Embed Size (px)
Citation preview

UNIVERSIDADE POTIGUAR – UNPPRÓ-REITORIA DE PESQUISA E PÓS-GRADUAÇÃO
PROGRAMA DE PÓS-GRADUAÇÃO EM ADMINISTRAÇÃO - PPGAMESTRADO PROFISSIONAL EM ADMINISTRAÇÃO - MPA
NICHOLLAS RENNAH ADELINO DE ALMEIDA
FERRAMENTAS DE WEB MINING E SEU USO NA EXTRAÇÃO DE INFORMAÇÃODAS REDES SOCIAIS DIGITAIS PARA TOMADAS DE DECISÕES
ESTRATÉGICAS
NATAL/RN2012

NICHOLLAS RENNAH ADELINO DE ALMEIDA
FERRAMENTAS DE WEB MINING E SEU USO NA EXTRAÇÃO DE INFORMAÇÃODAS REDES SOCIAIS DIGITAIS PARA TOMADAS DE DECISÕES
ESTRATÉGICAS
Dissertação de Mestrado apresentada aoPrograma de Pós-Graduação StrictoSensu em Administração da UniversidadePotiguar, como requisito para obtenção dotítulo de Mestre em Administração na áreade concentração em Estratégia eCompetitividade.
ORIENTADOR: Prof. Dr. Alípio RamosVeiga Neto
NATAL/RN2012

NICHOLLAS RENNAH ADELINO DE ALMEIDA
FERRAMENTAS DE WEB MINING E SEU USO NA EXTRAÇÃO DE INFORMAÇÃODAS REDES SOCIAIS DIGITAIS PARA TOMADAS DE DECISÕES
ESTRATÉGICAS
Dissertação de Mestrado apresentada aoPrograma de Pós-Graduação StrictoSensu em Administração da UniversidadePotiguar, como requisito parcial paraobtenção do título de Mestre emAdministração. Área de concentração:Estratégia e Competitividade.
Aprovado em: 14/11/2012
BANCA EXAMINADORA
________________________________________________Prof. Dr. Alípio Ramos Veiga Neto
OrientadorUniversidade Potiguar- UnP
________________________________________________Profª. Drª. Tereza de Souza
Membro ExaminadorUniversidade Potiguar- UnP
________________________________________________Prof. Dr. Samuel Xavier de Souza
Membro Examinador ExternoUniversidade Federal do Rio Grande do Norte - UFRN

AGRADECIMENTOS
Ao meu Deus, Jesus Cristo, pela sua misericórdia em está me concedendo
mais uma vitória na minha vida acadêmica e profissional. Sem Ele nada disso estaria
acontecendo.
À minha família, minha mãe Lucilene, minhas irmãs Niédja, Jéssica e Heloisa,
e, meu sobrinho Felipe que me deram estrutura para que eu pudesse me dedicar a
esse trabalho por inteiro.
À minha querida noiva e companheira Cibele Murinelli que amorosamente
esteve comigo durante todos os momentos nesse mestrado, dividindo, quando
possível, todas as situações alegres e difíceis nessa jornada, juntamente com sua
maravilhosa família que me propiciaram um convívio saudável e momentos de
relaxamento em meio a tantas tribulações.
Ao professor e orientador Dr. Alípio Veiga, meus sinceros agradecimentos,
pela orientação e confiança depositada.
Aos meus colegas da UFERSA nesse mestrado: Gilmar, Gilberto, Dairone,
Wilton, Daiane e Vanessa pela convivência e compartilhamento de muitos bons
momentos em nossas viagens.
Agradeço a todos que, direta ou indiretamente contribuíram para a realização
deste trabalho.

RESUMO
É cada vez mais frequente o surgimento de novas metodologias e instrumentos quepossibilitam a extração das informações de forma automatizada de grandes basesde dados como as redes sociais. Dentre eles, encontram-se as ferramentas demineração Web (web mining) que possibilitam coletar, processar, analisar evisualizar os dados dentre os comentários disponíveis nas redes sociais. Este estudoteve o objetivo de investigar as ferramentas de mineração Web existentes nomercado e quais informações elas oferecem aos gestores de marketing para tomadade decisão estratégica em PMEs. Para tanto, foi realizada uma descrição dascaracterísticas mercadológicas e das funcionalidades dos sistemas de mineraçãoWeb encontrados, tais como as ferramentas de monitoramento de redes sociais(MRS) e software de mineração de textos (MT) disponíveis na Internet em Junho de2012. Como resultado, constatou-se que as ferramentas de MRS se mostraram maisadequadas para a realização de coleta e análise dos dados, enquanto os softwarede MT oferecem vantagem somente na etapa de processamento estatístico dostextos, sendo necessária a utilização conjunta dos dois tipos de sistemas para umaquantidade maior de dados. As informações mais disponibilizadas pelas ferramentasde MRS são relacionadas a segmentação de usuários ou comentários, tais como aanálise de sentimento e a análise de tópico e temas. As informações sobre as açõesdo concorrente foram pouco satisfatórias, pois as ferramentas não ofereciamfunções para que as suas marcas e as dos concorrentes fossem analisadasparalelamente. É possível considerar que as ferramentas disponíveis de mineraçãoWeb podem fornecer informações para tomadas de decisões estratégicas, noentanto será necessária a presença de profissional de análise de redes sociais pararealizar os procedimentos de forma satisfatória.
Palavras-Chave: web mining, monitoramento de redes sociais, Sistema deInformação de Marketing, mineração de texto, informações estratégicas.

ABSTRACT
It is increasingly common the appearance of new methodologies and tools thatenable the automatic extraction of information from large databases such as socialnetworks. Among them, there are web mining tools that enable to collect, process,analyze and visualize data from comments available in social networks. This studyaimed to investigate the Web mining tools available in the market and whatinformation they provide to marketing managers for strategic decision making inSMEs. Therefore, we described the market characteristics and functionalities of theWeb mining tools found, such as social networking monitoring tools (SNM) and textmining software (TM) available on the Internet in June 2012. As a result, it was foundthat the SNM tools were more suitable to perform the collection data analysis, whilethe TM software offers advantage only in the stage of statistical processing of texts,requiring the combined use of both types of systems for a larger amount of data. Themost of the information provided by SNM tools were related to users or comments,such as sentiment analysis and analysis of themes and topic. The information aboutthe actions of competitor were unsatisfactory because the tools do not offer thecompanies functions for their brands and the brands of the competitors to beanalyzed in parallel. It is possible to consider that the tools available for web miningcan provide information for strategic decision making, however it will require thepresence of a social network analysis professional to perform the proceduressatisfactorily.Keywords: web mining, social network monitoring, Marketing Information Systems,text mining, strategic information.

LISTA DE QUADROS
Quadro 1: Conceitos de Sistemas de Informação de Marketing............................... 18
Quadro 2: Modelos de SIM ....................................................................................... 20
Quadro 3: Atributos da qualidade da informação propostos por O´Brien (2004) ...... 28
Quadro 4: Tipos de informações estratégicas para as empresas............................. 32
Quadro 5: Técnicas e etapas da Mineração de texto................................................ 53
Quadro 6: Funcionalidades das ferramentas de MRS .............................................. 67
Quadro 7: Variáveis e Categorias Pertinentes aos Aplicativos de Análise de
Informações Sociais.................................................................................................. 68
Quadro 8: Lista de métricas de desempenho das ferramentas Web Analytics ......... 69
Quadro 9: Características das ferramentas de MRS ................................................ 70
Quadro 10: Lista de funcionalidades das ferramentas de web mining...................... 74
Quadro 11: Lista de ferramentas de MRS ................................................................ 81
Quadro 12 - Lista de ferramentas de Mineração de Texto investigadas................... 85
Quadro 13: Relação entre as funcionalidades análise de dados com o formato de
visualização ............................................................................................................ 101

LISTA DE TABELAS
Tabela 1: Custo da ferramentas de MRS brasileiras ................................................ 82
Tabela 2: Custo da ferramentas de MRS internacionais........................................... 83
Tabela 3: Lista de ferramentas de MRS com disponibilidade de contas gratuitas .... 84
Tabela 4 - Menores valores cobrados pelas ferramentas de MT.............................. 86
Tabela 5: Maiores valores cobrados pelas ferramentas de MT ................................ 87
Tabela 6: Funcionalidades de coleta de dados nos software de MRS...................... 88
Tabela 7: Funcionalidades de processamento de dados nos software de MRS....... 91
Tabela 8: Funcionalidades de análise de dados nos software de MRS.................... 92
Tabela 9: Funcionalidades de visualização de dados nos software de MRS.......... 100
Tabela 10: Processamento de dados nos software de mineração de textos .......... 102
Tabela 11: Itens coletados para exemplificar o uso dos software de MT................ 102
Tabela 12: Redução de termos por técnica de processamento de texto ................ 105
Tabela 13: Lista de termos e clusters gerados no exemplo.................................... 106

LISTA DE FIGURAS
Figura 1: Tripé do Sistema de Informação de Marketing .......................................... 17
Figura 2: Modelo de SIM proposto por Chiusoli (2005)............................................. 21
Figura 3: Dimensões das especificidades de gestão da pequena empresa ............. 35
Figura 4: Categorias da Mineração Web .................................................................. 38
Figura 5: Exemplo de aplicação de Case Folding..................................................... 42
Figura 6: Exemplo da aplicação de stoplist............................................................... 42
Figura 7: Exemplo de aplicação de Stemming.......................................................... 43
Figura 8: Processo de indexação automática ........................................................... 45
Figura 9: Tipos de agrupamentos ............................................................................. 49
Figura 10: Modelo de classificação de documentos ................................................. 50
Figura 11: Demonstração do cálculo de precisão e cobertura.................................. 53
Figura 12: A evolução das ferramentas na Internet ................................................. 55
Figura 13: Cronologia do ano de lançamento das rede social entre 1997 a 2008. ... 57
Figura 14: Página principal do Facebook - Perfil do criador Mark Zuckerberg ......... 59
Figura 15: Tela do Twitter ........................................................................................ 60
Figura 16: Fases da pesquisa................................................................................... 72
Figura 17: Exemplo de tela de coleta e resgate dos dados ...................................... 89
Figura 18- Exemplo de gráfico de estatística de mídia ............................................. 93
Figura 19: Exemplo de Tela de filtragem de dados................................................... 93
Figura 20: Tipos de gráficos gerados a partir da filtragem de dados ........................ 94
Figura 21: Exemplo de comentário com classificação de sentimento errada .......... 95
Figura 22: Exemplo de um gráfico de análise de sentimento ................................... 95
Figura 23: Exemplo de gráfico de análise de tópicos e temas.................................. 96
Figura 24: Exemplo de lista e nuvem de palavras .................................................... 97
Figura 25: Exemplo de lista de usuários influenciadores .......................................... 97

Figura 26: Exemplo de gráfico de análise de concorrentes ...................................... 99
Figura 27: Exemplo de interface pipeline utilizada nos software MT ...................... 103
Figura 28: Exemplo do fluxo de normalização dos dados....................................... 104
Figura 29: Exemplo da visualização de cluster em gráfico de rede ........................ 107
Figura 30 - Exemplo de lista de palavras por cluster .............................................. 108

LISTA DE ABREVIATURAS E SIGLAS
AMA American Marketing AssociationCRM Customer Relationship ManagementCSV Comma-separated valuesFIPE Fundação Instituto de Pesquisas EconômicasHTML HyperText Markup LanguageIBGE Instituto Brasileiro de Geografia e EstatísticaIC Inteligência CompetitivaMT Mineração de textosMRS Monitoramento de redes sociaisPME Pequenas e médias empresasRI Recuperação da informaçãoSCIP Society of Competitive Intelligence of ProfessionalsSEBRAE Serviço de Apoio às Micro e Pequenas EmpresasSIM Sistema de Informação de MarketingSVM Support Vector MachineTF Term FrequencyTF-IDF Term Frequency – Inverse Document FrequencyTI Tecnologia da InformaçãoXML eXtensible Markup LanguageWWW World Wide Web

SUMÁRIO
1 INTRODUÇÃO ..................................................................................................... 111.1 QUESTÃO DE PESQUISA................................................................................. 131.2 OBJETIVOS ....................................................................................................... 131.2.1 Objetivo Geral............................................................................................... 131.2.2 Objetivos Específicos .................................................................................. 131.3 JUSTIFICATIVA ................................................................................................. 142 SISTEMA DE INFORMAÇÃO DE MARKETING.................................................. 152.1 CONCEITO......................................................................................................... 162.2 MODELOS DE SISTEMAS DE INFORMAÇÃO DE MARKETING ..................... 192.2.1 Subsistema de Pesquisa de Marketing ...................................................... 212.2.2 Subsistema de Inteligência Competitiva .................................................... 242.3 INFORMAÇÃO NO PROCESSO DE TOMADA DE DECISÃO .......................... 272.3.1 Fontes dos dados e informações ............................................................... 292.3.2 Coleta de dados na internet ........................................................................ 353 MINERAÇÃO WEB .............................................................................................. 373.1 CATEGORIAS DA MINERAÇÃO WEB .............................................................. 383.2 ETAPAS DA MINERAÇÃO DE CONTEÚDO NA WEB ...................................... 393.2.1 Etapa de Pre-processamento ...................................................................... 403.2.2 Etapa de Processamento (Tarefas da Mineração de texto) ...................... 443.2.3 Etapa de Pós-processamento ..................................................................... 524 MINERAÇÃO WEB NAS REDES SOCIAIS......................................................... 544.1 REDES SOCIAIS................................................................................................ 544.1.1 Facebook....................................................................................................... 584.1.2 Twitter ........................................................................................................... 594.2 O COMPORTAMENTO DOS USUÁRIOS NAS REDES SOCIAIS..................... 614.3 PROCESSO DE MINERAÇÃO WEB NAS REDES SOCIAIS ............................ 634.3.1 Monitoramento das redes sociais............................................................... 634.3.2 Processo de monitoramento de redes sociais .......................................... 654.3.3 Pesquisas sobre monitoramento de redes sociais ................................... 665 METODOLOGIA................................................................................................... 715.1 TIPO DE PESQUISA.......................................................................................... 715.2 FASES DA PESQUISA ...................................................................................... 715.3 PARÂMETROS PARA ESCOLHA DAS FERRAMENTAS DE MINERAÇÃO WEB
72

5.3.1 Universo e Amostra ..................................................................................... 735.3.2 Seleção de variáveis .................................................................................... 735.4 TRATAMENTO DOS DADOS ............................................................................ 796 RESULTADOS..................................................................................................... 816.1 DESCRIÇÃO DAS CARACTERÍSTICAS MERCADOLÓGICAS DASFERRAMENTAS....................................................................................................... 816.1.1 Ferramentas de Monitoramento de Redes Sociais (MRS) ........................ 816.1.2 Ferramentas de Mineração de Texto (MT).................................................. 846.2 DESCRIÇÃO FUNCIONAL DAS FERRAMENTAS SELECIONADAS ............... 886.2.1 Ferramentas de Monitoramento de redes sociais (MRS).......................... 886.2.2 Ferramentas de Mineração de textos (MT)............................................... 1017 CONSIDERAÇÕES FINAIS ............................................................................... 110REFERÊNCIAS ...................................................................................................... 113

11
1 INTRODUÇÃO
O cenário atual do mundo corporativo tem se pautado em um ambiente
bastante competitivo, no qual se torna necessário o uso de informações adequadas
para tomar decisões estratégicas. A informação como apoio para tomadas de
decisões é um assunto muito explorado na literatura de estratégia de marketing, no
entanto, a necessidade de decidir com rapidez leva vários gestores a tomar suas
decisões baseadas somente em sua própria experiência. Encontrar a informação
pontual e adequada pode ser um problema frente a quantidade de dados que são
disponibilizados nos mais diversos meios de armazenamento eletrônico. A
informação existe, porém, percebe-se que poucos executivos estão amparados por
técnicas apropriadas para coletá-las e processá-las de modo rápido e prático que
possibilite a manutenção de sua posição competitiva no mercado. Evidencia-se a
necessidade de um sistema que avalie as necessidades de informação dos gestores
e as obtenha de maneira oportuna para melhorar a eficácia da tomada de decisão.
Para as pequenas e médias empresas (PME) que apresentam características
específicas de decisão, direção e organização em relação às grandes empresas,
precisando se adaptar às práticas estratégicas contemporâneas para sobreviver no
mundo competitivo, a utilização de sistemas automatizados de coleta de informação
pode fazer diferença para o sucesso.
As PME’s contribuem de forma relevante no desenvolvimento e na economia
de uma região, no entanto, assim como nas grandes empresas, gerir um pequeno
negócio exige uma série de desafios que precisam ser vencidos. As soluções para
resolução de problemas e tomadas de decisão, embora se pareçam comuns entre
esses tipos de empresas, têm caminhos diferentes para serem solucionados. É
constante encontrar ferramentas que originalmente foram desenvolvidas para as
grandes empresas, sendo aplicadas às PMEs. A literatura sobre estratégia para
pequenas empresa é muito influenciada por duas abordagens: uma de perspectiva
econômica e outra empreendedora. Ao longo do tempo, a abordagem de natureza
econômica tem predominado, no entanto, a de natureza empreendedora surge
atualmente com forte influência do comportamento individual sobre o processo de
formação da estratégia na prática. Nesse contexto, a informação surge como um
subsídio importante na estratégia empresarial e no auxílio das tomadas de decisões.
O desafio é tornar as informações que estão dispersas dentro e fora da organização

12
úteis para a execução de práticas estratégicas mais próximas do cotidiano das
PME’s.
Atualmente, a Internet surge como um ambiente democrático no qual a
informação pode ser gerada, armazenada, distribuída e coletada de diversas
maneiras. Novas ferramentas possibilitam que usuários criem gratuitamente seus
próprios conteúdos digitais, o que contribui para o aumento da quantidade de
informações disponíveis. Esse crescimento exige que torne cada vez mais
necessário o uso mecanismos eficazes e eficientes para recuperação de
conhecimentos úteis da web. Um exemplo do crescimento da internet é o surgimento
das redes sociais digitais, no qual seus usuários geram e disseminam suas opiniões,
comportamentos e desejos sobre os mais variados assuntos. Por querer saber
“como as pessoas pensam” a respeito de suas marcas, produtos e serviços, as
empresas passaram a dar maior atenção para o que os seus clientes estão
relatando nas redes sociais, resolvendo críticas e coletando elogios e sugestões
para seus negócios.
As redes sociais digitais podem mostrar como determinado grupo de
seguidores reage a uma ação de marketing. A postura dos consumidores frente ao
comportamento das empresas pode surgir como um sinalizador de mudanças de
cenários e, neste caso, os empresários procurariam posicionar melhor seus
negócios no mercado para atrair consumidores mais exigentes (PORTER, 2005). Os
dados coletados e processados das redes sociais digitais podem constituir uma fonte
de vantagem competitiva, proporcionando às empresas mais informações para uma
estratégia mais próxima dos desejos desse segmento de consumidores. Com o
avanço tecnológico por meio da Internet e o desenvolvimento de sistemas
específicos para gestão de informações, a área de marketing passou a contar com
uma estrutura tecnológica para extrair dados da Web e definir estratégias de
mercado de acordo com o processamento desses dados. Grandes empresas, devido
a seu bom aporte financeiro e tecnológico, são capazes de coletar e processar
informações por meio de sistemas mais robustos, no entanto, para as pequenas e
médias empresas esse papel ainda se restringe a processamentos manuais de
coleta de dados (CHIUSOLI, 2010). Apesar das informações poderem ser obtidas de
forma manual na Internet, devido a sua grande quantidade, a forma mais adequada
de extrair essas informações seria por meio de procedimentos automatizados de

13
mineração de dados na Internet, conhecida como Web Mining. O objetivo desta
técnica no marketing é vasculhar grandes bases de dados na Internet pela busca de
padrões escondidos, extraindo informações ocultas dos consumidores e úteis para a
tomada de decisões de negócios.
1.1 QUESTÃO DE PESQUISA
A partir das considerações anteriores buscou-se responder a seguinte
questão:
● Quais as ferramentas de mineração Web existentes no mercado e quais
informações elas oferecem aos gestores de marketing para tomada de
decisão estratégica em PMEs?
1.2 OBJETIVOS
1.2.1 Objetivo Geral
Investigar as ferramentas de mineração Web existentes no mercado e quais
informações elas oferecem aos gestores de marketing para tomada de decisão
estratégica em PMEs.
1.2.2 Objetivos Específicos
Como objetivos específicos foram propostos:
● Levantar as principais ferramentas de mineração Web disponíveis até
junho de 2012;
● Descrever e comparar as características mercadológicas de cada
ferramenta;
● Descrever e comparar as funcionalidades de cada ferramenta;
● Identificar possíveis tratamentos estatísticos a que os dados coletados
possam ser submetidos.

14
1.3 JUSTIFICATIVA
As informações e opiniões disponibilizadas a cada momento na Internet pelos
consumidores despertam o interesse das empresas em coletá-las e utilizá-las como
fonte de vantagem competitiva. Diante dessa crescente forma de obter
conhecimento, surgem a cada ano novas metodologias e ferramentas que consigam
extrair as informações de forma inteligente de grandes bases de dados, como as
redes sociais digitais na Internet. Elicitar dados da Internet de forma manual pode
ser um trabalho muito custoso e demorado para quem o realiza, principalmente
quando se trata de pesquisas feitas por meio de questionários, no qual o
pesquisador fica na dependência da dedicação dos indivíduos alvo da pesquisa.
Existem poucas pesquisas sobre a coleta de dados inteligentes da Internet, no
entanto, abordagens sobre mineração de texto e mineração Web se apresentam
como meios alternativos para coleta e analise de texto em forma de opinião nas
redes sociais.
Esta pesquisa se justifica pela crescente utilização das redes sociais por parte
dos consumidores e pelo surgimento de ferramentas de mineração de dados na
Internet como alternativa para extrair informações oriundas da fonte de informação
externa dos Sistemas de Informação de Marketing (SIM), no qual o objetivo é auxiliar
os gestores de empresas na obtenção de informação que possa servir de base para
tomadas de decisões estratégicas. Para a ciência, esse trabalho pode significar um
caminho alternativo ao questionário convencional para coletar informações para
pesquisas científicas. Para a área do marketing, assinala como um meio
complementar de extrair informações sobre mercados e consumidores,
especificadamente os usuários internautas das redes sociais digitais.

15
2 SISTEMA DE INFORMAÇÃO DE MARKETING
A informação pode ser considerada o insumo principal para o planejamento
de marketing no processo de tomada de decisão estratégica. Em suas
argumentações, Porter (2005) defende que a informação é uma fonte de vantagem
competitiva para as empresas, pois as que detêm conhecimento sobre sua cadeia
de valor, concorrente e sobre o mercado, podem tomar decisões baseadas em
estratégias menos abstratas e mais tangíveis, resultando em um desempenho mais
sólido no mercado competitivo. No entanto, Chiusoli (2005) argumenta que nem
todas as empresas conseguem encontrar informações em tempo hábil para tomada
de decisão rápida. O resultado disso são deliberações baseadas somente na
experiência do empresário. Como alternativa para sanar esse problema, Gounaris,
Panigyrakis e Chatzipanagiotou (2007) sugerem que as empresas monitorem
constantemente o ambiente de marketing para obter proveito das informações
disponibilizadas. Chiusoli (2005) acrescenta que as empresas que mais se
adequarem a essa nova estrutura de informação de marketing, antecipando o
quadro de mudanças de cenários, se posicionarão no mercado de forma mais
favorável.
Segundo Mattar (2008), a problemática da informação de marketing foi
abordada no período que antecedeu a primeira metade da década de 1960 através
da pesquisa de mercado, que estava voltada para o ambiente externo à empresa,
mais especificamente para o mercado. No entanto, o autor ressalta que a
necessidade de informação para o planejamento e controle de marketing é muito
mais ampla e implica a busca de informações em inúmeras outras fontes, inclusive
no próprio ambiente interno à empresa. Ele critica as pesquisas da época por
produzir dados irrelevantes, preocupando-se apenas com problemas não repetitivos,
que considerava um ato falho na promoção de informações de marketing. Na
segunda metade da década de 1960 com o advento da teoria dos sistemas, a
problemática da informação de marketing passou a ser tratada de forma mais ampla,
integrada e sistemática pelos autores de marketing. O controle do fluxo da
informação foi defendido também por Fletcher e Wheeler (1989) que argumentavam
que era necessário obter os dados de forma sistemática em um formato padronizado
apropriado para que os gestores tomem decisões em tempo real. Na década de
1980, apesar de ter havido um processo de valorização da informação de mercado,

16
Miniotti (1992) notava que no Brasil os gestores ainda utilizavam as informações de
forma inadequada, pois eram poucos que após a coleta sistemática de dados
conseguiam armazená-los e transformá-los em informações importantes. Além
disso, Chiusoli (2005) acreditava que mesmo após 20 anos, provavelmente ainda
poucas empresas conseguiam tomar decisões gerenciais baseadas em informações
coletadas por meio de procedimentos estruturados. Divergindo dessa posição, Star e
Reynolds (2006) argumentam que depois dos trabalhos originais de Michael Porter,
houve um amadurecimento no uso sistemático da informação por parte das
empresas (PORTER, 2005). Elas compreenderam como os sistemas de informações
podem ser usados para melhorar a efetividade organizacional e dar suporte à
estratégia fundamental do negócio.
A definição de sistemas de informação de marketing (SIM) foi ao longo do
tempo caminhando do contexto tecnológico e técnico para conceitos mais
gerenciais, relacionadas a objetivos e resultados organizacionais (WIERENGA;
BRUGGEN, 2000). O autor afirma ainda que a busca por novas tecnologias da
informação (TI) é uma forma alternativa para se adaptar à nova realidade do
mercado que necessita de informações rápidas e precisas. Corroborando com essa
afirmação, Khauaja e Campomar (2007) argumentam que para lidar com o aumento
do fluxo de informação, interno e externo, as organizações precisam tirar proveito
das oportunidades oferecidas pela TI. Elas devem identificar de que forma a
tecnologia da informação pode criar vantagem competitiva, visto que TI afeta todas
as camadas da cadeia de valor, integrando o fornecedor ao cliente, percorrendo as
unidades estratégicas da empresa, incluindo o marketing. Daniel, Wilson e
McDonald (2003) enfatizam que o suporte de TI ao planejamento de marketing pode
ajudar no uso das ferramentas de marketing e facilitar o planejamento contínuo.
Percebe-se que a TI pode oferecer recursos capazes de auxiliar no processo de
obtenção de informação de valor nas decisões estratégicas, independente se as
fontes de dados são internas ou externas à empresa.
2.1 CONCEITO
Antes de apresentar os conceitos sobre Sistemas de Informação de Marketing
(SIM) encontrados na literatura, vale ressaltar o significado das três sentenças

