Embed Size (px)
Citation preview

Análise de Dados Simbólicos: Questões e Perspectivas. O caso particular dos O caso particular dos Dados Intervalares
Paula BritoFEP / LIAAD-INESC Porto, LAUniv. of Porto, [email protected]

ProgramaDos dados clássicos aos dados simbólicosVariáveis “simbólicas”Classificação conceptual versus classificação
baseada em medidas de proximidadeClassificação não-hierárquica : Nuvens dinâmicas
2
EstandardizaçãoUm modelo de regressãoDispersão, associação e combinações lineares de
variáveis intervalaresAnálise discriminanteModelização de variáveis intervalaresConclusões e Perspectivas

Dos dados clássicos aos dados simbólicos
Análise de Dados Clássica:Dados são representados numa matriz n x pcada um dos n indivíduos (em linha) toma um
3
cada um dos n indivíduos (em linha) toma um valor único para cada uma das p variáveis (em coluna)
Modelo demasiado simples para representar variabilidade incerteza

Dos dados clássicos aos dados simbólicosDados simbólicos → novos tipos de
variáveis:Variáveis a valores conjunto: os seus valores são
4
subconjuntos de um conjunto subjacenteVariáveis intervalaresVariáveis categóricas multi-valuadas
Variáveis Modais: os seus valores são distribuições sobre um conjunto subjacenteVariáveis Histograma

Dos dados clássicos aos dados simbólicos :
Variáveis intervalaresΩ = ω
1, ..., ω
n
5
Y com domínio subjacente O ⊆ ||||||||RR
I = conjunto de intervalos de O
Y : Ω → I
ωi→ [l
i, u
i]

Dados Intervalares
Y1 … Y j ... Yp
ω1 [l11 , u11] ... [l1j , u1j] ... [l1p , u1p]
... ... ... ...
6
... ... ... ...
ωi [l i1 , ui1] ... [l ij , uij] … [l ip , uip]
… … … …
ωn [ln1 , un1] … [lnj , unj] … [lnp , unp]

Variáveis Modais
Ω = ω1
, ..., ωn
Y com domínio subjacente O=m1, …, mk
7
Y : Ω → D
ωi→ )(pm , ),(pm ii
kk11ωω
L
Y com domínio subjacente O=m1, …, mk

A questão central
Os métodos de análise multivariada baseiam-se com frequência em medidas dispersão.
Como avaliar a dispersão de dados simbólicos ?
8
Como avaliar a dispersão de dados simbólicos ?
Dispersão em torno de um “ponto” central versus medidas de generalidade :
Estamos a medir a mesma coisa ou coisas diferentes ?

Análise Classificatória Métodos baseados em medidas de proximidade vs
métodos conceptuais.
Métodos conceptuais : usualmente baseados em medidas de generalidade : se “reunirmos” dois elementos, que parte do espaço
9
se “reunirmos” dois elementos, que parte do espaço de descrição é coberto ?
Métodos baseados em medidas de proximidade : usualmente generalizações dos métodos correspondentes para dados “standard”. No entanto…

Classificação Hierárquica e Piramidal
Classificação “Numérica” – baseada em proximidades Indices da Máximo, Mínimo, Média, Diâmetro,… Ward: inércia (Hardy, 2006)
10
Classificação Simbólica : as classes são “conceitos” Generalidade Mínima Aumento Mínimo da Generalidade A generalidade é avaliada segundo o método de
generalização

Avaliação da generalidade:variáveis intervalares
Numa população de idades entre 15 e 60 anos, com salários entre 0 e 10000€, considere um grupo descrito por
[idade ∈ [ 20 , 45]] ∧ [salário ∈ [1000 , 3000]] = e11 ∧ e12
m(Vi) = max Vi – min Vi (amplitude)
11
[idade ∈ [ 20 , 45]] ∧ [salário ∈ [1000 , 3000]] = e11 ∧ e12
55,04525
15602045
)11e(G ==−−=
2,0100002000
01000010003000
)12e(G ==−
−=
11,02,0*55,0)1s(G ==

