Embed Size (px)
Citation preview

Aplicações Internet FTP (File Transfer Protocol) WWW (World Wide Web) Introdução Realização da web URLs HTTP Cookies Segurança Caching
Replicação de servidores web HTML Tipos de páginas dinâmicas Web sem fios USENET News Newsgroups Formato artigos Distribuição dos artigos Peer-to-peer
Gnutella

WWW - 2 Luis Bernardo
Aplicações Internet As aplicações são o principal motivo para a realização da rede Internet, e o que motivou todo o esforço de desenvolvimento de novas facilidades no nível IP e transporte. Um componente importante das aplicações é o protocolo de nível aplicação, que descreve como é realizada a comunicação entre os componentes. Na Internet, a entidade normalizadora é normalmente a IETF (www.ietf.org), sendo os protocolos tipicamente definidos em normas abertas, especificadas em RFCs. As aplicações Internet obedecem, na maior parte, a um modelo cliente-servidor, onde os componentes desempenham o papel de cliente, de servidor, ou ambos simultaneamente. Algumas das aplicações Internet são:
Aplicação Protocolo de nível aplicação
Protocolo de transporte
Correio Electrónico SMTP, POP3, IMAP TCP
Transferência de ficheiros FTP TCP
Web HTTP TCP
Difusão de mensagens NNTP TCP
Terminal Remoto Telnet, SSH TCP
Servidor Ficheiros Remotos NFS UDP ou TCP
Feixes multimédia RTP, MPEG ou
proprietário
UDP (ou TCP)
Telefonia IP SIP, H323 ou
proprietário
UDP
Serviço de directórios DNS, LDAP (X.500) UDP ou TCP
Serviços peer-to-peer Proprietário TCP
Estas aplicações são usadas directamente pelos utilizadores, exceptuando o serviço de directórios DNS, que oferece um serviço para outras aplicações.

WWW - 3 Luis Bernardo
FTP (File Tranfer Protocol) O FTP começou a ser usado em 1971. O FTP é um protocolo cliente-servidor (definido no RFC 959) que permite trocar ficheiros com outras máquinas ligadas à Internet.
Interface
utilizador
FTP
Cliente
FTP
Servidor
FTP
Sistema de
ficheiros local
Sistema de
ficheiros remoto
Transferência de ficheiros
Um utilizador corre um programa cliente (ftp, browser, etc.), fornecendo um nome de utilizador e palavra de passe, ou ligando-se anonimamente (Nome: anonymous ou ftp com palavra de passe igual ao endereço de correio electrónico). A interface de utilizador FTP permite ao utilizador modificar os sistemas de ficheiros local e remoto. O protocolo FTP usa sinalização fora de banda. • Após a autenticação do utilizador, o Cliente FTP cria uma ligação TCP de controlo para Servidor FTP (no porto 21).
• Por cada ficheiro enviado ou recebido é estabelecida uma ligação TCP com o porto 20 (por omissão) do servidor, que se desliga após a transferência.
MODO - quem cria ligação : passivo (cliente) / activo (servidor)
Cliente FTP Servidor FTP
Ligação TCP de controlo (21)
Ligação TCP de dados (20)
O servidor mantém o estado (directório remoto actual, ligações activas, etc.) por cada cliente.

WWW - 4 Luis Bernardo
O protocolo FTP define as mensagens trocadas na ligação de controlo. As mensagens são trocadas em modo texto (ASCII com 7 bits). Alguns dos comandos do Cliente para o Servidor:
• USER nome_de_utilizador: Enviar a identificação do utilizador;
• PASS palavra_de_passe: Enviar a palavra de passe do utilizador;
• PORT A1,A2,A3,A4,a1,a2: Define endereço IP e porto para onde devem ser realizadas as ligações;
• LIST: Listar o conteúdo da directoria remota corrente;
• PASV: Pedido para usar o modo passivo. retorna IP e porto do servidor;
• RETR nome_ficheiro: Pedir o envio do ficheiro ao servidor a partir da directoria corrente;
• STOR nome_ficheiro: Pedir para guardar o ficheiro no servidor na directoria corrente.
Existem outros comandos para mudar de directoria, controlar o formato para envio dos dados, etc. As respostas do Servidor para o Cliente também são enviadas em modo texto. Algumas respostas típicas: • 125 Data connection already open; transfer starting
• 200 Okay
• 227 Entering Passive Mode A1,A2,A3,A4,a1,a2
• 331 Username OK, password required
• 425 Can't open data connection
• 452 Error writing file

WWW - 5 Luis Bernardo
Exemplo de sequência de comandos: (C)liente envia ficheiro de Servidor (B) →→→→ para Servidor (A) Utilizador – Servidor A
C→A : Connect
C→A : PASV
A→C : 227 Entering Passive
Mode A1,A2,A3,A4,a1,a2
C→A : STOR
Utilizador – Servidor B
C→B : Connect
C→B : PORT
A1,A2,A3,A4,a1,a2
B→C : 200 Okay
C→B : RETR B→A : Connect to HOST-A, PORT-a
Exemplo de cliente FTP em modo de texto (ftp): Comandos disponíveis:
dir escrever uma listagem do conteúdo da directoria remota
cd mudar a directoria de trabalho na máquina remota
ascii definir tipo de ficheiros a transferir como ASCII
binary definir tipo de ficheiros a transferir como binário
get transferir um ficheiro do servidor para o cliente
mget transferir ficheiros (suporta wildcards) do servidor para o cliente
prompt comuta on/off as confirmações do utilizador
put transferir um ficheiro do cliente para o servidor
bye Terminar a sessão ftp, e sair do programa
WWW - 6 Luis Bernardo
WWW (World Wide Web)
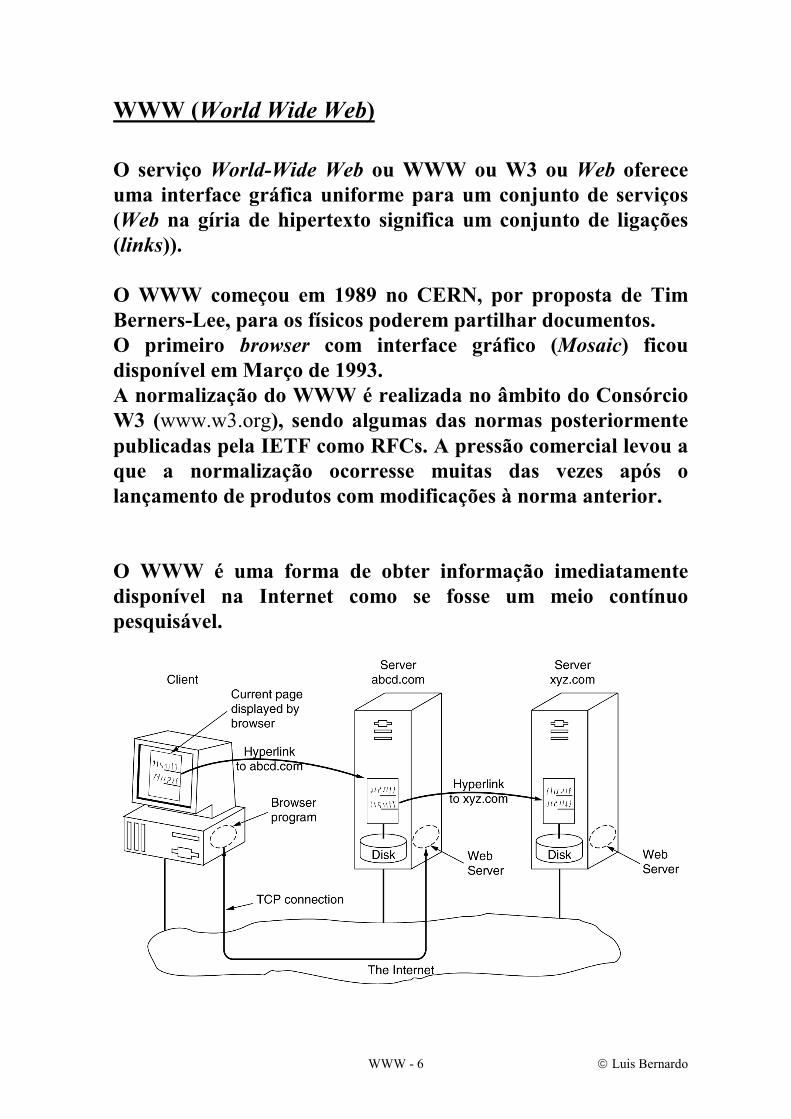
O serviço World-Wide Web ou WWW ou W3 ou Web oferece uma interface gráfica uniforme para um conjunto de serviços (Web na gíria de hipertexto significa um conjunto de ligações (links)). O WWW começou em 1989 no CERN, por proposta de Tim Berners-Lee, para os físicos poderem partilhar documentos. O primeiro browser com interface gráfico (Mosaic) ficou disponível em Março de 1993. A normalização do WWW é realizada no âmbito do Consórcio W3 (www.w3.org), sendo algumas das normas posteriormente publicadas pela IETF como RFCs. A pressão comercial levou a que a normalização ocorresse muitas das vezes após o lançamento de produtos com modificações à norma anterior. O WWW é uma forma de obter informação imediatamente disponível na Internet como se fosse um meio contínuo pesquisável.

