
PONTIFÍCIA UNIVERSIDADE CATÓLICA DE MINAS GERAISPrograma de Pós-Graduação em Informática
Análise de Estruturas Métricas para
Recuperação de Vídeo Utilizando Vocabulário Visual
Henrique Batista da Silva
Belo Horizonte2011

Henrique Batista da Silva
Análise de Estruturas Métricas para
Recuperação de Vídeo Utilizando Vocabulário Visual
Dissertação apresentada ao Programa de Pós-Graduação em Informática como requisito parcialpara obtenção do título de Mestre em Informática pelaPontifícia Universidade Católica de Minas Gerais.
Orientador: Zenilton Kleber Gonçalves do PatrocínioJúnior
Belo Horizonte2011

FICHA CATALOGRÁFICA Elaborada pela Biblioteca da Pontifícia Universidade Católica de Minas Gerais
Silva, Henrique Batista da S586a Análise de estruturas métricas para recuperação de vídeo utilizando
vocabulário visual / Henrique Batista da Silva. Belo Horizonte, 2011. 104f.: il.
Orientador: Zenilton Kleber Gonçalves do Patrocínio Júnior Dissertação (Mestrado) – Pontifícia Universidade Católica de Minas Gerais.
Programa de Pós-Graduação em Informática.
1. Gravação de vídeo. 2. Processamento de imagens. 3. Programação. 4. Vocabulário. I. Patrocínio Júnior, Zenilton Kleber Gonçalves do. II. Pontifícia Universidade Católica de Minas Gerais. Programa de Pós-Graduação em Informática. III. Título.
CDU: 681.3.093


AGRADECIMENTOS
Agradeço ao meu orientador, professor Zenilton, pela ajuda, paciência e por toda
sua dedicação a este trabalho.
Agradeço aos meus pais pelo apoio e paciência ao longo de todo este período de
trabalho.
Agradeço ao Microsoft Innovation Center (MIC BH) pelo �nanciamento a pesquisa.
Agradeço ao VIPLAB pela infraestrutura oferecida para a realização deste traba-
lho.
Agradeço aos amigos e companheiros bolsistas Kleber, Ângelo, André e Anna pela
companhia nos trabalhos do dia a dia. Agradeço também a amiga Adriana, pela com-
panhia de sempre nos estudos.
Agradeço também aos alunos de iniciação cientí�ca e de trabalhos de diplomação
do VIPLAB e todos que de alguma forma contribuíram para a conclusão deste trabalho.

RESUMO
Pesquisas envolvendo recuperação de vídeo em grandes bases de dados têm experimentadoum grande aumento. Isso se deve pelo fato da crescente popularidade da utilização devídeos pelos diversos setores da sociedade. Sistemas para recuperação de vídeos têm sidomuito utilizados, surgindo a necessidade de utilizar meios para prover o armazenamento erecuperação destes tipos de mídia. A maneira mais comum utilizada para consulta na basedestes sistemas é por meio de palavras-chave, porém este tipo de consulta não é e�cientepara recuperação de vídeos relevantes. Desta forma, torna-se importante o estudo detécnicas para facilitar a recuperação de vídeos baseada no conteúdo visual e que sejamrelevantes para o usuário. O presente trabalho tem como objetivo principal a análisecomparativa do uso de estruturas métricas para a indexação e a recuperação de vídeosutilizando vocabulário visual. Os experimentos realizados neste trabalho mostram que aquantidade de informação e a alta complexidade dos dados utilizados para descrever osvídeos ainda são fatores que impactam na recuperação e�ciente do conteúdo, porém, �couevidenciado que algumas estruturas métricas apresentam comportamento muito satisfa-tório para recuperação de vídeos, principalmente se forem aliadas a uma estratégia queincorpore informações sobre a distribuição espacial das palavras do vocabulário visual.
Palavras-chave: Recuperação de Vídeos. Vocabulário Visual. Estruturas Métricas.

ABSTRACT
Research involving video retrieval in large databases have experienced a large increase dueto the popularity of videos utilization by various society sectors. Videos retrieval systemshave been used, resulting in the need for means to provide the storage and retrieval ofthese media types. The most common way used as query in these systems database isthrough keywords. However, this type of query is not e�cient for retrieving relevantvideos. Thus, it becomes important to study techniques to facilitate the retrieval ofvideos based on visual content that is relevant to the user. The present work has as mainobjective the comparative analysis of metric structures to indexing and retrieval of videousing visual vocabulary. The conducted experiments in this master thesis show that theamount of information and the high complexity of the data used to describe the videos arestill factors that impact on e�cient recovery of contents. This work has shown that somestructures exhibit strong performance metrics for video retrieval, mainly if combined witha strategy that incorporates information about the spatial distribution of visual words inthe vocabulary.
Keywords: Videos Retrieval. Visual Vocabulary. Metric Structures.

LISTA DE FIGURAS
FIGURA 1 Extração de Features. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . 21
FIGURA 2 Processo genérico de indexação. Fonte: Elaborada pelo autor. . . . . . . 21
FIGURA 3 Processo genérico de busca. Fonte: Elaborada pelo autor. . . . . . . . . . . 22
FIGURA 4 Método de sumarização. Fonte: (AVILA, 2008). . . . . . . . . . . . . . . . . . . . . . 27
FIGURA 5 Uso de um descritor D. Fonte: (TORRES; FALCÃO, 2006). . . . . . . . . . . . 27
FIGURA 6 Uso de um descritor composto. Fonte: (TORRES et al., 2005). . . . . . . . 28
FIGURA 7 Histograma de cor gerado a partir de uma imagem. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
FIGURA 8 Exemplo de características locais / pontos de interesse. Fonte: (TUY-
TELAARS; MIKOLAJCZYK, 2008). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
FIGURA 9 Classe de transformações necessárias para lidar com as mudanças de
ponto de visão. Em (a) e (b) regiões circulares de tamanho �xo não são
su�cientes para lidar com a mudança do ponto de visão. Foi necessário
um deformação na região circular, gerando uma elipse apresentada em (c).
Fonte: (MIKOLAJCZYK et al., 2005). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
FIGURA 10 Harris-A�ne. Fonte: (MIKOLAJCZYK et al., 2005). . . . . . . . . . . . . . . . . . 31
FIGURA 11 MSER. Fonte: (MIKOLAJCZYK et al., 2005). . . . . . . . . . . . . . . . . . . . . . . . . 32
FIGURA 12 Representa cada região por um Histograma das orientações dos gra-
dientes, correspondendo ao tamanho das setas no lado direito da �gura,

que é um vetor de 128 dimensões. Fonte: (LOWE, 2004). . . . . . . . . . . . . . . 34
FIGURA 13 Representação por bag of feature. Fonte: Adaptada de Lopes, Avila e
Peixoto (2009). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
FIGURA 14 Arquivo invertido para indexação de Bag of Features. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
FIGURA 15 Representação 2D da M-Tree. Fonte: (ZEZULA et al., 2006). . . . . . . . . 38
FIGURA 16 Um exemplo do algoritmo de Slim-Down. O elemento Si a esquerda
passa a pertencer a outra região, reduzindo o raio de uma das regiões, sem
aumentar o raio da outra. Fonte: Adaptada de Zezula et al. (2006). . . . 39
FIGURA 17 Ilustração da estrutura de uma D-Index. Fonte: Adaptada de Zezula
et al. (2006). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
FIGURA 18 Diagrama da estrutura D-Index. Fonte: (DOHNAL, 2004). . . . . . . . . . . 40
FIGURA 19 Processo de indexação de vídeo. Fonte: Elaborada pelo autor. . . . . . . 43
FIGURA 20 Processo de amostragem aleatória dos quadros-chave do vídeo. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
FIGURA 21 Regiões de interesse de um quadro do vídeo. Em (a) são exibidas as
regiões de interesse detectadas pelo Harris A�ne e em (b) regiões de
interesse detectadas pelo MSER. Fonte: Elaborada pelo autor. . . . . . . . . 45
FIGURA 22 Processo de criação do vocabulário visual. Fonte: Elaborada pelo au-
tor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
FIGURA 23 Processo de inserção do vocabulário visual no índice. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
FIGURA 24 Processo de descrição de um dos quadros-chave do vídeo. Fonte: Ela-

borada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
FIGURA 25 Criação das bag of features dos quadros do vídeo. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
FIGURA 26 Processo de indexação dos quadros-chave. Fonte: Elaborada pelo au-
tor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
FIGURA 27 Processo de busca. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . 51
FIGURA 28 Em (a) Passos 1 e 2 do processo de consistência espacial, em (b) seleção
das palavras espacialmente mais próximas do quadro da base e da imagem
de consulta, em (c) e (d) passo 7 dos processo de consistência espacial.
Fonte: Adaptada de Sivic (2006). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
FIGURA 29 Histogramas da distribuição de distâncias dos vocabulários gerados.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
FIGURA 30 Quadros do vídeo utilizados para consultas. O retângulo na imagem
representa a região que será utilizada para consulta. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
FIGURA 31 (a) Grá�co do número total de acessos a disco realizado por cada es-
trutura para criar o índice do arquivo invertido em função do tamanho do
vocabulário visual e (b) Grá�co do número total de cálculos de distância
realizado por cada estrutura para criar o índice do arquivo invertido em
função do tamanho do vocabulário visual. Fonte: Elaborada pelo autor. 61
FIGURA 32 (a) Grá�co do número total de acessos a disco realizado por cada estru-
tura para indexação dos quadros do vídeo no arquivo invertido em função
do tamanho do vocabulário visual, e (b) o grá�co do número total de
cálculos de distância realizado por cada estrutura para indexação dos qua-
dros do vídeo no arquivo invertido em função do tamanho do vocabulário
visual. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62

FIGURA 33 Valores médios do F1-Score em função da quantidade de quadros retor-
nados (∆), para cada uma das quatro estruturas analisadas, com vocabu-
lário de tamanho 4000 e sem consistência espacial. Fonte: Elaborada pelo
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
FIGURA 34 Valores médios do F1-Score em função da quantidade de quadros re-
tornados (∆), após a realização do processo de consistência espacial para
vocabulário de tamanho 4000. Fonte: Elaborada pelo autor. . . . . . . . . . . 64
FIGURA 35 Valores médios de acessos a disco em função da quantidade de quadros
retornados (∆), para vocabulário de tamanho 4000. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
FIGURA 36 Valores médios de cálculos de distância em função da quantidade de
quadros retornados, sem realização da consistência espacial e para voca-
bulário de tamanho 4000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . 67
FIGURA 37 Percentual do número de cálculos de distância necessários para se rea-
lizar a consistência espacial em relação ao número total de cálculos de
distância para cada valor de ∆ e para vocabulário de tamanho 4000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
FIGURA 38 Valores médios de F1-Score em função de ∆, para vocabulário de ta-
manho 8000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
FIGURA 39 Valores médios do F1-Score em função de ∆, após a realização do pro-
cesso de consistência espacial, para vocabulário de tamanho 8000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
FIGURA 40 Número médio de acessos a disco em função de ∆, para vocabulário de
tamanho 8000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . 72
FIGURA 41 Valores médios de cálculos de distância em função de ∆, sem realiza-
ção da consistência espacial e para vocabulário de tamanho 8000. Fonte:

Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
FIGURA 42 Percentual do número de cálculos de distância necessários para se rea-
lizar a consistência espacial em relação ao número total de cálculos de
distância para cada valor de ∆ e para vocabulário de tamanho 8000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
FIGURA 43 Valores médios do F1-Score em função de ∆, após a realização do pro-
cesso de consistência espacial, para vocabulário de tamanho 16000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
FIGURA 44 Valores médios do F1-Score em função de ∆, após a realização do pro-
cesso de consistência espacial, para vocabulário de tamanho 16000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
FIGURA 45 Número médio de acessos a disco em função de ∆, para vocabulário de
tamanho 16000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . 77
FIGURA 46 Valores médios de cálculos de distância em função de ∆, sem realiza-
ção da consistência espacial e para vocabulário de tamanho 16000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
FIGURA 47 Percentual do número de cálculos de distância necessários para se rea-
lizar a consistência espacial em relação ao número total de cálculos de
distância para cada valor de ∆ e para vocabulário de tamanho 16000.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
FIGURA 48 Valores médios de F1-Score em função de ∆, para vocabulário de ta-
manho 32000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
FIGURA 49 Valores médios do F1-Score em função de ∆, após a realização do pro-
cesso de consistência espacial, para vocabulário de tamanho 32000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
FIGURA 50 Número médio de acessos a disco em função de ∆, para vocabulário de

tamanho 32000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . 82
FIGURA 51 Valores médios de cálculos de distância em função de ∆, sem realiza-
ção da consistência espacial e para vocabulário de tamanho 32000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
FIGURA 52 Percentual do número de cálculos de distância necessários para se rea-
lizar a consistência espacial em relação ao número total de cálculos de
distância para cada valor de ∆ e para vocabulário de tamanho 32000.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
FIGURA 53 Valores médios de F1-Score sem realização da consistência espacial, em
função do tamanho do vocabulário visual utilizado. Fonte: Elaborada pelo
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
FIGURA 54 Valores médios do F1-Score em função do tamanho do vocabulário
visual, após consistência espacial. Fonte: Elaborada pelo autor. . . . . . . . 87
FIGURA 55 Número médio de acessos a disco em função do tamanho do vocabulário
visual. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
FIGURA 56 Número médio de cálculos de distância em função do tamanho do vo-
cabulário visual. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . 88
FIGURA 57 Valores médios para o número de acessos a disco e cálculos de distân-
cia das quatro estruturas antes da realização da consistência espacial, (a)
valores para D-Index, (b) valores para M-Tree, (c) valores para Slim-Tree
e (d) valores para estrutura de acesso sequencial. Fonte: Elaborada pelo
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
FIGURA 58 Valores médios de F1-Score sem a realização da consistência espacial
em função das estruturas de indexação e do tipo de segmentação realizada.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
FIGURA 59 (a) Grá�co do número médio de acessos a disco em função das estruturas

e segmentação. (b) grá�co de número médio de cálculos de distância em
função das estruturas e segmentação utilizadas. Fonte: Elaborada pelo
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
FIGURA 60 Taxa de F1-Score em função das estruturas de indexação utilizadas.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
FIGURA 61 Número de acessos a disco para criação das estrutura de indexação por
amostragem e por detecção de tomadas. Fonte: Elaborada pelo autor. 93
FIGURA 62 Resultado da avaliação qualitativa sem processo de consistência espacial
na consulta número 5. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . 94
FIGURA 63 Resultado da avaliação qualitativa com processo de consistência espa-
cial na consulta número 5, no qual sua realização não impactou de forma
considerável o resultado da busca. Fonte: Elaborada pelo autor. . . . . . . 95
FIGURA 64 Resultado da avaliação qualitativa sem processo de consistência espacial
na consulta número 9. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . 96
FIGURA 65 Resultado da avaliação qualitativa com processo de consistência es-
pacial na consulta número 9, no qual sua realização impactou de forma
considerável o resultado da busca. Fonte: Elaborada pelo autor. . . . . . . 97

LISTA DE QUADROS
QUADRO 1 Revisão de detectores de características. Fonte: Adaptado de Tuyte-
laars e Mikolajczyk (2008). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33

LISTA DE TABELAS
TABELA 1 Informações sobre vocabulários visuais utilizados. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
TABELA 2 Groundtruth das consultas. Fonte: Elaborada pelo autor. . . . . . . . . . . 59
TABELA 3 Valores totais de acessos a disco e cálculos de distância para cada
uma das estruturas analisadas e cada tamanho do vocabulário. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
TABELA 4 Valores totais de acessos a disco e cálculos de distâncias para cada
estrutura e cada tamanho de vocabulário na indexação. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
TABELA 5 Valores médios de Revocação, Precisão e F1-Score para as consultas
realizadas, antes da realização da consistência espacial e para vocabulário
de tamanho 4000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . 65
TABELA 6 Valores médios de Revocação, Precisão e F1-Score para as consultas rea-
lizadas após a consistência espacial, para vocabulário de tamanho 4000.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
TABELA 7 Valores médios para o número de acessos a disco e cálculos de distância
das estruturas sem realização da consistência espacial e para vocabulário
de tamanho 4000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . 68
TABELA 8 Valores médios de cálculos de distância para realizar a consistência
espacial e os valores totais de cálculos de distâncias da busca ao �nal
do processo da consistência espacial, para vocabulário de tamanho 4000.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69

TABELA 9 Valores médios de Revocação, Precisão e F1-Score para as consultas,
antes da realização da consistência espacial e para vocabulário de tamanho
8000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
TABELA 10 Valores médios de Revocação, Precisão e F1-Score para as consultas
após a consistência espacial, para vocabulário de tamanho 8000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
TABELA 11 Valores médios para o número de acessos a disco e cálculos de distância
das estruturas sem realização da consistência espacial e para vocabulário
de tamanho 8000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . 72
TABELA 12 Valores médios de cálculos de distância para realizar a consistência
espacial e os valores totais de cálculos de distâncias da busca ao �nal
do processo da consistência espacial, para vocabulário de tamanho 8000.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
TABELA 13 Valores médios de Revocação, Precisão e F1-Score para as consultas,
antes da realização da consistência espacial e para vocabulário de tamanho
16000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
TABELA 14 Valores médios de Revocação, Precisão e F1-Score para as consultas
após a consistência espacial, para vocabulário de tamanho 16000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
TABELA 15 Valores médios para o número de acessos a disco e cálculos de distância
das estruturas sem realização da consistência espacial e para vocabulário
de tamanho 16000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . 79
TABELA 16 Valores médios de cálculos de distância para realizar a consistência
espacial e os valores totais de cálculos de distâncias da busca ao �nal do
processo da consistência espacial, para vocabulário de tamanho 16000.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79

TABELA 17 Valores médios de Revocação, Precisão e F1-Score para as consultas,
antes da realização da consistência espacial e para vocabulário de tamanho
32000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
TABELA 18 Valores médios de Revocação, Precisão e F1-Score para as consultas
após a consistência espacial, para vocabulário de tamanho 32000. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
TABELA 19 Valores médios para o número de acessos a disco e cálculos de distância
das estruturas sem realização da consistência espacial e para vocabulário
de tamanho 32000. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . 83
TABELA 20 Valores médios de cálculos de distância para realizar a consistência
espacial e os valores totais de cálculos de distâncias da busca ao �nal do
processo da consistência espacial, para vocabulário de tamanho 32000.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
TABELA 21 Valores médios de Revocação, Precisão e F1-Score para as consultas rea-
lizadas em diferentes vocabulários sem realização da consistência espacial.
Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
TABELA 22 Valores médios de Revocação, Precisão e F1-Score para as consultas
realizadas em diferentes vocabulários após a consistência espacial. Fonte:
Elaborada pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
TABELA 23 Valores médios para o número de acessos a disco e cálculos de distância
das quatro estruturas. Fonte: Elaborada pelo autor. . . . . . . . . . . . . . . . . . . 89
TABELA 24 Valores médios para cálculos de distância para se realizar a consistência
espacial e valores médios totais de cálculos de distância. Fonte: Elaborada
pelo autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
TABELA 25 Valores médios de Revocação, Precisão e F1-Score para as buscas rea-
lizadas por tipo de segmentação. Fonte: Elaborada pelo autor. . . . . . . . 92

LISTA DE SIGLAS
RGB Red, Green, Blue
HSV Hue, Saturation, Value
HSI Hue, Saturation, Intensity
MSER Maximally Stable Extremal Region
EBR Edge-Based Region
SIFT Scale Invariant Feature Transform
PCA-SIFT Principal Components Analysis - SIFT
GLOH Gradient Location-Orientation Histogram
CBS Columbia Broadcasting System
vp Número de resultados verdadeiros positivos
fp Número de resultados falsos positivos
fn Número de resultados falsos negativos

SUMÁRIO
1 INTRODUÇÃO. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.1 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.1.1 Objetivo Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.1.2 Objetivos Especí�cos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1.2 Justi�cativas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1.3 Principais Contribuições . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
1.4 Organização do Texto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2 CONCEITOS E TRABALHOS CORRELATOS. . . . . . . . . . . . . . . . . . . . . . 25
2.1 Vídeo Digital . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.2 Segmentação/Sumarização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.2.1 Descritores de características . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.1.1 Descritores de cor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.2.1.2 Descritores de textura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2.2 Características locais de uma imagem . . . . . . . . . . . . . . . . . . . . . 30
2.2.3 Regiões de interesse de uma imagem . . . . . . . . . . . . . . . . . . . . . . 30
2.2.3.1 Detectores de características de imagem. . . . . . . . . . . . . . . . . . . . 31
2.2.3.2 Descritores de regiões de interesse . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.3 Vocabulário Visual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.3.1 Clusterização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.3.2 Bag of features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.4 Indexação e Busca . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.4.1 Arquivos Invertidos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.4.2 Estruturas Métricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.4.2.1 M-Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.4.2.2 Slim-Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.4.2.3 D-Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.5 Trabalhos Relacionados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3 INDEXAÇÃO E RECUPERAÇÃO DE VÍDEOS UTILIZANDO VO-
CABULÁRIO VISUAL. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42

3.1 Processo de Indexação de Vídeos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.1.1 Segmentação do Vídeo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.1.2 Construção do Vocabulário Visual . . . . . . . . . . . . . . . . . . . . . . . . 44
3.1.2.1 Extração de Descritores dos Quadros Selecionados . . . . . . . . . . . 45
3.1.2.2 Processo de Clusterização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.1.2.3 Eliminação de Stopwords . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.1.3 Indexação dos Quadros-chave do Vídeo . . . . . . . . . . . . . . . . . . . . 47
3.1.3.1 Criação do Índice do Arquivo Invertido . . . . . . . . . . . . . . . . . . . . 47
3.1.3.2 Extração de Descritores dos Quadros-chave do Vídeo . . . . . . . . 48
3.1.3.3 Construção de Bag of Features dos Quadros . . . . . . . . . . . . . . . 48
3.1.3.4 Indexação utilizando Arquivo Invertido . . . . . . . . . . . . . . . . . . . 49
3.2 Processo de Recuperação de Vídeos . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2.1 Consistência Espacial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.3 Utilização de Estruturas Métricas de Indexação . . . . . . . . . . . . . . . 54
3.4 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4 ANÁLISE DA UTILIZAÇÃO DE ESTRUTURAS MÉTRICAS NA
INDEXAÇÃO E RECUPERAÇÃO DE VÍDEOS . . . . . . . . . . . . . . . . . . . . 56
4.1 Parâmetros de Testes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.2 Criação do Vocabulário Visual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.3 Descrição do Groundtruth . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4 Descrição dos Testes Realizados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.5 Avaliação dos Resultados da Indexação . . . . . . . . . . . . . . . . . . . . . . 60
4.6 Métricas para Avaliação dos Resultados das Consultas . . . . . . . . . . 63
4.7 Avaliação dos Resultados das Consultas Obtidos em Função do
Tamanho do Vocabulário . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.7.1 Resultados para o Vocabulário de Tamanho 4000 . . . . . . . . . . . . . 65
4.7.2 Resultados para o Vocabulário de Tamanho 8000 . . . . . . . . . . . . . 70
4.7.3 Resultados para o Vocabulário de Tamanho 16000 . . . . . . . . . . . . 75
4.7.4 Resultados para o Vocabulário de Tamanho 32000 . . . . . . . . . . . . 80
4.7.5 Resultados Obtidos em Função da Variação do Tamanho do Vo-
cabulário Visual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
4.8 Resultados Obtidos Utilizando Segmentação por Detecção de To-
madas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4.9 Análise Qualitativa dos Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.10 Análise Global dos Resultados Obtidos nos Experimentos . . . . . . . 94

5 CONCLUSÕES. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
5.1 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102

