Embed Size (px)
Citation preview

Probabilidade: como medir e gerenciar a
incerteza?
Introducao
Os jornais informaram que ha uma chance de
60% de chover no proximo fim de semana no
Rio. Talvez seja melhor programar um cinema
em vez de programar uma ida a praia.
O noticiario da TV informou que a partir do
inıcio de setembro havera uma mudanca no
transito do Rio devido as obras do novo acesso
ao centro. Como eu passo pelo local da obra
diariamente, talvez seja melhor sair de casa um
pouco mais cedo para evitar grandes engarrafa-
mentos decorrentes da nova mudanca.
1

A nossa vida e cercada de incerteza: uma pe-
quena chance disso, uma grande chance daqui-
lo, etc.
Os conceitos de probabilidade, esperanca (valor
esperado), retorno e possibilidade nao sao ape-
nas para jogadores, sao ferramentas praticas
que podemos usar para avaliar riscos, determi-
nar opcoes preferidas e avaliar potenciais im-
pactos de certas decisoes.
2

PROBABILIDADE
Ja vimos como analisar um conjunto de dados
por meio de tecnicas graficas e numericas.
O resultado da analise nos permite ter uma boa
ideia da distribuicao desse conjunto de dados,
em outras palavras, de como esses dados sao
gerados.
Em particular, a distribuicao de frequencias
e um instrumento importante para avaliar a
variabilidade das observacoes de um fenomeno
aleatorio.
As frequencias relativas observadas podem ser
olhadas como estimativas de probabilidades de
ocorrencia de certos eventos de interesse.
3

Com suposicoes adequadas, e sem observar-
mos diretamente o fenomeno aleatorio de in-
teresse, podemos propor um modelo teorico
que reproduza de maneira razoavel a distribui-
cao das frequencias, quando o fenomeno e ob-
servado diretamente.
Modelos Probabilısticos
Tais modelos devem, de alguma forma,
1. identificar o conjunto de resultados possı-
veis do fenomeno aleatorio, que costumamos
chamar de espaco amostral, em geral de-
notado por S e
2. designar chances (probabilidades) aos re-
sultados ou conjuntos de resultados possı-
veis.
4

O conceito de probabilidade nos auxilia na quan-
tificacao da incerteza associada aos fenomenos
aleatorios, ou seja aos fenomenos cujos resul-
tados nao sao conhecidos previamente a sua
realizacao/observacao.
Na aula de hoje discutiremos conceitos rela-
cionados a incerteza e veremos
• como calcular probabilidades de eventos
compostos tais como a probabilidade de
chover hoje ou amanha e a probabilidade
de chover hoje e amanha;
• uma ferramenta simples, mas poderosa, a
arvore de probabilidade, muito util para re-
solver problemas de calculo de probabili-
dades;
5

Tambem veremos
• uma formalizacao de modo a propor mo-
delos probabilısticos usando o conceito de
variavel aleatoria;
• como calcular o valor esperado e a variancia
de uma variavel aleatoria discreta;
• o modelo binomial;
• o modelo normal.
6

Chamamos evento a qualquer subconjunto do
espaco amostral (S). Os eventos sao geral-
mente denotados por letras maiusculas A, B,
etc.
Em particular chamamos o conjunto vazio (∅)de evento impossıvel, pois ele nunca ocorrera
e, o espaco amostral (S), de evento certo, pois
sempre ocorrera um dos resultados possıveis.
Para o evento impossıvel designamos uma pro-
babilidade nula e para o evento certo desig-
namos uma probabilidade igual a 1 (ou 100%).
Vamos comecar a discussao com um exemplo
classico: o lancamento de uma moeda. Tem-
se dois resultados possıveis: cara ou coroa.
Mas, nao sabemos qual deles ira ocorrer.
7

A chance, ou probabilidade, de obter cara pode
ser pensada como a mesma de obter coroa, se
a moeda for balanceada e, desse modo pode-
mos atribuir 50% de chance a cada resultado
possıvel. (Interpretacao classica da probabili-
dade)
Por outro lado podemos desconfiar da hones-
tidade da moeda. Uma maneira de designar a
probabilidade de cara e, por exemplo, realizar
um grande numero de repeticoes do lancamen-
to da moeda e ir atualizando a frequencia re-
lativa de ocorrencia do numero de caras. De-
pois de muitas realizacoes, podemos atribuir a
chance de “ocorrer cara” a frequencia relativa
final. (Interpretacao frequentista da probabili-
dade.)
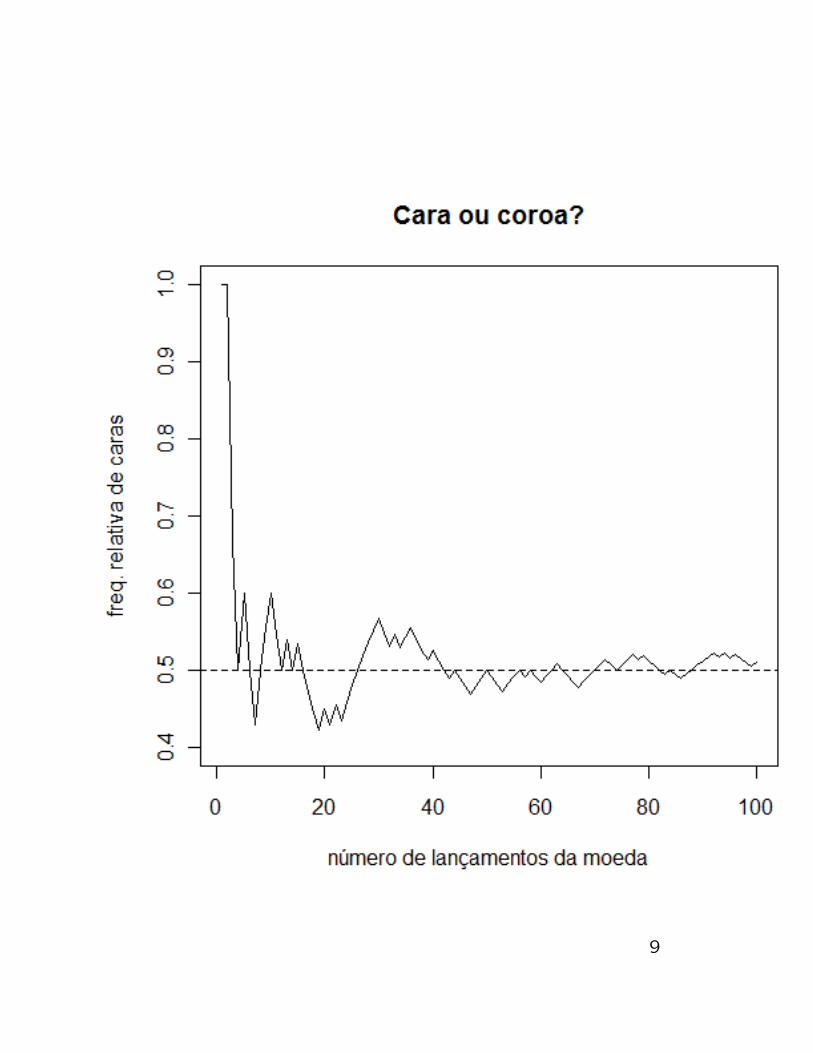
Veja nos graficos a seguir simulacoes desse
experimento com 100 lancamentos e 10000
lancamentos.
8
9
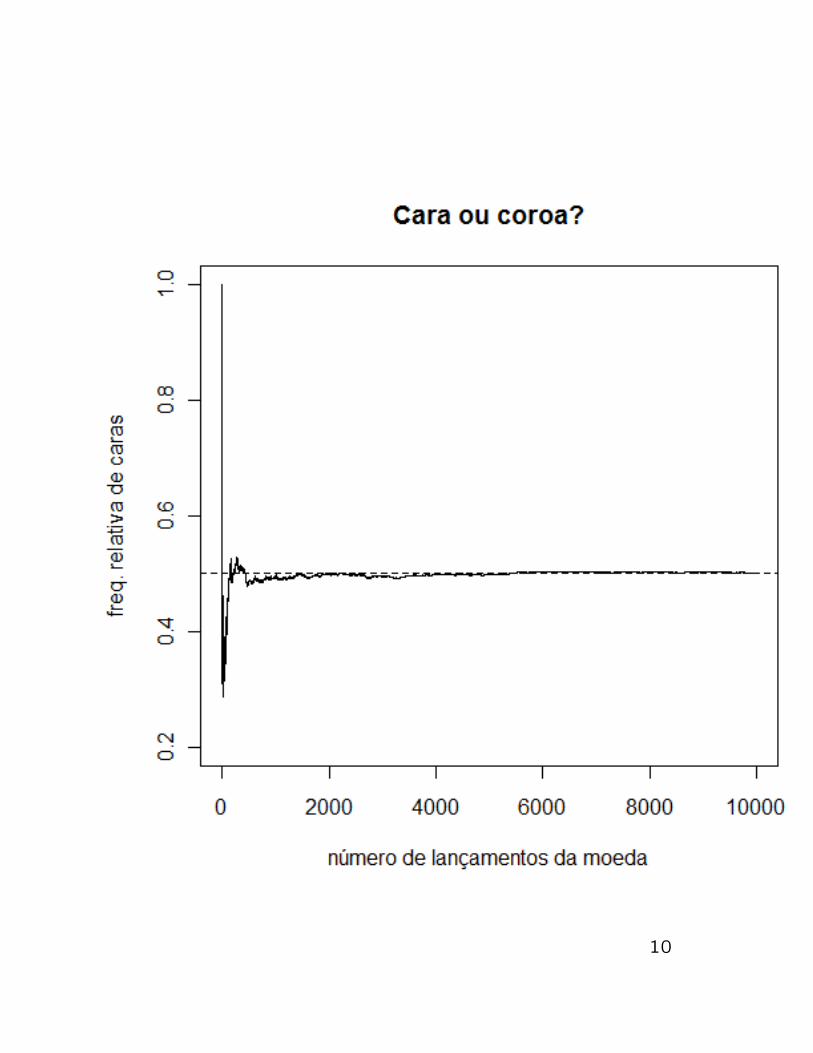
10

