Embed Size (px)
Citation preview

Prof. José Francisco Moreira Pessanha
Rio de Janeiro, 4 de setembro de 2012
Métodos Quantitativos em Contabilidade

Introdução
O propósito da inferência estatística consiste em fazer afirmações
sobre alguma característica de uma população baseando-se em
resultados de uma amostra da população.
A inferência estatística fornece procedimentos para extrair
conclusões sobre uma população a partir de dados amostrais
(MOORE,2005)

População
Conjunto formado por todos os elementos que compartilham
uma característica comum:
Exemplos:
População carioca
Conjunto dos domicílios cariocas
Conjunto de funcionários da Prefeitura
Conjunto de fornecedores da Prefeitura
População finita: se há um determinado número de
elementos (por exemplo, nº de domicílios em uma cidade)
População infinita: o tamanho da população é ilimitado.

Distribuição populacional Em cada elemento da população podemos observar um conjunto de
atributos, por exemplo:
o consumo de energia elétrica em uma unidade consumidora
o valor da fatura de energia elétrica de uma unidade consumidora
se o cliente é residencial ou não residencial
se o cliente é medido ou não é medido.
Em geral, os atributos não se distribuem com a mesma intensidade em
todos os elementos da população, mas, ao contrário, a distribuição da
intensidade dos atributos é desigual.
Para ilustrar, considere a seguinte população formada por 6 unidades
consumidoras e os respectivos consumos mensais em kWh.
Distribuição
populacional

Distribuição populacional
A distribuição populacional pode ser caracterizada minimamente por
meio de uma medida de posição e uma medida de dispersão.
Medida de posição (média): indica o valor típico da população.
Medida de dispersão (desvio-padrão): indica a variabilidade dos
elementos da população ao redor da média.
Quando calculadas com base em todos os elementos da população estas
medidas são denominadas por parâmetros populacionais.
população
1506
200180160140120100
média
16,34
6
15020015010022
padrãodesvio
kWh
kWh

Parâmetros populacionais Parâmetro populacional é uma função dos valores observados em todos os
elementos da população.
Considere uma população finita com N elementos, cada um apresentando um
valor xi (i=1,N) em uma determinada característica X de interesse.
Com base nos valores de todos os elementos da população calculam-se os
parâmetros populacionais, entre os quais destacam-se:
N
i
ixN 1
1
N
1i
ixN
N
i
ixN 1
22 1
N
i
ixN 1
21
Média populacional
N
i
ixN 1
1
Total populacional
Variância populacional Desvio-padrão populacional
Proporção N
P
Total de elementos da população com a característica de interesse, por
exemplo, total de clientes com consumo acima de 150 kWh e, neste caso,
P = proporção de clientes com consumo acima de 150 kWh.

Censo
Um censo é a inspeção de todos os elementos da população,
para extrair de cada um deles as informações de interesse.
Os valores exatos dos parâmetros populacionais são obtidos
por meio de um censo da população.
Problemas:
Censos podem ter custos proibitivos
Censos podem demandar muito tempo para serem
concluídos e, portanto, os resultados não são imediatos e
podem estar desatualizados.
Em uma população infinita é impossível examinar todos os
elementos da população.

Censo
O censo de uma grande população é uma operação
complexa que envolve um enorme contingente de
recenseadores.
O envolvimento de muita gente cria problemas na
coordenação e controle das operações do censo, o que
aumenta as chances de erros, denominados por erros não
amostrais
Erros não amostrais: entrevistas mau aplicadas ou não
realizadas, erros de medida, erros de digitação dos dados
coletados, enfim erros que não estão nos dados, mas no
sistema para obtê-los.
Logo, os censos não são necessariamente exatos.

Censo
Quando fazer um censo ?
Quando a população é pequena, por exemplo, a
população de uma localidade do interior do país.
Quando se exige precisão completa, como no
setor de faturamento de uma empresa de serviço
público em que todos os clientes são medidos.

Amostragem Consiste na seleção e análise de um subconjunto finito (amostra) dos
elementos da população sob estudo.
Objetivo: estimar os parâmetros da distribuição populacional, por exemplo, a
média populacional e a proporção de elementos portadores de determinada
característica, a partir das observações de uma amostra da população.
O fato de investigar apenas uma parcela da população torna as pesquisas por
amostragem mais econômicas e mais rápidas que os censos.
Muito empregada em controle de qualidade e testes destrutivos, situações em
que não faz sentido fazer um censo.
É a alternativa ao censo.
Pesquisas por amostragem envolvem um menor número de agentes na coleta
de dados, tornando possível treiná-los exaustivamente visando uniformizar os
métodos de coleta de dados e, conseqüentemente, reduzir significativamente o
erro não amostral.

Amostragem
A partir das respostas dos indivíduos amostrados queremos inferir a partir dos
dados amostrais alguma conclusão sobre a população mais ampla que a
amostra representa.
A inferência estatística fornece métodos para extrair conclusões sobre uma
população a partir de dados amostrais.
Em função da flutuação amostral não podemos ter certeza de que nossas
conclusões são corretas, pois uma amostra diferente poderia conduzir a
conclusões diferentes. A inferência estatística usa a linguagem da
probabilidade para expressar o grau de confiança das conclusões.

Estimação Seja x1, x2,..., xn os valores observados em uma amostra aleatória de
tamanho n (n < N) acerca de uma característica X.
Os valores observados na amostra podem ser inseridos nas seguintes
fórmulas matemáticas denominadas estimadores, cujos resultados
numéricos são as estatísticas amostrais, estimativas dos valores
desconhecidos dos parâmetros populacionais:
n
i
ixn
X1
1XNT
2
1
2
1
1
n
i
i Xxn
S 2
11
1
n
i
i Xxn
S
np
ˆ
Média amostral Estimador do total
Variância amostral Desvio-padrão amostral
Proporção Total de elementos da amostra com a característica de interesse.

Parâmetro, estimador e estimativa
Considere
Uma população
Uma variável aleatória X que a cada elemento da população associa um
valor numérico X().
A distribuição de probabilidade de X depende de uma constante (parâmetro)
cujo valor é desconhecido e desejamos estimar
Uma amostra aleatória de tamanho n é retirada da população e medidos
valores x1, x2,...,xn da variável X nos n elementos da amostra. Tais valores
formam o conjunto de dados.
Um estimador do parâmetro é uma função (X1, X2,...,Xn) que associa a cada
possível conjunto de dados (amostra) x1, x2,...,xn o resultado (x1, x2,...,xn) .
Trata-se, portanto de uma variável aleatória.
Cada possível valor numério de um estimador é uma estimativa de .

Exemplo – Pesquisa Eleitoral A população é o universo de eleitores da cidade
A cada eleitor uma variável aleatória X() vale 1, se o eleitor vota no
candidato A e X() vale 0, caso contrário.
O parâmetro é a proporção p populacional de eleitores que votariam em A.
Distribuição da variável aleatória X é Bernoulli(p)
Considere uma amostra aleatória de n eleitores
A amostra aleatória é o conjunto de variáveis aleatórias X1,X2,...,Xn, cada Xi
tem distrbuição Bernoulli(p). As variáveis aleatórias X1,X2,...,Xn são
independentes e identicamente distribuidas.
Conjunto de dados: valores observados x1, x2,...,xn em uma partciular amostra
aleatória de tamanho n, xi =1 se o i-ésimo eleitor da amostra vota em A e xi = 0
se o iésimo eletor da amostra não vota em A.
Estimador pontual de p é a função
Estimativa de p, é o resultado de em uma particular amostra
n
i
in Xn
XXp
1
11
,...,ˆ
nxxp ,...,ˆ 1
Distribuição amostral
População
Amostra 1
Amostra 2
Amostra 3
Amostra k
Parâmetro
1X
2X
3X
kX
População
Amostra 1
Amostra 2
Amostra 3
Amostra k
Parâmetro
1X
2X
3X
kX
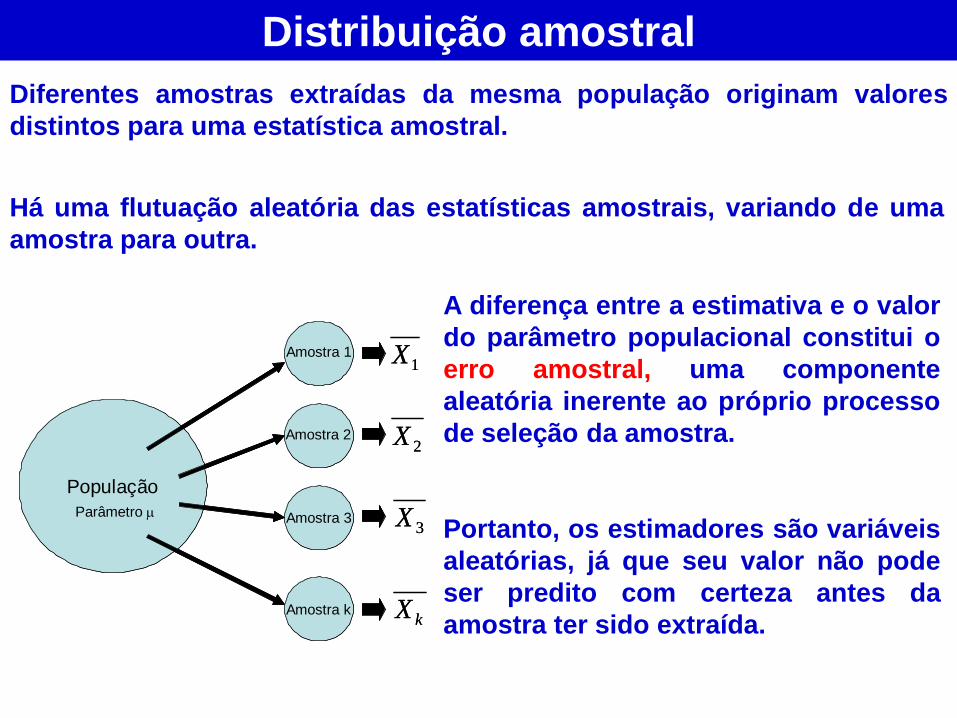
Diferentes amostras extraídas da mesma população originam valores
distintos para uma estatística amostral.
A diferença entre a estimativa e o valor
do parâmetro populacional constitui o
erro amostral, uma componente
aleatória inerente ao próprio processo
de seleção da amostra.
Portanto, os estimadores são variáveis
aleatórias, já que seu valor não pode
ser predito com certeza antes da
amostra ter sido extraída.
Há uma flutuação aleatória das estatísticas amostrais, variando de uma
amostra para outra.

Distribuição amostral
Distribuição amostral: distribuição de probabilidade de
uma estatística amostral quando consideramos todas as
possíveis amostras aleatórias de tamanho n extraídas de
uma população de Tamanho N (n<N).
A distribuição amostral descreve a variabilidade de uma
estatística e indica quão prováveis são os diversos valores
que ela pode assumir.
A capacidade de usar amostras para fazer inferências
sobre parâmetros populacionais depende do conhecimento
que temos sobre a distribuição amostral.
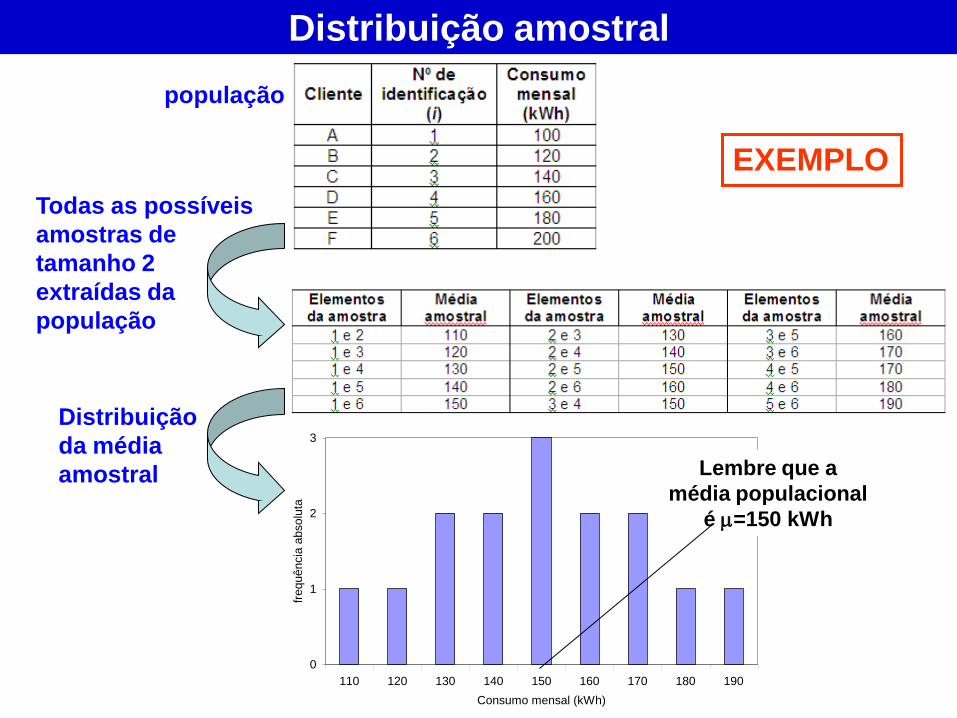
Todas as possíveis
amostras de
tamanho 2
extraídas da
população
Distribuição amostral
0
1
2
3
110 120 130 140 150 160 170 180 190
Consumo mensal (kWh)
frequência
absolu
ta
população
Distribuição
da média
amostral
EXEMPLO
Lembre que a
média populacional
é =150 kWh
Distribuição amostral
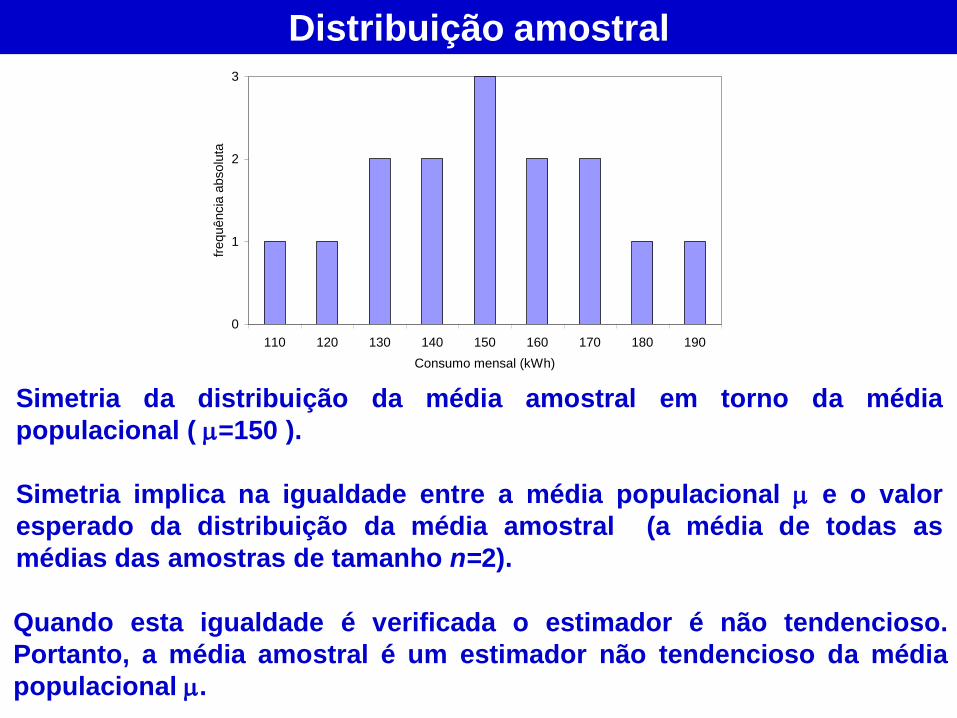
Simetria da distribuição da média amostral em torno da média
populacional ( =150 ).
Simetria implica na igualdade entre a média populacional e o valor
esperado da distribuição da média amostral (a média de todas as
médias das amostras de tamanho n=2).
0
1
2
3
110 120 130 140 150 160 170 180 190
Consumo mensal (kWh)
frequência
absolu
ta
Quando esta igualdade é verificada o estimador é não tendencioso.
Portanto, a média amostral é um estimador não tendencioso da média
populacional .
Distribuição amostral
0
1
2
3
110 120 130 140 150 160 170 180 190
Consumo mensal (kWh)
fre
qu
ên
cia
ab
so
luta
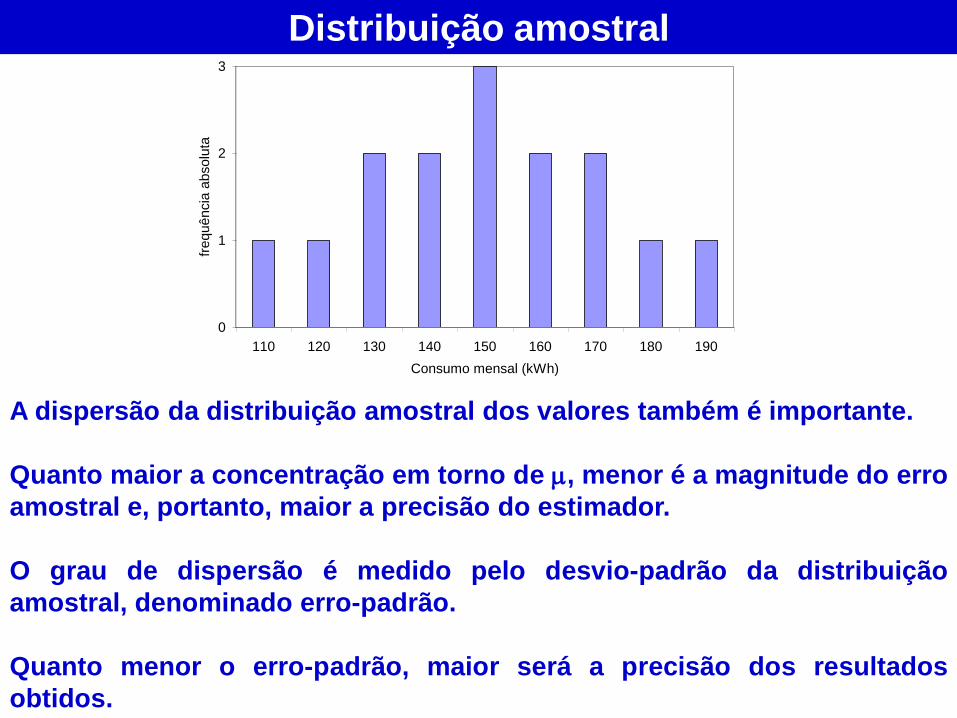
A dispersão da distribuição amostral dos valores também é importante.
Quanto maior a concentração em torno de , menor é a magnitude do erro
amostral e, portanto, maior a precisão do estimador.
O grau de dispersão é medido pelo desvio-padrão da distribuição
amostral, denominado erro-padrão.
Quanto menor o erro-padrão, maior será a precisão dos resultados
obtidos.
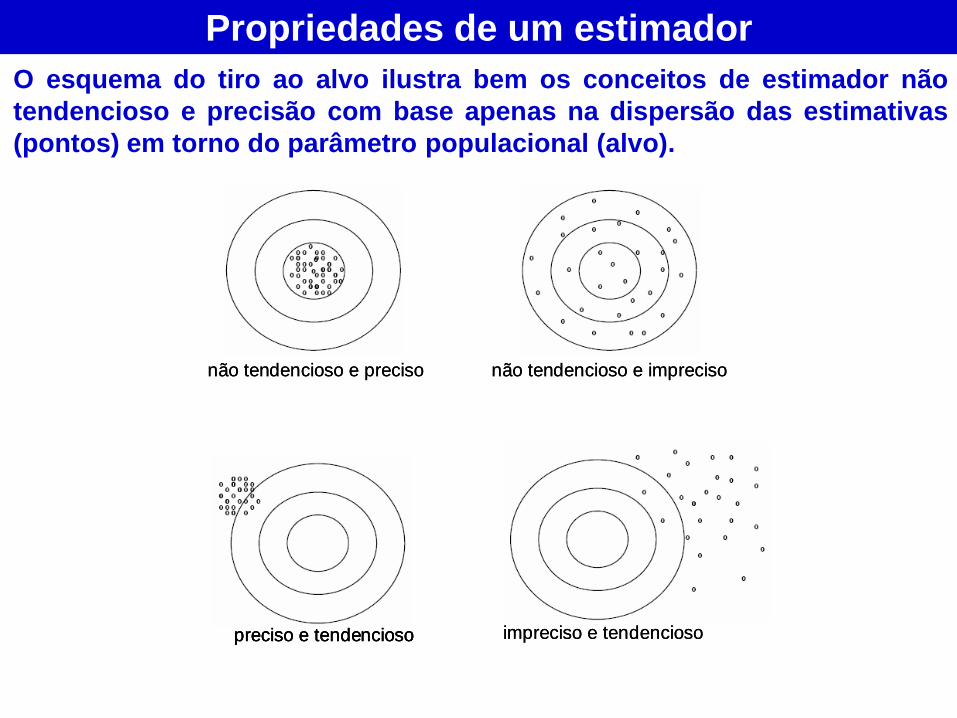
Propriedades de um estimador
O esquema do tiro ao alvo ilustra bem os conceitos de estimador não
tendencioso e precisão com base apenas na dispersão das estimativas
(pontos) em torno do parâmetro populacional (alvo).
não tendencioso e preciso não tendencioso e impreciso
preciso e tendencioso impreciso e tendencioso
não tendencioso e preciso não tendencioso e impreciso
preciso e tendenciosopreciso e tendencioso impreciso e tendencioso

