T. R. AZEVEDO, Fernando M. de. Uma hipermídia educacional adaptativa através do uso de redes neurais artificiais. XVII Simpósio Brasileiro de Informática na Educação – SBIE. São Paulo, 2007. Disponível em: <http://www.brie.org/pub/index.php/sbie/article/viewFile/561/547 > Acesso em: 04/12/2012.
BARONE, Dante A C. ET AL. Uma proposta de aplicação de lógica Fuzzy para modelagem do processo de raciocínio de um assistente virtual. Taguatinga, 2007. Disponível em: <http://br-ie.org/pub/index.php/sbie/article/download/ 584/570> Acesso em: 20/09/2012.
BRAGA, A. P.; CARVALHO, A. L.; LUDEMIR, T. B. Redes Neurais Artificiais: Teorias e Aplicações. Rio de Janeiro: LTC, 2011.
COPPIN, B. Inteligência Artificial. Rio de Janeiro: LTC, 2010.
FLEURY, M T L.; OLIVEIRA, M de M Jr. Gestão Estratégica do Conhecimento. São Paulo: Atlas, 2001.
GOTTI, F. J. A.; COSTA, I.; SHIGUEMORI, E. H. Computational Intelligence applied to student’s performance evaluation. in Higher Education. In: VIII ICIEOM, 2012, Guimarães, Pt. Anais do VIII ICIEOM, 2012.
GOTTI, F. J. A.; COSTA, I.; SHIGUEMORI, E. H. Computing Intelligence applied to an evaluation of the academic management. In: ICPR - 22th International Conference on Production Research, 2013, Foz do Iguaçu, Pr. Anais do ICPR 22th, 2013.
GOTTI, F. J. A.; COSTA, I.; SHIGUEMORI, E. H. Inteligência Computacional Aplicada em Avaliações da Gestão Acadêmica em uma IES. In: The VII International Conference on Engineering and Computer, 2011, Guimarães. Anais do VII ICECE, 2011.

78
GOTTI, F. J. A.; COSTA, I.; SHIGUEMORI, E. H. Proposta de uma Metodologia para Avaliação da Gestão Acadêmica em um IES Utilizando a Inteligência Computacional. In: IV Sidepro - Simpósio sobre Redes de Empresas e Cadeias de Fornecimento, 2011, São Paulo. Anais do IV Sidepro, 2011.
GUEDES, J. C., Aplicação de Redes Neurais na Avaliação de Bens.
HAYKIN, S. Redes Neurais: Princípios e Práticas. São Paulo: Bookman, 2008.
HONGMEI, Li. (2013) Application Research of BP Neural Network in English Teaching Evaluation. Telkomnika, Vol. 11, nº 8, pp. 4602~4608.
IEEEXplore. Disponível em: <http://www.ieeexplore.com>.
INEP/MEC. Disponível em: <http://www.inep.gov.br/superior/enade/default.asp>.
LIMA, F. G.; PERERA, L. C.; KIMURA, H.; SILVA FILHO, A. C. Aplicação de redes neurais na análise e na concessão de crédito ao consumidor. R. Adm., São Paulo, v.44, n.1, p.34-45, jan./fev./mar. 2009.
LINDEN, R., Algorítmos Genéticos. 3ª ed. Rio de Janeiro: Ciência Moderna, 2012.
MATHWORKS. Global Optimization Toolbox User's Guide, Release 2012b, Disponível em: <http://www.mathworks.com/help/pdf_doc/gads/gads_tb.pdf> acesso em 11/01/2013.
MATSUMOTO, Élia Yathie. MATLAB 6.5: fundamentos de programação. São Paulo, Érica, 2002, p. 9.
MEIRELES, M. Sistemas de Informação: quesitos de excelência dos sistemas de informação operativos e estratégicos. 5ed. São Paulo: Arte & Ciência, 2012.
MICHAELIS. Dicionário Digital. Editora Melhoramentos, Disponível em <http://michaelis.uol.com.br/moderno/portugues/definicao/inteligencia_94193.html>, acesso em 02/2013.
OLIVEIRA JÚNIOR, H. A., Inteligência Computacional: Aplicada à Administração, Economia e Engenharia em MAtLab. São Paulo: Thomson Learning, 2007.

79
PALMA NETO, L. G.; Nicoletti, M. do C. Introdução às Redes Neurais Construtivas. São Carlos: EduFSCar, 2005.
PELLISISTEMAS. Disponível em: <http://www.pellisistemas.com.br/novo/pt/biblioteca/default.asp?assunto=3>. Acesso em 15/07/2013. (Biblioteca afiliada ao INPE).
REZENDE, Solange Oliveira. Sistemas Inteligentes: fundamentos e aplicações. Barueri, SP: Manole, 2005.
SANTOS, Giovanni Almeida. RISSOLI, Vandor Roberto Vilardi. A monitoria estudantil aliada a um assistente virtual inteligente no suporte à aprendizagem via internet. Taguatinga, 2010. Disponível em:<http://www.ccae.ufpb.br/sbie2010/anais/ WAPSEDI_files/79033_1.pdf >. Acesso em: 12/06/2012.
SANTOS, Giovanni Almeida. RISSOLI, Vandor Roberto Vilardi. Benefícios no uso de uma assistente inteligente no ensino-aprendizagem de programação computacional. Aracaju, 2011. Disponível em: <http://www.br-ie.org/sbie-wie2011/workshops/wavalia /94982_1.pdf>Acesso em: 12/06/2012.
SHANTHI, D, Sahoo, G., Saravanan, N. Designing an Artificial Neural Network Model for the Prediction of Thrombo-embolic Stroke. International Journals of Biometric and Bioinformatics IJB. Vol. 3, No 1, p. 172-178.
SILVA, R. Balanced Scorecard – BSC: Gestão do Ensino Superior, Gestão profissionalizada da qualidade de ensino para instituições de ensino superior privado. Curitiba: Juruá, 2009.
SOUZA, P N P. de; SILVA, E B da. Como Entender e Aplicar A Nova LDB. São Paulo: Pioneira, 2001.
STEWART, T A. Capital Intelectual – A Nova Vantagem Competitiva das Empresas. Rio de Janeiro: Campus, 1998.
SUN, Wei; YANG, Xiaoye. (2012) BP Neural Network for Power Supply Enterprise Credit Evaluation Based on Genetic Algorithm Optimization. Journal of Information & Computational Science. Vol. 9, nº 14, 4017–4023.
TATIBANA, C. Y.; KAETSU, D. Y. Uma Introdução ás Redes Neurais Artificiais. 2008. Disponível em: < http://www.din.uem.br/ia/neurais/>. Acesso em: 28 jul. 2011.