17
separadas que compõem esse termo: sistema, informação e marketing. Mayros e
Werner (1982) foram os primeiros a designar esse tripé como base para o
entendimento global do SIM, como ilustrado na Figura 1.
Figura 1: Tripé do Sistema de Informação de Marketing
Fonte: Adaptado de Mayros e Werner (1982)
O primeiro elemento do tripé é o sistema, que segundo Stair e Reynolds
(2008) é um conjunto de elementos interrelacionados e interdependentes que visam
atingir um objetivo comum. O´Brien (2004) cita as organizações empresariais como
exemplo de sistemas, no qual é composto por três componentes básicos: entrada,
processamento e saída. As entradas alimentam o processador do sistema que
armazena e transforma a entrada em uma saída. Assim, as empresas como
sistemas organizacionais podem utilizar os seus recursos econômicos (entradas)
transformando-os por vários processos (processamento) e gerando resultados em
forma de bens e serviços (saídas).
O segundo elemento do tripé do SIM é a informação, que Laudon e Laudon
(2007) definem como dados apresentados em uma forma significativa e útil para os
seres humanos. Para Robic (2003), a informação torna-se um recurso cada vez mais
importante no dia a dia das empresas, principalmente para a área de marketing.
O terceiro e último elemento do SIM é o marketing, que para a American
Marketing Association (AMA) é uma função organizacional e um conjunto de
processos para a criação, comunicação e entrega de valor aos consumidores e para
administração do relacionamento com os consumidores de forma que beneficie a
organização e seus stakeholders (AMA, 2012).
Sistema de Informação de Marketing
Sistema
Unifica o processo de trocade informações entre osdepartamentos e as três
áreas funcionais daempresa: Estratégia, tática
e operacional.
Informação
Consiste em dadosselecionados e
processados utilizados natomada de decisões.
Marketing
Decisões sobreconsumidores, mercado,produto, força de vendas.
18
Para Campomar e Ikeda (2006), nesse tripé o sistema mantém a estrutura
dos componentes utilizados (dados, informações, modelos estatísticos, relatórios
gerenciais), a informação é decorrente da transformação desses dados e o
marketing gera novas demandas de análises de mercado que são trabalhados pelo
SIM. Com os conceitos independentes do sistema, informação e marketing expostos,
a literatura aborda definições semelhantes e complementares sobre os sistemas de
informação de marketing (SIM). Para facilitar a visualização elaborou-se um quadro
contendo a evolução dos principais conceitos a respeito do SIM (Quadro 1).
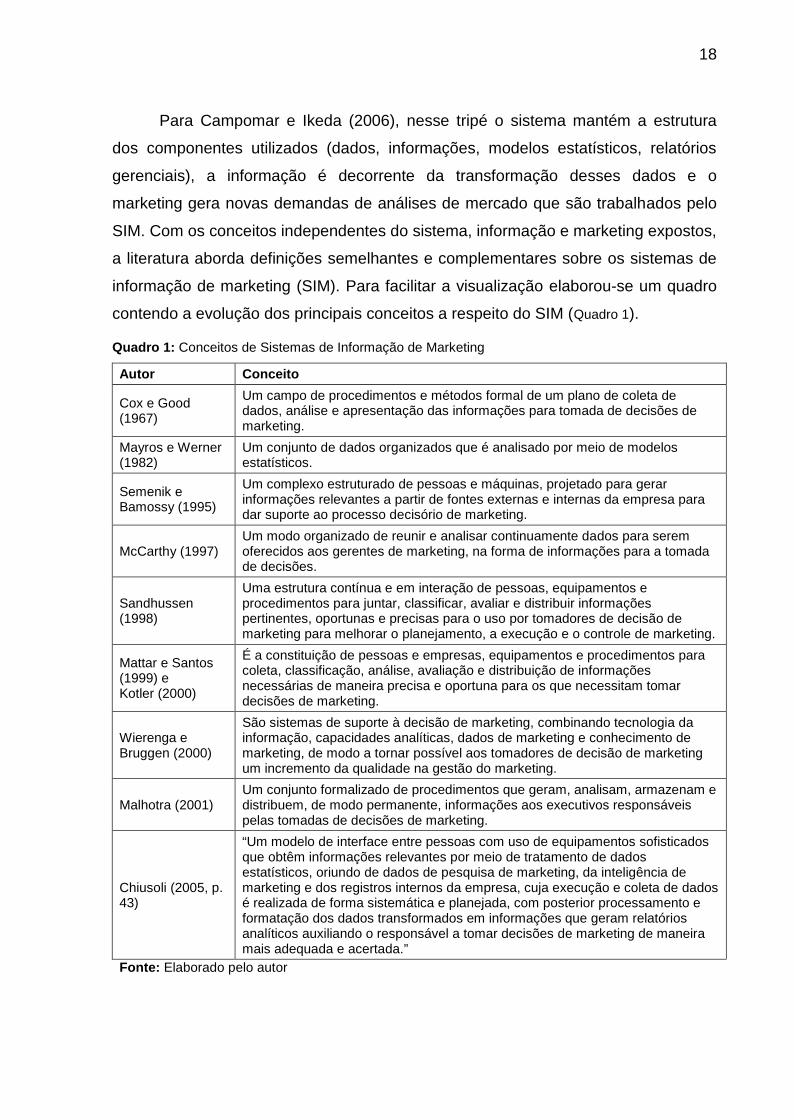
Quadro 1: Conceitos de Sistemas de Informação de Marketing
Autor Conceito
Cox e Good(1967)
Um campo de procedimentos e métodos formal de um plano de coleta dedados, análise e apresentação das informações para tomada de decisões demarketing.
Mayros e Werner(1982)
Um conjunto de dados organizados que é analisado por meio de modelosestatísticos.
Semenik eBamossy (1995)
Um complexo estruturado de pessoas e máquinas, projetado para gerarinformações relevantes a partir de fontes externas e internas da empresa paradar suporte ao processo decisório de marketing.
McCarthy (1997)Um modo organizado de reunir e analisar continuamente dados para seremoferecidos aos gerentes de marketing, na forma de informações para a tomadade decisões.
Sandhussen(1998)
Uma estrutura contínua e em interação de pessoas, equipamentos eprocedimentos para juntar, classificar, avaliar e distribuir informaçõespertinentes, oportunas e precisas para o uso por tomadores de decisão demarketing para melhorar o planejamento, a execução e o controle de marketing.
Mattar e Santos(1999) eKotler (2000)
É a constituição de pessoas e empresas, equipamentos e procedimentos paracoleta, classificação, análise, avaliação e distribuição de informaçõesnecessárias de maneira precisa e oportuna para os que necessitam tomardecisões de marketing.
Wierenga eBruggen (2000)
São sistemas de suporte à decisão de marketing, combinando tecnologia dainformação, capacidades analíticas, dados de marketing e conhecimento demarketing, de modo a tornar possível aos tomadores de decisão de marketingum incremento da qualidade na gestão do marketing.
Malhotra (2001)Um conjunto formalizado de procedimentos que geram, analisam, armazenam edistribuem, de modo permanente, informações aos executivos responsáveispelas tomadas de decisões de marketing.
Chiusoli (2005, p.43)
“Um modelo de interface entre pessoas com uso de equipamentos sofisticadosque obtêm informações relevantes por meio de tratamento de dadosestatísticos, oriundo de dados de pesquisa de marketing, da inteligência demarketing e dos registros internos da empresa, cuja execução e coleta de dadosé realizada de forma sistemática e planejada, com posterior processamento eformatação dos dados transformados em informações que geram relatóriosanalíticos auxiliando o responsável a tomar decisões de marketing de maneiramais adequada e acertada.”
Fonte: Elaborado pelo autor

19
Percebe-se que os elementos envolvidos nos conceitos de sistemas de
informação de marketing são as pessoas, equipamentos e procedimentos. A entrada
desse sistema é composta pelos dados coletados sobre o ambiente de marketing
(interno e externo), no qual são processados e resultam em informação como saída
do sistema. O objetivo comum é centrado no suporte ao plano de marketing e no
auxílio do gerenciamento das informações da empresa, permitindo que os gestores
tenham um suporte nas suas tomadas decisões.
2.2 MODELOS DE SISTEMAS DE INFORMAÇÃO DE MARKETING
Existem diversos modelos de sistemas de informação de marketing e Chiusoli
(2005) aborda em seu trabalho 22 extraídos da literatura. Ao final da sua pesquisa, o
autor sugere seu próprio modelo. Buscando apresentar de forma suscinta esses
modelos, optou-se por ilustrar em forma de quadro (Quadro 2) um resumo contendo
as contribuições dos autores de marketing apresentados por Chiusoli (2005) quanto
aos modelos de sistemas de informação de marketing e suas principais
características.
Chiusoli (2005) apresenta uma proposta de um modelo de SIM aplicado às
atividades estratégicas que engloba as principais características dos modelos
estudados. O modelo apresenta as fontes de dados provenientes do ambiente
externo e interno de marketing. As entradas podem ter informações originadas a
partir dos dados internos da empresa, pesquisa de marketing e inteligência
competitiva. Posteriormente os dados são processados e ficam dispostos na etapa
de tomada de decisão, dividido em uma estrutura de marketing (planejamento,
segmentação e posicionamento do produto ou serviço) e subsistemas de saída
(decisões de produto ou serviço, preço, canal e comunicação). O foco é transformar
os dados, outrora sem sentido, para uma estrutura capaz de prover informações
adequadas para os executivos se basearem nas tomadas de decisões estratégicas.
A Figura 2 mostra a diagramação desse modelo proposto por Chiusoli (2005).
20
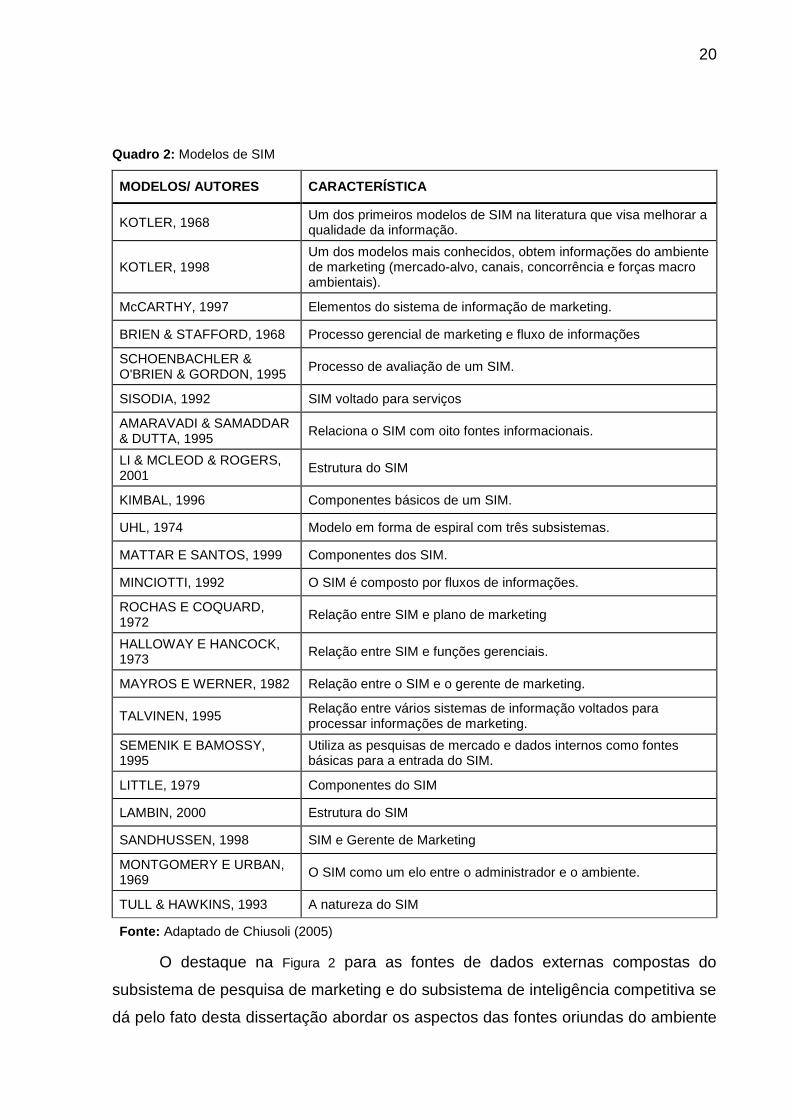
Quadro 2: Modelos de SIM
MODELOS/ AUTORES CARACTERÍSTICA
KOTLER, 1968 Um dos primeiros modelos de SIM na literatura que visa melhorar aqualidade da informação.
KOTLER, 1998Um dos modelos mais conhecidos, obtem informações do ambientede marketing (mercado-alvo, canais, concorrência e forças macroambientais).
McCARTHY, 1997 Elementos do sistema de informação de marketing.
BRIEN & STAFFORD, 1968 Processo gerencial de marketing e fluxo de informações
SCHOENBACHLER &O'BRIEN & GORDON, 1995 Processo de avaliação de um SIM.
SISODIA, 1992 SIM voltado para serviços
AMARAVADI & SAMADDAR& DUTTA, 1995 Relaciona o SIM com oito fontes informacionais.
LI & MCLEOD & ROGERS,2001 Estrutura do SIM
KIMBAL, 1996 Componentes básicos de um SIM.
UHL, 1974 Modelo em forma de espiral com três subsistemas.
MATTAR E SANTOS, 1999 Componentes dos SIM.
MINCIOTTI, 1992 O SIM é composto por fluxos de informações.
ROCHAS E COQUARD,1972 Relação entre SIM e plano de marketing
HALLOWAY E HANCOCK,1973 Relação entre SIM e funções gerenciais.
MAYROS E WERNER, 1982 Relação entre o SIM e o gerente de marketing.
TALVINEN, 1995 Relação entre vários sistemas de informação voltados paraprocessar informações de marketing.
SEMENIK E BAMOSSY,1995
Utiliza as pesquisas de mercado e dados internos como fontesbásicas para a entrada do SIM.
LITTLE, 1979 Componentes do SIM
LAMBIN, 2000 Estrutura do SIM
SANDHUSSEN, 1998 SIM e Gerente de Marketing
MONTGOMERY E URBAN,1969 O SIM como um elo entre o administrador e o ambiente.
TULL & HAWKINS, 1993 A natureza do SIM
Fonte: Adaptado de Chiusoli (2005)
O destaque na Figura 2 para as fontes de dados externas compostas do
subsistema de pesquisa de marketing e do subsistema de inteligência competitiva se
dá pelo fato desta dissertação abordar os aspectos das fontes oriundas do ambiente

21
da Internet, neste caso, as fontes externas do SIM. Essas fontes podem ser
subdivididas em Subsistema de Pesquisa de Marketing e Subsistema de Inteligência
de Marketing. O primeiro consiste nos esforços de coleta e análise de dados por
meio de estudos de levantamento de campo junto aos atuais clientes e potenciais
consumidores com a finalidade de descobrir informações relevantes sobre uma
situação específica de marketing da empresa. O Subsistema de Inteligência de
Marketing ou Inteligência Competitiva tem o objetivo de transformar dados coletados
do ambiente competitivo em elementos de inteligência estratégica para suporte da
tomada de decisões (Grisi et al, 2001).
Figura 2: Modelo de SIM proposto por Chiusoli (2005)
Fonte: Adaptado de Chiusoli (2005)
2.2.1 Subsistema de Pesquisa de Marketing
A maioria dos modelos de SIM apresentados no Quadro 2 aponta o elemento
pesquisa de marketing com grande relevância. A pesquisa de marketing é uma das
formas mais utilizadas de se obter informações para tomadas de decisões. Mattar
Ambienteinterno
AmbienteExterno
Subsistemabase de dados
internos
Subsistemade pesquisade marketing
Subsistemade
Inteligênciade marketing
Segm
enta
ção
e Po
sici
onam
ento
Sistema deapoio a
decisões demarketing
Decisões deproduto eserviço
Decisões decanal
Decisões depreço
Decisões decomunicação
Executivode
marketing
Tomadorde decisão
Fontes dedados
Subsistemas deentradas
Processamento dosdados de entradas
Plan
ejam
ento
e E
stru
tura
Decisões de marketing

22
(2008) a considera como uma ferramenta importante na alimentação de dados e
monitoramento do ambiente de marketing. O objetivo da pesquisa de marketing,
segundo o autor, é descobrir fatos, atitudes e opiniões por meio de uma investigação
sistemática, controlada e crítica dos dados. É possível também identificar e
solucionar problemas e oportunidades de marketing, ligando o consumidor, cliente e
o público com o homem de marketing por meio da informação (MALHOTRA, 2001).
Geralmente as grandes empresas contam com um setor estruturado para a
realização das pesquisas de marketing, enquanto outras podem contratar empresas
terceirizadas para realizar esse serviço.
A primeira etapa para a realização de uma pesquisa de marketing é definir o
problema e os objetivos da pesquisa. Definir corretamente o problema significa
entender e explicitar quais os problemas ou oportunidades de marketing que geram
a necessidade de informação para tomada de decisão. Chiusoli (2001) julga essa
etapa como a mais difícil, pois o gerente pode perceber algo errado sem saber o que
exatamente está causando essa situação.
A segunda etapa é o desenvolvimento do plano de pesquisa para a coleta das
informações. Este plano deve conter as fontes de informação, o detalhamento das
abordagens específicas da pesquisa e forma de contato. A coleta de dados
necessários que o gerente de marketing precisa obter pode ser realizada por meio
de dados primários, secundários ou de ambas as formas de coletas. De acordo com
Mattar (2008), os dados primários têm a característica de não terem sido coletados
antes e tem o objetivo de atender as necessidades específicas da pesquisa em
andamento. Já os dados secundários, se caracterizam por terem sido coletados
antes, tabulados, ordenados e muitas vezes até analisados e que estão catalogados
à disposição dos interessados, como por exemplo, os dados oriundos de órgãos
governamentais como o IBGE, SEBRAE, FIPE ou fontes de negócio como guias,
anuários, Internet etc. (KOTLER; ARMSTRONG, 2003).
Diferentemente da abordagem para coletar dados secundários que já existem,
os dados primários exige um esforço maior, pois será necessário realizar uma série
de procedimentos para coletá-los, como mostrado por Kotler e Armstrong (2003).
Para levantar esse tipo de dado é preciso definir: a) abordagem da pesquisa
(observação, levantamento, pesquisa experimental); b) métodos de contato (Correio,
telefone, pessoal, Internet); c) plano de amostragem (unidade de amostragem,

23
tamanho da amostra e procedimentos de amostragem); e d) procedimentos de
pesquisa (Questionário ou instrumentos mecânicos).
Como visto, é possível coletar dados primários e secundários do ambiente da
Internet. Kotler e Armstrong (2003) argumentam que o método de contato pela
Internet tem como ponto forte a economia de tempo e dinheiro, pois proporciona
uma rapidez na coleta dos dados e muitas vezes a custo zero. Como ponto fraco o
autor cita a falta de controle sobre a amostra que é deficitária. Como pontos que
precisam ainda ser levados em conta, a Internet proporciona uma boa flexibilidade
na coleta dos dados, quantidade de dados que podem ser coletados e a taxa de
resposta. Malhotra (2001) corrobora com algumas afirmações de Kloter e Armstrong
(2003), mas discorda quanto à taxa de respostas. Ele afirma que a maior
desvantagem de coletar dados primários na Internet por meio de pesquisa de
marketing é a baixo índice de respostas aos questionários enviados aos indivíduos.
Um dos motivos para esse baixo índice é a falta de interesse do indivíduo, que ao
ser abordado por meio de e-mail para acessar um questionário online lhe falta
estímulo para respondê-lo naquele momento, deixando pra depois até “cair no
esquecimento”. Esse fator pode ser minimizado utilizando as redes sociais para
aproximar o pesquisador do público-alvo escolhido. Segundo Ribeiro (2009), as
estabilidades encontradas no desenvolvimento das pesquisas, associadas aos
dados coletados por questionários, mostram que a utilização dos sites de redes
sociais está intensamente relacionada com as práticas sociais cotidianas. Pesquisas
de ótica psicossocial também atestam estas afirmações, ao observar como algumas
dinâmicas de interação social observadas na comunicação face-a-face são
reproduzidas e outras são reconfiguradas nos ambientes online.
A terceira etapa para a pesquisa de marketing é a implementação do plano de
pesquisa por meio da coleta e análise dos dados que pode ser feita pelo próprio
departamento de marketing ou por empresas especializadas em pesquisa de
marketing. Pelo fator tempo e custo, a utilização da Internet como ambiente para
coleta de dados é mais adequada para as situações das pequenas e médias
empresas. Nessas empresas, nem sempre é possível ter um setor para tratar
exclusivamente de pesquisas de marketing devido a sua pouca alocação de
recursos, estruturas e pessoal. Nesse caso, as atividades de operacionalização da
coleta de dados são feita por equipes contratas temporariamente para tal finalidade

24
ou por funcionários que agregam multi-funções dentro da empresa (SARQUIS,
2003).
A quarta e última etapa é de interpretação e apresentação dos resultados. Nela
o gestor pode interpretar e apresentar os resultados da pesquisa à equipe como um
todo e, principalmente, à direção da empresa, fornecendo as informações mais
importantes. A partir de então, os dados poderão alimentar o Sistema de Informação
de Marketing para futuras análises ou mesmo serem utilizadas como entradas
quantitativas de procedimentos estatístico tais como: análise de regressão múltipla,
análise discriminante, análise conjunta, análise de cluster, análise fatorial e escala
multidimensional (MALHOTRA, 2001; HAIR et al, 2005).
2.2.2 Subsistema de Inteligência Competitiva
Apesar de Chiusoli (2005) utilizar o termo “Subsistema de Inteligência de
marketing” em seu modelo, optou-se por utilizar nessa dissertação a expressão
“subsistema de Inteligência competitiva” por considerá-la mais adequada para a
aplicação na coleta de dados na Internet.
O surgimento do conceito de Inteligência Competitiva (IC) é datado na década
de 80 e definido como uma integração entre as áreas de planejamento estratégico,
marketing e informação, tendo como principal objetivo o constante monitoramento do
ambiente externo, principalmente os movimentos do mercado com rapidez e
precisão (BATTAGLIA, 1999). Segundo Telma (2011), a IC é um resultado do
consórcio das ciências da Informação, tecnologia da informação e administração.
Enquanto a ciência da informação se responsabiliza pelo gerenciamento da
informação, a TI enfatiza as suas ferramentas de gerenciamento de redes e
mineração de dados e, a administração é representada por suas áreas de estratégia,
marketing e gestão. A SCIP (Society of Competitive Intelligence of Professionals)
define Inteligência Competitiva como um sistema de coleta, análise e gerenciamento
legal de informação externa que pode afetar planos, decisões e operações de uma
empresa (SCIP, 2012).
De acordo com Battaglia (1999), a informação e a velocidade de seu uso é a
fundamentação da inteligência competitiva. Isso se justifica pelo fato da inteligência
competitiva fazer uso de diversos tipos e fontes de informações em uma velocidade
muito grande com o objetivo de monitorar desenvolvimentos e pesquisa de produtos,

25
processos, serviços e posições de mercado. A Internet é considerada aqui como
ambiente de informação externa e como ferramenta no processo de inteligência
competitiva, já que oferece a baixo custo facilidades e vantagens por possibilitar
acesso rápido, global e interativo em tempo integral.
Diferentemente da mídia tradicional, na Internet o consumidor tem a
possibilidade de ter uma participação mais ativa na produção do conteúdo midiático
sobre marcas ou produtos. Telma (2011) aborda essa questão em sua pesquisa,
citando o trabalho sobre marketing digital de Kotler, Kartajaya e Setiawan (2010):
Cada meio de comunicação tem sua característica, tais como os meiostradicionais TV, rádio e mídia impressa. Mas é na Internet que o consumidortem a possibilidade de “gritar” para outras pessoas o que sente, pensa oupercebe sobre determinado assunto. É neste canal que a interação doconsumidor com marcas ou produtos ocorre com maior proximidade frenteaos demais, com troca de informações, contato individualizado, e respostasmais rápidas. (TELMA, 2011 apud KOTLER; KARTAJAYA; SETIAWAN,2010, p. 26).
O monitoramento do ambiente competitivo na Internet não só analisa dados
objetivos como a publicidade planejada (compra de espaço e aparição pelos
anunciantes), mas também coleta e analisa os dados subjetivos de publicidade
espontânea, gerada a partir de comentários dos consumidores nos sites, blogs e
redes sociais (SILVA, 2011). Neste segundo caso, o consumidor pode assumir um
papel muito importante, podendo atuar de duas formas: quando ele tem uma boa
experiência de compra e se identifica com a empresa passa a propagar a marca
positivamente. Doutro modo, quando está insatisfeito com a marca passa a
disseminar comentários negativos que antes poderiam ficar ocultos ou menos
expressivos no cotidiano não virtual.
Com o surgimento da Web 2.0, onde diversos aplicativos são criados para
atender variadas demandas dos usuários, abrolharam também as redes sociais,
mecanismos que unem o poder da Web 2.0 aliado ao poder da colaboração oriunda
de todas as partes do planeta, oferecendo aos usuários a possibilidade de
compartilhar conhecimento com qualquer outro usuário da rede (AFONSO, 2009). As
empresas podem se utilizar dessa “febre” entre os internautas para extrair
informações relevantes de consumidores e empresas, disseminando feitos das
marcas e conceitos que queiram transmitir aos seus consumidores. Telma (2011)
afirma também que as empresas devem ouvir o que seus consumidores estão
falando nas redes sociais. Neste caso, o monitoramento das redes sociais é crucial

26
para entender a repercussão de uma marca ou produto e entender o padrão de
comportamento de determinado grupo de consumidores.
Boa parte dos estudos acerca de inteligência competitiva focaliza em
empresas de grande porte pelo fato delas terem desenvolvidos sistemas sofisticados
nessa esfera. Por isso, pouco se conhece a respeito de como executivos e
profissionais de pequenas empresas lidam com essa questão. Silva (2003) acredita
que a proposta de considerar a Internet como ambiente de fontes de informação
pode ser um processo alcançável por qualquer organização e aplicável
principalmente às empresas de pequeno e médio porte, tenham elas fins lucrativos
ou sociais.
O processo de Inteligência Competitiva compreende três etapas de acordo
com Afonso (2009). A primeira etapa é a de planejamento e organização, no qual
são feitas as estruturas organizacionais para a realização da inteligência competitiva
com estabilidade ao longo do tempo. Wives (2002) ressalta que esta primeira etapa
pode ser dispensada caso a empresa já saiba qual a necessidade da informação. A
segunda etapa é a de busca de informações que trata da exploração de informações
a cerca do ambiente externo. As atividades englobam primeiramente a identificação
de todas as fontes potenciais de informação e, em seguida é realizada a pesquisa e
coleta os dados certos de forma legal e ética a partir de todas as fontes disponíveis e
posteriormente são listadas em ordem (BOSE, 2008). A última etapa do processo de
inteligência competitiva é a de interpretação dos resultados que tem o objetivo de
traduzir as informações coletadas do ambiente externo para as necessidades
estratégicas da empresa.
As principais características das fases dos processos de Inteligência
Competitiva apresentados por Miller (2001) são: identificação das necessidades dos
responsáveis pelas tomadas de decisões da empresa, obtenção de informações
relevantes a partir de fontes de informações, tais como: balanços patrimoniais,
publicações internas, relatórios gerenciais, jornais, revistas, rumores, Internet ou
fornecedores. Por fim, na identificação e análise de padrões significativos com base
nas informações coletadas gerando subsídios para tomadas de decisões.

27
2.3 INFORMAÇÃO NO PROCESSO DE TOMADA DE DECISÃO
Após a apresentação dos conceitos sobre os sistemas de informação de
marketing e definir as características dos dois subsistemas de informações oriundas
do ambiente externo – Pesquisa de Marketing e Inteligência Competitiva – vale
ressaltar o que os autores consideram como informação importante para tomada de
decisão estratégica. Tendo ciência disso, é possível reconhecer se o resultado da
saída do SIM está de acordo com as necessidades dos gestores nas tomadas de
decisões nas empresas. De acordo com Laudon e Laudon (2007), para utilizar o SIM
de maneira adequada, a empresa precisa, a curto e longo prazo, ter a noção clara
de quais dados são necessários coletar para sua operação. Wierenga e Bruggen
(2000) colaboram afirmando que um SIM eficiente deve ser aquele que coleta e
armazena dados que contribuem de fato para a tomada de decisão de marketing da
empresa.
Segundo Grisi et al. (2001), para uma tomada de decisão mais assertiva, os
executivos necessitam de informações sobre o ambiente de marketing, tais como,
informações sobre o consumidor, dos concorrentes e das forças macro ambientais
que possam interagir com as empresas e seus produtos, cujo papel era atribuído à
pesquisa de mercado, registros internos à empresa e fontes de inteligência de
marketing. Para Mattar (2008), as principais informações que um gerente de
marketing necessita precisa incluir elementos sobre os consumidores (desejos,
necessidades, motivações e hábitos), ações e atividades da concorrência, evolução
do mercado, evolução das vendas e lucros da empresa, recursos disponíveis da
empresa e comportamento das variáveis ambientais (legislações, economia, grupos
de interesse, etc.). Percebe-se entre os autores uma unanimidade em subdividir as
informações em fontes internas e externas à empresa, ou seja, tanto os dados de
entrada do SIM como as informações resultantes do processamento desses têm sua
origem e destino o ambiente interno e externo.
Para Chiusoli (2005), é necessário conhecer a importância de determinado
tipo informação para selecionar a melhor estratégia para coletá-la, no entanto o
autor relaciona três problemas comumente encontrados nas empresas a esse
respeito. No primeiro é apresentado que muitas vezes a empresa dispõe de grande
quantidade de informações, no entanto, ela é de baixa qualidade, o que compromete
todo o processo de tomada de decisão. O segundo problema é que mesmo
28
dispondo de muitas informações de boa qualidade, o gestor não percebe a
importância de seu uso e toma decisões baseadas apenas em sua intuição ou
experiência própria. E por último, mesmo que o gestor veja a necessidade de utilizar
a boa informação armazenada, utiliza de forma incorreta, seja por incapacidade de
coletar os dados certos ou mesmo interpretá-los erroneamente. O autor conclui
argumentando que os gestores se queixam que as informações estão muitas vezes
dispersas ou em documentos sem clareza analítica.
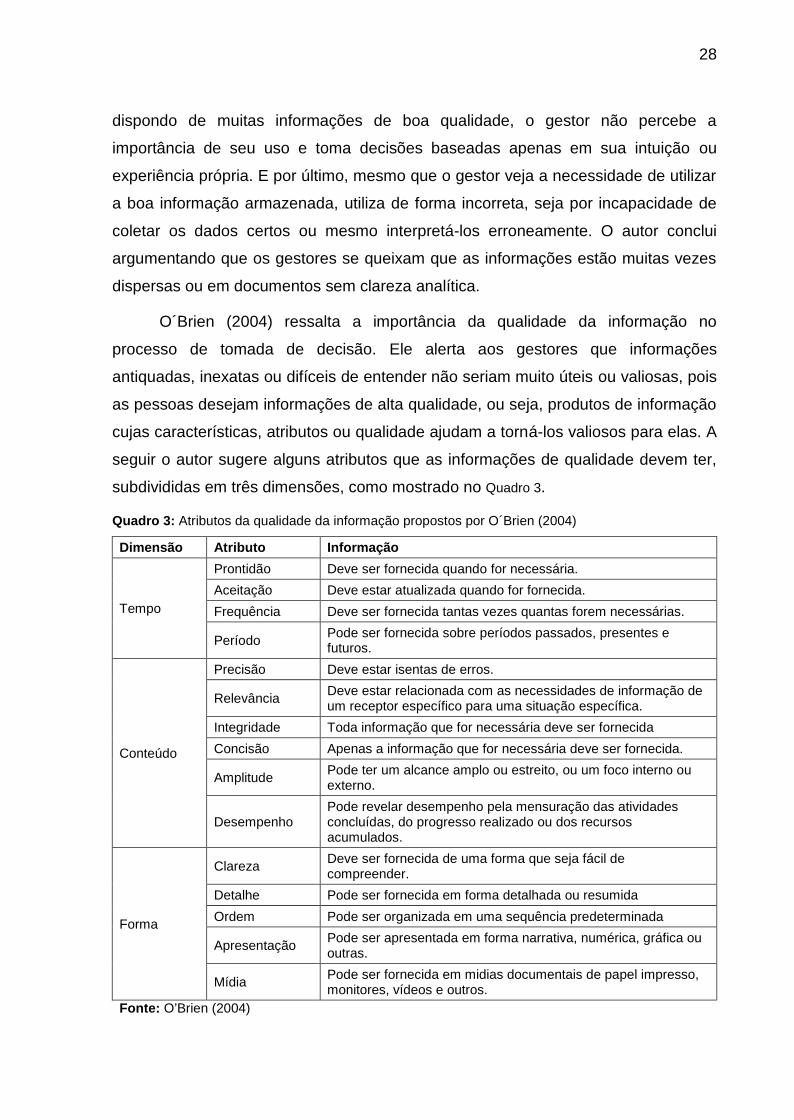
O´Brien (2004) ressalta a importância da qualidade da informação no
processo de tomada de decisão. Ele alerta aos gestores que informações
antiquadas, inexatas ou difíceis de entender não seriam muito úteis ou valiosas, pois
as pessoas desejam informações de alta qualidade, ou seja, produtos de informação
cujas características, atributos ou qualidade ajudam a torná-los valiosos para elas. A
seguir o autor sugere alguns atributos que as informações de qualidade devem ter,
subdivididas em três dimensões, como mostrado no Quadro 3.
Quadro 3: Atributos da qualidade da informação propostos por O´Brien (2004)
Dimensão Atributo Informação
Tempo
Prontidão Deve ser fornecida quando for necessária.Aceitação Deve estar atualizada quando for fornecida.Frequência Deve ser fornecida tantas vezes quantas forem necessárias.
Período Pode ser fornecida sobre períodos passados, presentes efuturos.
Conteúdo
Precisão Deve estar isentas de erros.
Relevância Deve estar relacionada com as necessidades de informação deum receptor específico para uma situação específica.
Integridade Toda informação que for necessária deve ser fornecidaConcisão Apenas a informação que for necessária deve ser fornecida.
Amplitude Pode ter um alcance amplo ou estreito, ou um foco interno ouexterno.
DesempenhoPode revelar desempenho pela mensuração das atividadesconcluídas, do progresso realizado ou dos recursosacumulados.
Forma
Clareza Deve ser fornecida de uma forma que seja fácil decompreender.
Detalhe Pode ser fornecida em forma detalhada ou resumidaOrdem Pode ser organizada em uma sequência predeterminada
Apresentação Pode ser apresentada em forma narrativa, numérica, gráfica ououtras.
Mídia Pode ser fornecida em midias documentais de papel impresso,monitores, vídeos e outros.
Fonte: O’Brien (2004)