Propriedades da média e da variância amostrais
A média amostral é um estimador não tendencioso da média
populacional:
n
i
iXn
X
1
1 XE
A variância amostral é um estimador não tendencioso da variância
populacional:
n
i
i XXn
S
1
22
1
1 22 SE
Prova-se que e são variáveis aleatórias independentes X2S

Teorema Central do Limite
Nas situações práticas dispomos de apenas uma
única amostra de tamanho n da população
investigada.
Então como construir a distribuição da média
amostral com apenas uma amostra?
As distribuições amostrais são deduzidas
matematicamente e a forma da distribuição
depende do estimador adotado, do tamanho da
amostra e da distribuição original da
característica de interesse X na população.

Teorema Central do Limite
No caso da média amostral, o Teorema do Limite Central
estabelece que, independentemente da distribuição populacional
da característica de interesse X, para amostras suficientemente
grandes (n30) a distribuição de probabilidade da média amostral
converge para uma distribuição normal com média e variância
2/n, à medida que aumenta o tamanho da amostra.
Se a amostra representar mais de 5% do tamanho da população
(n/Nx100% > 5%) a variância da distribuição da média amostral deve ser
corrigida pelo fator de correção finita:
nNX
2
,~
n grande (>30)
1,~
2
N
nN
nNX
n grande (>30)
Fator de correção finita
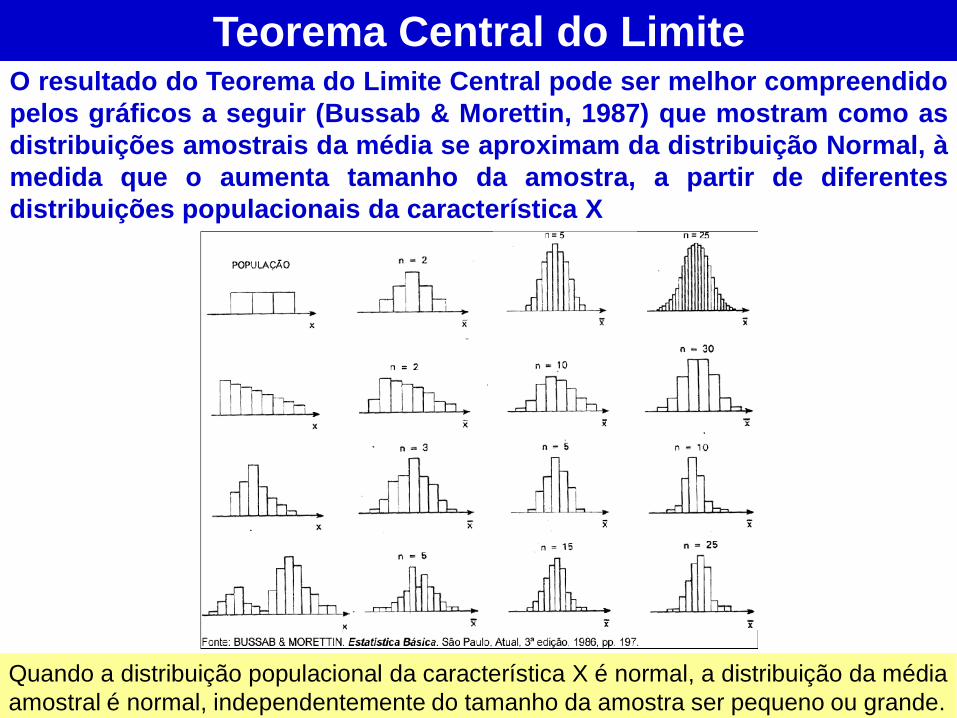
Teorema Central do Limite O resultado do Teorema do Limite Central pode ser melhor compreendido
pelos gráficos a seguir (Bussab & Morettin, 1987) que mostram como as
distribuições amostrais da média se aproximam da distribuição Normal, à
medida que o aumenta tamanho da amostra, a partir de diferentes
distribuições populacionais da característica X
Quando a distribuição populacional da característica X é normal, a distribuição da média
amostral é normal, independentemente do tamanho da amostra ser pequeno ou grande.

Teorema Central do Limite
A aproximação à curva normal pode ser utilizada em outros
estimadores, tais como o estimador do total e o estimador de
proporção.
No caso do estimador de proporção a sua distribuição
amostral converge para uma normal com média igual a
proporção populacional p e variância igual a p(1-p)/n:
n
pppNp
1,~ˆ
1
1,~ˆ
N
nN
n
pppNp
Em populações finitas (n/N x 100% > 5%) a variância do
estimador deve ser corrigida pelo fator de correção finita:

Amostragem aleatória simples

Amostragem aleatória simples (AAS)
Consiste em selecionar aleatoriamente uma amostra de n elementos em
uma população com N elementos (n<N).
Os elementos são sorteados sem reposição e não importa a ordem de
seleção dos elementos.
Assim, o total de amostras de n elementos que podem ser obtidas de uma
população de tamanho N é:
Todos os elementos da população têm igual probabilidade de pertencer a
amostra. Portanto, todas as possíveis amostras de tamanho n são
equiprováveis.
A probabilidade de um elemento pertencer a amostra é dada pela razão
n/N, conhecida como fração de amostragem.
!!
!
nNn
N
n
N

Exemplo O número total de amostras possíveis de tamanho 3 de uma população
formada pelos oito primeiros números naturais {1,2,3,4,5,6,7,8} é 56:
5678
123
678
!5!3
!8
!38!3
!8
3
8
x
xx
xx
Seja X1 o primeiro elemento a ser sorteado.
P(X1=i1) = 1/8 para todo i1 = 1,2,3,4,5,6,7,8
Seja X2 o segundo elemento a ser sorteado
P(X2=i2 | X1=i1) = 1/7 , para todo i2 diferente de i1
Seja X3 o terceiro elemento a ser sorteado
P(X3=i3|X1=i1 . X2=i2) = 1/6, para todo i3 diferente de i1 e i2
Considere uma das possíveis amostras de três elementos: A={2,5,7}
A probabilidade de que tal amostra seja selecionada é
N =8
n =3
Aiii
iXiXiXP
321,,
332211 ,, Soma das probabilidades de todas
as permutações de 2,5 e 7

Exemplo O número de permutações dos elementos da amostra A = {2, 5, 7} é igual
a 6:
257 275 527 572 725 752
Cada uma das permutações tem probabilidade
(1/8) x (1/7) x (1/6)
Como há 6 permutações
A probabilidade de selecionar a amostra A={2, 5, 7} é
6 x (1/8) x (1/7) x (1/6) = 1/56
Evidentemente, qualquer outra amostra de tamanho 3 tem a mesma
probabilidade de 1/56 de ser selecionada.
Na AAS cada possível amostra de tamanho n tem igual probabilidade de
ser selecionada

Tamanho da amostra
Para dimensionarmos uma amostra devemos especificar duas constantes:
1) Máximo desvio ou erro tolerável (d) entre a média amostral e a média
populacional.
2) A probabilidade de que o máximo desvio ou erro entre a média
amostral e média populacional seja maior do que d.
Os valores das constantes e d devem ser pequenos, tal que
dXP
1dXP
Probabilidade de que o desvio entre a
média amostral e a média populacional
ultrapasse o máximo tolerável é igual a
Probabilidade de que o desvio entre a
média amostral e a média populacional
seja menor que máximo tolerável é igual
a 1-

Tamanho da amostra (população infinita)
1dXP
1dXdP
nNX
2
,~
Pelo Teorema Central do Limite
Admitindo população infinita
1222 n
d
n
X
n
dP
Dividindo a desigualde pelo desvio padrão
1
n
dz
n
dP
z~N(0,1)
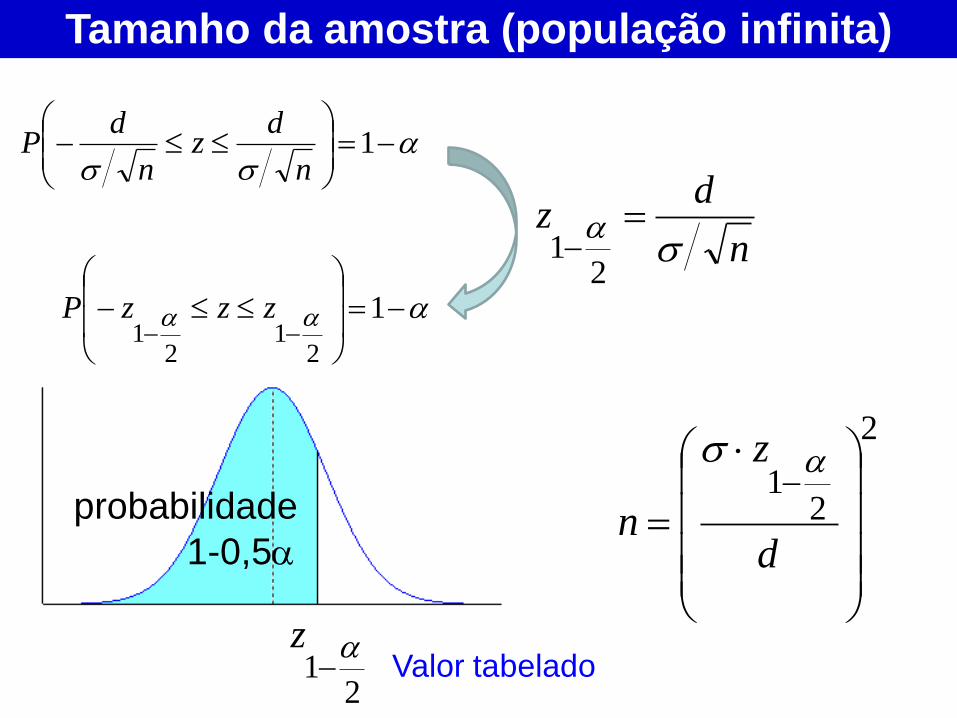
Tamanho da amostra (população infinita)
1
n
dz
n
dP
1
21
21
zzzP
n
dz
2
1
2
21
d
z
n
21
z
Valor tabelado
1-0,5
probabilidade

Tamanho da amostra (população finita)
Pelo Teorema Central do Limite a distribuição
da média amostral é Normal.
Logo, a probabilidade de que o desvio entre a média populacional e a média
amostral seja menor do que e é 1-.
1
111
22222
zzzP
nN
nN
d
nN
nN
X
nN
nN
dP
XXX
1dXdPdXP
Tamanho da amostra
nN
nNdz X
2
21 1
Logo
2
21
22
2
21
2
1
zdN
zN
n
X
X
1,~
2
N
nN
nNX

Tamanho da amostra
222/1
2
222/1
1 X
X
zdN
Nzn
N = tamanho da população
d = margem de erro fixada
2X = variância da distribuição populacional
1- = nível de confiança, usualmente 95% ( = 5%)
z1- /2 = abscissa da distribuição normal que deixa uma
probabilidade 1-/2 a esquerda
2
222/1
d
zn X
No caso de populações grandes ou infinitas
podemos usar a seguinte fórmula:
222/1
2
222/1
1 X
X
StdN
NStn
No caso de populações finitas e com
variância populacional não conhecida
devemos usar a seguinte fórmula:
S2X = estimativa da variância da distribuição populacional
t1-/2 = abscissa da distribuição t que deixa uma probabilidade 1-/2 a esquerda
Tamanho da amostra Exemplo
Cliente Número EndereçoConsumo no mês anterior
(kWh)
10000001 301
10000002 204
10000003 303
10000004 205
10000005 191
10000006 391
10000007 349
10000008 274
10000009 285
10000010 394
10000011 274
10000012 392
10000013 309
10000014 180
10000015 290
10000016 356
10000017 199
10000018 474
10000019 392
10000020 226
10000021 521
10000022 178
10000023 242
10000024 206
10000025 348
10000026 109
10000027 414
10000028 223
10000029 316
10000030 280
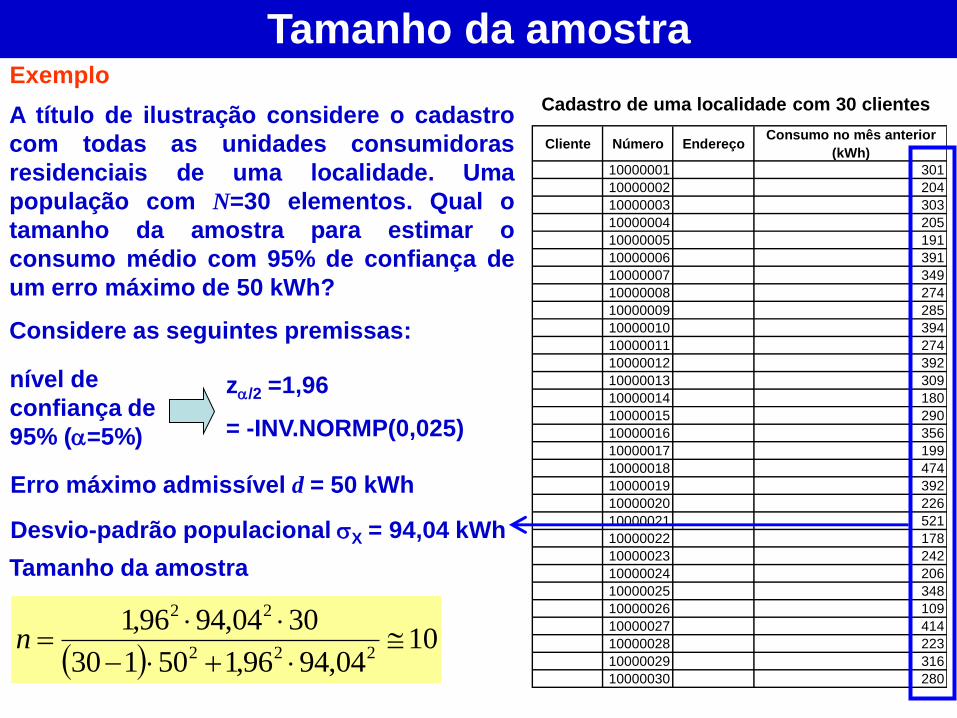
A título de ilustração considere o cadastro
com todas as unidades consumidoras
residenciais de uma localidade. Uma
população com N=30 elementos. Qual o
tamanho da amostra para estimar o
consumo médio com 95% de confiança de
um erro máximo de 50 kWh?
Considere as seguintes premissas:
nível de
confiança de
95% (=5%)
z/2 =1,96
= -INV.NORMP(0,025)
Erro máximo admissível d = 50 kWh
Desvio-padrão populacional X = 94,04 kWh
10
04,9496,150130
3004,9496,1222
22
n
Tamanho da amostra
Cadastro de uma localidade com 30 clientes

Tamanho da amostra
N = tamanho da população
e = margem de erro fixada
p = proporção populacional
= nível de confiança 1%, 5% ou 10%
z1- /2 = abscissa da distribuição normal que deixa uma
probabilidade 1-/2 a esquerda
No caso de populações grandes ou infinitas
podemos usar a seguinte fórmula:
Note que o tamanho da amostra depende da proporção populacional, justamente
o parâmetro que queremos estimar por amostragem.
Podemos considerar estimativas obtidas em estudos anteriores, fazer uma
amostra piloto ou, na impossibilidade de obter tais estimativas, podemos fixar p
em 0,5, pois assim maximizamos o produto p(1-p) o que resulta em um maior
tamanho para a amostra,
ppzdN
Nppzn
11
1
22/1
2
22/1
2
22/1 1
d
ppzn
Tamanho da amostra para estimar uma proporção.