80
VAHLDICK, Adilson. ET AL.O uso de técnicas Fuzzy em ambientes inteligentes de aprendizagem. São José (SC), 2008. Disponível em: <http://200.169.53.89/ download/CD%20congressos/2008/SBIE/sbie_posters/O%20Uso%20de%20T%C3%A9cnicas%20Fuzzy%20em%20Ambientes%20Inteligentes.pdf> Acesso em: 04/06/2013.
WEBBER, Carine. ET AL. Ferramenta especialista para avaliação de software educacional. Caxias do Sul, 2009. Disponível em: <http://ceiesbc.educacao.ws/ pub/index.php/sbie/article/download/1115/1018> Acesso em: 24/06/2013. YIN, R. K. Estudo de Caso – Planejamento e Métodos. São Paulo: Bookman, 1994.
ZENG, X., Yeung, D. S.(2001) Sensivity Analysis of Multilayer Perceptron to Input and Weight Perturbsations. IEEE Transactions on Systems, Man and Cybernetics. Vol. 12, No 6, November 2001.
ZHANG, G. P. (2000) Neural Networks for Classification: A Survey. IEEE Transactions on Systems, Man and Cybernetics. Vol. 30, No 04, November 2000.
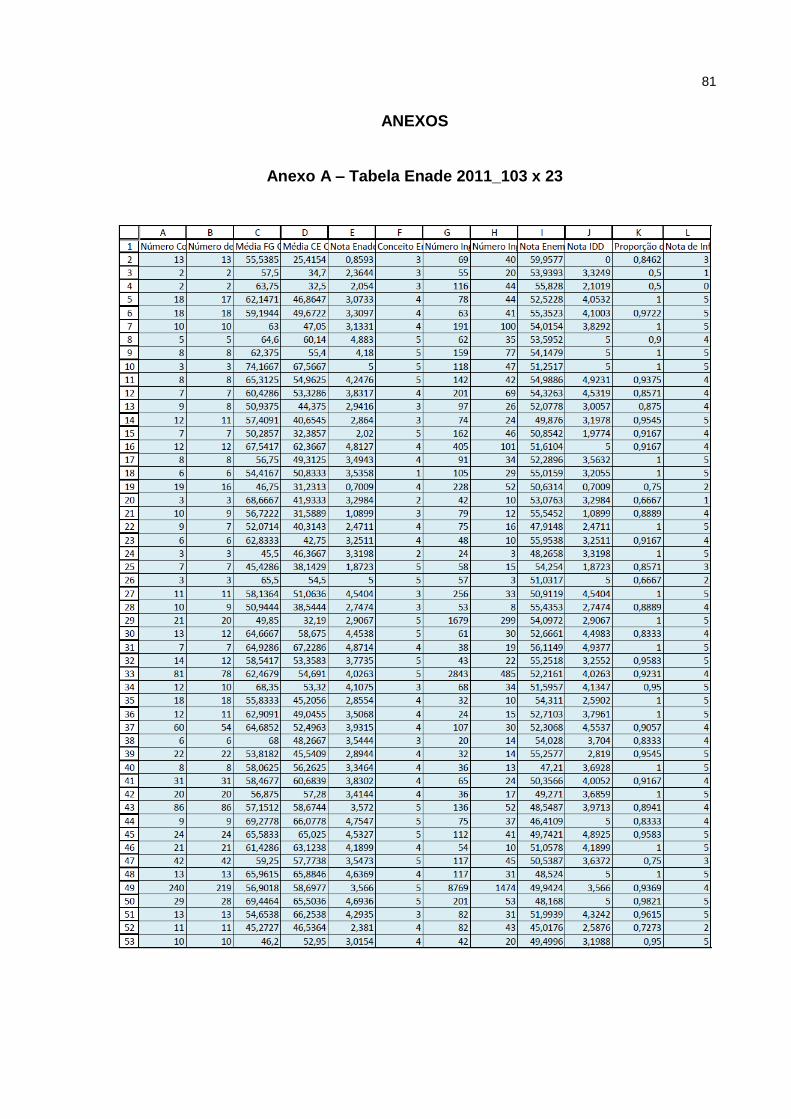
81
ANEXOS
Anexo A – Tabela Enade 2011_103 x 23

