Embed Size (px)
Citation preview

Modelos de Previsao para Populacoes Raras
e Agrupadas sob Amostragem Adaptativa
TESE DE DOUTORADO
por
Kelly Cristina Mota Goncalves
Universidade Federal do Rio de Janeiro
Instituto de Matematica
Departamento de Metodos Estatısticos

Modelos de Previsao para Populacoes Rarase Agrupadas sob Amostragem Adaptativa
Kelly Cristina Mota Goncalves
Tese de Doutorado submetida ao Corpo Docente do Instituto de Matematica -
Departamento de Metodos Estatısticos da Universidade Federal do Rio de Janeiro -
UFRJ, como parte dos requisitos necessarios a obtencao do grau de Doutor em Estatıstica.
Aprovada por:
Prof. Fernando A. S. Moura
PhD - UFRJ - Presidente.
Prof. Alexandra Mello Schmidt
PhD - UFRJ.
Prof. Mariane Branco Alves
PhD - UFRJ.
Prof. Heleno Bolfarine
PhD - USP.
Prof. Josemar Rodrigues
PhD - UFSCAR.
Rio de Janeiro, RJ - Brasil
2014
ii

CIP - Catalogação na Publicação
Elaborado pelo Sistema de Geração Automática da UFRJ com osdados fornecidos pelo(a) autor(a).
G635mGonçalves, Kelly Cristina Mota Modelos de Previsão para Populações Raras eAgrupadas sob Amostragem Adaptativa / KellyCristina Mota Gonçalves. -- Rio de Janeiro, 2014. 143 f.
Orientador: Fernando Antônio da Silva Moura. Tese (doutorado) - Universidade Federal do Riode Janeiro, Instituto de Matemática, Programa dePós-Graduação em Estatística, 2014.
1. Modelos de superpopulação. 2. Amostrageminformativa. 3. Modelos de mistura. 4. Inferênciabayesiana. I. Moura, Fernando Antônio da Silva,orient. II. Título.
iii

A minha maezinha e ao meu paizinho (in memorian),
meus orgulhos.
iv

“Quero falar de uma coisa
Adivinha onde ela anda
Deve estar dentro do peito
Ou caminha pelo ar
Pode estar aqui do lado
Bem mais perto que pensamos
A folha da juventude
E o nome certo desse amor
Ja podaram seus momentos
Desviaram seu destino
Seu sorriso de menino
Quantas vezes se escondeu
Mas renova-se a esperanca
Nova aurora, cada dia
E ha que se cuidar do broto
Pra que a vida nos de
Flor, flor, e fruto
Coracao de estudante
Ha que se cuidar da vida
Ha que se cuidar do mundo
Tomar conta da amizade
Alegria e muito sonho
Espalhados no caminho
Verdes, planta e sentimento
Folhas, coracao,
Juventude e fe.”
Coracao de estudante - Milton Nascimento.
v

Agradecimentos
Agradeco sempre em primeiro lugar a Deus pelo dom da vida e por iluminar meus
caminhos. Por estar ao meu lado em todos os momentos me protegendo e provendo varias
bencaos em minha vida. Sem Ele nada disso seria possıvel.
A minha maezinha Tereza por estar sempre ao meu lado cuidando de mim e torcendo
pelo meu sucesso. Agradeco por ser minha melhor companheira e por ter ajudado no dia-
a-dia para que eu pudesse dedicar-me exclusivamente a minha formacao academica nestes
anos. Ao meu paizinho Juarez (in memorian) pelo seu carinho e por ter se esforcado o
maximo para me dar educacao. Sei que no ceu o senhor esta em festa e como sempre
cheio de orgulho da sua Kellynha. Meus pais amados, essa vitoria tambem e de voces!
Agradeco tambem aos tios e primos pela torcida e por terem estado sempre ao meu
lado, principalmente nos momentos em que mais precisei.
Ao meu orientador Fernando Moura, por acreditar em mim e estar sempre disponıvel
para me ajudar. Meu crescimento durante estes 6 anos de trabalho juntos (entre mestrado
e doutorado) tambem se deve a voce.
Ao meu amorzinho Andres por sempre me apoiar em tudo e me dar o amor que muitas
vezes curou o meu estresse nestes anos. Obrigada por ser o anjinho que tornou meus dias
mais felizes nestes anos de muito estudo!
Aos professores do DME-UFRJ que passaram pela minha formacao academica
nestes anos. Em especial ao professor Helio Migon pela forca e oportunidade de
trabalhar juntos em outros assuntos, e a professora Alexandra Schmidt pela torcida de
sempre e por ter incentivado a minha entrada neste programa de pos-graduacao. Aos
vi

inesquecıveis professores do IM-UFRJ que ajudaram a formar minha base matematica
nesta instituicao.
Aos amigos que fiz durante estes anos de pos-graduacao no DME-UFRJ. Em especial,
a Panela Camila, Joao, Larissa e Renata pela torcida e amizade verdadeira. A minha
turma Gustavo, Joao, Jony e Larissa pelo companheirismo nas disciplinas cursadas. Aos
demais amigos Patrıcia, Mariana, Josiane, Vera (in memorian) e Felipe, veteranos que
estiveram sempre por perto. Agradeco a todos voces pelos inesquecıveis momentos que
passamos juntos. Grandes amizades que espero levar para toda a vida.
Agradeco tambem aos professores Alexandra Schmidt, Mariane Branco, Heleno
Bolfarine e Josemar Rodrigues por aceitarem participar desta banca.
Agradeco a CAPES pelo apoio financeiro, sem o qual nao seria possıvel realizar este
sonho. Ao GET-UFF pela flexibilidade, que me ajudou a exercer esta dupla jornada.
Agradeco tambem pelas experiencias academicas que tive no GET ao longo desses anos
e que me ajudaram a amadurecer em diversos aspectos.
Finalmente, agradeco a UFRJ, que tornou-se minha segunda casa nestes anos.
Quando entrei nesta instituicao era uma menina de 17 anos ainda em duvida sobre
sua carreira. Ao longo desses 9 anos aqui me graduei, encontrei uma area pela qual
me apaixonei, me tornei uma profissional e amadureci como pessoa. Sou profundamente
grata a esta instituicao por hoje ser quem eu sou.
Ao escrever estes Agradecimentos a emocao algumas vezes tomou conta de mim, isso
mostra a importancia desta conquista em minha vida. E um filme que passa na cabeca
neste momento. Obrigada a todos pela realizacao deste sonho!
vii

Resumo
Populacoes raras, como animais em extincao, pessoas infectadas por doencas raras,
usuarios de drogas, entre outros, tendem a distribuir-se de forma agrupada em regioes.
Em levantamentos estatısticos com populacoes deste tipo, em que o principal interesse
e estimar o total populacional, este comportamento dificulta o processo de obtencao de
informacao por meio de uma amostra aleatoria simples, tornando-se necessarios metodos
de amostragem complexos. Thompson (1990) propos um metodo eficiente para estas
situacoes, denominado amostragem adaptativa por conglomerados.
Por outro lado, Rapley e Welsh (2008) propuseram uma abordagem para inferencia em
populacoes deste tipo baseada em modelos. Sob o enfoque Bayesiano, o modelo proposto
e construıdo no nıvel agregado dos grupos e incorpora o planejamento da amostragem
adaptativa por conglomerados a verossimilhanca. Alem disso, supoe homogeneidade entre
todas as unidades, mesmo as pertencentes a grupos distintos, o que resulta na frequencia
esperada do total do fenomeno dentro de um grupo proporcional ao seu tamanho.
O objetivo deste trabalho e criar modelos alternativos para a previsao do total
populacional em uma determinada regiao. Inicialmente, o modelo agregado e estendido
para populacoes que evoluam dinamicamente. Em particular, o interesse esta em
populacoes raras que apresentam crescimento ou decrescimento dentro dos grupos ate
a estabilizacao com a evolucao do tempo.
Em seguida, o interesse e propor um modelo de mistura alternativo ao modelo
agregado, que contemple situacoes mais gerais. A proposta e formulada em um nıvel
desagregado da populacao, o que possibilita a insercao de estruturas com suposicoes
mais realistas, como a heterogeneidade entre grupos. O modelo e avaliado sob diversos
estudos de simulacao e, finalmente, aplicado ao plano amostral adaptativo duplo, o qual
e um plano que permite a extracao de mais informacoes acerca da populacao, mas sem
exceder os custos.
Palavras-chave: Amostragem informativa; modelos de mistura Poisson; RJMCMC.
viii

Abstract
Rare populations, such as endangered species, individuals infected by rare diseases and
drug users tend to cluster in regions. In many research studies with those populations,
where the main interest is to predict the population total, this behavior makes it difficult
the selection of a representative sample, making necessary complex sampling methods.
Thompson (1990) introduced an efficient method for these situations, called adaptive
cluster sampling.
On the other hand, Rapley e Welsh (2008) proposed a model-based approach to
make inference in those populations. From the Bayesian point of view, the proposed
model is built on the aggregated level of groups and takes into account the inclusion
probability of the adaptive sampling in the model likelihood. Furthermore, their model
supposes homogeneity between all units, even those belonging to different networks,
which is equivalent to assuming that the expected total in a group is proportional to its
size.
The aim of this work is to propose alternative models in order to predict the
population total in a region. Initially, the agregated model is extended to populations
that dinamically evolve. In particular, the interest is in rare populations which present
an increase or decrease within the groups, but stabilizes after some time.
Then, the interest is to propose a mixture model for more general situations,
alternative to the agregated model. The formulation of the model is done in the unit level,
what allows incorporating more realistic structures, such as the heterogeneity among units
belonging to different groups. The model is evaluated by carrying out some simulation
studies and finally applied to the adaptive cluster double sampling, which extracts more
informations about the population, without exceeding the costs.
Keywords: Informative sampling; Poisson mixture model; RJMCMC.
ix

Sumario
1 Introducao 1
1.1 Contribuicoes da tese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 Organizacao da tese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Inferencia em populacao finita 7
2.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Amostragem adaptativa por conglomerados . . . . . . . . . . . . . . . . . 9
2.2.1 Estimador do tipo Horvitz-Thompson modificado . . . . . . . . . 13
2.2.2 Amostragem estratificada adaptativa por conglomerados . . . . . 15
2.2.3 Amostragem adaptativa por conglomerados em dois estagios . . . 16
2.2.4 Custo operacional do plano amostral . . . . . . . . . . . . . . . . 16
2.2.5 Eficiencia do plano amostral . . . . . . . . . . . . . . . . . . . . . 18
2.3 Modelos de superpopulacao . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3.1 Desenho amostral informativo . . . . . . . . . . . . . . . . . . . . 21
2.4 Conclusoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3 Amostragem adaptativa por conglomerados baseada em modelos 25
3.1 Um modelo agregado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.1 Possıveis cenarios gerados pelo modelo . . . . . . . . . . . . . . . 29
3.1.2 Estudo simulado para alguns cenarios . . . . . . . . . . . . . . . . 30
3.1.3 Estudo simulado com populacao real . . . . . . . . . . . . . . . . 37
3.2 Um modelo para populacoes moveis, em crescimento ou decrescimento . . 40
3.2.1 Amostragem adaptativa para populacoes moveis . . . . . . . . . . 41
x

3.2.2 Incorporando estrutura de crescimento e decrescimento ao modelo 43
3.2.3 Modelo de crescimento exponencial . . . . . . . . . . . . . . . . . 45
3.2.4 Estudo simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2.5 Comparacao do modelo de crescimento com outras abordagens . . 55
3.3 Conclusoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4 Modelo de mistura para populacoes raras e agrupadas sob amostragem
adaptativa 60
4.1 Uma revisao sobre modelos de mistura de distribuicoes . . . . . . . . . . 62
4.1.1 Inferencia Bayesiana em modelos de mistura . . . . . . . . . . . . 64
4.2 Modelo de mistura Poisson proposto . . . . . . . . . . . . . . . . . . . . 68
4.2.1 Distribuicao a priori para λ . . . . . . . . . . . . . . . . . . . . . 72
4.2.2 Inferencia para o modelo . . . . . . . . . . . . . . . . . . . . . . . 74
4.3 Estudo simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.3.1 Considerando diferentes configuracoes . . . . . . . . . . . . . . . . 81
4.3.2 Considerando diferentes nıveis de heterogeneidade . . . . . . . . . 84
4.3.3 Analise de sensibilidade da distribuicao a priori . . . . . . . . . . 88
4.4 Comparacao com o modelo agregado . . . . . . . . . . . . . . . . . . . . 91
4.4.1 Simulacao baseada no desenho amostral . . . . . . . . . . . . . . 92
4.4.2 Simulacao baseada no modelo . . . . . . . . . . . . . . . . . . . . 95
4.5 Modelo de mistura sob amostragem adaptativa dupla . . . . . . . . . . . 97
4.5.1 Amostragem adaptativa dupla . . . . . . . . . . . . . . . . . . . . 98
4.5.2 Modelo proposto sob amostragem dupla com variavel auxiliar
indicadora de presenca . . . . . . . . . . . . . . . . . . . . . . . . 99
4.5.3 Avaliacao do modelo proposto sob amostragem adaptativa e
adaptativa dupla . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.6 Conclusoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5 Conclusoes e trabalhos futuros 108
5.1 Trabalhos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
5.1.1 Planejamento amostral otimo . . . . . . . . . . . . . . . . . . . . 110
xi

A Resultados dos modelos ajustados no Capıtulo 3 112
A.1 Modelo (3.1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
A.2 Modelo de crescimento (3.4) . . . . . . . . . . . . . . . . . . . . . . . . . 116
B Calculos envolvidos na inferencia para o modelo proposto 118
B.1 Distribuicoes condicionais completas . . . . . . . . . . . . . . . . . . . . 118
B.2 Probabilidade de aceitacao do algoritmo RJMCMC . . . . . . . . . . . . 121
xii

Lista de Tabelas
3.1 RaEQM e RaVAR dos estimadores para α, β, γ e T , entre os valores
obtidos no ajuste usando a probabilidade de selecao da amostra na funcao
de verossimilhanca (3.3) e sem usa-la, sob 100 amostras artificiais. . . . 36
3.2 Estudo simulado com a populacao de marrecos da asa azul: eficiencia
relativa para o estimador do total populacional com base no desenho
amostral adaptativo (estimador de Horvitz-Thompson modificado) e no
ajuste do modelo (3.1), com relacao a amostragem aleatoria simples de
tamanho n. A eficiencia do estimador Bayesiano com relacao ao estimador
de Horvitz-Thompson tambem e apresentada na ultima coluna. . . . . . . 40
3.3 Sumario da distribuicao a posteriori dos parametros do modelo de
crescimento proposto: sao apresentados o EQM e EAM, a amplitude media
dos intervalos HPD de 95% e a probabilidade de cobertura para as 100
populacoes geradas. Os resultados estao separadas para as populacoes em
crescimento e decrescimento. . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.1 Analise da convergencia das cadeias a posteriori dos parametros do modelo
proposto supondo distribuicao a priori independente e dependente para λ
para uma populacao artificial. . . . . . . . . . . . . . . . . . . . . . . . . 78
4.2 Sumario a posteriori da estimacao pontual e intervalar dos parametros do
modelo proposto e de T sob as 500 simulacoes, para diferentes valores de
α, β e N = 200. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
xiii

4.3 Sumario a posteriori da estimacao pontual e intervalar dos parametros do
modelo proposto e de T sob as 500 simulacoes, para diferentes valores de
α, β e N = 400. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.4 Sumario a posteriori da estimacao pontual e intervalar dos parametros do
modelo proposto e de T sob as 500 simulacoes, para diferentes valores de
α, β e N = 600. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.5 Sumario para a estimacao pontual e intervalar dos parametros do
modelo e o total populacional para as 500 populacoes, variando o nıvel
de homogeneidade nas redes, a partir do valor do CV fixado para a
distribuicao de λ, para N = 400. . . . . . . . . . . . . . . . . . . . . . . 87
4.6 Analise da convergencia das cadeias com a distribuicao a posteriori dos
parametros dos modelos de mistura e agregado para a populacao real. . . 94
4.7 Sumario da estimacao pontual e intervalar do total populacional obtido do
ajuste do modelo de mistura e do modelo agregado. . . . . . . . . . . . . 95
4.8 Sumario a posteriori para a estimacao pontual e intervalar dos parametros
dos modelos sob as 500 simulacoes onde λ foi gerado de uma distribuicao
Gama com CV=50% e CV=25%, para N = 400 e (α, β) = (0.15, 0.10). . 96
4.9 Sumario a posteriori do total populacional T para os quatro planejamentos
considerados com base nas 500 amostras simuladas. . . . . . . . . . . . 104
4.10 Resumo das principais conclusoes acerca dos estudos simulados realizados
com o modelo de mistura proposto em (4.4). . . . . . . . . . . . . . . . . 107
xiv

Lista de Figuras
2.1 Ilustracao do procedimento de amostragem adaptativa por conglomerados
para uma populacao rara e agrupada distribuıda em uma regiao com 400
unidades. No painel a esquerda temos uma amostra inicial de n1 =
10 unidades representadas pelos quadrados em cinza. A partir desta
amostra, vizinhos sao adicionados a amostra sempre que ha pelo menos
uma observacao (pontos em preto) na unidade selecionada, configurando
finalmente o plano amostral da direita. . . . . . . . . . . . . . . . . . . . 11
2.2 Ilustracao dos conceitos importantes na amostragem adaptativa por
conglomerados: os quadrados com borda em negrito correspondem ao
conglomerado observado, os quadrados em cinza sao as unidades da
rede e a parte hachurada as unidades da borda. A unidade selecionada
inicialmente esta em cinza mais escuro. . . . . . . . . . . . . . . . . . . . 13
3.1 Populacoes artificiais geradas a partir do modelo proposto por Rapley e
Welsh (2008), para alguns valores fixos para os parametros α e β e para
γ = 10, numa grade regular de tamanho N = 400. . . . . . . . . . . . . . 31
3.2 Populacao real de marrecos da asa azul na regiao da Florida, nos Estados
Unidos, no ano de 1992, disposta numa grade regular de tamanho N = 200. 38
3.3 Ilustracao da evolucao dinamica de interesse de uma populacao rara e
agrupada numa regiao sobreposta a uma grade regular com N = 400
unidades. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
xv

3.4 Curvas de crescimento e decrescimento de interesse para αt, t = 1, . . . , 50.
Em (a) fixou-se a = −1.73, b = −1.41 e c = −0.15, e em (b) a = −2.20,
b = 0.94 e c = −0.15, o que resulta no parametro αt variando de 0.05 e
0.15 e de 0.2 a 0.1, respectivamente. . . . . . . . . . . . . . . . . . . . . . 47
3.5 Distribuicao a priori conjunta para o vetor (a, b)′. . . . . . . . . . . . . . 49
3.6 Sumario da distribuicao a posteriori de αt e do total populacional para
uma populacao em crescimento e decrescimento ao longo do tempo. Em
preto esta a media a posteriori de αt e total populacional Tt, t = 1, . . . , 50,
com intervalo HPD de 95% em cinza e valor verdadeiro em azul. . . . . . 54
3.7 Sumario da distribuicao a posteriori do total populacional a cada instante
de tempo T para 100 populacoes em crescimento e outras 100 em
decrescimento geradas. Sao apresentados os EQMR, EAR, probabilidade
de cobertura e amplitude media dos intervalos HPD de 95%. . . . . . . . 56
3.8 Comparacao do modelo proposto de crescimento exponencial (3.4) com o
ajuste independente ao longo do tempo do modelo (3.1). Em (a) estao
as probabilidades de cobertura dos intervalos HPD de 95%, em (b) a
amplitude media destes intervalos, em (c) esta a REQMR para cada
abordagem utilizada e em (d) as REQMR para todos os tempos incluindo
na comparacao o estimador de Horvitz-Thompson. . . . . . . . . . . . . . 58
4.1 Comparacao das medias da distribuicao de Poisson e Poisson truncada no
zero. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.2 Densidade a posteriori para alguns parametros do modelo proposto e para o
total populacional T com base em um dado artificial supondo distribuicao
a priori para λ independente. A linha vertical cheia representa o valor
verdadeiro e a linha pontilhada o intervalo HPD de 95%. . . . . . . . . . 79
4.3 Densidade a posteriori para alguns parametros do modelo proposto e para o
total populacional T com base em um dado artificial supondo distribuicao
a priori para λ dependente. A linha vertical cheia representa o valor
verdadeiro e a linha pontilhada o intervalo HPD de 95%. . . . . . . . . . 80
xvi

4.4 Erro relativo para λs e λs ao longo de 500 simulacoes, para N = 400 e
diferentes configuracoes de α e β. . . . . . . . . . . . . . . . . . . . . . . 85
4.5 Distribuicao a priori para λj usada nas simulacoes variando o valor do
CV da distribuicao. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
4.6 Sumario da distribuicao a posteriori de R assumindo diferentes
distribuicoes a priori para λ. As cruzes representam a mediana da
distribuicao a posteriori, o cırculo o valor verdadeiro de R e a linha o
intervalo HPD de 95%. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
4.7 EMQR para cada λj assumindo diferentes distribuicoes a priori para λ. Os
resultados com a distribuicao a priori independente sao representados pelos
cırculos vazios e a linha cheia, os resultados para a distribuicao dependente
com τ = 5 sao representados pelos triangulos e a linha tracejada, as cruzes
com a linha pontilhada representam os resultados quando τ = 10 e τ = 20
sao os cırculos cheios e a linha traco e ponto. . . . . . . . . . . . . . . . 90
4.8 EQMR, probabilidade de cobertura e amplitude media do intervalo HPD
de 95% para o total populacional T sob cada distribuicao a priori assumida
para λ e para cada valor de R fixado. Os cırculos vazios e a linha
representam os resultados para R = 5, os triangulos com a linha tracejada
quando R = 6 e as cruzes com a linha pontilhada para R = 7. . . . . . . 91
4.9 Traco das cadeias com a distribuicao a posteriori para α, β e T obtida do
ajuste do modelo de mistura (a) e do modelo agregado (b). A linha em
cinza representa o valor verdadeiro de T . . . . . . . . . . . . . . . . . . . 93
4.10 ER para T para as 500 amostras obtidos a partir do ajuste do modelo de
mistura e do modelo agregado. . . . . . . . . . . . . . . . . . . . . . . . . 95
4.11 Boxplot com o ER para T , a partir do modelo de mistura e do modelo
agregado para as 500 populacoes, tal que λ foi gerado de uma distribuicao
Gama com CV=50% e CV=25%. . . . . . . . . . . . . . . . . . . . . . . 97
4.12 Sumario a posteriori de λs2 para os planejamentos (i) e (ii-a) com base
nas 500 amostras simuladas. . . . . . . . . . . . . . . . . . . . . . . . . . 105
xvii

1.1 Tracos das cadeias dos parametros α, β, γ e total populacional T para um
dado artificial gerado fixando α = 0.05 e β ∈ 0.05, 0.1, 0.15, 0.2, com
respectivos valores verdadeiros em cinza. . . . . . . . . . . . . . . . . . . 113
1.2 Tracos das cadeias dos parametros α, β, γ e total populacional T para
um dado artificial gerado fixando α = 0.1 e β ∈ 0.05, 0.1, 0.15, 0.2, com
respectivos valores verdadeiros em cinza. . . . . . . . . . . . . . . . . . . 113
1.3 Tracos das cadeias dos parametros α, β, γ e total populacional T para um
dado artificial gerado fixando α = 0.15 e β ∈ 0.05, 0.1, 0.15, 0.2, com
respectivos valores verdadeiros em cinza. . . . . . . . . . . . . . . . . . . 114
1.4 Tracos das cadeias dos parametros α, β, γ e total populacional T para
um dado artificial gerado fixando α = 0.2 e β ∈ 0.05, 0.1, 0.15, 0.2, com
respectivos valores verdadeiros em cinza. . . . . . . . . . . . . . . . . . . 114
1.5 Sumario da distribuicao a posteriori dos parametros α, β, γ e T para
100 populacoes em 16 cenarios com amostra inicial de 5%N e 10%N . Em
(a) os triangulos representam as probabilidades de cobertura dos intervalos
HPD de 95% para a amostra de 5%, os cırculos cheios para a amostra de
10% e a linha tracejada em vermelho o nıvel nominal de 95%. Em (b)
estao o EQM para cada parametro e o EQMR para T . . . . . . . . . . . . 115
1.6 Sumario da distribuicao a posteriori de Θ e do total populacional para
uma populacao em crescimento ao longo do tempo. Em (a)-(e) estao os
tracos das cadeias da distribuicao a posteriori dos parametros a, b, c, β e
γ. De (f)-(j) estao os tracos das cadeias para os totais em alguns tempos.
A linha em cinza representa o valor verdadeiro usado na geracao dos dados
artificiais. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
1.7 Sumario da distribuicao a posteriori de Θ e do total populacional para
uma populacao em decrescimento ao longo do tempo. Em (a)-(e) estao
os tracos das cadeias da distribuicao a posteriori dos parametros a, b, c,
β e γ. De (f)-(j) estao os tracos das cadeias para os totais em alguns
tempos. A linha em cinza representa o valor verdadeiro usado na geracao
dos dados artificiais. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
xviii

Capıtulo 1
Introducao
Em diversos levantamentos estatısticos e possıvel deparar-se com dificuldades na
coleta de dados, devido ao objeto de estudo ser difıcil de ser observado. Isto pode ocorrer
simplesmente por ser um subconjunto pequeno da populacao toda, exibir um padrao de
grupos esparsamente distribuıdos numa regiao, ou ainda por apresentar uma mobilidade
ao longo do tempo. Sao alguns exemplos de populacoes com estas caracterısticas: animais
e plantas em extincao, minorias etnicas, usuarios de drogas, indivıduos com doencas
raras e imigrantes recentes numa regiao. Problemas de monitoramento de populacoes
raras tornaram-se uma prioridade para muitos orgaos publicos, como por exemplo o
monitoramento de especies ameacadas de extincao para as agencias de conservacao.
Em geral detectar e estimar a abundancia ou distribuicao de populacoes com estas
caracterısticas e uma tarefa difıcil.
Kalton e Anderson (1986) afirmam que populacoes raras sao definidas basicamente
como uma pequena fracao da populacao total, como por exemplo em estudos de
doencas raras, em que o interesse se concentra em grupos especıficos de sexo e idade.
No entanto, McDonald (2004) afirma que populacoes raras nao sao necessariamente
aquelas que possuem poucos indivıduos, e sim aquelas em que os indivıduos apresentam
comportamento elusivo ou estao esparsamente distribuıdos em grandes espacos. Nesta
abordagem estao as populacoes raras e agrupadas, as quais apresentam um padrao de
distribuicao espacial altamente concentrado, com grupos esparsos em uma regiao. Assim,
uma populacao com comportamento em forma de grupos espalhados em um espaco
1

geografico grande tem uma raridade geografica maior do que uma populacao de mesmo
tamanho confinada em um espaco geografico menor.
A amostragem de populacoes raras e uma tarefa ardua, porque os custos de localizacao
de tais populacoes sao substanciais e podem exceder os recursos disponıveis. Alem disso,
em geral, a densidade populacional media e pequena com relacao a area total, mas quando
uma abundancia substancial em alguns pontos e localizada, concentracoes em vizinhancas
tendem a ser detectadas, e ao aplicar-se um planejamento amostral tradicional, muitas
unidades podem apresentar zeros na contagem, enquanto a maior parte das unidades
com contagens diferentes de zero se mantem concentrada em alguns locais que nao foram
amostrados. Este fenomeno resulta em estimadores altamente imprecisos. Por esses
motivos, metodos especıficos tem sido desenvolvidos para a amostragem de populacoes
raras e agrupadas.
Em meio ao surgimento de diversas tecnicas de amostragem para populacoes raras,
como as revisadas em Sudman e Kalton (1986), Kalton e Anderson (1986) e Kalton
(2001), a amostragem proposta por Thompson (1990) ganhou destaque na literatura
como uma tecnica eficiente para levantamentos estatısticos em populacoes deste tipo.
Denominada como amostragem adaptativa por conglomerados, a tecnica aproveita a ideia
intuitiva de que se os elementos da populacao foram encontrados em uma area, as areas
vizinhas tem maior probabilidade de possuırem elementos com as mesmas caracterısticas.
Extensoes desta tecnica de amostragem podem ser vistas em Thompson e Seber (1996)
e Turk e Borkowski (2005).
Por outro lado, a biosfera esta constituıda de sistemas que mudam com o passar
do tempo, dependendo da organizacao do sistema e dos recursos disponıveis. Kalton
(1991) revisa metodos de amostragem para populacoes moveis. O estudo da dinamica
das populacoes naturais e importante para compreender o que ocorre nos ecossistemas em
equilıbrio. Da mesma forma, populacoes raras e agrupadas tambem podem apresentar
uma dinamica populacional ao longo do tempo e tal fator pode ser gerador de dificuldades
maiores ainda nos levantamentos estatısticos. McDonald (2004) apresenta estudos
por amostragem que produzem estimativas inadequadas simplesmente pelo fato do
pesquisador perder a populacao-alvo em um curto intervalo de tempo, devido ao grande
2

poder de deslocamento, mortes, entre outros fatores. Estudos acerca de populacoes de
animais selvagens constituem um campo de aplicacao que em muitos aspectos difere de
levantamentos com uma populacao de arvores, por exemplo. Os animais podem circular
e se esconder naturalmente, e alem disso o proprio processo de amostragem em si pode
induzir a esta mobilidade. Assim, um planejamento amostral eficiente pode nao existir
e a probabilidade de inclusao de um animal na amostra e calculada depois da amostra
ter sido planejada. Por isso, a probabilidade de obter erros amostrais e tambem maior
em pesquisas com uma populacao de animais ou outra com esta mesma caracterıstica.
Para estes e outros casos, um levantamento estatıstico por amostragem, que considera
esta dinamica da populacao e trabalha com coletas de amostras ao longo de um perıodo
de tempo, pode produzir resultados mais precisos que planejamentos que nao levem tal
dinamica em consideracao.
Todas as tecnicas citadas acima fundamentam-se na teoria de amostragem baseada
na aleatorizacao do desenho amostral, ou seja, o mecanismo probabilıstico de selecao da
amostra define um procedimento predeterminado de aleatorizacao, denominado desenho
amostral. Como apontado por Skinner et al. (1989), a principal razao desta abordagem
e sua caracterizacao como livre de distribuicao.
Em algumas situacoes especıficas, como em estimacao em pequenos domınios, esta
abordagem, baseada no desenho amostral, pode mostrar-se ineficiente, fornecendo
preditores inadequados. Isto porque neste caso, o tamanho da amostra resultante de
uma pesquisa e muito pequeno para que estimadores baseados somente no desenho
amostral apresentem precisao aceitavel. Alem disso, em termos de estimacao intervalar,
e necessario recorrer ao Teorema Central do Limite, o qual nao pode ser aplicado em
muitas situacoes praticas, em que o tamanho da amostra nao e suficientemente grande
e/ ou no caso em que suposicoes de independencia das variaveis aleatorias envolvidas
nao sao realistas. Uma possıvel solucao para estes casos e a utilizacao de modelos de
superpopulacao. Nesta abordagem sao usadas suposicoes explıcitas, buscando realizar
inferencia sobre a parte desconhecida, que nao seja baseada apenas na parte observada,
mas na distribuicao conjunta das variaveis de interesse.
3

Com base nestas ideias, e possıvel tambem fazer inferencia em populacoes raras e
agrupadas usando as tecnicas de amostragem citadas, mas sob a abordagem baseada
em modelos, em particular sob o enfoque Bayesiano. Nestes problemas a perspectiva
Bayesiana pode ter grandes vantagens sobre abordagens baseadas em desenho amostral
ou em modelos frequentistas, tais como: (i) podem-se obter estimativas para quantidades
para as quais a amostra coletada e pequena, incorporando informacoes a priori do
comportamento da populacao; (ii) a incerteza inerente ao procedimento de estimacao
e levada em consideracao na previsao, pois seguindo o paradigma de Bayes, e possıvel
obter uma distribuicao preditiva, entre outras.
Neste contexto, Rapley e Welsh (2008) propoem, de forma pioneira, um modelo,
sob o enfoque Bayesiano, que incorpora o planejamento da amostragem adaptativa por
conglomerados, a fim de inferir sobre o total populacional em uma regiao de interesse.
Uma caracterıstica importante de tal modelo e que a unidade de analise e dada por um
nıvel agregado de unidades menores, dessa forma trata-se de uma alternativa a introducao
das localizacoes espaciais, a fim de facilitar a inferencia. No entanto, nao incorporar
efeitos espaciais e estimar parametros populacionais em nıveis agregados pode trazer
perdas de informacoes de interesse em nıveis menores e na precisao das estimativas. Alem
disso, duas suposicoes fortes deste modelo sao que em media as unidades da populacao sao
homogeneas com relacao ao fenomeno de interesse e que o total esperado de ocorrencias
do fenomeno em um determinado grupo e proporcional ao tamanho deste grupo na regiao.
1.1 Contribuicoes da tese
O objetivo deste trabalho e fazer previsoes em populacoes raras, agrupadas e moveis
usando amostragem adaptativa por conglomerados, sob uma abordagem baseada em
modelos de superpopulacao, sob o enfoque Bayesiano.
Primeiramente, o interesse esta em estender o modelo de Rapley e Welsh (2008) com
o objetivo de fazer inferencias sobre populacoes dinamicas. Em particular, o interesse
esta em populacoes em crescimento ou decrescimento que atingem a uma estabilizacao
com a evolucao do tempo.
4

Em seguida, sem considerar evolucao no tempo, e proposto um modelo para
populacoes raras e agrupadas, alternativo ao de Rapley e Welsh (2008). baseado em
misturas de distribuicoes. Tal modelagem possibilita fazer inferencia em um nıvel
desagregado da populacao e suposicoes mais realistas, como por exemplo heterogeneidade
entre unidades que compoem grupos distintos.
Finalmente, esta proposta e estendida para problemas em que a amostragem
adaptativa por conglomerados torna-se muito custosa e faz-se necessario o uso de um
planejamento alternativo. Em particular, sera considerada a amostragem adaptativa
dupla por conglomerados proposta por Felix-Medina e Thompson (2004). Neste contexto,
e considerada tambem a insercao de variaveis auxiliares que podem ajudar na estimacao.
O software livre R (R Core Team, 2013) foi utilizado tanto para programar os
algoritmos quanto para a construcao dos graficos apresentados.
1.2 Organizacao da tese
No Capıtulo 2 e introduzida a notacao de amostragem de populacao finita, a qual
sera utilizada ao longo do texto, e e feita uma ampla revisao de literatura sobre
planos amostrais informativos, modelos de superpopulacao e amostragem adaptativa por
conglomerados.
No Capıtulo 3 e apresentado o modelo proposto por Rapley e Welsh (2008), descrito
acima, o qual serviu-nos de inspiracao para as propostas deste trabalho. Um estudo
simulado e apresentado, a fim de verificar o desempenho do modelo para alguns cenarios.
Alem disso, e apresentada uma populacao real, a qual e utilizada ao longo deste trabalho,
e em particular neste capıtulo, esta e usada em uma avaliacao do desempenho do modelo
em questao. Finalmente, e proposta uma extensao deste modelo para uma classe de
populacoes moveis e, em crescimento ou decrescimento, ao longo do tempo.
No Capıtulo 4 e proposto um novo modelo de mistura de probabilidades para previsao
em populacoes deste tipo. Este modelo e mais geral que o proposto por Rapley e Welsh
(2008) pois modela as unidades desagregadas, o que permite prever neste nıvel menor
e incorporar estruturas que acomodem suposicoes mais complexas para a populacao.
5

Alguns estudos simulados sao apresentados a fim de avaliar o desempenho do modelo
proposto. Experimentos baseados em modelos e desenho sao feitos com o objetivo
de comparar o modelo proposto neste trabalho com o modelo de Rapley e Welsh
(2008). Finalmente, e feita uma aplicacao do modelo de mistura ao planejamento
amostral apresentado em Felix-Medina e Thompson (2004), o qual permite a realizacao
de pesquisas com um custo mais controlado e o uso de variaveis auxiliares.
Finalmente, o Capıtulo 5 conclui o trabalho, resumindo o que foi desenvolvido e
apresentando propostas futuras.
6

Capıtulo 2
Inferencia em populacao finita
Neste capıtulo sao apresentados a notacao e definicoes importantes na teoria de
amostragem de populacao finita que serao utilizadas ao longo deste trabalho. Neste
contexto, existem duas possıveis abordagens: (i) a baseada na aleatorizacao do desenho
amostral, com a populacao fixa, e (ii) modelos de superpopulacao (detalhes em Bolfarine
e Zacks (1992)). Na Secao 2.1 a primeira abordagem e apresentada. Em particular,
a Secao 2.2 apresenta um plano amostral utilizado para populacoes raras e agrupadas
proposto por Thompson (1990) e algumas extensoes. Finalmente, na Secao 2.3 a segunda
abordagem e apresentada, com enfase a modelos, para os quais o planejamento amostral
e relevante para a analise Bayesiana do modelo.
2.1 Introducao
Segundo Cassel et al. (1977), uma populacao finita e uma colecao de N unidades
denotada pelo conjunto de ındices P = 1, . . . , N, para a qual temos interesse numa
caracterıstica y, para N supostamente conhecido. Associada a unidade i, i = 1, . . . , N ,
tem-se o valor yi. Se a unidade i e observada, nao e somente o valor de yi que e registrado
mas, tambem, o fato de que foi exatamente a unidade i que gerou essa medida. Denote
a observacao completa pelo par (i, yi) e, portanto, existem N pares, (i, yi), i = 1, . . . , N ,
para a populacao toda.
7

Defina y = (y1, . . . , yN)′ como o parametro populacional da populacao finita. Por
exemplo, o numero de pessoas com alguma doenca em N bairros, ou o numero de animais
de uma determinada uma especie em N localizacoes. No contexto de populacoes finitas,
em geral o objetivo e estimar funcoes de y, como por exemplo o total populacional
T =∑N
i=1 yi = 1′Ny, onde 1N e o vetor unitario de dimensao N×1, a media populacional
µ = T/N e a variancia populacional σ2 =∑N
i=1 (yi − µ)2/N . Em particular, o interesse
neste trabalho concentrar-se-a em estimar o total populacional.
A inferencia sobre estes parametros e feita com base em informacoes obtidas sobre
o vetor y por meio de uma amostra ordenada s ⊂ P , de tamanho n, dada por s =
i1, . . . , in. A amostragem de populacao finita baseada na aleatorizacao do desenho
amostral distingue-se de outras partes da estatıstica, pois trata a populacao de forma
fixa. Nesta abordagem, o mecanismo probabilıstico de selecao da amostra define um
procedimento predeterminado de aleatorizacao, denominado desenho amostral. Este e
representado por uma funcao de probabilidade, conhecida como planejamento amostral,
definida no conjunto S de todas as possıveis amostras s, onde [s] fornece a probabilidade
de selecionar a amostra s. Um desenho amostral [.] e chamado nao informativo se, e
somente se, [.] e uma funcao que nao depende dos valores de y associados a s. Denote
um planejamento amostral informativo por [s | y].
Uma vez que s e selecionada, o resultado observado pode ser especificado como o
conjunto de pares d = (i, yi) : i ∈ s. Em alguns casos, o interesse esta apenas nos
valores de y e nao no par completo, por isso defina ys = yi : i ∈ s. Sejam s = P − s e
portanto ys = yi : i ∈ P − s, os valores de y que nao pertencem a amostra.
Neste contexto, um conceito importante que vira a facilitar expressoes mais a frente
e o conceito de consistencia. De acordo com Cassel et al. (1977), uma amostra s e
dita consistente com uma particular populacao y0 = (y01, . . . , y
0N)′ se, e somente se,
yi = y0i para todo i ∈ s. Em outras palavras uma amostra e consistente com uma
particular populacao se, e somente, se os valores de y das unidades amostradas coincidem
com os valores de y das mesmas unidades na populacao. Dessa forma, para qualquer
planejamento amostral dado por [.] e, qualquer vetor populacional y, tem-se que a
8

probabilidade de uma quantidade aleatoria D tomar um valor d e dada por: [s], se
s e consistente com y e 0, caso contrario.
Analogamente, pode-se definir I como o vetor de dimensao N indicador de inclusao
na amostra s ⊂ S, de cada unidade da populacao, isto e Ii = 1 se i ∈ s e Ii = 0 se
i /∈ s. Note que Ii segue uma distribuicao de Bernoulli com probabilidade de sucesso
πi, i = 1, . . . , N, tal que πi e a probabilidade de inclusao da unidade i na amostra.
Assim, por exemplo, o estimador de Horvitz-Thompson (Horvitz e Thompson (1952))
para o total T e sua variancia podem ser escritos como:
THT =N∑i=1
yiIiπi, V (THT ) =
N∑i=1
1− πiπi
y2i + 2
N∑i=1
∑j>i
πij − πiπjπiπj
yiyj, (2.1)
tal que πij representa a probabilidade de inclusao das unidades i e j conjuntamente na
amostra.
A outra tecnica usada na inferencia em populacoes finitas e a baseada em modelos
de superpopulacao, na qual a amostra permanece fixa, e as observacoes populacionais
sao representadas por realizacoes de variaveis aleatorias, e a inferencia se refere a uma
superpopulacao hipotetica, na qual uma lei de probabilidade governa as variaveis de
interesse. Esta metodologia tambem sera vista com detalhes na Secao 2.3.
Na proxima secao e apresentado um planejamento amostral especıfico, voltado para
levantamentos em populacoes raras e agrupadas.
2.2 Amostragem adaptativa por conglomerados
Em pesquisas dentro de regioes pode-se sobrepor uma grade regular e a selecao da
amostra envolve a selecao de um subconjunto de celulas da grade. Para populacoes
esparsas e agrupadas, a maioria das amostras de tamanho pequeno consistem de celulas
vazias, resultando em muitas amostras que geram estimativas imprecisas da quantidade
de interesse. A amostragem adaptativa por conglomerados e uma alternativa para esta
dificuldade pois trata-se de um planejamento voltado para populacoes raras e agrupadas.
Proposta inicialmente por Thompson (1990), o metodo mostrou-se eficiente em pesquisas
epidemiologicas, sobre doencas raras, com animais, plantas e de carater social.
9