WWW - 7 Luis Bernardo
Recorrendo a saltos e pesquisas em hipertexto, o utilizador navega através de um mundo de informação em parte escrito à mão, e em parte gerado por computador a partir de bases de dados e sistemas de informação existentes. Como ferramentas de interface com o utilizador, os clientes WWW correm no computador deste, permitindo-lhe aceder à rede através de simples selecções com o rato, enquanto os servidores WWW, normalmente numa máquina completamente diferente, algures noutra parte do mundo, oferecem um método eficiente e simples de fornecer informação aos utilizadores, sobre a forma de ficheiros que são transferidos para a máquina do cliente. O WWW define:
•••• A ideia de um mundo onde cada pedaço de informação tem uma referência pela qual pode ser acedido;
•••• Um sistema de endereçamento (URL - Uniform Resource Locator), que permite endereçar vários tipos de objectos acessíveis através de protocolos já em uso, tais como FTP, NNTP, telnet, e HTTP (e outros mais antigos: Gopher, WAIS);
•••• Um protocolo de nível aplicação (HTTP - Hypertext Transfer Protocol) oferecido pelos servidores WWW genuínos para transferência de ficheiros entre clientes e servidores;
•••• Uma linguagem de hipertexto com marcas de formatação (HTML - Hypertext Markup Language) que todos os clientes WWW devem entender, e que é usada para a transmissão de informação, tais como texto, imagens, menus e informação sobre a formação da informação no cliente.

WWW - 8 Luis Bernardo
Realização da web O cliente realiza o carregamento de ficheiros a partir de um servidor e apresenta os ficheiros recebidos. Caso o browser não suporte algum tipo de dados, pode recorrer a um plug-in (a) (e.g. Macromedia shockwave) ou a uma aplicação externa (e.g. Acrobat PDF Reader).
Um servidor Web é numa visão simplista um servidor de ficheiros com requisitos elevados de desempenho, que recebe pedidos e os satisfaz (de preferência) em paralelo.
A operação mais lenta é o acesso ao ficheiro – num único processo, pode ser melhorada com a memorização do conteúdo dos últimos ficheiros abertos.
Pode ainda ser melhorado utilizando-se vários processos em diferentes máquinas.
Neste caso, deve-se optimizar a capacidade de comutação do “Front End” – o distribuidor.

WWW - 9 Luis Bernardo
URLs (Uniform Resource Locators) Um URL começa por definir o protocolo, seguindo-se informação dependente do protocolo que inclui na maior parte dos casos o nome da máquina, o porto e o caminho para o objecto. Home Page da FCT http://www.fct.unl.pt
http://[email protected]:8000/servlet?xpto=ola Servidor de FTP Anónimo: ftp://ftp.dee.fct.unl.pt Autenticado: ftp://user:[email protected]
Ficheiro local file://home/lflb/OpenORB/README Newsgroup soc.culture.portuguese Grupo: news:soc.culture.portuguese
Artigo: news:[email protected] Mail para um utilizador maito:[email protected] Pesquisas na base de dados da Biblioteca Nacional telnet://porbase.ibl.pt Gopher (percursor do serviço web baseado em texto) gopher://gopher.tc.umn.edu/11/Libraries Os URLs têm um problema: definem explicitamente a localização dos recursos na rede, impossibilitando uma evolução transparente para o utilizador O IETF está a trabalhar na definição da evolução dos URLs: URN – Uniform Resource Names URN introduz nomes independentes do endereço do servidor, que são resolvidos no DNS para o nome de um servidor. e.g. urn:ietf:rfc:2141

WWW - 10 Luis Bernardo
HTTP (HyperText Transfer Protocol)
O protocolo HTTP corre sobre TCP, tipicamente no porto 80. Este protocolo permite transferir documentos, partes de documentos, e efectuar pesquisas. A filosofia do HTTP é diferente do protocolo FTP: a sinalização é enviada pelo mesmo canal que os dados (in-band), não sendo guardado nenhum estado no servidor para cada cliente – cada pedido é independente dos anteriores.
Até 1997 foi usada a versão 1.0 do protocolo (RFC 1945) que envia cada pedido a um servidor por uma ligação TCP independente. Cada ficheiro de uma página é enviado por uma ligação diferente. A versão 1.1 (RFC 2068 de 1997) corrige esta limitação, passando a suportar a reutilização de ligações (a ligação termina após um período de inactividade). A versão 1.1 permite dois modos de funcionamento:
Sem pipelining, o pedido de cada ficheiro da página é realizado após receber a resposta ao pedido anterior.
Com pipelining vários pedidos podem ser enviados sem esperar pela resposta do primeiro, sendo as resposta recebidas pela ordem porque são feitos os pedidos. Cliente Servidor
SYN
SYN/ACK
ACK/GET x.html
<x.html>
SYN
SYN/ACK
ACK/GET x.gif
<x.gif>
HTTP 1.0
Cliente Servidor
SYN
SYN/ACK
ACK/GET x.html
<x.html>
GET x.gif
<x.gif>
HTTP 1.1
Cliente Servidor
SYN
SYN/ACK
ACK/GET x.html
<x.html>
GET x.gif
<x.gif>
HTTP 1.1 com
pipelining