82
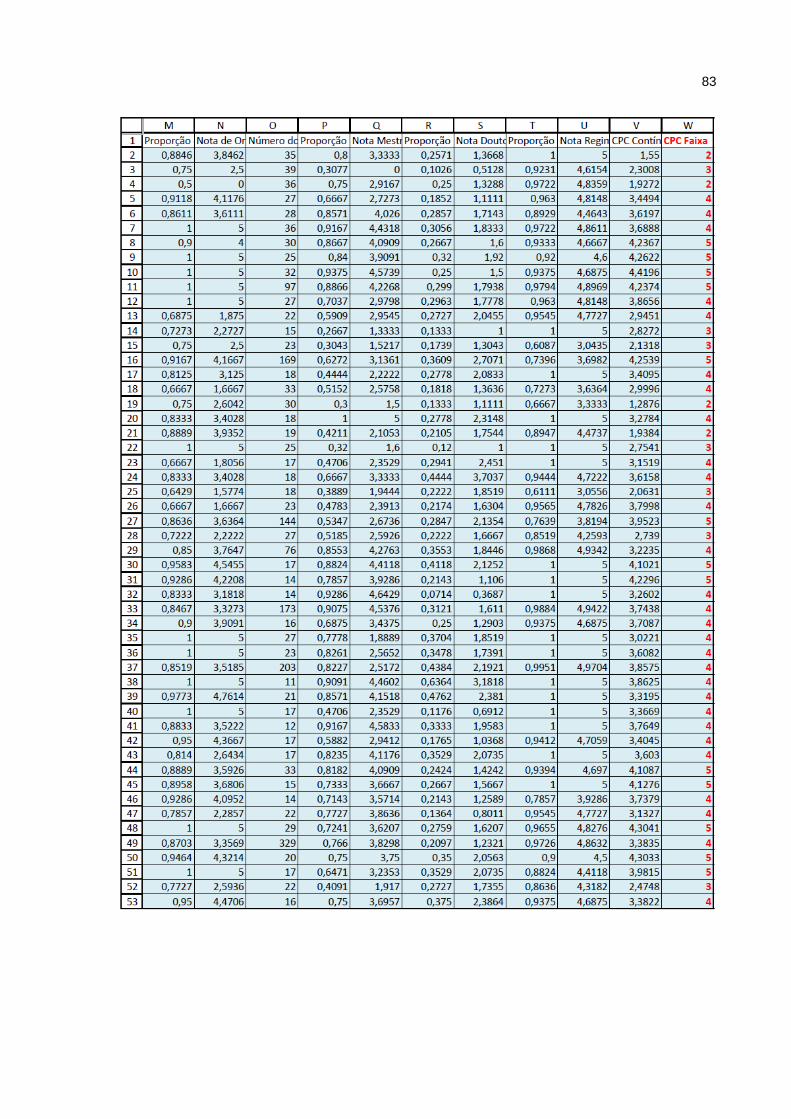
83
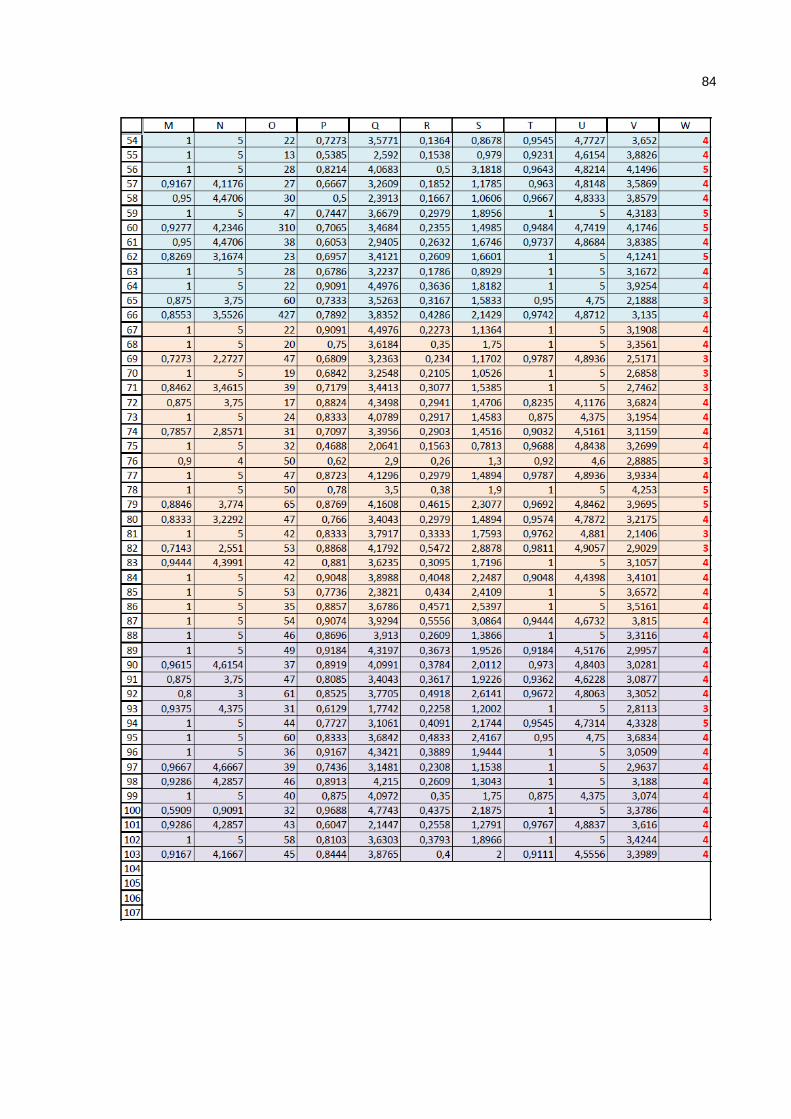
84
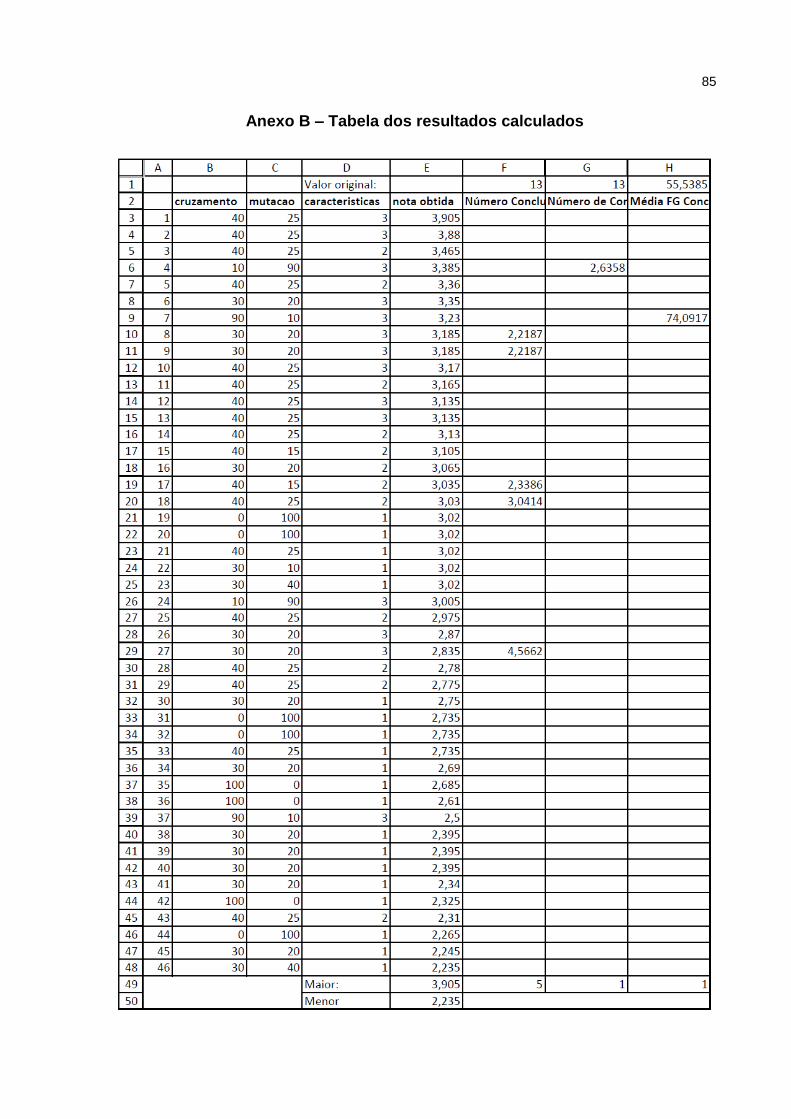
85
Anexo B – Tabela dos resultados calculados