A tecnica utiliza informacoes dos valores observados para ter mais exito na coleta
de unidades da populacao, aumentado assim a eficiencia dos estimadores. Isso se deve
ao fato de que se espera ser mais provavel encontrar um elemento com caracterısticas
semelhantes a outro na sua vizinhanca, quando a populacao e agrupada. Dessa forma,
este desenho caracteriza-se como informativo, pois a probabilidade de selecao da amostra
depende dos valores de y.
Na Figura 2.1 o metodo e ilustrado para uma populacao distribuıda em uma regiao
particionada em uma grade regular no plano com N = 400 quadrados. Assim como
em Thompson (1990), defina os quadrados como unidades de observacao primaria e a
vizinhanca de um quadrado como o conjunto de quadrados que apresentam um lado
contıguo a este. Daqui em diante no lugar do termo quadrado sera utilizado unidade. O
procedimento de amostragem inicia-se com a amostragem aleatoria simples sem reposicao
de n1 = 10 unidades, as quais estao dispostas em cinza na grade. Suponha que uma
unidade e classificada como de interesse se pelo menos uma observacao e encontrada
nesta. Note que das 10 unidades selecionadas, apenas 2 satisfazem esta condicao. Em
seguida, as unidades vizinhas a estas 2 unidades sao tambem incluıdas na amostra.
O processo continua ate que todas as unidades vizinhas com observacoes de interesse
sejam adicionadas a amostra e finaliza nas unidades vizinhas que nao apresentem tais
observacoes. Observe na Figura 2.1 a direita o processo finalizado com n = 45 unidades
amostrais, representados pelas unidades em destaque.
Ainda que no exemplo descrito na Figura 2.1, a vizinhanca tenha sido definida dessa
forma, outros tipos de vizinhancas podem ser consideradas, como por exemplo uma grade
sistematica em torno da unidade inicial, ligacoes geneticas e sociais no caso de populacoes
humanas, entre outras.
A condicao para adicao de vizinhos a amostra pode ser tambem definida de forma
mais geral como ter mais observacoes que um numero mınimo fixado.
Alem disso, note que a medida que as unidades vizinhas sao agregadas a amostra,
em torno da primeira unidade selecionada e formado um grupo de unidades amostrais,
estes grupos formados sao denominados conglomerados. Tal conglomerado so tem sua
fronteira finalizada ate que vizinhos observados nao satisfacam a condicao de interesse,
10

Figura 2.1: Ilustracao do procedimento de amostragem adaptativa por conglomerados para
uma populacao rara e agrupada distribuıda em uma regiao com 400 unidades. No painel a
esquerda temos uma amostra inicial de n1 = 10 unidades representadas pelos quadrados
em cinza. A partir desta amostra, vizinhos sao adicionados a amostra sempre que ha
pelo menos uma observacao (pontos em preto) na unidade selecionada, configurando
finalmente o plano amostral da direita.
portanto todo conglomerado e formado por unidades na fronteira que nao satisfazem tal
condicao. Estas unidades sao chamadas unidades de borda. Se uma unidade selecionada
na amostra inicial nao e de interesse, nao ha acrescimos de vizinhos na amostra a partir
desta unidade.
Um conglomerado, descontadas as unidades de borda, e denominado rede. Note
que neste planejamento uma rede e sempre a mesma, independente da unidade da rede
selecionada na amostragem inicial.
Embora as unidades da amostra inicial selecionadas via amostragem aleatoria simples
sem reposicao sejam distintas, selecoes repetidas podem ocorrer na amostra final quando
um conglomerado inclui mais de uma unidade na amostra inicial. Ou seja, se duas
unidades que nao sejam de borda no mesmo conglomerado sao selecionadas inicialmente,
entao este conglomerado pode ocorrer duas vezes na amostra final. Uma unidade i da
11

populacao pode ser incluıda na amostra tanto se qualquer unidade da rede a qual i
pertence e selecionada na amostra inicial, ou se qualquer unidade da rede a qual i e
uma unidade de borda e selecionada. Por definicao as unidades que nao satisfazem a
condicao de interesse, assim como as unidades de borda, sao tambem redes de tamanho
1. Portanto, uma amostra adaptativa por conglomerados, que se inicia com a selecao sem
reposicao de n1 unidades iniciais, tem no final um numero de redes nao vazias distintas
sempre menor ou igual a n1, mas note que o tamanho final da amostra e uma variavel
aleatoria e, portanto, nao pode ser fixado.
A fim de ilustrar os conceitos de conglomerado, de rede e unidades de borda descritos,
na Figura 2.2 esta uma parte da amostra vista na Figura 2.1. Os quadrados com borda
em negrito correspondem ao conglomerado observado, os quadrados em cinza compoem
a rede nao vazia e a parte hachurada sao as unidades da borda. A unidade selecionada
inicialmente esta em cinza mais escuro.
Em geral, as redes e que sao usadas como unidades de analise no lugar das celulas
da grade, pois as celulas da grade dentro de redes tem uma estrutura de dependencia
e trabalhar no nıvel de rede permite-nos evitar fazer esta estrutura de dependencia de
forma explıcita.
Segundo Cassel et al. (1977) um desenho amostral e chamado nao informativo ou
ignoravel se, e so se, a funcao planejamento amostral [.] nao depende dos valores de y
associados aos ındices em s. Desenhos informativos podem afetar as inferencias quando
sao erroneamente ignorados. Note que o desenho adaptativo e informativo, pois a
probabilidade de selecao de uma amostra depende dos valores da variavel de interesse.
Este tipo de planejamento sera descrito com mais detalhes na Secao 2.3.
Estimadores convencionais sob este planejamento amostral tendem a ser viesados,
pois as unidades com observacao de interesse sao amostradas desproporcionalmente. Com
base nesta ideia, Thompson (1990) obteve um estimador nao viesado sob este desenho
amostral para a media populacional, o qual esta brevemente descrito a seguir.
12

Figura 2.2: Ilustracao dos conceitos importantes na amostragem adaptativa por
conglomerados: os quadrados com borda em negrito correspondem ao conglomerado
observado, os quadrados em cinza sao as unidades da rede e a parte hachurada as unidades
da borda. A unidade selecionada inicialmente esta em cinza mais escuro.
2.2.1 Estimador do tipo Horvitz-Thompson modificado
Thompson (1990) apresentou um estimador nao viesado para a media populacional
que corresponde a uma modificacao do estimador de Horvitz-Thompson, no qual cada
observacao yi na unidade amostral e dividida pela sua probabilidade de inclusao. Em
particular, sera descrito a seguir o estimador do total populacional, que e uma simples
transformacao da media.
Nesse caso uma unidade i e incluıda na amostra se qualquer unidade da rede a qual
i pertence (incluindo ela mesma) e observada na amostra inicial, ou se qualquer unidade
da rede a qual i e uma unidade de borda e selecionada. Dessa forma, defina ai como o
numero de unidades na rede para os conglomerados em que i e uma unidade de borda e
ci como o numero de unidades na rede que contem i. Note que se i satisfaz a condicao
de interesse, ou seja se i e uma unidade em cinza na Figura 2.2, tem-se ai = 0 e ci = 10.
Mas se i nao satisfaz a condicao de interesse, ou seja se i e uma unidade hachurada na
Figura 2.2, ci = 1 e ai = 10.
13

A probabilidade de inclusao da unidade i para qualquer uma das n1 selecoes e dada
por
πi = 1−(N − ci − ai
n1
)/
(N
n1
). (2.2)
Note que, ao final do processo de amostragem, ci e uma quantidade conhecida para
as unidades amostradas, enquanto que ai pode ser maior do que o observado na amostra,
pois nao temos o conhecimento se existe outra rede na qual i seja unidade de borda,
i = 1, . . . , N , tal que N e o numero de unidades da grade. Portanto, o estimador de
Horvitz-Thompson para o total populacional em (2.1), com probabilidade de inclusao πi
dado por (2.2) nao deve ser usado sob este desenho amostral.
Um estimador nao-viesado para este caso pode ser obtido como uma modificacao
do estimador de Horvitz-Thompson, apresentado em (2.1). O estimador faz uso das
observacoes que nao satisfazem a condicao de interesse so quando estas sao observadas na
amostra inicial. Assim, a probabilidade de que uma unidade seja utilizada no estimador
pode ser calculada, mesmo se sua verdadeira probabilidade de inclusao seja desconhecida.
Portanto, defina a probabilidade de inclusao neste caso por:
π∗k = 1−(N − ckn1
)/
(N
n1
),
em que ck e o numero de unidades na rede que inclui a unidade k.
Seja a variavel indicadora I∗k que assume o valor 0 se a unidade k na amostra s nao
satisfaz a condicao de interesse ou se k nao foi selecionada na amostra inicial, e caso
contrario assume o valor 1. O estimador modificado portanto e dado por:
THT ∗ =ν∑k=1
ykI∗k
π∗k, (2.3)
em que ν e o tamanho efetivo da amostra final, ou seja o numero de unidades distintas.
Para obter a expressao da variancia do estimador e mais conveniente formula-lo em
termo das redes do que das unidades individuais. Denote por N∗ o numero de redes na
populacao. Note que para toda unidade k da rede j, j = 1, . . . , N∗, I∗k e sempre a mesma,
portanto I∗j seria uma variavel indicadora que assume o valor 0 se a rede j e vazia ou
se nao foi observada na amostra, caso contrario assume o valor 1. A probabilidade de
14

inclusao π∗k de uma unidade k e igual para todas as unidades na mesma rede j. Denote a
probabilidade de inclusao de uma rede j na amostra por αj. O total na rede j e definido
como y∗j =∑
k:k∈Uj
yk, em que Uj e o conjunto de unidades que compoem a rede j.
Dessa forma, (2.3) pode ser reescrito como:
THT ∗ =N∗∑j=1
y∗j I∗j
αj. (2.4)
Note que como as redes sao as unidades de analise neste caso, a fim de compatibilizar
a notacao com a Secao 2.1, o vetor populacional agora seria dado por y∗ = (y∗1, . . . , y∗N∗)
′
e o tamanho da populacao de interesse entao deixaria de ser N um numero conhecido e
passaria a ser N∗, um numero desconhecido.
Para calcular a variancia do estimador e necessario calcular a probabilidade αjl de
se selecionar duas redes simultaneamente, e dessa forma tem-se (detalhes em Thompson
(1990)):
V (THT ∗) =N∗∑j=1
N∗∑l=1
y∗j y∗l
αjαl(αjl − αjαl),
em que αjl = 1−(N−cjn1
)/(Nn1
)−(N−cln1
)/(Nn1
)−(N−cj−cl
n1
)/(Nn1
).
A partir do trabalho de Thompson (1990), algumas extensoes deste planejamento
amostral, alem da selecao inicial baseada na amostragem aleatoria simples, surgiram na
literatura e serao apresentadas a seguir.
2.2.2 Amostragem estratificada adaptativa por conglomerados
Uma das extensoes naturais desta tecnica de amostragem seria considerar o primeiro
estagio de amostragem nao como uma amostra aleatoria simples, mas como amostragem
estratificada. Tal extensao foi proposta em Thompson (1991). A amostragem adaptativa
tira vantagens de tendencias de agrupamento da populacao, quando a localizacao e forma
dos conglomerados nao podem ser previstos a priori. Enquanto a tradicional amostragem
estratificada (detalhes em Bolfarine e Zacks (1992)) e usada a fim de agrupar unidades
mais homogeneas entre si, baseada em informacao a priori sobre a populacao ou na
15

simples proximidade das unidades. O planejamento amostral proposto combina estes
dois metodos.
Nesta abordagem a populacao e divida na grade em estratos e unidades dentro destes
estratos sao selecionadas por amostragem aleatoria simples. Se a unidade selecionada
satisfaz a condicao, todas as unidades na sua vizinhanca sao observadas e a amostragem
adaptativa e realizada.
2.2.3 Amostragem adaptativa por conglomerados em dois
estagios
Proposta por Salehi e Seber (1997), esta e uma extensao do metodo introduzido em
Thompson (1991). Neste caso, a grade de tamanho N e particionada em M (M < N)
unidades primarias. Num primeiro estagio uma amostra de m das M unidades primarias e
selecionada sem reposicao, num segundo estagio, observa-se nas m unidades maiores uma
amostra de unidades sem reposicao. A partir destas unidades secundarias observadas,
a amostragem nas m unidades segue usando a tecnica de amostragem adaptativa por
conglomerados. Note que quando m = M voltamos a metodologia de amostragem
estratificada adaptativa por conglomerados, pois todas as particoes teriam amostras
coletadas.
2.2.4 Custo operacional do plano amostral
Assim como a amostragem por conglomerados convencional, a amostragem adaptativa
por conglomerados possui a vantagem de agrupar as unidades de analise em
conglomerados, o que minimiza o tempo e os custos de deslocamento. Mas se muitas
unidades na vizinhanca satisfazem a condicao de interesse, a amostra pode consistir da
maioria das unidades na populacao e, portanto, ser muito custosa. Logo, o esforco na
obtencao da amostra esta associado a estrutura da populacao, e por isso e importante
que a populacao seja rara.
Algumas sugestoes para a limitacao do esforco na amostragem adaptativa sao descritas
em Thompson e Seber (1996). Alem disso, Brown e Manly (1998) propoem um metodo
16

chamado de amostragem adaptativa restrita por conglomerados, o qual limita o esforco
na obtencao da amostra e permite que uma aproximacao para o tamanho da amostra final
seja obtida previamente. Na proposta, uma amostra inicial de tamanho fixo e selecionada
e amostragem adaptativa por conglomerados e feita. Se o tamanho da amostra final e
menor que um limite pre-definido, entao outra unidade “inicial” e selecionada. Se incluir
esta unidade e sua vizinhanca, caso a condicao de interesse seja cumprida, resultar numa
amostra de tamanho maior que o limite pre-definido, entao o conglomerado e incluıdo
na amostra mas nenhuma outra unidade e observada. Logo, esta metodologia exige
uma reducao do tamanho da amostra inicial, para que esta produza uma amostra final
com tamanho proximo do limite desejado. Dessa forma, a variacao no tamanho final e
reduzida e o planejamento dos esforcos envolvidos na coleta de observacoes pode ser feito
com menos incerteza.
Por outro lado, tambem com o objetivo principal de controlar o numero de medidas
da variavel de interesse, Felix-Medina e Thompson (2004) introduziram a tecnica de
amostragem adaptativa dupla por conglomerados, a qual combina ideias de amostragem
em dois estagios e amostragem adaptativa por conglomerados e exige a disponibilidade
de uma variavel auxiliar mais facil de medir. Na primeira fase a variavel auxiliar e
usada para selecionar uma amostra adaptativa por conglomerados. Com a rede obtida
nesta primeira fase, sao selecionadas subamostras subsequentes, as quais sao obtidas
usando planos amostrais convencionais. Apenas nesta ultima fase os valores da variavel
de interesse sao registrados e estimativas para a media populacional, por exemplo, sao
obtidas usando um estimador do tipo regressao.
Este plano amostral proposto permite ao pesquisador controlar o numero de medicoes
da variavel de interesse, alocar a subamostra na fase final proximo a lugares interessantes,
iniciar a coleta da segunda fase antes da primeira estar concluıda e usar a variavel auxiliar
na estimacao.
Note que podem ser usados diferentes tipos de variaveis auxiliares neste caso, como
as de avaliacao rapida que levam o pesquisador para as areas mais promissoras, onde
observacoes exatas da variavel podem ser feitas. Por exemplo, numa pesquisa sobre
mexilhoes de agua doce, a amostragem e feita a partir de mergulho para observar a
17

abundancia de mexilhoes. Assim, a variavel auxiliar pode ser uma avaliacao preliminar
da presenca ou ausencia de mexilhoes, e a variavel de interesse o numero de mexilhoes,
a qual e uma variavel difıcil de ser medida porque alguns mexilhoes sao parcialmente
escondidos pela areia e pedras no fundo do rio.
Note que este procedimento nao controla o numero de observacoes da variavel auxiliar
e sim da variavel de interesse. No entanto, em geral, procura-se escolher variaveis
auxiliares correlacionadas com a variavel de pesquisa mas que sejam mais faceis de serem
observadas e que produzam menos custos.
2.2.5 Eficiencia do plano amostral
Ao comparar a eficiencia da amostragem adaptativa por conglomerados com a
amostragem aleatoria simples, por exemplo, Thompson e Seber (1996) notam que um
fator decisivo para uma maior eficiencia relativa e a variabilidade dentro da rede.
Os estimadores sob o desenho da amostragem adaptativa por conglomerados, como o
apresentado em (2.4), nao levam em conta a variabilidade dentro das redes pois a variavel
resposta e dada pelos valores agregados dentro destas. Quanto maior essa variabilidade,
maior a vantagem, em termos de eficiencia relativa, em usar amostragem adaptativa por
conglomerados do que a aleatoria simples.
Portanto, conclui-se que, para que a amostragem adaptativa por conglomerados seja
um plano amostral eficiente em termos de precisao e custos e necessario que a populacao
de estudo exiba de fato um comportamento raro e agrupado. Logo, antes de propor
um planejamento amostral complexo como este, e importante conhecimentos a priori da
populacao em analise. Neste contexto, supondo que a variavel y seja uma variavel de
contagem do numero de elementos que apresentam o atributo de interesse, para avaliar
a raridade da populacao pode ser utilizada a proporcao de unidades contendo ao menos
um elemento da populacao rara, definida como:
PR =1
N
N∑i=1
I(yi > 0), (2.5)
18

onde I(.) e a funcao indicadora que assume o valor 1, se a unidade i apresenta ao menos
um elemento de interesse, e 0 caso contrario. Para avaliar a variabilidade dentro das
redes defina
V IR =
∑N∗
j=1
∑i:i∈Uj (yi − µj(i))2∑Ni=1 (yi − µ)2
, (2.6)
em que µj(i) e a media dos valores de yi nas unidades da rede que contem a unidade i e µ
e a media global da populacao. Note que se nao ha redes de tamanho maior que 1, tem-se
que V IR = 0, mas caso todas as unidades estejam numa unica rede, V IR = 1. Dessa
forma, V IR pode ser considerada uma medida relacionada ao grau de agrupamento da
populacao.
Apresentamos portanto o metodo de amostragem adaptativa por conglomerados e
suas extensoes propostas na literatura. Vimos que o metodo e flexıvel e pode ser
aplicado a diversos problemas estatısticos reais. No entanto, e importante ressaltar que a
eficiencia do metodo depende da raridade e agrupamento espacial da populacao, portanto
e interessante o conhecimento previo da populacao em estudo, dada a complexidade desta
metodologia. Smith et al. (2004) apresentam estas e outras questoes praticas que devem
ser tratadas antes da proposta de tal planejamento num estudo por amostragem.
Alguns trabalhos na literatura mostram a eficiencia deste tipo de amostragem
comparado a outros planos convencionais em aplicacoes a problemas reais, entre eles
podemos citar Thompson e Collins (2002), Danaher e King (1994), Smith et al. (1995),
Roesch (1993) e Conners e Schwager (2002).
A amostragem adaptativa por conglomerados fornece uma forma de lidar com
populacoes agrupadas sob o paradigma baseado no desenho amostral. Entretanto, sob
a abordagem baseada em modelo a metodologia de Rapley e Welsh (2008) e ate entao
a unica proposta na literatura para este cenario. Na proxima secao e apresentada a
abordagem de modelos de superpopulacao para um contexto geral.
19

2.3 Modelos de superpopulacao
Outra abordagem de inferencia, amplamente utilizada na literatura, para populacoes
finitas e a baseada em modelos de superpopulacao. Basicamente, o processo de
inferencia estatıstica a partir de uma amostra compreende um conjunto de princıpios
e procedimentos que podem envolver, por exemplo, o conhecimento de algum processo
aleatorio que possa ter gerado o verdadeiro valor desconhecido da caracterıstica de
interesse para cada unidade da populacao. Esse processo e representado por um modelo
que e utilizado como base para se fazer inferencia.
Enquanto na teoria convencional de amostragem as unidades da populacao sao
tratadas como constantes fixas, nao expressando nenhuma relacao entre as unidades da
amostra e as unidades nao amostradas, sob o enfoque de modelos de superpopulacao, os
valores das caracterısticas de interesse sao considerados realizacoes de variaveis aleatorias,
para os quais existe uma distribuicao conjunta de todos os valores da populacao, a qual
e uma forma de expressar uma relacao entre as unidades amostradas e nao amostradas.
Logo, este enfoque complementa o planejamento amostral nao informativo em relacao as
unidades nao amostradas. O vetor populacional y = (y1, . . . , yN)′ e, portanto, tratado
como uma realizacao do vetor aleatorio Y = (Y1, . . . , YN)′. A inferencia classica sobre
uma funcao do vetor populacional de interesse y procede com respeito a distribuicao
amostral de uma estatıstica, sob repetidas realizacoes geradas pelo modelo, com a amostra
selecionada permanecendo fixa. Esta forma de inferencia em populacoes finitas pode ser
vista com maiores detalhes em Cassel et al. (1977).
Segundo o modelo, suponha que Y dado θ ∈ Θ segue uma distribuicao de
probabilidades dada por [Y | θ]. Seja y = (y1, . . . , yN)′ o vetor populacional gerado
segundo a distribuicao [Y | θ]. Pode-se definir uma matriz H = (H1, . . . ,HN) de
dimensao N × k, tal que Hi = (Hi1, . . . , Hik)′ representa variaveis adicionais associadas
com a estrutura da populacao. Suponha que a distribuicao conjunta de H, a qual depende
de um parametro φ ∈ Φ ∈ Rk, e dada por [H | φ].
20

2.3.1 Desenho amostral informativo
De forma mais complexa, o mecanismo de selecao amostral pode depender dos valores
das variaveis de interesse na populacao, ou seja, as probabilidades de inclusao das
unidades na amostra estariam relacionadas com as variaveis respostas. Tal situacao
caracteriza um plano amostral informativo. Um exemplo tıpico sao os estudos de caso-
controle, em que a amostra e selecionada de tal forma que haja casos (unidades com
determinada condicao de interesse) e controles (unidades sem essa condicao), sendo de
interesse a modelagem do indicador de presenca ou ausencia da condicao em funcao de
variaveis preditoras. Esse indicador e uma das variaveis de pesquisa e e considerado no
mecanismo de selecao da amostra.
Sob a abordagem de modelos de superpopulacao, e importante antes de propor
o modelo, analisar se as probabilidades de selecao dos elementos da populacao estao
relacionadas com as variaveis respostas, mesmo condicionado a covariaveis do modelo.
Neste caso, e relevante para inferencia levar em consideracao o plano amostral, seja na
definicao do modelo ou na construcao da funcao de verossimilhanca.
Segundo, Gelman et al. (1995) e natural nestes casos expandir o espaco amostral e
incluir na verossimilhanca o planejamento amostral. A verossimilhanca completa, da
amostra s, do vetor Y, e das variaveis H pode ser escrita como:
[s,Y,H | θ,φ] = [s | Y,H][Y | H,θ][H | φ]. (2.7)
A expressao em (2.7) e avaliada em todos os valores da variavel, mas na verdade a
real informacao que tem-se a partir de uma amostra e (s,Ys,Hs). A verossimilhanca dos
dados observados, supondo continuidade, e dada por:
[s,Ys,Hs | θ,φ] =
∫ ∫[s,Y,H | θ,φ]dYsdHs
=
∫ ∫[s | Y,H][Y | H,θ][H | φ]dYsdHs.
(2.8)
Ja no caso discreto tem-se:
[s,Ys,Hs | θ,φ] =∑Yi:i∈s
∑Hi1:i∈s
· · ·∑
Hik:i∈s
[s | Y,H][Y | H,θ][H | φ]. (2.9)
21

Em particular, escolheu-se apresentar os demais resultados supondo variaveis
contınuas. Sob o enfoque Bayesiano, o interesse esta na obtencao da distribuicao a
posteriori do vetor parametrico. Neste caso, a distribuicao conjunta a posteriori dos
parametros (θ,φ), e dada por:
[θ,φ | s,Ys,Hs] ∝ [θ,φ][s,Ys,Hs | θ,φ]
= [θ,φ]
∫ ∫[s,Y,H | θ,φ]dYsdHs
= [θ,φ]
∫ ∫[s | Y,H][Y | H,θ][H | φ]dYsdHs.
A distribuicao a posteriori de θ, em geral e a de maior interesse, e e obtida integrando
a expressao acima em φ, da seguinte forma:
[θ | s,Ys,Hs] ∝ [θ]
∫ ∫ ∫[φ | θ][s | Y,H][Y | H,θ][H | φ]dYsdHsdφ. (2.10)
No caso de optar-se por ignorar o mecanismo de selecao da amostra, a distribuicao a
posteriori de θ e dada por:
[θ | Ys,Hs] ∝ [θ][Ys | Hs,θ][Hs | φ]
= [θ]
∫ ∫[Y | H,θ][H | φ]dYsdHs.
(2.11)
Quando os dados nao observados nao fornecem informacao adicional, ou seja, quando
[θ | Ys,Hs] dada em (2.11) se iguala a [θ | s,Ys,Hs] dada em (2.10), diz-se que o
desenho amostral e ignoravel, por exemplo no caso da amostragem aleatoria simples
com reposicao. Entretanto, esquemas amostrais desse tipo sao raramente empregados
na pratica, por razoes de eficiencia e custo. Em vez disso, sao geralmente empregados
planos amostrais que envolvem algum conhecimento da estrutura da populacao, como
a estratificacao, conglomeracao e probabilidades desiguais de selecao (amostragem
complexa).
Duas condicoes neste caso sao suficientes para garantir ignorabilidade do desenho: (i)
[s | Y,H] = [s | Ys,Hs]; (ii) [φ | θ] = [φ]. A importante consequencia destas definicoes
e que, de (2.10), segue que, de fato, se o plano amostral e ignoravel com respeito ao
parametro de interesse θ, [θ | s,Ys,Hs] = [θ | Ys,Hs]. Logo, a informacao adicional
trazida por s pode ser descartada quando se deseja fazer inferencia sobre θ, caso contrario
22

nao pode ser eliminada. Ignorar erroneamente o plano amostral informativo na inferencia
pode trazer consequencias na estimacao dos parametros.
Como consequencia ainda se tem os seguintes resultados:
(i) se s e consistente com y entao [s | Y] = [s | Ys], e assim [s | Y] = [s] se, e somente
se, [s | Ys] = [s];
(ii) se s e consistente com y, [s | Y,H] = [s | Ys,H] e diz-se que o planejamento
amostral e nao informativo em relacao a Ys;
(iii) se em (2.7) [s,Y,H | θ,φ] = [s | H][Y | H,θ][H | φ], diz-se que o planejamento e
informativo para H, mas nao informativo para Y. Neste caso, se H e conhecido a
expressao em (2.8) pode ser reescrita da forma:
[s,Ys,H | θ,φ] = [s | H][H | φ]
∫[Y | H,θ]dYs.
Neste trabalho sera amplamente utilizada a abordagem baseada em modelos de
superpopulacao, discutindo a inferencia sobre os parametros do modelo e previsao de
ys a partir de dados obtidos por amostragem adaptativa por conglomerados, o qual e um
plano amostral informativo.
Como visto, a inferencia para populacoes raras e agrupadas e usualmente abordada
com base no desenho amostral. De forma alternativa, Rapley e Welsh (2008) propoem
uma inferencia neste contexto baseada em modelos usando a amostragem adaptativa.
Este plano amostral e informativo e, portanto, as ideias discutidas na Secao 2.3.1
sao aplicadas a este modelo. Esta metodologia sera apresentada no proximo capıtulo,
juntamente com uma proposta de extensao do modelo para populacoes dinamicas.
2.4 Conclusoes
Neste capıtulo foi feita uma revisao das duas possıveis abordagens de inferencia em
populacao finita. Como o objetivo deste trabalho e inferir acerca de populacoes raras
e agrupadas, o foco deste capıtulo foi apresentar o plano amostral adaptativo e suas
extensoes na literatura, por ser um plano amostral cabıvel a este tipo de populacao. A
23

eficiencia e o custo desta metodologia estao relacionados diretamente com a estrutura da
populacao em questao, portanto um conhecimento a priori pode auxiliar na construcao
do planejamento amostral. Em particular, com relacao ao custo operacional do metodo,
existem propostas na literatura, e algumas destas foram apresentadas neste capıtulo.
Por outro lado, como o interesse deste trabalho e propor um modelo de
superpopulacao para este contexto, fez-se necessario apresentar o conceito de plano
amostral informativo, pois este devera ser relevante na construcao da funcao de
verossimilhanca do modelo neste caso.
24

Capıtulo 3
Amostragem adaptativa por
conglomerados baseada em modelos
Como uma alternativa a inferencia sobre o total populacional baseada nos planos
amostrais descritos anteriormente, Rapley e Welsh (2008) tratam tal problema sob uma
perspectiva baseada em modelos. A inferencia para este modelo fundamenta-se no
paradigma Bayesiano e leva em consideracao o fato de que as unidades foram amostradas
de forma adaptativa por conglomerados, um plano informativo. Na Secao 3.1 esta
metodologia e apresentada, o ajuste do modelo e estudado em alguns cenarios e sua
eficacia e ilustrada para uma populacao real.
Na Secao 3.2 e proposta uma extensao deste modelo para populacoes em crescimento
ou decrescimento ao longo do tempo. Tal proposta e comparada com o ajuste do modelo
de Rapley e Welsh (2008) de forma independente ao longo do tempo.
3.1 Um modelo agregado
Rapley e Welsh (2008) propoem um modelo complexo, que usa as redes como unidades
de analise, de forma a nao ter que introduzir componentes espaciais no modelo, o que
pode vir a facilitar a inferencia. Portanto, por este motivo, nos referimos a este modelo
como um modelo agregado. O uso da abordagem Bayesiana e uma extensao natural da
ideia da amostragem adaptativa por conglomerados, pois incorpora o conhecimento a
25

priori de que a populacao e rara e agrupada tanto para a inferencia como para o desenho
amostral. A fim de ilustrar a eficiencia de sua proposta, Rapley e Welsh (2008) comparam
seus estimadores com os estimadores desenvolvidos em Thompson (1990) por meio de
um estudo de simulacao, mostrando ser mais eficiente, principalmente num contexto de
conhecimento a priori. O modelo esta descrito a seguir.
Seja Ω uma regiao que contem uma populacao esparsa e agrupada, na qual sobrepoe-
se uma grade regular com N unidades. Uma unidade e dita nao vazia se esta contem pelo
menos uma observacao, e vazia caso contrario. Seja X ≤ N o numero de unidades nao
vazias em Ω. Seja R ≤ X o numero de redes nao vazias em Ω, Ci o numero de unidades
nao vazias dentro da rede i nao vazia e portanto C = (C1, . . . , CR)′ e o vetor com o numero
de unidades nao vazias dentro de cada rede nao vazia. Logo X =∑R
i=1Ci. Como existem
N − X unidades vazias, as quais sao definidas como redes vazias de tamanho 1, entao
ha N −X + R redes em Ω. Dessa forma, pode-se estender o vetor de dimensao R para
Z = (C′,1′N−X)′ em que 1′N−X e um vetor de 1’s de dimensao N −X, logo Zi = Ci, se i
e uma rede nao vazia e Zi = 1, caso contrario, para i = 1, . . . , N −X +R.
Seja Y ∗i o total observado na rede nao vazia i e, portanto, Y∗ = (Y ∗1 , . . . , Y∗R)′ denota
o vetor com o total populacional em cada uma das R redes nao vazias. Tambem podemos
estender neste caso o vetor de dimensao R para um de dimensao N −X + R da forma
(Y∗′,0′N−X)′, em que 0′N−X e um vetor de 0’s de dimensao N −X, o qual representa o
numero de observacoes em cada rede vazia. O objetivo e fazer inferencia sobre o total da
populacao de interesse T =∑R
i=1 Y∗i .
Fazendo uma analogia com a notacao definida na Secao 2.3 do Capıtulo 2, note que
e possıvel obter a seguinte relacao: N∗ = N − X + R, Hi1 = Ci e Hi2 = X, θ = γ,
φ = (α, β)′ e n = m. Note que apesar do tamanho da grade N ser conhecido, o tamanho
da populacao de interesse (redes nao vazias), a qual esta sendo modelada, ou seja, R,
e desconhecido e precisa ser estimado, portanto tambem pode ser interpretado como
Hi3 = R.
Isto e feito especificando a distribuicao conjunta de X,R,C e Y∗ para a populacao
toda e o mecanismo de amostragem que fornece uma particular amostra s = i1, . . . , im
de m redes das N −X +R redes na populacao. Um aspecto importante desta proposta
26

e que a estrutura da rede e totalmente determinada por X, R e C e nao se faz necessario
modelar as localizacoes espaciais das redes.
Primeiramente modela-se a estrutura de rede vazia/ nao vazia e entao, condicional a
estrutura de rede, modela-se a contagem nas redes nao vazias. Como o modelo aplica-se a
unidades nao vazias, para evitar problemas de degeneracao assume-se que ha pelo menos
uma celula nao vazia em Ω e, portanto uma rede nao vazia, logo as distribuicoes sao
truncadas a esquerda no valor igual a 1. Dessa forma, o modelo e dado por:
Y ∗i | Ci, R, γ ∼ Poisson Truncada independente (γCi), Y∗i ≥ Ci, i = 1, . . . , R,
C | X,R ∼ 1R + Multinomial
(X −R, 1
R1R
), Ci = 1, . . . , X −R + 1,
R∑i=1
Ci = X
R | X, β ∼ Binomial Truncada (X, β), R = 1, . . . , X, (3.1)
X | α ∼ Binomial Truncada (N,α), X = 1, . . . , N.
O truncamento na distribuicao de Poisson tambem faz-se necessario para levar em
conta o fato de que cada unidade em uma rede nao vazia deve conter ao menos uma
observacao de interesse, logo Y ∗i ≥ Ci, i = 1, . . . , R. Note que o parametro γ e
interpretado como o numero medio de observacoes em cada celula nao vazia, dentro
de cada rede nao vazia na populacao. Vale ressaltar que a distribuicao de Poisson pode
ser trocada por outro modelo, mas Rapley e Welsh (2008) mantiveram-se nesta proposta.
Alem disso, um modelo log-linear comum nao foi adotado para a variavel resposta por
questoes de custo computacional e problemas numericos no ajuste, mas o uso de tecnicas
mais eficientes de aproximacao, tais como em Gilks e Wild (1992), poderia facilitar a
implementacao deste modelo.
Este modelo e aplicado a amostras coletadas segundo o metodo adaptativo descrito
na Secao 2.2. Lembrando que o procedimento de amostragem consiste em observar Yi
para i ∈ s e seu delineamento depende da estrutura da populacao, a qual e desconhecida,
portanto este plano amostral caracteriza-se como informativo e deve ser incorporado a
funcao de verossimilhanca do modelo para realizacao de inferencia.
Logo, o proximo passo e definir a probabilidade de selecionar uma amostra s =
i1, . . . , im, ou seja, [s]. Ja vimos que tal mecanismo utiliza o argumento de que se
27

uma celula dentro de uma rede e amostrada, entao toda a rede deve ser observada e,
portanto, a probabilidade de selecionar uma rede e proporcional ao seu tamanho. Para
motivar a construcao da probabilidade de selecao de uma amostra, considere o seguinte
exemplo: seja uma populacao com 8 redes de tamanhos 5, 5, 1, 1, 1, 3, 3, 1 dos quais
obtemos a amostra 5, 1, 5, 3. A probabilidade de selecionar a primeira unidade e igual
a probabilidade de selecionar uma unidade de tamanho 5, que e igual a 5 × 2/20, a
probabilidade de selecionar uma unidade de tamanho 1 no segundo passo, dado o anterior
e de 1× 4/15 e, assim a probabilidade de selecao da particular amostra e igual a 5×220×
× 1×420−5× 5×1
20−5−1× 3×2
20−5−1−5.
Portanto, a probabilidade de selecao de uma particular amostra pode ser generalizada
da forma:
[s | C, R,X] =m∏j=1
Zij × gij ,j∑N−X+Ri=1 Zi −
∑j−1k=0 Zik
, (3.2)
onde gij ,j e o numero de redes de tamanho Zij que restam apos j − 1 redes terem sido
selecionadas e Zi0 = 0. Note que a probabilidade da selecao de s depende apenas das
variaveis associadas com a estrutura da populacao e nao diretamente com Y∗, logo, o
resultado (iii) da Subsecao 2.3.1 se aplicaria neste caso e diz-se que o plano amostral e
informativo com relacao a H.
Incorporando esta probabilidade de selecao da amostra ao modelo, tem-se por (2.7)
com [s | Y∗,H] = [s | H], a seguinte funcao de verossimilhanca global:
[s,Y∗,C, R,X | α, β, γ] = [s | C, R,X][Y∗ | C, R,X, γ][C, R,X | α, β, γ]
=m∏j=1
Zij × gij ,j∑N−X+Ri=1 Zi −
∑j−1k=0 Zik
×
N
X
αX(1− α)N−X
1− (1− α)N(3.3)
×
X
R
βR(1− β)X−R
1− (1− β)X× (X −R)!
R∏i=1
1
(Ci − 1)!
(1
R
)Ci−1
×R∏i=1
exp−γCi + Y ∗i log(γCi)Y ∗i ![1−
∑Ci−1j=0 exp−γCi + j log(γCi)− log(j!)]
.
Com a amostra coletada, parte das variaveis do modelo e conhecida. Usando o ındice s
para identificar a parte observada e s a parte nao observada, os vetores sao particionados
da seguinte forma: Y∗ = (Y∗s′,Y∗s
′)′ , C = (C′s,C′s)′, R = Rs +Rs e X = Xs +Xs.
28

