Embed Size (px)
Citation preview

1
Índice Página
I – Introdução................................................................................................................. 1
1 – População e amostra......................................................................................................... 2
2 – Intervalo de confiança da média da população ................................................................ 4
3 – Comparação das médias de duas amostras – Teste t ........................................................ 6
4 – Testes à normalidade da distribuição e à homogeneidade das variâncias........................ 9
5 – Teste t para amostras relacionadas (emparelhadas) ...................................................... 10
6 – Testes a variáveis não paramétricas – Teste de ajustamento do Qui-Quadrado ............ 12
7 – Teste de independência (Pearson) do Qui-Quadrado. Tabelas de contingência ............ 14
II – Análise de variância .............................................................................................. 17
8 – Delineamento experimental completamente casualizado. ............................................. 17
9 – Análise de variância de 1 factor (One-way Anova) ....................................................... 17
10 – Teste F .......................................................................................................................... 18
11 – Teste de Duncan e testes de Tukey .............................................................................. 22
12 – Delineamento experimental de blocos casualizados .................................................... 24
13 – Estrutura factorial – Anova de dois factores ................................................................ 27
14 – Anova de três factores – Interacções de 1ª e 2ª ordem................................................. 32
15 – Método dos talhões subdivididos (Split-plot) .............................................................. 33
III – Análise de regressão ............................................................................................ 39
16 – Regressão linear ........................................................................................................... 39
17 – Regressão não linear..................................................................................................... 43
18 – Transformações matemáticas dos resultados ............................................................... 46
19 – Regressão múltipla ....................................................................................................... 48
20 - Modelos de regressão.................................................................................................... 51
IV – Análise multivariada............................................................................................ 57
21 – Análise factorial de componentes principais................................................................ 57
22 – Análise de clusters........................................................................................................ 62
Bibliografia .................................................................................................................. 69

2
I – Introdução
1 – População e amostra A estatística é uma ciência que recorre a técnicas quantitativas para avaliar e estudar as incertezas e os seus efeitos no planeamento e interpretação de experiências e de observações de fenómenos da natureza e da sociedade.
Estatística descritiva. Capítulo da estatística em que se utiliza um conjunto de técnicas analíticas que tem por objectivo resumir os dados recolhidos numa dada investigação a relativamente poucos números e gráficos.
Estatística indutiva. Capítulo da estatística que tem como objectivo averiguar até que ponto se podem generalizar e validar os resultados encontrados numa amostra relativa a uma população. (Inferência estatística).
Biometria. Desenvolvimento e aplicação dos métodos estatísticos ao delineamento, análise e interpretação, das experiências de agricultura e biologia. Amostra de uma população com distribuição normal Uma população com distribuição normal pode ser caracterizada pela média e pela variância: N – (μ, σ2). A amostra, ao acaso, dessa população pode-se caracterizar por N – ( x , s2). Considerando uma amostra proveniente de uma população com distribuição normal: População Amostra
Média μ x
Desvio padrão σ s
Variância σ2 s2 = Σ( x - x )2/(n-1)
Erro padrão σ/√n s/√n
Coeficiente de variância (σ/μ) *100 (s/ x ) *100 Exercício 1
Considerando N – (15,4) calcular a probabilidade de x ≤ 11
Z ≤ σμ−x
≤ (11-15) /2 ≤ -2 logo P=0,5-0,4772=0,0228=2,28%
Estatística descritiva
Estatística indutiva Característica
da população: Características da amostra:
Estudo da amostra: - Tabelas; gráficos; etc.
População Amostra
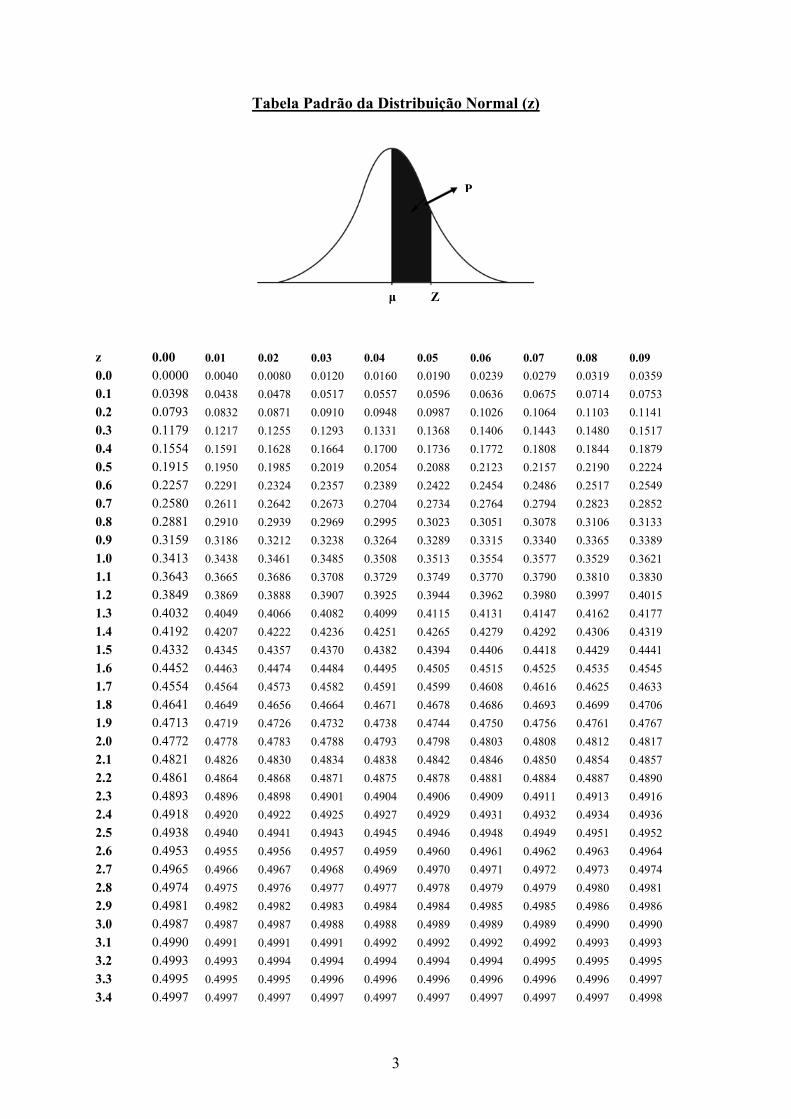
3
Tabela Padrão da Distribuição Normal (z)
P
μ Z
z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.0000 0.0040 0.0080 0.0120 0.0160 0.0190 0.0239 0.0279 0.0319 0.0359 0.1 0.0398 0.0438 0.0478 0.0517 0.0557 0.0596 0.0636 0.0675 0.0714 0.0753 0.2 0.0793 0.0832 0.0871 0.0910 0.0948 0.0987 0.1026 0.1064 0.1103 0.1141 0.3 0.1179 0.1217 0.1255 0.1293 0.1331 0.1368 0.1406 0.1443 0.1480 0.1517 0.4 0.1554 0.1591 0.1628 0.1664 0.1700 0.1736 0.1772 0.1808 0.1844 0.1879 0.5 0.1915 0.1950 0.1985 0.2019 0.2054 0.2088 0.2123 0.2157 0.2190 0.2224 0.6 0.2257 0.2291 0.2324 0.2357 0.2389 0.2422 0.2454 0.2486 0.2517 0.2549 0.7 0.2580 0.2611 0.2642 0.2673 0.2704 0.2734 0.2764 0.2794 0.2823 0.2852 0.8 0.2881 0.2910 0.2939 0.2969 0.2995 0.3023 0.3051 0.3078 0.3106 0.3133 0.9 0.3159 0.3186 0.3212 0.3238 0.3264 0.3289 0.3315 0.3340 0.3365 0.3389 1.0 0.3413 0.3438 0.3461 0.3485 0.3508 0.3513 0.3554 0.3577 0.3529 0.3621 1.1 0.3643 0.3665 0.3686 0.3708 0.3729 0.3749 0.3770 0.3790 0.3810 0.3830 1.2 0.3849 0.3869 0.3888 0.3907 0.3925 0.3944 0.3962 0.3980 0.3997 0.4015 1.3 0.4032 0.4049 0.4066 0.4082 0.4099 0.4115 0.4131 0.4147 0.4162 0.4177 1.4 0.4192 0.4207 0.4222 0.4236 0.4251 0.4265 0.4279 0.4292 0.4306 0.4319 1.5 0.4332 0.4345 0.4357 0.4370 0.4382 0.4394 0.4406 0.4418 0.4429 0.4441 1.6 0.4452 0.4463 0.4474 0.4484 0.4495 0.4505 0.4515 0.4525 0.4535 0.4545 1.7 0.4554 0.4564 0.4573 0.4582 0.4591 0.4599 0.4608 0.4616 0.4625 0.4633 1.8 0.4641 0.4649 0.4656 0.4664 0.4671 0.4678 0.4686 0.4693 0.4699 0.4706 1.9 0.4713 0.4719 0.4726 0.4732 0.4738 0.4744 0.4750 0.4756 0.4761 0.4767 2.0 0.4772 0.4778 0.4783 0.4788 0.4793 0.4798 0.4803 0.4808 0.4812 0.4817 2.1 0.4821 0.4826 0.4830 0.4834 0.4838 0.4842 0.4846 0.4850 0.4854 0.4857 2.2 0.4861 0.4864 0.4868 0.4871 0.4875 0.4878 0.4881 0.4884 0.4887 0.4890 2.3 0.4893 0.4896 0.4898 0.4901 0.4904 0.4906 0.4909 0.4911 0.4913 0.4916 2.4 0.4918 0.4920 0.4922 0.4925 0.4927 0.4929 0.4931 0.4932 0.4934 0.4936 2.5 0.4938 0.4940 0.4941 0.4943 0.4945 0.4946 0.4948 0.4949 0.4951 0.4952 2.6 0.4953 0.4955 0.4956 0.4957 0.4959 0.4960 0.4961 0.4962 0.4963 0.4964 2.7 0.4965 0.4966 0.4967 0.4968 0.4969 0.4970 0.4971 0.4972 0.4973 0.4974 2.8 0.4974 0.4975 0.4976 0.4977 0.4977 0.4978 0.4979 0.4979 0.4980 0.4981 2.9 0.4981 0.4982 0.4982 0.4983 0.4984 0.4984 0.4985 0.4985 0.4986 0.4986 3.0 0.4987 0.4987 0.4987 0.4988 0.4988 0.4989 0.4989 0.4989 0.4990 0.4990 3.1 0.4990 0.4991 0.4991 0.4991 0.4992 0.4992 0.4992 0.4992 0.4993 0.4993 3.2 0.4993 0.4993 0.4994 0.4994 0.4994 0.4994 0.4994 0.4995 0.4995 0.4995 3.3 0.4995 0.4995 0.4995 0.4996 0.4996 0.4996 0.4996 0.4996 0.4996 0.4997 3.4 0.4997 0.4997 0.4997 0.4997 0.4997 0.4997 0.4997 0.4997 0.4997 0.4998

4
2 – Intervalo de confiança da média da população Exercício 2 Considere a amostra de % de proteína: 12,9 13,4 12,4 12,8 13 12,7 12.4 13,5 13,9
Calcule o intervalo de confiança de 95% para média da % de proteína deste alimento. Inferência estatística: assume-se que os dados resultam de uma amostra ao acaso de uma população com uma distribuição normal e com uma média μ e uma variância σ2 que são desconhecidas e utilizam-se os valores da média e da variância da amostra para estimar os da população. x = 13 n = 9 Graus de Liberdade (GL) = n-1 = 8 s2 = Σ( x - x )2/(n-1) = 0,26 Erro Padrão (Se) = s/√n = 9/26,0 = 0,17 Para GL = 8 e P≤0,05 ( tabela Student* t, para bi caudal) resulta t(8) = 2,306 I.C.(95%) = x ± t * Se = 13 ± 2,306 * 0,17 = 13 ± 0,392 ≈ 12,61 a 13,39 Existe uma forte probabilidade da média da % da proteína deste alimento se situar entre 12,6% e 13,4%
Excel / Exercício 2 Ferramentas - Análise de dados - Estatística descritiva - Nível de confiança 95%
* STUDENT – Pseudónimo de William Gosset
se não aparecer análise de dados nas ferramentas vá aos suplementos
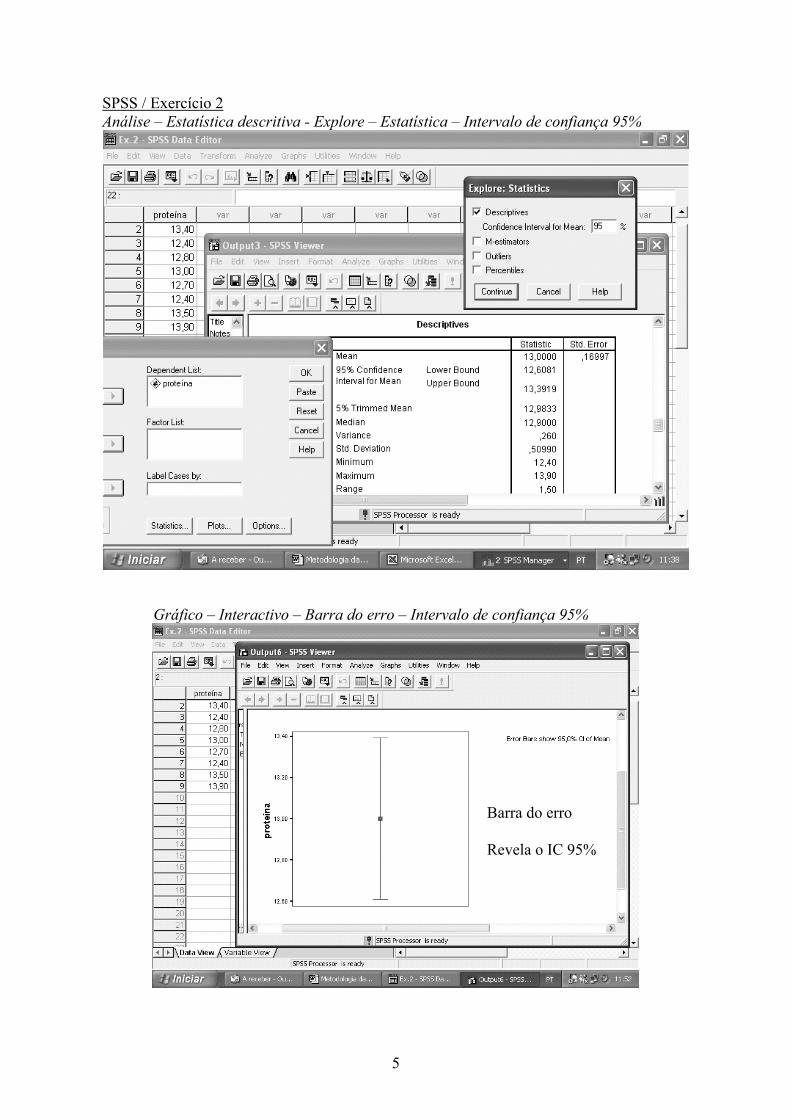
5
SPSS / Exercício 2 Análise – Estatística descritiva - Explore – Estatística – Intervalo de confiança 95%
Gráfico – Interactivo – Barra do erro – Intervalo de confiança 95%
Barra do erro Revela o IC 95%