86
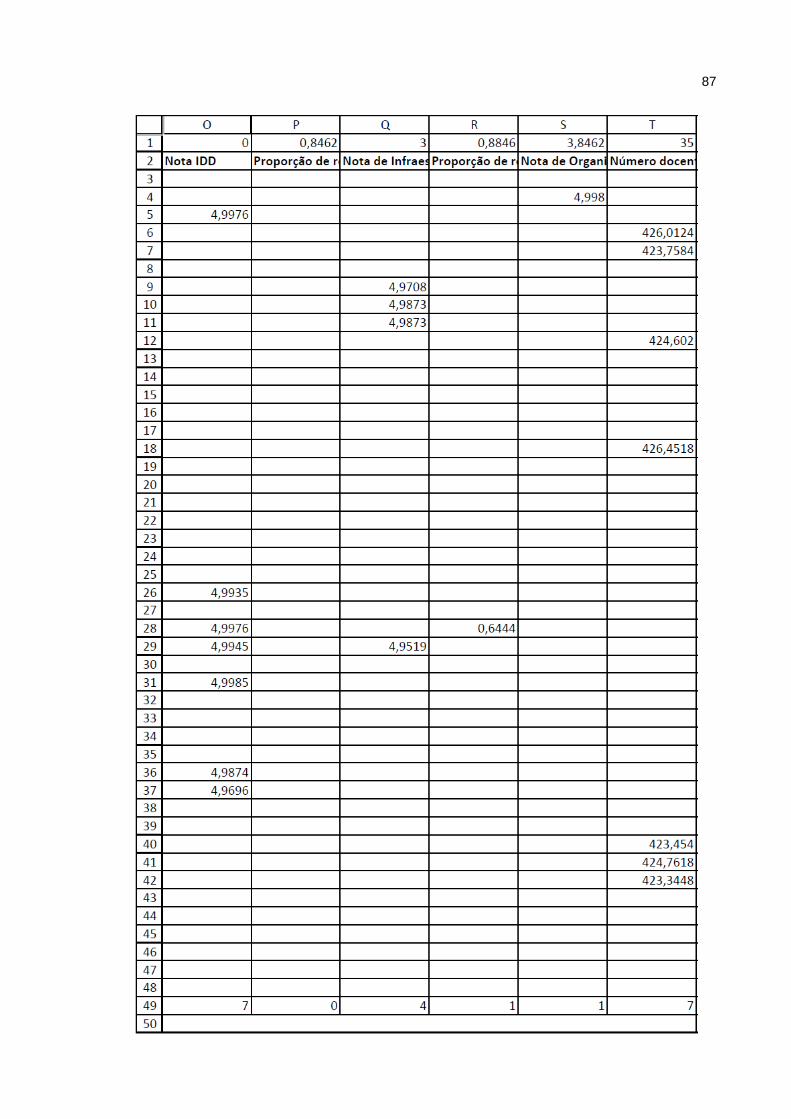
87
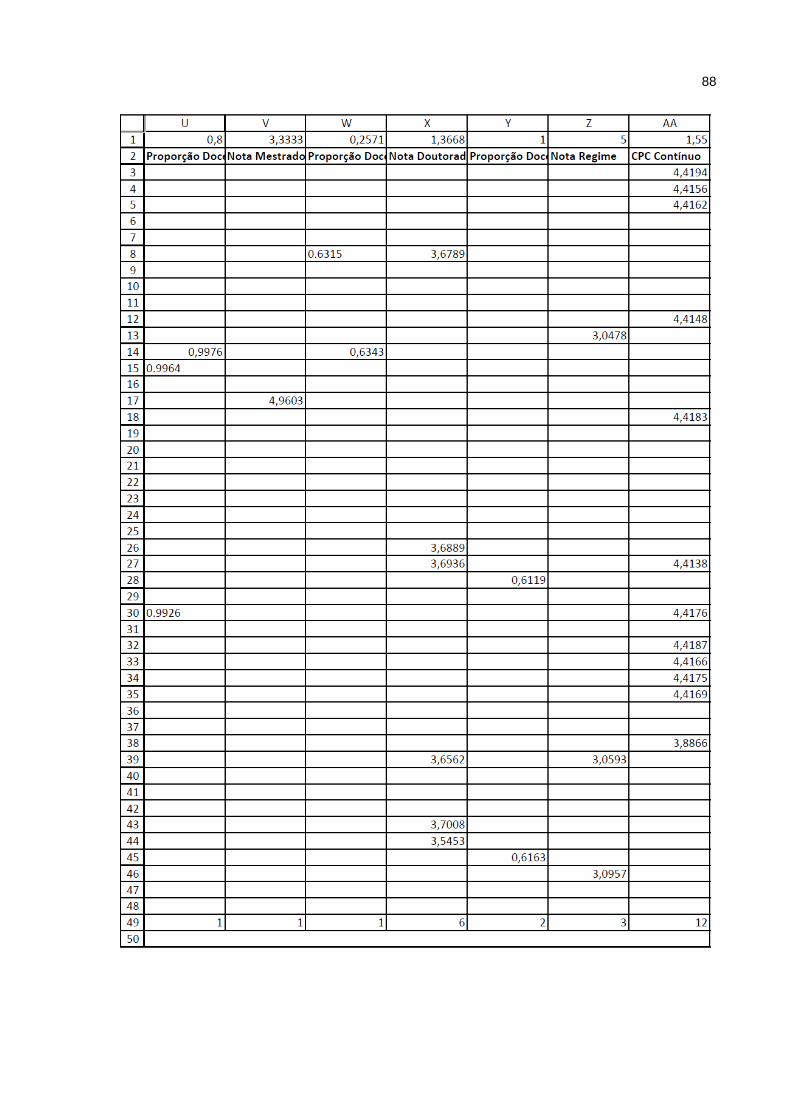
88

