Embed Size (px)
Citation preview

Estrutura de covariancia espacial
multivariada nao separavel
Rafael Santos Erbisti
Universidade Federal do Rio de Janeiro
Instituto de Matematica
Departamento de Metodos Estatısticos
2015

Estrutura de covariancia espacial multivariada nao
separavel
Rafael Santos Erbisti
Dissertacao de Mestrado submetida ao Programa de Pos-Graduacao em Estatıstica
do Instituto de Matematica da Universidade Federal do Rio de Janeiro - UFRJ, como
parte dos requisitos necessarios a obtencao do tıtulo de Mestre em Estatıstica.
Aprovada por:
Thaıs Cristina Oliveira da Fonseca
DME/IM - UFRJ - Orientadora.
Mariane Branco Alves
DME/IM - UFRJ - Coorientadora.
Alexandra Mello Schmidt
DME/IM - UFRJ.
Juliano Junqueira Assuncao
Dpto. Economia - PUC Rio.
Rio de Janeiro, RJ - Brasil
2015
ii

CIP - Catalogação na Publicação
Elaborado pelo Sistema de Geração Automática da UFRJ com osdados fornecidos pelo(a) autor(a).
E65eErbisti, Rafael Santos Estrutura de covariância espacial multivariadanão separável / Rafael Santos Erbisti. -- Rio deJaneiro, 2015. 53 f.
Orientadora: Thaís Cristina Oliveira da Fonseca. Coorientadora: Mariane Branco Alves. Dissertação (mestrado) - Universidade Federaldo Rio de Janeiro, Instituto de Matemática,Programa de Pós-Graduação em Estatística, 2015.
1. geoestatística. 2. funções de covariânciacruzada. 3. funções de covariância espacialmultivariada não separáveis. 4. dimensõeslatentes. 5. inferência bayesiana. I. Fonseca,Thaís Cristina Oliveira da, orient. II. Alves,Mariane Branco, coorient. III. Título.
iii

Aos meus pais, pela educacao, exemplo
e incentivo que sempre deram.
iv

Agradecimentos
A todos que contribuıram para a realizacao deste trabalho, fica expresso aqui minha
gratidao, especialmente:
As minhas orientadoras, Thais Fonseca e Mariane Alves, pela disponibilidade e de-
dicacao. Agradeco por poder trabalhar com tao excelentes profissionais. O conhecimento
e experiencia transmitidos por voces foram essenciais para meu desenvolvimento.
Aos meus pais, Renzo Erbisti e Bellanir Erbisti, por sempre acreditarem e me apoia-
rem em todos os momentos. Sem voces nada disso seria possıvel.
A minha irma, Juliana Erbisti, pelo companheirismo e amizade de toda a vida.
A Paloma Rocha, por me apoiar em todos os momentos, me ajudando no que fosse
preciso, sempre com muito amor, carinho e paciencia.
Agradeco aos amigos Caroline Ponce, Juliana Freitas e Luiz Fernando Costa, que
me acompanharam durante esses dois anos de mestrado. Dividimos experiencias, preo-
cupacoes e madrugas em claro, mas tambem dividimos alegrias, muitas risadas e bons
momentos, principalmente as tercas-feiras, quando, depois de horas de estudo, pedıamos
pizza para aliviar o estresse.
A Paulo Tafner e Carolina Botelho, por todo apoio e colaboracao.
A professora Alexandra Schmidt, pelo apoio e incentivo que recebi desde a conversa
que tivemos ao final do processo seletivo do mestrado.
Agradeco a todos os professores do programa de pos-graduacao em Estatıstica da
UFRJ que, de alguma forma, contribuıram para a minha formacao.
v

Resumo
A aplicacao de modelos espaciais tem crescido substancialmente em diversas areas,
como, por exemplo, nas ciencias ambientais, ciencias climaticas e agricultura. O obje-
tivo deste trabalho e introduzir uma nova classe de funcoes de covariancia nao separavel
para dados espaciais multivariados. Com isso, precisamos especificar uma funcao de co-
variancia cruzada valida, que define a dependencia entre componentes do vetor resposta
entre as localizacoes. Entretanto, sabemos que funcoes de covariancia cruzada nao sao
simples de serem especificadas. A funcao de covariancia nao separavel proposta e base-
ada na combinacao convexa de funcoes de covariancia separaveis e em dimensoes latentes
que representam as componentes. A partir de algumas proposicoes foi observado que
a estrutura de covariancia encontrada e valida e flexıvel. Alem disso, utilizamos apro-
ximacoes de matrizes de covariancia cheia a partir do produto de Kronecker de duas
matrizes separaveis de menor dimensao. Essas aproximacoes foram aplicadas apenas na
funcao de verossimilhanca para que a interpretacao do modelo nao fosse desconsiderada.
Analisamos o caso mais simples do modelo proposto e encontramos resultados bastante
satisfatorios. Vimos tambem que ha a necessidade de estudar outras especificacoes da
funcao proposta.
Palavras-Chaves: geoestatıstica, modelos espaciais multivariados, funcoes de covariancia
cruzada, funcoes de covariancia espacial multivariada nao separaveis, dimensoes latentes,
inferencia bayesiana.
vi

Abstract
Spatial models have been increasingly applied in several areas, such as environmental
science, climate science and agriculture. This work aimed to introduce a new class of non-
separable covariance functions for multivariate spatial data. Therefore, we have to specify
a valid cross-covariance function, which defines the dependency of the response vector
components between the locations. However, we know that cross-covariance functions are
not easily specified. In this work, we propose a nonseparable covariance function that
is based on the convex combination of separable covariance functions and on the latent
dimensions that represent the components. Based on some propositions, it was observed
that this covariance structure is valid and flexible. Moreover, we use approximations of
full-covariance matrices from the Kronecker product of two separable matrices of minor
dimensions. These approximations have been applied only to the likelihood function in
order to not disregard the interpretation of the model. We analyzed the simplest case
of the proposed model and satisfactory results were obtained. Furthermore, we observed
that it is necessary to study other specifications of the proposed function.
Keywords: geostatistics, multivariate spatial models, cross covariance functions, non-
separable multivariate spatial covariance, functions, latent dimensions, bayesian infe-
rence.
vii

Sumario
1 Introducao 1
2 Modelos para analise geoestatıstica 4
2.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Modelo univariado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3 Modelo multivariado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.1 Modelos separaveis . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1.1 Limitacoes dos modelos separaveis . . . . . . . . . . . . 8
2.3.2 Algumas propostas de modelos multivariados . . . . . . . . . . . . 10
3 Modelo proposto 14
3.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Representacao por mistura . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.2 Representacao por mistura proposta . . . . . . . . . . . . . . . . 15
3.2.3 Estrutura de covariancia nao separavel . . . . . . . . . . . . . . . 16
3.2.4 Funcao proposta . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.4.1 Reparametrizacao . . . . . . . . . . . . . . . . . . . . . 18
3.2.4.2 Alguns modelos . . . . . . . . . . . . . . . . . . . . . . . 20
3.2.5 Conclusoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4 Procedimento de inferencia 23
4.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
viii

4.2 Inferencia Bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2.1 Especificacoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2.2 Previsao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5 Aproximacoes separaveis 27
5.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.2 Solucao do problema PPKCC . . . . . . . . . . . . . . . . . . . . . . . . 28
5.3 Erro de aproximacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.3.1 Comportamento do erro de aproximacao . . . . . . . . . . . . . . 30
5.4 Utilizando a aproximacao separavel . . . . . . . . . . . . . . . . . . . . . 30
6 Exemplos simulados 39
6.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
6.2 Simulacao 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
6.3 Simulacao 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
6.4 Comentarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
7 Conclusoes e trabalhos futuros 49
ix

Lista de Tabelas
5.1 Resumo das distribuicoes a posteriori de cada modelo. . . . . . . . . . . 34
6.1 Resumo da distribuicao a posteriori. . . . . . . . . . . . . . . . . . . . . . 41
x

Lista de Figuras
5.1 Erro de Aproximacao por Separabilidade variando o valor do parametro
de separabilidade α0. Linha vermelha avalia o erro utilizando duas compo-
nentes (p = 2) e a linha preta com tres componentes (p = 3). (a) Mesmos
alcances espaciais. (b) Alcances espaciais diferentes para cada componente. 31
5.2 Resumo das observacoes simuladas: (a) localizacoes. (b) matriz de co-
variancia. (c) histograma da componente 1. (d) histograma da compo-
nente 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.3 Curvas de contorno da funcao de verossimilhanca. (1) curvas em preto:
estrutura de covariancia nao separavel. (2) curvas em vermelho: estrutura
de covariancia aproximada. . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.4 Curvas a posteriori e curva a priori. (1) curva vermelha: posteriori estru-
tura aproximada. (2) curva preta: posteriori estrutura nao separavel. (3)
curva azul tracejada: priori. . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.5 Previsoes e erro quadratico medio (EQM). (1) pontos vermelhos: valores
observados. (2) pontos pretos: valores preditos. . . . . . . . . . . . . . . 38
6.1 Cadeias da distribuicao a posteriori. (1) linha azul: valor verdadeiro. . . 44
6.2 Histograma da distribuicao a posteriori. (1) linha vermelha: verdadeiro
valor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6.3 Funcoes de covariancia: mediana a posteriori (linha azul cheia), intervalo
de credibilidade de 95% (linha azul tracejada), funcao do modelo original
(linha verde cheia). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
6.4 Cadeias da distribuicao a posteriori. (1) linha azul: valor verdadeiro. . . 47
xi

6.5 Funcoes de covariancia: mediana a posteriori (linha azul cheia), intervalo
de credibilidade de 95% (linha azul tracejada), funcao do modelo original
(linha verde cheia). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
xii

Capıtulo 1
Introducao
A estatıstica espacial e a area da estatıstica que estuda metodos para a coleta, des-
cricao, visualizacao, modelagem e analise de dados que possuem coordenadas geograficas,
ou seja, e a area na qual se considera a importancia do arranjo espacial na analise ou inter-
pretacao dos resultados. De fato, na avaliacao de certos tipos de fenomenos a utilizacao
da dimensao espacial pode trazer resultados mais realistas do que quando a ignoramos.
Por exemplo, ao tratarmos dados sobre precos de imoveis na cidade do Rio de Janeiro
fica clara a importancia de considerar informacoes sobre localizacoes geograficas na mo-
delagem, ja que muitos fatores espaciais podem influenciar o preco de um imovel, tais
como proximidade de regioes de favela, tipos de transportes publicos no entorno etc.
Os diferentes tipos de dados espaciais sao geralmente classificados de acordo com sua
natureza. De maneira geral, podemos dizer que a estatıstica espacial pode ser dividida
em tres grandes areas: processos pontuais, dados de area e geoestatıstica (Cressie, 1993).
Neste trabalho iremos nos concentrar em dados georreferenciados, que segundo Sch-
midt e Sanso (2006), sao obtidos a partir de localizacoes fixas ao longo de uma regiao de
interesse, possivelmente em diferentes instantes do tempo. Ao analisar observacoes desse
tipo, espera-se que medidas feitas em localizacoes proximas entre si sejam altamente
correlacionadas, enquanto que para localizacoes separadas por grandes distancias, ocorra
um comportamento mais independente. Como exemplo, podemos considerar a tempera-
tura medida nas estacoes meteorologicas de Copacabana, Ipanema e Bangu. E razoavel
pensar que haja um comportamento semelhante entre as temperaturas de Copacabana e
1

Ipanema, porem, as temperaturas de Copacabana e Bangu tendem a ser independentes,
devido a distancia entre essas duas regioes. Com isso, e natural pensar que o principal in-
teresse na modelagem de dados georreferenciados e especificar uma funcao que capte essa
dependencia espacial. Neste contexto, a funcao que desempenha esse papel e a funcao
de covariancia.
A utilizacao de funcoes de covariancia estacionarias e isotropicas e bastante comum.
Segundo Schmidt e Sanso (2006) estacionariedade exige que as funcoes de media e co-
variancia sejam invariantes sob translacoes e isotropia corresponde a uma simetria radial
onde a dependencia entre localizacoes e determinada, simplesmente, pela distancia entre
elas.
A aplicacao de modelos espaciais tem crescido substancialmente em diversas areas.
Frequentemente, as observacoes sao multivariadas, isto e, ha um vetor de respostas em
diversas localizacoes ao longo do espaco. Em outras palavras, dada a localizacao, e
possıvel obter informacoes sobre diferentes componentes, por exemplo, estacoes de moni-
toramento do ar podem medir nıveis de diversos poluentes, tais como ozonio, monoxido
de carbono, oxidos de nitrogenio, material particulado etc.
A literatura sobre abordagens capazes de modelar dados espaciais multivariados e
extensa. Banerjee et al. (2004) apresentam alguns metodos de modelagem para dados
dessa natureza. Um deles esta baseado na ideia de separabilidade. De fato, o uso de
modelos separaveis e conveniente, pois a matriz de covariancia pode ser expressa como
um produto de Kronecker de matrizes menores vindas da dimensao espacial e do vetor
de respostas e, assim, determinantes e inversas sao facilmente obtidos, fornecendo consi-
deravel ganho computacional. Entretanto, essa abordagem possui algumas desvantagens
que serao discutidas neste trabalho.
Outro metodo bastante conhecido e o modelo de coregionalizacao linear (MCL), que
permite modelar dados multivariados utilizando alcances diferentes e estrutura de co-
variancia nao separavel. Este modelo e suas generalizacoes estao descritos e muito bem
definidos em Banerjee et al. (2004).
Apanasovich e Genton (2010) apresentam uma classe geral de modelos flexıveis e
computacionalmente viaveis. Um dos objetivos do artigo e representar o vetor de com-
2

ponentes a partir de dimensoes latentes (pontos) no espaco k-dimensional, 1 ≤ k ≤ p, p
sendo o numero de componentes.
O objetivo deste trabalho e introduzir uma classe de modelos de covariancia nao
separavel para dados multivariados espaciais baseada na ideia de Fonseca e Steel (2011)
e tambem na representacao do vetor de componentes apresentada por Apanasovich e
Genton (2010). A partir de algumas proposicoes e possıvel observar que a estrutura
de covariancia encontrada e valida e flexıvel. Ademais, a matriz de covariancia nao
necessariamente sera simetrica.
Este trabalho esta organizado em sete capıtulos, incluindo este. O segundo capıtulo
especifica os modelos univariado e multivariado com estrutura separavel. Alem disso, faz
uma breve revisao sobre as princiais caracterısticas dos modelos de coregionalizacao linear
e da proposta de Apanasovich e Genton (2010). O capıtulo 3 introduz uma nova classe
de modelos de covariancia nao separavel baseado na ideia de Fonseca e Steel (2011) e na
definicao de dimensoes latentes proposta por Apanasovich e Genton (2010). O quarto
capıtulo apresenta o procedimento de inferencia feito na estimacao do modelo proposto.
O capıtulo 5 mostra como encontrar aproximacoes separaveis para a matriz de covariancia
cheia com estrutura nao separavel. O penultimo capıtulo apresenta simulacoes que ana-
lisam o desempenho do modelo proposto em captar e gerar estruturas separaveis. Por
fim, o capıtulo 7 apresenta as conclusoes e trabalhos futuros desta pesquisa.
3