Amostragem aleatória simples (AAS) Exemplo do cálculo do tamanho da amostra para estimar proporções
Cliente Número EndereçoConsumo no mês anterior
(kWh)
10000001 301
10000002 204
10000003 303
10000004 205
10000005 191
10000006 391
10000007 349
10000008 274
10000009 285
10000010 394
10000011 274
10000012 392
10000013 309
10000014 180
10000015 290
10000016 356
10000017 199
10000018 474
10000019 392
10000020 226
10000021 521
10000022 178
10000023 242
10000024 206
10000025 348
10000026 109
10000027 414
10000028 223
10000029 316
10000030 280
Considere o cadastro com todas as
unidades consumidoras residenciais de
uma localidade. Uma população com N=30
elementos. Qual o tamanho da amostra para
estimar a proporção de clientes com ar
condicionado?
Considere as seguintes premissas:
nível de
confiança de
95% (=5%)
z/2 =1,96
= -INV.NORMP(0,025)
Erro máximo admissível d = 0,2
Desvio-padrão populacional X = 0,5 x 0,5
14
5,096,12,0130
305,096,1222
22
n
Tamanho da amostra
Cadastro de uma localidade com 30 clientes
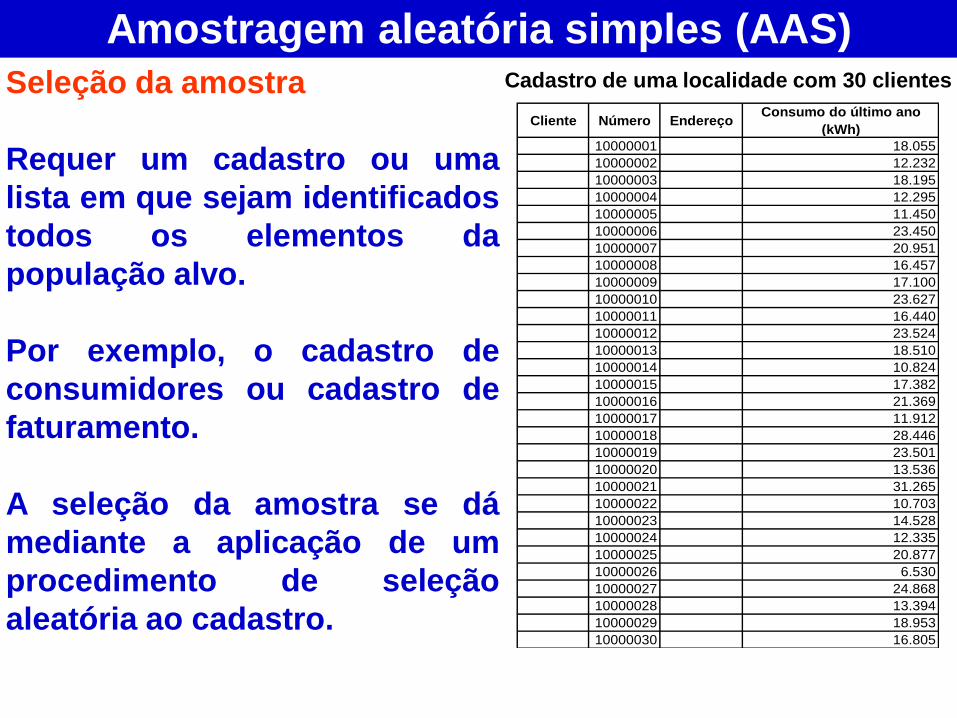
Amostragem aleatória simples (AAS)
Seleção da amostra
Requer um cadastro ou uma
lista em que sejam identificados
todos os elementos da
população alvo.
Por exemplo, o cadastro de
consumidores ou cadastro de
faturamento.
A seleção da amostra se dá
mediante a aplicação de um
procedimento de seleção
aleatória ao cadastro.
Cadastro de uma localidade com 30 clientes
Cliente Número EndereçoConsumo do último ano
(kWh)
10000001 18.055
10000002 12.232
10000003 18.195
10000004 12.295
10000005 11.450
10000006 23.450
10000007 20.951
10000008 16.457
10000009 17.100
10000010 23.627
10000011 16.440
10000012 23.524
10000013 18.510
10000014 10.824
10000015 17.382
10000016 21.369
10000017 11.912
10000018 28.446
10000019 23.501
10000020 13.536
10000021 31.265
10000022 10.703
10000023 14.528
10000024 12.335
10000025 20.877
10000026 6.530
10000027 24.868
10000028 13.394
10000029 18.953
10000030 16.805

Amostragem aleatória simples (AAS) Seleção da amostra
Como fazer a seleção ?
Vamos selecionar uma amostra de
tamanho n=10, a partir do cadastro ao
lado, onde N=30.
Pode-se sortear 10 números aleatórios
entre 1 e 30 e selecionar os clientes
que ocupem as respectivas posições
no cadastro.
Use o comando =aletatórioentre(1;30)
no Excel e não considere os números
repetidos.
Números sorteados: 3, 14, 10, 20, 5, 1,
15, 23, 9, 6
Cadastro de uma localidade com 30 clientes
Cliente Número EndereçoConsumo do último ano
(kWh)
10000001 18.055
10000002 12.232
10000003 18.195
10000004 12.295
10000005 11.450
10000006 23.450
10000007 20.951
10000008 16.457
10000009 17.100
10000010 23.627
10000011 16.440
10000012 23.524
10000013 18.510
10000014 10.824
10000015 17.382
10000016 21.369
10000017 11.912
10000018 28.446
10000019 23.501
10000020 13.536
10000021 31.265
10000022 10.703
10000023 14.528
10000024 12.335
10000025 20.877
10000026 6.530
10000027 24.868
10000028 13.394
10000029 18.953
10000030 16.805
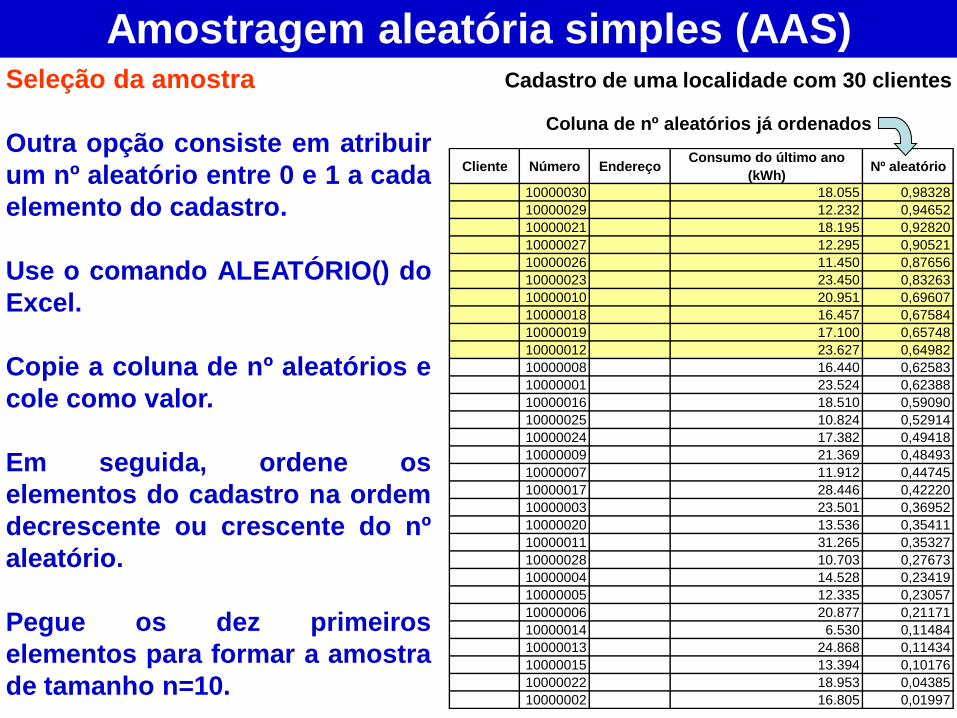
Amostragem aleatória simples (AAS) Seleção da amostra
Outra opção consiste em atribuir
um nº aleatório entre 0 e 1 a cada
elemento do cadastro.
Use o comando ALEATÓRIO() do
Excel.
Copie a coluna de nº aleatórios e
cole como valor.
Em seguida, ordene os
elementos do cadastro na ordem
decrescente ou crescente do nº
aleatório.
Pegue os dez primeiros
elementos para formar a amostra
de tamanho n=10.
Cadastro de uma localidade com 30 clientes
Cliente Número EndereçoConsumo do último ano
(kWh)Nº aleatório
10000030 18.055 0,98328
10000029 12.232 0,94652
10000021 18.195 0,92820
10000027 12.295 0,90521
10000026 11.450 0,87656
10000023 23.450 0,83263
10000010 20.951 0,69607
10000018 16.457 0,67584
10000019 17.100 0,65748
10000012 23.627 0,64982
10000008 16.440 0,62583
10000001 23.524 0,62388
10000016 18.510 0,59090
10000025 10.824 0,52914
10000024 17.382 0,49418
10000009 21.369 0,48493
10000007 11.912 0,44745
10000017 28.446 0,42220
10000003 23.501 0,36952
10000020 13.536 0,35411
10000011 31.265 0,35327
10000028 10.703 0,27673
10000004 14.528 0,23419
10000005 12.335 0,23057
10000006 20.877 0,21171
10000014 6.530 0,11484
10000013 24.868 0,11434
10000015 13.394 0,10176
10000022 18.953 0,04385
10000002 16.805 0,01997
Coluna de nº aleatórios já ordenados

Intervalo de confiança
Estimação por intervalo

Intervalo de confiança para a média
Como a média amostral segue uma distribuição normal com
média e variância 2/n, podemos esperar com 95% de
probabilidade que a média amostral seja diferente do valor
populacional por no máximo 1,96 desvios-padrão
%9596,196,1 XDPXXDPP
nNX
2
,~
nn
XDP
2
%9596,196,1 XDPXXDPP

Intervalo de confiança para a média
%9596,196,1 XDPXXDPP
%9596,196,1 XDPXXDPXP
o intervalo tem uma probabilidade de 95%
de conter a média populacional.
Logo, há uma probabilidade de 5% do intervalo não conter a média, ou seja,
uma probabilidade de 5% de erro.
Substituíndo a média amostral por seu valor numérico, a expressão acima
deixa de ser uma probabilidade legítima e transforma-se no intervalo com 95%
de confiança de conter a média populacional:
XDPXXDPX 96,196,1
XDPXXDPX 96,1,96,1
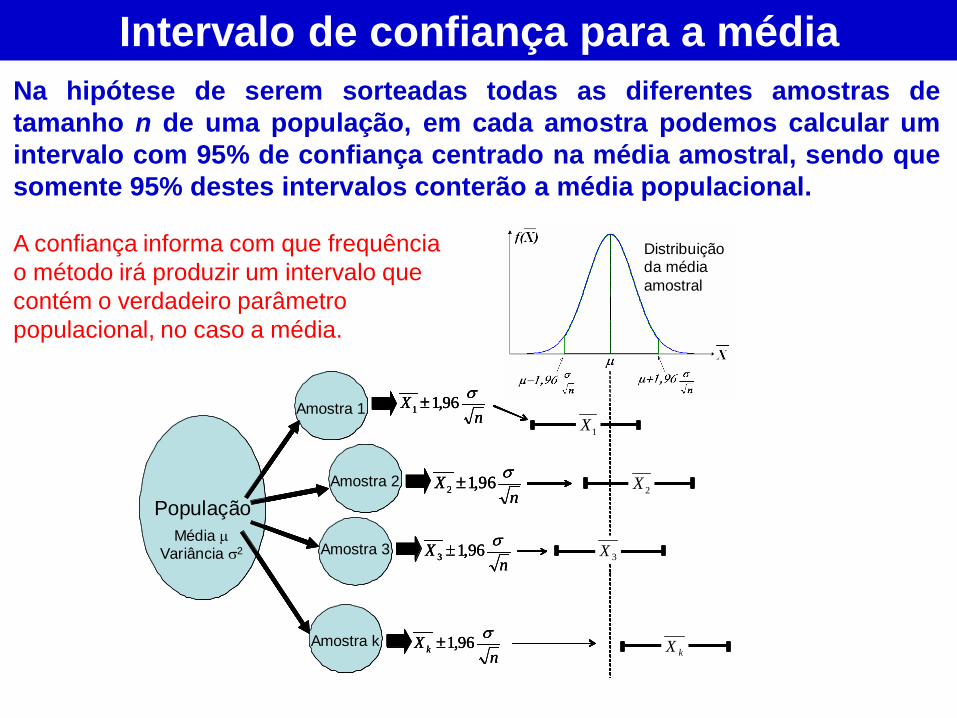
Intervalo de confiança para a média
Na hipótese de serem sorteadas todas as diferentes amostras de
tamanho n de uma população, em cada amostra podemos calcular um
intervalo com 95% de confiança centrado na média amostral, sendo que
somente 95% destes intervalos conterão a média populacional.
População
Amostra 1
Amostra 2
Amostra 3
Amostra k
Média Variância 2
nX
96,1
1
nX
96,1
2
nX
96,1
3
nX
k
96,1
1X
2X
3X
kX
Distribuição da média
amostral
População
Amostra 1
Amostra 2
Amostra 3
Amostra k
Média Variância 2
nX
96,1
1
nX
96,1
2
nX
96,1
3
nX
k
96,1
1X
2X
3X
kX
População
Amostra 1
Amostra 2
Amostra 3
Amostra k
Média Variância 2
nX
96,1
1
nX
96,1
2
nX
96,1
3
nX
k
96,1
1X
2X
3X
kX
Distribuição da média
amostral
A confiança informa com que frequência
o método irá produzir um intervalo que
contém o verdadeiro parâmetro
populacional, no caso a média.
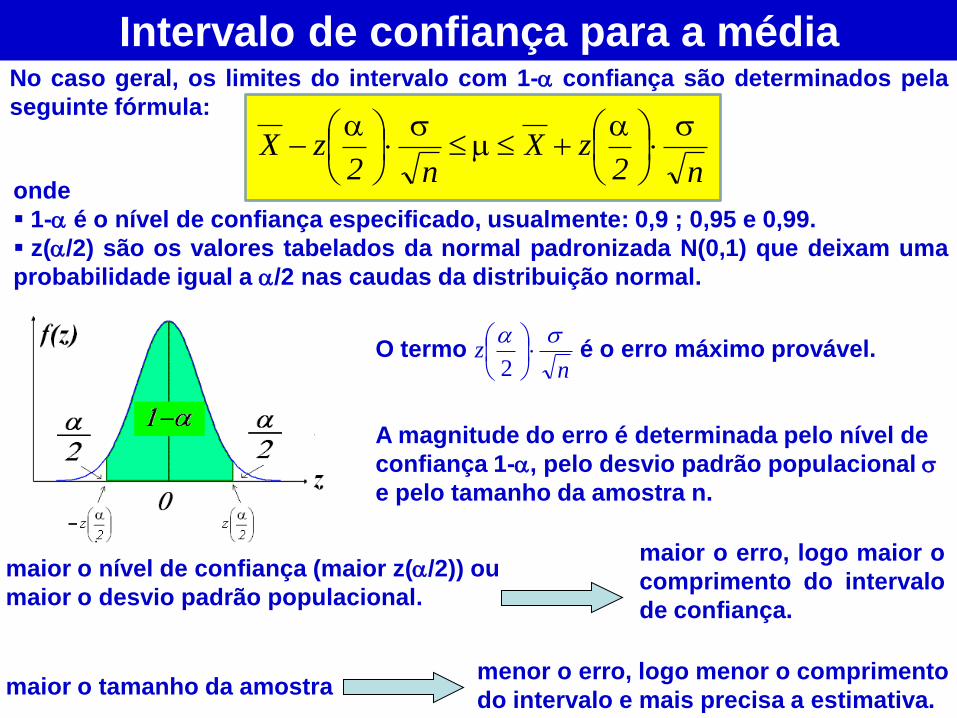
No caso geral, os limites do intervalo com 1- confiança são determinados pela
seguinte fórmula:
Intervalo de confiança para a média
n2zX
n2zX
onde
1- é o nível de confiança especificado, usualmente: 0,9 ; 0,95 e 0,99.
z(/2) são os valores tabelados da normal padronizada N(0,1) que deixam uma
probabilidade igual a /2 nas caudas da distribuição normal.
O termo é o erro máximo provável.
A magnitude do erro é determinada pelo nível de
confiança 1-, pelo desvio padrão populacional
e pelo tamanho da amostra n.
nz
2
maior o tamanho da amostra menor o erro, logo menor o comprimento
do intervalo e mais precisa a estimativa.
maior o erro, logo maior o
comprimento do intervalo
de confiança.
maior o nível de confiança (maior z(/2)) ou
maior o desvio padrão populacional.

