Embed Size (px)
Citation preview

BD II – Armazenamento
de dados e Indexação
Professor: Luis Felipe Leite

Como é possível quando escrevemos um comando sql, aparecer a resposta correta?

Armazenamento e indexação
Para entendermos melhor essa questão, é necessário começar de baixo para cima, do básico.
De certa forma, pode ser vista como uma abordagem bottom-up. (Mas esta é apenas uma comparação).
Se começaremos do básico, começaremos de onde?

Aonde armazenamos nossos dados?

Métodos de armazenamento
Disco:● HD● Cd / DVD
SSD (Solid State Drive).
Fita magnética ou Fita DAT.
Memória RAM.

Hierarquia de Armazenamento
Armazenamento primário.● Mais caro;● Operado pela CPU;● Mais rápido e mais disponível;● Ram e Cache
Armazenamento secundário.● Mais barato;● Precisa da memória para se comunicar com a CPU;● Mais lento;● Disco e fita magnética.

Disco HD

Disco HD
Cheio de partes mecânicas.
A rotação é altíssima, embora este fato seja uma vantagem, se o disco sofre um impacto é quase certo que se ele estiver em funcionamento, vai pifar.
Embora a agulha se mexa em uma velocidade impressionante, nunca será tão rápido quanto uma memória.

Disco HD
A agulha do disco não encosta nele, mas fica a uma distância bem pequena.
E como é feita a gravação?
O cabeçote ou a agulha magnetiza a superfície, criando um campo magnético para esquerda ou direita. 0 1 0 1 0 1.
Quanto mais próximo o cabeçote for do disco, maior a densidade de gravação.

Disco HD
A velocidade de rotação também é importante.
Mas para gravar e ler, seja em qual velocidade for, é necessário uma estrutura lógica magnética em cima da superfície.
Trilha e setores.

Disco HD
● Estrutura magnética criada depois que o disco sai de fábrica.
● Círculos magnéticos sobre a superfície.
● Onde são armazenados os dados.

Disco HD
● Alguns cuidados para que uma trilha não mexa na outra.
● A quantidade de trilhas varia.

Disco HD
● E o setor?
● Uma parte da trilha que é a menor unidade de leitura e gravação.
● O setor é lido por um todo ou gravado por um todo.
● Vários bits aparecem de uma vez só

E o SSD?

Solid State Drive
Praticamente sem partes mecânicas.O SSD tem um limite de gravações.Existe o TRIM.Não se deve utilizar toda a capacidade de armazenamento.Menor, mais veloz e consome menos energia.Não indicado para banco de dados.

Então como fica
Leitura e gravação no buffer antes.
Dado.
Registro.

Organização de arquivos.
Sequencial.
Heap.
Hash.

Organização de arquivos - Sequencial
É um dos métodos mais simples de organização de arquivos.
Neste método cada arquivo/registro é armazenado um depois do outro, de maneira sequencial.
Isto pode ser alcançado de duas maneiras:● Pilha;● Classificação.

Organização de arquivos – Sequencial: Pilha
Os registros são armazenados um depois do outro da mesma maneira que eles são inseridos na tabela. Quando um novo registro é inserido, é colocado automaticamente no fim da fila.

Organização de arquivos – Sequencial: Classificação/Organização
No método sorted, os arquivos são classificados/organizados (seja na ascendente ou na descentende) a cada vez que eles são inseridos no sistema.
Essa classificação/organização pode ser feita tanto por um chave primária por exemplo, quanto por qualquer outra coluna.

Organização de arquivos - Sequencial: Classificação/Organização
Toda vez que um novo registro é inserido, ele será colocado no fim da fila. Diferentemente do método pilha, logo depois desta inserção, o registro será organizado para cima ou para baixo, de acordo com o valor de sua chave. Por fim, ele será colocado em sua posição correta.

