Embed Size (px)
Citation preview

Introdução à Computação de Alto Desempenho Utilizando GPU
Seminário de Programação em GPGPU
Eng. Thársis T. P. [email protected]
Instituto de Matemática e Estatística - Universidade de São Paulo

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 2
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 3
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

CPU GPU
Própria para tarefas sequenciais Cache eficiente Maior quantidade de memória
principal Controle de fluxo Número de cores de 1 ordem de
grandeza 1, 2 threads por core
Própria para tarefas com paralelismo de dados
Múltiplas ULAs Maior (capacidade) operações de
ponto flutuante por segundo Alto throughput de memória Dezenas de multiprocessors Múltiplas threads por
multiprocessor
01/04/2011 4Instituto de Matemática e Estatística - Universidade de São Paulo

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 5
Figura 1: Número de operações de ponto flutuante por segundo

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 6
Figura 2: Throughput de memória CPU x GPU

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 7
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 8
General-purpose computing on Graphics Processing Units Técnica de uso de GPU para computação de propósito geral
Linguagens/API’s
OpenGL DirectX Cg Brook Brook+ OpenCL CUDA

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 9

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 10
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 11
Código otimizado depende de conhecimento da arquiteturaespecífica
Shared memory / Cache configuráveis
Quantos cores?
Precisão de ponto flutuante depende da geração da arquitetura
SFUs (Special Function Units): limitante de operaçõestranscendentais
Qual memória usar: Shared memory, Constant Memory, Global Memory, registradores, local memory, Host Memory?
Quantas threads/bloco, blocos/SM, registradores/thread, threads/SM, Warps/SM, threads/Warp ????

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 12
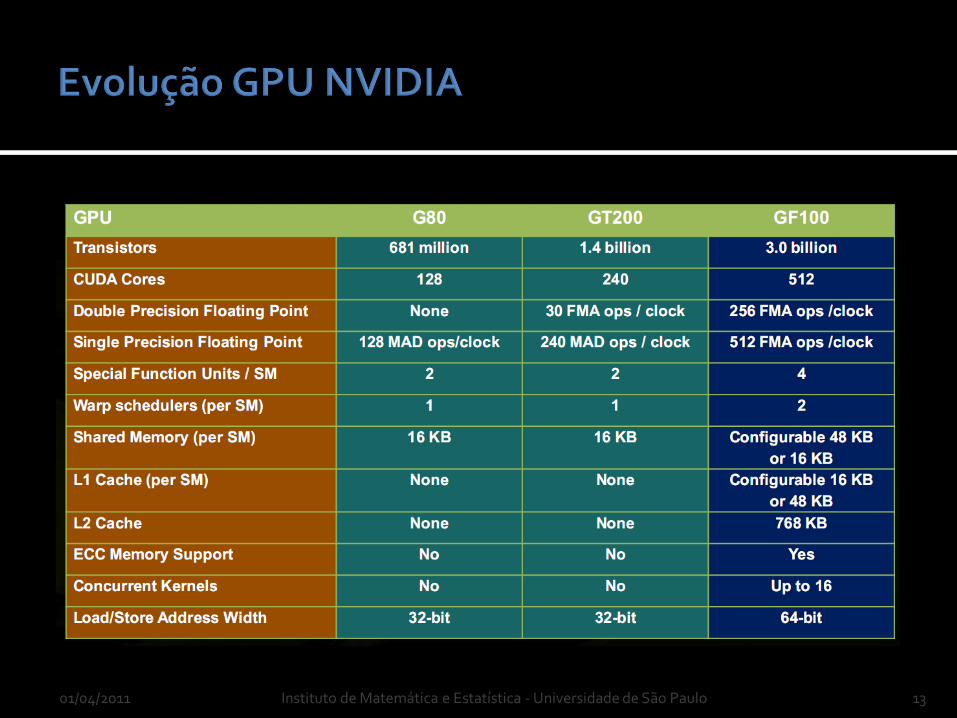
01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 13