Avaliação da generalidade:variáveis modais
Ao generalisar pelo Máximo
que usa para cada variável j o coeficiente de afinidade
∑∏===
jk
1iij
p
1j j1 p
k1
)a(G
12
que usa para cada variável j o coeficiente de afinidade (Matusita, 1951)entre (p1j,…,pkjj) e a distribuição uniforme: G1(a) é máximo (=1) para pij = 1/kj, i=1,…k : uniforme
Consideramos uma descrição tanto mais geral quanto mais as distribuições se aproximarem da uniforme.
Método correpondente para a generalização pelo mínimo

Quais são mais dissemelhantes???
Se O = [0, 100] Sejam I1 = [10, 20] , I2 = [30, 40] Sejam I3 = [10, 100] , I4 = [9, 99]
I1 ∪ I2 = [10, 40] 3,030
)II(G ==∪
13
I1 ∪ I2 = [10, 40]
I3 ∪ I4 = [9, 100]
3,010030
)II(G 21 ==∪
91,010091
)II(G 43 ==∪
[ ] 800)2040()1030()II(L2/122
212 =−+−=∪
[ ] 2)910()99100()II(L2/122
432 =−+−=∪

Quais são mais dissemelhantes???
Este problema não ocorre com dados clássicos!
d (10, 30) > d (10, 20)
14
d (10, 30) > d (10, 20) e
G([10, 30]) > G([10, 20])

Classificação Hierárquica e Piramidal Avaliação da Generalidade
Grau de GeneralidadeProporção do espaço de descrição coberto pela descrição da classe
15
p
1=j)j(eG = (a)G ∏
[ ] j
p
1jjjj eVRYa
p
1j∧=∧===