20
1 INTRODUÇÃO
Pesquisas envolvendo recuperação de vídeo em grandes bases de dados têm ex-
perimentado um grande aumento. Isso se deve pelo fato da crescente popularidade da
utilização de vídeos pelos diversos setores da sociedade. O avanço tecnológico tem faci-
litado consideravelmente o crescimento dessa popularidade. Segundo Shao, Shen e Zhou
(2008), com os avanços do hardware, principalmente em relação a queda do custo de ar-
mazenamento, e também com o avanço dos softwares, como os aplicativos para edição
de vídeo, há hoje uma grande quantidade de dados de vídeos sendo utilizados em di-
versos campos, como em arquivos de vídeo pessoal, comercial e organizacional. Shao,
Shen e Zhou (2008) ressaltam também que a disseminação do acesso a banda larga tem
contribuído muito para a popularidade de vídeos também na Web. Haja vista a grande
quantidade de vídeos publicados nas diversas plataformas abertas para visualização e
compartilhamento de conteúdo multimídia disponíveis hoje na Internet.
Sistemas para recuperação de vídeos têm sido muito utilizados, principalmente
na Internet. Desta forma, surge então a necessidade de utilizar meios para prover o
armazenamento e recuperação destes tipos de mídia. A maneira mais comum utilizada
para consulta na base destes sistemas é por meio de palavras-chave, em que a consulta é
realizada em metadados cadastrados para cada vídeo na base de dados, e assim os vídeos
são retornados ao usuário como resultado da busca.
Devido a alta complexidade dos arquivos de vídeo e a grande quantidade de dados
a serem armazenados, este tipo de consulta não é e�ciente para recuperação de vídeos
relevantes, o que torna a busca ine�ciente, devido ao resultado pouco relevante para
o usuário. Segundo Shao, Shen e Zhou (2008) esta abordagem é inadequada para busca
baseada em similaridade em grandes base de dados de vídeo, uma vez que é uma tarefa que
envolve esforço humano, e assim descrições erradas e incompletas podem ser realizadas e
impactar negativamente o resultado da busca. Desta forma, torna-se importante o estudo
de técnicas para facilitar a recuperação de vídeos relevantes para o usuário.
Diferentemente da busca baseada em metadados, a busca baseada em conteúdo
do vídeo é complicada pois os arquivos são complexos e difíceis de serem manipulados e
armazenados de forma e�ciente. Um vídeo pode conter um enorme volume de informação,
tanto em relação ao seu tamanho como também quanto as várias informações contidas
em cada quadro, como, por exemplo, a escala de cor de cada pixel. Devido a esse alto

21
Figura 1: Extração de Features. Fonte: Elaborada pelo autor.
volume de informação o processo de busca de vídeos em uma base de dados torna-se
lento e complexo. Sendo assim, de maneira geral, para a indexação de uma coleção de
vídeos é necessário, primeiramente, extrair características de cada quadro de um vídeo.
Após realizada esta extração, tem-se um vetor de características multidimensional que
representa o conteúdo do vídeo, contendo informações sobre cor, textura, luminosidade,
entre outras.
Após obtenção destes vetores de características é necessário realizar uma suma-
rização para reduzir a quantidade de dados que serão posteriormente armazenados. A
Figura 1 apresenta o processo de extração de características e sumarização de um vídeo.
Na Figura 1 também é apresentado outros dois métodos para produzir um vetor de
características sumarizado. Um deles baseia-se em, primeiramente, realizar a sumarização
do vídeo, reduzindo assim o número de quadros que o vídeo contém, para posteriormente
ser realizado a extração das características nos quadros do vídeo sumarizado. O outro
método consiste em realizar uma extração de características que também realiza a suma-
rização do vídeo, gerando um vetor de características sumarizado.
Após todo o processo de obtenção destes vetores de características é necessário
Figura 2: Processo genérico de indexação. Fonte: Elaborada pelo autor.

22
Figura 3: Processo genérico de busca. Fonte: Elaborada pelo autor.
armazená-los em uma estrutura de indexação. Neste processo, cada vetor de característi-
cas será indexado e esses vetores serão a representação de cada vídeo da coleção na base
de dados, como apresentado na Figura 2.
Por �m, o processo de busca na estrutura de indexação deverá ser realizado, para
isto é necessário ter uma imagem ou um vídeo para consulta. Para o processo de busca, é
necessário realizar o mesmo processo descrito anteriormente de processamento do vídeo,
para o vídeo da consulta. Assim, é realizada a extração de características e sumarização
do vídeo, para obter o vetor de características, e então será realizada uma busca por
similaridade na estrutura de indexação para encontrar o vídeo mais similar, ou encontrar
os vídeos que são mais similares ao vídeo da consulta. A Figura 3 apresenta como é
realizado este processo de busca.
Como motivação para a presente proposta destaca-se a crescente utilização de
arquivos de vídeos em diversos setores da sociedade, principalmente na Internet com
plataformas de compartilhamento de vídeo, e com isso surge a necessidade de técnicas
e�cientes para armazenamento e busca deste tipo de conteúdo.
1.1 Objetivos
Esta seção descreve o objetivo principal deste trabalho juntamente com seus obje-
tivos especí�cos.
1.1.1 Objetivo Geral
Este trabalho tem como objetivo principal realizar uma análise comparativa do uso
de estruturas métricas para a indexação e recuperação de vídeos utilizando vocabulário
visual.

23
1.1.2 Objetivos Especí�cos
Os objetivos especí�cos deste trabalho são:
a) aplicar duas abordagem para segmentação de vídeo e realizar uma análise do
impactos das diferentes abordagem na etapa de recuperação;
b) aplicar técnicas de detecção de regiões de interesse e extração de descritores
sobre os quadros do vídeo;
c) construir vocabulários visuais de diferentes tamanhos, por meio de clusteriza-
ção dos descritores do vídeo, para análise do impacto do tamanho do vocabu-
lário na indexação e recuperação do vídeo;
d) Construir uma estrutura de arquivo invertido para indexação dos quadros-
chave do vídeo;
e) implementar quatro estruturas de indexação, sendo três métricas e uma de
acesso sequencial, para armazenar o vocabulário visual;
f) realizar experimentos de indexação e busca com as diferentes estruturas de
indexação e avaliar o comportamento em relação a variação do vocabulário; e
g) implementar técnica de consistência espacial de reclassi�cação do resultado
para avaliar o impacto desta abordagem na recuperação do vídeo.
1.2 Justi�cativas
O crescente aumento na utilização de arquivos de vídeos tem feito com que a busca
de vídeos por similaridade seja de grande importância para a recuperação de vídeos que
sejam relevantes para o usuário.
A alta complexidade de conteúdo baseado em vídeo tem di�cultado o bom de-
sempenho e a rápida recuperação deste tipo de conteúdo, tendo assim, como principais
desa�os para a recuperação de vídeo, a representação e�caz e compacta do vídeo, as mé-
tricas e�cientes de similaridade e a indexação e�ciente das representações compactas dos
vídeos (SHEN; OOI; ZHOU, 2005).
A manipulação de arquivos de vídeos é di�cultada devido a alta complexidade deste
tipo de arquivos e, em grande parte, também são muito grandes para serem facilmente
armazenados. Desta forma, para um armazenamento e�ciente destes arquivos torna-se
necessário a utilização de técnicas para reduzir o tamanho destes vídeos para então serem
indexados em uma estrutura apropriada.

24
1.3 Principais Contribuições
Com base nos objetivos apresentados nesta proposta, pode-se destacar as seguintes
contribuições deste trabalho:
a) Avaliação do impacto da variação do tamanho do vocabulário visual no pro-
cesso de indexação e recuperação do vídeo;
b) Avaliação do impacto da realização da consistência espacial para reclassi�cação
dos quadros-chave do vídeo na etapa de busca;
c) Avaliação do impacto da escolha das técnicas de segmentação do vídeo, por
amostragem dos quadros e por detecção de tomadas, sobre o processo de busca
de vídeos;
d) Desenvolvimento de uma ferramenta para recuperação de vídeos por uma ima-
gem de consulta ou mesmo por uma região da imagem de consulta; e
e) Análise qualitativa e quantitativa do comportamento de quatro diferentes es-
truturas para indexação e recuperação de dados multidimensionais aplicadas
à indexação de vídeo.
1.4 Organização do Texto
Este trabalho contém cinco capítulos, organizados da seguinte forma. O Capítulo
2 apresenta o referencial teórico sobre os principais conceitos utilizados neste trabalho e
trabalhos relacionados. O Capítulo 3 contém a metodologia proposta pelo trabalho. No
Capítulo 4 são apresentados os experimentos realizados neste trabalho. No capítulo 5 são
apresentadas as conclusões deste trabalho e sugestões de trabalhos futuros.

25
2 CONCEITOS E TRABALHOS CORRELATOS
Este capítulo aborda os principais conceitos e trabalhos relacionados de modo a
fundamentar cada etapa do processo de indexação e recuperação de vídeo e está organizado
da seguinte forma. Na seção 2.1, descreve-se o conceito de vídeo digital. Já a seção 2.2
aborda os conceitos de segmentação, sumarização de vídeo e os principais os conceitos
de detecção e descrição de regiões de interesse. A seção 2.3 apresenta os conceitos de
vocabulário visual e Bag of Features utilizada para representar os quadros do vídeos. A
seção 2.4 apresenta os conceitos das estruturas métricas utilizadas neste trabalho. Por
�m, na seção 2.5 serão apresentados os principais trabalhos relacionados.
2.1 Vídeo Digital
Tipicamente os vídeos são compostos por uma sequência de quadros, estes quadros
são imagens estáticas que são exibidas continuamente em um determinado período de
tempo (geralmente um vídeo é composto por 24 ou 30 quadros por segundo).
Sendo A ⊂ N2, A = {0, · · · ,W− 1}×{0, · · · ,H− 1}, em queW e H são a largura
e altura de cada quadro, respectivamente, e, T ⊂ N, T = {0, · · · ,N− 1}, em que N é
o tamanho de um vídeo, Guimarães et al. (2009) de�nem o conceito de quadro e vídeo
como segue:
Um quadro f é uma função de A para o subconjunto de N, em que para cada
posição no espaço (x, y) em A, f (x, y) representa o valor na escala de cinza (ou cor) na
posição do pixel (x, y). O intervalo no valor da escala de cinza (ou cor) em N depende do
número de bits por pixel do quadro.
Um vídeo VN, no domínio A× T, pode ser visto como uma sequência de quadros
f. Ele pode ser descrito pela Equação 1.
VN = (f)t∈T (1)
em que N é o número de quadros contidos no vídeo.
2.2 Segmentação/Sumarização
Um modelo hierárquico para análise de vídeo e segmentação normalmente é divi-
dido em quatro níveis baseando-se na dimensão temporal. No nível mais baixo, pode ser

26
encontrada a mais básica unidade, um único quadro do vídeo. Vários destes quadros jun-
tos formam uma tomada, que representam uma gravação contínua de câmera. Algumas
tomadas que apresentam uma coerência narrativa são agrupadas em cenas, e seu conjunto
corresponde ao vídeo (GUIMARÃES et al., 2009).
Normalmente a segmentação é considerada a primeira etapa no processo de análise
e indexação de vídeos. A detecção de transições de tomadas é parte deste processo e con-
siste em identi�car o limite entre duas tomadas consecutivas. Em Guimarães et al. (2009)
é apresenta uma abordagem para detecção de transições abruptas entre duas tomadas,
envolvendo a comparação do conteúdo entre dois quadros.
No trabalho de Patrocínio Jr. et al. (2010) foi proposto uma abordagem para
identi�cação de transições, tanto abruptas quanto graduais, usando como medida de dis-
similaridade a cardinalidade máxima do matching calculado usando um grafo bipartido
em relação à uma janela deslizante.
Após as tomadas de um vídeo serem identi�cadas, é então realizada a extração dos
quadros-chave, que podem ser selecionados por amostragem, como apresentado em Mendi
e Bayrak (2010), ou até mesmo ser utilizada técnicas de sumarização de vídeo.
Sumarização de vídeo é o processo de extração de uma representação compacta
(resumo) sobre a estrutura de um vídeo, devendo esta ser menor do que o vídeo origi-
nal (SEBE; LEW; SMEULDERS, 2003). Segundo Avila (2008), o objetivo da sumarização
é fornecer de forma rápida e concisa o conteúdo do vídeo sem que haja perda da infor-
mação original. Desta forma, os resumos produzidos podem ser usados para facilitar a
recuperação de vídeos em uma grade base de dados. A partir de técnicas de sumarização
existentes é possível extrair quadros chaves de um vídeo, estes quadros são chamados de
key-frames, ou quadros-chave. Essa abordagem gera um conjunto de imagens estáticas.
Estes quadros devem ser o mais signi�cantes possível em relação ao conteúdo original do
vídeo.
No trabalho de Avila (2008) foi proposto uma metodologia para sumarização au-
tomática de vídeos baseada na extração de características de baixo nível das imagens e
na utilização de um algoritmo de agrupamento. A utilização de um algoritmo de agrupa-
mento tem o objetivo de produzir resumos através do agrupamento dos quadros do vídeo
baseado na similaridade entre eles.
A Figura 4 ilustra a metodologia proposta por Avila (2008), em que baseia-se
primeiramente na realização da segmentação do vídeo em quadros, posteriormente ocorre
a extração de características, em seguida os quadros são agrupados e o quadro mais
signi�cativo de cada grupo é selecionado. Após a seleção, elimina-se do conjunto os

27
Figura 4: Método de sumarização. Fonte: (AVILA, 2008).
quadros semelhantes. E então, um resumo do vídeo é gerado.
2.2.1 Descritores de características
O tipo mais simples de representar os quadros que compõe o vídeo utiliza caracte-
rísticas de imagem de baixo nível (propriedades dos pixels), tais como cor, textura, região
ou borda (BROWNE; SMEATON, 2005). O cálculo da similaridade entre dois quadros do
vídeo é realizado por meio de descritores. Segundo Torres et al. (2008) um descritor
pode ser caracterizado por uma função de extração de características (utiliza técnicas de
processamento de imagens para gerar o vetor de características) e por uma função de
distância que calcula a similaridade entre os vetores de características dos vídeos.
Segundo Torres e Falcão (2006), um vetor de características ~vÎ de uma imagem
Î pode ser considerado como um ponto no espaço Rn : ~vÎ = (v1, v2, . . . , vn), onde n é a
dimensão do vetor.
Torres e Falcão (2006) de�nem formalmente um descritor de imagem D como uma
tupla (εD, δD), em que:
a) εD :{Î}→ Rn é uma função, que extrai um vetor de características ~vÎ de uma imagem
Î ; e
b) δD : Rn × Rn → Rn é uma função de similaridade que calcula a similaridade en-
Figura 5: Uso de um descritor D. Fonte: (TORRES; FALCÃO, 2006).

28
Figura 6: Uso de um descritor composto. Fonte: (TORRES et al., 2005).
tre duas imagens como o inverso da distância entre seus vetores de características
correspondentes.
Ainda segundo Torres e Falcão (2006), pode-se observar na Figura 5 a utilização
de um descritor para o cálculo da similaridade entre duas imagens. A função εD extrai
os vetores de características ~vÎA e ~vÎB da imagens ÎA e ÎB, respectivamente. Em seguida,
a função de similaridade δD é utilizada para calcular o valor da similaridade d entre as
duas imagens da consulta.
Um fator muito comum em sistemas de recuperação de imagem e vídeo é a com-
binação de dois ou mais descritores para a extração de características de uma imagem.
Sendo assim, Torres et al. (2005) de�nem um descritor composto D̂ como sendo um par
(D, δD), em que:
a) D = {D1,D2, . . . ,Dk} é um conjunto de k descritores simples pré-de�nidos; e
b) δD é uma função de similaridade que combina os valores de similaridade obtidos de
cada descritor Di ∈ D, i = 1,2,. . . ,k.
A Figura 6 apresenta o funcionamento de um descritor composto.
2.2.1.1 Descritores de cor
Os descritores de cor são os mais utilizados para representação de imagens. A
informação sobre a cor é representada como um ponto em um espaço tridimensional.
Existem vários modelos de cores que permitem sua especi�cação de forma padronizada,
como caso do RGB (Red, Green, Blue), o HSV (Hue, Saturation, Value), o HSI (Hue,

29
Figura 7: Histograma de cor gerado a partir de uma imagem. Fonte: Elaborada pelo autor.
Saturation, Intensity), o YCbCr (muito utilizado em vídeos), entre outros (PEDRINI;
SCHWARTZ, 2007).
Almeida et al. (2008) classi�cam descritores de cor em três tipos: descritores de
abordagem global, baseado em partição ou baseado em região (local). Os descritores
baseados na abordagem global compreendem métodos que descrevem globalmente a dis-
tribuição de cores na imagem.
No caso dos descritores baseado em partição o objetivo é decompor espacialmente
a imagem em um número �xo de regiões para obter a distribuição espacial de cor. Os
descritores de cor baseado em região têm o objetivo de encontrar grupos similares de
pixels em uma imagem (ALMEIDA et al., 2008).
O descritor de cor mais comum é o histograma, com ele é possível descrever glo-
balmente o conteúdo de cor de uma imagem pelo percentual de pixels de cada cor. Este
descritor é invariante quanto a translação e rotação da imagem e não considera a distri-
buição espacial de cor (TORRES; FALCÃO, 2006).
Segundo Pedrini e Schwartz (2007, p.104), �o histograma de uma imagem corres-
ponde à distribuição dos níveis de cinza da imagem, o qual pode ser representado por um
grá�co indicando o número de pixels na imagem para cada nível de cinza�.
A Figura 7 ilustra uma imagem e o histograma gerado a partir dela.
2.2.1.2 Descritores de textura
Não existe, na literatura, um consenso ou uma de�nição formal para textura. Mas
Tamatura et al. citado por Pedrini e Schwartz (2007, p.287) a�rma que, �a textura é
constituinte de uma região macroscópica, em que sua estrutura é formada pela repetição
de padrões, nos quais seus elementos ou primitivas encontram-se arranjados conforme
uma regra de composição�.
Segundo Pedrini e Schwartz (2007, p.288), �a extração de características de texturas
é responsável por executar transformações nos dados de entrada, de modo a descrevê-los

30
de maneira simpli�cada, porem, representativa�.
2.2.2 Características locais de uma imagem
Segundo Tuytelaars e Mikolajczyk (2008, p.178), �Uma característica local é um
padrão de imagem que difere da sua vizinhança imediata. É geralmente associada com
uma mudança de uma propriedade de imagem ou várias propriedades simultaneamente,
embora não seja necessariamente localizada exatamente sobre essa mudança�.
As propriedades da imagem comumente considerados são a intensidade, cor e tex-
tura, apresentadas anteriormente. A Figura 8 apresenta um exemplo de características
locais que, neste caso, são identi�cadas por pontos em uma imagem (comumente chamados
de pontos de interesse em uma imagem) (TUYTELAARS; MIKOLAJCZYK, 2008).
2.2.3 Regiões de interesse de uma imagem
Nas subseções anteriores, foram apresentados algumas técnicas para descrever uma
imagem, baseado em descritores de baixo nível. Entretanto, existem métodos que detec-
tam regiões de interesse em uma imagem que, em seguida, são descritas por descritores
de imagem. Estas regiões são chamadas de regiões a�ns covariantes.
Regiões a�ns covariantes, segundo Mikolajczyk et al. (2005), são regiões que devem
corresponder às mesmas características da imagem original, ou seja, sua forma não é �xa,
mas adapta-se automaticamente correspondendo as mesmas regiões da imagem subjacente
de diferentes pontos de vista, de modo que elas são a projeção da mesma superfície 3D.
Na Figura 9 é apresentado um exemplo de regiões a�ns covariantes.
Figura 8: Exemplo de características locais / pontos de interesse. Fonte: (TUYTELAARS; MI-KOLAJCZYK, 2008).

31
(a) (b) (c)
Figura 9: Classe de transformações necessárias para lidar com as mudanças de ponto de visão.Em (a) e (b) regiões circulares de tamanho �xo não são su�cientes para lidar com a mudança doponto de visão. Foi necessário um deformação na região circular, gerando uma elipse apresentadaem (c). Fonte: (MIKOLAJCZYK et al., 2005).
2.2.3.1 Detectores de características de imagem
A ideia dos detectores de regiões de interesse em uma imagem, segundo Sivic e
Zisserman (2008), é permitir o reconhecimento de objetos em imagens, apesar das mu-
danças em perspectiva, iluminação e oclusão parcial. Essas regiões são um subconjunto de
pixels da imagem. Estes métodos de detecção diferem da detecção e segmentação clássica,
pois os limites da região não têm que ser correspondentes às mudanças na aparência da
imagem como cor ou textura.
Em Mikolajczyk et al. (2005), são apresentados vários métodos para detectar re-
giões de interesse. Na Figura 10 é apresentado o resultado de um dos detectores, chamado
Harris-A�ne. As elipses na �gura são uma adaptação sobre os pontos de interesse da
imagem.
O Harris-A�ne caracteriza-se por detectar cantos ou junções presentes na imagem.
que são regiões de alta curvatura. Segundo Pedrini e Schwartz (2007, p.168), �uma junção
pode ser de�nida como um ponto de intersecção entre dois ou mais segmentos da borda
de objetos�. Mais detalhes sobre este detector encontra-se em Mikolajczyk et al. (2005).
Figura 10: Harris-A�ne. Fonte: (MIKOLAJCZYK et al., 2005).

32
Outro detector de região, mostrado na Figura 11, é o MSER (Maximally Stable
Extremal Region). Este detector representa componentes conexos na imagem, em que
as propriedade de todos os pixels dentro da região são de maior ou menor intensidade,
ou seja, são regiões extremamente brilhantes ou são regiões extremamente escuras, em
relação aos demais pixels. Mais detalhes da implementação deste detector podem ser
encontrados em Mikolajczyk et al. (2005).
Além dos detectores citados na presente seção, em Tuytelaars e Mikolajczyk (2008)
e Mikolajczyk et al. (2005) são apresentados outros detectores juntamente com uma análise
comparativa dos mesmo. Entre eles, é importante citar alguns baseado em detecção de
canto, como Hessian-A�ne e EBR (Edge-Based Region).
O objetivo do Hessian-A�ne é detectar pontos de interesse na imagem e determi-
nar uma região elíptica para cada um dos pontos. O detector EBR consiste em explorar as
bordas presentes na imagem que, por serem características relativamente estáveis, podem
ser detectadas por diversos pontos de vista, escalas ou mudanças de iluminação (MIKO-
LAJCZYK et al., 2005).
O Quadro 1 apresenta uma revisão dos resultados de alguns dos principais detec-
tores do estudo comparativo realizado por Tuytelaars e Mikolajczyk (2008). Os autores
classi�caram os detectores em diferentes grupos, sendo que todos os detectores apresen-
tados nesta tabela são invariantes a rotação, escala e transformação a�m. Para �ns de
comparação, é apresentado alguns dos detectores de canto e região. A tabela com os
resultados detalhados, pode ser encontrada em Tuytelaars e Mikolajczyk (2008).
2.2.3.2 Descritores de regiões de interesse
Após identi�cadas as regiões de interesse na imagem, torna-se necessário um mé-
todo que descreva as regiões identi�cadas. Mikolajczyk e Schmid (2005) realizaram uma
pesquisa comparativa dos vários descritores presentes na literatura.
Figura 11: MSER. Fonte: (MIKOLAJCZYK et al., 2005).

