Embed Size (px)
Citation preview

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 01Semana 01
DBMS Database Management SystemDBMS Database Management SystemObjetivoObjetivo
Compreender as estruturas de arquivos de dados→
Compreender a importância dos sistemas de banco de dados→
Leitura ComplementarLeitura Complementar
CSV: → https://tools.ietf.org/html/rfc4180 JSON: → http://www.json.org/json-pt.html XML Document Type: → http://www.w3schools.com/xml/xml_doctypes.asp
AvaliaçãoAvaliação
→ Exatidão:Exatidão: o programa desenvolvido está de acordo com os requisitos? → Estilo:Estilo: a estrutura do arquivo e o programa seguem as boas práticas?
ComeçandoComeçando
Por muitos anos os sistemas de arquivos foram utilizados massivamente no desenvolvimente de programas. Os programas manipulavam seus dados em estruturas de arquivoestruturas de arquivo próprias, cuja especificação era definida pela linguagem de programação adotada e pelos desenvolvedores do programa. Se os arquivos de dadosfossem compartilhados entre dois ou mais programas, estes deveriam conhecer e manipular a mesma estrutura de arquivo, bem como implementar mecanismos de acesso concorrenteacesso concorrente.
Considerando a figura acima, é possível ilustrar o acesso concorrente pelos sistemas A e B aos arquivos de dados (textotexto ou bináriobinário) A, B e C. Quando um programa precisa alterar a estrutura de um arquivo os demais programas devem ser readequados, caso contrário deixam de manipular este arquivo. Assim, um programa pode manipular duas ou mais estruturas diferentes de arquivo de dados, tornando-se complexo e de difícil manutenção. Portanto, a produtividadeprodutividade no desenvolvimento de programas com sistemas de arquivos é baixa – não que hoje, com os sistemas de banco de dados, a produtividade é alta, mas evoluiu não que hoje, com os sistemas de banco de dados, a produtividade é alta, mas evoluiu muito! :-)muito! :-).
É implícito nesse modelo de armazenamento as dificuldades de integraçãointegração e interoperabilidadeinteroperabilidade dos arquivos. Também é possível deduzir alguns dos possíveis problemas na implementação das regras de negócio nas aplicações, tais como, redundância, diferença e/ou falta de regras de negócio em uma ou outra aplicação.
Pg. Pg. 11//44

Ainda existem diversas aplicações que fazem uso de sistemas de arquivos. Algumas são aplicações maduras, tornando-se inviável a refatoração para sistemas de banco de dados. Outras são aplicações simples em que a inclusão de mais uma camada de aplicação (sistema de banco de dados) as tornariam menos eficientes; ou até mesmo inviáveis (e.g. alguns tipos de sistemas embarcados).
Com o advento dos sistemas de banco de dados o modelo de arquivos nãonão deixou de existir. É comum as aplicações utilizarem sistemas de arquivos para gerar arquivos de logarquivos de log ou estado das aplicações.
Definindo uma estrutura de arquivo com o formato CSVDefinindo uma estrutura de arquivo com o formato CSV
Comma-Separated ValuesComma-Separated Values (CSV) é uma implementação de arquivo de texto cujos registros são separados pelo delimitador quebra de linhaquebra de linha \n\n e os valores de cada registro pelo delimitador vírgulavírgula ,,. O formato CSV também usa aspas duplasaspas duplas """" para definir valores do tipo conjunto de caracteres.
Considere o ficheiro de dados abaixo, denominado RegionsRegions. Cada registro é composto por um identificador da região e um nome da região. O identificador é do tipo de dados inteiro e o nome da região um conjunto de caracteres.
Uma possível estrutura de arquivo CSV para representar os registros do ficheiro RegionsRegions é:
A estrutura de arquivoestrutura de arquivo acima é simples e não possui mecanismos de integridade (e.g. unicidade de registro, obrigatoriedade de valor, etc.) e distinção entre os diferentes tipos de valores numéricos (e.g. inteiro, real, data, etc.). Ou as colunas são do tipo numeral ou do tipo conjunto de caracteres (neste caso o ouou é exclusivo). A primeira linha do arquivo refere-se ao cabeçalho das colunas e as demais aos registros. Cada linha armazena somente um registro. O cabeçalho das colunas e os registros são separados por vírgula ,,.
Considerando a descrição acima, os dados do ficheiro RegionsRegions são armazenados da seguinte forma:
Pg. Pg. 22//44
Regions---------------------------------Id | Name---------------------------------1 | Europe2 | Americas3 | Asia4 | Middle East and Africa
<Nome do Ficheiro>.csv------------------------------------------------------------------------------Coluna A,Coluna B,...,Coluna N[valor_A1 ou "valor_A1"],[valor_B1 ou "valor_B1"],...,[valor_N1 ou "valor_N1"][valor_A2 ou "valor_A2"],[valor_B2 ou "valor_B2"],...,[valor_N2 ou "valor_N2"]...[valor_AM ou "valor_AM"],[valor_BM ou "valor_BM"],...,[valor_NM ou "valor_NM"]
Regions.csv--------------------------"Id","Name"1,"Europe"2,"Americas"3,"Asia"4,"Middle East and Africa"

Manipulando o arquivo Manipulando o arquivo Regions.csvRegions.csv
Na pasta do usuário aluno /home/aluno/home/aluno (ou c:/users/aluno/c:/users/aluno/) crie uma pasta denominada TSI33ATSI33A. Em seguida salve nesta pasta o arquivo CSV Regions.csvRegions.csv.
Abra o arquivo Regions.csvRegions.csv a partir da aplicação LibreOffice (GNU-Linux) ou Microsoft Excel (MS-Windows). Caso a aplicação solicite a seleção do padrão do conjunto de caracteres (character setcharacter set), selecione Unicode(UTF-8)Unicode(UTF-8). Na linha 6 da planilha insira o conjunto de valores (5,"South America"). Salve o arquivo no mesmo formato.
Por se tratar de um arquivo de texto é possíel manipulá-lo com qualquer editor de texto. Faça um teste com um editor de texto simples (Sublime Text ou Notepad) O processo realizado anteriormente não funcionaria se o arquivo fosse do tipo binário.
Apresentando a aplicação Apresentando a aplicação CSVAppCSVApp para manipular o arquivo para manipular o arquivo Regions.csvRegions.csv
A aplicação CSVAppCSVApp foi desenvolvida na linguagem de programação Java e visa incluir, alterar e excluir registros no arquivo Regions.csvRegions.csv.
Na pasta /home/aluno/TSI33A/home/aluno/TSI33A (ou c:/users/aluno/TSI33Ac:/users/aluno/TSI33A), criada na seção anterior, salve o arquivo CSVApp.jarCSVApp.jar.
No terminal do GNU-Linux (CTRL+ALT+TCTRL+ALT+T) ou prompt de comando do MS-Windows (Iniciar→cmd→<ENTER>Iniciar→cmd→<ENTER>) execute os seguintes comandos (ou duplo clique sobre o arquivo .jar):
$cd TSI33A
$java -jar CSVApp.jar
Após a aplicação CSVAppCSVApp iniciar explore suas funcionalidades. Tente incluir o registro (5,"South America"). A aplicação identificou a duplicidade?A aplicação identificou a duplicidade?
Neste caso, as regras de integridade dos dados devem ser implementadas na própria aplicação, sendo uma atividade “onerosa” aos programadores :-(:-( .
Conhecendo outros formatos de arquivos de dadosConhecendo outros formatos de arquivos de dados
Javascript Object NotationJavascript Object Notation (JSON) e Extensible Markup LanguageExtensible Markup Language (XML) são formatos de texto simples, flexíveis e interoperáveis, utilizados para troca de dados entre aplicações - principalmente Aplicações WebAplicações Web.Esses formatos, como qualquer outro, são definidos através de um conjunto simples de regras sintáticas (mais completas se comparado ao formato CSV :-)mais completas se comparado ao formato CSV :-) ).
JSON e XML são formatos equivalentes, por isso, tudo que pode ser representado em JSON também pode ser representado em XML. Então, por que optar entre um ou outro formato de dados? Então, por que optar entre um ou outro formato de dados? Em relação aos formatos JSON e XML uma das diferenças está no tamanho da representação dos dados. O formato JSON é menor, pois não possui tagstags para representação dos dados. Ambos formatos são amplamente utilizados (e.g. o FacebookFacebook utiliza o formato JSON e a NF-eNF-e o formato XML).
Pg. Pg. 33//44

Não é o objetivo deste material avaliar os dois formatos, portanto, tenha uma excelente leitura tenha uma excelente leitura complementar :-)complementar :-).
Os próximos dois quadros mostram, respectivamente, a representação nos formatos XML e JSON dos registros do ficheiro RegionsRegions.
XML→ XML→
<?xml version="1.0"?><regions> <region id=1> <region_name>Europe</region_name> </region> <region id=2> <region_name>Americas</region_name> </region> <region id=3> <region_name>Asia</region_name> </region> <region id=4> <region_name>Middle East and Africa</region_name> </region> </regions>
JSON→ JSON→
{ "regions": {"region": [{"region_id":1,"region_name":"Europe"}, {"region_id":2,"region_name":"Americas"}, {"region_id":3,"region_name":"Asia"}, {"region_id":4,"region_name":"Middle East and Africa"}] }}
Muitos frameworksframeworks de desenvolvimento de aplicações Web utilizam os padrões JSON e XML para popular componentes (grids, combobox, autocomplete, text box, etc.), configurar conexões, etc - as vezes são extensões desses padrões.
ExercitandoExercitando
1. Após explorar as funcionalidades da aplicação CSVAppCSVApp, desenvolva sua própria aplicação seguindo os seguintes requisitos:
A aplicação pode ser desenvolvida em qualquer linguagem de programação (→ de programaçãode programação enão de scriptde script).
A aplicação deve manipular (incluir, alterar e excluir) registros do ficheiro → RegionsRegions no formato JSONJSON ou CSVCSV (desafio o JSON :-):-) ) .
A aplicação deve permitir que somente uma execução por vez da aplicação possa manipular o →
arquivo (controle primitido de acesso concorrenteacesso concorrente).
Pg. Pg. 44//44

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 02Semana 02PostgreSQLPostgreSQL
ObjetivoObjetivo
Introdução aos utilitários básicos do PostgreSQL e a ferramenta pgAdmin III→
Conhecer o catálogo do PostgreSQL→
Executar scripts SQL para criar e popular bases de dados→
Leitura ComplementarLeitura Complementar
Using pgAdmin III: → http://www.pgadmin.org/docs/1.20/using.html PostgreSQL Client Applications: → http://www.postgresql.org/docs/9.4/static/reference-client.html
AvaliaçãoAvaliação
→ Exatidão:Exatidão: os comandos utilitários estão corretos? → Estilo:Estilo: os comandos utilitários fazem uso adequado dos parâmetros?
ComeçandoComeçando
O PostgreSQL fornece utilitáriosutilitários de linha de comando que permitem aos usuários do sistema de banco dedados gerenciar bases de dados e usuários, bem como conectar e executar interativamente sentenças SQL. Nem todos os utilitários são de uso geral; alguns podem exigir privilégios especiais.
createdb cria um novo banco de dados no PostgreSQL→
dropdb Remove um banco de dados no PostgreSQL→
createuser defne uma nova conta de usuário no PostgreSQL→
dropuser remove uma conta de usuário no PostgreSQL→
psql terminal interativo do PostgreSQL→
A característica comum destes utilitários é que eles podem ser executados em qualquer servidor, independentemente de onde o servidor do sistema de banco de dados reside. A lista completa dos programas utilitários está disponível no endereço eletrônico http://www.postgresql.org/docs/9.4/static/reference-client.html
Criando o usuário Criando o usuário userdbuserdb e banco de dados e banco de dados hrhr
No terminal do GNU-Linux ou prompt de comando do MS-Windows execute:
$createuser -h localhost -U postgres -d -S -P -e userdb
Ao solicitar a senha, informe o mesmo nome do usuário (****** → userdb). Detalhe dos parâmetros:
-h especifca o servidor do sistema de banco de dados-U usuário do sistema de banco de dados com permissão de executar o comando-d permite o novo usuário criar bancos de dados-S retira o privilégio de superusuário do novo usuário-P solicita a defnição de uma senha para o novo usuário-e exibe o comando no terminal
Pg. Pg. 11//44