6
3 – Comparação das médias de duas amostras – Teste t Exercício 3
Considere as seguintes produções (t/ha) de uma experiência com duas variedades de couve:
Variedade A: 22,9 19,8 24,4 27,9 23,1 25,7 28,2 25,6 26,2 28,7 31,5 37
Variedade B: 13,7 18,2 17,5 15,1 21,6 19,2 21,6 24,8 25,2 27,8 25,2 34 Hipótese nula H0: (μ1 - μ2) = 0 ou H0: μ1 = μ2 XA – N-(μ1, σ1
2) XB – N-(μ2, σ22) XA e XB são independentes então:
XA - XB tem uma média igual a 21 xx − e uma variância igual a σ12/n1+ σ2
2/n2
A estimativa de μ1 - μ2 baseia-se em 21 xx −
Hipótese nula, H0: μ1 = μ2 Hipótese alternativa, H1: μ1 ≠ μ2 (aceite se P <0,05)
Variância ponderada Sp2 =
2)1()1(
21
222
211
−+−+−
nnsnsn
Valor de t t = )11(
21
2
21
nns
xx
p +
−
1x = 26,75 2x =21,99 Sp2 = 26,58 GL = (12-1) + (12-1) = (24-2) = 22
Teste t t(22) = 2,26 implica P < 0,05 logo, há evidência para rejeitar H0 e aceitar H1 Logo, existe evidência para sugerir que a variedade A é mais produtiva que a variedade B. Com um intervalo de confiança de 95% pode-se estimar que a variedade A será mais produtiva entre 0,40 e 9,12 t/ha do que a variedade B.
21 xx − ± t(22) )/1/1( 212 nnsp +
(26,75-21,99) ± 2,074 * 2,1 = 4,76 ± 4,36 = 0,40 e 9,12 O intervalo de confiança de 99% já conteria o zero, ou seja, o ponto em que 21 xx = A diferença significativa mínima (LSD - Least Significant Difference) (P <0,05) entre as médias das duas variedades é igual ao erro padrão multiplicado pelo valor de t para 22 graus de liberdade e o valor de P = 5%, isto é, 2,1*2,074 = 4,36 t/ha. Assume-se a normalidade da distribuição. (Normalidade) Assume-se que as variâncias das duas populações são iguais. (Homogeneidade da variância)
Diferença entre as médias
Erro padrão para comparação entre as médias
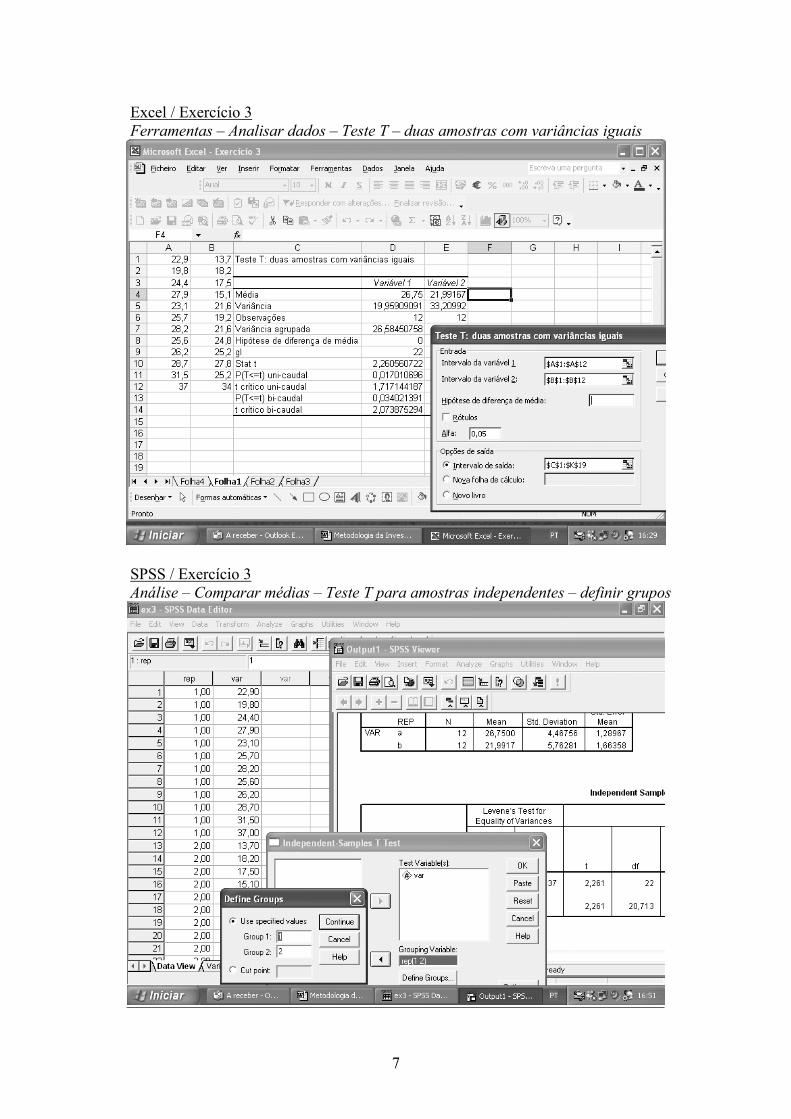
7
Excel / Exercício 3 Ferramentas – Analisar dados – Teste T – duas amostras com variâncias iguais
SPSS / Exercício 3 Análise – Comparar médias – Teste T para amostras independentes – definir grupos
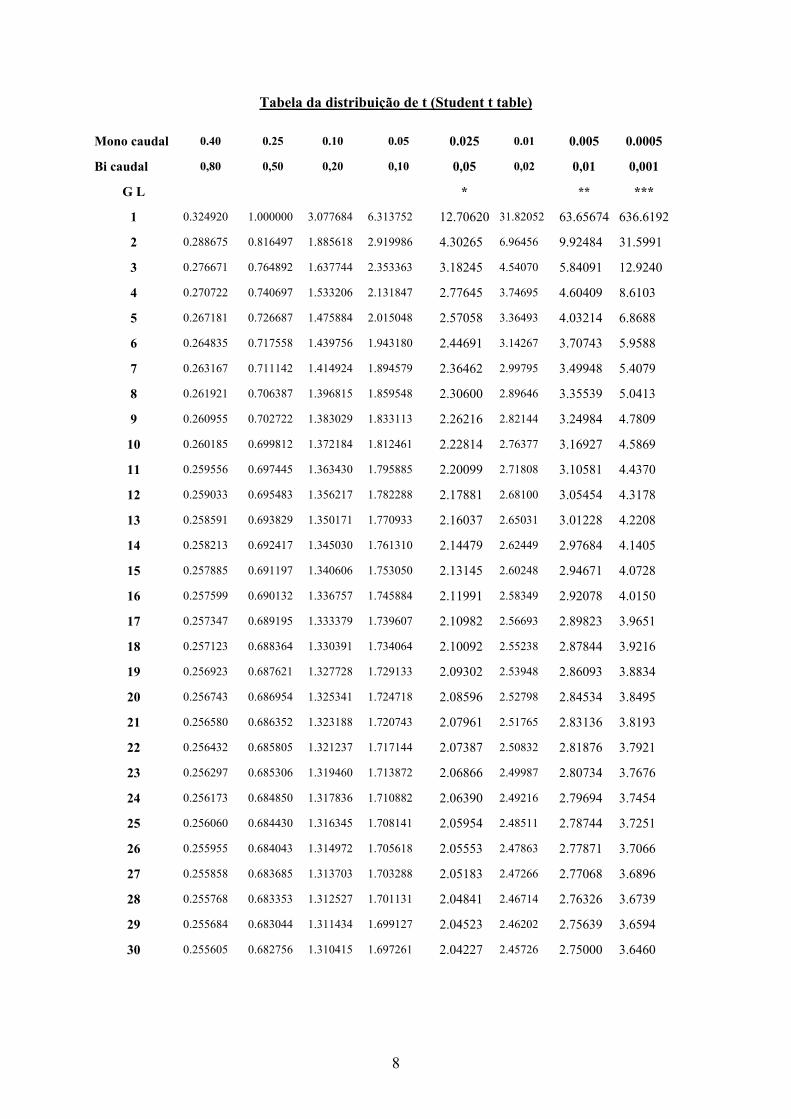
8
Tabela da distribuição de t (Student t table) Mono caudal 0.40 0.25 0.10 0.05 0.025 0.01 0.005 0.0005 Bi caudal 0,80 0,50 0,20 0,10 0,05 0,02 0,01 0,001
G L * ** ***
1 0.324920 1.000000 3.077684 6.313752 12.70620 31.82052 63.65674 636.6192
2 0.288675 0.816497 1.885618 2.919986 4.30265 6.96456 9.92484 31.5991 3 0.276671 0.764892 1.637744 2.353363 3.18245 4.54070 5.84091 12.9240 4 0.270722 0.740697 1.533206 2.131847 2.77645 3.74695 4.60409 8.6103 5 0.267181 0.726687 1.475884 2.015048 2.57058 3.36493 4.03214 6.8688 6 0.264835 0.717558 1.439756 1.943180 2.44691 3.14267 3.70743 5.9588 7 0.263167 0.711142 1.414924 1.894579 2.36462 2.99795 3.49948 5.4079 8 0.261921 0.706387 1.396815 1.859548 2.30600 2.89646 3.35539 5.0413 9 0.260955 0.702722 1.383029 1.833113 2.26216 2.82144 3.24984 4.7809
10 0.260185 0.699812 1.372184 1.812461 2.22814 2.76377 3.16927 4.5869 11 0.259556 0.697445 1.363430 1.795885 2.20099 2.71808 3.10581 4.4370 12 0.259033 0.695483 1.356217 1.782288 2.17881 2.68100 3.05454 4.3178 13 0.258591 0.693829 1.350171 1.770933 2.16037 2.65031 3.01228 4.2208 14 0.258213 0.692417 1.345030 1.761310 2.14479 2.62449 2.97684 4.1405 15 0.257885 0.691197 1.340606 1.753050 2.13145 2.60248 2.94671 4.0728 16 0.257599 0.690132 1.336757 1.745884 2.11991 2.58349 2.92078 4.0150 17 0.257347 0.689195 1.333379 1.739607 2.10982 2.56693 2.89823 3.9651 18 0.257123 0.688364 1.330391 1.734064 2.10092 2.55238 2.87844 3.9216 19 0.256923 0.687621 1.327728 1.729133 2.09302 2.53948 2.86093 3.8834 20 0.256743 0.686954 1.325341 1.724718 2.08596 2.52798 2.84534 3.8495 21 0.256580 0.686352 1.323188 1.720743 2.07961 2.51765 2.83136 3.8193 22 0.256432 0.685805 1.321237 1.717144 2.07387 2.50832 2.81876 3.7921 23 0.256297 0.685306 1.319460 1.713872 2.06866 2.49987 2.80734 3.7676 24 0.256173 0.684850 1.317836 1.710882 2.06390 2.49216 2.79694 3.7454 25 0.256060 0.684430 1.316345 1.708141 2.05954 2.48511 2.78744 3.7251 26 0.255955 0.684043 1.314972 1.705618 2.05553 2.47863 2.77871 3.7066 27 0.255858 0.683685 1.313703 1.703288 2.05183 2.47266 2.77068 3.6896 28 0.255768 0.683353 1.312527 1.701131 2.04841 2.46714 2.76326 3.6739 29 0.255684 0.683044 1.311434 1.699127 2.04523 2.46202 2.75639 3.6594 30 0.255605 0.682756 1.310415 1.697261 2.04227 2.45726 2.75000 3.6460
9
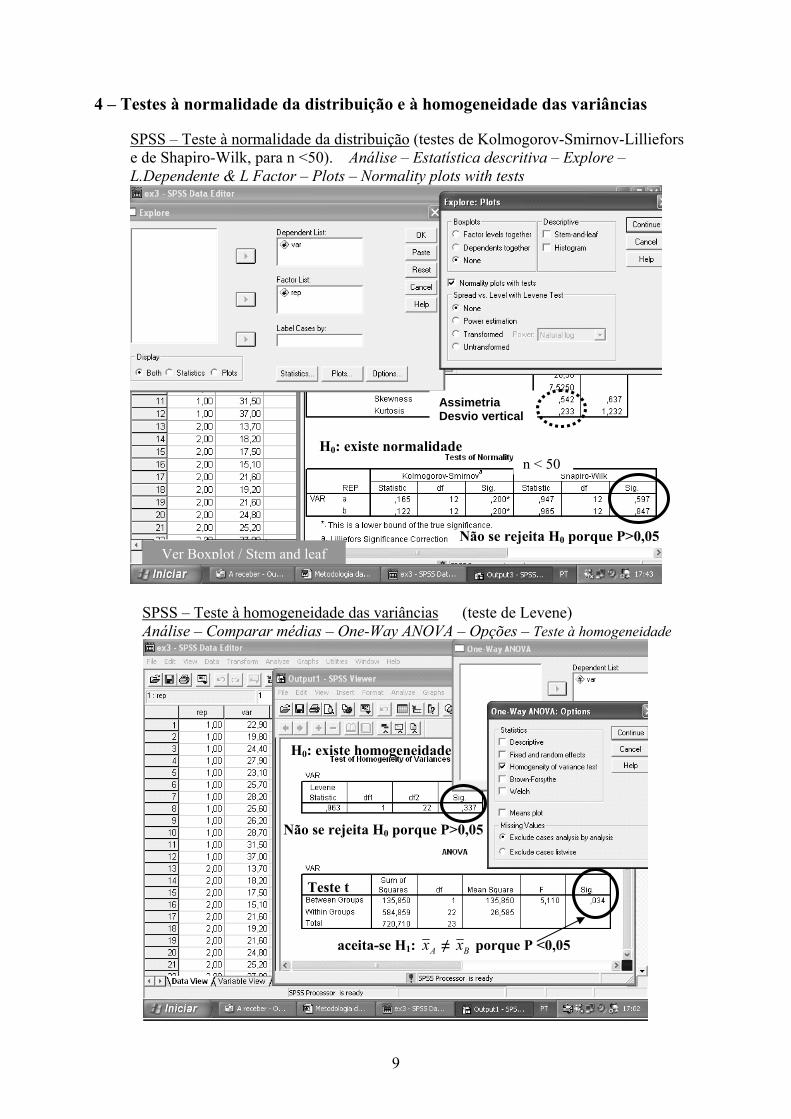
4 – Testes à normalidade da distribuição e à homogeneidade das variâncias
SPSS – Teste à normalidade da distribuição (testes de Kolmogorov-Smirnov-Lilliefors e de Shapiro-Wilk, para n <50). Análise – Estatística descritiva – Explore – L.Dependente & L Factor – Plots – Normality plots with tests
SPSS – Teste à homogeneidade das variâncias (teste de Levene) Análise – Comparar médias – One-Way ANOVA – Opções – Teste à homogeneidade
AssimetriaDesvio vertical
n < 50
Não se rejeita H0 porque P>0,05
H0: existe homogeneidade
Teste t - aceita-se H1: Ax ≠ Bx porque P <0,05
H0: existe normalidade
Não se rejeita H0 porque P>0,05
Teste t
Ver Boxplot / Stem and leaf

10
5 – Teste t para amostras relacionadas (emparelhadas) Exemplos: estudos com gémeos; formação de pares de observações, antes e depois de um tratamento; ou com um individuo tratado e outro não, emparelhados pela idade ou sexo. A hipótese nula diz que não há diferença entre os valores médios para os membros de um par na população, ou que a diferença entre as médias da população é zero. Se a correlação entre os dois grupos é pequena deve-se considerar as amostras independentes para aumentar o número de graus de liberdade.
Exercício 4
Considere que os dados das variedades de couve A e B referidas no exercício anterior estavam
emparelhados porque cada par de dados era proveniente de um campo diferente.
Neste teste a hipótese nula H0: (μ1 - μ2) = 0 ou H0: μ1 = μ2 é enunciada como: H0: μD = 0 em que D representa a diferença entre os dois valores de cada par.
Valor de t t (n-1) =
ns
D
D2
t (11) =
12105,1575,4 = 4,24 logo, P <0,01
Verifica-se que a evidência de que a variedade A é mais produtiva do que a variedade B é
mais forte quando as amostras são tratadas como emparelhadas (P <0,01) do que quando as
amostras foram tratadas como independentes (P <0,05) apesar da redução de 22 para 11 no
número de graus de liberdade.
Com um intervalo de confiança de 95% pode-se estimar que a variedade A será mais
produtiva entre 2,29 e 7,22 t/ha do que a variedade B.
Dx ± t(11) nsD /2 logo, 4,75 ± 2,2 * 1,122 = 2,29 e 7,22
A diferença significativa mínima (LSD) para comparação entre as médias das duas variedades
seria 2,2 * 1,122 = 2,47 t/ha
Média das diferenças ou diferença média
Erro padrão da diferença
11
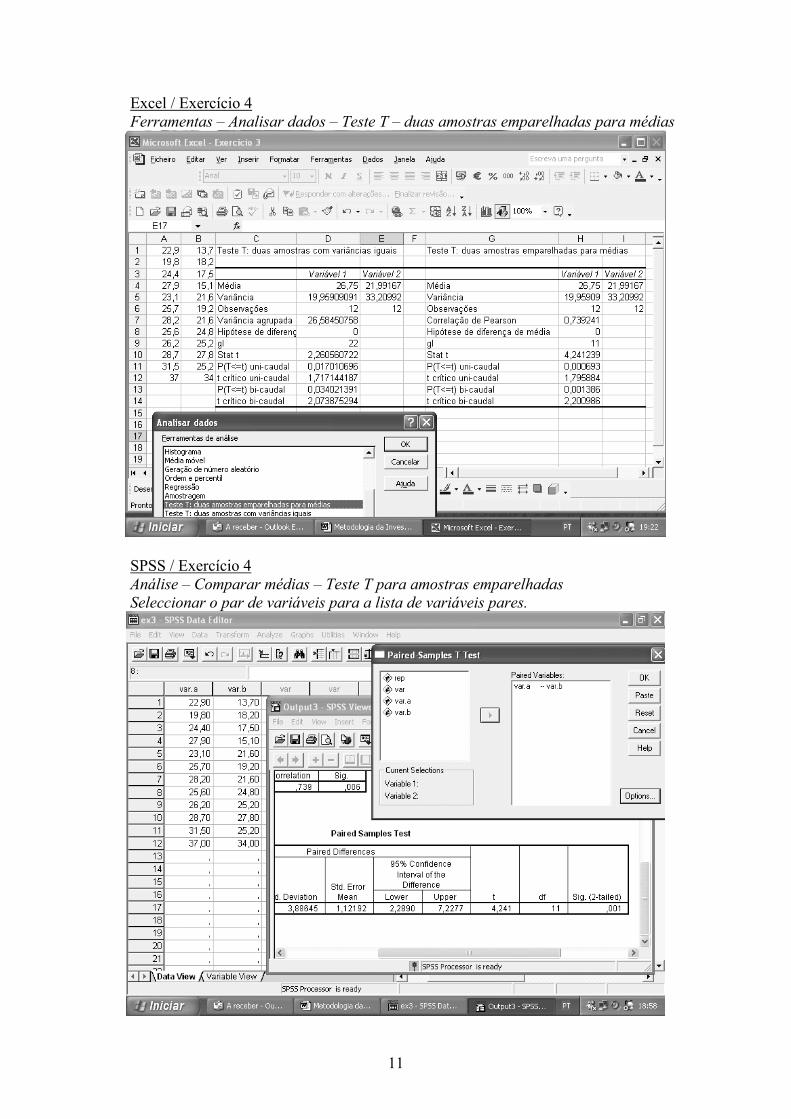
Excel / Exercício 4 Ferramentas – Analisar dados – Teste T – duas amostras emparelhadas para médias
SPSS / Exercício 4 Análise – Comparar médias – Teste T para amostras emparelhadas Seleccionar o par de variáveis para a lista de variáveis pares.

12
6 – Testes a variáveis não paramétricas – Teste de ajustamento do Qui-Quadrado Os dados das variáveis podem ser discretos (ex. numero de folhas numa planta) ou contínuos (ex. produção) e neste caso são avaliadas por testes paramétricos como o teste t. No entanto, existem dados que podem ser distribuídos por categorias como nas classificações e que têm de ser analisados através de testes não paramétricos como o teste do Qui-Quadrado. Estes dados não obedecem à distribuição normal.
O teste de ajustamento (goodness of fit) do Qui-Quadrado ( 2χ ) compara as frequências dos valores observados com as frequências dos valores esperados, das diferentes categorias de uma variável aleatória. A hipótese nula afirma que os valores observados se ajustam aos valores esperados. Exercício 5 – Teste a frequências hipotéticas
No transporte de tomate para a indústria utilizaram-se novas embalagens para verificar se o número de frutos que resistiam intactos ao transporte aumentava relativamente à relação de três tomates resistentes para cada tomate danificado, como era habitual. Numa amostra colhida ao acaso de 300 tomates verificaram-se que 85 foram danificados ficando 215 intactos. Testar a hipótese nula da relação entre frutos resistentes e frutos danificados ser 3:1.
Cálculo do Qui-Quadrado ∑ −=
EsperadoEsperadoObservado 2
2 )(χ
Classe Observado Esperado (O-E) (O-E)2 / E Resistente Danificado
215 85
225 75
-10 +10
0,44 1,33
Total 300 300 0 1,77
=2χ 1,77 (n.s.) G.L. = nº de classes -1 = 2-1 = 1 ou, (2-1) *(2-1) = 1*1 = 1 Como se verifica pela tabela do Qui-Quadrado não há evidência para rejeitar a hipótese nula e aceitar que as novas embalagens sejam mais resistentes do que as anteriores. Exercício 6
Num teste ao sabor de maçãs assadas numa forma tradicional (T) ou num novo método (N) foram entregues a cada participante três maças, das quais, 2T e 1N, e solicitou-se que identificassem a maça que diferia das outras duas. Dos 60 participantes, 28 seleccionaram a maça correcta. Será que este teste suporta a hipótese nula (H0) de que os dois grupos de maça são indistinguíveis pelo sabor? Ou haverá evidência para aceitar a hipótese alternativa (H1). Classe Observado Esperado (O-E) (O-E)2 / E T N
32 28
40 20
-8 +8
1,6 3,2
Total 60 60 0 =2χ 4,8* Aceita-se H1

13
SPSS / Exercício 5 Data – Weight cases –Frequency variable Análise – Testes não paramétricos – chi-square – Valores esperados
SPSS / Exercício 6

14
7 – Teste de independência (Pearson) do Qui-Quadrado. Tabelas de contingência O teste de independência do Qui-Quadrado (X2 de Pearson) permite averiguar se as variáveis
estão relacionadas. A hipótese nula afirma que as variáveis são independentes.
Valor de ∑ −=
EEO 2
2 )(χ assumindo a independência das variáveis.
Utilizam-se tabelas de consistência.
Os valores esperados resultam do valor = (Total da linha * Total da coluna) / Total global Exercício 7 Para testar a hipótese que afirma que o aparecimento de úlceras gástricas ou cancros do
estômago é independente do consumo de cerveja, vinho ou água, analisaram-se 8766
indivíduos, ao acaso, e obtiveram-se os seguintes resultados:
Tabela de contingência 3X3 Úlcera Cancro Saudável Total da linha
Cerveja
Vinho
Água
983
679
134
383
416
84
2892
2625
570
4258
3720
788
Total da coluna 1796 883 6087 Total global 8766
Frequências esperadas Desvios (O-E) (O-E)2 / E 2χ 872,4 428,9 2956,7 110,6 -45,9 -64,7 14,02 4,91 1,42
762,2 374,7 2583,1 -83,2 41,3 41,9 9,08 4,55 0,68
161,4 79,4 547,2 -27,4 4,6 22,8 4,65 0,27 0,95 40,53***
G.L. = (3-1)*(3-1) = 2*2 = 4 Aceita-se H1: Existe associação entre as doenças referidas e o tipo de bebidas consumidas.