33
Um destes descritores, proposto por Lowe (1999), é o SIFT (Scale Invariant Feature
Transform). Em seu trabalho, Lowe (1999) descreve que esta abordagem de descrição
transforma uma imagem em uma grande coleção de vetores de características locais, sendo
que cada vetor é invariante a translação, escala e rotação da imagem, e parcialmente
invariante a mudanças de iluminação e projeção 3D, conforme ilustrado na Figura 12.
A quantidade de regiões de interesse em uma imagem pode variar em relação ao
tipo de detector escolhido e também em relação à imagem a ser descrita, como apresentado
no trabalho de Mikolajczyk e Schmid (2005).
Devido a esta quantidade de informações geradas para cada quadro do vídeo a
utilização de um descritor que reduza o número de dimensões pode-se tornar vantajoso.
Neste caso o PCA-SIFT (Principal Components Analysis - SIFT ) reduz a dimensão do
vetor de características para 36 dimensões, reduzindo a quantidade de informação a ser
indexada.
EmMikolajczyk e Schmid (2005) é encontrada uma descrição mais detalhada destes
e demais descritores, principalmente quanto a performance de cada um. Para os experi-
mentos, os autores utilizaram detectores de regiões como Harris-A�ne e Hessian-A�ne,
e seus resultados mostram que o descritor SIFT foi um dos que obtiveram melhores resul-
tados junto com o descritor GLOH (Gradient Location-Orientation Histogram), que é uma
extensão do SIFT, mas que foi implementado para aumentar sua robustez e capacidade
de distinção.
2.3 Vocabulário Visual
2.3.1 Clusterização
A clusterização é uma das etapas para criar o vocabulário visual de um vídeo.
É utilizada para classi�cação dos descritores em classe de palavras visuais. O problema
da clusterização surgiu de diversas aplicações, como mineração de dados e descoberta de
conhecimento, segundo Kanungo et al. (2002).
Ainda segundo segundo Kanungo et al. (2002), o método mais usado na literatura
LocalizaçãoDetector Canto Região Repetibilidade Exatidão Robustez E�ciênciaHarris-A�ne X +++ +++ ++ ++Hessian-A�ne X +++ +++ +++ ++EBR X +++ +++ + +MSER X +++ +++ ++ +++
Quadro 1: Revisão de detectores de características. Fonte: Adaptado de Tuytelaars eMikolajczyk (2008).

34
Figura 12: Representa cada região por um Histograma das orientações dos gradientes, corres-pondendo ao tamanho das setas no lado direito da �gura, que é um vetor de 128 dimensões.Fonte: (LOWE, 2004).
para clusterização é o K-means, proposto por MacQueen (1967), e baseia-se na ideia de
que, dado um conjunto de n pontos em um espaço real de d-dimensões Rd, e um inteiro
k, o problema é determinar o conjunto de k pontos em Rd, chamados de centros, com o
objetivo de minimizar a distância média entre cada ponto vizinho do centro.
Em Kanungo et al. (2002), ainda foi proposto uma heurística, chamado de Lloyd's
algorithm, que baseia-se na ideia de que o posicionamento ideal de um centro é o centroide
do cluster associado.
2.3.2 Bag of features
Os quadros do vídeo, para serem indexados, precisam ser representados por algum
tipo de informações na base de dados. Lopes, Avila e Peixoto (2009), utilizam o conceito
de bag of features, para reconhecimento de objetos em imagem colorida e apresenta o
processo geral para sua criação..
A Figura 13, apresenta o processo de criação de uma bag of feature. Na abordagem
de Lopes, Avila e Peixoto (2009), em um primeiro momento os pontos de interesse são
identi�cados na imagem, posteriormente estes pontos são descritos por um descritor de
pontos de interesse. Na próxima etapa é criado o vocabulário visual, em que cada descritor
é associado a um cluster que representa uma palavra visual do vocabulário.
Por �m, o histograma (bag of feature) é calculado contando-se a ocorrência de cada
palavra para um determinado quadro da base.

35
Seleção de Pontos
Descrição de Pontos
VocabulárioClassificação
Associação com cluster
Cálculo do Histograma
Figura 13: Representação por bag of feature. Fonte: Adaptada de Lopes, Avila e Peixoto (2009).
2.4 Indexação e Busca
Busca é uma operação presente em praticamente todas as áreas da computação.
Tradicionalmente, as operações de busca são aplicadas à dados estruturados. Esta busca é
baseada na exata igualdade entre o objeto de consulta e os objetos armazenados em uma
base de dados. Como exemplo deste procedimento de consulta destaca-se os Sistemas de
Gerenciamento de Banco de Dados (SGDB) tradicionais.
As bases de dados têm evoluído para o armazenamento de dados não estruturados,
como imagens e vídeos, por exemplo. Este tipo de conteúdo tem a desvantagem de ser de
difícil manipulação, o que restringe as consultas realizadas sobre eles. Desta forma, surge a
necessidade da utilização de modelos de busca mais e�cientes do que os modelos utilizados
sobre dados estruturados. Neste contexto, a busca por similaridade surge como uma
técnica para recuperar os objetos que são similares, ou próximos, ao objeto da consulta
(CHAVEZ et al., 2001).
Segundo Chavez et al. (2001), a similaridade é modelada como uma função de
distância que satisfaz a desigualdade triangular, e o conjunto de objetos é chamado de
espaço métrico. Esta abordagem baseia-se na função de similaridade que é calculada por
meio de um conjunto de vetores de Bag of Features e que se tornam um ponto no espaço
multidimensional.
Na literatura existem vários tipos de estruturas de indexação que podem ser utili-
zadas para armazenamento e busca de vídeos (neste caso, Bag of Features dos quadros).
Uma das estruturas, muito utilizada para busca de atributos textuais, é chamado arquivo
invertido.
2.4.1 Arquivos Invertidos
Segundo Frakes e Baeza-Yates (1992), um arquivo invertido é um índice de atribu-
tos, sendo que cada atributo contém uma referência a uma lista de documentos que contém

36
Clusterização/ Indexação
22 45 51 55 65 78
Bag of Features Arquivo de índice – Classes de descritores
Índice de descritores
Lista encadeada de referências
Sequencial
. . . .
Indexado
Direto
Figura 14: Arquivo invertido para indexação de Bag of Features. Fonte: Elaborada pelo autor.
o atributo. O uso de um arquivo invertido melhora a e�ciência da busca, entretanto, como
desvantagem é a necessidade de armazenar uma estrutura de dados que varia de 10 a 100
por cento ou mais do tamanho do próprio conteúdo e uma necessidade de atualização
desse índice a medida que o conjunto de dados sofre alterações.
Em Frakes e Baeza-Yates (1992) são apresentadas várias estruturas para se im-
plementar arquivos invertidos, como os vetores ordenados, que armazenam uma lista de
atributos em um vetor ordenado, incluindo um número de documentos associados para
cada atributo do vetor ordenado. Os vetores ordenados são rápidos, porém apresentam
desvantagem quando a atualização do índice é realizada.
Outra estrutura apresentada é a árvore B, que é muito e�ciente para dados que
são constantemente atualizados. Em relação aos vetores ordenados, a árvore B utiliza
mais espaço em disco, porém, além da atualização, a busca também é mais rápida. Mais
detalhes destas estruturas podem ser encontradas em Frakes e Baeza-Yates (1992).
No contexto de recuperação de vídeos, pode-se utilizar uma estrutura de arquivo
invertido, em que em seu índice, são armazenadas as palavras do vocabulário visual, e
cada palavra contém uma referência a uma lista de quadros do vídeo que contém aquela
palavra, conforme ilustrado na Figura 14.
O índice do arquivo invertido pode ser implementado através de acesso sequencial,
ou através de estruturas de acesso mais e�ciente, como estruturas multidimensionais. No
entanto, para dados adimensionais ou dados de alta dimensionalidade utiliza-se estruturas
métricas para lidar com este tipo de dado.

37
2.4.2 Estruturas Métricas
Estruturas métricas são estruturas que armazenam objetos utilizando uma função
de distância associada a eles. Elas podem ser divididas em estruturas métricas estáticas,
em que não permitem inserção e remoção dos elementos após sua criação, e estruturas
métricas dinâmicas que são adequadas para inserção e remoção após a criação do índice.
No trabalho de Chavez et al. (2001) são apresentadas várias estruturas métricas.
Neste trabalho serão apresentadas com mais detalhes as estruturas M-Tree, Slim-Tree e
D-Index.
2.4.2.1 M-Tree
A M-Tree foi proposta por Ciaccia, Patella e Zezula (1997), é o primeiro método de
acesso dinâmico da literatura. Tem a proposta de organizar um conjunto de um espaço
métrico. A M-Tree é uma árvore balanceada, capaz de lidar com arquivos de dados
dinâmicos e não requer reorganização periódica.
Seus elementos são todos armazenados em folha e são representados por sua chave
ou vetor de característica. Um objeto interno é um conjunto de entradas em que a cada
entrada esta associado um ponteiro para a raiz da subárvore. E todos estes objetos
têm um raio de cobertura, que é calculado por uma função de distância, pois a M-Tree
pode indexar objetos utilizando vetores de características que são comparados por uma
função de distância. Um exemplos grá�co da representação da M-Tree é apresentado na
Figura 15.
No processo de inserção de um novo elemento, é escolhido o nó de menor distância.
Caso haja mais de uma opção escolhe-se o nó de representante mais próximo e armazena
o novo elemento na folha, caso esta esteja cheia, é necessário particionar o nó (processo
conhecido como split), para escolher dois novos representantes e dois novos nós.
Para particionamento do nó, Ciaccia, Patella e Zezula (1997) apresentam cinco
algoritmos de escolha de novos representantes:
a) m_RAD (mínimo da soma dos raios): avalia todos os pares de elementos como
representantes e promove o par de elementos com menor valor da soma entre
os seus raios;
b) mM_RAD (mínimo do máximo dos raios): similar ao m_RAD, porém, pro-
move os elementos minimizando o raio máximo dos representantes;
c) M_LB_DIST (distância máxima): mantém o elemento representante já exis-
tente como um dos novos representantes, e então promove-se o segundo com
maior distância para ele;

38
Figura 15: Representação 2D da M-Tree. Fonte: (ZEZULA et al., 2006).
d) RANDOM (aleatória): promove-se dois novos representantes aleatoriamente;
e
e) SAMPLING (amostragem e aleatória): seleciona-se aleatoriamente um con-
junto de elementos, e dentre os elementos deste conjunto, promove os elementos
cuja soma do raio entre os dois seja a menor.
Na M-Tree, é utilizada como política padrão de escolha dos novos representantes
o mínimo do máximo dos raios (mM_RAD) por apresentar os melhores resultados.
2.4.2.2 Slim-Tree
A Slim-Tree, proposta por Traina Jr. et al. (2000), é uma extensão da M-Tree,
apresentada anteriormente. É uma árvore dinâmica e balanceada. Como as demais es-
truturas, a Slim-Tree agrupa seus elementos em uma página de tamanho �xo no disco,
sendo que cada página corresponde a um nó da árvore e seus elementos são armazenados
em suas folhas.
Diferentemente da M-Tree, a Slim-Tree possui como política padrão de inserção
a MINOCCUP, que, ao inserir um novo elemento, seleciona a região da árvore que tem
menor ocupação (a região mais vazia), com o objetivo de maximizar a ocupação de cada
região. Para particionamento (split), a Slim-Tree utiliza um algoritmos baseado na MST
(Minimum Spanning Tree), em que é criada uma Árvore Geradora Mínima para os elemen-
tos e remove-se a aresta de maior valor (aresta com maior distância entre dois elementos).

39
Srep1
Si
Srep2
x Srep1
Si
Srep2
Figura 16: Um exemplo do algoritmo de Slim-Down. O elemento Si a esquerda passa a pertencera outra região, reduzindo o raio de uma das regiões, sem aumentar o raio da outra. Fonte:Adaptada de Zezula et al. (2006).
Este algoritmo possui tempo computacional m2 logm, apresentando menor tempo
computacional do que o algoritmo mais efetivo da M-Tree para particionamento, que é
cúbico.
Em Traina Jr. et al. (2000) também foi proposto um algoritmo de pós processa-
mento para diminuir a sobreposição entre as regiões (problema da interseções entre os
elementos, muito comum na M-Tree), o algoritmo Slim-Down. Este algoritmo baseia-se
em transferir um elemento de uma região para outra quando isso proporciona uma redu-
ção no raio desta região, sem que o raio da outra seja modi�cado, conforme apresentado
na Figura 16.
2.4.2.3 D-Index
Proposto por Dohnal et al. (2003), a D-Index é uma estrutura de indexação métrica
baseado em hashing. O objetivo é minimizar o número de acessos a disco e número de
x
dm
p 2p S[0] 1,p
Sl - 1 1,p
S[1] 1,p
O3
O1
O2
Figura 17: Ilustração da estrutura de uma D-Index. Fonte: Adaptada de Zezula et al. (2006).

40
Figura 18: Diagrama da estrutura D-Index. Fonte: (DOHNAL, 2004).
cálculos de distâncias.
Na estrutura D-Index, escolhe-se um elemento pivot, de�ni-se um raio de abran-
gência, e uma distância para a região de exclusão. Na inserção, todos os elementos que
�carem na região interna da coroa circular, apresentada na Figura 17, serão armazenados
em um bucket, e todos os elementos que �carem na região externa serão armazenados em
outro bucket da estrutura, que são chamados de buckets separáveis.
Portanto, para todos os elementos na coroa circular, a região de exclusão, serão
armazenado no bucket de exclusão. No entanto, esta estrutura pode ser organizada com
maior número de níveis e buckets em cada um deles, conforme apresentado na Figura 18,
sendo que em cada nível usa-se uma função de particionamento (split) distinta para par-
ticionar o espaço de modo a se armazenar os objetos de forma e�ciente.
No exemplo da Figura 18, no primeiro nível, os elementos serão armazenados em
quatro diferentes buckets, e para os elementos que �carem na região de exclusão, serão
armazenados no segundo nível e será criado mais quatro buckets para este, e então o
processo se repete até que todos os elementos que não se enquadrarem em nenhum dos
buckets �carão na região de exclusão global de toda a estrutura.

41
2.5 Trabalhos Relacionados
No trabalho de Sivic e Zisserman (2009), foi apresentado uma abordagem para
recuperação de vídeos baseado nos sistemas de recuperação de informação baseado em
texto.
Nesta abordagem, os quadros-chave do vídeo são indexados em uma estrutura de
arquivo invertido, utilizado métodos sequenciais de acesso a disco, em que cada quadro é
representado por uma bag of feature.
Nesta abordagem, Sivic e Zisserman (2009) utilizam um vocabulário visual para
compor o índice. Este vocabulário visual é construindo a partir da clusterização de
descritores extraídos de regiões de interesses da imagem. Na recuperação, é retornado os
quadros do vídeo utilizando o modelo vetorial para cálculo da similaridade entre a bag of
feature dos quadros da base e a bag of feature da imagem de consulta. Posteriormente, a
consistência espacial é calculada para reordenar os quadros, sendo que a distribuição das
palavras visuais ao logo do quadro determina se este é mais ou menos relevante, e assim
ele pode ser reclassi�cado.
No trabalho de Homola, Dohnal e Zezula (2010) foi proposto uma abordagem para
busca de uma subregião de uma imagem. Neste trabalho as imagem da base são também
descritas utilizando descritores de região de interesse. Para a indexação dos elementos,
foi implementado a M-Tree como estrutura de indexação.

42
3 INDEXAÇÃO E RECUPERAÇÃO DE VÍDEOS UTILIZANDOVOCABULÁRIO VISUAL
Este trabalho tem como proposta a análise de estruturas métricas para indexação
e recuperação de vídeos. Neste capítulo, será apresentado o processo desenvolvido para
indexação e recuperação de vídeos, bem como a utilização das estruturas para tais ope-
rações.
Como apresentado anteriormente, um vídeo contém uma grande quantidade de
informação, portanto, de forma a viabilizar a realização do processo de recuperação, é
comum subdividir o armazenamento nas seguintes etapas: segmentação do vídeo, extração
de características e descrição do conteúdo. Finalmente, na etapa de indexação, uma
estrutura é utilizada para armazenar o conteúdo descrito do vídeo para sua posterior
recuperação.
Por sua vez, o processo de busca apresentado neste trabalho inicia-se a partir de
uma imagem de consulta (ou mesmo de uma região de uma imagem), na qual se realiza
a extração de características para então se empregar métodos de busca para recuperação
do conteúdo do vídeo similar a consulta.
Este capítulo está organizado da seguinte forma. Na seção 3.1, é descrito o processo
de indexação de vídeos. Já a seção 3.2 aborda o processo de recuperação. A seção 3.3 apre-
senta as três estruturas métricas utilizadas neste trabalho para indexação e recuperação
de vídeo. Por �m, na seção 3.4 serão apresentadas considerações �nais do capítulo.
3.1 Processo de Indexação de Vídeos
A Figura 19 apresenta uma visão geral do processo de indexação de vídeo desenvol-
vido neste trabalho, em que os quadros do vídeo são descritos através de um vocabulário
visual. Inicialmente, como pode ser visto na Figura 19, o vídeo precisa ser segmentado
e seus quadros-chave devem ser devidamente selecionados. Os quadros-chaves seleciona-
dos são usados tanto para criar o vocabulário visual como para indexar o conteúdo do
vídeo. Para criar o vocabulário visual, uma amostra dos quadros-chave é obtida. Então,
é realizado um processo de identi�cação e descrição de características e, posteriormente,
no processo de clusterização, estas características são agrupadas em classes de descri-
tores, chamadas de palavras visuais, que são inseridas em uma estrutura de indexação,
constituindo então o índice do arquivo invertido.
Para indexar o conteúdo do vídeo, os quadros-chave selecionados são submetidos

43
Segmentação
Amostragem dos quadros-chave
Extração de Descritores
Indexação
Extração de Descritores Clusterização
Índice
Criação do vocabulário visual
Estrutura de Indexação (Arquivo Invertido)
Indexação dos quadros do vídeo
Criação do índice
Figura 19: Processo de indexação de vídeo. Fonte: Elaborada pelo autor.
ao mesmo processo de identi�cação e descrição de características, que por sua vez, são
classi�cadas dentro das palavras visuais do índice e indexadas no arquivo invertido.
3.1.1 Segmentação do Vídeo
Como mencionado anteriormente, um vídeo é composto por várias imagens, sendo
necessário segmentá-lo. Neste trabalho são utilizadas duas abordagens para segmentação
de vídeo: na primeira, como um vídeo pode conter geralmente de 24 a 30 quadros por
segundo (podendo esta taxa variar), seleciona-se um quadro a cada segundo do vídeo,
sem que nenhuma operação sobre os quadros seja realizada. Já na segunda abordagem,
foi utilizada a detecção de tomadas apresentada em Guimarães et al. (2009) e Patrocínio
Jr. et al. (2010). Nesta abordagem a transição entre duas tomadas é identi�cada pela
existência de dissimilaridade entre os quadros, uma vez que quadros similares são con-
siderados pertencentes a mesma tomada. Em Guimarães et al. (2009), foi apresentada
uma técnica de identi�cação de transições abruptas, enquanto que em Patrocínio Jr.
et al. (2010) foi apresentado um método que identi�ca tanto transições abruptas quanto
graduais entre duas tomadas. Em seguida, um quadro de cada tomada é então extraído do
vídeo (quadro-chave), e os demais quadros são desconsiderados. Daí em diante os quadros-
chave extraídos passam a representar o conteúdo das tomadas e, consequentemente, de
todo o vídeo.
A etapa de segmentação de vídeo é importante por auxiliar na identi�cação de

44
Vídeo Quadros-chave
Segmentação/ Sumarização
Amostragem dos quadros-chave
Amostra dos quadros
Figura 20: Processo de amostragem aleatória dos quadros-chave do vídeo. Fonte: Elaboradapelo autor.
quadros-chave e assim reduzir o conteúdo visual que será armazenado. Além disso, a
abordagem de detecção de tomadas permite que apenas um quadro de cada tomada seja
selecionado, reduzindo ainda mais o número de informações a serem armazenadas sem
perder informações relevantes que caracterizam o vídeo.
O objetivo de se aplicar duas abordagens de segmentação diferentes é mensurar o
impacto da detecção de tomadas nas métricas utilizadas para avaliação dos testes realiza-
dos, uma vez que a �segmentação por amostragem� pode desconsiderar quadros relevantes
do vídeo, ou até mesmo considerar dois ou mais quadros muito semelhantes (caso sejam
quadros de mesma tomada), e assim contribuir para o aumento da quantidade de infor-
mação armazenada, impactando no tempo de resposta sem necessariamente melhorar a
taxa de acerto das buscas realizadas.
3.1.2 Construção do Vocabulário Visual
O método de indexação e recuperação de vídeo deste trabalho baseia-se na utili-
zação de vocabulário visual, abordagem similar àquela apresentada por Sivic e Zisserman
(2009). Como descrito anteriormente, Sivic e Zisserman (2009) apresentam uma aborda-
gem de recuperação de vídeo análoga ao método utilizado na recuperação de textos. Nesta
abordagem, deve-se criar um vocabulário composto por palavras visuais (semelhante às
palavras textuais em sistemas de recuperação de texto). Estas palavras visuais são obtidas
por meio da clusterização do conteúdo visual dos quadros do vídeo. Porém, para criação
do vocabulário visual, utiliza-se apenas uma amostra aleatória dos quadros selecionados
na etapa de segmentação (quadros-chave selecionados do vídeo), conforme processo apre-
sentado na Figura 20. O ideal seria que esta amostra representasse o conteúdo visual de
todo o vídeo do qual ela foi extraída, podendo ser obtida, por exemplo, através de técnicas
de sumarização. Neste trabalho, optou-se pela utilização de uma amostra aleatória dos
quadros-chave, semelhante ao realizado por Sivic e Zisserman (2009).
Segundo Sivic e Zisserman (2009), a ideia de se utilizar apenas uma amostra dos

45
(a) (b)
Figura 21: Regiões de interesse de um quadro do vídeo. Em (a) são exibidas as regiões deinteresse detectadas pelo Harris A�ne e em (b) regiões de interesse detectadas pelo MSER.Fonte: Elaborada pelo autor.
quadros-chave do vídeo, no lugar de todos os quadros, se justi�ca pelo alto custo compu-
tacional deste processo, como descrito nas seções a seguir.
3.1.2.1 Extração de Descritores dos Quadros Selecionados
Para a construção do vocabulário visual, é necessário, primeiramente, obter a des-
crição dos quadros selecionados do vídeo. Em um sistema de recuperação de informação
baseado em conteúdo visual, deve-se gerar algum tipo de descrição deste conteúdo visual
(como por exemplo a utilização de histograma do cores) para que, então, esta informação
seja manipulada e armazenada.
Sendo assim, realiza-se a extração de características de cada um dos quadros se-
lecionados para a amostra de quadros-chave do vídeo. Este processo de extração de
características de quadros do vídeo é baseado na detecção de regiões a�m covariantes,
que, como descrito anteriormente, são regiões invariantes a mudança de ponto de visão,
de escala, de iluminação e também capazes de lidar com a oclusão (MIKOLAJCZYK et al.,
2005).
Neste trabalho foram utilizados dois tipos de detectores de regiões a�m covariantes,
conforme apresentado em Mikolajczyk et al. (2005): o detector MSER (Maximally Stable
Extremal Region) e o detector Harris-A�ne, que identi�cam regiões de interesse nos qua-
dros do vídeo baseado em suas características de reconhecimento. Na Figura 21(a) cada
elipse representa uma região de interesse obtida pelo detector Harris-A�ne, enquanto que
na Figura 21(b) cada elipse corresponde a uma região identi�cada pelo MSER.
A escolha de tais detectores se motivou pelo fato de que eles identi�cam pontos de
interesse de natureza complementar, isto é, MSER identi�ca regiões enquanto que Harris
A�ne identi�ca cantos e bordas (MIKOLAJCZYK et al., 2005).
Para se descrever as regiões identi�cadas por cada um dos detectores foi utilizado
o descritor SIFT (Scale Invariant Feature Transform), que produz um vetor de caracte-

