Embed Size (px)
Citation preview

1
Modelagem e Simulação de um Sistema de Aprendizado de Reforço
para Robôs
André Luiz Carvalho Ottoni
(UFSJ) – [email protected]
Rubisson Duarte Lamperti
(UFSJ) – [email protected]
Erivelton Geraldo Nepomuceno
(UFSJ) – [email protected]
Marcos Santos de Oliveira
(UFSJ) – [email protected]
Fernanda Felipe de Oliveira
(UFSJ) – [email protected]
Resumo: Este trabalho apresenta a modelagem e simulação de um sistema de aprendizado
por reforço para um sistema multiagente (multirrobô) cooperativo. A plataforma adotada é o
futebol de robôs simulado da Robocup. A metodologia de desenvolvimento adotada consiste
das etapas: definição das ações dos agente; definição dos estados do ambiente; definição da
matriz de recompensa imediata; implementação no simulador RcSoccerSim. Além disso, é
proposta uma análise da evolução do aprendizado do time de robôs, através da adoção do
índice de aprendizado.
Palavras-chave: Modelagem; Simulação; Aprendizado por Reforço; Multiagente; Robôs.
1. Introdução
As máquinas inteligentes ou robôs estão cada vez mais presentes na sociedade e nas
indústrias. Participam de operações que necessitam de alta precisão. Além disso, poupam o
esforço e a vida humana ao executar tarefas consideradas perigosas. A complexidade de
algumas tarefas pode se tornar ainda maior quando se trata de máquinas autônomas, ou seja,
máquinas capazes de estabelecerem ações devido a eventos dinâmicos imprevisíveis (Kim e
Oh, 2010).
Em algumas indústrias os robôs participam dos processos de produção e são
importantes para garantir o sucesso final da tarefa. Mas para garantir um produto de
qualidade, é necessário que esses robôs estejam programados de forma eficiente.
Os robôs podem realizar tarefas individualmente ou por cooperação, dependendo da
dificuldade para alcançar o objetivo. No caso de tarefas por cooperação, os agentes devem
trabalhar em conjunto, sendo que cada um dos deles tem um papel no trabalho, formando os
chamados sistemas multiagentes.
As pesquisas em Inteligência Artificial buscam o desenvolvimento de robôs
autônomos ou agentes inteligentes. Para isso, são estudas diversas técnicas, como Redes
Neurais Artificiais, Lógica Fuzzy, Processos de Markov e o Aprendizado por Reforço (AR).
O Aprendizado por Reforço é uma técnica de aprendizado de máquina, na qual o agente

2
aprende por meio de interação direta com o ambiente e seu algoritmo converge para uma
situação de equilíbrio (Sutton and Barto, 1998). No AR, um agente pode aprender em um
ambiente não conhecido previamente, por meio de experimentações. Dependendo de sua
atuação, o agente recebe uma recompensa ou uma penalização e, desta forma, o algoritmo
encontra um conjunto de ações que levam o agente a percorrer o caminho ótimo. A este
conjunto, formado pelas melhores ações, dá-se o nome de política ótima.
Um aspecto importante das pesquisas que envolvem o AR é a decisão de quando parar
o processo de otimização. Ou seja, definir quando os agentes devem continuar aprendendo ou
se as experiências acumuladas já são suficientes. Baseado nisso, este trabalho propõe uma
análise da evolução do desempenho de um sistema multiagente cooperativo que utiliza o
algoritmo Q-learning de Aprendizado por Reforço, através do índice de aprendizagem.
O estudo de caso é a modelagem e simulação de um sistema de aprendizado por
reforço para um sistema multiagente (multirrobô) cooperativo. A plataforma adotada é o
futebol de robôs simulado em duas dimensões da Robocup.
2. Conceitos Preliminares
2.1 Sistemas Multiagentes
Os sistemas multiagentes constituem um campo relativamente novo nas ciências da
computação. Embora o início da investigação neste campo se tenha dado nos anos 80, só em
meados dos anos 90 esta ganhou uma notoriedade digna de destaque (Wooldridge, 2002).