Organização de arquivos – Sequencial: Classificação/Organização

Organização de arquivos – Sequencial: Vantagens
É uma arquitetura simples quando comparada a outras formas de organização de arquivos, não necessitando de muito esforço no armazenamento dos dados.
Quando existirem grandes volumes de dados, este método acaba se tornando rápido e eficiente.
É um bom método para geração de reports ou cálculos estatísticos.
É um bom método para ser armazenado em fitas magnéticas. Um material considerado barato.

Organização de arquivos – Sequencial: Desvantagens
No método sorted sempre vai existir um esforço a mais para organizar os registros. Toda vez que for feito um insert, update ou delete por exemplo, o registro será organizado de novo.
Todo esse processo leva tempo e deixa o sistema mais lento.

Organização de arquivos – HEAP
Essa é a forma mais simples de organização, sendo semelhante ao estilo da pilha. O registro é inserido na ordem que chega, não existindo nenhum tipo de classificação ou organização dos registros.

Organização de arquivos – HEAP
Uma vez que o bloco de dados está cheio, o próximo registro será gravado em um próximo e assim por diante. A diferença deste método para o de pilha sequencial é que a escolha do bloco escolhido não será feita de forma sequencial, mas de forma aleatória.
A responsabilidade de guardar os registros e de gerenciá-los fica a cargo do SGBD.

Organização de arquivos – HEAP
Caso seja necessário uma inserção, atualização ou exclusão, o arquivo deverá ser lido por completo, para daí ser efetuada a transação.
No caso específico da exclusão de um registro, ele será excluído do bloco de dados, mas seu espaço não será liberado e por consequência, não poderá ser usado.

Organização de arquivos – HEAP
A medida que o número de registros aumenta, a memória usada também aumenta e a eficiência cai.
O DBA deve periodicamente liberar todo este espaço ocioso.

Organização de arquivos – HEAP: Vantagens
É um método muito bom quando uma grande quantidade de dados deve ser inserida de uma vez só no banco.
É indicado para arquivos pequenos, visto que a busca por eles aqui é mais rápida. A medida que o arquivo cresce, esse tipo de busca se torna muito demorada.

Organização de arquivos – HEAP: Desvantagens
É ineficiente para bancos de dados muito grandes, pois o tempo para buscar e modificar um registro é muito alto.
Deve existir um gerenciamento de memória apropriado para garantir performance. Caso contrário, o sistema ficará cheio de espaço não usado na memória.

Organização de arquivos – HASH
A função de HASH pode ser tanto uma função matemática simples, como também complexa.
Esta função é aplicada em alguma colunas/atributos, sejam elas colunas chave ou não para obter o endereço do bloco.
Assim, cada registro é armazenado de forma aleatória, independentemente da ordem em que elas vêm.

Organização de arquivos – HASH
Neste método, uma função HASH é usada para calcular o endereço do bloco onde os registros vão ser guardados.
Quando um registro tem de ser recuperada, o endereço é gerado e, a partir desse endereço, o arquivo inteiro é recuperado.
Como cada registro será único, nenhum esforço maior é necessário para fazer esse acesso.
Da mesma forma quando um novo registro tem que ser inserido, atualizado ou excluído.

Organização de arquivos – HASH

Organização de arquivos – HASH

Organização de arquivos – HASH: Vantagens
Este método é muito útil para sistema de transações online onde a recuperação, inserção ou atualização de dados deve ser rápida.
Além disso, este método pode suportar múltiplas transações, já que cada registro é independente dos outros.
Não é necessário nenhum tipo de organização ou classificação no método HASH, salvando tempo, memória e desempenho.
Já que o endereço é conhecido pela função HASH, acessar qualquer registro é muito rápido.

Organização de arquivos – HASH: Desvantagens
Usando o método HASH, pode ser possível que alguns registros sejam acidentalmente deletados dependendo da escolha da chave. Ex: A função de HASH usar uma chave que pode se repetir.
Já que todos os registros são guardados aleatoriamente, eles estão espalhados na memória. Em razão disso, não existe um uso eficiente do armazenamento primário.
Buscar intervalos de dados é ineficiente. Como os dados são armazenados aleatoriamente, buscar um intervalo entre dois valores por exemplo não dará certo.
Hardware e software requerido para o gerenciamento de memória é mais custoso neste caso. Programas mais complexos devem ser escritos para que este método seja mais eficiente.