Capıtulo 2
Modelos para analise geoestatıstica
2.1 Introducao
Segundo Cressie (1993), os dados geoestatısticos podem ser considerados uma rea-
lizacao de um processo estocastico {Y (s) : s ∈ D}, onde D e um subconjunto de <d com
volume d-dimensional positivo. Em outras palavras, o ındice espacial s varia continu-
amente ao longo da regiao D. Geralmente d = 2 (latitude e longitude) ou d = 3 (por
exemplo, latitude, longitude e altitude).
A principal discussao sobre a analise de dados espaciais se refere ao modo de se fazer
inferencia sobre o processo espacial Y (s) e, posteriormente, prever em localizacoes novas
ou nao medidas (Banerjee et al., 2004).
Antes de definir os modelos utilizados para tratar dados geoestatısticos, apresenta-
remos os conceitos de estacionaridade e isotropia descritos em Banerjee et al. (2004).
Assim, assuma que o processo espacial tenha media µ(s) = E[Y (s)] e que a variancia
de Y (s) exista para todo s ∈ D. Portanto, o processo e dito fracamente esta-
cionario se a media e constante para toda localizacao s ∈ D (isto e, µ(s) = µ) e se
Cov(Y (s), Y (s′)) = C(s−s′), para todo s, s′ ∈ D. Note que essa ultima condicao implica
que a covariancia entre quaisquer duas localizacoes s e s′ pode ser resumida a partir de
uma funcao de covariancia que depende apenas da distancia entre s e s′. Baseado em
Schmidt e Sanso (2006), a isotropia e uma restricao mais forte, pois corresponde a uma
simetria radial onde a funcao que define a dependencia entre localizacoes e determinada
4

pela distancia entre elas. Em outras palavras, C(s, s′) = C(‖s−s′‖), onde ‖s−s′‖ denota
a distancia euclidiana entre s e s′.
Observe que quando um processo e estacionario e isotropico, sua variancia e constante
e os elementos da matriz de covariancia podem ser escritos como a multiplicacao de σ2
(variancia) e uma funcao de correlacao valida (isto e, positiva definida) que depende da
distancia euclidiana das localizacoes e de um vetor parametrico. E de se esperar que
a funcao de correlacao seja monotona nao-crescente e que exista algum parametro que
controle seu decaimento, ja que e ela a responsavel pela suavidade do processo.
Ha diversas funcoes de correlacao validas existentes na literatura. Aqui, vamos listar
duas delas:
1. Famılia exponencial potencia
ρ(h; Θ) = exp
{−(
h
θ1
)θ2}(2.1)
onde h e a distancia euclidiana entre dois pontos no espaco, θ2 ∈ (0, 2]. Quando
θ2 = 2 temos um caso particular da funcao de correlacao gaussiana. Quando θ2 = 1
obtemos a funcao de correlacao exponencial.
2. Famılia cauchy
ρ(h; Θ) =
(1 +
(h
θ1
)θ2)−θ3(2.2)
onde h e a distancia euclidiana entre dois pontos no espaco, θ1 > 0 , θ2 ∈ (0, 2] e
θ3 > 0.
Frequentemente, Y (s) segue um processo gaussiano e com isso, precisamos especificar
apenas o primeiro e o segundo momentos da distribuicao. Neste trabalho, todos os
processos espaciais analisados sao gaussianos.
Antes de comecarmos a apresentar os modelos geoestatısticos e importante definir
o conceito de alcances espaciais. Para tratar disso, voltaremos ao exemplo citado no
capıtulo 1. Vimos que e natural assumir que as temperaturas medidas nas estacoes
meteorologicas de Copacabana e Ipanema tendem a ter uma maior correlacao do que
as temperaturas de Copacabana e Bangu, pois os dois primeiros bairros sao vizinhos e
5

estao localizados proximos ao mar e tambem porque ha uma grande distancia geografica
entre Bangu e a Zona Sul, sendo Bangu um bairro afastado da orla da cidade. Assim,
e razoavel pensar que a correlacao diminui conforme a distancia aumenta, porem, como
saber qual e o valor da distancia na qual a correlacao cai para valores desprezıveis? O
alcance espacial e justamente o valor dessa distancia.
Nas proximas secoes sao apresentados alguns metodos para analise de dados geoes-
tatısticos.
2.2 Modelo univariado
Esta secao introduz a analise de processos espaciais a partir do caso mais simples,
isto e, processos que analisam a dependencia espacial de apenas uma componente.
Para isso, considere o processo espacial {Y (s) : s ∈ D}, onde D ⊂ <d. Normalmente,
em geoestatıstica, dadas as observacoes do processo de interesse em n localizacoes, Y =
[Y (s1), Y (s2), ..., Y (sn)]T , assume-se que
Y|µ,Σ ∼ Nn(µ,Σ)
onde µ e um vetor de dimensao n representando a media do processo e Σ e uma matriz
n× n que representa a estrutura de covariancia.
A partir disso, podemos descrever o processo Y(.) atraves do modelo
Y = Xβ + ε (2.3)
onde X representa a matriz das variaveis explicativas, β e o vetor de parametros das
regressoras e ε e o erro aleatorio tal que ε ∼ Nn(0,Σ). Sabe-se que cada elemento da
matriz de covariancia depende somente da variancia do processo e de uma funcao de
correlacao espacial valida. Considerando um processo estacionario de segunda ordem
(fracamente estacionario), temos que
Cov[Y (s), Y (s′)] = C(s− s′) = C(h), ∀s, s′ ∈ D
depende apenas das distancias entre as localizacoes s e s′, h = s - s′. Portanto, a matriz
de covariancia sera dada por
Σ = σ2ρ(h,Φ)
6

onde σ2 e a variancia do processo e ρ(.,Φ) e uma funcao de correlacao valida. Observe
que Φ e o vetor parametrico que descreve a funcao de correlacao.
2.3 Modelo multivariado
Quando se faz inferencia com base em dados multivariados, como por exemplo, dife-
rentes fatores climaticos mensurados em estacoes meteorologicas, o objetivo principal e
identificar a dependencia entre as variaveis medidas em todas as localizacoes.
Para isso, denotaremos Y(s) como o vetor de variaveis aleatorias na localizacao s, de
dimensao p × 1, ou seja, Y = [Y(s1),Y(s2), ...,Y(sn)]T , onde Yi(s) representa a i-esima
variavel, i = 1, 2, ..., p, na localizacao s ∈ D. Deste modo, se Y e dito um processo
gaussiano, para defini-lo, precisamos determinar apenas dois objetos de analise: a funcao
de media e as funcoes de covariancia cruzada (Apanasovich et al., 2012).
A funcao de covariancia cruzada valida ira definir a dependencia entre as componentes
do vetor resposta. Entretanto, sabe-se que funcoes de covariancia cruzada nao sao simples
de serem especificadas, pois para qualquer numero de localizacoes e qualquer escolha
dessas localizacoes, a matriz de covariancia resultante deve ser positiva definida (Gelfand
e Banerjee, 2010).
De acordo com Banerjee et al. (2004), o objeto crucial e a covariancia cruzada
C(s, s′) ≡ Cov(Y(s),Y(s′)), que e uma matriz de dimensao p× p e nao necessariamente
simetrica (isto e, Cov(Yi(s), Yj(s′)) nao precisa ser igual a Cov(Yj(s), Yi(s
′))).
De acordo com Wackernagel (1995), as funcoes de covariancia cruzada Cij(h), do
conjunto de p variaveis aleatorias Yi(s), podem ser definidas da seguinte maneira:
Se
E[Yi(s)] = mi, s ∈ D; i = 1, 2, ..., p
entao, a estrutura de covariancia cruzada e definida como
E[(Yi(s)−mi)(Yj(s + h)−mj)] = Cij(h), s, s + h ∈ D; i, j = 1, 2, ..., p
onde a media de cada variavel Yi(s), em cada localizacao do domınio, e igual a constante
mi.
7

2.3.1 Modelos separaveis
Para modelar dados dessa natureza podemos utilizar uma forma bem simples, baseada
na ideia de separabilidade. Para definir a estrutura de covariancia de modo separavel
vamos considerar {Y(s) : s ∈ D ⊂ <2; Y ∈ <p} sendo um campo aleatorio multivariado.
Por exemplo, Y(s) pode ser formado pelas componentes (Temperatura, Umidade)(s).
A funcao de covariancia cruzada para duas componentes i e j do vetor Y, entre duas
localizacoes quaisquer s e s′, pode ser descrita por
Cij(s, s′) = aijρ(s, s′) (2.4)
onde A = {aij} e uma matriz positiva definida p×p e ρ(s, s′) e uma funcao de correlacao
valida.
Como Y e formado por um empilhamento das observacoes nas n localizacoes, a matriz
de covariancia resultante e
Σ = R⊗A (2.5)
onde Rij = ρ(si, sj) e ⊗ denota o produto de Kronecker. Note que Σ sera positiva
definida desde que R e A tambem sejam.
A utilizacao de modelos espaciais com estrutura separavel e bastante comum. A
justificativa e simples. A matriz de covariancia cheia Σ, de dimensao np× np, pode ser
escrita a partir do produto de Kronecker de duas matrizes de menor dimensoes (p× p e
n× n). A partir das propriedades do produto de Kronecker, e possıvel calcular a inversa
e o determinante de Σ da seguinte maneira:
Σ−1 = R−1 ⊗A−1
|Σ| = |R|p|A|n
De fato, e mais conveniente em termos computacionais utilizar a estrutura definida
na equacao 2.4, porem, este tipo de modelagem possui algumas limitacoes.
2.3.1.1 Limitacoes dos modelos separaveis
Banerjee et al. (2004) apresentam algumas limitacoes associadas ao modelo separavel.
Segundo os autores, a estrutura de covariancia sera simetrica, ou seja, Cov(Yi(s), Yj(s′)) =
8

Cov(Yj(s), Yi(s′)) para todo i, j, s e s′. Alem disso, se ρ for estacionario, a correlacao
generalizada e dada por
Cov(Yi(s), Yj(s + h))√Cov(Yi(s), Yi(s + h))Cov(Yj(s), Yj(s + h))
=aij√aiiajj
independente de s e h. A ultima restricao citada pelos autores e que se a correlacao
espacial ρ for isotropica e estritamente decrescente, entao o alcance espacial sera identico
para cada componente de Y(s).
Essa ultima limitacao apresentada pode ser entendida de outra maneira. Consi-
dere os processos espaciais univariados {Y (s) : s ∈ D} e {X(s) : s ∈ D}, onde
D ⊂ <2, conforme definido na secao 2.2. Logo, sao obtidos os seguintes vetores Y =
[Y (s1), Y (s2), ..., Y (sn)]T e X = [X(s1), X(s2), ..., X(sn)]T .
Sabe-se que e possıvel representar a relacao linear espacial abaixo para qualquer ponto
no domınio
E[Y|X] = β0 + β1X (2.6)
Para garantir a relacao definida em (2.6), considere o vetor empilhado (X,Y)T , de
dimensao 2n × 1, com distribuicao Normal Multivariada e estrutura de covariancia se-
paravel, como definido em 2.4, isto e, X
Y
∼ N2n(µ,Σ), Σ = A⊗R
Dada esta distribuicao, note que X ∼ Nn(µx, a11R) e Y ∼ Nn(µy, a22R). Assim,
a partir das propriedades da distribuicao normal multivariada, e possıvel observar que
Y|X ∼ Nn(µ∗,Σ∗), onde
µ∗ = µy + (a12R)(a11R)−1(X− µx)
= µy +a12a11
RR−1(X− µx)
= µy +a12a11
(X− µx)
= µy −a12a11µx +
a12a11
X
9

e
Σ∗ = a22R− (a12R)(a11R)−1(a12R)
= a22R−a212a11
RR−1R
= a22R−a212a11
R
=
(a22 −
a212a11
)R
Portanto, a distribuicao de Y|X pode ser escrita da seguinte maneira: Y|X ∼ Nn(β0+
β1X, σ2R), onde
β0 = µy −a12a11µx β1 =
a12a11
σ2 = a22 −a212a11
Entretanto, fazendo a analise de maneira contraria, ou seja, se partirmos do ponto
em que definimos X ∼ Nn(µx, a11R) e Y|X ∼ Nn(β0 + β1X, σ2S), onde S e uma matriz
qualquer que determina a dependencia espacial, teremos que a estrutura de covariancia
de Y sera
Cov[Yi, Yj] = σ2Sij + β21a11Rij
= a22Sij −a212a11
Sij +a212a11
Rij (2.7)
Neste caso, e facil observar que para obtermos o caso separavel devemos fazer uma
restricao quanto a estrutura de S. De fato, a equacao 2.7 sera igual a a22R, isto e,
equivalente ao caso separavel se, e somente se, S = R, ou seja, se a dependencia espacial
de Y|X for a mesma de X.
2.3.2 Algumas propostas de modelos multivariados
Nesta secao, serao apresentadas, de maneira resumida, algumas abordagens utiliza-
das no procedimento de estimacao de processos espaciais multivariados. Iremos descrever
duas propostas ja exitentes na literatura com o objetivo de analisar suas principais ca-
racterısticas para, posteriormente, relaciona-las com as propriedades do modelo proposto
neste trabalho.
10