Intervalo de confiança para a média
Quando a população é finita e o tamanho da amostra constitui mais de 5% da
população (n/N x 100% > 5%), devemos aplicar o fator de correção finita na
fórmula da variância da distribuição amostral da média:
1N
nN
n2zX
1N
nN
n2zX
Todos os resultados anteriores também são válidos para pequenas amostras
(n30) desde que extraídas de populações normais com variância 2
conhecida.
VAR00001
50,0
45,0
40,0
35,0
30,0
25,0
20,0
15,0
10,0
40
30
20
10
0
Std. Dev = 7,65
Mean = 20,9
N = 50,00
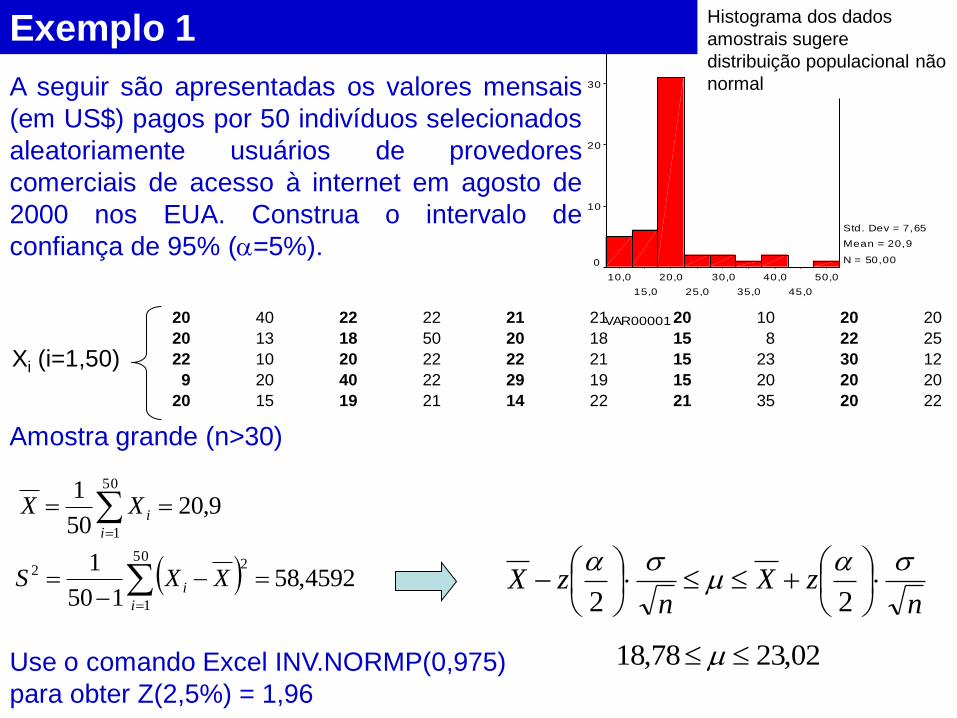
Exemplo 1
A seguir são apresentadas os valores mensais
(em US$) pagos por 50 indivíduos selecionados
aleatoriamente usuários de provedores
comerciais de acesso à internet em agosto de
2000 nos EUA. Construa o intervalo de
confiança de 95% (=5%).
nzX
nzX
22
20 40 22 22 21 21 20 10 20 20
20 13 18 50 20 18 15 8 22 25
22 10 20 22 22 21 15 23 30 12
9 20 40 22 29 19 15 20 20 20
20 15 19 21 14 22 21 35 20 22
Amostra grande (n>30)
9,2050
1 50
1
i
iXX
4592,58150
1 50
1
22
i
i XXS
Use o comando Excel INV.NORMP(0,975)
para obter Z(2,5%) = 1,96
02,2378,18
Xi (i=1,50)
Histograma dos dados
amostrais sugere
distribuição populacional não
normal

Em uma amostra de 15 tubos de imagem, a vida útil média é de 8000
horas. Em geral, a vida útil de tubos de imagem é assumida como sendo
normal. Suponha que o desvio padrão da vida útil dos tubos de imagem
de TV para uma marca particular é conhecido como sendo 500 horas.
Construa o intervalo de confiança de 95% para a vida útil média.
Exemplo 2
n
zXn
zX
%5.2%5.2
Como o intervalo acima não contém o total de horas em um ano (8760
horas), é razoável admitir que a vida útil média de um tubo de imagem seja
menor que um ano.
15
50096,18000
15
50096,18000
04,825397,7746
z(/2) = z(2,5%)
Use o comando Excel
INV.NORMP(0,975) = Z(2,5%) = 1,96
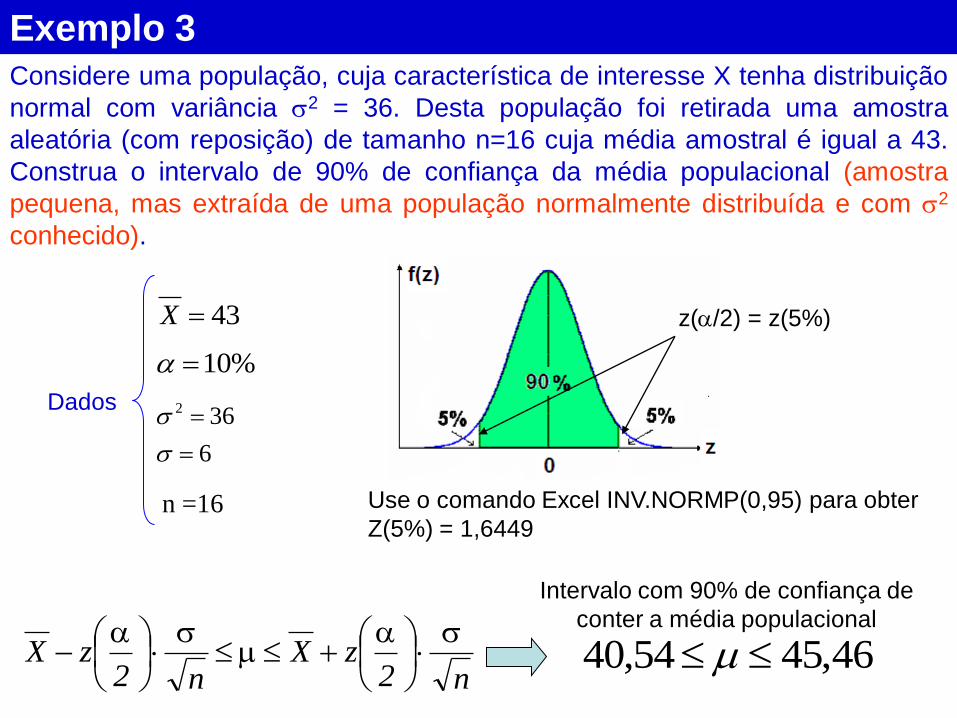
Exemplo 3
Considere uma população, cuja característica de interesse X tenha distribuição
normal com variância 2 = 36. Desta população foi retirada uma amostra
aleatória (com reposição) de tamanho n=16 cuja média amostral é igual a 43.
Construa o intervalo de 90% de confiança da média populacional (amostra
pequena, mas extraída de uma população normalmente distribuída e com 2
conhecido).
%10
6
362
43X z(/2) = z(5%)
Use o comando Excel INV.NORMP(0,95) para obter
Z(5%) = 1,6449
n2zX
n2zX
n =16
Dados
46,4554,40
Intervalo com 90% de confiança de
conter a média populacional

Intervalo de confiança para a média
Até o momento admitimos que a variância populacional é conhecida, uma
situação que não acontece na prática.
Em geral 2 não é conhecida e deve ser substituída por sua estimativa
amostral S2.
Em função desta modificação os valores críticos que definem a região de
rejeição, z(/2), passam a ser definidos pela tabela da distribuição t de
Student com n-1 graus de liberdade e não mais pela tabela da distribuição
N(0,1).
Assim, por exemplo, o valor crítico ao nível de significância de 10% é 1,75
(use o comando =INVT(0,1;15) no MS Exel ®), ligeiramente superior ao valor
crítico de 1,64 definido pela N(0,1).
O uso da distribuição t pressupõe que a população seja normalmente
distribuída.
Distribuição t

Intervalo de confiança para a média
Para pequenas amostras (n 30) extraídas de uma população normalmente
distribuída com o estimador S2 no lugar de 2, pois 2 não é conhecido, tem-se
que:
n
StX
n
StX
22
22
1212
22
N
nN
n
StX
N
nN
n
StX
Para amostras aleatórias de uma população finita em que n/Nx100% > 5%
Neste caso deve-se substituir o z-score com distribuição normal pelo t-score ou
t(/2) com distribuição t de Student com n-1 graus de liberdade:
12
~
nt
n
S
X Variável aleatória com distribuição t de
Student com n-1 graus de liberdade
Distribuição t
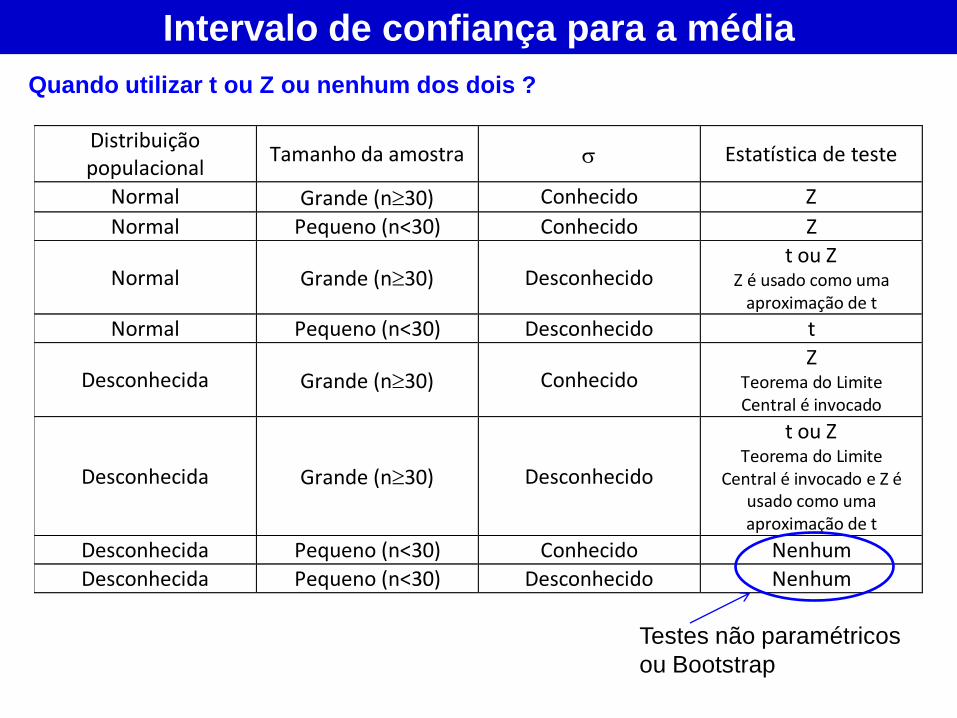
Distribuição populacional
Tamanho da amostra Estatística de teste
Normal Grande (n30) Conhecido Z
Normal Pequeno (n<30) Conhecido Z
Normal Grande (n30) Desconhecido t ou Z
Z é usado como uma aproximação de t
Normal Pequeno (n<30) Desconhecido t
Desconhecida Grande (n30) Conhecido Z
Teorema do Limite Central é invocado
Desconhecida Grande (n30) Desconhecido
t ou Z Teorema do Limite
Central é invocado e Z é usado como uma aproximação de t
Desconhecida Pequeno (n<30) Conhecido Nenhum
Desconhecida Pequeno (n<30) Desconhecido Nenhum
Intervalo de confiança para a média
Quando utilizar t ou Z ou nenhum dos dois ?
Testes não paramétricos
ou Bootstrap

Assuma que estes valores são provenientes de uma população normalmente
distribuída e calcule o intervalo com 90% de confiança para o número médio de galões
necessários para percorrer as 100 milhas.
Intervalo de confiança:
Exemplo 4
Uma agência governamental deseja estimar as milhas por galão que um
determinado modelo de veículo é capaz de fazer.
Para isto a agência adquire um destes veículos, enche o tanque de
combustível e um motorista treinado dirige o carro por 100 milhas. Então o
veículo é reabastecido e o mesmo motorista dirige o carro por mais 100 milhas,
ao final do percurso o veículo é novamente reabastecido e assim segue o
experimento. A operação é realizada 10 vezes e o número de galões
necessários para reabastecer o tanque de combustível nestas 10 vezes é
apresentado a seguir:
4,78 4,42 3,94 4,15 4,90 3,92 3,94 4,68 4,32 4,23
n
StX
n
StX
22
22

Exemplo 4
Amostra Xi (i=1,10): 4,78 4,42 3,94 4,15 4,90 3,92 3,94 4,68 4,32 4,23
n=10 328,410
1 10
1
i
iXX 1303,0110
1 10
1
22
i
i XXS 8331,1%5 t
n
StX
n
StX
22
22
10
1303,08331,1328,4
10
1303,08331,1328,4
537,4119,4 Intervalo com 90% de confiança para o número
médio de galões necessários para percorrer 100
milhas
A partir deste resultado também podemos construir o Intervalo com 90% de confiança a
médio de milhas percorridas por galão de combustível
28,2404,22 100/4,119 100/4,537
Use o comando
Excel =INVT(0,1;9)

A vida útil média de uma amostra de 10 lâmpadas é 4000 horas, com
desvio padrão da amostra de 200 horas. Sabendo que a vida útil de uma
lâmpada é assumida como sendo aproximadamente normal, construa o
intervalo de confiança de 95% para a média da vida útil.
Exemplo 5
n
stX
n
stX %5.2%5.2 99
1) A vida útil da lâmpada é uma variável aleatória com distribuição normal
2) Amostra é pequena n = 10
3) Desvio padrão estimado a partir da amostra (s = 200)
Logo deve-se utilizar a distribuição t na definição do intervalo de
confiança para a média
10
2002622,24000
10
2002622,24000
2,41438,3856 =INVT(0.05,9)=2,2622

Assim, os limites do intervalo com 100(1-)% de confiança para a
proporção p são determinados conforme a seguir:
Intervalo de confiança para a proporção
n
ppzpp
n
ppzp
ˆ1ˆ
2ˆ
ˆ1ˆ
2ˆ
Em grandes amostras, a aproximação à curva normal pode ser utilizada
em outros estimadores, tal como o estimador de proporção, cuja
distribuição amostral converge para uma normal com média igual a
proporção populacional p e variância igual a p(1-p)/n:
n
pppNp
1,~ˆ

Dados estimativa da proporção dos que votam no candidato A
tamanho da amostra
= 5% nível de significância
Exemplo 6
6,0ˆ p
Uma empresa de pesquisa eleitoral entrevistou por telefone 400 eleitores
registrados, perguntando-lhes se votariam no candidato A ou no candidato B.
Como resultado foi observado que 60% dos entrevistados responderam que
votariam no candidato A.
Deduza o erro padrão, a margem de erro e o intervalo de 95% de confiança para a
proporção dos que indicam preferência pelo candidato A.
0245,0
400
4,06,0ˆ1ˆ
n
ppsp
400n
048,00245,096,1%5,22 pp szsz
648,0552,02ˆ2ˆ pszppszp pp
Erro padrão =
Margem de erro =
Intervalo de confiança
A vista do intervalo de confiança resultante (55% , 65%) o candidato A pode sentir-se
razoavelmente seguro quanto a suas perspectivas em relação a eleição