O comando acima criou o usuário userdbuserdb para manipular a futura base de dados hrhr. É importante salientar que os usuários do sistema operacional e do PostgreSQL são distintos; podem ser os mesmos. Para maiores detalhes do comando createusercreateuser acesse a documentação no endereço eletrônico http://www.postgresql.org/docs/9.4/static/app-createuser.html ou digite man createuserman createuser no terminal do GNU-Linux.
Em seguida execute o comando:
$createdb -h localhost -U userdb -e hr
O comando createdbcreatedb cria um novo banco de dados no PostgreSQL, cujo proprietário é o usuário userdbuserdb. Neste caso foi criado o banco de dados hrhr. Para maiores detalhes do comando createdbcreatedb acesse a documentação no endereço eletrônico http://www.postgresql.org/docs/9.4/static/app-createdb.html ou digite man createdbman createdb no terminal do GNU-Linux.
Os próximos dois comandos remove e recria, respectivamente, o banco de dados hrhr; execute-os:
$dropdb -h localhost -U userdb -e hr$createdb -h localhost -U userdb -e hr
Acessando o banco de dados Acessando o banco de dados hrhr
O utilitário psql psql permite aos usuários do sistema de banco de dados conectar e executar interativamente sentenças SQL. O usuário pode inserir as sentenças no prompt do psqlpsql ou salvar em um arquivo, executando-o a partir do comando \i\i.
No terminal do GNU-Linux ou prompt de comando do MS-Windows execute:
$psql -h localhost -U userdb -d hr
Detalhe dos parâmetros:
-h especifca o servidor do sistema de banco de dados-U usuário com permissão de executar o comando-d especifca o banco de dados da conexão
Os símbolos =#=# e =>=> referem-se, respectivamente, ao prompt de superusuáriosuperusuário e usuáriousuário da linha de comando do psqlpsql nos sistemas operacionais GNU-Linux e Microsoft Windows. Qual é o seu prompt?
Criando e populando o esquema do banco de dados Criando e populando o esquema do banco de dados hrhr
As instruções SQL podem ser executadas individualmente no utilitário psqlpsql ou por meio de arquivos de lote, chamados de scripts SQL. Arquivos de script SQL .sql.sql possuem instruções para criar, remover e alterar esquemas de banco de dados e inserir, remover e alterar dados do banco de dados.
Na pasta do usuário aluno /home/aluno/home/aluno (ou c:/users/aluno/c:/users/aluno/) crie uma pasta denominada TSI33A/pSet02TSI33A/pSet02. Em seguida salve nesta pasta os arquivos de script SQL HR_DDL_PostgreSQL.sqlHR_DDL_PostgreSQL.sql e HR_DML_PostgreSQL.sqlHR_DML_PostgreSQL.sql.
Pg. Pg. 22//44
Para criarcriar o esquema e popularpopular o banco de dados hrhr execute no prompt do psqlpsql:
=>\i /home/aluno/TSI33A/pSet02/HR_DDL_PostgreSQL.sql
=>\i /home/aluno/TSI33A/pSet02/HR_DML_PostgreSQL.sql
Uma série de comandos será executado para criar e popular a base de dados, entre eles, CREATE, INSERT e ALTER. Execute o comando \d\d no prompt do psqlpsql para verifcar as tabelas do esquema do banco de dados.
=>\d
Demais comandos do utilitário psqlpsql podem ser visualizados a partir da ajuda. No prompt do psqlpsql execute o comando \?\? para visualizar os comandos disponíveis.
=>\?
Para sair do utiliário psqlpsql execute o comando \q\q no prompt do psqlpsql.
=>\q
O psqlpsql é um utilitário muito versátil que permite ao usuário enviar qualquer sentença SQL para execução. Toda instalação do PostgreSQL vem com este utilitário. Para detalhes acesse a documentação no endereço eletrônico http://www.postgresql.org/docs/current/static/app-psql.html ou digite man psqlman psql noterminal do GNU-Linux.
Chega de linha de comando? Então vamos para um GUIChega de linha de comando? Então vamos para um GUI
Execute a aplicação pgAdmin IIIpgAdmin III. Em seguida adicione uma nova conexão (File Add Server) com os →
seguintes dados:
→ Name:Name: Conexão local → Host:Host: localhost ou 127.0.0.1 → Maintenance DB:Maintenance DB: hr → User:User: userdb → Password:Password: userdb
Por conseguinte, inicie a Conexão localConexão local e abra um editor SQL (Tools Query tool ou → CTRL+E). Lembra dos scripts SQL HR_DDL_PostgreSQL.sqlHR_DDL_PostgreSQL.sql e HR_DML_PostgreSQL.sqlHR_DML_PostgreSQL.sql? No Query tool abra o arquivo de script HR_DDL_PostgreSQL.sqlHR_DDL_PostgreSQL.sql (File Open) e o execute (Query Execute pgScript ou → →
F6). Faça o mesmo com o arquivo de script HR_DML_PostgreSQL.sqlHR_DML_PostgreSQL.sql. Pronto, aprendemos a executar scripts :-):-).
Conhecendo o catálogo do PostgreSQLConhecendo o catálogo do PostgreSQL
Os catálogos dos sistemascatálogos dos sistemas são repositórios onde os sistemas de banco de dados armazenam metadados do esquema, tais como informações sobre as tabelas, visões, funções e informações estatísticas do banco de dados.
Pg. Pg. 33//44

No PostgreSQL, os catálogos são tabelas normaistabelas normais. Se o usuário tiver permissão é possível remover e recriar as tabelas, adicionar e remover colunas, atualizar, inserir e remover valores (portanto, muito cuidado muito cuidado quando conectar com o usuário “postgres” :-|quando conectar com o usuário “postgres” :-| ). No entanto, a manipulação incorreta do catálogo pode danifcar o sistema de banco de dadosdanifcar o sistema de banco de dados. Por isso, normalmente, não se deve alterar os catálogos do sistema de forma livreforma livre (à mão). Para isso, há sempre comandos SQL. Para detalhes, acesse a documentação no endereço eletrônico http://www.postgresql.org/docs/9.4/static/catalogs.html.
ExercitandoExercitando
1. Use os utilitários do PostgreSQL para:
Criar o usuário → usertsi33ausertsi33a
Criar um banco de dados denominado → dbtsi33adbtsi33a. O proprietário do banco de dados deve sero usuário usertsi33ausertsi33a
Executar os scripts → SQL HR_DDL_PostgreSQL.sqlHR_DDL_PostgreSQL.sql e HR_DML_PostgreSQL.sqlHR_DML_PostgreSQL.sql na base de dados dbtsi33adbtsi33a
Executar e interpretar o comando → \d regions\d regions no prompt do psqlpsql
2. Para acessar o banco de dados dbtsi33adbtsi33a com o utilitário psqlpsql é necessário especifcar o parâmetro -U-U. No entanto, é possível suprimir o parâmetro -U-U se o usuário usertsi33a usertsi33a for criado no Sistema Operacional. Assim, será possível conectar ao banco de dados dbtsi33adbtsi33a com o seguinte comando
$psql -h localhost -d dbtsi33a
Crie o usuário → usertsi33ausertsi33a (com as permissões adequadas) no Sistema Opercional GNU-Linuxou MS-Windows. Em seguida, teste o comando acima.
3. Conecte a ferramenta pgAdmin III à base de dados dbtsi33adbtsi33a. Abra uma editor arbitrário de consultas e interprete a execução das seguintes consultas (copie a consulta, cole no editor e execute com F5):
→ SELECT * FROM pg_catalog.pg_tables WHERE SCHEMANAME LIKE 'dbtsi33a';
→ SELECT * FROM pg_catalog.pg_tables;
→ SELECT * FROM pg_catalog.pg_views WHERE SCHEMANAME LIKE 'dbtsi33a';
4. Use os utilitários do PostgreSQL e do Sistema Operacional para:
Remover o banco de dados → dbtsi33adbtsi33a. remover o usuário → usertsi33ausertsi33a do PostgreSQL. remover o usuário → usertsi33ausertsi33a do Sistema Operacional.
5. Dois conceitos importantes em sistemas de banco de dados são os esquemasesquemas e as instâncias instâncias (estados). É peculiar a diferença entre esses conceitos, por isso, é recomendado estudá-los a partir de um banco dedados real. Considerando o banco de dados hrhr, responda:
Qual é o esquema do banco de dados → hrhr? É possível mensurar o tamanho da instância → hrhr? Se sim, como?
Pg. Pg. 44//44

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 03Semana 03
Relational ModelRelational ModelObjetivoObjetivo
Apresentar a existência de outros modelos de dados→
Compreender o modelo relacional a partir de um estudo de caso (→ Order EntityOrder Entity)
Leitura ComplementarLeitura Complementar
→ Capítulo 11 e Capítulo 12:Capítulo 11 e Capítulo 12: ELMASRI, Ramez; NAVATHE, Shamkant B. Sistemas de banco de dados. 6 ed. São Paulo: Pearson Addison Wesley, 2011.
→ Human Resources (HR)Human Resources (HR): http://docs.oracle.com/cd/B14117_01/server.101/b10771/rationale002.htm#BEGIN
AvaliaçãoAvaliação
→ Exatidão:Exatidão: as regras de integridades do modelo OEOE foram identificadas adequadamente? → Estilo:Estilo: as regras de integridade estão coesas com o domínio da aplicação?
ComeçandoComeçando
O modelo relacional é amplamente utilizado nos diversos segmentos do desenvolvimento de software. Suaestrutura foi proposta por Edgar Frank CoddEdgar Frank Codd e publicada no artigo Relational Model of Data for Large Relational Model of Data for Large Shared Data BanksShared Data Banks em 1970. O artigo está disponível na ACM Digital LibraryACM Digital Library http://dl.acm.org/citation.cfm?id=362685 (acesse com o proxy da UTFPR :-)acesse com o proxy da UTFPR :-) )
Na década de 70 outros modelos de banco de dados já existiam (e.g. modelo hierárquicomodelo hierárquico e modelo em modelo em rederede), contudo, esses modelos apresentavam complexidade na recuperação das informações e eram fortemente dependentes da aplicação. Portanto, o modelo de dados relacional passou a ser utilizado pelos fornecedores de sistemas de banco de dados.
Com a evolução do desenvolvimento de software, a massificação das linguagens orientadas a objetos, a interoperabildiade entre aplicações e a necessidade de novos tipos de dados, novos modelos de dados foram propostos. Dentre eles estão o modelo de dados de objetosmodelo de dados de objetos e o modelo de dados XMLmodelo de dados XML.
O modelo de dados de objetos foi concebido de modo a integrar diretamente a base de dados ao software desenvolvido por uma linguagem de programação orientada a objetos. No modelo relacional a comunicação entre o banco de dados e a aplicação orientada a objetos necessita de um mapeamento mapeamento mapeamento objeto-relacionalmapeamento objeto-relacional, portanto, com o uso de banco de dados de objetos esse mapeamento deixa de ser realizado. O HibernateHibernate é um exemplo de framework que faz o mapeamento objeto-relacional (se alcançarmos as metas, veremos até o final da disciplina TSI33A :-) ).
Nesse mesmo contexto, o modelo de dados XMLmodelo de dados XML foi proposto devido à evolução das aplicações web e fontes de dados que disponibilizam dados XML na web.
É importante destacar que os modelos supracitados possuem linguagens próprias de definição, manipulação e consulta de dados, implementados pelos sistemas de banco de dados que comportam esses modelos. Por exemplo, as linguagens Object Definition LanguageObject Definition Language (ODL) e Object Query LanguageObject Query Language (OQL) referem-se ao modelo de dados de objetos e as linguagens XML PathXML Path (Xpath) )e XQueryXQuery (XML Query) ao modelo de dados XML.
Pg. Pg. 11//44

Fornecedores de SGBDRs reconheceram a necessidade de incorporar outros padrões de modelos de dados e, consequentemente, sistemas de banco de dados híbridossistemas de banco de dados híbridos surgiram no mercado (e.g. IBM DB2 Database, Oracle Database, PostgreSQL, etc.).
Estudando um modelo de dados relacionalEstudando um modelo de dados relacional
No website da ferramente SQL Developer Data ModelerSQL Developer Data Modeler (http://www.oracle.com/technetwork/developer-tools/datamodeler/sample-models-scripts-224531.html) estão disponíveis quatro modelos de dados relacionais. Um desses modelos é o HR data modelHR data model. A descrição do domínio do negócio está disponível no endereço http://docs.oracle.com/cd/B14117_01/server.101/b10771/rationale002.htm#BEGIN.
Na base de dados HRHR cada colaboradorcolaborador tem uma identificação, um e-mail, o código do seu cargo, o código do seu departamento, um salário e o código do seu gerente. Alguns colaboradores ganham uma comissão além do seu salário.
A base de dados também controla informações sobre os departamentosdepartamentos e cargoscargos da empresa. Cada cargo tem um identificador, um título e o piso e teto salarial. Cada departamento tem um identificador, um nome, o código do gerente e uma localizaçãolocalização. Cada departamento está associada a um único local.
Cada localização tem um endereço, um CEP, uma cidade, um estado e o código do país.Alguns colaborares trabalham por um longo período na empresa e já ocuparam diferentes cargos. Quando um colaborador muda de cargo a empresa registra o seu históricohistórico, armazenando a data de inícioe fim do cargo, o identificador do cargo e o identificador do departamento de lotação.
Por se tratar de uma empresa multinacional existem diversas filiais. Desta forma, os departamentos estão distribuídos em diversos paísespaíses. Cada país possui um identificador, um nome e o identificador da região. Aregião refere-se ao continente do país, portanto, as instalações da empresa são distribuídas em regiõesregiões. Cada região possui um identificador e um nome.
Pg. Pg. 22//44

Estudando as regras de integridade do modelo de dados relacionalEstudando as regras de integridade do modelo de dados relacional
O modelo relacional possui um conjunto de regras que visam à integridade dos dados. São quatro as principais regras de integridade (domínio, mandatório ou nulo, chaves e semântica.), sendo estas exemplificadas através do diagrama acima.
A regra de integridade de domíniointegridade de domínio limita os valores de atributo das relações. Por exemplo, a relação JOBSpossui os atributos MIN_SALARY e MAX_SALARY, cujos valores não podem ser, respectivamente, inferior azero e inferior a MIN_SALARY. Outro exemplo refere-se à relação JOB_HISTORY, cujo valor do atributo START_DATE deve ser igual ou inferior ao atributo END_DATE.
A regra de integridade de valor mandatório ou nulointegridade de valor mandatório ou nulo define valores madatórios ou opcionais de atributos das relações. Por exemplo, alguns departamentos não possuem gerente por estratégia organizacional, portanto, o atributo MANAGER_ID da relação DEPARTMENTS deve ser opcional e não mandatório. Por outro lado, o atributo DEPARTMENT_NAME é mandatório, pois os departamentos devem ter um nome.
A regra de integridade de chavesintegridade de chaves é subdividida em chave primáriachave primária, chave únicachave única e chave estrangeirachave estrangeira. A chave primária refere-se ao atributo ou conjunto de atributos cujo valor garante a unicidade da tupla, sendo este valor madatório. Por exemplo, em uma situação homônima na relação EMPLOYEES, em que oscolaboradores possuem o mesmo cargo e estão alocados no mesmo departamento, o atributo EMPLOYEE_ID deve distinguí-los (diferenciá-los), portanto, este atributo é a chave primária da relação.
A chave estrangeira refere-se à integridade referencialintegridade referencial dos dados, ou seja, o conjunto de valores que o atributo pode assumir deve existir em uma relação de referência entre este atributo e a chave primária da relação. Por exemplo, os países estão situados em regiões, contudo, o atributo REGION_ID da relação COUNTRIES só pode receber valores que existam para o atributo REGION_ID da relação REGIONS. O mesmo ocorre entre os atributos DEPARTAMENT_ID da relação EMPLOYEES e o atributo DEPARTMENT_IDda relação DEPARTMENTS.
Assim como a chave primária, a chave únicachave única também garante a unicidade do valor do atributo ou conjunto de atributos. No entanto, a chave única não é mandatório e, consequentemente, permite valor nulo ao atributo. Outra diferença é que a chave única não permite integridade referencial, ou seja, não é possível definir uma chave estrangeira com um atributo ou conjunto de atributos chave única.
A regra de integridade semânticaintegridade semântica está associada a definição de regras de negócio ao esquema do modelo de dados. Entende-se por regras de negócio regras de negócio as regras de lógica, processos, etc. Por exemplo, para toda alteração de cargo ou departamento de um colaborador uma tupla deve ser inserida na relação JOB_HISTORY com os valores anteriores. Esse processo deve ser automático a partir da alteração dos atributos JOB_ID e/ou DEPARTMENT_ID da relação EMPLOYEES. Assim, é possível manter um histórico dos colaboradores (cargos e departmentos que ele atuou).
A integridade semântica é abrangente e pode envolver qualquer restrição que ocorre no mundo real. Por exemplo, o número de seguridade social ou cadastro de pessoa física possui uma lógica de definição. O valor desse atributo pode ser validado a partir da definição de regras semânticas. Caso a regra não seja satisfeita, a tupla não poderá ser inserida na relação (e.g. função para validar o CPF).
Pg. Pg. 33//44