WWW - 11 Luis Bernardo
O desempenho do HTTP 1.1 é superior ao HTTP 1.0, pois para além do tempo perdido no re-estabelecimento da ligação, também há a ineficiência introduzida pelo algoritmo de Slow-Start do TCP, que gere a janela de congestão. O HTTP 1.1 é compatível com o HTTP 1.0, permitindo que um cliente 1.0 funcione com um servidor 1.1 e que um cliente 1.1 funcione com um servidor 1.0.
Formato de mensagens HTTP As mensagens de controlo são enviadas sobre a forma de texto legível. A mensagem de pedido, do cliente para o servidor tem a seguinte estrutura:
O HTTP inclui vários métodos predefinidos:
GET Requer a leitura de uma página
HEAD Requer a leitura do cabeçalho de uma página
PUT Requer a gravação de uma página
POST Requer o acrescentar de dados a uma página
DELETE Apaga uma página
TRACE Ecoar pedido recebido
CONNECT Requer a criação de um túnel
OPTIONS Requer informação sobre opções disponíveis
Método sp URL sp Versão cr lf
Nome campo cabeçalho : valor cr lf
Nome campo cabeçalho : valor cr lf
cr lf
Corpo da mensagem
Pedido
Linhas cabeçalho …

WWW - 12 Luis Bernardo
A mensagem de resposta do servidor tem a seguinte estrutura:
Os códigos de estado devolvidos podem ser:
Código Tipo Exemplo de razões 1xx Informação Rec. pedido, continua processamento
2xx Sucesso Acção terminada com sucesso
3xx Redirecção Necessárias mais acções para completar
4xx Erro do cliente Pedido errado, não pode ser executado
5xx Erro do servidor Servidor falhou com pedido válido Exemplos:
100 Agree: Servidor aceita processar pedido
200 OK: Sucesso, informação retornada no corpo da mensagem
204 No Content: Ficheiro vazio
301 Moved Permanently: Moveu-se para URL em 'Location:'
304 Cached Page Valid: Página em cache ainda é válida
400 Bad Request: Pedido não entendido pelo servidor
401 Unauthorized: Requerida autenticação do cliente
403 Forbidden Page: Página não acessível
404 Not found: O ficheiro pedido não existe
501 Internal Error
503 Try Again Later
505 HTTP Version Not Suported: Versão não suportada
Versão sp Código estado sp Frase cr lf
Nome campo cabeçalho : valor cr lf
Nome campo cabeçalho : valor cr lf
cr lf
Corpo da mensagem
Pedido
Linhas cabeçalho …

WWW - 13 Luis Bernardo
Campos de cabeçalho
Cabeçalho Tipo Conteúdo User-Agent Pedido Informação sobre o browser e a sua plataforma
Accept Pedido Os tipos de páginas que o cliente suporta
Accept-Charset Pedido Os códigos de caracteres suportados pelo cliente
Accept-Encoding Pedido As codificações de página suportadas
Accept-Language Pedido As línguas suportadas (português, inglês, …)
Host Pedido Nome DNS do servidor
Authorization Pedido Lista de credenciais do cliente
Cookie Pedido cookies previamente definidos pelo servidor
Date Ambos Data e hora de envio da mensagem
Upgrade Ambos Protocolo pretendido pelo emissor
Server Resposta Informação sobre o servidor
Content-Encoding Resposta Como o conteúdo está codificado (e.g. gzip)
Content-Language Resposta Língua usada na página
Content-Length Resposta Comprimento da página (bytes)
Content-Type Resposta Tipo MIME da página
Last-Modified Resposta Data e hora de última modificação da página
Location Resposta Comando para enviar o cliente para outro URL
Accept-Ranges Resposta O servidor aceita pedidos de blocos de bytes
Set-Cookie Resposta O servidor quer que o cliente guarde um cookie
Exemplo de interacção Pedido:
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/4.0
Accept-language:pt
Resposta: HTTP/1.1 200 OK
Connection: close
Date: Thu, 23 Oct 2002 12:30:00 GMT
Server: Apache/1.3.0 (Unix)
Last-Modified: Thu, 20 Oct 2002 10:00:00 GMT
Content-Length: 6821
Content-Type: text/html
… { dados dados dados } …

WWW - 14 Luis Bernardo
Cookies O protocolo HTTP não guarda nenhuma memória sobre interacções anteriores de um utilizador. As extensões para manter um "estado" na interacção utilizador-servidor recorrem a campos de cabeçalho mantidos no cliente, que são enviados em todos os pedidos do cliente. Cada cookie é uma cadeia de caracteres com até 4KB. Existem 3 versões: V0 –Netscape (1995) http://wp.netscape.com/newsref/std/cookie_spec.html V1 – RFC 2109 (1997) – acrescenta controlo de versões V2 – RFC2965 (2000) – usa Set-Cookie2/Cookie2 Descreve-se a V0, suportada por TODOS os browsers: Set-Cookie: NAME=VALUE; Expires=DATE; Path=PATH;
Domain=DOMAIN_NAME; Secure
• NAME=VALUE – define o nome e o valor do cookie. É o único campo obrigatório, podendo-se usa a forma simplificada “Set-Cookie: VALUE” para um nome vazio.
• Expires=DATE – define a validade do cookie. Se não for definido, o cookie desaparece quando se fecha o browser. Pode-se eliminar um cookie enviando uma data anterior à data actual.
• Domain=DOMAIN_NAME – Define o nome do servidor (usa-se o endereço IP se não estiver definido). Cada domínio pode ter até 20 cookies.
• path=PATH – documento raiz a partir da qual todos os documento levam o mesmo cookie. Se não for definido, o cookie apenas é enviado para a página pedida.
• secure – se seleccionado, o cookie apenas é enviado para ligações seguras.

WWW - 15 Luis Bernardo
Exemplo: Set-Cookie: CUSTOMER=213123; path=/; expires=Wednesday,
09-Nov-07 23:12:40 GMT
Recebe nos pedidos seguintes para todos os documentos: Cookie: CUSTOMER=213123
O servidor pode definir vários cookies em campos de cabeçalho Set-cookie separados, que são devolvidos concatenados (separados por ‘;’) num único campo de cabeçalho Cookie nos pedidos futuros. Os cookies são usados com vários propósitos: • Mecanismo para validação de utilizadores: após validado uma vez, reenvia o cookie nos pedidos seguintes;
• Memorizar a preferência dos utilizadores; • Nos servidores de comércio electrónico para manter o carrinho de compras electrónico, com os itens seleccionados;
• Contadores de acessos a servidores (e.g. cookie Counter incrementado em cada acesso);
• Espionagem de preferências de utilizadores.
E.g. uma empresa coloca um link para uma imagem (http://www.sneak.com/3423423423.gif) – que pode ser apenas um ponto – em vários servidores aderentes (Amazon, …). No cookie mantém a lista de todos os locais visitados e informações pessoais que possam ter sido cedidas por alguns dos servidores visitados. Depois vende a base de dados de utilizadores …
Falham para utilizadores que usam várias máquinas, ou que desligam a recepção de cookies.

