Embed Size (px)
Citation preview

CENTRO UNIVERSITÁRIO POSITIVO
NÚCLEO DE CIÊNCIAS EXATAS E TECNOLÓGICAS
ENGENHARIA DA COMPUTAÇÃO
HARDWARE PARA PROCESSAMENTO
DIGITAL DE IMAGENS
Rodrigo Marcel Ribeiro
Monografia apresentada à disciplina de Projeto Final como requisi to parcial à conclusão
do Curso de Engenharia da Computação, orientada pelo Prof. Alessandro Zimmer
UNICENP/NCET
Curitiba
2007

TERMO DE APROVAÇÃO
Rodrigo Marcel Ribeiro
Hardware para Processamento Digital de imagens
Monografia aprovada como requisito parcial à conclusão do Curso de Engenharia da
Computação do Centro Universitário Positivo, pela seguinte banca examinadora:
Prof. Alessandro Zimmer
Prof. Adriana Cursino Thomé
Prof. Valfredo Pilla Jr
Curitiba, 15 de Dezembro de 2007

AGRADECIMENTOS
Agradeço à Deus por ter tornado possível o desenvolvimento deste projeto e feito com que
apesar das dificuldades o sucesso tenha sido obtido . Não posso deixar de agradecer à minha
noiva Juliana Serafim da Silva , por todo o apoio durante os anos anteriores de curso e a
motivação, disciplina, paciência e carinho durante o desenvolvimento deste projeto. Agradeço
também à Luis Fabiano Canteri por me motivar nos momentos em que pensei em desistir e pelas
dicas valiosas de como resolver os principais problemas. Finalmente agradeço à meus pais por
me apoiar durante todo este tempo e patrocinar este sonho de me tornar Engenheiro da
Computação.

RESUMO
Este documento apresenta um sistema baseado em hardware para o processamento digital
de imagens. Entre as operações que o sistema é capaz de realizar estão: limiarização, aplicação
de máscaras e filtros de suavização.
O desenvolvimento é baseado em uma FPGA ( Field Programmable Gate Array ) que
recebe as imagens através de uma int erface paralela e realiza o processamento necessário,
retornando o resultado através da mesma interface.
A motivação para desenvolver tal sistema, uma vez que existem inúmeras soluções
baseadas em software, é justamente a inexistência de sistemas baseados em hardware, que
podem ser muito úteis no campo da visão computacional.
Palavras chave: Processamento de imagens, FPGA, VHDL, Filtros de Convolução

DIGITAL IMAGE PROCESSING HARDWARE
ABSTRACT
This document introduces a hardware based syste m to digital image processing. Some of
the operations that the system is capable to perform are: thresholding, mask application and
smoothing filters.
The development is based on a FPGA (Field Programmable Gate Array) who receives the
images through a parallel interface and do the processing, returning the result by the same
interface.
The motivation to develop this system, once there are a lot of software-based solutions is
this lack of hardware-based systems, wich can be very useful in the computer vision field.
Key words: Image processing, FPGA, VHDL, Convolution Filters

SUMÁRIO
Lista de Tabelas................................ ................................ ................................ .......................... 7Lista de Equações ................................ ................................ ................................ ....................... 8Lista de Siglas ................................ ................................ ................................ ............................ 9Lista de Figuras ................................ ................................ ................................ ........................ 10Capítulo 1 – Introdução ................................ ................................ ................................ ............ 12Capítulo 2 – Fundamentação Teórica ................................ ................................ ........................ 14
2.1 Processamento de Imagens ................................ ................................ ............................. 142.1.1 Histórico................................ ................................ ................................ ................. 142.1.2 Fundamentos de Imagens Digitais ................................ ................................ ........... 172.1.3 Transformadas de Imagens ................................ ................................ ..................... 182.1.4 Realce de Imagens ................................ ................................ ................................ .. 192.1.5 Segmentação de Imagens ................................ ................................ ........................ 23
2.2 Hardware Reconfigurável ................................ ................................ ............................... 242.2.1 VHDL (VHSIC Hardware Description Language) ................................ .................. 252.2.2 Série Cyclone de FPGAs ................................ ................................ ........................ 272.2.3 Arquitetura da Família Cyclone ................................ ................................ .............. 28
Capítulo 3 – Especificação do Projeto ................................ ................................ ....................... 343.1 Módulo de Software ................................ ................................ ................................ ....... 343.2 Módulo de Hardware ................................ ................................ ................................ ...... 36
3.2.1 Prococolo de Comunicação ................................ ................................ ..................... 373.2.2 Unidade de Controle ................................ ................................ ............................... 373.2.3 Operações de Processamento ................................ ................................ .................. 373.2.4 Memória Interna ................................ ................................ ................................ ..... 37
3.3 Operações e Algoritmos de Processamento de Imagens ................................ .................. 373.3.1 Processamento Espacial ................................ ................................ .......................... 37
Capítulo 4 – Projeto do Sistema................................ ................................ ................................ 394.1 Requisitos do Sistema ................................ ................................ ................................ .... 394.2 Módulo Software – Interface com o Usuário ................................ ................................ .. 39
4.2.1 Funcionalidades ................................ ................................ ................................ ...... 404.2.2 Projeto da Aplicação Cliente ................................ ................................ ................... 41
4.3 Módulo de Hardware ................................ ................................ ................................ ...... 464.3.1 Protocolo de Comunicação ................................ ................................ ..................... 484.3.2 Unidade de Controle ................................ ................................ ............................... 524.3.3 Controlador de Acesso à Memória ................................ ................................ .......... 534.3.4 Operação NOT ................................ ................................ ................................ ....... 554.3.5 Operação Limiarização ................................ ................................ ........................... 574.3.6 Operação Filtro de Convolução ................................ ................................ ............... 584.3.7 Operação Filtro de Mediana ................................ ................................ .................... 59
Capítulo 5 – Validação e Resultados ................................ ................................ ......................... 615.1 Operação NOT ................................ ................................ ................................ ............... 615.2 Operação de Limiarização ................................ ................................ .............................. 625.3 Operação Filtro Passa-Baixa ................................ ................................ .......................... 635.4 Operação Filtro Passa-Alta................................ ................................ ............................. 645.5 Operação Filtro Mediana ................................ ................................ ................................ 66
Capítulo 6 – Conclusão................................ ................................ ................................ ............. 68Capítulo 7 – Referências Bibliográficas ................................ ................................ .................... 69APÊNDICE A – CRONOGRAMA DO PROJETO ................................ ................................ .. 70

7
LISTA DE TABELAS
Tabela 1 – Recursos do Dispositivo (Adaptado de Cyclone Device Handbook) ........................ 27Tabela 3 – Sinais de Controle: Módulo de Comunicação ................................ .......................... 51Tabela 4 – Códigos de Operações ................................ ................................ ............................. 52Tabela 5 – Sinais de Controle: Unidade de Controle ................................ ................................ . 53Tabela 6 – Sinais de Controle: Controlador de Acesso à Memória ................................ ............ 54Tabela 7 – Sinais de Controle: Operação NOT ................................ ................................ .......... 56Tabela 8 – Sinais de Controle: Operação Limiarização ................................ ............................. 57Tabela 9 – Sinais de Controle: Operação Filtro de Convolução ................................ ................. 58Tabela 10 – Sinais de Controle: Operação Filtro de Mediana ................................ .................... 60Tabela 11 – Operação NOT: Matriz de pixels original ................................ .............................. 61Tabela 12 – Operação NOT: Matriz de pixels resultado via hardware ................................ ....... 61Tabela 13 – Operação NOT: Matriz de pixels resultado esperada ................................ .............. 61Tabela 14 – Operação Limiarização: Matriz de pixels original ................................ .................. 62Tabela 15 – Operação Limiarização: Matriz de pixels resultado via hardware ........................... 62Tabela 16 – Operação Limiarização: Matriz de resultado esperada ................................ ........... 63Tabela 17 – Filtro Passa-Baixa: Máscara de entrada ................................ ................................ . 63Tabela 18 – Filtro Passa-Baixa: Matriz de pixels original ................................ ......................... 64Tabela 19 – Filtro Passa-Baixa: Matriz de pixels resultado via hardware ................................ .. 64Tabela 20 – Filtro Passa-Baixa: Matriz de pixels resultado calculada ................................ ........ 64Tabela 21 – Filtro Passa-Alta: Máscara de entrada ................................ ................................ .... 65Tabela 22 – Filtro Passa-Alta: Matriz de pixels original ................................ ............................ 65Tabela 23 – Filtro Passa-Alta: Matriz de pixels resultado via hardware ................................ ..... 65Tabela 24 – Filtro Passa-Alta: Matriz de pixels calculada ................................ ......................... 65Tabela 25 – Filtro de Mediana: Matriz de pixels original ................................ .......................... 66Tabela 26 – Filtro de Mediana: Matriz de pixels resultado via hardware ................................ ... 66Tabela 27 – Filtro de Mediana: Matriz de pixels calculada ................................ ........................ 67

8
LISTA DE EQUAÇÕES
Equação 1 – Matriz de Pixels................................ ................................ ................................ .... 17Equação 2 – Armazenamento de Imagens Digit alizadas................................ ............................ 18Equação 3 – Vizinhança de 4 de um Ponto ................................ ................................ ............... 18Equação 4 – Vizinhança de 8 de um Ponto ................................ ................................ ............... 18Equação 5 – Tranformada de Fourier ................................ ................................ ........................ 19Equação 6 – Transformada Discreta de Fourier ................................ ................................ ......... 19Equação 7 – Transformada Espacial ................................ ................................ ......................... 20Equação 8 – Transformada de Freqüência ................................ ................................ ................. 20Equação 9 – Teorema da Convolução ................................ ................................ ....................... 38

9
LISTA DE SIGLAS
FPGA – Field Programmable Gate Array
DFT – Discrete Fourier Transform – Transformada Discreta de Fourier
FFT – Fast Fourier Transform – Transformada Rápida de Fourier
HDL – Hardware Description Language – Linguagem de Descrição de Hardware
VHDL – VHSIC Description Language – Linguagem de Descrição de Hardware VHSIC
PC – Personal Computer – Computador Pessoal
IOB – Input / Output Block – Blocos de Entrada e Saída
CLB – Configuration Logic Blocks – Blocos Lógicos Configuráveis
ASIC – Application-Specific Integrated Circuit – Circuito Integrado de Aplicação Específica
LAB – Logic Array Blocks – Arranjo de Blocos Lógicos
LE – Logic Elements – Elementos Lógicos
M4K RAM – Bloco de Memória RAM de uma FPGA Cyclone
IOE – Input Output Elements – Elementos de Entrada e Saída
PLL – Phase-Lock Loop – Alterador de Fase de um Sinal
LUT – Lookup Table – Tabela de Procura
E/S – Entrada / Saída
RAM – Random Access Memory – Memória de Acesso Aleatório
ROM – Read-Only Memory – Memória de Somente Leitura
FIFO – First In, First Out – Primeiro a Entrar, Primeiro a Sair
ACK – Acknowledge - Conhecimento
SR – Send Request – Solicita Envio
ROK – Receice OK – Envio Ok
EOF – End Of File – Final de Arquivo
EPP – Enhanced Parallel Port
BMP – Bitmap – Mapa de Bits
JPG – Joint Photographics Experts Group – Formato de Compressão de Imagens