ExercitandoExercitando
1. Considerando a descrição do domínio de negócio Order EntryOrder Entry (OE), disponvível no endereço http://docs.oracle.com/cd/B14117_01/server.101/b10771/rationale003.htm, e o modelo lógico abaixo, identifique e descreva:
As regras de integridade de domínio→
As regras de integridade de valor mandatório ou nulo→
As regras de integridade de chaves (primária, única e estrangeira)→
As regras de integridade semântica→
2. “Obter informações organizacionais em sistemas de processamento de arquivos apresenta numerosas desvantagens” (SILBERSHATZ, 1999). Podemos citar como desvantagem os problemas de integridade dos dados. Por exemplo, um sistema acadêmico não deve permitir a exclusão de registros de alunos que foram matriculados e possuem qualquer modalidade de lançamento no sistema (notas bimestrais, nota final,boletos, registros de empréstimo de livros, etc). Marque e justifique a alternativa que expressa o tipo de integridade do modelo relacional que trata a questão apresentada.
Integridade de obrigatoriedade→
Integridade referencial→
Integridade de domínio→
Integridade de atomicidade→
Pg. Pg. 44//44

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 04Semana 04
Structured Query Language (SQL) Structured Query Language (SQL) &&&& Consultas ConsultasObjetivoObjetivo
Introduzir os diferentes padrões da SQL→
Construir consultas SQL básicas→
AvaliaçãoAvaliação
→ Exatidão:Exatidão: a sintaxe das consultas SQL estão corretas? → Estilo:Estilo: as consultas SQL são claras e seguem as boas práticas?
ComeçandoComeçando
A Structured Query LanguageStructured Query Language (SQL) é a linguagem padrão dos sistemas de banco de dados relacionais comerciais (proprietários e opensource) e foi padronizada em 1986 pelos órgãos American National American National Standards InstituteStandards Institute (ANSI) e International Standards OrganizationInternational Standards Organization (ISO). A especificação do primeiro padrão é a norma ISO/IEC 9075ISO/IEC 9075 e, como qualquer outra linguagem, a SQL evoluiu desde a sua concepção; o padrão mais recente foi publicado em 2011.
Popularmente o primeiro padrão é chamado de SQL-86SQL-86 ou SQL1SQL1, com sua revisão em 1989 (SQL-89SQL-89). Em 1992 o padrão SQL-86/89 foi revisado e expandido, resultando no padrão SQL-92SQL-92 ou SQL2SQL2 (especificado pela norma ISO/IEC 9075:1992ISO/IEC 9075:1992). A principal novidade deste padrão foi a especificação de funcionalidades comuns (corecore), que toda implementação de sistema de banco de dados em conformidade deve implementar, e demais funcionalidades (extensionsextensions), normalmente disponibilizadas em pacotes pelos fornecedores de sistemas de banco de dados. Uma diferença entre os padrões SQL-92 e SQL-89 é o estilo e a performance de consultas com a operação de junção.
Abaixo é apresentado um exemplo de junção externa a esquerdajunção externa a esquerda (LEFT JOIN) nos padrões SQL-86 e SQL-92.
SQL-86→
SELECT E.FIRST_NAME, J.JOB_TITLEFROM EMPLOYEES E, JOBS JWHERE J.JOB_ID(+) = E.JOB_ID;
SQL-92→
SELECT E.FIRST_NAME, J.JOB_TITLEFROM EMPLOYEES E,
LEFT JOIN JOBS J ON E.JOB_ID = J.JOB_ID;
Outras diferenças envolveram: tipos de dados; operações de junções; e projeção condicionada (CASE). Para manter a compatibilidade os novos padrões SQL mantêm as funcionalidades dos padrões anteriores. Assim, o padrão SQL-92 é compatível com o padrão SQL-86/89 (cuidadocuidado - o inverso não é verdadeiro).
Alguns sistemas de banco de dados não admitem todos os estilos da mesma instrução. Por exemplo, o PostgreSQL iniciou no padrão SQL-92, portanto, não admite a junção externa no padrão SQL-86. Já o Oracle Database admite todos os estilos de comandos.
Pg. Pg. 11//55

O próximo padrão reconhecido foi o SQL:1999SQL:1999, chamada de SQL3SQL3, que consiste em uma série de especificações (ISO/IEC 9075-1:1999ISO/IEC 9075-1:1999,ISO/IEC 9075-2:1999ISO/IEC 9075-2:1999,ISO/IEC 9075-3:1999ISO/IEC 9075-3:1999, entre outras).
Os padrões SQL:2003SQL:2003 e SQL:2006SQL:2006 incorporaram poucas funcionalidades ao padrão SQL:1999. A principal mudança ocorreu na SQL:2003, dividindo a especificação em partes:
ISO/IEC 9075-1 Framework (SQL/Framework)→
ISO/IEC 9075-2 Foundation (SQL/Foundation)→
ISO/IEC 9075-3 Call Level Interface (SQL/CLI)→
ISO/IEC 9075-4 Persistent Stored Modules (SQL/PSM)→
ISO/IEC 9075-9 Management of External Data (SQL/MED)→
ISO/IEC 9075-10 Object Language Bindings (SQL/OLB)→
ISO/IEC 9075-11 Information and Definition Schemas (SQL/Schemata)→
ISO/IEC 9075-13 Routines and Types using the Java Language (SQL/JRT)→
ISO/IEC 9075-14 XML-related specifications (SQL/XML)→
Cada sistema de banco de dados cobre um conjunto de partes da especificação SQL. Por exemplo, o PostgreSQL 9.4PostgreSQL 9.4 cobre as partes 1, 2, 9, 11 e 14. A parte 3 é coberta pelo driver ODBCODBC e a parte 13 pelo plugin PL/JavaPL/Java. As partes 4 e 10 não são implementadas pelo PostgreSQL 9.4.
Em geral, os padrões SQL:2003/2006 introduziram funcionalidades de XML (SQL/XML) e funções de janelas (windows functionswindows functions). Por exemplo, a consulta abaixo faz uso de funções de janelas para agrupar porcargo a soma dos salários dos colaboradores (e.g. 5 Analistas com salário U$ 2,000.00 resulta em U$ →
10,000.00).
SELECT DISTINCT JOB_ID, SUM(SALARY) OVER (PARTITION BY JOB_ID) FROM EMPLOYEES;
O padrão SQL:2008 também é dividido em diversas partes e incorporou, pincipalmente, recursos de objetos (banco de dados de objetos). Por fim, novas revisões originaram o padrão SQL:2011SQL:2011 (ISO/IEC ISO/IEC 9075:20119075:2011).
Muitos dos novos recursos dos padrões SQL já haviam sido implementados por fornecedores de sistemas de banco de dados antes da especificação e publicação dos padrões. Portanto, os grandes fornecedores e as grandes comunidades de sistemas de banco de dados são colaboradores e participantes da evolução da SQL.
Brincando com os padrões SQL no SQLFiddleBrincando com os padrões SQL no SQLFiddle
SQLFiddleSQLFiddle é uma ferramenta online de fácil manipulação para testes SQL. A ferramenta está disponível no endereço http://sqlfiddle.com/. Abra um navegador de Internet (Google Chrome, Mozilla Firefox ou Internet Explorer) e acesse a ferramenta SQLFiddle.
Na ferramenta, selecione o sistema de banco de dados Oracle 11g R2 Oracle 11g R2 (lado superior esquerdo). Em seguida copie as instruções abaixo e cole no quadro esquerdoquadro esquerdo da ferramenta. Clique no botão Build Build SchemaSchema.
Pg. Pg. 22//55

CREATE TABLE JOBS ( JOB_ID CHAR(10) NOT NULL, JOB_TITLE VARCHAR(35) NOT NULL);
INSERT INTO JOBS (JOB_ID,JOB_TITLE) VALUES ('AD_PRES','President');INSERT INTO JOBS (JOB_ID,JOB_TITLE) VALUES ('SA_MAN','Sales Manager');INSERT INTO JOBS (JOB_ID,JOB_TITLE) VALUES ('IT_PROG','Programmer');
CREATE TABLE EMPLOYEES ( EMPLOYEE_ID INTEGER NOT NULL, FIRST_NAME VARCHAR(20), JOB_ID CHAR(10), SALARY NUMERIC(8,2));
INSERT INTO EMPLOYEES (EMPLOYEE_ID,FIRST_NAME,JOB_ID,SALARY) VALUES (100,'Steven','AD_PRES',24000);INSERT INTO EMPLOYEES (EMPLOYEE_ID,FIRST_NAME,JOB_ID,SALARY) VALUES (104,'Bruce','IT_PROG',6000);INSERT INTO EMPLOYEES (EMPLOYEE_ID,FIRST_NAME,JOB_ID,SALARY) VALUES (107,'Diana','',4200);INSERT INTO EMPLOYEES (EMPLOYEE_ID,FIRST_NAME,JOB_ID,SALARY) VALUES (145,'John','SA_MAN',14000);INSERT INTO EMPLOYEES (EMPLOYEE_ID,FIRST_NAME,JOB_ID,SALARY) VALUES (146,'Karen','SA_MAN',13500);
Por conseguinte, copie a consulta abaixo e cole no quadro direitoquadro direito. Clique no botão Run SQLRun SQL. Observe sea consulta executará com sucesso.
SELECT E.FIRST_NAME, J.JOB_TITLEFROM EMPLOYEES ELEFT JOIN JOBS J ON J.JOB_ID = E.JOB_ID;
Faça o mesmo com a consulta abaixo. Observe que a consulta foi escrita de outra forma, contudo, possui o mesmo retorno.
SELECT E.FIRST_NAME, J.JOB_TITLEFROM EMPLOYEES E, JOBS J WHERE J.JOB_ID(+) = E.JOB_ID;
Agora selecione o sistema de banco de dados MySQL 5.5.32MySQL 5.5.32. Em seguida, clique novamente no botão Build SchemaBuild Schema. Execute novamente as duas consultas acima. Observe que a segunda consulta gerou um erro de sintaxe, pois a sintaxe da junção externa da segunda consulta não é interpredada pela versão do sistema banco de dados MySQL 5.5.32.
Apresentando um novo modeloApresentando um novo modelo
A base de dados BMBM registra os movimentos bancários das empresas cadastradas. Cada empresaempresa possuium identificador, uma nome e o saldo geral atualizado. O saldo geral refere-se ao saldo de todos as contas da empresa.
A base de dados também controla informações das contascontas das empresas. Cada conta tem um identificador, um número da conta, uma descrição, um banco e o saldo atualizado da conta.
As empresas registram os movimentosmovimentos bancários (lançamentos de crédito e débido) de cada conta. Cada movimento tem um identificador de movimento, a empresa e conta que realizou o movimento, a descrição do movimento, a data, tipo e valor do movimento. A fim de otimizar a recuperação dos dados, um resumoresumo mensal das movimentações é armazenado. Por exemplo, uma determinada empresa possui movimentos diários entre os anos 2000 e 2014. Mensalmente é registrado o saldo mensal na tabela resumo. Se a empresa recuperar o saldo do mês de Agosto de 2010, somente verificará o resumo destemês – não é necessário somar os créditos e débitos de todos os movimentos até essa data.
Pg. Pg. 33//55

Inteprete o modelo físico abaixo.
Na pasta do usuário aluno /home/aluno/home/aluno (ou c:/users/aluno/c:/users/aluno/) crie uma pasta denominada TSI33A/pSet04TSI33A/pSet04. Em seguida salve nesta pasta o arquivo de script SQL BM_DDL_DML_PostgreSQLBM_DDL_DML_PostgreSQL.
No terminal do GNU-Linux ou prompt de comandos do MS-Windows execute:
$createuser -h localhost -U postgres -d -S -P -e userlocal
Em seguida execute os comandos:
$createdb -h localhost -U userlocal -e bm
$psql -h localhost -U userlocal -d bm
Após acessar a base de dados, crie o esquema e popule o banco de dados bmbm com o arquivo de script BM_DDL_DML_PostgreSQLBM_DDL_DML_PostgreSQL.
=>\i /home/aluno/TSI33A/pSet04/BM_DDL_DML_PostgreSQL.sql
Uma série de comandos será executado para criar e popular a base de dados, entre eles, CREATE, INSERT e ALTER. Execute o comando \d\d no prompt do psqlpsql para verificar as tabelas do esquema do banco de dados.
Por conseguinte, fecha o utiliário psqlpsql.
=>\q
Pg. Pg. 44//55

ExercitandoExercitando
1. Conectar a ferramenta pgAdmin IIIpgAdmin III a base de dados bmbm. Abra uma editor arbitrário de consultas e elabore as seguintes consultas:
Recupere o saldo geral atualizado das empresas (use a tabela empresa)→
Recupere o saldo de cada conta da empresa Cooperativa de Pesquisa Agrícola→
Liste os movimentos de débido da empresa Jacar Materiais de Construção→
Recupere as empresas ordenando-as pela maior saldo→
2. Verifique por meio de consultas se a empresa Transportadora Ortox possui:
Depósitos em dinheiro→
Depósito em cheque→
Movimento de débido superior ao movimento de crédito→
3. Você recorda do modelo Order Entity do pSet03pSet03? Vamos criá-lo :-):-)
Execute as seguintes instruções→
$createdb -h localhost -U userlocal -e tsi33a
$psql -h localhost -U userlocal -d tsi33a
(os próximos comandos exigem primeiro a execução dos scripts HR_DDL_PostgreSQL.sqlHR_DDL_PostgreSQL.sql e HR_DML_PostgreSQL.sqlHR_DML_PostgreSQL.sql, pois existe uma dependência entre os scripts)
=>\i /home/aluno/TSI33A/pSet04/OE_DDL_PostgreSQL.sql
=>\i /home/aluno/TSI33A/pSet04/OE_DML_PostgreSQL.sql
Considere a base de dasdos Order Entity (OE), a partir do pgAdmin III elabore as seguintes consultas:
Recupere o código, o nome e a descrição dos produtos da → categoria 17categoria 17 Recupere os dados dos produtos que → possuem catálogo de endereço possuem catálogo de endereço eletrônico (urlurl) Recupere o nome e sobrenome dos→ clientes solteiros clientes solteiros do sexo feminino sexo feminino Crie uma consulta para responder a pergunta: Todos os clientes italianos são solteiros?→
Crie uma consulta para responder a pergunta: Existe um armazém em New Jersey?→
Pg. Pg. 55//55