89
Anexo C - Arquivos do SCIAAD
ativacaoRNAObterResposta.fig
ativacaoRNAObterResposta.m
ativa_bp_gen_ss.exe
avaliacaoRNA.m
desnormalizar.m
encontraLimites.m
normalizar.m
otimizacaoGrafico.fig
otimizacaoGrafico.m
otimizacaoLimites.fig
otimizacaoLimites.m
otimizacaoOtimizar.fig
otimizacaoOtimizar.m
otimizacaoParametros.fig
otimizacaoParametros.m
otimizacaoVetor.fig
otimizacaoVetor.m
treinamentoRNAParametros.m
treinamentoRNATreinar.fig
telaPrincipal.fig
telaPrincipal.m
treinamentoRNABemVindo.fig
treinamentoRNABemVindo.m
treinamentoRNAGrafico.fig
treinamentoRNAGrafico.m
treinamentoRNAImportacaoNomeColunas.fig
treinamentoRNAImportacaoNomeColunas.m
treinamentoRNAImportacaoSelecionaArquivo.fig
treinamentoRNAImportacaoSelecionaArquivo.m
treinamentoRNAImportacaoXY.fig
treinamentoRNAImportacaoXY.m
treinamentoRNAImportacaoXYValid.fig
treinamentoRNAImportacaoXYValid.m
treinamentoRNALimites.fig
treinamentoRNALimites.m
treinamentoRNAParametros.fig
treinamentoRNATreinar.m
treina_bp_gen_ss.exe

90
Anexo D – Conjunto de treinamento da RNA
Conjunto de treinamento para 50.000 épocas.
1000 1.978939458484428E-002 8.105938447217682E-002
2000 1.981493950083780E-002 8.102414126607357E-002
3000 1.981733838628922E-002 8.105978980209468E-002
4000 1.981243153470209E-002 8.110210643961424E-002
5000 1.980529536306596E-002 8.114308085455584E-002
6000 1.979764026224141E-002 8.118224838251856E-002
7000 1.979003960613540E-002 8.122006003182813E-002
8000 1.978266082937402E-002 8.125688698122818E-002
9000 1.977552893274852E-002 8.129294946669817E-002
10000 1.976862357524043E-002 8.132836688882986E-002
11000 1.976191403376464E-002 8.136320097620198E-002
12000 1.975537089629056E-002 8.139748192089084E-002
13000 1.974896924618649E-002 8.143122314693811E-002
14000 1.974268891058350E-002 8.146442959723793E-002
15000 1.973651383145205E-002 8.149710239983150E-002
16000 1.973043128524309E-002 8.152924147998064E-002
17000 1.972443118119896E-002 8.156084698486102E-002
18000 1.971850549092255E-002 8.159192001603088E-002
19000 1.971264780319790E-002 8.162246296088736E-002
20000 1.970685298253453E-002 8.165247959749676E-002
21000 1.970111690902125E-002 8.168197507775406E-002
22000 1.969543628043147E-002 8.171095585155981E-002
23000 1.968980846151109E-002 8.173942956862076E-002
24000 1.968423136889178E-002 8.176740497835340E-002
25000 1.967870338286932E-002 8.179489183840198E-002