WWW - 16 Luis Bernardo
Segurança na interacção utilizador-servidor A segurança pode ser melhorada através de campos de cabeçalho e de extensões do protocolo HTTP. Autenticação (RFC 2617) O cliente carrega a página de entrada, sendo retornado o código "401 Authorization Required" e um campo de cabeçalho "WWW-Authenticate:" com a descrição do tipo de autenticação usada. O modo mais simples (Basic) devolve o nome do domínio do servidor. O mais complicado (Digest) acrescenta informação criptográfica. Aos pedidos seguintes o cliente adiciona o campo de cabeçalho "Authorization:", com informação de autenticação. No modo Basic inclui "nome:passwd" codificada no formato Base64. No modo Digest envia uma assinatura digital da password. Cookies O cliente carrega a página de entrada, sendo redireccionado para uma página que lhe pede os nomes de utilizador e palavra de passe, e define um cookie com um certificado. Extensão de segurança - HTTPS Nenhum dos métodos anteriores garante privacidade dos dados O HTTPS corresponde à utilização de HTTP sobre canais seguros SSL (Secure Socket Layer), que cifram os dados. Identificação de URLs que suportam HTTPS: https://... Suporta privacidade, integridade e autenticação de servidores. Este e outros métodos baseados em técnicas de cifra são descritos mais à frente, nas aulas sobre segurança.

WWW - 17 Luis Bernardo
Caching no cliente
Para reduzir o tempo de carregamento de páginas, o cliente HTTP pode guardar os documentos recebidos anteriormente na memória ou num ficheiro (no conjunto designados de cache).
Até quando é que o documento guardado é válido? Heurística baseada na data da última modificação. O HTTP suporta o campo de cabeçalho "If-modified-since:" que permite validar se um documento ainda é válido. Pedido 1:
GET /somedir/page.html HTTP/1.0
User-agent: Mozilla/4.0
…
Resposta 1: HTTP/1.0 200 OK
Date: Thu, 23 Oct 2002 12:30:00 GMT
Server: Apache/1.3.0 (Unix)
Last-Modified: Thu, 23 Oct 2002 12:00:00 GMT
Content-Type: text/html
… { dados dados dados } …
Pedido 2: GET /somedir/page.html HTTP/1.0
User-agent: Mozilla/4.0
If-Modified-Since: Thu, 23 Oct 2002 12:00:00 GMT
…
Resposta 2: HTTP/1.0 304 Not Modified
Date: Thu, 23 Oct 2002 12:35:00 GMT
Server: Apache/1.3.0 (Unix)
O HTTP permite evitar a utilização da cache no cliente. No HTTP 1.0 existe um cabeçalho "pragma: no-cache". No HTTP 1.1 foi criado um campo de cabeçalho "cache-control:" para o pedido e para a resposta onde se pode definir o valor "no-cache", mas também o tempo máximo que a cópia permanece válida "max-age".

WWW - 18 Luis Bernardo
Caching em procuradores
Para além dos clientes, as respostas dos servidores também podem ser guardadas em servidores intermediários entre os clientes e os servidores, designados de proxy (procurador). Após receber um pedido de um cliente (1), reenvia-o para o servidor pretendido (2). A resposta recebida (3) é enviada de volta ao cliente (4), mas também é armazenada localmente. Caso um novo cliente faça o mesmo pedido dentro de um intervalo de tempo, o proxy retorna a informação em cache.
Cliente Proxy Servidor
cache
1 2*
3* 4
BD
A utilização de proxies numa organização com uma rede de informação interna rápida:
• reduz a quantidade de tráfego trocada com o exterior;
• reduz o tempo médio de acesso à rede;
• permite simplificar a configuração de firewalls ao permitir limitar o acesso ao exterior (para WWW) apenas à máquina onde o proxy está a correr;
• tem a desvantagem de as páginas em cache poderem estar desactualizadas. Os utilizadores podem sempre forçar uma nova leitura no servidor, usando os campos de controlo de caching.
O HTTP 1.1 suporta procuradores, existindo opções no campo de cabeçalho "cache-control:" destinadas a definir o nível de partilha entre utilizadores de uma página (e.g. private, public, s-maxage (max-age para proxies)).

WWW - 19 Luis Bernardo
O RFC 2617 define como é feita a autenticação no acesso a proxies: O proxy retorna o código "407 Proxy Authorization Required" e um campo de cabeçalho "Proxy-Authenticate:" com a descrição do tipo de autenticação requerida. O modo mais simples (Basic) devolve o nome do domínio do proxy. Aos pedidos seguintes o cliente adiciona o campo de cabeçalho "Proxy-Authorization:", com informação de autenticação. No modo Basic inclui "nome:passwd" codificada no formato Base64. Podem ser enviadas várias autorizações encadeadas num pedido HTTP. Vários proxies podem ser ligados criando um serviço hierárquico de caching distribuído por toda a rede (e.g. Squid, Apache).
Neste caso pode-se usar um protocolo mais complexo de coordenação (e.g. ICP – Internet Cache Protocol – RFC 2186).

WWW - 20 Luis Bernardo
Replicação de servidores web
Embora a utilização de caches nos clientes e em procuradores reduza a carga sentida nos servidores, nem todo do conteúdo das páginas pode ser guardado em caches (páginas dinâmicas, pedidos com cookies, autenticação, etc.). Estima-se que mais de 40% das respostas a pedidos web não podem ser guardadas em cache (segundo o livro "Web Caching and Replication" de M. Rabinovich e O. Spatcheck). Quando uma página vai ser acedida por milhões de utilizadores (e.g. Jogos Olímpicos, NASA Pathfinder, NetAid, etc.), torna-se necessário replicar a página em vários servidores Web, distribuindo a resolução dos pedidos pelos vários servidores. A replicação pode ser realizada pelo cliente Web, que mantém uma lista dos servidores Web disponíveis e selecciona um aleatoriamente (e.g. Netscape e www.netscape.com). Apenas resulta para um conjunto limitado de servidores!
Alternativamente, o cliente pode correr uma applet que carrega a lista de endereços de servidores alternativos (de um serviço de directórios), realiza um teste rápido de desempenho, e selecciona o servidor que tiver a resposta mais rápida (e.g. smart clients).
Complica a realização do cliente! A replicação deve ser realizada de forma transparente para o cliente, de maneira a ser aplicável a qualquer URL.