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 05Semana 05
Junções Junções &&&& Base de Dados Remota Base de Dados RemotaObjetivoObjetivo
Compreender a confguração de acesso remoto do PostgreSQL→
Consolidar o conteúdo de junções da SQL→
Leitura ComplementarLeitura Complementar
→ Chapter 19. Client AuthenticationChapter 19. Client Authentication: : http://www.postgresql.org/docs/9.4/static/auth-pg-hba-conf.html → Coderwall:Coderwall: https://coderwall.com/p/cr2a1a/allowing-remote-connections-to-your-postgresql-vps-installation
AvaliaçãoAvaliação
→ Exatidão:Exatidão: a estrutura das consultas está correta? → Estilo:Estilo: a estrutura das consultas está indentada e segue as boas práticas?
ComeçandoComeçando
A confguração padrãoconfguração padrão de instalação do PostgreSQL perminte somente acesso localacesso local ao sistema de banco de dados, (i.e., através dos endereços 127.0.0.1127.0.0.1 ou localhostlocalhost). Essa confguração inicial garante a segurança do sistema de banco de dados até que sejam defnidas políticas e estratégias de acesso e uso das bases de dados e manutenção do sistema de banco de dados.
Em ambientes corporativos, cujos dados são valiosos, é comum o servidor de banco de dados ser acessível somente na rede interna. Assim, as aplicações ou executam na mesma redemesma rede do sistema de bancode dados ou por meio de containerscontainers ou servidores de aplicaçãoservidores de aplicação.
Por exemplo, aplicações desktopdesktop são instaladas nas estações de trabalho e, por meio da rede interna, acessam o sistema de banco de dados para recuperar, armazenar, alterar e excluir dados. Também é possível que aplicações dektop acessem o sistema de banco de dados a partir de redes privadas ou acesso remoto (e.g. Virtual Private NetworkVirtual Private Network – VPN, Terminal ServerTerminal Server – TS). Outro viés de acesso são as aplicações para webaplicações para web. Estas possuem containers containers ou servidores servidores de aplicações aplicações (e.g. Apache TomcatApache Tomcat, JBossJBoss, GlassfshGlassfsh) que estão, normalmente, na mesma rede do sistema de banco de dados. Outras estratégias de acesso envolvendo redes de computadores também são empregadas (e.g. roteamento, fltros - IPTables, etc.).
Além da infraestrutura de acesso também é possível administrar o sistema de banco de dados em relação aos usuários, ao acesso as bases de dados, aos utilitários e às instruções SQL. Uma breve exemplifcação será apresentanda para posterior acesso ao servidor amazonia.td.utfpr.bramazonia.td.utfpr.br (PostgreSQL 9.4).
Configurando o acesso remoto no PostgreSQLConfigurando o acesso remoto no PostgreSQL
Após a instalação do PostgreSQL no servidor de banco de dados, além de outros serviços essenciais paraa manutenção remota (e.g. SSHSSH), faz-se necessário confgurar os arquivos pg_hba.conf e postresql.conf. A localização destes arquivos depende do sistema operacional e da instalação do PostgreSQL, portanto, o material será baseado no GNU-Linux distro Ubuntu 14.04.1 LTS com a instalação padrão do PostgreSQL 9.4.
Pg. Pg. 11//66

O primeiro passo é adicionar registros de autenticação de cliente no arquivo pg_hba.conf. No terminal, execute:
$sudo pico /etc/postgresql/9.4/main/pg_hba.conf
Como indicado abaixo, a confguração aceita conexões somente a partir do localhost.
# host DATABASE USER ADDRESS METHOD# "local" is for Unix domain socket connections only local all all peer # IPv4 local connections: host all all 127.0.0.1/32 md5 # IPv6 local connections: host all all ::1/128 md5
Para permitir conexões de qualquer hosthost, somente para a base de dados tsi33atsi33a, altere a linha indicada para:
# host DATABASE USER ADDRESS METHOD# IPv4 local connections: host tsi33a all 0.0.0.0/0 md5
O pg_hba.conf permite controlar o acesso combinando o IP ou máscara de rede, banco, usuário e método de acesso. Consulte o endereço http://pt.wikibooks.org/wiki/PostgreSQL_Pr%C3%A1tico/Confgura%C3%A7%C3%B5es/Confgurar_acessos para maiores detalhes.
O segundo passo é alterar o arquivo postgresql.conf. No terminal, execute:
$sudo pico /etc/postgresql/9.4/main/postgresql.conf
Como indicado abaixo, o serviço do sistema de banco de dados aceita somente sessões do localhostlocalhost.
#listen_addresses = 'localhost' # what IP address(es) to listen on;max_connections = 100 # (change requires restart)
O máximo de conexões também pode ser alterado para prover maior segurança. Sabendo o número máximo de usuários ou conexões simultâneas, defna esse número como valor do parâmetro max_connections.
Altere a linha indicada para:
listen_addresses = '*' # what IP address(es) to listen on;max_connections = 15 # (change requires restart)
Reinicie o serviço do PostgreSQL para que os novos valores sejam aplicados. No terminal, execute:
$sudo service postgresql restart
Outras confgurações são possíveis para os arquivos pg_hba.conf e postgresql.conf. Procure conhecer como administrar a segurança das conexões com o PosgreSQL.
Pg. Pg. 22//66

Acessando o sistema de banco de dados do servidor Acessando o sistema de banco de dados do servidor amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br
No terminal do GNU-Linux ou prompt de comando do MS-Windows execute (substitua <RA> pelo registro acadêmico) :
$psql -h amazonia.td.utfpr.edu.br -U <RA> -d tsi33a
Cada aluno possui um usuário do sistema de banco de dados (seu registro acadêmico) e um esquema de banco de dados (com o mesmo nome do usuário). Todos os usuários podem acessar a base de dados tsi33atsi33a, contudo, só podem manipular o seu próprio esquema. Um esquema é uma organização lógica de objetos de banco de dados.
Por defaultdefault, a senha padrão é o próprio nome do usuário. Desta forma, após conectar à base de dados tsi33atsi33a, execute o comando abaixo para alterar a senha (substitua o valor nova_senha):
=>ALTER ROLE "1135520" WITH PASSWORD 'nova_senha';
A mesma conexão pode ser realizada na ferramenta pgAdmin IIIpgAdmin III. Certifque-se de desconectar do utilitário psqlpsql, pois cada usuário pode utilizar somente duas sessão do sistema de banco de dados. Essa regra desegurança foi defnida no momento da criação dos usuários.
Exemplo de criação do usuário do sistema de banco de dados (prompt psqlpsql e utilitário createusercreateuser):
#>CREATE ROLE "0000000" WITH NOSUPERUSER NOCREATEDB NOCREATEROLE NOINHERIT NOREPLICATION CONNECTION LIMIT 2CONNECTION LIMIT 2 LOGIN PASSWORD '0000000' VALID UNTIL '2015-07-03';
$createuser -S -D -R -I --no-replication -c 2-c 2 -l -h localhost -P -e 0000000
Os comandos acima exigem privilégios administrativos para serem executados, potanto, se desejar, teste no sistema de banco de dados local (não é possível em amozonia.td.utfpr.edu.br).
Por que duas sessõesduas sessões de conexão e não apenas uma? Bom, A ferramenta PgAdmin III trata as sessões de forma diferente do utilitário psqlpsql. Cada janela do PgAdmin III exige uma sessão com o sistema de banco de dados. Desta forma, o janela principal possui uma sessão e o editor arbitrário de SQL outra sessão.
Criando e populando a base de dados Criando e populando a base de dados tsi33atsi33a no servidor no servidor amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br
Na pasta do usuário aluno /home/aluno/home/aluno (ou c:/users/aluno/c:/users/aluno/) crie uma pasta denominada TSI33A/pSet05TSI33A/pSet05. Salve nesta pasta o arquivo de script SQL HR_DDL_DML_PostgreSQL.sqlHR_DDL_DML_PostgreSQL.sql. Em seguida, execute o comando abaixo no terminal (GNU_Linux) ou prompt de comando (MS-Windows):
$psql -h amazonia.td.utfpr.edu.br -U <RA> -d tsi33a -f /home/aluno/TSI33A/pSet05/HR_DDL_DML_PostgreSQL.sql
O parâmetro -f-f do utilitário psql invoca de forma implícita o comando \i. Com o parâmetro -f é possível executar o script que cria e popula a base de dados tsi33atsi33a em sistema de banco de dados remoto.
Pg. Pg. 33//66

ExercitandoExercitando
1. Acesse a base de dados tsi33atsi33a no servidor amazonia.utfpr.edu.bramazonia.utfpr.edu.br (use o utilitário psql ou a ferramenta PgAdmin III). Em seguida, elabore as seguintes consultas:
Recupere o → nome completonome completo, cargocargo e valor do salário por horasalário por hora dos programadores. Assuma que os colaboradores trabalham 160 horas/mês
EMPLOYEE_ID | EMPLOYEE_NAME | JOB_ID | JOB_TITLE | SALALRY/HOUR -------------+------------------+------------+------------+-------------- 103 | Alexander Hunold | IT_PROG | Programmer | 56.25 104 | Bruce Ernst | IT_PROG | Programmer | 37.50 105 | David Austin | IT_PROG | Programmer | 30.00 106 | Valli Pataballa | IT_PROG | Programmer | 30.00 107 | Diana Lorentz | IT_PROG | Programmer | 26.25
Recupere o → cargocargo atualatual e os cargos anteriorescargos anteriores dos colaboradores que alteraram de cargo desde a data de contratação. Ordene os registros por pelo primeiro nome
FIRST_NAME | JOB_CURRENT | JOB_PREVIOUS------------+-------------------------------+-------------------------- Den | Purchasing Manager | Stock Clerk Jonathon | Sales Representative | Sales Manager Jonathon | Sales Representative | Sales Representative Lex | Administration Vice President | Programmer Michael | Marketing Manager | Marketing Representative Neena | Administration Vice President | Public Accountant Neena | Administration Vice President | Accounting Manager Payam | Stock Manager | Stock Clerk
Recupere o nome e país dos departamentos que não possuem gerente→
DEPARTMENT_NAME | COUNTRY_NAME----------------------+-------------------------- Payroll | United States of America Recruiting | United States of America Retail Sales | United States of America Government Sales | United States of America IT Helpdesk | United States of America NOC | United States of America IT Support | United States of America Operations | United States of America Contracting | United States of America Construction | United States of America Manufacturing | United States of America Benefits | United States of America Shareholder Services | United States of America Control And Credit | United States of America Corporate Tax | United States of America Treasury | United States of America
2. As informações sobre os cargos da empresa (e.g. programadores, analistas de TI, contadores, etc.) são armazenadas na tabela JOBSJOBS. Além do identifcador e da descrição do cargo também são registrados o pisopiso e tetoteto salarial.
Considerando que a tabela EMPLOYEESEMPLOYEES não possui mecanismo para restringir a inclusão de colaboradorescom salário inferior ao piso salarial ou superior ao teto salarial, alguns registros podem estar inconsistentesem relação ao domínio do negócio. Como responsável pelas consultas no banco de dados:
elabore uma consulta que recupere os registros com → inconsistênciainconsistência de salário inferior ao piso piso salarialsalarial ou superior ao teto salarialteto salarial. Liste o nome completonome completo dos colaboradores, o saláriosalário e os respectivos pisopiso e tetoteto salarial.
EMPLOYEE_NAME | SALARY | MIN_SALARY | MAX_SALARY---------------+---------+------------+------------ Matthew Weiss | 8600.00 | 5500.00 | 8500.00
Pg. Pg. 44//66