Interpretacoes da probabilidade
1) Classica.
Baseia-se em espacos amostrais finitos e equi-provaveis.
Problemas com esta interpretacao:
Nem todos os espacos amostrais sao finitos.
Ha espacos amostrais finitos que nao sao equi-provaveis.
Baseia-se na ideia de probabilidade (equipro-vavel) para definir probabilidade.
Essa interpretacao no entanto e muito util emdeterminados experimentos aleatorios tais co-mo o lancamento de uma moeda, o lancamen-to de cinco dados, o sorteio de uma carta debaralho, etc.
11

Exemplo: Voce esta pensando em apostar no
numero 13 no proximo giro de roleta. Qual e
a probabilidade de que voce perca?
Uma roleta tem 38 fendas, das quais somente
uma tem o numero 13. A roleta e construıda
de tal modo que as 38 fendas sejam igualmente
provaveis. Dentre as 38 fendas, ha 37 que
resultam em uma perda. Logo, a probabili-
dade de perder nesse caso e, sendo A o evento
“perder”
P (A) =37
38
12

2) Frequentista
Para avaliar a probabilidade de um determi-nado evento de interesse, o experimento e re-alizado um grande numero de vezes, sob asmesmas condicoes. A cada realizacao vamoscalculando a frequencia relativa de ocorrenciado evento A, como fizemos no exemplo ante-rior “Cara ou Coroa?”. Associamos como aprobabilidade do evento A, a frequencia rela-tiva de ocorrencia do evento A apos muitasrepeticoes.
No exemplo “Cara ou Coroa?”, o grafico comas frequencias relativas ao longo das repeticoesindica que tendemos para o valor 0,5 comoprobabilidade de ocorrer cara.
Problemas com esta interpretacao:
Nao define com clareza o que e um grandenumero de vezes, nem o que significa “sob asmesmas condicoes”.
13

Nem todo fenomeno aleatorio pode ser obser-
vado mais de uma vez.
Essa interpretacao de probabilidade e usada na
Inferencia Classica.
Exemplo: Calcule a probabilidade de que uma
pessoa adulta escolhida ao acaso tenha voado
em um aviao comercial.
O espaco amostral, considerando a observacao
de cada adulto, pode ser olhado como binario
com os resultados “sucesso” e “fracasso” em
que sucesso representa que a pessoa voou em
aviao comercial e fracasso que nao voou. Ob-
serve que esses eventos nao sao necessaria-
mente igualmente provaveis.
Aqui podemos usar a interpretacao frequen-
tista baseando-nos em alguma pesquisa.
14

Suponha que uma pesquisa observou que en-
tre 900 adultos escolhidos ao acaso, 750 con-
firmaram ter voado em aviao comercial. Nesse
caso, nossa resposta, baseada na frequencia
relativa, para o evento A: “ter voado em aviao
comercial” e
P (A) =750
900' 0,833.
15

3) Subjetiva. O indivıduo, baseado em in-
formacoes anteriores e na sua opiniao pessoal
a respeito do evento em questao, pode ter uma
resposta para a probabilidade desse evento.
O ingrediente basico quando se associam pro-
babilidades e coerencia. Se um indivıduo julgar
que um evento A e mais provavel que o seu
complementar, entao ele devera associar a esse
evento uma probabilidade maior do que 50%
ao evento A.
Problemas com essa interpretacao: Pesquisa-
dores diferentes podem associar probabilidades
diferentes para um mesmo evento!
16

A Inferencia Bayesiana toma como uma de
suas bases o fato de que todas as probabili-
dades sao subjetivas.
Exemplo: Qual e a probabilidade de que seu
carro seja atingido por um meteorito em 2013?
Na ausencia de dados historicos sobre mete-
oritos colidindo com carros, nao podemos usar
a interpretacao frequentista. Observe que ha
dois resultados possıveis nesse problema:
{colidir,nao colidir},
mas eles nao sao igualmente provaveis de modo
que nao podemos usar a interpretacao classica
de probabilidade.
17

Observe que nesse exemplo podemos fazer uso
da interpretacao subjetiva. Todos nos sabe-
mos que a probabilidade em questao e muito
pequena. Vamos entao estima-la em
1
1000000000000= 10−12
equivalente a 1 em um trihao.
Esta estimativa subjetiva, baseada em nosso
conhecimento geral, e bem provavel que esteja
perto da verdadeira probabilidade.
18

19

Definicao Axiomatica da Probabilidade
A Axiomatizacao da Probabilidade e devida aomatematico russo Kolmogorov e ocorreu noinıcio do Seculo XX.
Independentemente da interpretacao de pro-babilidade adotada, a probabilidade e uma fun-cao P (.) que mede chances de eventos. Afuncao probabilidade esta definida na colecaode eventos e assume valores entre 0 e 1, sa-tisfazendo os seguintes axiomas:
A1 : P (A) ≥ 0 para todo evento A na colecaode eventos. A probabilidade de um eventoqualquer e sempre um numero nao-negativo.
A2 : P (S) = 1. A probabilidade do eventocerto e igual a 1.
A3 : Se A ∩B = ∅, entao P (A ∪B) = P (A) + P (B).
Se os eventos A e B sao disjuntos, entao a probabilidadeda uniao dos dois (de pelo menos um deles ocorrer) e asoma de suas probabilidades.
20

Propriedades da probabilidade
A partir dos axiomas, diversas propriedades daprobabilidade podem ser deduzidas.
P1 : P (∅) = 0
P2 : Se A ⊂ B, entao P (A) ≤ P (B).
P3 : 0 ≤ P (A) ≤ 1, para todo evento A.
P4 : Propriedade do evento complementar deA: Ac
Ac = S \A = {s ∈ S|s 6∈ A}
P (Ac) = 1− P (A)
21

Eventos Uniao e Intersecao de dois eventos
Considere um experimento aleatorio e sejam
A e B dois eventos associados a esse experi-
mento.
O evento uniao de A e B, denotado por
A ∪ B, corresponde ao evento “ocorrencia de
pelo menos um dos dois A ou B”
O evento intersecao de A e B, denotado por
A ∩ B, corresponde ao evento “ocorrencia si-
multanea de A e B”.
22

Esses dois eventos, chamados de eventos com-
postos, pois sao obtidos por meio de operacoes
entre dois ou mais eventos, sao diferentes. En-
quanto o evento uniao de A e B representa a
ocorrencia de pelo menos um, o que significa
que podera ter ocorrido somente A, somente
B ou os dois simultaneamente; o evento in-
tersecao corresponde a ocorrencia dos dois si-
multaneamente.
Observe que como A ∩B ⊂ A ∪B segue que
P (A ∩B) ≤ P (A ∪B).
A igualdade e possıvel? Sob que condicao?
23

Veremos a seguir uma propriedade util para
calcular a probabilidade da uniao de dois even-
tos.
P5 : P (A ∪B) = P (A) + P (B)− P (A ∩B).
Um caso particular ocorre quando A ∩ B = ∅,pois nesse caso P (A ∩B) = 0 e
P (A ∪B) = P (A) + P (B).
Mas lembre-se que essa ultima equacao so vale
se a intersecao entre os eventos A e B for
vazia.
24

Probabilidades Condicionais
Suponha que num dado problema de mode-
lagem probabilıstica, embora voce nao conheca
o resultado do fenomeno sob estudo, seja pos-
sıvel ter informacoes acerca do resultado. Por
exemplo, ao lancar um dado, embora o valor
da face obtida seja desconhecido, voce receba
a informacao de que esse valor e um numero
ımpar.
Como ficam as probabilidades associadas a um
evento de interesse nesse caso? Suponha por
exemplo que o evento de interesse seja obter
face “6”.
Dado que nos temos informacoes sobre o re-
sultado faz sentido atualizarmos as nossas in-
certezas a cerca do evento de interesse.
25

Probabilidade Condicional: Definicao
A probabilidade condicional de ocorrer um e-
vento A, dado que sabemos que ocorreu um
evento B, P (B) > 0 e definida por
P (A|B) =P (A ∩B)
P (B).
Probabilidades condicionais tem um espaco a-
mostral reduzido, pois so nos preocupamos com
os resultados baseados no que ja aconteceu.
Essa definicao e util para designar uma forma
de obter probabilidades de eventos intersecao
de dois eventos, a saber,
P (A ∩B) = P (A|B)× P (B)
→ regra da multiplicacao ←26

Exemplo: Numa turma de 20 alunos da disci-plina Estatıstica em um curso de Graduacao,15 sao mulheres e 5 sao homens. Dois alunosdessa turma serao sorteados ao acaso, e semreposicao, de modo a formar uma comissao derepresentantes da turma. Pede-se calcular aprobabilidade de que ambos sejam do mesmogenero.
Solucao: Vamos chamar de evento Ai o evento“a i-esima pessoa sorteada e do genero femi-nino”, i = 1,2, pois sao apenas dois sorteios.
O evento desejado, vamos chamar de eventoE, ambos do mesmo genero, e um evento com-posto:
E = (A1 ∩A2)︸ ︷︷ ︸ambas mulheres
∪ (Ac1 ∩Ac2)︸ ︷︷ ︸
ambos homens
Como A1 ∩ A2 e Ac1 ∩ Ac2 sao disjuntos, segue
que P (E) = P (A1 ∩A2) + P (Ac1 ∩Ac2).
27