46
rísticas de 128 dimensões (LOWE, 1999). O SIFT é aplicado em cada região de interesse
detectada no quadro do vídeo, gerando assim um vetor de características (chamado de
descritor) para cada uma destas regiões. Dependendo das características presentes nos
quadros, centenas (ou até mesmo milhares) de descritores podem ser gerados para cada
quadro do vídeo.
3.1.2.2 Processo de Clusterização
Uma vez obtidos todos os descritores para cada um dos quadros da amostra, é
necessário realizar a clusterização destes descritores para gerar palavras visuais que irão
compor o vocabulário visual do vídeo. Para obtenção do vocabulário visual, foi utilizado
a implementação do algoritmo de clusterização K-means, apresentado em Kanungo et al.
(2002), agrupando-se, assim, os descritores em classes ou palavras visuais.
A clusterização é realizada de forma separada para cada tipo de detector utilizado.
Desta forma, o algoritmo K-means foi executado para cada detector separadamente, ge-
rando um conjunto de centróides. Neste contexto, cada um dos centróides representa uma
palavra visual do vocabulário.
Ao �nal do processo de clusterização, dois conjuntos de palavras visuais são obtidos:
um conjunto com todas as palavras visuais originadas dos descritores gerados a partir do
detector MSER e outro conjunto com as palavras originadas dos descritores gerados a
partir do detector Harris-A�ne. Entretanto, para obtenção do vocabulário, as palavras
visuais destes dois conjuntos criados separadamente, devem ser unidas para compor o
vocabulário do vídeo. Depois que o vocabulário visual é criado não há mais distinção entre
descritores, pois o intuito é uni�car as diferentes características presentes nos quadros do
vídeo em um único vocabulário visual, conforme pode ser visto na Figura 22.
3.1.2.3 Eliminação de Stopwords
Semelhante ao processo de recuperação de textos, após o processo de clusterização
para obtenção das palavras visuais é necessário eliminar um conjunto de palavras muito
frequentes, denominado stopwords (FRAKES; BAEZA-YATES, 1992), isto é, palavras que
estão presentes na maioria dos quadros do vídeo.
Ao �nal do processo de clusterização, obtém-se os centróides juntamente com a
frequência dos descritores associados a cada cluster nos quadros do vídeo utilizados para
criação do vocabulário. Desta forma, os centróides com maior frequência estão presentes
na maioria dos quadros e devem ser eliminados do vocabulário.
O objetivo da eliminação de stopwords é reduzir o número de características que,
por ocorrerem em muitos quadros distintos do vídeo, serão pouco discriminativas para

47
Amostra dos Quadros
Detecção (Harris-Affine)
Detecção (MSER)
SIFT
... 23 54 32
... 54 67 98
... 12 43 32
... 63 35 87
K-means
K-means
... 21 32 45
... 46 90 21
... 73 37 78
... 43 23 65
StopList
Vocabulário Visual
SIFT
76 80 81
13 34 98 ...
93 73 95 ...
... 21 32 45
... 43 23 65
33 22 69 ...
StopList
... 43 23 65
33 22 69 ...
43 23 65
93 73 95 ...
...
... 43 23 65
33 22 69 ...
43 23 65
93 73 95 ...
...
Figura 22: Processo de criação do vocabulário visual. Fonte: Elaborada pelo autor.
representar um determinado quadro. A Figura 22 ilustra o processo completo de criação
do vocabulário visual e a eliminação de stopwords.
No capítulo de experimentos será apresentada uma análise sobre o impacto do
tamanho do vocabulário visual no processo de busca.
3.1.3 Indexação dos Quadros-chave do Vídeo
No processo de indexação do vídeo, é utilizada uma estrutura de arquivo invertido
para armazenamento dos quadros do vídeo. Após geração do vocabulário visual e elimi-
nação de stopwords, é necessário criar o índice do arquivo invertido com as palavras do
vocabulário visual. O método de indexação dos quadros será apresentado em detalhes nas
próximas seções.
3.1.3.1 Criação do Índice do Arquivo Invertido
O processo de criação do índice do arquivo invertido consiste na inserção de todas
as palavras visuais geradas no processo de clusterização, descrito anteriormente conforme
Figura 22. Este processo é feito separadamente pois não depende do conteúdo dos quadros
que serão indexados (apenas do vocabulário visual). Uma vez criado, nenhuma nova
inserção será realizada no índice (apenas ajustes de referências).
A Figura 23 ilustra o processo de inserção do vocabulário visual no índice do arquivo
invertido. Tal índice será, posteriormente, utilizado para indexação dos quadros-chave do

48
Índice Estrutura de Indexação
(Arquivo Invertido)
Vocabulário Visual
... 43 23 65
33 22 69 ...
43 23 65
93 73 95 ...
...
Figura 23: Processo de inserção do vocabulário visual no índice. Fonte: Elaborada pelo autor.
vídeo.
3.1.3.2 Extração de Descritores dos Quadros-chave do Vídeo
Semelhante ao processo descrito na seção 3.1.2.1, é necessário extrair as carac-
terísticas dos quadros-chave do vídeo, utilizando os mesmos detectores de regiões a�m
covariantes, Harris-A�ne e MSER, e também utilizando o descritor SIFT para descrever
tais regiões.
A Figura 24 ilustra o processo de descrição de um dos quadros-chave do vídeo.
Ao �nal deste processo, é importante observar que, os descritores gerados não podem ser
considerados palavras visuais, e sim, apenas simples descritores de regiões do quadro.
O processo ilustrado na Figura 24 é realizado para todos os quadros-chave do vídeo.
Desta forma, cada quadro do vídeo será representado por um conjunto de descritores que,
por sua vez, serão indexados pelo arquivo invertido.
3.1.3.3 Construção de Bag of Features dos Quadros
Durante a indexação cada quadro passa a ser representado por um bag of words ou
bag of features (histograma das palavras visuais do vocabulário). Portanto é necessário
se calcular a frequência de cada palavra visual do vocabulário para cada um dos quadros.
Tal abordagem baseia-se no trabalho de Sivic e Zisserman (2009), em que a recuperação
dos quadros do vídeo se dá por meio da utilização do modelo vetorial, processo análogo à
recuperação de texto, em que cada documento é representado por um vetor de frequência
de suas palavras (bag of words).
Considerando que exista um vocabulário de V palavras visuais, cada quadro passa

49
Detecção (Harris-Affine)
Detecção (MSER)
SIFT
... 23 54 32
... 54 67 98
... 12 43 32
... 63 35 87
SIFT
... 12 43 32
... 63 35 87
23 54 32
... 54 67 98
Quadro Q
Descritores do Quadro Q
Figura 24: Processo de descrição de um dos quadros-chave do vídeo. Fonte: Elaborada peloautor.
a ser representado por um vetor de V elementos, conforme apresentado na Equação 2.
vd = (t1, ..., ti, ..., tV )T (2)
Cada elemento ti do vetor vd é obtido pelo produto entre a frequência da palavra
no quadro e a frequência inversa do quadro (ver Equação 3).
ti =nid
nd
logN
Ni
(3)
em que nid é o número de ocorrências da palavra i no quadro d, nd é o número total de
palavras no quadro d, Ni é o número de quadros que contém a palavra i, e N é o número
total de quadros indexados na base (SIVIC; ZISSERMAN, 2009).
A Figura 25 ilustra o processo de criação de bag of features para os quadros-chave
do vídeo.
3.1.3.4 Indexação utilizando Arquivo Invertido
Para cada quadro-chave do vídeo, cada um de seus descritores será pesquisado
no índice do arquivo invertido, com o intuito de se determinar qual das palavras visuais
melhor representa este descritor. Este processo é realizado através do cálculo da distância
entre cada um dos descritores do quadro e todas as palavras visuais armazenadas. Como
as palavras foram geradas pelo processo de clusterização, cada palavra (cluster) possui
um raio (maior distância entre o centróide e quaisquer dos descritores daquele cluster).
Se a distância calculada entre um descritor e a palavra for menor ou igual ao raio da-

50
... 23 54 32
... 54 67 98
... 12 43 32
... 63 35 87
Descritores do Quadro Qi
Índice Vocabulário
Visual
V
ti
Cálculo de Frequência
Figura 25: Criação das bag of features dos quadros do vídeo. Fonte: Elaborada pelo autor.
quela palavra visual (que é o centroide do cluster), este descritor será considerado como
pertencente a este cluster. Esta classi�cação signi�ca que tal palavra visual ocorre no
quadro-chave em questão.
Para melhor classi�cação, cada descritor deve ser sempre analisado com todas as
palavras visuais até encontrar a palavra de menor distância, pois quanto menor a distância,
maior será a similaridade entre o descritor e a palavra visual.
Tal processo é ilustrado na Figura 26. Porém, mais adiante, ainda neste capí-
tulo, mais detalhes sobre este processo de indexação e o uso de estruturas métricas para
melhorar a e�ciência serão apresentados.
Índice
Estrutura de Indexação (Arquivo Invertido)
... 23 54 32
... 54 67 98
... 12 43 32
... 63 35 87
Descritores do Quadro Qi
Q1 Q2 Qn
Indexação dos quadros do vídeo
Busca
Figura 26: Processo de indexação dos quadros-chave. Fonte: Elaborada pelo autor.

51
1
Índice
Estrutura de Indexação (Arquivo Invertido)
Busca Extração de Descritores
Ordenados por similaridade entre BoFs
Imagem de consulta
Consistência Espacial
Ordenados pela consistência espacial
1-NN Classificação Vetorial
Δ
Figura 27: Processo de busca. Fonte: Elaborada pelo autor.
3.2 Processo de Recuperação de Vídeos
A Figura 27 ilustra o processo de recuperação do vídeo por meio de uma imagem
(ou região de uma imagem) de consulta, em que, primeiramente, a imagem de consulta
é descrita utilizando o mesmo processo aplicado aos quadros-chave (isto é, processo de
detecção de regiões de interesse e extração de descritores). Posteriormente, a busca é
realizada e recupera-se todos os quadros-chave que possuam alguma palavra visual em
comum com a imagem (ou região) de consulta.
Seguindo o trabalho de Sivic e Zisserman (2009), durante o processo de recupera-
ção, os quadros-chave são classi�cados utilizando o modelo vetorial, em que a similaridade
é obtida pelo cálculo do cosseno do menor ângulo entre o vetor que representa a imagem
ou região de consulta e os vetores da base (associados aos quadros-chave do vídeo). Os
quadros obtidos como resposta são ordenados de acordo com tais valores de similaridade,
e assim são retornados.
Ao �nal deste processo, os quadros-chaves retornados são submetidos ao processo
de consistência espacial, no qual serão reordenados, com o intuito de que os quadros-chave
mais similares à imagem (ou região) da consulta obtenham melhor classi�cação e assim
serão retornados.

52
3.2.1 Consistência Espacial
Baseado na técnica de ordenação do resultado de consulta utilizada pelos sistemas
de recuperação de texto, Sivic e Zisserman (2009) apresentam uma técnica análoga para
classi�cação dos quadros no resultado da consulta. Em tal abordagem, após a recuperação
dos quadros do vídeo realizada utilizando o modelo vetorial descrito anteriormente, é
realizada uma nova classi�cação dos quadros do vídeo baseado na distribuição espacial
das regiões covariantes do quadro.
Esta abordagem baseia-se na escolha aleatória de uma palavra (região covariante)
da imagem de consulta e na busca desta mesma palavra no quadro do vídeo retornado da
base. Após encontrada a palavra correspondente, as palavras espacialmente mais próximas
da palavra selecionada são obtidas, tanto na imagem de consulta quanto no quadro do
vídeo retornado. Desta forma, é calculada a correspondência destas palavras da imagem
de consulta com o quadro da base, em que, a cada ocorrência um voto é computado para
à palavra do quadro da base, e somente uma única vez para cada palavra. Este processo
é realizado entre a imagem de consulta e todos os quadros do vídeo que têm alguma
similaridade no cálculo do modelo vetorial.
Desta forma, têm-se no �nal do processo, o somatório da quantidade de votos
que cada quadro da base recebeu. Assim, a nova classi�cação dos quadros é realizada,
somando-se a quantidade de votos com o valor da similaridade de cada documento na
base (calculado utilizando o modelo vetorial) em que os quadros com maior valor são
considerados os mais relevantes (SIVIC; ZISSERMAN, 2009).
Este processo heurístico para cálculo da consistência espacial, apresentado por Sivic
e Zisserman (2009) e utilizado neste trabalho para reclassi�cação dos quadros, pode ser
muito caro computacionalmente em termos de tempo, pelo fato de que deve ser realizado
para todas as palavras de todos os quadros retornados da base para cada palavra da
imagem de consulta.
Devido a este alto custo computacional (em relação ao tempo), neste trabalho
se propõe que parte do processo seja realizado no momento da indexação, assim para
cada quadro indexado do vídeo são calculados e armazenados, para cada palavra visual,
as palavras visuais mais próximas, utilizando uma Kd-tree como estrutura auxiliar na
descoberta das k palavras mais próximas.
Para cada uma das palavras é necessário armazenar em uma estrutura e�ciente
quais são as palavras espacialmente mais próximas. Sendo assim, um outro arquivo inver-
tido é utilizado, sendo que, o índice deste é composto por todas as palavras do quadro, e
cada palavra será associada a uma lista das palavras mais próximas do quadro em questão.

53
Este processo é realizado para cada quadro-chave indexado do vídeo, com o objetivo
de diminuir o tempo computacional no momento da busca. O algoritmo para o processo
de consistência espacial consiste dos seguintes passos (SIVIC; ZISSERMAN, 2009):
a) selecione uma palavra visual pc aleatoriamente na imagem de consulta;
b) pesquisar pela ocorrência da palavra visual pc no quadro da base. Caso não
encontre, repita o passo �a� e selecione outra palavra visual na imagem de
consulta, do contrário, execute passo �c�;
c) calcular a distância espacial das coordenadas da palavra visual pc para cada
uma das demais palavras visuais pci da imagem da consulta;
d) repita o passo �c� para o quadro da base;
e) ordene a lista de palavras visuais da imagem de consulta de forma ascendente
pela distância entre cada palavra visual pci e a palavra visual pc;
f) repita o passo ��e� para o quadro da base;
g) para cada uma das 15 primeiras palavras visuais pci da imagem da consulta,
pesquisar sua ocorrência nas 15 primeiras palavras visuais do quadro da base,
caso encontre, contabilize para a palavra visual pci da imagem da consulta e
também a palavra visual do quadro da base um voto, e as marque para que
não sejam mais votadas;
h) repita os passos de �a� até �g� para as demais palavras visuais da imagem de
consulta que não tenham sido votadas;
i) somar o total de votos que o quadro da base atual recebeu;
j) repita os passos de �a� até �i� para cada quadro da base retornado como res-
posta à consulta;
k) ordene o resultado pelos quadros da base mais votados.
A Figura 28 ilustra os passos do processo de consistência espacial descritor nos
passo do algoritmo apresentado.
Como descrito anteriormente, para diminuir o tempo de processamento para rea-
lização da consistência espacial, neste trabalho alguns passos do algoritmo são realizados
previamente, no momento da indexação dos quadros.
No momento da indexação de cada quadro do vídeo, utiliza-se uma Kd-Tree para
armazenar todas as palavras visuais do quadro em questão e então realiza uma busca, na
Kd-Tree para retornar as 15 palavras mais próximas de cada uma das palavras. Além
disso, um arquivo invertido é criado para cada quadro do vídeo indexado, em que cada
uma das palavras visuais será associada a uma lista com as 15 palavras visuais mais
próximas a ela, evitando que este processamento seja realizado no momento da busca.

54
Imagem de Consulta Quadro do Vídeo da Base
Busca por Abrangência r = 0
(a)
Imagem de Consulta Quadro do Vídeo da Base
(b)
Imagem de Consulta Quadro do Vídeo da Base
(c)
Imagem de Consulta Quadro do Vídeo da Base
(d)
Figura 28: Em (a) Passos 1 e 2 do processo de consistência espacial, em (b) seleção das palavrasespacialmente mais próximas do quadro da base e da imagem de consulta, em (c) e (d) passo 7dos processo de consistência espacial. Fonte: Adaptada de Sivic (2006).
Desta forma, para a execução do passo 4, apenas uma busca na lista da palavra é
realizada para retornar as 15 palavras visuais mais próximas, reduzindo assim, o tempo
para realização da consistência espacial.
3.3 Utilização de Estruturas Métricas de Indexação
O objetivo da utilização de um arquivo invertido se dá pelo fato da sua e�ciência
no processo de busca, apesar da desvantagem de ocupar muito espaço em disco.
A busca em um arquivo invertido é realizada no índice que, no contexto deste tra-
balho, é composto pelo vocabulário visual (palavras visuais). Cada palavra está associada
a uma lista contendo todos os quadros do vídeo em que ela está presente. Este processo
ocorre tanto no momento da indexação dos quadros-chave do vídeo, quanto no estágio de
busca e realização da consistência espacial, que é ilustrado na Figura 27.
Dependendo do tamanho do vocabulário, o processo de busca no índice do arquivo
invertido pode ser muito caro computacionalmente, em relação ao tempo, principalmente
se o resultado é obtido por meio de busca sequencial, em que todas as palavras do voca-
bulário são veri�cadas e o cálculo de distância para cada uma delas seja realizado.
Existem estruturas que podem se comportar de maneira mais e�ciente no processo
de busca, como as estruturas métricas apresentadas no capítulo anterior. Para avaliação

55
do processo de indexação e busca de vídeo, foram implementadas três outras estruturas
(além do acesso sequencial já utilizado) para acesso ao índice do aquivo invertido: a M-
Tree (CIACCIA; PATELLA; ZEZULA, 1997), a D-Index (DOHNAL et al., 2003) e a Slim-Tree
(TRAINA JR. et al., 2000), uma variação da M-Tree.
O processo utilizado para indexação e busca do vídeo se mantém o mesmo para
as diferentes estruturas, pois as estruturas são aplicadas apenas como mecanismo para
acesso/busca no índice do arquivo invertido.
As estruturas implementadas também são utilizadas para o processo de consistência
espacial, elas também constituem o índice dos arquivos invertidos que são criados para os
quadros-chaves indexados.
Mais adiante, no capítulo de experimentos, serão apresentados os resultados das
buscas, como também os números de acessos a disco e de cálculos de distância necessários
para cada estrutura utilizada.
3.4 Considerações Finais
Este capítulo apresentou o método utilizado para indexação e busca de vídeos
utilizado neste trabalho. Como descrito, o método baseia-se no processo de recuperação de
texto, apresentado por Sivic e Zisserman (2009), utilizando um vocabulário visual criado a
partir de uma amostra dos quadros do vídeo. Porém, diferentemente do trabalho de Sivic
e Zisserman (2009), este propõe a utilização de estruturas métricas de indexação para uso
tanto durante a busca dos quadros-chaves quanto durante o processo de classi�cação por
meio da consistência espacial.

56
4 ANÁLISE DA UTILIZAÇÃO DE ESTRUTURAS MÉTRICAS NAINDEXAÇÃO E RECUPERAÇÃO DE VÍDEOS
Neste capítulo serão apresentados os experimentos de indexação e recuperação de
vídeos realizados com as diferentes estruturas de indexação descritas anteriormente, com
o intuito de se obter uma avaliação destas estruturas em relação ao processo de criação do
índice e indexação dos quadros do vídeo, como também obter uma avaliação em relação
ao processo de busca, no qual, foram utilizadas métricas quantitativas para se medir os
resultados.
Para a indexação do vídeo foi utilizada a abordagem descrita anteriormente com
arquivo invertido, em que o índice do mesmo foi implementado de quatro formas diferen-
tes. Em um primeiro momento o índice foi implementado por meio de acesso sequencial ao
disco, sem utilizar nenhuma estruturas para otimizar o tempo de busca. Isso foi feito tanto
para avaliar o real impacto das estruturas de indexação, como também para se comparar
com os resultados de Sivic e Zisserman (2009). Além da abordagem sequencial foram
também implementadas e testadas as seguintes estruturas de indexação: M-Tree (CIAC-
CIA; PATELLA; ZEZULA, 1997), Slim-Tree (TRAINA JR. et al., 2000) e D-Index (DOHNAL et
al., 2003), todas utilizadas como estrutura de indexação do arquivo invertido usado para
as buscas como para os arquivos invertidos usados na realização de consistência espacial.
4.1 Parâmetros de Testes
Para realização dos experimentos, foi utilizado o vídeo de um dos capítulos da série
The Big Bang Theory da CBS (Columbia Broadcasting System). O vídeo contém 28682
quadros e possui duração de 19 minutos de 56 segundos. O vídeo possui 476 tomadas,
sendo que o tamanho médio das tomadas é de 59 quadros.
Toda a implementação para indexação e recuperação de vídeos, bem como as es-
truturas de indexação foram codi�cadas na linguagem de programação C#, por meio da
plataforma Microsoft Visual Studio 2008, sem auxílio de nenhuma biblioteca adicional.
As estruturas M-Tree e Slim-Tree foram testadas com tamanho de páginas de
tamanho igual a 100 e com chaves de 128 dimensões, que é o número de dimensões das
palavras visuais. Para cálculo de distância foi utilizado a norma Euclidiana. Para a D-
Index de�niu-se o número de níveis da estrutura igual a 9, o número de entradas de cada
bloco igual a 100, a distância usada para se de�nir a região de exclusão igual a 20 e os

57
pivots foram selecionados aleatoriamente (sendo 2 pivots para o primeiro nível e 1 pivot
para os demais). Como nas demais estruturas, também foi utilizado a norma Euclidiana
para cálculo da distância e chaves de 128 dimensões. Estes parâmetros foram escolhidos
por meio de análise realizada após a obtenção de alguns resultados experimentais.
4.2 Criação do Vocabulário Visual
Inicialmente, o vídeo foi segmentado de forma simples em que um quadro por
segundo foi extraído para compor a base de dados, totalizando 1146 quadros utilizados
para representar o vídeo. A partir destes quadros, uma amostra aleatória de 96 (≈ 8%
do total) quadros foi extraída para criação do vocabulário visual (proporção semelhante
a adotada por Sivic e Zisserman (2009)).
Conforme processo descrito anteriormente, sobre os quadros da amostra do vídeo
foram executados os detectores de regiões a�m covariantes Harris-A�ne e MSER separa-
damente, em seguida, aplicou-se o SIFT para descrever as regiões identi�cadas, gerando
assim um vetor de 128 dimensões para cada região de interesse dos quadros.
Foram gerados, no total, 61628 descritores a partir dos pontos detectados pelo
MSER e 86135 descritores a partir dos pontos detectados pelo Harris-A�ne. Para cons-
trução do vocabulário visual foi realizada a clusterização dos descritores utilizando o
algoritmo K-means de forma separada para cada tipo de detector, procurando-se manter
a proporção de 3:5 em relação ao número de descritores produzidos pelo Harris-A�ne e
MSER, respectivamente, em conformidade com Sivic e Zisserman (2009).
Para os experimentos, foram criados quatro tamanhos diferentes de vocabulários:
4000, 8000, 16000 e 32000, mantendo-se a proporção de 3:5, como pode ser visto na
Tabela 1. Cada um destes vocabulários foram indexados utilizando-se do arquivo inver-
tido, cujo índice foi implementado de quatros formas diferentes, utilizando as estruturas
mencionadas anteriormente.
Para avaliação da di�culdade relacionada aos dados utilizados, foi realizada a aná-
lise de di�culdade intrínseca dos vocabulários gerados. A Figura 29 apresenta os histo-
Tabela 1: Informações sobre vocabulários visuais utilizados. Fonte: Elaborada pelo autor.
Tamanho do Número de Palavras Di�culdade
Vocabulário Harris A�ne MSER Intrínseca
4000 1500 3500 0,27788000 3000 5000 0,274116000 6000 10000 0,274732000 12000 20000 0,2694