A funcao de verossimilhanca marginal dos dados observados e obtida somando a
expressao acima sob todas as quantidades desconhecidas, como visto em (2.9).
3.1.1 Possıveis cenarios gerados pelo modelo
A distribuicao espacial da populacao ao longo da regiao e caracterizada no modelo
pelos parametros α e β. O parametro α controla o numero esperado de unidades nao
vazias, pois E(X | α) = Nα/1− (1− α)N e β o numero esperado condicional de redes
nao vazias pois, E(R | X, β) = Xβ/1−(1−β)X. Note que se α se aproxima de 0 entao
E(X | α) se aproxima de 1, que e o menor valor que X pode assumir segundo o modelo
proposto, mas se α esta proximo de 1 entao E(X | α) tende a N . De forma analoga
temos que, condicional a X, se β esta proximo de 0 entao E(R | β) esta proximo de 1,
mas para valores de β perto de 1, E(R | β) tende a X, o numero total de unidades nao
vazias.
Como tratamos de populacoes esparsas, ambos os parametros sao pequenos em
geral, e combinados, controlam a raridade e agrupamento destas. Populacoes raras sao
caracterizadas pelo modelo para valores pequenos de α, enquanto populacoes agrupadas
estao caracterizadas para valores pequenos de β, mas este nıvel de agrupamento depende
tambem do valor de X, o qual depende de α devido a estrutura condicional do modelo.
Alem disso, as probabilidades da distribuicao multinomial sao tratadas como
conhecidas e iguais. Sob o modelo, o tamanho esperado, condicional a X e R, da rede e
1 + (X −R)/R = X/R.
Para ilustrar o impacto dos parametros no modelo, na Figura 3.1 temos alguns dados
artificiais gerados a partir do modelo para alguns valores fixos de α e β, γ = 10 e uma
grade regular de tamanho N = 400.
Observe que para α e β iguais a 0.05 tem-se uma populacao altamente rara, portanto,
intuitivamente, espera-se dificuldades de estimacao numa populacao deste tipo, mesmo
utilizando a tecnica de amostragem adaptativa por conglomerados.
Em contrapartida, para α e β iguais a 0.20 terıamos uma populacao altamente dispersa
na regiao, o que estaria descaracterizando a raridade e agrupamento geografico. Logo, o
uso deste modelo complexo nao seria justificavel.
29

Note tambem que fixando α igual a 0.05 e aumentando β, isto reflete uma populacao
com poucas unidades com observacoes, porem mais espalhada que o primeiro caso.
Finalmente, aumentando o valor de α e fixando β igual a 0.05, ha um maior numero de
unidades nao vazias, o que ainda assim resulta em mais redes que o primeiro caso devido
a estrutura de condicionamento do modelo, diminuindo o grau de raridade espacial, mas
sem destruir o comportamento agrupado da populacao.
Note que como a partir do modelo nao temos informacao sobre a localizacao das redes,
na Figura 3.1 a localizacao destas foi feita de forma arbitraria e sem perda de generalidade,
sem comprometer a ilustracao. Alem disso, como estas populacoes foram geradas sob o
modelo agregado, nao e possıvel verificar o agrupamento da populacao usando a medida
em (2.6), pois nesta necessita-se da contagem em cada unidade da grade, o que nao e
obtido na geracao dos dados. Portanto, esta ilustracao do comportamento do modelo
sera feita apenas de forma visual.
A partir desta ilustracao espera-se que populacoes raras e agrupadas possam ser
geradas a partir deste modelo para valores controlados de α e β. Lembre-se que temos
particular interesse em populacoes deste tipo, pois o interesse e explorar cenarios em que,
com um custo controlado, a amostragem adaptativa possa ser mais eficiente, em termos
de precisao, que qualquer plano amostral nao informativo e mais comumente utilizado.
3.1.2 Estudo simulado para alguns cenarios
Como o procedimento de inferencia baseia-se na metodologia Bayesiana, a fim de
avaliar o modelo apresentado por Rapley e Welsh (2008), foram analisadas amostras das
distribuicao a posteriori dos parametros do modelo e do total populacional T . Para
isso o modelo proposto deve ser completado com uma distribuicao a priori para o vetor
(α, β, γ). Supondo independencia a priori entre estes, assume-se:
α ∼ Beta(aα, bα), β ∼ Beta(aβ, bβ) e γ ∼ Gama(aγ, bγ),
em que Beta(a, b) representa a distribuicao Beta parametrizada com media igual a aa+b
e
variancia ab(a+b+1)(a+b)2 e Gama(a, b) a distribuicao Gama parametrizada com media igual
a ab
e variancia ab2
.
30

(α,β)=(0.05,0.05)
(α,β)=(0.05,0.20)
(α,β)=(0.20,0.05)
(α,β)=(0.20,0.20)
Figura 3.1: Populacoes artificiais geradas a partir do modelo proposto por Rapley e Welsh
(2008), para alguns valores fixos para os parametros α e β e para γ = 10, numa grade
regular de tamanho N = 400.
Rapley e Welsh (2008) fazem um estudo de elicitacao da distribuicao a priori para
estes parametros, avaliando a sensibilidade dos estimadores. Vale ressaltar que, ainda
sob distribuicoes a priori nao informativas, o modelo fornece estimativas razoaveis para
os parametros e para o total populacional. No entanto, visto que o modelo e voltado
para aplicacoes a populacoes raras e agrupadas e dada a analise ilustrativa feita na
Figura 3.1, foram utilizados os seguintes valores: aα = aβ = 2 e bα = bβ = 9,
caracterizando distribuicoes a priori para α e β informativas. No entanto, neste contexto,
31

esta distribuicao com alta probabilidade centrada em um intervalo apenas reflete a
priori a estrutura rara e agrupada da populacao, o que e o mınimo de conhecimento
para justificar o uso de tal modelo complexo. Para γ utilizou-se aγ = 1 e bγ = 0.1,
caracterizando assim uma distribuicao a priori pouco informativa para γ, mas com
mais massa de probabilidade no valor medio de unidades por rede com base na amostra
selecionada, ou seja pela media do vetor Y∗s/Cs.
Como a distribuicao a posteriori do vetor parametrico Θ = (Xs, Rs,Cs,Y∗s , α, β, γ)
nao possui forma analıtica fechada faz-se necessario o uso de metodos de simulacao
estocastica, como o metodo de Monte Carlo via Cadeias de Markov (MCMC). Em
particular, o amostrador de Gibbs com passos de Metropolis-Hastings foi utilizado. Alem
disso, o preditor do total populacional T e dado por:
T = 1′RsY∗s + 1′
RsY∗s ,
cuja amostra da distribuicao a posteriori tambem pode ser obtida via MCMC.
Os passos da amostragem sao descritos por:
(1) faca j = 1 e especifique valores iniciais para Xs, Rs, Cs e Y∗s ;
(2) sorteie α da distribuicao condicional completa [α | X,R,C,Y∗, β, γ] = [α | X];
(3) sorteie β de [β | X,R,C,Y∗, α, γ] = [β | X,R];
(4) sorteie γ de [γ | X,R,C,Y∗, α, β] = [γ | R,C,Y∗];
(5) sorteie (Xs, Rs,Cs,Y∗s) de [Xs, Rs,Cs,Y
∗s | Xs, Rs,Cs,Y
∗s , α, β, γ];
(6) faca j = j + 1 e volte ao passo (2).
As condicionais completas e as distribuicoes propostas podem ser vistas com
detalhes em Rapley e Welsh (2008). A fim de mostrar a eficiencia do modelo para a
previsao do total populacional, foram geradas algumas populacoes raras e agrupadas
artificiais, para alguns valores fixos dos parametros, e o modelo (3.1) foi ajustado a tais
dados. Dessa forma e possıvel comparar a estimativa do total com o valor verdadeiro
gerado. Cada populacao foi simulada numa grade regular com N = 400 unidades.
32

Populacoes foram geradas para 16 cenarios diferentes a partir das combinacoes de
α, β ∈ 0.05, 0.10, 0.15, 0.20 e γ = 10. Para cada valor dos parametros gerou-se 100
populacoes, e de cada uma selecionou-se uma amostra adaptativa com dois tamanhos
iniciais distintos de 5%N e 10%N . Vale ressaltar que, apesar da amostra aleatoria simples
inicial ser de 20 ou 40 unidades, o numero de redes observadas ao final da amostragem
adaptativa era menor ou igual a esse numero, pois em alguns casos duas ou mais unidades
selecionadas faziam parte da mesma rede na populacao.
As Figuras 1.1, 1.2, 1.3 e 1.4 no Apendice A apresentam as trajetorias das cadeias
obtidas para cada parametro e para o total populacional T com o respectivo valor
verdadeiro em cinza, para uma das 100 populacoes geradas com amostra inicial de
tamanho 10%N . Para todas as cadeias foram geradas 200.000 iteracoes, sendo as 10.000
primeiras descartadas como aquecimento e foram tomadas amostras de 190 em 190, a
fim de obter-se 1.000 amostras independentes. Ha indıcios de convergencia para todos
os 16 cenarios simulados, visto que as cadeias sao estacionarias e movem-se em torno do
valor verdadeiro fixado na geracao dos dados. O mesmo ocorre quando seleciona-se uma
amostra adaptativa de tamanho inicial n1 = 5%N .
Na Figura 1.5 no Apendice A estao um sumario da distribuicao a posteriori dos
parametros α, β, γ e de T para as 100 populacoes artificiais para cada um dos 16 cenarios
gerados a partir do modelo e para os dois tamanhos de amostra distintos. Tais cenarios
estao na seguinte ordem na figura: fixa-se um valor de α e depois varia-se β. A Figura
1.5 (a) apresenta uma analise de propriedades frequentistas dos estimadores. Nela estao
as probabilidades de cobertura dos intervalos HPD de 95% para as amostra de 5%N e
10%N , o erro quadratico medio (EQM) para cada parametro e o erro quadratico medio
relativo (EQMR) para o total populacional. Os intervalos HPD apresentados ao longo
deste trabalho foram obtidos usando o comando emp.hpd do pacote TeachingDemos do
software R.
Note que em termos da cobertura media dos intervalos, enquanto os parametros β e γ
apresentam resultados proximos do desejado para todos os cenarios, o parametro α tem
maior variabilidade e resultados mais satisfatorios sao obtidos no geral a medida que o
valor de α aumenta, para β nao muito pequeno. O mesmo se passa com a estimacao do
33

total populacional T . Isto ocorre pois quanto maior α, mais unidades com observacoes de
interesse, o que traz mais informacoes que auxiliam na estimacao e previsao. Por outro
lado, analisando o EQMR de T , que e o nosso maior interesse, observa-se tambem que,
fixado α, no geral os valores do EQM e EQMR diminuem a medida que β aumenta. Isto
ocorre pois o parametro β esta associado ao numero de redes e a medida que β aumenta,
cresce o numero de redes, fazendo com que os grupos na populacao se espalhem mais, o
que tambem facilita o procedimento de inferencia com base numa amostra. Neste mesmo
caso, observe que, mesmo com uma amostra de 5%N o modelo ja se ajusta bem aos
dados e as conclusoes sao analogas.
Uma alternativa para melhorar o ajuste deste modelo sob cenarios em que α e β sao
extremamente pequenos e elicitar outras distribuicoes a priori independentes para α e β.
Rapley (2004) apresenta uma lista de distribuicoes a priori utilizadas e que resultaram
num melhor desempenho do modelo em populacoes geradas para diferentes valores de α e
β. Neste trabalho, foi utilizada apenas uma distribuicao a priori informativa para todos
os cenarios, com o unico interesse de garantir que o desenho amostral seja razoavel ao
problema e a robustez desta para diferentes valores de α e β num intervalo. Portanto, e
uma possıvel distribuicao a priori a ser utilizada quando o unico conhecimento previo que
se tem a respeito da populacao e que esta e rara e agrupada. No entanto, se informacoes
mais precisas sobre o tipo ou estrutura da populacao estao disponıveis, resultados mais
vantajosos podem ser obtidos para alguns casos especıficos.
E importante mencionar que este estudo simulado foi feito sob todas as possıveis
amostras. Por exemplo, nos casos em que α = β = 0.05 a populacao e extremamente rara
e agrupada, portanto e alta a probabilidade de selecionar uma amostra que nao contenha
unidade alguma com observacao ou que contenha todas as unidades nao vazias da
populacao. Isso prejudica a qualidade das estimativas. Esta e mais uma explicacao para
o fato de que os resultados sao mais proximos do desejado para populacoes menos raras
e agrupadas. Uma possibilidade para este caso e repetir o estudo simulado descartando
estas amostras nao representativas, no entanto, como elas tem alta chance de ocorrer
em alguns casos optou-se por mante-las, a fim de nao mascarar estes problemas nos
resultados.
34

Conclui-se desta forma que, em termos de estimativas pontuais e intervalares, a
eficiencia do modelo aumenta a medida que os valores de α e β aumentam. Entretanto,
e importante lembrar que a amostragem adaptativa pode ser custosa, portanto esta e
razoavel em cenarios de raridade e agrupamento da populacao. Logo, recomenda-se o
uso de tal modelo complexo nestes cenarios, mas com um numero esperado controlado
de unidades e redes com a caracterıstica de interesse, de forma que a amostra adaptativa
coletada seja a mais representativa possıvel sem altos custos.
Por outro lado, ja foi visto que como o plano amostral adaptativo por conglomerados e
nao-ignoravel, a probabilidade de selecao deve ser incluıda na funcao de verossimilhanca,
pois esta tambem traz informacoes para a estimacao dos parametros do modelo. O
objetivo agora e simplesmente verificar o ajuste do modelo para o caso em que o plano
amostral e erroneamente considerado ignoravel, ou seja, quando a probabilidade de
selecao e descartada da funcao de verossimilhanca completa em (3.3).
Para isso, o modelo em (3.1) foi ajustado para as mesmas 100 amostras do estudo
anterior, mas, agora, desconsiderando a probabilidade de selecao da amostra em (3.3).
Na Tabela 3.1 e apresentada uma comparacao entre as duas abordagens usando
a razao dos EQM (RaEQM) e das variancias (RaVAR) entre os estimadores obtidos
considerando a probabilidade de selecao e sem considera-la, para n1 = 10%N .
Portanto, valores menores que 1 indicam que considerar o plano amostral na funcao de
verossimilhanca produz resultados mais vantajosos sob ambos os criterios. Vale informar
que as probabilidades de cobertura para os intervalos HPD de 95% gerados para os dois
metodos apresentam-se proximo do nıvel nominal desejado, logo nao seriam um criterio
relevante na comparacao e, por isso, nao foram apresentadas.
Observando a Tabela 3.1 e possıvel verificar que desconsiderar esta parcela na funcao
de verossimilhanca completa, gera na grande maioria das vezes, estimativas viesadas
e com maior variancia, principalmente para o parametro α e para o total T . Apenas
para dados artificiais gerados a partir do modelo fixando α = β = 0.20 esta conclusao
e diferente em termos do EQM para todos os parametros. Contudo, a variancia ainda
permanece menor quando incluıda a probabilidade de selecao. Isso ocorre pois, este
cenario gera uma populacao mais esparsa, e menos rara que os outros cenarios estudados.
35
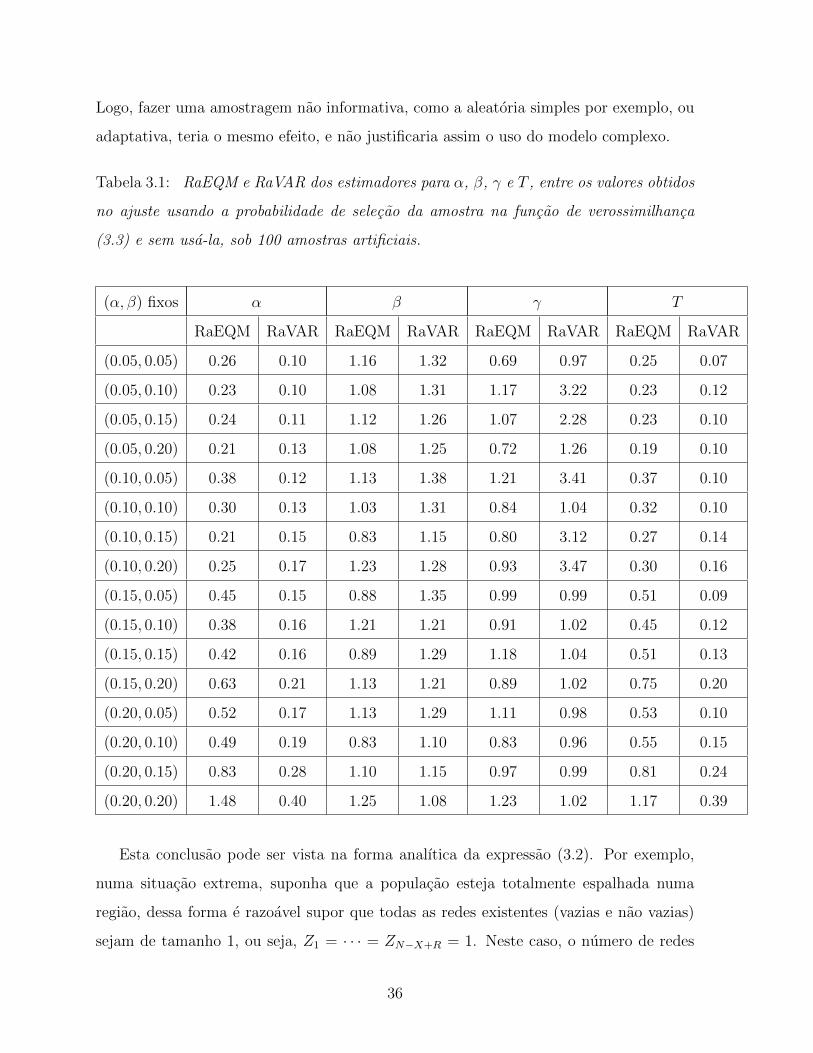
Logo, fazer uma amostragem nao informativa, como a aleatoria simples por exemplo, ou
adaptativa, teria o mesmo efeito, e nao justificaria assim o uso do modelo complexo.
Tabela 3.1: RaEQM e RaVAR dos estimadores para α, β, γ e T , entre os valores obtidos
no ajuste usando a probabilidade de selecao da amostra na funcao de verossimilhanca
(3.3) e sem usa-la, sob 100 amostras artificiais.
(α, β) fixos α β γ T
RaEQM RaVAR RaEQM RaVAR RaEQM RaVAR RaEQM RaVAR
(0.05, 0.05) 0.26 0.10 1.16 1.32 0.69 0.97 0.25 0.07
(0.05, 0.10) 0.23 0.10 1.08 1.31 1.17 3.22 0.23 0.12
(0.05, 0.15) 0.24 0.11 1.12 1.26 1.07 2.28 0.23 0.10
(0.05, 0.20) 0.21 0.13 1.08 1.25 0.72 1.26 0.19 0.10
(0.10, 0.05) 0.38 0.12 1.13 1.38 1.21 3.41 0.37 0.10
(0.10, 0.10) 0.30 0.13 1.03 1.31 0.84 1.04 0.32 0.10
(0.10, 0.15) 0.21 0.15 0.83 1.15 0.80 3.12 0.27 0.14
(0.10, 0.20) 0.25 0.17 1.23 1.28 0.93 3.47 0.30 0.16
(0.15, 0.05) 0.45 0.15 0.88 1.35 0.99 0.99 0.51 0.09
(0.15, 0.10) 0.38 0.16 1.21 1.21 0.91 1.02 0.45 0.12
(0.15, 0.15) 0.42 0.16 0.89 1.29 1.18 1.04 0.51 0.13
(0.15, 0.20) 0.63 0.21 1.13 1.21 0.89 1.02 0.75 0.20
(0.20, 0.05) 0.52 0.17 1.13 1.29 1.11 0.98 0.53 0.10
(0.20, 0.10) 0.49 0.19 0.83 1.10 0.83 0.96 0.55 0.15
(0.20, 0.15) 0.83 0.28 1.10 1.15 0.97 0.99 0.81 0.24
(0.20, 0.20) 1.48 0.40 1.25 1.08 1.23 1.02 1.17 0.39
Esta conclusao pode ser vista na forma analıtica da expressao (3.2). Por exemplo,
numa situacao extrema, suponha que a populacao esteja totalmente espalhada numa
regiao, dessa forma e razoavel supor que todas as redes existentes (vazias e nao vazias)
sejam de tamanho 1, ou seja, Z1 = · · · = ZN−X+R = 1. Neste caso, o numero de redes
36

nao vazias passa a ser o numero de unidades nao vazias na populacao, ou seja, R = X.
Portanto, para todo j = 1, . . . ,m, Zij = 1, gij ,j = N − (j − 1),∑N−X+R
i=1 Zi = N e∑j−1k=0 Zik = m− [m− (j − 1)]. Portanto, a probabilidade de selecao em (3.2) se reduz a:
[s | C, R,X] =1×NN − 0
× 1× (N − 1)
N − 1× · · · × 1× [N − (m− 1)]
N − (m− 1)= 1,
para qualquer amostra s sorteada. Logo, a probabilidade de inclusao da amostra
permanece inalterada para qualquer amostra s selecionada desta populacao.
3.1.3 Estudo simulado com populacao real
A fim de ilustrar a eficiencia do modelo em (3.1), sera feita a seguir uma comparacao
do estimador obtido do ajuste de tal modelo com o estimador de Horvitz-Thompson
modificado, dado em (2.4), obtido com base no desenho amostral adaptativo por
conglomerados. Alem disso, ambos serao comparados a amostragem aleatoria simples
sem reposicao. Esta ilustracao sera feita a partir de sorteios de repetidas amostras de
uma populacao verdadeira. Tal populacao constitui-se de marrecos da asa azul na regiao
da Florida, nos Estados Unidos, no ano de 1992. Em particular, esta e uma especie
rara de aves aquaticas com um comportamento agrupado. Esta mesma populacao e
outras duas especies, as quais apresentam diferentes graus de agrupamento, foram usadas
para comparacao da eficiencia da amostragem adaptativa com relacao a outros planos
amostrais em Smith et al. (1995).
A Figura 3.2 corresponde a area de estudo, dada em Smith et al. (1995), a qual foi
subdividida em N = 200 unidades de uma grade regular, tal que cada unidade apresenta
o numero de indivıduos da populacao de marrecos da asa azul naquela regiao. Observe
que esta populacao caracteriza-se com um aspecto raro e extremamente agrupado.
Alem disso, usando as expressoes em (2.5) e (2.6) para avaliar numericamente estas
propriedades na populacao, obteve-se PR = 0.11 e V IR = 0.71, o que tambem indica
que a populacao em estudo tem estas caracterısticas, justificando assim o uso do plano
amostral adaptativo.
Para avaliar a eficiencia dos metodos de amostragem citados, para esta particular
populacao, foram sorteadas 100 amostras e para cada amostra obtivemos uma estimativa
37

53
204212
10103
33
1507144
1
66399
2
2
14122 114
603
2
Figura 3.2: Populacao real de marrecos da asa azul na regiao da Florida, nos Estados
Unidos, no ano de 1992, disposta numa grade regular de tamanho N = 200.
do total populacional T . Tal estimativa foi obtida com base no estimador nao viesado
para o total sob os planos adaptativo e aleatoria simples, e no caso do ajuste do modelo
Bayesiano em (3.1) sao obtidas amostras da distribuicao a posteriori, e tal estimativa
pontual e dada pela media a posteriori de T .
Em cada uma das 100 amostras, sorteia-se aleatoriamente e sem reposicao n1 unidades
iniciais na grade e, se pelo menos um marreco da asa azul e observado, as unidades
vizinhas, ou seja, as de lado contıguo, sao incluıdas na amostra, e o procedimento e
repetido ate o momento em que uma unidade de borda, ou seja, sem qualquer marreco
de asa azul, e obtida. Dessa forma, cada amostra adaptativa possui n unidades divididas
em m redes (m ≤ n1). E com base nestas n unidades, estimamos o total populacional
a partir do estimador em (2.4) e no modelo (3.1). Alem disso, tambem foram obtidas
estimativas para T considerando amostras aleatorias simples de tamanho n, com base no
estimador TAAS = Ny.
A mesma distribuicao a priori descrita anteriormente para o modelo (3.1) foi utilizada
neste estudo, exceto a distribuicao de γ, para o qual foram usados aγ = 5 e bγ =
2, como recomendado em Rapley e Welsh (2008) para a maioria dos casos. Notou-
se que ao atribuir distribuicoes para γ com alta massa de probabilidade em valores
38

maiores, surgiram problemas de superestimacao do total populacional, devido as amostras
coletadas conterem na sua maioria a rede de maior tamanho, a qual apresenta maiores
valores de Y , diferente dos dados artificiais que eram gerados de um modelo que supoe
homogeneidade entre as unidades.
Na Tabela 3.2 temos a eficiencia de cada estimador para alguns tamanhos de amostra
iniciais. A eficiencia de um estimador e dada pela razao entre as variancias para cada
estimador em questao, logo se esta razao e maior que 1 significa que, em termos de
precisao, o estimador do denominador e mais eficiente do que o outro. Em particular,
defina, ef(TAASHT ∗ ) a eficiencia do estimador da amostragem aleatoria simples com relacao ao
estimador de Horvitz-Thompson modificado descrito pela expressao em (2.4), ef(TAASB )
a eficiencia do estimador da amostragem aleatoria simples com relacao ao estimador
Bayesiano e ef(THT∗
B ) denota a eficiencia do estimador de Horvitz-Thompson modificado
com relacao ao estimador Bayesiano. Alem disso, E(n) denota o valor esperado do
tamanho final da amostra adaptativa utilizando as 100 amostras geradas, portanto, e o
tamanho medio das amostras aleatorias simples selecionadas para a comparacao.
Observe que, para qualquer tamanho de amostra, as duas abordagens que usam o
plano amostral adaptativo sao mais eficientes que a amostragem aleatoria simples. Exceto
para n1 = 4, em que a conclusao se inverte quando compara-se TAAS com relacao a
THT ∗ . Quando comparados entre si, o modelo em (3.1) apresenta maior eficiencia que a
estimacao com base no desenho amostral adaptativo.
Portanto, conclui-se que o modelo (3.1) e eficiente e apresenta vantagens quando
comparado com as outras metodologias. Com base nesta conclusao, o interesse agora
e estender este modelo para outros contextos usuais. Na proxima secao e proposta
uma extensao do modelo (3.1) para populacoes que apresentam constante mobilidade,
incorporando esta caracterıstica ao proprio modelo.
Vale ressaltar que um modelo inflacionado de zeros poderia ser uma alternativa para
previsao nestas populacoes raras, devido ao excesso de zeros. Esta classe de modelos
ganhou destaque com Lambert (1992). A ideia geral desta classe de modelos e baseada
na inclusao de massa de probabilidade no ponto zero, inflacionando suas possibilidades
de existir no modelo, por meio de uma mistura de distribuicoes. No entanto, neste
39

Tabela 3.2: Estudo simulado com a populacao de marrecos da asa azul: eficiencia
relativa para o estimador do total populacional com base no desenho amostral adaptativo
(estimador de Horvitz-Thompson modificado) e no ajuste do modelo (3.1), com relacao a
amostragem aleatoria simples de tamanho n. A eficiencia do estimador Bayesiano com
relacao ao estimador de Horvitz-Thompson tambem e apresentada na ultima coluna.
n1 E(n) ef(TAASHT ∗ ) ef(TAASB ) ef(THT∗
B )
4 16.74 0.44 14.37 33.33
10 25.23 1.68 12.36 7.14
20 39.91 2.60 7.12 2.70
40 66.63 3.19 4.30 1.35
trabalho o objetivo e fazer previsao acerca de uma populacao dividida em redes, as quais
por definicao sao unidades nao vazias, portanto nao e contemplada a possibilidade de ser
zero. A amostragem adaptativa por conglomerados e portanto uma abordage, totalmente
cabıvel a esta situacao e nao fornece informacoes sobre as unidades vazias, apenas sobre
as nao vazias. Por isso o modelo de Rapley e Welsh (2008) e formulado apenas para as
redes nao vazias.
3.2 Um modelo para populacoes moveis, em
crescimento ou decrescimento
A biosfera esta constituıda de sistemas que mudam com o passar do tempo. O modo
pelo qual o sistema muda depende de sua organizacao e dos recursos disponıveis a ele. Por
exemplo, alguns ecossistemas aumentam em tamanho e complexidade, enquanto outros
detem seu crescimento. O estudo da dinamica das populacoes naturais e importante para
compreender o que ocorre nos ecossistemas em equilıbrio. Este tipo de comportamento,
em geral, e observado em populacoes de animais, habitats ou outra especie sensıvel a
mudancas.
40

Neste caso, o mais comum e trabalhar com modelos espaco-temporais, mas quando
trata-se de populacoes raras e agrupadas podemos ter grandes dificuldades em ajustar tais
modelos comumente vistos na literatura, principalmente se a elaboracao do planejamento
amostral nao levar este fator em consideracao na coleta dos dados. McDonald
(2004) apresenta estudos por amostragem que resultaram em estimativas altamente
imprecisas simplesmente pelo fato do pesquisador em curto intervalo de tempo “perder”
a populacao-alvo, devido ao grande poder de deslocamento, mortes, entre outros fatores.
Inclusive, o proprio procedimento de coleta dos dados pode ser um fator gerador de
dispersao da populacao de interesse. Uma opcao para estes cenarios e a replicacao
da coleta de dados ao longo de um perıodo de tempo, com o objetivo de ganhar mais
informacoes sobre este comportamento movel, difıcil de ser estudado. Dessa forma, alem
de gerar estimativas mais precisas, tal abordagem pode ser altamente relevante para
possibilitar possıveis intervencoes mais precisas no futuro neste tipo de populacao, em
casos de epidemia, por exemplo.
O objetivo desta secao e propor para situacoes como as descritas acima, modelos
de previsao que incorporem o plano de amostragem adaptativa, mas que leve em conta
nao so a raridade e esparsidade geografica, como o modelo proposto por Rapley e Welsh
(2008), mas que tambem levem em conta a mobilidade da populacao ao longo de um
perıodo de tempo.
3.2.1 Amostragem adaptativa para populacoes moveis
Um comportamento de mobilidade, crescimento ou decrescimento em um espaco ao
longo de um perıodo de tempo e comumente visto em populacoes biologicas. Em geral,
esta caracterıstica e algo natural da especie em estudo, ou pode simplesmente surgir
num estudo por levantamentos estatısticos, pelo fato do metodo de amostragem utilizado
alterar seu habitat natural, incentivando esta dinamica populacional.
Por outro lado, estas populacoes biologicas, por exemplo, tambem em geral sao uma
fracao pequena da populacao e estao distribuıdas numa regiao em grupos. Ja foi visto que,
para populacoes com tais comportamentos, a amostragem adaptativa por conglomerados
pode ser bastante eficiente quando comparada a outros planos mais comuns e menos
41

custosos. Mas, segundo McDonald (2004), se a populacao, alem destas caracterısticas,
tem alta mobilidade por fatores naturais, ou se move ou se destroi na coleta dos dados,
adaptacoes neste planejamento devem ser realizadas. O mesmo ocorre se a populacao de
interesse tende a crescer, indicando situacoes de alastramento.
McDonald (2004) apresenta algumas alternativas para o problema da mobilidade,
tais como: redefinir a vizinhanca de forma que nao inclua somente unidades de lado
contıguo e a criacao de um ındice de presenca de especies, que nao seja a observacao
direta. Este ultimo recai na amostragem adaptativa dupla, proposta por Felix-Medina
e Thompson (2004) e apresentada na Secao 2.2.4. Um exemplo desta e um estudo de
monitoramento da abundancia de gambas na Nova Zelandia. Para detectar a regiao
de interesse, sao colocados de forma adaptativa blocos de cera com algum atrator e a
frequencia de mordidas neste bloco e um indicador da distribuicao de gambas na regiao.
Em seguida, uma subamostra desta amostra adaptativa e observada nestes locais a fim
de obter uma estimativa do total de gambas na regiao.
Por outro lado, sob o ponto de vista de inferencia baseada em modelos de
superpopulacao, o modelo (3.1), proposto por Rapley e Welsh (2008) e apresentado
na secao anterior, nao se ajusta explicitamente a populacoes com esta dinamica. A
princıpio, para inferencia num unico instante de tempo, as alternativas descritas acima
e apresentadas por McDonald (2004) podem ser facilmente inseridas na funcao de
verossimilhanca do modelo, com mudancas somente na definicao da vizinhanca e redes.
Uma outra alternativa, que pode gerar estimativas ainda mais confiaveis e a coleta de
dados ao longo de um perıodo de tempo e uso destas amostras repetidas para inferir sobre
os parametros populacionais. Esta abordagem pode ser util tambem para o entendimento
do comportamento elusivo da populacao em perıodos de tempo, alem de previsao para
tempos futuros. Neste caso, para cada tempo terıamos uma amostra coletada, e para cada
tempo terıamos uma estimativa calculada com base no estimador de Horvitz-Thompson
dado em (2.4), por exemplo. No caso da abordagem baseada em modelo, o modelo (3.1)
seria ajustado para cada tempo de forma independente. E poucas sao as alternativas na
literatura para dados deste tipo. Em particular, temos interesse em estender o modelo
42

(3.1), proposto por Rapley e Welsh (2008), incorporando este comportamento movel para
que se ajuste a populacoes deste tipo.
3.2.2 Incorporando estrutura de crescimento e decrescimento
ao modelo
Como o objetivo e propor um modelo para previsao em populacoes que evoluem
dinamicamente, de forma que a amostragem adaptativa por conglomerados ainda seja
um plano amostral eficiente, serao tratadas apenas situacoes em que este crescimento
se da em sua maior parte dentro das redes, de forma a nao descaracterizar a raridade
e agrupamento da populacao, os quais sao os principais motivos para o uso deste plano
amostral.
Na Figura 3.3 temos uma ilustracao da dinamica de uma populacao artificial
sobreposta a uma grade regular com N = 400 unidades. Para gerar esta populacao
foi utilizado o processo pontual conglomerado de Poisson (ver Diggle et al. (1983)), o
qual gera configuracoes de eventos agregados, onde os conglomerados sao interpretados
como grafos e, portanto, formados por pais e filhos. Em particular, fixou-se o numero de
redes e de observacoes em cada rede na geracao. Dessa forma, dado o numero R de redes
nao-vazias, as coordenadas dos centroides (pais) destas R redes (grafos) sao sorteadas de
uma distribuicao Uniforme definida neste espaco. A partir destas R localizacoes, com
o numero de observacoes Yi (filhos), para cada rede i, i = 1, . . . , R, as localizacoes dos
Yi − 1 filhos sao gerados para cada rede de uma distribuicao Normal com media nas
coordenadas dos pais e variancia fixada. O numero Yi para cada rede i foi gerado de uma
distribuicao Poisson. Como o objetivo era apenas ilustrar uma populacao dinamica de
interesse, observe que para tal ilustracao nao foram necessarias as variaveis numero de
celulas nao-vazias e numero de celulas em cada rede que fazem parte do modelo (3.1), pois
o processo utilizado na geracao e um processo pontual, e processos deste tipo independem
da divisao da area, no caso da grade regular, o que nao comprometeu de forma alguma
a ilustracao.
43
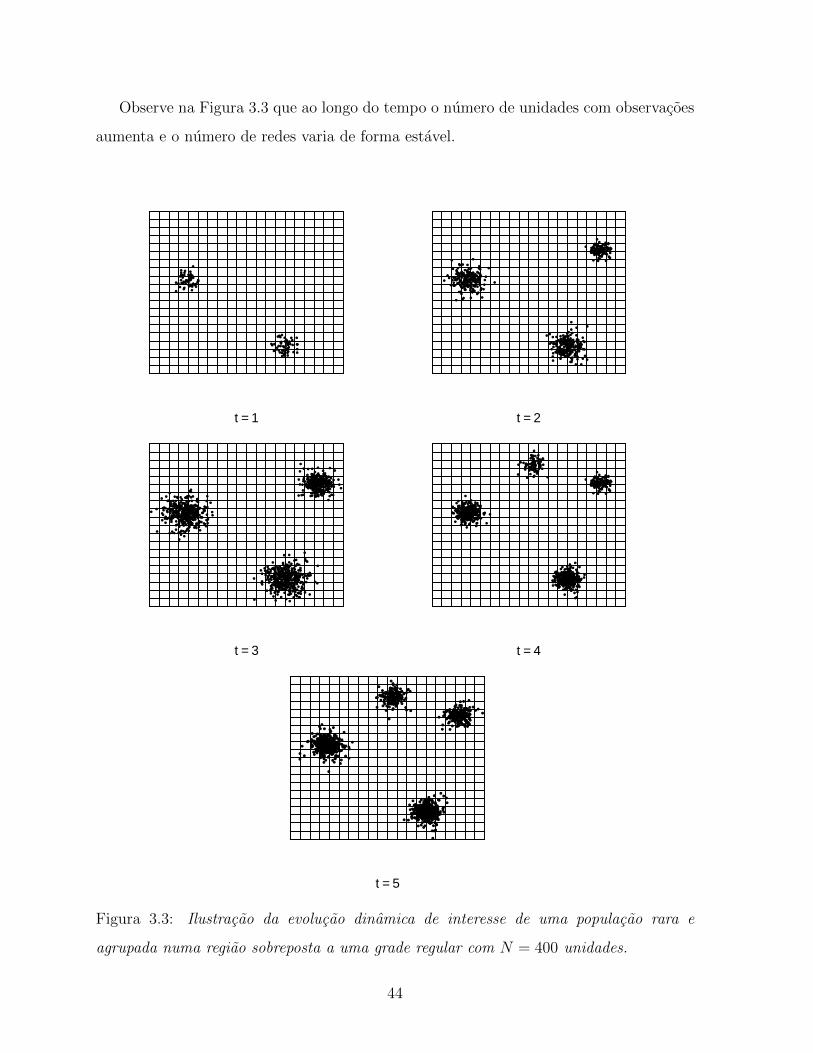
Observe na Figura 3.3 que ao longo do tempo o numero de unidades com observacoes
aumenta e o numero de redes varia de forma estavel.
t = 1
t = 2
t = 3
t = 4
t = 5
Figura 3.3: Ilustracao da evolucao dinamica de interesse de uma populacao rara e
agrupada numa regiao sobreposta a uma grade regular com N = 400 unidades.
44