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 14
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 15
Define arquitetura base e features de uma GPU NVIDIA
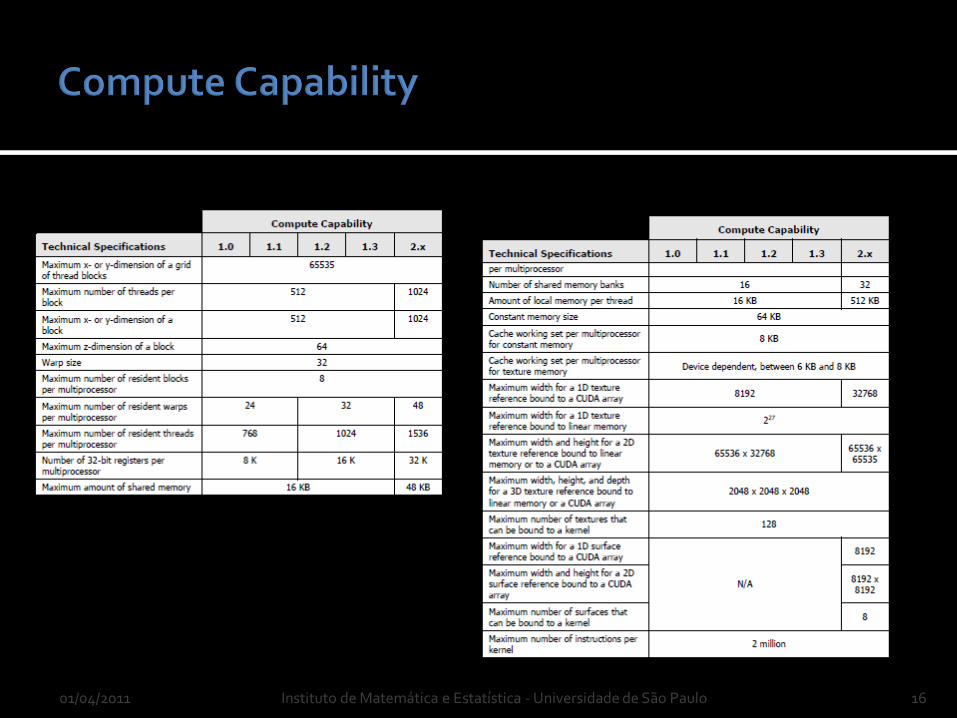
01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 16

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 17
Compute capability: 2.0 Single Precision Floating
Point Performance : 1.03 TFlops
Device copy overlap: Enabled
Kernel timeout : Disabled
Total dedicated memory: 3GB GDDR5
Constant mem: 64KB
Numero de multiprocessadores: 14
Shared mem por mp: 48KB
Registers por mp: 32768 Threads in warp: 32 Max threads per block: 1024 Max thread dimension:
(1024, 1024, 64) Max grid dimension: (65535,
65535, 1)