WWW - 21 Luis Bernardo
Replicação transparente de servidores Web
Podem ser usadas várias estratégias para replicar os servidores Web e permitir a distribuição transparente de clientes pelas várias réplicas.
IPCliente Servidor 1Serviço
DNS
1 2 3
1. Redirecção no serviço de nomes DNS;
2. Redirecção num servidor distribuidor (dispatcher);
3. Redirecção nos servidores web

WWW - 22 Luis Bernardo
Redirecção no serviço de nomes DNS É criada um nome único no serviço DNS associado a uma lista de endereços IP dos servidores Web. Para cada pedido, o servidor DNS devolve um dos endereços IP.
Cliente
Servidor 1
Servidor 2
Serviço
DNS
Servidor n
Problema: Escolha do servidor Web para cada cliente Solução: • Round-robin (em sequência - um de cada vez); • Usando informação sobre o estado do servidor (só para LANs);
• Usando informação sobre a proximidade dos servidores aos clientes (e.g. Cisco DistributedDirector, I2-DSI)
Problema: Carga escondida Durante o tempo de vida da resposta (TTL), todos os servidores DNS usados na resolução do nome, procuradores Web e o cliente vão usar o mesmo servidor Web. "Se um cliente da rede A resolver o nome, todos os clientes dessa rede vão usar o mesmo servidor durante o TTL da resposta"

WWW - 23 Luis Bernardo
Solução:
• TTL= 0 (não funciona a longo prazo !!!)
• TTL adaptativo – contabilizar o número de pedidos DNS por domínio de origem, medir a carga de cada servidor por origem - baixar TTL para pedidos DNS vindos de domínios de origem com muitos acessos quando algum servidor começa a ficar demasiado carregado (demasiado complicado para uma rede real !!!).
O serviço DNS funciona na Internet porque os servidores DNS intermédios e os clientes memorizam em caches as respostas anteriores. Com TTL=0 desligava-se todas as caches do DNS, obrigando os servidores dos domínios raiz a participar na resolução de grande parte dos nomes. O tempo de atraso entre a modificação do TTL e a modificação da carga também é um problema de controlo complexo, que pode originar instabilidade.
WWW - 24 Luis Bernardo
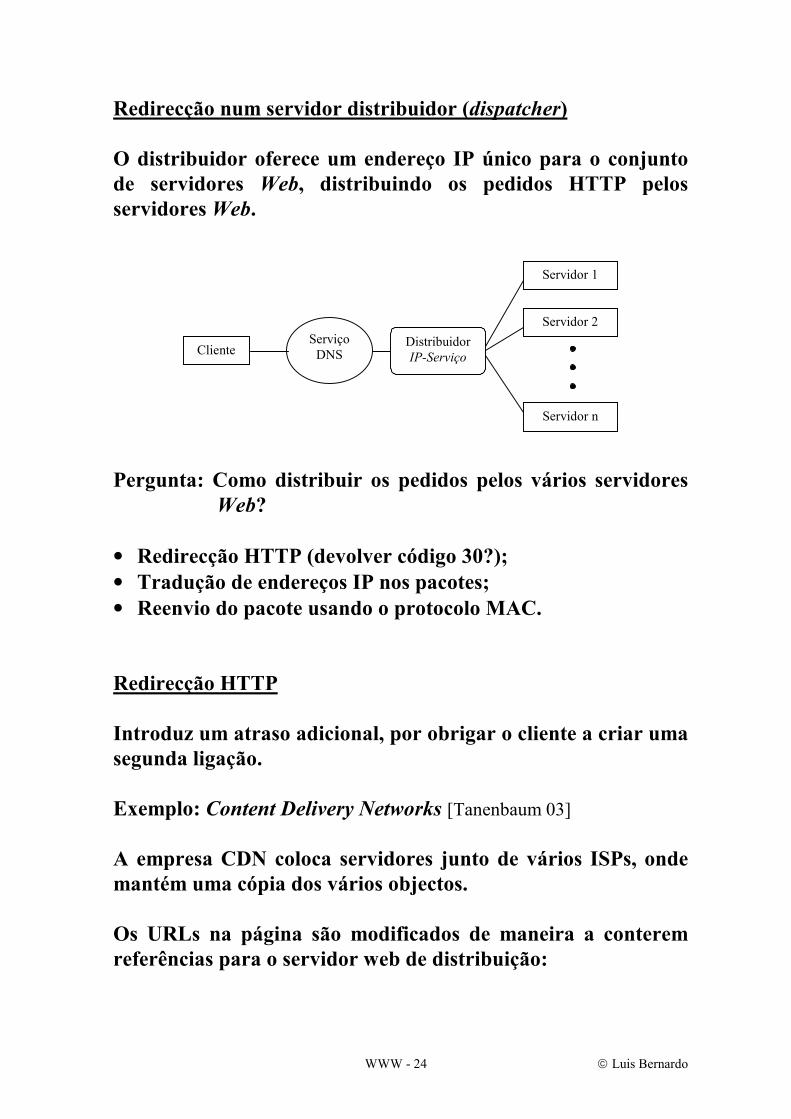
Redirecção num servidor distribuidor (dispatcher) O distribuidor oferece um endereço IP único para o conjunto de servidores Web, distribuindo os pedidos HTTP pelos servidores Web.
Cliente
Servidor 1
Distribuidor
IP-Serviço
Servidor 2
Serviço
DNS
Servidor n
Pergunta: Como distribuir os pedidos pelos vários servidores
Web? • Redirecção HTTP (devolver código 30?); • Tradução de endereços IP nos pacotes; • Reenvio do pacote usando o protocolo MAC. Redirecção HTTP Introduz um atraso adicional, por obrigar o cliente a criar uma segunda ligação. Exemplo: Content Delivery Networks [Tanenbaum 03] A empresa CDN coloca servidores junto de vários ISPs, onde mantém uma cópia dos vários objectos. Os URLs na página são modificados de maneira a conterem referências para o servidor web de distribuição:

WWW - 25 Luis Bernardo
Durante a resolução da página, o pedido de cada imagem é direccionado para o melhor servidor CDN. O(s) servidor(es) (cdn-server.com) usam a informação sobre a distância entre o cliente e as várias réplicas da página (pode usar a informação de encaminhamento do protocolo BGP, etc.) e sobre a carga nesses servidores.

WWW - 26 Luis Bernardo
Tradução de endereços IP Realiza uma operação semelhante a um roteador NAT. Mantém uma tabela para todas as ligações activas, associando os clientes a servidores Web:
(IP de cliente / porto de cliente / IP de servidor Web)
Para cada pacote IP, o IP do serviço é substituído pelo endereço IP do servidor Web, sendo transparente tanto para os clientes como para os servidores Web. O distribuidor e os servidores Web podem estar em várias LANs. Exemplo de produtos: MagicRouter e Cisco LocalDirector Reenvio de pacotes usando o protocolo MAC O distribuidor e os servidores Web encontram-se na mesma LAN, e todos estão configurados com o endereço IP do serviço. O distribuidor mantém uma tabela para todas as ligações activas, associando os clientes a servidores Web: (IP de cliente / porto de cliente / Endereço MAC de servidor Web)
Todos os servidores Web conhecem o endereço MAC do distribuidor, e este conhece os endereços MAC de todos os servidores Web, não sendo usado o ARP para enviar os pacotes IP. Exemplo de produtos: IBM Network Dispatcher

WWW - 27 Luis Bernardo
Redirecção nos servidores web Usa o DNS para realizar uma primeira distribuição entre servidores Web. Numa segunda fase, os servidores Web realizam uma redistribuição entre eles – usando redirecção HTTP ou reescrita de endereços IP.
Cliente
Servidor 1
Servidor 2
Serviço
DNS
Servidor n
A função de distribuição é realizada pelos vários servidores, evitando a criação de um ponto centralizado de estrangulamento.