3. A folha de pagamento é, normalmente, uma lista mensal referente à remuneração dos colaboradores deuma empresa. A empresa gera a folha de pagamento a partir de uma série de procedimentos trabalhistas. Considerando apenas as tabelas do Instituto Nacional do Seguro SocialInstituto Nacional do Seguro Social (INSS) e Imposto de Renda RetidoImposto de Renda Retidona Fontena Fonte (IRRF), que são alíquotas descontadas do salário do colaborador, recupere do banco de dados os seguintes dados (utilize a projeção condiconalprojeção condiconal para os impostos do INSS e IRRF):
nome completo dos colaboradores→
o nome do cargo dos colaboradores→
salário bruto (valor armazenado na base de dados)→
alíquota do INSS (→ vigência 01/01/2014 vigência 01/01/2014 http://www.previdencia.gov.br/inicial-central-de-servicos-ao-segurado-formas-de-contribuicao-empregado/)
valor a ser descontado do INSS→
alíquota do IRRF (→ exercício 2015exercício 2015 http://www.receita.fazenda.gov.br/Aliquotas/ContribFont2012a2015.htm) valor a ser descontado do IRRF→
EMPLOYEE_NAME | JOB_TITLE | SALARY |(%)INSS| INSS |(%)IRRF IRRF -------------------+---------------------------------+----------+-------+---------+------+--------- Steven King | President | 24000.00 | 11.00 | 2640.00 | 27.5 | 6600.00 Neena Kochhar | Administration Vice President | 17000.00 | 11.00 | 1870.00 | 27.5 | 4675.00 David Austin | Programmer | 4800.00 | 11.00 | 528.00 | 27.5 | 1320.00 Valli Pataballa | Programmer | 4800.00 | 11.00 | 528.00 | 27.5 | 1320.00 Nancy Greenberg | Finance Manager | 12008.00 | 11.00 | 1320.88 | 27.5 | 3302.20 Daniel Faviet | Accountant | 9000.00 | 11.00 | 990.00 | 27.5 | 2475.00 John Chen | Accountant | 8200.00 | 11.00 | 902.00 | 27.5 | 2255.00 Alexander Khoo | Purchasing Clerk | 3100.00 | 11.00 | 341.00 | 15.0 | 465.00 Karen Colmenares | Purchasing Clerk | 2500.00 | 11.00 | 275.00 | 7.5 | 187.50 Adam Fripp | Stock Manager | 8200.00 | 11.00 | 902.00 | 27.5 | 2255.00 Julia Nayer | Stock Clerk | 3200.00 | 11.00 | 352.00 | 15.0 | 480.00 James Landry | Stock Clerk | 2400.00 | 11.00 | 264.00 | 7.5 | 180.00 Steven Markle | Stock Clerk | 2200.00 | 11.00 | 242.00 | 7.5 | 165.00 TJ Olson | Stock Clerk | 2100.00 | 9.00 | 189.00 | 7.5 | 157.50 Renske Ladwig | Stock Clerk | 3600.00 | 11.00 | 396.00 | 22.5 | 810.00 Trenna Rajs | Stock Clerk | 3500.00 | 11.00 | 385.00 | 15.0 | 525.00 Curtis Davies | Stock Clerk | 3100.00 | 11.00 | 341.00 | 15.0 | 465.00 John Russell | Sales Manager | 14000.00 | 11.00 | 1540.00 | 27.5 | 3850.00 Jennifer Dilly | Shipping Clerk | 3600.00 | 11.00 | 396.00 | 22.5 | 810.00 Timothy Gates | Shipping Clerk | 2900.00 | 11.00 | 319.00 | 15.0 | 435.00 Randall Perkins | Shipping Clerk | 2500.00 | 11.00 | 275.00 | 7.5 | 187.50 Sarah Bell | Shipping Clerk | 4000.00 | 11.00 | 440.00 | 22.5 | 900.00 Kevin Feeney | Shipping Clerk | 3000.00 | 11.00 | 330.00 | 15.0 | 450.00 Jennifer Whalen | Administration Assistant | 4400.00 | 11.00 | 484.00 | 22.5 | 990.00
4. Em relação ao exercício 3,
incluir na consulta a projeção do → salário líquidosalário líquido dos colaboradores
5. Considerando a instalação padrão do PostgreSQL nos laboratórios de informática do Campus Toledo da UTFPR (user=postgresuser=postgres, password=postgrespassword=postgres), altere a confguração permitindo o acesso remoto a partir da rede interna. Em seguida:
Teste o acesso remoto com o seu vizinho de bancada→
6. Na pasta do pSet05 /home/aluno/TSI33A/pSet05/home/aluno/TSI33A/pSet05 (ou c:/users/aluno/TSI33A/pSet05c:/users/aluno/TSI33A/pSet05) salve os arquivos de script SQL OE_DDL_PostgreSQL.sqlOE_DDL_PostgreSQL.sql e OE_DML_PostgreSQL.sqlOE_DML_PostgreSQL.sql. Em seguida, execute os comandos abaixo no terminal (GNU_Linux) ou prompt de comando (MS-Windows):
Pg. Pg. 55//66
$psql -h amazonia.td.utfpr.edu.br -U <RA> -d tsi33a -f /home/aluno/TSI33A/pSet05/OE_DDL_PostgreSQL.sql
$psql -h amazonia.td.utfpr.edu.br -U <RA> -d tsi33a -f /home/aluno/TSI33A/pSet05/OE_DML_PostgreSQL.sql
Posterior a execução dos comandos, acesse a base de dados tsi33atsi33a no servidor amazonia.utfpr.edu.bramazonia.utfpr.edu.br (use o utilitário psql ou a ferramenta PgAdmin III) e elabore as seguintes consultas:
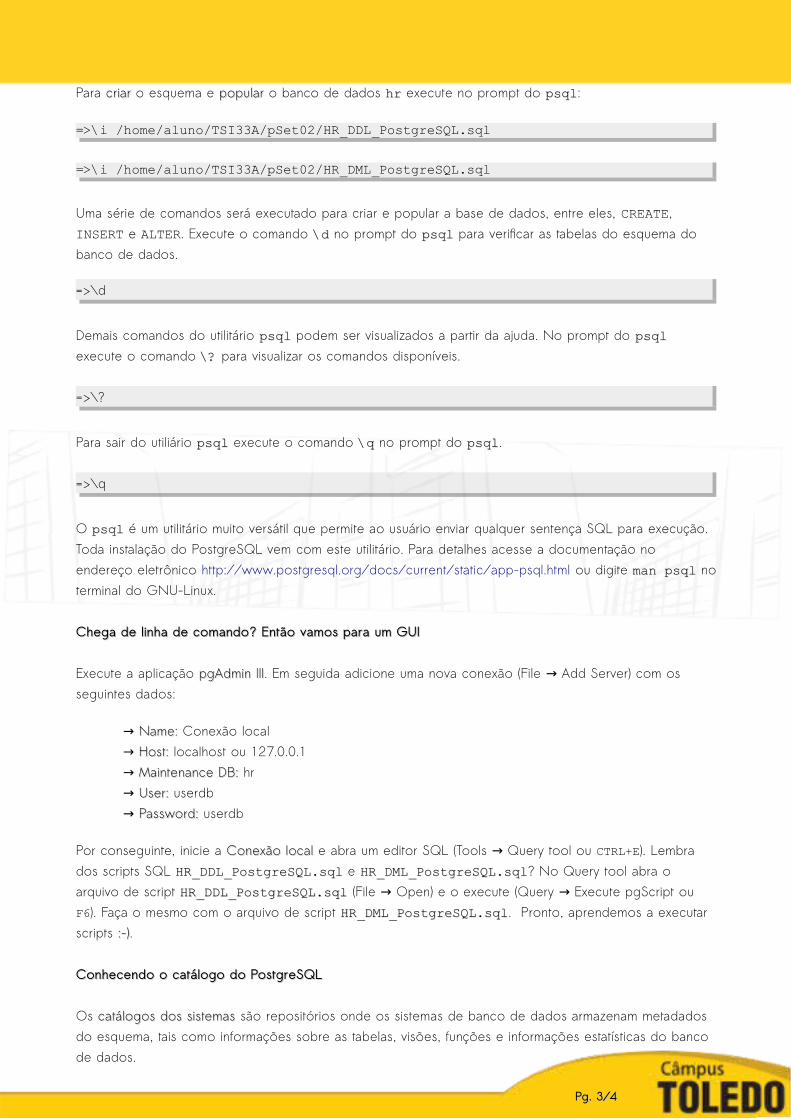
Projete o → nome completonome completo dos clientesclientes e de seus respectivos gerentes de contagerentes de conta. Sabe-se que ocampo CUSTOMERS.ACCOUNT_MGR_ID é chave estrangeira de EMPLOYEES.EMPLOYEE_ID.
Projete o nome dos armazéns e de seus respectivos países. Sabe-se que o campo →
WAREHOUSES.LOCATION_ID é chave estrangeira de LOCATIONS.LOCATION_ID.
Pg. Pg. 66//66

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 06Semana 06
Subcadeias de Caracteres Subcadeias de Caracteres &&&& Funções de Agregação Funções de Agregação && && PaginaçãoPaginaçãoObjetivoObjetivo
Introduzir as cláusulas → LIMIT e OFFSET Consolidar o uso das funções de manipulação de caracteres→
Consolidar o uso das funções de agregação→
Leitura ComplementarLeitura Complementar
→ Chapter 7. QueriesChapter 7. Queries: http://www.postgresql.org/docs/9.4/static/queries-limit.html → Chapter 9. Functions and OperatorsChapter 9. Functions and Operators: http://www.postgresql.org/docs/9.4/static/functions-string.html
AvaliaçãoAvaliação
→ Exatidão:Exatidão: a estrutura das consultas está correta? → Estilo:Estilo: a estrutura das consultas está indentada e segue as boas práticas?
ComeçandoComeçando
No desenvolvimento de software, principalmente software para Internet, é comum o uso da técnica de paginaçãopaginação para dividir os registros da consulta em pequenas páginas. Por exemplo, o GMailGMail utiliza a paginação para exibir os e-mails (aproximadamente 50 e-mails por página), o Gestional Libre de Parc Gestional Libre de Parc InformatiqueInformatique (GLPI) faz uso da paginação para exibir os chamados de manutenção ou serviço (entre 10 a 1000 registros por página). Portanto, a paginação é comum no desenvolvimento de software para Web.
Além de proporcionar um bom layoutlayout de impressão, a paginação também maximiza a velocidade de recuperação e apresentação dos dados, pois exige menos recursos para obtê-los. Outra vantagem da paginação é o carregamentocarregamento mais rápido das páginas web (AJAXAJAX também facilita nesse tarefa).
Enfim, e como fazer a paginação? A paginação pode ser realizada com regras na camada de aplicação, frameworks ou por consultas SQL. Se todos os registros forem recuperados da base de dados, a paginação deve ser tratada na camada de aplicação, contudo, é possível recuperar os registros já paginados por meio de frameworks ou da própria SQL. Este material abordará paginação em SQL com PostgreSQL.
As cláusulas As cláusulas LIMITLIMIT e e OFFSETOFFSET
As cláusulas LIMITLIMIT e OFFSETOFFSET permitem recuperar apenas uma parte dos registros da consulta, possibilitando a montagem da paginação.
A cláusula LIMIT permite que seja recuperado somente a quantidade de registros especificado pelo parâmetro, desconsiderando o restante dos registros. Em suma, a consulta é executada no lado servidor e retorna para o lado cliente somente a quantidade especificada de registros. O exemplo abaixo recupera os 5 primeiros nomes da relação EMPLOYEES.
Pg. Pg. 11//44

SELECT FIRST_NAME, LAST_NAMEFROM EMPLOYEESLIMIT 5;
FIRST_NAME | LAST_NAME------------+----------- Steven | King Neena | Kochhar Lex | De Haan Alexander | Hunold Bruce | Ernst
O próximo exemplo também recupera os 5 primeiros nomes da relação EMPLOYEES, contudo, do conjunto ordenado por ordem alfabética.
SELECT FIRST_NAME, LAST_NAMEFROM EMPLOYEESORDER BY FIRST_NAMELIMIT 5;
FIRST_NAME | LAST_NAME------------+----------- Adam | Fripp Alana | Walsh Alberto | Errazuriz Alexander | Khoo Alexander | Hunold
A cláusula OFFSET permite ignorar uma determinada quantidade de registros antes de começar a retorná-los. O exemplo abaixo recupera 5 nomes da relação EMPLOYEES, iniciando do 2 registro (o valor 1 na cláusula OFFSET indica ignorar 1 registro).
SELECT FIRST_NAME, LAST_NAMEFROM EMPLOYEESORDER BY FIRST_NAMELIMIT 5OFFSET 1;
FIRST_NAME | LAST_NAME------------+----------- Alana | Walsh Alberto | Errazuriz Alexander | Khoo Alexander | Hunold Alexis | Bull
Perceba que o próximo registro após o “Alexander,Hunold” (“Alexis,BullAlexis,Bull”) foi exibido ao invés do registro “Adam,Fripp”.
Consultas com as cláusulas LIMIT e OFFSET são mais eficientes e possuem um custo menor comparado ao uso de gridsgrids de dados nas linguagem de programação. Quando utilizamos gridsgrids de dados estamos aplicando uma paginação no lado cliente (a partir de filtros da grid); e isso exige a recuperação de todos os registros.
Como dica, sempre use a cláusula ORDER BY para definir uma ordem única para os registros, caso contrário, a consulta retornará um subconjunto imprevisível de registros (normalmente a ordem de inserção).
Pg. Pg. 22//44

Subcadeias de caracteresSubcadeias de caracteres
O uso de funções e operadores de subconjuntos de caracteres é simples, o difícil é saber quais são as funções e operadores existentes no sistema de banco de dados utilizado. Assim, faça uma leitura das tabelas Table 9-6. SQL String Functions and OperatorsTable 9-6. SQL String Functions and Operators e Table 9-7. Other String FunctionsTable 9-7. Other String Functions no endereço http://www.postgresql.org/docs/9.4/static/functions-string.html.
Funções de agregaçãoFunções de agregação
Da mesma forma que no tópico Subcadeias de caracteres, faça uma leitura das tabelas Table 9-49. Table 9-49. General-Purpose Aggretate FunctionsGeneral-Purpose Aggretate Functions e Table 9-50. Aggregate Fuctions for StatisticsTable 9-50. Aggregate Fuctions for Statistics no endereço http://www.postgresql.org/docs/9.4/static/functions-aggregate.html.
ExercitandoExercitando
1. Acesse a base de dados tsi33atsi33a no servidor amazonia.utfpr.edu.bramazonia.utfpr.edu.br (use o utilitário psql ou a ferramenta PgAdmin III). Em seguida, elabore as seguintes consultas:
Recupere a quantidade de colaboradores dos departamentos que possuem dois ou mais →
colaboradores. Ordene o resultado em ordem descrescente pela quantidade de colaboradores
DEPARTMENT_ID | DEPARTMENT_NAME | QTD---------------+-----------------+------- 50 | Shipping | 45 80 | Sales | 34 100 | Finance | 6 30 | Purchasing | 6 60 | IT | 5 90 | Executive | 3 20 | Marketing | 2 110 | Accounting | 2
Recupere, pela técnica de paginação e em ordem alfabética, o tempo de serviço dos cinco →
primeiros colaboradores
NAME | YEARS-------------------+------------ Adam Fripp | 9 years Alana Walsh | 8 years Alberto Errazuriz | 9 years Alexander Khoo | 11 years Alexander Hunold | 9 years
Repita a consulta do item anterior recuperando a segunda página de registros. Use a cláusula →
OFFSET para isso
NAME | YEARS-------------------+------------ Alexis Bull | 9 years Allan McEwen | 10 years Alyssa Hutton | 9 years Amit Banda | 6 years Anthony Cabrio | 7 years
Pg. Pg. 33//44

2. Considerando a base de dados tsi33atsi33a e a consulta abaixo para recuperar os primeiros 50 nomes da relação EMPLOYEES, responda:
SELECT FIRST_NAME, LAST_NAMEFROM EMPLOYEESORDER BY FIRST_NAMELIMIT 25OFFSET 0;
→ Para as próximas páginas basta alterar o valor da cláusula OFFSET por múltiplos de 25? Assim, tem-se uma paginação de 25 registros para exibir os 107 registros
Quantas páginas são necessárias para exibir os 107 registros?→
Quantos registros a última página exibirá?→
3. Considerando o modelo Order EntityOrder Entity (OE), acesse a base de dados tsi33atsi33a no servidor amazonia.utfpr.edu.bramazonia.utfpr.edu.br (use o utilitário psql ou a ferramenta PgAdmin III). Em seguida, elabore as seguintes consultas:
Recupere o → valor total dos pedidosvalor total dos pedidos para cada cliente do sexo masculinosexo masculino
Recupere o → valor totalvalor total, os valores maiormaior e menormenor e o valor médiovalor médio dos pedidos
Recupere distintamente (independente de quantos pedidos) a → quantidade de clientesquantidade de clientes que possuem pedidos
Recupere a → quantidade totalquantidade total e o valor totalvalor total de "Mobile phoneMobile phone" que foram pedidos em 2014
Recupere → todos os dadostodos os dados (pedidos e itens de pedido) dos pedidos 100944, 100945, 100946, 100980, 100999. Além dos códigos do produto, cliente e representante comercial, os respectivosnomes, se existirem, também devem ser projetados (nome do produtonome do produto, nome do clientenome do cliente e nome nome do representante comercialdo representante comercial). Sabe-se que o campo ORERS.SALES_REP_ID é chave estrangeira de EMPLOYEES.EMPLOYEE_ID.
Pg. Pg. 44//44