15
SPSS / Exercício 7 Data – Weight cases –Frequency variable Análise – Estatística descritiva – Crosstabs – Statistics – Chi-square (Cells – Counts: observed, expected; Residuals: unstandardized)

16
Probabilidade acumulada (Tabela do X2)
D. F. 0.005 0.010 0.025 0.05 0.10 0.25 0.50 0.75 0.95 0.99 0.995 1 0.39E-4 0.00016 0.00098 0.0039 0.0158 0.102 0.455 1.32 3.84 6.63 7.88 2 0.0100 0.0201 0.0506 0.103 0.211 0.575 1.39 2.77 5.99 9.21 10.6 3 0.0717 0.115 0.216 0.352 0.584 1.21 2.37 4.11 7.81 11.3 12.8 4 0.207 0.297 0.484 0.711 1.06 1.92 3.36 5.39 9.49 13.3 14.9 5 0.412 0.554 0.831 1.15 1.61 2.67 4.35 6.63 11.1 15.1 16.7 6 0.676 0.872 1.24 1.64 2.20 3.45 5.35 7.84 12.6 16.8 18.5 7 0.989 1.24 1.69 2.17 2.83 4.25 6.35 9.04 14.1 18.5 20.3 8 1.34 1.65 2.18 2.73 3.49 5.07 7.34 10.2 15.5 20.1 22.0 9 1.73 2.09 2.70 3.33 4.17 5.9 8.34 11.4 16.9 21.7 23.6
10 2.16 2.56 3.25 3.94 4.87 6.74 9.34 12.5 18.3 23.2 25.2 11 2.60 3.05 3.82 4.57 5.58 7.58 10.3 13.7 19.7 24.7 26.8 12 3.07 3.57 4.40 5.23 6.30 8.44 11.3 14.8 21.0 26.2 28.3 13 3.57 4.11 5.01 5.89 7.04 9.3 12.3 16.0 22.4 27.7 29.8 14 4.07 4.66 5.63 6.57 7.79 10.2 13.3 17.1 23.7 29.1 31.3 15 4.60 5.23 6.26 7.26 8.55 11.0 14.3 18.2 25.0 30.6 32.8 16 5.14 5.81 6.91 7.96 9.31 11.9 15.3 19.4 26.3 32.0 34.3 17 5.70 6.41 7.56 8.67 10.1 12.8 16.3 20.5 27.6 33.4 35.7 18 6.26 7.01 8.23 9.39 10.9 13.7 17.3 21.6 28.9 34.8 37.2 19 6.84 7.63 8.91 10.1 11.7 14.6 18.3 22.7 30.1 36.2 38.6 20 7.43 8.26 9.59 10.9 12.4 15.5 19.3 23.8 31.4 37.6 40.0 21 8.03 8.90 10.3 11.6 13.2 16.3 20.3 24.9 32.7 38.9 41.4 22 8.64 9.54 11.0 12.3 14.0 17.2 21.3 26.0 33.9 40.3 42.8 23 9.26 10.2 11.7 13.1 14.8 18.1 22.3 27.1 35.2 41.6 44.2 24 9.89 10.9 12.4 13.8 15.7 19.0 23.3 28.2 36.4 43.0 45.6 25 10.5 11.5 13.1 14.6 16.5 19.9 24.3 29.3 37.7 44.3 46.9 26 11.2 12.2 13.8 15.4 17.3 20.8 25.3 30.4 38.9 45.6 48.3 27 11.8 12.9 14.6 16.2 18.1 21.7 26.3 31.5 40.1 47.0 49.6 28 12.5 13.6 15.3 16.9 18.9 22.7 27.3 32.6 41.3 48.3 51.0 29 13.1 14.3 16.0 17.7 19.8 23.6 28.3 33.7 42.6 49.6 52.3 30 13.8 15.0 16.8 18.5 20.6 24.5 29.3 34.8 43.8 50.9 53.7 31 14.5 15.7 17.5 19.3 21.4 25.4 30.3 35.9 45.0 52.2 55.0 32 15.1 16.4 18.3 20.1 22.3 26.3 31.3 37.0 46.2 53.5 56.3 33 15.8 17.1 19.0 20.9 23.1 27.2 32.3 38.1 47.4 54.8 57.6 34 16.5 17.8 19.8 21.7 24.0 28.1 33.3 39.1 48.6 56.1 59.0 35 17.2 18.5 20.6 22.5 24.8 29.1 34.3 40.2 49.8 57.3 60.3 40 20.7 22.2 24.4 26.5 29.1 33.7 39.3 45.6 55.8 63.7 66.8 45 24.3 25.9 28.4 30.6 33.4 38.3 44.3 51.0 61.7 70.0 73.2

17
II – Análise de variância
8 – Delineamento experimental completamente casualizado. A colocação aleatória (ao acaso) dos tratamentos nos talhões experimentais e a repetição dos tratamentos são requisitos para uma boa experiência. A casualização dos tratamentos aumenta a precisão porque diminui o erro padrão para comparação entre as respectivas médias.
No delineamento experimental completamente casualizado (completely randomized design) os talhões são distribuídos para cada repetição de cada tratamento completamente ao acaso.
9 – Análise de variância de 1 factor (One-way Anova) ANOVA – Análise de variância Origem da variação GL
(df) ss – soma dos quadrados ms = ss/df = média
dos quadrados
Entre tratamentos Residual (do erro, ou dentro dos tratamentos)
t-1
t(r-1)
( )[ ] ( )[ ] ( )trx
rxx t
2221 ... Σ
−Σ++Σ
( ) ( )[ ] ( )[ ]r
xxx t
2212 ... Σ++Σ
−Σ
sp2
Variação total
tr-1 ( ) ( )
nxx
22 Σ−Σ
t = nº de tratamentos r = nº de repetições n = tr = nº de talhões Exercício 8
Numa experiência para comparar 4 variedades de melão utilizaram-se 6 talhões (6 repetições) para cada variedade. Os tratamentos localizaram-se, aleatoriamente, nos 24 talhões. Pretende-se testar se as produtividades das 4 variedades são iguais, e caso sejam diferentes avaliar essas diferenças, assumindo que os dados provêm de populações com distribuições normais e com variâncias idênticas.
Os resultados da produção (t/ha) foram os seguintes: Variedade A B C D (Total) Produção
25,12 17,25 26,42 16,08 22,15 15,92
40,25 35,25 31,98 36,52 43,32 37,1
18,3 22,6 25,9 15,05 11,42 23,68
28,05 28,55 23,20 31,68 30,32 37,58
xΣ 122,94 224,42 116,95 179,38 (643,69) ( )2xΣ 2629,23 8472,09 2434,12 5475,33 (19010,77)
x 20,49 37,4 19,49 29,90 s2 22,04 15,61 30,91 22,49 Sp
2 = (22,04 + 15,61 + 30,91 + 22,49) / 4 = 22,76

18
Soma dos quadrados Variação total = 19010,77 - (643,69)2/24 = 1746,74 Variação entre tratamentos = [ Σ(122,942 +…+ 179,382) ]/6 – (643,69)2/24 = 1291,48 Variação residual = 1746,74 - 1291,48 = 455,26 ANOVA Origem da variação gl ss ms
Entre tratamentos Residual
4 – 1 = 034 (6-1) = 20
1291,48455,26
430,49 22,76
Variação total 24 - 1 = 23 1746,74
Erro padrão da média para cada variedade = ns2
= 676,22 = 1,95
Erro padrão para comparação entre médias = ⎟⎟⎠
⎞⎜⎜⎝
⎛+
21
2 11nn
s = 75,2376,22
62 2
==s
10 – Teste F Para um teste global sobre se as variedades deram produtividades iguais pode-se calcular o valor de F pelo quociente entre a média quadrática dos tratamentos e a média quadrática do erro (variância do erro). O valor de F obtido pode ser testado recorrendo à tabela F para o número de graus de liberdade dos tratamentos (horizontal) e os graus de liberdade do erro (vertical). H0: μ1= μ2= μ3= μ4 H1: As médias não são iguais Tabela F F(3,20) = 430,49 / 22,76 = 18,9 *** logo, P<0,001 Existe forte evidência para aceitar que existem diferenças de produtividade entre as variedades testadas. Tabela das médias
Variedade A B C D
Produtividade (t/ha) 20,5 37,4 19,5 29,9
Erro padrão para comparação entre duas médias = 2,75 t/ha LSD = 2,09 * 2,75 = 5,75 t/ha Evidência sobre as médias de produtividade: A=C < D < B

19
Tabela F – Ponto P=0,05
1 2 3 4 5 6 7 8 9 10 11 12 15 20 30 40 50
3 10.13 9.55 9.28 9.12 9.01 8.94 8.89 8.85 8.81 8.79 8.76 8.74 8.70 8.66 8.62 8.59 8.58 4 7.71 6.94 6.59 6.39 6.26 6.16 6.09 6.04 6.00 5.96 5.94 5.91 5.86 5.80 5.75 5.72 5.70 5 6.61 5.79 5.41 5.19 5.05 4.95 4.88 4.82 4.77 4.74 4.70 4.68 4.62 4.56 4.50 4.46 4.44 6 5.99 5.14 4.76 4.53 4.39 4.28 4.21 4.15 4.10 4.06 4.03 4.00 3.94 3.87 3.81 3.77 3.75 7 5.59 4.74 4.35 4.12 3.97 3.87 3.79 3.73 3.68 3.64 3.60 3.57 3.51 3.44 3.38 3.34 3.32 8 5.32 4.46 4.07 3.84 3.69 3.58 3.50 3.44 3.39 3.35 3.31 3.28 3.22 3.15 3.08 3.04 3.02 9 5.12 4.26 3.86 3.63 3.48 3.37 3.29 3.23 3.18 3.14 3.10 3.07 3.01 2.94 2.86 2.83 2.80 10 4.96 4.10 3.71 3.48 3.33 3.22 3.14 3.07 3.02 2.98 2.94 2.91 2.85 2.77 2.70 2.66 2.64 11 4.84 3.98 3.59 3.36 3.20 3.09 3.01 2.95 2.90 2.85 2.82 2.79 2.72 2.65 2.57 2.53 2.51 12 4.75 3.89 3.49 3.26 3.11 3.00 2.91 2.85 2.80 2.75 2.72 2.69 2.62 2.54 2.47 2.43 2.40 15 4.54 3.68 3.29 3.06 2.90 2.79 2.71 2.64 2.59 2.54 2.51 2.48 2.40 2.33 2.25 2.20 2.18 20 4.35 3.49 3.10 2.87 2.71 2.60 2.51 2.45 2.39 2.35 2.31 2.28 2.20 2.12 2.04 1.99 1.97 30 4.17 3.32 2.92 2.69 2.53 2.42 2.33 2.27 2.21 2.16 2.13 2.09 2.01 1.93 1.84 1.79 1.76 40 4.08 3.23 2.84 2.61 2.45 2.34 2.25 2.18 2.12 2.08 2.04 2.00 1.92 1.84 1.74 1.69 1.66 50 4.03 3.18 2.79 2.56 2.40 2.29 2.20 2.13 2.07 2.03 1.99 1.95 1.87 1.78 1.69 1.63 1.60 60 4.00 3.15 2.76 2.53 2.37 2.25 2.17 2.10 2.04 1.99 1.95 1.92 1.84 1.75 1.65 1.59 1.56
~
Tabela F – Ponto P=0,01
1 2 3 4 5 6 7 8 9 10 12 15 20 30 40 50 3 34.12 30.82 29.46 28.71 28.24 27.91 27.67 27.49 27.35 27.23 27.05 26.87 26.69 26.50 26.41 26.35
4 21.20 18.00 16.69 15.98 15.52 15.21 14.98 14.80 14.66 14.55 14.37 14.20 14.02 13.84 13.75 13.69
5 16.26 13.27 12.06 11.39 10.97 10.67 10.46 10.29 10.16 10.05 9.89 9.72 9.55 9.38 9.29 9.24
6 13.75 10.92 9.78 9.15 8.75 8.47 8.26 8.10 7.98 7.87 7.72 7.56 7.40 7.23 7.14 7.09
7 12.25 9.55 8.45 7.85 7.46 7.19 6.99 6.84 6.72 6.62 6.47 6.31 6.16 5.99 5.91 5.86 8 11.26 8.65 7.59 7.01 6.63 6.37 6.18 6.03 5.91 5.81 5.67 5.52 5.36 5.20 5.12 5.07 9 10.56 8.02 6.99 6.42 6.06 5.80 5.61 5.47 5.35 5.26 5.11 4.96 4.81 4.65 4.57 4.52 10 10.04 7.56 6.55 5.99 5.64 5.39 5.20 5.06 4.94 4.85 4.71 4.56 4.41 4.25 4.17 4.12 11 9.65 7.21 6.22 5.67 5.32 5.07 4.89 4.74 4.63 4.54 4.40 4.25 4.10 3.94 3.86 3.81 12 9.33 6.93 5.95 5.41 5.06 4.82 4.64 4.50 4.39 4.30 4.16 4.01 3.86 3.70 3.62 3.57 15 8.68 6.36 5.42 4.89 4.56 4.32 4.14 4.00 3.89 3.80 3.67 3.52 3.37 3.21 3.13 3.08 20 8.10 5.85 4.94 4.43 4.10 3.87 3.70 3.56 3.46 3.37 3.23 3.09 2.94 2.78 2.69 2.64 30 7.56 5.39 4.51 4.02 3.70 3.47 3.30 3.17 3.07 2.98 2.84 2.70 2.55 2.39 2.30 2.25 40 7.31 5.18 4.31 3.83 3.51 3.29 3.12 2.99 2.89 2.80 2.66 2.52 2.37 2.20 2.11 2.06 50 7.17 5.06 4.20 3.72 3.41 3.19 3.02 2.89 2.79 2.70 2.56 2.42 2.27 2.10 2.01 1.95 60 7.08 4.98 4.13 3.65 3.34 3.12 2.95 2.82 2.72 2.63 2.50 2.35 2.20 2.03 1.94 1.88

20
Tabela F – Ponto P=0,001
1 2 3 4 5 6 7 8 9 10 15 20 30 50 4 74.14 61.25 56.18 53.44 51.71 50.53 49.66 49.00 48.48 48.05 46.76 46.10 45.43 44.88 5 47.18 37.12 33.20 31.09 29.75 28.84 28.16 27.65 27.25 26.92 25.91 25.40 24.87 24.44 6 35.51 27.00 23.70 21.92 20.80 20.03 19.46 19.03 18.69 18.41 17.56 17.12 16.67 16.31 7 29.25 21.69 18.77 17.20 16.21 15.52 15.02 14.63 14.33 14.08 13.32 12.93 12.53 12.20 8 25.42 18.49 15.83 14.39 13.49 12.86 12.40 12.05 11.77 11.54 10.84 10.48 10.11 9.80 9 22.86 16.39 13.90 12.56 11.71 11.13 10.70 10.37 10.11 9.89 9.24 8.90 8.55 8.26 10 21.04 14.91 12.55 11.28 10.48 9.93 9.52 9.20 8.96 8.75 8.13 7.80 7.47 7.19 11 19.69 13.81 11.56 10.35 9.58 9.05 8.66 8.36 8.12 7.92 7.32 7.01 6.68 6.42 12 18.64 12.97 10.80 9.63 8.89 8.38 8.00 7.71 7.48 7.29 6.71 6.41 6.09 5.83 15 16.59 11.34 9.34 8.25 7.57 7.09 6.74 6.47 6.26 6.08 5.54 5.25 4.95 4.70 20 14.82 9.95 8.10 7.10 6.46 6.02 5.69 5.44 5.24 5.08 4.56 4.29 4.01 3.77 30 13.29 8.77 7.05 6.13 5.53 5.12 4.82 4.58 4.39 4.24 3.75 3.49 3.22 2.98 40 12.61 8.25 6.60 5.70 5.13 4.73 4.44 4.21 4.02 3.87 3.40 3.15 2.87 2.64 50 12.22 7.96 6.34 5.46 4.90 4.51 4.22 4.00 3.82 3.67 3.20 2.95 2.68 2.44 60 11.97 7.77 6.17 5.31 4.76 4.37 4.09 3.87 3.69 3.54 3.08 2.83 2.56 2.32
Excel / Exercício 8 Ferramentas – Analisar dados – ANOVA: Factor único – Seleccionar o intervalo

21
SPSS / Exercício 8 Análise – Comparar médias – One-way ANOVA – Seleccionar a variável e o factor
SPSS / Exercício 8 Análise – Comparar médias – One-way ANOVA – PHM comparisons - LSD

