Embed Size (px)
Citation preview

Cap. 5 ___
___ 76___
Capítulo 5 MÉTODOS DE DETECÇÃO ALTERNATI-VOS
5.1 INTRODUÇÃO
Neste capítulo são apresentados métodos de detecção de outliers, alternativos ao mé-
todo baseado no teste das razões de verosimilhanças referido no capítulo anterior. A
primeira estratégia de diagnóstico consiste no estudo do comportamento dos resíduos
em presença de contaminação segundo uma metodologia desenvolvida por Rosado
(1984). Lee e Hui (1993), no contexto de um modelo AR(p), propuseram uma estra-
tégia de detecção de outliers aditivos com base nos elementos da diagonal da matriz de
projecção, designadas como medidas de alavanca ("leverages"). A técnica de diagnós-
tico consegue ainda identificar outliers inovadores e é particularmente eficaz quando
estão presentes múltiplos e consecutivos outliers.
Outro método de detecção no quadro dos modelos autoregressivos AR(p), relati-
vamente simples de implementar consiste nas estatísticas Q, propostas por Abraham e
Chuang (1989), as quais constituem uma medida do efeito da eliminação das observa-
ções outlier no valor estimado dos resíduos. Uma vantagem destas estatísticas traduz-
se na possibilidade não só de detectar mas também distinguir um AO de um IO. Os
autores propuseram ainda um procedimento, em quatro etapas, para modelar as séries
temporais em presença de outliers, no qual um processo ARMA(p,q) é aproximado
por um AR(p+q).

Cap. 5 ___
___ 77___
Uma outra perspectiva directamente relacionada com a anterior, embora diferente,
consiste na detecção de outliers influentes. Isto porque um outlier pode ou não afectar
consideravelmente as estimativas dos parâmetros do modelo, como sejam os coeficien-
tes ARMA e a variância do ruído. Nesse sentido, apresentamos um conjunto de méto-
dos e medidas de diagnóstico de observações influentes.
Como vimos no capítulo 2, a presença de outliers numa série pode ter efeitos dra-
máticos no valor estimado das autocorrelações, particularmente em séries temporais de
curta duração, o que pode ter implicações nefastas na fase de identificação do modelo
da metodologia de Box e Jenkins. Nessas circunstâncias, Chernick, Downing e Pike
(1982) propuseram, antes de iniciada a metodologia, o cálculo da matriz da função de
influência das autocorrelações de modo a identificar outliers influentes.
Peña (1990) no quadro dos modelos ARMA, apresentou estatísticas indicadoras de
AO e IO que têm forte influência no valor dos coeficientes estimados, as quais se ba-
seiam na substituição das observações discordantes por valores interpolados. Estas
medidas de diagnósticos são particularmente eficazes na detecção de outliers isolados.
No entanto a existência de múltiplos e consecutivos outliers coloca problemas aos
métodos de detecção. Isto porque o efeito de um único outlier num grupo pode ser
ocultado pelo efeito de outros outliers situados na vizinhança. Este comportamento
pode ser visto como uma forma de "masking". Nesse sentido, Yatawara e Lin (1994)
propuseram uma estatística de diagnóstico de observações influentes que permite de-
tectar múltiplos outliers.
Num extenso artigo Bruce e Martin (1989) propuseram duas medidas de diagnós-
tico para os modelos ARMA, baseadas na eliminação de observações e medição da al-
teração nas estimativas dos parâmetros. O diagnóstico DV mede as alterações na va-
riância estimada do ruído, e o diagnóstico DC mede a alteração nos coeficientes
ARMA estimados em presença de outliers. É ainda proposto uma estratégia de detec-
ção baseada num procedimento de eliminação iterativa, em presença de múltiplos e

Cap. 5 ___
___ 78___
consecutivos outliers. Por último, Ledolter (1990) aplicou às séries temporais as medi-
das de deslocamento da verosimilhança introduzidas por Cook (1986, 1987), as quais
medem a influência das perturbações nas estimativas dos parâmetros pela alteração
provocada no logaritmo da função de verosimilhança. Com base nelas Ledolter (1990)
propôs uma estatística simples de diagnóstico das observações influentes.
5.2 UM TESTE SIMPLES DE DISCORDÂNCIA
Como vimos anteriormente, o comportamento dos resíduos, obtidos a partir da estima-
ção pelo método dos MQ dos parâmetros do modelo subjacente à série temporal, pode
ser um indicador da presença de outliers, numa etapa preliminar de diagnóstico.
Um critério introduzido por Rosado (1984) designado por Método GAN (método
baseado no Modelo Generativo com Alternativa Natural como modelo de discordân-
cia) permite introduzir um alto grau de objectividade na resolução de problemas com
outliers, em particular nos testes de homogeneidade que, em última análise, podem
conduzir à rejeição ou aceitação de uma observação da amostra. Nesse trabalho, o au-
tor aborda o estudo das observações discordantes com formulação do problema de
detecção de outliers para uma distribuição especificada à priori baseado em critérios de
máxima verosimilhança.
No caso de uma amostra de observações x ,...,x1 n pertencentes a uma população
X com distribuição normal em que se supõe conhecido o parâmetro µ podemos for-
mular as seguintes hipóteses em termos de modelo de discordância por σ :
- H0 é a hipótese de homogeneidade, isto é, as observações x ,...,x1 n são provenientes
de uma população X com distribuição N( , )µ σ

Cap. 5 ___
___ 79___
- H j é a hipótese alternativa com xj observação discordante, ou seja, xj tem distribui-
ção N( , )µ σ′ para algum j n= 1,...., .
O autor estudou os casos em que os parâmetros σ e ′σ são ou não conhecidos
(i) σ e ′σ conhecidos
Considerando σ e ′σ e conhecidos, sob a hipótese nula de homogeneidade das obser-
vações, teremos,
( ) ( ) ( )L fi
n
i n ii
n
0 1 2
2
1
1
2
1
2= = − −
= =
∑Π x x, , expµ σσ π σ
µ (5.1.1)
e, sob a hipótese alternativa H j ,
( ) ( ) ( )L f fj
i ji j
n n
i j
i j
= ′ =′
−−
+
−
′
≠ − ≠∑Π x x
x x, , , , expµ σ µ σ
σ σ π
µσ
µσ
1
2
1
21
2 2
.
(5.1.2)
O método GAN propõe então, a estatística de detecção de outliers,
( )Sj
j= ′ −
−
maxσ σ
µσ
2 2
2x se σ σ< ′ (5.1.3)
ou
( )Sj
j= − ′
−
min σ σ
µσ
2 2
2x se ′ <σ σ . (5.1.4)

Cap. 5 ___
___ 80___
Sendo no primeiro caso S c> a região de regeição do teste de homogeneidade nas
observações x ,...,x1 n e no segundo caso S c< . Os pontos críticos são obtidos a partir
de
( )( )′ = −−c Fn
χ α12
1 11 se σ σ< ′
e
( )( )′ = − −−c Fn
χα
12
1 11 1 se ′ <σ σ .
É de referir que este modelo vai salientar como candidato a outlier uma observação
vulgarmente não considerada. Trata-se de x( )µ , a observação mais próxima de µ , no
caso em que ′ <σ σ . Quando ′ >σ σ os candidatos a outlier são os usualmente estu-
dados x( )1 e x n( ) .
(ii) σ conhecido e ′σ desconhecido
Sob estas condições para os parâmetros de dispersão e sob H0 temos,
( ) ( )L n ii
n
0 2
2
1
1
2
1
2= − −
=
∑σ π σ
µexp x , (5.1.5)
e, o máximo da função de verosimilhança sob H j ,
( )�
�
exp�
L jn n
i j
i j
=′
−−
−
−
′
− ≠∑1
2
1
2
1
21
2 2
σ σ π
µσ
µσ
x x
, (5.1.6)
com ′ = −∃σ µx j estimador de máxima verosimilhança para ′σ sob H j .
O teste de homogeneidade, nesta situação, conduz-nos à estatística

Cap. 5 ___
___ 81___
Sj
j
j=−
−
max expσ
µ
µσx
x1
2
2
. (5.1.7)
Sendo S c> a região de regeição. Neste caso, somos novamente conduzidos ao
estudo da observação x( )µ , para além das observações tradicionalmente estudadas x( )1
e x n( ) .
(ii) σ e ′σ desconhecidos
Este é o caso mais próximo da realidade no estudo de discordância de outliers por σ .
Assim sob a hipótese nula teremos que estimar σ2 por,
( ) ( )�σ µ µ2 2
1
21= − =
=∑
nsi
i
n
x (5.1.8)
e sob a hipótese alternativa estimamos σ2 por,
( ) ( )�σ µ µ2 2 21
1=
−− =
≠∑
nsi
i jjx (5.1.9)
e ′σ 2 por,
( )′ = −σ µ22
x j . (5.1.10)
Os máximos da função de verosimilhança sob a hipótese nula e alternativa, são res-
pectivamente,

Cap. 5 ___
___ 82___
( )( )
� expLs
nn0
1
2 2= −
µ π (5.1.11)
e
( )( ) ( )
� expLs
nj
j j
n n=−
−
−
1
2 21
x µ µ π. (5.1.12)
Deste modo, obtemos a estatística,
( )
( )( )
( )S
j
j
ii
j
ii
n
=−
−
−−
−
∑ ∑
−
minx
x
x
x
µ
µ
µ
µ
2
2
1
22
2
1
2
1 (5.1.13)
Sendo S c< a respectiva região de rejeição. Mendes (1993) construiu tabelas dos
pontos críticos para a estatística. Neste caso as observações candidatas a outlier são
x( )µ , x( )1 e x n( ) .
Considerando que numa série temporal xt ( )t n= 1, ... , , cujo modelo subjacente é
um ARMA(p,q), os et são variáveis aleatórias independentes identicamente distribuídas
( )N 0 2,σ , podemos assim numa primeira fase de diagnóstico identificar outliers
através do estudo da série dos resíduos aplicando o Método GAN. Há no entanto que
ter em atenção que um outlier pode afectar o valor de mais do que um resíduo, dada a
correlação que existe entre as observações, como vimos nos capítulos 2 e 3.
Nomeadamente no caso de múltiplos e consecutivos outliers, esta distorção poderá ser
significativa afectando a análise.