Exemplo 7
Uma amostra aleatória de 625 donas-de-casa revela que 70% delas preferem
a marca X de detergente. Construa um intervalo com 90% de confiança para a
proporção de donas-de-casa que preferem X.
Intervalo de confiança para a proporção p
Dados:
n
ppzpp
n
ppzp
ˆ1ˆ
2ˆ
ˆ1ˆ
2ˆ
%10
625
7,0ˆ
n
p
625
7,017,06449,17,0
625
7,017,06449,17,0
p
Use o comando INV.NORMP(0,95) do Excel para obter
Z(5%) = 1,6449
73,067,0 p

Intervalos de confiança para a
diferença nas médias de duas
populações
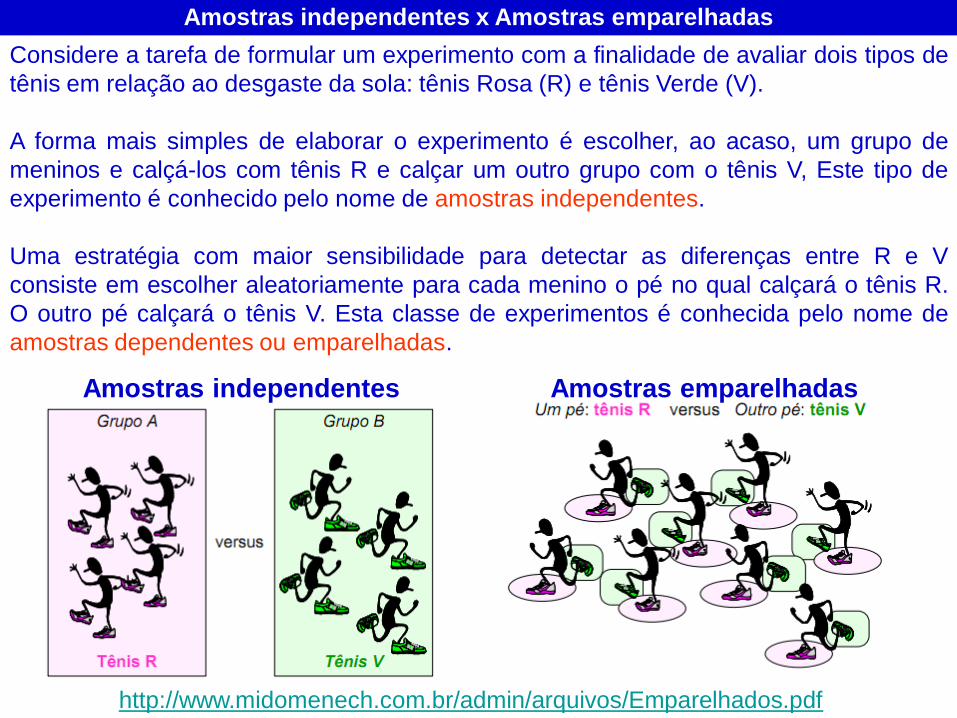
Amostras independentes
Amostras independentes x Amostras emparelhadas
Amostras emparelhadas
Considere a tarefa de formular um experimento com a finalidade de avaliar dois tipos de
tênis em relação ao desgaste da sola: tênis Rosa (R) e tênis Verde (V).
A forma mais simples de elaborar o experimento é escolher, ao acaso, um grupo de
meninos e calçá-los com tênis R e calçar um outro grupo com o tênis V, Este tipo de
experimento é conhecido pelo nome de amostras independentes.
Uma estratégia com maior sensibilidade para detectar as diferenças entre R e V
consiste em escolher aleatoriamente para cada menino o pé no qual calçará o tênis R.
O outro pé calçará o tênis V. Esta classe de experimentos é conhecida pelo nome de
amostras dependentes ou emparelhadas.
http://www.midomenech.com.br/admin/arquivos/Emparelhados.pdf

Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com a mesma variância 12= 2
2= 2 . Isto é
X ~ N(1,2)
Y ~ N(2,2)
Considere amostras aleatórias de X e Y (amostras independentes) e com
tamanhos m e n respectivamente, isto é
(x1,...,xm) e (y1,...,yn)
Todos os parâmetros são desconhecidos e o objetivo é construir
intervalos com 100(1-)% de confiança para a diferença das médias 1 - 2
Intervalo de confiança para a diferença nas médias de duas populações
1 - Caso de duas populações com variâncias iguais
(Amostras independentes)

A partir dos pressupostos assumidos sabemos que as distribuições
amostrais das médias amostrais são normais:
As médias amostrais são independentes então a diferença entre elas
também tem distribuição normal:
mNX
2
1,~
nNY
2
2 ,~
nmNYX
22
21 ,~
A partir dos resultados acima tem-se que:
1,0~
112
21 N
nm
YXZ
Intervalo de confiança para a diferença nas médias de duas populações
1 - Caso de duas populações com variâncias iguais
(Amostras independentes)

A variância 2 não é conhecida e pode ser estimada como
onde
2
11 2
2
2
12
nm
SnSmS pooled
m
i
i Xmxm
S1
222
11
1Variância amostral da amostra da população X
Variância amostral da amostra da população Y
Substituindo 2 por seu estimador tem-se que 2
pooledS
2
2
21 ~11
nm
pooled
t
nmS
YX
Intervalo de confiança para a diferença nas médias de duas populações
Distribuição t com m+n-2 graus de liberdade
1 - Caso de duas populações com variâncias iguais
(Amostras independentes)
n
i
i Ynyn
S1
222
21
1

1
21122
2
212 nm
pooled
nm t
nmS
YXtP
1
11
2
11
2
2
221
2
2nm
StYXnm
StYXP poolednmpoolednm
nmStYX
nmStYX poolednmpoolednm
11
2
11
2
2
221
2
2
Substituindo as estatísticas amostrais por seus valores numéricos, a expressão
acima deixa de ser uma probabilidade legítima e transforma-se no intervalo com
100(1-)% de confiança de conter a diferença entre as médias populacionais:
Para grandes amostras m+n >= 30 pode-se aproximar a distribuição t pela normal
padrão z. (t é aproximado por z)
1 - Caso de duas populações com variâncias iguais
(Amostras independentes)
Intervalo de confiança para a diferença nas médias de duas populações
Valores tabelados

De que maneira as empresas que vão à falência diferem daquelas que
continuam a operar?
Para responder a esta questão, um estudo comparou diversas características
de 68 empresas que estão em boa situação com 33 que faliram.
Uma das variáveis estudadas foi a razão entre o patrimônio e as dívidas
atuais. Grosso modo, trata-se do que a firma vale dividido pela quantia que ela
deve. As estatísticas amostrais são apresentadas a seguir:
Empresas bem sucedidas Empresas falidas
A estimativa da diferença da razão patrimônio/dívidas entre as firmas bem
sucedidas e aquelas que faliram é
Construa o intervalo de 95% confiança para a diferença das médias
6393,0
7256,1
1
1
S
X
4811,0
8236,0
2
2
S
X
902,08236,07256,121 XX
1 – Exemplo caso de duas populações com variâncias iguais
(Amostras independentes)
Intervalo de confiança para a diferença nas médias de duas populações

Vamos admitir populações com variâncias iguais.
Então, primeiro deve-se calcular a variância combinada
A margem de erro é
A diferença entre as bem sucedidas e falidas é em média 0,902 com margem de
erro de 0,2495 para uma confiança de 95%. Alternativamente, o intervalo com 95%
confiança para a diferença das médias é 0,902 0,2495 ou (0,6525 , 1,1515).
2495,033
1
68
13514,09842,1
11
2
2
99
nmSt pooled
3514,0
23368
4811,01336393,0168
2
11 222
2
2
12
nm
SnSmS pooled
O grau de liberdade da estatística t é m+n-2 = 68 + 33 – 2 = 99
Ao nível de confiança = 95%, o t(2,5%) é 1,9842. No Excel INVT(0,05;99) = 1, 9842
Como as amostras são grandes, então
poderíamos aproximar pela normal 1,96
1 – Exemplo caso de duas populações com variâncias iguais
(Amostras independentes)
Intervalo de confiança para a diferença nas médias de duas populações

Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com variâncias 12 e 2
2. Isto é
X ~ N(1,12)
Y ~ N(2,22)
Considere amostras aleatórias de X e Y (amostras independentes) e com
tamanhos m e n respectivamente, isto é
(x1,...,xm) e (y1,...,yn)
Todos os parâmetros são desconhecidos e o objetivo é construir
intervalos com 100(1-)% de confiança para a diferença das médias 1 - 2
Intervalo de confiança para a diferença nas médias de duas populações
2 - Caso de duas populações com variâncias diferentes
(Amostras independentes)

A partir dos pressupostos assumidos sabemos que as distribuições
amostrais das médias amostrais são normais:
As médias amostrais são independentes então a diferença das médias
amostrais também tem distribuição normal:
mNX
2
11,~
nNY
2
22 ,~
nmNYX
2
2
2
121 ,~
A partir dos resultados acima tem-se que:
1,0~
2
2
2
1
21 N
nm
YXZ
Intervalo de confiança para a diferença nas médias de duas populações
2 - Caso de duas populações com variâncias diferentes
(Amostras independentes)

A variância de cada população não é conhecida.
Substituindo as variâncias populacionais pelos respectivos estimadores,
obtém-se uma variável aleatória que não tem distribuição t
onde
Variância amostral da amostra da população X
Variância amostral da amostra da população Y
Porém pode ser aproximada por uma distribuição t com v graus de
liberdade determinado por:
2
11
22
2
22
1
22
2
2
1
n
nS
m
mS
n
S
m
S
v
Intervalo de confiança para a diferença nas médias de duas populações
n
S
m
S
YX
2
2
2
1
21
Arredonde o resultado para cima
2 - Caso de duas populações com variâncias diferentes
(Amostras independentes)
m
i
i Xmxm
S1
222
11
1
n
i
i Ynyn
S1
222
21
1
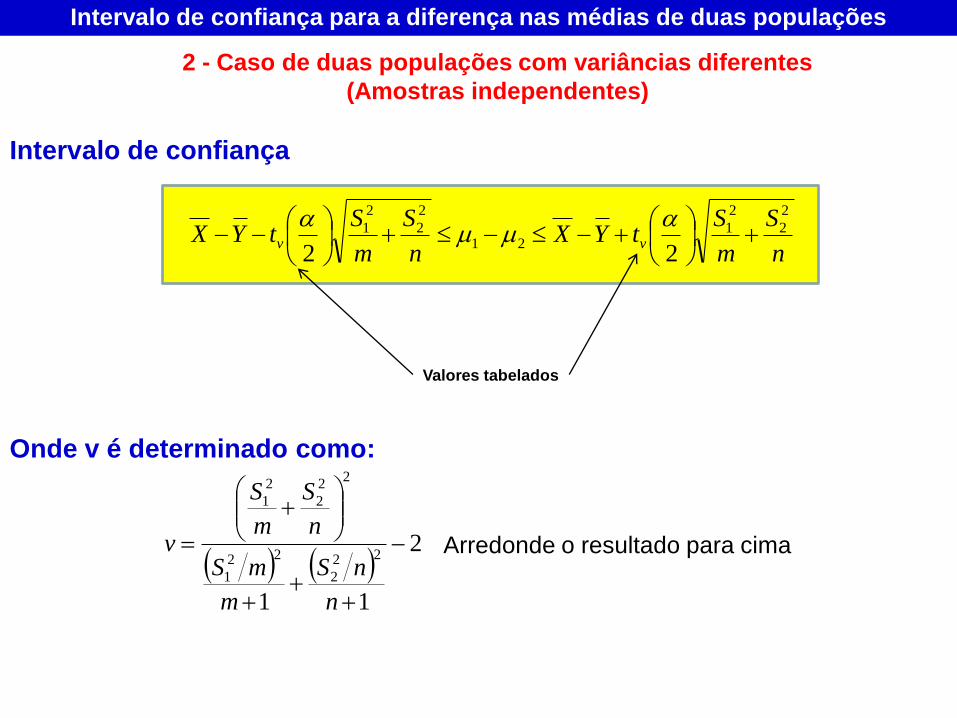
Intervalo de confiança
Onde v é determinado como:
2
11
22
2
22
1
22
2
2
1
n
nS
m
mS
n
S
m
S
v
Intervalo de confiança para a diferença nas médias de duas populações
n
S
m
StYX
n
S
m
StYX vv
2
2
2
121
2
2
2
1
22
Arredonde o resultado para cima
2 - Caso de duas populações com variâncias diferentes
(Amostras independentes)
Valores tabelados

De que maneira as empresas que vão à falência diferem daquelas que
continuam a operar?
Para responder a esta questão, um estudo comparou diversas características
de 68 empresas que estão em boa situação com 33 que faliram.
Uma das variáveis estudadas foi a razão entre o patrimônio e as dívidas
atuais. Grosso modo, trata-se do que a firma vale dividido pela quantia que ela
deve. As estatísticas amostrais são apresentadas a seguir:
Empresas bem sucedidas Empresas falidas
A estimativa da diferença da razão patrimônio/dívidas entre as firmas bem
sucedidas e aquelas que faliram é
Construa o intervalo de 95% confiança para a diferença das médias
6393,0
7256,1
1
1
S
X
4811,0
8236,0
2
2
S
X
902,08236,07256,121 XX
2 – Exemplo caso de duas populações com variâncias diferentes
(Amostras independentes)
Intervalo de confiança para a diferença nas médias de duas populações

Em amostras de tamanhos diferentes não é recomendável admitir a hipótese de
variâncias populacionais iguais, a menos que ambas as amostras sejam
realmente grandes, como neste caso.
Vamos construir o intervalo de confiança admitindo variâncias diferentes.
Então, primeiro deve-se calcular v, o nº de graus de liberdade da estatística t
850879,842
133
334811,0
168
686393,0
33
4811,0
68
6393,0
2
11
2222
222
22
2
22
1
22
2
2
1
n
nS
m
mS
n
S
m
S
v
Ao nível de confiança = 95% , o t(2,5%) é 1,9883. No Excel INVT(0,05;85) = 1, 9883
A margem de erro é
A diferença entre as bem sucedidas e falidas é em média 0,902 com margem de
erro de 0,2269 para uma confiança de 95%. Alternativamente, o intervalo com 95%
confiança para a diferença das médias é 0,902 0,2269 ou (0,6751 , 1,1289).
A título de ilustração, admitindo variâncias iguais o intervalo é (0,6525 ; 1,1515)
2269,033
4811,0
68
6393,09883,1
2
222
2
2
1
n
S
m
Stv
Como as amostras são grandes, então
poderíamos aproximar pela normal 1,96
2 – Exemplo caso de duas populações com variâncias diferentes
(Amostras independentes)
Intervalo de confiança para a diferença nas médias de duas populações

• Quando for necessário comparar, por exemplo, as vendas diárias
de duas filiais que operam com os mesmos produtos, ou os
resultados de um treinamento, confrontando o conhecimento antes
e depois do treinamento, os intervalos de confiança para a
diferenças das médias considerados até este momento não podem
ser aplicados, pois se referem a duas populações independentes.
• Agora, necessitamos analisar duas populações relacionadas, isto é,
duas populações dependentes.
• Neste caso, a variável de interesse será a diferença entre os pares
das duas amostras, no lugar das próprias amostras, que devem ter
o mesmo tamanho.
Amostras emparelhadas

Intervalo de confiança para a diferença nas médias de duas populações
3- Caso de amostras emparelhadas
Considere duas populações Normais com média 1 e 2 possivelmente distintas e
com variâncias 12 e 2
2. Isto é
X1 ~ N(1,12) e X2 ~ N(2,2
2)
Considere amostras aleatórias de X1 e X2 (amostras dependentes ou
emparelhadas) com tamanhos idênticos (n), isto é
(x11,x21), (x12,x22),..., (x1i,x2i),..., (x1n,x2n) formam um conjunto de n observações
emparelhadas.
Em cada par amostrado pode-se calcular o desvio di=x1i-x2i para i=1,...,n
O valor esperado dos desvios é D = E(D) = E(X1-X2) = 1 - 2
Assim, o intervalo de confiança para a diferença entre 1 e 2 pode ser realizado
por meio do intervalo para a média dos desvios D .
n
Std
n
Std d
nDd
n
2
1
2
122
2
1
22
1
1dnd
nS
n
i
id
n
i
idn
d1
1onde e
são estatísticas amostrais Valores tabelados

Intervalo de confiança para a diferença nas médias de duas populações
3- Exemplo caso de amostras emparelhadas
Um fabricante de automóveis coleta dados do consumo de combustível para uma
amostra de n=10 carros em várias categorias de pesos, usando um tipo padrão de
gasolina com e sem determinado aditivo. Os motores foram ajustados para as
mesmas especificações antes de cada teste, e os mesmos motoristas foram
usados para as duas condições de gasolina (sem que o motorista em questão
soubesse qual gasolina estava sendo usada em cada teste particular). Dadas as
informações da amostra construa o intervalo com 95% de confiança para a
diferença do consumo médio com e sem aditivo.
7,110
1
i
id 31,110
1
2 i
id
17,010
7,1
10
1 10
1
i
idd
1134,09
102
10
1
2
2
dd
S i
i
d
Para um nível de confiança de 95% tem-se que t9(2,5%)= INVT(0,05;9) = 2,2622

Intervalo de confiança para a diferença nas médias de duas populações
3- Exemplo caso de amostras emparelhadas
O intervalo para a média dos desvios entre os pares de observações das
amostras emparelhadas é
10
1134,02622,217,0
10
1134,02622,217,0 D
9319,05919,0 D
Como o intervalo contém o zero não podemos afirmar que as médias dos
consumos com e sem aditivo na gasolina são diferentes.