Note que a partir do modelo em (3.1) e possıvel incorporar esta dinamica populacional
acrescentando alguma estrutura temporal aos parametros α e β. Se tornarmos o
parametro α dinamico, deixando β fixo, o numero de unidades nao-vazias na populacao
se altera ao longo do tempo e, portanto, pela estrutura de condicionamento do modelo,
o numero de redes tambem pode se alterar.
Se for feito o contrario, ou seja tornar o parametro β dinamico, deixando α fixo,
teremos uma populacao cujo numero medio de unidades nao-vazias nao se altera ao longo
do tempo, mas sua disposicao dentro das redes sim, o que pode criar novas redes com
o numero de unidades reduzido, ou ainda desaparecer redes com o numero de unidades
crescendo dentro de algumas redes.
Uma outra possibilidade intuitiva e a incorporacao de dinamica nos dois parametros α
e β ao mesmo tempo, isso geraria uma populacao menos estavel que em qualquer um dos
dois cenarios citados anteriormente. Isto porque estarıamos alterando diretamente tanto
o numero de unidades na populacao, quanto o numero de redes. Note que a estrutura
dinamica a ser imposta deve ser de forma controlada, a fim de que a populacao-alvo rara
e agrupada nao se descaracterize ao longo do tempo.
Neste trabalho temos particular interesse na primeira extensao, onde cresce o numero
total de unidades na populacao ao longo do tempo e, por conta do condicionamento do
modelo, o numero de redes varia, mas de forma mais estavel que as outras duas opcoes.
Dessa forma, serao contemplados comportamentos de mobilidade caracterizados pelo
surgimento e desaparecimento de redes, e ainda pelo crescimento ou decrescimento do
numero de observacoes nas redes que permanecem, mas com uma estabilizacao no final
do tempo. Portanto, nao serao considerados cenarios com alastramento desordenado
ou desaparecimento global da observacao de interesse, como uma epidemia, no caso de
doenca, por exemplo.
3.2.3 Modelo de crescimento exponencial
Como o interesse esta em modelar populacoes que apresentam um crescimento ou
decrescimento medio de observacoes dentro das redes, mas com uma estabilizacao ao longo
do tempo, em particular, modelos de crescimento exponencial podem gerar populacoes
45

com esta estrutura, alem de serem amplamente utilizados em problemas reais em diversas
areas, como na ecologia. Considere que as observacoes obtidas a partir de um processo Yt
ao longo de perıodos de tempo t = 1, . . . , L sao modeladas a partir de uma distribuicao
de probabilidade na famılia exponencial, tal que E(Yt | θt) = λt, onde θt e um vetor de
parametros. Modelos caracterizados pela parametrizacao θt = (a, b, c)′ e por uma funcao
de ligacao h tal que
h(λt) = a+ b exp(ct) e
h(λt) =
λφt , se φ 6= 0
log(λt), se φ ≈ 0
sao chamados modelos de crescimento exponencial generalizados e podem ser vistos com
detalhes em Migon e Gamerman (2006).
O parametro c esta relacionado com a velocidade de crescimento/decrescimento (ou
curvatura), o parametro b com a intensidade do crescimento/decrescimento e a com a
localizacao da curva. Derivando a expressao a+b exp(ct) em relacao a t, podemos concluir
que a curva sera crescente se b e c tiverem o mesmo sinal e decrescente caso contrario.
Pela derivada segunda, podemos concluir que a curva tem concavidade voltada para cima
se b > 0 e para baixo se b < 0. Vale notar ainda que se c < 0 entao a curva tem um
comportamento nao explosivo, convergindo para a quando t→∞.
A principal vantagem em utilizar estes modelos e a possibilidade de manter as
medicoes de Yt na escala original, transformando apenas a trajetoria de Yt, o que torna
a interpretacao dos resultados mais simples. Alem disso, os intervalos de tempo nao
precisam ser igualmente espacados, permitindo que se trabalhe com dados provenientes
de pesquisas com datas de referencia distintas atraves de uma codificacao do ındice t de
tempo.
A proposta, portanto, e modelar o parametro α do modelo (3.1) a partir de uma
curva de crescimento exponencial. Como este parametro e uma probabilidade, e natural
usar-se na modelagem uma funcao de ligacao logıstica, portanto o modelo apresenta-se
da seguinte forma:
logit(αt) = log
(αt
1− αt
)= a+ b exp(ct), t = 1, . . . , L.
46
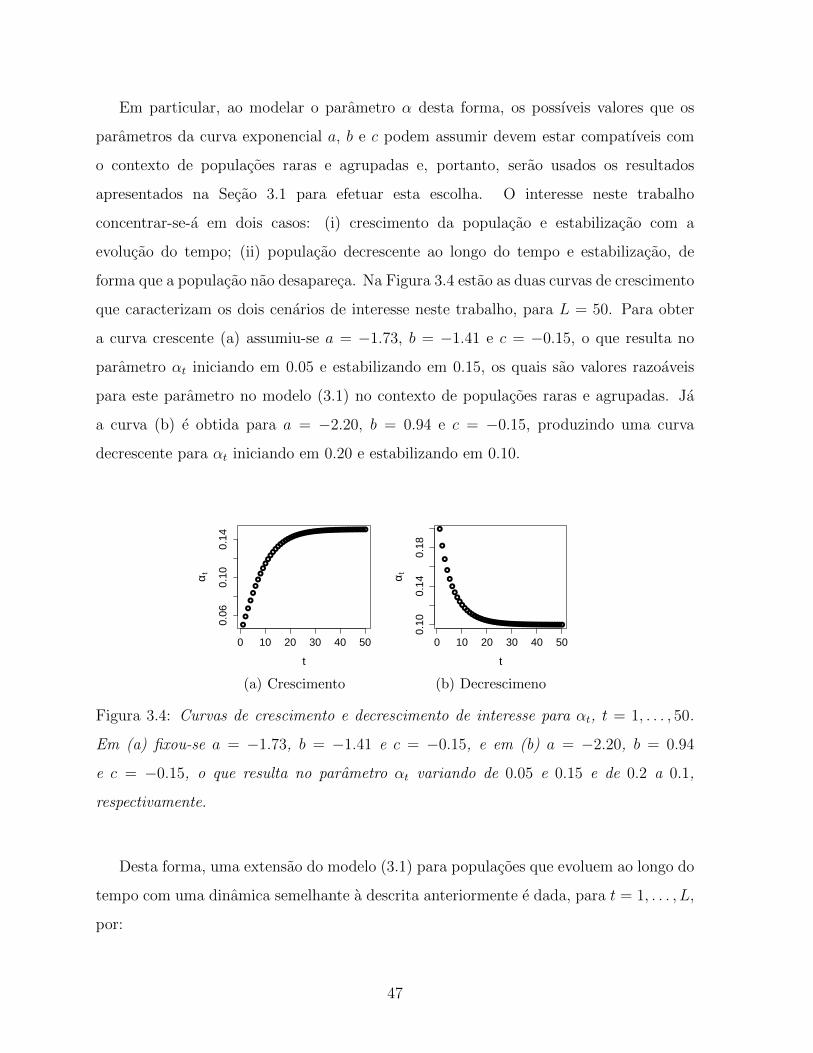
Em particular, ao modelar o parametro α desta forma, os possıveis valores que os
parametros da curva exponencial a, b e c podem assumir devem estar compatıveis com
o contexto de populacoes raras e agrupadas e, portanto, serao usados os resultados
apresentados na Secao 3.1 para efetuar esta escolha. O interesse neste trabalho
concentrar-se-a em dois casos: (i) crescimento da populacao e estabilizacao com a
evolucao do tempo; (ii) populacao decrescente ao longo do tempo e estabilizacao, de
forma que a populacao nao desapareca. Na Figura 3.4 estao as duas curvas de crescimento
que caracterizam os dois cenarios de interesse neste trabalho, para L = 50. Para obter
a curva crescente (a) assumiu-se a = −1.73, b = −1.41 e c = −0.15, o que resulta no
parametro αt iniciando em 0.05 e estabilizando em 0.15, os quais sao valores razoaveis
para este parametro no modelo (3.1) no contexto de populacoes raras e agrupadas. Ja
a curva (b) e obtida para a = −2.20, b = 0.94 e c = −0.15, produzindo uma curva
decrescente para αt iniciando em 0.20 e estabilizando em 0.10.
0 10 20 30 40 50
0.06
0.10
0.14
t
α t
(a) Crescimento
0 10 20 30 40 50
0.10
0.14
0.18
t
α t
(b) Decrescimeno
Figura 3.4: Curvas de crescimento e decrescimento de interesse para αt, t = 1, . . . , 50.
Em (a) fixou-se a = −1.73, b = −1.41 e c = −0.15, e em (b) a = −2.20, b = 0.94
e c = −0.15, o que resulta no parametro αt variando de 0.05 e 0.15 e de 0.2 a 0.1,
respectivamente.
Desta forma, uma extensao do modelo (3.1) para populacoes que evoluem ao longo do
tempo com uma dinamica semelhante a descrita anteriormente e dada, para t = 1, . . . , L,
por:
47

Y ∗it | Cit, Rt, γ ∼ Poisson Truncada independente (γCit), Y∗it ≥ Cit, i = 1, . . . , Rt,
Ct | Xt, Rt ∼ 1Rt + Multi
(Xt −Rt,
1
Rt
1Rt
), Cit = 1, . . . , Xt −Rt + 1,
Rt∑i=1
Cit = Xt,
Rt | Xt, β ∼ Binomial Truncada (Xt, β), Rt = 1, . . . , Xt, (3.4)
Xt | αt ∼ Binomial Truncada (N,αt), Xt = 1, . . . , N,
logit(αt) = a+ b exp(ct), t = 1, . . . , L,
em que Xt e o numero de celulas nao vazias no tempo t, Rt e o numero de redes nao vazias
no tempo t, Ct e o vetor com o numero de celulas nao vazias em cada uma das Rt redes
nao vazias no tempo t, Y ∗it e o numero de observacoes na rede nao vazia i no tempo t,
t = 1, . . . , L. O maior interesse esta em prever T = (T1, . . . , TL)′, em que Tt =∑Rt
i=1 Y∗it .
Alem disso, a variavel resposta neste caso segue uma distribuicao de Poisson, pois o
interesse concentra-se em dados de contagem, embora seja possıvel estender esta ideia
para outras distribuicoes na famılia exponencial, assim como (3.1).
Como trata-se de inferencia Bayesiana, o modelo (3.4) deve ser completado com a
distribuicao a priori para o vetor parametrico (a, b, c, β, γ). Neste caso, ao ajustar o
modelo, sob distribuicoes a priori nao-informativas para os parametros a, b e c, surgiram
problemas de identificabilidade, pois estes parametros devem estar restritos a valores de
αt pequenos. Portanto, conclui-se que para o ajuste razoavel do modelo (3.4) e necessario
atribuir uma distribuicao a priori informativa para estes parametros. Por outro lado,
ha interesse em permitir ao modelo que verifique se os dados fornecem um cenario de
crescimento ou decrescimento da populacao, o que e fornecido pelos valores de a e b, para
c negativo, afim de garantir cenarios de estabilizacao com o passar do tempo. Portanto,
supondo independencia entre os parametros a priori, sera atribuıda a priori para c uma
distribuicao Normal truncada nos reais negativos, denotada por c ∼ N(−∞,0)(µc, σ2c ).
Para (a, b) sera atribuıda a priori uma mistura de distribuicoes normais bivariadas que
contemplam os dois possıveis cenarios, da seguinte forma:
(a, b) ∼ w1N(µ1,Σ1) + (1− w1)N(µ2,Σ2),
48

em que µ1 = (−2.20, 0.94)′ e µ2 = (−1.73,−1.41)′ sao os vetores de media para cada
Normal e Σ1 e Σ2 sao as matrizes de covariancia de cada componente da mistura e
caracterizam o quanto esta distribuicao e informativa a priori. Note que a primeira
distribuicao da mistura caracteriza a curva de decrescimento e a segunda de crescimento.
Logo, o valor de w1 reflete o peso que sera dado as duas distribuicoes. Neste caso, se nao
ha informacao a priori para dar mais probabilidade de ocorrencia a uma das situacoes,
fixar w1 em 0.5 e uma forma de ser nao-informativo e permitir ao modelo que recupere o
comportamento da populacao ao longo do tempo. Na Figura 3.5 esta a distribuicao para
os parametros (a, b), fixando Σ1 = Σ2 = diag(0.01, 0.01).
a
b
Densidade
Figura 3.5: Distribuicao a priori conjunta para o vetor (a, b)′.
Alem disso, supoe-se a priori que β ∼ Beta(aβ, bβ) e γ ∼ Gama(aγ, bγ), como no
modelo em (3.1).
Note que os parametros a, b e c controlam os valores que αt assumem ao longo
do tempo e, usando o argumento de que as populacoes-alvo sao raras e agrupadas, e
necessario atribuir distribuicoes a priori para estes informando que αt assume valores
pequenos. O conhecimento a priori mınimo para aplicabilidade das tecnicas propostas
neste trabalho e que as populacoes em estudo sao raras e agrupadas, portanto a
distribuicao a priori deve ser ao menos informativa sobre este comportamento.
Vale lembrar que as variaveis do modelo sao compostas por uma parte conhecida e
outra desconhecida como descrito na Secao 3.1, no entanto agora devemos definir esta
particao para cada tempo t, da seguinte forma: Y∗t = (Y∗st′,Y∗st
′)′, Ct = (C′st ,C′st)′,
49

Zt = (C′t,1′N−Xt)
′, Rt = Rst + Rst e Xt = Xst + Xst , para t = 1, . . . , L. Sejam entao
X = (X1, . . . , XL)′, R = (R1, . . . , RL)′, C = (C′1, . . . ,C′L)′ e Y∗ = (Y∗1
′, . . . ,Y∗L′)′.
Alem disso, a cada tempo t uma amostra e selecionada de forma adaptativa e
independente dos outros tempos. Note que o modelo escrito desta forma agregada apenas
nos fornece informacoes numericas sobre as redes, portanto nao seria possıvel incorporar
a este modelo um planejamento amostral que nao fosse aplicado independentemente
ao longo do tempo, caso contrario necessitarıamos de informacoes adicionais, como
localizacao das unidades que foram selecionadas. Desta forma, a probabilidade de selecao
de uma amostra st = i1t , . . . , imt de mt redes no tempo t, t = 1, . . . , L, e dada por:
[st | Xt, Rt,Ct] =mt∏jt=1
Zijt × gijt ,jt∑N−Xst−Xst+Rst+Rstit=1 Zit −
∑jt−1kt=0 Zikt
,
onde mt e o numero de redes na amostra no tempo t, gijt ,jt e o numero de redes de
tamanho Zijt que restam apos jt − 1 redes terem sido selecionadas e Zi0 = 0.
Portanto, a funcao de verossimilhanca completa e dada por:
[s,X,R,C,Y∗ | a, b, c, β, γ] =L∏t=1
mt∏jt=1
Zijtgijt ,jt∑N−Xt+Rtit=1 Zit −
∑jt−1kt=0 Zikt
×
N
Xt
αtXt(1− αt)N−Xt1− (1− αt)N
×
Xt
Rt
βRt(1− β)Xt−Rt
1− (1− β)Xt
× (Xt −Rt)!Rt∏i=1
1
(Ci − 1)!
(1
Rt
)Cit−1
×Rt∏i=1
exp−γCit + Y ∗it log(γCit)Y ∗it ![1−
∑Cit−1j=0 exp−γCit + j log(γCit)− log(j!)]
,
para logit(αt) = log(
αt1−αt
)= a+ b exp(ct), t = 1, . . . , L e s = (s1, . . . , sL).
Como a distribuicao a posteriori do vetor parametrico Θ = (X,R,C,Y∗, a, b, c, β, γ)
nao possui forma analıtica fechada, faz-se necessario o uso de metodos de simulacao
estocastica, como o MCMC. Em particular, o amostrador de Gibbs com passos de
Metropolis-Hastings foi utilizado. Alem disso, o preditor de T = (T1, . . . , TL)′ e obtido
da seguinte forma:
Tt = 1′RstY∗st + 1′
RstY∗st ,
50

para t = 1, . . . , L cuja amostra da distribuicao pode ser obtida via MCMC.
Os passos do algoritmo MCMC sao descritos como:
(1) Faca j = 1 e especifique valores iniciais para X1t , Rst , Cst e Y∗st , para t = 1, . . . , L;
(2) Gere a da distribuicao [a | X,R,C,Y∗, b, c, β, γ] = [a | X, b, c];
(3) Gere b da distribuicao [b | X,R,C,Y∗, a, c, β, γ] = [b | X, a, c];
(4) Gere c da distribuicao [c | X,R,C,Y∗, a, b, β, γ] = [c | X, a, b];
(5) Gere β da distribuicao [β | X,R,C,Y∗, a, b, c, γ] = [β | X,R];
(6) Gere γ da distribuicao [γ | X,R,C,Y∗, a, b, c] = [γ | R,C,Y∗];
(7) Gere (Xst , Rst ,Cst ,Y∗st) da distribuicao [Xst , Rst ,Cst ,Y
∗st | Xst , Rst ,Cst ,Y
∗st ,
a, b, c, β, γ], para t = 1, . . . , L;
(8) Faca j = j + 1 e volte ao passo (2).
Note que este modelo e usado para estimacao do total populacional apos a observacao
de todos os tempos. Se optassemos por uma estimacao sequencial dos parametros do
modelo e de T a medida que as observacoes fossem coletadas, algumas dificuldades
poderiam surgir. Os parametros do modelo de crescimento exponencial estao associados
ao crescimento e estabilizacao da populacao, portanto, so serao realmente bem estimados
apos coletadas todas as observacoes ao longo dos tempos. Logo, recomenda-se que, se o
ajuste de tal modelo for feito de forma sequencial, ja tenham sido observados um numero
razoavel de instantes de tempo, para que o limite do crescimento tenha sido ao menos
atingido.
3.2.4 Estudo simulado
A fim de examinar o desempenho do modelo proposto, foram geradas 100 populacoes
artificiais com N = 400 unidades ao longo de L = 50 tempos, a partir do modelo
(3.4) com parametros (c, β, γ) fixados em (−0.15, 0.10, 10). Para contemplar os dois
tipos de evolucao ao longo do tempo de interesse para algumas populacoes, fixou-se
51

(a, b) = (−1.73,−1.41), o que caracteriza um cenario de crescimento ao longo do tempo,
e para outras (a, b) = (−2.20, 0.94), o que caracteriza um decrescimento. Estes valores
foram escolhidos de modo a representar as mesmas situacoes descritas na Figura 3.4 e
com cenarios de raridade e agrupamento semelhantes aos apresentados na Subsecao 3.1.2.
Para cada tempo t, inicialmente 5% das unidades amostrais foram selecionadas
por amostragem aleatoria simples sem reposicao e uma amostra adaptativa por
conglomerados para cada tempo foi selecionada de forma independente.
A distribuicao a priori utilizada para (a, b, c, β, γ) e descrita a seguir. Supondo
independencia a priori para cada parametro, para β e γ foram utilizadas as mesmas
distribuicoes descritas na Subsecao 3.1.2. Os parametros a, b e c controlam os valores
que αt assume ao longo do tempo e, usando o argumento de que as populacoes-alvo sao
raras e agrupadas, sera atribuıda uma distribuicao a priori para estes que informe que αt
e um parametro com valor pequeno e que a esta relacionado com a convergencia da curva
e b e c com o crescimento. Alem disso, note que a + b e igual ao valor inicial da curva
de crescimento. Portanto, foram atribuıdas distribuicoes a priori informativas para estes
parametros. No entanto, na distribuicao a priori para (a, b), usou-se w1 = 0.5, logo a
priori nao esta sendo informado se, com a evolucao do tempo, a populacao passou por
um crescimento ou decrescimento.
Para verificar o ajuste do modelo foram geradas 200.000 iteracoes, sendo as 10.000
primeiras descartadas como aquecimento e tomamos amostras de 190 em 190, a fim de
obtermos 1.000 amostras independentes. Nas Figuras 1.6 e 1.7, apresentadas no Apendice
A, esta um sumario da distribuicao a posteriori para duas das 100 populacoes geradas.
Na Figura 1.6 esta o resultado a posteriori para uma populacao que cresce ao londo tempo
e na Figura 1.7 para uma populacao que decresce. Na Figura 1.6 (a)-(e) e na Figura 1.7
(a)-(e) estao os tracos das cadeias da distribuicao a posteriori dos parametros a, b, c, β e
γ. As Figuras 1.6 e 1.7 (f)-(j) mostram as cadeias para o total em alguns instantes de
tempo arbitrarios. A linha em cinza representa o valor verdadeiro usado na geracao dos
dados artificiais. Observe que ha indıcios de convergencia para todos os parametros do
modelo.
52

Como temos amostras das distribuicoes a posteriori de a, b e c, temos uma amostra
da distribuicao de αt, t = 1, . . . , L. Nas Figuras 3.6 (a) e (b) estao em preto a media a
posteriori de αt, em azul o valor verdadeiro e em cinza o intervalo HPD de 95%. Pela
proximidade das linhas azuis e preta e pela linha azul estar contemplada pelo intervalo de
95% e possıvel concluir que este parametro e bem estimado. Finalmente, as Figuras 3.6
(c) e (d) apresentam os valores estimados para o total populacional para os 50 instantes
de tempo. Em preto esta a media a posteriori do total para cada tempo, as cruzes em
azul representam os valores verdadeiros do total populacional para cada tempo e em
cinza o intervalo HPD de 95%. Em sua grande maioria os pontos em azul pertencem ao
intervalo, portanto podemos concluir que os totais estao sendo bem estimados para cada
tempo. Note que em ambos os casos o modelo recupera a estrutura ao longo do tempo
dos dados.
Na Tabela 3.3 temos um sumario da distribuicao a posteriori dos parametros do
modelo de crescimento proposto para as 100 populacoes geradas. Sao apresentadas o
EQMR, erro medio absoluto relativo (EAR), a amplitude media dos intervalos HPD de
95% relativizada com relacao ao verdadeiro valor e respectiva probabilidade de cobertura.
Note que todos os parametros do modelo sao bem estimados, pois os respectivos EQMR
e EAR sao pequenos. As probabilidades de cobertura dos intervalos na maioria das vezes
se apresentam abaixo do nıvel nominal desejado de 95%, com excecao dos parametros γ,
β e c no caso de populacao em decrescimento. Uma explicacao plausıvel para este caso e
o fato de que as populacoes artificiais em decrescimento foram geradas de forma que em
todos os 50 instantes de tempo o numero de unidades nao vazias estivesse em torno de
10% e 20%, portanto de uma maneira geral estas populacoes apresentam-se menos raras
e agrupadas que as populacoes geradas para o cenario de crescimento.
Na Figura 3.7 estao os EQMR, EAR, cobertura e amplitude media relativizada com
relacao ao valor verdadeiro dos intervalos HPD de 95% para os totais populacionais para
cada tempo para as populacoes simuladas de crescimento e decrescimento. Por questoes
de melhor visualizacao grafica, a amplitude media apresentada e dada pela media dos
valores da amplitude obtida, para cada simulacao, dividida pelo valor verdadeiro do total
53
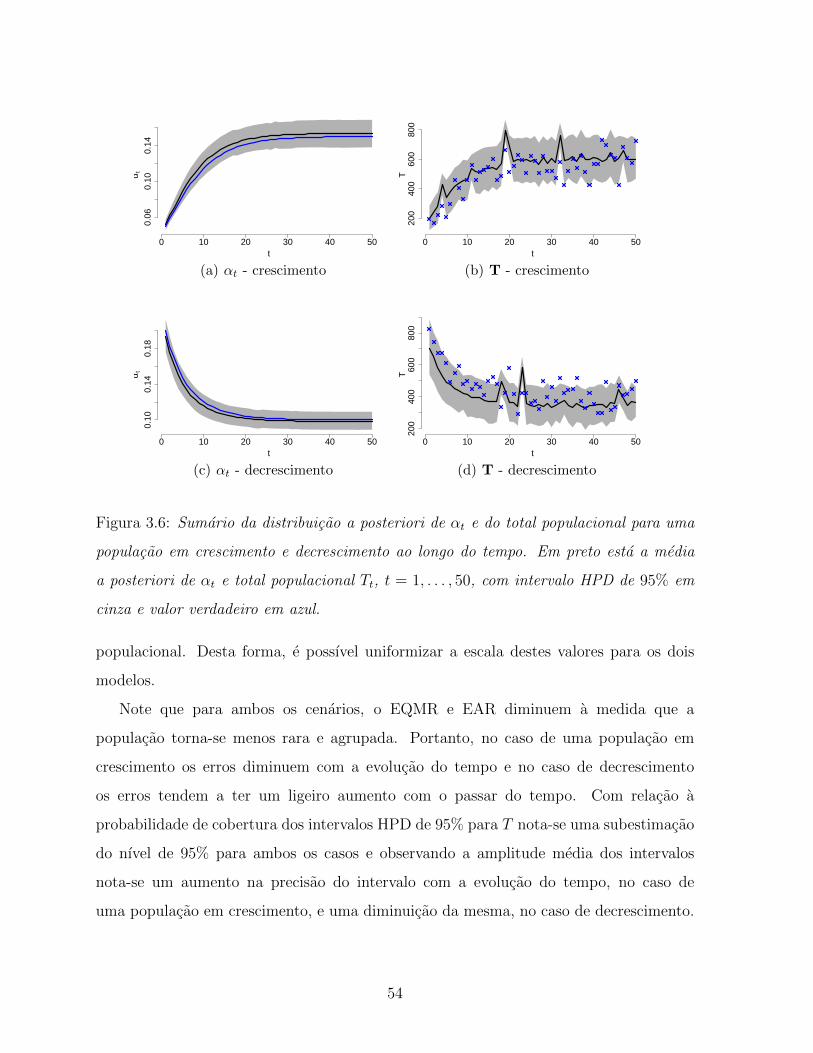
t
α t
0 10 20 30 40 50
0.06
0.10
0.14
(a) αt - crescimento
t
T
0 10 20 30 40 50
200
400
600
800
(b) T - crescimento
t
α t
0 10 20 30 40 50
0.10
0.14
0.18
(c) αt - decrescimento
t
T
0 10 20 30 40 50
200
400
600
800
(d) T - decrescimento
Figura 3.6: Sumario da distribuicao a posteriori de αt e do total populacional para uma
populacao em crescimento e decrescimento ao longo do tempo. Em preto esta a media
a posteriori de αt e total populacional Tt, t = 1, . . . , 50, com intervalo HPD de 95% em
cinza e valor verdadeiro em azul.
populacional. Desta forma, e possıvel uniformizar a escala destes valores para os dois
modelos.
Note que para ambos os cenarios, o EQMR e EAR diminuem a medida que a
populacao torna-se menos rara e agrupada. Portanto, no caso de uma populacao em
crescimento os erros diminuem com a evolucao do tempo e no caso de decrescimento
os erros tendem a ter um ligeiro aumento com o passar do tempo. Com relacao a
probabilidade de cobertura dos intervalos HPD de 95% para T nota-se uma subestimacao
do nıvel de 95% para ambos os casos e observando a amplitude media dos intervalos
nota-se um aumento na precisao do intervalo com a evolucao do tempo, no caso de
uma populacao em crescimento, e uma diminuicao da mesma, no caso de decrescimento.
54
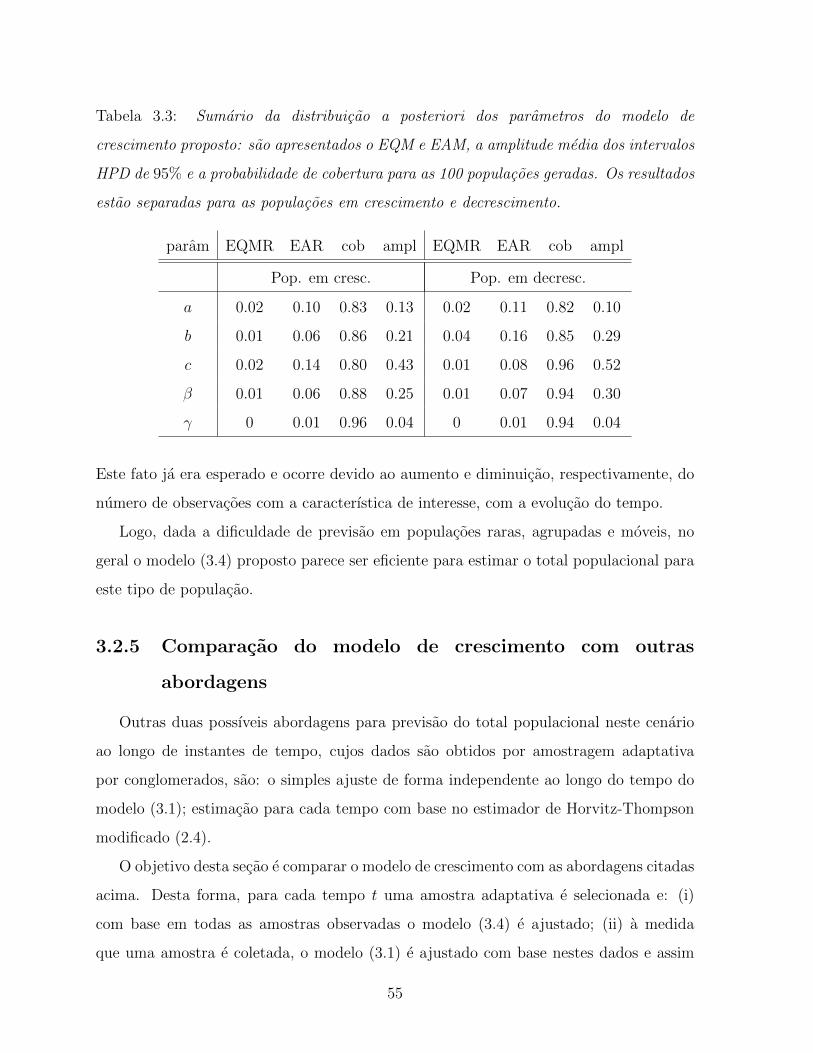
Tabela 3.3: Sumario da distribuicao a posteriori dos parametros do modelo de
crescimento proposto: sao apresentados o EQM e EAM, a amplitude media dos intervalos
HPD de 95% e a probabilidade de cobertura para as 100 populacoes geradas. Os resultados
estao separadas para as populacoes em crescimento e decrescimento.
param EQMR EAR cob ampl EQMR EAR cob ampl
Pop. em cresc. Pop. em decresc.
a 0.02 0.10 0.83 0.13 0.02 0.11 0.82 0.10
b 0.01 0.06 0.86 0.21 0.04 0.16 0.85 0.29
c 0.02 0.14 0.80 0.43 0.01 0.08 0.96 0.52
β 0.01 0.06 0.88 0.25 0.01 0.07 0.94 0.30
γ 0 0.01 0.96 0.04 0 0.01 0.94 0.04
Este fato ja era esperado e ocorre devido ao aumento e diminuicao, respectivamente, do
numero de observacoes com a caracterıstica de interesse, com a evolucao do tempo.
Logo, dada a dificuldade de previsao em populacoes raras, agrupadas e moveis, no
geral o modelo (3.4) proposto parece ser eficiente para estimar o total populacional para
este tipo de populacao.
3.2.5 Comparacao do modelo de crescimento com outras
abordagens
Outras duas possıveis abordagens para previsao do total populacional neste cenario
ao longo de instantes de tempo, cujos dados sao obtidos por amostragem adaptativa
por conglomerados, sao: o simples ajuste de forma independente ao longo do tempo do
modelo (3.1); estimacao para cada tempo com base no estimador de Horvitz-Thompson
modificado (2.4).
O objetivo desta secao e comparar o modelo de crescimento com as abordagens citadas
acima. Desta forma, para cada tempo t uma amostra adaptativa e selecionada e: (i)
com base em todas as amostras observadas o modelo (3.4) e ajustado; (ii) a medida
que uma amostra e coletada, o modelo (3.1) e ajustado com base nestes dados e assim
55
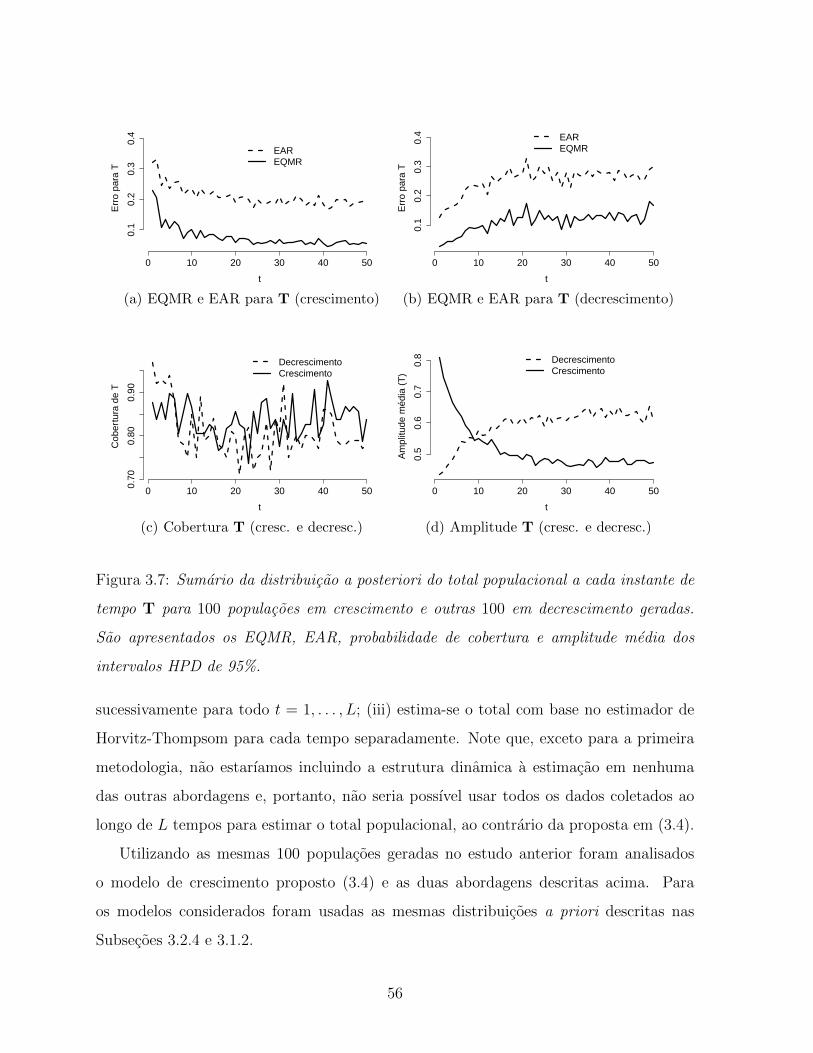
t
Err
o pa
ra T
0 10 20 30 40 50
0.1
0.2
0.3
0.4
EAREQMR
(a) EQMR e EAR para T (crescimento)
t
Err
o pa
ra T
0 10 20 30 40 50
0.1
0.2
0.3
0.4 EAR
EQMR
(b) EQMR e EAR para T (decrescimento)
t
Cob
ertu
ra d
e T
0 10 20 30 40 50
0.70
0.80
0.90
DecrescimentoCrescimento
(c) Cobertura T (cresc. e decresc.)
t
Am
plitu
de m
édia
(T
)
0 10 20 30 40 50
0.5
0.6
0.7
0.8 Decrescimento
Crescimento
(d) Amplitude T (cresc. e decresc.)
Figura 3.7: Sumario da distribuicao a posteriori do total populacional a cada instante de
tempo T para 100 populacoes em crescimento e outras 100 em decrescimento geradas.
Sao apresentados os EQMR, EAR, probabilidade de cobertura e amplitude media dos
intervalos HPD de 95%.
sucessivamente para todo t = 1, . . . , L; (iii) estima-se o total com base no estimador de
Horvitz-Thompsom para cada tempo separadamente. Note que, exceto para a primeira
metodologia, nao estarıamos incluindo a estrutura dinamica a estimacao em nenhuma
das outras abordagens e, portanto, nao seria possıvel usar todos os dados coletados ao
longo de L tempos para estimar o total populacional, ao contrario da proposta em (3.4).
Utilizando as mesmas 100 populacoes geradas no estudo anterior foram analisados
o modelo de crescimento proposto (3.4) e as duas abordagens descritas acima. Para
os modelos considerados foram usadas as mesmas distribuicoes a priori descritas nas
Subsecoes 3.2.4 e 3.1.2.
56

Dado que a convergencia foi obtida para todos os parametros e como nosso maior
interesse esta na previsao do total populacional com base em modelos, na Figura (3.8)
estao em (a) as probabilidades de cobertura dos intervalos HPD de 95% para T e em (b)
as amplitudes medias relativizadas destes intervalos para todos os 50 tempos, usando o
modelo proposto em (3.4) e as replicacoes ao longo do tempo do modelo (3.1). Chamamos
de “Crescimento”o modelo proposto em (3.4), “Estatico”o modelo estatico em (3.1) e “H-
T”o estimador de Horvitz-Thompson.
Note que apesar do ajuste independente fornecer uma probabilidade de cobertura
em media mais proxima do nıvel desejado de 95% que a extensao proposta, temos
uma incerteza significativamente maior. Por outro lado, em (c) temos um grafico de
dispersao com a raiz quadrada do erro quadratico medio relativo (REQMR) sob as
mesmas abordagens. Como todos os pontos encontram-se abaixo da reta, conclui-se que
a extensao proposta em (3.4) produz erros menores, logo em termos de estimacao pontual
parece ser mais vantajoso. Finalmente, em (d) estao os diagramas boxplot com os REQMR
para todos os tempos sob as duas abordagens baseadas em modelos e adicionalmente
para o estimador de Horvitz-Thompson modificado. E possıvel concluir que o ajuste
baseado em modelos de superpopulacao produz erros menores que a abordagem usando
a aleatorizacao do plano amostral e que o modelo proposto e o mais eficiente neste caso,
ja que usamos as observacoes coletadas ate o tempo L na estimacao dos parametros.
Portanto, conclui-se que a extensao em (3.4) proposta para populacoes dinamicas e
vantajosa em relacao ao estimador de Horvitz-Thompson e ao ajuste repetido ao longo
do tempo do modelo (3.1).
57
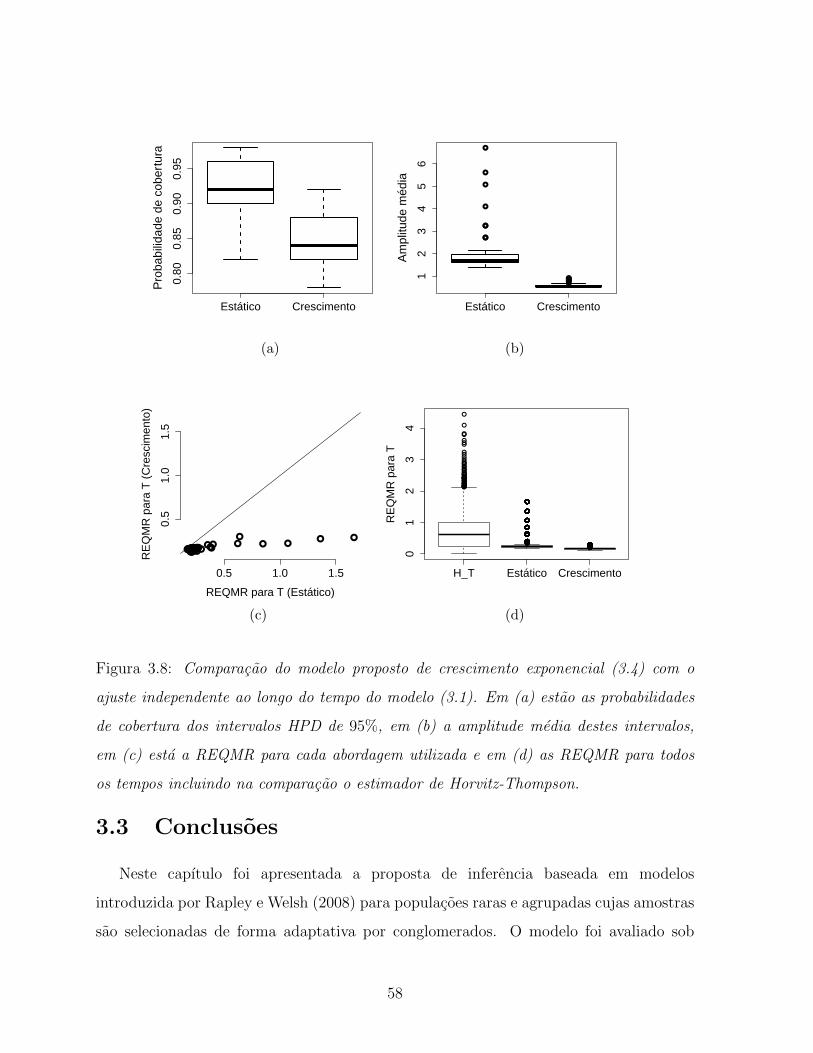
Estático Crescimento
0.80
0.85
0.90
0.95
Pro
babi
lidad
e de
cob
ertu
ra
(a)
Estático Crescimento
12
34
56
Am
plitu
de m
édia
(b)
REQMR para T (Estático)
RE
QM
R p
ara
T (
Cre
scim
ento
)
0.5 1.0 1.5
0.5
1.0
1.5
(c)
H_T Estático Crescimento
01
23
4
RE
QM
R p
ara
T
(d)
Figura 3.8: Comparacao do modelo proposto de crescimento exponencial (3.4) com o
ajuste independente ao longo do tempo do modelo (3.1). Em (a) estao as probabilidades
de cobertura dos intervalos HPD de 95%, em (b) a amplitude media destes intervalos,
em (c) esta a REQMR para cada abordagem utilizada e em (d) as REQMR para todos
os tempos incluindo na comparacao o estimador de Horvitz-Thompson.
3.3 Conclusoes
Neste capıtulo foi apresentada a proposta de inferencia baseada em modelos
introduzida por Rapley e Welsh (2008) para populacoes raras e agrupadas cujas amostras
sao selecionadas de forma adaptativa por conglomerados. O modelo foi avaliado sob
58

diversos estudos simulados, variando o grau de esparsidade e agrupamento da populacao,
o tamanho da amostra selecionada e ainda quando na inferencia o plano amostral
nao e incorporado erroneamente na expressao da verossimilhanca. O modelo teve um
bom desempenho em todos os casos, principalmente para valores de α e β que gerem
populacoes raras com um numero mınimo de redes nao vazias.
O modelo de Rapley e Welsh (2008) e construıdo em um nıvel agregado da populacao,
o que produz algumas facilidades na inferencia, no entanto, esta estrutura agregada induz
a algumas restricoes nas hipoteses do modelo, como a homogeneidade entre grupos e a
hipotese de que o numero de observacoes numa rede esta relacionado diretamente com
seu tamanho.
E comum que as populacoes consideradas neste trabalho, alem de terem um
comportamento raro e agrupado, apresentem uma constante mobilidade dentro de uma
regiao ao longo de um perıodo de tempo. Visando a este problema, foi introduzida uma
extensao dinamica do modelo agregado. O modelo se ajusta a amostras adaptativas
coletadas de forma independente ao longo do tempo e supoe uma dinamica populacional
de crescimento e decrescimento ao longo do tempo. Na inferencia sob o modelo de
crescimento e preciso observar as amostras ao longo de todos os tempos, ou de pelo
menos uma quantidade razoavel destes, o que exige maior custo operacional. Por outro
lado, o modelo em (3.1) so permite o uso de amostras independentes ao longo do tempo
e previsao para cada tempo separadamente, isto porque o modelo escrito desta forma
agregada apenas nos fornece informacoes numericas sobre as redes, portanto nao seria
possıvel incorporar a este modelo um planejamento amostral diferente, caso contrario
necessitarıamos de informacoes adicionais, como a localizacao das unidades que foram
selecionadas. Por esta e outras razoes, um modelo desagregado que informe as localizacoes
pode ser de interesse. No proximo capıtulo sera proposto um modelo que atenda a estas
necessidades.
59