Usando a regra da multiplicacao temos
P (A1 ∩A2) =
= P (A1)︸ ︷︷ ︸prob. do prim. ser mulher
×prob. do seg. ser mulher se prim. e mulher︷ ︸︸ ︷
P (A2|A1)
=15
20×
14
19=
21
38
P (Ac1∩Ac2) = P (Ac1)×P (Ac2|A
c1) =
5
20×
4
19=
2
38
Logo,
P (E) =21
38+
2
38=
23
38' 0,605
28
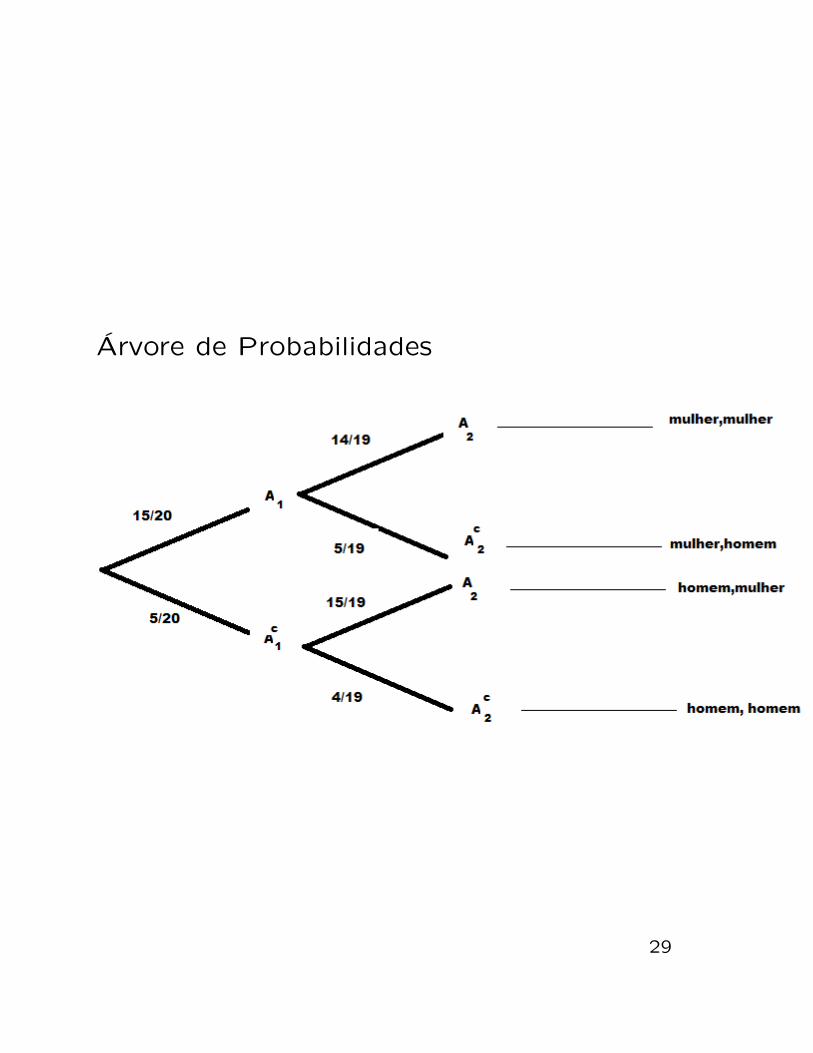
Arvore de Probabilidades
29

Observe que no exemplo anterior os sorteios
foram realizados sem reposicao de tal modo
que ao sortearmos a segunda pessoa o universo
passou a ser de 19 alunos, pois a primeira pes-
soa sorteada nao estava entre as possibilidades
do segundo sorteio.
Como fica a solucao do mesmo problema se
agora o sorteio e feito com reposicao?
Suponha agora que existem dois premios a se-
rem distribuıdos ao acaso e sem restricoes de
tal maneira que o primeiro sorteado tambem
possa receber o segundo premio.
Calcule a probabilidade de que os premios te-
nham sido recebidos por pessoas do mesmo
genero: apenas mulheres foram premiadas ou
apenas homens foram premiados.
30

Arvore de Probabilidades
1520 = 3
4 e 520 = 1
4.
P (E) =(
3
4
)2+(
1
4
)2=
5
8= 0,625
Podemos ver que as respostas sao ligeiramente diferentes. Um re-sultado util e que quando o tamanho da populacao amostrada tendea ser muito maior que o tamanho da amostra, as diferencas pas-sam a ser desprezıveis tal que o esquema de sorteio sem reposicaopoderia ser tratado como o esquema mais simples de sorteio comreposicao.
31

Eventos independentes
Dizemos que os eventos A e B sao indepen-
dentes, se a ocorrencia de um deles, por exem-
plo de B, nao interfere no nosso conhecimento
sobre a incerteza do outro A.
A e B sao eventos independentes se
P (A|B) = P (A).
Nesse caso, observe que vale a seguinte pro-
priedade
P (A ∩B) = P (A)× P (B),
para A e B eventos independentes.
Cuidado: essa ultima expressao nao e uma re-
gra geral. E uma propriedade que vale para
eventos independentes.
32

Voltando ao exemplo anterior observe que os
eventos A1 e A2 nao sao independentes no caso
do sorteio sem reposicao, pois P (A1 ∩ A2) 6=P (A1)P (A2) (verifique).
No entanto, no caso do sorteio com reposicao,
podemos verificar que os eventos A1 e A2 sao
independentes, pois vale
P (A1 ∩A2) = P (A1)P (A2).
Um propriedade interessante e a seguinte. Se
A e B sao eventos independentes, entao,
1. A e Bc sao eventos independentes;
2. Ac e B sao eventos independentes;
3. Ac e Bc sao eventos independentes.
33

Eventos independentes versus Eventos disjun-
tos
Cuidado: E comum ocorrer confusao com o
que chamamos em probabilidade de eventos
independentes com eventos disjuntos.
Sao situacoes bem diferentes.
Se dois eventos A e B sao disjuntos com
P (A) > 0 e P (B) > 0, entao A e B NAO po-
dem ser independentes!
Por que?
Lembre: dois eventos sao independentes em
probabilidade se a ocorrencia de um nao inter-
fere na probabilidade de ocorrencia do outro.
34

Lei dos Grandes Numeros (Bernoulli-seculo XVIII)
A medida que um experimento e repetido mui-
tas vezes, a probabilidade dada pela frequencia
relativa de um evento tende a se aproximar da
verdadeira probabilidade desse evento.
A lei dos grandes numeros nos diz que as esti-
mativas de probabilidades dadas pelas frequen-
cias relativas tendem a ficar melhores com mais
observacoes: uma estimativa de probabilidade
baseada em poucas tentativas pode estar bem
afastada do verdadeiro valor da probabilidade,
mas com um numero maior de tentativas, a
estimativa tende a ser mais precisa.
Uma pesquisa de opiniao sobre a preferencia pela marcaX de sabao em po com apenas 12 donas de casa esco-lhidas ao acaso pode facilmente resultar em estimativasmuito afastadas da verdadeira proporcao de donas decasa que preferem a marca X. No entanto, se entre-vistarmos 1200 donas de casa, nossa estimativa estaraproxima da verdadeira proporcao.
35

Variaveis Aleatorias
Considere um experimento cujo espaco amos-
tral e S. O conjunto S contem todos os resul-
tados possıveis. Em muitas situacoes ele sera
um conjunto cujos elementos nao sao numeros.
Por exemplo, considere o lancamento de uma
moeda duas vezes consecutivas. Nesse caso,
um espaco amostral para esse experimento e
S = {(ca, ca), (ca, co), (co, ca), (co, co)}
cujos elementos sao pares contendo as entradas
ca para cara e co para coroa.
De modo bastante informal, uma variavel alea-
toria e uma caracterıstica numerica do resul-
tado de um experimento.
No caso desse ultimo exemplo, podemos definir
a variavel alaetoria X como o numero de caras
obtidas.36

Observe que nesse caso,
X =
0, se ocorrer {(co, co)}1, se ocorrer {(ca, co), (co, ca)}2, se ocorrer {(ca, ca)}
Dizemos que o campo de definicao da variavel
aleatoria X e o conjunto {0,1,2} que repre-
senta os valores que X pode assumir.
Suponha agora que estejamos interessados em
observar o tempo de vida de uma lampada.
Observe que antes de realizar o experimento
nao e possıvel dizer qual sera a resposta. E
facil ver que um espaco amostral para esse ex-
perimento e S = {s ∈ R|s ≥ 0}. Nesse caso
o espaco amostral ja e numerico de tal forma
que podemos definir a variavel aleatoria como
o tempo de vida da lampada.
37

Dizemos que uma variavel aleatoria e discreta
se seu campo de definicao for um conjunto
finito ou enumeravel (resultante de uma con-
tagem, mas pode ser infinito).
No caso dos exemplos anteriores a variavel nu-
mero de caras e discreta e a variavel tempo de
vida da lampada nao e discreta.
A seguir apresentaremos modelos Probabilısti-
cos para variaveis aleatorias discretas: funcao
de probabilidade, funcao de distribuicao e suas
caracterizacoes.
38

Funcao de probabilidade: associa a cada valor
possıvel da v.a. discreta sua respectiva proba-
bilidade.
Se RX e o campo de definicao da v.a. discreta
X podemos representar sua funcao de proba-
bilidade da seguinte forma
p(x) =
{P (X = x), x ∈ RX0, caso contrario
Observe que P (X = x) = 0 quando x 6∈ RX,
ou seja quando x e um valor fora do campo
de definicao de X a respectiva probabilidade
e nula. Quando x ∈ RX, p(x) > 0 tal que
a funcao de probabilidade assume sempre va-
lores nao-negativos, isto e, p(x) ≥ 0, para todo
x. Alem disso, decorre dos axiomas da proba-
bilidade que∑
x∈RXp(x) = 1.
39

Observacao: qualquer funcao p(x) satistazendo
essas duas propriedades:
P1: p(x) ≥ 0 para todo x e
P2:∑
x∈RXp(x) = 1
e funcao de probabilidade para alguma v.a.
discreta X com campo de definicao RX.
Funcao de distribuicao (ou funcao de distribuicao
acumulada)
E definida da seguinte forma
F (x) = P (X ≤ x), x ∈ R
No caso das variaveis aleatorias discretas o
grafico da funcao de distribuicao e uma funcao
do tipo escada, nao decrescente. Veja um e-
xemplo a seguir.
40
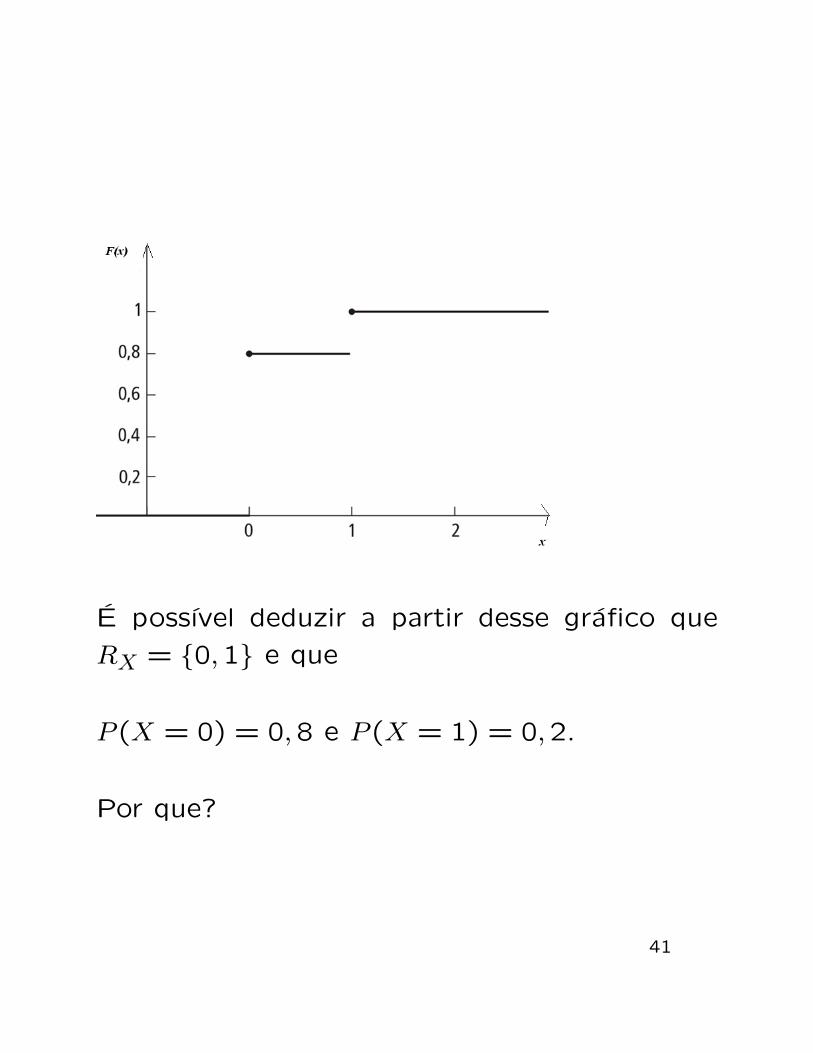
E possıvel deduzir a partir desse grafico que
RX = {0,1} e que
P (X = 0) = 0,8 e P (X = 1) = 0,2.
Por que?
41