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 07Semana 07
Subconsultas Subconsultas &&&& Operações de Conjuntos Operações de ConjuntosObjetivoObjetivo
Introduzir a verifcação de integridade de dados com o MD5→
Exercitar o conteúdo de subconsultas→
Exercitar o conteúdo de operações de conjuntos→
Leitura ComplementarLeitura Complementar
→ MDT5summer:MDT5summer: http://www.md5summer.org/download.html
AvaliaçãoAvaliação
→ Exatidão:Exatidão: a estrutura das consultas está correta? → Estilo:Estilo: a estrutura das consultas está indentada e segue as boas práticas?
ComeçandoComeçando
O Message-Digest algorithm 5Message-Digest algorithm 5 (MD5) é um algoritmo de hashhash de 128 bits especifcado pela RFC 1321RFC 1321 e muito utilizado na verifcação de integridade de arquivos. Algoritmos de hash são referências em relação à criptografa e integridade de dados, pois a partir de uma quantidade de dados (arquivo de texto ou binário) geram um valor de tamanho conhecido. Por exemplo, o arquivo da aula OE_PostgreSQL.tarOE_PostgreSQL.tar possui o seguinte hash MD5:
745f1cfca068d65ef924f06d51870354
Não importa quantas vezes seja gerado o hash MD5 do arquivo OE_PostgreSQL.tarOE_PostgreSQL.tar, sempre resultará no mesmo valor. O hash gerado pelo MD5 é de 32 caracteres32 caracteres, independente do formato, nome ou tamanho do arquivo.
O MD5 é utilizado na distribuição de software livre para verifcar a integridade do downloadintegridade do download. Comumente, o software é disponibilizado juntamente com o seu valor hash. Após os usuários realizarem download do arquivo binário ou compactado, eles podem comparar o valor hash gerado por eles com o hash disponível no site. Se os valores forem diferentes, então o conteúdo está corrompido ou foi alterado.
Ressalta-se que o MD5 não possui como fnalidade a garantia da procedênciagarantia da procedência de um arquivo, somente a verifcação da integridadeverifcação da integridade dos dados recuperados.
Gerando o MD5 de arquivosGerando o MD5 de arquivos
No GNU-Linux, o utilitário md5summd5sum permite calcular o código hash dos arquivos. A maioria das distribuições possui o md5summd5sum instalado de forma nativa, portanto, acesse o sistema operacional GNU-Linux.
Na pasta do usuário aluno /home/aluno//home/aluno/ crie uma pasta denominada TSI33A/pSet07TSI33A/pSet07. Em seguida salve nesta pasta o arquivo OE_PostgreSQL.tarOE_PostgreSQL.tar.
Pg. Pg. 11//33

Verifque a sintaxe básica e documentação do utilitário através do comando abaixo (execute no terminal):
$man md5sum
Para gerar o MD5 do arquivo OE_PostgreSQL.tarOE_PostgreSQL.tar execute no terminal:
$md5sum -t /home/aluno/TSI33A/pSet07/OE_PostgreSQL.tar
O parâmetro -t-t indica que o arquivo é texto. Caso seja um arquivo binário, especifque o parâmetro -b-b. O comando abaixo direciona a saída para o arquivo OE_PostgreSQL.txtOE_PostgreSQL.txt.
$md5sum -t /home/aluno/TSI33A/pSet07/OE_PostgreSQL.tar > OE_PostgreSQL.txt
Compare o MD5 do arquivo OE_PostgreSQL.txtOE_PostgreSQL.txt gerado no comando acima com o arquivo OE_PostgreSQL.hash.txtOE_PostgreSQL.hash.txt disponível no pSet-S07. O arquivo está íntegro?
ExercitandoExercitando
1. Na pasta do usuário aluno /home/aluno//home/aluno/ (ou c:/users/aluno/c:/users/aluno/) crie uma pasta denominada TSI33A/pSet07TSI33A/pSet07. Salve nesta pasta o arquivo compactado OE_PostgreSQL.tarOE_PostgreSQL.tar.
Verifque se o MD5 do download do arquivo OE_PostgreSQL.tarOE_PostgreSQL.tar corresponde ao MD5 do arquivo OE_PostgreSQL.hash.txtOE_PostgreSQL.hash.txt.
Em seguida, extraia os arquivos OE_DDL_PostgreSQL.sqlOE_DDL_PostgreSQL.sql e OE_DML_PostgreSQL.sqlOE_DML_PostgreSQL.sql do arquivo OE_PostgreSQL.tarOE_PostgreSQL.tar. Execute os comandos abaixo no terminal (GNU-Linux) ou prompt de comando (MS-Windows):
$md5sum -t OE_PostgreSQL.tar
$cat OE_DDL_PostgreSQL.sql OE_DML_PostgreSQL.sql | md5sum -t
Agora responda. Se o conteúdo dos arquivos é o mesmo, por que os MD5s gerados não são iguais?
2. Considerando os diagramas lógicos dos modelos Order Entry (OE)Order Entry (OE) e Human Resources (HR)Human Resources (HR), acesse a base de dados tsi33atsi33a do servidor amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br e elabore as seguintes consultas:
Recupere o nome completo dos → colaboradorescolaboradores e clientesclientes. Projete uma coluna extracoluna extra (PERSON_TP) para identifcar se o registro refer-se ao colaborador (EMP) ou ao cliente (CUS)
Recupere o nome completo dos colaboradores que são → gerentesgerentes e clientesclientes.
Refaça a consulta do item anterior utilizando a operação de diferença. Cuidado, o resultado →
deve ser o mesmo
Recupere o → nome completo nome completo dos clientesclientes que possuem o mesmo nome dos colaboradorescolaboradores
Pg. Pg. 22//33

Recupere os clientes que possuem o produto "Laptop 128/12/56/v90/110" em seus pedidos→
Recupere a quantidade e o valor de pedido dos produtos "Mouse" (considere que a palavra →
mouse em qualquer parte do nome do produto)
3. Buscando recompensar os representantes comerciaisrepresentantes comerciais, a empresa solicitou ao analista de banco de dados o desenvolvimento de uma consulta que recupere os principais dados dos representantes comerciais mais efcientes. A efciência, neste caso, está relacionada ao valor dos pedidosvalor dos pedidos emitidos por estes representantes.
A ideia da empresa é prospectar o aumento de 5% para os primeiros 105% para os primeiros 10 representantes mais efcientes, 3% para os próximos 53% para os próximos 5 mais efcientes e 2% para os demais2% para os demais representantes que possuam ao menos U$ 50,000.00 em pedidos. Para isso, a consulta deve projetar os seguintes dados: identifcador, primeiro nome, último nome e salário dos representantes comerciais; valor total dos pedidos realizados; e prospecção do percentual de aumento (novo salário).
Enfm, você é o analista e eu solicitei a consulta :-), mãos a obra!
Pg. Pg. 33//33

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 08Semana 08
Data Manipulation Language Data Manipulation Language &&&& Backup/Restore Backup/RestoreObjetivoObjetivo
Introduzir os utilitários de backup e restore do PostgreSQL→
Consolidar o conteúdo de linguagem de manipulação de dados→
AvaliaçãoAvaliação
→ Exatidão:Exatidão: os comandos e as instruções SQL estão corretas? → Estilo:Estilo: os comandos fazem uso adequado dos parâmetros?
ComeçandoComeçando
Quantas vezes você ouviu a pergunta: “Tem backup néTem backup né?”. No mundo corporativo os dados são tão valiosos que não se pode pensar em uma infraestrutura de sistema de banco de dados sem considerar osprocedimentos de backupbackup e restorerestore. Desta forma, todo sistema de banco de dados possui comandos pararealizar regularmente o backup e restore dos dados.
Regularmente backup e restore? Não seria regularmenteregularmente backup e esporadicamenteesporadicamente restore? CuidadoCuidado, quantas vezes você ouviu a frase: “O backup não funcionou!O backup não funcionou!”. Certo de que arquivos grandes podem ser facilmente corrompidos e as pequenas mudanças no sistema de banco de dados ou no schema dos dados podem influenciar no restorerestore, faça o restore regularmenterestore regularmente. AtençãoAtenção, faça os testes de restore em uma base de dados de homologaçãohomologação ou testeteste e nunca na base de produção, salvo quando necessário.
No sistema de banco de dados PostgreSQL 9.4 há três abordagens para fazer o backupbackup dos dados:
SQL dump;→
File system level backup; e→
Continuous archiving.→
Devido a compatibilidade do restorerestore entre versões mais recentes do sistema de banco de dados PostgreSQL (ou futuras versões) e a independência da arquitetura de máquina (e.g. 32bits, 64bits), neste pSetpSet será abordado o método SQL dump.
Para conhecer os outros métodos de backupbackup/restorerestore acesso o endereço eletrônico http://www.postgresql.org/docs/9.4/static/backup.html.
Fazendo o backup com o utilitário Fazendo o backup com o utilitário pg_dumppg_dump
A ideia do método SQL dumpSQL dump é gerar um arquivo com os comandos SQL que, quando alimentado de volta ao sistema de banco de dados, recriará o banco de dados no mesmo estadoestado em que estava no momento do dumpdump. Esse método foi utilizado para criar e popular a base de dados tsi33atsi33a do amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br com os modelos Human ResourcesHuman Resources (HR) e Order EntityOrder Entity (OE) :-):-) . Durante os pSetspSets anteriores o método também foi utilizado parcialmente com a execução dos scripts SQL.
O pg_dumppg_dump é um utilitário poderoso e responsável pelo SQL dump. Ele permite realizar o procedimento de backup a partir de qualquer hosthost que tenha acesso ao banco de dados (a conexão está sujeita aos mecanismos de autenticação de clientes).
Pg. Pg. 11//44

Em geral, para realilzar o backupbackup de toda a base de dados (e.g. tsi33atsi33a e todos os schemas) é necessário ter acesso à base de dados e aos objetos da base de dados (tabelas, visões, esquemas etc), por isso, as vezes o comando deve ser executado como superusuáriosuperusuário. Se você não tem privilégios suficientes para fazer backup de todo o banco de dados, é possível fazer backup de porções do banco de dados (determinados esquemas, determinadas tabelas, visões, etc.).
A sintaxe básica do pg_dumppg_dump é:
pg_dump [connection-option...][option...][dbnamedbname]
Veja o exemplo abaixo de backup do esquema useruser da base de dados tsi33atsi33a.
$pg_dump -h amazonia.td.utfpr.edu.br -U user -n user --inserts -c -v tsi33atsi33a > tsi33a_user.sql
Detalhe dos parâmetros:
-h especifica o servidor do sistema de banco de dados-U usuário do sistema de banco de dados com permissão de executar o comando-n o schemaschema da base de dados (omitir o parâmetro para selecionar todos os esquemas)--inserts os dados serão gerados conforme a sintaxe INSERT INTO...VALUES-c remove os objetos do banco de dados para recriá-los-v exibe as saídas no terminal ou prompt de comando> direcionamento da saída para o arquivo
No exemplo anterior o arquivo tsi33a_user.sqltsi33a_user.sql foi gerado em formato texto. Isso significa que é possível abrí-lo e identificar seus comandos por meio de qualquer editor de texto. Além disso, o arquivo não é comprimido. Essas são características do formato de saída padrão de arquivo do pg_dumppg_dump.
Outro formato de arquivo é o .dump.dump. Esse formato de saída é flexível e comprime os dados (compacta), além de realizar o backupbackup mais rápido. Para especificar esse formato de arquivo utilize o parâmetro -Fc-Fc.
$pg_dump -h amazonia.td.utfpr.edu.br -U user -n user -v -Fc tsi33atsi33a > tsi33a_user.dump
Agora vamos realizar o backupbackup do seu esquema na base de dados tsi33atsi33a do amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br. No terminal do GNU-Linux ou prompt de comando do MS-Windows execute (substitua <RA><RA> pelo número doregistro acadêmico):
$pg_dump -h amazonia.td.utfpr.edu.br -U <RA> -n <RA> --inserts -c -v tsi33atsi33a > tsi33a_<RA>.sql
Em seguida execute:
$pg_dump -h amazonia.td.utfpr.edu.br -U <RA> -n <RA> -v -Fc tsi33atsi33a > tsi33a_<RA>.dump
Após a execução dos dois comandos abra os arquivos tsi33a_<RA>.sql tsi33a_<RA>.sql e tsi33a_<RA>.dumptsi33a_<RA>.dump em um editor de texto simples. Os arquivos possuem o mesmo conteúdoOs arquivos possuem o mesmo conteúdo? Em seguida veja a propriedade tamanhotamanho dos arquivos. Qual arquivo possui o menor tamanhoQual arquivo possui o menor tamanho?
Pg. Pg. 22//44
Para detalhes do utilitário pg_dumppg_dump acesse a documentação no endereço eletrônico http://www.postgresql.org/docs/9.4/static/app-pgdump.html ou digite man pg_dumpman pg_dump no terminal do GNU-Linux.
Recuperando o backup com o utilitário Recuperando o backup com o utilitário psqlpsql e e pg_restorepg_restore
O restorerestore do banco de dados depende do formato de arquivo. Se o formato do arquivo for .sql.sql utilize o utilitário psqlpsql. Por exemplo:
$psql -h amazonia.td.utfpr.edu.br -U user -d tsi33a -f tsi33a_user.sql
Esse comando não é novidadenão é novidade. Ele foi executado na criação dos modelos Human ResourcesHuman Resources (HR) e OrderOrderEntity Entity (OE) no servidor amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br.
Quando o formato do arquivo for .dump.dump, utilize o utilitário pg_restorepg_restore. A sintaxe básica do pg_dumppg_dump é:
pg_restore [connection-option...][option...][filenamefilename]
Veja o exemplo abaixo de restore do arquivo tsi33a_user.dumptsi33a_user.dump no servidor amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br.
$pg_restore -h amazonia.td.utfpr.edu.br -U user -Fc -d tsi33a -n user -c -v tsi33a_user.dump
Agora é a sua vez de recuperar o backupAgora é a sua vez de recuperar o backup
Considere que você é um estagiário e execute o comando abaixo na base de dados tsi33atsi33a.
UPDATE EMPLOYEES SET MANAGER_ID = 101;
OpsOps! Você acaba fazer um ““belobelo”” trabalho na base de dados. Sabe o que você fezSabe o que você fez? Definiou a colaboradora Neena Kochhar como gerente de todos os colaboradores, inclusive ela mesma. Agora vocêprecisa realizar o restorerestore e desfazer esse “belobelo” trabalho.
No terminal do GNU-Linux ou prompt de comando do MS-Windows execute (substitua <RA><RA> pelo número do registro acadêmico):
$psql -h amazonia.td.utfpr.edu.br -U <RA> -d tsi33a -f tsi33a-user.sql
Verifique se a mudança feita anteriormente foi desfeita.
Faça novamente o “belobelo” trabalho. Em seguida execute:
$pg_restore -h amazonia.td.utfpr.edu.br -U user -Fc -d tsi33a -n <RA> -c -v tsi33a_user.dump
Verifique novamente o estado da tabela EMPLOYEES.
Para detalhes do utilitário pg_restorepg_restore acesse a documentação no endereço eletrônico http://www.postgresql.org/docs/9.4/static/app-pgrestore.html ou digite man pg_resotreman pg_resotre no terminal do GNU-Linux.
Pg. Pg. 33//44