Capıtulo 4
Modelo de mistura para populacoes
raras e agrupadas sob amostragem
adaptativa
O modelo proposto por Rapley e Welsh (2008) usa as redes como unidades de analise,
de forma a nao ter que introduzir componentes espaciais no modelo, o que pode vir a
facilitar a inferencia.
Neste caso, a modelagem e feita supondo que em media a distribuicao do total
das redes seja proporcional ao tamanho das redes. Isto equivale a tratar as unidades
populacionais como sendo homogeneas e que a intensidade do fenomeno em uma rede
depende do seu tamanho, ou seja, redes maiores apresentam em media sempre maior total.
No entanto, esta suposicao nem sempre e valida. Por exemplo, e comum que a intensidade
de um fenomeno em uma unidade varie de acordo com a rede a qual ela pertence devido
a influencia da vizinhanca. Ou ainda, dentro de uma mesma rede e possıvel que as
unidades de borda apresentem menor taxa de ocorrencia do que as unidades no centro da
rede. Alem disso, uma rede pode ter maior incidencia do fenomeno em suas unidades nao
somente por ser maior, mas por outros fatores externos que influenciem na sua disposicao.
Mas o fato de agregar a informacao para todas as unidades dentro de uma mesma
rede, alem de nao permitir previsao do total populacional em cada unidade da grade
regular, impossibilita a incorporacao de estruturas mais complexas uteis na insercao das
60

suposicoes descritas acima. Ou ainda, num contexto de populacoes moveis, como visto
na Secao 3.2, o modelo nao possibilita a insercao de um planejamento amostral que ao
longo do tempo use informacoes de tempos anteriores, pois o modelo nao apresenta uma
variavel de identificacao das unidades i da rede j que pertencem a amostra, e sim uma
variavel que agrega numericamente estas informacoes para cada rede. Por estas razoes,
a proposta de um modelo desagregado pode ser interessante em muitos contextos com
populacoes raras e agrupadas.
Por outro lado, a modelagem de eventos raros usando distribuicao de Poisson algumas
vezes revela uma significante sobredispersao, a qual pode ser diminuıda usando modelos
mistos hierarquicos. Esta abordagem vem sendo usada em muitas aplicacoes, como por
exemplo na modelagem de doencas raras, em que o numero de casos por area e pequeno,
como pode ser visto em Clayton e Bernardinelli (1992). Viallefont et al. (2002) sugerem
para a modelagem de eventos deste tipo um modelo de mistura Poisson, cujo numero de
componentes de mistura e desconhecido.
O objetivo deste capıtulo e propor um modelo de mistura desagregado que suponha
heterogeneidade entre unidades pertencentes a redes distintas e, portanto, o total em
cada rede nao dependeria somente do tamanho desta. A proposta e que este modelo se
aplique a populacoes raras e agrupadas, que sao amostradas usando o desenho adaptativo
por conglomerados, portanto a probabilidade de selecao deve ser incorporada a funcao
de verossimilhanca dos parametros do modelo. Note que o fato de modelar cada unidade
da grade permite tambem construir um modelo com suposicao de heterogeneidade entre
as celulas de uma mesma rede, o qual sera nosso interesse futuro.
Na Secao 4.1 e definida a classe de modelos de mistura de distribuicoes de
probabilidades e uma forma de fazer inferencia sob o enfoque Bayesiano para modelos
deste tipo. Na Secao 4.2 e apresentado o modelo proposto neste trabalho, discutindo
pontos como elicitacao de distribuicao a priori, inferencia e convergencia das cadeias
com as amostras da distribuicao a posteriori do vetor parametrico. Varios estudos
simulados sao realizados com o objetivo de avaliar o desempenho do modelo sob diferentes
configuracoes da populacao. Finalmente, na Secao 4.4 o modelo proposto neste capıtulo
e comparado ao modelo de Rapley e Welsh (2008), a partir de experimentos baseado em
61

modelos e no desenho amostral usando a populacao real de marrecos da asa azul, descrita
na Secao 3.1.3 do Capıtulo 3. Daqui em diante, o modelo de Rapley e Welsh (2008) sera
referido como “modelo agregado”.
4.1 Uma revisao sobre modelos de mistura de
distribuicoes
Modelos com mistura de distribuicoes sao frequentemente utilizados para modelar
fenomenos cujas observacoes sao provenientes de uma populacao composta por k
subpopulacoes, onde k pode ser conhecido ou desconhecido. Um modelo com mistura e
dado por uma soma ponderada de distribuicoes de probabilidades. Vejamos a definicao
a seguir.
Definicao 4.1.1 Qualquer combinacao linear convexa
k∑j=1
wjf(Y | φj), com 0 < wj < 1 ek∑j=1
wj = 1, (4.1)
das distribuicoes f(· | φj) pertencentes a uma famılia de distribuicoes parametricas
indexadas pelo vetor parametrico φj, e denominada uma mistura de distribuicoes com
k componentes, tal que wj, j = 1, . . . , k sao os pesos da mistura.
O modelo em (4.1) assume que temos uma populacao heterogenea, com k
subpopulacoes, de tamanhos proporcionais aos pesos wj, j = 1, . . . , k.
Em Marin et al. (2005) pode-se ver uma revisao desta modelagem e exemplos de
dados aos quais se aplica esta abordagem, como os dados de peso de militares recrutados
na Franca, que apresentam um comportamento bimodal de acordo com seu lugar de
origem. Assim, cada peso yi e proveniente a priori da densidade f1 ou f2, em que f1 esta
modelando os pesos dos homens das planıcies e f2 os pesos dos homens das montanhas,
com probabilidades w1 e w2 = 1 − w1. Note que a diferenca fundamental entre uma
regressao simples usando o lugar de origem como covariavel, para um modelo de mistura
deste tipo, e que as observacoes sao coletadas indiscriminadamente para toda a populacao,
ou seja, nao se conhece o lugar de origem de todos os militares, apenas supoe-se a priori
62

que a variavel resposta (peso) e influenciada por fatores (origem) que podem ou nao
ser conhecidos. Logo, a estrutura de mistura e cabıvel neste caso devido a perda de
informacao sobre a origem de cada homem.
A funcao de verossimilhanca de um modelo de mistura com k componentes, para uma
amostra y = (y1, . . . , yn)′ e dada por:
[y | w,φ] =n∏i=1
k∑j=1
wjf(yi | φj), (4.2)
onde φ = (φ1, . . . ,φk)′ e w = (w1, . . . , wk)
′. Esta funcao tem uma forma complexa
pois envolve uma expansao em kn termos, o que torna computacionalmente custoso o
desenvolvimento de estimadores de maxima verossimilhanca, ou no contexto Bayesiano,
a obtencao da distribuicao a posteriori do vetor parametrico.
Como uma alternativa a este problema, a estrutura oculta e explorada para facilitar o
procedimento de estimacao dos parametros. Utilizando o fato de que, para todo o vetor
aleatorio Y, proveniente de um modelo com mistura de distribuicoes com k componentes,
e possıvel associar uma variavel latente Z, de dimensao n, que indica a componente da
qual a observacao Yi e proveniente, isto e Zi = j, se a unidade i e proveniente da
componente j, i = 1, . . . , n, j = 1, . . . , k.
O vetor de dados observados em conjunto com as variaveis latentes produz mais
informacao para o modelo e passa a ser chamado de dados aumentados. Segundo Tanner
(1993), o objetivo de aumentar os dados e simplificar a forma analıtica da funcao de
verossimilhanca, condicionando-os a variavel latente. Condicional a Z = (Z1, . . . , Zn)′,
a funcao de verossimilhanca em (4.2) passa a ser escrita em termos de produtorios de
densidades simples, da forma:
[y | Z,w,φ] =k∏j=1
∏i:Zi=j
f(yi | φj),
tal que Zi’s sao supostamente independentes, com funcao de probabilidade dada por
P (Zi = j) = wj,
para j = 1, . . . , k e i = 1, . . . , n. Ao integrar sobre as variaveis latentes Z, retorna-se a
expressao em (4.1).
63

Finalmente, estimar o numero de componentes de mistura e uma questao importante
e complexa. Ao atribuir um numero menor que o necessario, o modelo nao consegue
capturar a verdadeira estrutura dos dados. Por outro lado, se esse numero for superior
ao ideal, o modelo torna-se menos parcimonioso e atribui massa de probabilidade
desnecessaria em algumas regioes do espaco e, consequentemente, a densidade fica
subestimada e nao identificavel.
4.1.1 Inferencia Bayesiana em modelos de mistura
Abordagens Bayesianas para inferencia em modelos de mistura tem despertado grande
interesse entre pesquisadores. Alem de permitir a inclusao de conhecimento a priori sobre
os parametros do modelo na analise, diminui a complexidade do modelo decompondo-o
em estruturas mais simples. Segundo Richardson e Green (1997) o paradigma Bayesiano
e o mais adequado ao contexto de misturas, principalmente quando o numero de
componentes e desconhecido e deve ser estimado.
No contexto Bayesiano o modelo de mistura deve ser completado com uma distribuicao
a priori para o vetor parametrico Θ = (k,w,φ). Como pode ser visto em Richardson
e Green (1997), supondo independencia a priori e que [φ | Z,w, k] = [φ | k] e [y |
φ,Z,w, k] = [y | φ,Z] a distribuicao conjunta das variaveis do modelo e dada por:
[k,w,Z,φ,y] = [k][w | k][Z | w, k][φ | k][y | φ,Z].
Para completa flexibilidade, atribuem-se aos hiperparametros da distribuicao a priori
tambem distribuicoes a priori independentes.
4.1.1.1 Identificabilidade do modelo
Uma caracterıstica importante de um modelo de mistura e que este apresenta-se
invariante sob permutacoes dos ındices dos seus componentes. Isto implica que os
parametros φi nao sao marginalmente identificaveis, ou seja a partir da funcao de
verossimilhanca nao e possıvel distinguir por exemplo φi de φj, para i 6= j. Nesta classe
de modelos, esta identificabilidade e tratada na realizacao da inferencia Bayesiana.
64

Primeiramente, note que se (φ1, . . . , φk)′ e maximo local, logo qualquer permutacao
dentro deste vetor tambem o e, portanto existem “k!” modas. Alem disso, se e utilizada
uma distribuicao a priori para φ permutavel, todas as condicionais completas sao
identicas para todas as componentes, entao a distribuicao a posteriori para φ se apresenta
multimodal o que dificulta a analise e interpretacao dos resultados. Considere por
exemplo, uma populacao constituıda de duas distribuicoes Normais, inequivocamente
rotuladas. A distribuicao a posteriori das duas medias irao se sobrepor, mas a extensao
desta sobreposicao depende da separacao entre elas e do tamanho da amostra. Quando as
medias sao bem diferentes, o rotulo na distribuicao a posteriori ao ordenar suas medias
geralmente coincidem com a rotulagem da populacao. Mas, se a diferenca diminui, o
fenomeno conhecido como label switching tende a ocorrer.
Portanto, uma alternativa usada neste problema e a imposicao de um unico tipo
de rotulo para as componentes. Por exemplo, num caso de mistura de distribuicoes
normais, em que φj = (µj, σ2j ), tal que µj e σ2
j sao respectivamente a media e a variancia
da distribuicao para a componente j, pode-se identificar as componentes de acordo
com a ordem crescente da media. Desta forma, a distribuicao a priori conjunta e “k!
multiplicado pela distribuicao original com a restricao para identificabilidade imposta”.
Vale ressaltar que em alguns casos a melhor alternativa sera impor tal restricao na media,
outras vezes na variancia, outras ainda no peso, como pode ser visto em Richardson e
Green (1997).
4.1.1.2 Algoritmo MCMC para modelos de mistura supondo k desconhecido
Em geral, os metodos de MCMC sao utilizados para amostrar da distribuicao a
posteriori do vetor parametrico. Os metodos de MCMC inicialmente eram utilizados
apenas para problemas em que a distribuicao a posteriori tivesse uma densidade com
respeito a uma medida subjacente fixa e, portanto, nao podiam ser utilizados em casos,
como na mistura de distribuicoes, em que o tamanho do espaco parametrico e tambem
um parametro desconhecido. Alguns trabalhos na literatura surgiram propondo metodos
de MCMC para problemas de dimensao variante, entre elas a abordagem denominada
MCMC com saltos reversıveis (do ingles, Reversible Jump Markov Chain Monte Carlo,
65

RJMCMC) ganhou destaque. Proposto em Green (1995), o algoritmo RJMCMC e como
um algoritmo de Metropolis-Hastings que permite a movimentacao entre modelos que
possuem espacos parametricos de diferentes dimensoes.
Em particular, Richardson e Green (1997) desenvolveram uma metodologia Bayesiana
para estimacao em modelos de mistura com numero de componentes desconhecido usando
metodos de RJMCMC. O metodo e brevemente descrito a seguir.
Considere que temos os modelos M1, . . . ,Mm, em que o modelo Mj, j = 1, . . . ,m
e indexado pelo vetor parametrico Θj pertencente ao espaco parametrico Φj. Suponha
que a distribuicao a priori para (Θj,Mj) e dada pelo produto entre [Θj |Mj] e [Mj].
Para este estado corrente, propoe-se um movimento do modelo Mj para o modelo Ml,
tal que l = 1, . . . ,m, j 6= l com probabilidade pl|j. Como os espacos parametricos Θj e Θl
possuem dimensoes diferentes, e preciso completar um dos espacos com espacos artificiais
adequados, para criar assim uma bijecao entre eles. Isto e feito, em geral, aumentando
o espaco parametrico do modelo com menor dimensao. Ou seja, se dim(Θj) < dim(Θl),
gera-se um vetor aleatorio u, independente de Θj, de uma distribuicao q(u) de dimensao
igual a diferenca dim(Θl)−dim(Θj) e obtem-se Θl usando uma transformacao ϕ : j → l
definida por T (Θj,u) = Θl. Este movimento proposto e aceito com probabilidade igual
a min(1, A), tal que
A =[y | Θl,Ml]
[y | Θj,Mj]
[Θl | Ml]
[Θj | Mj]
[Ml]
[Mj]
pj|lpl|jq(u)
∣∣∣∣ ∂Θl
∂(Θj,u)
∣∣∣∣ , (4.3)
onde o ultimo termo e o Jacobiano da transformacao ϕ : j → l.
O movimento contrario, ou seja de Θl para Θj, supondo dim(Θj) < dim(Θl), e feito
usando a transformacao inversa, logo o valor proposto para u e determinıstico. Assim, o
movimento inverso e aceito com probabilidade min(1, A−1).
Em geral, as probabilidades pj|l sao construıdas de forma que qualquer um dos
movimentos tenham a mesma probabilidade de serem propostos, a nao ser que no passo
corrente o valor de k seja 1 ou kmax, em que kmax e o maior valor que k pode assumir a
priori. Se k = 1 nao seria possıvel excluir alguma componente e diminuir a dimensao do
66

espaco parametrico, e se k = kmax nao seria possıvel incluir alguma. Nesses casos, entao
so e possıvel propor um dos dois movimentos.
Richardson e Green (1997) apresentam o metodo de inferencia RJMCMC para um
modelo de mistura normal. Restritos a uma vizinhanca de modelos Ml e Mp, tais que
dim(Θl) = k + 1 e dim(Θp) = k − 1, Richardson e Green (1997) utilizam o algoritmo
RJMCMC com os movimentos de “divisao”/ “combinacao” e “inclusao”/ “exclusao”
para estimar o valor de k. A parte de “inclusao”/ “exclusao” e inicialmente usada no
metodo, com o objetivo de tratar de amostras finitas que nao apresentem observacoes de
todos os grupos da populacao.
A proposta de “inclusao” consiste em adicionar uma nova componente j∗ vazia na
mistura, com novos parametros (wj∗ , φj∗) gerados de distribuicoes propostas. Alem disso,
os pesos devem ser reescalados para somar 1, fazendo w′j = wj(1 − wj∗), para todo j′.
A proposta de “exclusao” consiste em remover uma componente vazia da mistura e
reescalar os pesos para somar 1, fazendo w′j =wj
1−wj∗. Estes passos sao aceitos ou nao
com probabilidade dadas respectivamente por min(1, A) e min(1, A−1), para A como
descrito em (4.3).
Para evitar problemas de alta taxa de rejeicao da proposta “inclusao” sob distribuicao
a priori nao informativas, Richardson e Green (1997) propoem ainda o uso de movimentos
do tipo “divisao”/ “combinacao” de componentes existentes. No movimento de
“divisao”propoe-se a passagem de um modelo Mj de dimensao k para um modelo Ml
de dimensao k + 1 da seguinte forma: escolhe-se aleatoriamente uma componente de
mistura indexada por j∗ e propoe-se a divisao desta unica em um par (j1, j2). Neste caso,
e necessario alem de realocar as observacoes Yi tais que zi = j∗ em zi = j1 e zi = j2,
definir os novos valores de (wj1 , wj2 ,φj1 ,φj2)′. Estas componentes devem ser adjacentes
em relacao aos valores de φ, por conta da identificabilidade do modelo, como ja discutido
anteriormente. Por outro lado, ao propor o movimento de Mj para Mp, precisa-se
diminuir a dimensao do espaco parametrico correspondente em 1 unidade. De forma
analoga, isto e feito a partir da escolha aleatoria de um par de componentes de mistura
indexados por (j1, j2) e propondo a combinacao deste par em uma unica componente j∗.
Este movimento e chamado de “combinacao”.
67

A probabilidade de aceitacao das propostas “divisao” e “combinacao” tambem sao
dadas, respectivamente por min(1, A) e min(1, A−1), para A dado em (4.3).
A inferencia prossegue usando MCMC para amostrar da distribuicao a posteriori dos
parametros. Em Richardson e Green (1997) podem ser vistos maiores detalhes sobre esta
metodologia, incluindo a elicitacao da distribuicao a priori para o vetor parametrico, a
eficiencia dos passos do RJMCMC para modelos de mistura e uma aplicacao a dados
reais.
Dentre os aspectos observados no uso do RJMCMC para estimacao em modelos de
mistura normais, em Richardson e Green (1997) destaca-se o fenomeno conhecido como
label switching. Este comportamento pode ocorrer mesmo que a restricao no rotulo dos
parametros seja imposta na distribuicao a priori e caracteriza-se pela invariancia da
funcao de verossimilhanca sob nova rotulagem das componentes da mistura, conduzindo
a uma distribuicao a posteriori dos parametros sendo altamente simetrica e multimodal,
dificultando assim sua sumarizacao.
O modelo proposto neste trabalho e um modelo de mistura de distribuicoes de Poisson.
Na literatura, o trabalho de Viallefont et al. (2002) e um dos que usam esta classe de
modelos. No entanto, vale ressaltar que em todos os modelos citados supoe-se que o plano
amostral e nao informativo e, portanto, a forma de selecao da amostra nao contribui
para a funcao de verossimilhanca do modelo. Com esse objetivo, na proxima secao
sera proposto um modelo de superpopulacao de mistura, aplicavel a populacoes raras e
agrupadas, para dados coletados por amostragem adaptativa por conglomerados.
4.2 Modelo de mistura Poisson proposto
O modelo proposto a seguir pode ser aplicado a populacoes raras e agrupadas,
dispostas sobre uma grade regular, sob o enfoque Bayesiano. Tal modelo apresenta-
se como uma alternativa mais flexıvel ao modelo agregado, pois usa como unidade de
analise as proprias unidades da grade e supoe heterogeneidade entre as redes, e assim
tambem nao necessariamente redes maiores devem ter mais observacoes, ou vice-versa.
Alem disso, tratar a modelagem no nıvel da unidade primaria, permitiria incorporar
68

estruturas na media que supoem heterogeneidade para unidades dentro de uma mesma
rede. Por enquanto, o interesse esta apenas no primeiro caso.
Diferentemente dos modelos de mistura anteriormente apresentados, como o de
Viallefont et al. (2002), o modelo proposto e ajustado a dados obtidos sob um plano
amostral informativo, logo deve-se incluir a probabilidade de selecao da amostra na funcao
de verossimilhanca e, alem disso, as interpretacoes das variaveis mudam com relacao aos
problemas comuns de mistura. Em geral, o objetivo, ao ajustar um modelo de mistura,
e fazer inferencia acerca de: k, φj, wj, para j = 1, . . . , k, no entanto, neste caso, como
se trata de um modelo de superpopulacao, o vetor parametrico do modelo e composto
tambem por partes das variaveis que nao foram observadas e o principal objetivo e fazer
previsao. O modelo proposto e descrito a seguir.
Considere uma populacao rara com N unidades, das quais X apresentam uma
caracterıstica de interesse, ou seja sao unidades nao-vazias e estao divididas em R redes
nao-vazias. Logo, tem-se N − X redes vazias. Seja Yi a contagem deste determinado
fenomeno de interesse na unidade nao-vazia i, i = 1, . . . , X, logo Yi ≥ 1. Como se tratam
de populacoes raras, ou seja, cujo numero de unidades vazias e extremamente alto, assim
como Rapley e Welsh (2008), vamos modelar apenas as unidades nao-vazias da grade.
Suponha que a rede j nao-vazia e composta por Cj unidades primarias, j = 1, . . . , R. Para
facilitar o procedimento de inferencia, e natural definir uma variavel aleatoria latente de
alocacao εi, supostamente independentes para todo i e tais que P (εi = j) = wj = Cj/X,
j = 1, . . . , R. Dado o valor da variavel εi, as contagens Yi nas redes nao-vazias seguem
uma distribuicao de Poisson truncada em 0 independente, cuja media se altera de acordo
com a rede a qual pertence. O modelo, para j = 1, . . . , R, pode ser escrito da seguinte
forma:
69

Yi | εi = j, λj, X ∼ Poisson Truncada independente(λj), Yi ≥ 1, (4.4a)
P (εi = j) = wj = Cj/X, (4.4b)
λ | θ ∼ [. | θ, R], (4.4c)
C | X,R ∼ 1R + Multinomial (X −R, 1
R1R),
R∑i=1
Ci = X, (4.4d)
R | X, β ∼ Binomial Truncada (X, β), R = 1, . . . , X, (4.4e)
X | α ∼ Binomial Truncada (N,α), X = 1, . . . , N, (4.4f)
em que [. | θ, R] representa a distribuicao a priori de λ = (λ1, . . . , λR)′, a qual
depende do numero de grupos R e de um vetor de hiperparametros θ. Lembrando que
esta distribuicao deve satisfazer alguma restricao no ındice, devido a identificabilidade
do modelo. Alem disso, os parametros α, β e θ podem ser desconhecidos e, portanto,
sao atribuıdas distribuicoes a priori independentes a estes tambem. Denote por [.] cada
uma destas distribuicoes.
Este modelo, somente aplicavel as X unidades nao-vazias de uma populacao,
apresenta a estrutura de uma mistura de probabilidades, cujas componentes sao as R
redes nao-vazias, supostamente heterogeneas, e seus pesos sao proporcionais ao numero de
unidades nas redes, Cj, j = 1, . . . , R. No entanto, o fato do modelo proposto ser ajustado
a dados provenientes de amostragem adaptativa por conglomerados cria uma grande
diferenca nas variaveis entre um modelo de mistura comum e este modelo proposto. Num
modelo de mistura, a amostra selecionada somente traz informacoes acerca da variavel
Y ; por exemplo, nao e possıvel saber a qual grupo a unidade i observada pertence, pois
isto e uma divisao artificial. No entanto, neste modelo, a amostragem por conglomerados
adaptativos traz informacoes acerca de todas as variaveis. Ao coletar-se uma amostra
adaptativa, alem de observar a variavel Y para as unidades amostradas, sabe-se as redes
as quais elas pertencem e o tamanho desta rede, pois de acordo com este plano amostral
se uma unidade nao-vazia e selecionada aleatoriamente, toda a rede e observada.
Dessa forma, e adequado dividir as variaveis indicando pelo ındice s a parte observada
e por s a parte nao observada. Sejam entao X = Xs + Xs, R = Rs + Rs, ε = (ε′s, ε′s)′,
70

C = (C′s,C′s)′, Y = (Y′s,Y
′s)′. Neste caso, o objetivo esta em nao somente estimar os
parametros do modelo com base numa amostra, mas tambem fazer previsao das partes
nao-observadas. O objetivo final e prever o total populacional T =X∑i=1
Yi.
Finalmente, como o modelo aplica-se a dados coletados de forma adaptativa e este
planejamento amostral e nao-ignoravel, a probabilidade de selecao deve ser acrescentada
a funcao de verossimilhanca completa, de forma a trazer mais informacoes ao processo
de estimacao dos parametros. Como no modelo (3.1), a probabilidade de selecao de uma
particular amostra s = i1, . . . , im, composta por m redes, e dada por:
[s | X,R,C] =m∏l=1
Zil × gil,l∑N−X+Ri=1 Zi −
∑j−1k=0 Zik
, (4.5)
onde gil,l e o numero de redes de tamanho Zil que restam apos a selecao de j − 1 redes e
Zi0 = 0. O vetor Z e construıdo de forma a ter os tamanhos de todas as redes vazias e
nao-vazias, ou seja Z = (C′,1′X−R)′.
A funcao de verossimilhanca completa e dada por:
[s,X,R, ε,C,Y | λ, α, β] = [s | X,R,C][Y | ε,λ, X][ε | C, R,X]
× [C | R,X][R | X, β][X | α]
=m∏l=1
zil × gil,l∑N−X+Ri=1 zi −
∑j−1k=0 Zik
×Rs+Rs∏j=1
∏i:εi=j
λYij exp(−λj)Yi![1− exp(−λj)]
× 1
(Xs +Xs)Xs+Xs
Rs+Rs∏j=1
CCjj × (Xs +Xs −Rs −Rs)!
Rs+Rs∏j=1
1
(Cj − 1)!
(1
Rs +Rs
)Cj−1
×
Xs +Xs
Rs +Rs
βRs+Rs(1− β)Xs+Xs−Rs−Rs
1− (1− β)Xs+Xs×
N
Xs +Xs
αXs+Xs(1− α)N−Xs−Xs
1− (1− α)N.
A funcao de verossimilhanca marginal e obtida da seguinte forma:
[Xs, Rs, εs,Cs,Ys | λ, α, β] =∑
Ys,Cs,εs,Rs,Xs
[s,X,R, ε,C,Y | λ, α, β]
=∑
Ys,Cs,εs,Rs,Xs
[s,X,R,C | α, β][Y | ε,λ, X].
71

4.2.1 Distribuicao a priori para λ
Segundo Richardson e Green (1997) usar distribuicao a priori completamente nao
informativa e gerar distribuicao a posteriori propria nao e possıvel em modelos de mistura.
Como existem componentes da mistura que nao apresentam observacoes na amostra,
distribuicoes a priori independentes improprias e nao informativas nao podem ser usadas.
A alternativa neste caso e manter-se com a estrutura de independencia a priori usando
distribuicoes pouco informativas, as quais podem ou nao depender dos dados observados,
o que pode ser feito, por exemplo, inserindo estruturas a priori para os hiperparametros.
Por outro lado, existe uma relacao direta entre a distribuicao a priori de λ e a
distribuicao a posteriori de R. Uma sugestao neste caso e considerar distribuicoes a
priori dependentes para λ, de forma a modelar a distancia entre λjs consecutivos. Esta
distribuicao a priori foi introduzida por Roeder e Wasserman (1997) para misturas de
normais e e muito utilizada quando deseja-se ser nao informativo.
Note que, neste caso, o vetor λ pode ser definido como λ = (λ′s,λ′s)′, em que λs
refere-se a parte associada as redes observadas na amostra, para o qual espera-se obter
melhores resultados, e λs refere-se a parte associada as variaveis nao observadas. A fim
de garantir a identificabilidade, sera imposta sobre a distribuicao a priori de λ alguma
restricao sobre o ındice dos parametros. Mas esta restricao e necessaria apenas aos
elementos de λ que estao associadas as redes nao amostradas, ou seja a λs.
Com base nestas ideias serao utilizados dois tipos de distribuicoes a priori para o
parametro λ em (4.4c), as quais estao descritas a seguir.
4.2.1.1 Distribuicao a priori independente
Primeiramente, sera considerada a independencia entre os λj’s, tal que a distribuicao
conjunta de λ e dada por:
[λ | θ, R] = Rs![λ1 | θ] . . . [λR | θ], tal que λj < λj+1, para todo j ∈ [Rs + 1, Rs +Rs).
Em particular, sera considerado, que
λj ∼ Gama(d, ν), j = 1, . . . , R, para θ = (d, ν)
72

e introduz-se um nıvel hierarquico adicional assumindo que ν ∼ Gama(e, f).
Gelman (2006) apresenta formas de elicitar a priori esta distribuicao Gama. Uma
forma usual de ser nao informativo e escolher valores pequenos para seus dois parametros,
como 0.01. No entanto, deve-se evitar distribuicoes que tenham altas massas de
probabilidade no zero, o que pode incluir componentes com medias pequenas, tornando
difıcil estimar o modelo de mistura.
Viallefont et al. (2002) relatam uma sensibilidade da distribuicao a posteriori de
outros parametros do modelo de mistura Poisson de acordo com a escolha dos parametros
da Gama. Foi usada entao uma distribuicao a priori pouco informativa descrita em
Viallefont et al. (2002). Para d escolhe-se um valor maior que 1, por exemplo 1.1, pois
isso permite evitar a forma exponencial da distribuicao sem reduzir muito o coeficiente
de variacao (CV). Para o parametro ν escolhe-se e e f a priori tal que a aproximacao
a media de λj, d/(e/f) seja igual ao ponto medio das observacoes com variancia e/f 2
controlada.
4.2.1.2 Distribuicao a priori dependente
Esta distribuicao leva em conta a informacao da distancia entre dois parametros da
Poisson para duas componentes que sao consecutivas em termos dos valores de λj. Neste
caso o hiperparametro θ em (4.4c) e igual a uma constante positiva τ e a distribuicao a
priori conjunta para λ e dada por:
[λ | τ 2, R] = [λR | λR−1, τ2][λR−1 | λR−2, τ
2] . . . [λ1],
onde [λj | λj−1, τ2] e N(λj−1,∞)(λj−1, τ
2), que denota a densidade de uma Normal centrada
em λj−1 com variancia τ 2, truncada para ser maior que λj−1 e [λ1] ∝ 1, o que garante a
identificabilidade do modelo. Esta distribuicao indica baixa probabilidade a priori que
duas redes vizinhas sejam mais distantes que τ desvio padroes.
Segundo Viallefont et al. (2002) uma vantagem deste modelo e que o hiperparametro
τ 2, o qual controla a distancia entre as medias de duas componentes e sua variabilidade,
e explıcito, e controla o numero de grupos. Eles discutem as dificuldades de elicitar τ 2 e
a influencia deste hiperparametro na distribuicao a posteriori do vetor parametrico, em
73

especial na de R. Por exemplo, se τ 2 e pequeno quando comparado a verdadeira distancia
entre dois λjs consecutivos, ha uma tendencia em ajustar componentes intermediarios
entre os verdadeiros e assim obter uma distribuicao a posteriori favorecendo valores
mais altos para R. Baseado num estudo de simulacao, Roeder e Wasserman (1997)
recomendam assumir τ = 5, pois esta escolha resulta em resultados razoaveis.
O modelo proposto (4.4) e um modelo de superpopulacao e seu ajuste depende
da estimacao de parametros e previsao de quantidades populacionais que nao foram
observadas na amostra. Alem disso, tal modelo aplica-se a cenarios com populacoes
que podem ser extremamente raras e agrupadas. Logo, para um tamanho de amostra
relativamente pequeno, podem ser selecionadas amostras com poucas unidades nao-
vazias e pouco representativas, o que deve produzir estimativas inadequadas para o total
populacional. Para estes casos, recomenda-se elicitar distribuicoes a priori informativas.
4.2.2 Inferencia para o modelo
Como o modelo e descrito por um vetor parametrico Θ = (Xs, Rs, εs,Cs,Ys, α, β,λ)
de dimensao desconhecida, o algoritmo RJMCMC sera tambem utilizado neste caso,
como apresentado na Secao 4.1.1.2 para modelos normais. Basicamente o procedimento
de estimacao consiste dos seguintes passos:
(1) atualizacao de α, β, θ e λ;
(2) atualizacao das variaveis nao observadas Xs e Ys;
(3) atualizacao da alocacao εs e diretamente Cs e atualizado;
(4) proposta de “divisao” de uma rede em duas ou “combinacao” de duas redes em
uma.
As distribuicoes condicionais completas podem ser vistas no Apendice B. Sera descrito
a seguir com detalhes o passo (4).
De forma analoga ao procedimento de inferencia descrito em Viallefont et al. (2002),
serao utilizados os momentos de ordem zero e primeira ordem na proposta de “divisao”
de uma componente da mistura j∗ em duas novas j1 e j2, mas como a distribuicao da
74

variavel Yi, i = 1, . . . , X e Poisson Truncada, diferentemente de Viallefont et al. (2002),
o momento de primeira ordem nao e λj, j = 1, . . . , R, e sim λ′j = λj/1− exp(−λj).
Logo, os parametros propostos satisfazem as seguintes equacoes:
wj∗ = wj1 + wj2 ,
wj∗λ′j∗ = wj1λ
′j1
+ wj2λ′j2,
tal que λ′j−1 < λ′j1 < λ′j2 < λ′j+1, devido a questoes de identificabilidade do modelo.
Mas, para valores de λj razoavelmente grandes, λj e λ′j se aproximam, como podemos
ver na Figura 4.1, logo nestes casos as equacoes acima podem ser escritas em funcao
dos λj’s. Por outro lado, para os casos em que esta aproximacao nao e valida, a
solucao e estimar λ′j, e quando necessario expressar λj em funcao de λ′j, como na
funcao de verossimilhanca, uma aproximacao numerica faz-se util como, por exemplo,
a aproximacao de Taylor. Isto porque esta funcao, apesar de ser inversıvel, envolve um
polinomio com uma exponencial, para a qual, em geral, e impossıvel obter uma solucao
analıtica exata. Neste trabalho, utilizamos a aproximacao pela propria funcao identidade
em todos os exemplos, pois sao estudados casos em que λj e razoavelmente grande.
λ
0 1 2 3 4 5 6 7
01
23
45
67 λ
λ1 − exp(− λ)
Figura 4.1: Comparacao das medias da distribuicao de Poisson e Poisson truncada no
zero.
Para determinar os parametros associados a estas novas componentes, basta resolver
o sistema de equacoes anterior. Mas, como tem-se um sistema com 4 incognitas e 2
equacoes, para resolve-lo e preciso completa-lo gerando um vetor aleatorio u = (u1, u2).
Viallefont et al. (2002) consideram 3 formas diferentes de fazer isso, as quais baseiam-se
75

em diferentes intuicoes de como induzir a positividade dos parametros da Poisson. Neste
trabalho, sera utilizada apenas uma destas, a qual baseia-se em adicao de vizinhos de λj∗
dependentes e esta descrita a seguir.
Sao geradas duas variaveis auxiliares u1 ∼ U(0, 1) e u2 ∼ U(0, 1) e entao define-se as
seguintes transformacoes determinısticas:
wj1 = wj∗u1, wj2 = wj∗(1− u1),
λj1 = λj∗ − ρu2(1− u1), λj2 = λj∗ + ρu2u1,
onde
ρ =
min(λj∗ − λj∗−1)/(1− u1), (λj∗+1 − λj∗)/u1, 1 < j∗ < Rs,
minλ1/(1− u1), (λ2 − λ1)/u1, 1 = j∗ < Rs,
(λj∗ − λj∗−1)/(1− u1), 1 < j∗ = Rs,
λ1/(1− u1), 1 = j∗ = Rs.
No Apendice B e apresentada a expressao da probabilidade de aceitacao do movimento
descrito.
4.2.2.1 Diagnostico de convergencia
Para verificar que a convergencia e atingida no ajuste do modelo serao apresentados
histogramas com a distribuicao a posteriori dos parametros e medidas que avaliam a
convergencia propostas por Geweke (1992) e Raftery e Lewis (1992). A primeira medida
baseia-se em um teste de igualdade das medias da primeira e ultima partes da cadeia de
Markov. Se as amostras sao resultantes de uma distribuicao estacionaria, as duas medias
devem ser iguais e a estatıstica de teste tem assintoticamente uma distribuicao Normal
padrao. A outra medida verifica a independencia entre os valores gerados para a cadeia
baseado num fator de dependencia, se este for maior que 5 pode-se dizer que existe forte
autocorrelacao entre os valores da cadeia.
A fim de examinar o desempenho do modelo em (4.4), foram analisadas amostras da
distribuicao a posteriori dos parametros. Para isso, gerou-se uma populacao artificial em
uma grade regular de tamanho N = 400 para α = 0.15 e β = 0.1 fixados. Os valores
76

de λ foram gerados aleatoriamente de uma distribuicao Gama centrada em 8.5 com CV
fixado em 95%. Como o CV de uma distribuicao Gama(d,ν) e dado por 1/√d, sob
estas condicoes tem-se d = 1.1 e ν = 0.13. Foi selecionada uma amostra adaptativa por
conglomerados com tamanho inicial 5%N e, em particular, a populacao gerada apresenta
R = 8 redes e as redes observadas na amostra sao s = 2, 4, 7, de acordo com a ordem
crescente de λ.
Assumindo que os parametros α, β e λ sao independentes a priori considerou-
se a priori que α ∼ Beta(3, 15) e β ∼ Beta(1, 9). Estas distribuicoes, apesar de
informativas, neste caso estao trazendo o mınimo de informacao necessaria para aplicacao
deste modelo complexo, ou seja que a populacao e rara e agrupada. Isto porque, como
visto no Capıtulo 3, α e β sao parametros relacionados ao numero de celulas nao-vazias
e redes nao-vazias. Para λ foram consideradas as duas distribuicoes a priori citadas
na Secao 4.2.1, i.e. : (i) λj | ν ∼ Gama(d, ν), para j = 1, . . . , R, independentes; (ii)
λj | λj−1 ∼ N(λj−1,∞)(λj−1, τ2), para j = 1, . . . , R. Para a segunda distribuicao de λ
assumiu-se τ = 5, que e uma das sugestoes de Roeder e Wasserman (1997).
Para a obtencao de amostras da distribuicao a posteriori do vetor parametrico
Θ = (Xs, Rs, εs,Cs,Ys, α, β,λ, ν) e necessario o uso de metodos de simulacao estocastica,
em particular como a dimensao de Θ e tambem um parametro, utiliza-se o metodo
de RJMCMC, como descrito na Secao 4.2.2, com passos de Metropolis-Hastings e
Amostrador de Gibbs. Foram geradas 200.000 amostras, sendo as 10.000 primeiras
descartadas como aquecimento e amostras de 190 em 190 foram tomadas, a fim de obter-
se 1.000 amostras independentes resultantes.
A Tabela 4.1 apresenta o valor da estatıstica de teste de Geweke e do fator de
dependencia do criterio de Raftery-Lewis. Todos os resultados mostram a convergencia
das cadeias e a ausencia de forte autocorrelacao.
Nas Figuras 4.2 e 4.3 estao os histogramas com as densidades a posteriori para
os parametros α, β, ν, λ e o total populacional T , supondo distribuicao a priori
para λ independente e dependente, respetivamente. O respectivo valor verdadeiro
esta representado pela linha cheia e intervalo HPD de 95% pela linha pontilhada. A
77