29
Diante da necessidade de informação adequada, o marketing desponta como
a área funcional da empresa que mais se integra com as demais do ambiente
interno, como também se relaciona com as variáveis ambientais externas
(CHUISOLI, 2005). Percebe-se assim que muitas organizações entendem que a
forma mais adequada de prover informações de marketing para os tomadores de
decisão é a partir da estruturação de um sistema de informação de marketing (SIM),
mesmo que a prática, muitas vezes, não condiz com a teoria.
2.3.1 Fontes dos dados e informações
Como já foram mostrados, os autores de marketing concordam que os dados
e informações mais comuns do SIM se originam dos ambientes internos e externos à
organização (MATTAR, 2008; GRISI et al, 2001; WIERENGA E BRUGGEN, 2000,
CHIUSOLI, 2005). Em sua maioria defendem como fontes internas as áreas que
fazem parte da organização, enquanto as externas são as demais fontes.
(CRESCITELLI, OLIVEIRA e BARRETO, 2007).
A origem das informações do ambiente interno é apresentada por Wierenga
(2000) como sendo os departamentos de Marketing, Contabilidade, Vendas e
Operações. Para Kotler (2000), os departamentos responsáveis pelas informações
internas são o da contabilidade, marketing e atendimento ao cliente. Para o autor, a
maior vantagem das fontes internas é a rapidez e o baixo custo no acesso à
informação, no entanto, ela pode está desatualizada ou serem inadequadas aos
objetivos pretendidos. Para Crescitelli, Oliveira e Barreto (2007), as principais fontes
externas são a Internet, feiras do setor, concorrentes, funcionários dos concorrentes
ou até mesmo o lixo dos concorrentes.
As fontes de informação podem ser classificadas, segundo Dou (1995 apud
Periotto, 2010), em quatro tipos:
• Formal – composta de informações estruturadas, essas fontes são
encontradas geralmente em bancos de dados internos e utilizadas em
sistemas inteligentes para processar informações. Periotto (2010)
exemplifica que as fontes de informação formais podem ser: anais de
congressos, artigos, base de dados, catálogos e manuais, clipping,

30
institutos de pesquisa, jornais, legislação, livros especializados, normas
técnicas, patentes, relatórios técnicos, revistas especializadas e teses e
dissertações.
• Informal – geralmente textos ou conversas informais obtidas de clientes,
fornecedores e concorrentes. Por se tratar de dados não estruturados é
necessário realizar um tratamento adequado para serem utilizadas. Como,
por exemplo, Periotto (2010) cita: blogs, congressos e seminários, clientes,
empresas, especialistas, fornecedores, e-mail, funcionários, exposições e
feiras, fóruns e discussão, Internet, prestadores de serviços e redes
pessoais.
• Especializada – trata-se de informações personalizadas e úteis para a
empresa oriundas das pessoas internas à organização. Os dados obtidos
precisam ser analisados e processados para serem utilizados;
• Externa - referente a informações oriundas de eventos externos à
organizações, como por exemplo feiras, congressos e conferências. Os
dados precisam ser explicitados e analisados.
Quanto aos tipos de informações, Valentim (2006) classifica em nove
tipologias informacionais que atendem de forma específica as necessidades das
empresas para tomadas de decisões ou para operações cotidianas. São elas:
• Informação Estratégica: São utilizadas para auxiliar na alta administração
da empresa para formulação de estratégicas de médio e longo prazo.
Miranda (1999) reforça que esse tipo de informação é aquela obtida do
monitoramento do ambiente empresarial, a qual subsidia a formulação de
estratégias pelos tomadores de decisão nos níveis gerenciais da
organização.
• Informação de Negócio: Utilizadas para observar oportunidades e
ameaças no ambiente do negócio corporativo e também para os níveis
gerenciais da empresa definir ações de curto prazo.
• Informação Financeira: Auxilia os profissionais da área financeira nas
atividades de custo, lucro, riscos e controle.
• Informação comercial: auxilia os profissionais da área do comércio nos
processos relacionais à importação ou exportação de materiais, produtos
ou serviços.

31
• Informação Estatística: apresentam dados estatísticos que ajudam a
identificar padrões por meios estudos comparativos e séries históricas com
percentuais e números relacionados aos negócios da empresa.
• Informação sobre gestão: voltada aos gerentes e executivos no
planejamento e gestão dos projetos, gestão de pessoas etc.
• Informação tecnológica: auxiliam os profissionais de P&D fornecendo
dados de inovação tecnológica no desenvolvimento de novos produtos,
materiais e processos por meio do monitoramento da concorrência e do
mercado tecnológico.
• Informação Geral: são informações que não foram classificadas nas
outras tipologias e que ajudam nas tomadas de decisões em todo o âmbito
organizacional.
• Informação ‘Cinzenta’: Caracterizada pelo grau de dificuldade de obtê-la,
são informações não convencionais e desestruturadas. Por não ter um
formato bem definindo, esse tipo de informação geralmente é obtido
informalmente por meio de redes de relacionamentos.
No contexto desta pesquisa, ao retratar a importância de informações para
tomadas de decisões estratégicas, principalmente no uso de coleta de dados
automatizados da Internet, será necessário se aprofundar nas informações do tipo
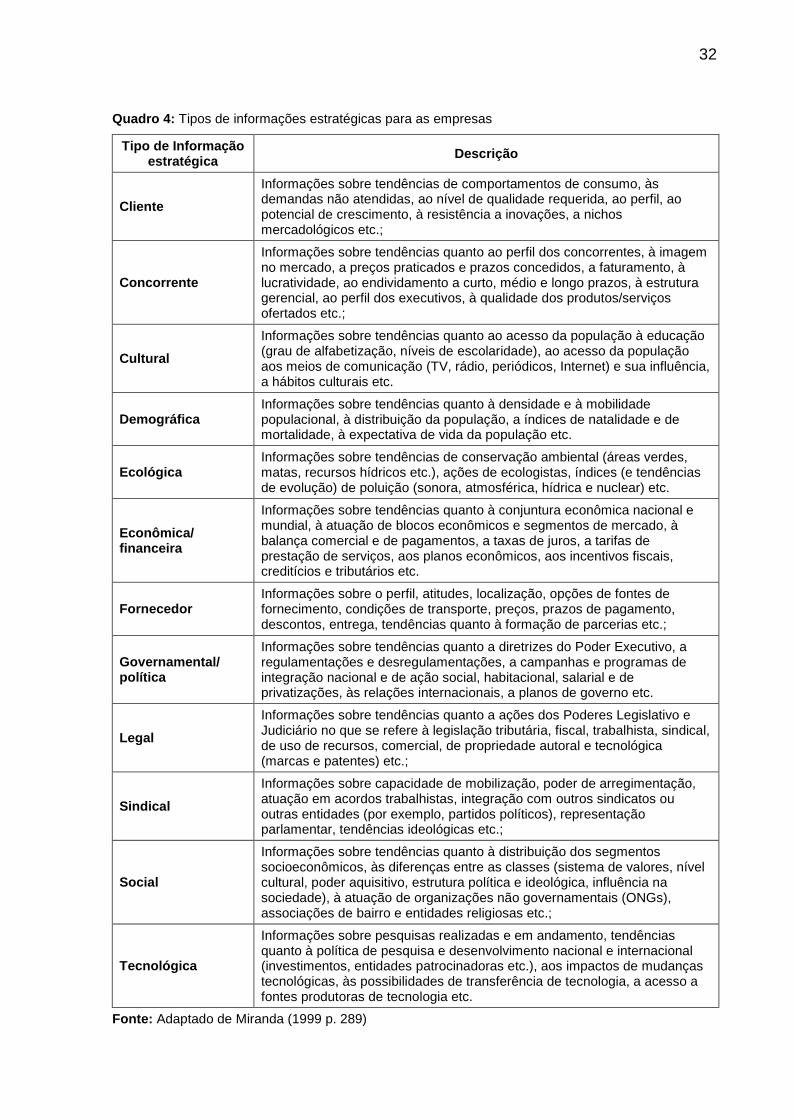
estratégicas, defendida por Miranda (1999) como cruciais para o amadurecimento da
organização a longo prazo. O autor destaca treze (13) tipos de informações
estratégicas que as empresas precisam estar atentas para utilizá-las em suas
tomadas de decisões. O Quadro 4 relaciona os tipos de informação estratégica
apresentada por Miranda (1999).
32
Quadro 4: Tipos de informações estratégicas para as empresas
Tipo de Informaçãoestratégica Descrição
ClienteInformações sobre tendências de comportamentos de consumo, àsdemandas não atendidas, ao nível de qualidade requerida, ao perfil, aopotencial de crescimento, à resistência a inovações, a nichosmercadológicos etc.;
Concorrente
Informações sobre tendências quanto ao perfil dos concorrentes, à imagemno mercado, a preços praticados e prazos concedidos, a faturamento, àlucratividade, ao endividamento a curto, médio e longo prazos, à estruturagerencial, ao perfil dos executivos, à qualidade dos produtos/serviçosofertados etc.;
CulturalInformações sobre tendências quanto ao acesso da população à educação(grau de alfabetização, níveis de escolaridade), ao acesso da populaçãoaos meios de comunicação (TV, rádio, periódicos, Internet) e sua influência,a hábitos culturais etc.
DemográficaInformações sobre tendências quanto à densidade e à mobilidadepopulacional, à distribuição da população, a índices de natalidade e demortalidade, à expectativa de vida da população etc.
EcológicaInformações sobre tendências de conservação ambiental (áreas verdes,matas, recursos hídricos etc.), ações de ecologistas, índices (e tendênciasde evolução) de poluição (sonora, atmosférica, hídrica e nuclear) etc.
Econômica/financeira
Informações sobre tendências quanto à conjuntura econômica nacional emundial, à atuação de blocos econômicos e segmentos de mercado, àbalança comercial e de pagamentos, a taxas de juros, a tarifas deprestação de serviços, aos planos econômicos, aos incentivos fiscais,creditícios e tributários etc.
FornecedorInformações sobre o perfil, atitudes, localização, opções de fontes defornecimento, condições de transporte, preços, prazos de pagamento,descontos, entrega, tendências quanto à formação de parcerias etc.;
Governamental/política
Informações sobre tendências quanto a diretrizes do Poder Executivo, aregulamentações e desregulamentações, a campanhas e programas deintegração nacional e de ação social, habitacional, salarial e deprivatizações, às relações internacionais, a planos de governo etc.
LegalInformações sobre tendências quanto a ações dos Poderes Legislativo eJudiciário no que se refere à legislação tributária, fiscal, trabalhista, sindical,de uso de recursos, comercial, de propriedade autoral e tecnológica(marcas e patentes) etc.;
SindicalInformações sobre capacidade de mobilização, poder de arregimentação,atuação em acordos trabalhistas, integração com outros sindicatos ououtras entidades (por exemplo, partidos políticos), representaçãoparlamentar, tendências ideológicas etc.;
Social
Informações sobre tendências quanto à distribuição dos segmentossocioeconômicos, às diferenças entre as classes (sistema de valores, nívelcultural, poder aquisitivo, estrutura política e ideológica, influência nasociedade), à atuação de organizações não governamentais (ONGs),associações de bairro e entidades religiosas etc.;
Tecnológica
Informações sobre pesquisas realizadas e em andamento, tendênciasquanto à política de pesquisa e desenvolvimento nacional e internacional(investimentos, entidades patrocinadoras etc.), aos impactos de mudançastecnológicas, às possibilidades de transferência de tecnologia, a acesso afontes produtoras de tecnologia etc.
Fonte: Adaptado de Miranda (1999 p. 289)

33
Quanto ao formato de apresentação da informação estratégica, Freitas, Lesca
e Cunha Jr. (1996) revela que precisa ser apresentada de forma resumida por meio
de quadros, tabelas e gráficos. Pelo fato da necessidade de tomar decisões a nível
global da empresa, o gerente estratégico precisa do entendimento do contexto em
que a organização está inserida, principalmente as informações de origem do
ambiente.
Conhecer o tipo de fonte de informação estratégica adequada à empresa é
importante, mas não é suficiente para realizar um planejamento subsidiado por
informações importantes. Após as etapas de identificar as necessidades, coletar e
tratar as informações, é necessário realizar uma das etapas mais críticas no
processo que é a análise da informação, que tem o objetivo de criar a inteligência
para a tomada de decisão (PERIOTTO, 2010). Para realizar a análise das
informações os gestores têm o auxilio de métodos que favorecem a utilização de
informações analisadas tais como: benchmarking, cenários, fatores críticos de
sucesso, forças de Porter, análise SWOT, análise de patentes, bibliometria, método
Delphi, além de ferramentas estatísticas como as análises de correlação e variância.
Barbosa (2002) apresenta um estudo sobre o processo de monitoramento do
ambiente organizacional externo sob a ótica de 91 empresários. Dentre os pontos
pesquisados foram os tipos de informação que os gestores utilizam para gerar uma
vantagem competitiva. Os resultados mostraram que as fontes de informação
eletrônicas são as mais utilizadas em decorrência do aumento do grau de
informatização das empresas, contudo nem sempre são mais confiáveis ou
relevantes. Em contrapartida, as fontes pessoais são menos utilizadas, entretanto
são mais confiáveis.
O mesmo autor, em 2006 realizou uma comparação entre os profissionais de
empresas de pequeno porte e as de grande porte. Foram avaliadas as fontes de
informação a respeito do ambiente organizacional. O autor revela que os dados
apresentados sugerem certa pobreza de dados informacionais das empresas de
pequeno porte em relação às grandes empresas, ou seja, os profissionais de
empresas de grande porte tem um maior acesso aos dados informacionais que os
de pequeno porte. Além disso, o nível de confiabilidade dos dados adquiridos é
menor em pequenas empresas (BARBOSA, 2006).

34
Em sua pesquisa, Krakauer (2011) procurou identificar como os empresários
brasileiros e americanos de pequenas e médias empresas utilizam as informações
do ambiente durante o processo de tomada de decisão estratégica. Foi detectado
que os empresários americanos trabalham com uma abordagem mais racional,
usando a informação formal do ambiente no processo do negócio. Já o brasileiro
procura utilizar mais a experiência, a intuição e o compartilhamento com a família
sobre suas decisões empresariais. Esse utiliza as fontes de informação informal e
com pouco auxílio de recursos tecnológicos.
Leone (1999) retrata que as empresas de pequeno e médio porte têm muitas
especificidades que as diferenciam das grandes corporações. A autora categoriza as
diferenças em três construtos: organizacionais, decisionais e individuais dos
gestores. Sobre as especificidades organizacionais essas empresas apresentam
pobreza de recursos, gestão centralizada, situação extra organizacional
incontrolável, fraca maturidade organizacional, estrutura simples e leve, ausência de
planejamento formal, fraca especialização, estratégia intuitiva, pouca formalidade e
sistema de informações simples. Sobre as especificidades decisionais as PMEs
apresentam tomadas de decisão baseada na intuição, horizonte temporal de curto
prazo, inexistência de dados quantitativos, alto grau de autonomia decisional,
racionalidade econômica, política e familiar. E por último, quanto às características
individuais das empresas elas apresentam onipotência do proprietário-dirigente,
identidade entre pessoa física e pessoa jurídica, dependência por parte dos
empregados, influência pessoal do proprietário-dirigente, simbiose entre patrimônio
social e patrimônio pessoal, propriedade dos capitais e propensão a riscos
calculados.
Ricci (2011) retrata as especificidades das pequenas empresas sob a
perspectiva de três dimensões ilustrada na Figura 3. Relacionados ao dirigente, as
principais características são: centralizador, baixo nível de especialização, pouco
conhecimento sobre ferramentas administrativas, exerce várias atividades e se
responsabiliza pela formulação da estratégica. As características relacionadas à
organização, as pequenas empresas são empresas pouco sofisticadas, com
estrutura simples, baixa complexidade nas estruturas organizacionais, dependem
dos interesses e anseios do seu dirigente, poder de decisão centralizada no
proprietário e pouca formalização. O ambiente organizacional caracteriza-se pela

35
falta de capital para investimento como tecnologia, impostos elevados, pouco acesso
à informação, falta de controle sobre variáveis ambientais, apoio governamental
escasso, carência de treinamento e falta de conhecimento sobre o ambiente interno
e externo por parte do gestor.
Fonte: Ricci (2011, p. 8)
2.3.2 Coleta de dados na internet
Coletar dados primários e secundários com rapidez e custo baixo pode ser
considerado um grande desafio na busca de uma informação relevante para uma
tomada de decisão. Encontrar um ambiente que tenha capacidade de fornecer uma
coleção de dados grande o suficiente para extrair informações a qualquer momento
se torna necessário para tomar decisões que estejam mais alinhadas com os
desejos dos consumidores (YAMASHITA, 2003). A Internet é considerada um
veículo que fornece os mais diversos conteúdos com um fluxo contínuo de
informações que podem ser coletadas a qualquer momento e muitas vezes de graça.
Crescitelli, Oliveira e Barreto (2007) considera a Internet um fator de impacto para os
Sistemas de Informação de Marketing, trazendo uma velocidade sem precedentes
para o acesso aos dados que as empresas procuram tais como as opiniões de
consumidores, empresas, concorrentes, indústria, governo dentre outros. Para os
autores, o problema reside no reconhecimento da autoria desse conteúdo
disponibilizado, tornando mais difícil a avaliação da sua confiabilidade, apesar dos
inúmeros sistemas de segurança da informação atualmente existentes.
Figura 3: Dimensões das especificidades de gestão da pequena empresa
Organização Contexto
Dirigente
Gestão daPequenaEmpresa

36
A Internet é um repositório de informações de hipermídia e banco de dados
que é apresentada por Magalhães T. (2009) como uma fonte de matéria-prima
amplamente distribuída e heterogênea. Com a democratização deste canal na última
década, a informação disponibilizada na Web deixou de ser estritamente alimentada
por empresas e indivíduos especializados em divulgação de conteúdo e passou a
ser alimentada por usuários comuns, muitas vezes sem muito entendimento do
linguajar técnico que outrora era utilizado pelos webmasters. Os usuários passaram
então a se preocupar somente com o conteúdo das informações e não com o seu
layout. Com a Web notam-se avanços na aproximação das pessoas, agregadas em
comunidades com interesses comuns e vínculos de socialização da informação, não
apenas para compartilhamento de conhecimento, mas também na execução de
atividades efetivamente laborais (PEDOTT, 2001).
A obtenção de informações na Web sobre consumidores e concorrentes pode
trazer alguma vantagem competitiva para a empresa. Wives (2002) afirma que os
empresários precisam estar sempre informados, diminuindo assim os riscos,
antecipando as crises e obtendo informações antes de seus concorrentes. O autor
afirma que é preciso monitorar sempre os elementos internos e externos à empresa,
tais como, clientes, fornecedores, concorrentes, produtos, tecnologias e mercados.
Apesar de haver um consenso da necessidade de integração de coleta de dados em
fontes internas e externas, percebe-se que a maior parte da informação não está
armazenada em banco de dados internos, mas em fontes externas às empresas.
Percebe-se que dinamismo com que a informação é disponibilizada pelos
usuários aumenta a quantidade de dados armazenados no repositório da Internet,
no entanto, esses dados estão dispersos, ocultando uma quantidade ilimitada de
informações que podem auxiliar no processo de tomada de decisão. Para que haja
um real aproveitamento de toda a quantidade de dados é necessário transformá-lo
em informação. Obter informações manualmente da Internet pode não ser uma
tarefa simples, pois exige habilidade em pesquisar os termos corretos, no lugar e no
momento certo. Pelo fato dos dados na Internet estarem espalhadas de forma não
estruturada, coletar as opiniões que os usuários estão constantemente
compartilhando na rede se faz necessário a utilização de algum mecanismo
automatizado de coleta de dados.

37
3 MINERAÇÃO WEB
A mineração Web ou Web mining é um ambiente de mineração de textos, que
por sua vez é um processo de obtenção de conhecimento originados a partir de
bases de dados textuais, ou seja, documentos que possuem pouca ou nenhuma
estrutura de dados (ARANHA, 2007). Mineração Web é referenciada quando o foco
é a coleta de informações no ambiente da Internet, no qual o objetivo é utilizar as
técnicas de mineração de texto para extrair conhecimento útil do conteúdo
disponibilizado em documentos não estruturados ou semiestruturados (LAU et al.,
2004). Os autores argumentam que, embora a mineração Web possa extrair dados
estruturados (mineração de dados ou data mining), a maior parte do conteúdo
encontrado na Internet é composta por dados textuais, gerando assim a
necessidade de explorar mais o processo de mineração de texto ao invés da
mineração de dados.
Scotto, Silliti e Vernazza (2004) definem mineração Web como um processo
de descoberta e analise de informações úteis em documentos na Internet,
envolvendo técnicas e aproximação baseadas na mineração de dados orientados ao
descobrimento e extração automática de informações em documentos e serviços na
Internet, considerando o comportamento e preferência do usuário. Em contrapartida,
Lau et al (2004) definem mineração Web como um processo de recuperação e
conversão de informação de texto (text mining) contido nas páginas em uma base de
dados organizada contendo variáveis chave de interesse para melhor entender
clientes.
Para Fernandes (2007), as empresas tem utilizado a mineração Web não
somente para analisar a estrutura de suas páginas, mas principalmente para
detectar as características das pessoas que as visitam, de forma a descobrir
interesses e poder oferecer produtos e serviços adequados aos desejos de seus
clientes. Para Koblitz (2010), a mineração Web pode poupar que as empresas
gastem tempo e dinheiro fazendo pesquisas sobre pontos de seus interesses, extrair
opiniões de pessoas que influenciam outras através de redes sociais e fazer uma
análise em tempo real do que as pessoas pensam. Guedes, Afonso e Magalhães
(2010) compartilham esse mesmo pensamento, pois “o que os outros pensam” pode

38
ser uma importante fonte para a maioria dos tomadores de decisão quando filtradas
e analisadas de forma adequada na Internet.
3.1 CATEGORIAS DA MINERAÇÃO WEB
De acordo com Kosala e Blockeel (2000), a mineração Web pode ser dividida
em três sub-áreas: Mineração de estrutura (Web Structure Mining), Mineração de
uso (Web usage mining) e mineração de conteúdo (Web content mining), como
observado na Figura 4.
Figura 4: Categorias da Mineração Web
Fonte: Kosala e Blockeel (2000)
De acordo com Liu (2007), a mineração de estrutura procura descobrir
conhecimento útil de hiperlinks, que representa a estrutura dos sites. O autor
exemplifica, mostrando que é possível encontrar importantes páginas na Web por
meio dos links, que incidentemente, é a tecnologia fundamental para os motores de
busca, como o Google e descobrir também comunidades virtuais, onde os usuários
compartilham interesses comuns, como o Orkut e Facebook. Segundo Shi, Ma e He
(2009), a mineração de estrutura Web procura descobrir o modelo subjacente das
estruturas dos links da Web, pois é baseado na característica de hyperlinks, que
pode ser usado para categorizar páginas Web e ser útil na geração de informações
similares e relacionadas entre diferentes sites. Ainda de acordo com a autora, esse
tipo de abordagem é interessante, pois a Internet tem mais informações
armazenadas sobre a estrutura dos dados do que mesmo sobre seu conteúdo em si.
Esta categoria, portanto, é o processo que tenta descobrir o modelo que está por
MineraçãoWeb(Web mining)
Mineração de EstruturaWeb
(Web Structure Mining)
Mineração de uso naWeb
(Web Usage Mining)
Mineração de ConteúdonaWeb
(Web Content Mining)

39
trás dessa estrutura de links, ou seja, o processo de inferir conhecimento através da
topologia, organização e estrutura de links da Web entre referências de páginas.
Essa categoria refere-se à descoberta de padrões de acesso de usuários na
Web, que registra todo o clique feito por cada usuário (LIU, 2007). Para isso são
utilizados arquivos de log, no qual são coleções de dados bem estruturados que
registra cada passo do usuário nos sites e que ficam armazenados nos servidores
de Internet (LAU et al, 2004). Para a autora, a descoberta de padrões de acesso é
realizada através de análise de interação do usuário com páginas Web e está focada
em técnicas que possam descrever e predizer o comportamento do usuário no
momento de interação com o site. Um exemplo de utilização dessa técnica é a
descoberta do perfil do usuário que pode ser útil na personalização da interface ou
do conteúdo, de forma a ajudar o site a atingir seu objetivo. Também pode ser
utilizado no marketing para saber quem frequenta determinado site e qual o
comportamento e interesse deste.
A mineração de conteúdo é uma categoria bastante utilizada na mineração
Web, pois a maior parte do conteúdo da Web se encontra no formato com pouca ou
sem estrutura, como documentos HTML, tabelas e etc. (LAU et al., 2004). Esta
técnica procura descobrir informações úteis de conteúdo, dados e documentos da
Web, através da busca automática de informações. Para Cooley (2000), a mineração
de conteúdo na Web pode ser descrita como sendo a busca automática de recursos
e recuperação das informações disponíveis na Internet, como por exemplo, as
ferramentas de busca como a Google, Yahoo, Bing entre outros. Para Liu (2007), a
mineração de conteúdo permite encontrar mais facilmente o conteúdo localizado nas
páginas, podendo realizar um processo de coleta, mineração e integração de dados
úteis, informações e conhecimento de conteúdo nas páginas Web.
3.2 ETAPAS DA MINERAÇÃO DE CONTEÚDO NA WEB
Os autores sobre a mineração Web ainda não são consensuais em definir as
etapas desse procedimento. Os modelos propostos são baseados nas etapas da
mineração de texto tradicional, ficando na responsabilidade do analista da
informação aplicar as tarefas necessárias para cada mineração. A mineração de
conteúdo na Web é composta de três etapas: pré-processamento, processamento e

40
pós-processamento (PINHEIRO, 2009). O autor alerta que não necessariamente é
obrigado seguir todas as etapas, pois o processo de mineração de texto é feito e
refeito de forma cíclica e pode ser utilizado de acordo com o que se deseja alcançar
como objetivo da mineração.
3.2.1 Etapa de Pré-processamento
Essa etapa corresponde à preparação dos dados para serem processados
com as técnicas de mineração de texto. Para isso, será necessário realizar a coleta
e limpeza dos dados.
Coleta da informação3.2.1.1
A busca por opinião funciona como os algoritmos de Recuperação de
Informação (RI) na Web, no qual se deseja encontrar uma opinião sobre um
determinado objeto, por exemplo, um notebook, uma empresa, um evento, etc.
Dessa forma, a recuperação sobre esse assunto seria, por exemplo, opiniões sobre
a marca, as características e a relação custo/benefício sobre este objeto
(PINHEIRO, 2009). Segundo Manning, Raghavan e Schütze (2009), o objetivo da
etapa de RI é encontrar documentos de natureza não estruturada que satisfaz uma
necessidade de informação armazenada em computadores. Magalhães L. (2009)
apresenta que o objetivo da RI é recuperação documentos usando um critério
booleano simples que busca pela presença ou ausência de determinadas palavras-
chave ou termos nos documentos, não se preocupando com o formato como as
opiniões estão dispostas. Palavras-chave podem ser combinadas de disjunções
(OU) e conjunções (E), proporcionando, assim, mais expressividade nas consultas.
O resultado da consulta pelas palavras-chave é um volume grande e estruturado de
textos, chamado de corpus1. Segundo Koblitz (2010), o corpus pode ser utilizado
para posterior análise estatística, verificação de ocorrências e validação de regras
linguísticas considerando o universo específico.
1 O plural de corpus é denominado corpora.

41
Conversão de arquivos3.2.1.2
O corpus normalmente pode ser exportado para um arquivo em formato texto
(HTML, DOC, PDF) ou mesmo pode ser transferido em forma de planilha eletrônica
(XML, CSV). No entanto, de acordo com Ticom (2007), os dados coletados
originalmente são convertidos para o formato XML (eXtensible Markup Language)
que tem uma estrutura bastante adequada para tratar dados não estruturados como
texto para facilitar a sua manipulação.
Tokenização3.2.1.3
A tarefa de tokenização (tokenize) é transformar grandes textos em mínimas
unidades possíveis, chamada de tokens. Segundo Miranda (2009), esse processo é
importante por que um texto, para ter sentido para o leitor, precisa possuir um fluxo
ordenado de palavras que seguem as normas linguísticas de um idioma, entretanto,
o computador não as entende assim. Para conseguir extrair características do texto,
a máquina precisa manipular pequenos fragmentos de texto. O autor afirmar que na
maioria das vezes, o token corresponde a uma palavra do texto, podendo também
estar relacionado a mais de uma palavra, símbolo ou caractere de pontuação. O que
diferencia um token do outro são os espaços entre eles e frequentemente os
algoritmos que executam a divisão do texto em tokens utilizam o espaço como
delimitador. Esse procedimento requer cuidado na execução da tarefa, pois na
língua portuguesa existem palavras compostas que ao serem separadas possam a
ter significados diferentes. As tarefas realizadas na tokenização são as seguintes, de
acordo com Ticom (2007):
o Case Folding (Transformação de letras): É um procedimento que
padroniza todas as palavras do texto em maiúscula ou minúscula.
Palavras idênticas diferenciadas pelo formato da letra pode confundir a
máquina na separação dos tokens. Transformando as palavras em um só
formato possibilita maior rapidez no processo de comparação de
caracteres (ver exemplo na Figura 5). Essa tarefa é muito importante para a
etapa de tratamento estatístico, no qual palavras com o mesmo nome,
diferenciando-se somente pela presença ou ausência de palavras
maiúscula, pode causar erro na interpretação do resultado.