Cap. 5 ___
___ 83___
Exemplo 5.1
No intuito de ilustrar a aplicação do Método, consideremos o seguinte exemplo em
que o processo subjacente à série segue um modelo AR(1):
x x et t t= +−0 5 1. ,
e os et ´s são variáveis aleatórias iid ( )N 0 012, . .
Foi simulada uma série de dados com n = 100 na qual foi introduzido um outlier
aditivo com efeito ω = 1 em T = 50. Na figura 5.1 temos a série dos residuos que se
obtem da estimação dos parâmetros do modelo.
Fig. 5.1 - Série dos resíduos
Aplicando o programa (veja-se ponto 7.2.1) que nos permite calcular o valor da
estatística (5.1.13) obtemos o seguinte "output":

Cap. 5 ___
___ 84___
*********************************************** DETECÇÃO DE OUTLIERS ********************************************** OBSERVAÇÃO RESÍDUO ESTATÍSTICA 50 1.107 .000002 30 -.001 .000871 16 .003 .003610 VALOR CRITICO A 5% .00006
VALOR CRITICO A 1% .00001
Assim no resíduo correspondente à observação T = 50, obtemos como era de espe-
rar um valor bastante reduzido. Neste caso, como o valor da estatística é inferior ao
valor crítico, considerando quer um nível de confiança a 5% ou a 1%, temos uma indi-
cação que o resíduo é proveniente de uma observação outlier.
5.3 MEDIDAS DE ALAVANCA DA AMOSTRA
Vimos no capítulo 2 que dada uma colecção de observações z z zn1 2, ,..., , considerando
que zt segue um modelo AR(p), pode-se representar o processo como
z et t t= +′x φ . (5.3.1)
com ( )x t t t t pz z z=′
− − −1 2, , ... , e ( )φ =′
φ φ1 , ... , p . Considerando as n observações,
temos ( )n p− equações
Z X e= +φ , (5.3.2)
onde ( )Z =′
+z zp n1 , ... , , ( )e=′
+e ep n1 , ... , e

Cap. 5 ___
___ 85___
X
x
x
x
=
=
−
+
− − −
+′
+′
′
z z z
z z z
z z z
p p
p p
n n n p
p
p
n
1 1
1 2
1 2
1
2
...
...
...
0 0 / 0 0.
Então o estimador dos mínimos quadrados de φ é dado por
( )�φ = ′ ′−X X X Z1 , (5.3.3)
e os valores ajustados são dados por
( )� �Z X X X X X Z HZ= = ′ ′ =−φ 1 , (5.3.4)
com ( )H X X X X= ′ ′−1 . A matriz dos resíduos é obtida considerando ( )R I H Z= − .
Vamos chamar a H matriz de projecção, análoga àquela considerada na regressão
linear. Designamos o elemento da diagonal da matriz H , htt , por ht em que
( )ht t t= ′ ′ −x X X x1 (5.3.5)
Os elementos fora da diagonal de H , são designados por hij .
Lee e Hui (1993) no contexto de um modelo AR(p), sugeriram um procedimento
de detecção de outliers com base no estudo dos elementos da diagonal da matriz de
projecção, conhecidas como medidas de alavanca da amostra.
Os elementos da diagonal da matriz H apresentam as seguintes propriedades im-
portantes:

Cap. 5 ___
___ 86___
(i) 0 1≤ ≤ht
(ii) Supondo que ht é elevado (próximo de 1 ). Como
h h ht t tj
t j
= +≠∑2 2 ,
então htj
t j
2 0≠∑ → ou htj → 0, ∀ ≠j t , quando ht → 1.
Na forma escalar, pode-se escrever
∃z h z h zt t t tj
t jj= +
≠∑ .
Segue-se que ∃zt é dominado pelo termo h zt t quando ht → 1. Então, ht pode ser
interpretado como uma medida do efeito alavanca induzido em ∃zt por zt .
(iii) Considerando que quando n → ∞, ( )np
− ′ → ∑1 X X , em que ∑ é a matriz de
covariâncias de x t . Defina-se
dt t t= ′ ∑−x x1 , t p n= +1,..., (5.3.6)
em que dt corresponde à distância de Mahalanobis entre x t e o vector nulo (ou no
caso geral o vector média dos x t `s). Como,
nhn
dt t t
p
t= ′′
→
−
xX X
x1
quando n → ∞.

Cap. 5 ___
___ 87___
Então com n elevado, examinar os ht `s equivale a examinar os dt `s. Deste modo,
ht pode ser considerado uma escala aproximada (dividindo por n) da distância de
Mahalanobis entre x t e o vector nulo.
Para a detecção de outliers em processos AR(p), dada a dependência que se veri-
fica entre as observações, é a o posição relativa de z z zt t t p, ,...,− − +1 1 no espaço de di-
mensão p que nos interessa e não apenas a posição de zt . Consequentemente, deve-
mos estudar o afastamento do vector ( )x t t t t pz z z=′
− − −1 2, , ... , , como base de detecção
das observações outlier.
A discussão do ponto (ii) sugere que se utilize ht para detectar o vector outlier x t .
Recorde-se que ( )ht t t= ′ ′ −x X X x1 . Supondo que zt −1 é discordante, essa observação
afectará x x xt t t p, ,...,+ + −1 1 e como tal h h ht t t p, ,...,+ + −1 1 serão empolados. Então, se ht −1
apresenta um valor reduzido (z z zt t t p− − − −2 3 1, ,..., não são outliers) e ht é elevado, pode-
se identificar zt −1 como um possível outlier.
No caso de outliers consecutivos, uma sequência de ht `s terá valores distorcidos. O
número exacto de outliers será no entanto difícil de determinar por inspecção.
Dado que dt tem uma distribuição χ( )p2 quando a distribuição do ruído é Gaussiana,
Hau e Hau e Tong citados por Lee e Hui (1993) sugeriram, como instrumento de de-
tecção de outliers, a construção do gráfico da série temporal dos nht `s e a sua compa-
ração com o valor critico a 5% da distribuição de referência.
Contudo, segundo Lee e Hui (1993), o gráfico da série temporal dos nht `s é inade-
quado para avaliar com precisão o efeito alavanca. Deste modo, sugeriram um proce-
dimento de detecção de outliers com base num simples exame dos ht `s.
No entanto, ht não pode ser quantificado pela distribuição de referência χ( )p2 . De
facto, a distribuição conjunta dos ht `s é intratável. Para ultrapassar esta dificuldade,

Cap. 5 ___
___ 88___
Lee e Hui (1993) propuseram um dispositivo gráfico que permite identificar as obser-
vações outliers com base nas estatísticas ordenadas dos ht `s em conjunto com um en-
velope construído por simulação. O procedimento de diagnóstico consiste nas seguin-
tes etapas:
(i) Estimar ∃φ e ∃σ2 a partir da série observada (contaminada) e calcular as medidas
de alavanca da amostra;
(ii) Simular m pseudo colecções de dados (de Z ) baseados nos ∃φ e ∃σ2 estimados;
(iii) Para cada colecção, calcular os ( )n p− valores ordenados das estatísticas ala-
vanca h i( ) ;
(iv) Colocar num gráfico o máximo e o mínimo de cada estatística de ordem das
m réplicas em conjunto com os valores da amostra ordenados.
O envelope simulado formado pelos dois vectores ( )n p− de estatísticas de ordem
de máximos e mínimos é construído para ajudar na interpretação das alavancas da
amostra. Na ausência de outliers, espera-se que os valores da amostra se situem dentro
dos limites do envelope. Outliers potenciais surgirão à direita, no gráfico, como distan-
tes pontos isolados. Se algum dos valores observados cair fora dos limites do enve-
lope, rejeitamos a hipótese de que não existem outliers. Normalmente são necessários
valores de m= 19 simulações para testar o máximo efeito alavanca observado a um ní-
vel de significância de aproximadamente 5% .
Num modelo AR(p) com k outliers consecutivos nos períodos T T T k, ,...,+ +1 , a
sequência h h hT T T k p+ + + + −1 2 1, ,..., será considerada significativa pelo envelope. Conse-
quentemente, o número exacto de outliers, k , e a sua localização T T T k, ,...,+ +1 po-
de ser determinada.
Segundo Lee e Hui (1993), o procedimento é eficaz na detecção de outliers aditi-
vos em modelos autoregressivos, embora a técnica proposta se aplique também a ou-

Cap. 5 ___
___ 89___
tliers inovadores. O método, segundo os autores, é particularmente eficaz quando es-
tão presentes múltiplos e consecutivos outliers.
Para testar as medidas de alavanca, nomeadamente verificar o seu comportamento
em presença de múltiplos AO e de um IO, consideremos os seguintes exemplos em que
o processo subjacente à série segue o modelo AR(1) do exemplo 5.1:
Exemplo 5.2
Foi simulada uma série de dados com n = 100 na qual foram introduzidos dois outliers
aditivos com efeito ω = 1 em T = 50 e T = 51.
Na figura 5.2 temos a série contaminada resultante da introdução dos dois AO. Os
estimadores dos mínimos quadrados são ∃ .φ = 0 523 e ∃ .σ = 0 087. Na figura 5.3 temos o
gráfico dos resíduos. Como se pode ver temos três resíduos com valores elevados r50,
r51, r52. Assim, poderíamos concluir erradamente que z52 é um outlier, se apenas consi-
derássemos os resíduos como método de diagnóstico. Este efeito é o chamado efeito
de "smearing".
Fig. 5.2 - Série contaminada

Cap. 5 ___
___ 90___
Fig. 5.3 - Resíduos estimados
Resíduos estimados t resíduos
45 -.023779 46 -.003035 47 .052419 48 .213965 49 -.100583 50 1.164655 51 .537776 52 -.555507 53 .030746 54 .066102 55 .003463
Examinando as medidas de alavanca da amostra, ht , na figura 5.4, verificamos que
o período 52 contribui com o valor mais elevado h52 0 34= . , ocorrendo o segundo
mais elevado em h51 0 28= . . Deste modo, x52 51= z e x51 50= z poderão ser considera-
dos outliers.
Cap. 5 ___
___ 91___
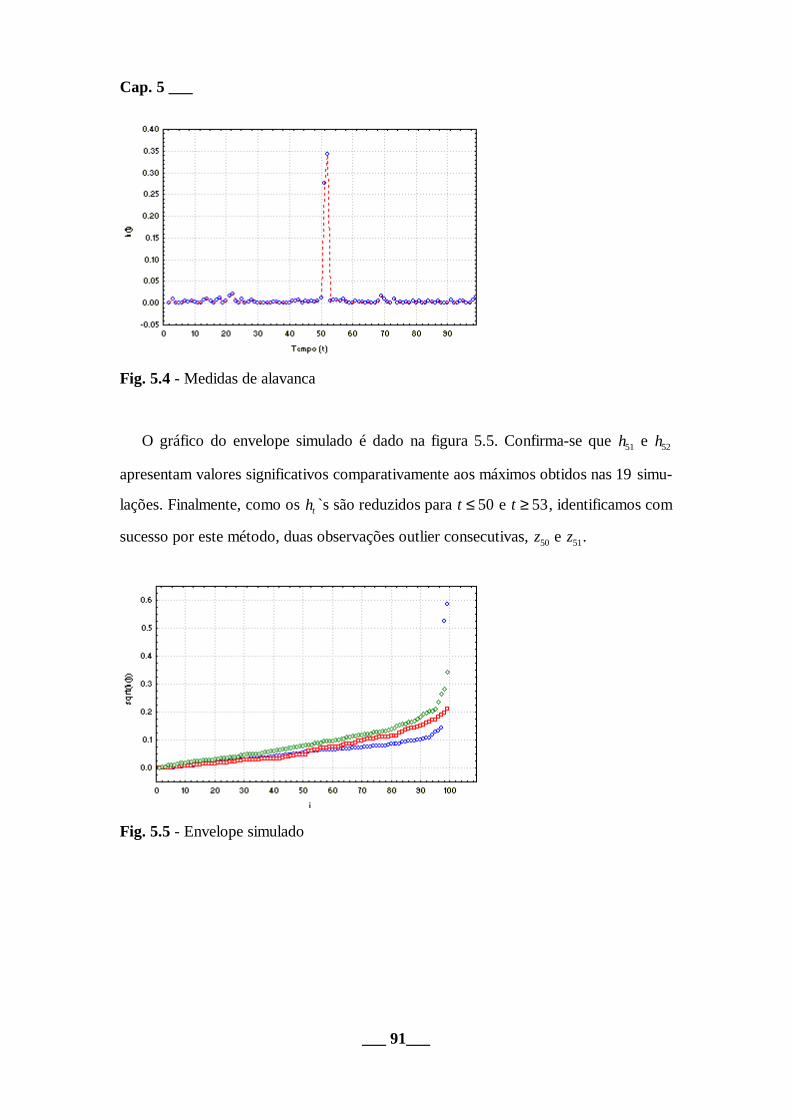
Fig. 5.4 - Medidas de alavanca
O gráfico do envelope simulado é dado na figura 5.5. Confirma-se que h51 e h52
apresentam valores significativos comparativamente aos máximos obtidos nas 19 simu-
lações. Finalmente, como os ht `s são reduzidos para t ≤ 50 e t ≥ 53, identificamos com
sucesso por este método, duas observações outlier consecutivas, z50 e z51.
Fig. 5.5 - Envelope simulado