Inicialmente, descreveremos os modelos de coregionalizacao especificados em Banerjee
et al. (2004). O modelo mais simples de coregionalizacao linear (MCL)1 e da forma
Y(s) = Aw(s), onde A e uma matriz p×p e as componentes de w(s), wj(s), j =
1, 2, ..., p, sao processos espaciais independentes e identicamente distribuıdos. Assim, se
os processos wj(s) tem media igual a zero, sao estacionarios com variancia igual a um
e cov(wj(s), wj(s′)) = ρ(s − s′), entao E(Y(s)) = 0 e a matriz de covariancia cruzada
associada a Y(s) e dada por
ΣY(s),Y(s′) ≡ C(s− s′) = ρ(s− s′)AAT
E possıvel observar que se fizermos AAT = T obtemos a especificacao da estrutura
de covariancia separavel, conforme equacao 2.4.
Ainda baseado em Banerjee et al. (2004), podemos descrever um MCL mais geral se
novamente especificarmos Y(s) = Aw(s), porem, desta vez, considerando os processos
wj(s) independentes mas nao identicamente distribuıdos. Portanto, sejam wj(s) processos
com media µj, variancia 1 e funcao de correlacao estacionaria ρj(h). Entao, temos que
E[Y(s)] = Aµ, onde µ = {µ1, ..., µp}T , e a matriz de covariancia cruzada obtida agora e
ΣY(s),Y(s′) ≡ C(s− s′) =
p∑j=1
ρj(s− s′)Tj
onde Tj = ajaTj , com aj sendo a j-esima coluna de A. Segundo os autores, uma ob-
servacao importante a ser feita e que essa combinacao linear produz processos esta-
cionarios.
Por fim, utilizando funcoes de correlacao monotonas e isotropicas, sera possıvel obter
um alcance para cada componente do processo. Portanto, essa abordagem permite mo-
delar as componentes utilizando diferentes alcances2, diferentemente do modelo separavel
apresentado na secao 2.3.1. Vale ressaltar que existem outras especificacoes do modelo
de coregionalizacao que acomodam estruturas de covariancia nao estacionarias3.
A segunda abordagem que sera apresentada e a descrita por Apanasovich e Genton
(2010). Os autores propoem uma metodologia baseada em dimensoes latentes e modelos
1Chamado de especificacao intrınseca.2Detalhes mais precisos podem ser vistos em Banerjee et al. (2004).3Ver Banerjee et al. (2004).
11

de covariancia ja existentes na literatura. O objetivo e desenvolver uma classe de funcoes
de covariancia cruzada que sejam interpretaveis e viaveis computacionalmente.
A ideia principal de Apanasovich e Genton e representar o vetor de componentes
como pontos num espaco k-dimensional, para um inteiro 1 ≤ k ≤ p, ou seja, fazer com
que a i-esima componente possa ser representada como ξi = {ξi1, ..., ξik}T .
Ja sabemos que se assumirmos que Y e gaussiano, precisamos apenas descrever as
funcoes de media e de covariancia. Portanto, estamos interessados na caracterizacao de
Cov[Yi(s), Yj(s′)] = Cij(s, s
′). Assim, Apanasovich e Genton garantem que, baseado nas
dimensoes latentes, a matriz de covariancia Σij = C{(s, ξi), (s′, ξj)} e positiva definida,
pois suas entradas sao obtidas a partir de uma covariancia valida. De fato, segundo os
autores, para qualquer s, s′ existe Cs,s′(.) tal que Cij(s, s′) = Cs,s′(ξi, ξj) para algum ξi,
ξj ∈ <k.
E importante lembrar que ao inves de especificarmos os ξi’s, podemos trata-los como
parametros. Alem disso, ha a possibilidade de trabalhar apenas com a distancia entre
as componentes do vetor, δij = ‖ξi − ξj‖. Segundo Apanasovich e Genton, essa ideia
de modelagem e semelhante a escala multidimensional (Cox e Cox, 2000) com distancias
latentes δij’s, onde para localizacoes fixas s e s′, grandes δij’s sao convertidos para cor-
relacoes cruzadas pequenas entre as i-esima e j-esima componentes do vetor.
Em uma das simulacoes, os autores comparam o desempenho do modelo proposto
por eles com o MCL. Para mostrar a flexibilidade extra que o modelo deles permite, eles
ajustam o modelo proposto e o MCL, quando, na verdade, a estrutura gerada e do mo-
delo proposto. Nessa simulacao, geram amostras de um processo espacial bidimensional
gaussiano, com media zero e especificacao da covariancia Cov[Yi(s), Yj(s′)]
Cij(‖h‖) = C(‖h‖, δij) =
a211exp(−α1‖h‖) (i = j = 1)
a221exp(−α1‖h‖) + a222exp(−α2‖h‖) (i = j = 2)
a11a21δ12 + 1
exp
{− α1‖h‖
(δ12 + 1)β2
}(i 6= j)
onde h = s− s′. Observe que o MCL e um caso especial da especificacao acima quando
δ12 = β = 0. A partir dos resultados da simulacao os autores afirmam que o modelo de
12

coregionalizacao nao e suficientemente flexıvel para fornecer estimativas sem vies para os
alcances. Alem dessa simulacao os autores utilizam outras especificacoes para mostrar a
flexibilidade do modelo proposto.
Apanasovich e Genton (2010) tambem avaliam a escolha do valor de k a partir de
simulacoes. Segundo eles, valores pequenos de k, como por exemplo, k = 1 ou k = 2, sao
geralmente suficientes4. Alem disso, esses modelos possuem extensoes que acomodam a
falta de simetria. Uma possıvel fraqueza dessa abordagem e que se o numero de variaveis
p for grande, entao o numero inteiro 1 ≤ k ≤ p de dimensoes latentes poderia tornar-se
grande demais.
De fato, a ideia de dimensoes latentes apresentada em Apanasovich e Genton (2010)
sera aplicada ao modelo proposto no capıtulo 3. Vale ressaltar que para as estimacoes
do modelo proposto realizadas neste trabalho utilizamos k = 1.
4Ver Apanasovich e Genton (2010).
13

Capıtulo 3
Modelo proposto
3.1 Introducao
O objetivo deste capıtulo e apresentar uma classe de funcoes de covariancia multi-
variada nao separaveis a partir da ideia de misturas apresentada por Fonseca e Steel
(2011). Tambem iremos introduzir a ideia de dimensoes latentes para representar o vetor
de componentes, como proposto em Apanasovich e Genton (2010). Fonseca e Steel (2011)
consideram funcoes de covariancia espaco-temporais. Neste trabalho, a funcao proposta
e avaliada no espaco multivariado, sem considerar o tempo.
Algumas caracterısticas importantes serao analisadas. A classe de funcoes gerada e
valida, flexıvel e permite diferentes especificacoes. Alem disso, sera visto que e possıvel
obter alcances espaciais distintos para diferentes componentes, o que nao ocorre nos
modelos separaveis.
3.2 Representacao por mistura
3.2.1 Introducao
Fonseca e Steel (2011) apresentaram uma classe geral de modelos espaco-temporais
nao separaveis baseada em misturas de funcoes de covariancia separaveis. Segundo os
autores, a formulacao de mistura pode gerar uma grande variedade de modelos de co-
14

variancia nao separavel validos.
Para definir o modelo proposto em Fonseca e Steel (2011), suponha que (s, t) ∈ D×T ,
D ⊆ <d, T ⊆ <, sejam coordenadas espaco-tempo que variam continuamente em D × T
e defina o processo espaco-temporal {Z(s, t) : s ∈ D, t ∈ T}, onde Z(s, t) = Z1(s)Z2(t),
(s, t) ∈ D × T , {Z1(s) : s ∈ D} e um processo aleatorio puramente espacial com funcao
de covariancia C1(s) e {Z2(t) : t ∈ T} e um processo aleatorio puramente temporal com
funcao de covariancia C2(t). Sendo Z1(s) e Z2(t) nao correlacionados.
A representacao por mistura da funcao de covariancia de Z(s, t) e definida por Fonseca
e Steel (2011) da seguinte maneira: Seja (U, V ) um vetor aleatorio bivariado nao negativo
com distribuicao G(u, v) e independente de {Z1(s) : s ∈ D} e {Z2(t) : t ∈ T}, entao a
funcao de covariancia correspondente a Z(s, t) e uma combinacao convexa de funcoes de
covariancia separaveis. Esta funcao e valida e geralmente nao separavel, e e dada por
C(s, t) =
∫ ∫C(s;u)C(t; v)g(u, v)dudv (3.1)
A ideia proposta neste trabalho e modificar a equacao 3.1 para o caso espacial multi-
variado. Neste momento, o interesse nao esta em avaliar o tempo e sim, as componentes.
A subsecao seguinte apresenta esta nova funcao de covariancia baseada na equacao 3.1.
3.2.2 Representacao por mistura proposta
Nesta subsecao, iremos considerar a mesma representacao apresentada pelos autores
e descrita na equacao 3.1, porem, avaliada no espaco multivariado. Para isso, seja um
vetor aleatorio bivariado nao negativo (U, V ) com distribuicao G(u, v) e independente
do processo Y(s). De maneira similar ao artigo de Fonseca e Steel (2011), temos que a
funcao de covariancia correspondente a Y(s) e uma combinacao convexa de funcoes de
covariancia separaveis. Esta funcao e valida e, geralmente, nao separavel e e dada por
Cij(s, ξ) =
∫ ∫C(s;u)Cij(ξ; v)g(u, v)dudv (3.2)
onde ξ representa a dimensao latente proposta no artigo de Apanasovich e Genton (2010)
e apresentada na secao 2.3.2 e s a localizacao no espaco. E facil observar que a funcao
15

(3.2) e definida por funcoes de covariancia validas e pelo vetor aleatorio (U, V ) com
distribuicao conjunta G(u, v).
Segundo Fonseca e Steel (2011), o passo fundamental na definicao da classe de funcoes
esta na representacao da dependencia entre U e V , pois e isso que ira gerar a interacao
entre o espaco e as componentes.
Vamos definir os variogramas γ1(s) ≡ γ1 e γ2(ξ) ≡ γ2 como funcoes contınuas de
s ∈ <d e ξ ∈ <p, respectivamente. A partir da especificacao acima, uma maneira de
resolver a integral em (3.2) de forma fechada e garantir que a estrutura de covariancia
gerada seja positiva definida e definindo C(s;u) = exp{−γ1u} e C(ξ; v) = exp{−γ2v}.
Com isso, obtemos a seguinte proposicao.
Proposicao 3.2.1 Considere um vetor aleatorio bivariado nao negativo (U, V ) com funcao
geradora de momentos conjunta M(., .). Se os variogramas γ1(s) ≡ γ1 e γ2(ξ) ≡ γ2 sao
funcoes contınuas de s ∈ <d e ξ ∈ <p, respectivamente, e C(s;u) = exp{−γ1u} e
C(ξ; v) = exp{−γ2v}, entao, a partir da funcao (3.2) segue
Cij(s, ξ) = M(−γ1,−γ2) (3.3)
que e uma funcao de covariancia valida.
Majumdar e Gelfand (2007) utilizam integracao de Monte Carlo para resolver uma
integral similar a (3.2), o que seria inviavel em aplicacoes com muitas observacoes. Apa-
nasovich et al. (2012) consideram uma versao multivariada da Matern, apresentando um
modelo flexıvel que permite diferentes comportamentos para diferentes componentes. De
fato, o modelo em (3.2) tambem tem essas caracterısticas e que serao apresentadas mais
adiante.
A seguir, definiremos a representacao do vetor (U, V ) de maneira semelhante a definida
por Fonseca e Steel (2011). Essa especificacao leva a funcoes nao separaveis e que possuem
propriedades bastante uteis.
3.2.3 Estrutura de covariancia nao separavel
A partir da Proposicao 3.2.1 e possıvel construir uma estrutura de covariancia nao
separavel, basta definir a distribuicao do vetor bivariado nao negativo (U, V ). Assim,
16

considere a seguinte proposicao.
Proposicao 3.2.2 Considere as variaveis aleatorias nao negativas e independentes X0,
X1 e X2, com respectivas funcoes geradoras de momentos M0, M1 e M2. Defina U e V
da seguinte maneira: U = X0 +X1 e V = X0 +X2. Se C(s;u) = exp{−γ1u} e C(ξ; v) =
exp{−γ2v}, como na Proposicao 3.2.1, entao a funcao de covariancia resultante a partir
de (3.2) e
Cij(s, ξ) = M0(−γ1 − γ2)M1(−γ1)M2(−γ2) (3.4)
Observe que se U e V forem nao correlacionados, isto e, U = X1 e V = X2, entao o
caso separavel e obtido, pois a funcao de covariancia sera representada como Cij(s, ξ) =
M1(−γ1)M2(−γ2). Observe que essa especificacao e semelhante a da equacao 2.4, pois
a estrutura e gerada a partir de uma funcao que depende apenas das componentes,
M2(−γ2), e outra que depende apenas das localizacoes, M1(−γ1).
A classe gerada na Proposicao 3.2.2 permite diferentes representacoes parametricas,
de acordo com as distribuicoes de X0, X1 e X2. Note que precisamos apenas atribuir
distribuicoes univariadas nao negativas para essas variaveis para especificar a funcao de
covariancia cruzada. Como consequencia da construcao, qualquer correlacao entre U e
V diferente de zero sera positiva.
Ao analisar a funcao gerada pela Proposicao 3.2.2, observou-se que Cij(0) = 1, ou
seja, a funcao Cij(s, ξ) e, na verdade, uma funcao de correlacao cruzada valida. Para
transformar essa funcao de correlacao numa funcao de covariancia, definimos, conforme
Majumdar e Gelfand (2007),
ρij(s, ξ) =Cij(s, ξ)
[Cii(0)Cjj(0)]1/2(3.5)
Note que temos que ρii(0) = 1. Considere Dcov como uma matriz diagonal com
entradas [Dcov]ii = Cii(0). Se Rij(s, ξ) = D−1/2cov Cij(s, ξ)D
−1/2cov , entao Rij(s, ξ) sera uma
funcao de correlacao cruzada valida. De fato, definindo D1/2σ = diag(σ1, ..., σp), σi > 0,
pode-se obter uma funcao de covariancia cruzada valida, que sera dada pela matriz
Cσ = D1/2σ Rij(s, ξ)D
1/2σ .
Observe que a equacao 3.5 e a propria definicao de correlacao que conhecemos. Como a
estrutura encontrada trata-se de uma funcao de correlacao cruzada valida, basta fazermos
17

a conta inversa para encontrar a funcao de covariancia cruzada valida. Com isso, e
possıvel modificar a Proposicao 3.2.2 e definirmos a Proposicao 3.2.3.
Proposicao 3.2.3 Considere as variaveis aleatorias nao negativas e independentes X0,
X1 e X2, com respectivas funcoes geradoras de momentos M0, M1 e M2. Defina U e
V da seguinte maneira: U = X0 + X1 e V = X0 + X2. Se C(s;u) = σiexp{−γ1u} e
C(ξ; v) = σjexp{−γ2v}, entao a funcao de covariancia resultante a partir de (3.2) e
Cij(s, ξ) = σiσjM0(−γ1 − γ2)M1(−γ1)M2(−γ2) (3.6)
que e uma funcao de covariancia valida.
3.2.4 Funcao proposta
Nesta secao, sera apresentada uma funcao de covariancia gerada a partir da Pro-
posicao 3.2.3. Para isso, vamos considerar que as variaveias X0, X1 e X2 seguem dis-
tribuicoes Gama. A partir do Teorema 3.2.1 obtemos classes de funcao de covariancia
Cauchy tanto para as componentes quanto para o espaco.
Teorema 3.2.1 Considere Xi ∼ Gama(αi, λi), i = 0, 1 e 2, entao, a partir da Pro-
posicao 3.2.3, a funcao de covariancia cruzada e
Cij(s, ξ) = σiσj
(1 +
γ1 + γ2λ0
)−α0(
1 +γ1λ1
)−α1(
1 +γ2λ2
)−α2
(3.7)
onde σi > 0, i = 1, ..., p, αk > 0 e λk > 0, k = 0, 1, 2.
Para a construcao da funcao de covariancia, definimos o variograma γ1 como a funcao
de distancia entre as localizacoes e o variograma γ2 como a funcao de distancia entre as
dimensoes latentes de cada componente. De fato, γ1 = ‖s−s′‖ = h e γ2 = ‖ξi−ξj‖ = δij.
3.2.4.1 Reparametrizacao
Com a parametrizacao proposta na equacao 3.7 e difıcil interpretar alguns parametros.
Alem disso, esperamos encontrar uma funcao que permita alcances espaciais diferentes
para cada componente e, de fato, isso nao esta ocorrendo. Como a dependencia de U
18

e V e governada pela variavel X0, tambem seria importante definir algum parametro
responsavel pelo comportamento da correlacao entre essas variaveis, pois ja foi visto que
se U e V forem nao correlacionados, o caso separavel e obtido.
Para isso, a ideia inicial foi fixar os parametros λi, i = 0, 1 e 2, em 1. Alem disso,
introduzimos um parametro extra no variograma das localizacoes. Tal parametro pode
variar de acordo com a componente i, j analisada, isto e, tomamos γ1 = ‖s−s′‖bij
= hbij
.
Feito isso, o modelo geral com todos os possıveis parametros e dado por
Cij(s, ξ) = σiσj
(1 + δij +
h
bij
)−α0(
1 +h
bij
)−α1
(1 + δij)−α2 (3.8)
onde σi e o desvio da componente i, bijs sao interpretados como alcances espaciais e os
αl, l = 1 e 2, podem ser interpretados como parametros de suavizacao da funcao. Um
parametro que deve ser estudado com maior atencao e α0.
Como ja mencionado, e importante encontrar alguma medidade de separabilidade
entre o espaco e as componentes. Assim como em Fonseca e Steel (2011), escolhemos a
correlacao entre as variaveis U e V como tal medida. De fato, vimos que se U e V forem
nao correlacionados, chegamos ao caso separavel. Portanto,
ρ = ρ(U, V ) =Cov(U, V )√
V ar(U)V ar(V )
=Cov(X0 +X1, X0 +X2)√
V ar(X0 +X1)V ar(X0 +X2)
=V ar(X0)√
[V ar(X0) + V ar(X1)][V ar(X0) + V ar(X2)]
=α0√
(α0 + α1)(α0 + α2)
Observe que pela construcao de U e V , 0 ≤ ρ ≤ 1. Alem disso, ρ = 0 indica
separabilidade, ja que neste caso U = X1 e V = X2. Portanto, e possıvel observar que
α0 e o parametro responsavel pelo grau de separabilidade do modelo. E facil visualizar
que se α0 = 0, entao, ρ = 0.
Neste caso onde α0 = 0, a equacao 3.8 pode ser escrita da seguinte maneira
Cij(s, ξ) = σiσj
(1 +
h
bij
)−α1
(1 + δij)−α2 (3.9)
19