42
Figura 5: Exemplo de aplicação de Case Folding
Fonte: Autoria própria
o Stopword/Stoplist (Retirada de palavras desnecessárias): As
stopwords são palavras de maior aparição no texto e, normalmente,
correspondem aos artigos, preposições, pontuação, conjunções,
pronomes e numerais de um idioma. A identificação e remoção desta
classe de palavras reduzem de forma considerável o tamanho final do
texto léxico, tendo como consequência benéfica o aumento de
desempenho do sistema como um todo (MAGALHÃES L., 2008). No
entanto, com a remoção de certos termos gramaticais causa uma perda no
sentido semântico do texto. Se a análise feita no texto for uma análise
qualitativa esta técnica não será útil, caso o objetivo é realizar uma análise
quantitativa (estatística) esta técnica poderá ser aplicada. O conjunto de
stopwords é denominado stoplist. Pinheiro (2009) apresenta em sua
pesquisa uma stoplist voltada para a língua portuguesa, que incluir
expressões regulares para remoção de email, datas, tempo, números,
valores financeiros e caracteres especiais. A Figura 6 mostra um exemplo
da aplicação da remoção de uma stoplist em um texto.
Figura 6: Exemplo da aplicação de stoplist
Fonte: Autoria própria
o Stemming (redução ao menor radical de cada palavra): Essa tarefa é
responsável por reduzir as diversas formas de um termo a uma forma
Em geral, as reações dosconsumidores às apelaçõesVERDES das empresas ocorrem emdetrimento do oferecimento deVantagens desejadas de custosmenores e desempenhos Melhores.
em geral, as reações dosconsumidores às apelações verdesdas empresas ocorrem emdetrimento do oferecimento devantagens desejadas de custosmenores e desempenhos melhores.
Em geral, as reações dosconsumidores às apelações verdesdas empresas ocorrem emdetrimento do oferecimento devantagens desejadas de custosmenores e desempenhos melhores.
geral reações consumidoresapelações verdes empresas ocorremdetrimento oferecimento vantagensdesejadas custos menoresdesempenhos melhores

43
comum (raiz) denominada stem (MORGADO JÚNIOR, 2008). Um stem é
um grupo natural de termos que compartilham interpretações semânticas
iguais ou similares (ver Figura 7). Além da eliminação dos prefixos e
sufixos, características de gênero, número e grau das palavras são
eliminadas. Isso significa que várias palavras acabam sendo reduzidas
para um único termo, o que pode reduzir o tamanho de um índice em até
50%, segundo Miranda (2009). Da mesma forma da tarefa de remoção de
stopword, com a aplicação do stemming, o texto perde seu sentido
semântico, entretanto, reduz-se bastante a quantidade dos tokens, sendo
possível realizar uma análise estatística com menos dados redundantes.
Figura 7: Exemplo de aplicação de Stemming
Fonte: Autoria própria
o Dicionário de dados (Thesaurus): É uma alternativa para melhorar os
resultados da aplicação, diminuindo também a quantidade de tokens
gerados. Esta tarefa utiliza-se de um dicionário de sinônimos que
correlaciona palavras diferentes e comuns a uma única palavra em todo o
texto. O objetivo, de acordo com Morgado Júnior (2008) é montar uma
relação de várias palavras para uma única palavra que possa substituí-la
sem alterar o contexto. Um exemplo seria a palavra “planta”, “árvore”,
“vegetal” poderiam ser padronizada em uma única palavra.
o N-grama (n-gram): É um método alternativo utilizado principalmente para
detectar erros ortográficos (MIRANDA, 2009). A ideia consiste em
identificar as sub-cadeias de tamanho n dos tokens encontrados no texto.
Por exemplo, a partir da palavra “poluir” e considerando n = 5, obtêm-se
as seguintes 5-grams: “_polu”, “polui”, “oluir” e “luir_”, onde “_” é usado
para indicar o início ou fim da palavra. Os erros ortográficos mais comuns
só afetam poucos constituintes de n-grama, então, é possível buscar pela
RECICLAGEMRECICLANDORECICLADORECICLARRECICLORECICLA
Seis termos
RECICL
Um termo

44
palavra correta através daqueles que compartilham a maior parte dos n-
gramas com a palavra errada. O objetivo é manter uma lista de n-gramas
que apontam para as palavras que o contém. Quando a palavra é
procurada, os n-gramas são processados e procurados no índice. A
palavra que apresentar o maior número de n-gramas associado será a de
maior relevância, indicando um possível candidato para correção
(ARANHA, 2006).
3.2.2 Etapa de Processamento (Tarefas da Mineração de texto)
A etapa de processamento contém tarefas que permitem extrair conhecimento
na forma de regras (por mecanismos de indução) e na forma de informação (por
dedução). Magalhães L. (2009) argumenta que a mineração de conteúdo na Web
utiliza as técnicas de mineração de texto, tais como a indexação, extração de
informações, lexicometria, clustering e classificação.
Indexação3.2.2.1
O objetivo principal da indexação dos textos é facilitar a identificação de
similaridade de significado entre suas palavras, considerando as variações
morfológicas e problemas com sinônimos (TICOM, 2007). Indexar significa identificar
as características de um documento e colocá-las em uma estrutura denominada
índice. De acordo com Miranda (2009), o processo de indexação pode ser manual,
no qual o analista fica encarregado de analisar o conteúdo de cada documento e
identificar as palavras-chave que o caracterizem, e o segundo é o processo
automático que passa por uma série de etapas de processamento para gerar um
arquivo de índice.
Segundo Miranda (2009), a primeira etapa da indexação automática procura
identificar as palavras ou as fronteiras das palavras feitas frequentemente por um
caractere em branco (espaço). A segunda elimina as palavras desnecessárias de um
texto (stopwords), em seguida, a terceira executa um procedimento de redução dos
termos ao seu menor radical, o stemming. A quarta é responsável pela detecção de
termos compostos, isto é, termos com mais de uma palavra. E por fim, esses termos
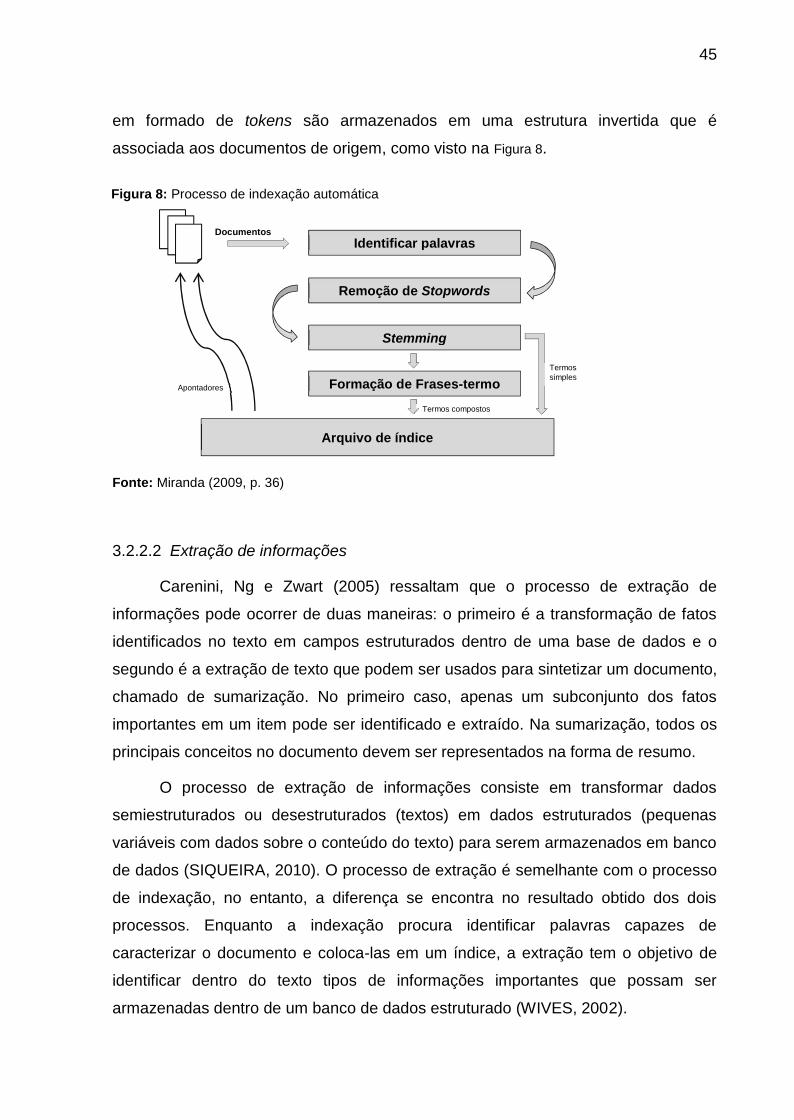
45
em formado de tokens são armazenados em uma estrutura invertida que é
associada aos documentos de origem, como visto na Figura 8.
Fonte: Miranda (2009, p. 36)
Extração de informações3.2.2.2
Carenini, Ng e Zwart (2005) ressaltam que o processo de extração de
informações pode ocorrer de duas maneiras: o primeiro é a transformação de fatos
identificados no texto em campos estruturados dentro de uma base de dados e o
segundo é a extração de texto que podem ser usados para sintetizar um documento,
chamado de sumarização. No primeiro caso, apenas um subconjunto dos fatos
importantes em um item pode ser identificado e extraído. Na sumarização, todos os
principais conceitos no documento devem ser representados na forma de resumo.
O processo de extração de informações consiste em transformar dados
semiestruturados ou desestruturados (textos) em dados estruturados (pequenas
variáveis com dados sobre o conteúdo do texto) para serem armazenados em banco
de dados (SIQUEIRA, 2010). O processo de extração é semelhante com o processo
de indexação, no entanto, a diferença se encontra no resultado obtido dos dois
processos. Enquanto a indexação procura identificar palavras capazes de
caracterizar o documento e coloca-las em um índice, a extração tem o objetivo de
identificar dentro do texto tipos de informações importantes que possam ser
armazenadas dentro de um banco de dados estruturado (WIVES, 2002).
Identificar palavras
Remoção de Stopwords
Stemming
Formação de Frases-termo
Arquivo de índice
Termos compostos
Documentos
Termossimples
Apontadores
Figura 8: Processo de indexação automática

46
O primeiro passo para a realização da extração é a definição de palavras que
devem ser extraídas. A identificação dessas palavras é feita através de marcadores
(tags) sintáticos ou semânticos que indicam a presença de uma informação
importante e que deve ser extraída.
Quanto à sumarização, Wives (2002) define como uma técnica que identifica
as palavras e frases mais importantes de um documento ou conjunto de documentos
com o objetivo de gerar um resumo ou sumário. Esse sumário proporciona uma
visão geral do conjunto de documentos e destaca as partes mais importantes e
interessantes. Desta forma o usuário pode identificar rapidamente o assunto
abordado por um documento ou conjunto de documentos sem ter que lê-lo(s) na
íntegra.
Os dados extraídos podem resultar nos seguintes objetos: (1) sumarização:
geração de um resumo; (2) centróide: lista de palavras que indica os temas ou
centros de interesse em torno de uma mesma informação. Esse centróide é
geralmente utilizado para representar o grupo. Essas palavras mais importantes
dariam para o usuário uma visão geral do assunto tratado no documento ou conjunto
de documentos. Esse formato de apresentação dos dados só ocorre após a
aplicação da técnica de clustering. (3) Passagem: identificação de trechos
relevantes.
Análise Lexicométrica3.2.2.3
A análise lexicométrica é uma técnica para tratamento estatístico de dados
qualitativos sob a ótica quantitativa para a caracterização topológica e combinatória
de elementos léxicos de um conjunto de dados textuais. Permite descobrir co-
relacionamentos e dados implícitos nos registros de um conjunto de documentos
pelo estudo e desenvolvimento de um processo de extração. Dentre as técnicas de
descoberta de conhecimento em bases textuais mais utilizadas no processo
lexicométrico existe a identificação de palavras mais frequentes presentes no
documento (WIVES, 2002). Esse tipo de análise serve para identificar o conteúdo
tratado em um documento ou um corpus. A identificação de palavras mais relevantes
de um texto é conseguida por meio da listagem das palavras ordenadas da mais

47
para a menos frequente. Assim, é possível identificar o assunto mais importante
dentro do conteúdo textual.
Para diferenciar as características mais relevantes de um texto utiliza-se a
atribuição de pesos. Esta técnica possibilita que as aplicações de mineração de
texto façam previsões utilizando vetores com uma quantidade grande de palavras ou
características (MANNING; RAGHAVAN; SCHÜTZE, 2009). Os três pesos mais
utilizados são:
• Binário – Esta medida de peso é a mais simples. O termo t recebe o valor
unitário true quando o mesmo é encontrado no documento d. De mesmo
modo, t recebe false caso não seja encontrado em d. Esta representação
é muito simples e deve ser utilizada dependendo do domínio.
• TF (Term Frequency): Essa medida probabilística define o número de
vezes que o termo t é encontrado no documento d. Os termos passam a
não fornecer informação relevante para a diferenciação de documentos
quando aparecem com frequência alta na maioria dos documentos.
• TF-IDF (Term Frequency – Inverse Document Frequency): Esta medida
probabilística atribui pesos que favorecem termos que ocorrem em
poucos documentos de uma seleção. O objetivo é computar a frequência
de um termo em um documento, levando em consideração sua
importância. Este efeito de importância se consegue através do fator idf,cuja finalidade é a de inverter a escala de um termo na medida em que a
sua presença nos documentos aumenta ou diminui.
A aplicação prática desse método nas pesquisas de marketing e inteligência
competitiva é a identificação de novos concorrentes que apareçam nas listagens, ou
mesmo o aparecimento de centros de interesse, tópicos mais relevantes, pessoas,
empresas, marcas mais comentadas (TELMA, 2011). É possível também obter uma
análise de tendência, caso seja aplicado determinados períodos de tempos para
verificar se determinada marca ou concorrente está sendo mais ou menos
frequentes nas postagens. Nas redes sociais, essa técnica é utilizada para identificar
as palavras mais frequentes em determinado período de tempo, tal como o Trending
Topic do Twitter (CUNHA, 2006).

48
Clustering3.2.2.4
O clustering (agrupamento ou conglomeração) é um método de descoberta de
conhecimento utilizado para classificar objetos ou casos em grupo relativamente
homogêneos, facilitando assim a identificação de classes semelhantes entre si, mas
diferentes de objetos em outras classes (MALHOTRA, 2001; WIVES, 2002). No caso
de documentos, o clustering identifica os documentos de assuntos similares e os
agrupam, gerando conjuntos de documentos semelhantes. Esse método é útil
quando não se tem uma ideia dos assuntos (das classes) tratados em cada
documento e deseja-se separá-los por assunto (WIVES, 2002).
Malhotra (2001) ressalta a importância desse método na pesquisa de
marketing, pois poderá ser utilizada para vários propósitos como a segmentação do
mercado. O autor exemplifica:
“Os consumidores podem ser agrupados com base nas vantagens queesperam da compra de um produto. Cada cluster consistiria emconsumidores relativamente homogêneos quanto ás vantagens queprocuram.” (MALHOTRA, 2001, p. 573)
Geralmente utilizada antes de um processo de classificação ou categorização,
o processo de clustering facilita a definição de classes, proporcionando ao analista
os co-relacionamentos entre os elementos de um conjunto de documentos e a
identificação de uma melhor distribuição de classes para os objetos selecionais. Ou
seja, não é necessário ter conhecimento prévio sobre os assuntos dos documentos
ou do contexto dos mesmos. Os assuntos e as classes dos documentos são
descobertos automaticamente pelo processo de agrupamento (WIVES, 2002).
O processo de agrupamento é precedido pela etapa de pré-processamento,
tais como transformações das letras para o formato minúsculo (case folding), a
retirada de termos desnecessários (stopwords) e a redução da palavra ao menor
radical (stemming).
Os agrupamentos em documentos de textos podem ser visualizados de duas
formas de agrupamento: partição disjunta ou grupos hierárquicos (TICOM, 2007). No
primeiro caso, um algoritmo de partição (k-means ou k-medoid) é aplicado à coleção
de documentos e estes são colocados em grupos distintos, geralmente não havendo
espécie alguma de relacionamento entre os grupos identificados. No segundo caso,
o processo aplica recursivamente os algoritmos hierárquicos (single-link ou average-
link) para a identificação de cluster e acaba gerando uma espécie de árvore, no qual

49
as folhas compreendem os grupos mais específicos e os nós intermediários
representam os grupos mais abrangentes. A Figura 9 mostra as representações
gráficas resultantes dos dois processos de agrupamento.
Fonte: Adaptado de Wives (2002)
Wives (2002) aborda as vantagens e desvantagens dessas duas topologias. A
topologia de partição disjunta não proporciona estruturas que indiquem co-
relacionamento entre grupos, não sendo possível identificar os assuntos mais
específicos e os mais abrangentes. Na segunda topologia, esse problema é
solucionado, pois oferece estruturas de navegação hierárquica entre os grupos,
facilitando a localização da informação. A desvantagem desse formato é a
necessidade de maior processamento dos dados e a complexidade da manutenção
dos clusters.
A análise de agrupamentos pode ter diversas aplicações em processamentos
de textos. Primeiro, a recuperação da informação textual é facilitada porque o
método desenvolvido consegue processar grande quantidade de documentos e
agrupá-los em clusters de documentos semelhantes. Podem também ser aplicados
no processo de descoberta de associações entre palavras, facilitando o
desenvolvimento de dicionários e thesaurus, que podem ser utilizados em
ferramentas de busca, expandindo consultas ou sistematizando a lista de palavras-
chave mais adequadas para coletar os dados. Outra aplicação é a utilização dos
grupos identificados em alguns processos de identificação de características
relevantes, capazes de identificar o padrão e, em diferentes períodos de tempo, as
tendências dos grupos (CAVALCANTI, 2011).
Partição disjunta Partição hierárquica
Figura 9: Tipos de agrupamentos

50
Classificação ou categorização3.2.2.5
A área de aplicação denominada como classificação tem por objetivo
identificar, por semelhança, cada novo documento como um dos tipos de categorias
(classes) previamente definidas (MATSUNAGA, 2007). A classificação de
documentos textuais, à priori, é uma técnica tipicamente realizada por humanos, que
leem o documento e classificam em categorias temáticas pré-definidas. Na Internet,
com o crescente número de documentos textuais sendo acrescentados e atualizados
fica impraticável a técnica manual, necessitando de automatização desse processo.
Ticom (2007) explica que a classificação de documentos pode ser dividida em
linear e não linear. Os classificadores lineares são mais simples e tem um modelo de
treinamento mais fácil de ser interpretado do que os modelos não lineares. Segundo
Morgado Júnior (2008), as categorias podem ser escolhidas para corresponder aos
tópicos ou temas dos documentos. Para o autor, alguns sistemas categorizadores
retornam uma única categoria para documento, enquanto outros retornam múltiplas
categorias. Nos dois casos, o resultado pode ser nenhuma categoria ou algumas
categorias com baixa confiabilidade. Nestes casos, o documento é rotulado como
categoria “desconhecida”, para posterior classificação manual. A Figura 10 retrata o
processo de uma classificação automática de documentos proposta por Morgado
Júnior (2008).
Figura 10: Modelo de classificação de documentos
Fonte: Adaptado de Morgado Júnior (2008)
Cat 1
Cat 2
Cat 3 ?
CategorizadorTreinamento
Cat 1 Cat 2 Cat 3

51
Verifica-se que existe uma etapa de treinamento, no qual a máquina detecta
os padrões de cada categoria e posteriormente, ao apresentar um documento novo,
o sistema categorizador o classificará em uma categoria pré-estabelecida.
Os tipos de classificação mais utilizados na mineração de textos, de acordo
com Ticom (2007); Matsunaga (2007); Morgado Júnior (2008) são:
o Classificador bayesiano (Naive Bayes): É um método probabilístico, no
qual se assume que todas as variáveis são independentes da variável de
classificação. Esse classificador assume que as características são
independentes para uma dada classe. Essa classificação é feita utilizando
dados de treinamento para estimar a probabilidade de um documento
pertencente a cada classe. São utilizados os termos do documento com
seus respectivos pesos para realizar a classificação. Para cada termo do
documento é calculada a probabilidade de o mesmo pertencer à categoria.
É feita uma combinação das probabilidades levando em consideração o
peso dos termos. Se o resultado for maior que determinado coeficiente, o
documento é incluído na categoria.
o Classificador SVM (Support Vector Machine): Esse classificador é o
mais utilizado em mineração de texto e se mostra mais eficiente que o
restante (MATSUNAGA, 2007). Essas técnicas utilizam uma função
chamada kernel para mapear um espaço de pontos de dados, os quais
não são linearmente separáveis em um novo espaço que é linearmente
separável (CAVALCANTI, 2011). Os documentos são divididos em dois
conjuntos definidos como base de treinamento e de teste. A base de
treinamento é usada para o algoritmo de classificação obter as
características das categorias da coleção. A base de teste valida o
desempenho do classificador, determinando as categorias as quais os
novos documentos pertencem. O SVM implementa a ideia de que seja
construído um hiperplano com base no mapeamento dos vetores de
entrada em um espaço de características com uma grande quantidade de
dimensões.
o K-NN (k vizinhos mais próximos): Dentre as técnicas de classificação,
esta é a que apresenta efetividade competitiva às técnicas SVMs. O
algoritmo k-NN calcula a similaridade entre documentos de teste e de

52
todos os documentos do conjunto de treinamento para decidir se um
documento pertence a uma determinada categoria, por fim são
selecionados os k documentos de treinamento mais similares ao
documento de teste (os k vizinhos mais próximos). Esse método exige
mais processamento computacional do que o modelo SVM, como também
é mais sensível à presença de termos não relevantes (MATSUNAGA,
2007).
o Árvore de decisão: é uma árvore em que os nós internos são rotulados
pelos termos, os ramos que partem dos nós são definidos pelos testes,
levando-se em consideração o peso que o termo tem no teste do
documento e as folhas pelas categorias. A maioria dos classificadores
utiliza a forma binária para representar os documentos gerando
consequentemente uma árvore binária.
o Redes neurais: É uma rede de unidades onde as unidades de entrada
representam os termos, as unidades de saída significam as categorias de
interesse e os pesos nas conexões representam as relações de
dependências. O classificador SVM é uma subclasse de redes neurais.
o Outros Modelos: Existem outros métodos para classificar um documento
de acordo com suas características, porém menos utilizados devido à sua
complexidade computacional, como também o desempenho ser muito
similar a outros métodos mais conhecidos. São eles: regressão linear,
regressão logística, método linear por ordenação (scoring), indução de
regras e algoritmos online (TICOM, 2007).
3.2.3 Etapa de Pós-processamento
Ticom (2007) apresenta que na mineração de texto sempre são usadas
medidas matemáticas que podem servir para mensurar a aplicação dos métodos
utilizados, tais como: classificação, clusterização, extração de características, entre
outras. As medidas de avaliação de desempenho mais utilizadas são, segundo
Pinheiro (2009) o índice de precisão (precision) que é a medida analisada no âmbito
de cada classe. É a razão entre o número de documentos corretamente classificados
e o número total de documentos associados à classe. Outra métrica utilizada é a
cobertura (recall) definida pela razão entre o número de previsões corretas positivas
sobre o número de documentos da classe positivos. Por fim, a Medida F (f-measure),
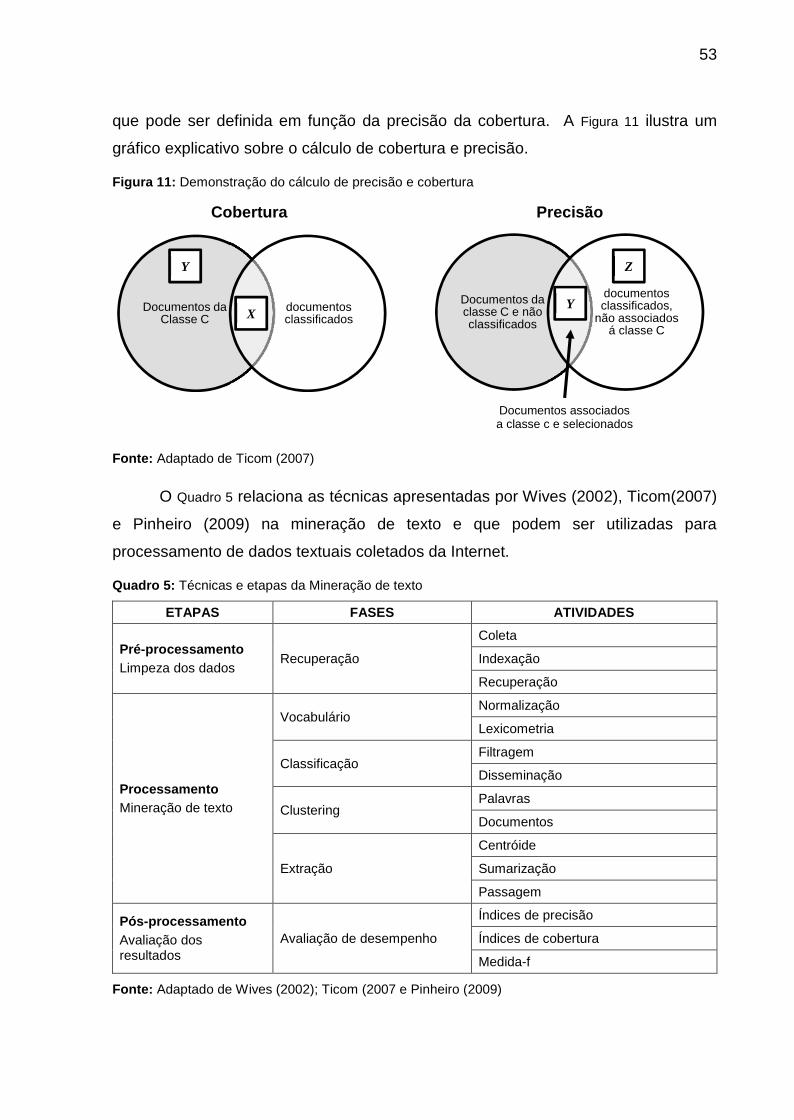
53
que pode ser definida em função da precisão da cobertura. A Figura 11 ilustra um
gráfico explicativo sobre o cálculo de cobertura e precisão.
Figura 11: Demonstração do cálculo de precisão e cobertura
Fonte: Adaptado de Ticom (2007)
O Quadro 5 relaciona as técnicas apresentadas por Wives (2002), Ticom(2007)
e Pinheiro (2009) na mineração de texto e que podem ser utilizadas para
processamento de dados textuais coletados da Internet.
Quadro 5: Técnicas e etapas da Mineração de texto
ETAPAS FASES ATIVIDADES
Pré-processamentoLimpeza dos dados
Recuperação
Coleta
Indexação
Recuperação
ProcessamentoMineração de texto
VocabulárioNormalização
Lexicometria
ClassificaçãoFiltragem
Disseminação
ClusteringPalavras
Documentos
Extração
Centróide
Sumarização
Passagem
Pós-processamentoAvaliação dosresultados
Avaliação de desempenho
Índices de precisão
Índices de cobertura
Medida-f
Fonte: Adaptado de Wives (2002); Ticom (2007 e Pinheiro (2009)
Documentos daClasse C
documentosclassificados
Documentos daclasse C e nãoclassificados
documentosclassificados,
não associadosá classe C
Documentos associadosa classe c e selecionados
Y
Y
Z
X
Cobertura Precisão

54
4 MINERAÇÃO WEB NAS REDES SOCIAIS
4.1 REDES SOCIAIS
Com o advento da Internet, uma miríade de ferramentas tecnológicas
surgiram como novas formas de comunicação, relacionamento e organização das
atividades humanas, dentre elas as redes sociais virtuais (AFONSO, 2009), também
chamada de redes sociais digitais (HASGALL; SHOHAM, 2007) ou redes sociais
online (SOUZA, 2010). Dentre as principais características observadas nessas
ferramentas é o comportamento colaborativo de seus participantes, que
ultimamente, tem se tornado foco de muitas discussões. Segundo Costa (2003), a
chamada “cultura digital” tem se tornado um marco na cultura ocidental por meio das
atividades colaborativas cuja a essência é a troca de informação, conhecimento e
comunicação.
Kaufman (2010) retrata a evolução da relação indivíduo versus internet ao
longo do tempo, conforme pode ser visualizado na Figura 12, subdividindo em três
grades fases: meio de comunicação e informação, comércio eletrônico e, por fim, o
fenômeno da colaboração. Na primeira era, correspondente de 1994 a 1998, a
Internet era palco de grandes empresas concentradoras de publicação de
informações e de ferramentas de comunicação instantâneas, os famosos bate-
papos. De 1998 a 2005, surgiu o comércio eletrônico como uma alternativa para
compras de produtosou serviços através do computador. E por último, a partir de
2006 surge o fenômeno da colaboração online, no qual os internautas compartilham
a criação e o desenvolvimento de informações, ativos comerciais, culturais e sociais.
O efeito do surgimento da era da colaboração gera uma grande quantidade
de informação online compartilhada entre os indivíduos. Kalfman (2010) afirma que
esse “estoque digital” é fundamental no processo de consulta e tomada de decisão,
podendo estar vinculada a um consumo imediato de um bem ou serviço ou fazendo
parte de um espaço público de colaboração, no qual os resultados não são
imediatos e os benefícios são coletivos.