ExercitandoExercitando
1. A base de dados tsi33atsi33a possui 359 produtos359 produtos cadastrados. É possível verificar essa quantidade a partir da consulta abaixo:
SELECT COUNT(PRODUCT_ID)FROM PRODUCT_INFORMATION;
Cada produto possui um statusstatus que pode assumir o valor: obsoletoobsoleto (obsolete), planejadoplanejado (planned), disponíveldisponível (orderable), em desenvolvimentoem desenvolvimento (under development) ou sem statussem status (NULL). A consulta abaixo recupera os possíveis valorespossíveis valores de statusstatus dos produtos:
SELECT DISTINCT PRODUCT_STATUSFROM PRODUCT_INFORMATION;
Informações sobre o estoque dos produtos são registradas na tabela INVENTORIESINVENTORIES, incluindo o armazém e a quantidade disponível. Alguns produtos novosprodutos novos ainda não possuem estoque e outros a quantidade quantidade disponíveldisponível no estoque é zero. Informações sobre o estoque dos produtos são importantes para as estratégias de logística e remanejamento, por isso, sua tarefa é:
Recuperar os produtos que → não possuem estoquenão possuem estoque ou a quantidade no estoque é zeroestoque é zero. Projete o identificador, nome e status dos produtos e, para os produtos com estoque zero, o identificador e nome do armazém, bem como a quantidade em estoque
PRODUCT_ID | PRODUCT_NAME | PRODUCT_STATUS | WAREHOUSE_ID | WAREHOUSE_NAME | QUANTITY_ON_HAND------------+---------------------+-------------------+--------------+----------------+------------------ 1940 | ESD Bracelet/Clip | orderable | 9 | Bombay | 0 1726 | LCD Monitor 11/PM | under development | | | 1743 | HD 18.2GB @10000 /E | planned | | | 1761 | CD-ROM 600/I/32x | under development | | | 1782 | Compact 400/DQ | obsolete | | | 1910 | FG Stock - H | orderable | | |10002 | Soy Formula | | | | 10003 | Rice Formula | | | | 10004 | Leakguard Overnight | | | |
Analisar o resultado do item anterior. Atualizar para 10 a → quantidade em estoquequantidade em estoque dos produtos disponíveisdisponíveis em um armazémarmazém e que possuem quantidade zeroquantidade zero.
Verificar se existem→ lançamentos de pedido lançamentos de pedido para os produtos sem statussem status. Caso existam, atualizar o valor do status para “obsoleteobsolete”, caso contrário, atualizar para “plannedplanned”
Inserir um → novo armazémnovo armazém, chamado BrazilBrazil, na localidade Rua Frei Caneca 1360, São Paulo/SP-Rua Frei Caneca 1360, São Paulo/SP-BRBR (verificar se a localidade já está cadastrada)
Inserir um estoque de 100 unidades (tabela → INVENTORIES) no armazém Brasilarmazém Brasil para os produtosdisponíveisdisponíveis e que não possuem estoque/armazémestoque/armazém
2. Remover os armazéns que não possuem produtos armazenados
Pg. Pg. 44//44

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 09Semana 09
Data Definition Language Data Definition Language &&&& Backup Regular (.sh Backup Regular (.sh |||| pgAgent) pgAgent)ObjetivoObjetivo
Introdução à automatização de backups→
Consolidar o conteúdo de instruções DDL→
Leitura ComplementarLeitura Complementar
→ Automated Backup on Linux:Automated Backup on Linux: https://wiki.postgresql.org/wiki/Automated_Backup_on_Linux → Livro:Livro: NEVES, Julio Cezar. Programação Shell Linux. 8. ed. Rio de Janeiro, RJ: Brasport, 2010.
549 p. ISBN 9788574524405.
AvaliaçãoAvaliação
→ Exatidão:Exatidão: a estrutura das instruções SQL e dos comandos de backup estão corretos? → Estilo:Estilo: a estrutura das instruções SQL e dos comandos de backup seguem as boas práticas?
ComeçandoComeçando
No pSet08pSet08 os utilitários pg_dumppg_dump e pg_restorepg_restore foram apresentados como instrumentos para realizar as atividades de backup e restore. Ambos utilitários são comumente utilizados no mundo do PostgreSQL, contudo, o pg_dumppg_dump é complementado com técnicas para realizar de forma automática e regular o backup das bases de dados. Assim, a atividade diária de backupbackup deixa de ser uma “preocupação” para o administrador do sistema de banco de dados.
No PostgreSQL duas abordagens são utilizadas: Shell Script + Shell Script + croncron e pgAgentpgAgent. Neste pSet (pSet09pSet09) a abordagem Shell Script + cron será explorada.
Programando seu script de backup com Shell ScriptProgramando seu script de backup com Shell Script
Shell scriptShell script é uma linguagem de scriptscript usada em vários sistemas operacionais, com diferentes dialetos, dependendo do interpretador de comandos utilizado. No GNU-Linux o interpretador de comandos é o bashbash.
O bloco de código abaixo é um Shell scriptShell script de execução do utilitário pg_dumppg_dump para criar um arquivo de backup (.dump.dump) conforme os valores das variáveis HOSTNAME, PORT, USER e DATABASE. Para não ocorrersubstituição do backup o nome do arquivo é formado pelo nome da basenome da base de dadosde dados mais a data e hora data e hora de geraçãode geração do backup.
#!/bin/sh
# variáveis do comando de backupHOSTNAME="amazonia.td.utfpr.edu.br"PORT="5432"USER="user"DATABASE="tsi33a"
# arquivo de backup em /tmp com no formato: $DATABSE<ano><mês><dia>_<hora><min.><seg.>pg_dump -h $HOSTNAME -p $PORT -U $USER -C -Fc $DATABASE >
/tmp/$DATABASE-`date +"%Y%m%d_%H%M%S"`.dump
Pg. Pg. 11//55
Na pasta do usuário aluno /home/aluno/home/aluno crie uma subpasta denominada TSI33A/pSet09TSI33A/pSet09. Em seguida, salve nesta pasta o arquivo de Shell scriptShell script cronPGBackup.sh.
No terminal do GNU-Linux adicione a permissão de execução para o arquivo cronPGBackup.sh:
$chmod +x /home/aluno/cronPGBackup.sh
Execute o script através do comando:
$./home/aluno/cronPGBackup.sh
Para ver o resultado (o arquivo de backup gerado pelo scripto arquivo de backup gerado pelo script) liste o conteúdo da pasta temporária.
$ls /tmp/
Não é o objetivo deste pSetpSet ensinar a programação Shell scriptShell script, apenas exemplificar seu uso para geraçãode backups. Portanto, para saber mais sobre Shell Script consulte o livro Programação Shell LinuxProgramação Shell Linux (Julio Cezar Neves) disponível na biblioteca do Campus Toledo da UTFPR.
Entendendo o daemon Entendendo o daemon croncron
O croncron é um daemondaemon que permite agendar a execução de comandos e processos nos sistemas GNU-Linux. UauUau! O que é um daemonO que é um daemon? Daemons são programas ou serviços que executam em backgroundbackground (segundo plano) e são, normalmente, inicializados no bootboot do sistema operacional.
Para executar os comandos e processos agendados, denominados de tarefastarefas, o croncron usa um arquivo de tabela de agendamento (crontabcrontab). O arquivo crontabcrontab situa-se no diretório geral /etc/etc ou no diretório específico (e exclusivo) para cada usuário /var/spool/cron//var/spool/cron/.
Execute no terminal do GNU-Linux os seguintes comandos (a senha é o mesmo nome do usuário postgres :-):-) ):
$su postgres
$crontab -e
O crontabcrontab possui o seguinte formato e entrada:
[minutos] [horas] [dias_do_mês] [mês] [dias_da_semana] [usuário] [comando]
Detalhes de cada coluna:
minutosminutos: 0 a 59 (* para quaquer minuto)horashoras: 0 a 23 (* para qualquer hora)dias_do_mêsdias_do_mês: 1 a 31 (* para todos os dias do mês)mêsmês: 1 a 12 (* para todos os meses)dias_da_semanadias_da_semana: 0 a 7 (* para todos os dias da semana)usuáriousuário: usuário que executará o comandocomandocomando: tarefa a ser executada
Pg. Pg. 22//55

Insira o conteúdo abaixo após a última linha do arquivo em edição (substitua <RA> pelo número do registro acadêmico; <X> pela hora corrente e <Y> pelo minuto corrente + 5 min):
# backup database tsi33a schema <RA><Y> <X> * * * postgres pg_dump -h amazonia.td.utfpr.edu.br -U <RA> -n <RA> -v -Fc tsi33a > /tmp/tsi33a_<RA>.dump
Salve o conteúdo do arquivo e aguarde o comando ser executado na hora e no minuto agendado no crontabcrontab. Em seguida, verifique se o arquivo foi gerado na pasta /tmp/tmp:
$ls /tmp/
Se o arquivo foi gerado, parabénsparabéns! Caso o arquivo não seja gerado você falhou :-) - tente novamente.
Agendando seu script de backup no Agendando seu script de backup no crontabcrontab
Em grandes ambientes corporativos, cujo volume de dados também é grande, o backupbackup é realizado duas duas ou mais vezes ao diaou mais vezes ao dia. Vamos contextualizar esse tipo de ambiente:
A Cooperativa Central de Pesquisa Agrícola – COODETECCOODETEC é uma empresa de base tecnológica voltada à agricultura que pesquisa e comercializa sementes de milho, soja e trigo de alta qualidade e adaptadas a diferentes climas e solos, com mais rendimento e menos risco. A COODETEC tem sede em Cascavel/PR, onde mantém escritório central, centro de treinamento, além dos laboratórios, câmaras secas e casas de vegetação. Outros centros da COODETEC estão localizados em Palotina/PR, Goioerê/PR, Paracatu/MG, Rio Verde/GO e Primavera do Leste/MT (Fonte: http://www.coodetec.com.br/site.php).
Entre os anos de 2008 e 2012 (período que eu trabalhei na COODETEC) a empresa gerava grandes volumes de dados, provenientes da produção, análise de qualidade, comercialização e pesquisa de sementes, além de outras fontes de dados, tais como, análise de solos, frota de veículos, relacionamento com produtores e clientes, informações contábies, informações de recursos humanos, etc.
O backupbackup da base de dados de empresas de porte igual ou superior a COODETEC é na escala de Gigabytes/Terabytes. Gerar um backup desse tamanho é oneroso e demorado, por isso é necessário queessa tarefa seja automatizada com verificações.
Uma forma de automatizar e verificar possíveis problemas é por meio de scripts e agendamento de tarefas.Agora agende a execução diária do script cronPGBackup.sh.
ExercitandoExercitando
1. Conside um sistema multi-empresamulti-empresa e multi-filialmulti-filial que gerencia representantesrepresentantes, fornecedoresfornecedores, clientesclientes e usuáriosusuários. Os representantes, fornecedores, clientes e usuários possuem um conjunto de dados que são comunscomuns entre eles e outro conjunto de dados que são específicosespecíficos. Portanto, a representação no modelo relacional possui um conjunto de entidades generalistas entidades generalistas (pessoas) e um conjunto de entidades entidades especializadasespecializadas (representantes, fornecedor,es clientes e usuários).
Pg. Pg. 33//55

Uma relaçao pessoapessoa (generalista) possui um ou mais endereços (i.e. um representante, fornecedor, cliente ou usuário possui um ou mais endereços). Uma relação clientecliente, além do endereço padrão endereço padrão na relação generalista, possui mais dois endereços: endereço de cobrançaendereço de cobrança e endereço de entregaendereço de entrega. A relação usuáriousuário possui um loginlogin, uma senhasenha e a relação de empresas e filiais que possui acesso.
As relações empresa, filial e pessoa possuem o atributo situaçãosituação, cujo objetivo é indicar se a entidade estáativaativa ou inativainativa. A situação do usuário indica se a entidade está ativa ou inativa para acessaracessar o sistemao sistema.
Analise o diagrama abaixo e identifique as regras de integridade (valor mandatório, chaves, domínio e semântica) e os tipos de dados.
Sua missãomissão é:
Definir as → instruções DDLinstruções DDL do diagrama (com as regras de integridade e os tipos de dados)
Criar a base de dados → homologacaohomologacao no servidor localhostlocalhost
$createdb -h localhost -U postgres homologacao
Recuperar o → backupbackup somente dos dadosomente dos dados a partir do arquivo homologacao.dumphomologacao.dump
$pg_restore -h localhost -U postgres -d homologacao -a -Fc -v homologacao.dump
Se o backupbackup homologacao.dumphomologacao.dump não funcionar, significa que você falhoufalhou.
2. Considerando a resolução do Exercício 1Exercício 1, elabore as seguintes consultas:
Recuperar o nome e CPF dos clientes que também são fornecedores→
Pg. Pg. 44//55
Recuperar a quantidade de usuários que são representantes e → nãonão são clientes
Recuperar o número de filiais em que cada usuário possui acesso, sendo a situação do acesso →
ativa
3. Elabore uma estratégia de backup e restore com Shell ScriptShell Script e croncron para a base de dados homologaçãohomologação. A estratégia deve realizar a cada 5 minutos o backup da base homologação, o restaurandoem uma base de dados de teste – com o propósito de testar o processo de backup/restore. A base de dados de teste deve ser denominada seguindo a seguinte sintaxe:
homologacao + <data + hora do backup>
Para isso, o script cronPGBackup.sh deve ser alterado. A cada nova base de dados de teste gerada a base anterior de teste deve ser removida.
Pg. Pg. 55//55