10
LISTA DE FIGURAS
Figura 1 – Diagrama em Blocos do Sistema ................................ ................................ .............. 13Figura 2 – Aplicação do Filtro de Médias em uma imagem com ruído FONTE: GONZALEZ(1992)................................ ................................ ................................ ................................ ....... 14Figura 3 – Sistema Bartlane de Transmissão de Imagens FONTE: GONZALEZ (1992) ........... 15Figura 4 – Melhoramento do Contraste de uma Imagem FONTE: GONZALEZ (1992) ............ 16Figura 5 – Melhoramento do Contraste de uma Imagem FONT E: GONZALEZ (1992) ............ 16Figura 6 – Alargamento de Contraste FONTE: CASTLEMAN (1996) ................................ ...... 21Figura 7 – Imagem Original................................ ................................ ................................ ...... 22Figura 8 – Imagem após um Filtro Passa -Baixa ................................ ................................ ........ 22Figura 9 – Filtro Passa-Alta no Sentido Horizontal ................................ ................................ ... 22Figura 10 – Filtro Passa-Alta ................................ ................................ ................................ .... 22Figura 11 – Fluxo de Projetos em VHDL FONTE: D’AMORE (2005) ................................ ..... 25Figura 12 – Circuito Lógico Comparador. Saída O=1 para A=B e O=0 para A!=B ................... 25Figura 13 – Diagrama em Blocos da Família Cyclone FONTE: ALTERA (2007) ..................... 28Figura 14 – Estrutura dos LABs da Família Cyclone FONTE: ALTERA (2007) ....................... 29Figura 15 – Sinais de Controle dos LABs FONTE: ALTERA (2007) ................................ ....... 29Figura 16 – LE do Cyclone FONTE: ALTERA (2007) ................................ ............................. 30Figura 17 – LE em Modo Normal FONTE: ALTERA (2007) ................................ ................... 31Figura 18 – LE em Modo Aritmético Dinâmico FONTE: ALTERA (2007) .............................. 32Figura 19 – Conexões de Interconnect FONTE: ALTERA (2007) ................................ ............ 32Figura 20 – Sinais de Controle do Bloco M4K RAM FONTE: ALTERA (2007) ...................... 33Figura 21 – Relação de Linhas do LAB com blocos M4K RAM FONTE: ALTERA (2007) ..... 33Figura 22 – Diagrama em Blocos do Sistema ................................ ................................ ............ 34Figura 23 – Fluxograma de Operação de Software ................................ ................................ .... 35Figura 24 – Módulo de Hardware ................................ ................................ ............................. 36Figura 25 – Protótipo de Tela de Controle do Sistema ................................ .............................. 40Figura 26 – Arquitetura do Módulo de Hardware................................ ................................ ...... 47Figura 27 – Esquema de Funcionamento da Porta Paralela ................................ ....................... 48Figura 28 – Ciclo de Envio de um Byte ................................ ................................ .................... 49Figura 29 – Ciclo de Recebimento de um Byte ................................ ................................ ......... 49Figura 30 – Diagrama Esquemático: Módulo de Comunicação ................................ ................. 50Figura 31 – Diagrama Esquemático: Unidade de Controle ................................ ........................ 52Figura 32 – Diagrama Esquemático: Controlador de Acesso à Memória ................................ ... 54Figura 33 – Diagrama Esquemático: Operação NOT ................................ ................................ 56Figura 34 – Diagrama Esquemático: Operação Limiarização ................................ .................... 57Figura 35 – Diagrama Esquemático: Operação Filtro de Convolução ................................ ........ 58Figura 36 – Diagrama Esquemático: Operação Filtro de Mediana ................................ ............. 60Figura 37 – Imagem Original ................................ ................................ ................................ .... 62Figura 38 – Imagem Resultado ................................ ................................ ................................ . 62Figura 39 – Imagem Original ................................ ................................ ................................ .... 63Figura 40 – Imagem Resultado ................................ ................................ ................................ . 63Figura 41 – Imagem Original ................................ ................................ ................................ .... 64Figura 42 – Imagem Resultado ................................ ................................ ................................ . 64Figura 43 – Imagem Original ................................ ................................ ................................ .... 66Figura 44 – Imagem Resultado ................................ ................................ ................................ . 66Figura 45 – Imagem Original ................................ ................................ ................................ .... 67Figura 46 – Imagem Resultado ................................ ................................ ................................ . 67

11

12
CAPÍTULO 1– INTRODUÇÃO
Processamento de imagem é qualquer forma de processamento de dados no qual a entr ada
e a saída são imagens tais como fotografias ou quadros. A maioria das técnicas envolve o
tratamento da imagem como um sinal bidimensional, no qual são aplicados padrões de
processamento de sinal. O resultado deste processamento não precisa ser necessar iamente uma
imagem, mas pode ser uma instância de certas características desta imagem.
O interesse em métodos de processamento de imagens digitais decorre de duas áreas
principais de aplicação: melhoria de informação visual para a interpretação humana e o
processamento de dados de cenas para percepção automática através de máquinas [GONZALEZ,
1992].
Embora os computadores estejam cada vez mais velozes [TANENBAUM, 2001], o
processamento digital de imagens exige muito poder de processamento e hardware especializado
é bastante utilizado para este fim.
Este documento apresenta um sistema de processamento digital de imagens baseado em
hardware reconfigurável implementado em uma FPGA, que é um dispositivo semicondutor
largamente utilizado para o processamento de informações digitais e pode ser programado de
acordo com as aplicações do usuário (programador).
Para definir o comportamento da FPGA o usuário (programador) pode optar por fazer
utilizando uma linguagem de descrição de hardware (HDL), como VHDL, ou um desenho
esquemático. Então usando uma ferramenta de automação de desenho eletrônico esta lógica é
aplicada à arquitetura da FPGA.
O sistema proposto envolve um microcomputador PC (Personal Computer) para a leitura
e pré-processamento da imagem. Esta imagem é enviada através de uma interface paralela à
FPGA que aplicará operações, filtros e transformadas sobre ela, de acordo com o que o usuário
desejar.
Este documento foi redigido em seis seções distintas, considerando esta como seção
introdutória. Na segunda seção encontra-se uma revisão da literatura. Nela é apresentada a base
teórico-conceitual, oferecendo um panorama da tecnologia utilizada e uma visão geral dos
estudos nessa área. Na terceira seção é apresentada a especificação técnica de software e
hardware, objetivos de cada módulo do projeto e funcionamento de cada um deles. Na quarta
seção encontra-se o projeto de desenvolvimento do sistema, software rodando no PC e hardware
(módulo de comunicação e módulo de processamento na FPGA).

13
As demais seções detalham os resultados obtidos, mostrando o funcionamento de cada
módulo, como resultados obtidos nos testes de cada um e resultado do sistema completo em
funcionamento. Também são apresentadas as conclusões obtidas com o desenvolvimento deste
projeto, bem como as limitações e direcionamento para futuras implementações.
A Figura 1 apresenta o diagrama em blocos contendo o funcionamento básico do sistema
proposto.
Figura 1 – Diagrama em Blocos do Sistema

14
CAPÍTULO 2 – FUNDAMENTAÇÃO TEÓRICA
2.1 Processamento de Imagens
Processamento de imagem é qualquer forma de processamento de dados no qual a entrada
e a saída são imagens tais como fotografias ou quadros. Ao contrário do tratamento de imagens,
que se preocupa somente na manipulação de figuras par a sua representação final, o
processamento de imagens é um estágio para novos processamentos de dados tais como
aprendizagem de máquina ou reconhecimento de padrões. A maioria das técnicas envolve o
tratamento da imagem como um sinal bidimensional, no qual são aplicados padrões de
processamento de sinal. O resultado deste processamento não precisa ser necessariamente uma
imagem, mas pode ser uma instância de certas características desta imagem.
Processamento digital de imagens é a utilização de algoritmos c omputacionais para
aplicar processamento de imagens em imagens digitais. O processamento digital de imagens tem
as mesmas vantagens sobre o processamento analógico de imagens que o processamento digital
de sinais tem sobre o processamento analógico de sina is: possibilita uma gama muito mais ampla
de algoritmos que podem ser aplicados na entrada e pode -se evitar problemas como ampliação
de ruído e distorção do sinal durante o processamento. [GONZALEZ, 1992]
Figura 2 – Aplicação do Filtro de Médias em uma imagem com ruídoFONTE: GONZALEZ (1992)
2.1.1 Histórico
O interesse em métodos de processamento de imagens digitais decorre de duas áreas
principais de aplicação: melhoria de informação visual para a interpretação humana e o

15
processamento de dados de cenas para percepção automática através de máquinas. Uma das
primeiras aplicações de técnicas de processamento de imagens foi o melhoramento de imagens
digitalizadas para jornais, enviadas por meio de cabo submarino de Londres para New York no
início dos anos 20. Um equipamento especializado em impressão codificava as imagens para
transmissão a cabo, as quais eram então reconstruídas numa impressora telegráfica contendo
apenas caracteres para a simulação de padrões de tons intermediários. A Figura 3 apresenta o
resultado obtido.
Figura 3 – Sistema Bartlane de Transmissão de ImagensFONTE: GONZALEZ (1992)
Melhoramentos nos métodos de processamento para transmissão de figuras digitais
continuaram a ser feitos ao longo dos 35 anos que se seguiram. Entretanto, foi necessária a
combinação do surgimento de computadores digitais de grande porte com o programa espacial
para chamar a atenção ao potencial dos conceitos de processamento de imagem. O e mprego de
técnicas de computação para o melhoramento de imagens produzidas por uma sonda espacial
iniciou-se no Jet Propulsion Laboratory (Pasadena, California) em 1964, quando imagens da
Lua, transmitidas pelo Ranger 7, foram processadas por um computador para corrigir vários tipos
de distorção de imagem inerentes à câmera de televisão a bordo. Essas técnicas serviram de base
para métodos melhorados no realce e restauração de imagens das missões Surveyor para a Lua, a
série Mariner, de missões para Marte, os vôos tripulados da Apolo para a Lua e outros.
De 1964 até hoje a área de processamento de imagens vem crescendo vigorosamente.
Além de aplicações no programa espacial, técnicas de processamento digitais são atualmente
utilizadas para resolver uma variedade de problemas. Embora frequentemente não relacionados,
esses problemas comumente requerem métodos capazes de melhorar a informação visual para
análise e interpretação humanas. Em medicina, procedimentos computacionais melhoram o
contraste ou codificam os níveis de intensidade em cores, de modo a facilitar a interpretação de
imagens de raios X e outras imagens biomédicas. Geógrafos usam técnicas similares para estudar

16
padrões de poluição em imagens aéreas ou de satélites. Em arqueologia, métodos de
processamento de imagens têm restaurado com sucesso, figuras fotografadas borradas, que eram
os únicos registros disponíveis de artefatos raros perdidos ou danificados. Em Física e áreas
relacionadas, técnicas computacionais rotineiramente realçam imagens de exp erimentos em áreas
como plasmas de alta energia e microscopia eletrônica. [GONZALEZ, 1992]
Figura 4 – Melhoramento do Contraste de uma ImagemFONTE: GONZALEZ (1992)
A Figura 5 mostra uma imagem onde houveram problemas no processo de aquisição e
sua devida correção após a aplicação da Transformada rápida de Fourier.
Figura 5 – Melhoramento do Contraste de uma ImagemFONTE: GONZALEZ (1992)

17
2.1.2 Fundamentos de Imagens Digitais
2.1.2.1 Modelo Simples de uma Imagem
O termo imagem refere-se a uma função de intensidade luminosa bidimensional,
denotada por f(x,y), em que o valor ou amplitude de f nas coordenadas espaciais (x,y) dá a
intensidade (brilho) da imagem naquele ponto.
As imagens que as pessoas percebem em atividades visuais corriqueiras consistem de luz
refletida dos objetos. A natureza básica de f(x,y) pode ser caracterizada por dois componentes:
(1) a quantidade de luz incindindo na cena sendo observada e (2) a quantidade de luz refletida
pelos objetos da cena. [CASTLEMAN, 1996]
2.1.2.2 Amostragem e Quantização
Para ser adequada para processamento computacional, uma função f(x,y) precisa ser
digitalizada tanto espacialmente quanto em amplitude. A digitalização das coordenadas espaciais
(x,y) é denominada amostragem da imagem e a digitalização da amplitude é chamada
quantização em níveis de cinza.
Suponhamos que uma imagem contínua f(x,y) é aproximada por amostras igualmente
espaçadas, arranjadas na forma de uma matriz NxM como mostrado na Equação 1.
)1,1(...)1,1()0,1(
............
)1,1(...)1,1()0,1(
)1,0(...)1,0()0,0(
),(
MNfNfNf
Mfff
Mfff
yxf
Equação 1 – Matriz de Pixels
O lado direito da equação representa o que é normalmente chamado de imagem digital.
Cada elemento da matriz denomina -se um elemento de imagem, ou pixel. O processo de
digitalização de imagens envolve decisões a respeito dos valores para N, M e o número de níveis
de cinza permitidos para cada pixel. O número de bits (b) necessários para armazenar uma
imagem digitalizada é obtido pela Equação 2, onde m é o número de bits necessários para
representar os níveis de cinza. Por exemplo, uma imagem de 128x128 com 256 níveis de cinza,
requer 128x128x8 = 131072 bits para armazenamento.