A funcao de probabilidade pode ser interpre-
tada como um modelo teorico para uma de-
terminada variavel em estudo.
Como no caso de distribuicoes de frequencias
empıricas (amostras) tambem podemos querer
caracterizar as distribuicoes de probabilidade
por meio de medidas-resumo.
O valor esperado de uma variavel aleatoria dis-
creta com funcao de probabilidade p(x) e defi-
nido por E[X] =∑
x∈RXx× p(x).
Assim como no caso de dados amostrais, o
valor esperado representa o centro de massa
da funcao de probabilidade.
Considere o exemplo de lancar uma moeda
duas vezes consecutivas. Vimos que o campo
de definicao da variavel definida como numero
de caras obtidas e {0,1,2}.42
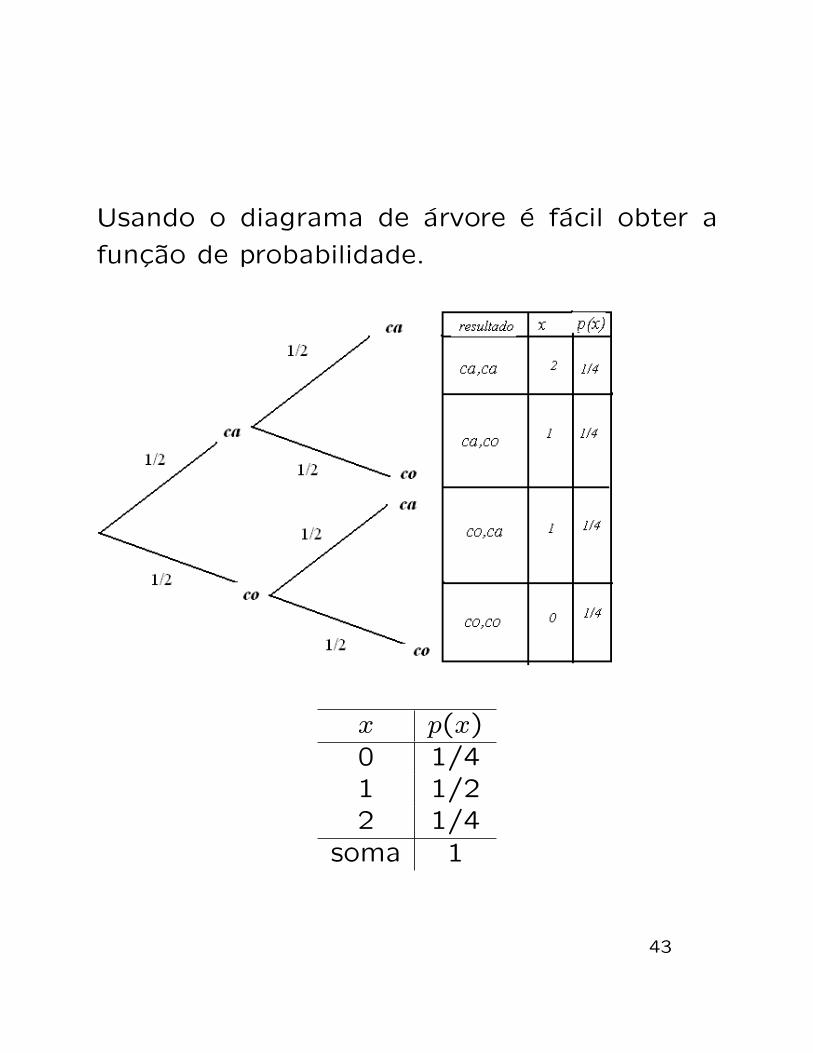
Usando o diagrama de arvore e facil obter a
funcao de probabilidade.
x p(x)0 1/41 1/22 1/4
soma 1
43

Assim, nesse exemplo, o valor esperado do
numero de caras e
E[X] = 0×1
4+ 1×
1
2+ 2×
1
4= 1
Que interpretacao deve ser dada a esse resul-
tado?
Podemos dizer que vamos observar uma cara
ao realizarmos esse experimento?
Na verdade o valor esperado representa uma
medida a longo prazo: se repetirmos este ex-
perimento “lancar a moeda duas vezes segui-
das” muitas vezes e irmos registrando o numero
de caras em cada repeticao, a media do numero
de caras obtidas ao longo das repeticoes, se
aproximara de 1, quanto maior for o numero
de repeticoes. (Lei dos Grandes Numeros).
44

Vimos que alem de caracterizar uma distribui-
cao de frequencias usando medidas de tenden-
cia central, tambem usamos medidas de dis-
persao. Para uma variavel aleatoria discreta
com funcao de probabilidade p(x), tambem faz
sentido usar a variancia para caracterizar a dis-
persao de seus valores possıveis em torno do
seu valor esperado.
V ar(X) =∑x∈RX
(x− E[X])2×p(x) =∑x∈Rx
x2×p(x)−(E[X])2
A variancia e uma medida nao-negativa e quan-
do ela e zero isso significa que nao ha vari-
abilidade e no caso de uma variavel aleatoria
discreta significa que P (X = E[X]) = 1.
No exemplo do numero de caras ao lancar uma
moeda duas vezes, tem-se V ar(X) = 12.
45

Existem infinitos modelos para representar a
geracao de variaveis aleatorias discretas. Al-
guns aparecem mais frequentemente e por isso
sao tratados de forma especial, tais como os
modelos binomial, geometrico, Poisson, etc.
Vamos tratar em particular do modelo bino-
mial, um dos mais comuns.
Um Ensaio de Bernoulli e um experimento para
o qual ha apenas dois resultados possıveis que
convencionamos chamar de sucesso ou fracasso.
Aqui sucesso nao precisa significar algo bom,
pode representar por exemplo, peca com de-
feito.
O modelo binomial ocorre quando repetimos
independentemente um numero fixado de vezes,
digamos n vezes, um Ensaio de Bernoulli, cuja
probabilidade de sucesso e p, 0 < p < 1.
46

Nesse contexto definimos a variavel aleatoriabinomial como sendo o numero de sucessosem n ensaios de Bernoulli cuja probabilidadede sucesso e p, 0 < p < 1.
Exemplos de situacoes que levam ao modelobinomial (n, p):
• numero de caras obtidas ao lancar umamoeda 10 vezes consecutivas;
• numero de faces “6” ao lancar cinco dadosbalanceados;
• numero de pecas defeituosas ao observaruma amostra aleatoria de 25 pecas pro-duzidas pela mesma maquina;
• numero de alunos que fazem aniversario noprimeiro trimestre ao observar uma amostraaleatoria de 10 alunos de uma turma.
47

Modelo Binomial
Notacao: X ∼ binomial(n, p)
Campo de definicao: RX = {0,1,2, ..., n}
Funcao de Probabilidade:
p(x) =
(nx
)px(1− p)n−x, x ∈ RX
0, caso contrario
(nx
)=
n!
x!(n− x)!
n! = n(n− 1)...3.2.1, 0! = 1
Valor esperado: E[X] = np
Variancia: V ar(X) = np(1− p)
48

Exemplo: Das variaveis descritas a seguir, assi-nale quais sao binomiais, e para essas apresenteos respectivos campo de definicao, valor espe-rado e variancia. Quando julgar que a variavelnao e binomial, aponte as razoes de sua con-clusao.
1. De uma urna com 10 bolas brancas e 20 pretas, vamos extrair,com reposicao, cinco bolas. X e o numero de bolas brancasnas cinco extracoes.
2. Refaca o problema anterior, mas dessa vez as extracoes saosem reposicao.
3. Temos cinco urnas com bolas pretas e brancas e vamos extrairuma bola de cada urna. X e o numero de bolas brancasobtidas no final.
4. Vamos realizar uma pesquisa em 10 cidades brasileiras, esco-lhendo ao acaso um habitante de cada uma delas e classifi-cando-o como pro ou contra um certo projeto do governofederal. X e o numero de pessoas contra o projeto.
5. Numa Industria existem 100 maquinas que fabricam uma peca.Cada peca e classificada como boa ou defeituosa. Escolhemosao acaso um instante de tempo e verificamos uma peca decada uma das maquinas. X e o numero de pecas defeituosasao final da verificacao.
49