Um detalhe importante que deve ser observado e que mesmo que α0 seja zero, so sera
possıvel obter o modelo separavel se os alcances espaciais bij forem todos iguais, ou seja,
se bij = φ, i, j = 1, 2, ..., p. Neste caso, e possıvel observar que as funcoes de correlacao
do modelo pertencem a famılia Cauchy. Caso os alcances espaciais nao sejam iguais, a
equacao 3.9 estara apenas especificada de maneira semelhente ao caso separavel, porem,
o modelo gerado sera nao separavel.
Outro caracterıstica importante refere-se ao fato do α0 ser um parametro que assume
apenas valores positivos. Portanto, ele nao podera ser igual a zero, mas sabemos que ele
pode assumir valores muito pequenos e proximos de 0.
3.2.4.2 Alguns modelos
A partir dessa construcao da funcao proposta na equacao 3.8, ha dois modelos menos
gerais que pretendemos estudar neste trabalho.
Modelo 1 (MNS-01)
Este modelo e menos geral que o proposto na equacao 3.8 e, alem disso, nao permite
que as componentes tenham alcances espaciais diferentes. Aqui, fixamos α1 = α2 = 1. A
funcao de covariancia resultante e
Cij(s, ξ) = σiσj
(1 + δij +
h
φ
)−α0(
1 +h
φ
)−1(1 + δij)
−1 (3.10)
Para este modelo temos que se α0 = 0, entao o caso separavel e obtido. Alem disso,
a funcao de correlacao pertence a classe Cauchy. Neste caso, podemos interpretar os
parametros da seguinte maneira: σi corresponde ao desvio da componente i, i = 1, 2, ..., p;
δij mede a distancia latente entre as componentes i e j, i, j = 1, 2, ..., p; φ representa o
alcance espacial das componentes; e α0 pode ser interpretado como o parametro de se-
perabilidade. Assim, analisando os possıveis casos, temos os seguintes resultados
se h = 0 e i = j: Cii(0, 0) = σ2i
se h = 0 e i 6= j: Cij(0, ξ) = σiσj (1 + δij)−(α0+1)
20

se h 6= 0 e i = j: Cii(s, 0) = σ2i
(1 + h
φ
)−(α0+1)
se h 6= 0 e i 6= j: Cij(s, ξ) = σiσj
(1 + δij + h
φ
)−α0(
1 + hφ
)−1(1 + δij)
−1
Modelo 2 (MNS-02)
Este modelo tambem e menos geral que o proposto na equacao 3.8, porem, permite
que as componentes tenham alcances espaciais diferentes. Aqui, tambem fixamos α1 =
α2 = 1. A funcao de covariancia resultante e
Cij(s, ξ) = σiσj
(1 + δij +
h
bij
)−α0(
1 +h
bij
)−1(1 + δij)
−1 (3.11)
Para este modelo temos que se α0 = 0, entao o caso separavel nao e obtido. Lembre
que uma das propriedades do modelo separavel apresentada na secao 2.3.1.1 referia-se ao
fato de que os alcances espaciais de cada componente deveriam ser iguais. Aqui, apesar
de obtermos uma especificacao semelhante a do modelo separavel, os alcances espaciais
podem ser diferentes e, com isso, nao conseguimos obter um modelo separavel. Portanto,
podemos interpretar os parametros bij da seguinte forma: bii representa o alcance espacial
da componente i, i = 1, 2, ..., p, e bij pode ser entendido como o alcance cruzado entre as
componentes i e j, i, j = 1, 2, ..., p. Com isso, os possıveis casos sao apresentados a seguir
se h = 0 e i = j: Cii(0, 0) = σ2i
se h = 0 e i 6= j: Cij(0, ξ) = σiσj (1 + δij)−(α0+1)
se h 6= 0 e i = j: Cii(s, 0) = σ2i
(1 + h
bii
)−(α0+1)
se h 6= 0 e i 6= j: Cij(s, ξ) = σiσj
(1 + δij + h
bij
)−α0(
1 + hbij
)−1(1 + δij)
−1
21

3.2.5 Conclusoes
Este capıtulo apresentou uma classe geral de funcoes de covariancia multivariada nao
separaveis. Vimos que a partir de determinadas especificacoes e possivel encontrar um
modelo com estrutura separavel.
Assim como em Fonseca e Steel (2011) esses modelos sao bastante flexıveis, pois
podem ser especificados de diversas maneiras. Para isso, basta assumir diferentes distri-
buicoes nao negativas para as variaveis X0, X1 e X2.
No modelo especificado na secao 3.2.4, observamos que podemos medir o grau de
separabilidade a partir de um unico parametro. Alem disso, o modelo permite trabalhar
com alcances espaciais diferentes para componentes distintas, uma propriedade bastante
importante.
22

Capıtulo 4
Procedimento de inferencia
4.1 Introducao
Quando fazemos inferencia sobre qualquer conjunto de dados, de fato, estamos inte-
ressados em obter informacoes referentes as quantidades nao observadas e desconhecidas.
Neste capıtulo, vamos apresentar uma breve revisao do procedimento de inferencia utili-
zado na implementacao da estrutura de covariancia proposta no capıtulo 3.
Para tanto, considere o vetor de observacoes y = (y1, ..., yp) obtido em cada uma
das n localizacoes s ∈ D. Como ja mencionado anteriormente, dados geoestatısticos sao
obtidos a partir de processos contınuos ao longo do espaco. Se o processo for gaussiano,
entao a funcao de verossimilhanca podera ser escrita da seguinte maneira:
l(y;θ) = (2π)−np2 |Σ|−1/2exp
{−1
2(y− µ)TΣ−1(y− µ)
}(4.1)
onde y e o vetor contendo as np observacoes, µ = Xβ e o vetor de medias, Σ e a estrutura
de covariancia de dimensao np×np que define a dependencia das p componentes entre si
em todas as n localizacoes, e θ e vetor parametrico. Neste caso, a estrutura de covariancia
e definida pela funcao proposta na equacao 3.8.
Assim, podemos definir o vetor parametrico θ que contem as quantidades desconheci-
das que precisaremos estimar. Portanto, θ = (σ, δ,α,b,β), onde σ = (σ1, ..., σp), δ e o
vetor formado pelas componentes latentes δij, i 6= j, i, j = 1, ..., p, α = (α0, α1, α2), b e o
vetor formado pelos alcances espaciais bij, i, j = 1, ..., p, e β = (β10, ..., βp0, β11, ..., βp1, ...,
23

β1q, ..., βpq), sendo q o numero de covariaveis incluindo intercepto.
4.2 Inferencia Bayesiana
Esta secao apresenta de maneira resumida o procedimento utilizado na estimacao dos
parametros do modelo proposto. Detalhes mais especıficos sobre inferencia bayesiana
podem ser vistos em Migon e Gamerman (1999) e DeGroot e Schervish (2011).
Quando trabalhamos sob o enfoque bayesiano, sabemos que a informacao dos dados
com respeito ao vetor parametrico θ, traduzida pela funcao de verossimilhanca, e combi-
nada com a informacao a priori, especificada atraves de uma distribuicao com densidade
p(θ). O resultado obtido a partir dessa combinacao e conhecido como distribuicao a
posteriori, p(θ|y). De fato, e razoavel pensar que apos observar os valores de y, a quan-
tidade de informacao a respeito de θ aumenta. O teorema de Bayes define a regra de
atualizacao utilizada para quantificar este aumento de informacao e e defindo da seguinte
forma:
p(θ|y) =p(y|θ)p(θ)
p(y),
onde p(y|θ) e a funcao de verossimilhanca, p(θ) e a densidade a priori e p(y) =∫p(y|θ)p(θ)dθ
pode ser considerada como uma constante em relacao ao θ.
4.2.1 Especificacoes
Dada a equacao 4.1, para que o modelo bayesiano fique completo, precisamos especifi-
car a distribuicao a priori p(θ). Assumindo independencia a priori entre os parametros,
temos que
p(θ) = p(σ)p(δ)p(α)p(b)p(β)
=
(p∏i=1
p(σi)
)(p−1∏i=1
p∏j=i+1
p(δij)
)(2∏
k=0
p(αk)
)(p∏i=1
p∏j=1
p(bij)
)p(β)
As distribuicoes a priori escolhidas para cada um dos parametros foram: σi ∼
Ga(ci, di), i = 1, ..., p, δij ∼ Ga(fij, gij), i 6= j, i, j = 1, ..., p, αk ∼ Ga(rk, sk), k = 0, 1, 2,
24

bij ∼ Ga(uij × med(ds), uij), i, j = 1, ..., p, med(ds) sendo a mediana das distancias
espaciais, β ∼ Npq(λ,Λ).
Para encontrar as distribuicoes a posteriori dos parametros desconhecidos utilizamos
simulacoes estocasticas de Monte Carlo via Cadeias de Markov (MCMC). Detalhes sobre
metodos MCMC podem ser encontrados em Gamerman e Lopes (2006). Apenas a dis-
tribuicao condicional completa de β apresentou forma analıtica fechada, portanto, para
este parametro foi possıvel gerar amostras da posteriori utilizando amostrador de Gibbs.
Assim, considere a funcao de verossimilhanca descrita na equacao 4.1, onde µ = Xβ.
Seja θ− o vetor parametrico excluindo o vetor β. Se a distribuicao a priori for β ∼
Npq(λ,Λ), entao a distribuicao condicional completa de β e
β|y,θ− ∼ Npq(λ∗,Λ∗)
onde Λ∗ =[XTΣ−1X + Λ−1
]−1e λ∗ = Λ∗
[XTΣ−1y + Λ−1λ
].
Para os outros parametros do modelo, θ−, nao foi possıvel encontrar distribuicoes
condicionais completas com forma fechada, com isso, utilizamos passos de Metropolis-
Hastings.
4.2.2 Previsao
Para fazer previsao de observacoes em determinadas localizacoes, considere yu como
o vetor de observacoes nao medidas em su localizacoes pertencentes a regiao D. Note que
essas localizacoes nao precisam, necessariamente, ser as mesmas localizacoes utilizadas
na estimacao do modelo.
A predicao de yu e baseada na distribuicao preditiva p(yu|yo), onde yo e o vetor dos
valores observados. Entao, temos a seguinte relacao
p(yu|yo) =
∫p(yu,θ|yo)dθ
=
∫p(yu|yo,θ)p(θ|yo)dθ (4.2)
Como estamos trabalhando com um modelo gaussiano, sabemos, por hipotese, que
(yo,yu|θ) tem distribuicao normal multivariada. Com isso, fica facil encontrar a distri-
buicao de (yu|yo,θ), basta utilizar as propriedades ja conhecidas da distribuicao normal
25

multivariada. Assim, temos que (yu|yo,θ) tambem seguira uma distribuicao normal
multivariada com media e variancia dadas por
µ∗ = µu + ΣuoΣ−1oo (yo − µo) (4.3)
e
Σ∗ = Σuu − ΣuoΣ−1oo Σou (4.4)
Suponha que θ(1), ...,θ(M) formem uma amostra da distribuicao a posteriori (θ|yo).
Sabe-se que a distribuicao preditiva a posteriori pode ser aproximada por Monte Carlo
da seguinte maneira:
p(yu|yo) =1
M
M∑i=1
p(yu|yo,θ(i)) (4.5)
26

Capıtulo 5
Aproximacoes separaveis
5.1 Introducao
O objetivo deste capıtulo e apresentar uma maneira eficiente de calcular a funcao de
verossimilhanca para os modelos nao separaveis propostos neste trabalho utilizando as
aproximacoes separaveis de Genton (2007).
Como apresentado na secao 2.3.1, ao utilizar uma estrutura de covariancia separavel e
possıvel decompor a matriz de covariancia resultante usando o produto de Kronecker. Isso
faz com que o tempo computacional seja reduzido, pois ao inves de trabalhar com matrizes
de dimensao np×np, calculam-se inversas e determinantes de matrizes de dimensoes n×n
e p× p.
O artigo de Genton (2007) discute aproximacoes separaveis feitas para matrizes de
covariancia espaco-temporais nao separaveis. O autor descreve uma aproximacao do
produto de Kronecker para uma matriz de covariancia a partir da norma de Frobenius.
O algoritmo proposto nesse artigo e simples e preserva as propriedades da matriz de
covariancia.
Neste capıtulo, utilizou-se a ideia de Genton (2007) no caso espacial multivariado.
Para isso, seja Σ a matriz de covariancia cheia de dimensao np × np. Sabe-se que no
caso separavel ha duas matrizes R = ρ(si, sj) ∈ <n×n e A = {aij} ∈ <p×p, tais que
Σ = R⊗A. A questao exposta por Genton (2007) e: dada a matriz Σ, como determinar
as duas matrizes R ∈ <n×n e A ∈ <p×p que satisfacam Σ = R⊗A?
27

Antes de apresentar a solucao deste problema, vale definir alguns conceitos que serao
abordados adiante:
• Operador vec(.): O operador vec(.) transforma uma matriz A ∈ <n1×n2 num
vetor vec(A) ∈ <n1n2 empilhando as colunas uma em cima da outra.
• Norma de Frobenius: Considere a matriz B = {bij} ∈ <n×n, entao a norma de
Frobenius de B (‖B‖F ) e dada por:
‖B‖F =
(n∑i=1
n∑j=1
b2ij
)1/2
• Proximidade do produto de Kronecker para uma matriz de covariancia
cheia (PPKCC): Considere a matriz Σ sendo a matriz de covariancia cheia de
dimensao np × np. A dificuldade esta em encontrar duas matrizes R ∈ <n×n e
A ∈ <p×p que minimizam a norma de Frobenius ‖Σ−R⊗A‖F .
• Decomposicao em Valores Singulares (DVS): Em Golub e Van Loan (1996)
ha um teorema que aponta que se B ∈ <n2×p2 e uma matriz real, entao existem
duas matrizes ortogonais U = [u1, ...,un2 ] ∈ <n2×n2e V = [v1, ...,vp2 ] ∈ <p
2×p2 ,
tais que
UTBV = diag (w1, ..., wr) ∈ <n2×p2 , r = posto(B) = min{n2, p2}
onde w1 ≥ w2 ≥ ... ≥ wr ≥ 0.
5.2 Solucao do problema PPKCC
Segundo Genton (2007) a solucao do problema PPKCC e dada pela Decomposicao
em Valores Singulares (DVS) de uma versao permutada da matriz de covariancia cheia
Σ ∈ <np×np.
A ideia e rearranjar Σ em outra matriz =(Σ) ∈ <n2×p2 , tal que a soma dos quadrados
de ‖Σ−R⊗A‖F seja a mesma de ‖=(Σ)− vec(R)⊗ vec(A)T‖F 1. Para isso, o autor
mostra que ‖Σ−R⊗A‖F = ‖=(Σ)− vec(R)⊗ vec(A)T‖F e ‖Σ‖F = ‖=(Σ)‖F .
1Informacoes mais precisas de como rearranjar a matriz Σ podem ser vistas em Genton (2007).
28