55
Fonte: AgenciaClick apud Kaufman, 2010
A maior parte das ferramentas de uso colaborativo é formada pelas redes
sociais digitais, onde cada indivíduo tem sua função e identidade cultural (TOMAEL;
ALCARÁ; CHIARA, 2005). Simplificando o conceito, rede social digital é geralmente
utilizada para descrever um grupo de pessoas que interagem primariamente através
de qualquer mídia de comunicação (SOUZA, 2010). Tecnicamente falando, trata-se
de uma representação grafológica no qual os “nós” são os atores (geralmente
pessoas) e as arestas são os relacionamentos entre eles. Esses grafos, estudados
pela área das ciências exatas, podem apresentar desde conexões esparsas (árvores
genealógicas) até conexões muito densas, como as redes de contatos na Internet
(BOYD e ELLISON, 2007). No campo da sociologia, as redes sociais podem ser
definidas, segundo Marteleto (2001, p.72), como um “[...] conjunto de participantes
autônomos, unindo ideias e recursos em torno de valores e interesses
compartilhados”. O foco principal seriam os estudos das estruturas das redes e o
caráter de identidade social e os padrões de relacionamentos dos indivíduos em si,
de acordo com sua posição dentro do grupo a que pertence (BOYD e ELLISON,
1994 1998 2000 2003 2006 2008
QUANTIDADE 77 Mi 400 Mi 500 Mi 1 Bi 1,4 BiDE USUÁRIOS
ERA DA INFORMAÇÃOE COMUNICAÇÃO
ERA DO COMÉRCIOELETRÔNICO
ERA DACOLABORAÇÃO
Figura 12: A evolução das ferramentas na Internet

56
2007). Portanto, uma rede social pode ser denominada como a forma representativa
de grupos com mesmos interesses e objetivos, sejam eles de amizade,
conhecimentos profissionais, culturais, religiosos ou afetivos que estão reunidos por
causa própria ou visam algum tipo de alteração na realidade do coletivo (RECUERO,
2008).
Os sites de redes sociais oferecem serviços na Web que permitem aos seus
usuários (1) construir um perfil público ou semipúblico dentro de um sistema
conectado, (2) articular uma lista de outros usuários com os quais eles compartilham
uma conexão e (3) ver e mover-se pela sua lista de conexões e pela dos outros
usuários (BOYD e ELLISON, 2007. p.211). Geralmente o que se encontra nas redes
sociais são páginas de apresentação do perfil do usuário, lista de amigos ou
membros do grupo, ferramentas de interação, tais como fórum, enquetes,
comentários, vídeos, chats, hipertextos (textos ou imagens que levam a outras
mensagens por meio de links) e outros. Recuero (2008) relata que o objetivo das
pessoas entrarem nas redes sociais é ganhar popularidade através da formação de
um grande número de amigos ou seguidores, no entanto, muitas vezes essas
pessoas entre si não se conhecem, não tendo como mensurar a quantidade exata
de verdadeiros relacionamentos entre os usuários. A autora ressalta que não é
apenas a lista de perfis associados que caracteriza uma rede, mas a interação entre
os indivíduos.
Segundo Malini (2008), o sucesso das redes sociais se dá por meio de três
forças: a democratização das ferramentas de produção de conteúdo com a
popularização dos computadores, a redução do custo de distribuição através da
internet e a ligação cada vez mais próxima entre oferta e procura amplamente
utilizado pelas ferramentas de busca. Recuero (2009) observa que cada vez mais as
empresas estão atentas ao cenário das redes sociais para obter vantagem
competitiva e explorar suas potencialidades para divulgar suas marcas.
Existem centenas de redes sociais espalhadas na Internet, reunindo pessoas
em torno dos mais diversos interesses. Boyd e Ellison (2007) propuseram uma revisão
histórica dos sites de redes sociais desde 1997, com o lançamento da primeira rede
social, o SixDegrees, até 2006 com a chegada das mais recentes ideias nesse ramo. A
Figura 13 ilustra essa evolução em forma de linha do tempo, acrescentando algumas
atualizações até 2008 (contribuição própria).
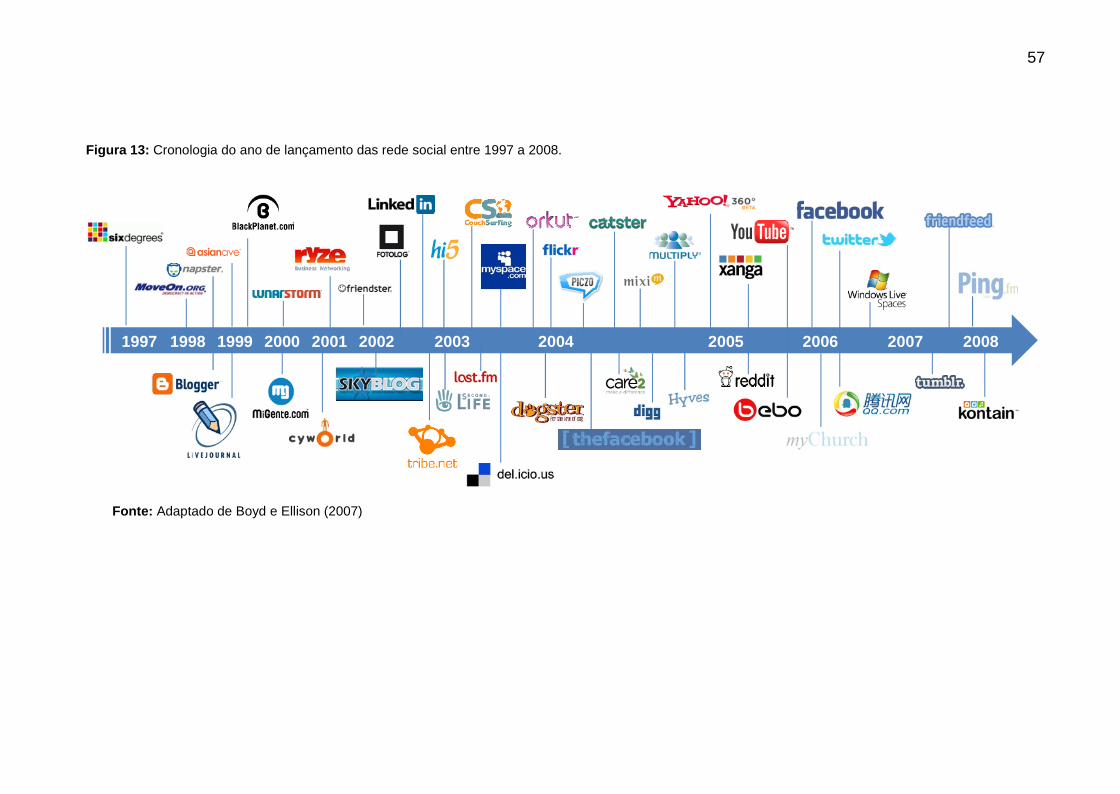
57
Fonte: Adaptado de Boyd e Ellison (2007)
1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008
Figura 13: Cronologia do ano de lançamento das rede social entre 1997 a 2008.

58
Segundo Ibope (2011), as três maiores redes sociais ativas no Brasil é o
Facebook, Orkut e Twitter. Em agosto de 2011, o Facebook atingiu a marca de 30,9
milhões de usuários únicos, ou 68,2% dos internautas no trabalho e em domicílios,
equiparando-se ao Orkut, até então o maior site social no Brasil, que registrara
alcance de 64%, ou 29 milhões de usuários, ou seja, mantendo-se em decadência
em relação aos demais. O Twitter manteve tendência de crescimento no Brasil e
marcou 14,2 milhões de usuários únicos, ou 31,3%. Com esses resultados, o Brasil
se consolida como um mercado com elevada utilização de sites sociais digitais em
relação aos outros países, com uso diversificado, refletindo o interesse dos
brasileiros pela Internet. Apesar do Orkut ainda estar em segundo lugar em número
de usuários no Brasil, a realidade mostra que os seus clientes estão cada vez mais
migrando para outras plataformas, portanto esta rede social não será objeto alvo
desta pesquisa, restando somente o Facebook e Twitter para análise.
4.1.1 Facebook
O Facebook (www.facebook.com) atualmente é o site de relacionamento com
maior número de usuários cadastrados. Seu fundador foi o ex-estudante de Havard,
Mark Zuckerberg, em 2004, nos Estados Unidos. De início, a função deste sistema
era restrita para universitários daquela faculdade, depois se expandiu para outras,
até que atingiu o grupo secundarista, ganhou a adesão de empresas e hoje possui,
segundo informa a própria página de estatística do site, cerca de 750 milhões de
usuários no mundo e, no Brasil, 30 milhões (FACEBOOK, 2012).
Cada usuário no Facebook possui uma página (ver Figura 14) onde pode
publicar textos, imagens e vídeos. Seus recursos são: o mural que é um espaço para
postar mensagens; News feed, que são postagens que não estão no mural,
Mensagens privadas, enviadas pelos visitantes pela caixa de entrada - só visíveis
para o dono da página; Classificados, local para anunciar imóveis, vagas de
emprego entre outras coisas; Jogos, forma de interação com amigos por meio de
animações de diversos significados como chamar atenção; Status, informações
referentes ao usuário; Eventos, próximos encontros sociais; Aplicativos, software
internos que executam tarefas específicas dentro do Facebook; Vídeos, que são
59
enviados do computador ou celular e comentários, para que os amigos deixem
recados.
Figura 14: Página principal do Facebook - Perfil do criador Mark Zuckerberg
Fonte: www.facebook.com/zuck
No site, os temas dos textos em geral falam sobre a vida pessoal e social dos
indivíduos ou revelam a admiração do usuário por algum tema cultural, artístico ou
musical. Seus amigos e seguidores podem interagir e complementar com opiniões
sobre o que foi dito. Segundo COMBÈS e KOCERGIN (2009), no novo modelo
editorial que se constrói o controle da qualidade da informação não é feito a priori
por um sistema de seleção editorial certificado, mas por um controle a posteriori da
seleção feita pelos leitores que passam ou não a diante o material produzido.
4.1.2 Twitter
O Twitter foi criado em outubro de 2006 por Jack Dorsey e é uma das redes
sociais que mais ganhou notabilidade nos últimos anos e poderia ser descrito como
o SMS da internet ou um microblog. De acordo com Twitter (2011), em setembro de
2011 existiam 175 milhões de contas registradas no site, no entanto, somente 100
milhões a mantinham ativas, a outra parcela apenas criou uma conta e não utilizou
com frequência.
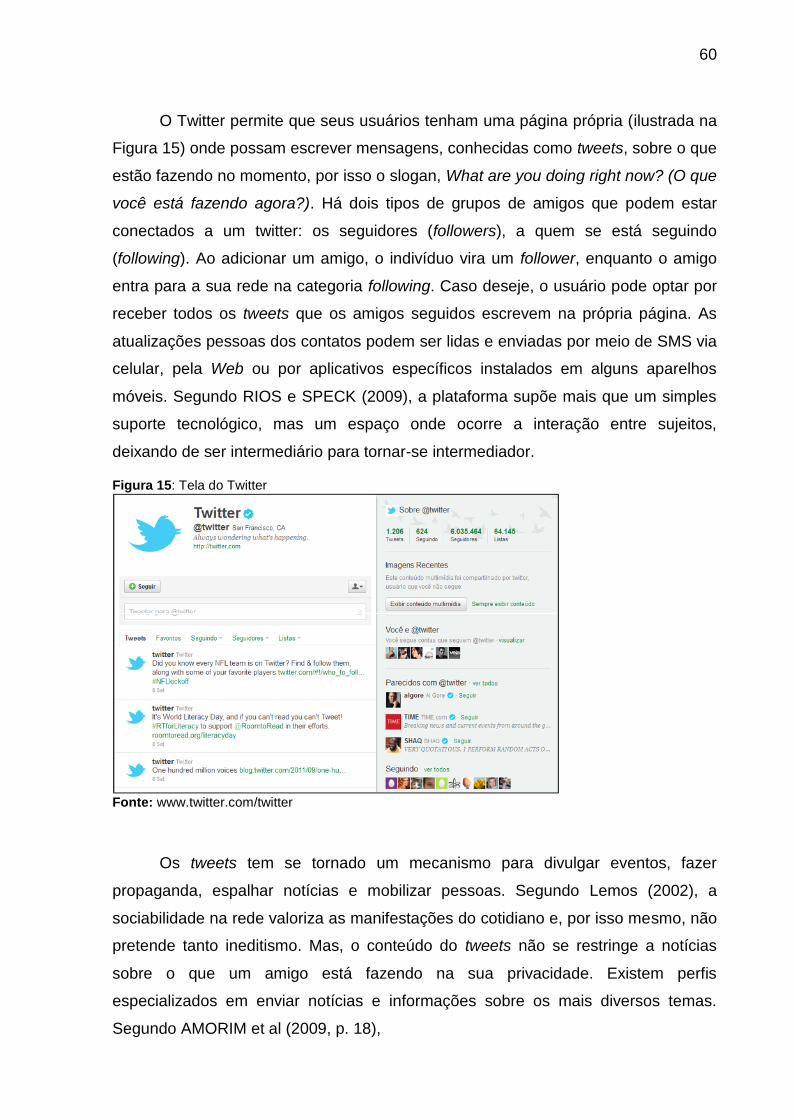
60
O Twitter permite que seus usuários tenham uma página própria (ilustrada na
Figura 15) onde possam escrever mensagens, conhecidas como tweets, sobre o que
estão fazendo no momento, por isso o slogan, What are you doing right now? (O que
você está fazendo agora?). Há dois tipos de grupos de amigos que podem estar
conectados a um twitter: os seguidores (followers), a quem se está seguindo
(following). Ao adicionar um amigo, o indivíduo vira um follower, enquanto o amigo
entra para a sua rede na categoria following. Caso deseje, o usuário pode optar por
receber todos os tweets que os amigos seguidos escrevem na própria página. As
atualizações pessoas dos contatos podem ser lidas e enviadas por meio de SMS via
celular, pela Web ou por aplicativos específicos instalados em alguns aparelhos
móveis. Segundo RIOS e SPECK (2009), a plataforma supõe mais que um simples
suporte tecnológico, mas um espaço onde ocorre a interação entre sujeitos,
deixando de ser intermediário para tornar-se intermediador.
Figura 15: Tela do Twitter
Fonte: www.twitter.com/twitter
Os tweets tem se tornado um mecanismo para divulgar eventos, fazer
propaganda, espalhar notícias e mobilizar pessoas. Segundo Lemos (2002), a
sociabilidade na rede valoriza as manifestações do cotidiano e, por isso mesmo, não
pretende tanto ineditismo. Mas, o conteúdo do tweets não se restringe a notícias
sobre o que um amigo está fazendo na sua privacidade. Existem perfis
especializados em enviar notícias e informações sobre os mais diversos temas.
Segundo AMORIM et al (2009, p. 18),

61
[...] muita gente que começa a usar o Twitter reclama da banalidade doconteúdo que circula. Isso não tem a ver com o serviço em si, mas com aspessoas que se está seguindo. Siga quem você admira e a qualidade dasmensagens tende a aumentar. Uma das diferenças do Twitter em relação aoutros sites de rede social é que, além de promover relacionamentos, oserviço também estimula a troca de informações entre seus participantes. Oato de repassar conteúdo é tão natural que os usuários adotaram um nomepara isso: retuitar ou RT. A primeira motivação para se retuitar é retransmitiruma informação que você considera relevante para o seu grupo deseguidores. Com pouco esforço - na verdade, quase nada - você podeprestar um serviço importante para eles.
Teixeira (2010) ressalta que a proposta do Twitter não é criar textos
complexos, mas, o envio de breves manchetes sobre a vida pessoal ou notícias de
um determinado assunto a quem interessar dentro da rede. Tendo em vista esse
objetivo, muitas empresas possuem seus perfis oficiais a fim de fazer parte da rede
de seus clientes e receber as reclamações e sugestões dos mesmos de maneira
gratuita e rápida. Segundo a agência EFE (2009), para multinacionais como
Starbucks, Dell e Amazon, o Twitter se tornou uma ferramenta fundamental em suas
relações públicas e fonte de informação sobre as opiniões de seus clientes, cada
vez mais engajados no serviço. Quando um líder com milhares de seguidores
dispara uma informação sobre algum problema enfrentado com uma empresa este
pode levantar a viralização da informação.
4.2 O COMPORTAMENTO DOS USUÁRIOS NAS REDES SOCIAIS
Os sites de redes sociais (SRS) acabam gerando duas situações inéditas, que
não acontecem no viver cotidiano dos usuários que a utilizam. A primeira é o
aumento da tendência em publicar informações de comportamentos rotineiros nas
redes sociais. Como por exemplo, no Facebook, a frase que a ferramenta utiliza pra
estimular a postagem de novas mensagens é: “No que você está pensando?”, já no
Twitter a frase é “O que está acontecendo?”. Esses sites demonstram traços
comportamentais e ações que até então não se encontravam no viver fora da rede.
A segunda situação é a possibilidade de quantificar e processar os seus dados
através do ambiente online ou com recursos adicionais (RAMIREZ, 2009).
Sobre a primeira situação explorada por Ramirez (2009) demonstra que o
usuário é estimulado nos sistemas de redes sociais a realizar ações reflexivas sobre
seus atos e comportamentos cotidianos, e principalmente, demonstrá-los
publicamente. Herbert Blumer em seus trabalhos sobre o interacionismo simbólico

62
abordou que o homem é um ator social que pode interagir consigo mesmo,
analisando suas ações e as dos outros continuamente, indicando a si mesmo como
agir a partir da projeção da perspectiva dos seus pares (BLUMER, 2001). Baseado
nos estudos do interacionismo simbólico, ele propõe uma compreensão dos
processos sociais envolvendo o relacionamento de três entidades: sociedade, mente
e self (base para compreender como o indivíduo se vê, e pressupõe o que os outros
veem). Essas reações podem realçadas pelas facilidades técnicas que as
ferramentas de redes sociais digitais propiciam, no qual o conteúdo exposto passa a
ter dentre outras acentuações convergentes reflexividade (PAPACHARISSI, 2011).
Outra característica comportamental dos usuários nas redes sociais é a
construção da identidade e pode ser encontrada nas pesquisas de Simon (2004).
Dentre os tipos de identidade na sociedade moderna, o autor revela que as pessoas
possuem múltiplas identidades. Isso significa que um mesmo usuário poderá se
comportar e realizar ações e reações diferentes de acordo com o tipo de
relacionamento que ele tenha com os outros usuários nos sites de redes sociais.
Além da multiplicidade, o comportamento identitário dos indivíduos englobam
características de variabilidade, flexibilidade, fragmentação e até mesmo
contradição. Ribeiro (2009) atribui a acentuação dessas características às
potencialidades sociotécnicas que os ambientes digitais proporcionam. Apesar
dessa possibilidade de exposição multivariada do comportamento dos indivíduos nos
SRS, Kennedy (2006) afirma que as identidades online e off-line ficaram mais
expostas com os diversos tipos de informações sendo publicadas pelo mesmo
usuário em redes sociais diferentes, gerando uma maior reflexividade sobre os
assuntos inconsistentes com a realidade.
Ainda de acordo com a característica identitária dos indivíduos, o pesquisador
e sociólogo Erving Goffman comparou o relacionamento entre pessoas como uma
peça de teatro, no qual as pessoas são os atores sociais que procuram oferecer uma
imagem idealizada de si que se encaixe nos padrões reconhecidos e valorizados
pela sociedade. O autor explica que há uma divergência entre o que é
conscientemente apresentado e o que é apenas emitido. Assim como no teatro, a
representação dos indivíduos pode ser distinta de acordo com o ambiente onde ele
esteja atuando, seja no palco ou nos bastidores. Todos os atos ocorridos nesse
evento são gerenciados para manter uma linha de conduta de acordo com a

63
situação atual. Para gerenciar o self é necessário ter um conjunto de recursos para
manter a aparência, ter uma consciência das interpretações realizadas pelos outros,
ter um desejo de manter aprovação social e ter uma vontade de usar esse conjunto
de táticas de gerenciamento de impressões (GOFFMAN, 2010). Nesse sentido,
percebe-se que nem tudo que os usuários comentam nas redes sociais estão
relacionados com a sua realidade e seu desejo. O ato de imaginar antecipadamente
a reação do seu público nas redes sociais pode incitar ou inibir determinadas ações,
que no viver cotidiano não teriam como ser contidos.
Descobrir o comportamento dos indivíduos que utilizam as redes sociais
permite entender até que ponto as informações colhidas para tomada de decisão
estratégica pode ser eficaz. Apesar das pesquisas apontarem essa dualidade de
comportamentos distintos nas redes sociais pela mesma pessoa, é importante
perceber que nesses ambientes a totalidade do conteúdo dos assuntos comentados
é mais válida do que a análise individual do comentário postado por cada usuário. O
comportamento em grupo poderá deixar escapar informações importantes para a
escolha de determinada decisão estratégica que só serão percebidas se forem
coletadas por ferramentas adequadas para tal finalidade.
4.3 PROCESSO DE MINERAÇÃO WEB NAS REDES SOCIAIS
A predominância de elementos textuais em forma de comentários, opiniões,
conversas dentre outros estão entre os tipos de materiais publicados nas redes
sociais, inclusive os conteúdos baseados em vídeos, imagens e mapas precisam de
comentários de texto tais como tags (etiquetas) e descrições para serem melhor
visualizados na Web (SILVA, 2012). Devido a grande quantidade de elementos
textuais sendo publicado nas redes sociais, ferramentas foram desenvolvidas com o
objetivo de coletar esses dados por meio de uma gama de sistemas de mineração
Web conhecidos como ferramentas de monitoramento de redes sociais.
4.3.1 Monitoramento das redes sociais
As redes sociais digitais tem ultrapassado seu status de modismo ou
utilização passageira e se consolidam na Internet como um grande palco, no qual os

64
seus usuários são os atores. Calcular o efeito gerado nesse interrelacionamento
entre pessoas nas redes sociais e medir o seu comportamento torna-se
demasiadamente importantes. Segundo Telma (2011), a principal vantagem de
monitorar o ambiente das redes sociais está na sua capacidade de coletar
conversas, sentimentos e menções da marca por meio de atividades multiformes
realizadas na Internet.
O monitoramento nas redes sociais (MRS) para fins comerciais podem ser
realizados da forma manual. Utilizando-se das ferramentas de buscas
disponibilizadas em cada rede, o analista poderá coletar suas informações por meio
de palavras-chave previamente selecionadas para monitorar produtos, marcas ou
entidades concorrentes. Em seguida, realiza-se manualmente a cópia de textos e
imagens importantes, armazenando-os em documentos de texto, planilhas
eletrônicas para, por fim, cruzar as informações para gerar relatórios satisfatórios
sobre o ambiente competitivo. Esse processo manual pode ser mais habitual do que
se imagina e também oferece um custo zero na sua aplicabilidade, no entanto, se
limita pelo grau de processamento da grande quantidade de dados oferecidas pelas
redes na Web (SILVA, 2012). Outro fator negativo é a atribuição de valores que
podem ser inconsistentes, caso seja feita manualmente e por analistas diferentes.
Percebe-se a necessidade de processar um maior número de dados coletados e que
tenham confiabilidade no seu processamento. As ferramentas capazes de coletar,
armazenar, analisar e disseminar informações são chamadas de ferramentas de
monitoramento de mídias sociais (SILVA, 2010).
O monitoramento das redes sociais pode acontecer de duas formas: coleta de
dados quantitativos e a coleta de dados qualitativos. A primeira utiliza a mineração
de estrutura Web e a mineração de uso Web (LIU, 2007) e tem o objetivo de coletar
dados objetivos e quantitativos para gerar relatórios analíticos e sintéticos sobre os
usuários, grupos de usuários, tendências, dados sociodemográficos dentre outros.
Esse tipo de monitoramento Telma (2011) chama de sistemas Web Analytics e
fornece infomações específicas sobre as redes sociais. O segundo tipo de
monitoramento é chamado de “buzz monitoring”, “monitoramento de mídias sociais
pleno”, “monitoramento de marcas e conversações” entre outros (SILVA e SANTOS,
2010). Baseados na mineração de conteúdo na Web, este tipo de monitoramento
busca coletar, armazenar, classificar, categorizar, adicionar informação e analisar

65
menções online públicas a determinados termos previamente definidos e seus
emissores (SILVA, 2011). Com um foco mais qualitativo, o objetivo desse formato de
coleta é identificar e analisar reações, sentimentos e desejos relativos a produtos,
entidades e campanhas (eventos), como também conhecer melhor o público
pertinente e realizar ações reativas e pro-ativas para alcançar os objetivos da
organização ou pessoa de forma ética e sustentável (SILVA, 2010).
A maior parte dessas ferramentas tem uma interface interativa e amigável que
facilita o seu uso por pessoas que não têm muitas habilidades tecnológicas, no
entanto, Silva e Santos (2010) constata que a maioria das empresas contratam
agências para realizar esse serviço.
4.3.2 Processo de monitoramento de redes sociais
Para iniciar um monitoramento, a maior exigência é selecionar um conjunto
finito de palavras-chave e informar o local donde ocorrerá a coleta. A maior parte
desses locais são as redes sociais mais conhecidas, como o Facebook, Twitter,
Youtube, Blogs dentre outros. Cada plataforma tem sua forma diferenciada de
disponibilizar os seus dados para essas ferramentas. Silva e Santos (2010)
apresentam duas maneiras que os sites de redes sociais disponibilizam seus dados
para coleta. O primeiro caso é a indexação do conteúdo em formatos que podem ser
acessados por meio de mecanismos de busca. O segundo caso é por meio das APIs
(Application Programming Interfaces) que são códigos padronizados disponibilizados
pelos construtores das redes sociais para que desenvolvedores externos criem
aplicações para acessar os dados e integrar serviços dentro das redes sociais. O
segundo caso fornece mais formatos de dados do que o primeiro.
Após o resgate dos dados, outra característica das ferramentas de
monitoramento de redes sociais é o armazenamento para processamento dos
dados. O armazenamento permite que o conteúdo resgatado fique a disposição para
que o analista adicione algumas informações extras ao conteúdo coletado, tais
como: tags, classificação, categorias etc. O processamento oferecido permite
agrupar o conteúdo por período de tempo, emissor, ambiente e por métricas de
alcance e visitação. A pesquisa de Telma (2011) apresenta doze métricas utilizadas

66
por essas ferramentas no processamento dos dados para monitorar os ambientes
internos e externos às empresas.
As medições quantitativas oferecidas pelas redes sociais e coletadas pelas
ferramentas se restringem a informações da presença de alguma marca, como
número de fãs no Facebook, ou o número de seguidores no Twitter ou tráfego de
referência nas redes sociais. Já as informações qualitativas podem ser analisadas
por meio do buzz gerado na rede. Buzz é um termo originário do marketing digital,
principalmente nas mídias digitais, que representa a repercussão de uma marca nas
mídias sociais. Salzman, Matathia e O´reilly (2003) exemplifica buzz da seguinte
forma:
Se algo é bom e seus amigos o mandam para você por que é bom, eis aí obuzz marketing. Mas se você recebe o comunicado de uma empresa quequer se passar por boa, isso é simples propaganda e não buzz marketing.Assim, o truque consiste em gerar buzz para a companhia sem que essemarketing pareça originar-se dela. (p. 14).
O resultado do processamento dos dados coletados pode ser visualizado por
meio de relatórios com gráficos de diversos formatos com informações sobre as
citações dos usuários, principais usuários que propagam comentários positivos
sobre o que está sendo monitorado ou mesmo usuários que proferem palavras
negativas. Os relatórios também oferecem a opção de mapas informando os dados
geográficos dos usuários, gráfico de palavras-chaves mais utilizadas (nuvem de
tags), índices de palavras positivas, negativas e neutras dentre outras.
4.3.3 Pesquisas sobre monitoramento de redes sociais
Dentre os trabalhos científicos mais recentes sobre o monitoramento de redes
sociais estão relacionados também com os trabalhos de monitoramento de mídias
sociais e ferramentas Web Analytics.
Stavrakantonakis at al (2012) apresentaram uma abordagem de avaliação de
ferramentas de monitoramento de mídia social sob a ótica de três perspectivas: o
conceito que eles implementam; a tecnologia que eles empregam; e a interface
(Quadro 6). No grupo de características conceituais, os autores abordam a
capacidade de coletar e analisar dados significativos (Análise), a capacidade que
permitem se achegar aos clientes (engajamento) e determinar os influenciadores
(influência), bem como a característica que permite que diferentes funcionários da

67
empresa utilizem a ferramenta para realizar tarefas distintas (gerenciamento de fluxo
de trabalho). No segundo grupo são definidas as características tecnológicas que
essas ferramentas devem conter para determinar a extensão do efeito das
mensagens nas redes sociais em relação às variáveis do construto anterior. A
tecnologia utilizada pelas ferramentas é a base necessária para que a coleta e
análise dos dados sejam satisfatórias. Por fim, são analisadas as características de
interface fornecidas para facilitar o utilizador na manipulação e visualizar os dados
por meio de relatórios, gráficos, planilhas dentre outros.
Quadro 6: Funcionalidades das ferramentas de MRSGrupo Funcionalidade
Conceito
AnáliseEngajamentoGerenciamento de fluxo de trabalhoInfluência
Tecnologia
CoberturaProcessamento em tempo realIntegração com aplicações de terceiros (API)Análise de sentimentoHistórico de dados
Interface com o usuárioPainel de controleExportação de dados
Fonte: Stavrakantonakis et al (2012)
Silva (2012), por sua vez, busca caracterizar e analisar os aplicativos de
análise de informações sociais quanto a sua utilização em processos interacionais
online. A pesquisa buscou compreender como tais aplicativos podem exercer papéis
nas dinâmicas interacionais online e utilizou como metodologia o mapeamento e
classificação dos aplicativos quanto a variáveis relacionadas às suas Práticas
Prescritas, Manejo dos Dados, Visualização, Motivação e Compartilhamento. Como
resultado verificou-se a importância de aspectos desses aplicativos que podem
condicionar as práticas de busca por informação social e auto-monitoramento, com
consequências para os processos de vigilância, memória, gerenciamento de
impressões e construção identitária. O Quadro 7 apresenta a lista de variáveis
estudadas por Silva (2012) para categorizar as ferramentas de análise de
informações sociais.