Variaveis aleatorias contınuas: de modo infor-
mal as variaveis aleatorias sao contınuas quan-
do resultam de algum tipo de medicao tal que
seu campo de definicao e um intervalo limitado
da reta, uma semi-reta ou a reta.
Por exemplo: o tempo de vida de uma lampada,
a altura de uma pessoa, o peso de uma pessoa,
o tempo de cura apos iniciar um tratamento,
etc.
O modelo probabilıstico usual para descrever o
comportamento de variaveis aleatorias contı-
nuas e a funcao de densidade de probabi-
lidade ou simplesmente densidade de proba-
bilidade.
A funcao de distribuicao F (x) = P (X ≤ x)
tambem pode ser usada para descrever o com-
portamento de uma variavel aleatoria contınua.
50
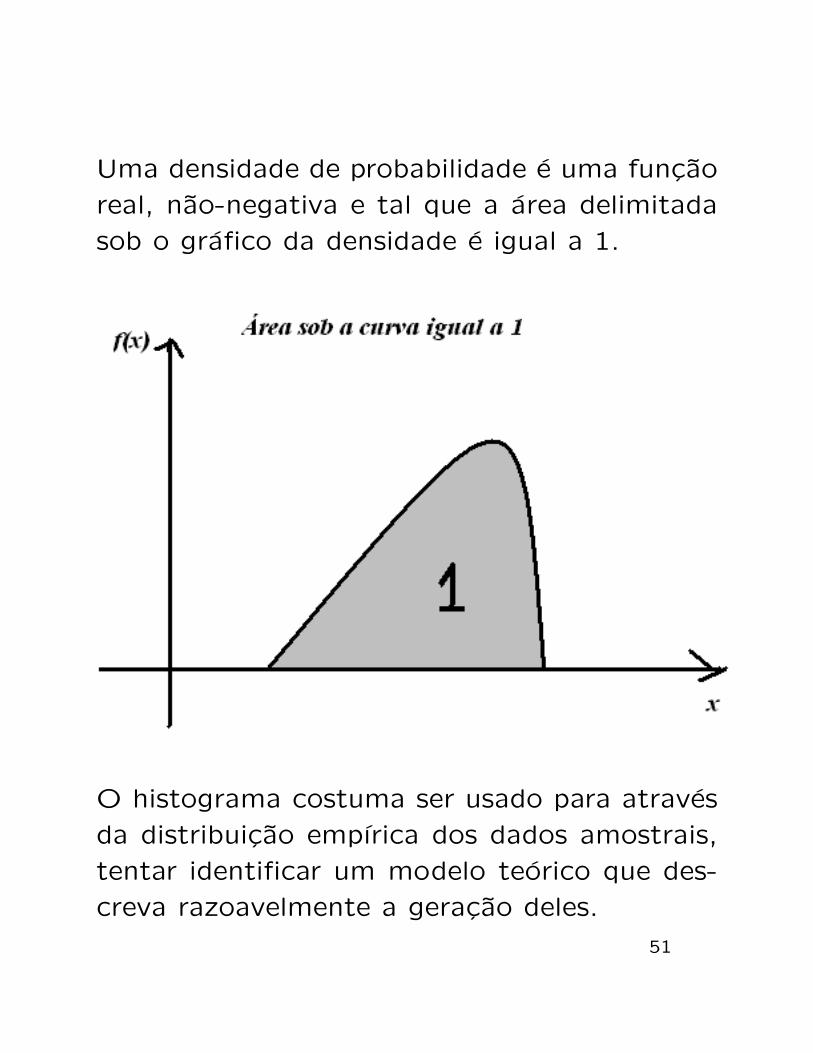
Uma densidade de probabilidade e uma funcao
real, nao-negativa e tal que a area delimitada
sob o grafico da densidade e igual a 1.
O histograma costuma ser usado para atraves
da distribuicao empırica dos dados amostrais,
tentar identificar um modelo teorico que des-
creva razoavelmente a geracao deles.
51

No caso de variaveis aleatorias contınuas o cal-
culo de probabilidades para valores da variavel
em intervalos do campo de definicao e mais
sofisticado e o calculo direto muitas vezes de-
manda conhecimentos de Calculo Integral, que
nao e um pre-requisito de Estatıstica Aplicada
II.
No entanto, isto nao impede prosseguir no es-
tudo dos modelos probabilısticos para variaveis
aleatorias contınuas, pois na maioria das situa-
coes que iremos estudar, poderemos facilmente
obter as probabilidades solicitadas usando tabe-
las e programas estatısticos.
52
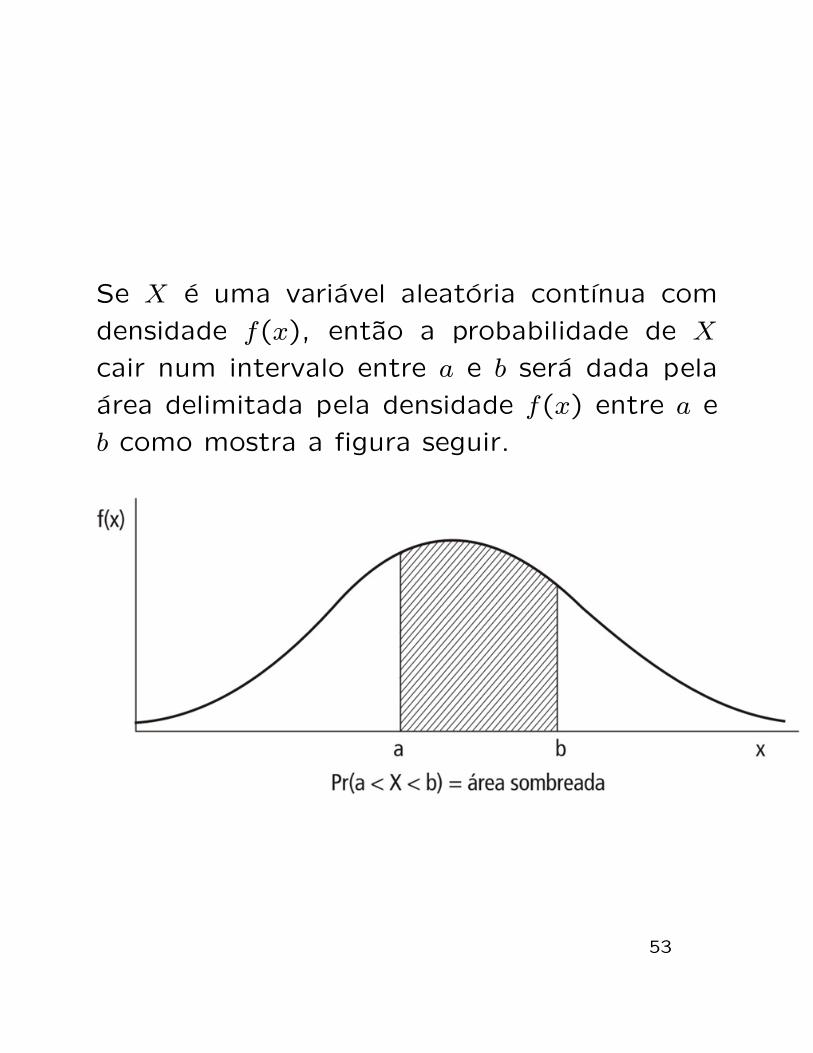
Se X e uma variavel aleatoria contınua com
densidade f(x), entao a probabilidade de X
cair num intervalo entre a e b sera dada pela
area delimitada pela densidade f(x) entre a e
b como mostra a figura seguir.
53

Se X e uma variavel aleatoria com densidade
f(x) tambem e possıvel calcular o valor espe-
rado de X e sua respectiva variancia, com as
mesmas interpretacoes apresentadas anterior-
mente: o valor esperado representa um centro
de massa em relacao a medida de probabili-
dade e a variancia representa a dispersao dos
valores no campo de definicao em relacao a
media.
A seguir vamos apresentar o modelo normal,
fundamental em probabilidade e inferencia es-
tatıstica. Suas origens remontam a Gauss em
seus trabalhos sobre erros de observacoes as-
tronomicas, por volta de 1810, daı o nome que
muitas vezes aparece de distribuicao gaussiana
para tal modelo.
54

Gauss levou a fama, pois foi ele o primeiro a
publicar sobre resultados praticos envolvendo a
distribuicao normal. No entanto, o primeiro a
se referir a distribuicao normal foi o Matematico
Frances De Moivre em 1733. De Moivre usou
a distribuicao normal para aproximar probabi-
lidades relacionadas a lancamentos de moedas,
chamou-a de curva exponencial em forma de
sino. Sua utilidade, porem, so foi tornar-se
aparente em 1809, quando o famoso matema-
tico alemao Gauss usou-a em aplicacoes sobre
a observacao de fenomenos astronomicos.
55

Do meio ao final do seculo XIX, boa parte dos
estatısticos comecou a acreditar que a maio-
ria dos conjuntos de dados teriam histogramas
cuja forma se adequava a forma de sino. De
fato, tornou-se aceito que era “normal” para
qualquer conjunto de dados “bem-comporta-
dos” seguir esse modelo. Ao longo do seculo
XX no entanto existem varios registros do mau
uso de tecnicas estatısticas, pois saiu-se u-
sando indiscrimidamente tecnicas que pressu-
punham a normalidade dos dados, quando eram
claramente nao normais.
Cuidado: Sempre verifique se o metodo de
analise estatıstica que voce ira usar e adequado
aos seus dados.
Uma explicacao parcial de porque tantos con-
juntos de dados conformam-se com a curva
normal e fornecida pelo teorema central do li-
mite que enunciaremos adiante.
56
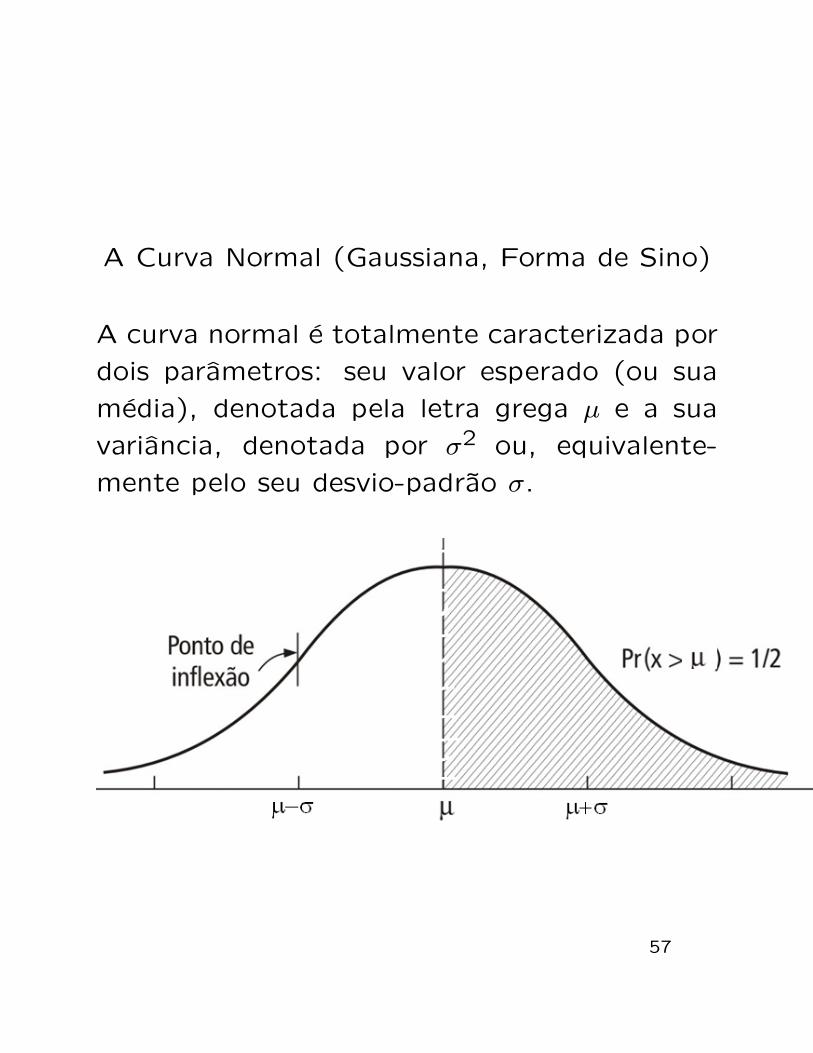
A Curva Normal (Gaussiana, Forma de Sino)
A curva normal e totalmente caracterizada por
dois parametros: seu valor esperado (ou sua
media), denotada pela letra grega µ e a sua
variancia, denotada por σ2 ou, equivalente-
mente pelo seu desvio-padrao σ.
57