A partir disso tem-se que o problema PPKCC e reduzido ao calculo do posto da
matriz retangular =(Σ) ∈ <n2×p2 , cuja solucao tambem pode ser encontrada em Golub
e Van Loan (1996). Baseando-se na DVS, a solucao do PPKCC e, portanto, dada por
vec(R) =√w1u1 vec(A) =
√w1v1 (5.1)
onde u1 e a primeira coluna da matriz U ∈ <n2×n2e v1 e a primeira coluna da matriz
V ∈ <p2×p2 .
Segundo Genton, e importante ressaltar que essa solucao resulta da norma de Frobe-
nius. A escolha de outras normas conduziria a um problema de otimizacao computacional.
5.3 Erro de aproximacao
Para medir se essa aproximacao proposta e adequada, o autor definiu um erro de
aproximacao por separabilidade, denotado por κΣ(R,A), da matriz Σ aproximada pelo
produto de Kronecker de duas matrizes R e A. Este erro e definido da seguinte maneira
κΣ(R,A) =‖Σ−R⊗A‖F
‖Σ‖F(5.2)
O ındice do erro de aproximacao por separabilidade, κΣ(R,A), assume valores entre
zero (se Σ for separavel) e√
1− 1r, e e minimizado pelas solucoes de R e A do problema
PPKCC. Para obter um ındice que varia entre zero e um, o que torna mais facil a analise,
definimos um erro padronizado, dado por:
κ∗Σ(R,A) =κΣ(R,A)√
1− 1r
(5.3)
Considerando o modelo proposto neste trabalho, e possıvel utilizar a aproximacao
apresentada acima para encontrar um modelo com estrutura separavel “proximo” ao
modelo nao separavel. Vale lembrar que essa abordagem sera aplicada ao caso espacial
multivariado, diferentemente de Genton (2007), que a utiliza no caso espaco-tempo.
A partir da definicao do modelo nao separavel no capıtulo 3, foi possıvel definir a
aproximacao separavel para este modelo seguindo os mesmos passos apresentados na
secao 5.2. E assim, podemos aproximar a funcao de verossimilhanca para estimacao dos
parametros do modelo de forma computacionalmente eficiente.
29

5.3.1 Comportamento do erro de aproximacao
Como ja visto no capıtulo 3, o modelo nao separavel proposto se reduz ao caso se-
paravel apenas quando o parametro α0 for igual a zero. Assim, quando α0 > 0 (α0 nao
assume valores negativos) a estrutura da matriz de covariancia e nao separavel.
Analisar o erro obtido ao trabalhar com uma estrutura aproximada e extremamente
relevante. Uma vez que as aproximacoes sejam satisfatorias, utilizar estruturas separaveis
apenas para eficiencia na avaliacao da funcao de verossimilhanca, mas ainda assim man-
tendo a interpretacao inicial do modelo proposto e bastante conveniente.
Uma simulacao foi realizada para que fosse possıvel verificar o comportamento do
erro de aproximacao por separabilidade de acordo com o parametro α0. Para isso, os
parametros do modelo foram fixados, deixando apenas o parametro de separabilidade α0
variando. O erro de aproximacao foi analisado em dois cenarios: (a) considerando mesmos
alcances espaciais para todas as componentes, isto e, bii = bjj = bij = bji = φ, i 6= j;
e (b) considerando alcances diferentes para componentes diferentes, ou seja, bii 6= bjj e
bij = bji, i 6= j.
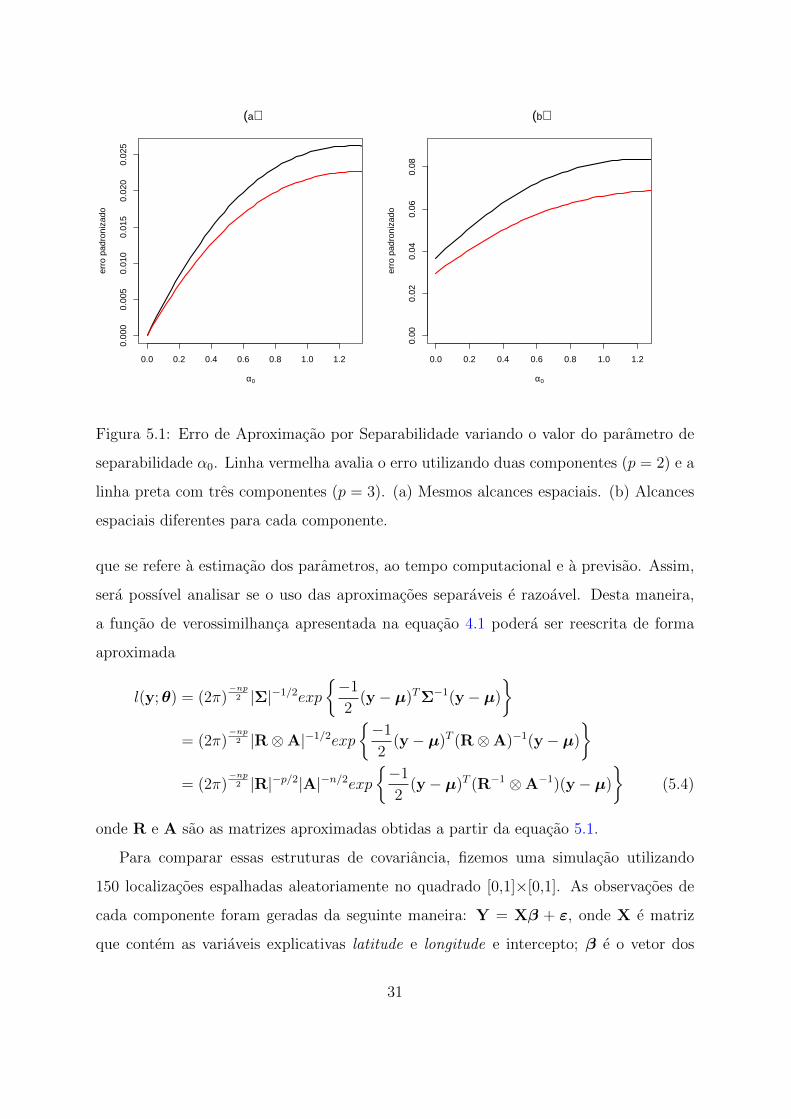
A Figura 5.1 apresenta o comportamento do erro de aproximacao por separabilidade
para cada um dos cenarios descritos acima, considerando duas e tres componentes. A
partir desta figura e possıvel notar que, independentemente do numero de componentes
e do cenario analisado, o erro de aproximacao por separabilidade e bastante pequeno.
Note que no cenario cujos alcances sao diferentes o erro e ligeiramente maior. Apesar
disso, utilizando uma estrutura separavel aproximada, esperamos que os resultados sejam
bastante proximos dos obtidos a partir da estrutura nao separavel.
Vale ressaltar que as curvas do cenario (b) nao comecam em zero porque, como ja men-
cionado, no caso de alcances espaciais diferentes para cada componente, a especificacao
α0 = 0 nao conduz a uma estrutura de covariancia separavel.
5.4 Utilizando a aproximacao separavel
Nesta secao, o MNS-01 sera utilizado para comparar as estruturas de covariancia
cheia e aproximada. O objetivo e verificar, em cada caso, o desempenho do modelo no
30
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.00
00.
005
0.01
00.
015
0.02
00.
025
(a)
α0
erro
pad
roni
zado
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.00
0.02
0.04
0.06
0.08
(b)
α0
erro
pad
roni
zado
Figura 5.1: Erro de Aproximacao por Separabilidade variando o valor do parametro de
separabilidade α0. Linha vermelha avalia o erro utilizando duas componentes (p = 2) e a
linha preta com tres componentes (p = 3). (a) Mesmos alcances espaciais. (b) Alcances
espaciais diferentes para cada componente.
que se refere a estimacao dos parametros, ao tempo computacional e a previsao. Assim,
sera possıvel analisar se o uso das aproximacoes separaveis e razoavel. Desta maneira,
a funcao de verossimilhanca apresentada na equacao 4.1 podera ser reescrita de forma
aproximada
l(y;θ) = (2π)−np2 |Σ|−1/2exp
{−1
2(y− µ)TΣ−1(y− µ)
}= (2π)
−np2 |R⊗A|−1/2exp
{−1
2(y− µ)T (R⊗A)−1(y− µ)
}= (2π)
−np2 |R|−p/2|A|−n/2exp
{−1
2(y− µ)T (R−1 ⊗A−1)(y− µ)
}(5.4)
onde R e A sao as matrizes aproximadas obtidas a partir da equacao 5.1.
Para comparar essas estruturas de covariancia, fizemos uma simulacao utilizando
150 localizacoes espalhadas aleatoriamente no quadrado [0,1]×[0,1]. As observacoes de
cada componente foram geradas da seguinte maneira: Y = Xβ + ε, onde X e matriz
que contem as variaveis explicativas latitude e longitude e intercepto; β e o vetor dos
31
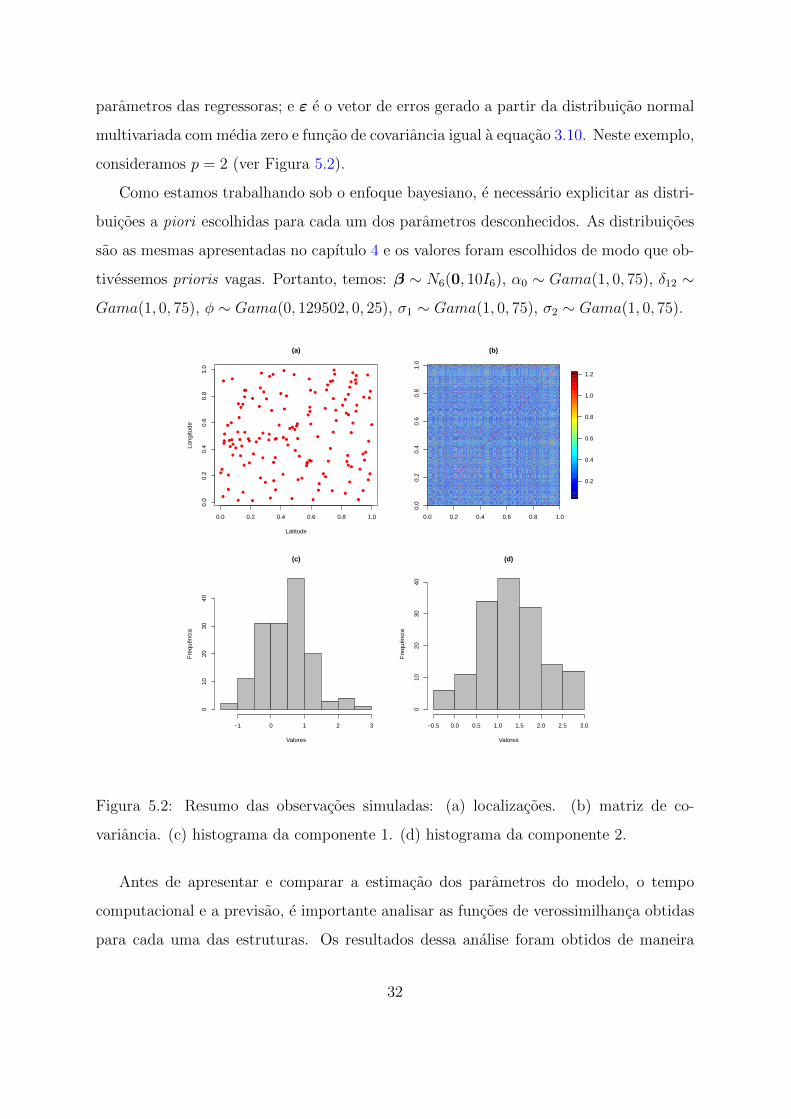
parametros das regressoras; e ε e o vetor de erros gerado a partir da distribuicao normal
multivariada com media zero e funcao de covariancia igual a equacao 3.10. Neste exemplo,
consideramos p = 2 (ver Figura 5.2).
Como estamos trabalhando sob o enfoque bayesiano, e necessario explicitar as distri-
buicoes a piori escolhidas para cada um dos parametros desconhecidos. As distribuicoes
sao as mesmas apresentadas no capıtulo 4 e os valores foram escolhidos de modo que ob-
tivessemos prioris vagas. Portanto, temos: β ∼ N6(0, 10I6), α0 ∼ Gama(1, 0, 75), δ12 ∼
Gama(1, 0, 75), φ ∼ Gama(0, 129502, 0, 25), σ1 ∼ Gama(1, 0, 75), σ2 ∼ Gama(1, 0, 75).
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
(a)
Latitude
Long
itude
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
(b)
0.2
0.4
0.6
0.8
1.0
1.2
(c)
Valores
Fre
quên
cia
−1 0 1 2 3
010
2030
40
(d)
Valores
Fre
quên
cia
−0.5 0.0 0.5 1.0 1.5 2.0 2.5 3.0
010
2030
40
Figura 5.2: Resumo das observacoes simuladas: (a) localizacoes. (b) matriz de co-
variancia. (c) histograma da componente 1. (d) histograma da componente 2.
Antes de apresentar e comparar a estimacao dos parametros do modelo, o tempo
computacional e a previsao, e importante analisar as funcoes de verossimilhanca obtidas
para cada uma das estruturas. Os resultados dessa analise foram obtidos de maneira
32