Cap. 5 ___
___ 92___
Exemplo 5.3
No caso da série simulada contaminada com um outlier inovador, o seu efeito corres-
ponde também a 1 introduzido em T = 50 (veja-se a figura 5.6).
Os estimadores dos mínimos quadrados são ∃ .φ = 0 52 e ∃ .σ = 0 086. Na figura 5.7
temos o gráfico dos resíduos, como se pode verificar temos apenas um valor elevado
r50. Repare-se que neste caso não se verifica o efeito de "smearing".
Fig. 5.6 - Série contaminada
Fig. 5.7 - Resíduos estimados
Cap. 5 ___
___ 93___
Resíduos estimados t resíduos
45 .090897 46 .064747 47 -.088082 48 .096685 49 -.100465 50 1.048394 51 -.001448 52 -.102744 53 .031166 54 .065620 55 -.003416
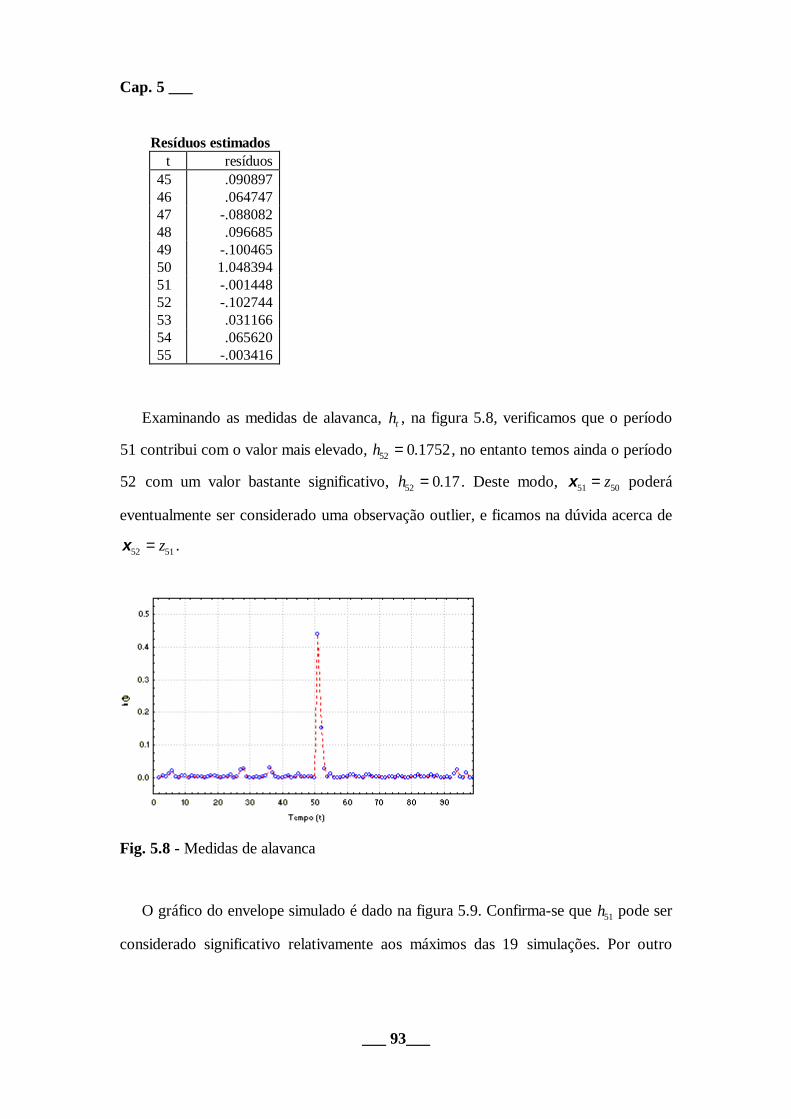
Examinando as medidas de alavanca, ht , na figura 5.8, verificamos que o período
51 contribui com o valor mais elevado, h52 0 1752= . , no entanto temos ainda o período
52 com um valor bastante significativo, h52 0 17= . . Deste modo, x51 50= z poderá
eventualmente ser considerado uma observação outlier, e ficamos na dúvida acerca de
x52 51= z .
Fig. 5.8 - Medidas de alavanca
O gráfico do envelope simulado é dado na figura 5.9. Confirma-se que h51 pode ser
considerado significativo relativamente aos máximos das 19 simulações. Por outro

Cap. 5 ___
___ 94___
lado, poderíamos ainda concluir erradamente que z51 é também um outlier dado que
h52 apresenta um valor significativo.
Fig. 5.9 - Envelope simulado
Em conclusão o método das medidas de alavanca funciona relativamente bem na
detecção de múltiplos e consecutivos AO e de um IO isolado. Embora neste último ca-
so com algumas reservas.
5.4 ESTATÍSTICAS Q
5.4.1 Construção das estatísticas Q
Na regressão linear assume-se que as observações zt são independentes. Uma observa-
ção pode ser eliminada sem afectar as seguintes e a eliminação de uma equação em
(5.3.2) equivale a eliminar uma observação. No contexto das séries temporais, isso já
não é verdade. Uma observação suspeita, zT , está envolvida não só numa equação mas
nas p+1 equações consecutivas de (5.3.2). Então pode ser necessário eliminar não só
uma mas p+1 equações.

Cap. 5 ___
___ 95___
Suponha-se que existe uma observação suspeita em t T= . A matriz X e os vecto-
res Z e R podem-se decompor como se segue:
( )
( )X
X
X
X
=
− ××
− − ×
1
2
3
T p p
k p
n T k p
,
( )
( )Z
Z
Z
Z
=
− ××
− − ×
1
2
3
1
1
1
T p
k
n T k
,
( )
( )R
R
R
R
=
− ××
− − ×
1
2
3
1
1
1
T p
k
n T k,
onde k é o numero de equações a eliminar. Os resíduos, R , podem-se exprimir na
forma decomposta como
R
I H H H
H I H H
H H H
Z
Z
Z
=− − −− − −− − −
11 12 13
21 22 23
31 32 33
1
2
3I
, (5.4.1)
em que
( )H X X X Xij i j i j= ′ ′ =−1 1 2 3, , , . (5.4.2)
Seguindo a sugestão de Drapper e John (1981) para situações de regressão, os au-
tores consideram as estatísticas

Cap. 5 ___
___ 96___
( )Qk T( ) = ′ −−
R I H R2 22
1
2 (5.4.3)
e
( )AP Q RSSk T k T( ) ( )= − −1 22I H , (5.4.4)
onde RSS é a soma do quadrado dos resíduos. Quando k = 1, ′ =R2 rT , e quando
k p= +1, ( )′ = +R2 r rT T p, . .. , . Qk T( ) pode ser decomposto em dois termos:
( )Qk T( ) *� �= ′ + −
′R R2 2 φ φ
( )( )× ′ + ′ −X X X X1 1 3 3� �
*φ φ
= +Q Qk T k T1 2( ) ( ) , (5.4.5)
onde ( ) ( )�*φ = ′ + ′ ′ + ′
−X X X X X Z X Z1 1 3 3
1
1 1 3 3 é o estimador de φ após a eliminação de k
equações.
Por simulação os autores concluíram que as estatísticas Qk , Qk1, e Qk 2 são indica-
dores úteis dos outliers. Dado que o comportamento amostral de AP é difícil de in-
terpretar, consideraram apenas as estatísticas Q.
Em situações práticas a posição de outlier pode não ser conhecida. Deste modo, o
procedimento de detecção sugerido requer que Qk t( ) , Qk t1( ) e Qk t2( ) sejam calculados
para todos os ( )t p p n k= + + − +1 2 1, , ... , , e isto implica ( )n k p− − +1 inversões da
matriz ( )I H− 22 , o que pode constituir um problema. Se os elementos fora da diagonal
da matriz ( )I H− 22 , − hij , são reduzidos em valor absoluto, os autores propõem que se
considere a seguinte aproximação, na qual não é exigida nenhuma inversão da matriz:
( )Q r hk t i ii t
t k
( ) ≈ −=
+ −
∑ 21
1 . (5.4.6)

Cap. 5 ___
___ 97___
Esta aproximação é geralmente adequada para grandes amostras. Uma vez obtido
Qk t( ) , Qk t2( ) pode ser calculado subtraindo Qk t1 2 2( ) = ′R R de Qk t( ) . Veja-se que quando
k = 1 (eliminando uma observação) o valor exacto e a aproximação são os mesmos.
5.4.2 Comportamentos das estatísticas Q em presença de outliers
Consideremos os modelos paramétricos geradores de outliers. Para um outlier aditivo
temos
(AO) z xt t tT= + ωξ( ), (5.4.7)
onde ω é uma constante e xt segue um modelo AR(p). Alternativamente pode-se con-
siderar o modelo para um outlier inovador
(IO) ( )( )z B et t tT= +−φ ωξ1 ( ) (5.4.8)
As estatísticas definidas em (5.4.3) e (5.4.4) são funções dos rt `s e dos
( )[ ]h i t t ki = + −, ... , 1 . O seu comportamento é diferente para os outliers aditivos e
inovadores. Assim, podem ser usadas não apenas para detectar mas também para dis-
tinguir um AO de um IO.
Um AO suspeito no período t T= afectará zT através de ω em (5.4.3) e conse-
quentemente rT i+ por ( )φ ω φi oi p= =0 1 1, , ... , ; . Um IO afectará rT por ω em (5.4.7)
e assim zT i+ por ( )ψ ωi i = 0 1, ,... , onde ψ i é o coeficiente de Bi em
ψ φ ψ ψ( ) ( )B B B B= = − − −−11 2
21 Λ .
Consideremos um processo AR(1). Supondo k = 1; então
H22 12
12
2= = − −=∑h z zT T tt
n, ( )Q r z zT T T tt
n
12
12
12
2
1
1( ) = − − −=
−
∑ , Q rT T112
( ) = , e

Cap. 5 ___
___ 98___
( )( )Q r z z r h hT T T tt T T T T122
12
12 2 1( ) = = −− −≠∑ . Q11 depende apenas de rT , enquanto que
Q1 e Q12 dependem de rT e de hT , contudo hT é relativamente reduzido comparado
com 1, e o comportamento de Q1 é dominado por rT . Por outro lado, ( )h hT T1− é
uma função monótona de hT e é uma medida da distância de X 2 ao centro do elipsóide
formado por ( )′ + ′X X X X1 1 3 3 . Assim o comportamento de Q12 depende de r zT T2
12
− .
Se o outlier em t T= é um AO, então rT e rT+1 são afectados, e assim Q T11( ),
Q T11 1( )+ , Q T1( ) e Q T1 1( )+ são mais elevados comparados com os restantes. Por outro lado,
Q T12( ) e Q T12 1( )+ são influenciados pelo outlier em t T= , embora muitas vezes o mais
elevado seja o último, dado que rT+1 e zT são afectados pelo outlier.
Se o outlier é do tipo IO, então apenas rT é afectado, o que implica que Q T1( ) e
Q T11( ) são mais elevados comparados com os outros. O comportamento de Q T12( ) é
menos fiável, dado que as observações z zT n,..., são todas afectadas.
O comportamento das estatísticas para processos de ordem superior ( )p⟩1 é similar
e está sumariado na Tabela 5.1. Em geral, segundo Abraham e Chuang (1989), expe-
riências de simulação indicam que Qk (ou Qk1) é mais útil para detectar outliers do que
Qk2 .