Um agente pode ser definido de várias formas. Será adotada uma definição bem
abrangente (Ferber e Gasser, 1991), que considera tanto agentes físicos ou agentes virtuais.
“Um agente é uma entidade real ou virtual, capaz de agir num ambiente, de se
comunicar com outros agentes, que é movida por um conjunto de inclinações (sejam objetivos
individuais a atingir ou uma função de satisfação a otimizar); que possui recursos próprios;
que é capaz de perceber seu ambiente (de modo limitado); que dispõe (eventualmente) de uma
representação parcial deste ambiente; que possui competência e oferece serviços; que pode
eventualmente se reproduzir e cujo comportamento tende a atingir seus objetivos utilizando as
competências e os recursos que dispõe e levando em conta os resultados de suas funções de
percepção e comunicação, bem como suas representações internas.”
Outras características efetivam a caracterização de um agente (Huhns e Singh 1997)
como: autonomia de decisão, autonomia de execução, competência para decidir e existência
de uma agenda própria (lista de objetivos que concretizam suas metas).
Um processo de cooperação consiste basicamente em distribuir metas, planos e tarefas
em uma comunidade de agentes. Para que haja cooperação entre os agentes, estes precisam
saber o objetivo desse processo de cooperação e como cooperar eficientemente. O agente
pode construir uma infinidade de estratégias para alcançar o objetivo por meio de um
conjunto de ações que podem ser realizadas. A cooperação é atingida não apenas pela
condução de ações individuais, mas principalmente pela execução compartilhada dos planos,
assim como por meio de um planejamento conjunto (Axelrod e Hamilton, 1981).
2.2 Aprendizagem de Máquina

3
A ideia por trás da aprendizagem é que as percepções devem ser usadas não apenas
para agir, mas também para melhorar a habilidade do agente para agir no futuro. A
aprendizagem ocorre à medida que o agente observa suas interações com o mundo e com seus
próprios processos de tomada de decisão. O tipo de realimentação disponível para
aprendizagem normalmente é o fator mais importante na determinação da natureza do
problema de aprendizagem que o agente enfrenta.
O campo de aprendizagem de máquina costuma distinguir três casos: aprendizagem
supervisionada, não supervisionada e por reforço. O problema de aprendizagem
supervisionada envolve a aprendizagem de uma função a partir de suas entradas e saídas. Já a
aprendizagem não supervisionada envolve a aprendizagem de padrões na entrada, quando não
são fornecidos valores se saída específicos. Enquanto na aprendizagem por reforço, em vez de
ser informado sobre o que fazer por um instrutor, um agente de aprendizado por reforço deve
aprender a partir do reforço (recompensa) (Russel e Norving, 2004).
2.3 Aprendizado Por Reforço
A Aprendizagem por Reforço (AR) é um formalismo da IA que permite a um agente
aprender a partir da sua interação com o ambiente no qual ele está inserido (Watkins, 1989;
Neri, 2011).
A ideia central da técnica de aprendizado por reforço é as percepções que são
utilizadas não apenas para agir, mas ao mesmo tempo, para melhorar a habilidade do agente
para agir no futuro. A aprendizagem ocorre à medida que o agente observa suas interações
com o ambiente e com seus próprios processos de tomada de decisão. Normalmente, o tipo de
realimentação disponível para o aprendizado é um fator importante na determinação da
natureza do problema (Russell and Norving, 2004).
As recompensas servem para definir políticas ótimas em processos de decisão de
Markov (PDMs). Uma política ótima é uma política que maximiza a recompensa total
esperada. A tarefa da aprendizagem por reforço consiste em usar recompensas para aprender
uma política ótima (Russell and Norving, 2004).
O aprendizado por reforço pode ser entendido com uma forma dos agentes aprenderem
o que fazer, particularmente quando não existe nenhum professor dizendo ao agente que ação
ele deve executar em cada circunstância. Para isso, o agente precisa saber que algo de bom
aconteceu quando ganhar, e que algo de ruim aconteceu quando perder. Essa espécie de
realimentação é chamada de recompensa ou reforço (Russell and Norving, 2004).