18
B=NxMxm
Equação 2 – Armazenamento de Imagens Digitalizadas
2.1.2.3 Relacionamento entre Pixels
Um pixel p nas coordenadas (x,y) possui quatro vizinhos horizontais e verticais, cujas
coordenadas são dadas por:
(x+1,y),(x-1,y),(x,y+1),(x,y-1)
Equação 3 – Vizinhança de 4 de um Ponto
Esse conjunto de pixels, chamado vizinhança -de-4 de p, é representado por N4(p). Cada
pixel está a uma unidade de distância de (x,y), sendo que alguns dos vizinhos de p ficarão fora da
imagem digital se (x,y) estiver na borda da i magem. Os quatro vizinhos diagonais de p possuem
como coordenadas:
(x+1,y+1), (x+1,y-1), (x-1,y+1), (x-1,y-1)
Equação 4 – Vizinhança de 8 de um Ponto
E são denotados por ND(p). Esses pontos, juntos com a vizinhança -de-4, são chamados
de vizinhança-de-8 de p, representada por N8(p).
2.1.3 Transformadas de Imagens
2.1.3.1 Introdução à Transformada de Fourier
A Transformada de Fourier é uma transformada integral que expressa uma função em
termos de funções de base sinusoidal, como soma ou integr al de funções sinusoidais
multiplicadas por coeficientes (“amplitudes”). Existem diversas variações diretamente
relacionadas desta transformada, dependendo do tipo de função a transformar.
Nos campos relacionados com o processamento de sinal, a transformad a de Fourier é
tipicamente utilizada para decompor um sinal nas suas componentes em freqüências e suas
amplitudes. [SWOKOWSKI, 1995]
Seja f(x) uma função contínua de uma variável real x. A tranformada de Fourier de f(x) é
definida pela Equação 5:

19
dxuxjxfuF ]2exp[)()(
Equação 5 – Tranformada de Fourier
2.1.3.2 Transforma Discreta de Fourier (DFT)
Para uso em computadores, seja para aplicações científicas ou processamento digital de
sinais, é preciso ter valores xk discretos. Para isso existe a versão da transformada para funções
discretas.
1
0
]/2exp[)(1
)(N
x
NuxjxfN
uF
Equação 6 – Transformada Discreta de Fourier
2.1.3.3 Transformada Rápida de Fourier (FFT)
O número de multiplicações e adições co mplexas necessárias para implementar a
Transformada Discreta de Fourier é proporcional a N2. Isto é, para cada um dos N valores de u, a
expansão do somatório requer N multiplicações complexas de f(x) por e N -1 adições dos
resultados. Os termos de podem s er computados uma vez e armazenados numa tabela para todas
as aplicações subsequentes. Por essa razão, a multiplicação de u por x nestes termos não é
usualmente considerada uma parte direta da implementação.
O algoritmo mais comum de FFT é o Cooley -Tukey, que recursivamente divide a DFT de
tamanho N=N1N2 em muitas DFTs menores de tamanhos N1 e N2. O uso mais comum é dividir
a transformada em 2 pedaços de tamanho N/2 a cada passo. [GONZALEZ, 1992]
2.1.4 Realce de Imagens
O objetivo principal das técnicas de realc e é processar uma imagem, de modo que o
resultado seja mais apropriado para uma aplicação específica do que a imagem original. As
abordagens discutidas nesta seção dividem -se em duas grandes categorias: métodos no domínio
espacial e métodos no domínio da f requência. O domínio espacial refere -se ao próprio plano da
imagem, e as abordagens nesta categoria serão baseadas na manipulação direta dos pixels das
imagens. Técnicas de processamento no domínio da frequência são baseadas na modificação das
transformadas de Fourier da imagem. [CASTLEMAN, 1996]

20
2.1.4.1 Métodos no Domínio Espacial
O termo domínio espacial refere -se ao agregado de pixels que compõem uma imagem, e
métodos no domínio espacial são procedimentos que operam diretamente sobre estes pixels.
Funções de processamento de imagens no domínio espacial podem ser expresas como :
g(x,y) = T[f(x,y)]
Equação 7 – Transformada Espacial
A abordagem principal para definir uma vizinhança em torno de (x,y) consiste em usar
uma subimagem quadrada ou retangular, centrada em (x,y). O centro da subimagem é movido de
pixel a pixel, aplicando o operador para cada posição (x,y) para obter g naquela posição.
A forma mais simples de T envolve uma vizinhança de 1x1 em que g depende apenas do
valor de f em (x,y) e T torna-se uma função de transformação de níveis de cinza. Vizinhanças
maiores permitem uma variedade de funções de processamento que vão além do simples realce
de imagens.
Independente da aplicação específica, a abordagem geral é fazer os valores de f de uma
vizinhança pré-estabelecida de (x,y) determinar o valor de g em (x,y). Uma das principais
abordagens nessa formulação baseia -se no uso das denominadas máscaras. Basicamente uma
máscara é uma pequena matriz bidimensional, na qual os valores dos coeficientes determinam a
natureza do processo, tal como o aguçamento de imagens. Técnicas de realce baseadas nesse tipo
de abordagem frequentemente são denominadas processamento por máscara ou filtragem.
2.1.4.2 Métodos no Domínio da Freqüência
O fundamento das técnicas no domínio da frequência é o teorema da convolução. Seja
g(x,y) uma imagem formada pela convolução de uma imagem f(x,y) e um operador linear
invariante com a posição h(x,y), então do teorema da convolução a seguinte relação no domínio
da frequência é verificada:
G(u,v) = H(u,v) F(u,v)
Equação 8 – Transformada de Freqüência
em que G, H e F são as transformadas de Fourier de g, h e f respectivamente. Muitos
problemas de realce de imagens podem ser expressos na forma da equ ação acima.

21
2.1.4.3 Alargamento de Contraste
A idéia por trás do alargamento de contraste consiste no aumento da escala dinâmica dos
níveis de cinza na imagem sendo processada. A Figura 6 exemplifica o processo de alargamento
de constraste.
Figura 6 – Alargamento de ContrasteFONTE: CASTLEMAN (1996)
2.1.4.4 Filtragem Espacial
O uso de máscaras espaciais para processamento de imagens é usualmente chamado
filtragem espacial e as máscaras espaciais, chamadas filtros espa ciais.
Os filtros passa-baixas atenuam ou eliminam os componentes de alta frequência no
domínio de Fourier, enquanto deixam as frequências baixas inalteradas. Os componentes de alta -
frequência caracterizam bordas e outros detalhes finos de uma imagem, de f orma que o efeito
resultante da filtragem passa-baixas é o borramento da imagem.
Do mesmo modo, filtros passa -alta atenuam ou eliminam os componentes de baixa -
frequência. Como esses componentes são responsáveis pelas características que variam
lentamente em uma imagem, tais como o contraste total e a intensidade média, o efeito resultante
da filtragem-passa-altas é uma redução destas características, correspondendo a uma aparente
agudização das bordas e outros detalhes finos.
Um terceiro tipo de filtragem, denominado filtragem passa -banda, remove regiões
selecionadas de frequências entre altas e baixas frequências. Esses filtros são usados para
restauração de imagens e raramente são interessantes para realce de imagens.

22
Figura 7 – ImagemOriginal
Figura 8 – Imagem apósum Filtro Passa-Baixa
Figura 9 – Filtro Passa-Alta no Sentido
Horizontal
Figura 10 – Filtro Passa-Alta
FONTE: CASTLEMAN (1992)
Filtros de suavização são usados para borramento e redução de ruído. O borramento é
utilizado em pré-processamento, tais como remoção de pequenos detalhes de uma imagem antes
da extração de objetos, e conexão de pequenas descontinuidades em linhas e curvas. A re dução
de ruídos conseguida pelo borramento com filtro linear assim como por filtragem não -linear.
Existem também os filtros de aguçamento, cujo objetivo principal é enfatizar detalhes
finos numa imagem ou realçar detalhes que tenham sido borrados, em conse quência de erros ou
como efeito natural de um método particular de aquisição de imagens. Os usos de aguçamento de
imagens são variados, incluindo aplicações desde impressão eletrônica e imagens médicas até
inspeção industrial e detecção automática de alvos em armas inteligentes.
2.1.4.5 Filtragem no Domínio da Freqüência
O realce no domínio da frequência é imediato, simplesmente computamos a transformada
de Fourier da imagem a ser realçada, multiplicamos o resultado por uma função de filtro de
transferência e tomamos a transformada inversa para produzir a imagem realçada.
As idéias de borramento, através da redução do conteúdo de alta frequência ou do
aguçamento através do aumento da magnitude dos componentes de alta -frequência relativamente
aos componentes de baixa-frequência, originam-se dos conceitos diretamente relacionados à
transformada de Fourier.
Na prática, pequenas máscaras espaciais são mais frequentementes usadas do que a
transformada de Fourier, por causa da sua simplicidade de implementação e velocidad e.
Entretanto, uma compreensão dos conceitos do domínio da frequência é essencial para a solução
de muitos problemas que não são facilmente tratáveis por técnicas espaciais.

23
2.1.5 Segmentação de Imagens
Geralmente, o primeiro passo em análise de imagens é a seg mentação da imagem. A
segmentação subdivide uma imagem em suas partes ou objetos constituintes. O nível até o qual
essa subdivisão deve ser realizada depende do problema sendo resolvido. Ou seja, a segmentação
deve parar quando os objetos de interesse na a plicação tiverem sido isolados.
Os algoritmos de segmentação para imagens monocromáticas são geralmente baseados
em uma das seguintes propriedades básicas de valores de níveis de cinza: descontinuidade e
similaridade. Na primeira categoria, a abordagem é p articionar a imagem baseado em mudanças
bruscas nos níveis de cinza. As principais áreas de interesse nessa categoria são a detecção de
pontos isolados e detecção de linhas e bordas na imagem. As principais abordagens da segunda
categoria baseiam-se em limiarização, crescimento de regiões e divisão e fusão de regiões.
2.1.5.1 Detecção de Bordas
Uma borda é o limite entre duas regiões com propriedades relativamente distintas de
nível de cinza. O objetivo da detecção de bordas é marcar os pontos onde a intensidade l uminosa
muda bruscamente. Essas mudanças bruscas geralmente refletem eventos importantes e
mudanças nas propriedades da cena.
A detecção de borda reduz drasticamente a quantidade de informação e filtra o que é
menos relevante em uma imagem, preservando sua s propriedades estruturais. Existem diversos
métodos para detecção de borda, porém podem ser agrupados em duas categorias: baseadaem
busca e baseada em cruzamento de zeros. Os métodos de busca funcionam procurando pelos
máximos e mínimos na derivada primei ra de uma imagem, enquanto os métodos de cruzamento
de zeros procuram por cruzamentos de zeros na derivada segunda da imagem.
2.1.5.2 Limiarização
Limiarização é uma das mais importantes abordagens para a segmentação de imagens.
Supondo uma imagem composta por ob jetos iluminados sobre um fundo escro, de maneira que
os pixels do objeto e os do fundo tenham seus níveis de cinza agrupados em dois grupos
dominantes, uma maneira óbvio de extrair os objetos do fundo é através da seleção de um limar
T que separe os dois grupos. Então, cada ponto (x,y) tal que f(x,y) > T é denominado um ponto
do objeto, caso contrário é denominado um ponto do fundo.

24
2.2 Hardware Reconfigurável
Uma FPGA é um dispositivo semicondutor que é largamente utilizado para o
processamento de informações digitais. Foi criador pela Xilinx Inc. e teve o seu lançamento no
ano de 1985 como um dispositivo que poderia ser programado de acordo com as aplicações do
usuário (programador) [WIKIPEDIA, 2007]. O FPGA é composto basicamente por três tipos de
componentes: blocos de entrada e saída (IOB), blocos lógicos configuráveis (CLB) e chaves de
interconexão (Switch Matrix). Os blocos lógicos são dispostos de forma bidimensional, as chaves
de interconexão são dispostas em formas de trilhas verticais e horizontais e ntre as linhas e as
colunas dos blocos lógicos.
CLB (Configuration Logic Blocks ): Circuitos idênticos, construídos pela reunião
de 2 a 4 flip-flops e utilizando lógica combinacional. Utilizando os CLBs, um
usuário pode construir elementos funcionais lógico s.
IOB (Input/Output Block): São circuitos responsáveis pelo interfaceamento das
saídas provenientes das saídas das combinações de CLBs. São basicamente
buffers, que funcionarão como um pino bidirecional de entrada e saída do FPGA.
Switch Matrix (Chaves de interconexões): Trilhas utilizadas para conectar os
CLBs e IOBs. O terceiro grupo é composto pelas interconexões. Os recursos de
interconexões possuem trilhas para conectar as entradas e saídas dos CLBs e IOBs
para as redes apropriadas. Geralmente, a conf iguração é estabelecida por
programação interna das células de memória estática, que determinam funções
lógicas e conexões internas implementadas no FPGA entre os CLBs e os IOBs. O
processo de escolha das interconexões é chamado de roteamento.
O FPGA é um chip que suporta a implementação de circuitos lógicos relativamente
grandes. Consiste de um grande arranjo de células ou blocos lógicos configuráveis contidos em
um único circuito integrado. Cada célula contém capacidade computacional para implementar
funções lógicas e realizar roteamento para comunicação entre elas.
Para definir o comportamento da FPGA o usuário pode optar por fazer utilizando uma
linguagem de descrição de hardware (HDL), como VHDL, ou um desenho esquemático. Então
usando uma ferramenta de automação de desenho eletrônico esta lógico é aplicada à arquitetura
da FPGA.