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 18
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 19
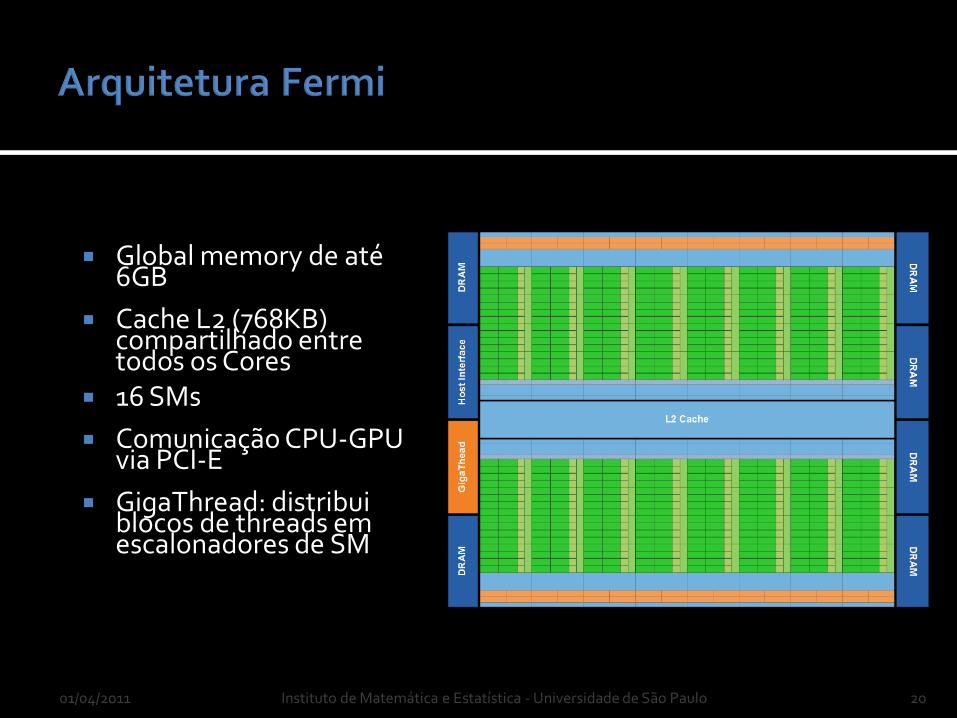
01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 20
Global memory de até 6GB
Cache L2 (768KB) compartilhado entre todos os Cores
16 SMs
Comunicação CPU-GPU via PCI-E
GigaThread: distribuiblocos de threads emescalonadores de SM

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 21
32 CUDA Cores por SM 1 CUDA Core executa 1 thread
por ciclo
16 Load/Store Units Pode limitar execução a 16
threads por clock
4 Special Function Units Executa instruções
transcedentais Pode limitar execução de warp
a 8 ciclos
64kB (48kB/16kB) configuráveispara Shared Memory e L1 Cache

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 22
1 Warp = 32 threads
2 Warps (potencialmente) executados ao mesmotempo
Máximo de 48 Warps por SM
Total de 1536 threads possíveis por SM

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 23
Fermi dual warp scheduler seleciona 2 warps e realiza umainstrução de cada warp em um grupo de 16 cores, 16 unidadesde load/store ou 4 SFUs
48 warps/SM. Para quê? Latency hiding: warp com
instrução de alta-latência é escalonado
Muitos escalonamentos = queda de desempenho? Zero-overhead thread
scheduling: seleção de warp para execução não introduzoverhead

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 24
Modelo SIMT: Single Instruction Multiple Thread
Apropriado quando todasthreads em um mesmo warp seguem o mesmo caminho de fluxo de controle
Quando threads em um warp seguem caminhos de fluxo de controle diferentes dizemosque elas divergem
Em situação de divergência, um warp necessita de múltiplos passos para ser executado. Um para cadacaminho de divergência.

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 25
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 26
Compute Unified Device Architecture
Arquitetura paralela de propósito geral
Tecnologia proprietária NVIDIA

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 27
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 28
Arquitetura de Computação Paralelapara propósito geral Facilita computação heterogênea (CPU +
GPU)
Suporte a varias linguagens e APIs
CUDA define: Modelo de programação
Modelo de memória
Modelo de execução

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 29
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 30
Porções paralelas da aplicação são executadas como kernels
CUDA threads
Lighweight
Fast switching
Milhares potencialmente executadas ao mesmo tempo

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 31
Um kernel é uma função executada emGPU
Cada thread possui um identificadorúnico
Seleção de input/output
Decisões de controle (cuidado!)
Threads com decisões de controledistintas podem causar divergência emwarp


Threads são agrupadas em blocos

Threads são agrupadas em blocos Blocos são agrupados em grid

Threads são agrupadas em blocos Blocos são agrupados em grid Um kernel é executado como um grid de blocos de threads