Outros intervalos de confiança

Considere uma população Normal com média e variância 2
desconhecidas da qual foi extraída uma amostra de tamanho n.
A partir dos registros amostrais foi calculada a variância amostral:
Intervalo de confiança para a variância da Normal
2
1
2
1
1
m
i
i Xxm
S
A distribuição amostral de (n-1)S2/2 é qui-quadrado com n-1 graus de
liberdade ou seja 2n-1. Com base nesta distribuição podemos determinar
um intervalo com probabilidade 1- de conter a variância populacional 2.
1
2
)1(
21 2
12
22
1 nn
SnP
Substituindo a estatística amostra S2 por seu valor numérico, a expressão acima
deixa de ser uma probabilidade legítima e transforma-se no intervalo com 100(1-
)% de confiança de conter a variância da normal
1
21
)1(
2
)1(
2
1
22
2
1
2
nn
SnSnP
2
1
)1(
2
)1(
2
1
22
2
1
2
nn
SnSn
Valores tabelados

Intervalo de confiança para a razão de variâncias
Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com variâncias 12 e 2
2. Isto é
X ~ N(1,12)
Y ~ N(1,22)
Considere amostras aleatórias e independentes de X e Y e com tamanhos
m e n respectivamente, isto é
(x1,...,xm) e (y1,...,yn)
Todos os parâmetros são desconhecidos e o objetivo é construir
intervalos com 100(1-)% para a razão das variâncias

Intervalo de confiança para a razão de variâncias
As estatísticas amostrais S12 e S2
2 são independentes e a distribuição
amostral de seus múltiplos é uma distribuição qui-quadrado
2
12
1
2
1 ~)1(
m
Sm
2
12
2
2
2 ~)1(
n
Sn
A razão das duas variáveis aleatórias acima segue uma distribuição F
)1;1(2
2
2
1
2
1
2
2
2
2
2
2
2
1
2
1
2
1
2
1 ~)1(
)1(
nm
n
m FS
S
S
S
n
m
Distribuição F com m-1 graus de
liberdade no numerador e n-1 graus
de liberdade no denominador

Intervalo de confiança para a razão de variâncias
1
221 1,12
2
2
1
2
1
2
21,1 nmnm F
S
SFP
1
221
2
1
2
21,12
1
2
2
2
1
2
21,1
S
SF
S
SFP nmnm
Substituindo as estatísticas amostrais por seus valores numéricos, a
expressão acima deixa de ser uma probabilidade legítima e transforma-se no
intervalo com 100(1-)% de confiança de conter a razão das variâncias:
2
1
2
21,12
1
2
2
2
1
2
21,1
221
S
SF
S
SF nmnm
Com base nesta distribuição podemos determinar um intervalo com
probabilidade 1- de conter a razão das variâncias populacionais.

Exercício 1
Numa experiência agronômica pretende-se avaliar o crescimento total de uma
certa espécie de plantas (expresso em peso seco) relativamente a dois regimes de
fertilização A e B. Ao fim de determinado tempo procedeu-se a medições, tendo-se
obtido os seguintes resultados:
a) Numa experiência anterior (com um elevado numero de plantas da mesma
cultivar) relativa ao tratamento A, obteve-se uma variância de 0.42. Verifique se os
dados atuais são consistentes com esse valor. Comente, justificando, se haveria
alguma(s) hipótese(s) necessária(s) à resolução do problema.
b) Verifique se os dois regimes de fertilização A e B evidenciam diferenças
significativas no que respeita ao crescimento das plantas. Explicite as hipóteses
necessárias à resolução do problema

Exercício 1
(a resolução também pode ser encontrada na planilha exercícios.xlsx)
a) Admitindo populações normais, vamos resolver a questão por meio do
intervalo de confiança para a variância da população A.
Primeiro deve ser calculada a variância da amostra extraída de A
Na sequência, para um nível de confiança de 95%, devem ser determinados
os valores críticos da distribuição qui-quadrado que deixam 2,5% de
probabilidade na cauda esquerda e 2,5% na cauda direita.
valor crítico da cauda direita = 16,01. No Excel INV.QUI(0,025;7)
valor crítico da cauda esquerda = 1,69. No Excel INV.QUI(0,975;7)
O intervalo com 95% de confiança para variância de A é
como o intervalo de confiança contém o valor 0,42 não temos razão para
afirmar, com 95% de confiança, que os dados
8197,02 AS
3953,33538,069,1
8197,0)18(
01,16
8197,0)18(
21
)1(
2
)1( 22
2
1
22
2
1
2
nn
SnSn

b) Admite-se a hipótese de normalidade.
O pressuposto de igualdade das variâncias pode ser avaliado por meio do
intervalo de confiança para a razão das variâncias. Assim, primeiro são
calculadas as variâncias em cada amostra
Na sequência, para um nível de confiança de 95%, devem ser determinados os
valores críticos da distribuição F que deixam 2,5% de probabilidade na cauda
esquerda e 2,5% na cauda direita.
valor crítico da cauda direita = 4,99. No Excel INV.F(0,025;7;7)
valor crítico da cauda esquerda = 0,20. No Excel INV.F(0,975;7;7)
O intervalo com 95% de confiança para a razão das variâncias é
Como o intervalo contém o 1 não temos razão para afirmar que as variâncias são
diferentes. Portando, o pressuposto de variâncias iguais é plausível,
8197,02 AS 9346,02 BS
3804,41756,09346,0
8197,099,4
9346,0
8197,02,0
221
2
2
2
2
2
2
1,12
2
2
2
1,1
B
A
B
A
B
Anm
B
A
B
Anm
S
SF
S
SF
Exercício 1
(a resolução também pode ser encontrada na planilha exercícios.xlsx)

b) As médias amostrais são
O intervalo de confiança para a diferença das médias onde se admite a
hipótese de populações normais com variâncias iguais é
onde
para um nível de confiança de 95% (=5%), o t crítico com 14 graus de
liberdade é 2,1448. (No Excel usar =INVT(0,05;14) )
O intervalo com 95% de confiança para a diferença das médias é
(-0,3168 ; 1,6899).
Como o intervalo contém o zero não podemos afirmar que as médias são
diferentes.
nmStXX
nmStXX poolednmBApoolednmBA
11
2
11
2
2
221
2
2
8772,0
288
9346,0188197,0182
pooledS
8033,5AX 1178,5BX
Exercício 1
(a resolução também pode ser encontrada na planilha exercícios.xlsx)

Exercício 2
Pretende-se verificar se um dado tratamento aos metais tem algum
efeito na quantidade de metal removido numa certa operação.
Uma amostra aleatória de 100 peças foi introduzida num liquido
durante 24 horas sem ser feito o tratamento, obtendo-se uma média
de 12.2 mm de metal removido e um desvio padrão de 1.1 mm.
Uma segunda amostra de 200 peças foi primeiro tratada e depois
introduzida durante 24 horas no tal liquido, resultando uma média de
9.1 mm de metal removido com um desvio padrão de 0.9 mm.
Determine um intervalo de confiança a 98% para a diferença entre as
verdadeiras quantidades médias de metal removido sem tratamento e
com tratamento.
Reduzirá o tratamento a quantidade de metal removido?

Exercício 2

Teste de hipóteses

Teste de hipóteses para a média As estatísticas amostrais como médias e proporções fornecem estimativas
pontuais dos parâmetros populacionais, porém, em função da variabilidade
inerente à amostragem aleatória, as estatísticas amostrais e os parâmetros
populacionais raramente coincidem.
É justamente na discrepância entre a estatística amostral e a hipótese sobre o
valor de um parâmetro populacional que encontraremos evidências para validar
ou refutar a hipótese acerca do parâmetro.
Desvios pequenos podem ser atribuídos ao erro amostral, inerente ao processo
de amostragem, e neste caso é razoável admitir que a hipótese seja verdadeira,
isto é, que a amostra poderia ter sido extraída de uma população, cujo parâmetro
populacional assume o valor alegado pela hipótese.
Por sua vez, discrepâncias grandes sugerem que a variabilidade não se deve
apenas ao erro amostral, mas a inadequação da hipótese acerca do valor do
parâmetro, ou seja, a hipótese é falsa.
Seguindo esta lógica, os testes de hipóteses decidem pela aceitação
(variabilidade casual atribuída ao erro amostral) ou pela rejeição (variabilidade
real não atribuída apenas ao erro amostral) da hipótese sobre o valor do
parâmetro populacional.

Teste de hipóteses para a média
O teste compara duas hipóteses: a hipótese nula H0 e a hipótese alternativa H1.
Por exemplo, com base no valor da média amostral podemos avaliar a
plausibilidade da hipótese da média populacional ser igual a um determinado
valor 0. Assim, podemos formular as seguintes hipóteses acerca da média
populacional:
H0: =0
H1: 0
Note que a hipótese H0 é uma afirmação sobre o valor do parâmetro populacional,
enquanto H1 oferece uma alternativa à alegação feita na hipótese nula.
A hipótese alternativa H1: 0 é bilateral, pois abrange valores menores e
maiores que 0, mas em outras situações pode assumir outras especificações,
por exemplo, nos testes unilaterais: H1: >0 ou H1: <0.
Para realizar o teste é fundamental estabelecer a distribuição amostral do
estimador do parâmetro populacional correspondente às hipóteses. No caso da
média, sabemos pelo Teorema do Limite Central que a distribuição da média
amostral é normal com média igual a média populacional e variância 2/n.
O teste permite avaliar a evidência fornecida
pelos dados sobre alguma afirmação (expressa
na hipótese nula H0) relativa à população.
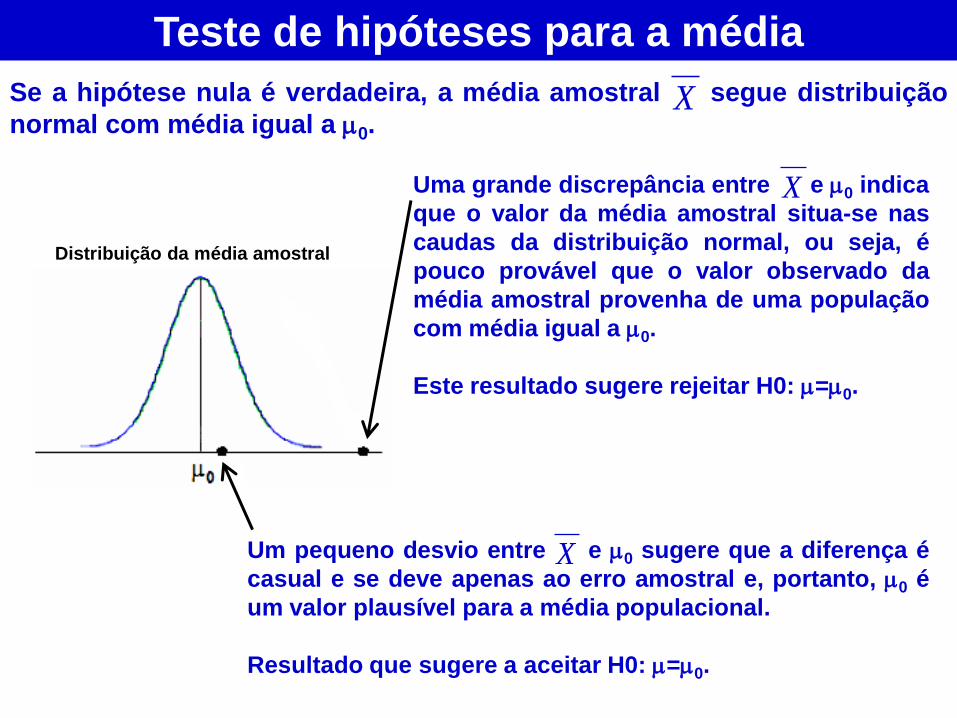
Uma grande discrepância entre e 0 indica
que o valor da média amostral situa-se nas
caudas da distribuição normal, ou seja, é
pouco provável que o valor observado da
média amostral provenha de uma população
com média igual a 0.
Este resultado sugere rejeitar H0: =0.
Teste de hipóteses para a média
Se a hipótese nula é verdadeira, a média amostral segue distribuição
normal com média igual a 0. X
X
Um pequeno desvio entre e 0 sugere que a diferença é
casual e se deve apenas ao erro amostral e, portanto, 0 é
um valor plausível para a média populacional.
Resultado que sugere a aceitar H0: =0.
X
Distribuição da média amostral
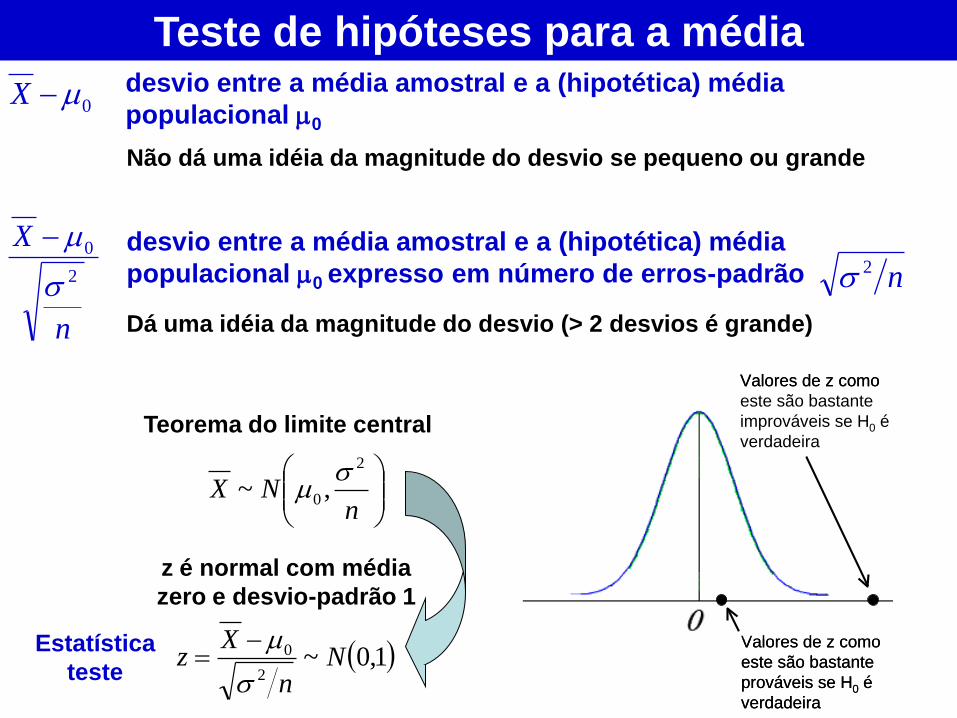
Teste de hipóteses para a média
0X desvio entre a média amostral e a (hipotética) média
populacional 0
n
X
2
0
desvio entre a média amostral e a (hipotética) média
populacional 0 expresso em número de erros-padrão n2
Dá uma idéia da magnitude do desvio (> 2 desvios é grande)
Não dá uma idéia da magnitude do desvio se pequeno ou grande
1,0~2
0 Nn
Xz
Teorema do limite central
nNX
2
0 ,~
z é normal com média
zero e desvio-padrão 1
Valores de z como
este são bastante
improváveis se H0 é
verdadeira
Valores de z como
este são bastante
prováveis se H0 é
verdadeira
Valores de z como
este são bastante
improváveis se H0 é
verdadeira
Valores de z como
este são bastante
prováveis se H0 é
verdadeira
Estatística
teste

probabilidade
1-
probabilidade
Teste de hipóteses para a média Podemos definir uma região com uma pequena probabilidade de
ocorrência nas caudas da distribuição amostral e rejeitar a hipótese nula
H0: =0 se o valor de z estiver nesta região.
A região de rejeição tem probabilidade /2 em cada cauda da distribuição.
Neste caso a hipótese alternativa é bilateral, H1: 0, logo grandes
desvios negativos ou positivos indicam que a hipótese nula não é
plausível.
A probabilidade é o nível de significância do teste e usualmente adota-
se o valor de 1%, 5% ou 10%.
-z(/2) e z(/2) são valores
tabelados em função do
nível de significância
(valores críticos)

Teste de hipóteses para a média
A regra de decisão é muito simples
valor para a estatística
teste z fora do intervalo
[-z(/2), z(/2)]
Rejeita-se a hipótese H0: =0
valor para a estatística
teste z no intervalo
[-z(/2), z(/2)] Aceita-se a hipótese H0: =0
A decisão sobre aceitar ou rejeitar a validade da hipótese
nula baseia-se nos resultados de uma amostra, os quais
estão sujeitos à variabilidade inerente ao processo de
amostragem, logo a regra de decisão não está livre de erros e
decisões incorretas podem ser tomadas.