58
0
0,005
0,01
0,015
0,02
0,025
0,03
2
22
42
62
82
102
122
142
162
182
202
222
242
262
282
302
322
342
362
382
402
422
442
462
482
502
522
542
562
582
602
622
642
662
682
702
722
742
762
782
802
822
842
862
Fre
qu
ênci
a %
Distâncias
(a) Vocabulário de tamanho 4000
0
0,005
0,01
0,015
0,02
0,025
0,03
2
22
42
62
82
102
122
142
162
182
202
222
242
262
282
302
322
342
362
382
402
422
442
462
482
502
522
542
562
582
602
622
642
662
682
702
722
742
762
782
802
822
842
862
Fre
qu
ênci
a %
Distância
(b) Vocabulário de tamanho 8000
0
0,005
0,01
0,015
0,02
0,025
0,03
2
22
42
62
82
102
122
142
162
182
202
222
242
262
282
302
322
342
362
382
402
422
442
462
482
502
522
542
562
582
602
622
642
662
682
702
722
742
762
782
802
822
842
862
Fre
qu
ênci
a %
Distâncias
(c) Vocabulário de tamanho 16000
0
0,005
0,01
0,015
0,02
0,025
0,03
2
22
42
62
82
102
122
142
162
182
202
222
242
262
282
302
322
342
362
382
402
422
442
462
482
502
522
542
562
582
602
622
642
662
682
702
722
742
762
782
802
822
842
862
Fre
qu
ênci
a %
Distância
(d) Vocabulário de tamanho 32000
Figura 29: Histogramas da distribuição de distâncias dos vocabulários gerados. Fonte: Elabo-rada pelo autor.
gramas da distribuição de distâncias para cada um dos vocabulários visuais criados, em
que se pode constatar um padrão semelhante a distribuição normal.
A última coluna da Tabela 1 apresenta os valores de di�culdade intrínseca para
cada um dos vocabulários visuais utilizados. A di�culdade intrínseca é uma métrica,
proposta por Chavez et al. (2001) para avaliar o grau de di�culdade de busca em um
conjunto de dados, conforme apresentado na Equação 4.
D =M2
2× V(4)
em que, D é a di�culdade intrínseca, M e V representam, respectivamente, a média e a
variância das distâncias entre as palavras visuais do vocabulário.
4.3 Descrição do Groundtruth
Utilizando a amostragem de um quadro por segundo, todos os 1146 quadros foram
descritos (totalizando 1667684 descritores) e indexados para sua posterior utilização nos
testes.
Para realização das consultas de teste, 10 objetos distintos foram selecionados de
diferentes quadros do vídeo, que podem ser vistos na Figura 30. Foram selecionados
alguns objetos que aparecem com muita frequência, ao longo do vídeo, de diferentes

59
1 2 3 4 5
6 7 8 9 10
Figura 30: Quadros do vídeo utilizados para consultas. O retângulo na imagem representa aregião que será utilizada para consulta. Fonte: Elaborada pelo autor.
ângulos de câmera e, em alguns momentos, são parcialmente ocultos. Foram também
escolhidos objetos com pouca ocorrência no vídeo, com intuito de avaliar a busca em
diferentes situações, algumas delas buscando objetos muito frequentes no vídeo, e em
outras situações, buscando objetos pouco frequentes ao longo do mesmo.
Para análise dos resultados das consultas criou-se um groundtruth a partir da
contagem manual das ocorrências dos objetos das consultas nos quadros indexados. Na
Tabela 2 é apresentado, para cada objeto da consulta, a quantidade de quadros e tomadas
do vídeo que contêm o objeto, como também o número de regiões de interesse detectadas
no objeto da consulta.
4.4 Descrição dos Testes Realizados
As consultas foram então realizadas para os 4 diferentes tamanhos de vocabulário
e para as 4 diferentes estruturas de indexação, com o objetivo de se medir a quantidade de
acessos a disco e o número de cálculos de distância necessários para se realizar as buscas.
Tabela 2: Groundtruth das consultas. Fonte: Elaborada pelo autor.
Objeto Quadros Tomadas Regiões de Interesse
1 83 30 212 107 35 53 123 36 1094 210 74 1035 96 33 1416 104 26 497 17 8 1188 76 19 369 4 2 13910 147 45 55

60
Além disso, ainda foram medidas as taxas de precisão e revocação para as consultas
realizadas.
Na abordagem implementada, após se obter o resultado da busca, os quadros que
compõem o resultado são reordenados pelo cálculo da consistência espacial, conforme apre-
sentado anteriormente. Para a realização da consistência espacial, optou-se por limitar
o número de quadros que serão reordenados, devido ao alto custo computacional desta
etapa em relação ao tempo de processamento. Portanto, os testes foram realizados com 4
variações do número de quadros (∆) que deveria ser retornado pela busca e reclassi�cado
pela consistência espacial: 100, 150, 200 e 250 quadros.
No cálculo de taxas de precisão e revocação, apenas as consultas cujo número de
ocorrência for menor que o limite sobre o número de quadros retornados pela busca (∆)
serão consideradas. Algumas consultas têm números de ocorrência no vídeo maior do que
alguns valores de ∆ e, portanto, nestes casos não serão consideradas.
4.5 Avaliação dos Resultados da Indexação
Nos experimentos realizados, foi avaliado o comportamento de cada estrutura sele-
cionada, no processo de criação do índice e no processo de indexação dos quadros do vídeo.
Nesta seção será apresentada uma comparação entre as estruturas para as operações men-
cionadas. A avaliação das estruturas durante o processo de busca será apresentado mais
adiante neste capítulo.
A Figura 31(a) apresenta um grá�co do número total de acessos a disco que cada
estrutura realizou para criar o índice do arquivo invertido em função do tamanho do
vocabulário visual. Pode-se observar que para vocabulários visuais menores houve pouca
diferença no desempenho. A medida que o tamanho do vocabulário visual aumenta, o
comportamento das estruturas se altera de maneira mais acentuada, por exemplo, no
caso da D-Index, houve um aumento muito signi�cativo em relação as demais estruturas,
quando o tamanho do vocabulário visual aumentou de 16000 para 32000. A M-Tree
e a Slim-Tree mantiveram um comportamento muito semelhante com os vocabulários
visuais de diferentes tamanhos. A estrutura de acesso sequencial obteve um número muito
inferior de acessos a disco em relação as demais estruturas, justamente por simplesmente
armazenar os dados sem realizar nenhuma política de armazenamento e�ciente dos dados.
A Figura 31(b) apresenta um grá�co do número total de cálculos de distância que
cada estrutura realizou para criar o índice do arquivo invertido em função do tamanho do
vocabulário visual. Neste grá�co, a estrutura de acesso sequencial não é apresentada pois
não há cálculos de distância, para esta operação devido a estrutura não realizar nenhuma

61
0,00
500000,00
1000000,00
1500000,00
2000000,00
2500000,00
3000000,00
3500000,00
4000 8000 16000 32000
Ace
sso
s a
Dis
co
Vocabulário
D-Index
M-Tree
Slim-Tree
Sequencial
(a)
0,00
1000000,00
2000000,00
3000000,00
4000000,00
5000000,00
6000000,00
7000000,00
8000000,00
9000000,00
4000 8000 16000 32000
Cál
culo
s d
e D
istâ
nci
a
Vocabulário
D-Index
M-Tree
Slim-Tree
(b)
Figura 31: (a) Grá�co do número total de acessos a disco realizado por cada estrutura paracriar o índice do arquivo invertido em função do tamanho do vocabulário visual e (b) Grá�co donúmero total de cálculos de distância realizado por cada estrutura para criar o índice do arquivoinvertido em função do tamanho do vocabulário visual. Fonte: Elaborada pelo autor.
outra operação sobre os dados no momento em que eles são inseridos. A D-Index obteve
baixos valores para o número de cálculos de distância realizados, mantendo-se sempre
com melhor desempenho que as demais estruturas, mesmo com o aumento do tamanho
do vocabulário visual. A M-Tree apresentou um desempenho pior em relação a Slim-Tree,
que foi se acentuando para os vocabulários visuais de tamanhos maiores.
A Tabela 3 apresenta de forma detalhadas os valores totais de acessos a disco e
cálculos de distância para cada uma das estruturas analisadas e cada tamanho de voca-
bulário.
O processo de indexação dos quadros do vídeo, como descrito anteriormente, en-
volve primeiramente, operações de busca nas estruturas de indexação, pois nenhum novo
elemento é inserido nos índices, apenas nas listas do arquivo invertido.
A Figura 32(a) apresenta um grá�co do número total de acessos a disco que cada
estrutura realizou para indexação dos quadros do vídeo no arquivo invertido em função
do tamanho do vocabulário visual. Pode-se observar que o comportamento das quatro
estruturas analisadas ao longo dos diferentes tamanhos para o vocabulário visual são
muito semelhantes. Sendo que a estrutura de acesso sequencial apresentou pior resultado
neste critério, e a Slim-Tree teve melhor desempenho entre as demais. A D-Index e M-
Tree apresentaram desempenho muito semelhante, com uma tendência de que o número
de acessos a disco da M-Tree cresça mais acentuadamente em função do crescimento do
vocabulário visual do que a D-Index.
A Figura 32(b) apresenta um grá�co do número total de cálculos de distância que
cada estrutura realizou para indexação dos quadros do vídeo no arquivo invertido em
função do tamanho do vocabulário visual. Neste grá�co, a estrutura de acesso sequencial
mostrou ter um desempenho muito ruim em relação as demais estruturas, chegando a
obter um número de cálculos de distância quase 6 vezes maior que as demais.

62
Tabela 3: Valores totais de acessos a disco e cálculos de distância para cada uma das estruturasanalisadas e cada tamanho do vocabulário. Fonte: Elaborada pelo autor.
Estrutura Tamanho do Número Total de Número Total de
Vocabulário Acessos a Disco Cálculos de Distância
D-Index 4000 69780 161168000 215512 3222916000 560888 6429132000 2953874 127483
M-Tree 4000 65016 6123098000 156504 146272216000 341440 325347732000 713818 7743372
Slim-Tree 4000 65484 2881628000 130650 74202616000 298904 172364032000 652696 3747896
Sequencial 4000 8000 08000 15996 016000 31982 032000 63740 0
Este comportamento pode se dá pelo fato de que, nas estruturas métricas anali-
sada (D-Index, M-Tree e Slim-Tree), a operação de busca nesta etapa de indexação dos
quadros é sempre pelo elemento mais próximo (utilizando a busca pelos vizinhos mais
próximos). No caso da estrutura de acesso sequencial, esta busca é realizada comparando
o elemento da consulta com todos os elementos do índice, processo que se mostrou muito
menos e�ciente em relação ao que as demais estruturas oferecem.
A Tabela 4 apresenta de forma detalhadas os valores totais de acessos a disco
e cálculos de distâncias para cada uma das estruturas analisadas e cada tamanho de
vocabulário no processo de indexação dos quadros.
0,00
500000000,00
1000000000,00
1500000000,00
2000000000,00
2500000000,00
3000000000,00
3500000000,00
4000000000,00
4000 8000 16000 32000
Ace
sso
s a
Dis
co
Vocabulário
D-Index
M-Tree
Slim-Tree
Sequencial
(a)
0,00
10000000000,00
20000000000,00
30000000000,00
40000000000,00
50000000000,00
60000000000,00
4000 8000 16000 32000
Cál
culo
s d
e D
istâ
nci
a
Vocabulário
D-Index
M-Tree
Slim-Tree
Sequencial
(b)
Figura 32: (a) Grá�co do número total de acessos a disco realizado por cada estrutura paraindexação dos quadros do vídeo no arquivo invertido em função do tamanho do vocabuláriovisual, e (b) o grá�co do número total de cálculos de distância realizado por cada estruturapara indexação dos quadros do vídeo no arquivo invertido em função do tamanho do vocabuláriovisual. Fonte: Elaborada pelo autor.

63
Tabela 4: Valores totais de acessos a disco e cálculos de distâncias para cada estrutura e cadatamanho de vocabulário na indexação. Fonte: Elaborada pelo autor.
Estrutura Tamanho do Número Total de Número Total de
Vocabulário Acessos a Disco Cálculos de Distância
D-Index 4000 316066610 21405599568000 603602628 428777311116000 1147674820 701613379832000 2341860070 9488917676
M-Tree 4000 354676872 9946616028000 698080184 183023127716000 1374536962 319287468132000 3012278628 5746261338
Slim-Tree 4000 20131460 19359876588000 372583608 376235791816000 737934780 764690010932000 1436032740 10541090717
Sequencial 4000 517648756 66707360008000 1008445656 1334147200016000 1979646868 2668294400032000 3563549812 53365888000
4.6 Métricas para Avaliação dos Resultados das Consultas
Em todas as consultas realizadas foram utilizadas as taxas de precisão e revocação
para se mensurar quantitativamente os resultados.
As taxas de precisão e revocação, são dadas pelas Equações 5 e 6, respectivamente.
Precisão =vp
vp+ fp(5)
Revocação =vp
vp+ fn(6)
em que vp, fp e fn representam os números de resultados verdadeiros positivos, falsos
positivos e falsos negativos, respectivamente.
Para se avaliar conjuntamente as taxas de precisão e revocação, foi utilizada a
métrica F1-Score que é dada pela Equação 7.
F1 = 2× (Precisão× Revocação)
(Precisão + Revocação)(7)

64
20,00%
22,00%
24,00%
26,00%
28,00%
30,00%
32,00%
34,00%
36,00%
38,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 33: Valores médios do F1-Score em função da quantidade de quadros retornados (∆), paracada uma das quatro estruturas analisadas, com vocabulário de tamanho 4000 e sem consistênciaespacial. Fonte: Elaborada pelo autor.
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 34: Valores médios do F1-Score em função da quantidade de quadros retornados (∆), apósa realização do processo de consistência espacial para vocabulário de tamanho 4000. Fonte:Elaborada pelo autor.

65
Tabela 5: Valores médios de Revocação, Precisão e F1-Score para as consultas realizadas, antesda realização da consistência espacial e para vocabulário de tamanho 4000. Fonte: Elaboradapelo autor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 50,00% 27,60% 35,57%150 47,29% 26,52% 33,98%200 52,58% 22,11% 31,13%250 56,26% 21,76% 31,38%
M-Tree 100 50,00% 27,60% 35,57%150 48,22% 27,04% 34,65%200 52,58% 22,11% 31,13%250 57,39% 22,20% 32,02%
SliM-Tree 100 50,00% 27,60% 35,57%150 48,22% 27,04% 34,65%200 52,58% 22,11% 31,13%250 57,39% 22,20% 32,02%
Sequencial 100 39,49% 21,80% 28,09%150 39,89% 22,37% 28,67%200 47,69% 20,06% 28,24%250 52,64% 20,36% 29,36%
4.7 Avaliação dos Resultados das Consultas Obtidos em Função do Tamanhodo Vocabulário
4.7.1 Resultados para o Vocabulário de Tamanho 4000
O grá�co da Figura 33, apresenta os valores médios do F1-Score em função da
quantidade de quadros retornados (∆), para cada uma das quatro estruturas analisadas.
Neste grá�co, nota-se que as estruturas D-Index, M-Tree e Slim-Tree tiveram praticamente
os mesmos valores de F1-Score. Já a estrutura de acesso sequencial teve um desempenho
pouco inferior as demais. A Tabela 5 apresenta de forma detalhada os valores médios
de Revocação, Precisão e F1-Score para as consultas realizadas antes da realização da
consistência espacial.
O grá�co da Figura 34 apresenta os valores médios do F1-Score em função da
quantidade de quadros retornados (∆) pelas buscas, após a realização do processo de
consistência espacial. Neste grá�co, nota-se que as estruturas D-Index, M-Tree e Slim-
Tree apresentaram valores médios similares para o F1-Score. Já a estrutura de acesso
sequencial novamente obteve um desempenho inferior às demais estruturas. A Tabela 6
apresenta de forma detalhada os valores médios de Revocação, Precisão e F1-Score para
as consultas realizadas após a consistência espacial.
O grá�co da Figura 35 apresenta os valores médios de acessos a disco em função
da quantidade de quadros retornados (∆) pela busca. Neste grá�co, os valores associados
à estrutura de aceso sequencial não foram apresentados pois o número de acessos a disco

66
Tabela 6: Valores médios de Revocação, Precisão e F1-Score para as consultas realizadas após aconsistência espacial, para vocabulário de tamanho 4000. Fonte: Elaborada pelo autor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 41,67% 43,40% 42,51%150 37,91% 34,25% 35,99%200 39,63% 29,56% 33,86%250 38,88% 27,93% 32,51%
M-Tree 100 43,48% 32,88% 37,44%150 38,04% 33,80% 35,80%200 34,87% 36,36% 35,60%250 41,57% 29,49% 34,51%
Slim-Tree 100 45,65% 34,62% 39,38%150 37,91% 34,96% 36,38%200 39,76% 29,71% 34,01%250 42,40% 30,08% 35,19%
Sequencial 100 38,04% 24,88% 30,09%150 33,69% 25,32% 28,91%200 39,63% 23,57% 29,56%250 42,61% 24,14% 30,82%
�cou 37 vezes superior a todas as demais estruturas analisadas, conforme valores médios
apresentados de forma detalhada na Tabela 7.
Observa-se que as estruturas D-Index e Slim-Tree mantiveram um comportamento
constante em relação ao número de acessos a disco independente do número de quadros
retornados (∆), sendo que a Slim-Tree obteve um número menor de acessos a disco.
O grá�co da Figura 36, apresenta os valores médios de cálculos de distância em
função da quantidade de quadros retornados pela busca, sem realização da consistência
espacial. As estruturas de acesso sequencial, Slim-Tree e D-Index tiveram um comporta-
mento semelhante, enquanto que a M-Tree obteve um melhor desempenho em relação as
demais.
0,00
2000,00
4000,00
6000,00
8000,00
10000,00
12000,00
14000,00
16000,00
18000,00
100 150 200 250
Número de Acesso a Disco
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Núm
ero
de A
cess
o a
Disc
o
Figura 35: Valores médios de acessos a disco em função da quantidade de quadros retornados(∆), para vocabulário de tamanho 4000. Fonte: Elaborada pelo autor.

67
0,00
50000,00
100000,00
150000,00
200000,00
250000,00
300000,00
350000,00
400000,00
100 150 200 250
Número de Cálculo de Distância
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
Núm
ero
de C
álcu
lo d
e Di
stân
cia
Figura 36: Valores médios de cálculos de distância em função da quantidade de quadros retor-nados, sem realização da consistência espacial e para vocabulário de tamanho 4000. Fonte:Elaborada pelo autor.
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
D-Index
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
M-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Slim-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Sequencial
Total
Cálc. Dist. Consistência
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Figura 37: Percentual do número de cálculos de distância necessários para se realizar a consis-tência espacial em relação ao número total de cálculos de distância para cada valor de ∆ e paravocabulário de tamanho 4000. Fonte: Elaborada pelo autor.
A Tabela 7 apresenta os valores médios para o número de acessos a disco e cálculos
de distância das quatro estruturas sem realização da consistência espacial.
Os grá�cos da Figura 37, apresentam o percentual do número de cálculos de dis-
tância necessários para se realizar a consistência espacial em relação ao número total de
cálculos de distância para cada uma das quantidade de quadros retornados pela busca
(∆). A Tabela 8 apresenta os valores médios de cálculos de distância somente para reali-
zar a consistência espacial juntamente com os valores totais de cálculos de distâncias da
busca ao �nal do processo da consistência espacial.
Nota-se na utilização da D-Index o impacto da consistência espacial é menor que
20%, no pior caso analisado, do valor total de cálculos de distância para realização da

68
Tabela 7: Valores médios para o número de acessos a disco e cálculos de distância das estruturassem realização da consistência espacial e para vocabulário de tamanho 4000. Fonte: Elaboradapelo autor.
Estrutura ∆ Número Médio de Número Médio de
Acessos a Disco Cálculos de Distância
D-Index 100 12006,00 308275,25150 11271,33 283228,11200 11231,78 280192,56250 11642,00 292392,90
M-Tree 100 15806,80 282841,60150 13045,56 223076,33200 8234,44 140931,56250 13554,00 228145,50
Slim-Tree 100 7545,20 336058,00150 6227,33 269601,11200 6227,33 269601,11250 6461,60 277781,30
Sequencial 100 718400,00 359200,00150 592888,89 296444,44200 592888,89 296444,44250 616000,00 308000,00
busca. Enquanto que na estrutura de acesso sequencial o impacto da consistência espacial
é aproximadamente 50% do número total de cálculos de distância da busca realizada. Nas
estruturas M-Tree e Slim-Tree, no pior caso analisado, o valor médio para os cálculos de
distância para consistência espacial não ultrapassou 40% do total da busca.

69
Tabela 8: Valores médios de cálculos de distância para realizar a consistência espacial e osvalores totais de cálculos de distâncias da busca ao �nal do processo da consistência espacial,para vocabulário de tamanho 4000. Fonte: Elaborada pelo autor.
Estrutura ∆ Número Médio de Cálculos de Distâncias
Consistência Espacial Total
D-Index 100 34569,25 342844,5150 48571,56 331799,67200 64171,22 331799,67250 80840,1 373233
M-Tree 100 217474 500315,6150 268774,56 491850,89200 233661,78 374593,33250 450237,9 678383,4
Slim-Tree 100 116048,4 452106,4150 144337,67 413938,78200 191882,89 461484250 242771,4 520552,7
Sequencial 100 10472747,2 10831947,2150 12378475 12674919,44200 16615064,78 16911509,22250 20821580,5 21129580,5
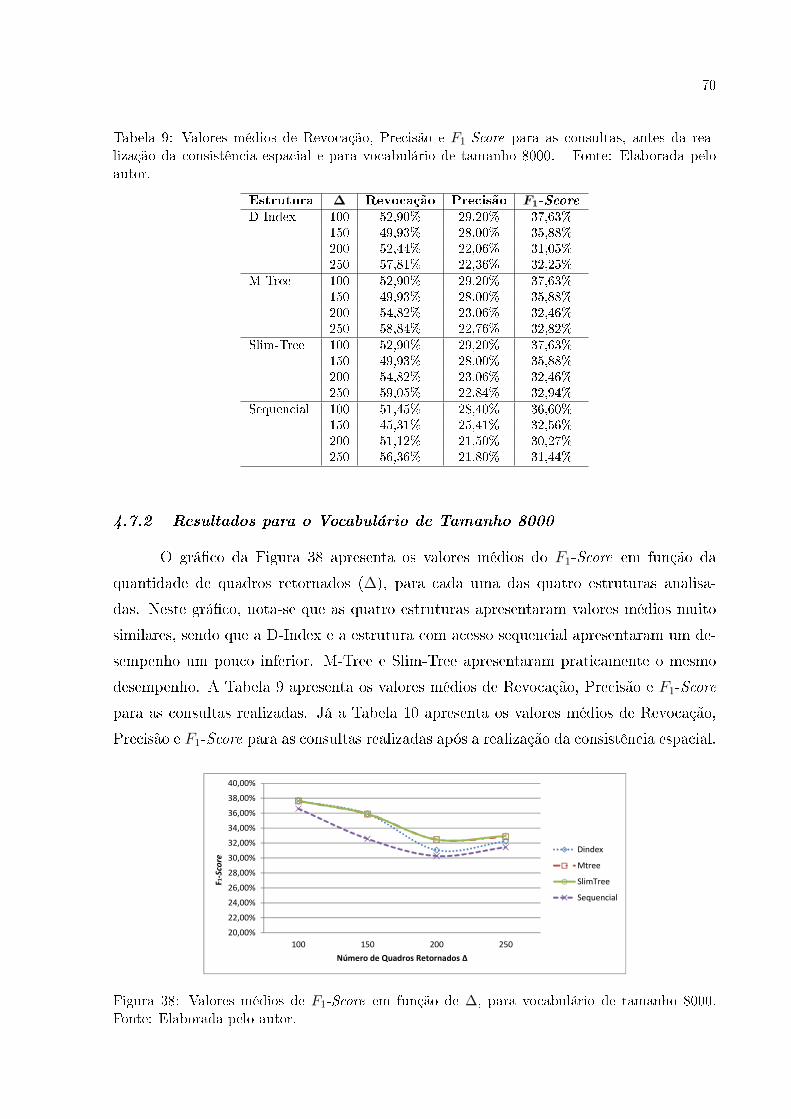
70
Tabela 9: Valores médios de Revocação, Precisão e F1-Score para as consultas, antes da rea-lização da consistência espacial e para vocabulário de tamanho 8000. Fonte: Elaborada peloautor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 52,90% 29,20% 37,63%150 49,93% 28,00% 35,88%200 52,44% 22,06% 31,05%250 57,81% 22,36% 32,25%
M-Tree 100 52,90% 29,20% 37,63%150 49,93% 28,00% 35,88%200 54,82% 23,06% 32,46%250 58,84% 22,76% 32,82%
Slim-Tree 100 52,90% 29,20% 37,63%150 49,93% 28,00% 35,88%200 54,82% 23,06% 32,46%250 59,05% 22,84% 32,94%
Sequencial 100 51,45% 28,40% 36,60%150 45,31% 25,41% 32,56%200 51,12% 21,50% 30,27%250 56,36% 21,80% 31,44%
4.7.2 Resultados para o Vocabulário de Tamanho 8000
O grá�co da Figura 38 apresenta os valores médios do F1-Score em função da
quantidade de quadros retornados (∆), para cada uma das quatro estruturas analisa-
das. Neste grá�co, nota-se que as quatro estruturas apresentaram valores médios muito
similares, sendo que a D-Index e a estrutura com acesso sequencial apresentaram um de-
sempenho um pouco inferior. M-Tree e Slim-Tree apresentaram praticamente o mesmo
desempenho. A Tabela 9 apresenta os valores médios de Revocação, Precisão e F1-Score
para as consultas realizadas. Já a Tabela 10 apresenta os valores médios de Revocação,
Precisão e F1-Score para as consultas realizadas após a realização da consistência espacial.
20,00%
22,00%
24,00%
26,00%
28,00%
30,00%
32,00%
34,00%
36,00%
38,00%
40,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 38: Valores médios de F1-Score em função de ∆, para vocabulário de tamanho 8000.Fonte: Elaborada pelo autor.