25
2.2.1 VHDL (VHSIC Hardware Description Language)
A VHDL foi originalmente desenvolvida sob o comando do Departamento de Defesa dos
Estados Unidos, em meados da década de 80, para doc umentar o comportamento de ASICs que
compunham os equipamentos vendidos às Formas Armadas americanas [YALAMANCHILI,
1998].
A VHDL, bem como outras linguagens, seguem um fluxo de projeto bem definido,
composto de sete etapas, como apresenta a Figura 11: Especificação de Requisitos,
Modelamento, Síntese de Alto Nível, Mapeamento Tecnológico, Implementação e ou
Fabricação, Testes e Simulação. O tempo e o custo de cada etapa dentro de um projeto é bastante
variável, dependo da tecnologia utilizada para implementar o sistema. [D'AMORE, 2005]
Figura 11 – Fluxo de Projetos em VHDLFONTE: D’AMORE (2005)
Projetos em VHDL possuem duas seções principais: ENTITY, que define as portas de
entrada e saída e ARCHITETURE, que define o funcionamento do projeto. Uma architecture
pode ser desenvolvida em três modos: fluxo de dados, funcional e estrutural. A Figura 12 mostra
o circuito lógico de um comparador, e abaixo uma descrição dos três modos de linguagem com
um exemplo para implementar o comparador.
Figura 12 – Circuito Lógico Comparador. Saída O=1 para A=B e O=0 para A!=B

26
Declaração da entity para o comparador, à qual pode -se utilizar qualquer uma das
architectures apresentadas a seguir:
Library ieee;
Use ieee.std_logic_1164.all;
Entity comparador is port (
A, B: in std_logic_vector (1 downto 0);
O: out std_logic;
);
end comparador;
A declaração entity do comparador define A e B como entradas de dois bits e O com o
saída de um bit. As duas primeiras linhas definem a biblioteca necessária para o tipo de dados
das entradas e saídas: std_logic e std_logic_vector. A funcionalidade do comparador pode ser
implementada em qualquer um dos três modos, descritos a seguir:
Fluxo de dados: Define as relações entre as entradas e saídas. As instruções não
são executadas de forma seqüencial como em linguagens de programação de
software. Cada saída tem seu valor alterado após um evento (mudança de valor)
em um sinal de entrada da qual seja dependente (ou sensistivo).
architecture fluxo_de_dados of comparador is
begin
0 <= ‘1’ when (A=B) else ‘0’;end fluxo_de_dados;
Funcional: Nesse modo, é feita a descrição da funcionalidade da entity por meio
de uma representação algorítmica, seme lhante a uma linguagem de programação
de software. A descrição funcional é definida por uma instrução process, que
possui uma lista das entradas pelas quais o process é sensistivo, ou seja, as
entradas que iniciam a execução após uma mudança no seu valor ( evento).
architecture funcional of comparador is
begin
process (A,B)
begin
if A=B then
C <= ‘1’;else
C <= ‘0’;

27
end if;
end process;
end funcional;
Estrutural: Nesse modo, o projeto é implementado pela declaração das portas
lógicas e componentes do projeto , e as suas interligações. A declaração dos
componentes está na linha use work.comportas.all e indica que xnor2 e and2
estão no mesmo local do projeto. Por meio da declaração signal definem-se as
ligações entre os componentes.
use work.comportas.all;
archicterure estrutural of com is
signal x: std_logic_vector (0 to 1);
begin
U0: xnor2 port map (a(0), b(0), x(0);
U1: xnor2 port map (a(1), b(1), x(1));
U2: and2 port map (x(0), x(1), x);
end estrutural;
2.2.2 Série Cyclone de FPGAs
A FPGA utilizada neste projeto é EP1C20F400C7 da família Cyclone, os dispositivos
desta família contém uma arquitetura bidimensional de linhas e colunas. Esta arquiterura é
composta por LABs (Logic Array Blocks), onde cada LAB contém 10 LEs (Logic Elements). As
linhas e colunas são inte rconectadas com velocidades que variam provendo interconexão
eficiente entre LABs e LEs.
Na Tabela 1, os blocos de memórias M4K RAM são agrupados nas colunas entre os
LAB’s. Na parte externa é possível ver os IOEs (elementos de en trada / saída) da FPGA, que
suportam diferentes padrões de E/S (entrada/saída). O número de blocos M4K RAM, PLLs,
linhas e colunas variam para cada dispositivo da família.
Tabela 1 – Recursos do Dispositivo (Adaptado de Cyclone De vice Handbook)
Device Columns Blocks PLLs LABColumns
LAB Rows
EP1C3 1 13 1 24 13EP1C4 1 17 2 26 17EP1C6 1 20 2 32 20EP1C12 2 52 2 48 26EP1C20 2 64 2 64 32

28
Figura 13 – Diagrama em Blocos da Família CycloneFONTE: ALTERA (2007)
2.2.3 Arquitetura da Família Cyclone
Cada LAB consiste em agrupamentos de 10 LEs, sinais de controle dos LABs,
interconexões locais, uma tabela de LUT ( Lookup Table), possuem interconexões por linhas e
colunas, apresentado na Figura 14.
As conexões locais de link direto ( Direct Link Connection) minimizam o uso das linhas e
colunas, provendo maior performance e flexibilidade. Existe uma ligação direta de cada LE que
o conecta a outros 30 LEs através de uma conexão de link direto.
Cada LAB possui uma lógica para dirigir sinais de controle a seus L Es. Os LABs contém
os seguintes sinais de controle: dois clocks, dois sinais de habilitação de clock, dois
asynchronous clears, synchronous clear, asynchronous preset/load, synchronous lo ad e sinais de
controle de soma/subtração, mostrados na Figura 15.

29
Figura 14 – Estrutura dos LABs da Família CycloneFONTE: ALTERA (2007)
Figura 15 – Sinais de Controle dos LABsFONTE: ALTERA (2007)
O LE é a menor unidade da lógica na arquitetura do Cyclone. O LE é compacto e fornece
características avançadas para utilização eficiente da lógica. Cada LE contém uma LUT de
quatro entradas, para que possa executar qualquer funçã o de quatro variáveis. Além disso, cada
LE contém um registrador programável e carry (selecionado). [ALTERA, 2007]
O LE possui os seguintes tipos de interconexão: local, linha, coluna, registrador
programável e link direto. Duas saídas da LE são direcionad as para roteamento de coluna ou

30
linha, uma para link direto e uma para interconexão local. Isso permite que a LUT e o registrador
programável trabalhem paralelamente.
Essas características são chamadas de Register Packing, que melhoram a utilização do
dispositivo, pois este dispositivo pode utilizar a LUT e o registrador em funções não
relacionadas. A estrutura do LE do Cyclone é apresentada na Figura 16.
Figura 16 – LE do CycloneFONTE: ALTERA (2007)
Os LES possuem uma característica de somador/subtrator dinâmico, que livra recursos
lógicos de usar um conjunto de LES para implementar ambas as operações. Essa característica é
controlada pelo sinal de controle addnsub, que coloca o LAB para realizar tanto A+B quando A-
B.
O dispositivo Cyclone possui dois modos de operação dos L ES: modo normal e modo
aritmético dinâmico. Cada modo usa os recursos do LE diferentemente.
Em cada modo, oito entradas são disponíveis para a LE (quatro dados de entrada da
interconexão local da LAB, carry-in0 e carry-in1 da LE anterior, o carry-in do LAB e a conexão
da cadeia de registradores), que são direcionadas para diferentes destinos para implementar a
função lógica desejada.

31
O modo normal é apropriado para aplicações de lógic a gerais e funções combinatórias. O
sinal addnsub só é permitido no modo normal se o LE está no final de uma cadeia de
somador/subtrator. Este modo é apresentado na Figura 17.
O modo aritmético dinâmico é ideal para implementar so madores, contadores,
acumuladores, funções de paridade e comparadores.
Um LE no modo aritmético usa quatro LUTs de duas entradas configuradas como um
somador ou subtrator dinâmico. O modo aritmético dinâmico é apresentado na Figura 18.
Figura 17 – LE em Modo NormalFONTE: ALTERA (2007)
Na arquitetura Cyclone, os LEs, blocos de memória M4K e dispositivos de E/S são
providos por uma estrutura de interconexão Multitrack. A interconexão Multitrack consiste de
linhas contínuas roteadoras e de performance otimizada de diferentes velocidades usadas para
realizar conexões inter e intra blocos. Simplifica o estágio de integração de projetos baseados em
blocos, eliminando os ciclos de re -otimização que geralmente geram mudanças de projeto.
Consiste de interconexões de linha e coluna com distâncias ficas. Linhas dedicadas
interconectam sinais roteados de e para LABs, PLLs, blocos de memória M4K dentro de uma
mesma linha. Essas linhas incluem (1) interconexões de lin ks diretos entre LABs e blocos
adjacentes e (2) R4 Interconnect (Row4) que liga quatro blocos ( Figura 19).
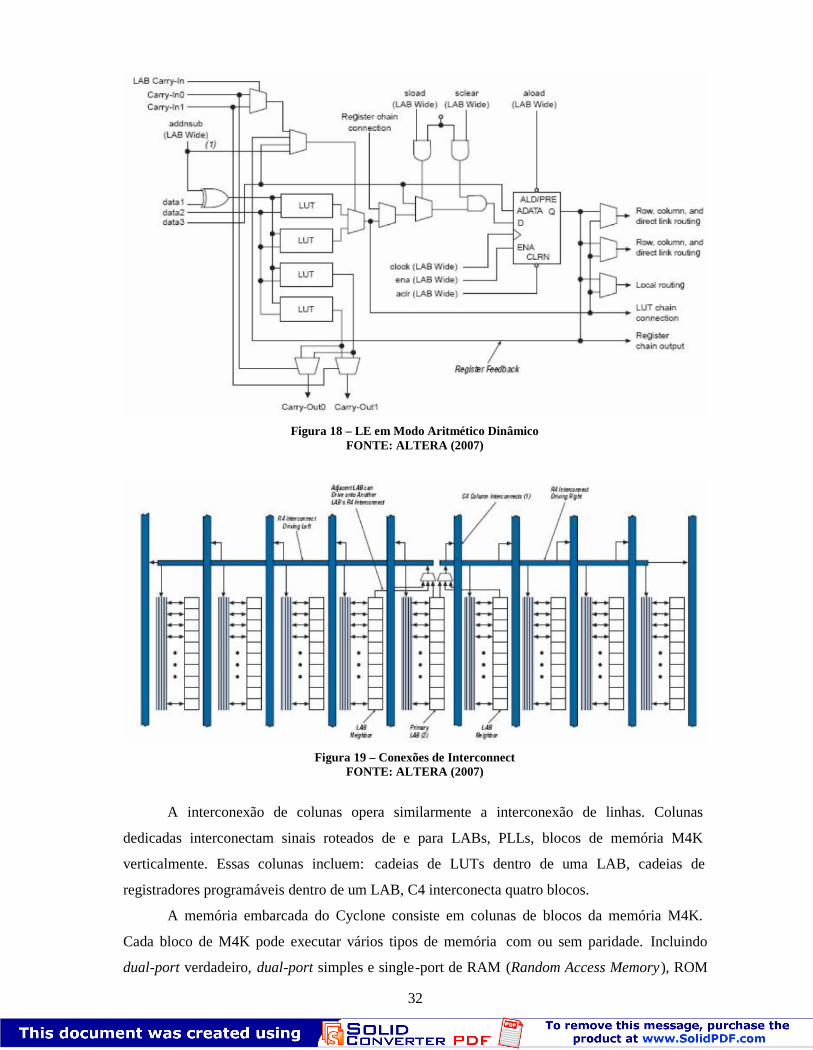
32
Figura 18 – LE em Modo Aritmético DinâmicoFONTE: ALTERA (2007)
Figura 19 – Conexões de InterconnectFONTE: ALTERA (2007)
A interconexão de colunas opera similarmente a interconexão de linhas. Colunas
dedicadas interconectam sinais roteados de e para LABs, PLLs, blocos de memória M4K
verticalmente. Essas colunas incluem: cadeias de LUTs dentro de uma LAB, cadeias de
registradores programáveis dentro de um LAB, C4 interconecta quatro blocos.
A memória embarcada do Cyclone consiste em colunas de blocos da memória M4K.
Cada bloco de M4K pode executar vários tipos de memória com ou sem paridade. Incluindo
dual-port verdadeiro, dual-port simples e single-port de RAM (Random Access Memory), ROM

33
(Read-Only Memory) e FIFO (First In First Out). A Figura 20 apresenta os sinais de controle dos
blocos de memória e a Figura 21 mostra a relação entre linhas dos LABs com os blocos de
memória do M4K.
Figura 20 – Sinais de Controle do Bloco M4K RAMFONTE: ALTERA (2007)
Figura 21 – Relação de Linhas do LAB com blocos M4K RAMFONTE: ALTERA (2007)