91
Anexo D - Conjunto de treinamento da RNA - continuação
26000 1.967322327943156E-002 8.182190083622543E-002
27000 1.966779017752549E-002 8.184844352455711E-002
28000 1.966240349775386E-002 8.187453226944749E-002
29000 1.965706292958186E-002 8.190018020844334E-002
30000 1.965176840480077E-002 8.192540121591030E-002
31000 1.964652007549575E-002 8.195020987233363E-002
32000 1.964131829514527E-002 8.197462143449213E-002
33000 1.963616360177559E-002 8.199865180363543E-002
34000 1.963105670232583E-002 8.202231748911097E-002
35000 1.962599845757039E-002 8.204563556530754E-002
36000 1.962098986710381E-002 8.206862362023852E-002
37000 1.961603205403064E-002 8.209129969459303E-002
38000 1.961112624912302E-002 8.211368221061011E-002
39000 1.960627377431646E-002 8.213578989067245E-002
40000 1.960147602550843E-002 8.215764166603280E-002
41000 1.959673445470993E-002 8.217925657659780E-002
42000 1.959205055167108E-002 8.220065366313557E-002
43000 1.958742582516166E-002 8.222185185366526E-002
44000 1.958286178413295E-002 8.224286984609440E-002
45000 1.957835991901943E-002 8.226372598937687E-002
46000 1.957392168345578E-002 8.228443816558685E-002
47000 1.956954847668757E-002 8.230502367530865E-002
48000 1.956524162694540E-002 8.232549912866187E-002
49000 1.956100237603049E-002 8.234588034410829E-002
50000 1.955683186532944E-002 8.236618225692739E-002
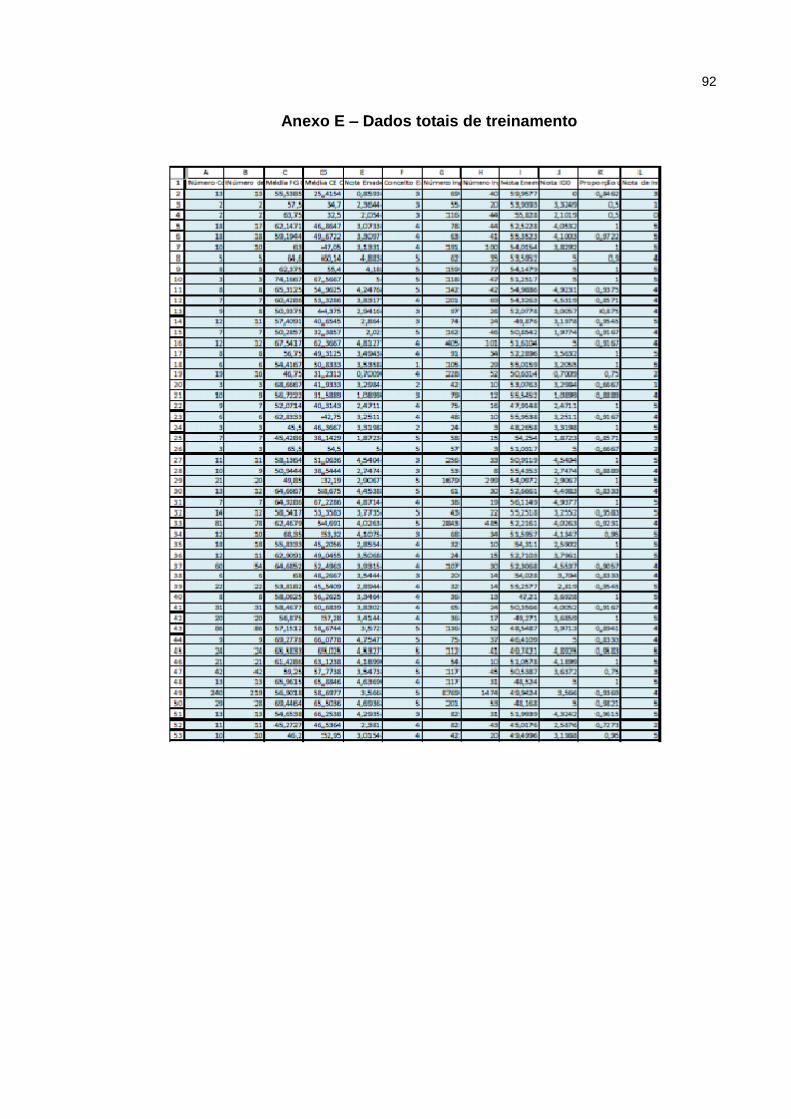
92
Anexo E – Dados totais de treinamento
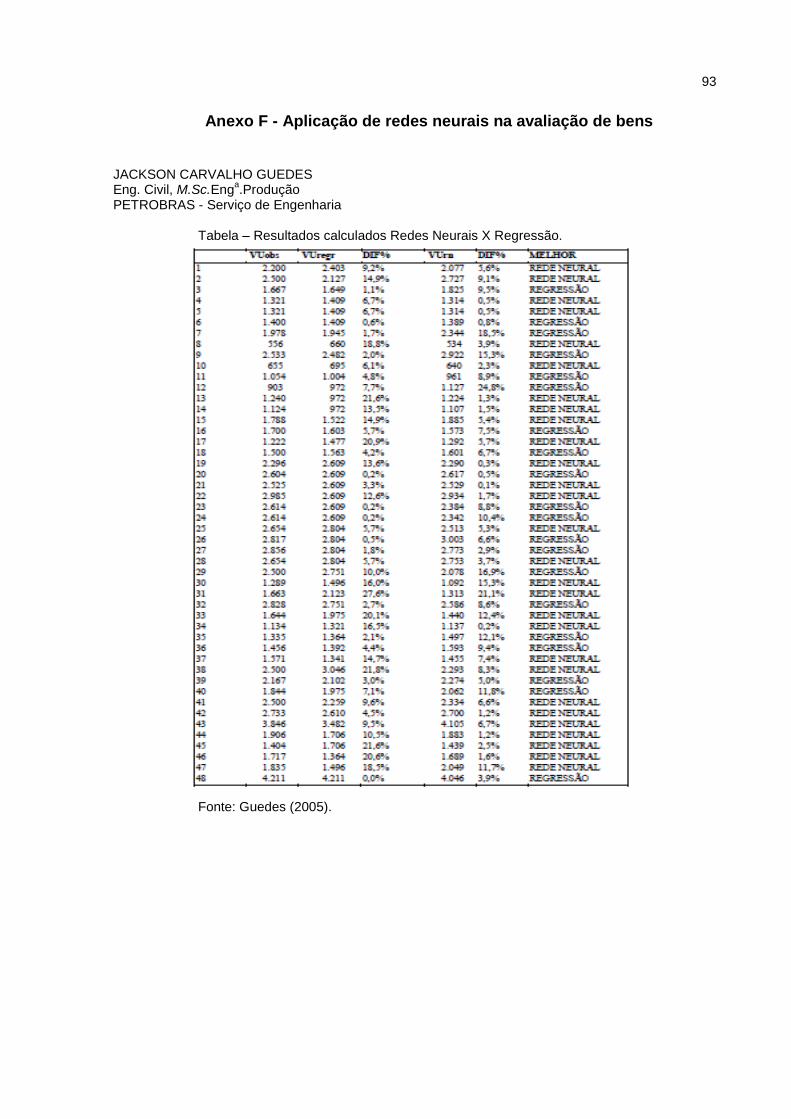
93
Anexo F - Aplicação de redes neurais na avaliação de bens
JACKSON CARVALHO GUEDES Eng. Civil, M.Sc.Eng
a.Produção
PETROBRAS - Serviço de Engenharia
Tabela – Resultados calculados Redes Neurais X Regressão.
Fonte: Guedes (2005).
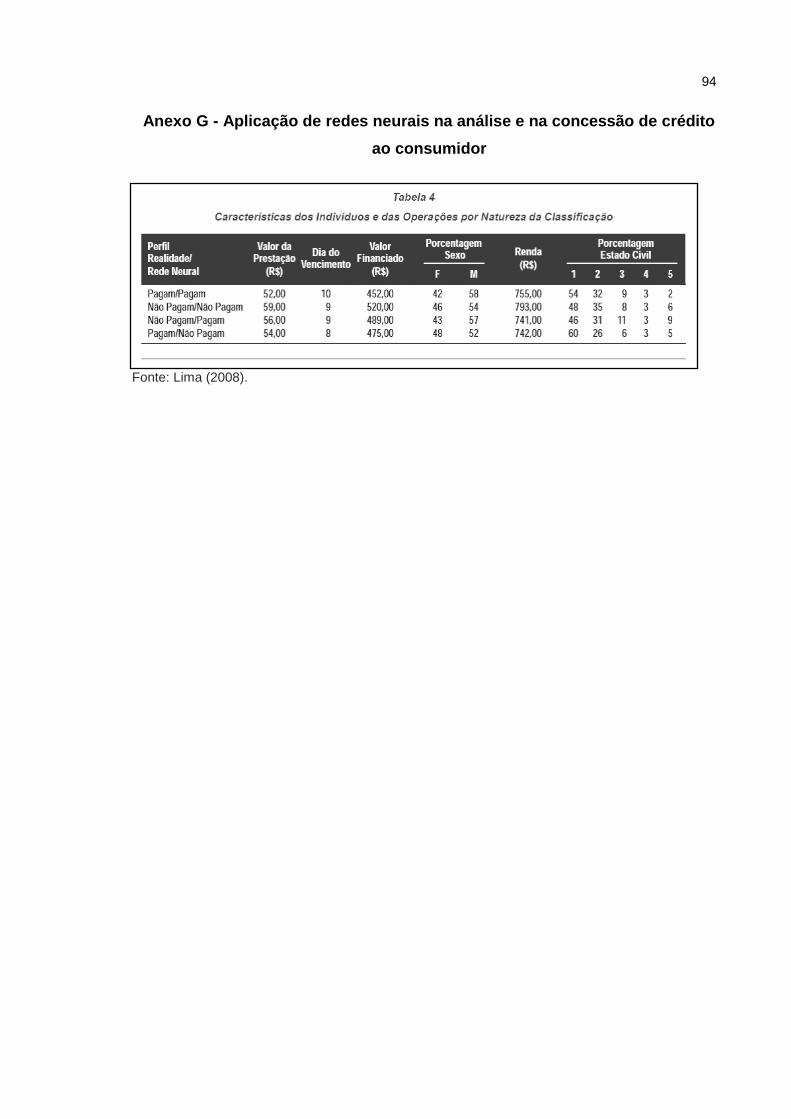
94
Anexo G - Aplicação de redes neurais na análise e na concessão de crédito
ao consumidor
Fonte: Lima (2008).