68
Quadro 7: Variáveis e Categorias Pertinentes aos Aplicativos de Análise de Informações SociaisFatores Características
Práticas prescritas
AutoconhecimentoExploraçãoComparaçãoPublicaçãoRetórica da Influência
Manejo dos dadosResgateProcessamentoClassificação
Visualização dosdados
Unidade de conteúdoQuantificações SimplesGráficos de Volume e TempoInfográficoLinha do TempoRedesMapas
MotivaçãoExperimentação/PesquisaDivulgação/publicidadeAnálise Profissional
CompartilhamentoUtilização PrivadaCompartilhamento DirecionadoCompartilhamento Público nos SRS
Fonte: Silva (2012, p. 117)
Na pesquisa de Telma (2011) é possível encontrar uma avaliação de
ferramentas de pesquisa com abordagem específica para mídias digitais com foco
nas práticas de Inteligência Competitiva nas organizações. A autora procura
demonstrar um determinado conjunto de ferramentas de Web Analytics disponíveis
no mercado, propondo uma metodologia de aplicação para os três níveis da
organização: estratégico, tático e operacional. As análises mostraram como as
referidas práticas podem auxiliar na identificação de padrões comportamentais e
quanto às especificidades de uma comunidade on-line, além de identificar possíveis
insights para ações e tendências de consumo. O trabalho também procurou mostrar
uma metodologia adaptada à realidade brasileira, para categorização das métricas
de acordo com quatro conjuntos de objetivos propostos por Lovett e Owyang (2010):
provocar o diálogo entre os usuários, promover defensores da marca ou da
organização, oferecer facilidade no suporte e estimular a inovação do conteúdo. O
Quadro 8 apresenta a lista de métricas utilizada para medir o desempenho
das ferramentas de monitoramento de redes sociais ou Web Analytics.
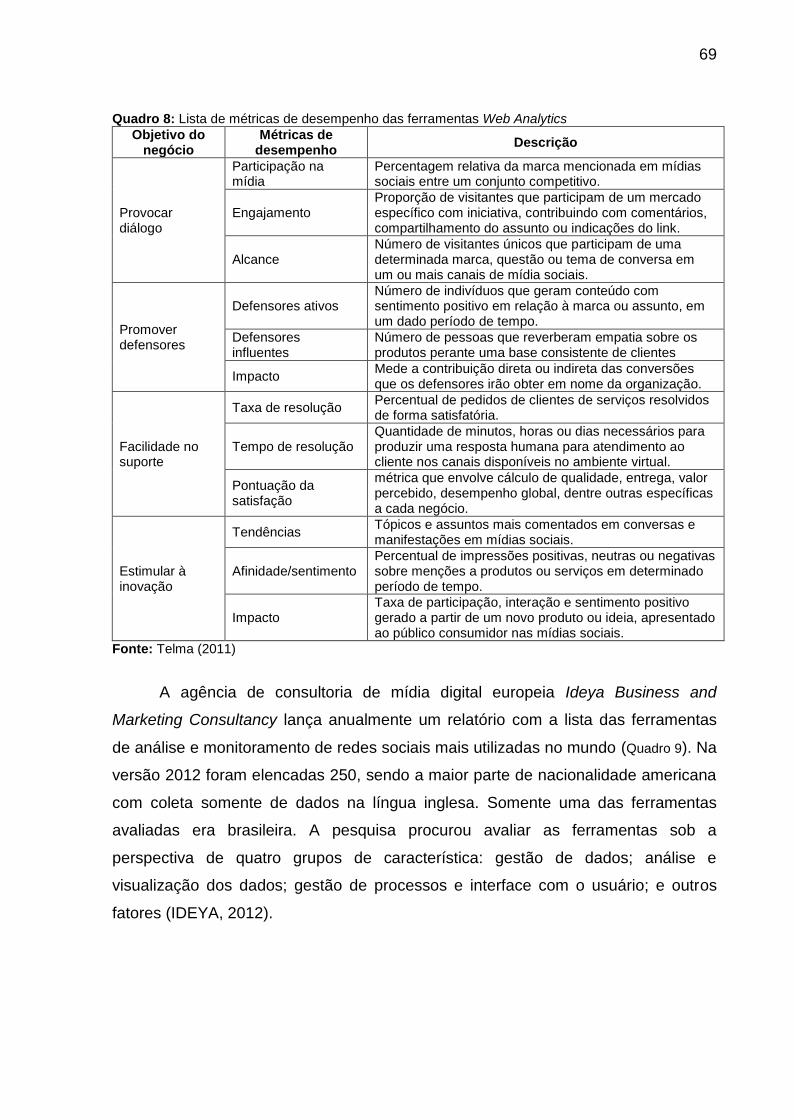
69
Quadro 8: Lista de métricas de desempenho das ferramentas Web AnalyticsObjetivo do
negócioMétricas de
desempenho Descrição
Provocardiálogo
Participação namídia
Percentagem relativa da marca mencionada em mídiassociais entre um conjunto competitivo.
EngajamentoProporção de visitantes que participam de um mercadoespecífico com iniciativa, contribuindo com comentários,compartilhamento do assunto ou indicações do link.
AlcanceNúmero de visitantes únicos que participam de umadeterminada marca, questão ou tema de conversa emum ou mais canais de mídia sociais.
Promoverdefensores
Defensores ativosNúmero de indivíduos que geram conteúdo comsentimento positivo em relação à marca ou assunto, emum dado período de tempo.
Defensoresinfluentes
Número de pessoas que reverberam empatia sobre osprodutos perante uma base consistente de clientes
Impacto Mede a contribuição direta ou indireta das conversõesque os defensores irão obter em nome da organização.
Facilidade nosuporte
Taxa de resolução Percentual de pedidos de clientes de serviços resolvidosde forma satisfatória.
Tempo de resoluçãoQuantidade de minutos, horas ou dias necessários paraproduzir uma resposta humana para atendimento aocliente nos canais disponíveis no ambiente virtual.
Pontuação dasatisfação
métrica que envolve cálculo de qualidade, entrega, valorpercebido, desempenho global, dentre outras específicasa cada negócio.
Estimular àinovação
Tendências Tópicos e assuntos mais comentados em conversas emanifestações em mídias sociais.
Afinidade/sentimentoPercentual de impressões positivas, neutras ou negativassobre menções a produtos ou serviços em determinadoperíodo de tempo.
ImpactoTaxa de participação, interação e sentimento positivogerado a partir de um novo produto ou ideia, apresentadoao público consumidor nas mídias sociais.
Fonte: Telma (2011)
A agência de consultoria de mídia digital europeia Ideya Business and
Marketing Consultancy lança anualmente um relatório com a lista das ferramentas
de análise e monitoramento de redes sociais mais utilizadas no mundo (Quadro 9). Na
versão 2012 foram elencadas 250, sendo a maior parte de nacionalidade americana
com coleta somente de dados na língua inglesa. Somente uma das ferramentas
avaliadas era brasileira. A pesquisa procurou avaliar as ferramentas sob a
perspectiva de quatro grupos de característica: gestão de dados; análise e
visualização dos dados; gestão de processos e interface com o usuário; e outros
fatores (IDEYA, 2012).
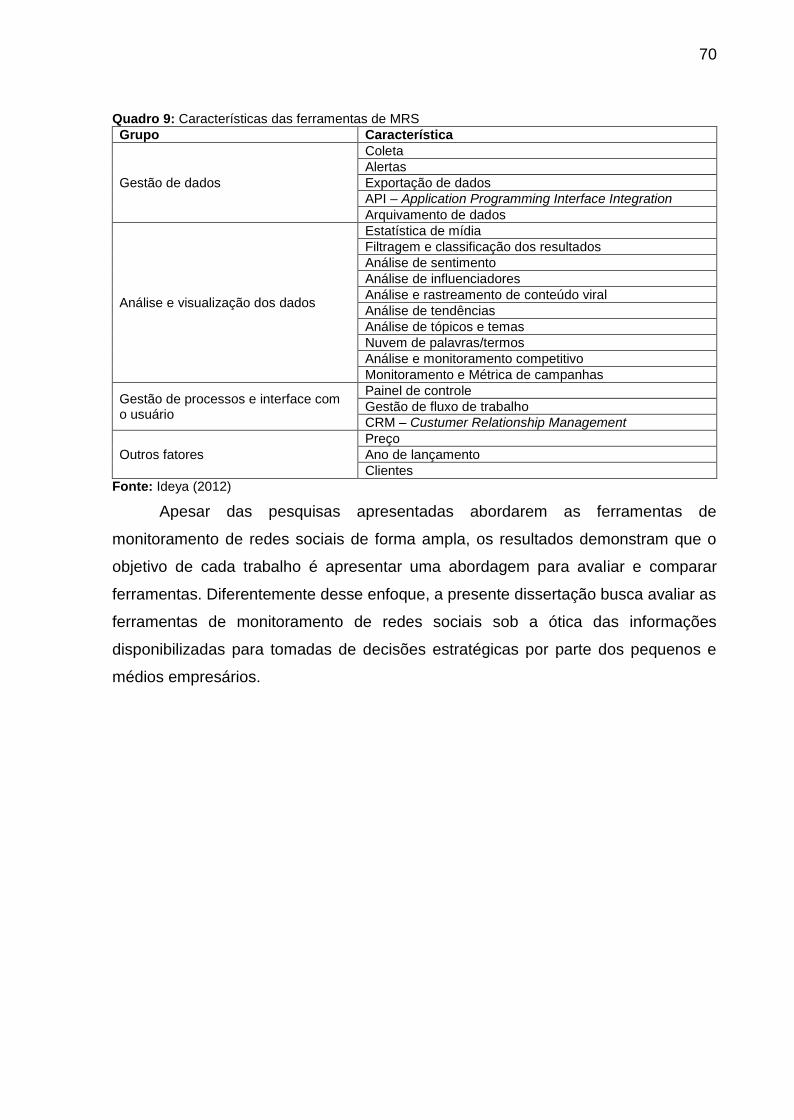
70
Quadro 9: Características das ferramentas de MRSGrupo Característica
Gestão de dados
ColetaAlertasExportação de dadosAPI – Application Programming Interface IntegrationArquivamento de dados
Análise e visualização dos dados
Estatística de mídiaFiltragem e classificação dos resultadosAnálise de sentimentoAnálise de influenciadoresAnálise e rastreamento de conteúdo viralAnálise de tendênciasAnálise de tópicos e temasNuvem de palavras/termosAnálise e monitoramento competitivoMonitoramento e Métrica de campanhas
Gestão de processos e interface como usuário
Painel de controleGestão de fluxo de trabalhoCRM – Custumer Relationship Management
Outros fatoresPreçoAno de lançamentoClientes
Fonte: Ideya (2012)
Apesar das pesquisas apresentadas abordarem as ferramentas de
monitoramento de redes sociais de forma ampla, os resultados demonstram que o
objetivo de cada trabalho é apresentar uma abordagem para avaliar e comparar
ferramentas. Diferentemente desse enfoque, a presente dissertação busca avaliar as
ferramentas de monitoramento de redes sociais sob a ótica das informações
disponibilizadas para tomadas de decisões estratégicas por parte dos pequenos e
médios empresários.

71
5 METODOLOGIA
Este capítulo apresenta o tipo de pesquisa utilizado, as fases realizadas, os
parâmetros para a escolha das ferramentas avaliadas e a processamento dos dados
para obtenção dos resultados.
5.1 TIPO DE PESQUISA
Entendeu-se esta pesquisa como exploratória e descritiva. A pesquisa foi
exploratória porque há pouco conhecimento acumulado e sistematizado a respeito
da mineração de dados na Web voltada para o SIM - Sistema de Informação de
Marketing. A pesquisa foi descritiva porque visou descrever os software de
mineração Web disponíveis para utilização pelas PMEs (Pequenas e Médias
Empresas), apresentando suas particularidades, facilidades de uso, forma de
apresentação dos dados coletados, assim como os tratamentos estatísticos que
porventura oferecem.
Segundo Mattar (2008), os estudos exploratórios tem o objetivo de abastecer
o pesquisador com um maior conhecimento sobre o tema ou problema de pesquisa
em questão. De acordo com Boyd Jr. e Westfall (1973), a flexibilidade é a
característica principal desta metodologia e deve ser pautada em procurar novas
ideias e relações, sem a preocupação de seguir um padrão formal de pesquisa.
Quanto à pesquisa descritiva, Chiusoli et al. (2010) revelam que essa abordagem
necessita de um planejamento que reduza o viés e que a precisão da prova obtida
seja ampliada, cujos objetivos tratam-se especificadamente de uma apresentação
das características de uma situação, um grupo ou um indivíduo específico.
5.2 FASES DA PESQUISA
Esta pesquisa está dividida em três fases, cada qual incluindo procedimentos
e técnicas que buscou alcançar os objetivos finais do projeto, conforme pode ser
observado na Figura 16.

72
Figura 16: Fases da pesquisa
Fonte: Autoria própria
A proposta foi levantar as principais características e parâmetros das
ferramentas de mineração Web que coletam dados do ambiente externo (internet e
redes sociais) do sistema de informação de marketing: os sistemas de
monitoramento de redes sociais e as ferramentas de mineração de texto. Foram
apresentados os fatores e variáveis dispostas na literatura sobre esses dois tipos de
sistemas.
A última fase teve como objetivo realizar a descrição dos dados obtidos sobre
as ferramentas coletadas e elencar as funcionalidades oferecidas para gerar
informações baseada nos dados coletados das redes sociais.
5.3 PARÂMETROS PARA ESCOLHA DAS FERRAMENTAS DE MINERAÇÃO
WEB
Esta pesquisa se limitou a estudar a coleta de dados do ambiente externo do
Sistema de Informação de Marketing. Pelo fato do processamento dos dados da
mineração de conteúdo na Web utilizar as técnicas de processamento de texto
Descrição das características das ferramentas e avaliação das suas funcionalidades
Levantamento das características das ferramentas de Mineração Web
Ferramentas de Monitoramento das redes sociais Ferramentas de Mineração de texto
Fundamentação teórica
Sistema de Informação deMarketing Mineração Web Redes sociais Digitais

73
encontrados na mineração de texto, foi realizada também uma análise nas
ferramentas de Mineração de texto.
Para fazer o levantamento das ferramentas de MRS e mineração de texto
foram realizadas buscas na Internet utilizando palavras-chaves, tais como:
“Monitoramento de redes sociais”, “monitoraçãor redes sociais”, “monitoramento de
mídias sociais” e “monitorar mídias sociais” juntamente com as ferramentas de
mineração de texto divulgadas pela KDnuggets2, site de uma comunidade de
pesquisadores especializada em Data Mining, Text Mining e Web Mining.
5.3.1 Universo e Amostra
Sendo o universo as ferramentas de mineração Web disponíveis na Internet,
a amostra foi formada pelos sistemas capazes de processar dados no idioma
português do Brasil. Procurou-se limitar nas ferramentas disponibilizadas para o
público brasileiro na página de busca da Google (www.google.com.br). Foram
selecionadas as ferramentas que apareceram nas primeiras 10 páginas de consulta
do sistema de busca da google.com até junho de 2012. Escolheu-se esse método
pelo fato dos 10 primeiros resultados da busca nesse site trazer os resultados mais
relevantes para o país de origem e idioma, neste caso o Brasil e a língua
portuguesa.
5.3.2 Seleção de variáveis
Os parâmetros utilizados para mapear as ferramentas de mineração Web
coletadas foram explorados nas pesquisas de Silva (2012), Telma (2011),
Stavrakantonakis et al (2012) e Ideya (2012). Os dois primeiros autores se limitaram
a pesquisar sobre as ferramentas de monitoramento de redes sociais e análise de
informações sociais, contribuindo com as funcionalidades descritivas das
ferramentas e dados quatintativos oferecidos pelos aplicativos. Wives (2002)
pesquisou sobre as tecnologias de descoberta de conhecimento em texto (Text
mining) e ofereceu as características para medir a capacidade que a ferramenta
oferece no processamento de informações textuais e quais resultados elas
2 http://www.kdnuggets.com/software/index.html
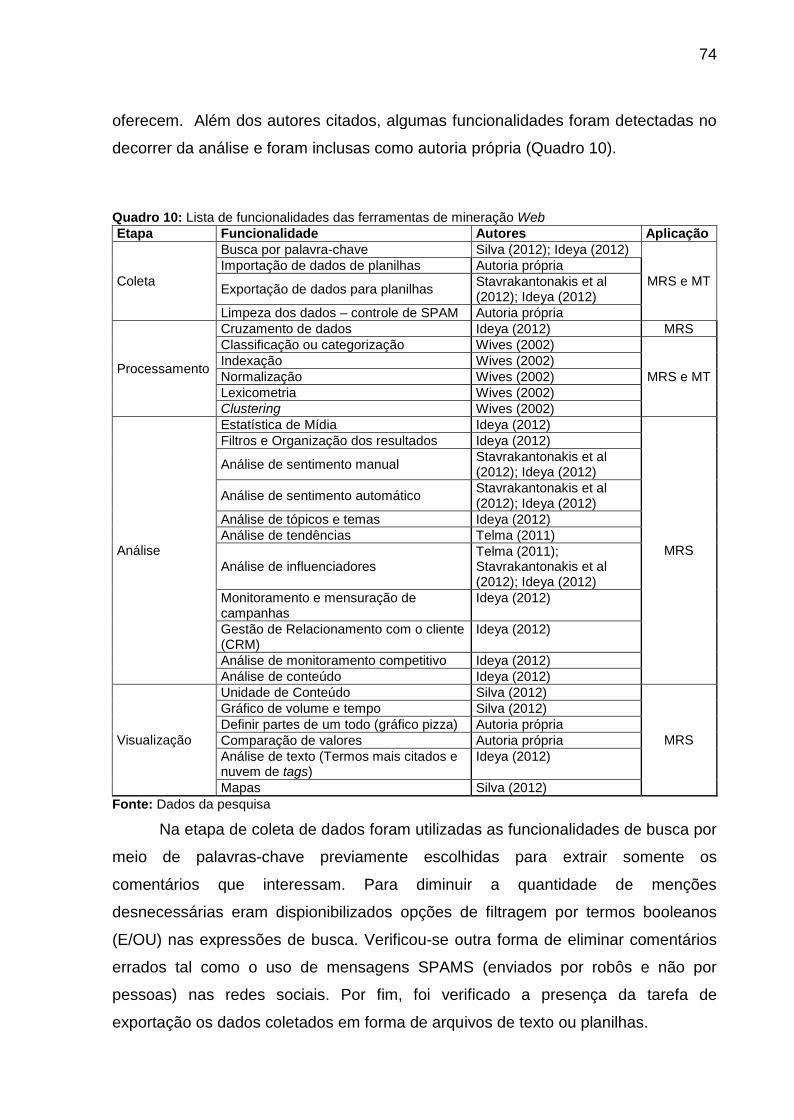
74
oferecem. Além dos autores citados, algumas funcionalidades foram detectadas no
decorrer da análise e foram inclusas como autoria própria (Quadro 10).
Quadro 10: Lista de funcionalidades das ferramentas de mineração WebEtapa Funcionalidade Autores Aplicação
Coleta
Busca por palavra-chave Silva (2012); Ideya (2012)
MRS e MTImportação de dados de planilhas Autoria própria
Exportação de dados para planilhas Stavrakantonakis et al(2012); Ideya (2012)
Limpeza dos dados – controle de SPAM Autoria própria
Processamento
Cruzamento de dados Ideya (2012) MRSClassificação ou categorização Wives (2002)
MRS e MTIndexação Wives (2002)Normalização Wives (2002)Lexicometria Wives (2002)Clustering Wives (2002)
Análise
Estatística de Mídia Ideya (2012)
MRS
Filtros e Organização dos resultados Ideya (2012)
Análise de sentimento manual Stavrakantonakis et al(2012); Ideya (2012)
Análise de sentimento automático Stavrakantonakis et al(2012); Ideya (2012)
Análise de tópicos e temas Ideya (2012)Análise de tendências Telma (2011)
Análise de influenciadoresTelma (2011);Stavrakantonakis et al(2012); Ideya (2012)
Monitoramento e mensuração decampanhas
Ideya (2012)
Gestão de Relacionamento com o cliente(CRM)
Ideya (2012)
Análise de monitoramento competitivo Ideya (2012)Análise de conteúdo Ideya (2012)
Visualização
Unidade de Conteúdo Silva (2012)
MRS
Gráfico de volume e tempo Silva (2012)Definir partes de um todo (gráfico pizza) Autoria própriaComparação de valores Autoria própriaAnálise de texto (Termos mais citados enuvem de tags)
Ideya (2012)
Mapas Silva (2012)Fonte: Dados da pesquisa
Na etapa de coleta de dados foram utilizadas as funcionalidades de busca por
meio de palavras-chave previamente escolhidas para extrair somente os
comentários que interessam. Para diminuir a quantidade de menções
desnecessárias eram dispionibilizados opções de filtragem por termos booleanos
(E/OU) nas expressões de busca. Verificou-se outra forma de eliminar comentários
errados tal como o uso de mensagens SPAMS (enviados por robôs e não por
pessoas) nas redes sociais. Por fim, foi verificado a presença da tarefa de
exportação os dados coletados em forma de arquivos de texto ou planilhas.

75
Foram utilizadas as formas de processamento de dados sugeridas por
Ideya(2012) como o cruzamento de dados e Wives (2002) com as técnicas de
classificação, indexação, normalização, lexicometria e clustering, visto que as
ferramentas de MRS trabalham também com as mesmas características das
ferramentas de mineração de texto.
Na etapa de análise de dados foram avaliadas somente nas ferramentas de
MRS com as características apresentadas por Telma (2011), Ideya (2012),
Stavrakantonakis et al (2012). As funcionalidades avaliadas foram: estatística de
mídia, filtro e organização dos resultados, análise de sentimento, análise de tópico e
temas, análise de tendências, análise de influenciadores, monitoramento de
campanhas, CRM, análise competitiva e análise de conteúdo.
Conhecida também por Share of Voice, a estatística de mídia é a
percentagem relativa da marca mencionada em mídias sociais entre um conjunto
competitivo. Telma (2011) compara essa métrica ao Market Share, que é a fatia de
participação da empresa em um determinado mercado. Enquanto esta compara a
receita média conquistada em relação a outras empresas, o share of voice busca
saber a sua participação nas fontes de informação das redes sociais. Essas
estatísticas apresentam a porcentagem de participação nas mídias ao longo de um
determinado período de tempo para o acompanhamento de históricos de
comparação. Quando apresentadas em gráficos no formato pizza, esta métrica pode
oferecer uma visão comparativa de qual mídia social tem um maior impacto dentre
os usuários.
A filtragem de informações após a coleta é importante para selecionar a
melhor coleção de dados e eliminar os ruídos trazidos pelo processo de busca por
palavra-chave. De acordo com Morgado Júnior (2009), é comum aparecer dados
não desejados dentre os itens coletados por causa da taxa de erro que ocorre ao
selecionar textos por palavras-chave. Esse ruído, de alguma forma, precisa ser
eliminado do corpus para não interferir na análise e interpretação dos dados.
Quanto maior o número de opções de filtragem melhor é a capacidade de organizar
e interpretar os dados coletados.
Sobre a característica de analisar de sentimento, Koblitz (2010) explica que o
objetivo dessa funcionalidade é entender como o leitor pode interpretar uma emoção
em um texto. Pang e Lee (2008) definem como um tratamento computacional de

76
dados textuais em forma de opinião, sentimento ou subjetividade. A emoção
detectada pode ser classificada atribuindo aos textos uma orientação, a qual pode
ser positiva, negativa ou neutra. Com a filtragem de um conteúdo pelo grau de
sentimento pode ser possível segmentar os usuários em categorias. Os usuários que
apresentam uma maior tendência em falar positivamente da marca são chamados
de advogados, defensores (SILVA, 2010; TELMA, 2011) ou evangelizadores da
marca (IDEYA, 2012). Aqueles que apresentam padrões que expressam muitos
comentários negativos sobre a marca são chamados de detratores ou destruidores
da marca. Silva (2010) alerta para analisar esses usuários de perto, pois os
detratores precisam ser convertidos em torno da marca com a resolução de seus
problemas e os defensores precisam ser estimulados a defender a marca em
determinadas situações de alta repercussão negativa nas redes sociais.
Referente à análise de tópicos e temas, os textos coletados na rede social
Twitter não trazem o tópico ou tema que está sendo comentado, sendo necessária
uma intervenção humana para definir que categoria esse texto se encaixa. Adição
de trechos informativos, chamados também de tags nas menções permite organizar
os comentários de acordo com as demandas de informação do analista. As
categorias podem identificar parâmetros ou variáveis que se pretende medir. Da
mesma maneira da análise de sentimento manual, a análise de tópicos e temas
exige a presença humana para classificar todos os itens coletados. Com essas
informações foi possível segmentar a coleção de comentários em diversos grupos ou
padrões. Uma prática muito comum no monitoramento de redes sociais é classificar
o comentário pelo tipo de emissor, categorizando-o como Institucional, Imprensa,
Cliente, Usuário comum etc (SILVA, 2010). Dessa forma, por exemplo, é possível
prospectar novos clientes, identificar usuários insatisfeitos, monitorar o que está
saindo na impressa online ou mesmo o que está sendo publicado pelas instituições
governamentais.
As análises de tendências são definidas por Telma (2011) como tópicos e
temas mais comentados em conversas e manifestações em redes sociais sobre
determinadas marcas de empresas, produtos ou serviços. Nas redes sociais os
usuários expressaram suas preferências, desejos, hábitos em forma de opinião.
Esses sentimentos fornecem informações que predizem alguma possível tendência.
Apesar de muitos dados, as tendências nascem de gestos isolados, sendo

77
necessária a intervenção de um analista para identificar a partir de uma filtragem e
organização do conteúdo quais são os grupos com o perfil de inovação e formadores
de opinião, pois serão eles que irão difundir práticas e/ou pensamentos que podem
evoluir e influenciar outras pessoas (SIQUEIRA, 2010). Deve ser levada em
consideração a influência que cada usuário tem nas mídias sociais para analisar
uma possível tendência.
Conhecida também pela métrica de alcance e reputação, a análise de
influência procurou identificar padrões entre os indivíduos das redes sociais que
estão propensos a falar muitas vezes sobre a marca, independente se o teor do
conteúdo seja positivo (defensores) ou negativo (detratores). A forma mais comum
apresentada pelas ferramentas estudadas para identificar as pessoas influentes nas
mídias sociais é por meio da métrica Klout, que mede a influência baseada na
habilidade dos usuários gerarem ações (SILVA, 2012). Essa métrica é gerada a
partir de diversos dados coletados dos perfis dos usuários e pode ser medida pela
escala de 0 a 100, ou seja, quanto maior o Klout maior a influência do usuário nas
redes sociais. O tamanho da influência interfere diretamente na análise da
repercussão de algo nas redes sociais. Quando um assunto é muito comentado
sobre a marca que está sendo monitorada e os usuários que estão comentando tem
uma influência alta existe uma tendência para gerar uma repercussão positiva ou
negativa sobre a marca. É importante a empresa ter o maior número de
influenciadores positivos ou defensores para poder aumentar o número de buzz
positivo da marca.
O monitoramento de campanhas tem a função de gerenciar e medir o
desempenho de eventos externos (SILVA e SANTOS, 2010). Essas campanhas são
temporárias e precisam ser monitoradas separadamente para não interferir no
monitoramento contínuo da marca.
Outra característica apresentada pelas ferramentas de monitoramento de
redes sociais é a Gestão de Relacionamento com o Cliente, conhecido pela sigla em
inglês CRM (Customer Relationship Management), que de acordo com Silva e
Santos (2010) são ferramentas que gerenciam as funções de contato com o cliente
com o objetivo de manter o melhor relacionamento possível entre a empresa e o
consumidor. As funções de gestão de relacionamento procuram armazenar as

78
informações mais importantes sobre o cliente, relacionando-o com outros dados
coletados.
Outra característica analisada nas ferramentas mapeadas foi a capacidade de
monitorar o mercado competitivo. Rastrear os passos de empresas concorrentes por
meio das redes sociais é um grande desafio, visto que as informações
disponibilizadas são controlados pelo usuário emissor. No entanto, saber o que os
usuários das redes sociais estão comentando sobre o concorrente, quais suas
experiências de consumo, críticas, opiniões, elogios, reações positivas e negativas
sobre as marcas e produtos do concorrente são algumas das análises que podem
ser feitas pelas ferramentas de monitoramento nas redes sociais. Sartori e Reis
(2010) ressaltam que antes de monitorar os passos do concorrente, em se tratando
de vantagem competitiva, primeiramente as empresas precisam gerenciar a sua
própria reputação nas redes sociais digitais e, posteriormente, se preocupar em
monitorar a reputação de empresas competidoras. O posicionamento da empresa no
próprio canal de mídia social, aumentando os laços relacionais com os clientes,
respondendo proativamente as suas manifestações e minimizando o impacto
negativo na imagem da empresa. Essas ações, segundo os autores, poderão
resultar em inovação do valor percebido pelo cliente. Wives (2002, p. 17) adverte
sobre o monitoramento competitivo:
Como os concorrentes também podem coletar as mesmas informações, jáque muitas fontes são públicas, eles e outros possíveis concorrentes(empresas distantes, mas do mesmo ramo ou de ramos similares quepodem mudar de ramo em busca de um novo nicho de mercado) devem serconstantemente monitorados para que possíveis ataques (invasões demercado) sejam prevenidos ou, similarmente ao que eles fariam, para quenovos nichos de mercado possam ser identificados.
Em relação à funcionalidade de análise de conteúdo procurou encontrar
elementos relevantes dentro de elementos textuais. Como a informação presente
nas redes sociais é representada em sua maior parte por textos foi necessário
entender como as ferramentas de monitoramento oferecem opções de analisar
sintático, léxico, semântico os comentários contidos nas redes sociais. Como
relatado por Wives (2002), a análise de conteúdo de texto extraídos da Web é
conhecido por usar as técnicas de mineração de textos para encontrar padrões em
meio às informações contidas nos documentos. Devido suas características
subjetivas, a análise de conteúdo precisa seguir um rigoroso processo de
manipulação de dados, começando com a filtragem correta dos comentários,

79
eliminando os ruídos normalmente coletados. Para a análise de conteúdo, Wives
(2002) sugere que o clustering é mais adequado para detectar padrões de grupos e
separar uma coleção de textos em subcoleções, juntamente com as técnicas de
extração e categorização. Essa funcionalidade poderá oferecer opções de
segmentação de usuários e comentários. Além disso, pode-se utilizar a análise no
decorrer histórico de suas postagens para a detecção de alguma tendência de
mudança de uma época para a outra.
Sobre a etapa de visualização de dados optou-se por utilizar os formatos
apresentados por Silva (2012) tais como a unidade de conteúdo, que mostra o
comentário da mesma forma que é visualizada nas redes sociais, gráfico de volume
e tempo que mostra em formato de linhas ou barras os quantitativos de volume de
comentário versus o tempo. Os gráficos em formato pizza apresentam informações
para entender seções de um conjunto ou população para permitir entender partes de
um todo. Esse tipo de visualização pode ser útil para comparar dados em formato de
porcentagem, que no final somem 100%. A comparação de valores permite ao
analista confrontar dados contidos em duas ou mais valores. Esse tipo de
visualização, geralmente mostrado através de gráficos em barra ou em linha retrata,
por exemplo, a divisão de tipos de público-alvo, comparação de repercussão da
marca da empresa com a do concorrente, comparação de campanhas publicitárias,
histórico de citações em um período de tempo por polaridade de sentimento etc. As
análises de textos geralmente são visualizadas por meio de relatórios com o ranking
de termos (tags) mais citadas nos comentários coletados ou por meio de gráfico de
nuvem de palavras. Este último apresenta uma lista de palavras, no qual as que
forem mais citadas aparecem com o tamanho maior do que as que forem menos
mencionadas. Esse tipo de visualização ajuda no entendimento de aparecimento de
tendências entre os termos coletados. É importante utilizar esse tipo de visualização
juntamente com os gráficos temporais para entender a presença ou ausência de
tendências no decorrer do tempo.
5.4 TRATAMENTO DOS DADOS
A busca pelas ferramentas na Internet e a avaliação dos dados ocorreram de
forma simultânea. Ao mesmo tempo que a ferramenta era encontrada no site de