22
11 – Teste de Duncan e testes de Tukey SPSS / Exercício 8 Análise – Comparar médias – One-way ANOVA – PHM comparisons – Duncan
SPSS / Exercício 8 Análise – Comparar médias – One-way ANOVA PHM comparisons – Tukey B, Tukey HSD
(Exercício 8: A=C < D < B)
23
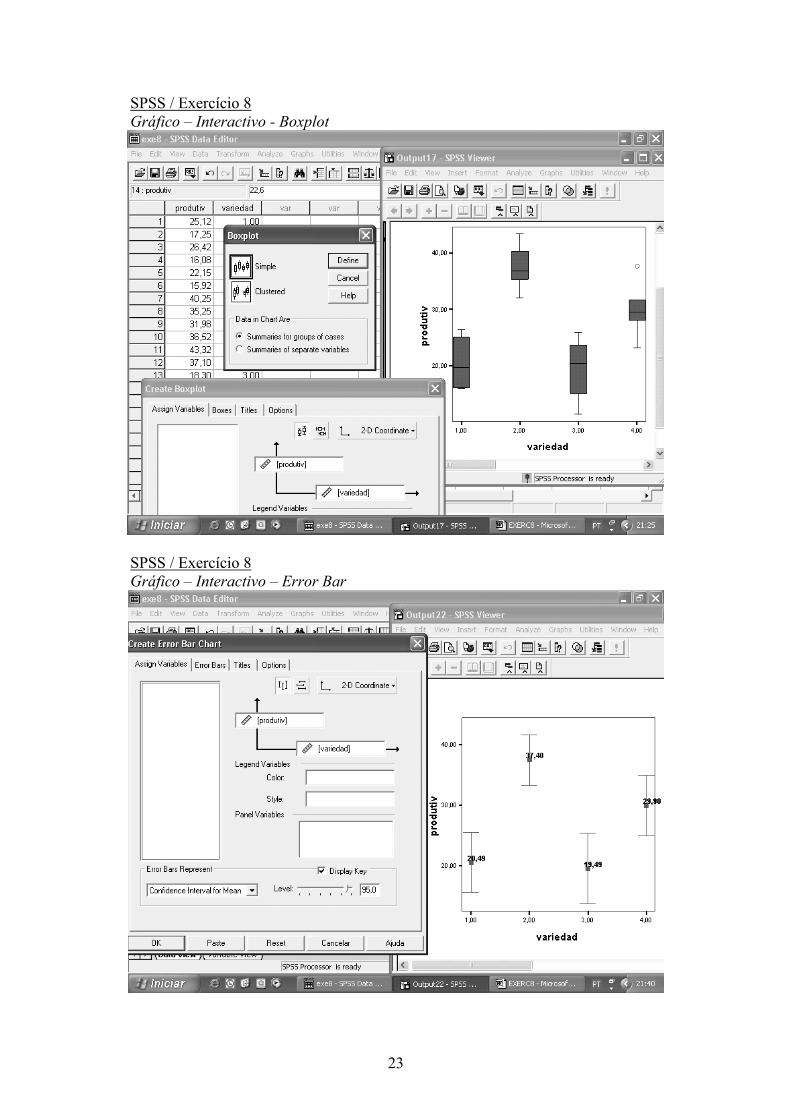
SPSS / Exercício 8 Gráfico – Interactivo - Boxplot
SPSS / Exercício 8 Gráfico – Interactivo – Error Bar

24
12 – Delineamento experimental de blocos casualizados Quando existe variação no ambiente de uma experiência podem-se constituir blocos. Cada bloco tem uma repetição de cada tratamento colocada aleatoriamente no bloco. Assim é possível diminuir a variação residual e aumentar a precisão da experiência. A variação no delineamento experimental de blocos casualizados (randomized block design) distribui-se pela variação entre blocos, variação entre tratamentos, e variação residual.
Considerando: t o nº de tratamentos; b o nº de blocos; n o nº de talhões; T1 a soma de todos os resultados do tratamento 1; B1 a soma de todos os resultados do bloco 1. Origem da variação gl ss ms F
Blocos b-1 ( )nx
tBBB b
2222
21 ... Σ
−+++ msB/s2
Tratamentos t-1 ( )nx
bTTT b
2222
21 ... Σ
−+++ msT/s2
Residual (erro) (b-1)(t-1) Por subtracção sp2
Total n-1 ( )nxx
22 Σ−Σ
Exercício 9 Efeito da temperatura e da humidade relativa na perda de peso de uma salada de quarta gama.
Experiência com um factor e três níveis (tratamentos) de factor.
Factor: Controlo ambiental; Tratamentos: Frio (F), Humidade (H), Frio e Humidade (FH).
Delineamento experimental de blocos casualizados (4 blocos * 3 tratamentos).
Resultados: Perda de peso (g) de 20 embalagens em 8 dias.
Tratamento/Bloco 1 2 3 4 Total
F 359 337 373 302 1371
H 372 340 343 341 1396
FH 330 288 295 313 1226
Total 1061 965 1011 956 3993

25
SS total = (3592+…+3132) - 39932/12 SS blocos = (10612+…+9562)/3 - 39932/12
SS residual = SS total - (SS bloc. + SS trat.) SS tratam = (13712+…+12262)/4 - 39932/12
ANOVA
Origem da variação
gl
ss
ms
F
Blocos 3 2330
Tratamentos 2 4212 2106 5,44*
Residual 6 2322 387
Total 11 8864
Hipótese nula: As perdas de peso são iguais com qualquer dos tratamentos. Como F corresponde a um valor de P <0,05 rejeita-se H0 e aceita-se que as perdas de peso possam diferir com os tratamentos.
Média geral = 3993/12 = 332,8 Coeficiente de variância = ( ) 100*8,332/387 = 5,9%
O coeficiente de variância é uma medida de precisão relativa. Normalmente, esperam-se valores de coeficientes de variância da ordem dos 5% ou menos quando o ambiente é controlado, 10% em culturas de campo e 20% ou mais em grandes experiências com animais.
Tabela das médias
Tratamento F H FH
Perdas de peso (g) 343 349 306
Erro padrão para comparação entre médias: Se = 4387*2 = 13,9 g
Teste t entre a média do tratamento F e a média do tratamento FH:
t = (343-306)/13,9 = 2,66 logo P <0,05 o que implica que as perdas de peso tenham sido menores com o tratamento FH do que com o tratamento F. LSD = t(6) * 13,9 = 2,447 * 13,9 = 34 g Teste de Waller-Duncan: F=H > FH ou F(a), H(a), FH(b) Conclusão: Não há diferenças significativas entre as perdas de peso da salada de quarta gama com os tratamentos F ou H, mas existe evidência (P <0,05) de que o tratamento FH resulta em perdas de peso menores do que qualquer dos outros tratamentos.

26
SPSS / Exercício 9 Análise – General linear model – Univariate – Colocar a variável dependente e os factores Modelo- Custom – All 2-way – colocar os factores no modelo
SPSS / Exercício 9 Análise – General linear model – Univariate – Post Hoc – Waller-Duncan
Options: Seleccionar observed power (que deve ser >0,8 para se rejeitar H0 com certeza)

27
13 – Estrutura factorial – Anova de dois factores O efeito de um nível de um factor pode depender do nível de outro factor. Por exemplo, o efeito de diferentes variedades de alface na produção desta cultura pode depender do nível de azoto mineral no solo. Uma variedade pode produzir mais do que outra em solos ricos, mas menos em solos pobres. Por esta razão, pode ser conveniente incluir na experiência os talhões necessários para analisar os efeitos principais dos factores (ex. variedades e fertilização), mas também, as possíveis interacções entre os factores. Considerando o factor variedade com dois níveis (A e B) e o factor fertilização com três níveis (100, 200 e 300), existem seis tratamentos possíveis (A100, A200, A300, B100, B200, B300) que resultam da multiplicação de duas variedades por três níveis de fertilização. Neste caso, a experiência fica com estrutura factorial dos tratamentos.
Considere-se este exemplo com dois factores: 1º variedade com dois níveis, 2º fertilização com três níveis. Na aproximação por um factor teríamos de decidir um determinado nível de fertilização e procurar, para essa dose, a melhor variedade, ou decidir sobre a variedade a utilizar e procurar, para essa variedade, a melhor dose de azoto. No entanto, este tipo de análise tem riscos, porque pode existir uma interacção entre a variedade e a fertilização.
Existe interacção entre dois factores quando a acção de um não permanece constante para qualquer nível do outro factor e vice-versa. Assim se a interacção for significativa os resultados de um factor dependem do nível do outro factor.
Produção
Nível de N
Interpretação dos resultados da experiência factorial
A forma como se interpretam os resultados de uma experiência factorial depende da existência ou não de uma interacção significativa e neste caso, da interacção ser muito menor, ou não, do que os efeitos principais: 1 – Se não existir interacção significativa as conclusões baseiam-se directamente nas médias dos efeitos principais. Assim, é suficiente comparar as médias dos níveis de cada factor. 2 – Se existir interacção significativa mas o valor F da interacção for muito inferior ao valor F dos efeitos principais as conclusões deverão basear-se na comparação entre as médias dos efeitos principais e na comparação entre as médias de tratamentos de cada nível de factor. 3 – Se a interacção for significativa e com um valor de F semelhante, ou superior, do que o valor F dos efeitos principais as conclusões baseiam-se apenas na comparação entre médias dos tratamentos já que aqui os efeitos principais de cada factor são de menor importância.
Var. A
Var. B
Var. B Var. A (melhor variedade depende do nível de N)
28
Análise de variância de uma experiência com estrutura factorial de tratamentos Exercício 10
Conduziu-se uma experiência com morangueiros em estufim para investigar a produção de 4 variedades e 3 datas de cobertura. Utilizou-se um delineamento experimental de blocos casualizados, com estrutura factorial de tratamentos e com 4 blocos. Os resultados encontram-se expressos em toneladas de morango por 3000m2 de estufim.
Data de
cobertura Variedade Blocos
I II III IV Total
Fevereiro V 10,2 10,1 12,1 12,3 44,7 R 11,1 9,8 8,6 9,4 38,9 F 6,8 9,5 9,5 10,3 36,1 G 5,3 7,5 4,6 7,3 24,7
Março V 8,0 9,7 12,0 7,8 37,5 R 9,7 7,9 10,3 11,2 39,1 F 8,6 9,6 9,5 10,0 37,7 G 3,4 4,2 7,3 7,6 22,5
Abril V 2,0 6,1 4,8 6,7 19,6 R 10,9 8,4 6,5 9,2 35,0 F 2,2 4,9 4,4 3,6 15,1 G 2,1 0,9 3,4 2,3 8,7
Total 80,3 88,6 93,0 97,7 359,6 ANOVA – Inicial
Ignorando a estrutura factorial e tratando a experiência como um factor com 12 tratamentos. SPSS - Análise – General linear model – Univariate – Colocar a variável dependente e os factores Modelo- Custom – All 2-way – colocar os factores no modelo (igual ao exercício 9)
Dependent Variable: PRODUÇÃO
13,692 3 4,564356,012 11 32,365 15,378 ,000
69,453 33 2,105
OrigemBLOCOTRATAMENError
ss df ms F Sig.
Pode-se rejeitar H0: as médias dos tratamentos são iguais, e aceitar que existem diferenças significativas entre os tratamentos. Neste caso procede-se a uma análise de variância mais detalhada.

29
Considerando: A = Factor A; B = Factor B; a = nº de níveis de A; b = nº de níveis de B A1 = nível 1 do factor A; TA1 a soma de todos os resultados do tratamento A1 t o nº de tratamentos (a*b); r o nº de (repetições) blocos; n o nº de talhões
ANOVA mais detalhada
Origem gl ss
Blocos
(a-1) ( )
nx
rbTT AA
222
21 ...)( Σ
−++ Efeito principal do factor A
Tratamentos (b-1) ( )nx
raTT BB
222
21 ... Σ
−++ Efeito principal do factor B
(a-1)(b-1) Por subtracção Efeito da interacção AB
Residual (erro)
Total
Tabela interacção nos dois sentidos
Data de cobertura Variedades
V R F G Total
Fevereiro 44,7 38,9 36,1 24,7 144,4
Março 37,5 39,1 37,7 22,5 136,8
Abril 19,6 35 15,1 8,7 78,4
Total 101,8 113,0 88,9 55,9 359,6
FC = Factor de correcção = ( ) rtx /2Σ = 359,62/48 = 2694
Cálculo da soma dos quadrados dos efeitos principais
SS variedades = 269412
9,55...8,101 22
−++ SS coberturas = 2694
164,78...4,144 22
−++
Cálculo da soma dos quadrados da interacção SS tratamentos = SS variedades + SS coberturas + SS interacção SS interacção = 356,02 – 152,69 – 163,01 = 40,32
30
ANOVA
Origem gl ss ms F P Blocos 3 13,69 4,57 Variedades 3 152,69 50,90 24,2 <0,001*** Coberturas 2 163,01 81,50 38,7 <0,001*** Var.*Cob. 6 40,32 6,72 3,2 <0,05* Erro 33 69,45 2,10 Total 47 439,16
Rejeitam-se as hipóteses de que as variedades ou as datas de cobertura não influenciam as produções de morango, mas também, que não exista interacção entre os dois factores.
Os resultados apresentam-se, então, numa tabela de médias dos tratamentos nos dois sentidos.
Tabela das médias dos tratamentos (t morango / 3000m2 de estufim)
Data de cobertura Variedades
V R F G Média
Fevereiro 11,2 9,7 9,0 6,2 9,0
Março 9,4 9,8 9,4 5,6 8,5
Abril 4,9 8,8 3,8 2,2 4,9
Média 8,5 9,4 7,4 4,7 7,5
Erro padrão para comparação entre duas médias e diferenças significativas mínimas: Variedades 12/2 2s = 0,59 LSD = t(33) * Se = 2,04 * 0,59 = 1,2
Datas de cobertura 16/2 2s = 0,51 LSD = t(33) * Se = 2,04 * 0,51 = 1,04
Tratamentos 4/2 2s = 1,03 LSD = t(33) * Se = 2,04 * 1,03 = 2,1
Sumário dos resultados: A produção de morangos de cada variedade não variou significativamente entre as datas de cobertura de Fevereiro e Março mas, com a excepção da variedade R, diminuiu com a data de cobertura de Abril. A variedade R foi a mais produtiva quando os morangueiros foram cobertos em Abril, e a variedade G foi a menos produtiva nas datas de cobertura de Fevereiro e Março. (Todas as afirmações estão baseadas num nível de significância em que P<0,05).
31
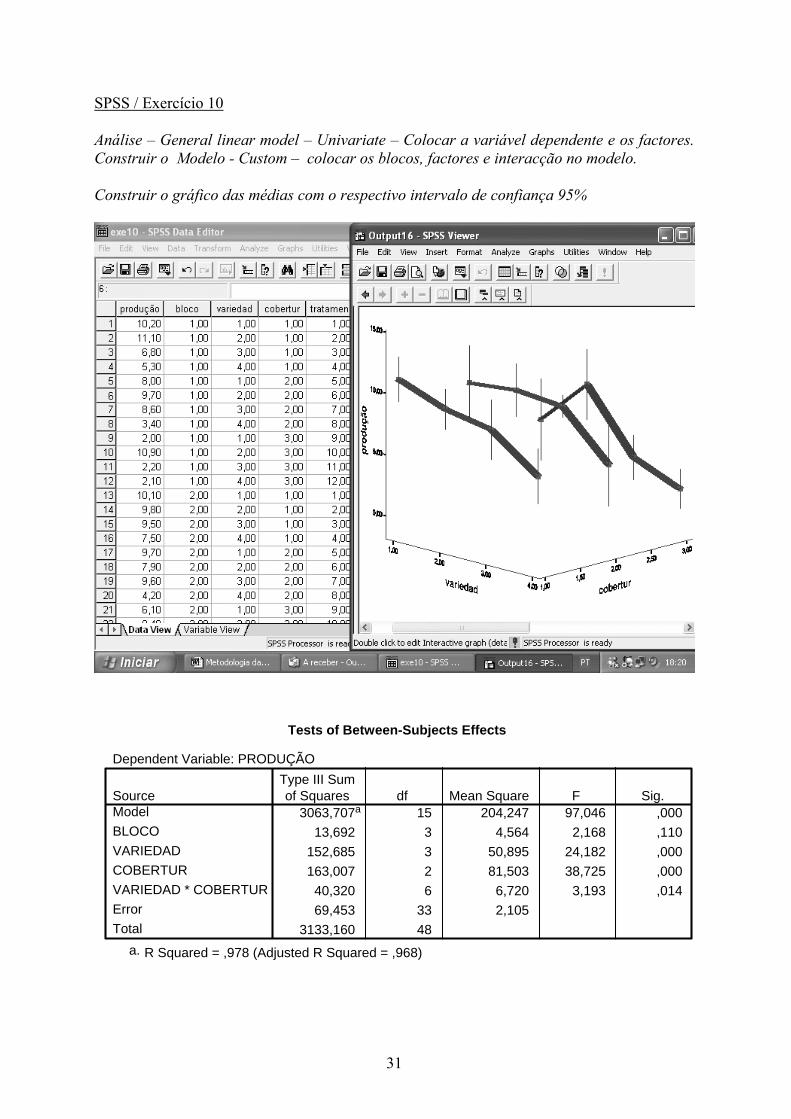
SPSS / Exercício 10 Análise – General linear model – Univariate – Colocar a variável dependente e os factores. Construir o Modelo - Custom – colocar os blocos, factores e interacção no modelo. Construir o gráfico das médias com o respectivo intervalo de confiança 95%
Tests of Between-Subjects Effects
Dependent Variable: PRODUÇÃO
3063,707a 15 204,247 97,046 ,00013,692 3 4,564 2,168 ,110
152,685 3 50,895 24,182 ,000163,007 2 81,503 38,725 ,000
40,320 6 6,720 3,193 ,01469,453 33 2,105
3133,160 48
SourceModelBLOCOVARIEDADCOBERTURVARIEDAD * COBERTURErrorTotal
Type III Sumof Squares df Mean Square F Sig.
R Squared = ,978 (Adjusted R Squared = ,968)a.
32
14 – Anova de três factores – Interacções de 1ª e 2ª ordem
As experiências com dois factores permitem verificar os efeitos principais e a interacção de 1ª ordem. As experiências com três factores permitem verificar os efeitos principais, as interacções de 1ª ordem entre cada dois factores, e a interacção de 2ª ordem entre os três factores. Quando o número de factores numa experiência aumenta o número de interacções também aumenta, e pode tornar-se difícil a análise dos efeitos principais e das interacções que se estabelecem. Exercício 11 Delineamento experimental de blocos casualizados com estrutura factorial (3 factores) Factores: N, P, K Níveis de factor: 1 e 2 Tratamentos = 23 = 8 Tratamentos: N1P1K1, N1P1K2, N1P2K1, N1P2K2, N2P1K1, N2P1K2, N2P2K1, N2P2K2 Considere os seguintes resultados de produção de alface (t/ha)
N P K B1 B2 B3 B4
1 1 1 15,20 15,90 17,20 21,40 1 1 2 17,10 16,30 17,30 21,20 1 2 1 16,20 22,20 17,60 23,00 1 2 2 18,40 17,20 19,30 22,10 2 1 1 19,10 22,10 24,30 25,00 2 1 2 19,40 27,70 22,50 27,10 2 2 1 18,70 28,30 23,10 26,90 2 2 2 36,30 32,20 33,20 34,50
Análise – General linear model – Univariate – Colocar a variável e os factores. Construir o Modelo - Custom – colocar os blocos, factores e interacções.