95
Anexo H – Descrição das variáveis do sistema
%% Declaração das variáveis globais utilizadas % Características da RNA global rnaTamanhoEntrada % caracteristicas de entrada global rnaTamanhoSaida % caracteristicas de saida global rnaNeuronios % quantidade de neuronios na camada escondida global rnaAprendizado % taxa de aprendizado da RNA global rnaErroDesejado % Erro admissível pela RNA. global rnaEpocas % Numero de Epocas de treinamento % Dados NÃO normalizados para a geração dos arquivos para o treinamento da RNA. global rnaX % matriz contendo o conjunto de treinamento X (valor de entrada) global rnaY % matriz contendo o conjunto de treinamento Y (valor de saida) global rnaXValid % matriz contendo o conjunto de validacao (X-Valid) global rnaYValid % matriz contendo o conjunto de validacao (Y-Valid) % Tamanho dos arquivos de treinamento global rnaQtdeExemplos % quantidade de exemplos mostrados a RNA. global rnaQtdeExemplosValid % quantidade de exemplos mostrados na RNA na fase de validação % Define os valores mínimo e maximo admitidos pela RNA. global rnaXMin % vetor contendo os valores minimos de cada característica de entrada X. global rnaXMax % vetor contendo os valores máximos de cada característica de entrada X. global rnaYMin % vetor contendo os valores minimos de cada característica de saída Y. global rnaYMax % vetor contendo os valores máximos de cada característica de saída Y. % Importacao dos dados de exemplo. global importacaoArquivoNome % nome do arquivo utilizado na importação na fase de treinamento da RNA. global importacaoArquivoCaminho % caminho do arquivo utilizado na importação na fase de treinamento da RNA. % Título das colunas da tabela

96
Anexo H - Descrição das variáveis do sistema continuação
global importacaoTituloColunasX % Célula que contém o título da tabela de entrada(tipo String). global importacaoTituloColunasY % Célula que contém o título da tabela de saída(tipo String). % Características do Algoritmo Genético (AG). global agPopulacao % Tamanho da população global agCruzamento % taxa de cruzamento (de 0 a 100) global agMutacao % taxa de cruzamento (de 0 a 100) global agGeracoesSemAlteracao % quantidade de gerações sem alteracao do melhor individuo. global agGeracoesIntermediarias % quantidade de gerações sem alteracao do melhor individuo da populacao atual. global agGeracoesMax % quantiade máxima de gerações. global agCaracteristicasParaCruzamento % quantidade de características disponíveis para o cruzamento. global agMin % vetor contendo os valores minimos admissíveis de cada caracteristica para a utilizaca do AG global agMax % vetor contendo os valores maximos admissíveis de cada caracteristica para a utilizaca do AG global agVetorParaOtimizar % vetor contendo os dados a serem otimizados global agCaracteristicasAutorizadas % vetor contendo as características elegíveis para o uso no AG. global agOperacao % informa qual operacao será realizada (maximizar = 1, minimizar = 0) global agValorAlvo % informa o valor a ser alcancado pelo AG.

97
Anexo I - Aceite Congresso Internacional - VII ICECE 2011
http://www.copec.org.br/icece2011/
The VII International Conference on Engineering and Computer Education - ICECE
'2011, happened
in Guimarães, cradle of Portugal, on September 25 -28, 2011.
The theme of the congress was: "Engineering Education Inspiring the Next Generation of
Engineers".
The official languages were English, Spanish and Portuguese.
The host Institution was UMINHO – University of Minho.
Prof. Dr. Claudio da Rocha Brito
General Chair
Prezado(s) Prof(s). Fernando José Gotti, IVANIR COSTA, Elcio Shiguemori Seu artigo foi aprovado para publicação nos anais e apresentação no ICECE 2011. Quanto a taxa de publicação já a recebemos. Estamos enviando atachado o formulário de inscrição, que tem um desconto para pagamentos até o dia 31 de Maio de 2011. Esperamos encontrá-lo no Portugal, em Setembro. Novamente, agradecemos por sua contribuição ao ICECE 2011. Atenciosamente, Prof. Dr. Claudio da Rocha Brito General Chair of ICECE 2011 VII International Conference on! Engineering and Computer Education Phone: +55-13-3227.1898 Fax: +55-13-3227.1998 Email: [email protected] Homepage: http://www.copec.org.br/icece2011/
98
Anexo J – Comprovante de publicação no XVIII ICIEOM 2012
99
Anexo I – Comprovante ICPR 22
ICPR 22 Organizers <[email protected]> 23 de abr
para mim, icosta11, elcio
inglêsportuguês
Traduzir mensagemDesativar para: inglês
Dear Fernando Jose Alho Gotti,
Congratulations, the full paper that you submitted to the 22nd ICPR has been accepted!
CONTRIBUTION DETAILS
-------------------- ID: 368
Title: Computing Intelligence applied to an evaluation of the academic management
Status: This contribution has been accepted.
OVERVIEW OF REVIEWS -------------------
Review 1 ========
Evaluation of the contribution