Índices

Índices
Os índices são uma estrutura de dados que recebe como entrada uma propriedade de registro (uma chave por exemplo).
A partir disso, é possível que os registros sejam achados rapidamente e sem a necessidade de examinar mais que uma pequena fração de todos os registros.
O propósito geral de um índice é tornar mais rápido o acesso a registros, com base em certos campos chamados de indexação.
Os campos cujos valores o índice se baseia formam, portanto, a chave de pesquisa.

Índices
Os índices independem da forma como os arquivos são organizados.
Eles são armazenados separadamente em um arquivo auxiliar chamado de arquivo de índice.
Em resumo, índices são estruturas auxiliares que tornam a pesquisa baseada em alguns campos, mais eficiente.

Arquivo de índice
São construídos sobre campos de indexação escolhidos entre os campos dos registros de um arquivo;
Armazenam os valores do campo de indexação associando ao endereço do registro onde o valor ocorre;
É um arquivo ordenado pelo campo de indexação de tal forma que é possível encontrar um valor no índice usando pesquisa binária.

Tipos de Índice
Denso: Sequência de blocos contendo os registros e os ponteiros de todos os itens no arquivo de dados.
Esparso: Tem como vantagem usar menos espaço, mas exige um tempo maior para localizar um registro. Além disso, o ponteiro aponta apenas para o registro “âncora de bloco” do arquivo de dados.

Estruturas de índice
Índice Primário;Índice de Cluster;Índice Secundário;Índices Multiníveis;

Estruturas de índice - Primário
Um índice primário é um arquivo ordenado, de tamanho fixo.
Os registros armazenados possuem dois campos: o primeiro campo é do mesmo tipo de dado do campo-chave do arquivo dos dados (já que será o campo que receberá o mesmo valor do campo-chave) e o segundo é um ponteiro para o endereço de bloco de disco.

Estruturas de índice - Primário
Existe uma entrada de índice no arquivo de índice para cada bloco do arquivo de dados.
Cada entrada no índice tem o valor da chave primária para o primeiro registro do bloco (registro de âncora ou âncora de bloco).
O problema com este tipo de índice é a inclusão e exclusão de múltiplos registros, que podem modificar os registros de âncora.

Estruturas de índice - Primário

Estruturas de índice - Cluster
Um índice de agrupamento também possui dois campos, sendo o primeiro campo do mesmo tipo do campo de agrupamento e o segundo campo é um ponteiro para um bloco de disco.
O primeiro campo possuirá um determinado valor e o segundo campo apontará para todos os dados que possuam o mesmo valor para aquele campo.
Este tipo de índice é esparso, pois possui uma entrada para cada valor distinto do campo de indexação e não para cada registro no arquivo.

Estruturas de índice - Cluster
Este tipo de índice também possui problemas de inclusão e exclusão de registros.
Os registros de dados estão fisicamente ordenados, repetindo-se os mesmos problemas observados para a indexação com índices principais.

Estruturas de índice - Cluster

Estruturas de índice – Por que são eficientes?
O número de blocos de índices é pequeno em comparação com o número de blocos de dados;
Tendo em vista que as chaves são ordenadas, a pesquisa é rápida, podendo se usar um algoritmo de pesquisa binária;
O índice pode ser pequeno o bastante para ser mantido permanentemente em buffers da memória principal.
Nesse caso, uma pesquisa para uma determinada chave envolve apenas acessos à memória principal, sem precisar de operação de entrada e saída.

Estruturas de índice – Secundário
Um índice secundário é outro meio para acessar um arquivo de dados, quando um índice primário já existe.
Um índice secundário pode ser criado em um campo qualquer único ou em um campo não chave com valores duplicados.
Um mesmo arquivo pode ter diversos arquivos e ser indexado por mais de um índice secundário.
Em geral são densos.