80
busca, esta era avaliada primeiramente sob a ótica das informações disponibilizadas
no site da ferramenta, no qual foram coletadas os dados descritivos. Depois era
verificado se a ferramenta disponibilizava uma versão gratuita para teste. Caso
positivo, era solicitado uma conta gratuita para realizar uma avaliação mais
aprofundada na ferramenta. Para facilitar a organização dos resultados, foram
comparadas separadamente as funcionalidades encontradas nas ferramentas de
monitoramento de redes sociais (MRS) e as oferecidas pelos software de mineração
de textos (MT).
A pesquisa por ferramentas de MRS foi realizada no período de 02 a 30 de
maio de 2012. Já a pesquisa por ferramentas de MT foi realizada no período de 01 a
30 de junho de 2012. Com a lista de todas as ferramentas com disponibilidade de
teste ou licença acadêmica na lingua portuguesa foi possível realizar uma coleta de
comentários nas redes sociais para testar o uso das ferramentas e poder avaliar as
funcionalidades. Para exemplificar as funcionalidades foram extraídos comentários
nas redes sociais Facebook e Twitter sobre uma marca de uma universidade
particular no mesmo período da coleta dos dados. O objetivo desse procedimento
era disponibilizar imagens dos formatos de informações geradas por essas
ferramentas.
Após a extração de comentários pelas ferramentas de MRS foi possível
exportá-los em forma de planilha para serem utilizados como entrada nos software
de MT. Apesar das quantidades de comentários coletados terem sido suficiente para
avaliar as funcionalidades das ferramentas de MRS, os softwares de mineração de
texto exigiram uma quantidade maior, sendo impossibilitado pelo curto espaço de
tempo para coleta gratuita. Entretanto, realizou-se uma segunda coleta de exemplo
utilizando não uma marca, mas dados sobre o meio ambiente, com o objetivo de
coletar mais itens. Dessa forma foi possível utilizá-los como dados de entradas para
testar as ferramentas de MT.
Vale frisar que o objetivo do trabalho não foi analisar e discutir os comentários
coletados nas ferramentas de MRS e sim verificar as funcionalidades que essas
ferramentas oferecem, sendo necessário exemplificar por meio de uma coleta teste.
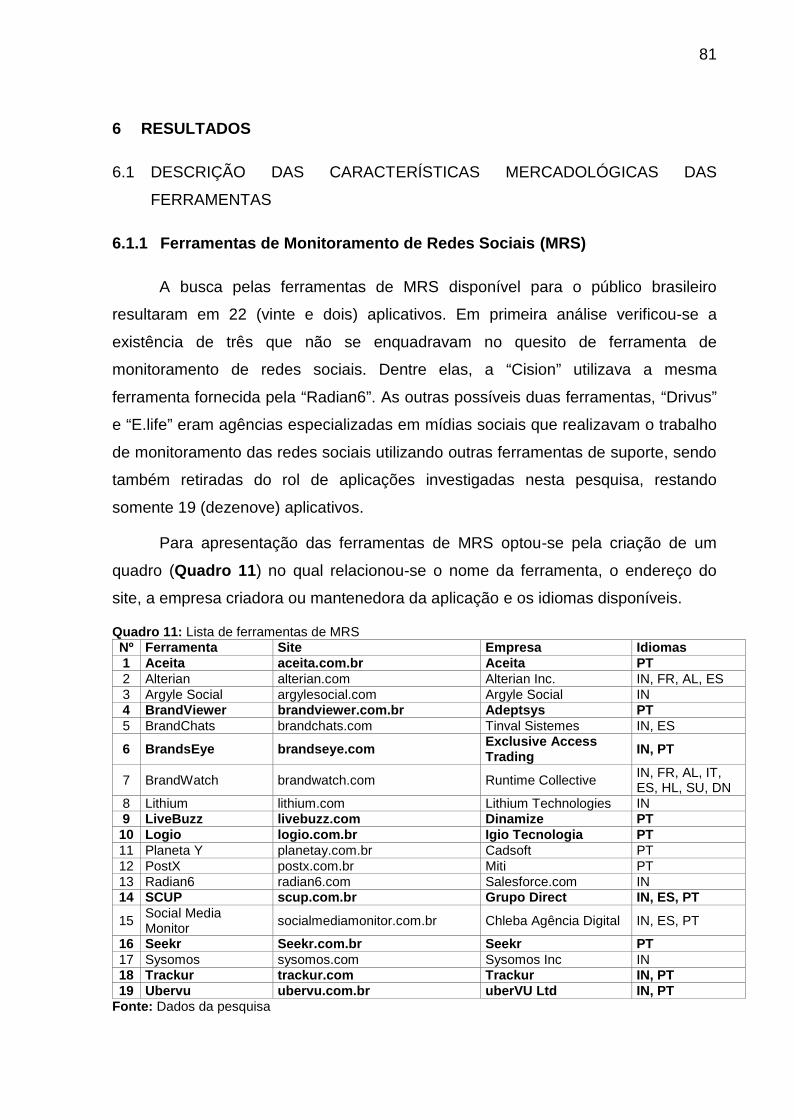
81
6 RESULTADOS
6.1 DESCRIÇÃO DAS CARACTERÍSTICAS MERCADOLÓGICAS DAS
FERRAMENTAS
6.1.1 Ferramentas de Monitoramento de Redes Sociais (MRS)
A busca pelas ferramentas de MRS disponível para o público brasileiro
resultaram em 22 (vinte e dois) aplicativos. Em primeira análise verificou-se a
existência de três que não se enquadravam no quesito de ferramenta de
monitoramento de redes sociais. Dentre elas, a “Cision” utilizava a mesma
ferramenta fornecida pela “Radian6”. As outras possíveis duas ferramentas, “Drivus”
e “E.life” eram agências especializadas em mídias sociais que realizavam o trabalho
de monitoramento das redes sociais utilizando outras ferramentas de suporte, sendo
também retiradas do rol de aplicações investigadas nesta pesquisa, restando
somente 19 (dezenove) aplicativos.
Para apresentação das ferramentas de MRS optou-se pela criação de um
quadro (Quadro 11) no qual relacionou-se o nome da ferramenta, o endereço do
site, a empresa criadora ou mantenedora da aplicação e os idiomas disponíveis.
Quadro 11: Lista de ferramentas de MRSNº Ferramenta Site Empresa Idiomas1 Aceita aceita.com.br Aceita PT2 Alterian alterian.com Alterian Inc. IN, FR, AL, ES3 Argyle Social argylesocial.com Argyle Social IN4 BrandViewer brandviewer.com.br Adeptsys PT5 BrandChats brandchats.com Tinval Sistemes IN, ES
6 BrandsEye brandseye.com Exclusive AccessTrading IN, PT
7 BrandWatch brandwatch.com Runtime Collective IN, FR, AL, IT,ES, HL, SU, DN
8 Lithium lithium.com Lithium Technologies IN9 LiveBuzz livebuzz.com Dinamize PT
10 Logio logio.com.br Igio Tecnologia PT11 Planeta Y planetay.com.br Cadsoft PT12 PostX postx.com.br Miti PT13 Radian6 radian6.com Salesforce.com IN14 SCUP scup.com.br Grupo Direct IN, ES, PT
15 Social MediaMonitor socialmediamonitor.com.br Chleba Agência Digital IN, ES, PT
16 Seekr Seekr.com.br Seekr PT17 Sysomos sysomos.com Sysomos Inc IN18 Trackur trackur.com Trackur IN, PT19 Ubervu ubervu.com.br uberVU Ltd IN, PT
Fonte: Dados da pesquisa
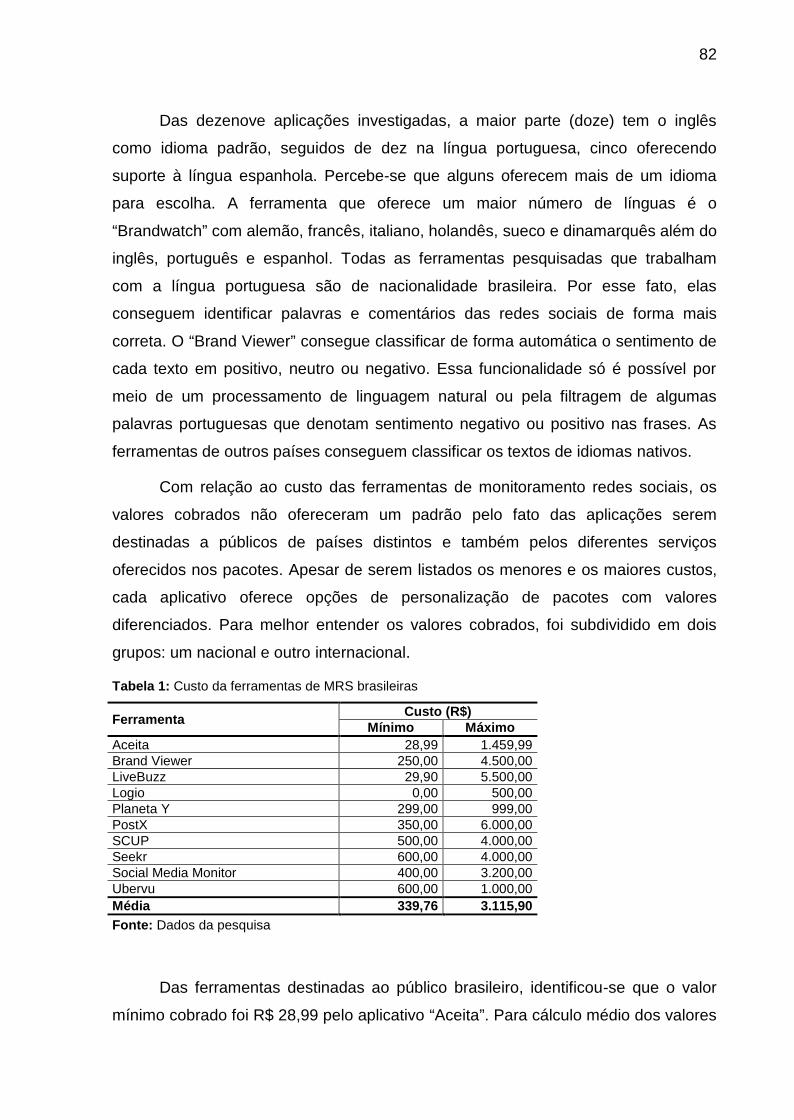
82
Das dezenove aplicações investigadas, a maior parte (doze) tem o inglês
como idioma padrão, seguidos de dez na língua portuguesa, cinco oferecendo
suporte à língua espanhola. Percebe-se que alguns oferecem mais de um idioma
para escolha. A ferramenta que oferece um maior número de línguas é o
“Brandwatch” com alemão, francês, italiano, holandês, sueco e dinamarquês além do
inglês, português e espanhol. Todas as ferramentas pesquisadas que trabalham
com a língua portuguesa são de nacionalidade brasileira. Por esse fato, elas
conseguem identificar palavras e comentários das redes sociais de forma mais
correta. O “Brand Viewer” consegue classificar de forma automática o sentimento de
cada texto em positivo, neutro ou negativo. Essa funcionalidade só é possível por
meio de um processamento de linguagem natural ou pela filtragem de algumas
palavras portuguesas que denotam sentimento negativo ou positivo nas frases. As
ferramentas de outros países conseguem classificar os textos de idiomas nativos.
Com relação ao custo das ferramentas de monitoramento redes sociais, os
valores cobrados não ofereceram um padrão pelo fato das aplicações serem
destinadas a públicos de países distintos e também pelos diferentes serviços
oferecidos nos pacotes. Apesar de serem listados os menores e os maiores custos,
cada aplicativo oferece opções de personalização de pacotes com valores
diferenciados. Para melhor entender os valores cobrados, foi subdividido em dois
grupos: um nacional e outro internacional.
Tabela 1: Custo da ferramentas de MRS brasileiras
Ferramenta Custo (R$)Mínimo Máximo
Aceita 28,99 1.459,99Brand Viewer 250,00 4.500,00LiveBuzz 29,90 5.500,00Logio 0,00 500,00Planeta Y 299,00 999,00PostX 350,00 6.000,00SCUP 500,00 4.000,00Seekr 600,00 4.000,00Social Media Monitor 400,00 3.200,00Ubervu 600,00 1.000,00Média 339,76 3.115,90Fonte: Dados da pesquisa
Das ferramentas destinadas ao público brasileiro, identificou-se que o valor
mínimo cobrado foi R$ 28,99 pelo aplicativo “Aceita”. Para cálculo médio dos valores
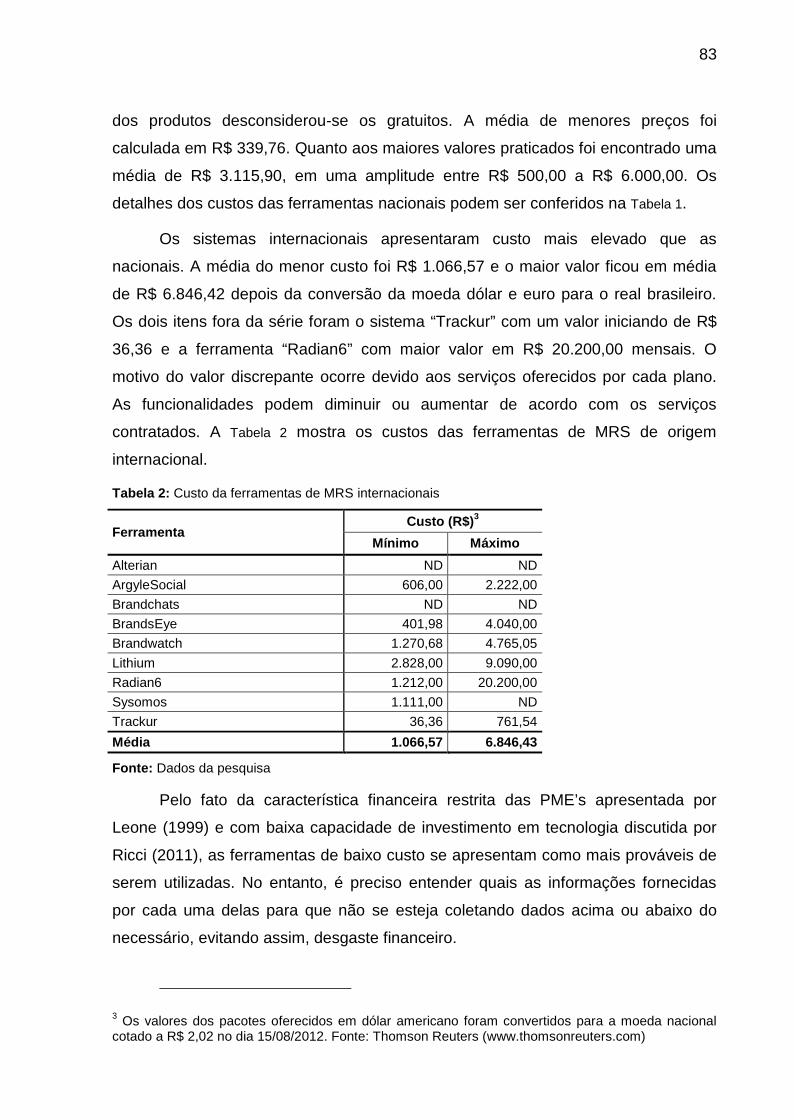
83
dos produtos desconsiderou-se os gratuitos. A média de menores preços foi
calculada em R$ 339,76. Quanto aos maiores valores praticados foi encontrado uma
média de R$ 3.115,90, em uma amplitude entre R$ 500,00 a R$ 6.000,00. Os
detalhes dos custos das ferramentas nacionais podem ser conferidos na Tabela 1.
Os sistemas internacionais apresentaram custo mais elevado que as
nacionais. A média do menor custo foi R$ 1.066,57 e o maior valor ficou em média
de R$ 6.846,42 depois da conversão da moeda dólar e euro para o real brasileiro.
Os dois itens fora da série foram o sistema “Trackur” com um valor iniciando de R$
36,36 e a ferramenta “Radian6” com maior valor em R$ 20.200,00 mensais. O
motivo do valor discrepante ocorre devido aos serviços oferecidos por cada plano.
As funcionalidades podem diminuir ou aumentar de acordo com os serviços
contratados. A Tabela 2 mostra os custos das ferramentas de MRS de origem
internacional.
Tabela 2: Custo da ferramentas de MRS internacionais
FerramentaCusto (R$)3
Mínimo MáximoAlterian ND NDArgyleSocial 606,00 2.222,00Brandchats ND NDBrandsEye 401,98 4.040,00Brandwatch 1.270,68 4.765,05Lithium 2.828,00 9.090,00Radian6 1.212,00 20.200,00Sysomos 1.111,00 NDTrackur 36,36 761,54Média 1.066,57 6.846,43
Fonte: Dados da pesquisa
Pelo fato da característica financeira restrita das PME’s apresentada por
Leone (1999) e com baixa capacidade de investimento em tecnologia discutida por
Ricci (2011), as ferramentas de baixo custo se apresentam como mais prováveis de
serem utilizadas. No entanto, é preciso entender quais as informações fornecidas
por cada uma delas para que não se esteja coletando dados acima ou abaixo do
necessário, evitando assim, desgaste financeiro.
3 Os valores dos pacotes oferecidos em dólar americano foram convertidos para a moeda nacionalcotado a R$ 2,02 no dia 15/08/2012. Fonte: Thomson Reuters (www.thomsonreuters.com)
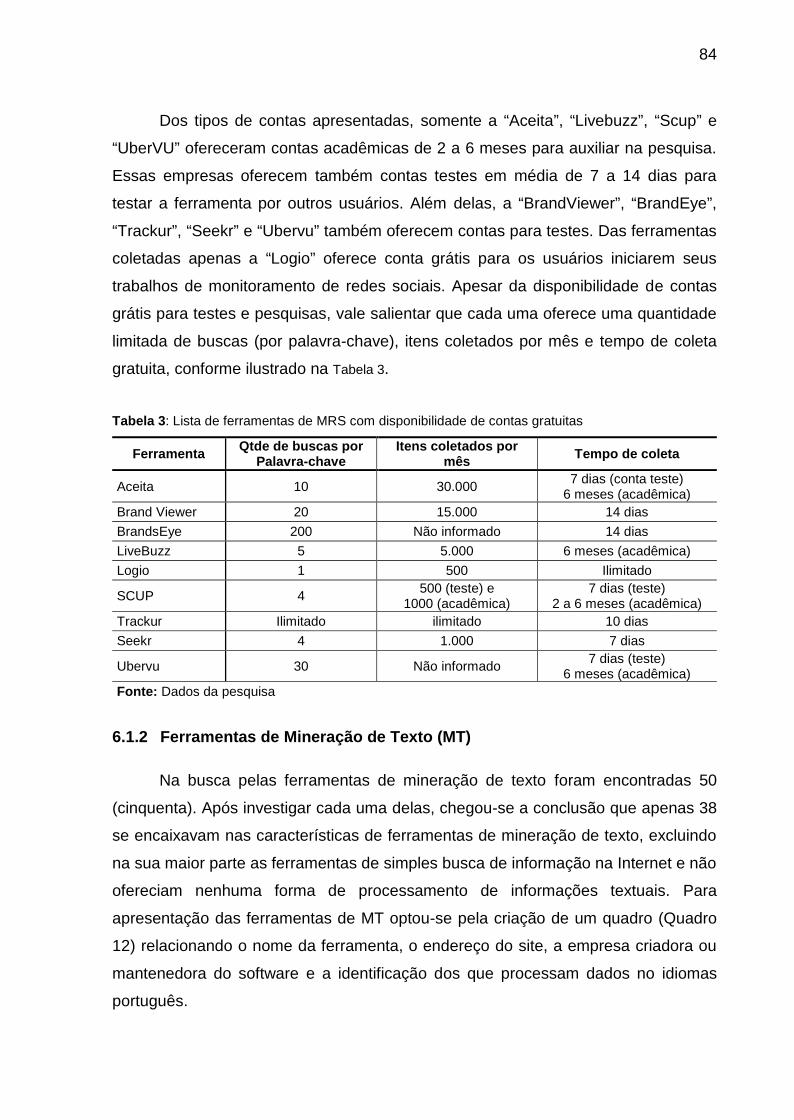
84
Dos tipos de contas apresentadas, somente a “Aceita”, “Livebuzz”, “Scup” e
“UberVU” ofereceram contas acadêmicas de 2 a 6 meses para auxiliar na pesquisa.
Essas empresas oferecem também contas testes em média de 7 a 14 dias para
testar a ferramenta por outros usuários. Além delas, a “BrandViewer”, “BrandEye”,
“Trackur”, “Seekr” e “Ubervu” também oferecem contas para testes. Das ferramentas
coletadas apenas a “Logio” oferece conta grátis para os usuários iniciarem seus
trabalhos de monitoramento de redes sociais. Apesar da disponibilidade de contas
grátis para testes e pesquisas, vale salientar que cada uma oferece uma quantidade
limitada de buscas (por palavra-chave), itens coletados por mês e tempo de coleta
gratuita, conforme ilustrado na Tabela 3.
Tabela 3: Lista de ferramentas de MRS com disponibilidade de contas gratuitas
Ferramenta Qtde de buscas porPalavra-chave
Itens coletados pormês Tempo de coleta
Aceita 10 30.000 7 dias (conta teste)6 meses (acadêmica)
Brand Viewer 20 15.000 14 diasBrandsEye 200 Não informado 14 diasLiveBuzz 5 5.000 6 meses (acadêmica)Logio 1 500 Ilimitado
SCUP 4 500 (teste) e1000 (acadêmica)
7 dias (teste)2 a 6 meses (acadêmica)
Trackur Ilimitado ilimitado 10 diasSeekr 4 1.000 7 dias
Ubervu 30 Não informado 7 dias (teste)6 meses (acadêmica)
Fonte: Dados da pesquisa
6.1.2 Ferramentas de Mineração de Texto (MT)
Na busca pelas ferramentas de mineração de texto foram encontradas 50
(cinquenta). Após investigar cada uma delas, chegou-se a conclusão que apenas 38
se encaixavam nas características de ferramentas de mineração de texto, excluindo
na sua maior parte as ferramentas de simples busca de informação na Internet e não
ofereciam nenhuma forma de processamento de informações textuais. Para
apresentação das ferramentas de MT optou-se pela criação de um quadro (Quadro
12) relacionando o nome da ferramenta, o endereço do site, a empresa criadora ou
mantenedora do software e a identificação dos que processam dados no idiomas
português.
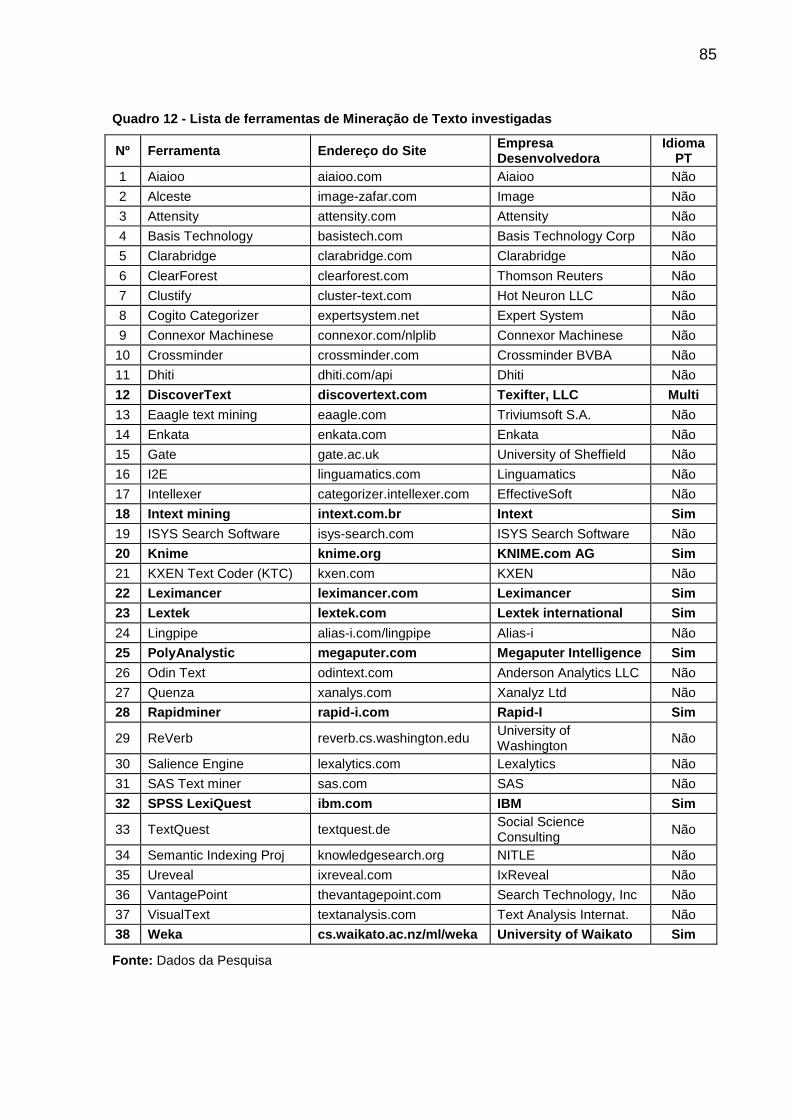
85
Quadro 12 - Lista de ferramentas de Mineração de Texto investigadas
Nº Ferramenta Endereço do Site EmpresaDesenvolvedora
IdiomaPT
1 Aiaioo aiaioo.com Aiaioo Não2 Alceste image-zafar.com Image Não3 Attensity attensity.com Attensity Não4 Basis Technology basistech.com Basis Technology Corp Não5 Clarabridge clarabridge.com Clarabridge Não6 ClearForest clearforest.com Thomson Reuters Não7 Clustify cluster-text.com Hot Neuron LLC Não8 Cogito Categorizer expertsystem.net Expert System Não9 Connexor Machinese connexor.com/nlplib Connexor Machinese Não
10 Crossminder crossminder.com Crossminder BVBA Não11 Dhiti dhiti.com/api Dhiti Não12 DiscoverText discovertext.com Texifter, LLC Multi13 Eaagle text mining eaagle.com Triviumsoft S.A. Não14 Enkata enkata.com Enkata Não15 Gate gate.ac.uk University of Sheffield Não16 I2E linguamatics.com Linguamatics Não17 Intellexer categorizer.intellexer.com EffectiveSoft Não18 Intext mining intext.com.br Intext Sim19 ISYS Search Software isys-search.com ISYS Search Software Não20 Knime knime.org KNIME.com AG Sim21 KXEN Text Coder (KTC) kxen.com KXEN Não22 Leximancer leximancer.com Leximancer Sim23 Lextek lextek.com Lextek international Sim24 Lingpipe alias-i.com/lingpipe Alias-i Não25 PolyAnalystic megaputer.com Megaputer Intelligence Sim26 Odin Text odintext.com Anderson Analytics LLC Não27 Quenza xanalys.com Xanalyz Ltd Não28 Rapidminer rapid-i.com Rapid-I Sim
29 ReVerb reverb.cs.washington.edu University ofWashington Não
30 Salience Engine lexalytics.com Lexalytics Não31 SAS Text miner sas.com SAS Não32 SPSS LexiQuest ibm.com IBM Sim
33 TextQuest textquest.de Social ScienceConsulting Não
34 Semantic Indexing Proj knowledgesearch.org NITLE Não35 Ureveal ixreveal.com IxReveal Não36 VantagePoint thevantagepoint.com Search Technology, Inc Não37 VisualText textanalysis.com Text Analysis Internat. Não38 Weka cs.waikato.ac.nz/ml/weka University of Waikato Sim
Fonte: Dados da Pesquisa

86
Com relação ao idioma, somente o software “InText Mining” é de
nacionalidade brasileira. A maior parte é composta de aplicativos de origem
americana, seguido de países europeus, como a França, Inglaterra, Alemanha e
Espanha.
Os valores de custo cobrados pelos softwares de MT se diferem dos cobrados
nas ferramentas de MRS. Devido a sua maior complexidade de processamento de
informações, os software de MT tem um custo superior, conforme ilustrado na Tabela
4. Dos itens avaliadas, somente nove revelaram os valores cobrados pelas licenças
dos seus respectivos sistemas. “Lextek” e “Aiaioo” foram as que apresentaram suas
versões de entrada mais baratas, pois não cobram pelo uso inicial do sistema.
“Intellexer”, “DiscoveryText”, “TextQuest” e “Intext Mining” apresentaram valores de
partida abaixo de R$ 1.000,00. Os maiores valores cobrados de entrada foram os
software “VantagePoint”, “Clustify” e “Basis Technology”.
Tabela 4 - Menores valores cobrados pelas ferramentas de MTFerramenta Menor custo (R$)
Lextek 0,00Aiaioo 0,00Intellexer 26,16DiscoverText 200,00TextQuest 747,00Intext mining 1.000,00VantagePoint 15.150,00Clustify 40.400,00Basis Technology 60.000,00Fonte: Dados da pesquisa
Quanto ao maior custo, a ferramenta “Intellexer” apresentou o teto mais baixo
no valor de R$ 402,00. As mais onerosas foram a “Clustify” e “Basis Technology”.
“DiscoveryText” e “VantagePoint” não disponibilizaram os valores maiores cobrados,
pois podem ser customizados. Dependendo da versão ou da funcionalidade
acrescentada na licença, o valor pode ser alterado (Tabela 5).