Threads são agrupadas em blocos Blocos são agrupados em grid Um kernel é executado como um grid de blocos de threads
GPU
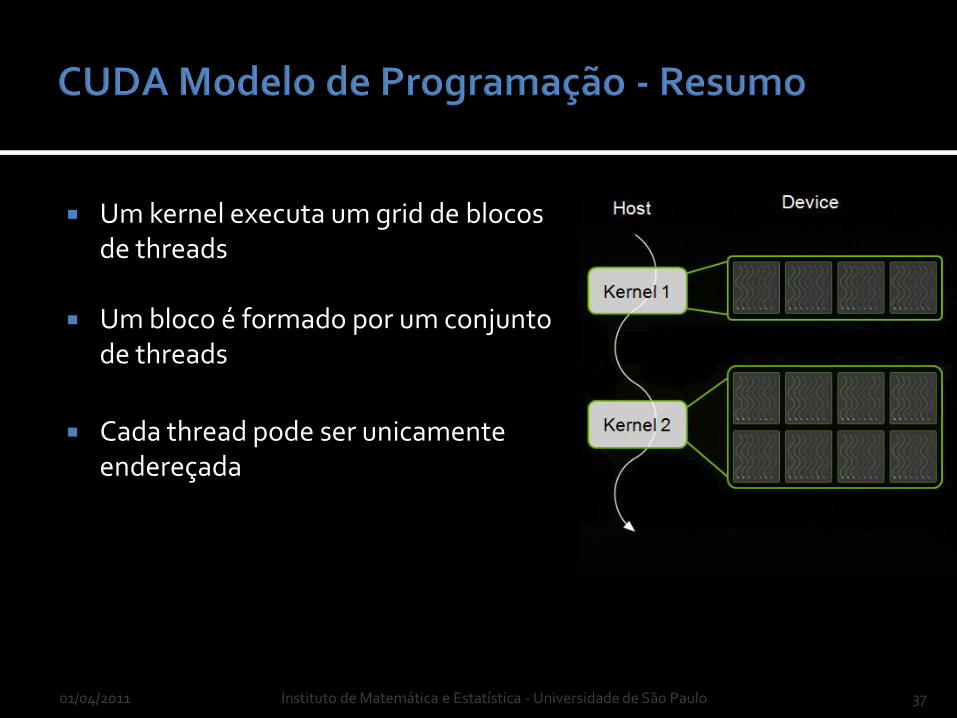
01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 37
Um kernel executa um grid de blocosde threads
Um bloco é formado por um conjuntode threads
Cada thread pode ser unicamenteendereçada

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 38
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 39
Thread
Registradores

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 40
Thread
Registradores
Thread
Local Memory

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 41
Thread
Registradores
Thread
Local Memory
Bloco
Shared Memory

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 42
Thread
Registradores
Thread
Local Memory
Bloco
Shared Memory
Grid
Global Memory

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 43
Registradores registradores são rápidos, porém escassos. Cadathread possui um conjunto privado de registradores.

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 44
Registradores registradores são rápidos, porém escassos. Cadathread possui um conjunto privado de registradores.
Shared Memory threads em um mesmo bloco compartilham um espaço de memória, o qual funciona como um cache manipuladoexplicitamente pelo programa

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 45
Registradores registradores são rápidos, porém escassos. Cadathread possui um conjunto privado de registradores.
Shared Memory threads em um mesmo bloco compartilham um espaço de memória, o qual funciona como um cache manipuladoexplicitamente pelo programa
Local Memory cada thread possui acesso a um espaço de memória local, além de seus registradores. Essa área de memóriaestá fora do micro-chip de processamento, junto à memóriaglobal, e portanto, ambas estas memórias possuem o mesmotempo de acesso.

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 46
Registradores registradores são rápidos, porém escassos. Cadathread possui um conjunto privado de registradores.
Shared Memory threads em um mesmo bloco compartilham um espaço de memória, o qual funciona como um cache manipuladoexplicitamente pelo programa
Local Memory cada thread possui acesso a um espaço de memória local, além de seus registradores. Essa área de memóriaestá fora do micro-chip de processamento, junto à memóriaglobal, e portanto, ambas estas memórias possuem o mesmotempo de acesso.
Global Memory esta memória está disponível para todas as threads em cada bloco e em todas as grades. Trata-se da únicamaneira de threads de diferentes blocos colaborarem.