34
CAPÍTULO 3 – ESPECIFICAÇÃO DO PROJETO
Este capítulo tem por objetivo descrever os principais componentes e funcionalidades do
hardware e do software que compõem o sistema. A seguir na Figura 22 – Diagrama em Blocos
do Sistema, segue a visão geral e a descrição funcional de cada módulo do sistema.
Figura 22 – Diagrama em Blocos do Sistema
O sistema apresentado consiste em um hardware dedicado ao processamento de imagens
digitais, que acoplado ao um computador PC, poderá efetuar diversas operações e aplicar alguns
filtros sobre imagens.
Há um software que é executado no PC e que faz a pré-leitura destas imagens,
fornecendo ao usuário uma lista com as operações disponíveis. Este software também faz a
comunicação paralela com o hardware, enviando a imagem selecionada e a operação desejada.
O módulo de hardware é composto de uma FPGA, que executa todo o processamento da
imagem e uma memória interna onde são armazenados temporariamente as imagens e os
resultados das operações.
3.1 Módulo de Software
Foi desenvolvido um software em linguagem Java, que rodará em plataforma Windows e
necessariamente terá as seguintes funcionalidades:

35
Função para o usuário selecionar a imagem a ser tratada
Exibição da imagem selecionada, antes do processamento
Área para usuário selecionar quais operações deseja aplicar à imagem
Função para envio da imagem ao módulo de hardware
Exibição da imagem após o processamento
Função para salvar a imagem tratada ou aplicação de novas operações
A Figura 23 – Fluxograma de Operação de Software apresenta o fluxograma de utilização
do software de controle.
Figura 23 – Fluxograma de Operação de Software

36
3.2 Módulo de Hardware
O coração do sistema é a FPGA, que funciona como uma unidade de processamento
gráfico. Todas as operações são realizadas através dela, que por sua vez será dividida em 4
módulos:
Protocolo de Comunicação
Unidade de Controle
Memória Interna
Operações de Processamento
Figura 24 – Módulo de Hardware

37
3.2.1 Prococolo de Comunicação
Foi desenvolvido um protocolo para comunicação com o computador PC e o software já
citado no item 3.1. A ligação física entre os co mponentes se dará através de um cabo de 1 4
pinos, sendo 6 pinos para controle de controle de conexão e 8 pinos para transmissão de dados .
3.2.2 Unidade de Controle
Um módulo dedicado ao controle do bloco de operações, passando os parâmetros
necessários a cada uma das operações. Após o processamento ser concluído, envia um sinal
indicando ao módulo de comunicação que a imagem está pronta a ser transferida de volta.
3.2.3 Operações de Processamento
Neste módulo, foram implementados os seguintes algoritmos de processame nto de
imagens:
Operação Lógica NOT.
Limiarização.
Filtro de Convolução.
Filtro de Mediana.
3.2.4 Memória Interna
O sistema trabalha com a memória interna da FPGA . No caso do chip Cyclone II, são
aproximadamente 7 Kilobytes de memória RAM. Como as imagens serã o transferidas sem
compactação, teremos que seguir a limitação de imagens de no máximo 72x72 pixels.
3.3 Operações e Algoritmos de Processamento de Imagens
Neste tópico serão apresentados os algoritmos de processamento de imagens disponíveis
no módulo de hardware.
3.3.1 Processamento Espacial
A Binarização é uma operação simples que exige um parâmetro Limiar, e é aplicada
ponto a ponto em todos os pixels da imagem. Qualquer ponto cujo valor esteja acima deste limiar

38
é passado ao valor máximo 255 e qualquer ponto c ujo valor esteja abaixo deste limiar é passado
ao valor mínimo 0. O resultado é uma imagem preto e branco com as regiões branca e preta,
sendo formadas de acordo com o limiar informado.
A Aplicação de Máscara é o resultado prático do Teorema da Convolução. Recebe
como parâmetro uma Máscara, que é uma matriz de tamanho n x n que é aplicada ponto a ponto
na imagem. O valor de cada pixel é calculado pela convolução dos pixels ao seu redor: Digamos
que a máscara desejada seja a apresentada a seguir:
w1 w2 w3w4 w5 w6w7 w8 w9
De acordo com o teorema da convolução, o valor do pixel seria dado por:
R= w1*z1 + w2*z2 + w3*z3 + ... + w9*z9 onde zn é o valor atual do pixel.
Equação 9 – Teorema da Convolução
O Filtro Passa-Baixa é um filtro de suavização que exige como Máscara de entrada,
uma matriz onde todos os valores sejam positivos. O valor de cada pixel é calculado em função
da média de seus vizinhos.
O Filtro por Mediana também é um filtro de suavização. O valor de cada pixel é
substituído pela mediana de seus vizinhos, ordenados primeiramente de maneira crescente ou
decrescente. Não há parâmetros para esta operação.
O Filtro Passa-Alta também é uma operação que recebe uma Máscara como parâmetro
e esta máscara é aplicada a todos o s pixels da imagem. A diferença desta operação é que a
máscara fornecida deve conter o valor w5 positivo e todos os outros como negativos, resultando
em um aguçamento das bordas, sobre um fundo bastante escuro.

39
CAPÍTULO 4 – PROJETO DO SISTEMA
Neste capítulo será apresentada uma descrição detalhada de todos com componentes que
compõem o sistema, assim como a maneira como estes componentes interagem entre si para o
funcionamento adequado do sistema.
O sistema é composto por um módulo de software rodando em um PC, que controla um
módulo de hardware que executa o processamento de imagens. A comunicação entre estes dois
módulos é feita através da porta paralela do microcomputador.
É através do módulo de software que o usuário seleciona a imagem desejada, escolhe a
operação a ser aplicada na imagem e após o processamento, é dada a opção para salvar a imagem
resultante.
4.1 Requisitos do Sistema
O sistema requer um computador PC, rodando sistema operacional Microsoft Windows
XP, dotado de uma porta paralela funcionando no mod o EPP. Também é necessário que esteja
instalado a Java Virtual Machine v1.6.
4.2 Módulo Software – Interface com o Usuário
A Figura 25 – Protótipo de Tela de Controle do Sistema é a tela principal do sistema.
Nela é possível visualizar os elementos que fazem todo o controle do hardware.

40
Figura 25 – Protótipo de Tela de Controle do Sistema
4.2.1 Funcionalidades
Carregar Imagem: Usuário é capaz carregar de alguma de suas unidades de
armazenamento, uma imagem nos f ormatos BMP ou JPG que será o alvo das operações
desejadas. A imagem escolhida é convertida para 255 níveis de cinza.
Escolher Operação: As operações que o sistema é capaz de executar são divididas entre
básicas pixel a pixel e os filtros espaciais. Estas operações serão descritas mais
detalhadamente em tópicos futuros, porém é através do módulo de software que o usuário
escolhe a função que será aplicada à imagem.
Definir Parâmetros: Cada operação possui parâmetro específicos que influenciam
diretamente no resultado final da imagem. Após selecionar a operação, é dada a opção ao
usuário de fazer esta parametrização.
Processar: Ao executar esta função o usuário confirma as opções selecionadas
anteriormente e envia a imagem ao módulo de hardware, juntamente co m os parâmetros
necessário ao processamento. Após a finalização do processamento, é retornada a
imagem resultada para exibição na tela.

41
Salvar Imagem: Uma vez a imagem resultante esteja na tela, é através desta opção o
usuário pode salvar esta imagem em di sco para uso futuro.
Salvar Log: O sistema grava um log com todas as ações efetuadas pelo usuário. Através
desta opção o usuário pode salvar este log em diso para posterior análise.
4.2.2 Projeto da Aplicação Cliente
Como já citado anteriormente, a aplicação cl iente foi desenvolvida em linguagem Java e
alguns conceitos de engenharia de software foram diretamente aplicados. A aplicação foi
desenvolvida inteiramente orientada a objetos, com utilização da arquitetura em camadas, o que
facilitaria a manutenção e substituição de qualquer componente no futuro.
O projeto de software foi dividido em três pacotes:
br.com.engcomputacao.dip.Imaging: Contendo as classes para manipulação,
leitura e persistência das imagens
br.com.engcomputacao.dip.Interface: Contendo as class es para a interação com o
usuário e controle dos demais módulos.
br.com.engcomputacao.dip.Transfer: Contendo as classes para comunicação com
o módulo de hardware.
jnpout32: Contendo as classes que abstraem o acesso ao hardware e fornecem
métodos para escrita e leitura das portas de comunicação do computador.
4.2.2.1 Diagrama de Classes
Image.java: Classe utilizada para manipular imagens.Atributos:bitmap Matriz de pixels da imagem.img Abstrai a imagem a ser manipulada.
Métodos:Image Construtor da classe, reponsável por ler a
imagem do disco.@param filename
printMatrix Imprime a matriz de pixels da imagemcarregada.
saveImage Salva a imagem carregada.@param filename: Nome do arquivo a sersalvo.@param formato: Formato da imagem: JPEG,BMP, GIF, PNG
saveMatrix Salva a matriz de pixels da imagemcarregada em um arquivo: matriz.txt
toGrayscale Converte uma imagem colorida para niveisde cinza.

42
A cada pixel é atribuído um valor de 0 a255.
ImageOperations.java: Classe que define as constantes de cada operação. A FPGA conhece cadaconstante definida aqui e seus valores não podem mudar.
Atributos:Cada atributo é uma constante acessada demaneira estática pelas outras classes .
DipTransferController.java: Classe controladora da transferência PC FPGA.Atributos:imageFile Imagem a ser transferidaLPT1 Abstração da porta paralela.stateMachine Máquina de estados que controla a
transferência
Métodos:DIPTransferController
Construtor da classe, reponsávelpor instanciar os atributosprivados.
jumpAddress Método para pular posicões dememoria e incrementar ponteiro daFPGA. Apenas é simulado orecebimento de um byte.@param num: Numero de posicoes aser pulado
receiveByte Método para receber um byte daFPGA.@return byte recebido
receiveHeaders Método de recebimento doscabeçalhos da imagem e parametros .
receiveImage Método para receber uma imagemapós processamento na FPGA.
sendByte Método para enviar um byte do PCp/ FPGA.@param value: byte a ser enviado
sendHeaders Método de envio dos cabeçalhos daimagem e parametros.
sendImage Método para enviar uma imagem paraprocessamento na FPGA.@param filename: arquivo a serenviado à FPGA
waitProcessing Aguarda resposta da FPGA.

43
EPPControl.java: Classe utilizada para controlar o funcion amento da porta paralela no modoEPP.
Atributos:controlAddress Endereço dos pinos de controle da portadataAddress Endereço dos pinos de dados da porta .portValue Valor atual da porta.pp Abstração de uma porta de comunicação.statusAddress Endereço dos pinos de status da porta.
Métodos:EPPControl Construtor da classe, responsável por
instanciar os atributos privados.pinInterrupt Recupera o valor atual do pino de
interrupção da porta.@return 1 ou 0
pinWait Valor atual do pino de espera da port a.@return 1 ou 0
read Método para ler da porta paralela.@param address: endereço a qual o dadoserá enviado@return value: valor atual do endereço
readControl Método para ler o valor dos pinos decontrole.@return value: valor atual dos pinos
readData Método para ler o valor dos pinos dedados.@return value: valor atual dos pinos
readStatus Método para ler o valor dos pinos destatus.@return value: valor atual dos pinos
write Método para escrever na porta paralela.@param value: valor a ser enviado
writeControl Método para escrever nos pinos decontrole.@param value: valor a ser enviado
writeData Método para escrever nos pinos dedados.@param value: valor a ser enviado
writeStatus Método para escrever nos pinos destatus.@param value: valor a ser enviado

44
TransferMachine.java: Classe utilizada para definir o comportamento da máquina de estadosprojetada para controlar a transferência de dados entre o PC e a FPGA .
Atributos:estadoAtual Estado em que a máquina se encontra
no instante atual.mode Define a direção da transferência,
envio ou recebimento.BEGIN_PROCESSING
Constante que informa à FPGA que atransferência foi concluída e oprocessamento pode ser iniciado.
RECV_* Constantes que definem o valor de umestado de recebimento. A FPGA possuios mesmos valores para controle damáquina interna.
RESET Estado inicial da máquina, reiniciatodos os processos.
SEND_* Constantes que definem o valor de umestado de envio. A FPGA possui osmesmos valores para controle damáquina interna.
Métodos:beginProcessing Seta o estado atual da máquina com a
constante BEGIN_PROCESSING.nextStep Seta o estado atual da máquina com a
próxima constante do processo.resetTransfer Seta o estado atual da máquina com a
constante RESET.setMode Seta a direção de transferência,
envio ou recebimento.