Modelo Normal
Notacao X ∼ N(µ, σ2)
Campo de definicao: R
Densidade:
f(x) =1
σ√
2πe−1
2
(x−µσ
)2
Valor esperado: E[X] = µ
Variancia: V ar(X) = σ2.
Assimetria: zero
Curtose: 3
58
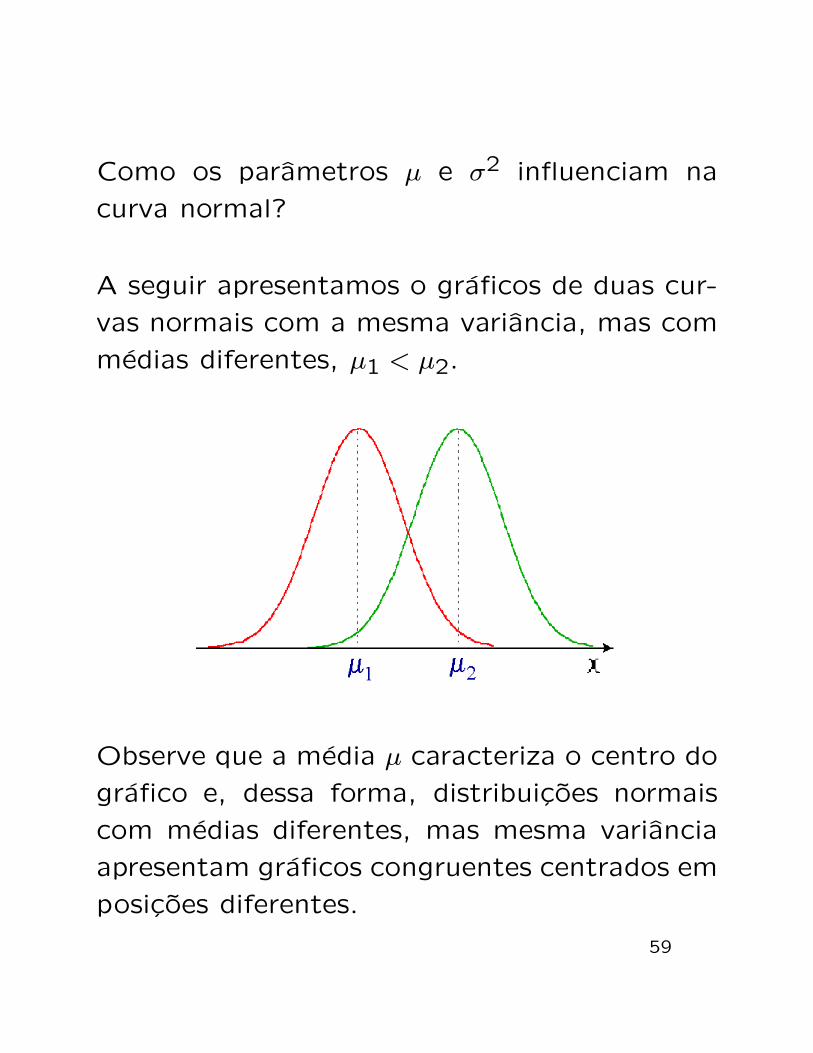
Como os parametros µ e σ2 influenciam na
curva normal?
A seguir apresentamos o graficos de duas cur-
vas normais com a mesma variancia, mas com
medias diferentes, µ1 < µ2.
Observe que a media µ caracteriza o centro do
grafico e, dessa forma, distribuicoes normais
com medias diferentes, mas mesma variancia
apresentam graficos congruentes centrados em
posicoes diferentes.
59
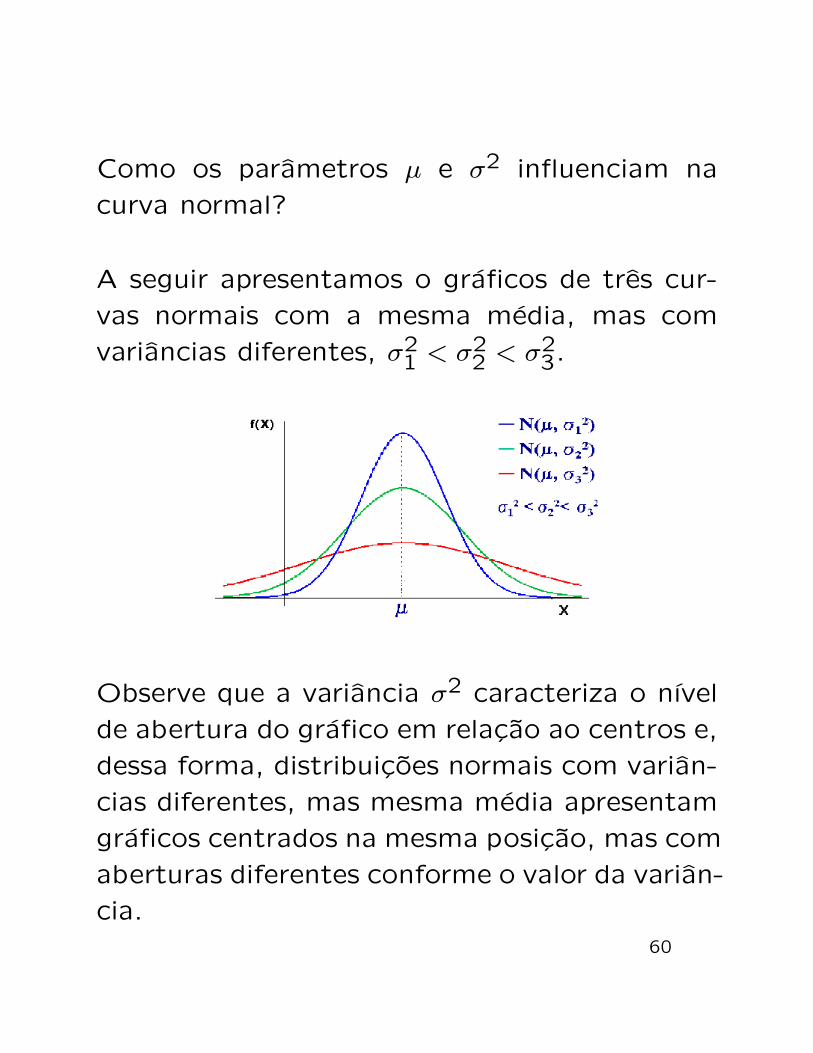
Como os parametros µ e σ2 influenciam na
curva normal?
A seguir apresentamos o graficos de tres cur-
vas normais com a mesma media, mas com
variancias diferentes, σ21 < σ2
2 < σ23.
Observe que a variancia σ2 caracteriza o nıvel
de abertura do grafico em relacao ao centros e,
dessa forma, distribuicoes normais com varian-
cias diferentes, mas mesma media apresentam
graficos centrados na mesma posicao, mas com
aberturas diferentes conforme o valor da varian-
cia.60
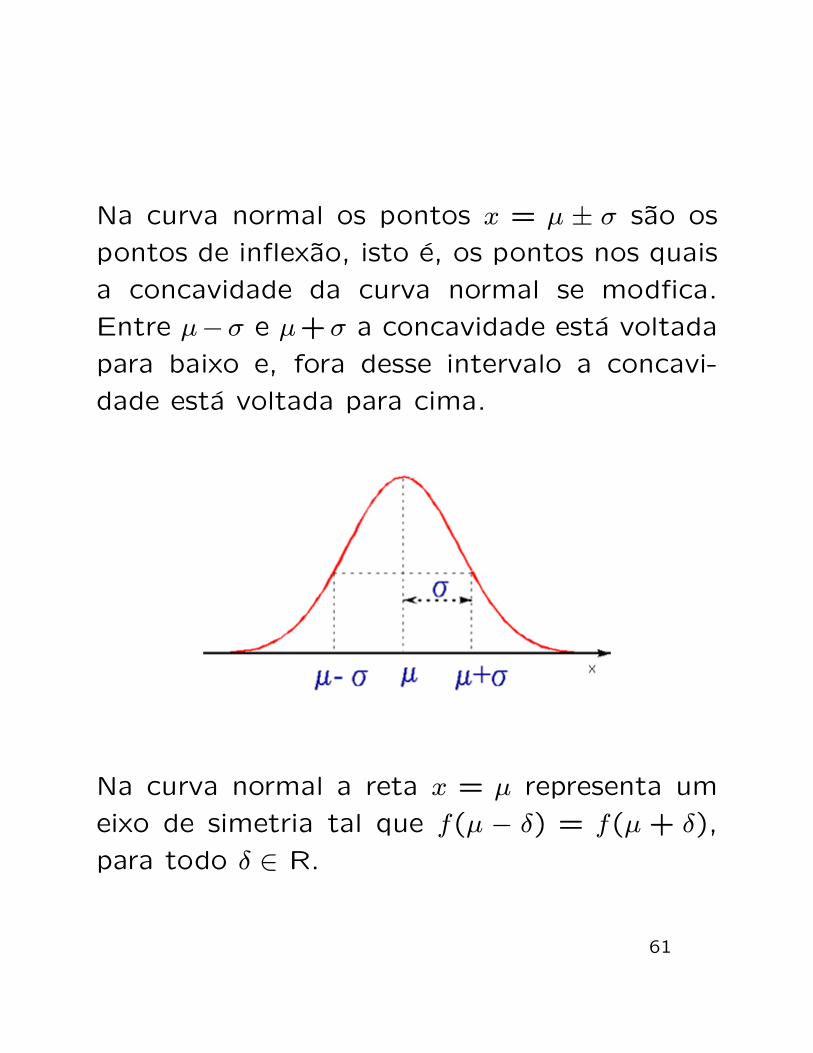
Na curva normal os pontos x = µ ± σ sao os
pontos de inflexao, isto e, os pontos nos quais
a concavidade da curva normal se modfica.
Entre µ−σ e µ+σ a concavidade esta voltada
para baixo e, fora desse intervalo a concavi-
dade esta voltada para cima.
Na curva normal a reta x = µ representa um
eixo de simetria tal que f(µ − δ) = f(µ + δ),
para todo δ ∈ R.
61