33
Tests of Between-Subjects Effects
Dependent Variable: PRODUÇÃO
108,307 3 36,102 6,969 ,002471,245 1 471,245 90,972 ,000114,005 1 114,005 22,008 ,000
64,980 1 64,980 12,544 ,00231,205 1 31,205 6,024 ,02363,845 1 63,845 12,325 ,00225,920 1 25,920 5,004 ,03643,245 1 43,245 8,348 ,009
108,782 21 5,180
SourceBLOCONPKN * PN * KP * KN * P * KError
Type III Sumof Squares df Mean Square F Sig.
15 – Método dos talhões subdivididos (Split-plot) Existem experiências em que não é possível utilizar determinados tratamentos, por razões práticas, em talhões pequenos. Por exemplo, se pretendermos testar o método de lavoura e variedades, podemos aplicar o método de lavoura em talhões grandes, dentro dos quais se colocam os talhões para as variedades. Exercício 12 A resposta de 6 variedades de alface a 3 formas de mobilização do solo foi investigada através de um delineamento experimental do tipo split-plot com 4 blocos. Os talhões principais corresponderam às formas de mobilização (X, Y, Z), e cada talhão principal foi dividido em 6 pequenos talhões correspondentes às 6 variedades (A, B, C, D, E, F). Os resultados expressos em t/ha foram os seguintes:
Mobilização Variedade Blocos
I II III IV Total A 11,8 7,5 9,7 6,4 35,4 B 8,3 8,4 11,8 8,5 37,0
X C 9,2 10,6 11,4 7,2 38,4 D 15,6 10,8 10,3 14,7 51,4 E 16,2 11,2 14,0 11,5 52,9 F 9,9 10,8 4,8 9,8 35,3
Total de X 71,0 59,3 62,0 58,1 A 9,7 8,8 12,5 9,4 40,4 B 5,4 12,9 11,2 7,8, 37,3
Y C 12,1 15,7 7,6 9,4 44,8 D 13,2 11,3 11,0 10,7 46,2 E 16,5 11,1 10,8 8,5 46,9 F 12,5 14,3 15,9 7,5 50,2
Total de Y 69,4 74,1 69,0 53,3, A 7,0 9,1 7,1 6,3 29,5 B 5,7 8,4 6,1 8,8 29,0
Z C 3,3 6,9 1,0 2,6 13,8 D 12,6 15,4 14,2 11,3 53,5 E 12,6 12,3 14,4 14,1 53,4 F 10,2 11,6 10,4 12,2 44,4
Total de Z 51,4 63,7 53,2 55,3

34
Análise dos talhões principais Mobilização Blocos
I II III IV TotalX 71,0 59,3 62,0 58,1 250,4Y 69,4 74,1 69,0 53,3 265,8Z 51,4 63,7 53,2 55,3 223,6
Total 191,8 197,1 184,2 166,7 739,8 Considerando: A = Factor A (main-plot); B = Factor B (split-plot);
a = nº de níveis de A; b = nº de níveis de B A1 = nível 1 do factor A; TA1 a soma de todos os resultados do tratamento A1 t o nº de tratamentos (a*b); r o nº de (repetições) blocos; n o nº de talhões
Y = Resultados dos talhões principais; y = Resultados dos talhões pequenos ANOVA – Talhões principais Origem gl ss ms
Blocos (r-1) ( )nx
abBB 22
22
1 ... Σ−
++
Efeito principal, A (a-1) ( )nx
rbTT AA
222
21 ...)( Σ
−++
Erro (a) (a-1)(r-1) Por subtracção sa2
Total ( )nx
bYY 22
22
1 ... Σ−
++
FC = ( )nx 2Σ =
728,739 2
= 7601,44
ANOVA – Talhões principais Origem gl ss ms F
Blocos (4-1)=3 44,76016*3
...1,1978,191 22
−++ = 29,35
Efeito principal A (3-1)=2 44,7601
6*4...)8,2654,250( 22
−++ = 38,01 19,00 2,62
Erro (a) 2*3=6 Por subtracção 43,56 7,26
Total 11 44,76016
3,55...4,6971 222
−+++ = 110,92

35
Análise dos pequenos talhões
Mobilização Variedade X Y Z Total
A 35,4 40,4 29,5 105,3 B 37,0 37,3 29,0 103,3 C 38,4 44,8 13,8 97,0 D 51,4 46,2 53,5 151,1 E 52,9 46,9 53,4 153,2 F 35,3 50,2 44,4 129,9
Total 250,4 265,8 223,6 739,8 ANOVA – Pequenos talhões Origem gl ss ms
Grandes talhões
Efeito principal, B (b-1) ( )nx
raTT BB
222
21 ...)( Σ
−++
Interacção AB (a-1)(b-1) ( ) )()(...)( 2212
211 BssAss
nx
rTT
−−Σ
−++
Erro (b) (r-1)a(b-1) Por subtracção sb2
Total rab-1 ( )nxy
22 Σ−Σ
ANOVA – Pequenos talhões Origem gl ss ms F Grandes talhões 11 110,92
Efeito principal B 5 51,26044,7601
3*4...)3,1033,105( 22
=−++ 52,10 10,32***
Interacção AB 10 70,16351,26001,3844,7601
4...)0,374,35( 22
=−−−++ 16,37 3,24**
Erro (b) 45 227,27 5,05 Total 71 40,76244,76012,12...3,88,11 222 =−+++
36
Tabela das médias Mobilização
Variedade X Y Z Média A 8,8 10,1 7,4 8,8 B 9,2 9,3 7,2 8,6 C 9,6 11,2 3,4 8,1 D 12,8 11,6 13,4 12,6 E 13,2 11,7 13,4 12,8 F 8,8 12,6 11,1 10,8
Média 10,4 11,1 9,3 10,3 Erros padrão para comparação entre duas médias Se gl t LSD Mobilização 78,024/2 2 =as 6 2,45 1,93
Variedade 91,012/2 2 =bs 45 2,02 1,84
2 variedades para a mesma mobilização 59,14/2 2 =bs 45 2,02 3,21
2 variedades de diferentes mobilizações 59,14/2 2 =bs 45 2,02 3,21
2 mobilizações para a mesma ou diferentes variedades ( 65,16*4/)52 22 =+ ab ss
Fórmula geral: ( )( ββ */)12 22 rss ab +− em que r é o número de blocos e β o número de
níveis do factor correspondente aos talhões pequenos. Neste caso, não se podem efectuar testes t exactos porque as médias quadráticas de ambos os erros estão envolvidas. Sumário dos resultados:
(i) A ANOVA dos talhões principais não evidenciou a existência de diferenças significativas na produção de alface em função dos tipos de mobilização experimentados.
(ii) A ANOVA dos pequenos talhões revela que existem diferenças significativas na produção entre as diferentes variedades.
(iii) As diferenças entre as variedades dependeram do tipo de mobilização utilizado porque a interacção entre as variedades e os tipos de mobilização foi significativa.
(iv) Para o tipo de mobilização X as melhores variedades foram a D e E; as diferenças entre variedades com a mobilização Y foram pequenas; para a mobilização Z as variedades D, E e F produziram mais do que as variedades A, B e C.

37
SPSS / Exercício 12
Proceder à análise de variância com blocos e dois factores (= exercício 10):
Análise - General linear model – Univariate – Colocar a produção na variável dependente, e
colocar os blocos e os factores (mobilização e variedades) nos factores fixos. Construir o
modelo. Posteriormente seleccionar Paste e acrescentar:
/TEST = mobiliza VS bloco*mobiliza uma linha antes de “/DESIGN …”.
Nesta última linha incluir bloco*mobiliza no texto, na ordem em que pretenda que apareça
no output. Finalmente seleccionar Run para obter o Output.
Run (All) => Output
UNIANOVA produção BY bloco mobiliza variedad /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /TEST = mobiliza VS bloco*mobiliza /DESIGN = bloco mobiliza bloco*mobiliza variedad mobiliza*variedad .
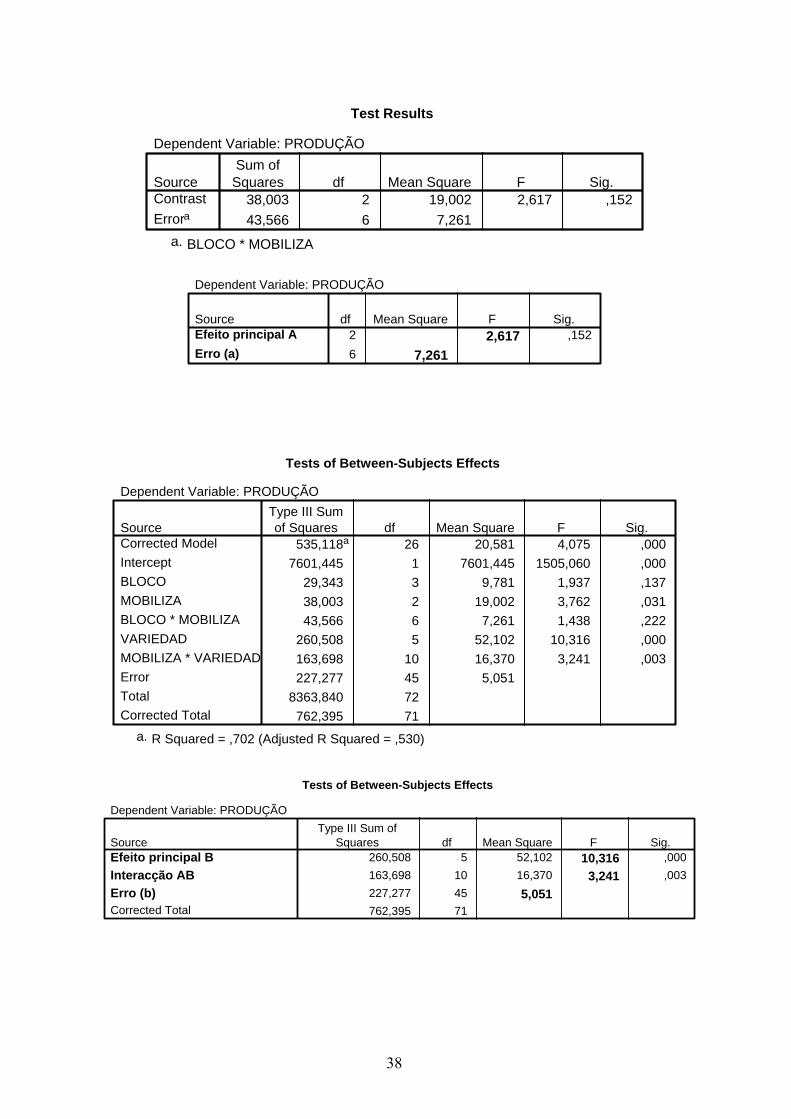
38
Test Results
Dependent Variable: PRODUÇÃO
38,003 2 19,002 2,617 ,15243,566 6 7,261
SourceContrastErrora
Sum ofSquares df Mean Square F Sig.
BLOCO * MOBILIZAa.
Dependent Variable: PRODUÇÃO
2 2,617 ,1526 7,261
SourceEfeito principal AErro (a)
df Mean Square F Sig.
Tests of Between-Subjects Effects
Dependent Variable: PRODUÇÃO
535,118a 26 20,581 4,075 ,0007601,445 1 7601,445 1505,060 ,000
29,343 3 9,781 1,937 ,13738,003 2 19,002 3,762 ,03143,566 6 7,261 1,438 ,222
260,508 5 52,102 10,316 ,000163,698 10 16,370 3,241 ,003227,277 45 5,051
8363,840 72762,395 71
SourceCorrected ModelInterceptBLOCOMOBILIZABLOCO * MOBILIZAVARIEDADMOBILIZA * VARIEDADErrorTotalCorrected Total
Type III Sumof Squares df Mean Square F Sig.
R Squared = ,702 (Adjusted R Squared = ,530)a.
Tests of Between-Subjects Effects
Dependent Variable: PRODUÇÃO
260,508 5 52,102 10,316 ,000163,698 10 16,370 3,241 ,003227,277 45 5,051762,395 71
SourceEfeito principal BInteracção ABErro (b)Corrected Total
Type III Sum ofSquares df Mean Square F Sig.

39
III – Análise de regressão
16 – Regressão linear Chama-se equação de regressão de uma variável (dependente) y em função das variáveis (independentes ou factores) x1, x2, …à equação: y = α + β1 x1 + β2 x2 … Nesta equação α é um parâmetro que representa a ordenada na origem, e β1, β2 … são os coeficientes de regressão parciais que representam a variação média de y por unidade de variação de x1, x2, … Regressão linear simples: y = a + b x
b = SxxSxy = ( )( )[ ]
( )2xxyyxx
−Σ−−Σ =
( )
( )nxx
nyxxy
22 Σ−Σ
ΣΣ−Σ
a = xby − = ( )n
xby Σ−Σ
n = nº de pares (x, y)
Teste à recta de regressão H0: (β=0) ou H0: y não depende de x ANOVA Origem gl ss ms F
Regressão 1 ( ) SxxSxy /2 F = t2
Residual n-2 Por subtracção
Total n-1 ( ) ( ) nyySyy /22 Σ−Σ=
Coeficiente de correlação (r) e coeficiente de determinação (r2) r2 = SS regressão / SS total = ( ) SyySxxSxy ./2 r2 = Coeficiente de determinação (proporção da variância explicada pela regressão)
(1 - r2) = variabilidade não explicada pela regressão
Previsão utilizando a recta a + bx ± t * Se
Erro padrão para previsão e um valor: Médio ( )
⎥⎦
⎤⎢⎣
⎡ −+
Sxxxx
ns
22 1 Isolado ( )
⎥⎦
⎤⎢⎣
⎡ −++
Sxxxx
ns
22 11

40
Coeficiente de correlação (r)
Graus de liberdade
Probabilidade P
(n -2) 0.05 0.01 0.001
1 0.997 1.000 1.0002 0.950 0.990 0.9993 0.878 0.959 0.9914 0.811 0.917 0.9745 0.755 0.875 0.9516 0.707 0.834 0.9257 0.666 0.798 0.8988 0.632 0.765 0.8729 0.602 0.735 0.847
10 0.576 0.708 0.82311 0.553 0.684 0.80112 0.532 0.661 0.78013 0.514 0.641 0.76014 0.497 0.623 0.74215 0.482 0.606 0.725
raus de liberdade
Probabilidade P
gl 0.05 0.01 0.001
16 0.468 0.590 0.70817 0.456 0.575 0.69318 0.444 0.561 0.67919 0.433 0.549 0.66520 0.423 0.457 0.65225 0.381 0.487 0.59730 0.349 0.449 0.55435 0.325 0.418 0.51940 0.304 0.393 0.49045 0.288 0.372 0.46550 0.273 0.354 0.44360 0.250 0.325 0.40870 0.232 0.302 0.38080 0.217 0.283 0.357
100 0.195 0.254 0.321
Exercício 13 Considere que o avanço em dias (y) no amadurecimento de maças foi avaliado para doses crescentes de etileno (x) obtendo-se os seguintes resultados:
y 6 9 13 12 14 18 x 1 2 3 4 5 6
Teste se o amadurecimento dependeu da dose de etileno. Estime a respectiva regressão linear.
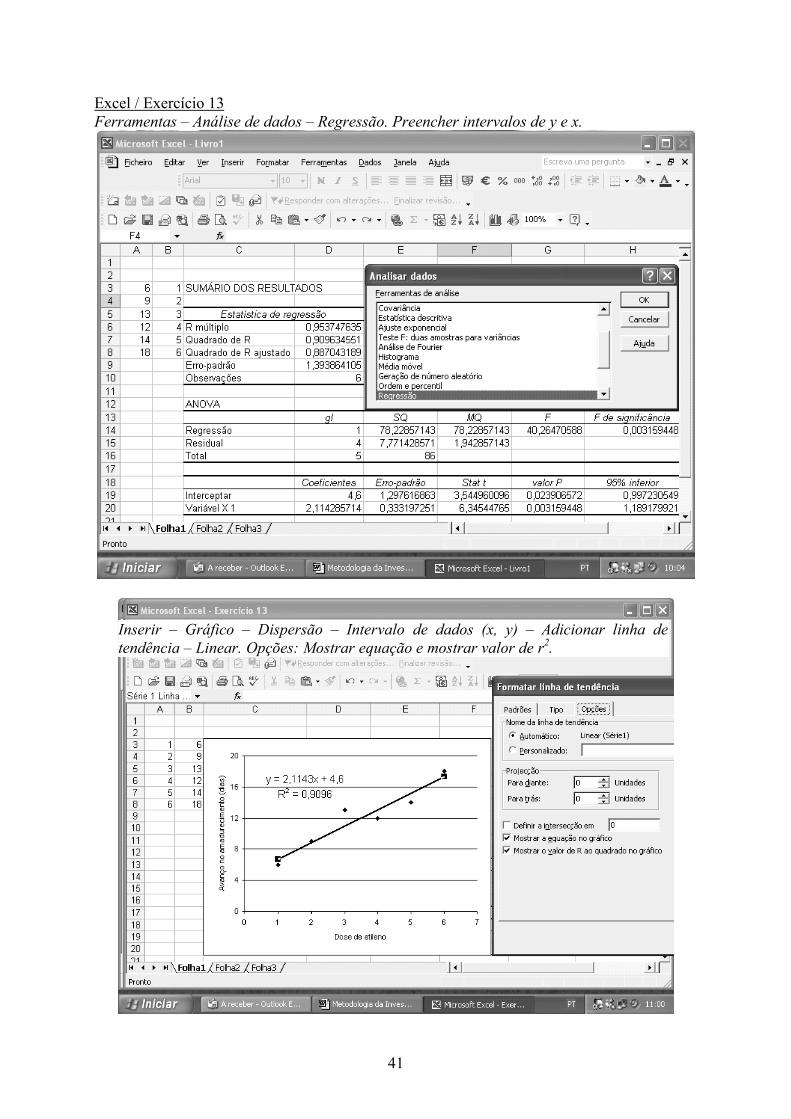
F = MS regressão / MS residual = (78,23/1) / (7,77/4) = 40,27 R2 = SS regressão / SS total = 78,23 / 86 = 0,91 Resultado: O amadurecimento (y) dependeu (P <0,01) da dose de etileno (x). Mais de 90% da variância no amadurecimento é explicada através da recta de regressão y = 4,6 + 2,114 x
n = 6 Σ (x) = 21 Σ(x2) = 91 Sxx = 91 – 212/6 = 17,5
Σ (xy ) = 289 Σ (y) = 7 2 Σ(y2) = 950 Sxy = 289 – [(72*21 )/6] = 37
SS total = Syy = 950 – 72 2 / 6 = 86 SS residual = 86 – 78,23 = 7,77 SS regressão = (Sxy )2 / Sxx = 372 / 17,5 = 78,23
b = 37 / 17,5 = 2,114 a = [72 – (21*2,114)] / 6 = 4,6 y = 4,6 + 2,114 x
41
Excel / Exercício 13 Ferramentas – Análise de dados – Regressão. Preencher intervalos de y e x.
Inserir – Gráfico – Dispersão – Intervalo de dados (x, y) – Adicionar linha de tendência – Linear. Opções: Mostrar equação e mostrar valor de r2.