71
Tabela 10: Valores médios de Revocação, Precisão e F1-Score para as consultas após a consis-tência espacial, para vocabulário de tamanho 8000. Fonte: Elaborada pelo autor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 44,93% 35,23% 39,49%150 38,04% 38,15% 38,10%200 37,91% 31,50% 34,41%250 40,54% 31,87% 35,69%
M-Tree 100 44,57% 35,55% 39,55%150 37,65% 38,20% 37,92%200 40,55% 33,77% 36,85%250 41,37% 33,44% 36,99%
Slim-Tree 100 44,93% 35,33% 39,55%150 28,93% 33,85% 31,20%200 40,69% 33,55% 36,78%250 42,09% 33,20% 37,12%
Sequencial 100 35,87% 32,04% 33,85%150 31,31% 31,85% 31,58%200 33,16% 27,46% 30,04%250 34,75% 27,68% 30,81%
O grá�co da Figura 39 apresenta os valores médios de F1-Score em função da
quantidade de quadros retornados pelas buscas (∆), após a realização do processo de
consistência espacial. Observa-se que a M-Tree apresentou valores médios com poucas
variações, enquanto que a D-Index e a Slim-Tree apresentaram pequenas oscilações no
desempenho. A estrutura com acesso sequencial apresentou pior resultado para os casos
analisados.
O grá�co da Figura 40 apresenta o número médio de acessos a disco em função
quantidades de quadros retornados pela busca (∆). Neste grá�co, os valores médios da
estrutura de acesso sequencial não foram apresentados pois o número de acesso a disco
foi mais de 37 vezes superior a todas as demais estruturas analisadas.
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 39: Valores médios do F1-Score em função de ∆, após a realização do processo de con-sistência espacial, para vocabulário de tamanho 8000. Fonte: Elaborada pelo autor.

72
Tabela 11: Valores médios para o número de acessos a disco e cálculos de distância das estruturassem realização da consistência espacial e para vocabulário de tamanho 8000. Fonte: Elaboradapelo autor.
Estrutura ∆ Número Médio de Número Médio de
Acessos a Disco Cálculos de Distância
D-Index 100 27036,00 704913,60150 22255,56 573302,33200 22234,44 573083,11250 23287,40 603126,40
M-Tree 100 31960,00 546596,00150 25731,11 433580,78200 25731,11 433580,78250 26452,00 442474,60
Slim-Tree 100 14549,60 662970,00150 10333,78 465935,00200 12008,00 534423,78250 12476,00 553146,70
Sequencial 100 1436440,80 718220,40150 1185481,33 592740,67200 1185481,33 592740,67250 1231692,00 615846,00
Observa-se que as estruturas D-Index e M-Tree mantiveram um comportamento
semelhante em relação ao número de acessos a disco independentemente do número de
quadros retornados pela busca, já a Slim-Tree obteve, em seu pior resultado, um valor de
acesso a disco quase 50% menor do que as demais estruturas.
O grá�co da Figura 41 apresenta o número médio de cálculos de distância em
em função da quantidade de quadros retornados pela busca (∆), sem a realização da
consistência espacial. As estruturas de acesso sequencial e a D-Index apresentaram um
comportamento muito semelhante, a Slim-Tree e M-Tree apresentaram um melhor desem-
0,00
5000,00
10000,00
15000,00
20000,00
25000,00
30000,00
35000,00
100 150 200 250
Número de Acesso a Disco
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Núm
ero
de A
cess
o a
Disc
o
Figura 40: Número médio de acessos a disco em função de ∆, para vocabulário de tamanho 8000.Fonte: Elaborada pelo autor.

73
0,00
100000,00
200000,00
300000,00
400000,00
500000,00
600000,00
700000,00
800000,00
100 150 200 250
Número de Cálculo de Distância
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
Núm
ero
de C
álcu
lo d
e Di
stân
cia
Figura 41: Valores médios de cálculos de distância em função de∆, sem realização da consistênciaespacial e para vocabulário de tamanho 8000. Fonte: Elaborada pelo autor.
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
D-Index
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
M-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Slim-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Sequencial
Total
Cálc. Dist. Consistência
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Figura 42: Percentual do número de cálculos de distância necessários para se realizar a consis-tência espacial em relação ao número total de cálculos de distância para cada valor de ∆ e paravocabulário de tamanho 8000. Fonte: Elaborada pelo autor.
penho, sendo que a M-Tree manteve-se sempre com menores valores médios de cálculos
de distância do que as demais estruturas.
A Tabela 11 apresenta de forma detalhada os valores médios para o número de
acessos a disco e número de cálculos de distância das quatro estruturas, sem a realização
da consistência espacial.
Os grá�cos da Figura 42 apresentam o percentual do número de cálculos de distân-
cia necessários para se realizar a consistência espacial em relação ao valor dos cálculos de
distância totais para cada uma das quantidade de quadros retornados (∆). A Tabela 12
apresenta os valores médios de cálculos de distância somente para se realizar a consistên-
cia espacial, e os valores médios totais de cálculos de distância ao �nal do processo da
consistência espacial.

74
Tabela 12: Valores médios de cálculos de distância para realizar a consistência espacial e osvalores totais de cálculos de distâncias da busca ao �nal do processo da consistência espacial,para vocabulário de tamanho 8000. Fonte: Elaborada pelo autor.
Estrutura ∆ Número Médio de Cálculos de Distâncias
Consistência Espacial Total
D-Index 100 35886,60 740800,20150 43437,11 616739,44200 56600,88 629683,99250 72755,10 675881,50
M-Tree 100 203412,60 750008,60150 250367,00 683947,78200 331247,11 764827,89250 412031,70 854506,30
Slim-Tree 100 108448,20 771418,20150 108482,89 574417,89200 177035,89 711459,67250 221802,20 774948,90
Sequencial 100 9510376,00 10228596,40150 11787239,33 12379980,00200 15639910,00 16232650,67250 20040790,80 20656636,80
Nota-se, nos grá�cos que o comportamento das estruturas D-Index e de acesso se-
quencial foi muito semelhante ao apresentado na Figura 37 para o vocabulário de tamanho
igual a 4000. Contudo, para a D-Index, agora o impacto da realização da consistência
espacial foi menor que 10%, no pior caso analisado, do valor médio total dos cálculos
de distância para realização da busca. Na estrutura de acesso sequencial o impacto da
realização da consistência espacial é aproximadamente 50% do valores médios médio dos
cálculos de distância totais da busca realiazada. Nas estruturas M-Tree e Slim-Tree, no
pior caso analisado, o valores médios dos cálculos de distância para realização da consis-
tência espacial não passou de 35% do tatol da busca, com uma pequena vantagem para a
utilização da Slim-Tree.

75
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 43: Valores médios do F1-Score em função de ∆, após a realização do processo de con-sistência espacial, para vocabulário de tamanho 16000. Fonte: Elaborada pelo autor.
4.7.3 Resultados para o Vocabulário de Tamanho 16000
O grá�co da Figura 43 apresenta os valores médios de F1-Score em função da
quantidade de quadros retornados pela busca (∆). Pode-se observar no grá�co que as
quatro estruturas analisadas obtiveram valores médios muito similares, sendo que a es-
trutura com acesso sequencial apresentou um desempenho um pouco inferior em relação
as demais. A Tabela 13 apresenta de forma detalhada os valores médios de Revocação,
Precisão e F1-Score para as consultas realizadas.
O grá�co da Figura 44 apresenta os valores médios de F1-Score em função da quan-
tidade de quadros retornados pela busca (∆), após a realização do processo de consistência
espacial. É possível observar que todas as estruturas analisadas obtiverem desempenho
muito semelhante, porém com uma pequena vantagem da estrutura de acesso sequencial
em relação as demais, diferentemente do resultado com vocabulários de tamanho 4000 e
8000 em que a estrutura com acesso sequencial apresentou os piores resultados. A Ta-
bela 14 apresenta de forma detalhada os valores médios de Revocação, Precisão e F1-Score
para as buscas após a realização da consistência espacial.
O grá�co da Figura 45 apresenta o número médio de acessos a disco em função da
quantidade de quadros retornados pela busca (∆). Neste grá�co, os valores associados
à estrutura de aceso sequencial não foram apresentados pois o número de acesso a disco
�cou mais de 37 vezes superior a todas as demais estruturas analisada.
É possível notar que o comportamento das estruturas D-Index e M-Tree se manteve
semelhante em relação ao número de acessos a disco independentemente do número de
quadros retornados pela busca, já a Slim-Tree obteve valores médios de acesso a disco
menores que as demais.
O grá�co da Figura 46 apresenta os valores médios de cálculos de distância em

76
Tabela 13: Valores médios de Revocação, Precisão e F1-Score para as consultas, antes da rea-lização da consistência espacial e para vocabulário de tamanho 16000. Fonte: Elaborada peloautor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 55,43% 30,60% 39,43%150 50,59% 28,37% 36,36%200 55,75% 23,44% 33,01%250 57,60% 22,28% 32,13%
M-Tree 100 55,43% 30,60% 39,43%150 51,12% 28,67% 36,73%200 54,95% 23,11% 32,54%250 57,08% 22,08% 31,84%
Slim-Tree 100 55,43% 30,60% 39,43%150 51,12% 28,67% 36,73%200 54,95% 23,11% 32,54%250 57,08% 22,08% 31,84%
Sequencial 100 48,55% 26,80% 34,54%150 46,63% 26,15% 33,51%200 52,97% 22,28% 31,36%250 55,33% 21,40% 30,86%
Tabela 14: Valores médios de Revocação, Precisão e F1-Score para as consultas após a consis-tência espacial, para vocabulário de tamanho 16000. Fonte: Elaborada pelo autor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 34,78% 43,05% 38,48%150 26,82% 38,96% 31,77%200 28,80% 34,12% 31,23%250 27,82% 33,58% 30,43%
M-Tree 100 34,78% 42,29% 38,17%150 26,29% 40,12% 31,76%200 27,08% 34,98% 30,53%250 27,40% 33,72% 30,23%
Slim-Tree 100 34,78% 42,29% 38,17%150 26,42% 40,16% 31,87%200 27,21% 35,03% 30,63%250 27,51% 33,76% 30,31%
Sequencial 100 36,96% 43,22% 39,84%150 28,27% 40,07% 33,15%200 30,12% 37,19% 33,28%250 30,20% 37,29% 33,37%

77
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 44: Valores médios do F1-Score em função de ∆, após a realização do processo de con-sistência espacial, para vocabulário de tamanho 16000. Fonte: Elaborada pelo autor.
0,00
10000,00
20000,00
30000,00
40000,00
50000,00
60000,00
70000,00
100 150 200 250
Número de Acesso a Disco
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Núm
ero
de A
cess
o a
Disc
o
Figura 45: Número médio de acessos a disco em função de ∆, para vocabulário de tamanho16000. Fonte: Elaborada pelo autor.
em função da quantidade de quadros retornados pela busca (∆), sem a realização da
consistência espacial. A estrutura de acesso sequencial foi a que obteve pior resultado.
A D-Index e a Slim-Tree obtiveram valores médios muito semelhantes, enquanto que a
M-Tree obteve um melhor desempenho, mantendo-se sempre com menores números de
cálculos de distância do que as demais estruturas. A Tabela 15 apresenta os valores
médios de forma detalhada para os números de acessos a disco e cálculos de distância das
quatro estruturas, sem a realização da consistência espacial.
Os grá�cos da Figura 47, apresentam o percentual do número de cálculos de dis-
tância necessários para se realizar a consistência espacial em relação ao número total de
cálculos de distância total da busca, para cada uma das quantidade de quadros retornados
(∆). A Tabela 16 apresenta o número médio de cálculos de distância somente para se
realizar a consistência espacial juntamente com os valores médios totais de cálculos de
distância ao �nal do processo da consistência espacial.

78
0,00
200000,00
400000,00
600000,00
800000,00
1000000,00
1200000,00
1400000,00
1600000,00
100 150 200 250
Número de Cálculo de Distância
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
Núm
ero
de C
álcu
lo d
e Di
stân
cia
Figura 46: Valores médios de cálculos de distância em função de∆, sem realização da consistênciaespacial e para vocabulário de tamanho 16000. Fonte: Elaborada pelo autor.
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
D-Index
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
M-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Slim-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Sequencial
Total
Cálc. Dist. Consistência
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Figura 47: Percentual do número de cálculos de distância necessários para se realizar a consis-tência espacial em relação ao número total de cálculos de distância para cada valor de ∆ e paravocabulário de tamanho 16000. Fonte: Elaborada pelo autor.
É possível observar nos grá�cos que o comportamento das estruturas D-Index e de
acesso sequencial foram muito semelhantes ao apresentado nas Figuras 37 e 42 para os
vocabulários de tamanho 4000 e 8000, respectivamente. Contudo, com vocabulário igual
a 16000, o impacto da consistência espacial é cerca de apenas 5%, no pior caso analisado
da D-Index.
Na estrutura de acesso sequencial, o impacto da consistência espacial é pouco
menor que 50% do total de cálculos de distância da busca. Nas estruturas M-Tree e Slim-
Tree, no pior caso analisado, o número de cálculos de distância para consistência espacial
não passou de 25% do total da busca, sendo que a Slim-Tree continua a apresentar um
desempenho um pouco melhor.
79
Tabela 15: Valores médios para o número de acessos a disco e cálculos de distância das estruturassem realização da consistência espacial e para vocabulário de tamanho 16000. Fonte: Elaboradapelo autor.
Estrutura ∆ Número Médio de Número Médio de
Acessos a Disco Cálculos de Distância
D-Index 100 51213,60 1332281,80150 42541,78 1062995,78200 42536,44 1075875,78250 43861,40 1128101,10
M-Tree 100 63994,40 1069764,40150 51250,89 853477,11200 51250,89 853477,11250 52856,20 878569,80
Slim-Tree 100 29788,80 1334519,20150 24582,44 1079503,11200 24582,44 1079503,11250 25534,20 1118792,70
Sequencial 100 2871983,60 1435991,80150 2370221,56 1185110,78200 2370221,56 1185110,78250 2462614,00 1231307,00
Tabela 16: Valores médios de cálculos de distância para realizar a consistência espacial e osvalores totais de cálculos de distâncias da busca ao �nal do processo da consistência espacial,para vocabulário de tamanho 16000. Fonte: Elaborada pelo autor.
Estrutura ∆ Número Médio de Cálculos de Distâncias
Consistência Espacial Total
D-Index 100 31551,80 1363833,60150 38809,11 1101804,89200 51440,56 1127316,33250 64915,70 1193016,80
M-Tree 100 172491,20 1242255,60150 210683,67 1064160,78200 286863,11 1140340,22250 361592,60 1240162,40
Slim-Tree 100 91191,80 1425711,00150 112008,22 1191511,33200 151128,78 1230631,89250 190937,30 1309730,00
Sequencial 100 5177480,60 6613472,40150 6567195,78 7752306,56200 8840509,44 10025620,22250 11186150,20 12417457,20

80
20,00%
22,00%
24,00%
26,00%
28,00%
30,00%
32,00%
34,00%
36,00%
38,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 48: Valores médios de F1-Score em função de ∆, para vocabulário de tamanho 32000.Fonte: Elaborada pelo autor.
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
50,00%
100 150 200 250
F1-Score
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 49: Valores médios do F1-Score em função de ∆, após a realização do processo de con-sistência espacial, para vocabulário de tamanho 32000. Fonte: Elaborada pelo autor.
4.7.4 Resultados para o Vocabulário de Tamanho 32000
O grá�co da Figura 48 apresenta os valores médios da F1-Score em função da
quantidade de quadros retornados pela busca (∆). É possível observar no grá�co que
as quatro estruturas analisadas obtiveram valores médios muito similares, com M-Tree e
Slim-Tree apresentando valores muito próximos. A Tabela 17 apresenta os valores médios
de Revocação, Precisão e F1-Score para as consultas realizadas.
Já o grá�co da Figura 49 apresenta os valores médios de F1-Score em função da
quantidade de quadros retornados pela busca (∆), após a realização do processo de consis-
tência espacial. É possível observar que todas as estruturas obtiverem desempenho muito
semelhante. A Tabela 18 apresenta detalhadamente os valores médios de Revocação,
Precisão e F1-Score para as consultas realizadas após a consistência espacial.
Por sua vez, o grá�co da Figura 50 apresenta o número médio de acessos a disco em
função da quantidade de quadros retornados pela busca (∆). Neste grá�co, a estrutura de

81
Tabela 17: Valores médios de Revocação, Precisão e F1-Score para as consultas, antes da rea-lização da consistência espacial e para vocabulário de tamanho 32000. Fonte: Elaborada peloautor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 51,09% 28,20% 36,34%150 44,52% 24,96% 31,99%200 49,01% 20,61% 29,02%250 55,43% 21,44% 30,92%
M-Tree 100 50,72% 28,00% 36,08%150 46,76% 26,22% 33,60%200 52,71% 22,17% 31,21%250 56,05% 21,68% 31,27%
Slim-Tree 100 50,72% 28,00% 36,08%150 46,76% 26,22% 33,60%200 52,71% 22,17% 31,21%250 56,05% 21,68% 31,27%
Sequencial 100 47,83% 26,40% 34,02%150 42,80% 24,88% 31,47%200 46,24% 20,56% 28,47%250 48,81% 20,07% 28,44%
Tabela 18: Valores médios de Revocação, Precisão e F1-Score para as consultas após a consis-tência espacial, para vocabulário de tamanho 32000. Fonte: Elaborada pelo autor.
Estrutura ∆ Revocação Precisão F1-Score
D-Index 100 37,32% 48,82% 42,30%150 23,25% 49,03% 31,54%200 24,44% 43,94% 31,41%250 25,96% 46,92% 33,42%
M-Tree 100 36,96% 50,25% 42,59%150 24,57% 49,87% 32,92%200 25,63% 46,86% 33,13%250 26,89% 47,02% 34,21%
Slim-Tree 100 34,78% 48,73% 40,59%150 23,78% 49,05% 32,03%200 24,31% 52,42% 33,21%250 26,27% 46,44% 33,55%
Sequencial 100 37,68% 54,17% 44,44%150 24,57% 42,96% 31,26%200 25,76% 38,84% 30,98%250 24,20% 35,51% 28,78%
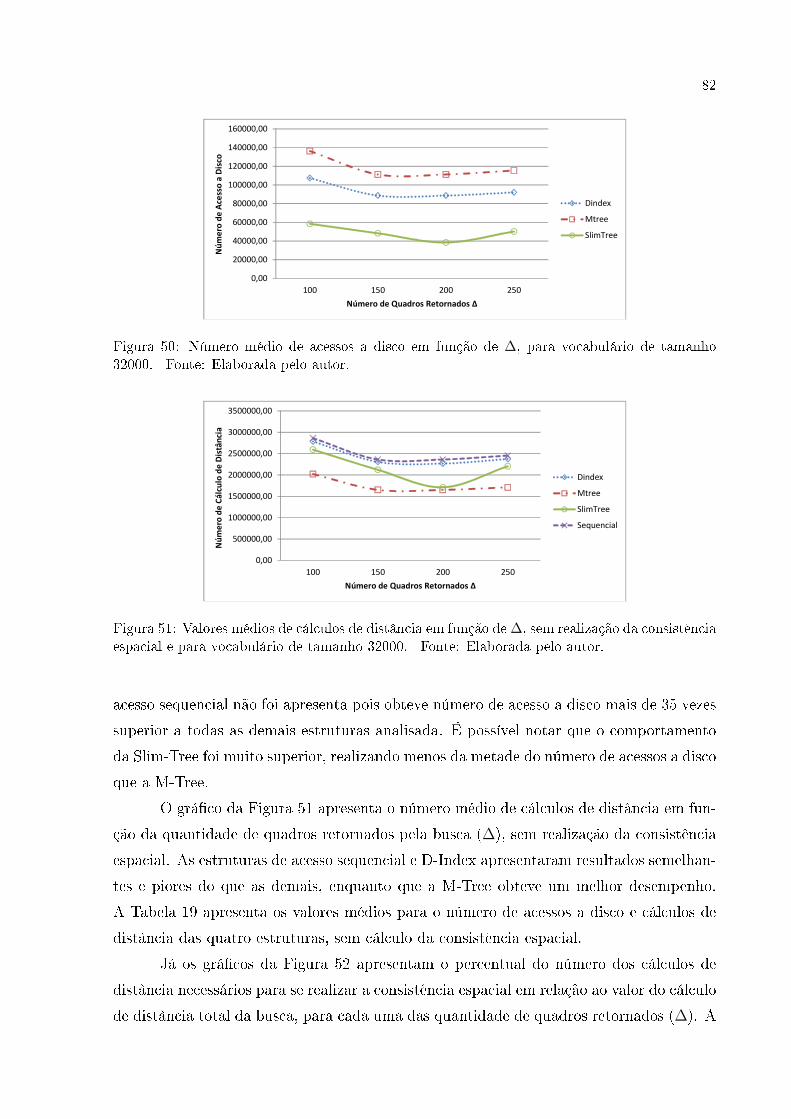
82
0,00
20000,00
40000,00
60000,00
80000,00
100000,00
120000,00
140000,00
160000,00
100 150 200 250
Número de Acesso a Disco
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Núm
ero
de A
cess
o a
Disc
o
Figura 50: Número médio de acessos a disco em função de ∆, para vocabulário de tamanho32000. Fonte: Elaborada pelo autor.
0,00
500000,00
1000000,00
1500000,00
2000000,00
2500000,00
3000000,00
3500000,00
100 150 200 250
Número de Cálculo de Distância
Número de Quadros Retornados Δ
Dindex
Mtree
SlimTree
Sequencial
Núm
ero
de C
álcu
lo d
e Di
stân
cia
Figura 51: Valores médios de cálculos de distância em função de∆, sem realização da consistênciaespacial e para vocabulário de tamanho 32000. Fonte: Elaborada pelo autor.
acesso sequencial não foi apresenta pois obteve número de acesso a disco mais de 35 vezes
superior a todas as demais estruturas analisada. É possível notar que o comportamento
da Slim-Tree foi muito superior, realizando menos da metade do número de acessos a disco
que a M-Tree.
O grá�co da Figura 51 apresenta o número médio de cálculos de distância em fun-
ção da quantidade de quadros retornados pela busca (∆), sem realização da consistência
espacial. As estruturas de acesso sequencial e D-Index apresentaram resultados semelhan-
tes e piores do que as demais, enquanto que a M-Tree obteve um melhor desempenho.
A Tabela 19 apresenta os valores médios para o número de acessos a disco e cálculos de
distância das quatro estruturas, sem cálculo da consistência espacial.
Já os grá�cos da Figura 52 apresentam o percentual do número dos cálculos de
distância necessários para se realizar a consistência espacial em relação ao valor do cálculo
de distância total da busca, para cada uma das quantidade de quadros retornados (∆). A

83
Tabela 19: Valores médios para o número de acessos a disco e cálculos de distância das estruturassem realização da consistência espacial e para vocabulário de tamanho 32000. Fonte: Elaboradapelo autor.
Estrutura ∆ Número Médio de Número Médio de
Acessos a Disco Cálculos de Distância
D-Index 100 107332,40 2784084,80150 88645,33 2305153,22200 88627,78 2266906,89250 92016,60 2373801,80
M-Tree 100 136286,00 2021688,80150 111265,56 1650493,33200 111265,56 1650493,33250 115482,60 1710653,00
Slim-Tree 100 58448,00 2593080,80150 48269,56 2120492,11200 38447,56 1710887,67250 50162,80 2204197,70
Sequencial 100 5723852,00 2861926,00150 4723842,22 2361921,11200 4723842,22 2361921,11250 4907980,00 2453990,00
Tabela 20 apresenta os valores médios para cálculos de distância somente para se realizar
a consistência espacial juntamente com os valores médios totais de cálculos de distância
ao �nal do processo da consistência espacial.
O comportamento das estruturas foi muito semelhante ao apresentado para os
vocabulários analisados anteriormente. Contudo, agora o impacto da consistência espacial
para D-Index é menor que 5%, no pior caso analisado.
Na estrutura de acesso sequencial, o impacto da consistência espacial ainda se
mantém alto, porém é um pouco menor que 40% do total dos cálculos de distância da
busca. Nas estruturas M-Tree e Slim-Tree, no pior caso analisado, o cálculo de distância
para consistência espacial não passou desta vez de 20% para M-Tree e de 10% para Slim-
Tree.