Distribuicao Normal Padrao
Quando µ = 0 e σ2 = 1 a distribuicao e chamadanormal padrao ou normal reduzida.
Z ∼ N(0,1)
Vamos usar a letra Z para denotar uma variavelaleatoria normal com distribuicao normal padrao.
Nesse caso, a densidade e dada por
fZ(z) =1√2π
e−z22 , z ∈ R
E[Z] = 0 e V ar(Z) = 1.
Outra notacao que sera adotada aqui e
φ(z) = P (Z ≤ z),
para a funcao de distribuicao da normal padrao.
62
Como calcular probabilidades usando o modelonormal?
Vamos comecar com a situacao em que
Z ∼ N(0,1), ou seja, em que a distribuicaoconsiderada e uma normal padrao.
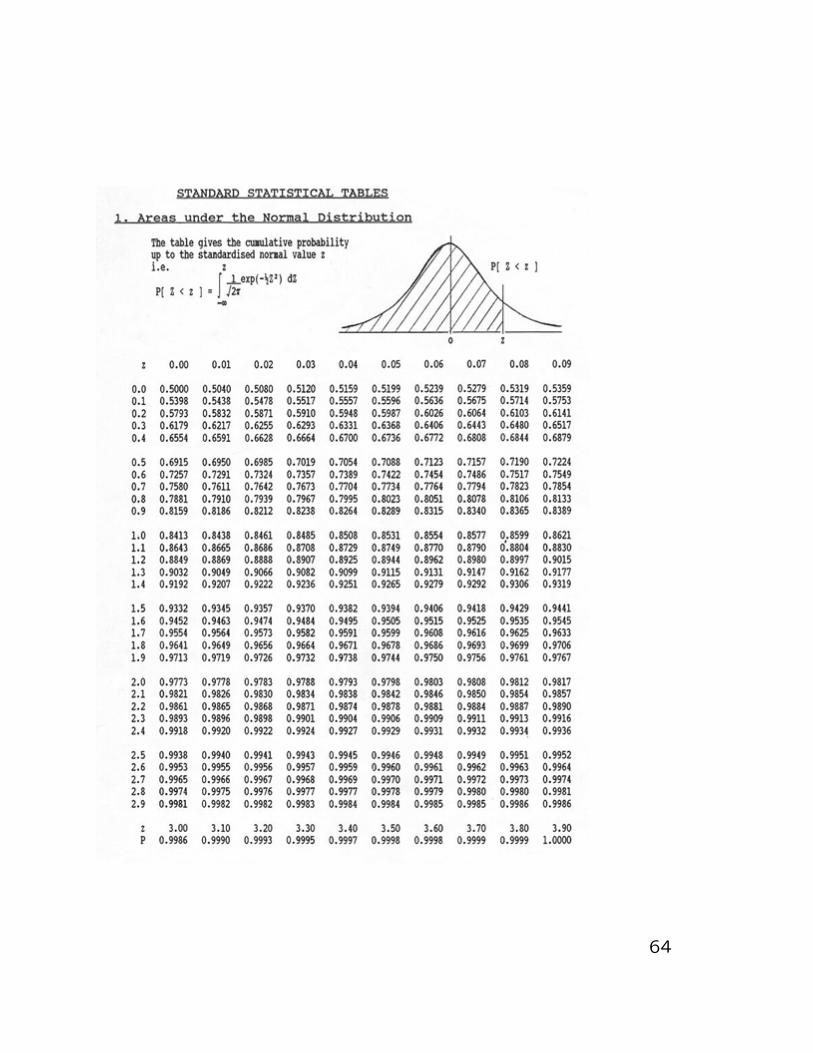
De fato, nao e possıvel calcular de forma e-xata probabilidades do tipo P (a < Z < b), maspodemos obter aproximacoes desses valores u-sando metodos numericos. No caso da dis-tribuicao normal padrao, valores de probabi-lidades especıficas sao tabulados. Em quasetodos os livros de estatıstica estao disponıveistabelas da distribuicao normal padrao.
63
64

A tabela anterior pode parecer incompleta, masela e util para calcular probabilidades de diver-sos intervalos, inclusive incluindo valores ne-gativos em seus extremos. Isso se deve a pro-priedade de simetria da curva normal padraoem torno de zero.
Cuidado: Sempre leia o cabecalho da tabelaque voce estiver usando, pois nao existe umanorma universal de apresentacao de tabelas danormal padrao. As vezes as tabelas fornecemprobabilidades acumuladas como a que acaba-mos de ver, outras vezes elas trazem probabil-idades da cauda inferior ou superior e outrasvezes elas fornecem probabilidades entre 0 eum numero positivo.
Usando a tabela que fornece probabilidades acu-muladas da normal padrao,
φ(z) = P (Z ≤ z), vamos ver exemplos de comoobter probabilidades referentes a outros inter-valos.
65

Pela tabela disponıvel vemos diretamente que,
por exemplo,
φ(1) = P (Z ≤ 1) = 0,8413
φ(1,64) = P (Z ≤ 1,64) = 0,9495
φ(2,33) = P (Z ≤ 2,33) = 0,9901
Lembre que a area total sob a curva e 1 e,
portanto, e facil deduzir que
P (Z > 1) = 1− φ(1) = 1− 0,8413 = 0,1587
P (Z > 1,64) = 1− φ(1,64) = 1− 0,9495 = 0,0505
P (Z > 2,33) = 1− φ(2,33) = 1− 0,9901 = 0,0099
66

Observe que como a curva normal padrao e
simetrica em torno de zero, segue que
φ(−z) = 1− φ(z), ∀z.
Logo,
φ(−1) = 1− P (Z ≤ 1) = 0,1587
φ(−1,64) = 1− P (Z ≤ 1,64) = 0,0505
φ(−2,33) = 1− P (Z ≤ 2,33) = 0,0099
67

Observe que
P (1 < Z < 2) = P (Z < 2) − P (Z < 1) = φ(2) − φ(1) =0,9773− 0,8413 = 0,1360
De modo similar
P (−2 < Z < −1) = P (1 < Z < 2) = 0,136
68

Observe queP (−1 < Z < 2) = P (Z < 2)− P (Z < −1) e
P (Z < −1) = P (Z > 1) = 1− P (Z ≤ 1) = 1− φ(1)
Logo,
P (−1 < Z < 2) = φ(2) + φ(1)− 1 = 0,9773 + 0,8413− 1 = 0,8186
No caso da normal padrao observe que para intervalos simetricosem torno de zero vale
P (−c < Z < c) = 2φ(c)− 1 e, a probabilidade das caudas,
P (|Z| > c) = 2 (1− φ(c)).
69

Logo, apesar da tabela parecer ser limitada, vi-
mos que e possıvel calcular, via aproximacoes,
probabilidades associadas a uma variavel alea-
toria com distribuicao normal padrao para quais-
quer intervalos fixados.
No entanto, na pratica, as variaveis em ques-
tao, apesar de serem consideradas normais,
certamente nao terao media zero e variancia
um.
Como calcular probabilidades no caso de uma
distribuicao normal qualquer?
Uma propriedade importante das curvas nor-
mais, independentemente de sua media e seu
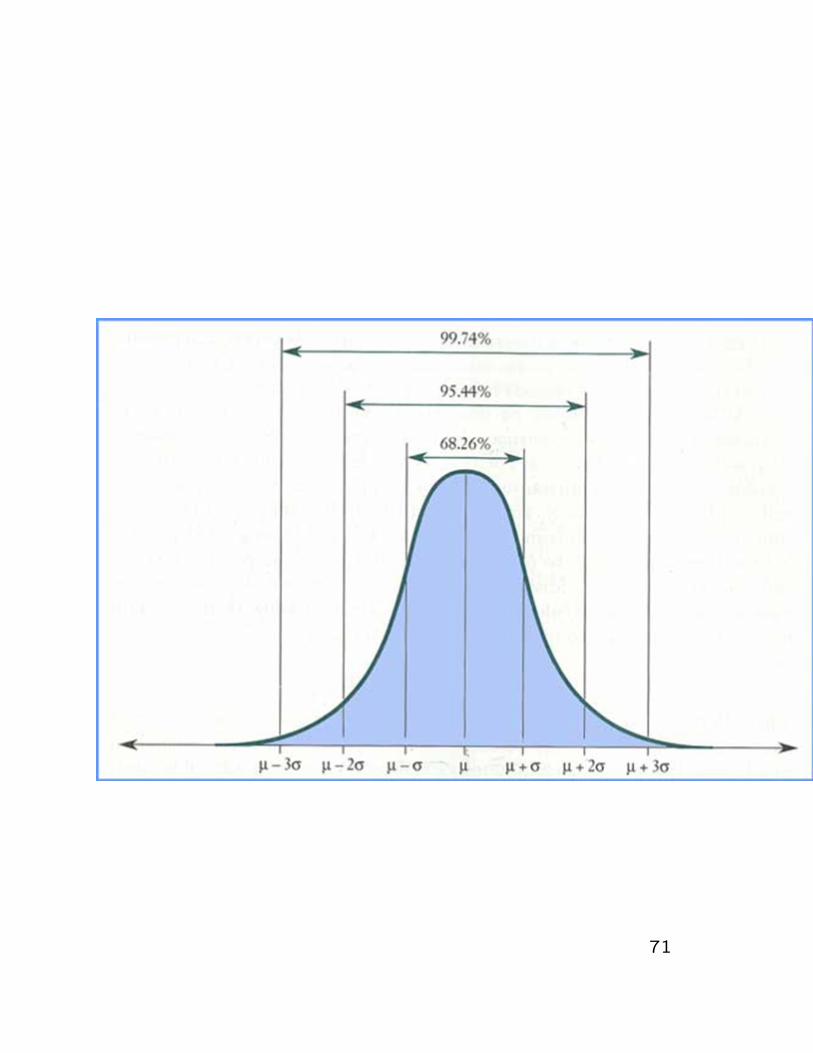
desvio-padrao, esta ilustrada na figura a seguir.
70
71