42
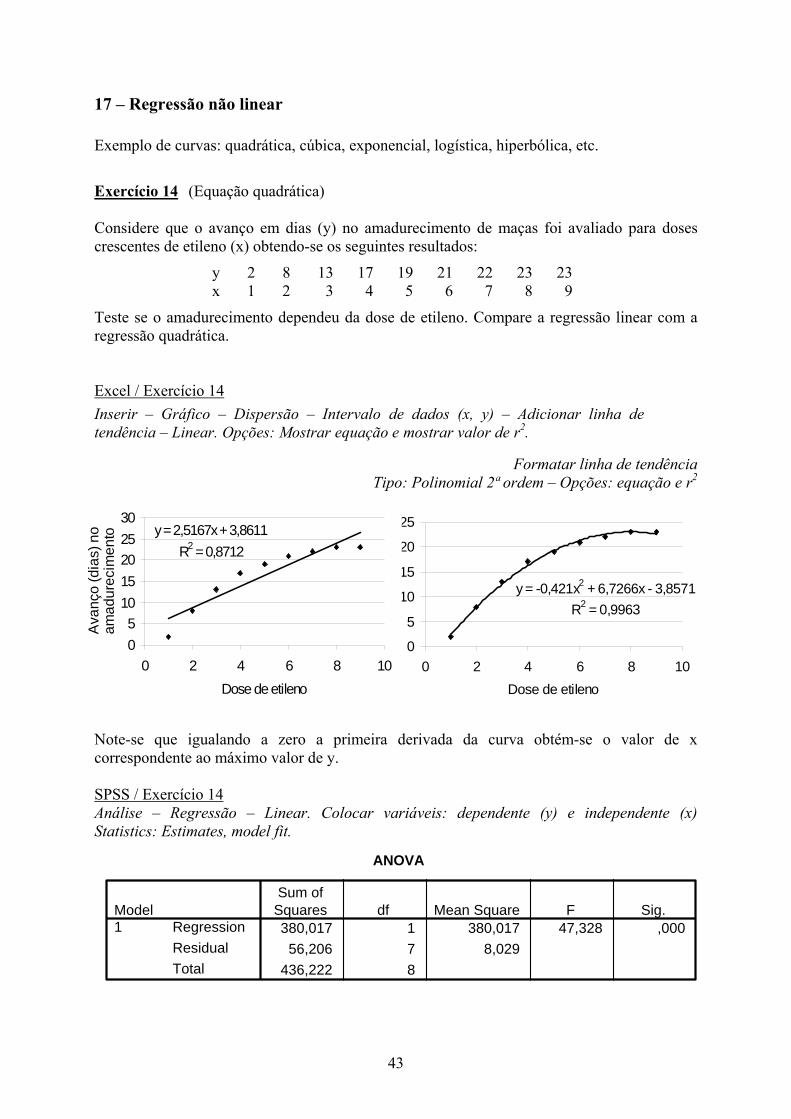
SPSS / Exercício 13 Análise – Regressão – Linear. Colocar variáveis: dependente (y) e independente (x) Statistics: Estimates, model fit.
Gráfico – Interactivo – Scatter plot. Colocar variáveis x e y – Fit regression
43
y = -0,421x2 + 6,7266x - 3,8571R2 = 0,9963
0
5
10
15
20
25
0 2 4 6 8 10Dose de etileno
Ava
nço
(dia
s) n
oam
adur
ecim
ento
17 – Regressão não linear Exemplo de curvas: quadrática, cúbica, exponencial, logística, hiperbólica, etc.
Exercício 14 (Equação quadrática) Considere que o avanço em dias (y) no amadurecimento de maças foi avaliado para doses crescentes de etileno (x) obtendo-se os seguintes resultados:
y 2 8 13 17 19 21 22 23 23 x 1 2 3 4 5 6 7 8 9
Teste se o amadurecimento dependeu da dose de etileno. Compare a regressão linear com a regressão quadrática. Excel / Exercício 14
Formatar linha de tendência Tipo: Polinomial 2ª ordem – Opções: equação e r2
Note-se que igualando a zero a primeira derivada da curva obtém-se o valor de x correspondente ao máximo valor de y. SPSS / Exercício 14 Análise – Regressão – Linear. Colocar variáveis: dependente (y) e independente (x) Statistics: Estimates, model fit.
ANOVA
380,017 1 380,017 47,328 ,00056,206 7 8,029
436,222 8
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Inserir – Gráfico – Dispersão – Intervalo de dados (x, y) – Adicionar linha de tendência – Linear. Opções: Mostrar equação e mostrar valor de r2.
y = 2,5167x + 3,8611R2 = 0,8712
05
1015202530
0 2 4 6 8 10Dose de etileno
Ava
nço
(dia
s) n
oam
adur
ecim
ento
44
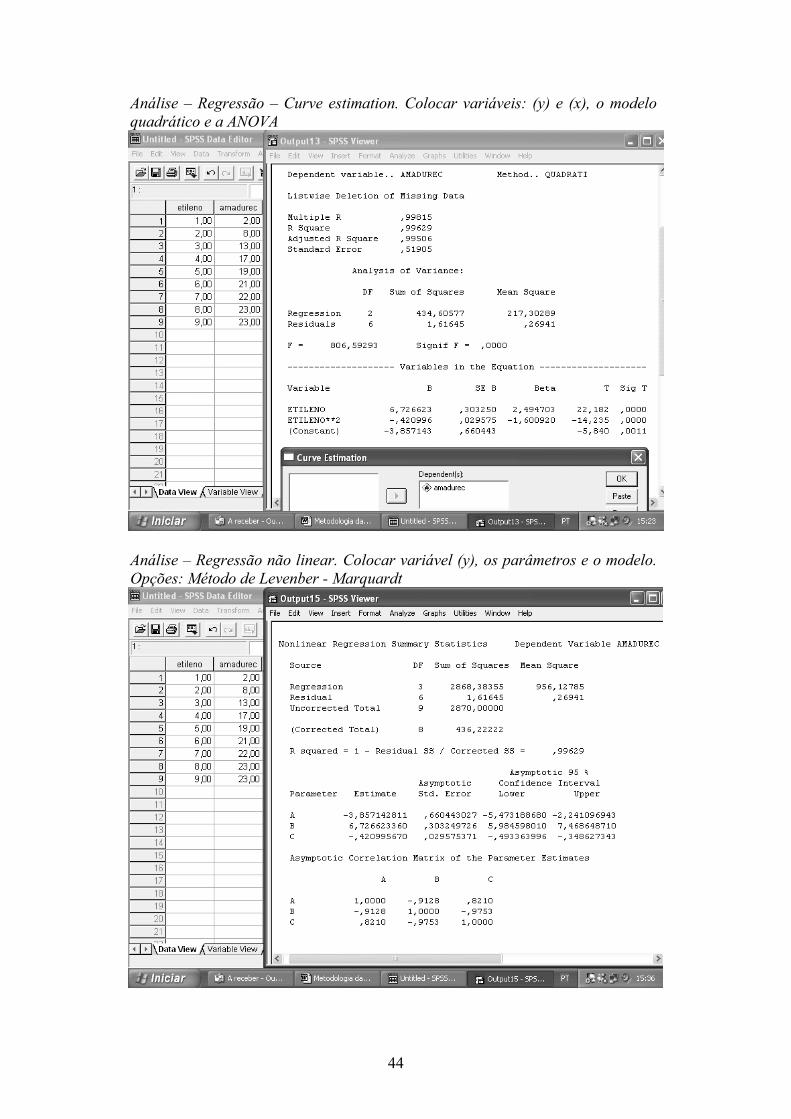
Análise – Regressão – Curve estimation. Colocar variáveis: (y) e (x), o modelo quadrático e a ANOVA
Análise – Regressão não linear. Colocar variável (y), os parâmetros e o modelo. Opções: Método de Levenber - Marquardt
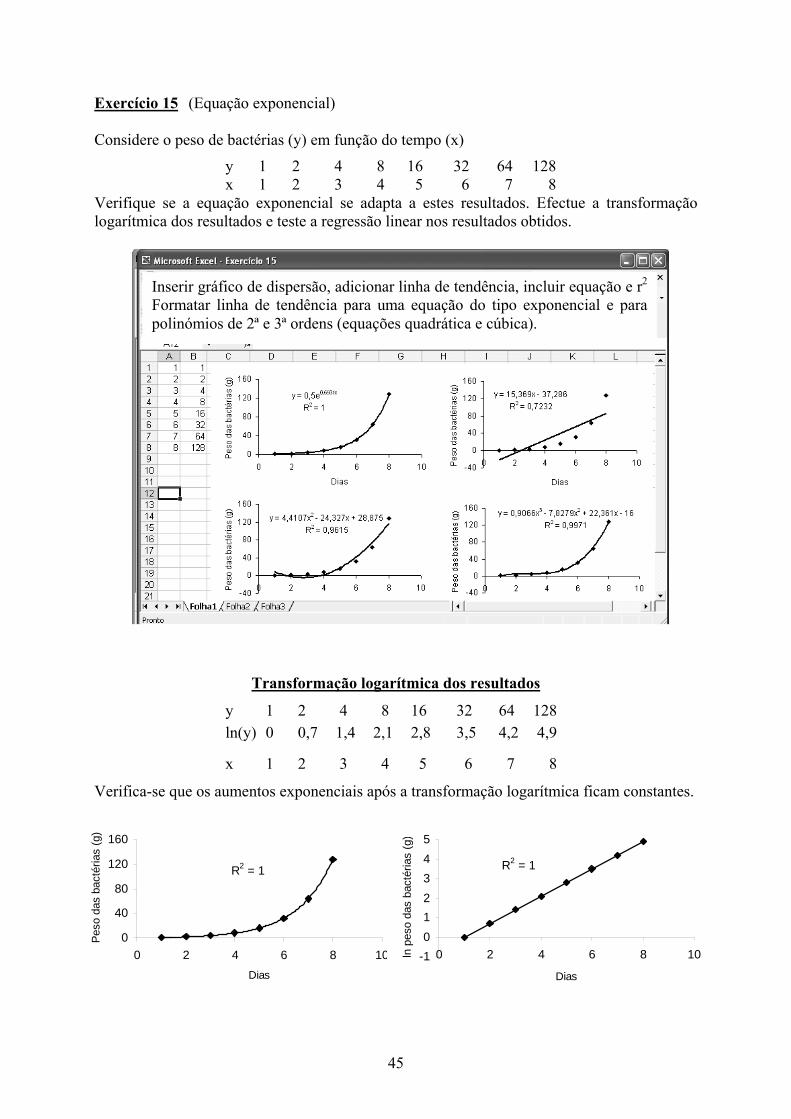
45
R2 = 1
0
40
80
120
160
0 2 4 6 8 10Dias
Peso
das
bac
téria
s (g
)
R2 = 1
-1012345
0 2 4 6 8 10
Dias
ln p
eso
das
bact
éria
s (g
)
Exercício 15 (Equação exponencial) Considere o peso de bactérias (y) em função do tempo (x)
y 1 2 4 8 16 32 64 128 x 1 2 3 4 5 6 7 8
Verifique se a equação exponencial se adapta a estes resultados. Efectue a transformação logarítmica dos resultados e teste a regressão linear nos resultados obtidos.
Transformação logarítmica dos resultados
y 1 2 4 8 16 32 64 128 ln(y) 0 0,7 1,4 2,1 2,8 3,5 4,2 4,9
x 1 2 3 4 5 6 7 8
Verifica-se que os aumentos exponenciais após a transformação logarítmica ficam constantes.
Inserir gráfico de dispersão, adicionar linha de tendência, incluir equação e r2
Formatar linha de tendência para uma equação do tipo exponencial e para polinómios de 2ª e 3ª ordens (equações quadrática e cúbica).

46
18 – Transformações matemáticas dos resultados
As transformações matemáticas dos resultados podem realizar-se para homogeneizar as
variâncias e/ou normalizar as variáveis.
As hipóteses são testadas nas variáveis transformadas (através de testes não paramétricos)
mas, se não for conveniente apresentar os dados na nova variável transformada, as médias
podem ser transformadas de volta para a medida original.
Entre as transformações desenvolvidas para homogeneizar as variâncias (e que podem
também conduzir à normalização da variável) incluem-se:
Transformação: Aplicar quando:
y iy forem contagens de números pequenos
1++ yy iy forem contagens e alguns iy forem iguais a zero
( )yLog a dispersão dos iy é elevada, e as variâncias proporcionais às médias
( )1+yLog a dispersão dos iy é elevada e alguns iy forem iguais a zero
11+y
Os iy forem muito próximos de zero
( )yarcsen Os iy forem proporções ou percentagens dispersas
Outras transformações para normalizar a variável incluem:
Transformação: Aplicar quando:
( ) ( )[ ]yyLog −+ 1/1 -1 ≤ y ≤ 1
( ) ( ) 2/32/1 1311 yy −−− 0 ≤ y ≤ 1

47
A transformação matemática de variáveis pode ser realizada numa folha de cálculo aplicando
a fórmula que se pretende para a transformação. No SPSS pode ser feita através do menu
Transform seguido de Compute.
48
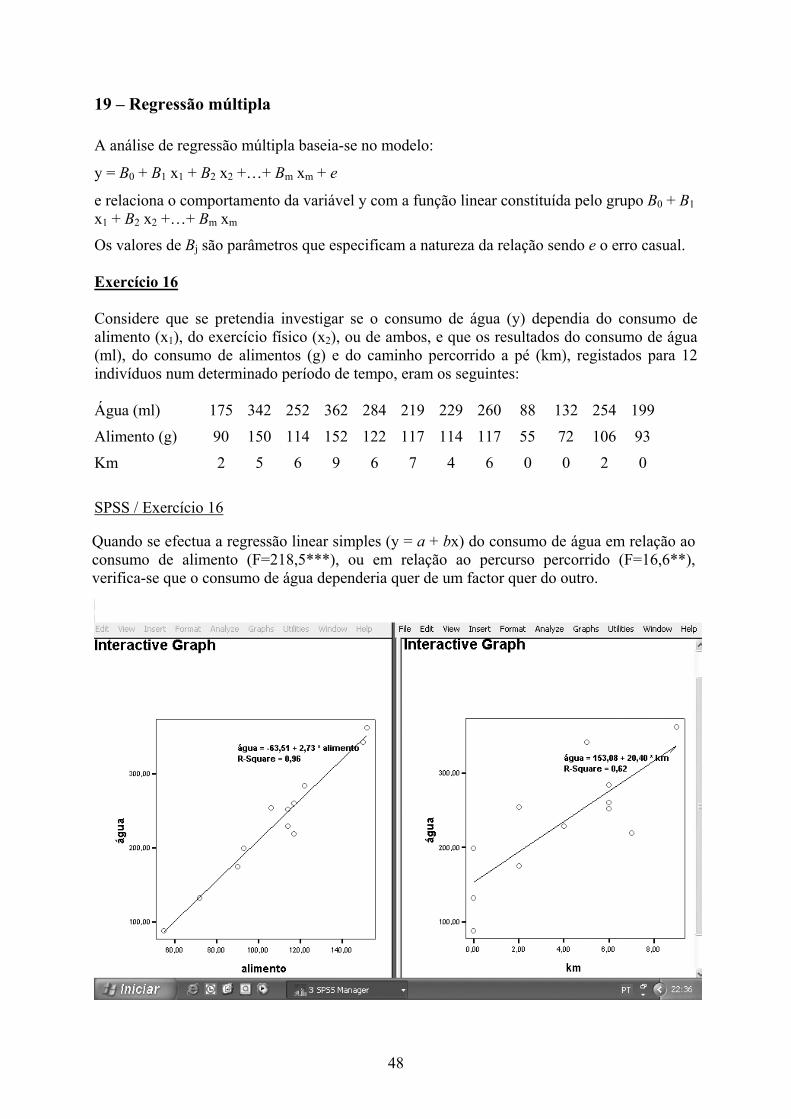
19 – Regressão múltipla A análise de regressão múltipla baseia-se no modelo:
y = B0 + B1 x1 + B2 x2 +…+ Bm xm + e
e relaciona o comportamento da variável y com a função linear constituída pelo grupo B0 + B1 x1 + B2 x2 +…+ Bm xm
Os valores de Bj são parâmetros que especificam a natureza da relação sendo e o erro casual. Exercício 16 Considere que se pretendia investigar se o consumo de água (y) dependia do consumo de alimento (x1), do exercício físico (x2), ou de ambos, e que os resultados do consumo de água (ml), do consumo de alimentos (g) e do caminho percorrido a pé (km), registados para 12 indivíduos num determinado período de tempo, eram os seguintes: Água (ml) 175 342 252 362 284 219 229 260 88 132 254 199
Alimento (g) 90 150 114 152 122 117 114 117 55 72 106 93
Km 2 5 6 9 6 7 4 6 0 0 2 0
SPSS / Exercício 16
Quando se efectua a regressão linear simples (y = a + bx) do consumo de água em relação ao consumo de alimento (F=218,5***), ou em relação ao percurso percorrido (F=16,6**), verifica-se que o consumo de água dependeria quer de um factor quer do outro.

49
No entanto, quando se efectua a regressão linear múltipla (y = a + bx1 + cx2), colocando a variável dependente e ambas as variáveis independentes (factores) no modelo e utilizando o método ENTER verifica-se que o valor de c não é significativo.
Coefficientsa
-83,077 28,141 -2,952 ,0163,031 ,345 1,084 8,786 ,000
-3,257 3,187 -,126 -1,022 ,333
(Constant)ALIMENTOKM
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: ÁGUAa.
Análise – regressão linear – colocar variável dependente e variáveis independentes Gráfico – interactivo – scatter plot – 3D – colocar variáveis

50
Quando se utiliza o método STEPWISE, a variável que se refere ao percurso percorrido é logo excluída do modelo. Isto porque apesar desta ter um efeito significativo sobre o consumo de água quando o modelo não inclui o efeito do consumo de alimento, não tem um efeito significativo quando a modelo já está a incluir o consumo de alimento.
Coefficientsa
-63,513 20,671 -3,073 ,0122,733 ,185 ,978 14,784 ,000
(Constant)ALIMENTO
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: ÁGUAa.
Excluded Variablesb
-,126a -1,022 ,333 -,322 ,286KMModel1
Beta In t Sig.Partial
Correlation Tolerance
CollinearityStatistics
Predictors in the Model: (Constant), ALIMENTOa.
Dependent Variable: ÁGUAb.
Acontece que existe uma elevada correlação entre estes dois factores (consumo de alimento e percurso percorrido) e que a aparente dependência do consumo de água do percurso percorrido se atribui a esta correlação. Donde se conclui que o consumo de água dependeu apenas do consumo de alimento, expressando-se essa relação através da equação:
Consumo de água (ml) = -63,5 + 2,73 (consumo de alimento, g)***
A interacção entre as variáveis independentes x1 e x2 pode ser avaliada através da inclusão no modelo do produto entre os factores, por exemplo, através de um modelo que se expresse por:
y = a + bx1 + cx2 + d x1x2
No presente exercício a interacção entre os dois factores seria, também, excluída, por não ter um efeito significativo no consumo de água.
Excluded Variables
-,126 -1,022 ,333 -,322 ,286-,099 -,699 ,502 -,227 ,229
KMINTERAC
Model1
Beta In t Sig.Partial
Correlation Tolerance
CollinearityStatistics
A regressão múltipla pode ser resolvida, também, através de regressão não linear no SPSS, escrevendo o modelo (após identificar os parâmetros) no módulo de regressão não linear, dentro da análise de regressão.