Tabela 4.1: Analise da convergencia das cadeias a posteriori dos parametros do modelo
proposto supondo distribuicao a priori independente e dependente para λ para uma
populacao artificial.
α β ν T λ1 λ2 λ3 λ4 λ5 λ6 λ7 λ8
Gewekeindep. 0.7 -0.4 -1.6 0.4 1.4 -1.3 1.4 -0.4 1.5 1.5 1.2 1.5
dep. -1.1 0.4 - -0.8 -0.3 -1.0 1.2 1.0 0.6 -0.4 -1.0 1.2
R-Lindep. 1.3 1.1 1.1 1.8 0.9 1.0 1.0 1.0 0.9 1.0 1.1 1.1
dep. 2.5 1.1 - 3.2 0.9 1.0 1.0 1.1 1.0 0.9 1.4 1.0
distribuicao a posteriori de λj para j ∈ s apresentada e condicional as amostras em que
R e estimado como o valor verdadeiro.
Note que a maioria dos parametros sao bem estimados sob as duas distribuicoes a
priori, com maior densidade a posteriori em torno do valor verdadeiro e o mesmo contido
no intervalo HPD de 95%. O parametro populacional β apresenta um pequeno vies,
mas em todos os casos ainda contido no intervalo HPD de 95%. Alguns λj’s para j ∈ s
apresentam um comportamento bimodal e baixa precisao, um comportamento que pode
ser esperado em modelos de mistura. Neste caso esta bimodalidade nao influenciou na
convergencia dos outros parametros e principalmente do total T , portanto nao afetou o
desempenho do modelo.
Por outro lado, λj’s para j ∈ s apresentam estimativas melhores, o que tambem era
esperado ja que existem informacoes adicionais com respeito as redes amostradas.
78
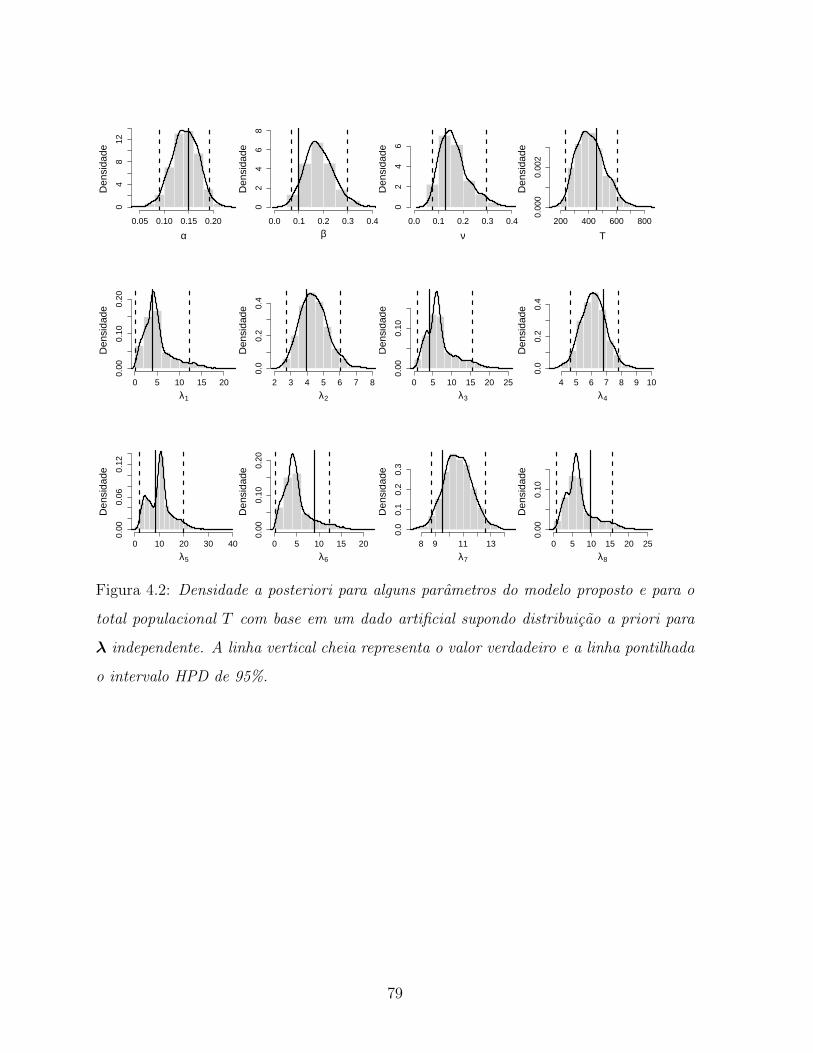
α
Den
sida
de
0.05 0.10 0.15 0.20
04
812
βD
ensi
dade
0.0 0.1 0.2 0.3 0.4
02
46
8
ν
Den
sida
de
0.0 0.1 0.2 0.3 0.4
02
46
T
Den
sida
de
200 400 600 800
0.00
00.
002
λ1
Den
sida
de
0 5 10 15 20
0.00
0.10
0.20
λ2
Den
sida
de
2 3 4 5 6 7 8
0.0
0.2
0.4
λ3
Den
sida
de0 5 10 15 20 25
0.00
0.10
λ4
Den
sida
de
4 5 6 7 8 9 10
0.0
0.2
0.4
λ5
Den
sida
de
0 10 20 30 40
0.00
0.06
0.12
λ6
Den
sida
de
0 5 10 15 20
0.00
0.10
0.20
λ7
Den
sida
de
8 9 11 13
0.0
0.1
0.2
0.3
λ8
Den
sida
de
0.00
0.10
0 5 10 15 20 25
Figura 4.2: Densidade a posteriori para alguns parametros do modelo proposto e para o
total populacional T com base em um dado artificial supondo distribuicao a priori para
λ independente. A linha vertical cheia representa o valor verdadeiro e a linha pontilhada
o intervalo HPD de 95%.
79
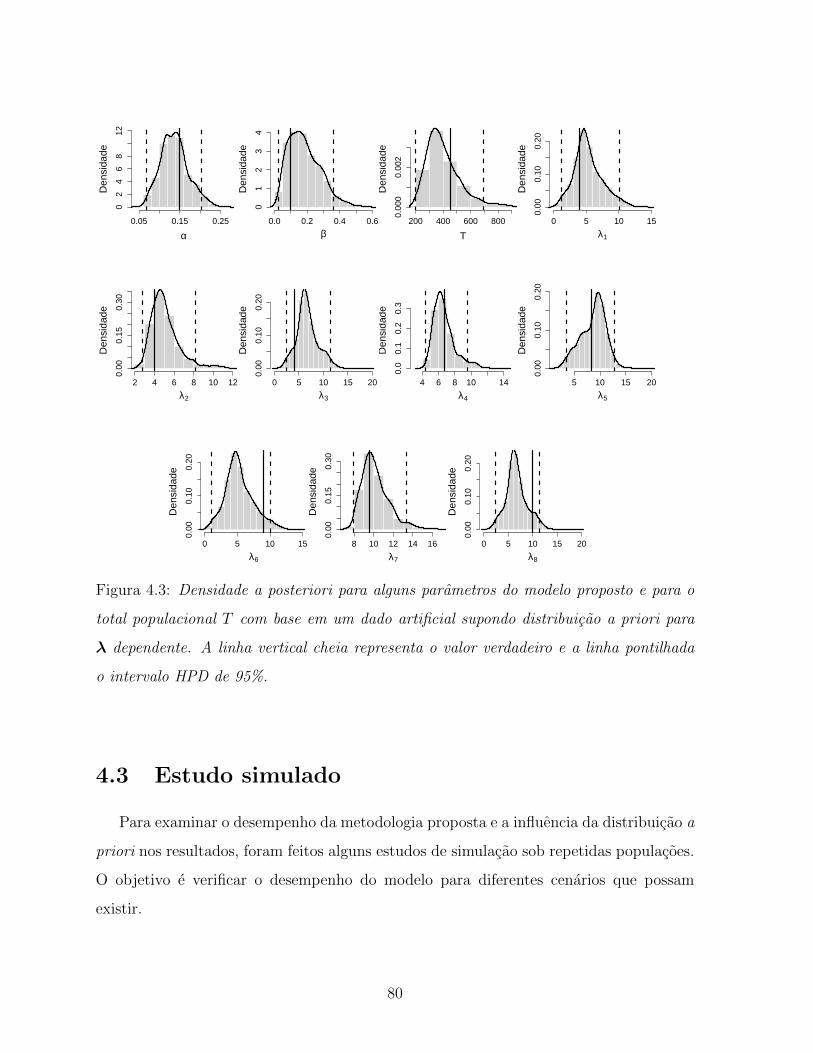
α
Den
sida
de
0.05 0.15 0.25
02
46
812
βD
ensi
dade
0.0 0.2 0.4 0.6
01
23
4
T
Den
sida
de
200 400 600 800
0.00
00.
002
λ1
Den
sida
de
0 5 10 15
0.00
0.10
0.20
λ2
Den
sida
de
2 4 6 8 10 12
0.00
0.15
0.30
λ3
Den
sida
de
0 5 10 15 20
0.00
0.10
0.20
λ4
Den
sida
de4 6 8 10 14
0.0
0.1
0.2
0.3
λ5
Den
sida
de
5 10 15 20
0.00
0.10
0.20
λ6
Den
sida
de
0 5 10 15
0.00
0.10
0.20
λ7
Den
sida
de
8 10 12 14 16
0.00
0.15
0.30
λ8
Den
sida
de
0 5 10 15 20
0.00
0.10
0.20
Figura 4.3: Densidade a posteriori para alguns parametros do modelo proposto e para o
total populacional T com base em um dado artificial supondo distribuicao a priori para
λ dependente. A linha vertical cheia representa o valor verdadeiro e a linha pontilhada
o intervalo HPD de 95%.
4.3 Estudo simulado
Para examinar o desempenho da metodologia proposta e a influencia da distribuicao a
priori nos resultados, foram feitos alguns estudos de simulacao sob repetidas populacoes.
O objetivo e verificar o desempenho do modelo para diferentes cenarios que possam
existir.
80

4.3.1 Considerando diferentes configuracoes
Foram geradas 500 populacoes considerando diferentes configuracoes para alguns
parametros variando os valores de N , R e X, assim como o nıvel de homogeneidade/
heterogeneidade da populacao. Primeiramente, N foi fixado em 200, 400 e 600, e para
cada um destes valores, os valores de α e β foram fixados, com o objetivo de criar
diferentes populacoes raras e agrupadas e variar R e X na simulacao. Em particular,
as populacoes foram simuladas para 4 pares de (α, β) com α, β ∈ 0.1, 0.15. Portanto
neste estudo sao apresentados resultados para 12 diferentes configuracoes. Neste caso,
foi considerada para λ apenas a distribuicao a priori independente, portanto, para cada
populacao λ foi gerado a partir de uma distribuicao Gama com d = 1.1 e ν = 0.13, o
que produz um CV igual a 95%. Desta maneira, estes valores fixados permitem gerar
populacoes raras e agrupadas com redes heterogeneas entre si. Finalmente, uma amostra
adaptativa foi selecionada de cada populacao, com primeiro estagio caracterizado por
uma amostra aleatoria simples sem reposicao de tamanho 5%N .
As Tabelas 4.2, 4.3 e 4.4 mostram um sumario com algumas propriedades frequentistas
da distribuicao a posteriori dos parametros do modelo proposto apos a convergencia,
para cada configuracao testada. Sao apresentados o EQMR, o EAR, a probabilidade de
cobertura (em porcentagem) dos intervalos HPD de 95%, com sua respectiva amplitude
media ao longo das 500 simulacoes. Em particular, as amplitudes dos intervalos para
T e para λs e λs estao relativizadas com relacao ao valor verdadeiro. Os resultados
para λj’s estao sumarizados em relacao a λs e λs, pois na simulacao o valor de R nao
foi fixado, R foi gerado de sua distribuicao, condicional ao valor de β, portanto para
cada populacao foi simulado um valor de R distinto, o que impede a apresentacao de
propriedades frequentistas para cada λj separadamente.
No geral, e possıvel observar que os parametros sao bem estimados. A cobertura
dos intervalos de 95% e proxima do nıvel nominal desejado. O EQMR e o EAR sao
pequenos para a maior parte dos parametros, exceto para β em alguns casos especıficos.
Entretanto, este fato nao tem um impacto significante na previsao de T , o qual e o maior
81
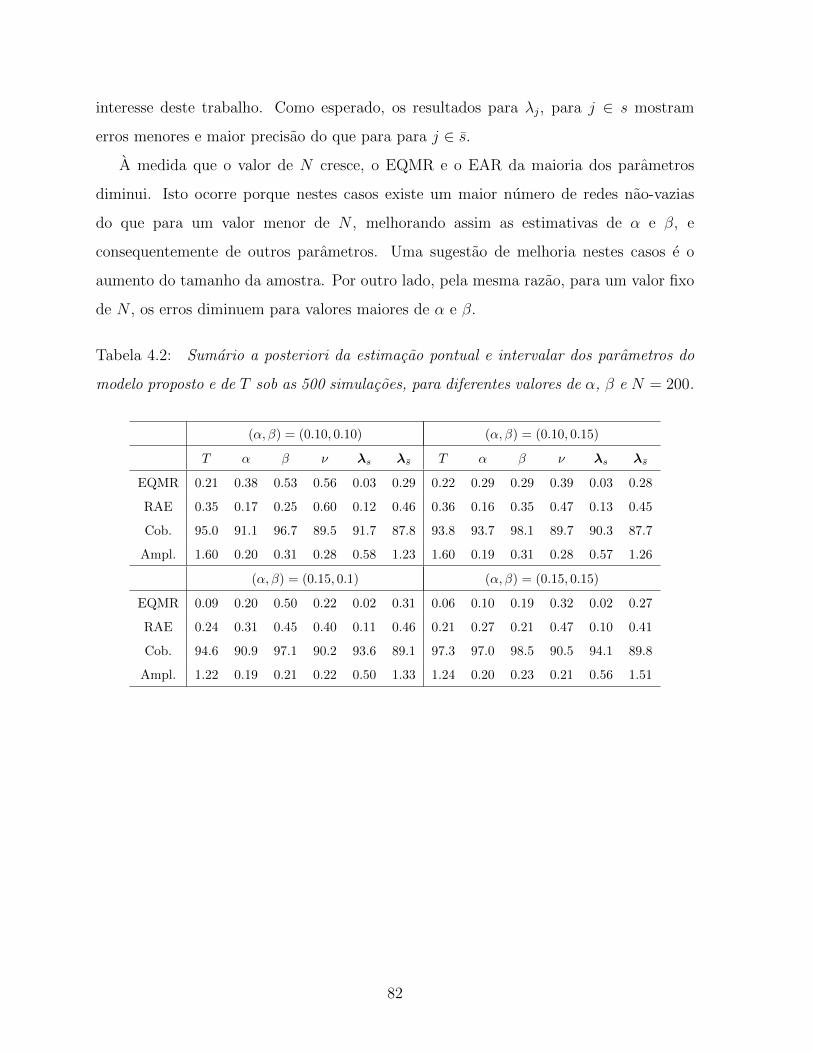
interesse deste trabalho. Como esperado, os resultados para λj, para j ∈ s mostram
erros menores e maior precisao do que para para j ∈ s.
A medida que o valor de N cresce, o EQMR e o EAR da maioria dos parametros
diminui. Isto ocorre porque nestes casos existe um maior numero de redes nao-vazias
do que para um valor menor de N , melhorando assim as estimativas de α e β, e
consequentemente de outros parametros. Uma sugestao de melhoria nestes casos e o
aumento do tamanho da amostra. Por outro lado, pela mesma razao, para um valor fixo
de N , os erros diminuem para valores maiores de α e β.
Tabela 4.2: Sumario a posteriori da estimacao pontual e intervalar dos parametros do
modelo proposto e de T sob as 500 simulacoes, para diferentes valores de α, β e N = 200.
(α, β) = (0.10, 0.10) (α, β) = (0.10, 0.15)
T α β ν λs λs T α β ν λs λs
EQMR 0.21 0.38 0.53 0.56 0.03 0.29 0.22 0.29 0.29 0.39 0.03 0.28
RAE 0.35 0.17 0.25 0.60 0.12 0.46 0.36 0.16 0.35 0.47 0.13 0.45
Cob. 95.0 91.1 96.7 89.5 91.7 87.8 93.8 93.7 98.1 89.7 90.3 87.7
Ampl. 1.60 0.20 0.31 0.28 0.58 1.23 1.60 0.19 0.31 0.28 0.57 1.26
(α, β) = (0.15, 0.1) (α, β) = (0.15, 0.15)
EQMR 0.09 0.20 0.50 0.22 0.02 0.31 0.06 0.10 0.19 0.32 0.02 0.27
RAE 0.24 0.31 0.45 0.40 0.11 0.46 0.21 0.27 0.21 0.47 0.10 0.41
Cob. 94.6 90.9 97.1 90.2 93.6 89.1 97.3 97.0 98.5 90.5 94.1 89.8
Ampl. 1.22 0.19 0.21 0.22 0.50 1.33 1.24 0.20 0.23 0.21 0.56 1.51
82
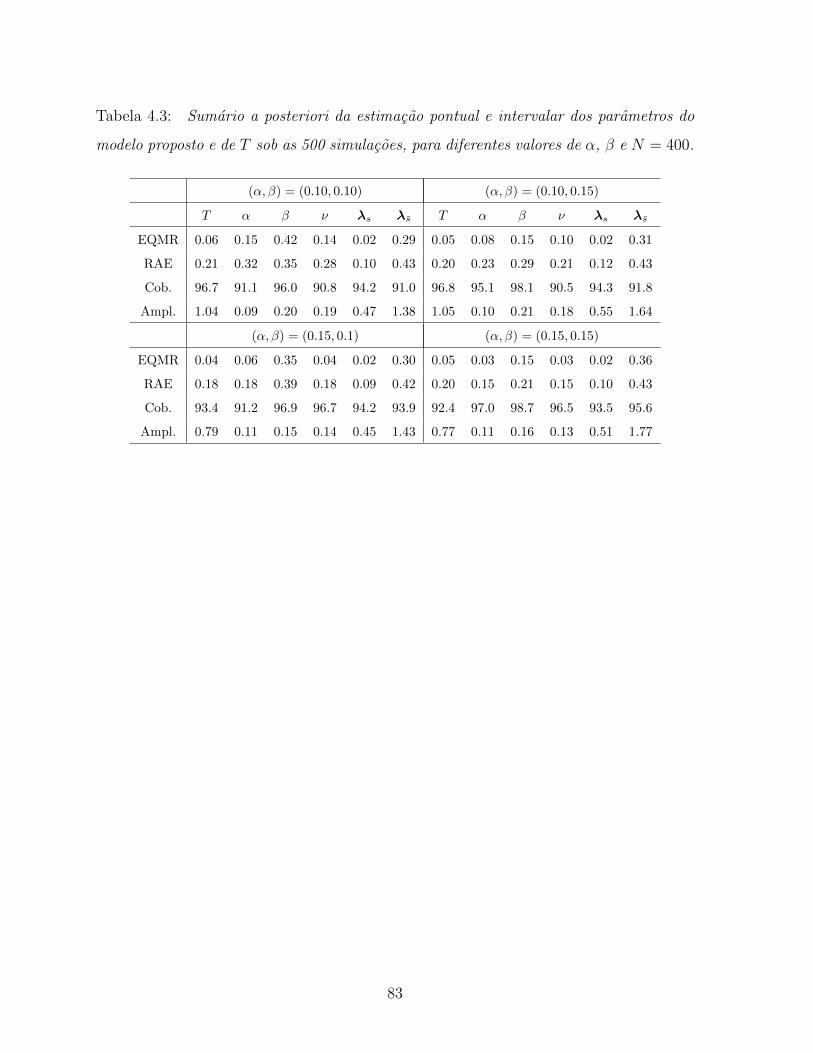
Tabela 4.3: Sumario a posteriori da estimacao pontual e intervalar dos parametros do
modelo proposto e de T sob as 500 simulacoes, para diferentes valores de α, β e N = 400.
(α, β) = (0.10, 0.10) (α, β) = (0.10, 0.15)
T α β ν λs λs T α β ν λs λs
EQMR 0.06 0.15 0.42 0.14 0.02 0.29 0.05 0.08 0.15 0.10 0.02 0.31
RAE 0.21 0.32 0.35 0.28 0.10 0.43 0.20 0.23 0.29 0.21 0.12 0.43
Cob. 96.7 91.1 96.0 90.8 94.2 91.0 96.8 95.1 98.1 90.5 94.3 91.8
Ampl. 1.04 0.09 0.20 0.19 0.47 1.38 1.05 0.10 0.21 0.18 0.55 1.64
(α, β) = (0.15, 0.1) (α, β) = (0.15, 0.15)
EQMR 0.04 0.06 0.35 0.04 0.02 0.30 0.05 0.03 0.15 0.03 0.02 0.36
RAE 0.18 0.18 0.39 0.18 0.09 0.42 0.20 0.15 0.21 0.15 0.10 0.43
Cob. 93.4 91.2 96.9 96.7 94.2 93.9 92.4 97.0 98.7 96.5 93.5 95.6
Ampl. 0.79 0.11 0.15 0.14 0.45 1.43 0.77 0.11 0.16 0.13 0.51 1.77
83
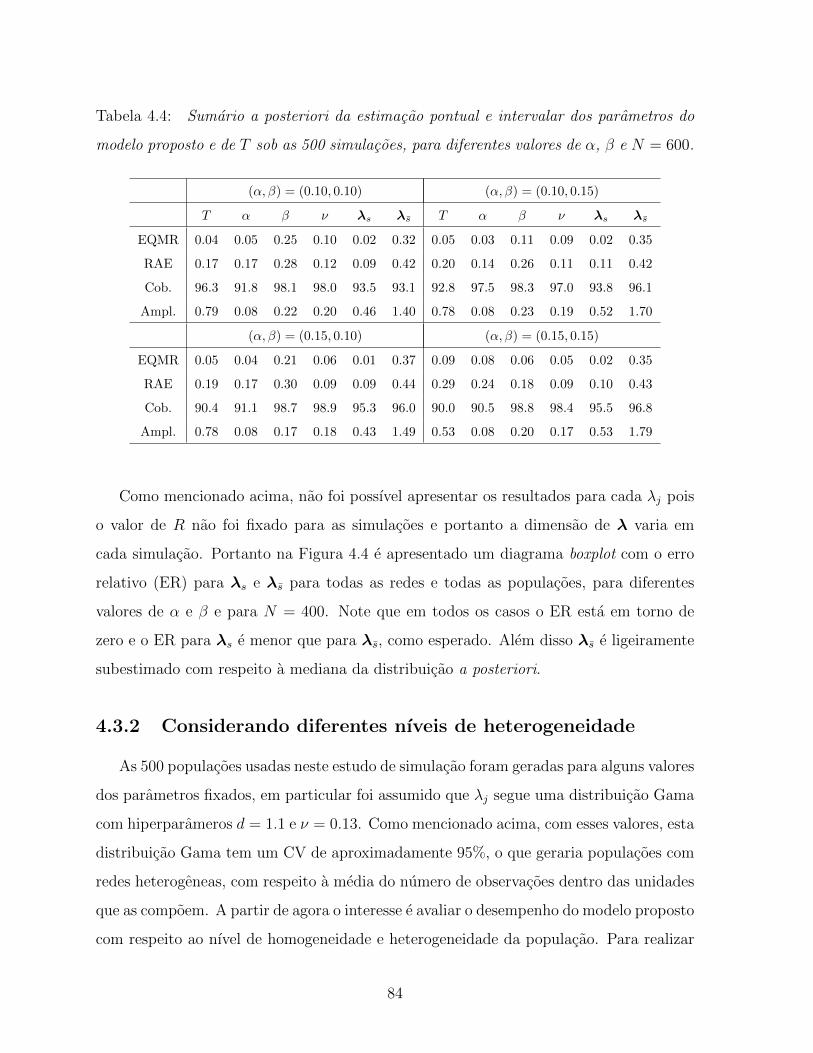
Tabela 4.4: Sumario a posteriori da estimacao pontual e intervalar dos parametros do
modelo proposto e de T sob as 500 simulacoes, para diferentes valores de α, β e N = 600.
(α, β) = (0.10, 0.10) (α, β) = (0.10, 0.15)
T α β ν λs λs T α β ν λs λs
EQMR 0.04 0.05 0.25 0.10 0.02 0.32 0.05 0.03 0.11 0.09 0.02 0.35
RAE 0.17 0.17 0.28 0.12 0.09 0.42 0.20 0.14 0.26 0.11 0.11 0.42
Cob. 96.3 91.8 98.1 98.0 93.5 93.1 92.8 97.5 98.3 97.0 93.8 96.1
Ampl. 0.79 0.08 0.22 0.20 0.46 1.40 0.78 0.08 0.23 0.19 0.52 1.70
(α, β) = (0.15, 0.10) (α, β) = (0.15, 0.15)
EQMR 0.05 0.04 0.21 0.06 0.01 0.37 0.09 0.08 0.06 0.05 0.02 0.35
RAE 0.19 0.17 0.30 0.09 0.09 0.44 0.29 0.24 0.18 0.09 0.10 0.43
Cob. 90.4 91.1 98.7 98.9 95.3 96.0 90.0 90.5 98.8 98.4 95.5 96.8
Ampl. 0.78 0.08 0.17 0.18 0.43 1.49 0.53 0.08 0.20 0.17 0.53 1.79
Como mencionado acima, nao foi possıvel apresentar os resultados para cada λj pois
o valor de R nao foi fixado para as simulacoes e portanto a dimensao de λ varia em
cada simulacao. Portanto na Figura 4.4 e apresentado um diagrama boxplot com o erro
relativo (ER) para λs e λs para todas as redes e todas as populacoes, para diferentes
valores de α e β e para N = 400. Note que em todos os casos o ER esta em torno de
zero e o ER para λs e menor que para λs, como esperado. Alem disso λs e ligeiramente
subestimado com respeito a mediana da distribuicao a posteriori.
4.3.2 Considerando diferentes nıveis de heterogeneidade
As 500 populacoes usadas neste estudo de simulacao foram geradas para alguns valores
dos parametros fixados, em particular foi assumido que λj segue uma distribuicao Gama
com hiperparameros d = 1.1 e ν = 0.13. Como mencionado acima, com esses valores, esta
distribuicao Gama tem um CV de aproximadamente 95%, o que geraria populacoes com
redes heterogeneas, com respeito a media do numero de observacoes dentro das unidades
que as compoem. A partir de agora o interesse e avaliar o desempenho do modelo proposto
com respeito ao nıvel de homogeneidade e heterogeneidade da populacao. Para realizar
84
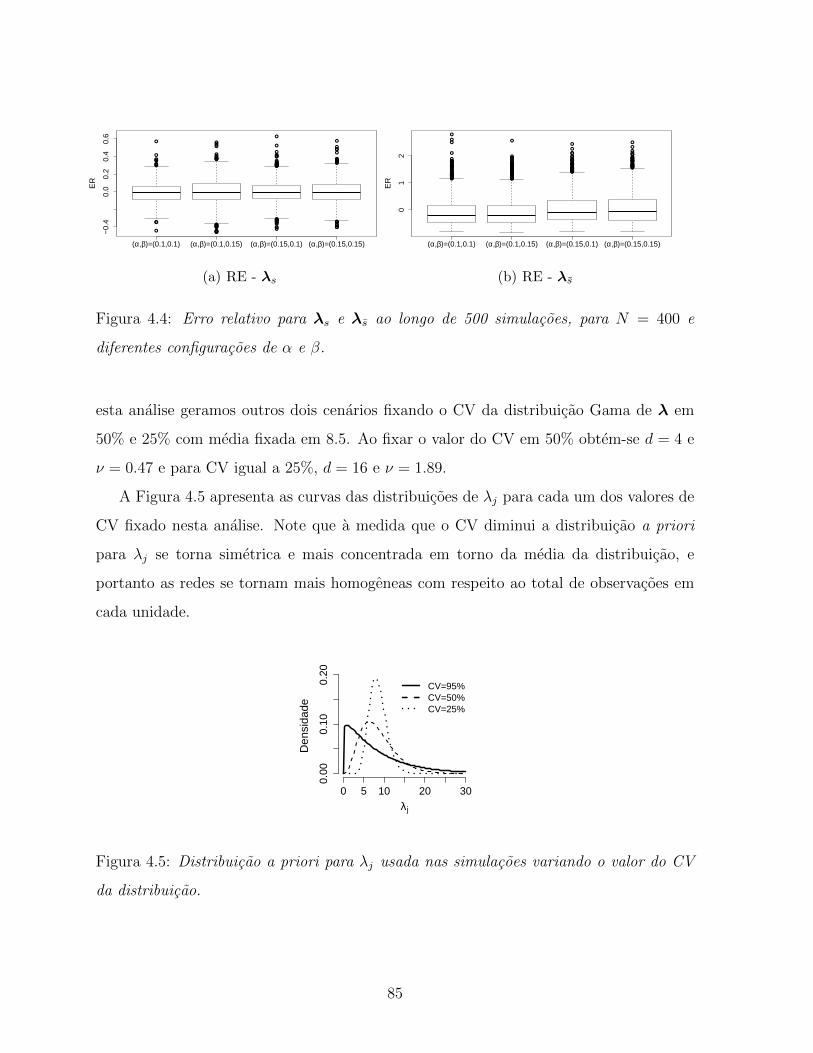
(α,β)=(0.1,0.1) (α,β)=(0.1,0.15) (α,β)=(0.15,0.1) (α,β)=(0.15,0.15)
−0.
40.
00.
20.
40.
6
ER
(a) RE - λs
(α,β)=(0.1,0.1) (α,β)=(0.1,0.15) (α,β)=(0.15,0.1) (α,β)=(0.15,0.15)
01
2
ER
(b) RE - λs
Figura 4.4: Erro relativo para λs e λs ao longo de 500 simulacoes, para N = 400 e
diferentes configuracoes de α e β.
esta analise geramos outros dois cenarios fixando o CV da distribuicao Gama de λ em
50% e 25% com media fixada em 8.5. Ao fixar o valor do CV em 50% obtem-se d = 4 e
ν = 0.47 e para CV igual a 25%, d = 16 e ν = 1.89.
A Figura 4.5 apresenta as curvas das distribuicoes de λj para cada um dos valores de
CV fixado nesta analise. Note que a medida que o CV diminui a distribuicao a priori
para λj se torna simetrica e mais concentrada em torno da media da distribuicao, e
portanto as redes se tornam mais homogeneas com respeito ao total de observacoes em
cada unidade.
λj
Den
sida
de
0 5 10 20 30
0.00
0.10
0.20
CV=95%CV=50%CV=25%
Figura 4.5: Distribuicao a priori para λj usada nas simulacoes variando o valor do CV
da distribuicao.
85

Desta forma, a analise apresentada a seguir e feita a partir de outras 500 populacoes
geradas fixando o CV da distribuicao de λj em 50% e outras 500 com CV fixado em 25%.
Em particular, esta simulacao foi feita apenas para o valor de N = 400 pois o interesse
neste era apenas verificar o desempenho do modelo variando o nıvel de homogeneidade.
Alem disso, de acordo com a Tabela 4.3 ja foi visto que este valor para N apresentou
resultados razoaveis segundo as propriedades frequentistas analisadas.
Na Tabela 4.5 e apresentado novamente um sumario com algumas propriedades
frequentistas dos estimadores obtidos a partir da distribuicao a posteriori para as 500
populacoes geradas com CV da distribuicao de λj fixada em 50% e 25%. Note que ainda
para casos mais homogeneos o modelo proposto em (4.4) tem um bom desempenho,
resultando em estimadores para todos os parametros com pequenos EQMR e EAR
e intervalos HPD de 95% com probabilidade de cobertura proxima do nıvel nominal
desejado.
Em particular, observe que os EQMR e EAR para T sao muito semelhantes aos valores
apresentados na Tabela 4.3 quando o CV da distribuicao de λj foi fixado em 95%, exceto
para o caso em que (α, β) = (0.10, 0.10), para o qual existe um numero pequeno de redes
nao vazias na populacao, e portanto um numero de redes ainda menor na amostra de
5%. O EQMR e o EAR para λs sao menores que os observados na Tabela 4.3, apesar
dos mesmos para ν serem maiores. Alem disso, a medida que o CV diminui a cobertura
empırica dos intervalos de 95% e subestimada, principalmente as obtidas para ν e λ. Uma
possıvel explicacao para estes resultado e que a distribuicao Gama com um CV pequeno
se aproxima de uma distribuicao Normal, o que parece complicar a inferencia para seus
hiperparametros, portanto para λ e consequentemente os outros parametros do modelo.
Logo, uma alternativa neste caso pode ser assumir uma outra distribuicao a priori para
λ. No entanto, vale destacar que ainda para esses casos estudados os EQMR e EAR sao
pequenos para a maioria dos parametros e principalmente para o total populacional, o
qual e o maior interesse neste trabalho.
86
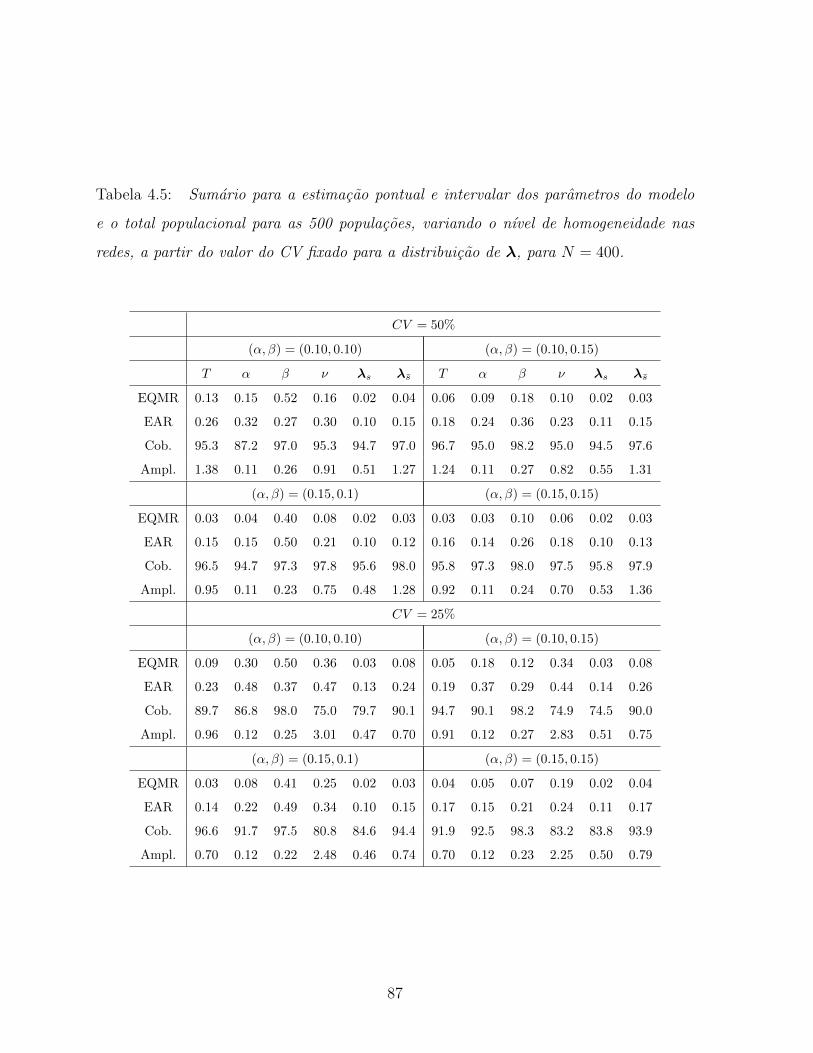
Tabela 4.5: Sumario para a estimacao pontual e intervalar dos parametros do modelo
e o total populacional para as 500 populacoes, variando o nıvel de homogeneidade nas
redes, a partir do valor do CV fixado para a distribuicao de λ, para N = 400.
CV = 50%
(α, β) = (0.10, 0.10) (α, β) = (0.10, 0.15)
T α β ν λs λs T α β ν λs λs
EQMR 0.13 0.15 0.52 0.16 0.02 0.04 0.06 0.09 0.18 0.10 0.02 0.03
EAR 0.26 0.32 0.27 0.30 0.10 0.15 0.18 0.24 0.36 0.23 0.11 0.15
Cob. 95.3 87.2 97.0 95.3 94.7 97.0 96.7 95.0 98.2 95.0 94.5 97.6
Ampl. 1.38 0.11 0.26 0.91 0.51 1.27 1.24 0.11 0.27 0.82 0.55 1.31
(α, β) = (0.15, 0.1) (α, β) = (0.15, 0.15)
EQMR 0.03 0.04 0.40 0.08 0.02 0.03 0.03 0.03 0.10 0.06 0.02 0.03
EAR 0.15 0.15 0.50 0.21 0.10 0.12 0.16 0.14 0.26 0.18 0.10 0.13
Cob. 96.5 94.7 97.3 97.8 95.6 98.0 95.8 97.3 98.0 97.5 95.8 97.9
Ampl. 0.95 0.11 0.23 0.75 0.48 1.28 0.92 0.11 0.24 0.70 0.53 1.36
CV = 25%
(α, β) = (0.10, 0.10) (α, β) = (0.10, 0.15)
EQMR 0.09 0.30 0.50 0.36 0.03 0.08 0.05 0.18 0.12 0.34 0.03 0.08
EAR 0.23 0.48 0.37 0.47 0.13 0.24 0.19 0.37 0.29 0.44 0.14 0.26
Cob. 89.7 86.8 98.0 75.0 79.7 90.1 94.7 90.1 98.2 74.9 74.5 90.0
Ampl. 0.96 0.12 0.25 3.01 0.47 0.70 0.91 0.12 0.27 2.83 0.51 0.75
(α, β) = (0.15, 0.1) (α, β) = (0.15, 0.15)
EQMR 0.03 0.08 0.41 0.25 0.02 0.03 0.04 0.05 0.07 0.19 0.02 0.04
EAR 0.14 0.22 0.49 0.34 0.10 0.15 0.17 0.15 0.21 0.24 0.11 0.17
Cob. 96.6 91.7 97.5 80.8 84.6 94.4 91.9 92.5 98.3 83.2 83.8 93.9
Ampl. 0.70 0.12 0.22 2.48 0.46 0.74 0.70 0.12 0.23 2.25 0.50 0.79
87