Cap. 5 ___
___ 99___
Estatísticas IO AO
Q11, Q1 eliminando uma equação ( )k = 1 .
Valores elevados em t T= e reduzidos os res-tantes.
Os valores em t T T T p= + +, ,...,1 são afec-tados.
Q12, eliminando uma equa-ção ( )k = 1 .
Os valores em t T T= +, ,...1 são afec-tados (pouco fiáveis).
Os valores em t T T T p= + +, ,...,1 são afec-tados.
Q p( )+1 1, Q p( )+1 , eliminando
p+1 equações
( )k p= +1 .
Valores elevados em t T p T p T= − − +, ,..., ,1 e reduzidos os restantes.
Os valores em t T p T p T p= − − + +, ,...,1 são afectados, com o maior valor em t T= .
Q p( )+1 2, eliminando p+1
equações ( )k p= +1 .
Os valores em t T p T= − ,..., ,... são afectados (pouco fiáveis).
Os valores em t T p T p T p= − − + +, ,...,1 são afectados, com o maior valor em t T= .
Tabela 5.1 - Comportamentos das estatísticas Q considerando um outlier em t T=
Exemplo 5.4
Consideremos o exemplo de Abraham e Chuang (1989) em que o modelo de base é um
AR(1)
x x et t t= +−0 5 1. ,
e os et ´s são variáveis aleatórias iid ( )N 0 1, .
Simulámos duas séries de dados com n = 100, e foram introduzidos respectiva-
mente um AO e um IO no momento T = 80 de efeito ω = 4 5. . Calculámos então as
estatísticas Q, respectivamente, Qk T( ) e Qk T2( ), correspondendo à eliminação de uma
observação k = 1 e k p= + =1 2 observações.

Cap. 5 ___
___ 100___
(AO)
´
Fig. 5.10 - Estatística Q t1( )
Fig. 5.11 - Estatística Q t12( )
Cap. 5 ___
___ 101___
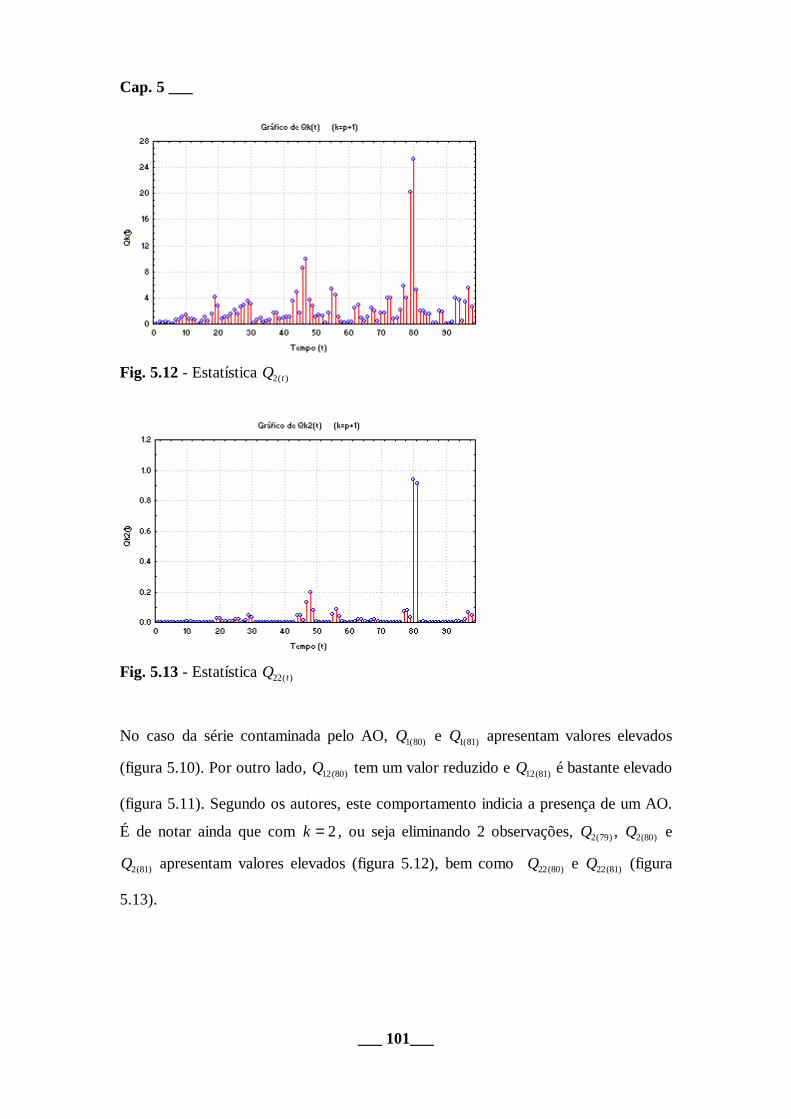
Fig. 5.12 - Estatística Q t2( )
Fig. 5.13 - Estatística Q t22( )
No caso da série contaminada pelo AO, Q1 80( ) e Q1 81( ) apresentam valores elevados
(figura 5.10). Por outro lado, Q12 80( ) tem um valor reduzido e Q12 81( ) é bastante elevado
(figura 5.11). Segundo os autores, este comportamento indicia a presença de um AO.
É de notar ainda que com k = 2, ou seja eliminando 2 observações, Q2 79( ) , Q2 80( ) e
Q2 81( ) apresentam valores elevados (figura 5.12), bem como Q22 80( ) e Q22 81( ) (figura
5.13).

Cap. 5 ___
___ 102___
(IO)
Fig. 5.14 - Estatística Q t1( )
Fig. 5.15 - Estatística Q t12( )
Cap. 5 ___
___ 103___
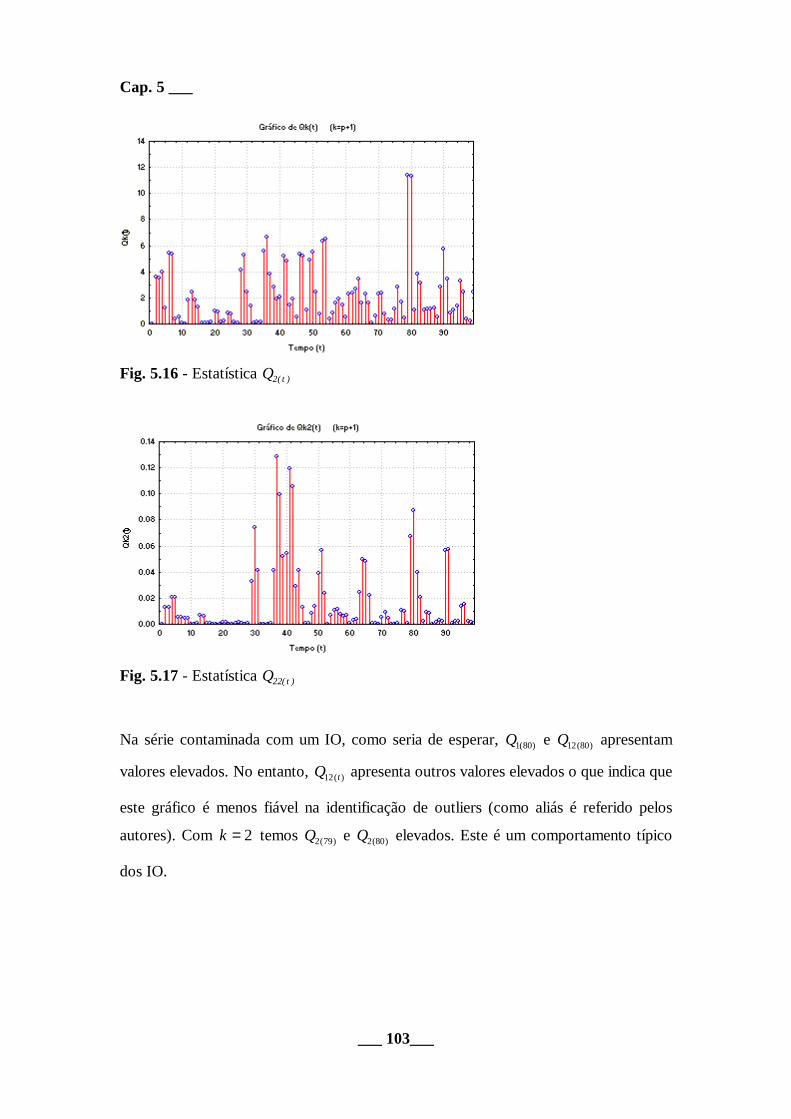
Fig. 5.16 - Estatística Q t2( )
Fig. 5.17 - Estatística Q t22( )
Na série contaminada com um IO, como seria de esperar, Q1 80( ) e Q12 80( ) apresentam
valores elevados. No entanto, Q t12( ) apresenta outros valores elevados o que indica que
este gráfico é menos fiável na identificação de outliers (como aliás é referido pelos
autores). Com k = 2 temos Q2 79( ) e Q2 80( ) elevados. Este é um comportamento típico
dos IO.

Cap. 5 ___
___ 104___
5.4.3 Distribuições assintóticas
Para identificar a localização dos outliers, Abraham e Chuang (1989) introduziram as
estatísticas max ( )t k tQ , max ( )t k tQ 1 e max ( )t k tQ 2 , dai que seja necessário identificar as
suas propriedades amostrais. As distribuições exactas da amostra são difíceis de
identificar, deste modo apela-se à teoria das grandes amostras.
Se não houver outliers, ∃φ converge em probabilidade para ( )φ φ φ� p → e
∃σ σ2 2p → , com ( ) ( )�σ 2 2
1= − −= +∑ z z n ptt p
n. Os resíduos rt convergem em proba-
bilidade para et e os elementos da matriz H convergem para 0 à medida que n aumen-
ta. Então
Q Q ek tp
k t ii t
t k
k12
12 2
( ) ( )*
( ) → = ≈=
+ −
∑ σ χ (5.4.9)
e
Q Qk tp
k t( ) ( )* → , Qk t
p2 0( ) → ,
max max( ) ( )*
tk t
p
tk tQ Q1 → ,
e
max max( ) ( )*
tk t
p
tk tQ Q → , (5.4.10)
onde χ( )k2 representa a distribuição do qui-quadrado com k graus de liberdade. Se
k = 1, então { }Qk t( )* é uma sequência de variáveis χ( )1
2 iid, e é uma sequência de variá-
veis dependentes χ( )k2 para k ≥ 2.
Caso 1: k = 1. Considere-se ( )F1 . como a função de distribuição acumulada de
σ χ21
2( ) e ( )( )[ ]τ τ= −m F Cm1 1 , com m n p= − e Cm( )τ é um valor critico. Então
( ) ( )Pr max exp( )*
tt mQ C1 ≤
→ −τ τ à medida que m→ ∞ . (5.4.11)