51
20 - Modelos de regressão Introdução à modelação
A matemática é um instrumento indispensável para a compreensão dos fenómenos. É utilizada para analisar as partes de um sistema ou as interacções entre essas partes. É também utilizada para auxiliar a efectuar a síntese das partes ou previsões quantitativas sobre o comportamento do sistema em diferentes condições, ambientais ou sócio-económicas, nomeadamente, pelo recurso a modelos de simulação. Os modelos matemáticos conceptuais ou teóricos distinguem-se dos modelos empíricos ou estatísticos, uma vez que estes são desenvolvidos para descrever os resultados da experimentação, ou para testar hipóteses científicas, enquanto que aqueles pretendem simular o comportamento do sistema com base em referências científicas consideradas como verdadeiras.
A análise estatística “não prova nada”. No entanto, oferece-nos um meio para avaliar o nível de probalidade das nossas hipóteses (formalizadas em equações matemáticas) serem verdadeiras ou falsas, ou para avaliar o nível de probabilidade das nossas equações de regressão serem consideradas verdadeiras para descrever os resultados, ou não. No entanto, a análise estatística relaciona-se apenas com as hipóteses que levantamos, as quais, podem não ser as mais indicadas. Por isso, é necessário definir correctamente os objectivos antes de se começar a investigar. A utilização de relações empíricas em modelos de simulação.
Se conseguirmos construir um modelo que descreva de forma razoável o sistema que pretendemos representar, descrição essa que se concretiza por equações matemáticas correspondentes aos anunciados das premissas que consideramos verdadeiras sobre sistema, então deveremos conseguir simular o comportamento do sistema sob a acção de diferentes condições ambientais.
Os modelos de simulação do crescimento vegetal, por exemplo, desenvolvidos com diversos objectivos, tais como, previsão de produções, escolha de cultivares, planeamento de práticas culturais ou melhoramento vegetal, utilizam frequentemente relações empíricas entre o crescimento vegetal e os factores ambientais. Nestas relações empíricas utiliza-se com frequência a acumulação térmica com base em registos metereológicos; a disponibilidade de azoto mineral; ou a precipitação e a evapotranspiração para calcular as necessidades de rega. No entanto, é geralmente difícil distinguir o papel das interacções entre os vários factores, o que implica a construção destes modelos com vários factores. Por outro lado, estabelecem-se vulgarmente relações empíricas entre os factores ambientais e a produção comercial sem que, no entanto, se estabeleçam quaisquer relações entre esses factores ambientais e os fenómenos biológicos, tais como, a fotossíntese, o metabolismo, a translocação e a distribuição dos assimilados, ou sobre a respiração ou a regulação hormonal, processos que determinam a produção. Por isso, é difícil optimizar estes modelos com vários factores ambientais ou aplicá-los de forma alargada e grandes áreas geográficas. Análise de crescimento
Crescimento é o aumento de tamanho do indivíduo ou o aumento no número de indivíduos e, está quase sempre associado com um aumento na complexidade com que o indivíduo, ou a comunidade de indivíduos, está organizada.
Imagine que inocula um meio de cultura com uma única bactéria que acabou de resultar de uma divisão bacteriana, e que quando uma desta bactérias se divide, cada bactéria resultante

52
alcança o peso da progenitora. Se considerarmos o peso w da progenitora, obtém-se o peso 2w. Consideremos ainda que o aumento de peso em cada geração é linear. Assim, o tempo que levou a passar do peso w para 2w, será igual aquele que é necessário para passar de 2w para 4w, e assim sucessivamente. A este tipo de crescimento chamamos exponencial e pode ser representado através da seguinte equação matemática:
W = w exp (μt)
em que, W é o peso da cultura no tempo t, w o peso da primeira célula e μ a constante de crescimento. Se aplicarmos os logaritmos a ambas as partes da equação obtém-se uma relação simples:
ln (W)= ln (w) + μt
Até agora considerou-se apenas a situação em que os nutrientes, bem como as restantes condições ambientais, não implicam qualquer restrição ao crescimento bacteriano. Obviamente, o crescimento não pode continuar indeterminadamente. Ou as bactérias esgotarão os nutrientes disponíveis no meio, ou produzirão suficientes produtos tóxicos que provocarão o abrandamento do crescimento. Em organismos mais complexos como as plantas e os animais, o número de células capazes de crescer e de se dividirem diminui com o tempo assim que as células se diferenciam e as suas funções biológicas se tornam mais específicas e restritas. Normalmente, o crescimento das plantas e dos animais diminui assim que o seu tamanho aumenta até, eventualmente, parar o crescimento quando amadurecem.
Existem várias formas de descrever este crescimento. Podemos observar a equação matemática que descreve as variações no peso das plantas ou animais com o tempo, sem considerar o sentido biológico da equação. Por exemplo, podemos descrever estas variações através de um polinómio do tipo: W= a+ bt + ct² sem se atribuir qualquer sentido biológico às constantes a, b, c. Esta descrição empírica do crescimento pode ter várias utilizações ao oferecer-nos uma descrição antecipada dos acontecimentos. No entanto, nada nos diz sobre o porquê dos acontecimentos.
Podemos, em contrapartida, observar a equação que relaciona, por exemplo, as variações nas taxas de crescimento da planta ou animal com o seu peso, e, posteriormente tentar perceber as implicações biológicas da equação então utilizada. Neste caso chamamos crescimento relativo. A taxa de crescimento relativo de uma planta ou animal é a taxa de crescimento dividida pelo seu peso. Isto é, a taxa de crescimento por unidade de peso. Quando uma planta cresce exponencialmente, o peso da planta em qualquer tempo t, Wt, pode ser relacionado com o seu peso inicial no tempo t=0, correspondendo a W0, e a constante de crescimento μ, da seguinte forma:
Wt = W0 exp(μt)
A taxa de crescimento da planta em qualquer tempo t, dW/dt, pode ser obtida através da derivada da equação de crescimento em relação ao tempo da seguinte forma:
dW/dt = μ W0 exp(μt)
multiplicando ambos os lados da equação por (1/Wt) obtém-se:
(dW/dt) / Wt = μ [W0 exp(μt)] / [W0 exp(μt)] = μ
A constante de crescimento μ é igual à taxa de crescimento relativo da planta. Durante o crescimento exponencial a taxa de crescimento relativo da planta é, portanto, constante, mas uma das características das plantas é que quantos maiores são, menores se tornam as suas taxas de crescimento relativo.

53
No estudo da mineralização do azoto podem-se aplicar modelos como:
Nm = N0 (1 – e-kt)
Em que N0 representa o azoto potencialmente mineralizável no tempo zero, Nm o azoto mineralizado no tempo t, e k a constante de mineralização. Este modelo, explica a mineralização líquida mas não explica a imobilização (ou mineralização negativa). Contudo, se expandirmos o modelo para:
Nm = N0 [1 – exp(-k1t -k2t2)]
torna-se possível prever a mineralização, mas também, quantificar o tempo necessário para a mineralização liquida ocorrer, quando exista um fase inicial de imobilização do azoto, porque só ocorre mineralização liquida quando Nm é positivo, isto é, quando:
[1 – exp(-k1t -k2t2)] > 0 exp(-k1t -k2t2) > -1 exp(-k1t -k2t2) < 1
(-k1t -k2t2) < 0 t(-k1 -k2t) < 0 (-k1 -k2t) < 0 (porque t é positivo)
para k1 negativo, k2 positivo, e o valor absoluto de k1 superior ao valor absoluto de k2,
(-k1 -k2t) < 0 -k2t < k1 t > -k1 / k2
Assim, ao contrário das equações quadráticas ou parabólicas, neste caso, este modelo diz-nos algo mais sobre o funcionamento deste processo.
Neste exemplo, em que t representa o tempo em semanas e n o azoto mineralizado no tempo t verifica-se que são necessárias 4,5 semanas para se passar da imobilização para a mineralização líquida.

54
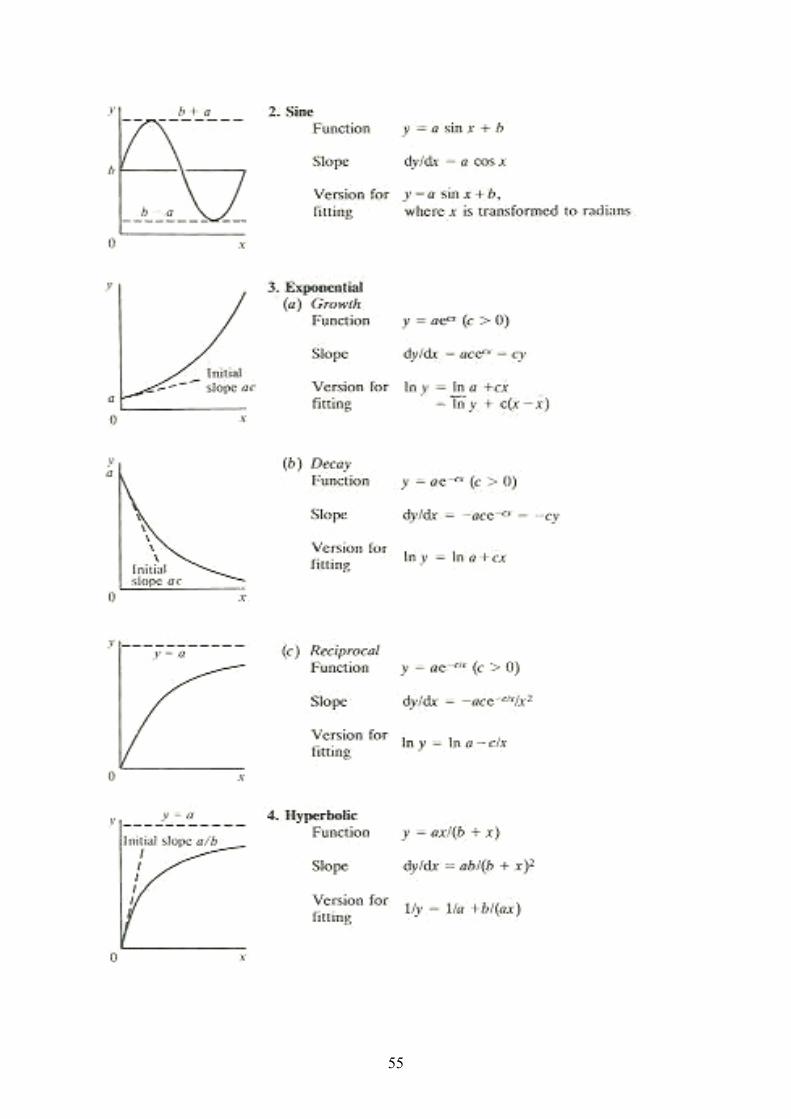
Existem diversas funções que podem ser utilizadas em estudos de crescimento relacionados com variações de factores ambientais. Milthorpe e Morby (1979) referem algumas das que são mais frequentemente utilizadas, nomeadamente:
55

56
53

57
IV – Análise multivariada
21 – Análise factorial de componentes principais A análise de componentes principais, é um método estatístico multivariado que permite transformar um conjunto de variáveis quantitativas iniciais correlacionadas entre si (x1, x2,…, xp), noutro conjunto com um menor numero de variáveis não correlacionadas (ortogonais) e designadas por componentes principais (y1, y2,…,yp), que resultam de combinações lineares das variáveis iniciais, reduzindo a complexidade de interpretação dos dados.
As componentes principais são calculadas por ordem decrescente de importância, isto é, a primeira explica a máxima variância dos dados, a segunda a máxima variância ainda não explicada pela primeira, e assim sucessivamente. A última componente será a que menos contribui para a explicação da variância total dos dados. Exercício 17 Considere os seguintes dados fictícios. Efectue a análise factorial dos componentes principais. Profissão Prestígio Suicídio Rendimento Educação
Contabilistas 83,00 23,90 3967,00 14,30 Arquitectos 91,00 33,90 5450,00 16,80 Autores 77,00 36,10 4327,00 15,50 Dentistas 90,00 20,80 4109,00 16,80 Professores Universitários 93,00 14,10 4458,00 17,00 Químicos 90,00 45,20 6498,00 15,80 Advogados 89,00 31,60 4993,00 16,00 Padres 90,00 24,90 6352,00 16,50 Médicos 98,00 31,50 9010,00 17,00 Trabalhadores Sociais 58,00 15,20 3189,00 15,80 Professores do Liceu 74,00 17,10 3476,00 16,00 Industriais 81,00 64,90 4700,00 12,20 Comerciantes 46,00 47,30 3785,00 11,00 Carpinteiros 39,00 22,30 2901,00 12,60 Seguros 40,00 33,40 3872,00 12,60 Vendedores 17,00 23,60 2597,00 12,20 Maquinistas 54,00 31,70 3477,00 11,20 Mecânicos 27,00 25,00 2730,00 9,30 Electricistas 30,00 28,30 3390,00 9,20 Guardas 11,00 13,80 1851,00 10,40 Cozinheiros 18,00 19,00 3369,00 9,20 Camionistas 13,00 16,40 2509,00 9,50 Barbeiros 20,00 30,40 2268,00 8,70 Criadas 6,00 22,50 1938,00 9,80 Recepcionistas 16,00 45,40 2239,00 8,60 Porteiros 7,00 19,60 1872,00 7,90 Polícias 41,00 49,50 2996,00 10,50 Marceneiros 35,00 16,80 3622,00 12,30 Canalizadores 24,00 16,10 2972,00 9,70 Engenheiros 68,00 34,80 4691,00 8,90 Pintores 14,00 40,00 2303,00 8,00

58
Para obter uma figura com os 4 gráficos tipo boxplot das variáveis, e verificar se existe algum valor aberrante (outlet), estandardizam-se as variáveis porque as unidades de medida são diferentes. O estudo da simetria e da normalidade é feito usando o comando Explore.
Análise – Estatística descritiva – Descriptives: variáveis & standardized values
Análise – Estatística descritiva – Explore. Coloque as variáveis com a inicial Z; Plots em Dependents together, e normality plots with tests
Descriptive Statistics
31 49,6774 31,7273731 28,8742 12,2961531 3739,0645 1557,6130031 12,3000 3,1807831
PRESTIGISUICÍDIORENDIMENEDUCAÇÃOValid N (listwise)
N Mean Std. Deviation
31 31 3131N =
Zscore(EDUCAÇÃO)Zscore(RENDIMEN)
Zscore(SUICÍDIO) Zscore(PRESTIGI)
4
3
2
1
0
-1
-2
9 129
12