2.3.1 Algoritmo Q-learning
O método de aprendizagem por reforço mais popular é o Q-learnig (Watkins, C. J. &
Dayan, P. (1992)). Trata-se de um algoritmo que permite estabelecer autonomamente uma
política de ações de maneira interativa. O algoritmo Q-learning converge para um
procedimento ótimo (Russell and Norving, 2004).
A ideia básica do Q-learning é que o algoritmo de aprendizagem aprende um função
de avaliação ótima sobre todo o espaço de pares estado-ação SxA. Desde que o
particionamento do espaço de estados do robô e do espaço de ações não omita e não
introduzam novas informações relevantes. Quando a função ótima Q for aprendida, o agente

4
saberá qual ação resultará na maior recompensa em uma situação particular s futura
(Monteiro, 2004).
A função Q(s,a), da recompensa futura esperada ao se escolher a ação a no estado s, é
aprendida através de tentativa e erro segundo a equação a seguir:
] , (1)
onde é a taxa de aprendizagem, r é a recompensa, resultante de tomar a ação a no estado s,
é fator de desconto e o termo é a utilidade do estado s
resultante da ação a, obtida utilizando a função Q que foi aprendida até o presente. A função
Q representa a recompensa descontada esperada ao se tomar uma ação a quando visitando o
estado s, seguindo-se uma política ótima desde então (Monteiro, 2004).
A forma procedimental do algoritmo Q-learning é (Monteiro, 2004):
Para cada s,a inicialize Q(s,a)=0
Observe s
Repita
Selecione ação a usando a política de ações atual
Execute a ação a
Receba a recompensa imediata r(s,a)
Observe o novo estado s’
Atualize o item Q(s,a) de acordo com a equação (1)
s s’
Até que critério de parada seja satisfatório
2.4 Futebol de Robôs Simulado
A robótica reúne diversas áreas do saber e está presente em vários setores da
sociedade. Uma importante organização internacional que promove o desenvolvimento da
robótica é a RoboCup. Esta organização foi criada para promover a Inteligência Artificial
(IA), a robótica e campos correlacionados.
A categoria de simulação 2D da Robocup simula partidas de futebol de robôs
autônomos. O simulador apresenta características de um ambiente dinâmico, ruidoso,
cooperativo e coordenado (Fraccaroli, 2010). Nesta liga não existem robôs/agentes físicos,
todo o ambiente e os agentes são virtuais. O simulador fornece aos agentes todos os dados que
são obtidos na realidade por meio de sensores e calcula o resultado das ações de cada agente.
A simulação 2D permite definir as estratégias de jogo para um time de robôs formado por
doze agentes, 11 jogadores e o técnico.
Cada partida realizada tem duração de aproximadamente dez minutos valor este
correspondente a seis mil ciclos de simulação, sendo separado em dois tempos de

5
aproximadamente cinco minutos (Fraccaroli, 2010). Na figura 1 é apresentado o ambiente
gráfico do simulador de futebol de robôs 2D da Robocup.
Figura 1: Imagem do Simulador Soccer Server da Robocup.
2.4.1 Time Base Agent2D (Helios Base)
O time Helios (Akiyama and Okayama, 2011) do Japão, foi o campeão da categoria de
simulação 2D da Robocup em 2010. Os desenvolvedores resolveram disponibilizar na internet
o código base do time. Essa iniciativa veio para facilitar o surgimento de novas equipes na
categoria de simulação 2D da Robocup. Foi escolhido utilizar o código base do Helios
(Agent2D), pois ele disponibiliza algumas habilidades básicas já implementas, como
interceptação de bola, chute, drible e movimentação. Além disso, já oferece implementado a
conexão com o RoboCup Soccer Server, servidor de execução dos jogos 2D da Robocup,
criada através de um socket, que possibilita enviar e receber mensagens.