Cap. 5 ___
___ 105___
Dado um nível de significância α, o valor critico ( )C τ pode ser obtido considerando
( ) ( )( )( )C F mm kτ α= + −−1 1 1ln . (5.4.12)
Também max ( )t
tQ11 e max ( )t
tQ1 têm a mesma distribuição assintótica que max( )*
ttQ1 .
Caso 2: k ≥ 2. Seja ( )Fk . a função de distribuição acumulada de σ χ2 2( )k . Então
( ) ( )Pr max exp( )*
tk t mQ C v≤
→ −τ τ , (5.4.13)
onde, para algum ( )v v0 1< ≤ e para cada τ > 0, ( )( )[ ]m F Cm1− →τ τ à medida que
m n p k= − − + → ∞1 . Dado um nível de significância α, temos ( )τ α= − −ln 1 v , e o
valor critico ( )Cm τ pode ser obtido por
( ) ( )( ) ( )( )C F vmm τ α= + −−1
1 1 1ln . (5.4.14)
Agora max ( )t
k tQ 1 e max ( )t
k tQ têm a mesma distribuição assintótica que max( )*
tk tQ em
(5.4.13).
5.4.4 Com p desconhecido
As estatísticas de diagnóstico foram obtidas sob a hipótese de que a ordem p do pro-
cesso é conhecida. Contudo na prática, pode não ser este o caso. Então uma estratégia
bastante comum é ajustar um processo de ordem superior. Vejamos então qual o com-
portamento das estatísticas Q quando um ( )AR p p p* *, ⟩ é ajustado aos dados.
Supondo que ( )Z =′
+ +z z zp p n1 2, , ... ,

Cap. 5 ___
___ 106___
X0 0
B C* =
e
VA 0
0 C=
−
,
onde
B =
− − +
+ −
− − −
z z z
z z z
z z z
p p p p
p p p p
n n n p
* * *
* * *
...
...
...
...
1 1
1
1 2
0 0 0,
C =
−
− +
− − −
z z
z z
z z
p p
p p
n p n p
*
*
*
...
...
...
...
1
1 2
1
0 0,
e
A =
− −
z z
z z
p
p p p
...
...
...* *
1
1
0 0 .
Então os estimadores dos MQ de ( )φ =′
φ φ1 , ... , p obtêm-se como em (5.3.3) , e os
estimadores dos MQ de ( ) ( )φ φ φ* , . .. , , ... , ,*= = ′ ′+φ φ φ φ1 1 2p p p são dados por
( )�* * * *φ = ′ − ′X X X Z1
. (5.4.15)
Seja agora ( )�( )φ φN = ′ ′
′0 , onde 0 é um vector ( )*p p− ×1 de zeros. Então
( )� �*( )
* *φ φ= − ′′ −N X X V R
1, com o vector de resíduos do verdadeiro modelo dado por
R Z X= − ∃φ . Segue-se que ( )� �* * * * *z zt t t= + ′′ ′ − ′x X X X V R
1 e

Cap. 5 ___
___ 107___
( )r rt t t* * * * *= + ′ ′ − ′x X X X R
1 ( )*t p⟩ , onde ∃*zt é o valor ajustado e rt
* é resíduo corres-
pondente à estimativa ∃*φ , e ( )x t t t pz z* , ... , *=
′− −1 . Segundo os autores, pode-se de-
monstrar que ( )r r nt t p* /= + −Ο 1 2 para t p> * . Espera-se então que os resíduos do ver-
dadeiro e do modelo estimado se comportem da mesma maneira para t p> * .
O comportamento das estatísticas Q depende, neste caso, de rt* e de H22
* (ou de ht*
quando são usadas aproximações). Então Qk , Qk1, e Qk2 têm basicamente o mesmo
comportamento que aquela da tabela 5.1, com p substituído por p* .
5.4.5 Um procedimento iterativo de estimação
Abraham e Chuang (1989) propõem ainda um procedimento iterativo em quatro etapas
para modelar séries temporais na presença de outliers na qual um processo ARMA é
aproximado por um processo AR, com detecção e ajustamento dos outliers.
Se zt segue um processo ARMA(p,q), este processo pode ser representado por
uma aproximação autoregressiva
z z et i t ii
p
t= +−=∑π
1
*
, (5.4.16)
para um qualquer desfasamento p* . Se o processo é puramente autoregressivo p p* = .
Caso contrário os coeficientes π são obtidos a partir de
( )( )( )π
φθ
BB
B=
e, por causa da invertibilidade de ( )θ B , estes coeficientes decaem e tornam-se prati-
camente 0 para algum desfasamento p* .

Cap. 5 ___
___ 108___
Deste modo, supondo que o modelo subjacente à série temporal é um ARMA(p,q)
esse processo pode ser aproximado por um AR(p+q). Na prática, para detecção de
outliers, os autores descobriram que esta pode ser uma boa aproximação.
Assim a estratégia de construção do modelo, proposto pelos autores, começa com
a estimação de um processo AR de ordem suficientemente elevada, propondo os se-
guintes procedimentos de construção do modelo, baseados nos métodos de detecção
de outliers referidos anteriormente:
Etapa 1
Usar uma qualquer técnica de selecção de modelos para identificar uma primeira tenta-
tiva de ordem ( )′ ′p q, , a qual pode não coincidir com a verdadeira ordem ( , )p q . Esco-
lha-se p p q* ⟩ ′ + ′ .
Etapa 2: Detecção dos outliers.
Estime-se ( )� � , ... , � *π =′
π π1 p pelo método dos MQ e calcule-se Qk (e/ou Qk2) para
k = 1 e k p= +* 1. Determine-se o outlier e o seu tipo baseado nos gráficos de Qk
(e/ou Qk1, Qk2). Os testes de significância baseados no máximo destas estatísticas
podem também ser usadas. Se não houver outliers vamos para a etapa 4; caso
contrário vamos para a etapa 3.
Etapa 3: Limpando a série.
Seja T a posição do outlier identificado na etapa 2. Se o outlier é do tipo AO, elimine-
se ( )T p− * equações até T de (5.1.2) para obter as estimativas %π . Ajustemos então a

Cap. 5 ___
___ 109___
T-ésima observação, considerando-a um valor omisso, usando a média estimada de zT
condicional a todas as outras observações, ( )E z z t TT t , ≠ ; ou seja, substituímos zt por
%z zt t= , t T≠
( )= ++ −=
∑ ~*
η j t j t jj
p
z z1
, t T= , (5.4.17)
com
( )~~ ~ ~
~, ... ,
*
*
*ηπ π π
πj
j i i ji
p
ii
pj p=
−
+=
+=
=
∑∑
1
2
11
1 .
Por outro lado, se o outlier for do tipo IO, elimine-se a T-ésima equação de (5.4.)
para estimar %π , e ajustar as observações como se segue:
%z zt t= , t T⟨
= −z rt t%, t T=
= − −z rt t T T% %ψ , t T⟩ , (5.4.18)
onde %rt é o resíduo correspondente à estimativa %π e %ψ j é o coeficiente de Bj em
( )1 11 22
1
1
− − − = − − −−
~ ~ ~ ~*
*
ψ ψ π πB B B Bp
p/ / .
Etapa 4: Especificação
Use-se a série limpa na especificação e estimação dos parâmetros do modelo final.

Cap. 5 ___
___ 110___
5.5 DIAGNÓSTICO BASEADO NA FUNÇÃO DE INFLUÊNCIA DAS AUTO-
CORRELAÇÕES
Chernick, Downing e Pike (1982) sugeriram que deveriam ser procurados outliers in-
fluentes examinando a matriz da função de influência das autocorrelações estimadas. O
parâmetro, S, pode ser considerado dependente da função de distribuição F , S F( ).
A função de influência de um estimador depende do parâmetro a estimar, do vector de
observações cuja influência está a ser medida e da sua função de distribuição de pro-
babilidades, e é dada segundo Hampel (1974), pela equação seguinte quando o limite
da direita existe
( )( )( )( ) ( )[ ]
I F S F xS F x S F
, , lim=− + −
→ε
ε εδε0
1. (5.5.1)
Neste equação, x é o ponto de interesse no espaço das observações, ε é um número
real positivo e δx é a função de distribuição que tem toda a sua massa de probabilida-
des concentrada no ponto x.
Consideremos uma série temporal discreta z z zn1 2, ,..., . Seja { }I j k, a matriz da fun-
ção de influência das autocorrelações do tipo n m× , em que n é o número de observa-
ções e m é o desfasamento (m deverá ser consideravelmente menor que n), cujo ele-
mento de ordem ( )j k, é uma função de
( )( )I H y yk j j k, , ,ρ + , (5.5.2)
em que yi é a observação estandardizada ( )y zi i= − µ σ , µ e σ são a média e o des-
vio padrão de zi , ρk é a autocorrelação de ordem k e H é a função de distribuição bi-
variada de ( )y yj j k, + com média nula, variância unitária e covariância ρk . Os autores
argumentam que o elemento de ordem ( )j k, da função de influência é dado por

Cap. 5 ___
___ 111___
( )
y yy y
j j k
k j j k
++
−+ρ 2 2
2, (5.5.3)
Deste modo com base na expressão anterior, pode-se calcular a influência de qualquer
par de observações, desfasadas k períodos, na estimativa de ρk . Quando ρk , σ , e µ
não são conhecidos, podem ser usadas estimativas.
Definindo
Uy y y y
j k
j j k
k
j j k
k, =
+
++
−
−
+ +
1 12
ρ ρ (5.5.4)
e
Vy y y y
j k
j j k
k
j j k
k, =
+
+−
−
−
+ +
1 12
ρ ρ . (5.5.5)
É fácil de ver que
( ) ( )1
22
2 2
− = −+
++
ρρ
k j k j k j j k
k j j kU V y y
y y, ,
e portanto
( )( ) ( )I H y y U Vk j j k k j k j k, , , , ,ρ ρ+ = −1 2 . (5.5.6)
Para um processo Gaussiano estacionário com µ , σ e ρk todos conhecidos, U j k, e Vj k,
são independentes ( )N 0 1, . Deste modo a distribuição de ( )( )I H y yk j j k, , ,ρ + é de fácil
tratamento pois resulta de uma constante por um produto de variáveis aleatórias nor-
mais. Esta distribuição pode então ser usada para determinar quais os valores da fun-

Cap. 5 ___
___ 112___
ção de influência invulgarmente elevados em termos absolutos face a um determinado
valor crítico.
Com base na forma como o outlier influencia as autocorrelações, os autores propu-
seram então um procedimento visual de detecção. Assim, na matriz da função de in-
fluência { }I j k, as estimativas da função excedendo em valor absoluto o valor crítico
deverão substituídas por ( )+ ou ( )− dependendo do sinal da estimativa. As outras ob-
servações são deixadas em branco.
Fig. 5.18 - Matriz da função de influência das autocorrelações
Considere-se o exemplo da figura 5.18. A observação yt influencia várias estimativas
da autocorrelação com desfasamentos diferentes. Surge no cálculo de cada elemento
na linha t da matriz e também nos elementos da diagonal das linhas anteriores come-
çando na coluna 1 da linha t −1 e continuando para cima e para a direita. Um outlier
terá, pois, uma influência positiva ou negativa muito grande em cada estimativa da
autocorrelação. Em consequência, se muitas das observações na linha t e na diagonal
superior ( ) ( )[ ]t t− −11 2 2, , , .... são elevados em valor absoluto, concluímos que yt é um
outlier, como é o caso que se verifica no exemplo.