100
Anexo I - Comprovante ICPR 22
Contribution to PR is original, relevant and significant (20%): 8 Content is substantive and has enough detail to provide value (20%): 8 Paper has suitable and reasonable support from the literature (20%): 8
Content is technically sound (20%): 8 Paper is well-organized and well-written (20%): 8
Total points (out of 10) : 8
Comments for the authors (optional)
---------------------------------------- Overall Recommendation: Reject
Good article, reasoned as well. A detail is the word "Erro" in the square
error formula, that was not translated and there is a small reversal verb in the sentence "According to the results obtained ..." that should be written as
"According to the obtained results ..."
However, this article was published in http://www3.unip.br/pesquisa/download/cadernos/PRODINTELEC_ENGPRODUCAO_2011.pdf
at page 417, as INTELIGÊNCIA COMPUTACIONAL APLICADA EM AVALIAÇÕES DA GESTÃO ACADÊMICA EM UMA IES.
I consider as an already published article.
-=-=-=-=-=-=-=-=-=-=-
Review 2 ========
Evaluation of the contribution
------------------------------ Contribution to PR is original, relevant and significant (20%): 10
Content is substantive and has enough detail to provide value (20%): 8 Paper has suitable and reasonable support from the literature (20%): 8
Content is technically sound (20%): 10 Paper is well-organized and well-written (20%): 10
Total points (out of 10) : 9.2
Comments for the authors (optional)
---------------------------------------- Overall Recommendation: Accept
-=-=-=-=-=-=-=-=-=-=-
We look forward to having high-quality research presentations and your
presence is valuable. In this e-mail, you will find: (1) deadlines, and (2) important notes.
Deadlines
- Early bird registration and final paper submission: May 10th 2013.
Important notes 1. Due to full paper deadline extension and because of referees' demands, a first list of accepted papers is being published today (April 22nd, 2013). The
final list of accepted papers will be published by May 1st, 2013.

101
Anexo I - Comprovante ICPR 22
2. In general, referees recommended authors to review their manuscripts for improving „grammar‟ quality. Particularly, English non-native speakers
should consider carefully revising their texts.
3. Authors should use ICPR 2013 template for providing their final full paper version. Word archives format are requested to be uploaded („.doc‟
1997-2004 or „.docx‟).
4. Conference fee includes attendance to all sessions, proceedings (in CD), coffee breaks, three lunches, one dinner and the Conference Banquet. Pay
attention to Early Bird deadline.
5. Each registration allows a maximum of two papers to be published in the Conference Proceedings.
6. Student fee applies to both graduate and undergraduate students. It‟s
required to present documentation showing full-time student status.
Production Research community thanks you for your submission to ICPR 2013 and all of us are willing to see you at Iguassu Falls!
Best regards,
Dr. Edson Pinheiro de Lima
ICPR 2013 Scientific Committee Chair
Dr. Sergio E. Gouvea da Costa ICPR 2013 Conference Chair
IFPR Secretary-General
P.S. Please apologize us if you are receiving multiple e-mails.

102
Anexo K – Revista Tema
Edson Wendland <[email protected]> 07/12/12 para mim Professor Fernando Alho Gotti, Agradecemos a submissão do trabalho "Aplicação da Lógica Fuzzy para Análise de Riscos em Projetos de Software." para a revista TEMA - Tendências em Matemática Aplicada e Computacional. Acompanhe o progresso da sua submissão por meio da interface de administração do sistema, disponível em: URL da submissão: http://www.sbmac.org.br/tema/seer/index.php/tema/author/submission/653 Em caso de dúvidas, entre em contato via e-mail. Agradecemos mais uma vez considerar nossa revista como meio de compartilhar seu trabalho.
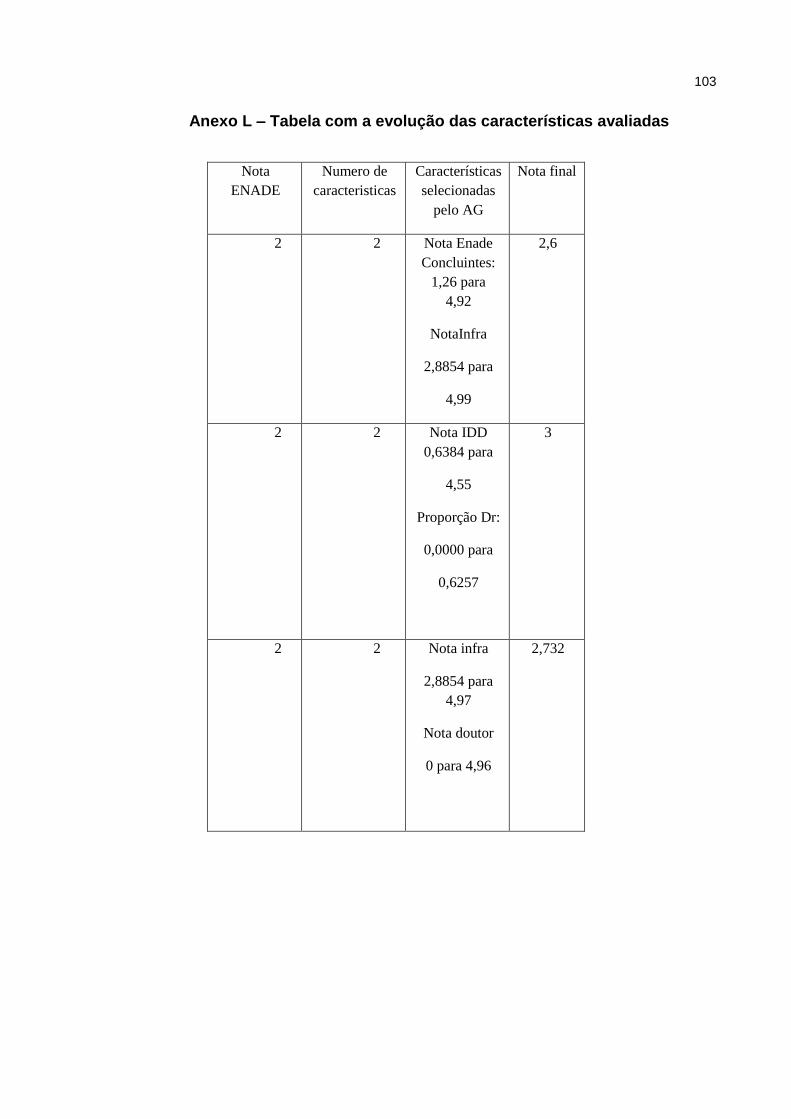
103
Anexo L – Tabela com a evolução das características avaliadas
Nota
ENADE
Numero de
caracteristicas
Características
selecionadas
pelo AG
Nota final
2 2 Nota Enade
Concluintes:
1,26 para
4,92
NotaInfra
2,8854 para
4,99
2,6
2 2 Nota IDD
0,6384 para
4,55
Proporção Dr:
0,0000 para
0,6257
3
2 2 Nota infra
2,8854 para
4,97
Nota doutor
0 para 4,96
2,732

104

105

106

107

108

109





