3. Modelagem e Simulação da Estratégia de Aprendizagem
A metodologia adotada para a desenvolvimento da estratégia de aprendizagem é
dividida em quatro etapas, as quais são:
1. Definição e discretização das ações dos agentes;
2. Definição e discretização dos estados do ambiente no qual os agentes estão
inseridos;

6
3. Definição dos valores dos reforços da tabela R, para cada par Estado (S) X Ação
(A);
4. Implementação no Simulador RcSoccerSim da Robocup de Futebol de Robôs.
3.1 Definição das Ações dos Agentes
Nesta etapa são definidas as possíveis ações de um agente no campo de futebol de
robôs simulado. As ações abaixo são apenas para o agente com posse de bola.
1. Ação: Drible Rápido (Carregar a bola em direção ao gol com velocidade alta);
2. Ação: Drible Lento (Carregar a bola em direção ao gol com velocidade baixa);
3. Ação: Drible Normal (Carregar a bola em direção ao gol com velocidade normal);
4. Ação: Passe/Chute (Passar a bola para um companheiro ou chutar em gol);
5. Ação: Segurar a Bola (Prender a bola junto ao corpo);
6. Ação: Avançar com a Bola.
3.2 Definição dos Estados do Ambiente
A interação dos agentes com o mundo virtual é interpretado por meio dos estados do
ambiente. Nesses estados são definidas as características do ambiente durante uma partida de
futebol de robôs. As características levadas em consideração são o posicionamento dos robôs
da própria equipe com a posse da bola e a distância dos adversários.
Nos Estados de 1 a 3, o agente adversário mais próximo está posicionado atrás do robô
com bola em relação ao eixo X, ou seja, o X do oponente é menor. Já nos Estados de 4 a 6, o
agente adversário mais próximo está posicionado a frente do robô com bola em relação ao
eixo X, ou seja, o X do oponente _e maior.
1. Estado: Adversário Longe Atrás (A distância entre os dois agentes _e maior que 4.5
m);
2. Estado: Adversário Perto Atrás (A distância entre os dois agentes _e menor que 4.5
m e maior que 2.5 m);
3. Estado: Adversário Muito Perto Atrás (A distância entre os dois agentes _e menor
que 2.5 m);
4. Estado: Adversário Longe na Frente (A distância entre os dois agentes _e maior que
4.5m);
5. Estado: Adversário Perto na Frente (A distância entre os dois agentes _e menor que
4.5m e maior que 2.5 m);
6. Estado: Adversário Muito Perto na Frente (A distância entre os dois agentes _e
menor que 2.5 m).
3.3 Definição da Matriz de Recompensa Imediata

7
A matriz de recompensa imediata Estado (S) x Ação (A) é modelada e apresentada na
Tabela 1 de reforço (R), em que as linhas representam os estados do ambiente e as colunas as
ações que os agentes podem tomar. A Tabela 1 foi definida arbitrariamente, pautando na
expectativa de um time mais ofensivo.
Tabela 1: Matriz de Recompensa Imediata.
Estado/Ação A1 A2 A3 A4 A5 A6
E1 -1 -1 -1 20 -1 -1
E2 0 -1 0 -1 -1 0
E3 5 -1 -1 -1 -1 -1
E4 -1 -1 -1 20 -1 -1
E5 -1 5 0 0 -1 0
E6 -1 -1 -1 10 10 -1
3.4 Implementação no Simulador
A etapa de implementação da estratégia de aprendizagem por reforço foi realizada no
simulador Rc-SoccerSim de futebol de robôs em duas dimensões da Robocup. Para isso, foi
adotado como time base o Agent2D (Helios Base).
Os parâmetros do algoritmo Q-learning, a taxa de aprendizagem e o fator de desconto
foram fixados em 0,95. Para armazenar as informações aprendidas pelos robôs foi criado um
arquivo denominado q.txt. Nesse arquivo, a matriz Q (6x6) de aprendizado foi iniciada com
zero para cada par estado X ação, indicando a inexistência de inteligência no time antes da
primeira simulação.