Estruturas de índice – Secundário

Estruturas de índice – Resumo

Estruturas de índice – Multinível
Um Índice Multinível pode ser definido como um índice de índices. No primeiro nível, o arquivo é ordenado, por exemplo, utilizando um índice qualquer conforme já visto anteriormente. Nos demais níveis, é criado um índice primário sobre os níveis anteriores e assim sucessivamente, até que o último índice ocupe apenas um bloco.

Estruturas de índice – Multinível
É necessário caso o arquivo de índice se torne muito grande.
Se este for o caso, é interessante indexá-lo em mais de um nível.
Mantendo os índices em arquivos menores, é possível mante-lo na memória primária, melhorando dessa forma o desempenho e a eficiência.
O problema é que um número maior de índices aumenta logicamente a complexidade do sistema.

Estruturas de índice – Multinível
A organização então segue:● Primeiro nível: arquivo ordenado pela chave de
indexação, valores distintos, entradas de tamanho fixo (como se fosse um índice primário).
● Demais níveis: índice primário sobre o índice do nível anterior e assim sucessivamente até que no último nível o índice ocupe apenas um bloco.
● Número de acessos a bloco: um a cada nível de índice, mais um ao bloco do arquivo de dados.

Estruturas de índice – Multinível

Otimização de Consultas

A importância de uma consulta
Por que consultar é tão importante?
Essa importância também gira em torno de como consultar? Ou apenas do que consultar?
O Big Data e as redes sociais estão aí para ficar.
Hoje temos métodos de consultas eficientes?

Como é feita a consulta em um banco
Em um banco de dados existe uma separação entre o usuário e o armazenamento físico.
O que o usuário busca, tem que ser traduzido e entendido para as partes mais inferiores do banco.

Como é feita a consulta em um banco
Uma consulta SQL tem a particularidade de ser voltada para “O que” e não “Como”.
O “Como” seria melhor, já que o programador mostra ou pelo menos deveria, que a ideia apresentada é a melhor.

Como é feita a consulta em um banco
O que é importante de se notar, é que uma otimização de consulta nunca vai procurar um jeito “ótimo” de processar a consulta.
Em razão de um custo computacional muito grande, o método alcançado será apenas eficiente.

Como é feita a consulta em um banco – Passos típicos

Análise léxica, sintática e validação
Esse passo se assemelha a uma questão de compiladores.
É basicamente analisar o que foi escrito e tentar transformar essa query em uma representação interna computacional.

Análise léxica, sintática e validação
É criado então uma estrutura de dados interna com os elementos da sua consulta.
Em linhas gerais, significa que o computador conseguiu interpretar e representar sua consulta.
Essa representação interna será chamada de árvore ou grafo de consulta.

Otimizador de Consultas
Com apenas essa análise, não necessariamente sua consulta será feita da melhor maneira.
A consulta possui muitas estratégias de execução possíveis.

Otimizador de Consultas
Imaginem o caso de que a consulta foi feita sim da melhor maneira. O que mais pode ser visto?
● Velocidade;● Índices;● Como ele pode rearrumar a consulta
para ela ser mais rápida.

Otimizador de Consultas
Nesta etapa, é onde o computador tenta chegar na consulta considerada “razoavelmente eficiente”.
Chegar na “ótima” ou “perfeita” não é interessante, pois o tempo para tentar chegar nesse estado é maior do que a própria consulta.
Dessa forma, são usadas heurísticas para chegar numa consulta razoavelmente boa.

Gerador de Código
Aqui é a parte que produz um código computacional para a execução de uma consulta.
Este código pode tanto ser interpretado ou compilado.

Processador em tempo de execução do banco de dados
Esta é a última parte, onde o processador executa o código da consulta.
Produz, por fim, o resultado da consulta.

Nosso foco será na otimização

O que vamos usar?
Algebra relacional.
Decomposição de consultas SQL.● A ideia de pegar consultas aninhadas e quebrar ela
em consultas independentes, sabendo que o resultado de uma entra no resultado da outra.

Decomposição de consultas - Exemplo

Vamos entender isso melhor.
Abordagem Bottom-up.
Quando disparamos uma consulta, pedimos ao banco que ele faça algumas coisas:
● Selecionar, ordenar, projetar…
Esses pedidos viram algoritmos, onde se tem uma programa escrito em alguma linguagem fazendo a mágica requisitada.