59
Análise factorial
Análise – Data reduction – Factor: Colocar variáveis.
• Descriptives: Univariate descritives;Inicial solution; Coefficients; Significance levels;
KMO and Bartlett´s test of sphericity.
• Extraction: Method principal components; Analyse correlation matrix; Display
unrotated factor solution; Scree plot; Eigenvalues over 1.
• Rotation: Method Varimax; Rotated solution; Loading plots.
• Scores: Save as variables: Regression; Display factor score coefficient matrix.
• Options: Exclude cases listwise; Sorted by size.
60
A matriz das correlações mede a associação linear entre as variáveis através do coeficiente de correlação de Pearson. A taxa de suicídio não está correlacionada com as restantes variáveis.
Correlation Matrix
1,000 ,208 ,831 ,868,208 1,000 ,255 -,088,831 ,255 1,000 ,702,868 -,088 ,702 1,000
,130 ,000 ,000,130 ,083 ,319,000 ,083 ,000,000 ,319 ,000
PRESTIGISUICÍDIORENDIMENEDUCAÇÃOPRESTIGISUICÍDIORENDIMENEDUCAÇÃO
Correlation
Sig. (1-tailed)
PRESTIGI SUICÍDIO RENDIMEN EDUCAÇÃO
KMO = 0,602 => Continua-se a análise factorial porque é considerada razoável.
KMO and Bartlett's Test
,602
83,6426
,000
Kaiser-Meyer-Olkin Measure of SamplingAdequacy.
Approx. Chi-SquaredfSig.
Bartlett's Test ofSphericity
Todas as variáveis têm forte relação com os factores retidos (>0,6) Communalities
1,000 ,9421,000 ,9821,000 ,8471,000 ,917
PRESTIGISUICÍDIORENDIMENEDUCAÇÃO
Initial Extraction
Extraction Method: Principal Component Analysis.
Mais de 90% da variância é explicada pelos dois factores retidos que têm valores próprios (Eigenvalues) superiores a 1.
Total Variance Explained
2,632 65,810 65,810 2,632 65,810 65,810 2,593 64,837 64,8371,056 26,406 92,216 1,056 26,406 92,216 1,095 27,378 92,216,236 5,896 98,111
7,554E-02 1,889 100,000
Component1234
Total % of VarianceCumulative % Total % of VarianceCumulative % Total % of VarianceCumulative %Initial Eigenvalues Extraction Sums of Squared Loadings Rotation Sums of Squared Loadings
Extraction Method: Principal Component Analysis.
KMO: Muito Boa 1-0,9 Boa 0,8-0,9 Média 0,7-0,8 Razoável 0,6-0,7 Má 0,5-0,6 Inaceitável <0,5.
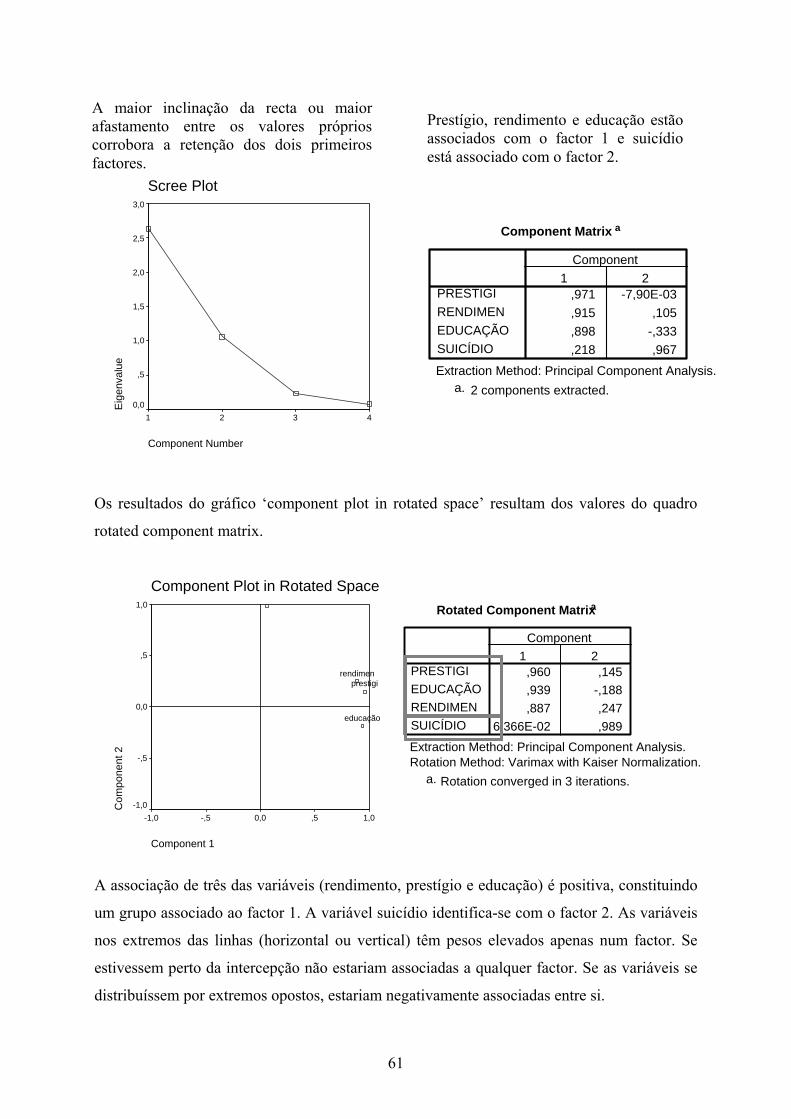
61
Scree Plot
Component Number
4321
Eige
nval
ue
3,0
2,5
2,0
1,5
1,0
,5
0,0
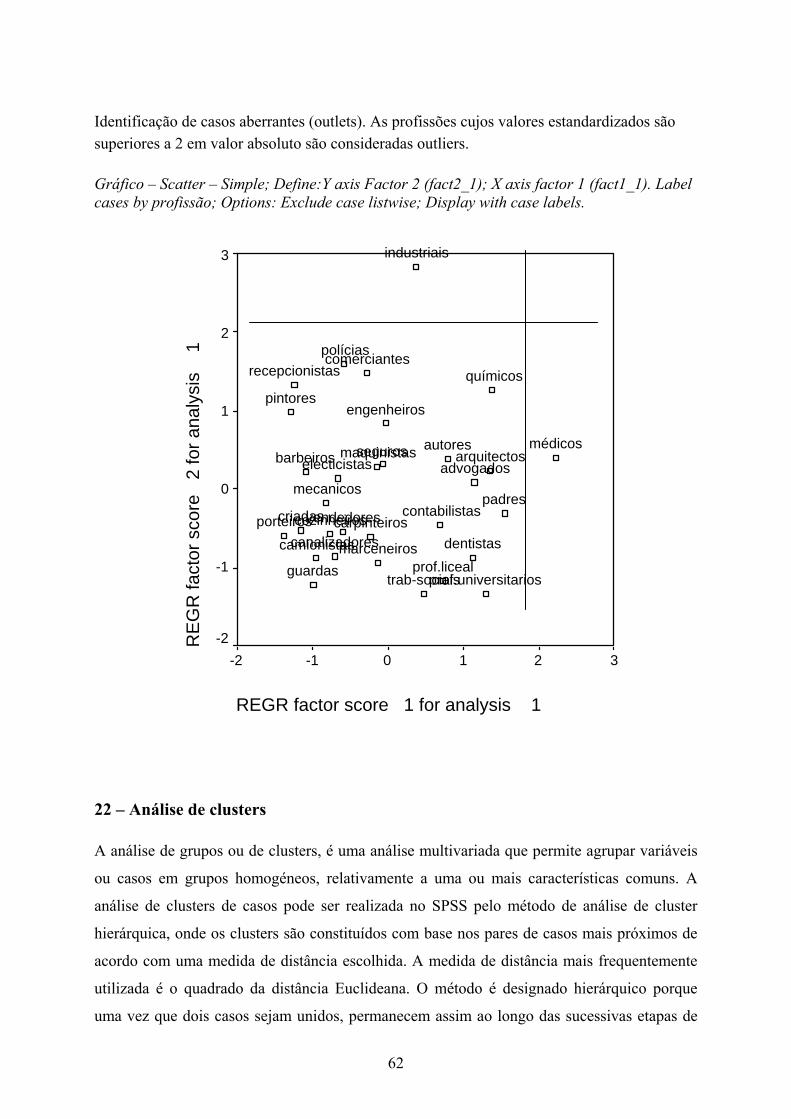
Os resultados do gráfico ‘component plot in rotated space’ resultam dos valores do quadro
rotated component matrix.
Component Plot in Rotated Space
Component 1
1,0,50,0-,5-1,0
Com
pone
nt 2
1,0
,5
0,0
-,5
-1,0
educação
rendimenprestigi
A associação de três das variáveis (rendimento, prestígio e educação) é positiva, constituindo
um grupo associado ao factor 1. A variável suicídio identifica-se com o factor 2. As variáveis
nos extremos das linhas (horizontal ou vertical) têm pesos elevados apenas num factor. Se
estivessem perto da intercepção não estariam associadas a qualquer factor. Se as variáveis se
distribuíssem por extremos opostos, estariam negativamente associadas entre si.
A maior inclinação da recta ou maior afastamento entre os valores próprios corrobora a retenção dos dois primeiros factores.
Rotated Component Matrixa
,960 ,145,939 -,188,887 ,247
6,366E-02 ,989
PRESTIGIEDUCAÇÃORENDIMENSUICÍDIO
1 2Component
Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization.
Rotation converged in 3 iterations.a.
Prestígio, rendimento e educação estão associados com o factor 1 e suicídio está associado com o factor 2.
Component Matrix a
,971 -7,90E-03,915 ,105,898 -,333,218 ,967
PRESTIGIRENDIMENEDUCAÇÃOSUICÍDIO
1 2Component
Extraction Method: Principal Component Analysis.2 components extracted.a.
62
Identificação de casos aberrantes (outlets). As profissões cujos valores estandardizados são superiores a 2 em valor absoluto são consideradas outliers. Gráfico – Scatter – Simple; Define:Y axis Factor 2 (fact2_1); X axis factor 1 (fact1_1). Label cases by profissão; Options: Exclude case listwise; Display with case labels.
REGR factor score 1 for analysis 1
3210-1-2
RE
GR
fact
or s
core
2
for a
naly
sis
1
3
2
1
0
-1
-2
pintoresengenheiros
canalizadoresmarceneiros
polícias
porteiros
recepcionistas
criadas
barbeiros
camionistas
cozinheiros
guardas
electicistas
mecanicos
maquinistas
vendedores
seguros
carpinteiros
comerciantes
industriais
prof.licealtrab-sociais
médicos
padres
advogados
químicos
prof.universitarios
dentistas
autoresarquitectos
contabilistas
22 – Análise de clusters A análise de grupos ou de clusters, é uma análise multivariada que permite agrupar variáveis
ou casos em grupos homogéneos, relativamente a uma ou mais características comuns. A
análise de clusters de casos pode ser realizada no SPSS pelo método de análise de cluster
hierárquica, onde os clusters são constituídos com base nos pares de casos mais próximos de
acordo com uma medida de distância escolhida. A medida de distância mais frequentemente
utilizada é o quadrado da distância Euclideana. O método é designado hierárquico porque
uma vez que dois casos sejam unidos, permanecem assim ao longo das sucessivas etapas de

63
agregação. Isto é, um cluster formado numa etapa posterior inclui clusters da etapa anterior e
assim sucessivamente. Quando as variáveis têm escalas diferentes deve-se estandardizar cada
variável para ter a mesma variância antes de se calcularem as distâncias.
O método hierárquico tem sete procedimentos para a ligação dos clusters:
1. Menor distância, ou vizinho mais próximo (nearest neighbor ou single linkage);
2. Maior distancia, ou vizinho mais afastado (furthest neighbor ou complete linkage);
3. Distância média entre clusters, ou entre grupos (between groups);
4. Distância média dentro dos clusters, ou dentro dos grupos (within groups);
5. Distância mediana (median cluster);
6. Centróide (centroide clustering);
7. Ward.
Os três primeiros procedimentos são os mais utilizados. O procedimento da menor distância
tende a criar um menor número de clusters maximizando a conectividade entre os clusters.
Pelo contrário o procedimento da menor distância tende a minimizar a distância entre clusters
e a produzir clusters mais compactos. Os restantes métodos abordados tendem a apresentar
características intermédias entre estes dois métodos extremos.
É recomendável a utilização de vários procedimentos de ligação de clusters. Se os resultados
da agregação diferirem muito com o procedimento é pouco provável que os dados tenham
clusters naturais distintos.
Exercício 18 Considere os resultados do quadro seguinte relativos a uma análise sensorial de 10 variedades
de maça, sujeitas a idêntico tratamento pós-colheita, em que se classificaram 4 atributos
(consistência, aroma, doçura, e persistência do sabor) de 0 a 100, para criar grupos
homogéneos de variedades de maça.
Variedade 1 2 3 4 5 6 7 8 9 10
Consistência 25 65 55 65 45 35 50 35 60 55 Aroma 20 75 40 65 50 25 45 10 70 50 Doçura 40 40 50 80 45 50 45 30 70 45 P. Sabor 30 30 50 45 30 5 40 20 20 40

64
SPSS / Exercício 21
Análise – Classify – Hierachical cluster – Seleccione as variáveis (atributos); Label case by
variedade (definida como string). Para agrupar as variedades seleccione cases na área cluster,
e na área display seleccione statistics e plots.
• Statistics Aglomeration schedule. Cluster membership range of solutions from 2 through
4 clusters (no início pode não utilizar a opção cluster membership).
• Plots Dendogram.
• Method nearest neighbor (fazer depois com furthest neighbor e between groups).
Interval Squared Euclidean Distance. Transform values Standardized none se as
variáveis tiverem amplitudes semelhantes, ou Z scores se as amplitudes não forem
semelhantes. Existem ainda outras opções em função do tipo de amplitude das
variáveis.
• Save Range of solutions from 2 through 4 clusters.
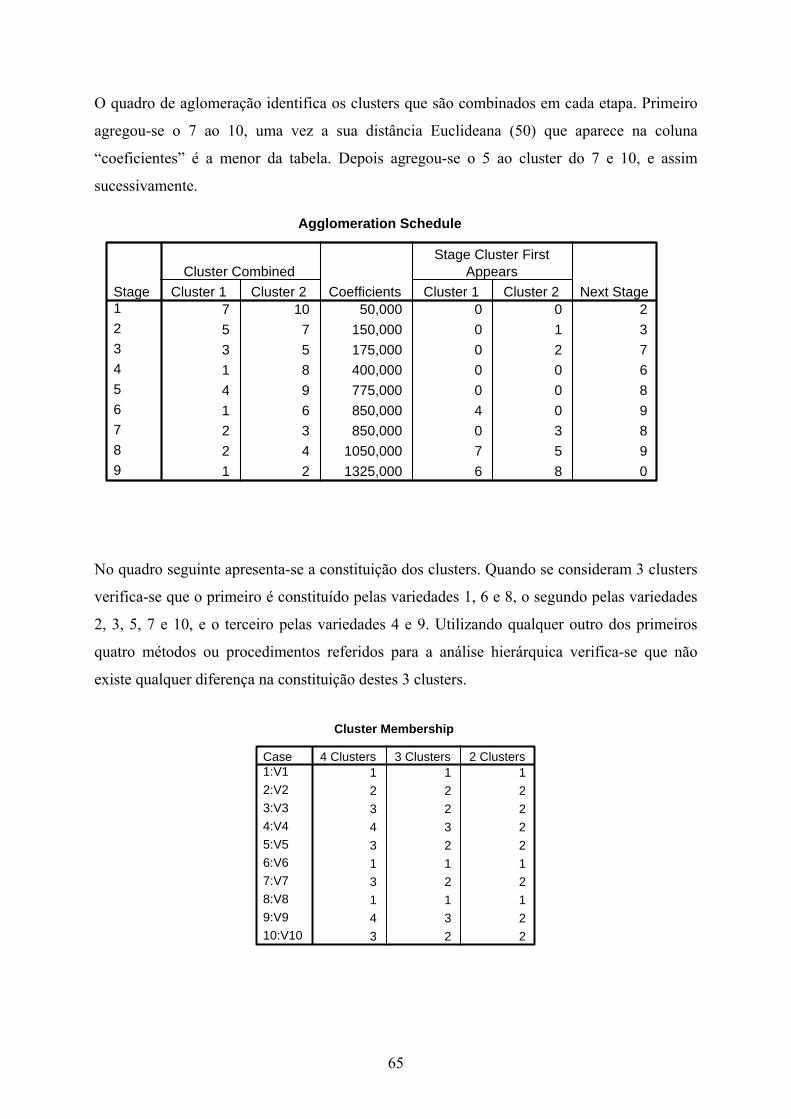
65
O quadro de aglomeração identifica os clusters que são combinados em cada etapa. Primeiro
agregou-se o 7 ao 10, uma vez a sua distância Euclideana (50) que aparece na coluna
“coeficientes” é a menor da tabela. Depois agregou-se o 5 ao cluster do 7 e 10, e assim
sucessivamente.
Agglomeration Schedule
7 10 50,000 0 0 25 7 150,000 0 1 33 5 175,000 0 2 71 8 400,000 0 0 64 9 775,000 0 0 81 6 850,000 4 0 92 3 850,000 0 3 82 4 1050,000 7 5 91 2 1325,000 6 8 0
Stage123456789
Cluster 1 Cluster 2Cluster Combined
Coefficients Cluster 1 Cluster 2
Stage Cluster FirstAppears
Next Stage
No quadro seguinte apresenta-se a constituição dos clusters. Quando se consideram 3 clusters
verifica-se que o primeiro é constituído pelas variedades 1, 6 e 8, o segundo pelas variedades
2, 3, 5, 7 e 10, e o terceiro pelas variedades 4 e 9. Utilizando qualquer outro dos primeiros
quatro métodos ou procedimentos referidos para a análise hierárquica verifica-se que não
existe qualquer diferença na constituição destes 3 clusters.
Cluster Membership
1 1 12 2 23 2 24 3 23 2 21 1 13 2 21 1 14 3 23 2 2
Case1:V12:V23:V34:V45:V56:V67:V78:V89:V910:V10
4 Clusters 3 Clusters 2 Clusters

66
O dendograma representa graficamente o esquema apresentado no quadro de agregação em
que as distâncias (ou coeficientes) foram reescalonadas numa escala de 0 a 25 e não de 0 a
1325 como se encontra no quadro de aglomeração.
Dendrogram using Single Linkage
Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ V7 7 òûòø
V10 10 ò÷ ùòø
V5 5 òòò÷ ùòòòòòòòòòòòòòòòòòòòòòòòòòø
V3 3 òòòòò÷ ùòòòòòòòø
V2 2 òòòòòòòòòòòòòòòòòòòòòòòòòòòòòòò÷ ùòòòòòòòòòø
V4 4 òòòòòòòòòòòòòòòòòòòòòòòòòòòòòûòòòòòòòòò÷ ó
V9 9 òòòòòòòòòòòòòòòòòòòòòòòòòòòòò÷ ó
V1 1 òòòòòòòòòòòòòûòòòòòòòòòòòòòòòòòø ó
V8 8 òòòòòòòòòòòòò÷ ùòòòòòòòòòòòòòòòòò÷
V6 6 òòòòòòòòòòòòòòòòòòòòòòòòòòòòòòò÷
A análise deste dendograma revela que existem dois clusters bem distintos formados pelas
variedades (1, 8 e 6) e (9, 4, 2, 3, 5, 10, 7). Neste último cluster parece clara a divisão entre as
variedades 4 e 9 e as restantes. Entre as restantes a variedade 2 afasta-se contudo das
variedades 3, 5, 7 e 10.
A distância entre clusters e o critério do R quadrado podem ser utilizados para avaliar o
número de clusters que se devem reter. Se a distância entre dois clusters é pequena, estes
devem ser agregados, pelo contrário se a distância é grande os dois clusters devem manter-se
separados. Isto pode-se verificar pelos coeficientes do quadro de aglomeração, ou pelo declive
da recta que une os dois clusters quando estes são representados em gráfico no eixo horizontal
relativamente às distâncias no eixo vertical. O R quadrado é uma medida da percentagem da
variabilidade total que é retida em cada uma das soluções dos clusters. O que se pretende é
alcançar uma percentagem elevada da variabilidade (e.g. > 80%) com um número reduzido de
clusters. Estes cálculos podem ser realizados com o auxílio da Anova one-way do SPSS. Para
isso a análise hierárquica de clusters realiza-se com o registo do cluster membership para um
range of solutions de 2 a 9.

67
Análise – Classify – Hierachical cluster. Save Range of solutions from 2 through 9 clusters.
As novas variáveis, da clu9_1 à clu2_1, indicam a constituição dos clusters para cada número
de clusters considerado, desde o máximo de 9 clusters até ao mínimo de 2 clusters. Estas
novas variáveis podem ser utilizadas para efectuar uma Anova one-way (análise / compare /
one way Anova) para as 4 variáveis (atributos das maças).
68
A adição das somas dos quadrados entre grupos (1677,5 + 4237,2 + 1972,5 + 1640) a dividir
pela adição das somas dos quadrados totais (1690 + 4250 + 1972,2 + 1640) resulta no valor
do R quadrado (0,997) para 9 clusters.
ANOVA
1677,500 8 209,688 16,775 ,18712,500 1 12,500
1690,000 94237,500 8 529,688 42,375 ,118
12,500 1 12,5004250,000 91972,500 8 246,563 , ,
,000 1 ,0001972,500 91640,000 8 205,000 , ,
,000 1 ,0001640,000 9
Between GroupsWithin GroupsTotalBetween GroupsWithin GroupsTotalBetween GroupsWithin GroupsTotalBetween GroupsWithin GroupsTotal
CONSISTÊ
AROMA
DOÇURA
P.SABOR
Sum ofSquares df Mean Square F Sig.
Procedendo de forma idêntica para as outras soluções de clusters resulta: Nº de clusters 1 2 3 4 5 6 7 8 9
R- quadrado 0 0,566 0,752 0,848 0,901 0,941 0,962 0,986 0,997
Para explicar mais de 75% da variabilidade total seriam necessários apenas 3 clusters. Para
explicar mais de 80% da variabilidade seriam necessários 4 clusters.

69
Bibliografia
Carvalho M 1988. A estatística aplicada à experimentação agrícola. Colecção Nova Agricultura nº 2. Edições Afrontamento.
Maroco J 2003. Análise estatística – Com utilização do SPSS. Edições Sílabo, Lda
Mead R & Curnow R 1987. Statistical methods in agriculture and experimental biology. University of Reading. Chapman and Hall. London.
Milthorpe F L & Moorby J 1979. An introduction to crop physiology. 2nd ed. Cambridge University Press, pp.224-227.
Pereira A 2003. SPSS - Guia prático de utilização. 4ªed. Edições Sílabo, Lda.
Pestana H P & Gageiro J N 2000. Análise de dados para ciências sociais. A complementaridade do SPSS. 2ª ed. Edições Sílabo, Lda.

70





