Cap. 5 ___
___ 113___
5.6 MEDIDAS DE INFLUÊNCIA DE PEÑA
Peña (1982, 1990) construiu estatísticas indicadoras das observações, nomeadamente
outliers aditivos e inovadores, que têm forte influência no valor dos coeficientes
ARMA estimados. Estatísticas essas que se baseiam na substituição das observações
discordantes por valores interpolados. No artigo de Peña (1982) é considerado um
processo AR(p), no artigo de (1990) as estatísticas propostas são generalizadas a um
modelo ARMA(p,q).
5.6.1 Para outliers aditivos
Suponha-se que xt segue um processo ARMA(p,q) e considere-se a aproximação au-
toregressiva dada por
x x et i t ii
p
t= +−=∑ π
1
*
,
para um qualquer desfasamento p* .
Assumindo agora que ocorre um outlier aditivo no período T , como vimos ante-
riormente, o modelo paramétrico para um AO é dado por
z xt t tT= + ωξ( )
ou seja, em vez de observarmos xt , observamos zt , onde z xt t= ( )t T≠ e z xT T= + ω .

Cap. 5 ___
___ 114___
Seja ( )π ( ) ,( ) ,( ), . .. , *T T p T
=′
π π1 o vector de parâmetros considerando que está pre-
sente um outlier, ou seja, retirando a cada observação o efeito provocado pela sua pre-
sença. Uma estimativa de π ( )T , assumindo a aproximação autoregressiva, é dada por
( )� � � � �( )π T y y y= ′
−′X X X Y
1
, (5.6.1)
com
�� � ... �
� � ... �
* *
*
X y
p p
n n n p
x x x
x x x
=
−
− − −
1 1
1 2
0 0 / 0 e ��
�
*
Y =
+x
x
p
n
1
0 ,
onde ∃x zt t= para t T≠ e ∃ ∃( )x zT T= − ω .
Considerando xT como um valor omisso, a sua estimativa é dada por
( )� �( )
*
x z zT j T j T jj
p
= ++ −=
∑η1
, (5.6.2)
onde
∃∃ ∃ ∃
∃
,( ) ,( ) ,( )
,( )
*
*ηπ π π
πj
j T i T i j Ti
p
i Ti
p=
−
+
+=
=
∑
∑1
2
1
1
. (5.6.3)
Da relação ∃ ∃( )ω = −z xT T pode-se concluir que, dados os parâmetros, uma estimativa do
outlier aditivo é dada pela diferença entre os dados observados e o seu óptimo de in-
terpolação, ∃( )x T , o qual pode ser interpretado como a melhor estimativa de xT usando
toda a informação amostral. É de notar que o cálculo de ∃( )x T é efectuado aplicando
coeficientes de ponderação à nova série

Cap. 5 ___
___ 115___
( )s j z zT j T j= ++ − . (5.6.4)
Estas ponderações são tais que −η j é o j -ésimo coeficiente da função geradora
( ) ( ) ( )π π πj B F21∑ −
e, então, pode ser interpretado como o coeficiente da função de
autocorrelação inversa do processo.
O sistema de equações dado por (5.6.1) e (5.6.2) tem de ser resolvido iterativa-
mente. Começando com um valor inicial ( )�( )π T 0 para ∃( )π T , as ponderações η j podem
então ser calculadas obtendo-se ( )�ω 0 . Este valor é usado para calcular
( ) ( )� �( )x zT T0 0= −ω , o que conduz a uma nova estimativa ( )�( )π T 1 . O processo é repeti-
do até à convergência.
Seja ∃π o estimador de π , assumindo que não existem outliers . Então
( )�π = ′ − ′X X X Zz z z
1,
onde a matriz X z e o vector Z correspondem aos dados observados e têm a mesma
estrutura de ∃X y e ∃Y e os mesmos valores excepto no período T . Claro que as colec-
ções de dados são idênticas se ∃( )x zT T= . Então,
X X Mz y= +∃ ∃ω , (5.6.5)
onde a matriz M é dada por
M 0 I 0′× − × × − −=
p T p p p p n p T* * * * * *( ) ( ); ; , (5.6.6)
0a b× é uma matriz nula rectangular, Ip p* *× é a matriz identidade. Por outro lado,

Cap. 5 ___
___ 116___
Z Y V= +∃ ∃ω , (5.6.7)
onde a matriz V pode-se decompor em
V 0 0′ ′− − ×
′− − ×= ( ) ( )* *; ;T p n p T1 1 11 . (5.6.8)
Para relacionar ∃( )π T e ∃π , vamos decompor as matrizes X z e ∃X y e os vectores Z e
∃Y de mesmo modo que em (5.6.6) e (5.6.8). Se considerarmos que
( ) ( ) ( )[ ]X X X Xz z z z′ ′ ′ ′= 1 2 3 onde
X z
p
T T p
z z
z z
′
− −
=
( )
...
...
*
*
11
1
0 / 0 ,
X z
T T p
T p T
z z
z z
′− +
+ −
=
( )
...
...
*
*
21
1
0 / 0 ,
e
X z
T p T
n n p
z z
z z
′+ +
− −
=
( )
...
...
*
*
31
1
0 / 0 ,
então
( ) ( ) ( )( )� � � �X X X X I X Xy y z z z z′ ′ ′= + − +ω ω2 2 2
= −′X X Az z T∃ω , (5.6.9)

Cap. 5 ___
___ 117___
onde ( ) ( )A X X IT z z= + −′2 2 �ω é uma matriz simétrica com ( )a a s i z zij ji T i T i= = = ++ −
e a z xii T T= + ∃( ) . Além do mais, decompondo o vector Z em
Z = + + + + +
′z z z z z z
p T T T p T p n* * *,..., ; ,..., ; ,...,1 1 1
=′′ ′ ′Z Z Z( ) ( ) ( )1 2 3 .
Então, de (5.6.5) e (5.6.7), ( ) ( )� � � �X Y X M Z Vy z′ ′
= − −ω ω e, como M V 0′ = ,
M Z Z′ = ( )2 e X Vz T T pz z′
− −= 1 ,..., * ,
∃ ∃ ∃X Y X Z Sy z T′ ′= − ω , (5.6.10)
onde ( ) ( )( )ST s s p′ = 1 , ... , * e ( )s j são dados por (5.6.4). Exprimindo os parâmetros es-
timados ∃( )π T como uma função dos dados observados, pelas equações anteriores,
( )X X A X Z Sz z T T z T′ ′− = −� � �( )ω ωπ , o que nos leva a
( ) ( )� � � �( ) ( )π π πT z z T T T= − −′ −
ω X X S A1
. (5.6.11)
Sendo ∃aT i+ os resíduos da estimação (5.6.1),
( )� � � � �, , * *a z z z zT i T i T T i i T T p T i p+ + + − + −= − − − − − −π π ω π1 1 / /
e ∃bT i− os resíduos para trás
∃ ∃ ∃ ∃, , ,* *b z z z zT i T i T T i i T T p T T i p− − − − − += − − − −π π π1 1Λ Λ .

Cap. 5 ___
___ 118___
Se considerarmos ∃ ∃ ∃ ,...,∃ ∃* *ET T T T p T p
a b a b′+ − + −= + +1 1 , então ∃ ∃
( )E S AT T T T= − ππ é um
vector de pseudo-resíduos e como tal (5.6.11) pode ser escrito como
( )� � � �( )π πT z z T= − ′ −
ω X X E1
. (5.6.12)
Uma maneira de medir a influência da observação zT é relacioná-la com a alteração
na estimativa dos parâmetros quando se assume que a observação é um outlier. Como
∃π e ∃( )π T são vectores, a forma usual de medir a sua distância é construir uma métrica
usando uma matriz semidefinida positiva relevante. Nomeadamente, a matriz de va-
riância de ambos os vectores estimados e construir uma distância de Mahalanobis. En-
tão
( )( ) ( )( )
D TpAO
T z z T=
− −′
′� � � �
�
( ) ( )
*
π π π πX X
σ 2 , (5.6.13)
onde a distância é dividida pela dimensão dos vectores envolvidos, p* , e pela variância
do ruído de modo a estandardizar a medida.
A estatística (5.6.13) pode ser também interpretada como medindo a alteração no
vector de previsão em um passo adiante. Usando os parâmetros estimados assumindo
que não existem outliers, o vector previsão é dado por ∃ ∃Z X= zπ , e usando os parâme-
tros estimados assumindo que existe um outlier aditivo em T , ∃ ∃( )Z XT z T= ππ . A dis-
tância Euclidiana entre os dois vectores de previsão é
( ) ( ) ( ) ( )( )� � � � � � � �( ) ( )Z Z Z Z X X− − = − −
′ ′′
T T T z z Tπ π π π , (5.6.14)

Cap. 5 ___
___ 119___
então ( )D TAO pode ser interpretada como uma medida estandardizada da distância
entre os vectores de previsão em um passo adiante construída com os vectores ∃π e
∃( )π T .
Usando (5.6.12), a estatística pode ser escrita como
( )( )
D TpAO
T z z T=
′ ′�
�
� �
*
ωσ
2
2
E X X E, (5.6.15)
deste modo a estatística de influência depende de dois factores; o primeiro mede o
efeito do outlier relativo ao desvio padrão do ruído, o segundo mede o valor relativo
da observação antes e depois do outlier.
A razão de verosimilhança para testar outlier aditivos, referida no capítulo 4, é as-
sintóticamente equivalente a
( )
λω
σ πAO T
i
,
�
� �
22
2 2 1=∑ − ,
então ( )D TAO pode ser escrita como função desta estatística,
( ) ( )( )
D TpAO
AO T
i
T z z T= ∑′ ′λ
π,
*�
� �2
2
E X X E. (5.6.16)
5.6.3 Para outliers inovadores
Considerando que existe um IO no período T , o modelo para outliers inovadores pode
ser representado por uma aproximação autoregressiva
z et t I tT
t= + +′x π ( )( )ωξ , (5.6.17)

Cap. 5 ___
___ 120___
em que ( )π ( ) ,( ) ,( ), .. . , *I I p I
=′
π π1 representa o vector de parâmetros assumindo que
existe um outlier inovador com um efeito ω e ( )x t t t pz z=
′− −1 , ... , * . Este é um modelo
linear com uma variável "dummy". Sendo ∃π o usual estimador com ω = 0, então
( )� � �( )π πI z z T= + ′ −ω X X x
1 (5.6.18)
e
∃ω = rT , (5.6.19)
onde r zT T T= − ′x ∃π .
A alteração na estimativa dos parâmetros provocada pela presença de um IO no
período T pode ser medida por
( )( ) ( )( )
D TpIO
I z z I=
−′
−′� � � �
�
( ) ( )
*
π π π πX X
σ 2 , (5.6.20)
a estatística pode ainda ser escrita como
( )( )D T
p
r
h
h
hIOT
T
T
T
=− −
1
1 1
2
2*�σ
, (5.6.21)
onde ( )hT T z z T= ′ ′ −x X X x
1 é a medida da distância entre o vector no período da inter-
venção xT e o vector nulo, é pois a medida de alavanca referida no capítulo 5. Esta
estatística pode ser interpretada como o produto de dois termos; o primeiro
( )r hT T2 2 1
1σ− −− é o resíduo estandardizado no período da observação; o segundo,

Cap. 5 ___
___ 121___
( )h hT T11
−−
, representa a distância de xT à origem. ( )D TIO pode-se também exprimir
como uma função da razão de verosimilhança, usada para testar os outliers inovadores:
( )( )
D Tp
h
hIO
IO T T
T
=−
λ ,
*
2
21
, (5.6.22)
onde λ ω σIO T,∃ ∃= é a razão para testar se a T-ésima observação é um outlier inovador.
É de notar que ( )D TIO depende apenas dos valores relativos de p* observações antes
da intervenção [os regressores em t T= , ( )xT T T pz z=
′− −1 , ... , * ] em contraste com
( )D TAO que depende também das observações depois da perturbação.
5.7 AS ESTATÍSTICAS Ci j( )
Yatawara e Lin (1994) propuseram uma estatística de diagnóstico de observações in-
fluentes que permite detectar conjuntos de observações. Estatística essa, construída de
modo a evitar o efeito "masking" provocado pela existência de múltiplos e consecuti-
vos outliers.
Lawrance citado por Yatawara e Lin (1994), no quadro dos modelos de regressão,
propôs a seguinte medida da influência do i -ésimo caso após a eliminação do j -ésimo
caso
( )( )( )C psi j i j j j j i j j( ) ( , ) ( ) ( ) ( ) ( , ) ( )� � � � /= − ′ −β β β βX X 2 , (5.7.1)
onde ∃( , )β i j é uma estimativa dos parâmetros de regressão linear β após a eliminação
do i -ésimo e j -ésimo caso, s2 é a variância dos resíduos e X ( )j é a matriz de obser-
vações X sem a linha j .