WWW - 28 Luis Bernardo
Comparação das abordagens para replicação transparente Abordagem Vantagens Desvantagens Baseada no cliente
• Distribuída • Não afecta servidor Web • Solução para LAN e WAN
• Aplicação limitada • Balanceamento de carga pouco preciso
Baseada no DNS
• Centralizado • Sem limitações desempenho • Solução para LAN e WAN
• Pouco controlo • Balanceamento de carga pouco preciso
Baseada num distribuidor
• Controlo total • Balanceamento de carga preciso
• Estrangulamento de desempenho no distribuidor
• Solução só para LAN Baseada nos servidores Web
• Controlo distribuído • Balanceamento de carga preciso para LAN e WAN
• Aumento de latência e de tempo de processamento nos servidores
Na prática usa-se uma combinação de várias tecnologias em paralelo. Exemplos: NetAid (1999) – realizado pela Cisco, usando uma combinação de Distributed Directors e de Local Directors em clusters de servidores – suportou 40 milhões de pedidos durante o concerto de angariação de fundos, com um pico de 2800 acessos por segundo.
Jogos Olímpicos de Inverno (1998) – realizado pela IBM, usando um esquema com dois níveis (DNS + Network Dispatcher) e roteadores que realizam caching de páginas Web – suportou 56.8 milhões de acessos num dia.

HTML (HyperText Markup Language)
O HTML foi desenvolvido em resposta à necessidade de descrever documentos em termos da sua estrutura lógica, e define um modelo de documentos hierárquico sob a forma de árvore. A sintaxe é expressa como um conjunto de elementos lógicos do documento delimitados por códigos genéricos (tags), um conjunto facultativo de atributos e um modelo de conteúdo que especifica que tipos de dados ou elementos podem ser colocados dentro de cada elemento. Alguns exemplos comuns:
<H1> Isto é um título </H1>
<H2> Isto também é um título, mas mais pequenino </H2>
<B> Isto está mais carregado </B>
<EM> e isto normalmente está em itálico </EM>
<IMG SRC="imagem.gif"> Isto é uma imagem que aparece no texto
(a imagem está num ficheiro chamado "imagem.gif")
<A HREF="texto.html">Isto é um link para outro documento</A>
(o outro documento chama-se "texto.html")
A evolução dos standards foi directamente impulsionada pela competição entre a Netscape e a Microsoft a nível de funcionalidades dos seus browsers. HTML 2.0 1994 HTML 3.2 1996 HTML 4.0 1998 Outros desenvolvimentos incluem: XML (Extensible Markup Language) Suporta ligações entre
páginas complexas. Formato electrónico para troca de dados. Suporta funcionalidades de “workflow” e de interacção entre objectos.
XHTML (eXtended HTML) Reformulação de HTML em XML. VRML (Virtual Reality Modeling Language)

WWW - 30 Luis Bernardo
O HTML inclui no mesmo ficheiro dados e informação de formação. Em XML a formatação dos dados é especificada separadamente utilizando XSL (eXtensible Style Language). Dados (XML)
Formatação dos dados (XSL)

WWW - 31 Luis Bernardo
A evolução do HTML permitiu uma funcionalidade crescente e melhores tempos de resposta resultantes da transferência do processamento dos servidores para os clientes e da redução da quantidade de dados transferidos na rede.
Rede hipertexto
→
Resposta simples
→
Resposta simples
com páginas
dinâmicas →
Rede de objectos
com páginas
dinâmicas
• servidor
ficheiros
baseado em
URLs
• Forms / CGI
• Tabelas
• Push
• Scripts
• DHTML
• Cookies /
sessions
• JSP / ASP
• applets
• ActiveX
• Interacções
via DCOM ou
CORBA ou
SOAP
Forms
Os Forms aparecem com o HTML 2.0 e suportam a definição de campos de entrada de dados, delimitados entre as tags <form> e </form>. Exemplo:
<form ACTION=”http://mariel.inesc.pt/cgi-bin/finger” method=POST> Name <input name =”Finger” size=40></form>
Um campo TYPE permite utilizar um conjunto de campos predefinidos (ex. RADIO VALUE - valores alternativos para um mesmo INPUT NAME, ou SUBMIT VALUE). Os dados são processados numa aplicação lançada pelo servidor WWW, que recebe os parâmetros no formato CGI (Common Gateway Interface) e retorna uma página HTML.

WWW - 32 Luis Bernardo
Tipos de páginas dinâmicas
Uma página dinâmica é gerada em tempo real, por uma aplicação que corre no servidor ou no cliente.
No servidor
Usam-se programas que recebem os parâmetros de uma form, enviados através do método POST, processam-nos usando dados disponíveis no servidor, e retornam o conteúdo de uma página web:
• CGI (Common Gateway Interface) – define interface para passar parâmetros para programa externo em C, C++, …, ou um interpretador de scripts Perl, Python, …;
• Código PHP, interpretado no servidor web;
• Código JSP (JavaServerPages, em Java);
• ASP (Active Server Pages, em Visual Basic Script da Microsoft).

WWW - 33 Luis Bernardo
No cliente É carregado código no browser, que corre localmente, e pode interagir com o utilizador, gerar dinamicamente páginas, campos de páginas, ou comunicar com outros objectos na rede:
• JavaScript – linguagem interpretada, inspirada em Java, embebida na página Web;
• Applets – código bytecode Java carregado a partir do servidor web;
• Controlos ActiveX – código nativo carregado a partir do servidor web.
O código JavaScript é definido entre as etiquetas <script language= “javascript” type=”text/javascript”> e </script> no cabeçalho da página HTML. Tem um desempenho limitado pois é interpretado no browser. Os browsers têm muitas vezes interpretadores de versões diferentes de JavaScript – pode não correr em todos os browsers. Uma Applet é uma aplicação (em bytecode) Java carregada a partir de um servidor WWW e que corre no browser. Exemplo:
<applet Code=game.class Width=100 Height=200></applet>
Por motivos de segurança, os browsers não permitem que as applets tenham acesso ao disco local e apenas permitem que elas comuniquem com a máquina a partir da qual foram carregadas – excepto se usarem alguma falha da JVM. Tem um desempenho superior a Javascript, especialmente se for usado um interpretador JIT. Um controlo ActiveX é código máquina compilado para várias arquitecturas, assinado por uma entidade supervisora. Tem o melhor desempenho, mas poderá ter problemas de segurança.