84
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
D-Index
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
M-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Slim-Tree
Total
Cálc. Dist. Consistência
0%
20%
40%
60%
80%
100%
100 150 200 250
Cálculo Distância %
Número de Quadros Retornados Δ
Sequencial
Total
Cálc. Dist. Consistência
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Cálc
ulo
de D
istân
cia
%Cá
lcul
o de
Dist
ânci
a %
Figura 52: Percentual do número de cálculos de distância necessários para se realizar a consis-tência espacial em relação ao número total de cálculos de distância para cada valor de ∆ e paravocabulário de tamanho 32000. Fonte: Elaborada pelo autor.
Tabela 20: Valores médios de cálculos de distância para realizar a consistência espacial e osvalores totais de cálculos de distâncias da busca ao �nal do processo da consistência espacial,para vocabulário de tamanho 32000. Fonte: Elaborada pelo autor.
Estrutura ∆ Número Médio de Cálculos de Distâncias
Consistência Espacial Total
D-Index 100 30757,60 2814842,40150 36793,11 2341946,33200 48816,22 2315723,11250 61865,20 2435667,00
M-Tree 100 172075,00 2193763,80150 212278,00 1862771,33200 281786,44 1932279,78250 356472,20 2067125,20
Slim-Tree 100 85941,60 2679022,40150 104069,44 2224561,56200 112703,00 1823590,67250 176309,90 2380507,60
Sequencial 100 2022866,00 4884792,00150 2511814,11 4873735,22200 3384125,33 5746046,44250 4398489,30 6852479,30

85
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
4000 8000 16000 32000
F1-Score
Vocabulário
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 53: Valores médios de F1-Score sem realização da consistência espacial, em função dotamanho do vocabulário visual utilizado. Fonte: Elaborada pelo autor.
4.7.5 Resultados Obtidos em Função da Variação do Tamanho do Vocabu-
lário Visual
Nos experimentos a seguir foram feitas avaliações da performance das estruturas
de indexação em função da variação do tamanho do vocabulário visual para o valor �xo
do número de quadros retornados pela busca ∆ = 100.
O grá�co da Figura 53 apresenta os valores médios de F1-Score sem realização
da consistência espacial em função do tamanho do vocabulário visual utilizado. Pode-se
observar no grá�co que as estruturas M-Tree, Slim-Tree e D-Index apresentam valores
praticamente idênticos, com um máximo de 39,43%. Já a estrutura de acesso sequencial
obteve resultado pior em relação as demais, com um máximo de 36,60%. A Tabela 21
apresenta os valores médios de Revocação, Precisão e F1-Score para as consultas realizadas
em diferentes vocabulários sem realização da consistência espacial.
O grá�co da Figura 54 apresenta os valores médios do F1-Score em função do ta-
manho do vocabulário visual, após a realização do processo de consistência espacial. É
possível observar que, desta vez, houve uma variação da qualidade das diferentes estru-
turas. Todas apresentaram resultados muito semelhantes para o vocabulário de tamanho
16000, porém, com vocabulários pequenos, a D-Index obteve resultados ligeiramente me-
lhores. Para vocabulários maiores, houve uma melhora muito acentuada da estrutura de
acesso sequencial. A Tabela 22 apresenta de forma detalhada os valores médios de Revo-
cação, Precisão e F1-Score para as consultas realizadas em diferentes vocabulários após a
consistência espacial.
O grá�co da Figura 55 apresenta o número médio de acessos a disco em função do
tamanho do vocabulário visual. Neste grá�co os dados referentes à estrutura de acesso
sequencial não foi apresentados pois o número de acessos a disco chegou a ser 45 vezes

86
Tabela 21: Valores médios de Revocação, Precisão e F1-Score para as consultas realizadas emdiferentes vocabulários sem realização da consistência espacial. Fonte: Elaborada pelo autor.
Estrutura Vocabulário Revocação Precisão F1-ScoreDindex 4000 50,00% 27,60% 35,57%
8000 52,90% 29,20% 37,63%16000 55,43% 30,60% 39,43%32000 51,09% 28,20% 36,34%
Mtree 4000 50,00% 27,60% 35,57%8000 52,90% 29,20% 37,63%16000 55,43% 30,60% 39,43%32000 50,72% 28,00% 36,08%
SlimTree 4000 50,00% 27,60% 35,57%8000 52,90% 29,20% 37,63%16000 55,43% 30,60% 39,43%32000 50,72% 28,00% 36,08%
Sequencial 4000 39,49% 21,80% 28,09%8000 51,45% 28,40% 36,60%16000 48,55% 26,80% 34,54%32000 47,83% 26,40% 34,02%
Tabela 22: Valores médios de Revocação, Precisão e F1-Score para as consultas realizadas emdiferentes vocabulários após a consistência espacial. Fonte: Elaborada pelo autor.
Estrutura Vocabulário Revocação Precisão F1-ScoreDindex 4000 41,67% 43,40% 42,51%
8000 44,93% 35,23% 39,49%16000 34,78% 43,05% 38,48%32000 37,32% 48,82% 42,30%
Mtree 4000 43,48% 32,88% 37,44%8000 44,57% 35,55% 39,55%16000 34,78% 42,29% 38,17%32000 36,96% 50,25% 42,59%
SlimTree 4000 45,65% 34,62% 39,38%8000 44,93% 35,33% 39,55%16000 34,78% 42,29% 38,17%32000 34,78% 48,73% 40,59%
Sequencial 4000 38,04% 24,88% 30,09%8000 35,87% 32,04% 33,85%16000 36,96% 43,22% 39,84%32000 37,68% 54,17% 44,44%

87
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
50,00%
4000 8000 16000 32000
F1-Score
Vocabulário
Dindex
Mtree
SlimTree
Sequencial
F1-Score
Figura 54: Valores médios do F1-Score em função do tamanho do vocabulário visual, apósconsistência espacial. Fonte: Elaborada pelo autor.
0,00
20000,00
40000,00
60000,00
80000,00
100000,00
120000,00
140000,00
160000,00
4000 8000 16000 32000
Número de Acesso a Disco
Vocabulário
Dindex
Mtree
SlimTree
Núm
ero
de A
cess
o a
Disc
o
Figura 55: Número médio de acessos a disco em função do tamanho do vocabulário visual.Fonte: Elaborada pelo autor.
superior ao de todas as demais estruturas analisadas, conforme valores apresentados de
forma detalhada na Tabela 23.
É possível notar que a Slim-Tree foi a estrutura que teve seu comportamento menos
afetado com o aumento do vocabulário, apresentando sempre menor valor para o número
médio de acessos a disco que as demais.
O grá�co da Figura 56 apresenta o número médio de cálculos de distância em
função do tamanho do vocabulário visual, sem realização do cálculo da consistência espa-
cial. A estrutura M-Tree obteve um melhor desempenho, apesar de todas apresentarem
comportamento semelhante em relação a variação do vocabulário.
A Tabela 23 apresenta os valores médios para o número de acessos a disco e cálculos
de distância das quatro estruturas antes da realização da consistência espacial. Enquanto
que a Tabela 24 apresenta os valores médios para cálculos de distância somente para se
realizar a consistência espacial juntamente com os valores médios totais de cálculos de

88
0,00
500000,00
1000000,00
1500000,00
2000000,00
2500000,00
3000000,00
3500000,00
4000 8000 16000 32000
Número de Cálculo de Distância
Vocabulário
Dindex
Mtree
SlimTree
Sequencial
Núm
ero
de C
álcu
lo d
e Di
stân
cia
Figura 56: Número médio de cálculos de distância em função do tamanho do vocabulário visual.Fonte: Elaborada pelo autor.
distância ao �nal do processo da consistência espacial.
O grá�co da Figura 57(a) apresenta o percentual do número dos cálculos de dis-
tância necessários para se realizar a consistência espacial em relação ao valor do cálculo
de distância total da busca, para cada uma das quantidade de quadros retornados (∆).
É possível observar que, na D-Index, o baixo impacto do número dos cálculos de
distância para a realização da consistência espacial foi aproximadamente 10% dos cálculos
totais de distância de busca, no pior caso analisado.
Os grá�cos das Figuras 57(b) e 57(c) apresentam a mesma análise para a M-Tree
e Slim-Tree, respectivamente. Também é possível observar que o número dos cálculos de
distância para realização da consistência espacial têm baixo impacto no número total de
cálculos de distâncias, em ambas as estruturas, sendo que na Slim-tree, este impacto é
ainda menor, não ultrapassando do valor de 20%.
Já na Figura 57(d) a mesma análise é apresentada para a estrutura de acesso
sequencial, no qual, é possível observar que o número de cálculos de distâncias necessários
para realização da consistência espacial foi de aproximadamente 50% do número total de
cálculos de distâncias da busca. Além de que, há uma perceptível queda neste impacto
para as demais estruturas a medida que o tamanho do vocabulário aumenta, porém, para
a estrutura de acesso sequencial, esta queda no impacto no tempo total da busca é menos
acentuado.

89
Tabela 23: Valores médios para o número de acessos a disco e cálculos de distância das quatroestruturas. Fonte: Elaborada pelo autor.
Estrutura Tamanho do Número Médio de Número Médio de
Vocabulário Acessos a Disco Cálculos de Distância
D-Index 4000 12006,00 308275,258000 27036,00 704913,6016000 51213,60 1332281,8032000 107332,40 2784084,80
M-Tree 4000 15806,80 282841,608000 31960,00 546596,0016000 63994,40 1069764,4032000 136286,00 2021688,80
Slim-Tree 4000 7545,20 336058,008000 14549,60 662970,0016000 29788,80 1334519,2032000 58448,00 2593080,80
Sequencial 4000 718400,00 359200,008000 1436440,80 718220,4016000 2871983,60 1435991,8032000 5723852,00 2861926,00
Tabela 24: Valores médios para cálculos de distância para se realizar a consistência espacial evalores médios totais de cálculos de distância. Fonte: Elaborada pelo autor.
Estrutura Tamanho do Número Médio de Cálculos de Distância
Vocabulário Consistência Espacial Total
D-Index 4000 34569,25 342844,508000 35886,60 740800,2016000 31551,80 1363833,6032000 30757,60 2814842,40
M-Tree 4000 217474,00 500315,608000 203412,60 750008,6016000 172491,20 1242255,6032000 172075,00 2193763,80
Slim-Tree 4000 116048,40 452106,408000 108448,20 771418,2016000 91191,80 1425711,0032000 85941,60 2679022,40
Sequencial 4000 10472747,20 10831947,208000 9510376,00 10228596,4016000 5177480,60 6613472,4032000 4398489,30 7260415,30
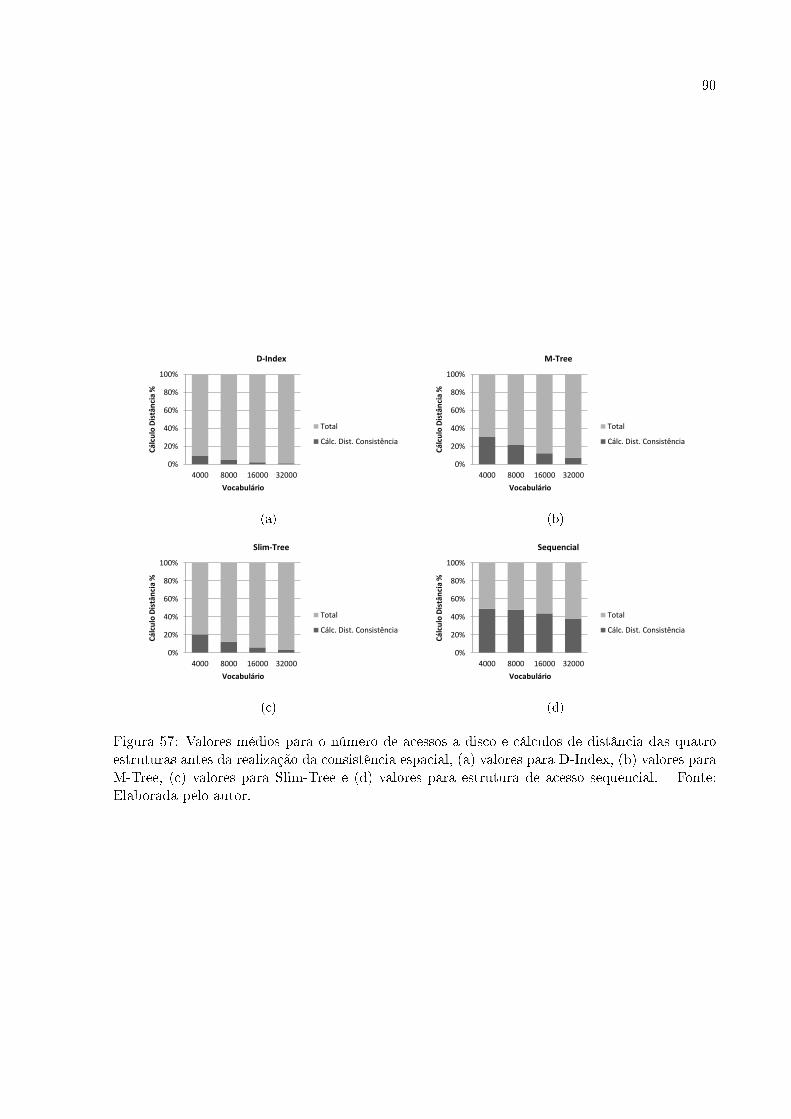
90
0%
20%
40%
60%
80%
100%
4000 8000 16000 32000
Cál
culo
Dis
tân
cia
%
Vocabulário
D-Index
Total
Cálc. Dist. Consistência
(a)
0%
20%
40%
60%
80%
100%
4000 8000 16000 32000
Cál
culo
Dis
tân
cia
%
Vocabulário
M-Tree
Total
Cálc. Dist. Consistência
(b)
0%
20%
40%
60%
80%
100%
4000 8000 16000 32000
Cál
culo
Dis
tân
cia
%
Vocabulário
Slim-Tree
Total
Cálc. Dist. Consistência
(c)
0%
20%
40%
60%
80%
100%
4000 8000 16000 32000
Cál
culo
Dis
tân
cia
%
Vocabulário
Sequencial
Total
Cálc. Dist. Consistência
(d)
Figura 57: Valores médios para o número de acessos a disco e cálculos de distância das quatroestruturas antes da realização da consistência espacial, (a) valores para D-Index, (b) valores paraM-Tree, (c) valores para Slim-Tree e (d) valores para estrutura de acesso sequencial. Fonte:Elaborada pelo autor.

91
0,00%
5,00%
10,00%
15,00%
20,00%
25,00%
30,00%
35,00%
D-Index M-Tree Slim-TreeF 1
-Sco
re
Estrutura de Indexação
Seg. por Amostragem
Seg. por Tomada
Figura 58: Valores médios de F1-Score sem a realização da consistência espacial em função dasestruturas de indexação e do tipo de segmentação realizada. Fonte: Elaborada pelo autor.
4.8 Resultados Obtidos Utilizando Segmentação por Detecção de Tomadas
De modo a se avaliar o impacto da segmentação de tomadas no método proposto
para indexação e recuperação de vídeos, o vídeo foi segmentado utilizando a abordagem
de identi�cação de tomadas de vídeos apresentado por Guimarães et al. (2009) e por
Patrocínio Jr. et al. (2010). Nesta abordagem, foram extraídos 312 quadros-chave do
vídeo, sendo um único quadro para cada tomada.
Para este experimento, apenas 312 quadros foram indexados. O vocabulário visual
utilizado foi o mesmo dos demais experimentos deste trabalho. Para o tamanho do voca-
bulário utilizou-se apenas tamanho 8000 e para (∆) igual a 250. Os demais parâmetros de
deste experimento são os mesmo do experimento anterior, no qual o vídeo foi segmentado
utilizando a seleção de quadros por simples amostragem.
O experimento anterior, tem como objetivo a avaliação de F1-Score a partir do
resultado da precisão e revocação das buscas realizadas de quadros do vídeo. Neste
experimento, as taxas de precisão e revocação devem ser calculadas por tomada.
No grá�co da Figura 58 é apresentado os valores médios de F1-Score sem a realiza-
ção da consistência espacial em função das estruturas de indexação utilizadas e do tipo de
segmentação realizada. Pode-se notar que o desempenho um pouco superior das buscas
realizadas com os quadros do vídeo segmentado por amostragem. Porém, na Tabela 25 é
possível perceber que os valores médios para as buscas realizadas no vídeo segmentado por
tomada obteve alta taxas de revocação, superior a 90%, porém baixas taxas de precisão,
o que interferiu no valor da F1-Score.
No grá�co da Figura 59(a) e no grá�co da Figura 59(b), apresenta-se o número
médio de acessos a disco e o número médio de cálculos de distância em função das es-
truturas utilizadas e do tipo de segmentação realizada, respectivamente. Pode-se notar

92
0,00
5000,00
10000,00
15000,00
20000,00
25000,00
30000,00
D-Index M-Tree Slim-Tree
Ace
sso
s a
Dis
co
Estrutura de Indexação
Seg. por Amostragem
Seg. por Tomada
(a)
0,00
100000,00
200000,00
300000,00
400000,00
500000,00
600000,00
700000,00
D-Index M-Tree Slim-Tree
Cál
culo
s d
e D
istâ
nci
a
Estrutura de Indexação
Seg. por Amostragem
Seg. por Tomada
(b)
Figura 59: (a) Grá�co do número médio de acessos a disco em função das estruturas e seg-mentação. (b) grá�co de número médio de cálculos de distância em função das estruturas esegmentação utilizadas. Fonte: Elaborada pelo autor.
que o houve uma redução do número médio, tanto de acessos a discos quanto de cálcu-
los de distâncias, ao se realizar as consultas utilizando a abordagem em que o vídeo foi
segmentado por detecção de tomadas.
No grá�co da Figura 60 é apresentado a taxa de F1-Score em função das estruturas
de indexação utilizadas. É possível observar que o resultado obtidos pelas duas abordagens
de segmentação é muito semelhante quando a consistência espacial é realizada. Porém
como o número de quadros-chave da segmentação por detecção de tomadas é menor os
tempos gastos na indexação e na recuperação também são menores.
Por �m, no grá�co da Figura 61 observa-se a relação entre os números de acessos
a disco no processo de criação das estruturas de indexação quando foi utilizado o método
de segmentação por detecção de tomadas e o método de segmentação por amostragem
dos quadros. Com a segmentação por detecção de tomadas, as estruturas apresentaram
números muito menores de acessos a disco, devido à menor quantidade de quadros do
vídeo a serem indexados, alcançando no máximo cerca de 30% do número total de acessos
a discos necessários quando foi utilizada a segmentação por amostragem.
Tabela 25: Valores médios de Revocação, Precisão e F1-Score para as buscas realizadas por tipode segmentação. Fonte: Elaborada pelo autor.
Segmentação Estrutura Revocação Precisão F1-Score
Seg. por Amostragem D-Index 57,81% 22,36% 32,25%M-Tree 58,84% 22,76% 32,82%Slim-Tree 59,05% 22,84% 32,94%
Seg. por Tomada D-Index 92,14% 11,75% 20,85%M-Tree 92,50% 11,80% 20,93%Slim-Tree 92,50% 11,80% 20,93%

93
0,00%
5,00%
10,00%
15,00%
20,00%
25,00%
30,00%
35,00%
40,00%
D-Index M-Tree Slim-TreeF 1
-Sco
re
Estrutura de Indexação
Seg. por Amostragem
Seg. por Tomada
Figura 60: Taxa de F1-Score em função das estruturas de indexação utilizadas. Fonte: Elabo-rada pelo autor.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
D-Index M-Tree Slim-Tree
Nú
me
ro d
e A
cess
os
a d
isco
%
Estrutura de Indexação
Amostragem
Detecção de Tomadas
Figura 61: Número de acessos a disco para criação das estrutura de indexação por amostrageme por detecção de tomadas. Fonte: Elaborada pelo autor.
4.9 Análise Qualitativa dos Resultados
De modo a se avaliar de forma qualitativa os resultados, serão apresentados de
forma detalhada os resultados obtidos para as consultas 5 e 9 utilizando a estrutura
D-Index e o vocabulário de tamanho 8000. Nos resultados da consulta número 5, o
processo de consistência espacial não afetou de forma considerável o resultado da busca,
já o resultado da consulta 9, a realização do processo de consistência espacial impactou
diretamente no resultado.
A Figura 62 apresenta o resultado obtido, com os cinco primeiro quadros de res-
posta para a consulta número 5 (ver Figura 30), sem a realização da consistência espacial.
Já a Figura 63 apresenta o resultado para a mesma consulta, porém com a realização da
consistência espacial. Neste exemplo, observa-se que o processo de consistência espacial
não impactou na qualidade do resultado obtido.
Para o exemplo apresentado na Figura 64 observa-se o resultado da busca obtido,
com os cinco primeiro quadros de resposta para a consulta 9 (ver Figura 30), sem a reali-

94
Consulta 20250 20275
20400 20375 20425
Figura 62: Resultado da avaliação qualitativa sem processo de consistência espacial na consultanúmero 5. Fonte: Elaborada pelo autor.
zação da consistência espacial. Nota-se que os dois primeiros quadros do vídeo retornados
representam falsos positivos, já que estes dois quadros não contém a região selecionada
na imagem de busca.
A Figura 65 também apresenta o resultado para a consulta 9 porém com a reali-
zação da consistência espacial. Neste exemplo, observa-se que o processo de consistência
espacial foi determinante para uma melhor qualidade nos resultados, pois os únicos quatro
quadros do vídeo em que a região da consulta ocorre foram retornados como os quatro
primeiros resultados da busca.
4.10 Análise Global dos Resultados Obtidos nos Experimentos
O objetivo dos experimentos realizados foi analisar o comportamento das diferen-
tes estruturas de indexação implementadas neste trabalho para a recuperação de vídeo,
utilizando-se de vocabulário visual.
Em relação às taxas de Precisão e Revocação avaliadas, nota-se que todas as es-
truturas têm praticamente o mesmo desempenho para busca sem consistência espacial,
com poucas variações, valendo destacar uma pequena desvantagem para a abordagem
utilizando acesso sequencial.
Porém, quando a consistência espacial foi utilizada, nota-se um comportamento
crescente de desempenho da estrutura de acesso sequencial, enquanto que as demais es-
truturas mantiveram seus valores relativamente constantes. Sendo claro uma melhora na
qualidade quando são retornados apenas 100 quadros da consulta. A taxa de Precisão
tende a aumentar para um número menor de quadros de resposta.