Cap. 5 ___
___ 122___
Os autores adoptaram o esquema sugerido por Lawrance, aplicando-o às séries
temporais, no quadro dos modelos autoregressivos AR(p). Após simplificações, Ci j( )
pode-se representar, recorrendo aos elementos da matriz H referida no capítulo 5,
como
( ) ( )[ ]{ }C h h h hi j ij i i ij( )
~/
~= − − +−
1 122
2
( )[ ]× ′ + ′ ′r h r r pi ij j i2
2
1~
/ / (5.7.2)
onde ( )( )~/h h h hij ij i j= − −1 1 (alavanca conjunta), ( )hij i j= ′ −x X X x1 [( , )i j -ésimo
elemento fora da diagonal de H ], ′= −r r s hi i i/ 1 (i -ésimo resíduo estandardizado) e
( )x i i i i pz z z=′
− − −1 2, , ... , .
A estatística Ci j( ) é uma função dos rt `s e de hij . Deste modo, múltiplos AO em
t T T Tl= 1 2, ,..., , ( )l = 1 2, ,... afectarão os resíduos r r r rT T T Tl l1 21 1 1 2+ + + +,..., ,..., , ,... por ω
[veja-se (5.4.7)] . De modo similar, múltiplos IO afectarão e e eT T Tl1 2, ,..., por ω e como
tal as observações z z z zT T T Tl l1 21 1 1 2+ + + +,..., ,..., , ,... [veja-se (5.4.8)]. Então Ci j( ) é afectado
pelos outliers.
Em situações práticas a posição dos outliers pode não ser conhecida. Então Ci j( )
deverá ser calculada para todos os ( )t p p n p= + + − +1 2 1, , ... , . Para identificar a po-
sição dos outliers deverá considerar-se a estatística max( )Ci j , dada por
( )
( ) ( )max
/~
( )( )
( )
( )i
i j
i i ij
jj i j
i jj i jCh h h
p h hr h r=
− +
− −× +
1
1 1
2
2 22
2
σ. (5.7.3)
Em que ( )hkl i k i i l( ) ( ) ( )= ′−
x X X x1
.

Cap. 5 ___
___ 123___
A distribuição amostral exacta de max( )Ci j não é conhecida. Recorrendo à teoria
das grandes amostras, Yatawara e Lin (1994) demonstraram que para um dado j fixo,
max ( )i i jC tem uma distribuição assintótica Cχ( )12 , em que
( )[ ]( )
( ) ( )Ch h h h
p h h
j j jj i jj i
jj i j
=− + +
− −
1 1
1 1
2 22
2 22
( ) ( )
( )σ (5.7.4)
é uma constante para um dado i fixo. Então a significância de um valor max( )i i jC
pode ser testado para um valor critico apropriado da distribuição do qui-quadrado.
A estatística Ci j( ) deverá, no entanto, ser utilizada em conjunto com outro método
de detecção. Isto porque a estatística funciona como um teste à observação ( )i após a
eliminação da observação outlier ( )j . Necessitamos pois, previamente, de detectar o
outlier correspondente à observação ( )j por um outro método de diagnóstico.
5.8 DIAGNÓSTICOS DV e DC
5.8.1 Estimativas dos parâmetros ARMA com dados omissos
Para o cálculo das medidas de influência de Bruce e Martin (1989), necessitamos de
estimar os coeficientes da série temporal, ( )β ,=′
φ φ θ θ1 1, ... , , ... ,p q ou a variância do
ruído σ2, com e sem o efeito outlier. Estas ultimas baseiam-se na substituição das ob-
servações outlier por valores interpolados, considerando as observações outlier como
omissas. Este procedimento corresponde ao utilizado por Peña (1990), no cálculo das
estimativas dos coeficientes ARMA, ∃( )π T (considerando uma aproximação autore-
gressiva), na presença de um AO.
Considerando que a T-ésima observação, zT , é uma observação outlier. As estima-
tivas dos coeficientes ARMA podem-se obter tratando a T-ésima observação como

Cap. 5 ___
___ 124___
um parâmetro desconhecido x T( ) , obtendo-se a sua estimativa ∃( )x T e calculando as es-
timativas ∃( )β T e ∃( )σ T2 a partir da colecção de dados na qual a observação zT é substituí-
da por ∃( )x T . Com os coeficientes da série temporal dados, ( )β ,=′
φ φ θ θ1 1, ... , , ... ,p q ,
a estimativa da observação eliminada no período T é dada, como anteriormente, por
( ) ( )�( )x z zT j T j T jj
β = ++ −≥
∑η1
(5.8.1)
ρ ηj j= − é a autocorrelação inversa de ordem j do processo. Já que a estimativa em
(5.8.1) sendo uma soma ponderada das observações adjacentes, é função de coeficien-
tes da série temporal deverá ser utilizado um procedimento iterativo para determinar,
para cada período temporal omitido T , as estimativas de máxima verosimilhança ∃( )x T ,
∃( )β T e ∃ ∃( )σ T tt
nn r2 1 2
1= −
=∑ . Os resíduos ∃rt utilizam ∃( )β T e são obtidos após a substituição
da T-ésima observação por ∃( )x T .
5.8.2 Diagnóstico para os coeficientes (DC)
Se a observação zT tiver uma influência excessiva na estimativa ∃β então isso revela-se
sob a forma de uma diferença substancial entre ∃β e ∃( )β T . Os autores definem então a
influência empírica da observação zT sobre os coeficientes como
( ) ( )EIC T n T= − −� �( )β β . (5.8.2)
A influência empírica ( )EIC T é um vector de dimensão h p q= + , e como tal, é difícil
de interpretar. Deste modo, seguindo a aproximação para a regressão linear, os autores
consideram um diagnóstico baseado na forma quadrática da função de influência em-
pírica, nomeadamente

Cap. 5 ___
___ 125___
( ) ( ) ( )DC Tn
T T= ′ −1 1EIC C EIC� , (5.8.3)
onde ∃C é uma estimativa da matriz de covariância C de ∃β .
Sob condições de regularidade em que ∃β é assintóticamente normal
( ) ( )� , ( )β β β− →n hN 0 C ,
em que ( )C β é a matriz de covariância assintótica, a qual está relacionada com a ma-
triz de informação assintótica, ( )I β , por
( ) ( )C Iβ β− =1. (5.8.4)
Se ∃( )I β é um estimador consistente de ( )I β , então
( ) ( )( )n h� � �
( )β β β β β− ′ − →I χ 2 , (5.8.5)
Um estimador de ( )I β é a informação esperada avaliada pelos estimadores de máxima
verosimilhança, ( )I �β . Usando esta expressão, temos o diagnóstico para os coeficientes
( ) ( ) ( ) ( )DC Tn
T T= ′1
EIC I EIC�β
( ) ( )( )= − ′ −n T T� � � � �
( ) ( )β β β β βI . (5.8.6)
Embora a distribuição de ( )DC T não seja conhecida, a utilização da distribuição
χ( )h2 permite-nos visualizar ( )DC T numa escala familiar. Assim, um método grosseiro
para avaliar se uma observação zT é influente é verificar se o p-value baseado na dis-
tribuição de referência χ( )h2 é inferior a 0 5. (e não 0 05. , veja-se Cook e Weisberg

Cap. 5 ___
___ 126___
(1982)). Este procedimento não é no entanto um teste de significância, servindo ape-
nas como indicador da influência.
5.8.3 Diagnóstico para a variância do ruído (DV)
A influência da observação zT pode também ser mediada pela avaliação do seu efeito
sobre o estimador da variância do ruído, ∃σ2. Bruce e Martin (1989) definem a influên-
cia empírica de uma observação zT sobre a variância do ruído por
( ) ( )EIC T n T= − −� �( )σ σ2 2 , (5.8.7)
Sob condições de regularidade, ∃σ2 é assintóticamente normal:
( ) ( )� ,( )σ σ σT n N2 2 40 2− → (5.8.8)
Então
n
21
2
2
2
12
�
( )
σσ
χ−
→ .
Deste modo, os autores propõem o seguinte diagnóstico para a variância do ruído
( )DV Tn
T
= −
21
2
2
2�
�( )
σσ
. (5.8.9)
Com a distribuição qui-quadrado com um grau de liberdade, χ( )12 , como distribuição de
referência. Então, suspeitamos que uma observações zT é influente se o p-value para
( )DV T é inferior a 0 5. usando a distribuição χ( )12 .