4.3.3 Analise de sensibilidade da distribuicao a priori
O interesse agora e comparar o desempenho do modelo sob uma outra alternativa de
distribuicao a priori para λ usada na literatura, que e a distribuicao a priori dependente.
Neste caso, o estudo de analise de sensibilidade e feita com a geracao de 500 populacoes
e uma amostra adaptativa de tamanho inicial de 5% selecionada de cada uma. Como
o maior interesse esta na comparacao da influencia de ambas as distribuicoes a priori
para λ nos resultados, foi escolhido efetuar a analise para somente alguns valores fixos de
R, a fim de viabilizar a apresentacao dos resultados para cada λj separadamente e nao
somente para para os parametros sumarizados em λs e λs. Em particular, para gerar as
populacoes usadas neste estudo, fixou-se N = 400 e buscou-se uma configuracao para α e
β que produz uma populacao rara e agrupada que tenha apresentado um bom desempenho
no estudo simulado realizado na Subsecao 4.3.1. Portanto, fixou-se (α, β) = (0.15, 0.10)
e gerou-se um grande numero de populacoes ate obter 500 populacoes com R = 5, outras
500 com R = 6 e 500 com R = 7. Estes valores de R foram escolhidos porque, de acordo
com sua distribuicao no modelo, dada pela equacao em (4.4e), estes sao valores com alta
probabilidade para (α, β) = (0.15, 0.10). Finalmente, como estao sendo especificadas
neste estudo duas distribuicoes a priori para λ, na geracao dos dados fixou-se para todas
as populacoes λ em um valor arbitrario gerado de uma distribuicao Uniforme definida
no intervalo (3,15).
Todos os resultados apresentados a seguir correspondem a 1.000 amostras
independentes da distribuicao a posteriori do vetor parametrico, geradas de 200.000
iteracoes do RJMCMC, com um aquecimento de 10.000 e um espacamento de 190. As
mesmas distribuicoes a priori usadas para α e β no estudo de simulacao apresentado na
Subsecao 4.3.1. Para λ foi considerada entao a distribuicao a priori Gama e a Normal
truncada dependente com desvio padrao τ ∈ 1, 5, 10, 20, ambas descritas na Secao 4.2.1
Primeiramente, para uma unica populacao gerada ajustamos o modelo proposto com
as distribuicoes a priori a fim de visualizarmos de forma preliminar o desempenho das
distribuicoes a priori consideradas e se os valores de τ considerados eram razoaveis. Dessa
forma, foi visto que o maior impacto da distribuicao a priori de λ esta na distribuicao
88

a posteriori de R. A Figura 4.6 apresenta o intervalo HPD de 95% obtido para R para
cada distribuicao a priori de λ considerada. Note que a distribuicao a posteriori de R
e altamente imprecisa quando τ = 1, no entanto a medida que o valor de τ assumindo
aumenta este comportamento melhora, e com τ = 20 tem-se inclusive um comportamento
similar ao obtido no caso da distribuicao a priori independente. Logo, deste momento
em diante decidiu-se descartar a distribuicao a priori Normal truncada dependente com
τ = 1.
Distribuições a priori
R
_
_
_
_
_
_
_
_
_
_
Indep τ = 1 τ = 5 τ = 10 τ = 20
510
1520
25
Figura 4.6: Sumario da distribuicao a posteriori de R assumindo diferentes distribuicoes
a priori para λ. As cruzes representam a mediana da distribuicao a posteriori, o cırculo
o valor verdadeiro de R e a linha o intervalo HPD de 95%.
Para as 500 populacoes geradas foi feita uma analise de sensibilidade com respeito
a distribuicao a posteriori de cada λj. A Figura 4.7 apresenta o EQMR para cada
λj em ordem crescente, mas separados para as amostras em que a rede j e observada
(a) e quando nao e (b). Os resultados com a distribuicao a priori independente sao
representados pelos cırculos vazios e pela linha cheia, ja os resultados para a distribuicao
dependente com τ = 5 sao representados pelos triangulos e a linha tracejada, ja as cruzes
e linha pontilhada representam τ = 10 e τ = 20 e representado pelos cırculos cheios e a
linha traco e ponto. Pela Figura 4.7 (a) e possıvel concluir que a distribuicao a priori
independente produz na maioria dos casos EQMR menor que a distribuicao dependente,
principalmente para os λj’s com valor absoluto menor. Os resultados mostram-se muito
similares para os diferentes valores de τ . Para λj para o caso em que a rede j nao pertence
a amostra o EQMR e maior do que quando j pertence a amostra, como esperado, e neste
89
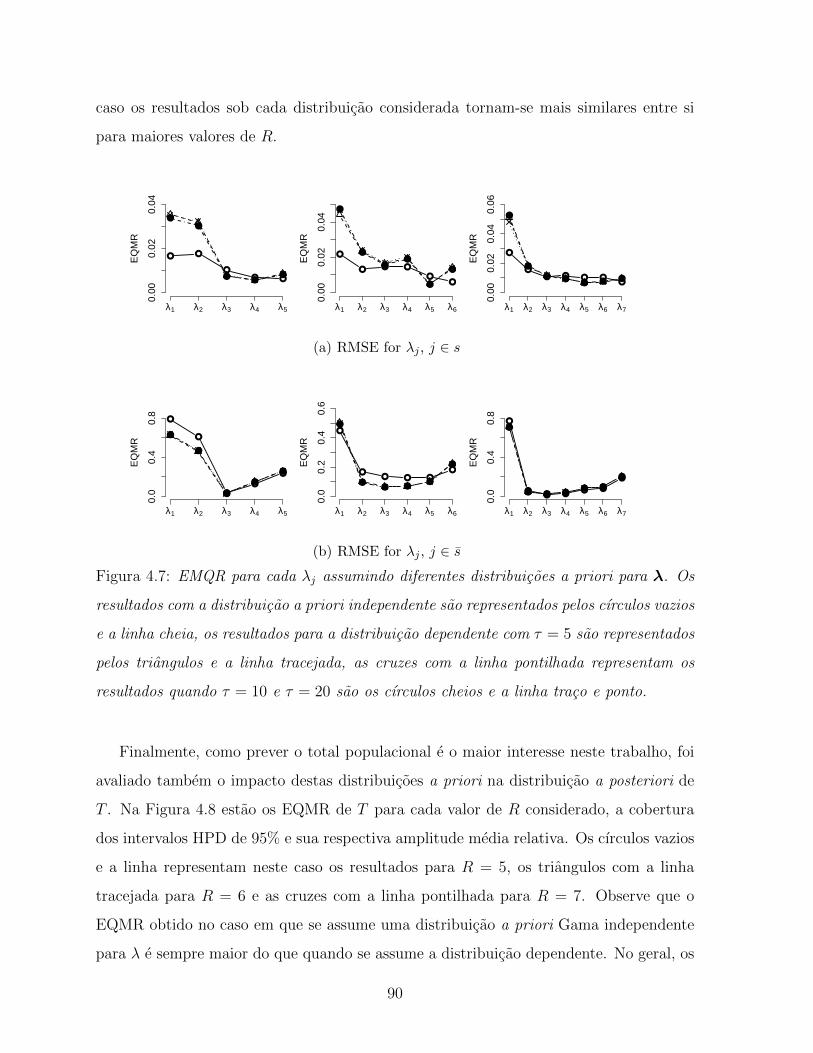
caso os resultados sob cada distribuicao considerada tornam-se mais similares entre si
para maiores valores de R.
EQ
MR
λ1 λ2 λ3 λ4 λ5
0.00
0.02
0.04
EQ
MR
λ1 λ2 λ3 λ4 λ5 λ6
0.00
0.02
0.04
(a) RMSE for λj , j ∈ s
EQ
MR
λ1 λ2 λ3 λ4 λ5 λ6 λ7
0.00
0.02
0.04
0.06
EQ
MR
λ1 λ2 λ3 λ4 λ5
0.0
0.4
0.8
EQ
MR
λ1 λ2 λ3 λ4 λ5 λ6
0.0
0.2
0.4
0.6
(b) RMSE for λj , j ∈ s
E
QM
R
λ1 λ2 λ3 λ4 λ5 λ6 λ7
0.0
0.4
0.8
Figura 4.7: EMQR para cada λj assumindo diferentes distribuicoes a priori para λ. Os
resultados com a distribuicao a priori independente sao representados pelos cırculos vazios
e a linha cheia, os resultados para a distribuicao dependente com τ = 5 sao representados
pelos triangulos e a linha tracejada, as cruzes com a linha pontilhada representam os
resultados quando τ = 10 e τ = 20 sao os cırculos cheios e a linha traco e ponto.
Finalmente, como prever o total populacional e o maior interesse neste trabalho, foi
avaliado tambem o impacto destas distribuicoes a priori na distribuicao a posteriori de
T . Na Figura 4.8 estao os EQMR de T para cada valor de R considerado, a cobertura
dos intervalos HPD de 95% e sua respectiva amplitude media relativa. Os cırculos vazios
e a linha representam neste caso os resultados para R = 5, os triangulos com a linha
tracejada para R = 6 e as cruzes com a linha pontilhada para R = 7. Observe que o
EQMR obtido no caso em que se assume uma distribuicao a priori Gama independente
para λ e sempre maior do que quando se assume a distribuicao dependente. No geral, os
90

intervalos de 95% apresentam maior probabilidade de cobertura do que o nıvel desejado e
no caso da hipotese de independencia a priori estes sao mais precisos, quando comparados
aos obtidos sob hipotese de dependencia a priori. Note que condicional ao valor de R,
os resultados para a distribuicao dependente sao bastante similares quando varia-se τ .
Distribuições a priori
EQ
MR
Indep τ = 5 τ = 10 τ = 20
0.02
0.04
0.06
0.02
0.04
0.06
0.02
0.04
0.06
Distribuições a priori
Cob
ertu
ra
Indep τ = 5 τ = 10 τ = 20
9294
9698
9294
9698
9294
9698
Distribuições a priori
Am
plitu
de
Indep τ = 5 τ = 10 τ = 20
0.6
0.8
1.0
1.2
1.4
0.6
0.8
1.0
1.2
1.4
0.6
0.8
1.0
1.2
1.4
Figura 4.8: EQMR, probabilidade de cobertura e amplitude media do intervalo HPD de
95% para o total populacional T sob cada distribuicao a priori assumida para λ e para
cada valor de R fixado. Os cırculos vazios e a linha representam os resultados para R = 5,
os triangulos com a linha tracejada quando R = 6 e as cruzes com a linha pontilhada
para R = 7.
Portanto, sob alguns criterios considerar uma distribuicao a priori independente
parece ser mais eficiente que a distribuicao a priori dependente e vice-versa. No entanto,
vale destacar que a distribuicao dependente e mais facil de interpretar, o que torna sua
elicitacao mais intuitiva em muitos casos, em que nao ha conhecimento a priori adequado
sobre a populacao.
4.4 Comparacao com o modelo agregado
O modelo de mistura em (4.4) foi proposto neste trabalho como uma alternativa ao
modelo agregado, principalmente quando nao e adequada a suposicao de homogeneidade
entre redes com respeito ao numero de observacoes dentro destas e quando o numero
esperado de observacoes nao e proporcional a sua area. O objetivo deste modelo proposto
e, portanto, aprimorar as estimativas populacionais obtidas com o ajuste do modelo
91

agregado atraves do uso de um modelo que leve em conta na sua formulacao a suposicao
de heterogeneidade entre redes. Isto e realizado na proposta atraves da modelagem no
nıvel das unidades primarias, no lugar das redes.
Para acessar a eficiencia da metodologia proposta, nesta secao e feita uma comparacao
do desempenho do modelo de mistura com o modelo agregado em duas situacoes. A
primeira comparacao consiste de um experimento de simulacao baseado no desenho
amostral com uma populacao real, ja o outro estudo e baseado em simulacoes sob o
modelo.
Para ajustar ambos os modelos, foram assumidas as mesmas distribuicoes a priori
usadas na Subsecao 4.3. Na execucao dos metodos de MCMC e RJMCMC foram
realizadas 200.000 iteracoes cada, 10.000 foram descartadas como aquecimento da cadeia
e as amostras finais foram tomadas de 190 em 190, a fim de obter 1.000 amostras
independentes.
4.4.1 Simulacao baseada no desenho amostral
O estudo apresentado a seguir baseia-se em verificar propriedades frequentistas dos
estimadores obtidos do ajuste de cada modelo, a partir da selecao de varias amostras
de uma populacao real. Tal populacao esta descrita na Secao 3.1.3 e e composta por
marrecos da asa azul na regiao da Florida, Estados Unidos, no ano de 1992.
O estudo consiste em selecionar 500 amostras adaptativas com tamanho inicial de
10%N desta populacao real. Note que esta populacao, a qual pode ser vista na Figura
3.2, e composta por 3 principais redes, as quais apresentam no geral um numero medio de
marrecos diferente para cada rede. E o total em cada rede nao e proporcional ao numero
de unidades em cada uma. Logo, as hipoteses do modelo agregado nao seriam adequadas
a este conjunto de dados. Por outro lado, o modelo de mistura assume heterogeneidade
entre redes, o que parece mais razoavel ao observar a Figura 3.2.
Alem disso, observe que existem duas unidades com um numero discrepante de
marrecos da asa azul, logo se as amostras selecionadas nao contivessem estas unidades,
seria extremamente difıcil estimar o total populacional proximo do valor verdadeiro.
92
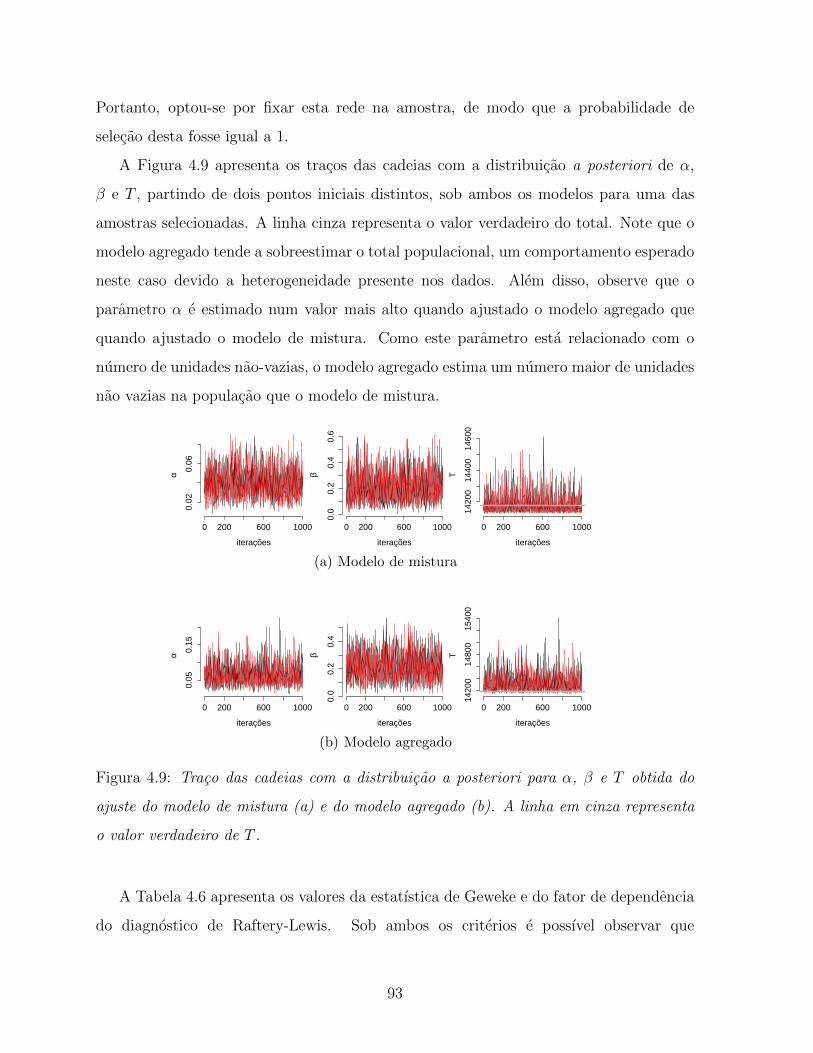
Portanto, optou-se por fixar esta rede na amostra, de modo que a probabilidade de
selecao desta fosse igual a 1.
A Figura 4.9 apresenta os tracos das cadeias com a distribuicao a posteriori de α,
β e T , partindo de dois pontos iniciais distintos, sob ambos os modelos para uma das
amostras selecionadas. A linha cinza representa o valor verdadeiro do total. Note que o
modelo agregado tende a sobreestimar o total populacional, um comportamento esperado
neste caso devido a heterogeneidade presente nos dados. Alem disso, observe que o
parametro α e estimado num valor mais alto quando ajustado o modelo agregado que
quando ajustado o modelo de mistura. Como este parametro esta relacionado com o
numero de unidades nao-vazias, o modelo agregado estima um numero maior de unidades
nao vazias na populacao que o modelo de mistura.
iterações
α
0 200 600 1000
0.02
0.06
iterações
β
0 200 600 1000
0.0
0.2
0.4
0.6
(a) Modelo de mistura
iterações
T
0 200 600 1000
1420
014
400
1460
0
iterações
α
0 200 600 1000
0.05
0.15
iterações
β
0 200 600 1000
0.0
0.2
0.4
(b) Modelo agregado
iterações
T
0 200 600 1000
1420
014
800
1540
0
Figura 4.9: Traco das cadeias com a distribuicao a posteriori para α, β e T obtida do
ajuste do modelo de mistura (a) e do modelo agregado (b). A linha em cinza representa
o valor verdadeiro de T .
A Tabela 4.6 apresenta os valores da estatıstica de Geweke e do fator de dependencia
do diagnostico de Raftery-Lewis. Sob ambos os criterios e possıvel observar que
93

a convergencia foi alcancada. Esta mesma conclusao vale para todas as amostras
selecionadas.
Tabela 4.6: Analise da convergencia das cadeias com a distribuicao a posteriori dos
parametros dos modelos de mistura e agregado para a populacao real.
Geweke Raftery-Lewis
Mistura Agregado Mistura Agregado
α 0.54 -0.12 1.05 0.95
β -0.75 -0.93 1.03 1.01
T 0.32 0.27 1.55 1.08
Na Tabela 4.7 apresenta-se uma comparacao com base em propriedades frequentistas
dos estimadores obtidos para o total populacional T , sob os dois modelos. Como temos
a populacao inteira de marrecos da asa azul e selecionamos amostras desta populacao, e
possıvel usar criterios de comparacao entre os modelos que usam o valor verdadeiro. Logo
sao apresentados o EQMR, o EAR, as probabilidades de cobertura dos intervalos HPD
de 95%, a media das amplitudes relativas destes intervalos, expressa pela razao entre
seu valor e o valor verdadeiro de T . E apresentado tambem a eficiencia do estimador do
total obtido do ajuste do modelo de mistura com relacao ao modelo agregado, sob as 500
amostras. Observe que o modelo proposto apresenta menores valores para os EQMR e
EAR, alem de probabilidade de cobertura dos intervalos mais proxima do nıvel nominal
desejado de 95%, mesmo tendo uma amplitude menor, portanto os intervalos gerados
sob esta abordagem sao mais precisos. Alem disso, como a eficiencia e menor que 1,
isto indica que a variancia do estimador para o total sob o modelo (4.4) proposto neste
trabalho e menor que sob o modelo agregado.
Finalmente, na Figura 4.10 e apresentado um diagrama boxplot com os ER para o
total populacional para as 500 amostras sorteadas sob os dois modelos em questao. Note
que os ER obtidos com base no modelo de mistura sao inferiores aos obtidos com o
modelo agregado, apesar de ambos no geral sobrestimarem o valor verdadeiro de T .
94

Tabela 4.7: Sumario da estimacao pontual e intervalar do total populacional obtido do
ajuste do modelo de mistura e do modelo agregado.
EQMR EAR Cobertura Amplitude ef(T )
Modelo proposto 0.02 0.05 97.7 0.450.78
Modelo agregado 0.05 0.18 84.5 0.63
Modelo de mistura Modelo agregado
−0.
050.
050.
150.
25
ER
Figura 4.10: ER para T para as 500 amostras obtidos a partir do ajuste do modelo de
mistura e do modelo agregado.
4.4.2 Simulacao baseada no modelo
O interesse neste estudo e avaliar o desempenho do modelo agregado sob populacoes
mais homogeneas simuladas do modelo de mistura em (4.4). Portanto, para as mesmas
500 populacoes usadas no estudo simulado apresentado na Subsecao 4.3.1 ajustou-se
o modelo agregado. Em particular este estudo destina-se as simulacoes realizadas
assumindo (α, β) = (0.15, 0.10) e a distribuicao Gama para λ com CV=50% e 25%,
que caracterizam populacoes com redes mais homogeneas.
Na Tabela 4.8 sao apresentadas propriedades frequentistas dos estimadores obtidos
do ajuste do modelo agregado. A fim de facilitar a comparacao, os resultados obtidos
do ajuste do modelo de mistura com as mesmas 500 populacoes sao apresentados em
parenteses na tabela. Os resultados para T indicam um maior EAR e EQMR no ajuste
do modelo agregado, mas essa diferenca parece diminuir a medida que o CV diminui. Por
outro lado, o estimador para β produzido no ajuste do modelo agregado apresenta para
95
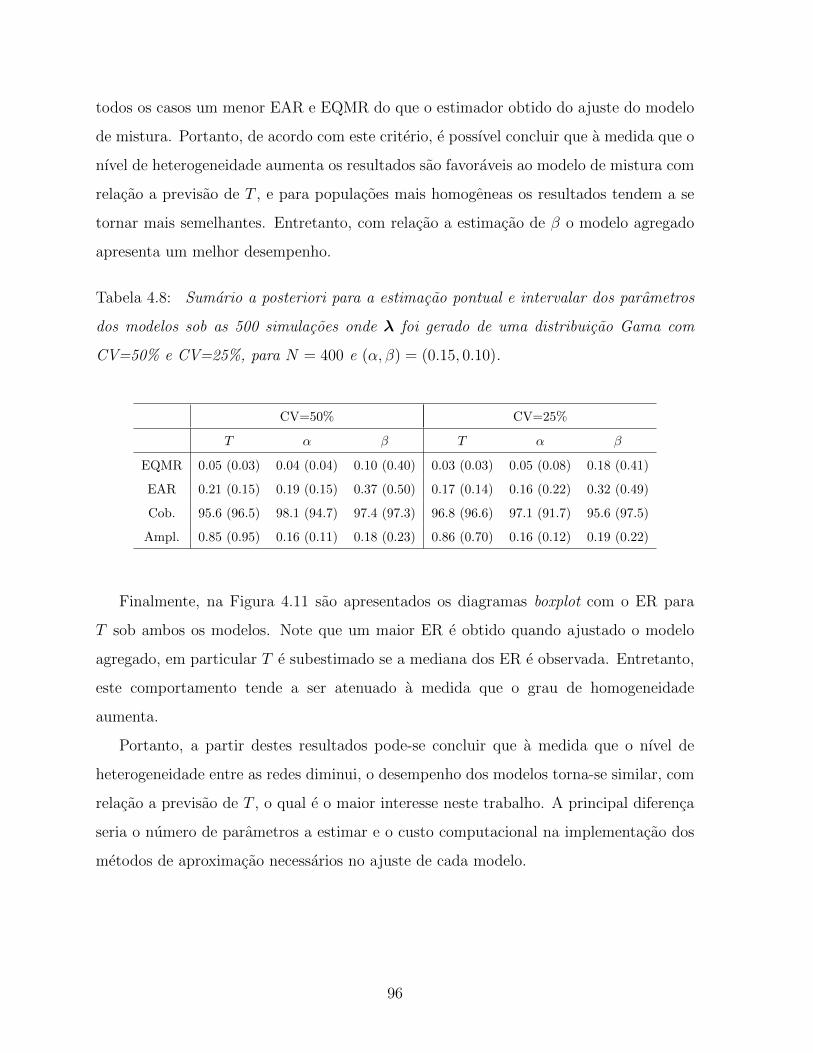
todos os casos um menor EAR e EQMR do que o estimador obtido do ajuste do modelo
de mistura. Portanto, de acordo com este criterio, e possıvel concluir que a medida que o
nıvel de heterogeneidade aumenta os resultados sao favoraveis ao modelo de mistura com
relacao a previsao de T , e para populacoes mais homogeneas os resultados tendem a se
tornar mais semelhantes. Entretanto, com relacao a estimacao de β o modelo agregado
apresenta um melhor desempenho.
Tabela 4.8: Sumario a posteriori para a estimacao pontual e intervalar dos parametros
dos modelos sob as 500 simulacoes onde λ foi gerado de uma distribuicao Gama com
CV=50% e CV=25%, para N = 400 e (α, β) = (0.15, 0.10).
CV=50% CV=25%
T α β T α β
EQMR 0.05 (0.03) 0.04 (0.04) 0.10 (0.40) 0.03 (0.03) 0.05 (0.08) 0.18 (0.41)
EAR 0.21 (0.15) 0.19 (0.15) 0.37 (0.50) 0.17 (0.14) 0.16 (0.22) 0.32 (0.49)
Cob. 95.6 (96.5) 98.1 (94.7) 97.4 (97.3) 96.8 (96.6) 97.1 (91.7) 95.6 (97.5)
Ampl. 0.85 (0.95) 0.16 (0.11) 0.18 (0.23) 0.86 (0.70) 0.16 (0.12) 0.19 (0.22)
Finalmente, na Figura 4.11 sao apresentados os diagramas boxplot com o ER para
T sob ambos os modelos. Note que um maior ER e obtido quando ajustado o modelo
agregado, em particular T e subestimado se a mediana dos ER e observada. Entretanto,
este comportamento tende a ser atenuado a medida que o grau de homogeneidade
aumenta.
Portanto, a partir destes resultados pode-se concluir que a medida que o nıvel de
heterogeneidade entre as redes diminui, o desempenho dos modelos torna-se similar, com
relacao a previsao de T , o qual e o maior interesse neste trabalho. A principal diferenca
seria o numero de parametros a estimar e o custo computacional na implementacao dos
metodos de aproximacao necessarios no ajuste de cada modelo.
96
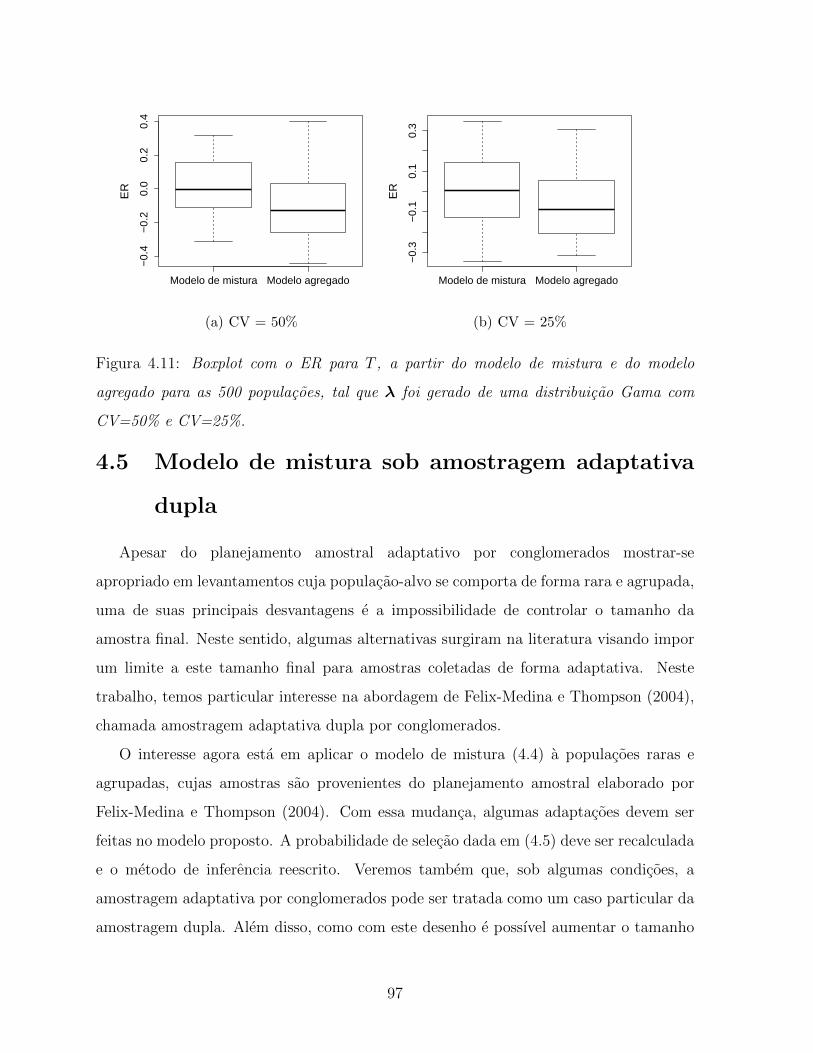
Modelo de mistura Modelo agregado
−0.
4−
0.2
0.0
0.2
0.4
ER
(a) CV = 50%
Modelo de mistura Modelo agregado
−0.
3−
0.1
0.1
0.3
ER
(b) CV = 25%
Figura 4.11: Boxplot com o ER para T , a partir do modelo de mistura e do modelo
agregado para as 500 populacoes, tal que λ foi gerado de uma distribuicao Gama com
CV=50% e CV=25%.
4.5 Modelo de mistura sob amostragem adaptativa
dupla
Apesar do planejamento amostral adaptativo por conglomerados mostrar-se
apropriado em levantamentos cuja populacao-alvo se comporta de forma rara e agrupada,
uma de suas principais desvantagens e a impossibilidade de controlar o tamanho da
amostra final. Neste sentido, algumas alternativas surgiram na literatura visando impor
um limite a este tamanho final para amostras coletadas de forma adaptativa. Neste
trabalho, temos particular interesse na abordagem de Felix-Medina e Thompson (2004),
chamada amostragem adaptativa dupla por conglomerados.
O interesse agora esta em aplicar o modelo de mistura (4.4) a populacoes raras e
agrupadas, cujas amostras sao provenientes do planejamento amostral elaborado por
Felix-Medina e Thompson (2004). Com essa mudanca, algumas adaptacoes devem ser
feitas no modelo proposto. A probabilidade de selecao dada em (4.5) deve ser recalculada
e o metodo de inferencia reescrito. Veremos tambem que, sob algumas condicoes, a
amostragem adaptativa por conglomerados pode ser tratada como um caso particular da
amostragem dupla. Alem disso, como com este desenho e possıvel aumentar o tamanho
97

da amostra e usar informacoes auxiliares, espera-se uma melhora na qualidade das
estimativas dos parametros do modelo e do total populacional sem exceder abusivamente
os custos disponıveis.
4.5.1 Amostragem adaptativa dupla
Proposto por Felix-Medina e Thompson (2004), este plano amostral trata-se de uma
variacao com multiplos estagios da amostragem adaptativa por conglomerados. Chamado
amostragem adaptativa dupla, o metodo permite ao pesquisador atingir aos seguintes
objetivos: controlar o numero de observacoes da variavel de interesse; alocar a amostra
final proxima a locais interessantes; e utilizar uma variavel auxiliar na estimacao do
parametro populacional de interesse.
A metodologia pode ser decomposta em tres estagios e esta descrita a seguir. Seja
H uma variavel auxiliar menos custosa que a variavel de interesse e mais facil de medir.
Suponha que nada se conhece sobre os valores desta variavel auxiliar antes do inıcio da
coleta da amostra.
A primeira fase do metodo consiste em selecionar uma amostra adaptativa por
conglomerados s1 baseada nos valores da variavel auxiliar H, gerando m1 diferentes
redes, vazias e nao-vazias.
A segunda fase consiste em selecionar uma subamostra s2 de m2 redes das m1
diferentes redes que estao na amostra s1. Esta selecao pode ser feita segundo planos
amostrais probabilısticos convencionais.
Finalmente, a terceira fase consiste em selecionar uma subamostra de unidades
primarias dentro de cada uma das redes em s2 e observar o valor da variavel de interesse
Y associada em cada uma destas. Denote por s3i (i = 1, . . . ,m2) a amostra de unidades
observada na rede i, cujo tamanho e dado por n3i, e portanto, s3 =⋃m2
i=1 s3i.
Segundo Felix-Medina e Thompson (2004), existem varias possibilidades de variacoes
dentro destas tres fases. Uma destas e omitir a segunda fase e subamostrar toda
rede em s1. Cada rede pode ser subamostrada antes mesmo do pesquisador terminar
o planejamento s1. Neste ultimo caso, ha necessidade em controlar o tamanho da
amostra antes de iniciar as outras fases. Outra possibilidade e combinar diferentes planos
98

probabilısticos para selecionar s2 e s3i (i = 1, . . . ,m2). A maioria das combinacoes
permite ao pesquisador um controle sobre custos e numero de medidas da variavel de
interesse.
Alem disso, com relacao as variaveis auxiliares, podem ser usadas variaveis quaisquer
correlacionadas com a variavel de interesse e mais faceis de medir, ou ainda por exemplo
variaveis de avaliacao rapida, as quais conduzem o pesquisador para as areas mais
promissoras, onde observacoes exatas da variavel podem ser feitas posteriormente. Por
exemplo, numa pesquisa sobre mexilhoes de agua doce, cujo interesse e estimar o total
de mexilhoes numa regiao, a variavel de interesse, ou seja o numero de mexilhoes, e uma
variavel difıcil de ser medida porque alguns mexilhoes sao parcialmente escondidos pela
areia e pedras no fundo do rio. Desta forma pode-se recorrer a amostragem adaptativa
dupla, com primeiro estagio caracterizada por uma amostra adaptativa somente para
detectar a presenca ou ausencia de mexilhoes, e esta ser usada como uma variavel auxiliar
no metodo.
4.5.2 Modelo proposto sob amostragem dupla com variavel
auxiliar indicadora de presenca
O modelo de mistura em (4.4) deve ser ajustado a populacoes raras e agrupadas, as
quais sao amostradas de forma adaptativa. Por outro lado, como o desenho amostral
adaptativo por conglomerados e informativo, a verossimilhanca completa do modelo
(4.4) acrescenta-se a probabilidade de inclusao da amostra, dada em (4.5). Neste
momento a ideia e substituir este desenho amostral, pelo proposto por Felix-Medina
e Thompson (2004). Esta pequena mudanca traz adaptacoes na verossimilhanca, por
conta da probabilidade de inclusao, e em alguns aspectos do procedimento de inferencia,
os quais serao descritos a seguir.
Assim como no exemplo do mexilhao, ha particular interesse em uma variavel auxiliar
H binaria, que assume o valor 1 se ha ao menos uma observacao de interesse, ou seja se
Yi > 0, e 0 caso contrario. Alem disso, suponha que s2 e s3i, (i = 1, . . . ,m2) sao sorteadas
99

segundo um desenho amostral aleatorio simples. Este estudo sera restrito a um plano
amostral adaptativo duplo com estas caracterısticas.
Desta forma, a amostra final s e composta pelas unidades que compoem s1 e s3.
Ou seja, pelas m1 redes amostradas de forma adaptativa na primeira fase e pelas n3i,
i = 1, . . . ,m2 unidades selecionadas dentro das m2 redes amostradas no segundo estagio.
Note que de s1 so se extrai informacoes acerca da estrutura das redes, sem observar Y
dentro destas. Enquanto que de s3i, para i = 1, . . . ,m2, se extrai informacoes acerca da
variavel de interesse Y dentro das unidades primarias selecionadas. Por esse motivo s e
caracterizada pela uniao de s1 e s3.
Portanto, ao selecionar uma amostra adaptativa dupla as informacoes observadas
surgem em etapas. Na primeira fase, a amostragem adaptativa com a variavel auxiliar do
tipo presenca/ ausencia, fornece informacoes acerca das variaveis X, R e C. Portanto,
de s1 tem-se Xs, Rs e Cs no modelo (4.4). O segundo estagio nao fornece nenhuma
informacao a mais sobre as variaveis do modelo. Finalmente, na terceira fase uma parte
da variavel de interesse Y e observada, ou seja Ys, o qual neste caso indica os totais
observados em uma subamostra de unidades de uma subamostra de redes nao-vazias.
Portanto, ao aplicar este planejamento amostral ao modelo proposto, este continua
com a mesma estrutura descrita em (4.4). Entretanto, a probabilidade de selecao de uma
amostra s deve ser revista, pois o planejamento amostral foi alterado. Em particular,
a probabilidade de inclusao dada em (4.5), devem ser acrescentadas a probabilidade de
inclusao de s2 e s3. Em particular, neste caso, em que consideramos s2 e s3 selecionadas
aleatoriamente, esta probabilidade e obtida da seguinte forma:
[s | X,R,C] =
m1∏l=1
zil × gil,l∑N−X+Ri=1 zi −
∑j−1k=0 zik
×m2∏h=1
1
m1 − (h− 1)×
×m2∏h=1
n3h∏i=1
1
Ch − (i− 1).
(4.6)
O segundo termo da multiplicacao na equacao em (4.6) refere-se justamente a amostra
s2, e e a probabilidade de selecao de m2 redes dentre m1 sob amostragem aleatoria simples
sem reposicao. O terceiro fator refere-se a amostra s3, ou seja e a probabilidade de selecao
de n3h unidades, h = 1, . . . ,m2, dentro das m2 redes observadas na segunda fase. Observe
100

que como os planos amostrais da segunda e terceira fases constituem-se de amostragem
aleatoria simples, os quais sao desenhos ignoraveis, estes nao fornecem informacao a mais
para a previsao das variaveis nao observadas. A unica parcela que depende das variaveis
nao observadas vem da expressao em (4.5), logo as outras parcelas sao constantes na
distribuicao a posteriori.
4.5.2.1 Inferencia
O procedimento de inferencia baseia-se na obtencao da distribuicao a posteriori para
o vetor parametrico Θ = (Xs, Rs, εs,Cs,Ys,Ys∩s3 , α, β,λ). Note que, a primeira vista,
a diferenca entre aplicar o modelo a este planejamento ou ao anterior esta na insercao de
Ys∩s3 . Pois neste caso, alem da previsao de Yi para as unidades i ∈ s, tambem devem
ser preditos Yi para as unidades i que apesar de fazerem parte da amostra s, nao foram
observadas em s3 e portanto sao desconhecidas, ou seja, para i ∈ s ∩ s3. Uma vantagem
e que, com este plano amostral menos custoso, a amostra s pode aumentar, portanto s
diminui e, portanto a dimensao do vetor parametrico diminui. Esta e outras diferencas
serao apresentadas a seguir.
Note que, diferente da amostragem adaptativa por conglomerados, o atual
planejamento induz uma nova particao, de Y, tal que Y = (Ys3 ,Ys∩s3 ,Ys)′. Note
que apesar de usarmos a notacao de s para as unidades que pertencem a amostra, como
a amostra e formada pela uniao de subamostras e apenas em s3 e que valores de Y
sao observados, Ys3 e a unica parte conhecida de Y e portanto Ys∩s3 e Ys devem ser
preditos. A diferenca entre estes dos ultimos e que existem informacoes adicionais sobre
a estrutura das redes que contem as unidades em s ∩ s3, o que auxilia na previsao de
Ys∩s3 , melhorando assim a qualidade das previsoes dos totais nestas unidades, quando
comparado a s. Portanto, no processo de inferencia com base na obtencao da distribuicao
a posteriori, e necessario incluir as distribuicoes condicionais completas do Apendice B a
distribuicao de Ys∩s3 . Dessa forma a expressao em (2.2) dada no Apendice B e reescrita
da seguinte maneira:
101

[Ys∩s3 ,Ys | ·] ∝
∏j:j∈Λ
∏i:εi=j
λYijYi!
∏j:j∈s2
∏i∈s3:εi=j
λYijYi!
,
tal que Λ = s ∪ s1 ∩ s2.
Com relacao a estimacao de λ tambem existe uma diferenca. O atual desenho
amostral induz a uma particao deste parametro um pouco diferente da obtida quando
se realiza somente a amostragem adaptativa por conglomerados em um unico estagio.
No caso da amostragem dupla terıamos uma particao da forma λ = (λs2 ,λs1∩s2 ,λs)′,
onde λs2 esta associado as redes que foram amostradas em s2 e portanto apresentam
informacao adicional Y para algumas unidades que as compoem, λs1∩s2 as redes que foram
amostradas em s1, mas que nao fazem parte de s2, e λs continua se referindo a parte de
λ associada as redes nao amostradas, sequer no primeiro estagio. Observe a distribuicao
condicional completa de λ na equacao (2.1) no Apendice B, esta depende das variaveis
Y e C, logo quanto maior o conhecimento acerca destas variaveis, melhor a estimacao
deste parametro. Portanto, espera-se que λs2 seja o parametro melhor estimado, pois
alem do conhecimento de uma parte de C proveniente de s1, s3 fornece adicionalmente
informacoes sobre Y para as redes selecionadas em s2. Por outro lado, λs1∩s2 deve ser o
segundo melhor estimado pois para as redes em s1∩ s2 ha apenas o conhecimento de uma
parte de C. Finalmente, o subvetor λs continua sendo o mais difıcil de ser estimado, por
falta de informacao.
Portanto, como este planejamento amostral permite aumentar o numero de
observacoes com um custo controlado, espera-se melhorar a estimacao de parametros e
previsao de quantidades populacionais que apresentaram alguma dificuldade. Isso porque
com este metodo e possıvel diminuir o numero de redes nao-vazias para as quais nao se tem
nenhum conhecimento. Com o desenho amostral construıdo em 3 estagios, e possıvel ao
menos conhecer para algumas redes o tamanho destas, mesmo sem observar diretamente
a variavel de interesse Y . Inclusive esta foi a maior motivacao para estendermos o modelo
(4.4) para um plano amostral alternativo que extraısse maiores informacoes da populacao,
sem extrapolar os custos operacionais. Neste caso escolheu-se a amostragem adaptativa
dupla, com variavel auxiliar do tipo ausencia/ presenca da caracterıstica de interesse.
102