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 47

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 48

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 49
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 50
Threads são executadas porcores
Um bloco consiste de conjuntos de warps
Um Warp é executado emem paralelo (SIMT) em um Multiprocessor
Um Kernel é lançado comoum grid
Um grid é executado no device

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 51
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 52
Biblioteca e um compilador para criação de rotinas em GPUs NVIDIA
API de mais alto nível em comparação com: Cg, OpenGL, DirectX
Exige conhecimento de arquitetura para codificação
Amplamente utilizada
Possui grande comunidade e boa documentação
Maioria de artigos publicados em programação em GPGPU utilizaCUDA C

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 53
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 54
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 55
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}// C functionint main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 56
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
// ponteiro para host memoryint *host_array = 0;
// aloca espaço em host memoryhost_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 57
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);// Ponteiro para device memoryint *device_array = 0;// Aloca espaço em device memorycudaMalloc((void**)&device_array,
num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 58
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
// configuracao de bloco e gridint block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 59
#include <stdlib.h>#include <stdio.h>// extensao __global __ define kernel__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
// lancamento do kernelkernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 60
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
// transfere resultado da GPU para CPUcudaMemcpy(host_array, device_array,
num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 61
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
// inspecao do resultadofor(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}
free(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 62
#include <stdlib.h>#include <stdio.h>
__global__ void kernel(int *array){
//do work}
int main(void){int num_elements = 256;
int num_bytes = num_elements * sizeof(int);
int *host_array = 0;
host_array = (int*)malloc(num_bytes);
int *device_array = 0;
cudaMalloc((void**)&device_array, num_bytes);
int block_size = 128;int grid_size = num_elements /
block_size;
kernel<<<grid_size,block_size>>>(device_array);
cudaMemcpy(host_array, device_array, num_bytes, cudaMemcpyDeviceToHost);
for(int i=0; i < num_elements; ++i){
printf("%d ", host_array[i]);}// desaloca memoriafree(host_array);cudaFree(device_array);
}

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 63

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 64
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 65
Definido por extensão __global__
Configurado por sintaxe <<<grid_size, block_size>>>

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 66

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 67
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 68

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 69
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 70
Todas as threads em um mesmo grid executam o mesmo kernel Necessidade de haver coordenadas únicas para distinção

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 71
Todas as threads em um mesmo grid executam o mesmo kernel Necessidade de haver coordenadas únicas para distinção
Coordenadas criadas pelo CUDA Runtime System:

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 72
Todas as threads em um mesmo grid executam o mesmo kernel Necessidade de haver coordenadas únicas para distinção
Coordenadas criadas pelo CUDA Runtime System: blockIdx índice do bloco

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 73
Todas as threads em um mesmo grid executam o mesmo kernel Necessidade de haver coordenadas únicas para distinção
Coordenadas criadas pelo CUDA Runtime System: blockIdx índice do bloco
threadIdx índice da thread

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 74
Todas as threads em um mesmo grid executam o mesmo kernel Necessidade de haver coordenadas únicas para distinção
Coordenadas criadas pelo CUDA Runtime System: blockIdx índice do bloco
threadIdx índice da thread
gridDim dimensão do grid