O modelo apresentado visou apenas o aprendizado quando o agente estivesse com a
posse de bola. Dessa forma, somente um robô por vez acessa o arquivo q.txt, mas o
conhecimento de cada um dos agentes fica acumulado na Matriz Q. Resultando em uma
comunicação entre os jogadores denominada de Quadro-Negro. O Quadro-Negro é uma
estrutura comum a todos os agentes, no caso o q.txt, onde podem realizar a escrita e a leitura
das informações aprendidas por cada robô. Essa estrutura de comunicação visa acelerar o
aprendizado dos robôs, visto que, as experiências dos agentes de acumulam em uma única
estrutura.
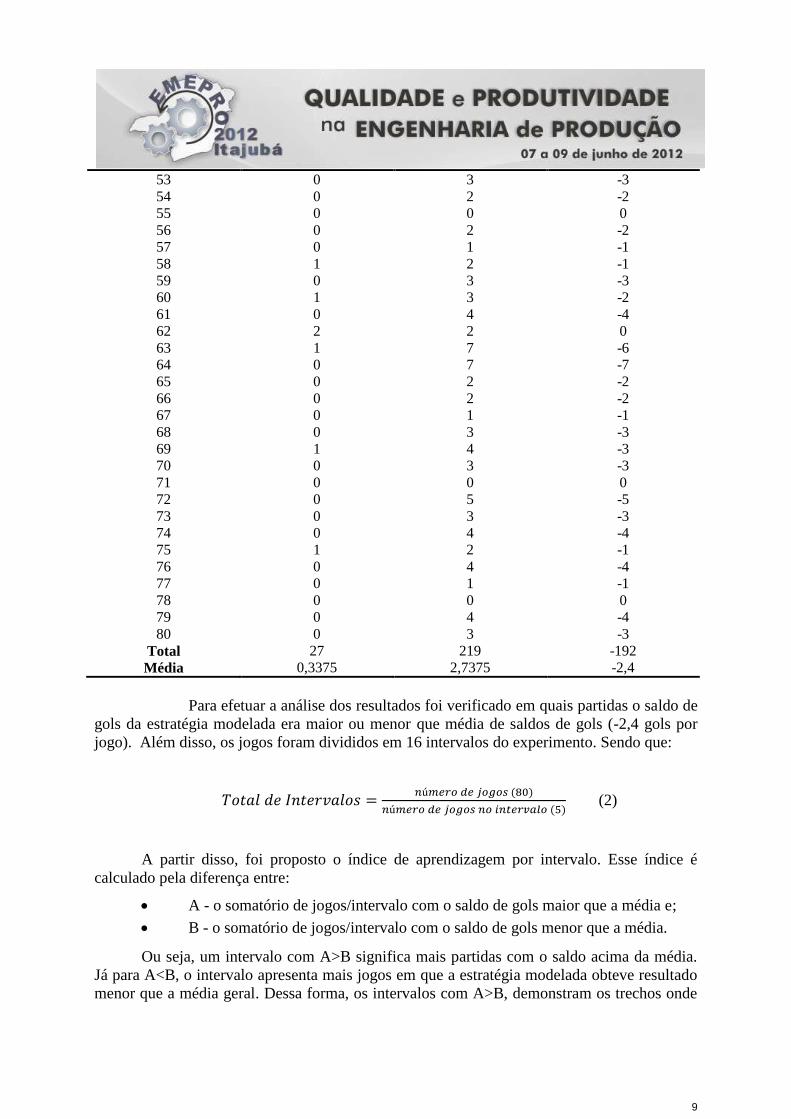
4. Análise dos Resultados
Procurou-se com este trabalho avaliar a evolução do aprendizado do time de robôs.
Para isso, foram simuladas 80 partidas de futebol de robôs na plataforma de RcSoccerSim. A
simulação foi feita adotando o Time Helios2011 como adversário para a estratégia modelada.
Ao final de cada partida foi armazenado o resultado final do jogo, ou seja, o número de gols
feitos por cada time. Os resultados seguem na Tabela 2:
Tabela 2: Resultado das Simulações.