Algoritmos para operações

Algoritmo Ordenação Externa
Existiria alguma diferença em ordenar alguma coisa no disco e ordenar algo na memória?
Seria muito ineficiente se um algoritmo que ordena memória fosse reproduzido igual diretamente no disco.
O algoritmo mais propício para ordenar páginas de disco é o merge-sort.

Algoritmo Ordenação Externa
Mas enfim, por que ordenação é importante?
A ordenação é adequada para manipular arquivos de registros grandes, que são armazenados em disco e que não cabem inteiramente na memória principal.
Podendo ser dividida dessa forma em ordenação completa na memória e ordenação externa pro disco.

Algoritmo Ordenação Externa
Na ordenação externa é feito o uso de algoritmos de sort para organizar e classificar os blocos de disco.
Similar ao que um índice faz.
O algoritmo que melhor faz esse tipo de orndenação do tipo merge/sort.
Ele pega as páginas de disco, separa, ordena, grava.

Algoritmo Ordenação Externa

Algoritmo Ordenação Externa

Algoritmo Ordenação Externa

E como podemos otimizar ainda mais?

Algoritmo Ordenação Externa
Aumentando a memória.
Se a memória aumenta é possível paralelizar os processamentos e diminuir os estágios de merge/sort.

Algoritmo Ordenação Externa

Algoritmo para Seleção
Vamos agora pensar na seleção em si.
São algoritmos de procura que localizam e recuperam os registros que estão de acordo com uma condição de seleção.
Tem-se vários algoritmos diferentes, que variam de acordo com a complexidade da seleção e o uso ou nãode índices.

Algoritmo para Seleção
Essa seleção é exatamente igual a chave primária.Única e possivelmente com um índice para ela.

Algoritmo para Seleção
Essa seleção é exatamente igual a outra chave.Será que alguma coisa muda computacionalmente?

Algoritmo para Seleção
Essa seleção pede uma faixa de valor.

Algoritmo para Seleção
A questão é que temos seleções diferentes.
Quais são as seleções que nós temos e quais algoritmos são mais indicados para cada tipo.
Existem algoritmos mais indicados para seleções “exatamente iguais”, “seleções compostas” e seleções de “faixa de valor”.

Algoritmo para Seleção
Pesquisa linear;Pesquisa binária;Usando índice primário;Usando chave hash (mais indicado para seleções iguais a chave);Combinado com Índice primário;Usando Índice de Cluster;Usando Índice secundário.

Junção ou Join

Join
Como funciona um JOIN?
SELECT Tab1.* FROM Tabela1 Tab1 LEFT JOIN Tabela2 Tab2 ON Tab1.Cod = Tab2.Cod
Podemos fazer a mesma amarração junto à cláusula WHERE assim como no exemplo abaixo onde estamos pegando os mesmos valores do exemplo acima.
SELECT Tab1.* FROM Tabela1 Tab1, Tabela2 Tab2 WHERE Tab1.Cod *= Tab2.Cod

Join de Loop Aninhado
for each ti for each tj if match (ti, tj) add-result (ti, tj)
Este tipo de algoritmo é um problema muito grande para o disco. Por que?

Join
A solução é que você divida a busca de bloco em bloco. Dessa forma eles podem ir um de cada vez para a memória sem sobrecarregar o número de transferências com o disco.
for each bi for each bj for each ti in bi for each tj in bj if match (ti, tj) add-result(ti, tj)

SQL para Algebra Relacional

Sql para Algebra Relacional
Essa árvore é um conjunto de operações que usa um conceito chamado de pipelining. Ou seja: enquanto uma saída é produzida, é gerado a entrada da operação subsequente.

Árvore de Consulta - Pipelining
Nesse primeiro passo ele lê a tabela toda.A medida que ele lê a tabela ele já vai entregando pro próximo.