WWW - 34 Luis Bernardo
A geração de páginas dinâmicas no cliente permite uma interacção mais rápida com o cliente, desde que não sejam usados dados do servidor. PHP JavaScript

WWW - 35 Luis Bernardo
Web sem fios
Objectivos: Combinar Internet e telefones móveis WAP (Wireless Application Protocol) 1.0 Primeira tentativa de normalização para uma rede:
• Orientada à ligação
• Ritmo de 9600 bits/segundo
Micro-browser
Semelhante a HTTP 1.1
Substitui TCP
Subconjunto de SSL
Semelhante a UDP
Páginas escritas em WML (Wireless Markup Language), uma aplicação de XML
Falhou comercialmente …

WWW - 36 Luis Bernardo
I-mode (information-mode) Serviço proprietário realizado em Fev. 1999 no Japão pela NTT DoCoMo Primeira versão usou:
• Rede de pacotes para dados e rede orientada à ligação para voz
• Serviço de dados sempre activo pago ao KByte • Ritmo de 9600 bits/segundo
Baseado em protocolos proprietários:
cHTML é baseado em HTML 1.0 com extensões (e.g. tel) Ênfase nos serviços
• Milhares de servidores webs com acesso pago. • Sucesso comercial no Japão.

WWW - 37 Luis Bernardo
WAP i-mode O que é? Pilha de protocolos Serviço
Aparelho Telemóvel, PDA, portátil Telemóvel
Acesso Acesso Dial Sempre ligado
Rede Comutação circuitos Circuitos+pacotes
Ritmo binário 9600 bps 9600 bps
Écran Monocromático Cores
Linguagem web WML (aplicação XML) cHTML
Linguagem scripts WMLscript -
Pagamento Por minuto Por pacote
Método pagamento Cartão crédito Conta telefónica
Imagens predefinidas Não Sim
Normalização Norma aberta do WAP fórum Proprietário da NTT
Onde é usado? Europa, Japão Japão
Utilizador típico Empresários Jovens
WAP (Wireless Application Protocol) 2.0 Evolução do WAP 1.0 que procurou incorporar aspectos do i-mode. Novas funcionalidades do WAP 2.0:
• Suporta tanto o modelo Push como o modelo Pull
• Integração de telefonia nas aplicações
• Mensagens multimédia
• 264 imagens predefinidas
• Interface para dispositivo de armazenamento
• Suporte de plug-ins para o browser WAP
• Adoptou a versão básica do XHTML, tornando as páginas compatíveis com browsers Web
Pode usar rede UMTS, com ritmos de 384Kbps, ou GPRS

WWW - 38 Luis Bernardo
Modificações técnicas:
TCP modificado:
• Janela fixa de 64 KB • Não usa “slow start” • MTU fixa de 1500 bytes • Algoritmo de retransmissão modificado
Características do XHTML:
Que futuro para o WAP 2.0 (sobre UMTS/GPRS)? Muito limitado pela emergência das redes 802.11 (11 Mbps; 54 Mbps) apenas para as zonas onde a rede 802.11 não chegar … Ver disciplina CSF para mais informações …

WWW - 39 Luis Bernardo
USENET NEWS
A Internet sempre suportou a distribuição de informação e notícias por milhares de utilizadores. Há dois métodos históricos na Internet para distribuir tais notícias: • através de e-mail: organizando listas de correio electrónico • através do sistema de Usenet News. O primeiro método é ineficiente quando o número de utilizadores interessados cresce muito, pois é criada uma cópia de cada mensagem por cada utilizador que tem de ser transferida independentemente das restantes. Com o sistema de Usenet News, há um conjunto de máquinas que mantêm uma base de dados de mensagens, designadas artigos. Os artigos estão organizados em temas designados newsgroups. Os utilizadores usam programas clientes que lhe permitem seleccionar apenas aquilo que querem ler. Mais recentemente as Usenet News perderam importância para a Web, com a utilização dos motores de pesquisa e de blogs. Newsgroups Os newsgroups são geralmente abertos, podendo qualquer pessoa enviar uma mensagem para lá. No entanto, quando uma grande percentagem das mensagens são lixo, o newsgroup pode ser convertido num newsgroup moderado. Nos grupos moderados, só ao moderador é permitido enviar uma mensagem. Quando uma pessoa pretende enviar uma mensagem para esse grupo, manda-a por e-mail para o moderador, e se este achar que ela tem interesse envia-a.

WWW - 40 Luis Bernardo
Os newsgroups estão organizados em categorias baseadas em assuntos. Alguns exemplos são:
comp: Computadores e software
comp.binaries.ibm.pc Programas para IBM PC
comp.virus Vírus e segurança. (Moderado)
soc: Assuntos de sociedade
soc.culture.portuguese Discussão das pessoas de Portugal
pt: Grupos portugueses
Formato dos artigos Os artigos têm uma estrutura semelhante a uma mensagem SMTP, com vários campos de cabeçalho comuns: From, Date, Subject, Reply-To e outros campos específicos das News: Linha Newsgroup
Especifica o(s) newsgroup(s) a que a mensagem pertence.
Linha Message-ID Contém um identificador único para a mensagem.
Linha Path Contém o caminho que a mensagem percorreu até chegar à maquina
onde se encontra.
Linha Approved Linha necessária caso a mensagem pertença a um newsgroup
moderado, consistindo no endereço de email do moderador.
Distribuição das Mensagens
Os artigos são armazenados em servidores de news. Cada cliente está ligado a um servidor. Um artigo é enviado numa determinada máquina para um conjunto de newsgroups. Quando essa máquina aceita o artigo envia-o para todas as suas vizinhas que estejam interessadas em pelo menos um dos newsgroups a que a mensagem pertence. O servidor pode também guardá-lo localmente e esperar que os servidores vizinhos lhe peçam por artigos novos.
WWW - 41 Luis Bernardo
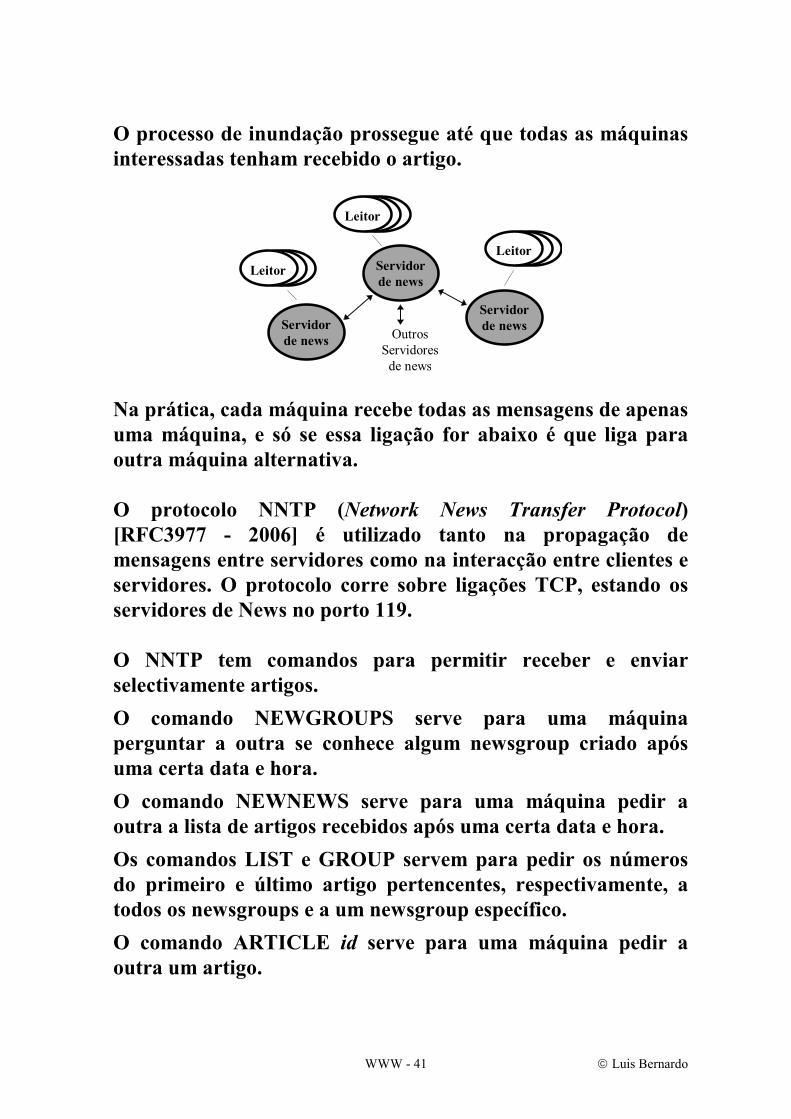
O processo de inundação prossegue até que todas as máquinas interessadas tenham recebido o artigo.
Servidorde news
Servidorde news
Servidorde news
Leitor
Leitor
Leitor
Outros
Servidores
de news
Na prática, cada máquina recebe todas as mensagens de apenas uma máquina, e só se essa ligação for abaixo é que liga para outra máquina alternativa. O protocolo NNTP (Network News Transfer Protocol) [RFC3977 - 2006] é utilizado tanto na propagação de mensagens entre servidores como na interacção entre clientes e servidores. O protocolo corre sobre ligações TCP, estando os servidores de News no porto 119. O NNTP tem comandos para permitir receber e enviar selectivamente artigos. O comando NEWGROUPS serve para uma máquina perguntar a outra se conhece algum newsgroup criado após uma certa data e hora. O comando NEWNEWS serve para uma máquina pedir a outra a lista de artigos recebidos após uma certa data e hora. Os comandos LIST e GROUP servem para pedir os números do primeiro e último artigo pertencentes, respectivamente, a todos os newsgroups e a um newsgroup específico. O comando ARTICLE id serve para uma máquina pedir a outra um artigo.