4.5.3 Avaliacao do modelo proposto sob amostragem
adaptativa e adaptativa dupla
Este estudo baseia-se na avaliacao do modelo de mistura proposto em (4.4) quando
se considera os dois planejamentos amostrais estudados neste trabalho: amostragem
adaptativa por conglomerados e a amostragem dupla. Note que neste particular estudo
optou-se por nao utilizar a populacao real de marrecos da asa azul, descrito na Subsecao
3.1.3, pois seu tamanho e relativamente pequeno para fins desta comparacao. Portanto,
foram geradas 500 populacoes com N = 600 unidades, X = 15%N unidades nao-vazias
e R = 10%X = 9 redes nao-vazias, e de cada uma destas foram simuladas as seguintes
amostras:
(i) adaptativa por conglomerados com tamanho inicial n1 = 10%N produzindo m1
redes na amostra;
(ii) adaptativa dupla por conglomerados com tamanho inicial n1 = 10%N produzindo
m1 redes na amostra e
(a) m2 = 100%m1 e n3i = 70%Ci, i = 1, . . . ,m2;
(b) m2 = 70%m1 e n3i = 100%Ci, i = 1, . . . ,m2;
(c) m2 = 70%m1 e n3i = 70%Ci, i = 1, . . . ,m2.
O interesse e comparar o ajuste do modelo sob estes quatro planejamentos. Os
cenarios (ii-a), (ii-b), (ii-c) tratam-se de variacoes do plano amostral duplo. Observe que,
apesar do cenario (ii-b) estar caracterizado como uma amostragem adaptativa dupla,
este tambem pode ser tratado como o planejamento (i), porem com um menor tamanho
inicial de amostra.
Para este estudo, foi utilizada a mesma distribuicao a priori usada na Subseccao 4.3,
supondo a distribuicao a priori para λ independente. Apos 200000 iteracoes, com um
burn-in de 10000 e espacamento de 190, foram obtidas 1000 amostras independentes da
distribuicao a posteriori do vetor parametrico Θ. Para todos os parametros observou-se
a convergencia.
103

Na Tabela 4.9 estao os EQMR, EAR, probabilidade de cobertura do intervalo
HPD de 95% e sua respectiva amplitude media relativizada para a previsao do total
populacional T . Note que para todos os planejamentos temos erros pequenos e intervalos
HPD com probabilidade de cobertura proxima do nıvel desejado de 95%. Mesmo no
planejamento (ii-c), em que se reduz de forma mais significante o tamanho da amostra
quando comparado aos demais, tem-se resultados que mostram boas previsoes neste caso.
Portanto, mesmo com um numero menor de observacoes da variavel de interesse e possıvel
obter resultados tao eficientes quanto os obtidos usando a amostragem adaptativa em um
estagio.
Tabela 4.9: Sumario a posteriori do total populacional T para os quatro planejamentos
considerados com base nas 500 amostras simuladas.
Amostra EQMR EAR Cobertura (%) Amplitude relativa
(i) 0.02 0.12 96.0 0.61
(ii-a) 0.03 0.14 95.9 0.62
(ii-b) 0.02 0.12 93.3 0.69
(ii-c) 0.03 0.13 95.8 0.62
Com relacao aos planos amostrais (i) e (ii-a) a diferenca esta no numero de unidades
que sao observadas dentro das redes amostradas. O segundo observa um numero menor
de unidades com relacao a variavel de interesse, portanto em contextos em que observar
Y e altamente custoso, pode-se preferir o plano (ii-a). Desta forma, o interesse agora
concentrar-se-a em comparar a performance do modelo de mistura sob estes dois planos
em particular. Quando comparados ambos os planejamentos com relacao a previsao do
total populacional T , nao foram observadas grandes diferencas, portanto com base neste
criterio ambos mostraram-se eficientes. Portanto, sera feita uma comparacao de ambas
as metodologias a partir da estimacao do parametro λs2 . A ideia em usar λ como criterio
de comparacao da-se pois este e um parametro importante para a previsao do total e esta
relacionado diretamente com as informacoes extraıdas dentro das redes.
104

Na Figura 4.12 esta um sumario da distribuicao a posteriori de λ ao longo das
500 simulacoes. Nesta sao apresentados o EAR, a probabilidade de cobertura do
intervalo HPD de 95% e sua respectiva amplitude media relativizada com relacao ao valor
verdadeiro. O triangulo com linha cheia representa o plano amostral (i) e o cırculo cheio
com linha pontilhada o plano amostral (ii-a). Note que o plano (i) produz erros relativos
ligeiramente menores que o plano (ii-a), o que era de se esperar pois este apresenta
um maior tamanho de amostra final. Alem disso, os intervalos HPD de 95% sao mais
precisos para todos os λjs sob o plano amostral (i). Com relacao as probabilidades de
cobertura nao ha nada conclusivo sobre qual plano e mais eficiente, ora um se apresenta
mais proximo do nıvel desejado, ora outro se apresenta. Observe que λ6 apresenta
uma subestimacao da probabilidade de cobertura, mas este fato ocorre para os dois
planejamentos em questao.
EA
R
λ1 λ2 λ3 λ4 λ5 λ6 λ7 λ8 λ9
0.01
0.03
0.05
Cob
ertu
ra
λ1 λ2 λ3 λ4 λ5 λ6 λ7 λ8 λ9
0.88
0.92
0.96
Am
plitu
de
λ1 λ2 λ3 λ4 λ5 λ6 λ7 λ8 λ9
0.3
0.5
0.7
0.9
Figura 4.12: Sumario a posteriori de λs2 para os planejamentos (i) e (ii-a) com base nas
500 amostras simuladas.
4.6 Conclusoes
Neste capıtulo apresentou-se a principal contribuicao deste trabalho, que foi a
proposta de um modelo desagregado que se ajuste a amostras adaptativas selecionadas
de populacoes raras e agrupadas. O modelo e construıdo no nıvel das unidades da grade,
o que permitiu a insercao da suposicao de heterogeneidade entre redes distintas. A
inferencia Bayesiana para o modelo e feita usando o metodo RJMCMC, pois neste caso o
tamanho do espaco parametrico e desconhecido. Portanto, o ajuste do modelo proposto
105

necessita de metodos mais custosos computacionalmente do que o modelo agregado, onde
apenas o MCMC e necessario.
No geral, o modelo apresentou uma boa performance nos estudos de simulacao
realizados e ao ajusta-lo com a populacao real do marreco da asa azul, resultados
mais satisfatorios foram obtidos quando comparado com o modelo agregado. Por outro
lado, foi possıvel observar que ao diminuir o grau de heterogeneidade da populacao
o desempenho do modelo agregado com relacao a estimacao de T , o qual e o maior
interesse neste trabalho, tende a melhorar e a tornar-se mais proximo ao obtido quando
ajustado o modelo de mistura. Portanto, recomenda-se o uso do modelo proposto quando
de fato a heterogeneidade e um comportamento presente nos dados, visto que o custo
computacional e maior neste caso.
Um sumario das conclusoes mais relevantes extraıdas dos estudos de simulacao
realizados neste capıtulo e apresentado na Tabela 4.10.
Finalmente, com o proposito de melhorar a previsao e estimacao do modelo de
mistura, foi apresentada uma aplicacao do modelo de mistura ao plano amostral
adaptativo duplo. Este planejamento tende a fornecer mais informacoes sobre a
populacao de pesquisa, com um custo operacional controlado. Nesta extensao verificou-se
que e possıvel obter resultados eficientes ainda que com um numero menor de observacoes
da variavel de interesse e usando uma variavel auxiliar indicadora de presenca da
caracterıstica de interesse.
106

Tabela 4.10: Resumo das principais conclusoes acerca dos estudos simulados realizados
com o modelo de mistura proposto em (4.4).
Variando N , α e β
(1) Melhores resultados a medida que os valores de N , α e β aumentam.
(2) Maiores dificuldades de estimacao de λs que λs.
Distribuicao a priori de λ
(1) Distribuicao a posteriori de R sensıvel a escolha de τ .
(2) Escolha de τ nao afeta a distribuicao a posteriori de T .
(3) Os EQMR obtidos na previsao de T sao menores quando assume-se distribuicao
a priori dependente para λ.
Nıvel de heterogeneidade
(1) Mesmo sob nıveis mais intensos de homogeneidade bons resultados sao
atingidos na previsao de T , mas surgem problemas na estimacao de ν e β.
(2) Comparando com o modelo agregado, percebe-se que o modelo proposto e adequado
principalmente para populacoes heterogeneas. Sob maiores nıveis de homogeneidade,
o desempenho dos modelos torna-se similar.
107

Capıtulo 5
Conclusoes e trabalhos futuros
Ao longo deste trabalho foram revisadas duas possıveis formas de fazer previsao em
populacoes raras e agrupadas: a inferencia baseada na aleatorizacao do plano amostral e
a abordagem baseada em modelos de superpopulacao. No primeiro caso, apresentou-
se o planejamento amostral adaptativo por conglomerados e, no segundo, o modelo
proposto por Rapley e Welsh (2008), o qual e ajustado sob o enfoque Bayesiano. Estudos
simulados com base em populacoes artificiais e real foram apresentados e ambas as
abordagens foram comparadas principalmente em nıveis de eficiencia da previsao do
total populacional. Tendo em vista um bom desempenho do modelo de Rapley e Welsh
(2008), as metodologias propostas neste trabalho permanecem no contexto de inferencia
em populacao finita baseada em modelos.
Realizar pesquisas em populacoes raras e agrupadas e uma tarefa ardua e necessita em
geral de metodologias especıficas que usem na sua formulacao a estrutura da populacao.
No entanto, estas populacoes podem ser ainda mais problematicas se apresentarem
uma dinamica populacional, o que e uma caracterıstica tambem comum neste contexto.
Buscando tratar situacoes como esta, foi apresentada uma extensao do modelo de Rapley
e Welsh (2008). Em particular, a extensao e voltada principalmente para populacoes em
crescimento ou decrescimento e final estabilizacao com a evolucao do tempo.
Por outro lado, questoes como a modelagem no nıvel agregado das redes, suposicoes
de homogeneidade entre as redes e de relacao direta entre a frequencia esperada de
um fenomeno e o tamanho de uma rede no qual ele e observado, restringem o modelo
108

de Rapley e Welsh (2008) a algumas especıficas populacoes com estas caracterısticas.
Com o objetivo de tratar destas questoes, foi proposto um modelo de mistura a nıvel
desagregado que supoe heterogeneidade entre as redes, e consequentemente que o numero
de ocorrencias de um fenomeno em uma rede nao depende necessariamente apenas do
tamanho desta. Como foi visto, para fazer inferencia para este modelo fez-se necessario
tecnicas mais sofisticadas, pois a dimensao do vetor parametrico e tambem um parametro.
Em particular, foi utilizado o metodo de RJMCMC. O modelo mostrou-se mais eficiente
que o modelo agregado em casos de heterogeneidade. Por outro lado, a medida que o
nıvel de heterogeneidade diminui a performance dos modelos torna-se semelhante.
Finalmente, a metodologia proposta foi aplicada ao plano amostral adaptativo duplo
por conglomerados, com o objetivo de adquirir mais informacoes que auxiliem a estimar
os parametros do modelo de mistura proposto em (4.4) associados as unidades que nao
foram observadas. Em particular, a variavel auxiliar utilizada nesta extensao caracteriza-
se como uma indicadora da ausencia ou presenca da observacao de interesse, ou seja, esta
totalmente relacionada com a variavel de pesquisa.
5.1 Trabalhos futuros
Na extensao apresentada na Secao 3.2 do Capıtulo 3 supor uma amostra independente
a cada instante de tempo pode nao ser viavel em algumas situacoes praticas. No entanto,
como o modelo e formulado de forma agregada, isto traz dificuldades a incorporar outros
planejamentos mais viaveis. Com isso, ha interesse em aplicar o modelo de mistura
proposto a planos amostrais que apresentem dependencia temporal.
Com relacao ao desenho amostral adaptativo duplo, seria interessante investigar
um tamanho de amostra otimo na primeira e/ou na segunda fase, de modo a ser
eficiente e minimizar o custo operacional. Alem disso, ha interesse tambem em aplicar a
metodologia, supondo outras variaveis auxiliares relacionadas com a variavel de interesse
que nao somente indicadoras de presenca da caracterıstica de interesse.
Alem disso, dentro de uma rede e comum que unidades tenham frequencia de
observacoes que varia de acordo com a distancia ao centroide da rede. Por exemplo,
109

espera-se que unidades dentro de uma rede tenham frequencia de observacoes que varia de
acordo com a distancia ao centroide da rede. O processo pontual conglomerado de Poisson
(ver Diggle et al. (1983)) e um exemplo de populacao com este comportamento. Dessa
forma, uma ideia futura para o modelo de mistura proposto e a insercao de componentes
espaciais na media da distribuicao da variavel resposta que dependam da distancia. Um
importante aspecto a ser considerado nesta proposta futura e a definicao do centroide,
visto que uma rede em geral nao e regular. Alem disso, a proposta seria incorporar esta
estrutura espacial na parte do modelo que se ajusta a amostra coletada, pois para a parte
nao amostrada nao ha conhecimento da localizacao e nem das unidades que compoem as
redes, o que inviabilizaria a ideia nestas unidades.
5.1.1 Planejamento amostral otimo
Como o desenho amostral adaptativo caracteriza-se pela selecao da amostra em fases,
seria razoavel estudar a incorporacao de um planejamento amostral otimo, a fim de buscar
unidades amostrais que possam ser mais promissoras para a estimacao do parametro
populacional de interesse.
Em desenhos amostrais convencionais a amostra completa e planejada de uma vez,
antes mesmo da selecao. Um exemplo de planejamento em duas fases e aquele em
que a amostra inicial de n1 unidades e selecionada e os valores de Y sao observados
e, posteriormente, uma amostra adicional de n2 unidades e selecionada, cujo tamanho
depende dos valores observados na primeira amostra. A amostragem adaptativa seria
uma classe de desenhos com L fases, em que L e uma variavel aleatoria.
De forma geral, um planejamento otimo e uma tarefa que costuma envolver
metodologias para obtencao de maximos e mınimos de funcoes objetivo. Estas funcoes
objetivo quantificam os ganhos e perdas associados as possıveis decisoes a serem tomadas.
A ideia de um planejamento otimo com duas fases e descrito a seguir e pode ser visto
com maiores detalhes em Thompson e Seber (1996).
Suponha um desenho com tamanho amostral fixo em n unidades e suponha que
dessas unidades n1 foram selecionadas e observadas. Seja ys1 os valores de Y associados
a esta amostra inicial. A amostra restante a ser observada e s2 e de forma analoga
110

defina ys2 . Logo, a amostra completa e dada por s = (s1, s2), com respectivos ys =
(ys1 ,ys2). O objetivo e prever uma funcao populacional qualquer W = w(Y), como
o total populacional por exemplo, a partir de uma funcao da amostra H(d), tal que
d = (s,ys). Deseja-se que H seja nao viesado de acordo com o modelo. A funcao que
minimiza o erro quadratico medio de previsao E ((H −W )2 | s) e a esperanca condicional
H(d) = E (W | d).
Finalmente, a questao e se a selecao das n2 unidades restantes deve depender dos
valores de ys1 . Neste caso, a ideia seria selecionar uma amostra s2 que minimize a funcao
objetivo:
gs2(s1,ys1) = E[(h(s1,ys1 , s2,Ys2)− w(Y))2 | s1,ys1
]=
∫(h− w)2[ys1 | s1,ys1 ]dys1 .
Este mesmo argumento pode ser estendido para desenhos com multiplas fases.
Portanto, um interesse futuro seria incorporar o planejamento amostral otimo nos
modelos estudados neste trabalho. Por exemplo, ao selecionar uma amostra adaptativa
inicial e verificar alguns locais mais informativos na regiao, e possıvel continuar o processo
de selecao da amostra propondo outros locais mais eficientes do que uma amostra aleatoria
simples inicial. Ou ainda no plano adaptativo duplo, onde a segunda fase depende da
primeira. Nessa mesma proposta e possıvel tambem avaliar um tamanho de amostra
otimo.
111

Apendice A
Resultados dos modelos ajustados
no Capıtulo 3
A.1 Modelo (3.1)
Neste apendice sao apresentados os tracos das cadeias dos parametros para o modelo
(3.1) e uma ilustracao do sumario da distribuicao a posteriori dos parametros obtido para
100 populacoes em 16 cenarios gerados.
112

iteração
α
0 400 1000
0.0
0.3
iteração
β
0 400 1000
0.0
0.4
iteração
γ
0 400 1000
020
iteração
T
0 400 1000
030
00
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.1
0.4
iteração
γ
0 400 1000
710
14
iteração
T
0 400 1000
500
2000
iteração
α
0 400 1000
0.05
0.30
iteração
β0 400 1000
0.1
0.3
iteração
γ
0 400 1000
79
12
iteração
T
0 400 1000
500
iteração
α
0 400 1000
0.0
0.3
iteração
β
0 400 1000
0.1
0.4
iteraçãoγ
0 400 1000
812
iteração
T
0 400 1000
015
00
Figura 1.1: Tracos das cadeias dos parametros α, β, γ e total populacional T para um
dado artificial gerado fixando α = 0.05 e β ∈ 0.05, 0.1, 0.15, 0.2, com respectivos valores
verdadeiros em cinza.
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.05
0.25
iteração
γ
0 400 1000
810
12
iteração
T
0 400 1000
1500
500
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.1
0.4
iteração
γ
0 400 1000
610
iteração
T
0 400 1000
015
00
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.05
0.25
iteração
γ
0 400 1000
912
iteração
T
500
1500
0 400 1000
iteração
α
0 400 1000
0.0
0.3
iteração
β
0 400 1000
0.1
0.4
iteração
γ
0 400 1000
812
iteração
T
0 400 1000
500
2000
2000
Figura 1.2: Tracos das cadeias dos parametros α, β, γ e total populacional T para um
dado artificial gerado fixando α = 0.1 e β ∈ 0.05, 0.1, 0.15, 0.2, com respectivos valores
verdadeiros em cinza.
113

iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.05
iteração
γ
0 400 1000
9.0
10.5
iteração
T
0 400 1000
600
1600
iteração
α
0 400 1000
0.0
0.3
iteração
β
0 400 1000
0.1
0.5
iteração
γ
0 400 1000
612
iteração
T
0 400 1000
015
00
iteração
α
0 400 1000
0.1
0.4
iteração
β0 400 10000.
050.
25iteração
γ
0 400 1000
810
12
iteração
T
0 400 1000
500
2000
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.05
0.30
iteraçãoγ
0 400 1000
811
iteração
T
0 400 1000
500
1500
Figura 1.3: Tracos das cadeias dos parametros α, β, γ e total populacional T para um
dado artificial gerado fixando α = 0.15 e β ∈ 0.05, 0.1, 0.15, 0.2, com respectivos valores
verdadeiros em cinza.
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.05
0.20
iteração
γ
0 400 1000
8.0
10.0
iteração
T
0 400 1000
500
2000
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.05
0.20
iteração
γ
0 400 1000
8.5
10.5
iteração
T
0 400 1000
500
2000
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.05
0.30
iteração
γ
0 400 1000
911
iteração
T
0 400 1000
500
2500
iteração
α
0 400 1000
0.1
0.4
iteração
β
0 400 1000
0.1
0.4
iteração
γ
0 400 1000
710
iteração
T
0 400 1000
500
2000
Figura 1.4: Tracos das cadeias dos parametros α, β, γ e total populacional T para um
dado artificial gerado fixando α = 0.2 e β ∈ 0.05, 0.1, 0.15, 0.2, com respectivos valores
verdadeiros em cinza.
114
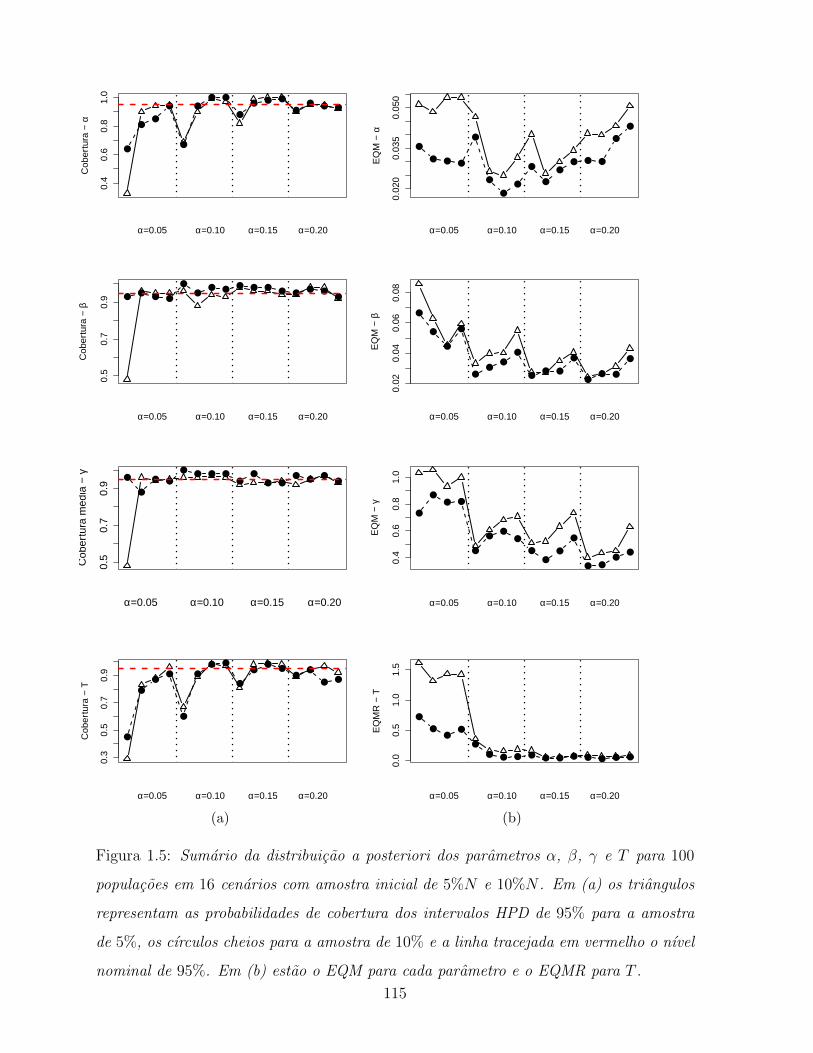
0.4
0.6
0.8
1.0
α=0.05 α=0.10 α=0.15 α=0.20
Cob
ertu
ra −
α
0.02
00.
035
0.05
0
α=0.05 α=0.10 α=0.15 α=0.20
EQ
M −
α
0.5
0.7
0.9
α=0.05 α=0.10 α=0.15 α=0.20
Cob
ertu
ra −
β
0.02
0.04
0.06
0.08
α=0.05 α=0.10 α=0.15 α=0.20
EQ
M −
β
0.5
0.7
0.9
α=0.05 α=0.10 α=0.15 α=0.20
Cob
ertu
ra m
édia
− γ
0.4
0.6
0.8
1.0
α=0.05 α=0.10 α=0.15 α=0.20
EQ
M −
γ
0.3
0.5
0.7
0.9
α=0.05 α=0.10 α=0.15 α=0.20
Cob
ertu
ra −
T
(a)
0.0
0.5
1.0
1.5
α=0.05 α=0.10 α=0.15 α=0.20
EQ
MR
− T
(b)
Figura 1.5: Sumario da distribuicao a posteriori dos parametros α, β, γ e T para 100
populacoes em 16 cenarios com amostra inicial de 5%N e 10%N . Em (a) os triangulos
representam as probabilidades de cobertura dos intervalos HPD de 95% para a amostra
de 5%, os cırculos cheios para a amostra de 10% e a linha tracejada em vermelho o nıvel
nominal de 95%. Em (b) estao o EQM para cada parametro e o EQMR para T .
115

A.2 Modelo de crescimento (3.4)
Nas Figuras 1.6 e 1.7 estao os resultados do ajuste do modelo (3.4) para duas das
populacoes artificiais geradas. A primeira e para uma populacao em crescimento ao longo
do tempo e a segunda para uma que decresce.
iteração
a
0 400 1000−1.
9−
1.6
(a) a
iteração
b
0 400 1000−1.
7−
1.3
(b) b
iteração
c
0 400 1000−0.
20−
0.10
(c) c
iteração
0 400 1000
β0.
090.
12
(d) β
iteração
γ
0 400 1000
9.8
10.2
(e) γ
iteração
T1
0 400 1000
100
300
(f) T1
iteração
T13
0 400 1000
300
700
(g) T13
iteração
T25
0 400 1000
400
800
(h) T25
iteraçãoT
37
0 400 1000
400
800
(i) T37
iteração
T49
0 400 1000
400
800
(j) T49
Figura 1.6: Sumario da distribuicao a posteriori de Θ e do total populacional para uma
populacao em crescimento ao longo do tempo. Em (a)-(e) estao os tracos das cadeias
da distribuicao a posteriori dos parametros a, b, c, β e γ. De (f)-(j) estao os tracos das
cadeias para os totais em alguns tempos. A linha em cinza representa o valor verdadeiro
usado na geracao dos dados artificiais.
116

iteração
a
0 400 1000
−2.
4−
2.1
(a) a
iteração
b
0 400 1000
0.7
1.0
(b) b
iteração
c
0 400 1000−0.
20−
0.10
(c) c
iteração
0 400 1000
β0.
080.
13
(d) β
iteração
γ
0 400 1000
9.6
10.2
(e) γ
iteração
T1
0 400 1000
500
900
(f) T1
iteração
T13
0 400 1000
200
500
(g) T13
iteração
T25
0 400 1000
200
500
(h) T25
iteração
T37
0 400 1000
200
450
(i) T37
iteração
T49
0 400 1000200
500
(j) T49
Figura 1.7: Sumario da distribuicao a posteriori de Θ e do total populacional para uma
populacao em decrescimento ao longo do tempo. Em (a)-(e) estao os tracos das cadeias
da distribuicao a posteriori dos parametros a, b, c, β e γ. De (f)-(j) estao os tracos das
cadeias para os totais em alguns tempos. A linha em cinza representa o valor verdadeiro
usado na geracao dos dados artificiais.
117

Apendice B
Calculos envolvidos na inferencia
para o modelo proposto
Neste apendice sao apresentadas expressoes importantes envolvidas no algoritmo
RJMCMC, utilizado para inferencia a posteriori para o modelo de mistura proposto (4.4).
Primeiramente estao as distribuicoes condicionais completas para o vetor parametrico
Θ = (Xs, Rs, εs,Cs,Ys, α, β,λ, ν). Dessa forma, a variavel resposta Ys, por exemplo,
e tambem considerada um parametro e portanto e estimada da mesma maneira que
as demais quantidades. Alem disso, sera apresentada a probabilidade de aceitacao do
algoritmo RJMCMC, passando por alguns calculos importantes.
B.1 Distribuicoes condicionais completas
Para as distribuicoes condicionais completas que apresentam forma analıtica
conhecida, o Amostrador de Gibbs pode ser utilizado. Para as que nao apresentam
forma fechada um metodo indireto de amostragem e necessario, em particular, passos
de Metropolis-Hastings podem caracterizar a obtencao dessas amostras a posteriori. As
118

distribuicoes apresentadas a seguir sao obtidas ao assumir-se as seguintes distribuicoes a
priori independentes para o modelo (4.4):
λj ∼ Gama(d, ν), j = 1, . . . , R,
ν ∼ Gama(e, f),
α ∼ Beta(aα, bα),
β ∼ Beta(aβ, bβ).
A seguir estao as distribuicoes condicionais completas.
• De α:
[α | ·] ∝ αXs+Xs(1− α)N−Xs−Xs
1− (1− α)Nαaα−1(1− α)bα−1.
Para gerar amostras desta distribuicao deve-se utilizar passos de Metropolis-Hastings,
visto que esta nao apresenta forma analıtica conhecida.
• De β:
[β | ·] ∝ βRs+Rs(1− β)Xs+Xs−Rs−Rs
1− (1− β)Xs+Xsβaβ−1(1− β)bβ−1.
Como [β | ·] tambem nao possui forma analıtica fechada, deve-se utilizar passos de
Metropolis-Hastings, para amostrar desta distribuicao de probabilidade.
• De λ: Para j = 1, . . . , Rs +Rs,
[λj | ·] ∝λ∑i:εi=j
Yi+d−1
j exp−λj(ν + Cj)1− exp(−λj)
. (2.1)
Observe que [λj | ·] nao possui forma fechada conhecida. Para gerar amostras de sua
distribuicao a posteriori e necessario utilizar um passo de Metropolis-Hastings.
• De εs: Para i, j ∈ s,
119

[εi = j | ·] ∝ CjXs +Xs
λYij exp(−λj)Yi![1− exp(−λj)]
.
Neste caso, εi e amostrado diretamente dos possıveis valores, com a probabilidade
acima. Note que o modelo proposto e aplicavel a populacoes divididas em redes nao-
vazias, logo toda rede deve ter pelo menos uma observacao. Portanto, na condicional
completa de εi ainda e incluıdo uma indicadora de que todas as Rs redes tenham pelo
menos uma unidade alocada.
• De (Xs,Cs):
[Xs,Cs | ·] ∝m∏l=1
Zil × gil,l∑N−X+Ri=1 Zi −
∑l−1k=0 Zik
αXs(1− α)−Xs
(N −Xs −Xs)!
(1− β)Xs
(1− (1− β)Xs+Xs)
× (Xs +Xs)−(Xs+Xs)
∏j:j∈s
CCjj
∏j:j∈s
1
(Cj − 1)!R−(Xs−Rs)
×∏j:j∈s
exp−λjCj[1− exp(−λj)]Cj
.
A amostragem de (Xs,Cs) e feita de forma conjunta, e como a distribuicao condicional
completa nao tem forma analıtica fechada, o algoritmo de Metropolis-Hastings e utilizado.
A proposta de Xs e baseada num passeio aleatorio em torno do valor corrente de Xs e a
proposta de Cs baseia-se na Multinomial(Xs −Rs,1Rs
1Rs).
• De Ys:
[Ys | ·] ∝∏j:j∈s
λ∑i:εi=j
Yi
j∏i:εi=j Yi!
. (2.2)
Portanto, Ysi ∼ Poisson truncada(λsi), j ∈ s. Logo, para amostrar desta distribuicao
podemos utilizar o Amostrador de Gibbs.
• De ν:
[ν | ·] ∝ ν(Rs+Rs)d+e−1 exp−ν(f +Rs+Rs∑j=1
λj).
Logo, ν ∼ Gamma ((Rs + Rs)d + e, f +∑Rs+Rs
j=1 λj) e para amostrar desta distribuicao
podemos utilizar o Amostrador de Gibbs.
120

B.2 Probabilidade de aceitacao do algoritmo
RJMCMC
Se e proposto um movimento de “divisao”, ou seja que leva de (Cj∗ , εj∗ , λj∗) a
(Cj1 ,Cj2 , εj1 , εj2 , λj1 , λj2), para j∗, j1 e j2 pertencentes a s, o movimento e aceito com
probabilidade dada por min(1, A), tal que A e dada por (4.3), e para este modelo tem a
seguinte forma:
A =exp−(Cj1λj1 + Cj2λj2)λ
∑i:εi=j1
Yi
j1λ∑i:εi=j2
Yi
j2(1− exp(−λj1))−Cj1 (1− exp(−λj2))−Cj2
exp−Cj∗λj∗λ∑i:εi=j∗
Yi
j∗ (1− exp(−λj∗))−Cj∗
[ij1 , ij2][ij∗]
× p(Rs + 1)
p(Rs)× (Cj∗ − 1)!
(Cj1 − 1)!(Cj2 − 1)!(Rs +Rs)
−(Cj1+Cj2−Cj∗ ) ×CCj1j1CCj2j2
CCj∗j∗
× (Rs + 1)
× νd
Γ(d)
(λj1λj2λj∗
)d−1
exp−ν(λj1 + λj2 − λj∗)
×pk|k+1
pk+1|kPallocq(u1)q(u2)× ρ Cj∗
Xs +Xs
,
onde a primeira linha consiste da razao das verossimilhanca avaliada nestes pontos, a
segunda e terceira linha apresentam a distribuicao a priori dos parametros. No final da
segunda linha, o termo Rs+1 vem da razao (Rs+1)!/Rs!, devido a ordem dos parametros.
A ultima linha apresenta a razao das probabilidades de transicao entre os espacos, onde
Palloc e a probabilidade desta particular alocacao ser feita, e o ultimo termo e o jacobiano
da transformacao.
121

Referencias Bibliograficas
Besag, J. (1974) Spatial interaction and the statistical analysis of lattice systems. Journal
of the Royal Statistical Society. Series B (Methodological), 36, 192–236.
Bolfarine, H. e Zacks, S. (1992) Prediction theory for finite populations. Springer-Verlag
New York:.
Brown, J. A. e Manly, B. J. F. (1998) Restricted adaptive cluster sampling.
Environmental and Ecological Statistics, 5, 49–63.
Cassel, C.-M., Sarndal, C.-E. e Wretman, J. H. (1977) Foundations of inference in survey
sampling. Wiley New York.
Clayton, D. e Bernardinelli, L. (1992) Bayesian methods for mapping disease risk.
Geographical and environmental epidemiology: methods for small area studies, 205–
220.
Conners, M. e Schwager, S. (2002) The use of adaptive cluster sampling for hydroacoustic
surveys. ICES Journal of Marine Science: Journal du Conseil, 59, 1314–1325.
Danaher, P. e King, M. (1994) Estimating rare household characteristics using adaptive
sampling. NZ Stat, 29, 14–23.
Diggle, P. J. et al. (1983) Statistical analysis of spatial point patterns. Academic Press.
Felix-Medina, M. H. e Thompson, S. K. (2004) Adaptive cluster double sampling.
Biometrika, 91, 877.
122

Gelman, A. (2006) Prior distributions for variance parameters in hierarchical models
(comment on article by browne and draper). Bayesian analysis, 1, 515–534.
Gelman, A., Carlin, J. B., Stern, H. S. e Rubin, D. B. (1995) Bayesian data analysis.
Chapman & Hall.
Geweke, J. (1992) Evaluating the accuracy of sampling-based approaches to the
calculations of posterior moments. Em Bayesian Statistics (eds. A. D. J. Bernardo,
J. Berger e A. Smith). Oxford University Press, New York.
Gilks, W. R. e Wild, P. (1992) Adaptive rejection sampling for Gibbs sampling. Applied
Statistics, 337–348.
Green, P. (1995) Reversible jump markov chain monte carlo computation and bayesian
model determination. Biometrika, 82, 711–732.
Horvitz, D. e Thompson, D. (1952) A generalization of sampling without replacement
from a finite universe. Journal of the American Statistical Association, 47, 663–685.
Kalton, G. (1991) Sampling flows of mobile human populations. Survey Methodology,
17, 183–194.
— (2001) Practical methods for sampling rare and mobile populations. Em Proceedings
of the Annual Meeting of the American Statistical Association, 5–9.
Kalton, G. e Anderson, D. (1986) Sampling rare populations. Journal of the Royal
Statistical Society. Series A (General), 149, 65–82.
Lambert, D. (1992) Zero-inflated poisson regression, with an application to defects in
manufacturing. Technometrics, 34, 1–14.
Marin, J.-M., Mengersen, K. e Robert, C. P. (2005) Bayesian modelling and inference on
mixtures of distributions. Handbook of statistics, 25, 459–507.
McDonald, L. L. (2004) Sampling rare populations. Em Sampling rare or elusive
species: concepts, designs, and techniques for estimating population parameters (ed.
W. Thompson), cap. 4, 11–42. Island Press Washington, DC, USA.
123

Migon, H. e Gamerman, D. (2006) Generalized exponential growth models a bayesian
approach. Journal of Forecasting, 12, 573–584.
Neyman, J. e Scott, E. (1958) Statistical approach to problems of cosmology. Journal of
the Royal Statistical Society. Series B (Methodological), 20, 1–43.
R Core Team (2013) R: A Language and Environment for Statistical Computing. R
Foundation for Statistical Computing, Vienna, Austria. URLhttp://www.R-project.
org.
Raftery, A. E. e Lewis, S. M. (1992) One long run with diagnostics: Implementation
strategies for markov chain monte carlo. Statistical Science, 7, 493–497.
Rapley, V. (2004) Model-Based Adaptive Cluster Sampling. Tese de Doutorado, University
of Southampton.
Rapley, V. e Welsh, A. (2008) Model-based inferences from adaptive cluster sampling.
Bayesian Analysis, 3, 717–736.
Richardson, S. e Green, P. (1997) On bayesian analysis of mixtures with an unknown
number of components. Journal of the Royal Statistical Society, Series B, 59, 731–792.
Roeder, K. e Wasserman, L. (1997) Practical bayesian density estimation using mixtures
of normals. Journal of the American Statistical Association, 92, 894–902.
Roesch, F. (1993) Adaptive cluster sampling for forest inventories. Forest Science, 39,
655–669.
Salehi, M. M. e Seber, G. (1997) Two-stage adaptive cluster sampling. Biometrics, 53,
959–970.
Skinner, C., Holt, D. e Smith, T. (1989) Analysis of complex surveys. John Wiley &
Sons.
Smith, D., Brown, J. e Lo, N. (2004) Application of adaptive sampling to biological
populations. Em Sampling rare or elusive species: concepts, designs, and techniques for
124

estimating population parameters. Island, Washington, DC, USA (ed. W. Thompson),
cap. 5, 77–122. Island Press Washington, DC, USA.
Smith, D., Conroy, M. e Brakhage, D. (1995) Efficiency of adaptive cluster sampling for
estimating density of wintering waterfowl. Biometrics, 51, 777–788.
Spiegelhalter, D. J., Best, N. G., Carlin, B. P. e Van Der Linde, A. (2002) Bayesian
measures of model complexity and fit. Journal of the Royal Statistical Society: Series
B (Statistical Methodology), 64, 583–639.
Sudman, S. e Kalton, G. (1986) New developments in the sampling of special populations.
Annual Review of Sociology, 12, 401–429.
Tanner, M. A. (1993) Tools for Statistical Inference: Methods for the Exploration of
Posterior Distributions and Likelhood Functions. Springer-Verlag.
Thompson, S. e Collins, L. (2002) Adaptive sampling in research on risk-related
behaviors. Drug and Alcohol Dependence, 68, 57–67.
Thompson, S. K. (1990) Adaptive cluster sampling. Journal of the American Statistical
Association, 85, 1050–1059.
— (1991) Stratified adaptive cluster sampling. Biometrika, 78, 389–397.
Thompson, S. K. e Seber, G. A. F. (1996) Adaptive sampling. Wiley New York.
Turk, P. e Borkowski, J. (2005) A review of adaptive cluster sampling: 1990–2003.
Environmental and Ecological Statistics, 12, 55–94.
Viallefont, V., Richardson, S. e Green, P. J. (2002) Bayesian analysis of Poisson mixtures.
Journal of Nonparametric Statistics, 14, 181–202.
125





