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 11Semana 11PL/pgSQLPL/pgSQL
ObjetivoObjetivo
Introduzir a criptografa a partir da → Cifra de CésarCifra de César Consolidar o conteúdo sobre → PL/pgSQLPL/pgSQL
Leitura ComplementarLeitura Complementar
→ Cífra de CésarCífra de César: http://pt.wikipedia.org/wiki/Cifra_de_C%C3%A9sar
AvaliaçãoAvaliação
→ Exatidão:Exatidão: o programa apresenta a saída desejada? → Estilo:Estilo: o código-fonte segue as boas práticas?
ComeçandoComeçando
A criptografacriptografa é a ciência e o estudo dos princípios e das técnicas pelas quais um texto legível pode ser escrito de forma secreta (i.e. cifradocifrado). Um texto cifradocifrado somente é compreendido se aplicado a chave de decifragemdecifragem. O processo de transformação é conhecido como ciframentociframento e a transformação inversa é conhecida como deciframentodeciframento. Uma texto não cifrado é claro (plaintextplaintext) e pode ser interceptado e lido por pessoas não autorizadas, por isso da necessidade de cifrá-lo.
As primeiras formas de criptografa usavam o método da substituiçãosubstituição. Esse tipo de criptografa era comum no ensino fundamental, lembram :-):-) ? As meninas se comunicavam por meio de papéis com escrita cifrada para que os meninos não interpretar o conteúdo. A cifra era feita trocando as letras do alfabeto (e.g. a letra AA correspondia à letra CC). Naturalmente, a colega (destinatária da mensagem) conhecia a chave e o método de ciframento e aplicava o deciframento do texto.
O estudo da criptografa cobre bem mais do que apenas a cifragemcifragem e decifragemdecifragem, pois é uma ciência queenvolve teoria da informação e matemática. Com o advento da computação, a criptografa evoluiu para o estudo de algoritmos criptográfcos implementados por sistemas computacionais. Atualmente existem diversos algorimtos de criptografa, alguns com objetivos bem específcos e outros com objetivos mais gerais. Independente disso, a ideia não é estudar os algorimtos de criptografa, mas desenvolver o conteúdo de cadeia de caracteres cadeia de caracteres a partir de métodos de substituição.
Cifra de CésarCifra de César
A Cifra de CésarCifra de César é uma das mais simples e conhecidas técnicas de criptografa. É um tipo de cifra de substituiçãocifra de substituição em que cada letra do texto é substituída por outra, satisfazendo uma relação de..parade..para (A→C, B→D, C→E, etc.).
Considere um alfabetoalfabeto A=(s0,s1,…,sn-1) com nn símbolos e um valor inteiro kk (chavechave), onde 0≤k≤n-10≤k≤n-1. Considere também as funções de cifragemcifragem Ck(si)=s(i+k) mod n e sua função inversa de decifragemdecifragem Dk(si)=s(i-k+n) mod n, onde
s(i-k+n) mod n é o símbolo referente à posição do resultado da operação de resto da divisãoCk(si) é a cifragemcifragem com a chave k do símbolo da posição iDk(si) é a decifragemdecifragem com a chave k do símbolo da posição i
Pg. Pg. 11//44

Para aplicar as funções supracitadas é necessário representar os símbolos do alfabeto em formato decimal.Na computação essa representação pode ser feita através da tabela ASCII. Assim, as funções cifragemcifragem e decifragemdecifragem devem considerar o alfabeto a partir do intervalo decimal (0..255) da tabela ASCII.
Considere o subalfabeto As=(A..Z) (65..90) da tabela ASCII.
65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
As A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Cada símbolo do alfabeto (si) é representado por um valor decimal (e.g. s65=A, s66=B, etc.). É importante ressaltar que o valor inicial do subalfabeto As é 65 e não 0, por isso, as funções de cifragemcifragem e decifragemdecifragemdevem considerar essa diferença
Ck(si)=s(i-p+k) mod n+p
Dk(si)=s(i-p-k+n) mod n+p
, sendo p o valor decimal inicial do subalfabeto As. Caso o valor decimal do alfabeto inicie em 0, p pode ser omitido.
Agora vamos aplicar a defnição acima em um exemplo prático. Para isso, considere a chave com valor 3 (k=3k=3), as funções de cifragem CC33((si)) e decifragem DD33((si)), e os valores decimais do subalfabeto As.
Aplicando a função de cifragem Ck(si)=s(i-p+k) mod n+p na cadeia de caracteres "STRING"
S C3(83)=s(83-65+3) mod 26 + 65 => 86 => VT C3(84)=s(84-65+3) mod 26 + 65 => 87 => WR C3(82)=s(82-65+3) mod 26 + 65 => 85 => UI C3(73)=s(73-65+3) mod 26 + 65 => 76 => LN C3(78)=s(78-65+3) mod 26 + 65 => 66 => QG C3(71)=s(78-65+3) mod 26 + 65 => 73 => J
temos como saída a cadeia de caracteres "VWULQJ".
Aplicando a função de decifragem Dk(si)=s(i-p-k+n) mod n+p no texto cifrado "VWULQJ".
V C3(86)=s(86-65-3+26) mod 26 + 65=> 86 => SW C3(87)=s(87-65-3+26) mod 26 + 65=> 84 => TU C3(85)=s(85-65-3+26) mod 26 + 65=> 82 => RL C3(76)=s(76-65-3+26) mod 26 + 65=> 73 => IQ C3(66)=s(66-65-3+26) mod 26 + 65=> 78 => NJ C3(73)=s(73-65-3+26) mod 26 + 65=> 71 => G
temos como saída a cadeia de caracteres "STRING".
Pg. Pg. 22//44

ExercitandoExercitando
1. Considere o alfabeto ASCIIASCII As=(A..Z,a..z) e os blocos de código PL/pgSQLPL/pgSQL abaixo. Implemente asfunções de cifragemcifragem Ck e decifragemdecifragem Dk na PL/pgSQLPL/pgSQL. Se o parâmetro de entrada das funções (P_TEXT) possuir um caracter que não pertence ao alfabeto As, então a função deve levantar uma exceção com a mensagem 'Existe(m) caracter(es) inválido(s)'.
CREATE OR REPLACE FUNCTION F_CK(P_TEXT VARCHAR) RETURNS VARCHAR AS $$DECLARE ...BEGIN ... RETURN ...END;$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION F_DK(P_TEXT VARCHAR) RETURNS VARCHAR AS $$DECLARE ...BEGIN ... RETURN ...END;$$ LANGUAGE plpgsql;
2. Acesse a base de dados tsi33atsi33a do servidor de banco de dados amazonia.td.utfpr.edu.bramazonia.td.utfpr.edu.br. Em seguida, execute os comandos SQL a seguir:
CREATE TABLE USERS ( USER_ID INTEGER NOT NULL, USER_NAME VARCHAR(20) NOT NULL, USER_PASSWD CHAR(8), CONSTRAINT PK_USERS PRIMARY KEY (USER_ID), CONSTRAINT UK_USER_NAME UNIQUE (USER_NAME), CONSTRAINT CK_PASSWD CHECK (CHAR_LENGTH(USER_PASSWD) = 8 OR USER_PASSWD IS NULL) );
INSERT INTO USERS (SELECT EMPLOYEE_ID, LOWER(EMAIL), NULL FROM EMPLOYEES);
Sua missão éSua missão é: elaborar uma instrução SQL para atualizar a senha dos usuários USER_PASSWD como sendoo nome do próprio usuário cifrado com Cifra de César. Para isso, utilize a função Ck do exercício anterior na instrução SQL.
3. Elabore uma função PL/pgSQLPL/pgSQL que atualize o valor do salário de todos os colaboradores colaboradores conforme regra abaixo:
Se o salário do colaborador for inferior ao previsto pelo seu cargo, então atualizar o salário →
para o valor mínimo do seu cargo.
Se o salário do colaborador estiver entre o mínimo e o máximo previsto pelo seu cargo, então →
atualizar o salário em 10% desde que não ultrapasse o valor máximo previsto pelo seu cargo.
Pg. Pg. 33//44

4. Crie um gatilho para registrar as mudanças de cargocargo e departamentodepartamento dos colaboradores, ou seja, que registre as mudanças de cargos e departamentos dos colaboradores na tabela JOB_HISTORY. O valor dasdatas de inícioinício e fmfm deve seguir a seguinte regra:
Se o colaborador não possui registro no histórico (→ JOB_HISTORY), então a data inicial do registro do histórico receberá a data de contratação (HIRE_DATE) do colaborador e a data fnal receberá a da data de modifcação do registro (data atual).
Se o colaborador possui registro no histórico (→ JOB_HISTORY), então a data inicial do registro do histórico receberá a data fnal do último lançamento do histórico desse colaborador e a data fnal receberá a data de modifcação do registro (data atual).
Pg. Pg. 44//44

TSI33A – Banco de Dados 1 TSI33A – Banco de Dados 1 Semana 14Semana 14
Projeto de Banco de Dados Projeto de Banco de Dados &&&& Estudo de Caso Cronograma Estudo de Caso CronogramaObjetivoObjetivo
Consolidar o conteúdo de projeto de banco de dados→
Introdução ao artefato cronograma de gestão de projetos→
AvaliaçãoAvaliação
→ Exatidão:Exatidão: o projeto de banco de dasdos está coerente com os requisitos? → Estilo:Estilo: o projeto de banco de dados faz uso das boas práticas de projeto de banco de dados?
ComeçandoComeçando
O cronogramacronograma é um instrumento de planejamento e controleinstrumento de planejamento e controle em que são definidas e detalhadas minuciosamente as atividades a serem executadas durante um período de tempo – normalmente longo e de atividades constantes.
Em nível gerencialnível gerencial, um cronograma é um artefato de controle importante para o levantamento dos custos de um projeto e, a partir deste artefato, pode ser feita uma análise de viabilidade antes da aprovação final do projeto. Outras áreas e segmentos da sociedade também utilizam cronogramas para administrar suas atividades. Por exemplo, na pesquisa científica o cronograma é utilizado como um plano da distribuição das diferentes etapas de execução da pesquisa, tais como, revisão bibliográfica e estudo de caso.
ExercitandoExercitando
A partir da análise do cronograma em anexo, modele um esquema de banco de dados relacionalmodele um esquema de banco de dados relacional para atender as necessidades de registro das atividades (tarefas) do cronograma. Crie os projetos lógicoprojetos lógico e físicofísico (PostgreSQL) com o apoio da ferramenta Oracle SQL Developer Data ModOracle SQL Developer Data Modelereler.
Alguns requisitos para ajudar no projeto do esquema de banco de dados do cronograma:
O esquema deve manter um cadastro de projetos, tarefas, grupo de tarefas e área de →
conhecimento. Uma tarefa pertence a um projeto específico e possui um grupo e uma área de conhecimento. Um grupo pode ser associado a outro grupo, ou seja, organização em grupo e subgrupo (hierarquia de grupos).
As informações mantidas sobre um projeto são: identificador, nome, descrição, data de início e→
término. As informações sobre as tarefas de um projeto são: projeto ao qual a tarefa pertence, grupo, →
duração, área de conhecimento, tarefa predecessora e indicador do status, sendo este último iniciadainiciada, não iniciadanão iniciada, interrompidainterrompida, canceladacancelada ou concluídaconcluída. O status pode ser representado por um texto ou caractere ou número.
As informações mantidas sobre o grupo são: identificador, nome e descrição, e caso seja um →
subgrupo, o grupo ao qual ele pertence. As informações sobre as áreas de conhecimento são: identificador, nome e descrição.→
Informações adcionais sobre o cronograma devem ser abstraídas a partir do documento em anexo. Não se esqueça de aplicar os conhecimentos de projeto de esquemas de banco de dados relacional e normalização.
Pg. Pg. 11/3/3
Id Nome da tarefa Duração Área deConhecimento
Predecessoras
1 Template de Projeto PMI-RIO 18 dias
2 Iniciação 2 dias
3 Desenvolver o termo de abertura do projeto 1 dia Integração
4 Identificar as partes interessadas 1 dia Comunicações 3
5 Planejamento 10 dias 2
6 Desenvolver o plano de gerenciamento do projeto 10 dias Integração
7 Coletar os requisitos 1 dia Escopo
8 Definir o escopo 1 dia Escopo 7
9 Criar a EAP 1 dia Escopo 8
10 Definir as atividades 1 dia Tempo 9
11 Sequenciar as atividades 1 dia Tempo 10
12 Estimar os recursos das atividades 1 dia Tempo 11
13 Estimar as durações das atividades 1 dia Tempo 12
14 Desenvolver o cronograma 1 dia Tempo 13;21
15 Estimar os custos 1 dia Custos 13
16 Determinar o orçamento 1 dia Custos 15;14;21
17 Planejar o gerenciamento dos riscos 1 dia Riscos
18 Identificar os riscos 1 dia Riscos 17
19 Realizar a análise qualitativa dos riscos 1 dia Riscos 18
20 Realizar a análise quantitativa dos riscos 1 dia Riscos 19
21 Planejar as respostas aos riscos 1 dia Riscos 20
22 Desenvolver o plano dos recursos humanos 1 dia RH
23 Planejar a qualidade 1 dia Qualidade
24 Planejar as comunicações 1 dia Comunicações
25 Planejar as aquisições 1 dia Aquisições 21;14;16
26 Execução 5 dias 5
27 Orientar e gerenciar a execução do projeto 5 dias Integração
28 Realizar a garantia de qualidade 1 dia Qualidade
29 Mobilizar a equipe do projeto 1 dia RH
30 Desenvolver a equipe do projeto 1 dia RH 29
31 Gerenciar a equipe do projeto 1 dia RH 30
D S T Q Q S S D S T Q Q S S D S T Q Q S S D S T Q Q S11/Out/09 18/Out/09 25/Out/09 1/Nov/09
Tarefa
Divisão
Andamento
Etapa
Resumo
Resumo do projeto
Tarefas externas
Etapa externa
Prazo final
Página 1
Projeto: Template_Projeto_PMI.mData: Qua 14/10/09
Id Nome da tarefa Duração Área deConhecimento
Predecessoras
32 Conduzir as aquisições 1 dia Aquisições
33 Distribuir as informações 1 dia Comunicações 32;31
34 Gerenciar as expectativas das partes interessadas 1 dia Comunicações 33
35 Controle 1 dia 5
36 Realizar o controle integrado de mudanças 1 dia Integração
37 Monitorar e controlar o trabalho no projeto 1 dia Integração
38 Verificar o escopo 1 dia Escopo
39 Controlar o escopo 1 dia Escopo
40 Controlar o cronograma 1 dia Tempo
41 Controlar os custos 1 dia Custos
42 Realizar o controle da qualidade 1 dia Qualidade
43 Relatar o desempenho 1 dia Comunicações
44 Monitorar e controlar os riscos 1 dia Riscos
45 Administrar as aquisições 1 dia Aquisições
46 Encerramento 1 dia 26;35
47 Encerrar o projeto ou fase 1 dia Integração
48 Encerrar as aquisições 1 dia Aquisições
D S T Q Q S S D S T Q Q S S D S T Q Q S S D S T Q Q S11/Out/09 18/Out/09 25/Out/09 1/Nov/09
Tarefa
Divisão
Andamento
Etapa
Resumo
Resumo do projeto
Tarefas externas
Etapa externa
Prazo final
Página 2
Projeto: Template_Projeto_PMI.mData: Qua 14/10/09