WWW - 42 Luis Bernardo
O comando POST serve para enviar um novo artigo para a rede. O comando IHAVE id serve para propagar um artigo recebido de outro servidor. O receptor pode aceitar e pedir o envio, ou rejeitar o artigo. Exemplo de mensagens trocadas entre dois servidores de news
S: 200 feeder.com NNTP server at your service (response to new connection)
C: NEWNEWS soc.couples 960901 030000 (any new news in sco.couples?) S:230 List of 2 articles follows
S:<[email protected]> (article 1 of 2 in soc.couples is from Berkeley)
S:<[email protected]> (article 2 of 2 in soc.couples is from AOL)
S:. (end of list)
C: ARTICLE <[email protected]> (please give me the Berkeley article) S:220 <[email protected]> follows
S:(entire article <[email protected]> is sent here)
S:. (end of article)
C: ARTICLE <[email protected]> (please give me the AOL article) S:220 <[email protected]> follows
S:(entire article <[email protected]> is sent here)
S:. (end of article)
C: NEWGROUPS 960901 030000 (any new groups ?) S:231 2 new groups follow
S:rec.pets
S:rec.sports
S:.
C:NEWNEWS rec.pets 0 0 (list everything you have) S:230 List of 1 article follows
S:.
C: ARTICLE <[email protected]> S:220 <[email protected]> follows
S:(entire article <[email protected]> is sent here)
S:.
C: POST S:340 (please send your posting)
C: (article posted on wholesome.com sent here) S:240 (article received)
C:IHAVE <[email protected]> S:435 (I already have it, please do not send it)
C:QUIT S:205

WWW - 43 Luis Bernardo
Serviços peer-to-peer Foi um dos mais recentes tipos de aplicações que surgiram na Internet – serviços de partilha de ficheiros entre utilizadores.
Designam-se de serviços "par-para-par" pois a aplicação corrida é simultaneamente um cliente e um servidor: • Cliente - oferece uma interface para o utilizador aceder ao serviço, permitindo-lhe pesquisar um ficheiro e carregá-lo para a máquina local;
• Servidor – oferece uma interface para que outros "clientes" pesquisem os ficheiros locais, transferindo-os para as suas máquinas.
Por vezes, designam-se os componentes da aplicação de "serventes" (do inglês servent). Gnutella O Gnutella adoptou uma estrutura de rede semelhante à usada no serviço Usenet News. Um novo "servente" pode ligar-se a um ou mais "serventes" que já façam partes da rede, criando uma ligação TCP para cada um, que permanece activa enquanto fizer parte da rede de partilha de ficheiros. Cada ligação é iniciada com uma troca de mensagens: GNUTELLA CONNECT/<protocol version string>\n\n GNUTELLA OK\n\n
A descoberta dos nós existentes da rede e a pesquisa de ficheiros partilhados em rede é feita usando um algoritmo de encaminhamento por inundação de pacotes, através da rede de "serventes".

WWW - 44 Luis Bernardo
O controlo de duplicação de pacotes é realizado através de: • Contador de nº de saltos, decrementado em cada salto; • Registo do identificador dos pacotes para as últimas N origens que passaram pelo "servente".
A descoberta de "serventes" na rede é realizada através da difusão de um pacote "Ping" através de todas as ligações activas do "servente".
Ping
Ping
Ping
Ping
A
Pong
Quando um "servente" recebe um pacote "Ping", e caso não conste na lista de pacotes recebidos, reenvia o pacote por todas as ligações excepto a por onde recebeu o Ping, por onde envia um pacote "Pong", indicando o número de ficheiros local e o número de bytes disponibilizados (na versão 0.4 do protocolo). Os "serventes" que recebem o "Ping" de A vão, por sua vez, responder com "Pong" que A reencaminha pela ligação por onde recebeu o "Ping" inicial. Após este processo, o servente cria uma tabela de encaminhamento, que associa as ligações aos "serventes". A pesquisa usa o mesmo algoritmo de inundação, mas difundindo um pacote "Query" com o nome do ficheiro a procurar, que é respondido com "Hit", apenas pelos "serventes" com ficheiros que obedeçam ao padrão procurado (e.g. ".gif").

WWW - 45 Luis Bernardo
Hit
Query
Hit
Hit
Query
Query
Push
PushFile
Push
Push
Após receber um “Hit” o servente cliente pode transferir o ficheiro criando uma ligação HTTP/TCP para um dos serventes que devolveram “Hit”. Caso o servente servidor não tenha um endereço público, a transferência do ficheiro pode ser desencadeada com o envio do pacote "Push", encaminhado usando as tabelas de encaminhamento, para um dos "serventes" que respondeu com "Hit". Esse servente cria uma ligação HTTP/TCP dedicada para transferir o ficheiro, usando os servidores HTTP que existem em todos os "serventes". Caso ambos tenham endereços privados, não é possível transferir o ficheiro. Este protocolo tem muitos problemas de escalabilidade e de segurança.





