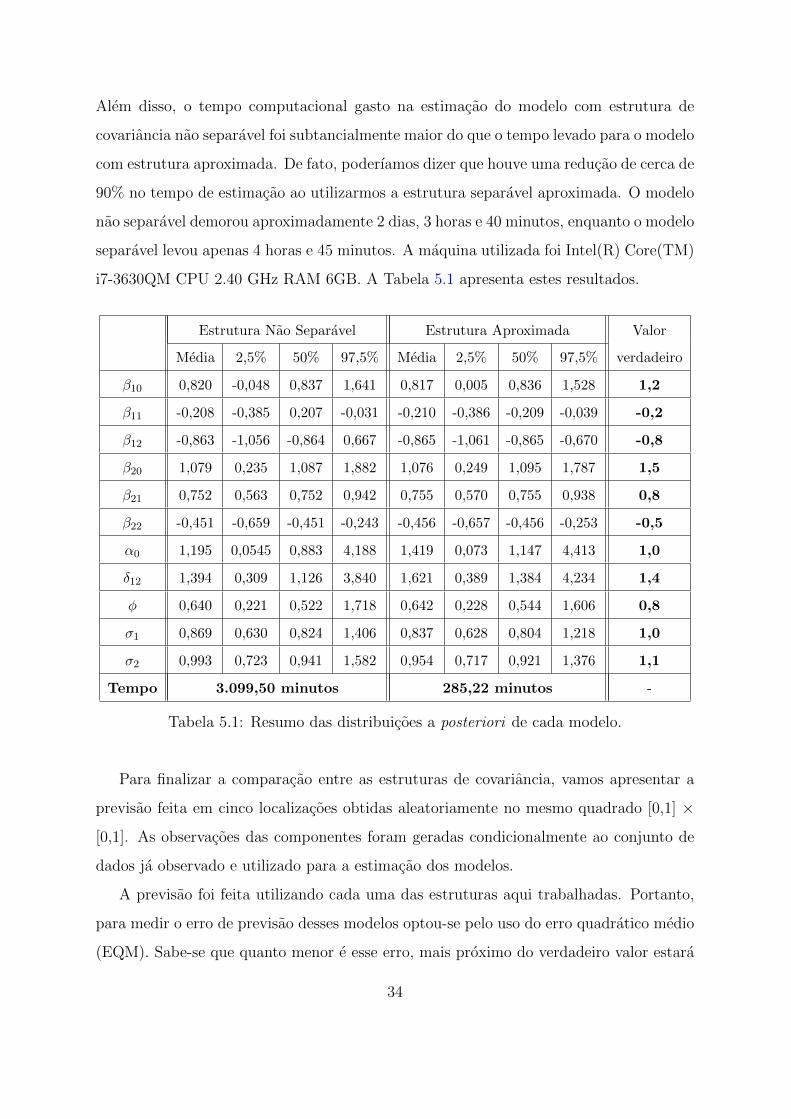
muito simples: a partir das variaveis explicativas latitude e longitude e da especificacao do
vetor β definimos a media do processo Gaussiano; em seguida, foram construıdas grades
de valores combinando os parametros (α0, δ12, φ, σ1 e σ2) 2 a 22; e entao, para cada
uma dessas dez grades obtidas foi possıvel desenhar as curvas de contorno da funcao de
verossimilhanca. Note que esse processo foi realizado utilizando a estrutura de covariancia
cheia e a estrutura de covariancia aproximada.
A Figura 5.3 apresenta as curvas da funcao de verossimilhanca para cada uma dessas
estruturas. Analisando esta figura, observa-se que as curvas de contorno da verossimi-
lhanca com estrutura separavel aproximada mostram-se bastante similares as curvas com
estrutura nao separavel. Apos essa analise, vamos iniciar o trabalho de avaliar e comparar
o desempenho dos modelos.
Como mencionado no capıtulo 4 o metodo de simulacao utilizado foi o MCMC. Para
ambos os casos rodamos 200.000 iteracoes. As distribuicoes a posteriori de cada um
dos parametros foram encontradas retirando um burn-in de 500 iteracoes e aplicando
saltos de 50 iteracoes, gerando uma amostra de tamanho 3.990. Para o monitoramento
de convergencia foram utilizados os algoritmos presentes no pacote Coda no R (Plummer
et al., 2006).
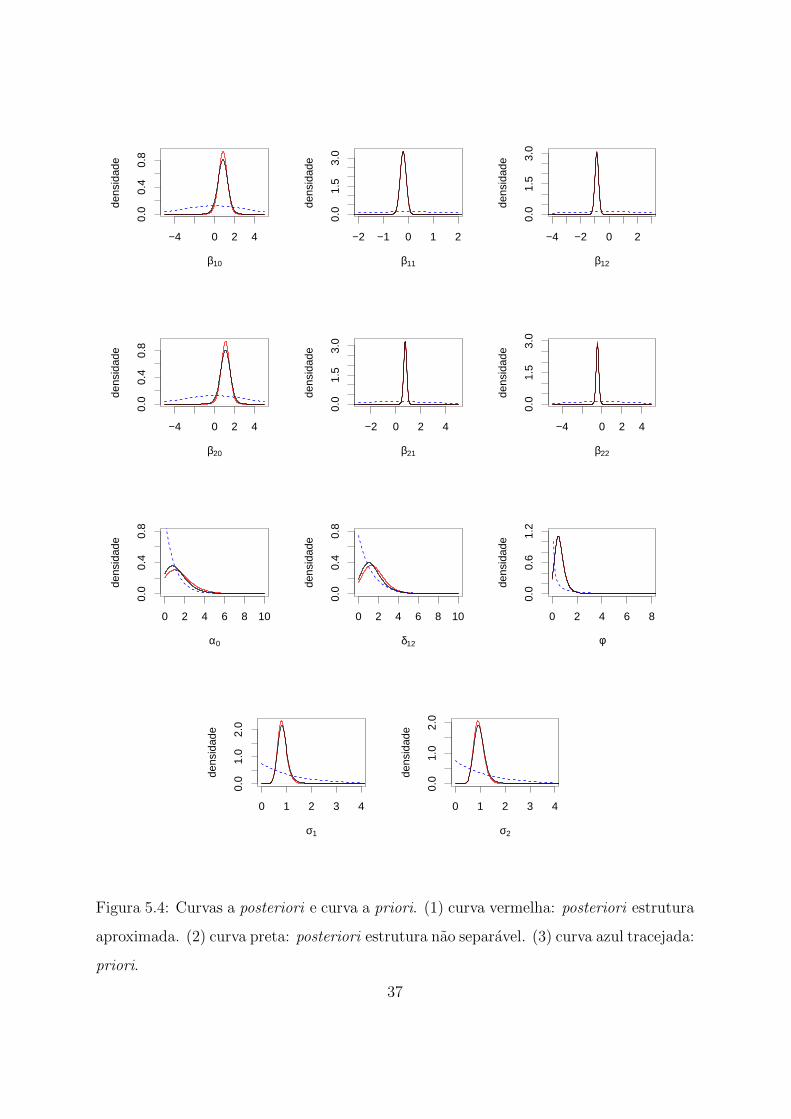
A Figura 5.4 apresenta as distribuicoes a posteriori de cada estrutura de covariancia
e as distribuicoes a priori definidas acima. Com isso, pode-se observar que nao ha
diferencas substanciais entre as distribuicoes a posteriori encontradas para cada estrutura
analisada. De fato, o comportamento de cada uma dessas curvas e bastante similiar para
todos os parametros.
No que se refere a estimacao dos modelos, nota-se que as estimativas pontuais (media
e mediana a posteriori) dos parametros sao bastante proximas em ambas estruturas,
apresentando diferenca na segunda ou terceira casa decimal. Somente as estimativas
de α0 e δ12 sao levemente diferentes. Entretanto, o intervalo de credibilidade contem o
verdadeiro valor do parametro em todos os casos. Tambem foi possıvel observar que o
intervalo de credibilidade do parametro β10 contem o zero apenas no caso nao separavel.
2Os valores dos parametros fixados em cada caso sao os mesmos escolhidos para gerar as observacoes
das componentes. Estes valores encontram-se na Tabela 5.1.
33
Alem disso, o tempo computacional gasto na estimacao do modelo com estrutura de
covariancia nao separavel foi subtancialmente maior do que o tempo levado para o modelo
com estrutura aproximada. De fato, poderıamos dizer que houve uma reducao de cerca de
90% no tempo de estimacao ao utilizarmos a estrutura separavel aproximada. O modelo
nao separavel demorou aproximadamente 2 dias, 3 horas e 40 minutos, enquanto o modelo
separavel levou apenas 4 horas e 45 minutos. A maquina utilizada foi Intel(R) Core(TM)
i7-3630QM CPU 2.40 GHz RAM 6GB. A Tabela 5.1 apresenta estes resultados.
Estrutura Nao Separavel Estrutura Aproximada Valor
Media 2,5% 50% 97,5% Media 2,5% 50% 97,5% verdadeiro
β10 0,820 -0,048 0,837 1,641 0,817 0,005 0,836 1,528 1,2
β11 -0,208 -0,385 0,207 -0,031 -0,210 -0,386 -0,209 -0,039 -0,2
β12 -0,863 -1,056 -0,864 0,667 -0,865 -1,061 -0,865 -0,670 -0,8
β20 1,079 0,235 1,087 1,882 1,076 0,249 1,095 1,787 1,5
β21 0,752 0,563 0,752 0,942 0,755 0,570 0,755 0,938 0,8
β22 -0,451 -0,659 -0,451 -0,243 -0,456 -0,657 -0,456 -0,253 -0,5
α0 1,195 0,0545 0,883 4,188 1,419 0,073 1,147 4,413 1,0
δ12 1,394 0,309 1,126 3,840 1,621 0,389 1,384 4,234 1,4
φ 0,640 0,221 0,522 1,718 0,642 0,228 0,544 1,606 0,8
σ1 0,869 0,630 0,824 1,406 0,837 0,628 0,804 1,218 1,0
σ2 0,993 0,723 0,941 1,582 0,954 0,717 0,921 1,376 1,1
Tempo 3.099,50 minutos 285,22 minutos -
Tabela 5.1: Resumo das distribuicoes a posteriori de cada modelo.
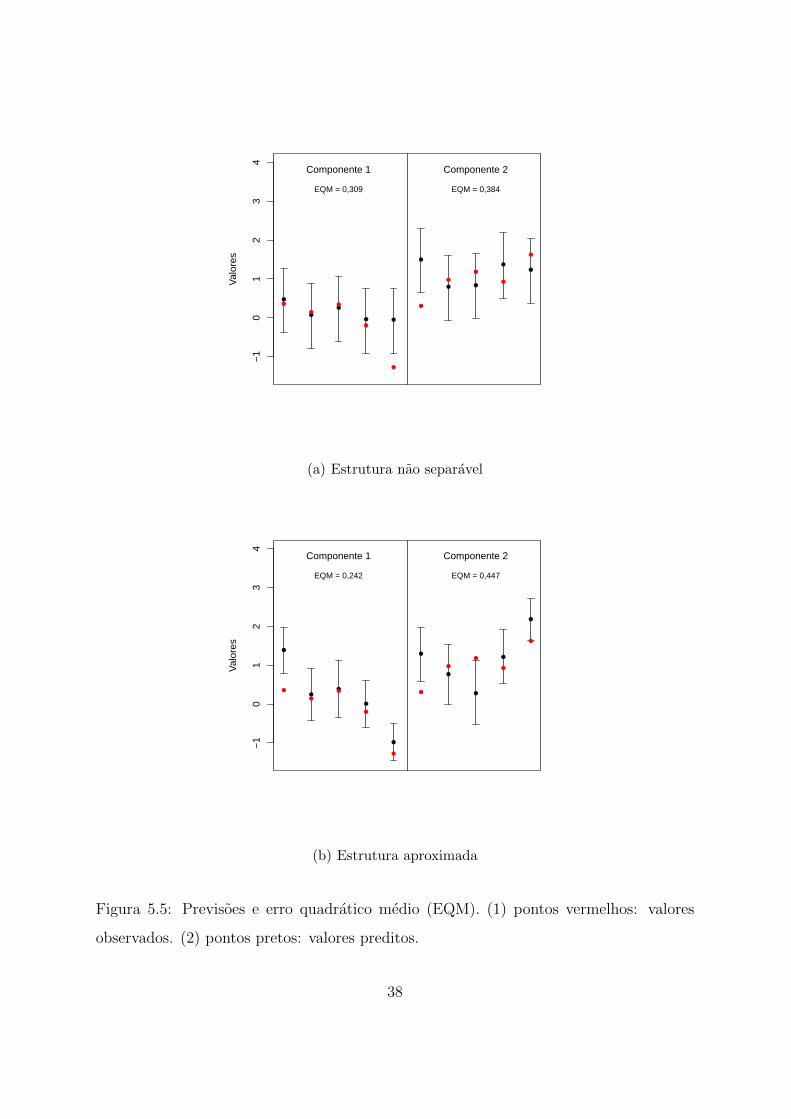
Para finalizar a comparacao entre as estruturas de covariancia, vamos apresentar a
previsao feita em cinco localizacoes obtidas aleatoriamente no mesmo quadrado [0,1] ×
[0,1]. As observacoes das componentes foram geradas condicionalmente ao conjunto de
dados ja observado e utilizado para a estimacao dos modelos.
A previsao foi feita utilizando cada uma das estruturas aqui trabalhadas. Portanto,
para medir o erro de previsao desses modelos optou-se pelo uso do erro quadratico medio
(EQM). Sabe-se que quanto menor e esse erro, mais proximo do verdadeiro valor estara
34

a previsao. A Figura 5.5(a) apresenta os valores preditos e observados, o intervalo de
credibilidade e o EQM para cada componente a partir da estrutura nao separavel. A Fi-
gura 5.5(b) apresenta as mesmas informacoes para a estrutura aproximada. Analisando
essas figuras, observa-se que os resultados encontrados sao bastante similares. Em ambos
os casos, quase todos os intervalos de credibilidade contem os verdadeiros valores. O
EQM obtido e relativamente pequeno e muito proximo nas duas estruturas, nao apresen-
tando diferencas substanciais. Vale ressaltar que a amplitude de todos os intervalos de
credibilidade com estrutura aproximada e menor do que a da estrutura nao separavel.
Assim, analisando todos os resultados apresentados nesta secao, e possıvel dizer que
a aproximacao e bastante adequada e pode ser utilizada no calculo da verossimilhanca e
inferencia para o modelo proposto. Nas simulacoes realizadas no capıtulo 6 utilizaremos
essa metodologia de aproximacao da matriz de covariancia.
35
0.5 0.7 0.9 1.1
02
4
φ
δ 12
2e+40
4e+40
6e+40 8e+40
2.2e+41 2e+40
4e+40
6e+40
8e+40
1e+41 1.6e+41
0.6 1.0 1.4
02
4
α0
δ 12
5e+40
1e+41
1.5e+41 2e+40 4e+40
6e+40
8e+40 1e+41
1.2e+41
1.4e+41 2e+41
0.8 0.9 1.0 1.1 1.2
02
46
σ1
δ 12
5e+40
1e+41
2e+40
4e+40
6e+40 8e+40 1.2e+41
0.9 1.1 1.3
02
46
σ2
δ 12
5e+40
1e+41
2e+40 4e+40
6e+40 8e+40 1e+41
1.4e+41
0.4 0.8 1.2
0.0
1.0
2.0
α0
φ
5e+40
1e+41
1.5e+41
2e+41
5e+40
1e+41
1.5e+41
2e+41
0.5 0.7 0.9
0.7
0.9
1.1
σ1
φ 2e+40
4e+40
6e+40
8e+40
1e+41 1.2e+41
1.4e+41
5e+40
1e+41
1.5e+41
2e+41
0.5 0.7 0.9 1.1
0.9
1.1
1.3
σ2
φ
2e+40
4e+40
6e+40 8e+40
1e+41 1.2e+41
2e+40
4e+40
6e+40
8e+40 1e+41
1.2e+41
1.4e+41
2e+
41
0.6 1.0 1.4
0.7
0.9
1.1
σ1
α 0
2e+40 4e+40
6e+40
8e+40
1e+41
1.2e+41
5e+40 1e+41
1.5e+41
2e+41 2.5e+41
0.4 0.8 1.2 1.6
0.9
1.1
1.3
σ2
α 0
2e+40
4e+40
6e+40
8e+40
1e+41
1.2e+41
2e+40
4e+40
6e+40
8e+40
1e+41
1.2e+41 1.4e+41
2.4e+41
0.9 1.1 1.3
0.8
1.0
1.2
σ1
σ 2
2e+40
4e+
40 6e+40
8e+40
1e+
41
2e+40
4e+40
6e+40
8e+40
1e+41
1.2
e+41
1.4
e+41
2e+41
2.4e+41
Figura 5.3: Curvas de contorno da funcao de verossimilhanca. (1) curvas em preto:
estrutura de covariancia nao separavel. (2) curvas em vermelho: estrutura de covariancia
aproximada.
36
−4 0 2 4
0.0
0.4
0.8
β10
dens
idad
e
−2 −1 0 1 2
0.0
1.5
3.0
β11
dens
idad
e
−4 −2 0 2
0.0
1.5
3.0
β12
dens
idad
e
−4 0 2 4
0.0
0.4
0.8
β20
dens
idad
e
−2 0 2 4
0.0
1.5
3.0
β21
dens
idad
e
−4 0 2 4
0.0
1.5
3.0
β22
dens
idad
e
0 2 4 6 8 10
0.0
0.4
0.8
α0
dens
idad
e
0 2 4 6 8 10
0.0
0.4
0.8
δ12
dens
idad
e
0 2 4 6 8
0.0
0.6
1.2
φ
dens
idad
e
0 1 2 3 4
0.0
1.0
2.0
σ1
dens
idad
e
0 1 2 3 4
0.0
1.0
2.0
σ2
dens
idad
e
Figura 5.4: Curvas a posteriori e curva a priori. (1) curva vermelha: posteriori estrutura
aproximada. (2) curva preta: posteriori estrutura nao separavel. (3) curva azul tracejada:
priori.
37
−1
01
23
4
Val
ores
●
●
●
● ●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
Componente 2Componente 1
EQM = 0,384EQM = 0,309
(a) Estrutura nao separavel
−1
01
23
4
Val
ores ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
Componente 2Componente 1
EQM = 0,447EQM = 0,242
(b) Estrutura aproximada
Figura 5.5: Previsoes e erro quadratico medio (EQM). (1) pontos vermelhos: valores
observados. (2) pontos pretos: valores preditos.
38