Algoritmo para classificação simbólica (conceptual)
Começando com as classes singulares
Em cada etapa formar uma classe (p,s) união de (p1 , s1) and (p2 , s2) tais que
16
p1, p2 possam ser reunidos, de acordo com a estrutura escolhida s = s1 ∪ s2 (completo)
extE s = p
a generalidade G(s) = G(s1 ∪ s2 ) é mínima
(p1 , s1) and (p2 , s2) tais que
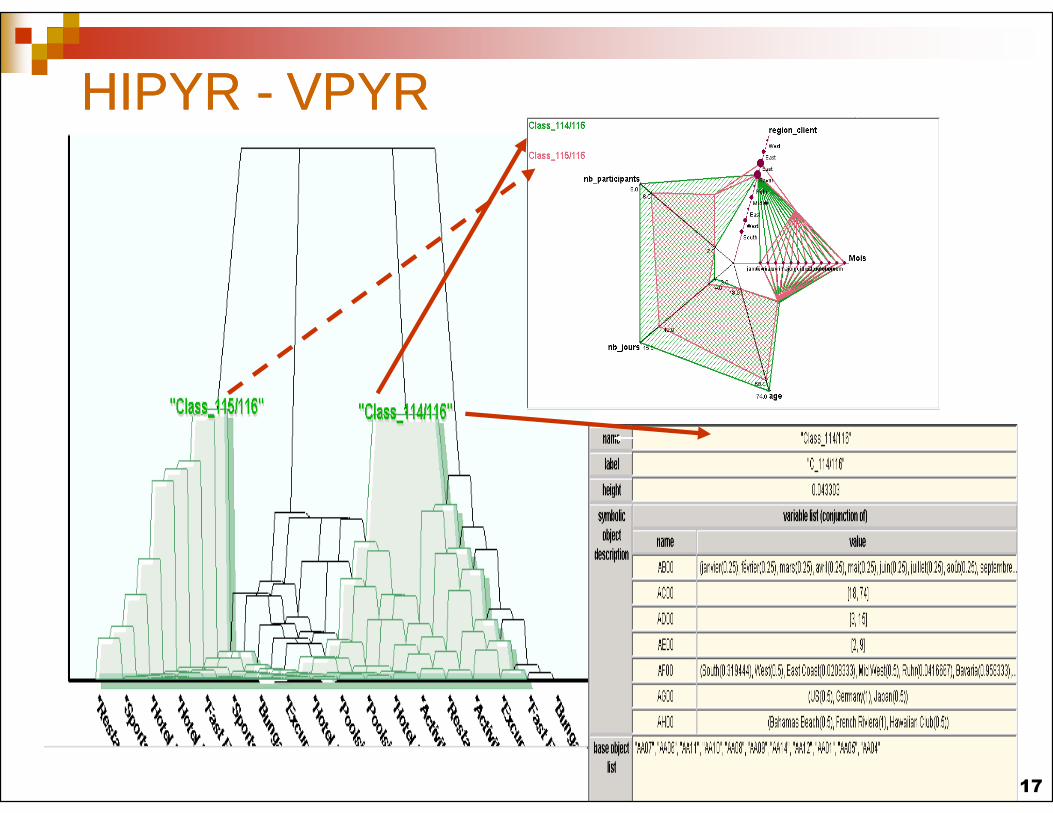
HIPYR HIPYR -- VPYRVPYR
17
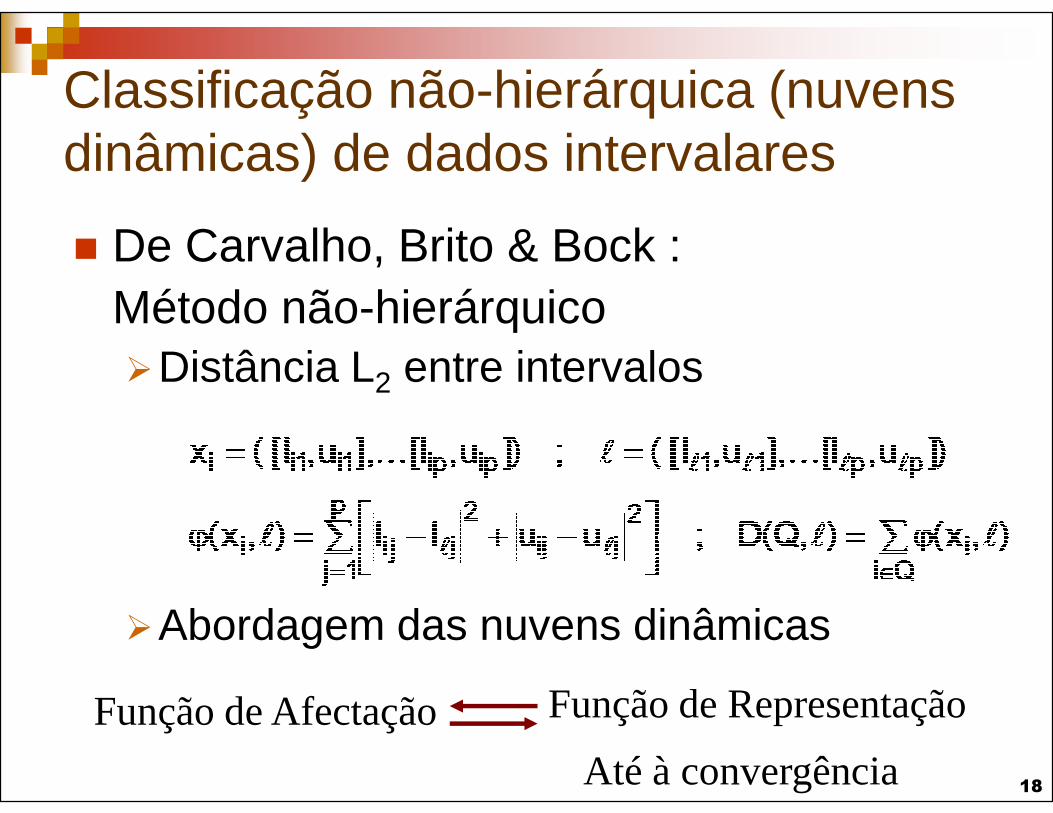
Classificação não-hierárquica (nuvens dinâmicas) de dados intervalares
De Carvalho, Brito & Bock :Método não-hierárquicoDistância L2 entre intervalos
18
Abordagem das nuvens dinâmicas
Até à convergência
Função de Afectação Função de Representação