Cap. 5 ___
___ 127___
A maior diferença entre o coeficiente DC para séries temporais e os diagnósticos
usuais dos coeficientes de regressão é o efeito de "smearing" de um outlier isolado ou
de um grupo de outliers a períodos adjacentes. Usando o diagnóstico para coeficientes,
um dado outlier pode ser considerado influente devido a um outlier num período adja-
cente. Por exemplo, no caso AR(p), um outlier isolado implica que DC apresente valo-
res significativos p períodos antes e depois da ocorrência do outlier. Então a interpre-
tação do diagnóstico DC não é tão clara como no caso da regressão. Em contraste, ar-
gumentam os autores, o diagnóstico para a variância do ruído ostenta efeitos
"smearing" muito mais reduzidos e muitas vezes negligenciáveis. Deste modo DV
apresenta melhores propriedades que DC, sendo por isso preferível a sua utilização.
5.8.4 Diagnóstico para múltiplos e consecutivos outliers
No caso de observações independentes, a estratégia de diagnóstico assenta, num dado
período, na eliminação de uma única observação. No entanto, a situação das séries
temporais difere do caso das observações independentes pois: (i) a estrutura impõe-se
por ordem temporal e (ii) observações influentes muitas vezes surgem na forma de
grupos de outliers estendendo-se por múltiplas observações. É então imperativo procu-
rar grupos influentes e não apenas observações isoladas.
Neste sentido Bruce e Martin (1989) propuseram medidas de diagnósticos com k
observações eliminadas. Considere-se { }A T T Tk= 1 2, , ... , uma subcolecção arbitrária
de { }1 2, ,... ,n , e ∃( )β A o estimador com as observações z zT Tk1,..., consideradas omissas.
Se alguma das observações da subcolecção A tiver uma influência excessiva na esti-
mativa ∃( )β A então isso revela-se sob a forma de uma diferença substancial entre ∃β e
∃( )β A .
O diagnóstico com k observações eliminadas para os coeficientes é dado por

Cap. 5 ___
___ 128___
( ) ( ) ( ) ( )DC An
A A= ′1
EIC I EIC�β
( ) ( )( )= − ′ −n A A� � � � �
( ) ( )β β β β βI . (5.8.10)
O diagnóstico com k observações eliminadas, para a variância do ruído é
( )DV An
A
= −
21
2
2
2�
�( )
σσ
. (5.8.11)
Neste caso, com múltiplos e consecutivos outliers, os autores propuseram uma estra-
tégia de diagnóstico que permite identificar a dimensão do grupo de outliers influentes
assente na eliminação iterativa de k observações e calculo dos diagnósticos.
Consideremos A Ak t= , consistido em k períodos de tempo centrados em
( )[ ] [ ]( )t t k t k: , ... ,− − +1 2 2 , onde y representa o maior inteiro menor ou igual a y.
Para um qualquer k , t é o ponto mais próximo à direita do centro do grupo Ak t, . Para
simplificar a notação representamos ( )DC Ak t, , ( )DV Ak t, , respectivamente por
DC k t( , ), ( )DV k t, . Para grupos situados no final da série, onde ( )[ ]t k≤ −1 2 ou
t n k> − 2 , ( )DC k t, e ( )DV k t, são calculados com o grupo truncado.
Em presença de uma observação influente isolada os coeficientes de diagnóstico
apresentam o seguinte padrão de comportamento: k −1 valores de ( )DV k, . ao redor
da localização do outlier isolado em T são significativos e têm aproximadamente o
mesmo valor que ( )DV k T, . Isto corresponde ao que intuitivamente se poderia esperar
de um outlier isolado: a eliminação do grupo que inclui esse outlier tem o mesmo
efeito que teria a sua eliminação.
Comportamento similar ocorre em presença de um grupo de outliers. Em geral,
para um grupo de k0 outliers centrados em T , verifica-se a seguinte propriedade dos
grupos (PG):

Cap. 5 ___
___ 129___
Para k k≥ 0, existem k k− +0 1 subconjuntos Ak t, que contêm o grupo e ao eliminar
esses subconjuntos, o valor de ( )DV k t, é sensivelmente o mesmo e significativo (o
p-value associado é inferior a 0 5. ).
Então, julgamos se um grupo influente centrado em T , é do tamanho k0 1≥ se
( )DV k T0 , é significativo, e se verifica a PG. Se ( )DV k T0 , é significativo mas a PG
falha, então temos uma indicação que está presente um grupo extenso de outliers. Isto
providência uma estratégia para identificar o tamanho do grupo de observações in-
fluentes.
Calcule-se os diagnósticos "leave-k -out" para sucessivos k = 1 2, ,... até que o va-
lor de ( )DV k t, não aumente significativamente para nenhum t . O tamanho do
grupo será estimado pelo primeiro valor de k menos um.
5.9 MEDIDAS DE DESLOCAMENTO DA VEROSIMILHANÇA
Considerando zT como uma observação outlier temos três deslocamentos possíveis da
verosimilhança com interesse, segundo Ledolter (1990). O primeiro mede o desloca-
mento quando ambos, os coeficientes da série temporal ( )β ,=′
φ φ θ θ1 1, ... , , ... ,p q e a
variância σ2, têm interesse:
( ) ( ) ( )[ ]LD L LT T Tβ β β, �, � � , �( ) ( )σ σ σ2 2 22= −
= − + −
n n
s
T
T
T
log�
� �( )
( )
( )
σσ σ
2
2
2
2 1 . (5.9.1)

Cap. 5 ___
___ 130___
Onde ∃( )β T e ∃( )σ T2 são calculados pelo processo descrido no ponto 6.4.1. Obtemos a úl-
tima expressão após a substituição das estimativas no logaritmo da função de verosimi-
lhança condicional ( ) ( ) ( )L n ett
nβ, / log /σ σ σ2 2 2 2
12 1 2= − − =∑constante . A estima-
tiva da variância s T( )2 é calculada com ∃( )β T , mas utiliza todas as observações, incluindo
zT , para obter os resíduos. É diferente de ∃( )σ T2 , a qual utiliza a mesma estimativa dos
coeficientes da série temporal mas substitui a T-ésima observação por ∃( )x T .
O segundo diagnóstico mede o deslocamento quando apenas os coeficientes da sé-
rie temporal β têm interesse:
( ) ( ) ( )[ ]LD L L s nsT T T
T
β β β= − = −
2 2 2
2
2�, � � , log
�
( ) ( )( )
σσ
. (5.9.2)
O terceiro diagnóstico mede o deslocamento quando apenas σ2 tem interesse:
( ) ( ) ( )[ ]LD L LT Tσ σ σ2 2 22= −�, � �, �( )β β
= − + −
n n
T T
log�
�
�
�( ) ( )
σσ
σσ
2
2
2
2 1 . (5.9.3)
Exemplo 5.5 : Processo AR(1)
Considerando um processo AR(1), as autocorrelações inversas são dadas por
( )ρ φ φ121= − + e ρ j = 0 para j > 1. A observação no período T é substituída por
( ) ( )�( )x z zT T Tφφφ
=+
++ −1 2 1 1 (5.9.4)
o qual é uma soma ponderada das duas observações adjacentes. A estimativa ∃( )φ T é
obtida minimizando-se

Cap. 5 ___
___ 131___
( ) ( )[ ] ( )[ ]σ φ φ φ φ φ φ21
2
1
2
1
2
1
1( ) � �( ) ( )
,
= − + − + −
− + −
≠ +∑
nz z z x x zt t T T T T
t T T
(5.9.5)
e a estimativa de σ2 a partir de ( )� �( ) ( )σ σ φT T2 2= . Nos cálculos deve ser utilizado um
procedimento iterativo. O deslocamento da verosimilhança é obtido substituindo as es-
timativas de ∃( )φ T e ∃
( )σ T2 conjuntamente com ( )s z z nT t T tt
n
( ) ( )�2
1
2
1= − −=∑ φ e a
estimativa de máxima verosimilhança ∃φ = −= −=∑ ∑z z zt tt
n
tt
n
11 12
1 e
( )� �σ φ21
2
1= − −=∑ z z nt tt
n a partir da colecção completa de observações nas equações
anteriores.
O deslocamento conjunto da verosimilhança quando ambos, β e σ2, têm interesse é
um limite superior da soma dos deslocamentos da verosimilhança individuais,
( ) ( ) ( )LD LD LDT T Tβ β+ ≤σ σ2 2, (5.9.6)
Após a substituição das expressões anteriores, a desigualdade (5.9.6) traduz-se em
log�
� � �
�
�
( ) ( )
( )
( )
( ) ( )
s sT T
T
T
T T
2 2
2 2
2
2
2
2
σσ σ σ
σσ
≤ − .
Como s T T( ) ( )∃ ∃2 2 2≥ ≥σ σ , então a s bT T T= ≥ = ≥( ) ( ) ( )
∃ ∃ ∃2 2 2 2 1σ σ σ , esta desigualdade é ver-
dadeira pois ( )log a b a b≤ − para a b≥ ≥ 1.
Foi observado por Bruce e Martin (1989) que a estimativa da variância do ruído é
mais sensível aos outliers que as estimativas dos coeficientes ARMA. Então é razoável
considerar o deslocamento da verosimilhança em ordem a σ2 como um diagnóstico
possível de outliers. O deslocamento em (5.9.3) pode-se escrever como

Cap. 5 ___
___ 132___
( )LD n nTT T
σσσ
σσ
22
2
2
21 1 1= − + −
+ −
log
�
�
�
�( ) ( )
≈ − −
− −
+ −
n n
T T T
�
�
�
�
�
�( ) ( ) ( )
σσ
σσ
σσ
2
2
2
2
22
211
21 1
( )= −
=
nDV T
T21
2
2
2�
�( )
σσ
(5.9.7)
o qual é o diagnóstico para a variância do ruído considerado por Bruce e Martin
(1989).
As equações (5.9.3) e (5.9.7) mostram que
W nTT
( )( )
�
�= −
σσ
2
2 1 , (5.9.8)
é um elemento fundamental do deslocamento da verosimilhança para a variância do
ruído. Compara duas estimativas da variância do ruído; uma é calculada com todas as
observações disponíveis, enquanto a outra considera a T-ésima observação como um
parâmetro adicional.
Segundo Ledolter (1990), ( )[ ]n n WT−1 / ( ) tem uma distribuição ( )F n1 1, − , e se n é
suficientemente elevado, WT( ) tem uma distribuição χ( )12 .
5.10 CONCLUSÃO
Em conclusão, as medidas de diagnostico apresentadas são de certo modo complemen-
tares e deverão ser utilizadas consoante as necessidades do utilizador e da informação

Cap. 5 ___
___ 133___
que se tem acerca da série a analisar. Podemos começar por analisar os resíduos se-
gundo a metodologia de Rosado (1984), a qual constitui uma metodologia relativa-
mente fácil de implementar. Outro método de detecção de outliers bastante acessível,
no contexto de um modelo AR(p), consiste na utilização das designadas medidas de
alavanca. Se suspeitamos que estão presentes múltiplos e consecutivos outliers esta
técnica de diagnóstico é particularmente adequada. Na presença de AO e IO o método
de detecção baseado nas estatísticas Q será talvez o mais adequado, pois permitem
não só detectar mas também distinguir um AO de um IO. Em presença de séries tem-
porais cujo processo subjacente é um ARMA(p,q), pode-se sempre utilizar a aproxi-
mação autoregressiva AR(p* ) e aplicar então estes métodos de detecção.
Se o nosso objectivo consiste na detecção de outliers influentes, pode-se começar a
análise da série temporal e antes da etapa da identificação do modelo na metodologia
de Box-Jenkins, pelo cálculo da matriz da função de influência das autocorrelações,
como uma fase prévia de identificação de observações influentes. Numa fase posterior
pode-se calcular as estatísticas de Peña (1990) as quais permitem identificar os AO e
IO que têm forte influência no valor dos coeficientes ARMA estimados. Como medi-
das alternativas de influência temos o diagnóstico DC de Bruce e Martin (1989) que
mede a alteração da variância do ruído estimada em presença de outliers e as medidas
de deslocamento da verosimilhança.
Na presença de múltiplos e consecutivos outliers pode-se utilizar a estatística de
diagnóstico de Yatawara e Lin (1994) a qual permite detectar conjuntos de observa-
ções ou pode-se seguir uma estratégia de detecção baseada num procedimento de eli-
minação iterativa proposta por Bruce e Martin (1989).
![Cap5 Vegeta..o atualiz17[1].10.4iepa.ap.gov.br/estuario/arq_pdf/vol_1/cap_5_vegetacao... · 2016. 5. 8. · Title: Microsoft Word - Cap5 Vegeta..o_atualiz17[1].10.4.doc Author: Marcell](https://img.document.onl/doc/110x75/61186976dbd1e32ae54019e9/cap5-vegetao-atualiz171104iepaapgovbrestuarioarqpdfvol1cap5vegetacao.jpg)




