Teste de hipóteses para a média
1) Se a média populacional é 0 (H0 é verdadeira), podemos
selecionar uma amostra que produza uma estatística teste
cujo valor esteja na região de rejeição.
Neste caso incorremos no erro tipo I: rejeitar uma hipótese
verdadeira.
2) Se a amostra selecionada é proveniente de uma população
com média diferente de 0, o valor da estatística teste pode
pertencer ao intervalo [-z(/2), z(/2)], a região de aceitação
da hipótese nula.
Neste caso, incorremos no erro tipo II: aceitar uma hipótese
falsa.

O importante é reconhecer que estamos tomando decisões em condições
de incerteza e, portanto, sujeitos a dois tipos de erro:
Erro tipo I : rejeitar H0 quando H0 é verdadeira
Erro tipo II : aceitar H0 quando H0 é falsa
Exemplo:
H0 réu é inocente (todos são inocentes até que se prove o contrário)
H1 réu é culpado
Teste de hipóteses para a média

A probabilidade do erro tipo I é dada pelo nível de significância especificado para o teste
A probabilidade do erro tipo II é denotada por .
Estas probabilidades estão inversamente relacionadas.
A redução da probabilidade do erro tipo I aumenta o valor crítico z(/2), o que reduz a região de rejeição
da hipótese nula nas caudas da distribuição amostral e, portanto, aumenta a probabilidade do erro tipo II.
Enquanto a hipótese nula estipula um valor 0 para a média populacional, a hipótese alternativa admite
que a média pode ser qualquer valor desde que diferente de 0.
Assim, não há um único valor para a probabilidade , mas um conjunto de valores calculados para cada
um dos possíveis valores para a média populacional. Em função da dificuldade de calcular , o
procedimento usual em testes de hipóteses consiste em especificar uma pequena probabilidade de erro
tipo I (nível de significância) e ignorar o erro tipo II (STEVENSON, 1981).
Note que o erro tipo I só pode ocorrer quando a hipótese H0 é verdadeira e o erro tipo II só pode
acontecer quando a hipótese H0 é falsa.
Assim, quando rejeitamos H0 existe uma pequena probabilidade de estarmos cometendo o erro tipo I.
Porém, quando aceitamos H0 como verdadeira, a probabilidade de estarmos cometendo o erro tipo II
pode ser grande.
Por esta razão, HOFFMANN (1998) recomenda que quando o resultado de um teste de hipótese é
significativo, a conclusão deve ser escrita em termos de “rejeitar H0 ao nível de significância ”, porém
quando o resultado é não significativo, a conclusão deve ser escrita em termos de “não há razão para
rejeitar H0 ao nível de significância ”, mas não em termos de “aceitar H0”.
Teste de hipóteses para a média
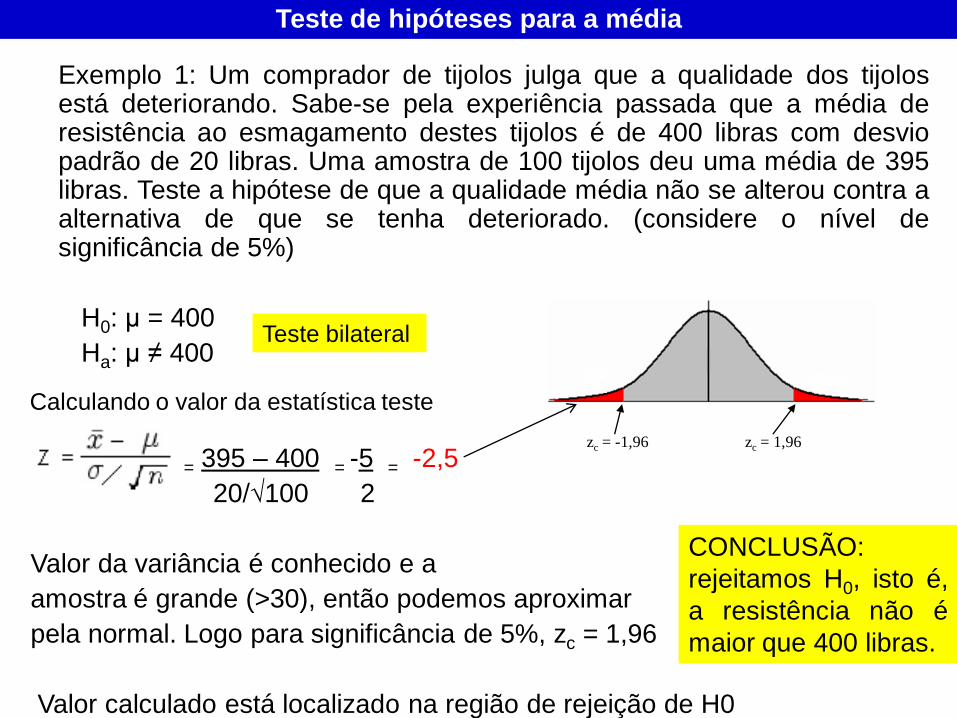
Exemplo 1: Um comprador de tijolos julga que a qualidade dos tijolos está deteriorando. Sabe-se pela experiência passada que a média de resistência ao esmagamento destes tijolos é de 400 libras com desvio padrão de 20 libras. Uma amostra de 100 tijolos deu uma média de 395 libras. Teste a hipótese de que a qualidade média não se alterou contra a alternativa de que se tenha deteriorado. (considere o nível de significância de 5%)
H0: μ = 400
Ha: μ ≠ 400
= 395 – 400 = -5 = -2,5
20/√100 2
Valor da variância é conhecido e a
amostra é grande (>30), então podemos aproximar
pela normal. Logo para significância de 5%, zc = 1,96
Valor calculado está localizado na região de rejeição de H0
CONCLUSÃO:
rejeitamos H0, isto é,
a resistência não é
maior que 400 libras.
zc = -1,96 zc = 1,96
Teste bilateral
Calculando o valor da estatística teste
Teste de hipóteses para a média

Exemplo 2: Os registros dos últimos anos de um colégio atestam para os calouros
admitidos que a nota média 115 pontos (teste vocacional). Para testar a hipótese de
que a média de uma nova turma é a mesma, tirou-se, ao acaso, uma amostra de 50
notas, obtendo-se uma média 118 e um desvio padrão 20. Admita = 5%, para efetuar
o teste.
H0: = 115 (hipótese nula, com 0 =115)
versus
H1: 115 (hipótese alternativa)
Como é desconhecida, a estatística do teste é:
T = nS
X 0 =
5020
115118 = 1,06,
Para = 5% /2 o valor t/2 da tabela t-Student bicaudal com ( n– 1) = 49 graus de liberdade
é t/2 =.2,093.
Como |T| = 1,06 < 2,093, concluímos que não rejeitamos H0 , isto é, ao nível de 5% de
significância concluímos que a nova turma tem a mesma nota média no teste vocacional que
os do registro dos últimos anos.
Teste bilateral
Usamos a distribuição t, pois
a variância não é conhecida,
mas como a amostra é
grande (>30) poderíamos
aproximar pela normal.
Teste de hipóteses para a média

Exemplo 3: Um trecho de uma rodovia, quando é utilizado o radar, são
verificadas em média 7 infrações diárias por excesso de velocidade. O
chefe da polícia acredita que este número pode ter aumentado. Para
verificar isso, o radar foi mantido por 10 dias consecutivos. Os resultados
foram:
8, 9, 5, 7, 8, 12, 6, 9, 6, 10
Os dados trazem evidências do amento das infrações? Use = 10%
H0: µ ≤ 7
Ha: µ > 7
Média amostral = 8+9+5+7+8+12+6+9+6+10 = 8
10
Não conhecendo σ, estimamos s, onde s = 2,1
A amostra é pequena (<30) com variância desconhecida,
logo devemos usar a distribuição t,
Estatística teste = = 1,5
Calculando valor crítico (tc) no Excel = INVT(0,10;9) = 1,83
t = 1,5 tc = 1,83
CONCLUSÃO: Ao nível de
significância de 10 % não
rejeitamos H0, o que implica que
o número de infrações não teve
um aumento significativo.
Teste unilateral com região de
rejeição no lado direito
Teste de hipóteses para a média
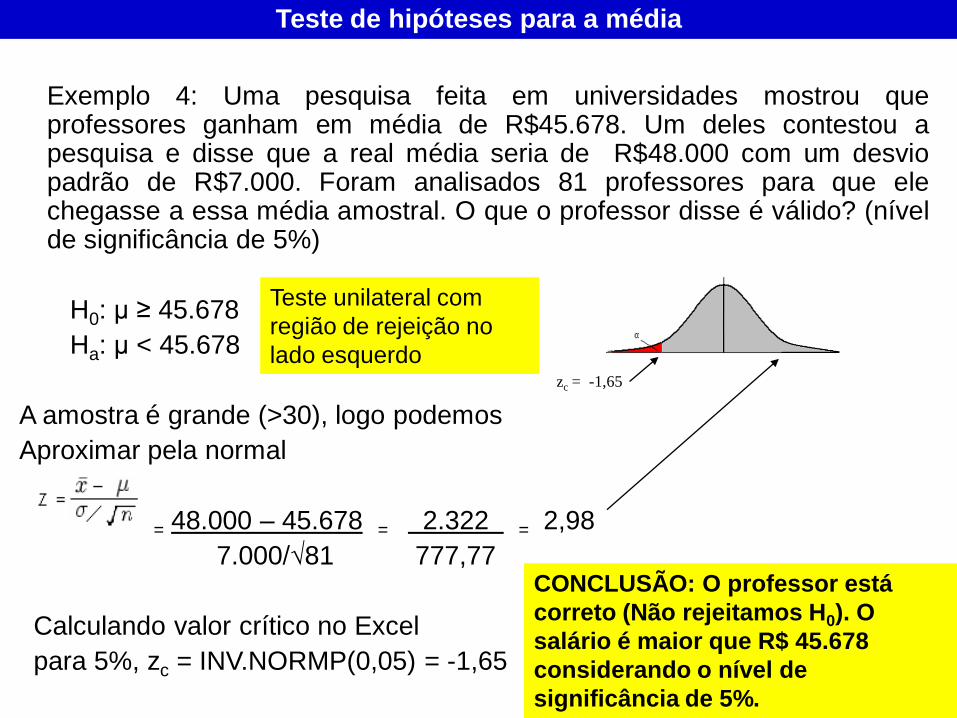
Exemplo 4: Uma pesquisa feita em universidades mostrou que professores ganham em média de R$45.678. Um deles contestou a pesquisa e disse que a real média seria de R$48.000 com um desvio padrão de R$7.000. Foram analisados 81 professores para que ele chegasse a essa média amostral. O que o professor disse é válido? (nível de significância de 5%)
H0: μ ≥ 45.678
Ha: μ < 45.678
A amostra é grande (>30), logo podemos
Aproximar pela normal
= 48.000 – 45.678 = 2.322 = 2,98
7.000/√81 777,77
Calculando valor crítico no Excel
para 5%, zc = INV.NORMP(0,05) = -1,65
CONCLUSÃO: O professor está
correto (Não rejeitamos H0). O
salário é maior que R$ 45.678
considerando o nível de
significância de 5%.
zc = -1,65
Teste unilateral com
região de rejeição no
lado esquerdo
Teste de hipóteses para a média

Teste de hipóteses para a proporção
Com base na distribuição amostral do estimador pode-se construir um
teste de hipóteses para a proporção populacional semelhante ao teste da
média:
Em grandes amostras, a aproximação à curva normal pode ser utilizada
em outros estimadores, tal como o estimador de proporção, cuja
distribuição amostral converge para uma normal com média igual a
proporção populacional p e variância igual a p(1-p)/n:
n
pppNp
1,~ˆ
H0: p=p0
H1: pp0
Sob a hipótese nula a estatística teste tem distribuição normal padrão:
1,0~)1(
ˆ
00
0 Nnpp
pp
Estatística teste
Para um dado nível de significância a hipótese nula é rejeitada se o
valor absoluto da estatística teste for maior que o valor z(/2)

Exemplo 1: Um certo analgésico adotado em determinado hospital é eficaz em 70% dos
casos.
Um grupo de médicos chineses em visita a esse hospital afirma que a utilização de
acupuntura produz melhores resultados.
A direção do hospital resolve testar o método alternativo em 80 pacientes, com a
finalidade de adotá-lo em definitivo se ele apresentar eficiência satisfatória numa
proporção de casos maior que do anestésico atual.
Na amostra foi observado que em 85% dos casos o método de acupuntura apresenta a
eficiência satisfatória. Que decisão tomar ao nível de 5% de significância?
Trata-se de um teste sobre uma proporção p, onde p é a eficiência do método
alternativo.
H0 p=0,7
H1 p>0,7
Teste de hipóteses para a proporção
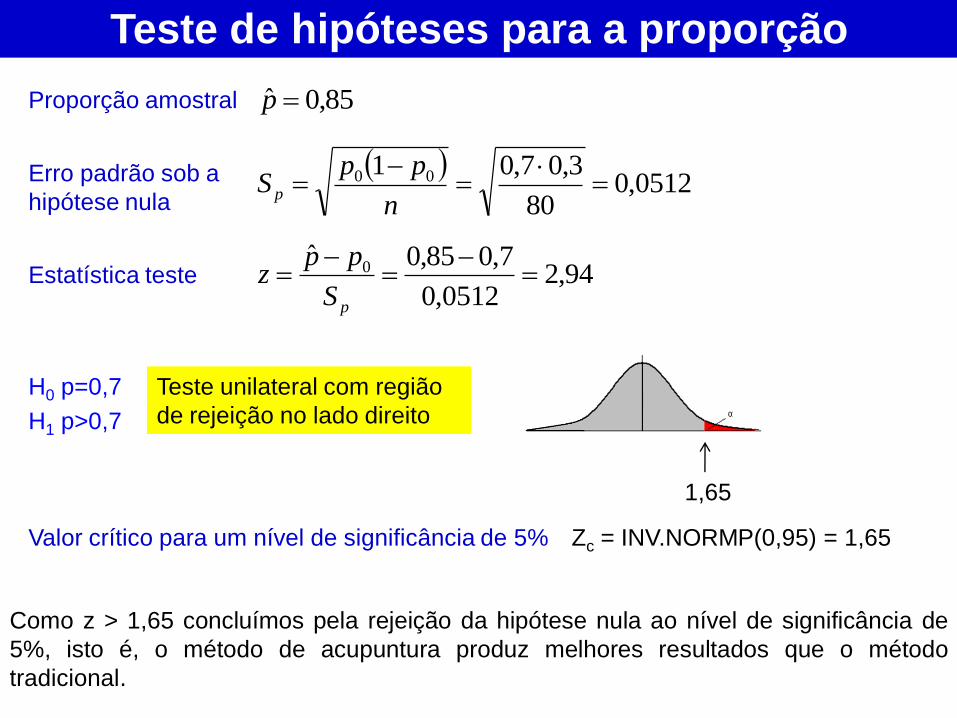
Teste de hipóteses para a proporção
85,0ˆ p
0512,0
80
3,07,01 00
n
ppS p
Proporção amostral
Erro padrão sob a
hipótese nula
Estatística teste 94,20512,0
7,085,0ˆ0
pS
ppz
Valor crítico para um nível de significância de 5% Zc = INV.NORMP(0,95) = 1,65
Como z > 1,65 concluímos pela rejeição da hipótese nula ao nível de significância de
5%, isto é, o método de acupuntura produz melhores resultados que o método
tradicional.
H0 p=0,7
H1 p>0,7
Teste unilateral com região
de rejeição no lado direito
1,65
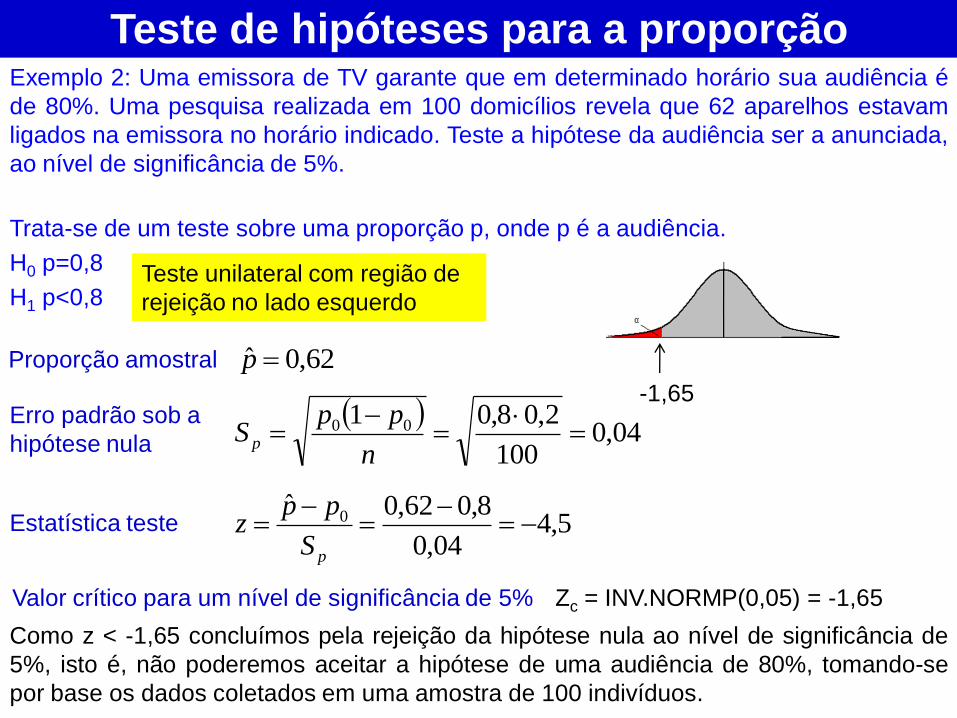
Teste de hipóteses para a proporção Exemplo 2: Uma emissora de TV garante que em determinado horário sua audiência é
de 80%. Uma pesquisa realizada em 100 domicílios revela que 62 aparelhos estavam
ligados na emissora no horário indicado. Teste a hipótese da audiência ser a anunciada,
ao nível de significância de 5%.
Trata-se de um teste sobre uma proporção p, onde p é a audiência.
H0 p=0,8
H1 p<0,8 Teste unilateral com região de
rejeição no lado esquerdo
04,0
100
2,08,01 00
n
ppS p
Erro padrão sob a
hipótese nula
Estatística teste 5,404,0
8,062,0ˆ0
pS
ppz
62,0ˆ pProporção amostral
Valor crítico para um nível de significância de 5% Zc = INV.NORMP(0,05) = -1,65
-1,65
Como z < -1,65 concluímos pela rejeição da hipótese nula ao nível de significância de
5%, isto é, não poderemos aceitar a hipótese de uma audiência de 80%, tomando-se
por base os dados coletados em uma amostra de 100 indivíduos.