Trasnformacao de Padronizacao
Um resultado importante que vale para a dis-
tribuicao normal e que ao efetuarmos trans-
formacoes afins numa variavel aleatoria nor-
mal, a variavel transformada continua sendo
uma variavel normal, isto e se X e normal e
definimos Y = aX + b, com a 6= 0, entao Y
tambem e normal.
72

Para relacionar uma normal qualquer a normal
padrao temos o seguinte resultado
1. se X ∼ N(µ, σ2), entao
Z =X − µσ︸ ︷︷ ︸
transf. de padronizacao
∼ N(0,1)
Essa relacao torna possıvel calcular pro-
babilidades associadas a uma variavel nor-
mal qualquer, transformando-a numa nor-
mal padrao.
2. se Z ∼ N(0,1), entao X = σZ+µ ∼ N(µ, σ2).
Podemos usar qualquer uma das relacoes.
73

Discussao Tecnica sobre QI
Fonte: http://www.mensa.com.br/pag.php?p=23.
Origem da ideia do Quociente de Inteligencia (QI)
O psicologo frances Alfred Binet foi um dos precur-sores do estudo da inteligencia humana e idealizou testespara medi-la e, com isso, tentar melhorar o desem-penho escolar das criancas. A inteligencia humana,como outras caracterısticas fısicas e psicologicas, temgrande variacao dentro dos indivıduos. E natural, por-tanto, que existam pessoas mais, e menos, inteligentes.Conhecendo-se esta caracterıstica pode-se acompanharmelhor cada crianca em sua vida academica.
A ideia original do teste de QI de Binet seria comparara idade cronologica com a idade intelectual. Por co-modidade definiu-se que o QI medio sempre vale 100pontos.
Uma crianca, digamos com 5 anos de idade, que apre-sentasse um QI de 120 teria, portanto, uma idade in-telectual 20% acima da inteligencia media das criancascom 5 anos de idade, ou seja, esta crianca teria umaidade intelectual media equivalente a de uma crianca de6 anos de idade.
No caso de adultos, entretanto, faz muito pouco sentidodizer que uma pessoa com idade de 40 anos tem a idadeintelectual de um adulto de 48 anos.
74

O valor do QI, para adultos, passa a ser pouco signi-ficativo e, em geral, e melhor classificar a inteligenciaem termos de porcentagem.
E mais informativo dizer que uma pessoa tem uma in-teligencia maior do que, por exemplo, 98% da populacao(ou seja, a inteligencia desta pessoa esta entre os 2%mais inteligentes da populacao) do que dizer que o QIe, por exemplo, 148.
A seguir discussao sobre o QI refere-se ao QI adulto.
Acredita-se que a distribuicao de QI na populacao tenhauma funcao densidade de probabilidade normal. Vimosque para especificar completamente uma distribuicaonormal e necessario fixar o valor dos parametros: mediae desvio padrao.
Por convencao, como ja comentado, a media e semprefixada como 100. Para “converter” um QI em umaporcentagem (ou vice-versa) e sempre necessario quese conheca o desvio padrao. Nao tem sentido falar emQI (numerico) sem citar, tambem, qual desvio padraoesta sendo utilizado.
75

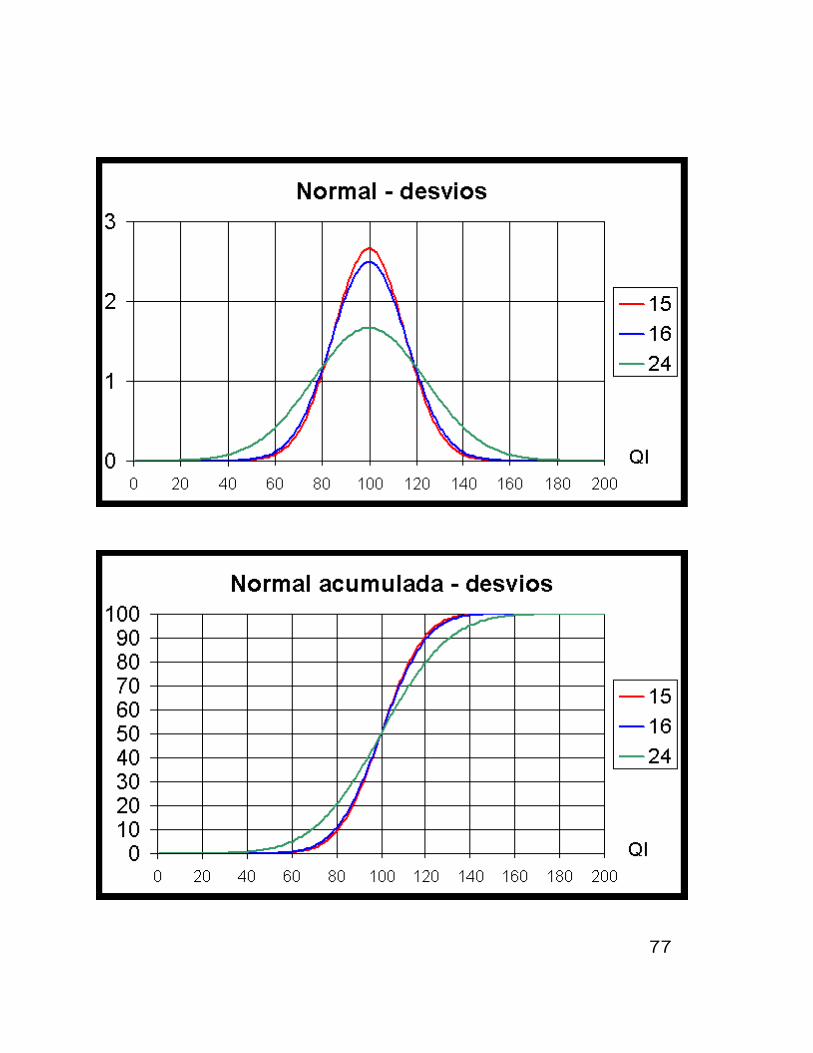
Ha diversos testes de QI e cada um deles foi
calibrado (empiricamente) para um valor de
desvio padrao. Ha, por exemplo, testes famosos
com desvios de 15, 16 e 24. Note que ha muita
diferenca entre estes desvios e, consequente-
mente, a conversao entre QI e porcentagem e
bastante diferente em cada caso.
O QI informado pela Mensa, no resultado de
seus testes, tem desvio padrao 24.
Uma pessoa com QI topo 2% pode ter um QI
numerico maior ou igual a 130(131) se d.p.=15,
132(133) se d.p.=16 ou 148(149) se d.p. 24.
Observe que isso equivale a dizer dois desvios
padrao acima da media (2,05 desvios a cima
da media).
As figuras a seguir ilustram a distribuicao de
QI com os tres desvios citados.
76
77

Exemplo: Supondo uma distribuicao N(100,242)para o QI, responda aos itens a seguir.
Determine a probabilidade de que uma pessoasubmetida ao teste apresnte QI
1. maior ou igual a 148;
2. menor que 76;
3. entre 80 e 120;
4. entre 120 e 148.
5. Calcule os quartis da distribuicao do QI.
6. Encontre um intervalo simetrico em tornoda media 100, que compreenda 95% dosresultados desse teste.
78

Solucao do item (1)
Temos que X ∼ N(100,242) e queremos cal-
cular (X ≥ 148).
Observe que
P (X ≥ 148) = 1− P (X < 148)
P (X < 148) = P(X−100
24< 148−100
24
)= P (Z < 2) = φ(2) =
0,9773
Logo, P (Z ≥ 1148) = 1− 0,9773 = 0,0227 ou, equiva-lentemente, 2,27%.
Observe nao e possıvel encontrar um valor de QI inteiron tal que P (X ≥ n) = 0,02.
Vamos tentar resolver esse problema
n =? tal que P (X ≥ 2) = 0,02
Nesse caso, φ(n−100
24
)= 0,98.
79

Nao ha na tabela um valor exatamente igual
a 0,98 e devemos usar o valor mais proximo.
Podemos ver que na tabela disponıvel o valor
que associa a probabilidade acumulada mais
proxima de 98% e 2,05. Logo,
n−10024 = 2,05 tal que n = 149,2.
De fato, a resposta maior ou igual a 149 para
QI topo seria mais apropriada. No entanto,
costuma-se adotar certas aproximacoes para
distribuicoes normais: a cauda superior, dois
desvios padrao acima da media corresponde a
aproximadamente 2% da distribuicao.
Vimos, usando a tabela, que e cerca de 2,27%,
mas para facilitar e habito arredondar para 2%.
80

Referencias bibliograficas:
(1) Busssab e Morettin - Estatıstica Basica.
Editora Saraiva
(2) Triola, M. - Introducao a Estatıstica - LTC
(3) Thurman - Estatıstica - Saraiva
(4) Pinheiro e outros - Estatıstica Basica - a
arte de trabalhar com dados - Elsevier
(5) Ross, S. - A First Course in Probability -
Prentice-Hall
(6) Dancey e Reidy - Estatıstica sem Matematica
para Psicologia - Penso
(7) http://www.mensa.com.br/pag.php?p=23.
Em 28/08/2013
81

![ANÃ LISE DE INVESTIMENTO SOB INCERTEZA[1]pro.poli.usp.br/wp-content/uploads/2012/pubs/analise-de-investimen... · Figura 15 – Distribuição de probabilidade do valor presente](https://img.document.onl/doc/110x75/5c48d3b793f3c31f4f7b7182/ana-lise-de-investimento-sob-incerteza1propoliuspbrwp-contentuploads2012pubsanalise-de-investimen.jpg)



