Capıtulo 6
Exemplos simulados
6.1 Introducao
Este capıtulo ira ilustrar o comportamento da estrutura de covariancia proposta a
partir de alguns exemplos simulados. Em todos os casos, os dados foram gerados a partir
de um processo Gaussiano. As localizacoes s foram geradas de maneira aleatoria na
regiao D = [0, 1] × [0, 1]. Esses pontos no espaco sao os mesmos utilizados no capıtulo
5 e apresentados na Figura 5.2. E importante citar que serao analisadas apenas duas
componentes (p = 2) e que o processo de inferencia segue o especificado no capıtulo 4.
6.2 Simulacao 1
O primeiro exemplo simulado tem como objetivo estudar a funcao de covariancia
proposta na equacao 3.10. O interesse e gerar observacoes com a estrutura separavel
apresentada na secao 2.3.1 e analisar se o modelo MNS-01 consegue captar essa separa-
bilidade, isto e, se o modelo e capaz de gerar valores pequenos de α0, ja que α0 nao pode
ser igual zero.
Observe que no caso separavel tınhamos os parametros da matriz A = {aij} e o
alcance espacial, φ, da funcao de correlacao. Utilizando o modelo nao separavel, MNS-
01, com α0 = 0, temos que a funcao de covariancia passa a ser definida de maneira
semelhante a equacao 2.4. Note que continuamos com o alcance da funcao de correlacao
39

(φ), porem, os parametros da matriz A sao definidos de outra maneira. Dessa forma,
temos que A ={
σiσj1+δij
}. E facil notal que reconstruımos os parametros aij a partir da
funcao proposta. Portanto, sera possıvel verificar se, de fato, ha convergencia para o
verdadeiro valor de cada um dos parametros do modelo separavel, ja que a cada iteracao
do MCMC podemos calcular os novos aij.
O procedimento de simulacao foi feito da seguinte maneira: geramos as observacoes
de duas componentes nas 150 localizacoes do quadrado [0, 1] × [0, 1] a partir do mo-
delo Y = Xβ + ε, onde X e matriz que contem intercepto e as variaveis explicativas
latitude e longitude; β e o vetor dos parametros das regressoras; e ε e o vetor de er-
ros gerado a partir da distribuicao normal multivariada com media zero e funcao de
covariancia igual a equacao 2.4. Vale lembrar que a funcao de correlacao utilizada per-
tence a classe Cauchy e depende apenas do alcance espacial φ. Neste exemplo, o ve-
tor parametrico e dado por θ = (a11, a22, a12, φ,β). Os dados foram gerados usando
θ = (0, 8; 0, 7; 0, 5; 0, 2; 1, 2;−0, 2;−0, 8; 1, 5; 0, 8;−0, 5).
Como vamos estimar os parametros a partir do modelo MNS-01, e necessario atri-
buir prioris para os parametros dessa funcao de covariancia. Assim, as prioris utili-
zadas foram: β ∼ N6(0, 10I6), φ ∼ Gama(0, 12795, 0, 25), σ1 ∼ Gama(1, 0, 75), σ2 ∼
Gama(1, 0, 75), δ12 ∼ Gama(1, 0, 75) e α0 ∼ Gama(1, 1). As amostras da distribuicao a
posteriori foram obtidas usando um esquema MCMC de 200.000 iteracoes, com burn-in
de 500 iteracoes e saltos de tamanho 50, resultando numa amostra de tamanho 3.990. A
analise de convergencia foi baseada nos testes ja existentes na literatura e encontrados
no pacote Coda do R.
As trajetorias das cadeias geradas estao apresentadas na Figura 6.1. A Tabela 6.1
contem o resumo das amostras da distribuicao a posteriori dos parametros. Alem disso,
a Figura 6.2 apresenta o histograma da posteriori.
A Figura 6.3 exibe sumarios das amostras a posteriori da funcao de covariancia es-
pacial para cada componente, alem da funcao de covariancia cruzada. Adicionalmente,
desenhamos a funcao de covariancia utilizada na geracao dos dados. Assim, caso o MNS-
01 seja capaz de captar a estrutura separavel gerada, espera-se que a funcao original
esteja bastante proxima da funcao estimada. Analisando esta figura nota-se que, para
40

todos os casos, a funcao original esta contida no intervalo de credibilidade de 95%. Alem
disso, a funcao de covariancia espacial estimada parece estar bastante proxima da funcao
original, captando a estrutura utilizada na geracao dos dados.
Analisando todos os resultados obtidos, e possıvel dizer que o modelo proposto conse-
gue captar a separabilidade da estrutura de covariancia. De fato, os valores gerados de α0
sao proximos de zero, a mediana da distribuicao a posteriori foi igual a 0,45, indicando
que metade da amostra gerada assume valores ate 0,45. O limite superior do intervalo de
credibilidade deste parametro foi consideravelmente alto, porem, isso pode ser explicado
pelo comportamento da trajetoria da cadeia vista na Figura 6.1.
E importante citar que todos os outros parametros convergem para o verdadeiro
valor utilizado na geracao dos dados. De fato, essa analise so pode ser feita para todos
os parametros porque e possıvel reconstruir a estrutura separavel a partir da funcao nao
separavel proposta no MSN-01.
Parametros Valor verdadeiro 50% 2,5% 97,5%
β10 1,2 1,149 -0,073 2,513
β11 -0,2 -0,941 -2,460 0,375
β12 -0,8 -1,530 -2,961 -0,168
β20 1,5 1,520 0,430 2,669
β21 0,8 0,051 -1,233 1,189
β22 -0,5 -0,761 -1,994 0,479
a11 0,8 0,799 0,516 1,716
a12 0,5 0,507 0,322 1,095
a22 0,7 0,587 0,373 1,256
φ 0,2 0,241 0,115 0,639
α0 0,0 0,454 0,019 2,353
Tabela 6.1: Resumo da distribuicao a posteriori.
41

6.3 Simulacao 2
Agora, vamos analisar o caso contrario, isto e, vamos gerar observacoes a partir da
estrutura do MNS-01 com parametro de separabilidade α0 > 0 e estimar utilizando o
modelo com estrutura separavel (equacao 2.4). Sabemos que se α0 for consideravelmente
maior que zero, entao o modelo separavel nao e adequado para a estimacao. Portanto,
o objetivo e verificar que a estrutura gerada com α0 > 0 nao consegue ser captada
pelo modelo separavel. Com isso, sera possıvel observar que a funcao proposta neste
trabalho tanto consegue captar estruturas separaveis quanto trabalhar com estruturas
nao separaveis.
O procedimento de simulacao foi feito da seguinte maneira: geramos as observacoes
de duas componentes nas 150 localizacoes do quadrado [0, 1] × [0, 1] a partir do modelo
Y = Xβ + ε, onde X e matriz que contem intercepto e as variaveis explicativas latitude
e longitude; β e o vetor dos parametros das regressoras; e ε e o vetor de erros gerado a
partir da distribuicao normal multivariada com media zero e funcao de covariancia igual
a equacao 3.10. Neste exemplo, o vetor parametrico e dado por θ = (σ1, σ2, φ, δ12, α0,β).
Os dados foram gerados usando θ = (1; 1, 1; 0, 5; 1, 4; 1; 1, 2;−0, 2;−0, 8; 1, 5; 0, 8;−0, 5).
Como a estimacao dos parametros e feita a partir do modelo separavel, e necessario
atribuir prioris para os parametros dessa funcao de covariancia. Assim, as prioris uti-
lizadas foram: β ∼ N6(0, 10I6), φ ∼ Gama(0, 2559, 0, 5) e A ∼ IWishart(I2, 3). As
amostras da distribuicao a posteriori tambem foram obtidas usando o metodo MCMC
com 200.000 iteracoes, aplicando burn-in de 500 iteracoes e saltos de tamanho 50, re-
sultando numa amostra de tamanho 3.990. As trajetorias das cadeias geradas estao
apresentadas na Figura 6.4.
A Figura 6.5 exibe sumarios das amostras a posteriori da funcao de covariancia es-
pacial para cada componente, alem da funcao de covariancia cruzada. Aqui, tambem
desenhamos a funcao de covariancia utilizada na geracao dos dados. Assim, caso o mo-
delo separavel seja capaz de captar a estrutura nao separavel gerada, espera-se que a
funcao original esteja bastante proxima da funcao estimada.
Ao analisar a Figura 6.5 e possıvel observar que o modelo separavel nao consegue
42