Função de Afectação :
Dados os representantes (L1,…, Lk), a partição P = P1,…, Pk é definida por:
Ph = ω ∈ Ω : D(Lh , ω) ≤ D(Lm , ω), 1 ≤ m ≤ k
19
Função de Representação :
Dada a partição (P1,…, Pk), os representantes (L1,…, Lk) são definidos por :
Lh = L ∈ L : D(Ph , L) minimiza D(Ph , •)

Nuvens dinâmicas para dados intervalares
Aplicando iterativamente a função de afectação seguida da função de representação em alternância faz diminiur motonotamente o valor de
∑=k
hh ),P(D)P,L(W l
20
até que um mínimo local seja atingido.O método minimiza assim
com respeito à partição P.
∑==1h
hh ),P(D)P,L(W l
∑ ∑ ∑ −+−== ∈ =
k
1h Pi
p
1j
2hjij
2hjij
h
)]uu[]ll([))P(L,L(W

Estandardização
Os valores de dissemelhanças e os resultados de uma classificação são fortemente afectados por variações na escala das variáveis.
Algum tipo de estandardização deve ser efectuada antes do processo de classificação,
21
Algum tipo de estandardização deve ser efectuada antes do processo de classificação, por forma a ser possível obter um resultado 'objectivo' ou ‘invariante’ por efeito de escala.
A mesma transformação deve ser aplicada quer ao limite superior quer ao limite inferior de cada intervalo.

Estandardização 1Usa a dispersão dos centros dos intervalos
O primeiro método considera a média e a dispersão dos centros dos intervalos e estandardiza por forma a que os pontos centrais dos intervalos resultantes tenham média zero e dispersão 1 em cada dimensão.
22
dispersão 1 em cada dimensão.
Iij = [lij , uij] I’ij = [l’ij , u’ij]

Estandardização 2Usa a dispersão dos limites dos intervalos
Avaliar a dispersão de uma variável intervalar pela dispersão dos limites dos intervalos:
23
Iij = [lij , uij] I’ij = [l’ij , u’ij]

Estandardização 3Usa a amplitude global
O terceito método de estandardização transforma, para cada variável,os intervalos I ij = [lij , uij] (i=1,...,n) por forma a que a amplitude global dos n intervalos transformados seja o intervalo [0,1].
24
intervalos transformados seja o intervalo [0,1].
Minj = Min lij , uij, i=1,…,n = Min lij, i=1,…,n
Maxj = Max lij , uij, i=1,…,n = Max uij, i=1,…,n Iij = [lij , uij] I’ij = [l’ij , u’ij]

Resultados Experimentais
Estudos de simulação mostraram que a estandardização melhora de forma importante a qualidade da classificação obtida (identificação de uma estrutura imposta).
25
imposta).
A estandardização 2 forneceu resultados ligeiramente melhores no caso de classes mal-separadas com intervalos de grandes amplitudes.