95
Consulta 20250 20275
20400 21250 20425
Figura 63: Resultado da avaliação qualitativa com processo de consistência espacial na consultanúmero 5, no qual sua realização não impactou de forma considerável o resultado da busca.Fonte: Elaborada pelo autor.
Quanto ao comportamento das estrutura em relação ao número de acessos a disco
�cou evidenciado o desempenho ruim da estrutura de acesso sequencial, que teve um
valor muito elevado, chegando a ser 30 (ou mais) vezes maior que as demais estruturas.
Neste critério de avaliação, a Slim-Tree sempre se saiu melhor, realizando uma quantidade
menor de acessos a disco durante as consultas. Quanto ao número de cálculos de distân-
cia realizados pelas estruturas, a M-Tree apresentou sempre o melhor desempenho, pois
realiza uma quantidade menor de cálculos de distância em comparação com as demais
estruturas que mantiveram comportamento muito semelhante ao longo dos testes.
Uma vez que o tempo gasto para operações de acesso a disco tende a ser maior que
o gasto no cálculo de distância, o desempenho da Slim-Tree é, portanto, superior as demais
estruturas em relação ao tempo médio das buscas (mantendo a qualidade dos resultados
de F1-Score semelhante às demais). Porém deve-se destacar o maior tempo necessário
para se criar uma Slim-Tree. Quando a consistência espacial foi realizada, a estrutura
sequencial se mostrou não ser muito e�ciente para esta operação, pois somente a realização
da consistência espacial consumiu cerca de metade (na maioria dos experimentos) dos
cálculos de distância realizados, dobrando-se assim, o número de cálculos de distâncias
necessários para a busca. Deve-se, contudo, destacar que a realização da consistência
espacial, contribuiu para um aumento signi�cativo da precisão dos resultados obtidos.
Quanto ao comportamento das estruturas em relação a variação no tamanho do vo-
cabulário visual, as estruturas de indexação métricas obtiveram valores de F1-Score muito
semelhantes quando a consistência espacial não foi realizada, sendo que para o vocabulário

96
Consulta 4550 4650
28500 27400 28525
Figura 64: Resultado da avaliação qualitativa sem processo de consistência espacial na consultanúmero 9. Fonte: Elaborada pelo autor.
visual de tamanho igual a 16000 foram alcançados os melhores valores de F1-Score. Já a
estrutura de acesso sequencial teve o pior desempenho em relação aos valores de F1-Score
quando a consistência espacial não foi realizada. Entretanto, quando a consistência es-
pacial é realizada a estrutura de acesso sequencial apresentou uma crescente melhora dos
valores de F1-Score na medida que o vocabulário visual aumentou de tamanho, enquanto
que as demais estruturas praticamente não apresentaram variação signi�cativa dos valores
de F1-Score.
Entretanto, é importante ressaltar que, para a estrutura de acesso sequencial, ape-
sar da acentuada melhora na qualidade dos seus resultados quando a consistência espacial
é realizada, esta operação consome quase a metade do tempo total de busca que já é
elevado. Enquanto que nas demais estruturas, o tempo gasto com a realização da consis-
tência espacial foi menos signi�cativo.
Quanto aos valores médios para número de acessos a disco e cálculos de distância,
�cou mais uma vez evidenciado o bom desempenho da Slim-Tree, quando ocorre a va-
riação no tamanho do vocabulário visual. Como já era esperado, todas as estruturas de
indexação apresentaram um crescimento do número de acessos a disco e de cálculos de
distância, na medida que o vocabulário visual aumentou de tamanho. Porém, como todas
elas apresentaram um comportamento semelhante em relação ao número de cálculos de
distância, a Slim-Tree foi a estrutura que apresentou menor sensibilidade à variação do
tamanho do vocabulário em relação ao número de acessos a disco. A estrutura de acesso
sequencial apresentou novamente um baixo desempenho, tendo valores muito elevados
para número de acessos a disco em função do crescimento do vocabulário visual.

97
Consulta 28500 27400
28525 27375 10675
Figura 65: Resultado da avaliação qualitativa com processo de consistência espacial na consultanúmero 9, no qual sua realização impactou de forma considerável o resultado da busca. Fonte:Elaborada pelo autor.
Importante notar que, para o conjunto de dados utilizado neste trabalho, os valores
de F1-Score apresentaram diferenças entre as estruturas, esta diferença se dá pela fato
de que no processo de busca realiza-se a busca pelo vizinho mais próximo, 1-NN, e caso
exista vários elementos com a mesma distância até o elemento da consulta, a consulta
pelo vizinho mais próximo pode retornar valores diferentes para cada tipo de estrutura
utilizada.
Outro ponto importante a se destacar é que utilizando a segmentação por tomadas,
em que foi selecionado apenas um quadro-chave de cada tomada, o número de acessos a
disco para criação das estruturas foi, no pior caso, menos de 30% do valor para criação das
estruturas utilizando seleção de quadros por amostragem, sem afetar de forma considerável
os valores de F1-Score na busca. O que se deve pelo fato da menor quantidade de quadros-
chave selecionados no método de detecção de tomadas em relação a maior quantidade de
quadros selecionados no método de amostragem.

98
5 CONCLUSÕES
Conforme exposto neste trabalho, foi abordado todo o processo de indexação e
recuperação de vídeos. Foi descrito que, primeiramente, na etapa de indexação do vídeo,
é necessário segmentá-lo em um sequência de quadros. Sobre esta sequência, é realizada a
extração de quadros-chave, que foi feita de maneira aleatória e também utilizando detecção
de tomadas, conforme apresentado em Guimarães et al. (2009) e em Patrocínio Jr. et al.
(2010).
Posteriormente, uma amostragem dos quadros-chave foi obtida para criação do
vocabulário visual, que por sua vez, é constituído de palavras visuais obtidas pela cluste-
rização dos descritores de região de interesse extraídos da amostra dos quadros-chave do
vídeo. Este vocabulário visual constitui o índice do arquivo invertido, no qual os quadros-
chave do vídeo são indexados e representados por um histograma, chamado de bag of
feature.
Na recuperação do vídeo, realizada por meio de uma imagem de consulta ou mesmo
por uma região desta, foi utilizado o modelo vetorial para cálculo da similaridade entre os
bag of features, e posteriormente, este resultado é reordenador pelo processo de consistên-
cia espacial entre as palavras visuais do quadros-chave do vídeo e a imagem de consulta,
semelhante ao apresentado em Sivic (2006) e em Sivic e Zisserman (2009).
O índice do arquivo invertido foi o principal objeto de estudo deste trabalho, que
teve como objetivo apresentar uma análise comparativa de estruturas de indexação para
recuperação de vídeos utilizando vocabulário visual.
Para avaliação do processo de indexação e recuperação de vídeo, foram implemen-
tadas três estruturas métricas de indexação, além da estrutura de acesso sequencial, para
acesso ao índice do aquivo invertido: a M-Tree (CIACCIA; PATELLA; ZEZULA, 1997), a
D-Index (DOHNAL et al., 2003) e a Slim-Tree (TRAINA JR. et al., 2000), uma variação da
M-Tree.
O objetivo dos experimentos realizados foi analisar o comportamento destas estru-
turas de indexação para a recuperação de vídeo, utilizando o vocabulário visual.
Foram realizadas buscas nas estruturas com diferentes valores para o tamanho do
vocabulário visual, e com e sem a realização da consistência espacial, conforme apresentado
anteriormente. Foi possível avaliar que, em função do tamanho do vocabulário visual,
todas as estruturas têm praticamente o mesmo desempenho, para valores de F1-Score, na

99
busca sem consistência espacial, com uma pequena desvantagem para a estrutura de acesso
sequencial, que, por sua vez, obteve um comportamento crescente de desempenho quando
a consistência espacial foi utilizada. Enquanto que as demais estruturas mantiveram seus
valores relativamente constantes.
Houve também uma melhora na qualidade dos valores de F1-Score quando são
retornados apenas 100 quadros da consulta. A taxa de Precisão tende a aumentar para
um número menor de quadros de resposta.
A estrutura de acesso sequencial obteve um desempenho inferior quanto em relação
ao número de acessos a disco, chegando a ser 30 (ou mais) vezes maior que as demais
estruturas. Neste critério de avaliação, a Slim-Tree sempre se saiu melhor, realizando
uma quantidade menor de acessos a disco durante as consultas.
Quanto ao número de cálculos de distância realizados pelas estruturas, a M-Tree
apresentou sempre o melhor desempenho, pois realiza uma quantidade menor de cálculos
de distância em comparação com as demais estruturas que mantiveram comportamento
muito semelhante ao longo dos testes.
Uma vez que o tempo gasto para operações de acesso a disco tende a ser maior
que o gasto no cálculo de distância, o desempenho da Slim-Tree é, portanto, superior
as demais estruturas em relação ao tempo médio das buscas (mantendo a qualidade dos
resultados de F1-Score semelhante às demais). Porém deve-se destacar o maior tempo
necessário para se criar uma Slim-Tree.
Quando a consistência espacial foi realizada, de maneira geral sempre houve um
aumento nos valores de precisão dos resultados em relação às consultas em que a consis-
tência espacial não é realizada. Contudo, é importante ressaltar que, para a estrutura de
acesso sequencial, apesar da acentuada melhora na qualidade dos seus resultados quando
a consistência espacial é realizada, esta operação consome quase a metade do tempo total
de busca que já é elevado. Enquanto que nas demais estruturas, o tempo gasto com a
realização da consistência espacial foi menos signi�cativo.
Quanto aos valores médios para número de acessos a disco e cálculos de distância,
�cou mais uma vez evidenciado o bom desempenho da Slim-Tree, quando ocorre a va-
riação no tamanho do vocabulário visual. Como já era esperado, todas as estruturas de
indexação apresentaram um crescimento do número de acessos a disco e de cálculos de
distância, na medida que o vocabulário visual aumentou de tamanho. Porém, como todas
elas apresentaram um comportamento semelhante em relação ao número de cálculos de
distância, a Slim-Tree foi a estrutura que apresentou menor sensibilidade à variação do
tamanho do vocabulário em relação ao número de acessos a disco. A estrutura de acesso

100
sequencial apresentou novamente um baixo desempenho, tendo valores muito elevados
para número de acessos a disco em função do crescimento do vocabulário visual.
É importante destacar que, para o conjunto de dados utilizado neste trabalho, o
bom desempenho da estrutura D-Index no processo de consistência espacial se dá pelo fato
do seu melhor desempenho para realização de busca por abrangência em que o valor do
raio é zero, ou seja, quando se desejar encontrar o mesmo elemento da consulta. Processo
diferente da busca realizada sem a consistência em que apenas a busca pelo vizinho mais
próximos é realizada, e neste tipo de consulta, a estrutura Slim-Tree se mostrou mais
efetiva quanto a número de acesso a disco.
Como resultado deste trabalho, foi obtida uma publicação em relação ao método de
segmentação de vídeo por detecção de tomadas, utilizando análise de transições abruptas,
(GUIMARÃES et al., 2009). Mais recentemente, foi obtida uma publicação, também para
detecção de transições em um vídeo, mas com o objetivo de reconhecer transições abruptas
e graduais (PATROCÍNIO JR. et al., 2010).
Como contribuição principal do trabalho, vale destacar a análise do desempenho
das estruturas métricas de indexação tanto para busca quanto para o processo de classi�-
cação por meio da consistência espacial. Pelos resultados apresentados, pode-se concluir
que para o processo de busca sobre o conjunto de dados utilizado neste trabalho, a Slim-
Tree é a estrutura mais adequada por apresentar baixos valores de acesso a disco (fator
determinante para o tempo de busco sobre os dados utilizados). No entanto, para a reali-
zação da consistência espacial, a estrutura D-Index torna-se a mair adequada justamente
por apresentar melhor desempenho para buscas por abrangência com valor de raio zero.
5.1 Trabalhos Futuros
Baseado na análise dos resultados deste trabalho, pode-se sugerir as seguintes linhas
de investigação como trabalhos futuros:
a) Explorar outros algoritmos para construção do vocabulário visual, para me-
lhorar o desempenho, em relação a tempo de processamento do processo de
clusterização, ou mesmo, inserir todos os descritores dos quadros da amostra
como índice no arquivo invertido.
b) Explorar algoritmos para criação de forma e�ciente das estruturas de indexa-
ção, como por exemplo, a utilização dos algoritmos de Bulk Loading para carga
dos dados.
c) Analisar o impacto da política de escolha de pivots na D-Index, visto que pode
impactar diretamente no desempenho da estrutura.

101
d) Análise e teste da utilização dos outros detectores de regiões como também
de outros descritores, como por exemplos a utilização de descritores de cor de
imagens.
e) Técnicas de sumarização poderiam ser utilizadas para melhorar a escolha dos
quadros-chave do vídeo. Uma vez que as tomadas sejam identi�cadas, uma
análise de técnicas de sumarização poderia melhorar a escolha dos quadros-
chave mais relevantes do vídeo.
f) Avaliar outras estruturas métricas de indexação, tanto para memória primária
quanto para memória secundária.
g) Explorar possíveis melhorias no algoritmo de consistência espacial, com obje-
tivo de diminuir o custo computacional do mesmo.

102
REFERÊNCIAS
ALMEIDA, J.; ROCHA, A.; TORRES, R.; GOLDENSTEIN, S. Making colorsworth more than a thousand words. In: ACM SYMPOSIUM ON APPLIEDCOMPUTING, v. 23, 2008, Fortaleza, Ceara, Brazil. ACM, New York, USA: ACM,Mar. 2008. p. 1180-1186.
AVILA, S. E. F. de. Uma abordagem baseada em características de cor para aelaboração automática e avaliação subjetiva de resumos estáticos de vídeos.Set. 2008. Dissertação, mestrado - UFMG, Belo Horizonte.
BROWNE, P.; SMEATON, A. F. Video retrieval using dialogue, keyframe similarityand video objects. In: IEEE INTERNATIONAL CONFERENCE ON IMAGEPROCESSING, Genoa, Italy. IEEE Computer Society, Glasnevin, Dublin 9, Ireland:IEEE, 2005, sep. 2005. p. 1208-1211.
CHAVEZ, E.; NAVARRO, G.; BAEZA-YATES, R.; MARROQUIN, J. Searching inmetric spaces. ACM Computing Surveys, New York, USA, v. 33, n. 3, p. 273-321,Mar. 2001.
CIACCIA, P.; PATELLA, M.; ZEZULA, P. M-tree: An e�cient access method forsimilarity search in metric spaces. In: INTERNATIONAL CONFERENCE ONVERY LARGE DATA BASES, v. 23, 1997, Athens, Greece. International Conferenceon Very Large Data Bases, San Francisco, CA, USA: Morgan Kaufmann Publishers Inc.,1997. p. 426-435.
DOHNAL, V. Indexing Structures for Searching in Metric Spaces. Feb. 2004.Tese, doutorado - Masaryk University Faculty Of Informatics, Brno.
DOHNAL, V.; GENNARO, C.; SAVINO, P.; ZEZULA, P. D-index: Distance searchingindex for metric data sets. Multimedia Tools Application, Kluwer AcademicPublishers, Hingham, MA, USA, v. 21, n. 3, p. 9-33, sep. 2003.
FRAKES, W. B.; BAEZA-YATES, R. A. Information retrieval: data structuresand algorithms. 1. ed. Upper Saddle River, NJ, USA: Prentice-Hall, Inc., 1992. 504p.
GUIMARÃES, S. J. F.; JR, Z. K. G. d. P.; PAULA, H. B. d.; SILVA, H. B. A newdissimilarity measure for cut detection using bipartite graph matching. InternationalJournal of Semantic Computing, [s.l.], v. 3, n. 2, p. 155-181, Jun. 2009.
HOMOLA, T.; DOHNAL, V.; ZEZULA, P. Sub-image searching through intersection oflocal descriptors. In: INTERNATIONAL CONFERENCE ON SIMILARITYSEARCH AND APPLICATIONS, 3, 2010, Istanbul, Turkey. ACM, New York, NY,USA: ACM, 2010. p. 127-128.
KANUNGO, T.; MOUNT, D. M.; NETANYAHU, N. S.; PIATKO, C. D.; SILVERMAN,R.; WU, A. Y. An e�cient k-means clustering algorithm: Analysis and implementation.IEEE Transactions on Pattern Analysis and Machine Intelligence, Washington,DC, USA, v. 24, n. 7, p. 881-892, jul. 2002.

103
LOPES, A. P. B.; AVILA, S. E. F. D.; PEIXOTO, A. N. A. A bag-of-featuresapproach based on hue-sift descriptor for nude detection. In: EUROPEAN SIGNALPROCESSING CONFERENCE, n. 17, 2009, [s.l.]. 2009. p. 1552-1556.
LOWE, D. G. Object recognition from local scale-invariant features. In: INTERNA-TIONAL CONFERENCE ON COMPUTER VISION. 1999, Kerkyra, Greece.International Conference On Computer Vision, Washington, DC, USA: IEEE ComputerSociety, set. 1999. p. 1150-1157.
LOWE, D. G. Distinctive image features from scale-invariant keypoints. InternationalJournal of Computer Vision, Kluwer Academic Publishers, Hingham, MA, USA,v. 60, n. 2, p. 91-110, nov. 2004.
MACQUEEN, J. B. Some methods for classi�cation and analysis of multivariateobservations. In: BERKELEY SYMPOSIUM ON MATHEMATICALSTATISTICS AND PROBABILITY, n. 5, 1967, [s.l.]. Berkeley Symposium OnMathematical Statistics And Probability. Berkeley, California: University of CaliforniaPress, 1967. p. 281-297.
MENDI, E.; BAYRAK, C. Shot boundary detection and key frame extraction usingsalient region detection and structural similarity. In: ANNUAL SOUTHEASTREGIONAL CONFERENCE. n. 48, 2010, Oxford, Mississippi. Annual SoutheastRegional Conference. New York, NY, USA: ACM, 2010. p. 66:1-66:4.
MIKOLAJCZYK, K.; SCHMID, C. A performance evaluation of local descriptors. IEEETransactions on Pattern Analysis and Machine Intelligence, IEEE ComputerSociety, Los Alamitos, CA, USA, v. 27, n. 10, p. 1615-1630, oct. 2005.
MIKOLAJCZYK, K.; TUYTELAARS, T.; SCHMID, C.; ZISSERMAN, A.; MATAS,J.; SCHAFFALITZKY, F.; KADIR, T.; GOOL, L. V. A comparison of a�ne regiondetectors. International Journal of Computer Vision, Kluwer Academic Publishers,Hingham, MA, USA, v. 65, n. 1-2, p. 43�72, nov. 2005.
PATROCÍNIO JR., Z. K. G.; GUIMARÃES, S. J. F.; SILVA, H. B.; SOUZA, K. J.An uni�ed transition detection based on bipartite graph matching approach. In:IBEROAMERICAN CONGRESS ON PATTERN RECOGNITION, n. 15,2010, São Paulo, Brazil. Iberoamerican Congress On Pattern Recognition, São Paulo,Brazil: Springer-Verlag, nov. 2010. p. 184-192.
PEDRINI, H.; SCHWARTZ, W. Análise de Imagens Digitais: Princípios,Algoritmos e Aplicações. 1. ed. [S.l.]: Thomson Learning, 2007. 528 p.
SEBE, N.; LEW, M. S.; SMEULDERS, A. W. M. Video retrieval and summarization.Computer Vision and Image Understanding, v. 92, n. 2-3, p. 141-146, nov./dec.2003.
SHAO, J.; SHEN, H. T.; ZHOU, X. Challenges and techniques for e�ective and e�cientsimilarity search in large video databases. Very Large Database Endowment, VLDBEndowment, v. 1, n. 2, p. 1598-1603, aug. 2008.

104
SHEN, H. T.; OOI, B. C.; ZHOU, X. Towards e�ective indexing for very largevideo sequence database. In: INTERNATIONAL CONFERENCE ONMANAGEMENT OF DATA, n. 5, 2005, Baltimore, Maryland. InternationalConference On Management Of Data, New York, USA: ACM, 2005. p. 730-741.
SIVIC, J. E�cient Visual Search of Images and Videos. 2006. Tese, doutorado -University of Oxford, Oxford.
SIVIC, J.; ZISSERMAN, A. E�cient Visual Search for Objects in Videos. 2008.
SIVIC, J.; ZISSERMAN, A. E�cient visual search of videos cast as text retrieval. IEEETransactions on Pattern Analysis and Machine Intelligence, [s.l.], v. 31, n. 4, p.591-606, apr. 2009.
TORRES, R. D. S.; FALCÃO, A. X. Content-based image retrieval: Theory andapplications. Revista de Informática Teórica e Aplicada, v. 13, p. 161-185, 2006.
TORRES, R. da S.; AO, A. X. F.; GONCALVES, M. A.; ZHANG, B.; FAN, W.; FOX,E. A.; CALADO, P. A new framework to combine descriptors for content-based imageretrieval. In: CONFERENCE ON INFORMATION AND KNOWLEDGEMANAGEMENT, n.40, 2005, Bremen, Germany: ACM Press, 2005. p. 335-336.
TORRES, R. da S.; ZEGARRA, J. A. M.; SANTOS, J. A.; FERREIRA, C. D.;PENATTI, O. A. B.; ANDALÓ, F. A.; JR, J. G. A. Recuperação de imagens: Desa�ose novos rumos. In: Seminário Integrado de Software e Hardware, Belém: [s.n.],2008.
TRAINA JR., C.; TRAINA, A. J. M.; SEEGER, B.; FALOUTSOS, C. Slim-trees: Highperformance metric trees minimizing overlap between nodes. In: INTERNATIONALCONFERENCE ON EXTENDING DATABASE TECHNOLOGY:ADVANCES IN DATABASE TECHNOLOGY, n. 7, 2000, London, UK:Springer-Verlag, 2000, p. 51-65.
TUYTELAARS, T.; MIKOLAJCZYK, K. Local invariant feature detectors: a survey.Foundation and Trends in Computer Graphics and Vision, Now Publishers Inc.,Hanover, MA, USA, v. 3, n. 3, p. 177-280.
ZEZULA, P.; AMATO, G.; DOHNAL, V.; BATKO, M. Similarity Search: TheMetric Space Approach. [S.l.]: Springer, 2006. 220 p.
Recommended

