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 75
Todas as threads em um mesmo grid executam o mesmo kernel Necessidade de haver coordenadas únicas para distinção
Coordenadas criadas pelo CUDA Runtime System: blockIdx índice do bloco
threadIdx índice da thread
gridDim dimensão do grid
blockDim dimensão dos blocos
01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 76
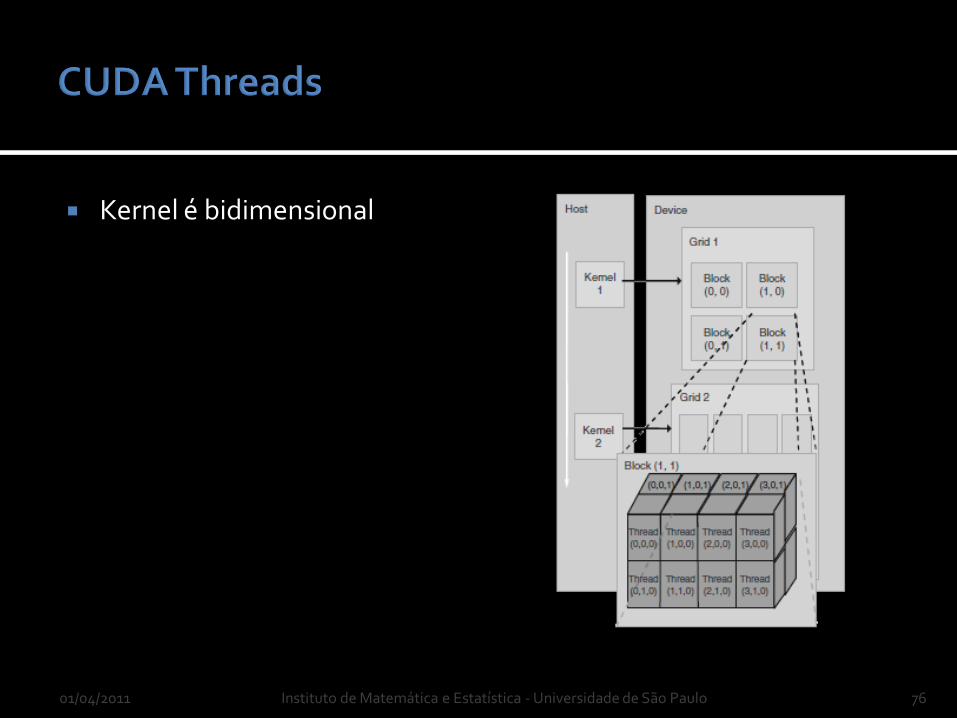
Kernel é bidimensional

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 77
Kernel é bidimensional
Indexação de bloco blockIdx.x blockIdx.y

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 78
Kernel é bidimensional
Indexação de bloco blockIdx.x blockIdx.y
Blocos são tridimensionais

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 79
Kernel é bidimensional
Indexação de bloco blockIdx.x blockIdx.y
Blocos são tridimensionais
Indexação de thread threadIdx.x
threadIdx.y
threadIdx.z

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 80

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 81
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 82

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 83
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
Comunidade GPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 84
01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 85
Universidades brasileiras ensinando CUDA

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 86
Centro Nacional de Processamento de Alto Desempenho

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 87
Introdução CPU X GPU GPGPU
Arquitetura GPU moderna Compute Capability NVIDIA Fermi
CUDA Arquitetura Modelo de programação Modelo de memória Modelo de execução
CUDA C ModeIo de Computação Heterogênea Kernels CUDA Memories CUDA Threads Libs
ComunidadeGPGPU
Referências

01/04/2011 Instituto de Matemática e Estatística - Universidade de São Paulo 88
CUDA by example, an introduction to General-Purpose GPU Programming, J. Sanders and E. Kandrot, Addison Wesley.
CUDA Zone (http://www.nvidia.com/object/cuda home new.html), Março 2011.
GPUBrasil (http://gpubrasil.com), Março 2011.
Optimization principles and application performance evaluation of a multithreaded gpu using cuda. Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen mei W. Hwu. In PPoPP, pages73-82. ACM, 2008.
NVIDIA CUDA C Best Practices Guide. NVIDIA, Version 3.2, 20/8/2010.
NVIDIA CUDA C Programming Guide. NVIDIA, Version 3.2, 11/9/2010.
Programming Massively Parallel Processors: A Hands-on Approach, D. Kirk, W. Hwu, Morgan Kaufman.
The GPU Computing Era. J. Nickolls and W. Dally. IEEE Micro, 30(2):56–69, 2010.
The Top 10 Innovations in the New NVIDIA Fermi Architecture, and the Top 3 Next Challenges. David Patterson, September 30, 2009.
NVIDIA's Next Generation CUDA Compute Architecture: Fermi. NVIDIA Whitepaper, Version 1.1.

Introdução à Computação de Alto Desempenho Utilizando GPU
Seminário de Programação em GPGPU
Eng. Thársis T. P. [email protected]
Instituto de Matemática e Estatística - Universidade de São Paulo





