Estandardização 2 : Consequências
Medida de “Covariância”
26
“Correlação”
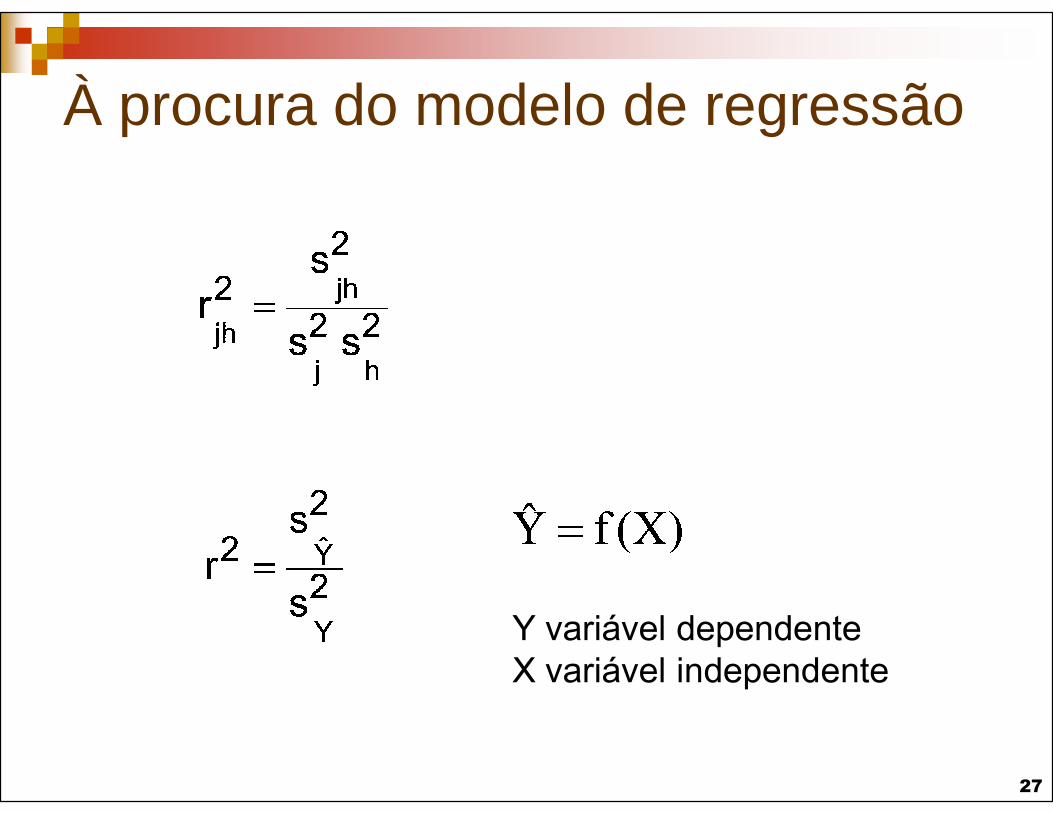
À procura do modelo de regressão
27
Y variável dependente
X variável independente

Modelo de Regressão
i =1,..., n
28
α e β minimizam
Este modelo foi obtido independentemente por Neto e
De Carvalho por minimização directa do critério (1).
(1)

Resultados Experimentais
Experiências de Monte-Carlo Simulação de dados intervalares data com
diferentes graus de “linearidade”Diferentes graus de variabilidade (amplitude
dos intervalos) e qualidade do ajustamento
29
dos intervalos) e qualidade do ajustamento
Performance análoga à obtida pelo método baseado nos centros (Billard and Diday)(MSE nos limites superiores e inferiores, R2 dos limites superiores e inferiores)

Dispersão, associação e
combinações lineares (Duarte Silva & Brito)
I=[I ij]i=1,...,n, j=1,...,p I ij= [lij, uij]
ββββ=[β ]
30
ββββ=[βij]i=1,...,p, j=1,...,r
Z=[Zij]i=1,...,n, j=1,...,r
βZ ⊗= I
],[ ijijij zzZ =

Dispersão, associação
e combinações lineares
ββ=β⊗ II SSt (P2)
ij
p
jji β II
1∑ ×=β⊗=
ll (P1)
31
∑β=
∑β=
=
=p
1jijji
p
1jijji
uz
lz
ll
ll
(LC1)
∑ β+∑ β=
∑ β+∑ β=
<β>β
<β>β
0ijj
0ijji
0ijj
0ijji
jj
jj
luz
ulz
ll
ll
lll
lll
(LC2)
ββ=β⊗ II SSt (P2)

Dispersão, associação
e combinações lineares
LC1 é apropriada quando os limites inferiores (respec. superiores) das diferentes variáveis tendem a ocorrer simultaneamente
32
simultaneamente
“Correlação Interna” Positiva
LC1 não verifica P1
LC2 verifica P1 e é apropriada na ausência de correlação interna.

Dispersão, associação e
combinações lineares
Medidas de dispersão sj2 and associação
sjj’ dependem de lij e de uij simetricamente
33
LC1 e LC2 verificam P2
Variâncias de combinações lineares são formas
quadráticas, cujas razões são maximizadas por uma
análise tradicional de valores e vectores próprios.