45
Aplicacao.java: Classe principal, responsável pelo gerenciamento do hardware e interação com ousuário.
Atributos:dip Controlador da Tranferência.
Métodos:Aplicação Construtor da classe,
responsável por instanciar osatributos privados.
addLog Adiciona o último evento najanela de log.@param line: linha a seradicionada
clickCarregarImagem
Abre uma janela para escolha daimagem a ser processada.
clickClearLog
Limpa a janela de log.
clickDefinirParametros
Abre janela para entrada dosparâmetros da operaçãoselecionada.
clickProcessar
Faz as verificações necessáriase inicia o processo deenvio/recebimento da imagem.
clickSalvarImagem
Abre uma janela para gravaçãoda imagem processada.
clickSaveLog
Abre uma janela para gravaçãodo arquivo de log.
displayImageOnPanel
Atualiza a imagem no painel devisualização.
getIntegerValue Abre uma janela para entrada deum valor inteiro.@return value: valor de 0 a255.
getMatrix3x3 Abre uma janela para entrada deuma matriz 3x3.@return value[9]: matriz 3x3 deinteiros
getOperationValue Retorna o valor da operaçãoselecionada na tela.@return opcode: constante daoperação selecionada
getParams Retorna os parâmetros daoperação.@return Object: parâmetro daoperação
hardwareProcessing Efetua o processo deenvio/processamento/recebimentoda imagem.
imageLoaded Retorna se existe uma imagemcarregada no painel devisualização.@return true ou false
main Método inicial do aplicativo,mostra a tela principal.
showConfirmBox Exibe uma janela deconfirmação.
showErrorBox Exibe uma janela de erro.showInfoBox Exibe uma janela de informação.

46
4.2.2.2 Características da Aplicação
Ao se iniciar a aplicação, é exibida a tela ao usuário, mostrada na Figura 25 – Protótipo
de Tela de Controle do Sistema . Uma vez selecionada a imagem desejada o sistema executa um
processo de converter esta imagem para uma matriz de pixels. Esta matriz é que será enviada à
FPGA, juntamente com as dimensões da imagem e parâmetros de operação.
Cada vez que a imagem é atualizada, tanto na abertura de uma nova imagem quanto no
recebimento do resultado do processamento, a matriz de pixels também é atualizada. Esta matriz
é salva em um arquivo ‘matriz.txt’ que pod e ser utilizado para validação dos resultados e
conferência do valor de cada pixel.
A aplicação oferece ao usuário a possibilidade de escolher entre duas operações básicas
de processamento de imagens: Operação lógica NOT e Binarização. Além da possibilidad e de
aplicar Filtros de Convolução: Passa -Alta e Passa-Baixa e também um Filtro de Mediana.
Outras opções estão desabilitadas na interface pois durante a implementação do projeto
tais operações se mostraram inviáveis de serem desenvolvidas principalmente d evido à sua
complexidade, são elas as operações de domínio da frequência.
4.3 Módulo de Hardware
Para implementação deste módulo foi escolhida uma FPGA Altera da família Cyclone. O
principal motivo para escolha deste chip foi a disponibilidade de kits de dese nvolvimento nos
laboratórios do Unicenp, assim como também ferramentas eficientes para o projeto.
Como estamos trabalhando com imagens a principal limitação na escolha deste hardware
foi a pequena quantidade de memória RAM interna, o que nos limitou a trab alhar com imagens
de no máximo 72x72 pixels. Esta característica já havia sido levantada durante a especificação
do projeto, porém como o objetivo maior é mostrar a viabilidade de implementar estes
algoritmos em hardware não é um fator impeditivo.
A opção de projeto foi desenvolver o módulo todo baseado em componentes individuais
que mais tarde pudessem ser acoplados aos outros de forma a montar a arquitetura mostrada na
Figura 26 – Arquitetura do Módulo de Hardware . Esta arquitetura também permite que mais
algoritmos possam ser implementados futuramente, uma vez que cada operação é um bloco
individual e todas as operações não invadem os outros blocos.

47
Figura 26 – Arquitetura do Módulo de Hardware
O módulo de hardware foi desenvolvido inteiramente em linguagem VHDL e como já
apresentado na Figura 26 – Arquitetura do Módulo de Hardware , os principais componentes são:
Protocolo de Comunicação: É a camada do hardware que se comunica com o
microcomputador e armazena os dados recebidos na memória interna.
Unidade de Controle de Operações: Esta unidade faz a leitura da memória para
verificar qual operação foi escolhida e os parâmetros necessários para sua
aplicação. Após a leitura destes dados, ativa uma das unidades de processamento
de acordo com a operação.
Controlador de Acesso de Memória: É o componente que faz o controle da
memória RAM interna. Como são diversos componentes compartilhando o
mesmo recurso, é responsável por multiplexa r o acesso.

48
Memória de Trabalho: Interna à FPGA é uma memória de acesso rápido para
efetuar as operações e aplicar os algoritmos em cada um dos pontos que
compõem a imagem. Composta dos blocos M4K RAM já citados anteriormente.
Operação NOT: Componente que efetua a operação lógica NOT em imagens.
Mais detalhes serão fornecidos ainda neste capítulo.
Operação Limiarização: Componente que efetua a operação de binarização em
imagens. Mais detalhes serão fornecidos ainda neste capítulo.
Operação Filtro Convolução: Componente que aplica filtros de convolução em
imagens. Mais detalhes serão fornecidos ainda neste capítulo.
Operação Filtro de Median: Componente que aplica um filtro de mediana em
imagens. Mais detalhes serão fornecidos ainda neste capítulo.
4.3.1 Protocolo de Comunicação
O módulo de software faz o envio e recebimento da imagem à FPGA através da porta
paralela do microcomputador. Esta porta é composta de 25 pinos, dos quais 13 pinos estão
disponíveis para a comunicação. A Figura 27 – Esquema de Funcionamento da Porta Paralela
apresenta o funcionamento desta porta.
Figura 27 – Esquema de Funcionamento da Porta Paralela

49
O protocolo de comunicação estabelecido, possui 2 modos de operação: Escrita, que faz o
envio de dados à FPGA para armazenamento em memórias auxiliares e o de Leitura que recebe
dados da FPGA para visualização no módulo de software.
O ciclo de escrita é apresentado na Figura 28 – Ciclo de Envio de um Byte .
Figura 28 – Ciclo de Envio de um Byte
O ciclo de leitura é apresentado na Figura 29 – Ciclo de Recebimento de um Byte .
Figura 29 – Ciclo de Recebimento de um Byte
O módulo de comunicação foi implementado na FPGA e seu diagrama esquemático
consta na Figura 30 – Diagrama Esquemático: Módulo de Comunicação.

50
Figura 30 – Diagrama Esquemático: Módulo de Comunicação
Este componente é composto de três processos, um para controle de endereçamento e
status, uma máquina de estados para controle da transferência de dados e um último que realiza o
acesso à memória interna.
4.3.1.1 Controle de endereçamento e status
Este processo controla o ponteiro qu e define a posição de memória na qual o byte
recebido será gravado. O ponteiro interno é incrementado cada vez que a máquina de estados
chega no último passo para a transferência de um byte. Existem dois sinais
begin_processing e transfering que servem para informar às outras unidades da
arquitetura o andamento da transferência e o momento de iniciar o processamento . Um sinal de
entrada processing_ok é disponibilizado às outras unidades para informar que o
processamento está finalizado.
4.3.1.2 Controle da transferência de dados
Este processo controla a máquina de estados que executa a leitura /escrita byte a byte da
imagem recebida/enviada. Existem quatro pinos de controle p_control[3..0] que são lidos
e que definem qual o próximo estado da máquina e a ação a ser ex ecutada no momento. Os
estados desta máquina são: idle, waitdata, receiveok . Indicando respectivamente que a máquina
está: parada, aguardando dado e dado recebido, respectivamente.
4.3.1.3 Acesso à memória Interna
Dependendo da direção do fluxo de dados, solicita ao controlador de acesso à memória ,
escrita ou leitura de dados. Fornece os pulsos de clock e sinais de controle necessários para tais
acessos.

51
4.3.1.4 Sinais do Componente
A tabela a seguir descreve todos os sinais deste componente e suas funções.
Tabela 2 – Sinais de Controle: Módulo de Comunicação
Direção Nome Descrição
entrada p_control[3..0] Pinos de controle da máquina
de estados de transferência
entrada data_from_memory[8..0] Entrada de dados provenientes
da memória RAM
entrada clk Sinal de clock global
entrada processing_ok Sinal que indica que o
processamento está finalizado
bidirecional p_data[8..0] Comunicação de dados com a
porta paralela
saída data_to_memory[8..0] Saída de dados com destino à
memória RAM
saída p_interrupt Pino de status da transferência
saída p_wait Pino de status da transferência
saída address[12..0] Ponteiro de endereçamento
saída wren Sinal que ativa a leitura ou
escrita na memória RAM
saída clk_ram Sinal que fornece a borda de
descida para leitura e
gravação da memória RAM
saída begin_processing Sinal que informa outros
componentes que o
processamento pode ser
iniciado
saída transfering Sinal que informa outros
componentes que uma
transferencia de dados está em
andamento

52
4.3.2 Unidade de Controle
Este componente monitora quando deve ser iniciado o processamento e ativa o bloco
correspondente à operação desejada . O sinal begin_processing indica que a transferência
de dados terminou e que a memória RAM deve ser acessada para verificar qual o código d e
operação foi enviado e qual é o bloco que deve ser ativo.
Além de ativar o bloco de operação, fornece ao controlador de acesso à memória a
informação de qual bloco deve ganhar acesso à memória no momento. Após ativar o bloco de
operação fica aguardando uma resposta do mesmo, indicando que o processamento foi
concluído.
Cada bloco de operação é ativado de acordo com um código gravado na posição de
memória 50. Estes códigos são os mesmos já citados na classe ImageOperations.java, já citados
anteriormente. A Tabela 3 – Códigos de Operações, contempla todos estes códigos.
Tabela 3 – Códigos de Operações
Constante Valor Operação
ImageOperations.OP_NOT 0x05h Operação NOT
ImageOperations.OP_BINARIZACAO 0x06h Operação
Limiarização
ImageOperations.OP_OP_FILTRO_PASSA_BAIXA 0x08h Filtro de Convolução
ImageOperations.OP_OP_FILTRO_POR_MEDIANA 0x09h Filtro de Mediana
ImageOperations.OP_OP_FILTRO_PASSA_ALTA 0x0Ah Filtro de Convolução
O diagrama esquemático do comp onente é apresentado na Figura 31 – Diagrama
Esquemático: Unidade de Controle , assim como seus sinais de entrada e saída na Tabela 4 –
Sinais de Controle: Unidade de Controle .
Figura 31 – Diagrama Esquemático: Unidade de Controle

53
Tabela 4 – Sinais de Controle: Unidade de Controle
Direção Nome Descrição
entrada clk Sinal de clock global
entrada transfering Sinal que indica que uma
transferência de dados está em
curso
entrada begin_processing Sinal que indica que a
transferência terminou e o
processamento deve iniciar
entrada data_from_memory[8..0] Entrada de dados provenientes
da memória RAM
entrada finish_op[3..0] Sinal que recebe a informação
que o processamento está
concluído.
saída processing_ok Sinal que indica ao módulo de
comunicação que o
processamento está finalizado
e a transferência de iniciar
saída sel_memory_mux[2..0] Indica ao controlador de
acesso à memória, qual bloco
deve possuir o acesso
saída address[12..0] Ponteiro de endereçamento
saída wren Sinal que ativa a leitura ou
escrita na memória RAM
saída clk_ram Sinal que fornece a borda de
descida para leitura e
gravação da memória RAM
saída start_op[3..0] Sinal que indica qual bloco de
operação deve ser ativo
4.3.3 Controlador de Acesso à Memória
Este bloco tem exatamente o funcionamento de um multiplexador. A sua característica é
fornecer oito pontos de acesso à uma única memória RAM, mediante um sinal de controle que é
recebido da unidade de controle.