Simulação Estratégia
Modelada
Helios2011 Saldo =
Gols Feitos – Gols
Sofridos
1 0 5 -5
2 1 6 -5

8
3 1 6 -5
4 0 1 -1
5 0 2 -2
6 0 1 -1
7 0 3 -3
8 0 3 -3
9 0 1 -1
10 1 3 -2
11 1 4 -3
12 0 3 -3
13 0 3 -3
14 1 4 -3
15 1 2 -1
16 1 3 -2
17 0 4 -4
18 0 3 -3
19 2 4 -2
20 0 2 -2
21 0 5 -5
22 0 2 -2
23 0 1 -1
24 1 4 -3
25 0 3 -3
26 2 1 1
27 0 1 -1
28 2 4 -2
29 1 1 0
30 0 4 -4
31 0 2 -2
32 0 3 -3
33 1 4 -3
34 0 1 -1
35 0 1 -1
36 1 2 -1
37 0 2 -2
38 0 2 -2
39 0 2 -2
40 0 3 -3
41 0 2 -2
42 0 2 -2
43 0 4 -4
44 1 3 -2
45 0 3 -3
46 1 4 -3
47 1 3 -2
48 0 2 -2
49 0 2 -2
50 0 0 0
51 0 2 -2
52 0 4 -4
9
53 0 3 -3
54 0 2 -2
55 0 0 0
56 0 2 -2
57 0 1 -1
58 1 2 -1
59 0 3 -3
60 1 3 -2
61 0 4 -4
62 2 2 0
63 1 7 -6
64 0 7 -7
65 0 2 -2
66 0 2 -2
67 0 1 -1
68 0 3 -3
69 1 4 -3
70 0 3 -3
71 0 0 0
72 0 5 -5
73 0 3 -3
74 0 4 -4
75 1 2 -1
76 0 4 -4
77 0 1 -1
78 0 0 0
79 0 4 -4
80 0 3 -3
Total 27 219 -192
Média 0,3375 2,7375 -2,4
Para efetuar a análise dos resultados foi verificado em quais partidas o saldo de
gols da estratégia modelada era maior ou menor que média de saldos de gols (-2,4 gols por
jogo). Além disso, os jogos foram divididos em 16 intervalos do experimento. Sendo que:
(2)
A partir disso, foi proposto o índice de aprendizagem por intervalo. Esse índice é
calculado pela diferença entre:
A - o somatório de jogos/intervalo com o saldo de gols maior que a média e;
B - o somatório de jogos/intervalo com o saldo de gols menor que a média.
Ou seja, um intervalo com A>B significa mais partidas com o saldo acima da média.
Já para A<B, o intervalo apresenta mais jogos em que a estratégia modelada obteve resultado
menor que a média geral. Dessa forma, os intervalos com A>B, demonstram os trechos onde

10
o time de robôs obteve uma sequência de melhores resultados finais nas partidas.
Direcionando então, a encontrar os pontos mais próximos de resultados ótimos.
A figura 2 apresenta o índice calculado para cada um dos 16 intervalos de
simulação. Além disso, pelo gráfico é possível observar a evolução do aprendizado do time de
robôs.
Figura 2: Índice de Aprendizagem por Intervalo de Simulação.
A partir do gráfico é possível concluir que:
Os intervalos de 1 até 3 apresentaram índices negativos. Ou seja, entre os jogos
1 a 15, a estratégia modelada apresentou uma predominância de resultados abaixo da média
geral. Nesse trecho, como ainda havia pouco conhecimento acumulado pelos robôs, isso é
explicado.
Os intervalos de 6 até 12 apresentaram índices positivos. Ou seja, entre os
jogos 31 a 60, a estratégia modelada apresentou uma predominância de resultados acima da
média geral. Nesse trecho, pode-se afirmar que o sistema de aprendizado obteve uma
convergência positiva. Essa convergência indica que o time de robôs soube utilizar o
conhecimento acumulado para conseguir os melhores resultados.
Os intervalos de 13 até 16 apresentaram índices negativos. Ou seja, entre os
jogos 61 a 80, a estratégia modelada apresentou uma predominância de resultados abaixo da
média geral. Nesse trecho, pode-se afirmar que o sistema de aprendizado obteve uma
convergência negativa. Essa convergência indica uma queda na evolução do aprendizado do
time de robôs com relação ao trecho anterior. Isso pode constatar o início de um processo de
perda de aprendizado.