Análise Discriminante 1. Abordagem Distribucional
Hipótese equidistribucional(Bertrand, Goupil, 2000) :
Assume-se uma distribuição uniforme
34
Assume-se uma distribuição uniforme em cada intervalo observado
A dist. empírica de cada variável intervalar é uma mistura de n leis uniformes
K grupos : mistura de K misturas

Análise discriminante1. Abordagem Distribucional
( ) ( )2n
ijij
n2ijij
2ij
2j ul
1uull
1s
+−++= ∑∑
∑=
+=
n
1i
ijijj
2
ul
n
1m
35
( ) ( )1i
ijij21i
2ijijij
2ij
2j ul
n4
1uull
n3
1s
+−++= ∑∑==
( )( )
( ) ( )
+
+−
−++=
∑∑
∑
==
=n
1i'ij'ij
n
1iijij2
n
1i'ij'ijijij'jj
ululn4
1
ululn4
1s

Análise discriminante1. Abordagem Distribucional
A partir destas medidas pode ser obtida a
decomposição em componentes intra-
grupos e (j≠j’) and entre-grupos .jjw 'jjw 'jjb
36
grupos e (j≠j’) and entre-grupos .jjw 'jjw 'jjb
As funções lineares são então
dadas pelos valores próprios de W-1B.

2. Abordagem dos Vértices
Cada indivíduo é representado pelos vértices do
hipercubo respectivo :
⇒ a matriz original é expandida numa matriz de
dimensão (n × 2p) × p
37
dimensão (n × 2p) × p
Efectua-se uma análise clássica da matriz dos
vértices.
Os limites da l-ésima função discriminante no
indivíduo ωi são:
Qq,zMinz iqi ∈= ll Qq,zMaxz iqi ∈= ll

3. Abordagem dos centros e amplitudes
Cada intervalo é representado pelo seu centro cij e
amplitude rij
Duas análises clássicas são então efectuadas :
38
Separadamente para C=[cij] e R=[rij]
Conjuntamente para a matriz [C | R]

Regras de Classificação
As regras de classificação são obtidas a
partir das representações no espaço
discriminante
Dist. Euclideana
39
PontuaisDist. Euclideana
Dist. Mahalanobis
IntervalaresDist. Hausdorff
Outras distâncias intervalares
|||,Max|),( llllll jijiji zzzzzz −−=δ

Resultados Experimentais
Separação apenas em termos de localização de centros : Os métodos que integram explicitamente as
amplitudes têm pior desempenho
40
Separação em termos de localização de centros e de amplitudes: Os métodos que integram explicitamente as
amplitudes têm o melhor desempenho Métodos baseados em abordagens intervalares
capturam a informação sobre as amplitudes numa certa medida

Conclusões
A extensão das metodologias clássicas à análise de dados intervalares levanta novos problemas:Como avaliar a dispersão ?
41
Como avaliar a dispersão ?
Como definir combinações lineares ?Que propriedades se mantém válidas ? ...

Conclusões
Representações em espaços de baixa dimensão podem assumir diferentes formas :
Intervalos, põe em evidência a variabilidade inerente a cada observação
Pontos, permitem distinguir diferentes
42
Pontos, permitem distinguir diferentes contribuições para a separação entre os grupos
Em geral : necessidade de modelos estatísticos, que abram caminho à estimação e aos testes de hipóteses.

Uma modelização para variáveis intervalaresSejam cij e rij o centro e a amplitude do intervalo Iij = Yj(ωi).
Admitamos que a distribuição conjunta dos centros
43
Admitamos que a distribuição conjunta dos centros C e dos logaritmos das amplitudes R é multinormal, isto é R*=log R,
(C, R*) ~ N(µ, Σ),
[ ] t*RC |µµ=µ
ΣΣΣΣ
*R*RC*R
*CRCC

Diferentes configurações
Mod Caracterização Σ1 Sem restrições Sem restrições
2 Cj não-correlacionado com Rℓ, ℓ ≠ j ΣCR* = ΣR*C diagonal
3 Y ’s independentes Σ ,Σ = Σ , Σ diag.
44
3 Yj ’s independentes ΣCC,ΣCR* = ΣR*C, ΣR*R* diag.
4 C’s não-correlacionados com R’s ΣCR* = ΣR*C = 0
5 C’s e R’s não-correlacionados Σ diagonal
Notar que : 2 é um caso particular de 1, 3 e 4 são casos particulares de 2, 5 é um caso particular de todos os outros.