Árvore de Consulta - Pipelining
Nesse passo é feita a seleção de quem é de 1990 e já passa pro próximo.
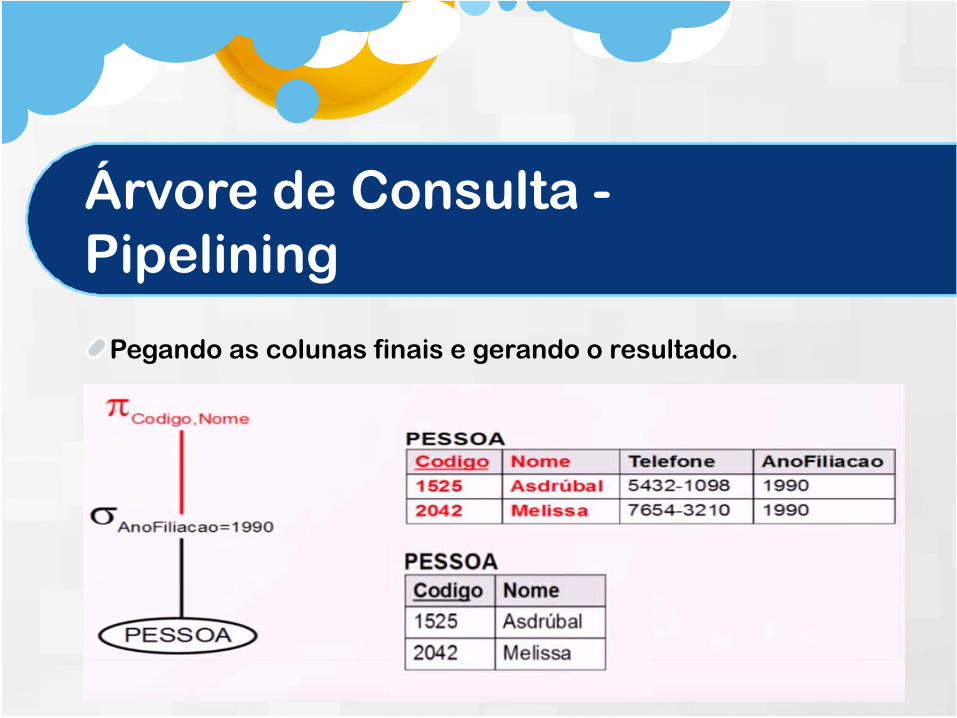
Árvore de Consulta - Pipelining
Pegando as colunas finais e gerando o resultado.

Heurísticas para otimização

Heurísticas para otimização das árvores.
É possível que essas árvores de consultas sejam otimizadas.
Uma heurística é uma espécie de chute. Seu conceito pode ser definido como podendo ser um algoritmo que encontra boas soluções a maioria das vezes, mas não tem garantias de que sempre encontrará ou um algoritmo que tem processamento rápido, mas não tem provas de que será rápido para todas as situações.

Heurísticas para otimização das árvores.
Aplicando heurísticas podemos quebrar seleções e ou mover níveis para mais perto das folhas. Dessa forma, é possível trabalhar com mais liberdade e em blocos menores de consulta, otimizando todo o processo.

Heurísticas para otimização das árvores.
Vamos pegar então três tabelas. Nossa projeção final é o título.Categoria.nome vai ser poesia.Temos um Join entre o livro e o pertence.E temos um join entre categoria e pertence.Por fim, temos um filtro que os livros devem ser acima do ano de 1996.

Heurísticas para otimização das árvores.
Comecemos do pior jeito. Temos o livro e pertence em um join (ou produto cartesiano) dos dois. Vamos pegar o resultado desse produto e fazer um novo produto cartesiano com categoria. O resultado é uma tabela gigante onde será cruzado tudo com tudo.Este resultado receberá uma enorme seleção que achará a projeção final.

Heurísticas para otimização das árvores.
Se aplicarmos heurísticas de quebra de seleções por exemplo, podemos ter o seguinte resultado:

Heurísticas para otimização das árvores.
Por fim, podemos aproximar as consultas ao máximo das folhas e quebrar ainda mais.

Até a prova.






