54
O sinal sel[2..0] define quem terá acesso à RAM no momento e conecta os sinais
data[8..0], wren, address[12..0], clock, q[8..0] da memória ao bloco
ativo.
O diagrama esquemático do componente é apresentado na Figura 32 – Diagrama
Esquemático: Controlador de Acesso à Memória , assim como seus sinais de entrada e saída na
Tabela 5 – Sinais de Controle: Controlador de Acesso à Memória .
Figura 32 – Diagrama Esquemático: Controlador de Acesso à Memória
Tabela 5 – Sinais de Controle: Controlador de Acesso à Memória
Direção Nome Descrição
entrada datain[7..0][8..0] Oito entradas de dados
provenientes dos blocos de
operação e demais
componentes da arquitetura
entrada Address[7..0][12..0] Oito entradas de
endereçamento provenientes
dos blocos de operação e
demais componentes da
arquitetura

55
entrada wren[7..0] Oito sinais de controle de
escrita e leitura provenientes
dos blocos de operação e
demais componentes da
arquitetura
entrada clk[7..0] Oito sinais de clock para
gravação e leitura
provenientes dos blocos de
operação e demais
componentes da arquitetura
saída dataout[7..0][8..0] Oito saídas de dados
provenientes dos blocos de
operação e demais
componentes da arquitetura
saída RAM_datain[8..0] Saída de dados para gravação
na memória RAM
saída RAM_address[8..0] Endereçamento da memória
RAM
saída RAM_wren Sinal de controle de escrita e
leitura da memória RAM
saída RAM_clk Sinal que fornece a borda de
descida para leitura e
gravação da memória RAM
4.3.4 Operação NOT
Este bloco tem a função de buscar a imagem da memória RAM e aplicar a operação
lógica NOT em cada um dos pixels da imagem.
Em um primeiro momento as informações de altura e largura d a imagem são lidas da
memória e com esta informação são lidos todos os pixels da imagem, invertendo seu valor e
gravando novamente na mesma posição de memória.
Após o término da operação em todos os pixels da imagem, um sinal finish_op é
enviado à unidade de controle, informando que o processamento foi finalizado com sucesso.
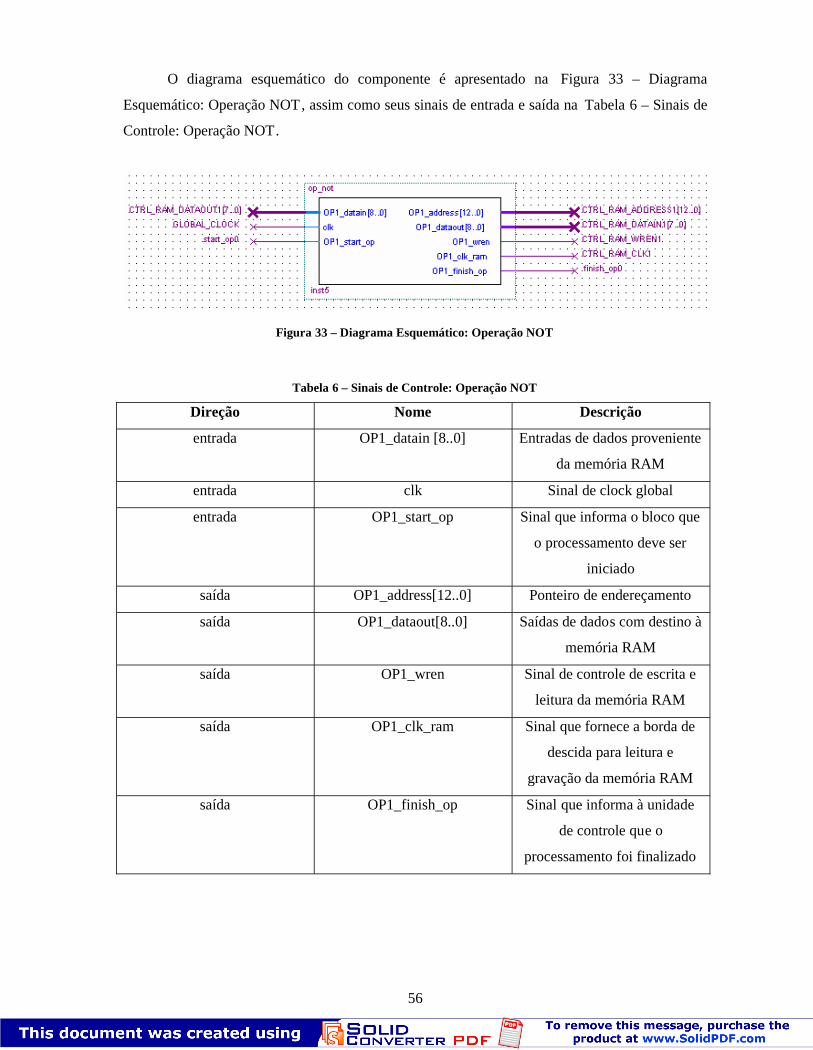
56
O diagrama esquemático do componente é apresentado na Figura 33 – Diagrama
Esquemático: Operação NOT, assim como seus sinais de entrada e saída na Tabela 6 – Sinais de
Controle: Operação NOT.
Figura 33 – Diagrama Esquemático: Operação NOT
Tabela 6 – Sinais de Controle: Operação NOT
Direção Nome Descrição
entrada OP1_datain [8..0] Entradas de dados proveniente
da memória RAM
entrada clk Sinal de clock global
entrada OP1_start_op Sinal que informa o bloco que
o processamento deve ser
iniciado
saída OP1_address[12..0] Ponteiro de endereçamento
saída OP1_dataout[8..0] Saídas de dados com destino à
memória RAM
saída OP1_wren Sinal de controle de escrita e
leitura da memória RAM
saída OP1_clk_ram Sinal que fornece a borda de
descida para leitura e
gravação da memória RAM
saída OP1_finish_op Sinal que informa à unidade
de controle que o
processamento foi finalizado

57
4.3.5 Operação Limiarização
Este bloco tem a função de buscar a imagem da memória RAM e aplicar um limiar em
cada um dos pixels da imagem. Em um primeiro momento as informações de altura e largura d a
imagem são lidas da memória , assim como também o limiar passado como parâmetro .
A operação consiste em alterar o valor dos pixels para 255 quando o valor atual for maior
que o limiar e alterar para 0 quando o valor atual for menor que o limiar.
Após o término da operação em todos os pixels da imagem, um sinal finish_op é
enviado à unidade de controle, informando que o processamento foi finalizado com sucesso.
O diagrama esquemático do componente é apresentado na Figura 34 – Diagrama
Esquemático: Operação Limiarização , assim como seus sinais de entrada e saída na Tabela 7 –
Sinais de Controle: Operação Limiarização .
Figura 34 – Diagrama Esquemático: Operação Limiarização
Tabela 7 – Sinais de Controle: Operação Limiarização
Direção Nome Descrição
entrada OP2_datain [8..0] Entradas de dados proveniente
da memória RAM
entrada clk Sinal de clock global
entrada OP2_start_op Sinal que informa o bloco que
o processamento deve ser
iniciado
saída OP2_address[12..0] Ponteiro de endereçamento
saída OP2_dataout[8..0] Saídas de dados com destino à
memória RAM
saída OP2_wren Sinal de controle de escrita e
leitura da memória RAM
saída OP2_clk_ram Sinal que fornece a borda de

58
descida para leitura e
gravação da memória RAM
saída OP2_finish_op Sinal que informa à unidade
de controle que o
processamento foi finalizado
4.3.6 Operação Filtro de Convolução
Este bloco tem a função de buscar a imagem da memória RAM e aplicar um filtro de
convolução em cada um dos pixels da imagem. Em um primeiro momento as informações de
altura e largura da imagem são lidas da memória, assim como também a matriz de máscara
passada como parâmetro.
A operação consiste aplicar a cada pixel, uma média de sua vizinhança de 8. Para cada
pixel da imagem, busca-se da memória sua vizinhança e efetua -se multiplicações com os valores
da máscara, dividindo o resultado pelo tamanho da janela, que é 9.
Existe uma peculiaridade nas bordas da imagem, onde não existe vizinhança em um ou
mais lados do pixel, então é espelhado o outro lado de forma a manter a média.
Após o término da operação em todos os pixels da imagem, um sinal finish_op é
enviado à unidade de controle, informando que o processamento foi finalizado com sucesso.
O diagrama esquemático do componente é apresentado na Figura 35 – Diagrama
Esquemático: Operação Filtro de Convolução , assim como seus sinais de entrada e saída na
Tabela 8 – Sinais de Controle: Operação Filtro de Convolução .
Figura 35 – Diagrama Esquemático: Operação Filtro de Convolução
Tabela 8 – Sinais de Controle: Operação Filtro de Convolução
Direção Nome Descrição
entrada OP3_datain [8..0] Entradas de dados proveniente
da memória RAM

59
entrada clk Sinal de clock global
entrada OP3_start_op Sinal que informa o bloco que
o processamento deve ser
iniciado
saída OP3_address[12..0] Ponteiro de endereçamento
saída OP3_dataout[8..0] Saídas de dados com destino à
memória RAM
saída OP3_wren Sinal de controle de escrita e
leitura da memória RAM
saída OP3_clk_ram Sinal que fornece a borda de
descida para leitura e
gravação da memória RAM
saída OP3_finish_op Sinal que informa à unidade
de controle que o
processamento foi finalizado
4.3.7 Operação Filtro de Mediana
Este bloco tem a função de buscar a imagem da memória RAM e aplicar um filtro de
mediana em cada um dos pixels da imagem.
Em um primeiro momento as informações de altura e largura da imagem são lidas da
memória. A operação consiste aplicar a cada pixel, o valor da mediana de sua vizinhança . Para
cada pixel da imagem, busca -se da memória sua vizinhança e ordena-se de maneira crescente os
valores. O novo valor do pixel será o valor que estiver no meio deste veto r de pixels.
Existe uma peculiaridade nas bordas da imagem, onde não existe vizinhança em um ou
mais lados do pixel, então é espelhado o outro lado de forma a manter a média.
Após o término da operação em todos os pixels da imagem, um sinal finish_op é
enviado à unidade de controle, informando que o processamento foi finalizado com sucesso.
O diagrama esquemático do componente é apresentado na Figura 36 – Diagrama
Esquemático: Operação Filtro de Mediana , assim como seus sinais de entrada e saída na Tabela
9 – Sinais de Controle: Operação Filtro de Mediana.

60
Figura 36 – Diagrama Esquemático: Operação Filtro de Mediana
Tabela 9 – Sinais de Controle: Operação Filtro de Mediana
Direção Nome Descrição
entrada OP4_datain [8..0] Entradas de dados proveniente
da memória RAM
entrada clk Sinal de clock global
entrada OP4_start_op Sinal que informa o bloco que
o processamento deve ser
iniciado
saída OP4_address[12..0] Ponteiro de endereçamento
saída OP4_dataout[8..0] Saídas de dados com destino à
memória RAM
saída OP4_wren Sinal de controle de escrita e
leitura da memória RAM
saída OP4_clk_ram Sinal que fornece a borda de
descida para leitura e
gravação da memória RAM
saída OP4_finish_op Sinal que informa à unidade
de controle que o
processamento foi finalizado

61
CAPÍTULO 5 – VALIDAÇÃO E RESULTADOS
Para validar os resultados das operações disponíveis foram comparados os valores
obtidos na matriz de pixels de cada imagem, com resultados das mesmas operações efetudas via
software Matlab v6.5 que é uma ferramenta técnica de conhecimento geral no meio acadêmico.
Como ficaria de difícil exibição neste documento, matrizes de pixels de imagens com
largura superior a 20 colunas, o padrão definido foi de trabalhar com imagens de 10x10 pixels.
5.1 Operação NOT
Foram executados diversos testes com esta operação e o índice de acerto do sistema foi
de 100%. A seguir segue uma matriz de pixels obtida via hardware e outra pré-calculada.
Tabela 10 – Operação NOT: Matriz de pixels original
255 0 255 251 255 255 244 255 255 245254 255 0 255 247 255 255 243 246 255255 246 255 0 255 243 255 255 245 255250 255 253 255 0 255 255 247 255 255255 251 253 247 255 0 252 255 252 247249 255 255 255 251 239 5 255 255 242255 233 255 255 252 255 250 0 0 25250 255 247 249 255 246 255 0 13 241255 252 255 255 251 249 8 252 240 12250 255 252 245 255 3 252 248 255 232
Tabela 11 – Operação NOT: Matriz de pixels resultado via hardware
0 255 0 4 0 0 11 0 0 101 0 255 0 8 0 0 12 9 00 9 0 255 0 12 0 0 10 05 0 2 0 255 0 0 8 0 00 4 2 8 0 255 3 0 3 86 0 0 0 4 16 250 0 0 130 22 0 0 3 0 5 255 255 2305 0 8 6 0 9 0 255 242 140 3 0 0 4 6 247 3 15 2435 0 3 10 0 252 3 7 0 23
Tabela 12 – Operação NOT: Matriz de pixels resultado esperada
0 255 0 4 0 0 11 0 0 101 0 255 0 8 0 0 12 9 00 9 0 255 0 12 0 0 10 05 0 2 0 255 0 0 8 0 00 4 2 8 0 255 3 0 3 86 0 0 0 4 16 250 0 0 130 22 0 0 3 0 5 255 255 2305 0 8 6 0 9 0 255 242 140 3 0 0 4 6 247 3 15 2435 0 3 10 0 252 3 7 0 23