Testar configurações 3, 4 and 5 versus 1: testar a independência de conjuntos de variáveis testes clássicos.
Testar a configuração 2 versus 1 e as
45
Testar a configuração 2 versus 1 e as configurações 3, 4 e 5 versus uma mais geral do que 1 princípio da razão de verosimilhanças.

Os e.m.v. para µ and Σ na config. 1 são obviamente os clássicos.
Prova-se que para as configurações 3, 4 e 5 e.m.v. podem ser obtidos a partir de estimadores não-restritos inserindo “zeros” onde necessário.
46
restritos inserindo “zeros” onde necessário.
Este resultado não se mantém para a conf. 2 onde Σnão pode ser escrita como uma matriz diagonal por blocos. Não se conhece nenhuma forma “fechada” para o e.m.v.; a optimização poderá ser efectuada por métodos numéricos.

ANOVA E MANOVACada variável intervalar Yj é modelisada por um par (Cj ,Rj*): análise de variância de Yj é obtida por uma MANOVA bi-dimensional de (Cj ,Rj*).
Assumindo um modelo a um factor com k níveis (uma partição em k grupos?...):
47
em k grupos?...): A hipótese nula consiste em considerar que os μ•jℓ são iguais em todos os grupos. Razão de verosimilhanças (não podem ser garantidas condições habituais para outros testes). Mesmo raciocínio para os casos 3, 4 e 5. A configuração 1 é a clássica, Config. 2: métodos numéricos.

Em todos os casos a razão de verosimilhanças λ é assimptoticamente qui-quadrada com n − k g.l.
Uma análise simultânea de todas as variáveis Y ’s pode ser efectuada por uma MANOVA 2p dimensional.
48
ser efectuada por uma MANOVA 2p dimensional.

Perspectivas
Aplicação desta modelização a outros modelos multivariados.
Limitação do modelo normal :
Impõe uma distribuição simétrica para os centros e uma relação específica ente a variância a a assimetria
49
uma relação específica ente a variância a a assimetria para as amplitudes.
Modelo mais geral : família das distribuiçõesskew-normal (e.g.Azzalini 1985, 2005). Esta distribuição generaliza a Gaussiana introduzindo um parâmetro de forma adicional, mantendo muitas das propriedades matemáticas do modelo normal.

Referências Brito, P. (2007): "Modelling and Analysing Interval Data". In: "Advances in
Data Analysis", Decker, R., Lenz, H.-J. (Eds.), Series "Studies in Classificasão, Data Analysis and Knowledge Organizasão", Springer, Berlin, Heidelberg, New-York, 197-208.
Duarte Silva, A. P. , Brito, P. (2006). "Linear Discriminant Analysis for Interval Data". Computasãoal Statistics, 21, 2, 289-308.
De Carvalho, F., Brito, P., Bock, H.-H. (2006). "Dynamic Clustering for Interval Data Based on L2 Distance". Computasãoal Statistics, 21, 2, 231-250.
50
250.
Brito, P. (2002). "Hierarchical and Pyramidal Clustering for Symbolic Data", Journal of the Japanese Society of Computasãoal Statistics, Vol. 15, 2, 231-244.
Brito, P., De Carvalho, F. (2002): "Symbolic Clustering of Constrained Probabilistic Data". In: "Exploratory Data Analysis in Empirical Research", Opitz, O., Schvaiger, M., (Eds.), Series "Studies in Classificasão, Data Analysis and Knowledge Organizasão", Springer Verlag, Heidelberg, 12-21.
Brito, P. (2000): "Hierarchical and Pyramidal Clustering with Complete Symbolic Objects". In: "Analysis of Symbolic Data", Bock, H.-H., Diday, E., (Eds.), Springer Verlag, Berlin-Heidelberg, 312-324.
Brito, P. (1995). "Symbolic Objects : Order Structure and Pyramidal Clustering", Annals of Operasãos Research, 55, 277-297.





