TESTES DE HIPÓTESES
COM DUAS AMOSTRAS

O teste de hipóteses da diferença das médias de duas populações é freqüentemente utilizado para determinar se é ou não razoável concluir que as médias de duas populações são diferentes. Por exemplo:
– Se o mesmo produto oferecido por dois fornecedores diferentes apresenta a
mesma quantidade de peças com defeitos.
– Determinar se o novo remédio para controle de diabetes é eficiente acompanhando dois grupos de pacientes, o primeiro grupo que recebeu o remédio e o outro que recebeu apenas placebo, produto com a mesma forma, porém sem o elemento ativo.
– O gerente de compras pode estar interessado em determinar se o mesmo produto oferecido por dois fornecedores diferentes apresenta o mesmo prazo real de entrega.
– Da mesma forma, o gerente de salários necessita conhecer se os salários da mesma categoria de trabalhadores têm o mesmo valor em duas cidades diferentes.
Teste de hipóteses para a diferença nas médias

Teste de hipóteses para a diferença nas médias
Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com variâncias 12 e 2
2, Isto é
X ~ N(1,12)
Y ~ N(1,22)
Considere amostras aleatórias de X e Y (amostras independentes) e com
tamanhos m e n respectivamente, isto é
(x1,...,xm) e (y1,...,yn)
Em cada amostra são calculadas a média e a variância ( ).
Todos os parâmetros são desconhecidos e desejamos testar a diferença
das médias:
H0 1 - 2 =
H1 1 - 2
2
2
2
1 ,,, SSYX
O critério de rejeição é semelhante ao utilizado
nos testes de hipóteses para a média
1 - Caso de duas amostras independentes

Teste de hipóteses para a diferença nas médias
1.1 – Amostras independentes de duas populações com variâncias iguais
onde
2
11 2
2
2
12
nm
SnSmS pooled
Variância amostral da amostra da população X
Variância amostral da amostra da população Y
Sob H0 a estatística teste tem distribuição t com m+n-2 graus de liberdade
2
2
~11
nm
pooled
t
nmS
YX
Variância combinada
Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com a mesma variância 12= 2
2= 2 .
Todos os parâmetros são desconhecidos e desejamos testar
H0 1 - 2 =
H1 1 - 2
m
i
i Xmxm
S1
222
11
1
n
i
i Ynyn
S1
222
21
1

Teste de hipóteses para a diferença nas médias
Admitindo um nível de significância de 5%, teste a hipótese de que o
consumos médios sejam idênticos (=0)
Estatística teste sob H0
Deseja-se estimar a diferença no consumo de combustível (km/l) entre as
versões Caminhonete (C) e Sedan (S) de um determinado modelo de
automóvel. Por estudos já realizados anteriormente (e ainda válidos)
sabe-se que os consumos destes automóveis são normalmente
distribuídos e tem variâncias idênticas. Uma amostra de 30 caminhonetes
e 15 sedans foi analisada obtendo-se as seguintes estatísticas amostrais
para o consumo:
22 (km/l) 2012,23
km/l 1748,8
C
C
S
X
22 (km/l) 6108,38
km/l 8742,8
S
S
S
XCaminhonetes Sedan
H0 C - S = 0
H1 C - S 0
43
2
~
15
1
30
1
0t
S
YX
pooled
43
1429 222 SCpooled
SSS
1.1 – Exemplo amostras independentes de duas populações com variâncias iguais

Teste de hipóteses para a diferença nas médias
Sob H0 a estatística teste tem distribuição t com 43 graus de liberdade.
Primeiro é calculado o valor da variância combinada.
2183,2843
6108,38142012,23292
pooledS
Após obtém-se o valor da estatística teste 4164,0
15
1
30
12183,28
8742,81748,8
O valor crítico ao nível de 5% (valor tabelado obtido pelo Excel) é
tcrítico = INVT(0,05,43) = 2,0167
Valor absoluto calculado (0,4164) < Valor crítico ao nível de 5% (2,0167),
logo não rejeitamos a hipótese nula (H0).
Conclusão: A um nível de 5% de significância não há evidências
amostrais que permitam rejeitar a hipótese de que os consumos médios
dos dois modelos sejam idênticos.
1.1 – Exemplo amostras independentes de duas populações com variâncias iguais

Teste de hipóteses para a diferença nas médias
onde
Variância amostral da amostra da população X
Variância amostral da amostra da população Y
Sob H0 a estatística teste tem distribuição t com v graus de liberdade
Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com variâncias 12 e 2
2.
Todos os parâmetros são desconhecidos e desejamos testar
H0 1 - 2 =
H1 1 - 2
2
11
22
2
22
1
22
2
2
1
n
nS
m
mS
n
S
m
S
v
vt
n
S
m
S
YX~
2
2
2
1
Arredonde o resultado para cima
1.2 – Amostras independentes de duas populações com variâncias diferentes
m
i
i Xmxm
S1
222
11
1
n
i
i Ynyn
S1
222
21
1

Teste de hipóteses para a diferença nas médias
Admitindo um nível de significância de 5%, teste a hipótese de igualdade
das médias (=0)
Estatística teste sob H0
Deseja-se estimar a diferença no consumo de combustível (km/l) entre as
versões Caminhonete (C) e Sedan (S) de um determinado modelo de
automóvel. Por estudos já realizados anteriormente (e ainda válidos)
sabe-se que os consumos destes automóveis são normalmente
distribuídos. Uma amostra de 30 caminhonetes e 15 sedans foi analisada
obtendo-se as seguintes estatísticas amostrais para o consumo:
2
115
15
130
30
15302222
222
SC
SC
SS
SS
vv
SC
SC tSS
XX~
1530
0
22
22 (km/l) 2012,23
km/l 1748,8
C
C
S
X
22 (km/l) 6108,38
km/l 8742,8
S
S
S
XCaminhonetes Sedan
H0 C - S = 0
H1 C - S 0
onde
1.2 – Exemplo amostras independentes de duas populações com variâncias diferentes

Teste de hipóteses para a diferença nas médias
Exemplo para o caso de duas populações com variâncias diferentes
O valor crítico ao nível de 5% (valor tabelado obtido pelo Excel) para uma
distribuição t com v graus de liberdade é:
tcrítico = INVT(0,05,23) = 2,0687
O valor calculado da estatística teste (tcalc) é
232
115
156108,38
130
302012,23
15
6108,38
30
2012,23
22
2
v
3823,0
15
6108,38
30
2012,23
8742,81748,8
calct
O nº de graus de liberdade v
Valor absoluto calculado (0,3823) < Valor crítico ao nível de 5% (2,0687),
logo não rejeitamos a hipótese nula (H0).
Conclusão: A um nível de 5% de significância não há evidências
amostrais que permitam rejeitar a hipótese de médias idênticas.

Teste de hipóteses para a diferença nas médias
Exemplo para o caso de duas populações com variâncias diferentes
(teste para igualdade de proporções)
Valor crítico ao nível de 5% = zc = INV.NORMP(0,025) = 1,96
Estatística teste sob H0
Uma amostra de 50 residências em uma comunidade mostra que 10 delas
estão assistindo, pela TV, a um especial sobre a economia nacional. Em
uma segunda comunidade, 15 de uma amostra aleatória de 50 residências
estão assistindo ao especial na TV. Teste a hipótese de que a proporção
geral de espectadores nas duas comunidades não têm diferença, usando
um nível de significância de 5%.
H0: p1 - p2 = 0
H1: p1 - p2 0
O teste pode ser conduzido como o teste para avaliar a
diferença nas médias para amostras independentes.
)1,0(~)ˆ1(ˆ)ˆ1(ˆ
0ˆˆ
2
22
1
11
21 N
n
pp
n
pp
ppz
Valor calculado para a estatística teste = z = -1,16
Conclusão: Como valor absoluto de z é menor que o valor crítico,
decidimos não rejeitar a hipótese nula.
3,050/15ˆ
2,050/10ˆ
2
1
p
p
50
50
2
1
n
n

Teste de hipóteses para a diferença nas médias
Exemplo para o caso de duas populações com variâncias diferentes
(teste para igualdade de proporções)
Em virtude dos protestes feitos sobre as más condições de trabalho em
certas fábricas de roupas dos EUA, em 1998 uma comissão conjunta do
governo e da indústria recomendou que as empresas que monitoram os
padrõe apropriados de produção tenham a permissão de utilizar uma
etiqueta “No Sweat” em seus produtos. Será que a presença dessas
etiquetas influencia o comportamento dos consumidores?
Uma pesquisa feita com residentes dos EUA e com idade acima de 18
anos perguntou-lhes que chance haveria de eles comprarem uma roupa
com a etiqueta “No Sweat”. Assim, cada entrevistado foi classificado
como um “valorizador da etiqueta” ou “não valorizador da etiqueta”. As
proporções amostrais por sexo são apresentadas na tabela abaixo:
Teste a hipótese de que as proporções dos que valorizam a etiqueta é a
mesma entre os homens e as mulheres. Use = 5%.

Teste de hipóteses para a diferença nas médias
Exemplo para o caso de duas populações com variâncias diferentes
(teste para igualdade de proporções)
Valor crítico ao nível de 5% = zc = INV.NORMP(0,025) = 1,96
Estatística teste sob H0
Hipóteses
H0: pM - pH = 0
H1: pM - pH 0
O teste pode ser conduzido como o teste para avaliar a
diferença nas médias para amostras independentes.
)1,0(~)ˆ1(ˆ)ˆ1(ˆ
0ˆˆN
n
pp
n
pp
ppz
H
HH
M
MM
HM
Valor calculado para a estatística teste = z = 3,4181
Conclusão: Como valor absoluto de z é menor que o valor crítico,
decidimos rejeitar a hipótese nula. Ao nível de significância de 5% as
proporções de mulheres e homens que valorizam a etiqueta são
diferentes.
108,0ˆ
213,0ˆ
H
M
p
p
251
296
H
M
n
n

Amostras emparelhadas
• Quando for necessário comparar, por exemplo, as vendas diárias
de duas filiais que operam com os mesmos produtos, ou os
resultados de um treinamento, confrontando o conhecimento antes
e depois do treinamento, os procedimentos de teste de hipóteses
para diferença das médias utilizados até este momento não podem
ser aplicados, pois se referem a duas populações independentes.
• Agora, necessitamos analisar duas populações relacionadas, isto é,
duas populações dependentes.
• Neste caso, a variável de interesse será a diferença entre os pares
das duas amostras, no lugar das próprias amostras, que devem ter
o mesmo tamanho.

3- Caso com amostras emparelhadas
Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com variâncias 12 e 2
2. Isto é
X1 ~ N(1,12) e X2 ~ N(2,2
2)
Considere amostras aleatórias de X1 e X2 (amostras dependentes ou
emparelhadas) com tamanhos idênticos (n), isto é
(x11,x21), (x12,x22),..., (x1i,x2i),..., (x1n,x2n) formam um conjunto de n
observações emparelhadas.
Em cada par amostrado pode-se calcular o desvio di=x1i-x2i para i=1,...,n
O valor esperado dos desvios é D = E(D) = E(X1-X2) = 1 - 2
Assim, o teste da diferença entre 1 e 2 pode ser realizado por meio do
teste t com as hipóteses
Teste de hipóteses para a diferença nas médias
H0 D = 0
H1 D 0

• Como premissa, a população das diferenças tem distribuição
aproximadamente normal e a amostra das diferenças é extraída
aleatoriamente da população das diferenças.
• Assim a estatística teste sob H0 tem distribuição t com n-1 graus de
liberdade
12
~0
n
d
t
n
S
d
• O teste segue o mesmo funcionamento do teste t para a média,
ou seja, a hipótese nula é rejeitada ao nível de significância
se o valor absoluto da estatística teste é maior que o valor
tabelado para a tn-1(/2).
Teste de hipóteses para a diferença nas médias
3- Caso com amostras emparelhadas
2
1
22
1
1dnd
nS
n
i
id
n
i
idn
d1
1e onde

Teste de hipóteses para a diferença nas médias
3 - Exemplo caso com amostras emparelhadas
Um fabricante de automóveis coleta dados do consumo de combustível para uma
amostra de n=10 carros em várias categorias de pesos, usando um tipo padrão de
gasolina com e sem determinado aditivo. Os motores foram ajustados para as
mesmas especificações antes de cada teste, e os mesmos motoristas foram
usados para as duas condições de gasolina (sem que o motorista em questão
soubesse qual gasolina estava sendo usada em cada teste particular). Dadas as
informações da amostra teste ao nível de significância de 5% a hipótese de que
não há diferença entre o consumo médio obtido com e sem aditivo.
7,110
1
i
id 31,110
1
2 i
id
17,010
7,1
10
1 10
1
i
idd
1134,09
102
10
1
2
2
dd
S i
i
d
Para um nível de significância de 5% tem-se que t9(2,5%)= INVT(0,05;9) = 2,2622

Teste de hipóteses para a diferença nas médias
3 - Exemplo caso com amostras emparelhadas
O valor calculado da estatística teste é
59,1101134,0
17,0
Como o valor calculado da estatística teste (1,59) é maior que o valor crítico (2,262),
então podemos concluir pela não rejeição da hipótese nula, ou seja, não há diferenças
entre o consumo obtido com e sem o aditivo.
12
~0
n
d
t
n
S
d
t calculado =

Teste de igualdade de variâncias
• Freqüentemente, é necessário verificar se é ou não razoável
concluir que as variâncias das duas populações são
diferentes.
• O teste F é um teste de hipóteses utilizado para verificar se
as variâncias de duas populações com distribuição normal
são diferentes, ou para verificar qual das duas populações
com distribuição normal têm mais variabilidade.
• De outra maneira, conhecidas duas amostras com qualquer
tamanho, o teste F dá condições para determinar se as duas
amostras pertencem à mesma população.

Teste de igualdade de variâncias
Considere duas populações Normais com média 1 e 2 possivelmente
distintas e com variâncias 12 e 2
2, Isto é
X ~ N(1,12)
Y ~ N(1,22)
Considere amostras aleatórias de X e Y (amostras independentes) e com
tamanhos m e n respectivamente, isto é
(x1,...,xm) e (y1,...,yn)
Em cada amostra são calculadas a média e o desvio-padrão ( ).
Todos os parâmetros são desconhecidos e desejamos testar a igualdade
das variâncias:
2
2
2
1 ,,, SSYX
alternativamente

A estatística teste é a razão das variâncias amostrais
Sob H0 a estatística teste tem distribuição F com m+1 graus de liberdade
no numerador e n-1 graus de liberdade no denominador:
Teste de igualdade de variâncias
1;12
2
2
1 ~ nmFS
S
Comparando o F calculado (Fcalc) com o F crítico (Fc), se Fcalc>Fc, então a
hipótese nula deve ser rejeitada
1;1 nmF
A maior variância amostral entra no numerador
A menor variância amostral entra no denominador

Teste de igualdade de variâncias Exemplo
Deseja-se verificar se há diferenças no consumo de combustível entre as versões
Caminhonete (C) e Sedan (S) de um determinado modelo de automóvel. Por
estudos anteriores sabe-se que os consumos destes são normalmente
distribuidos e, num processo onde foram coletadoas 30 iobservações para a
Caminhonete e 15 observações para o Sedan, obteve-se respectivamente
variâncias de 23,2012 (km/l)2 e 38,6108 (km/l)2. Teste a hipótese de que as
variâncias para os consumos dos dois modelos sejam idênticas, ao nível de
significância de 5%.
6642,12012,23
6108,382
2
C
S
S
S
Como a amostra do Sedan apresentou a maior variância amostral, a
estatística teste tem distribuição F com 14 graus de liberdade no
numerador e 29 graus de liberdade no denominador:
29,142
2
~ FS
S
C
S
O valor calculado da estatística teste é
Ao nível de significância de 5% o valor crítico (obtido pelo Excel) é:
Fc = INVF(0,05;14;29) = 2,05
Conclusão: Ao nível de 5% de significância não podemos rejeitar a hipótese de
que as variâncias dos consumos dos dois modelos sejam idênticas, sendo as
diferenças encontradas explicadas por variações estatísticas no processo de
amostragem.





