62
Figura 37 – Imagem OriginalFigura 38 – Imagem Resultado
5.2 Operação de Limiarização
Foram executados diversos testes com esta operação e o índice de acerto do sistema foi
de 100%. A seguir segue uma matriz de pixel s obtida via hardware e outra calculada
previamente.
Esta operação tem como parâmetro um limiar, que foi definido para o valor 100.
Tabela 13 – Operação Limiarização: Matriz de pixels original
251 0 242 232 255 255 255 255 136 255255 234 4 247 240 255 255 136 255 255239 254 240 0 255 255 255 130 255 255148 146 103 109 151 129 134 176 134 133255 255 241 238 255 104 255 255 255 255255 245 225 245 85 255 21 255 255 250255 252 247 251 103 255 255 12 14 820 34 16 19 23 39 20 13 15 12255 255 110 255 255 255 8 255 234 2255 240 255 255 255 0 255 255 247 215
Tabela 14 – Operação Limiarização: Matriz de pixels resultado via hardware
255 0 255 255 255 255 255 255 0 255255 255 0 255 255 255 255 0 255 255255 255 255 0 255 255 255 0 255 255255 255 255 255 255 255 0 255 255 255255 255 255 255 255 0 255 255 255 255255 255 255 255 0 255 0 255 255 255255 255 255 255 0 255 255 0 0 00 0 0 0 0 0 0 0 0 0
255 255 0 255 255 255 0 255 255 0255 255 255 255 255 0 255 255 255 255

63
Tabela 15 – Operação Limiarização: Matriz de resultado esperada
255 0 255 255 255 255 255 255 0 255255 255 0 255 255 255 255 0 255 255255 255 255 0 255 255 255 0 255 255255 255 255 255 255 255 0 255 255 255255 255 255 255 255 0 255 255 255 255255 255 255 255 0 255 0 255 255 255255 255 255 255 0 255 255 0 0 00 0 0 0 0 0 0 0 0 0
255 255 0 255 255 255 0 255 255 0255 255 255 255 255 0 255 255 255 255
Figura 39 – Imagem Original Figura 40 – Imagem Resultado
5.3 Operação Filtro Passa-Baixa
Foram executados diversos testes com esta operação e o índice de acerto do sistema foi
bastante satisfatória. Observou-se uma diferença de valores nas bordas das imagens, mas não
trata-se de um erro e sim uma diferença ocasionada pelo fato do MatLab não tratar a vizinhança
dos pixels da borda espelhando o outro lado do pixel. Observou -se também uma pequena
diferença de valores devido ao fato de trabal harmos exclusivamente com ponto fixo no sistema e
com truncamento da parte não-inteira dos valores.
A seguir segue uma matriz de pixels obtida via hardware e outra calculada previamente.
Esta operação tem como parâmetro uma máscara, que foi definida para:
Tabela 16 – Filtro Passa-Baixa: Máscara de entrada
1 1 1
1 1 1
1 1 1

64
Tabela 17 – Filtro Passa-Baixa: Matriz de pixels original
37 34 36 41 41 37 39 46 38 3840 36 36 39 39 35 34 38 39 3943 37 34 36 38 35 31 31 36 3643 37 34 36 40 40 36 32 31 3441 38 36 38 45 49 46 42 33 3942 43 43 44 49 55 55 50 42 4847 51 52 49 51 56 56 53 47 5252 57 58 52 50 54 55 52 46 5064 49 27 61 52 52 48 44 56 5345 59 59 34 43 40 67 50 53 71
Tabela 18 – Filtro Passa-Baixa: Matriz de pixels resultado via hardware
36 36 37 38 38 37 37 38 39 3837 37 36 37 37 36 36 36 37 3738 37 36 36 37 36 34 34 35 3639 38 36 37 39 40 38 35 34 3640 39 38 40 44 46 45 40 39 4043 43 43 45 48 51 51 47 45 4549 49 49 49 51 53 54 50 48 4953 50 50 50 53 52 52 50 50 5054 52 50 48 48 51 51 52 52 5351 48 46 47 50 55 53 52 50 49
Tabela 19 – Filtro Passa-Baixa: Matriz de pixels resultado calculada
4 7 11 12 13 13 13 13 13 13 8 48 16 24 24 25 25 25 25 26 26 17 813 25 37 36 37 37 36 36 36 37 25 1214 26 37 36 36 37 36 34 34 35 23 1214 26 38 36 37 39 40 38 35 34 23 1214 27 39 38 40 44 46 45 40 39 25 1314 29 43 43 45 48 51 51 47 45 29 1515 32 49 49 49 51 53 54 50 48 31 1618 35 50 50 50 53 52 52 50 50 33 1717 36 52 50 48 48 51 51 52 52 36 1912 24 33 32 30 31 33 33 35 36 25 135 11 18 16 15 13 16 17 18 19 13 7
Figura 41 – Imagem Original Figura 42 – Imagem Resultado
5.4 Operação Filtro Passa-Alta
Foram executados diversos testes com esta operação e o índice de acerto do sistema foi
bastante satisfatória. Observou-se uma diferença de valores nas bordas das imagens, mas não

65
trata-se de um erro e sim uma diferença ocasionada pelo fato do MatLab não tratar a vizinhança
dos pixels da borda espelhando o outro lado do pixel. Observou -se também uma pequena
diferença de valores devido ao fato de trabalharmos ex clusivamente com ponto fixo no sistema e
com truncamento da parte não-inteira dos valores.
A seguir segue uma matriz de pixels obtida via hardware e outra calculada previamente.
Esta operação tem como parâmetro uma máscara, que foi definida para:
Tabela 20 – Filtro Passa-Alta: Máscara de entrada
-1 -1 -1
-1 2 -1
-1 -1 -1
Tabela 21 – Filtro Passa-Alta: Matriz de pixels original
37 34 36 41 41 37 39 46 38 3840 36 36 39 39 35 34 38 39 3943 37 34 36 38 35 31 31 36 3643 37 34 36 40 40 36 32 31 3441 38 36 38 45 49 46 42 33 3942 43 43 44 49 55 55 50 42 4847 51 52 49 51 56 56 53 47 5252 57 58 52 50 54 55 52 46 5064 49 27 61 52 52 48 44 56 5345 59 59 34 43 40 67 50 53 71
Tabela 22 – Filtro Passa-Alta: Matriz de pixels resultado via hardware
24 25 25 24 24 24 24 23 26 2523 25 24 24 24 24 24 24 24 2424 25 24 24 24 24 24 23 23 2424 25 24 25 26 26 26 24 24 2526 27 26 27 29 29 29 26 28 2729 29 29 30 32 33 33 30 31 2933 32 32 33 34 34 35 33 33 3235 31 31 32 36 34 33 33 35 3333 35 41 28 31 33 35 37 34 3536 28 26 36 36 42 31 35 32 26
Tabela 23 – Filtro Passa-Alta: Matriz de pixels calculada
4 7 11 12 13 13 13 13 13 13 8 48 4 13 12 12 12 12 12 10 13 4 813 11 25 24 24 24 24 24 24 24 12 1214 11 25 24 24 24 24 24 23 23 11 1214 12 25 24 25 26 26 26 24 24 11 1214 13 27 26 27 29 29 29 26 28 12 1314 15 29 29 30 32 33 33 30 31 13 1515 16 32 32 33 34 34 35 33 33 14 1618 18 31 31 32 36 34 33 33 35 17 1717 14 35 41 28 31 33 35 37 34 18 1912 9 14 12 19 17 20 11 18 18 2 135 11 18 16 15 13 16 17 18 19 13 7
Matriz de pixels calculada

66
Figura 43 – Imagem Original Figura 44 – Imagem Resultado
5.5 Operação Filtro Mediana
Foram executados diversos testes com esta operação e o índice de acerto do sistema foi
bastante satisfatória. Observou-se uma pequena diferença nos resultados, porém até a data de
apresentação do projeto o problema não havia sido solucionado .
A seguir segue uma matriz de pixels obtida via hardware e outra calculada previamente.
Esta operação tem como parâmetro uma máscara, que foi definida para:
Tabela 24 – Filtro de Mediana: Matriz de pixels original
37 34 36 41 41 37 39 46 38 3840 36 36 39 39 35 34 38 39 3943 37 34 36 38 35 31 31 36 3643 37 34 36 40 40 36 32 31 3441 38 36 38 45 49 46 42 33 3942 43 43 44 49 55 55 50 42 4847 51 52 49 51 56 56 53 47 5252 57 58 52 50 54 55 52 46 5064 49 27 61 52 52 48 44 56 5345 59 59 34 43 40 67 50 53 71
Tabela 25 – Filtro de Mediana: Matriz de pixels resultado via hardware
36 36 36 39 39 38 38 39 39 3937 37 36 39 39 38 36 38 38 3837 37 36 37 39 37 35 35 36 3838 38 37 37 39 40 38 35 35 3742 42 38 42 45 48 48 42 41 4143 43 44 47 49 53 54 49 48 4851 52 52 51 52 55 55 53 50 5152 52 52 52 52 53 54 53 52 5357 58 58 52 52 52 52 53 53 5449 48 47 48 52 55 54 55 53 53

67
Tabela 26 – Filtro de Mediana: Matriz de pixels calculada
37 37 37 37 38 38 38 38 38 3839 36 36 38 38 38 39 39 39 3837 37 37 36 36 36 36 36 36 3537 37 37 37 36 36 34 34 34 3438 38 41 41 41 39 39 39 42 4243 43 43 44 44 48 48 48 49 5051 51 51 51 51 52 52 52 52 5352 54 54 52 52 52 52 50 50 5252 52 52 52 52 52 52 53 52 5245 45 45 45 50 53 53 53 53 53
Figura 45 – Imagem OriginalFigura 46 – Imagem Resultado

68
CAPÍTULO 6 – CONCLUSÃO
Este projeto contempla um sistema de processamento digital de imagens baseado em
hardware reconfigurável implementado em uma FPGA. As operações disponíveis são
principalmente de suavização e realce.
A implementação de algoritmos em linguagem de descrição de hardware é bastante
trabalhosa e muito mais complexa do que quando utilizando linguagens de alto nível. A não
existência de estruturas de dados complexas foi uma da s grandes dificuldades no
desenvolvimento deste projeto.
Os resultados obtidos foram muito bons, conforme apresentados no capítulo anterior. O s
algoritmos implementados tiveram a validação do funcionamento e a performance do sistema foi
excelente, visto que o único gargalo ficou sendo a quantidade de memória . Realmente provou-se
viável efetuar a implementação de processamento de imagens em FPGA’s.
Entre os aspectos do projeto que poderiam ter sido melhorados está um módulo extra de
memória, para se poder trabalhar com imagens de resolução maior. Apesar da validação
matemática dos métodos, ficou um pouco difícil a v isualização das imagens devido ao seu
tamanho reduzido.
Uma melhoria deste projeto seria a implementação de algoritmos de processamento de
imagens no domínio da frequência, que partem do algoritmo de FFT, passando por filtros e FFT
inversa.

69
CAPÍTULO 7 – REFERÊNCIAS BIBLIOGRÁFICAS
ALTERA CORPORATION. FPGA Cyclone – DATASHEET. Disponível na Internet em
http://altera.com/literature/hb/cyc/cyc_c5v1_01.pdf. Acessado em março de 2007.
CASTLEMAN, KENNETH R. Digital Image Processing . Upper Saddle River, New Jersey,
Prentice Hall, 1996.
D'AMORE, ROBERTO. VHDL : Descrição e Síntese de Circuitos Digitais . Rio de Janeiro,
LTC, 2005.
GONZALEZ, RAFAEL C; WOODS, RICHAR DS E. Processamento de Imagens Digitais .
Editora Edgard Bluncher. São Paulo 2003.
SWOKOWSKI, Earl William. Cálculo com Geometria Analítica. Makron Books, São Paulo
1995.
TANENBAUM, A. S. Organização Estruturada de Computadores . Rio de Janeiro, LTC,
2001.
YALAMANCHILI, S. VHDL starter’s guide . Upper Saddle River, New Jersey, Prentice Hall
1998.
WIKIPEDIA. FPGA. Disponível em : <http://pt.wikipedia.org/wiki/FPGA> . Acesso em
Junho/2007.

70
APÊNDICE A – CRONOGRAMA DO PROJETO
Atividade Prazo
Entrega da Proposta de Projeto Final 05/03/2007
Estudo de Sistemas de Processamento Digitalde Imagens
Março/2007
Entrega das Especificações Técnicas doProjeto
02/04/2007
Estudo e Projeto do Hardware a ser Utilizado Março-Abril/2007
Estudo da Linguagem VHDL Abril-Maio/2007
Entrega da Monografia e dos TestesPreliminares do Projeto
Abril-16/06/2007
Implementação do Protocolo de Comunicaçãoentre Software e Hardware
30/04/2007
Implementação dos Algoritmos deProcessamento de Imagens
Junho-Agosto/2007
Operações no Domínio Espacial Junho/2007
Operações no Domínio da Freqüência Julho/2007
Melhorias e Ajustes Agosto/2007
Apresentação da Prévia da Implementação doProjeto Especificado
06/08/2007
Elaboração da Documentação e Monografia doProjeto
Setembro/2007
Apresentação do Projeto Implementado 01/10/2007
Entrega da Documentação Completa doProjeto
05/11/2007
Defesa Formal do Projeto 26/11/2007
Entrega da Documentação Final do Projeto,Revisada e Corrigida, Monografia, ManuaisTécnico e do Usuário, Artigo Científico.Entrega do CD com os Manuais em FormatoWeb.
10/12/2007





