11
5. Considerações Finais
A utilização dos robôs nas indústrias vem como uma forma de otimização de tarefas e
garantir a segurança dos trabalhadores em situações de alto risco. Por isso, os estudos em
robótica e inteligência artificial têm sido alvo de pesquisas importantes.
Este trabalho teve como meta investigar a evolução do aprendizado de robôs por meio
da técnica de aprendizado por reforço. O estudo de caso adotado foi o futebol de robôs
simulado, pois apresenta um ambiente dinâmico e cooperativo para os agentes.
O estudo deste trabalho partiu da modelagem da estratégia de aprendizado, a partir da
definição das ações dos agentes, estados do ambiente e matriz de recompensa imediata. Em
seguida, foram simulados 80 jogos na plataforma de futebol robôs RcSoccerSim da Robocup.
Sendo que, em cada jogo os robôs acumulavam o aprendizado, buscando otimizar os
resultados do time.
Na tentativa de analizar os resultados das simulações foi proposto o índice de
aprendizagem. Esse índice indica a predominância de uma sequência de resultados acima da
média de saldo gols (índice positivo) ou a predominância de resultados abaixo da média de
saldo de gols (índice negativo). Os calculos demostraram que entre as simulações 31 e 60 o
time de robôs obtiveram convergência positiva do índice. Ou seja, nesse trecho o sistema de
aprendizado mais aproximou de um controle ótimo dos robôs.
Em trabalhos futuros, serão simulados mais jogos para verificar se o sistema
multiagente alcançará novamente uma convergência positiva do índice de aprendizado. Ou se
o sistema continuará em declínio de aprendizado.
Referências
AKIYAMA, H. , SHIMORA H., NAKASHIMA, T., NARIMOTO, Y. AND OKAYAMA (2011). HELIOS2011
Team Description. In Robocup 2011.
AXELROD, R. E HAMILTON, W. D. (1981). The Evolution of Cooperation. Science, 211(4489):1390–1396.
FERBER, J. & L. GASSER (1991). Intelligence artificielle distribuée. Tutorial Notes of the 11th Conference on
Expert Systems and their Applitions (Avignon' 91), FR.
FRACCAROLI, E. S. (2010). Análise de Desempenho de Algoritmos Evolutivos no Domínio do Futebol de
Robôs, Dissertação apresentada à Escola de Engenharia de São Carlos da Universidade de São Paulo.
HUHNS, M. & M. SINGH (1997). Agents and multiagents systems: Themes, approaches and challenges. Em
Readings in Agents, pp. 1-13.
KIM, Y. C., C. S.-B. AND OH, S. R. (2010). Mapbuilding of a real mobile robot with ga-fuzzy controller.,
International Journal of Fuzzy Systems. pp. 696 - 703.
MONTEIRO, S. T. E RIBEIRO, C. H. C. (2004). Desempenho de algoritmos de aprendizagem por reforço sob
condições de ambiguidade sensorial em robótica móvel, Revista Controle & Automação Vol.15 no.3.
NERI, J. R. F, SANTOS, C. H. F E FABRO, J. A (2011). Descrição Do Time GPR-2D 2011. In: Competição
Brasileira de Robótica, 2011.
RUSSELL, S. J. AND NORVING, P. (2004). Inteligência Artificial., 2st edn, Campus.
SUTTON, R. AND BARTO, A. (1998). Reinforcement Learning: an introduction., 1st edn, Cambridge, MA:
MIT Press.
WOOLDRIDGE, M., JENNINGS, N., and KINNY, D. The Gaia Methodology for Agent-Oriented Analysis and
Design, International Journal of Autonomous Agents and Multi-Agent Systems, v. 3, 2000.

12
WATKINS, C. J. (1989). Models of Delayed Reinforcement Learning. PhD thesis, Psychology Department,
Cambridge University, Cambridge, United Kingdom.
WATKINS, C. J. E DAYAN, P. (1992). Technical note q-learning, Machine Learning .





