representar bem a estrutura gerada pelo modelo MNS-01. Para a primeira componente,
a curva do modelo original (linha verde cheia) ficou fora do intervalo de credibilidade de
95% para grandes distancias. Entranto, para a segunda componente, toda a curva da
funcao original nao ficou contida no intervalo de credibilidade de 95%. Alem disso, na
Figura 6.5(c) nota-se que o modelo separavel apresentou grande variabilidade, permitindo
gerar valores negativos para covariancia cruzada.
6.4 Comentarios
Os resultados encontrados foram bastante satisfatorios. A partir da Simulacao 1,
vimos que o modelo proposto com alcances iguais (MNS-01) e capaz de captar estruturas
separaveis. Os valores gerados do parametro de separabilidade α0 foram pequenos apesar
da trajetoria da cadeia, indicando fraca correlacao entre as variaveis aleatorias U e V .
De fato, sabemos que se U e V forem nao correlacionados, entao o modelo MNS-01 se
reduz ao modelo separavel.
Alem disso, este mesmo modelo MNS-01 tambem gera estruturas nao separaveis. Os
resultados encontrados na Simulacao 2 mostram que o modelo separavel nao e capaz de
captar a estrutura do MNS-01 com parametro de separabilidade α0 > 0.
43
0 1000 3000
−1
13
iteração
β 10
0 1000 3000
−3
−1
1
iteração
β 11
0 1000 3000
−4
−1
2
iteração
β 12
0 1000 3000
−2
13
iteração
β 20
0 1000 3000
−2
02
iteração
β 21
0 1000 3000
−3
−1
1
iteração
β 22
0 1000 3000
12
34
iteração
a 11
0 1000 3000
0.5
1.5
2.5
iteração
a 12
0 1000 3000
0.5
2.0
iteração
a 22
0 1000 3000
01
23
4
iteração
φ
0 1000 3000
02
4
iteração
α 0
Figura 6.1: Cadeias da distribuicao a posteriori. (1) linha azul: valor verdadeiro.
44
β10
dens
idad
e
−1 1 2 3 4
0.0
0.3
0.6
β11
dens
idad
e
−4 −2 0 1 2
0.0
0.3
β12
dens
idad
e
−4 −2 0 2
0.0
0.3
β20
dens
idad
e
−2 0 2 4
0.0
0.3
0.6
β21
dens
idad
e
−3 −1 1 2 3
0.0
0.3
0.6
β22
dens
idad
e
−3 −1 1 2
0.0
0.3
0.6
a11
dens
idad
e
0 1 2 3 4
0.0
1.0
a12
dens
idad
e
0.5 1.5 2.5
0.0
1.5
a22
dens
idad
e
0.5 1.5 2.5
0.0
1.0
2.0
φ
dens
idad
e
0 1 2 3 4
0.0
1.0
α0
dens
idad
e
0 1 2 3 4 5
0.0
0.6
Figura 6.2: Histograma da distribuicao a posteriori. (1) linha vermelha: verdadeiro valor.
45
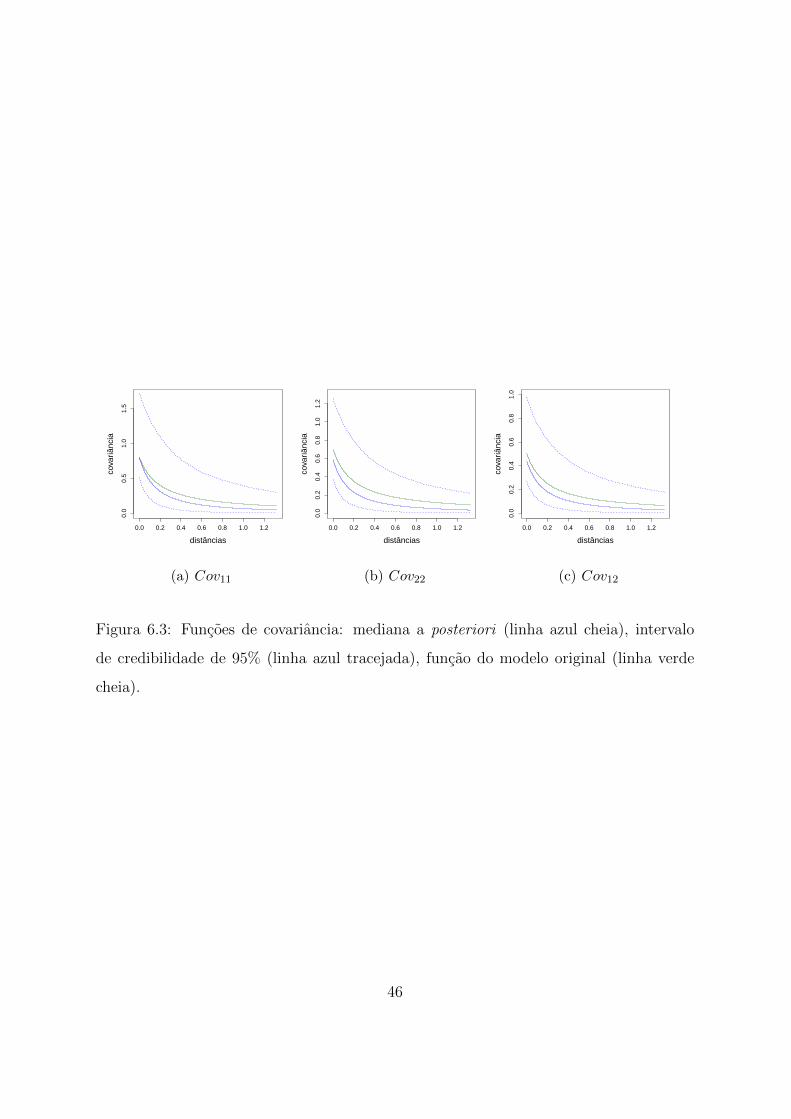
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.0
0.5
1.0
1.5
distâncias
cova
riânc
ia
(a) Cov11
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
distâncias
cova
riânc
ia
(b) Cov22
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.0
0.2
0.4
0.6
0.8
1.0
distâncias
cova
riânc
ia
(c) Cov12
Figura 6.3: Funcoes de covariancia: mediana a posteriori (linha azul cheia), intervalo
de credibilidade de 95% (linha azul tracejada), funcao do modelo original (linha verde
cheia).
46
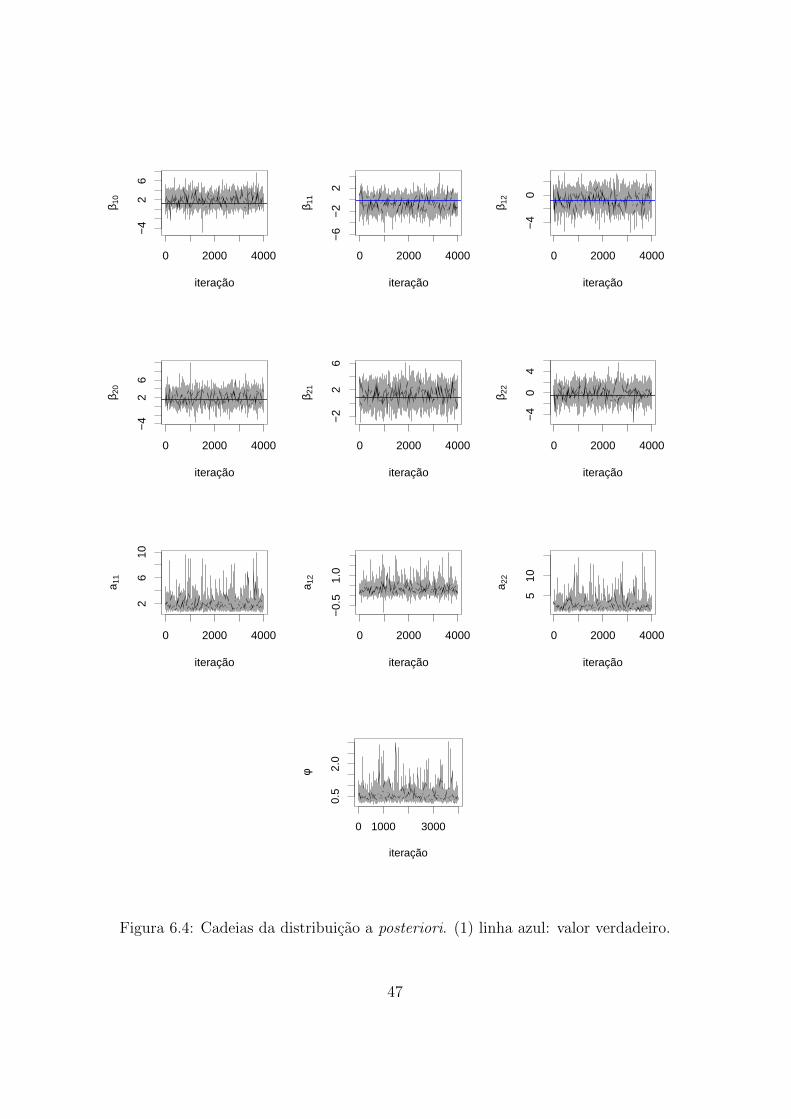
0 2000 4000
−4
26
iteração
β 10
0 2000 4000
−6
−2
2
iteração
β 11
0 2000 4000
−4
0
iteração
β 12
0 2000 4000
−4
26
iteração
β 20
0 2000 4000
−2
26
iteração
β 21
0 2000 4000
−4
04
iteração
β 22
0 2000 4000
26
10
iteração
a 11
0 2000 4000
−0.
51.
0
iteração
a 12
0 2000 4000
510
iteração
a 22
0 1000 3000
0.5
2.0
iteração
φ
Figura 6.4: Cadeias da distribuicao a posteriori. (1) linha azul: valor verdadeiro.
47
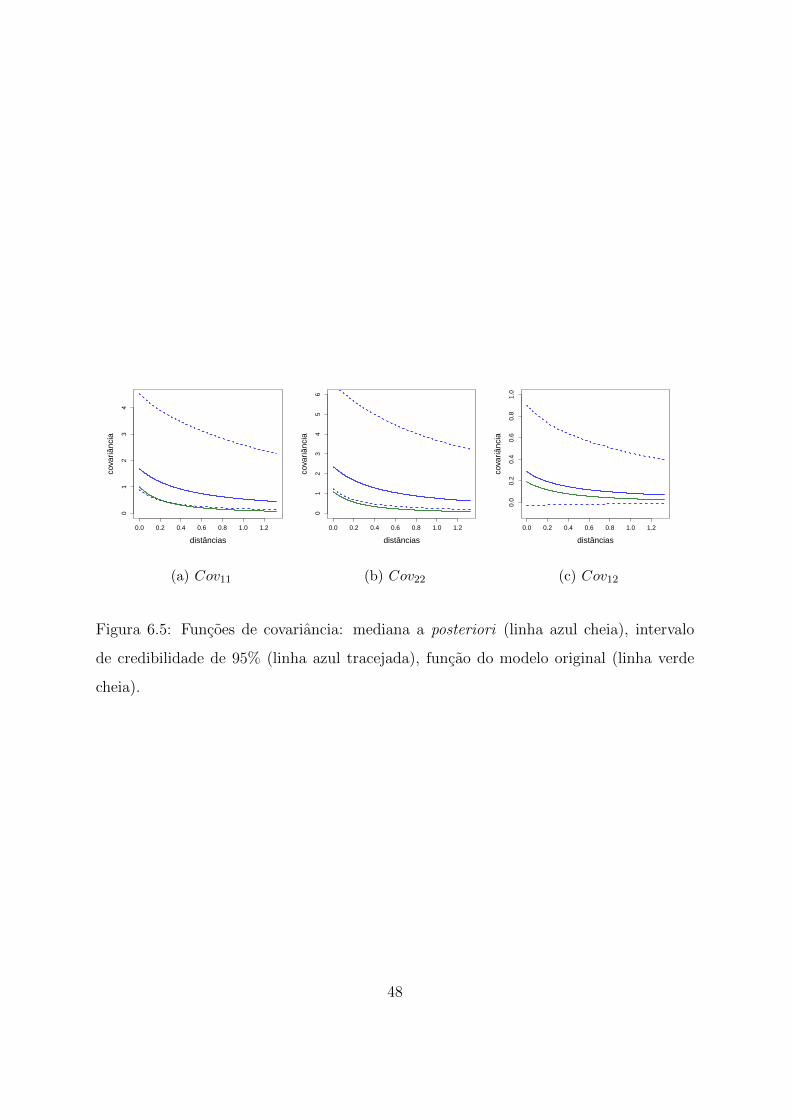
0.0 0.2 0.4 0.6 0.8 1.0 1.2
01
23
4
distâncias
cova
riânc
ia
(a) Cov11
0.0 0.2 0.4 0.6 0.8 1.0 1.2
01
23
45
6
distâncias
cova
riânc
ia
(b) Cov22
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.0
0.2
0.4
0.6
0.8
1.0
distâncias
cova
riânc
ia
(c) Cov12
Figura 6.5: Funcoes de covariancia: mediana a posteriori (linha azul cheia), intervalo
de credibilidade de 95% (linha azul tracejada), funcao do modelo original (linha verde
cheia).
48

Capıtulo 7
Conclusoes e trabalhos futuros
Este trabalho teve como objetivo introduzir uma nova classe de modelos de covariancia
nao separavel para dados espaciais multivariados a partir da ideia de Fonseca e Steel
(2011) e tambem da representacao do vetor de componentes apresentada por Apanasovich
e Genton (2010).
A funcao proposta na Proposicao 3.2.3 e valida e permite diferentes especificacoes.
Alem disso, o modelo separavel e um caso particular dessa funcao.
A partir de determinada parametrizacao, definimos a funcao de covariancia multiva-
riada nao separavel apresentada na equacao 3.8. A partir dessa especificacao, vimos que
a funcao proposta permite trabalhar com alcances espaciais diferentes para cada compo-
nente e, alem disso, possui um parametro capaz de medir separabilidade. Foi visto que
se este parametro assume o valor zero, entao reduzimos nosso modelo ao caso separavel.
Por definicao, esse parametro nao pode assumir o valor zero. Entretanto, esperamos que
fosse possıvel gerar valores muito pequenos deste parametro na estimacao do modelo.
De fato, o trabalho se iniciou avaliando um caso mais simples da funcao especificada
na equacao 3.8, isto e, analisamos uma funcao nao separavel com os mesmos alcances es-
paciais para todas as componentes e com alguns parametros fixados, definida na equacao
3.10.
Sabemos que ao trabalhar com dados multivariados e essencial descobrir metodos que
nos auziliem no tratamento de conjuntos de observacoes de grandes dimensoes. Vimos
que terıamos que fazer estimacoes e previsoes utilizando matrizes de dimensoes con-
49

sideravelmente grandes, tendo um custo computacional expressivo. Assim, utilizamos
aproximacoes de matrizes de covariancia cheia a partir do produto de Kronecker de duas
matrizes separaveis de menor dimensao. Essa ideia foi baseada no artigo de Genton
(2007), que propoe aproximacoes separaveis para matrizes espaco-tempo.
Utilizamos essas aproximacoes separaveis apenas na funcao de verossimilhanca pois
nao queremos perder a interpretacao do modelo proposto. Vimos que para o modelo
mais simples (equacao 3.10) as aproximacoes separaveis foram bastante satisfatorias.
Alem disso, foi possıvel reduzir o tempo computacional drasticamente. Portanto, nas
simulacoes realizadas foi razoavel utilizar as aproximacoes separaveis.
Realizamos um estudo de simulacao para analisar a funcao proposta na equacao 3.10.
De fato, querıamos verificar que essa funcao tanto e capaz de captar estruturas separaveis
quanto trabalhar com estruturas nao separaveis. Os resultados obtidos se comportaram
conforme o esperado. Quando geramos observacoes a partir do modelo separavel, nossa
funcao foi capaz de captar essa separabilidade. As cadeias obtidas a partir do MCMC
convergiram para o verdadeiro valor do parametro. Alem disso, nosso modelo conseguiu
gerar valores pequenos do parametro de separabilidade. Ao trabalharmos de maneira
inversa, isto e, gerando observacoes do modelo nao separavel e tentando estimar com
o modelo separavel, vimos que a estrutura gerada nao conseguiu ser captada a partir
da funcao separavel. Esses resultados indicam que a funcao proposta permite trabalhar
tanto com estruturas separaveis quanto nao separaveis.
A continuacao deste trabalho e extremamente importante. A avaliacao do modelo
proposto na equacao 3.11, que permite alcances diferentes para cada componente, e
essencial. Ainda nao temos informacoes sobre a utilizacao das aproximacoes separaveis
para este caso. Trabalhar com o modelo proposto tendo alcances diferentes sem utilizar
essas aproximacoes necessitara um tempo computacional consideravel. Os codigos para a
estimacao deste modelo ja foram programados, porem, estao ocorrendo erros numericos
que ainda nao conseguimos resolver.
Tambem e necessario trabalhar com outras especificacoes da funcao de covariancia
proposta. Com isso, poderemos encontrar funcoes que apresentem outro tipo de compor-
tamento. E evidente que todo o estudo teorico realizado aqui tambem devera ser feito
50

para as novas especificacoes. A comparacao das funcoes de covariancia obtidas a partir
da Proposicao 3.2.3 com outras funcoes ja existentes na literatura e imprescindıvel
Alem disso, pretendemos introduzir a analise temporal a partir de Modelos Dinamicos.
Esse estudo e fundamental para gerarmos uma classe de modelos capazes de trabalhar
com dados multivariados espaciais ao longo do tempo.
51

Referencias Bibliograficas
Apanasovich, T. V. e Genton, M. G. (2010). “Cross-covariance functions for multivariate
random fields based on latent dimensions.” Biometrika, 97, 1, 15–30.
Apanasovich, T. V., Genton, M. G., e Sun, Y. (2012). “A Valid Matern Class of Cross-
Covariance Functions for Multivariate Random Fields With Any Number of Compo-
nents.” Journal of the American Statistical Association, 107, 1, 15–30.
Banerjee, S., Carlin, B. P., e Gelfand, A. E. (2004). Hierarchical Modeling and Analysis
for Spatial Data. Monographs on Statistics and Applied Probability, 1st ed. Chapman
& Hall/CRC.
Cox, T. F. e Cox, M. A. A. (2000). Multidimensional Scaling . Boca Raton, FL: Chapman
e Hall/CRC.
Cressie, N. (1993). Statistics for Spatial Data. New York: Wiley.
DeGroot, M. H. e Schervish, M. J. (2011). Probability and Statistics . 4th ed. Pearson.
Fonseca, T. C. O. e Steel, M. F. J. (2011). “A General Class of Nonseparable Space-time
Covariance Models.” Environmetrics , 22, 2, 224–242.
Gamerman, D. e Lopes, H. F. (2006). Markov Chain Monte Carlo: stochastic simulation
for bayesian inference. 2nd ed. CRC Press.
Gelfand, A. e Banerjee, S. (2010). “Multivariate Spatial Process Models.” In Handbook
of Spatial Statistics , 495–515. Chapman and Hall.
52

Genton, M. (2007). “Separable approximations of space-time covariance matrices.” En-
vironmetrics , 18, 681–695.
Golub, G. H. e Van Loan, C. F. (1996). Matrix Computations . The Johns Hopkins
University Press.
Majumdar, A. e Gelfand, A. E. (2007). “Multivariate Spatial Modeling for Geostatistical
Data Using Convolved Covariance Functions.” Mathematical Geology , 39, 7, 225–245.
Migon, H. e Gamerman, D. (1999). Statistical Inference: an integrated approach. 1st ed.
Arnold.
Plummer, M., Best, N., Cowles, K., e Vines, K. (2006). “CODA: Convergence Diagnosis
and Output Analysis for MCMC.” R News , 6, 7–11.
Schmidt, A. M. e Sanso, B. (2006). “Modelagem Bayesiana da Estrutura de Covariancia
de Processsos Espaciais e Espaco Temporais.” 17-th SINAPE .
Wackernagel, H. (1995). Multivariate Geostatistics: an introduction with applications .
Springer.
53





