87
Tabela 5 - Maiores valores cobrados pelas ferramentas de MT
Ferramenta Maior custo (R$)
DiscoverText CustomizadoVantagePoint CustomizadoIntellexer 402,00Intext mining 3.000,00Lextek 4.040,00Aiaioo 8.080,00TextQuest 18.675,00Basis Technology 377.740,00Clustify 505.000,00Fonte: Dados da pesquisa
Da mesma forma que as ferramentas de monitoramento de redes sociais, os
software de mineração de texto precisam ser adequados à realidade das PMEs. Vale
frizar que o valor pago nesse tipo de sistema é a licença permanente, diferente das
ferramentas de MRS que é preciso pagar uma mensalidade. As funcionalidades
também se diferenciam de acordo com a licença escolhida.
Quanto à disponibilidade do software para testes ou pesquisas acadêmicas,
verificou-se que 63,1% (24 ferramentas) disponibilizam versões de testes para os
seus usuários. Metade delas oferece a ferramenta completa por um tempo limitado,
geralmente 30 dias. Das ferramentas para teste restantes, seis oferecem recursos
limitados por tempo indeterminado e as outras seis disponibilizam o software
completo sem limites de tempo, visto que são software livres e foram desenvolvidas
com um propóstito de fomentar as pesquisas acadêmicas, tais como o Weka, Knime,
Gate e o Rapid Miner.
Quanto ao tipo de software, 31 são ferramentas que são instaladas nos
computadores denominadas de standalone. Para isso é necessário baixar, instalar e
utilizar em um computador. O restante (oito) são executadas diretamente na Internet
por meio de navegadores. Utilizar aplicações standalone tem uma grande
desvantagem, pois exige que o computador tenha capacidade de processamento
elevado, dependendo da quantidade de dados que tenha pra analisar. Muitas vezes
é necessário ter um computador muito sofisticado e caro para obter informações
rápidas.

88
6.2 DESCRIÇÃO FUNCIONAL DAS FERRAMENTAS SELECIONADAS
Dentre as ferramentas mapeadas, foram escolhidas 9 de monitoramento de
redes sociais e 9 de mineração de textos, totalizando 18 ferramentas selecionadas
para descrever e comparar as funcionalidades. O critério para a escolha foi a
disponibilidade gratuita ou com versão acadêmica para testes e também a
capacidade de processar documentos na língua portuguesa. Por se tratar de
sistemas online, as ferramentas de MRS disponibilizavam contas para a coleta e
processamentos dos dados diretamente na Internet por um determinado período de
tempo. Neste caso, foi possível avaliá-las dentro do período permitido. Dentre as
ferramentas de mineração de texto, a maior parte das informações foi obtida dentro
do site do desenvolvedor, visto que era necessária a instalação de todos eles para
analisá-los no computador. Outros dados foram obtidos por meio de mensagens de
e-mail com o desenvolvedor da ferramenta.
6.2.1 Ferramentas de Monitoramento de redes sociais (MRS)
Para melhor entendimento do fluxo de trabalho utilizado nas ferramentas de
MRS, foram relacionadas as funcionalidades encontradas nos sistemas avaliados
subdivididas em em quatro etapas principais: coleta, processamento, análise e
visualização de dados.
Etapa de coleta de dados6.2.1.1
Esta fase procurou destacar a caracterização das ferramentas de
monitoramento de redes sociais de acordo com suas funcionalidades de coleta de
dados, visto que este passo foi necessário para que o processamento, análise e
visualização da informação fossem possíveis (Tabela 6).
Tabela 6: Funcionalidades de coleta de dados nos software de MRS
Funcionalidades de coleta de dados
Ace
itaB
rand
Vie
wer
Bra
nds
Eye
Live
Buz
zLo
gio
SCU
PTr
acku
rSe
ekr
Ube
rvu F %
Busca por palavra-chave X X X X X X X X X 9 100Exportação de dados para planilhas X X X X X X X X X 9 100Limpeza dos dados – controle de SPAM - - - X - - - - - 1 11Fonte: Dados da pesquisa
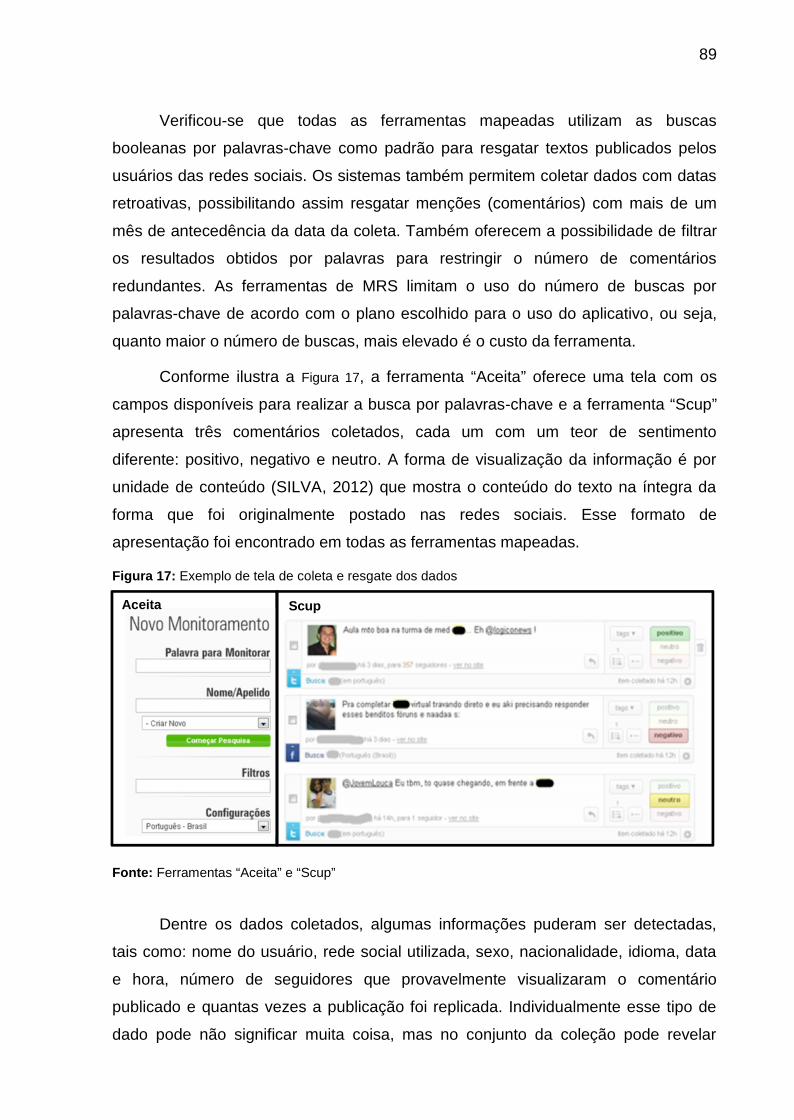
89
Verificou-se que todas as ferramentas mapeadas utilizam as buscas
booleanas por palavras-chave como padrão para resgatar textos publicados pelos
usuários das redes sociais. Os sistemas também permitem coletar dados com datas
retroativas, possibilitando assim resgatar menções (comentários) com mais de um
mês de antecedência da data da coleta. Também oferecem a possibilidade de filtrar
os resultados obtidos por palavras para restringir o número de comentários
redundantes. As ferramentas de MRS limitam o uso do número de buscas por
palavras-chave de acordo com o plano escolhido para o uso do aplicativo, ou seja,
quanto maior o número de buscas, mais elevado é o custo da ferramenta.
Conforme ilustra a Figura 17, a ferramenta “Aceita” oferece uma tela com os
campos disponíveis para realizar a busca por palavras-chave e a ferramenta “Scup”
apresenta três comentários coletados, cada um com um teor de sentimento
diferente: positivo, negativo e neutro. A forma de visualização da informação é por
unidade de conteúdo (SILVA, 2012) que mostra o conteúdo do texto na íntegra da
forma que foi originalmente postado nas redes sociais. Esse formato de
apresentação foi encontrado em todas as ferramentas mapeadas.
Figura 17: Exemplo de tela de coleta e resgate dos dados
Aceita Scup
Fonte: Ferramentas “Aceita” e “Scup”
Dentre os dados coletados, algumas informações puderam ser detectadas,
tais como: nome do usuário, rede social utilizada, sexo, nacionalidade, idioma, data
e hora, número de seguidores que provavelmente visualizaram o comentário
publicado e quantas vezes a publicação foi replicada. Individualmente esse tipo de
dado pode não significar muita coisa, mas no conjunto da coleção pode revelar

90
padrões de segmento que podem ser explorados, tais como: qual a rede social que
mais fala a marca da empresa, ou mesmo dados demográficos como média de
idade, localização dos usuários, sexo etc.
A maior parte dos tipos de arquivos exportados são CSV e PDF. O CSV é um
arquivo de texto, que contém dados tabulados como uma planilha eletrônica. Este
tipo de arquivo pode ser utilizado como arquivo de entrada em sistemas de
processamento de dados textuais, como as ferramentas de mineração de texto. Ou
seja, caso o usuário deseje processar os dados para obter mais informações além
das oferecidas, pode utilizar os arquivos exportados para serem utilizados em outros
aplicativos.
Durante a análise detectou-se uma funcionalidade na ferramenta “Livebuzz”
que tem tarefa de diminuir o número de comentários SPAMS (a quantidade de itens
coletados que são enviados por robôs e não por pessoas). Mesmo assim, ela exige
a presenta do fator humano para identificar pessoalmente as mensagens
indesejadas ou que estejam impedindo a análise dos dados. Outras funcionalidades
para evitar problemas com mensagens consideradas lixo não foram identificadas nas
outras ferramentas.
Etapa de Processamento de dados6.2.1.2
A etapa de processamento os dados das ferramentas de MRS oferece aos
gestores basicamente as funções de cruzamento de dados coletados com algumas
informações adicionais fornecidas manualmente. O objetivo é transformar os dados,
que outrora coletados não são úteis, em informações importantes para tomadas de
decisão. A maior parte dos cruzamentos de dados tem a ver com a relação de
quantidade de itens coletados versus o tempo. A variável de tempo é importante
dentro dos software de MRS, pois permite conhecer o histórico da coleta de itens
específicos, identificando o volume de conteúdo publicado ao longo do tempo.
A funcionalidade de classificação ou categorização automática de texto foi
encontrada em somente duas (2) das ferramentas de MRS monitoradas. O processo
de classificação utiliza a frequência de algumas palavras para categorizar
automaticamente os comentários pelo seu grau de sentimento como positivo,
negativo e neutro. Vale salientar que o restante das ferramentas que não
apresentam classificação automática oferece a forma manual como alternativa,

91
exigindo a presença de um analista para classificar cada comentário de acordo com
o grau de sentimento. Isso confirma o que apresentou Magalhães L. (2009), que a
manipulação manual dos dados coletados poderia até diminuir a taxa de erro ao
classificar corretamente um item, mas por conter grande quantidade de dados
demanda muito tempo em relação ao processo automatizado.
As ferramentas de MRS não apresentaram a indexação, normalização,
lexicometria e clustering como forma de processamento de dados. Isso evidencia
que os procedimentos de análises estatísticas são escassos nesse tipo de sistema,
conforme demonstrado na Tabela 7.
Tabela 7: Funcionalidades de processamento de dados nos software de MRS
Funcionalidades de processamento de dadosA
ceita
Bra
ndVi
ewer
Bra
ndsE
yeLi
veB
uzz
Logi
oSC
UP
Trac
kur
Seek
rU
berv
u F %
Cruzamento de dados X X X X X X X X X 9 100Classificação ou categorização - X X - - - - - - 2 22Indexação - - - - - - - - - 0 0Normalização - - - - - - - - - 0 0Lexicometria - - - - - - - - - 0 0Clustering - - - - - - - - - 0 0Fonte: Dados da pesquisa
Etapa de Análise de Dados6.2.1.3
As funcionalidades de análise de dados oferecidas pelas ferramentas de
monitoramento de redes sociais foram classificadas de acordo com as métricas
utilizadas pela Ideya (2012). Cada função pode fornecer informações úteis para
tomadas de decisões de acordo com o objetivo da coleta: as estatísticas de mídia
fornecem dados sobre a audiência; filtro e organização dos dados podem ser
utilizados para selecionar somente os dados necessários; análise de sentimento
classifica o comentário como positivo, negativo ou neutro; análise de tópicos e temas
servem para segmentar em grupos os comentários coletados; análise de tendências
buscam identificar termos mais comentados para detectar mudanças no ambiente
externo; análise de influenciadores verifica os usuários mais influentes sobre o
assunto pesquisado; monitoramento e mensuração de campanhas acompanham
comentários acerca de campanhas de marketing; gestão de relacionamento com o
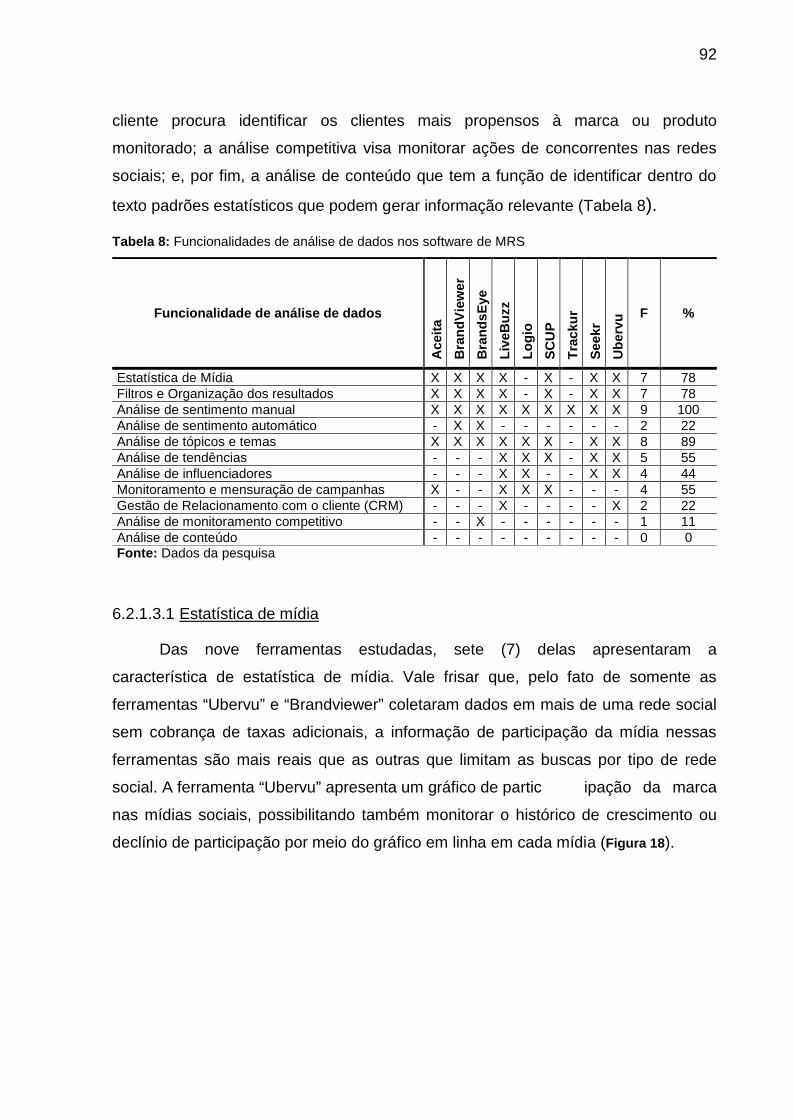
92
cliente procura identificar os clientes mais propensos à marca ou produto
monitorado; a análise competitiva visa monitorar ações de concorrentes nas redes
sociais; e, por fim, a análise de conteúdo que tem a função de identificar dentro do
texto padrões estatísticos que podem gerar informação relevante (Tabela 8).
Tabela 8: Funcionalidades de análise de dados nos software de MRS
Funcionalidade de análise de dados
Ace
itaB
rand
View
erB
rand
sEye
Live
Buz
zLo
gio
SCU
PTr
acku
rSe
ekr
Ube
rvu F %
Estatística de Mídia X X X X - X - X X 7 78Filtros e Organização dos resultados X X X X - X - X X 7 78Análise de sentimento manual X X X X X X X X X 9 100Análise de sentimento automático - X X - - - - - - 2 22Análise de tópicos e temas X X X X X X - X X 8 89Análise de tendências - - - X X X - X X 5 55Análise de influenciadores - - - X X - - X X 4 44Monitoramento e mensuração de campanhas X - - X X X - - - 4 55Gestão de Relacionamento com o cliente (CRM) - - - X - - - - X 2 22Análise de monitoramento competitivo - - X - - - - - - 1 11Análise de conteúdo - - - - - - - - - 0 0Fonte: Dados da pesquisa
6.2.1.3.1 Estatística de mídia
Das nove ferramentas estudadas, sete (7) delas apresentaram a
característica de estatística de mídia. Vale frisar que, pelo fato de somente as
ferramentas “Ubervu” e “Brandviewer” coletaram dados em mais de uma rede social
sem cobrança de taxas adicionais, a informação de participação da mídia nessas
ferramentas são mais reais que as outras que limitam as buscas por tipo de rede
social. A ferramenta “Ubervu” apresenta um gráfico de partic ipação da marca
nas mídias sociais, possibilitando também monitorar o histórico de crescimento ou
declínio de participação por meio do gráfico em linha em cada mídia (Figura 18).
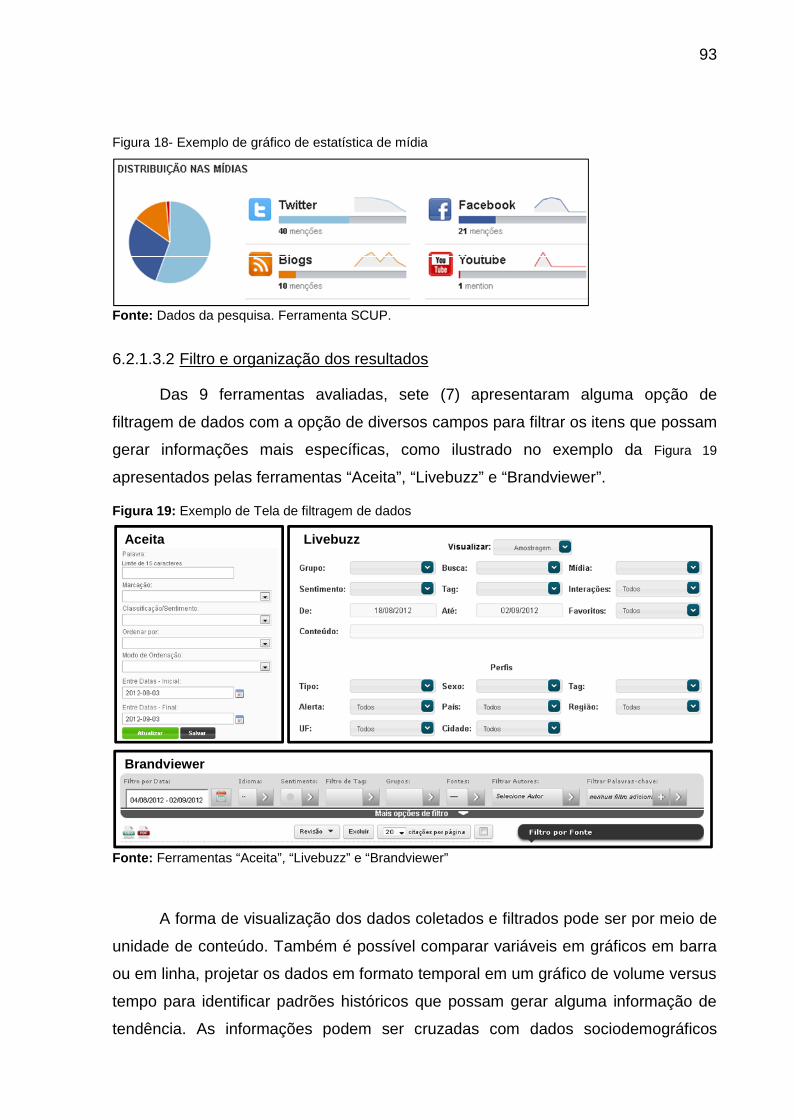
93
Figura 18- Exemplo de gráfico de estatística de mídia
Fonte: Dados da pesquisa. Ferramenta SCUP.
6.2.1.3.2 Filtro e organização dos resultados
Das 9 ferramentas avaliadas, sete (7) apresentaram alguma opção de
filtragem de dados com a opção de diversos campos para filtrar os itens que possam
gerar informações mais específicas, como ilustrado no exemplo da Figura 19
apresentados pelas ferramentas “Aceita”, “Livebuzz” e “Brandviewer”.
Figura 19: Exemplo de Tela de filtragem de dados
Fonte: Ferramentas “Aceita”, “Livebuzz” e “Brandviewer”
A forma de visualização dos dados coletados e filtrados pode ser por meio de
unidade de conteúdo. Também é possível comparar variáveis em gráficos em barra
ou em linha, projetar os dados em formato temporal em um gráfico de volume versus
tempo para identificar padrões históricos que possam gerar alguma informação de
tendência. As informações podem ser cruzadas com dados sociodemográficos
Aceita Livebuzz
Brandviewer

94
coletados dos indivíduos, tais como sexo, localização, idade etc. Na Figura 20 é
ilustrado o exemplo de um gráfico de volume e tempo visualizado na ferramenta
“Ubervu” que mostra o histórico das visualizações diárias da marca coletada e a
localização da origem dos comentários em um mapa geográfico.
Figura 20: Tipos de gráficos gerados a partir da filtragem de dados
Fonte: Ferramenta “UberVU”
6.2.1.3.3 Análise de sentimento
Todas as ferramentas oferecem a opção de análise de sentimento manual,
com a atribuição positiva, neutra ou negativa. A “BrandsEye” apresenta uma escala
mais complexa com dez opções de classificação (de -5 a -1 e de +1 a +5). A
ferramenta “Aceita” apresenta além das três opções tradicionais o atributo
“oportunidade” para identificar comentários que identifiquem insights sobre novas
marcas de produtos, serviços ou empresas.
Dos sistemas avaliados verificou-se que somente “BrandsEye” e
“Brandviewer” fornecem capacidade de atribuir um sentimento automático nos
comentários. A ferramenta “BrandsEye” exige que o usuário classifique
manualmente no mínimo 170 comentários de cada categoria para que o sistema
“aprenda” qual o padrão a ser seguido na classificação automática. Para realizar
essa tarefa com uma maior precisão será necessário o trabalho de um analista que
compreenda o conteúdo dos dados e possa classificar manualmente cada um deles.
A “Brandviewer” não determina um treinamento prévio para detectar o padrão de
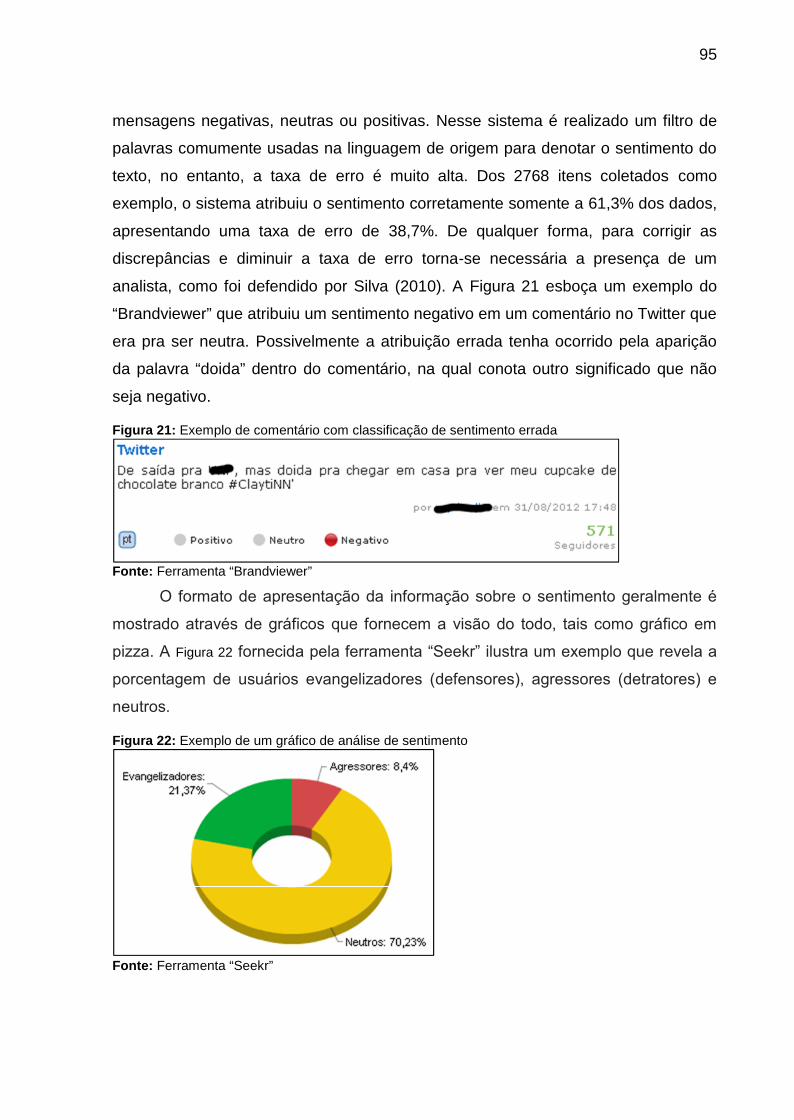
95
mensagens negativas, neutras ou positivas. Nesse sistema é realizado um filtro de
palavras comumente usadas na linguagem de origem para denotar o sentimento do
texto, no entanto, a taxa de erro é muito alta. Dos 2768 itens coletados como
exemplo, o sistema atribuiu o sentimento corretamente somente a 61,3% dos dados,
apresentando uma taxa de erro de 38,7%. De qualquer forma, para corrigir as
discrepâncias e diminuir a taxa de erro torna-se necessária a presença de um
analista, como foi defendido por Silva (2010). A Figura 21 esboça um exemplo do
“Brandviewer” que atribuiu um sentimento negativo em um comentário no Twitter que
era pra ser neutra. Possivelmente a atribuição errada tenha ocorrido pela aparição
da palavra “doida” dentro do comentário, na qual conota outro significado que não
seja negativo.
Figura 21: Exemplo de comentário com classificação de sentimento errada
Fonte: Ferramenta “Brandviewer”
O formato de apresentação da informação sobre o sentimento geralmente é
mostrado através de gráficos que fornecem a visão do todo, tais como gráfico em
pizza. A Figura 22 fornecida pela ferramenta “Seekr” ilustra um exemplo que revela a
porcentagem de usuários evangelizadores (defensores), agressores (detratores) e
neutros.
Figura 22: Exemplo de um gráfico de análise de sentimento
Fonte: Ferramenta “Seekr”

96
6.2.1.3.4 Análise de tópicos e temas
Dentre as ferramentas selecionadas somente a “Trackur” não apresentou a
função de classificação do conteúdo pelo tópico ou tema. A ferramenta “Livebuzz”
oferece a opção de selecionar uma determinada amostra dos dados coletados para
facilitar a classificação manual dos tópicos do conteúdo analisado. Essa função é
necessária, visto que a quantidade de dados é muito grande para classificar
manualmente. A forma de visualização dos dados é por gráfico de barras, pizza ou
em linha. Para exemplificar um gráfico de análise de tópicos e temas, é possível
visualizar na Figura 23 os dados classificados manualmente na ferramenta
“Brandviewer” de acordo com o tema.
Figura 23: Exemplo de gráfico de análise de tópicos e temas
Fonte: Ferramenta “Brandviewer”
6.2.1.3.5 Análise de tendências
A visualização mais comum de tendências encontradas nas ferramentas de
monitoramento de redes sociais são os termos mais citados e a nuvem de palavras
(tags) presentes em metade dos sistemas investigados. Outros gráficos podem
ajudar na informação temporal da tendência, como os gráficos em linha que
denotam o histórico das palavras mais comentadas num determinado espaço de
tempo. A Figura 24 ilustra o exemplo de duas visualizações sobre a tendência nas
ferramentas “SCUP” e “Seekr”. O exemplo mostra que muitas tags aparecem
desnecessariamente, tais como, conjunções, numerais e outros termos que não
denotam tendências, pelo contrário, confunde o analista. Esse problema foi
identificado por Pinheiro (2009), que sugeriu a utilização de stopwords para eliminar
termos desnecessários e corrigir o problema, no entanto, nenhuma ferramenta

97
analisada apresentou essa correção. Isso faz com que a informação disponibilizada
nos gráficos contenha falhas, podendo gerar interpretações errôneas.
Figura 24: Exemplo de lista e nuvem de palavras
Fonte: Ferramentas “SCUP” e “Seekr”
6.2.1.3.6 Análise de influenciadores
Dentre as ferramentas mapeadas, quatro dos nove apresentaram a opção de
gerenciar os usuários mais influentes com a opção de gerar informações a partir
deles. O exemplo da Figura 25 revela os usuários mais influentes dentre os que
realizaram comentários dos itens coletados na ferramenta “Livebuzz”. Os usuários
são marcados em verde (defensores), os vermelhos (detratores) e os amarelos
(neutros).
Figura 25: Exemplo de lista de usuários influenciadores
Fonte: Ferramenta “Livebuzz”

98
6.2.1.3.7 Monitoramento e mensuração de campanhas
A capacidade de monitorar e medir o desempenho de eventos exógenos
como campanhas podem ser encontrada em mais da metade das ferramentas em
análise. A principal característica identificada foi a opção de vincular o volume de
menções coletadas, associação de palavras e análise de sentimento com as
campanhas previamente cadastradas no sistema. Geralmente, essa funcionalidade é
utilizada por agências de propaganda e comunicação que tem o desafio de
coordenar ofertas e demandas de informação com os setores internos da empresa,
como o marketing e vendas, por exemplo.
6.2.1.3.8 Gestão de Relacionamento com o cliente (CRM)
Somente as ferramentas “Livebuzz” e “Ubervu” apresentaram alguma forma
de gerenciar o relacionamento com os clientes. A maior parte dos sistemas
examinados oferece a opção de classificar o usuário quanto à sua influência, não
sendo considerada uma funcionalidade de gestão de informações dos usuários. A
ferramenta “Livebuzz” apresenta a opção de resolução de problemas, que permite os
gestores atenderem de forma pontual as reclamações dos clientes. A ferramenta
“Ubervu” disponibiliza a opção de designar tarefas para outras pessoas da equipe
resolver problemas junto ao usuário da rede social.
6.2.1.3.9 Análise competitiva
Dentre as ferramentas mapeadas, a maior parte não oferece a opção clara de
análise competitiva. Para que isso ocorra é necessário criar monitoramentos
paralelos de marcas ou produtos concorrentes para que possa ocorrer uma
comparação de resultados. Isso aumenta ainda mais a carga de trabalho manual
exercido por um profissional de análise de mídias sociais ou por agências de
comunicação especializadas. Sobre os possíveis trabalhos dos analistas, Silva
(2010) afirma que:
Relatórios aprofundados, análises pontuais ou alertas são alguns dosprodutos de informação competitiva que podem ser redigidos pelosanalistas. É preciso entregar diferenciadamente as informações relevantesapresentadas em formato usável e pertinente aos diferentes setores,diretores ou profissionais da organização. (p. 45)
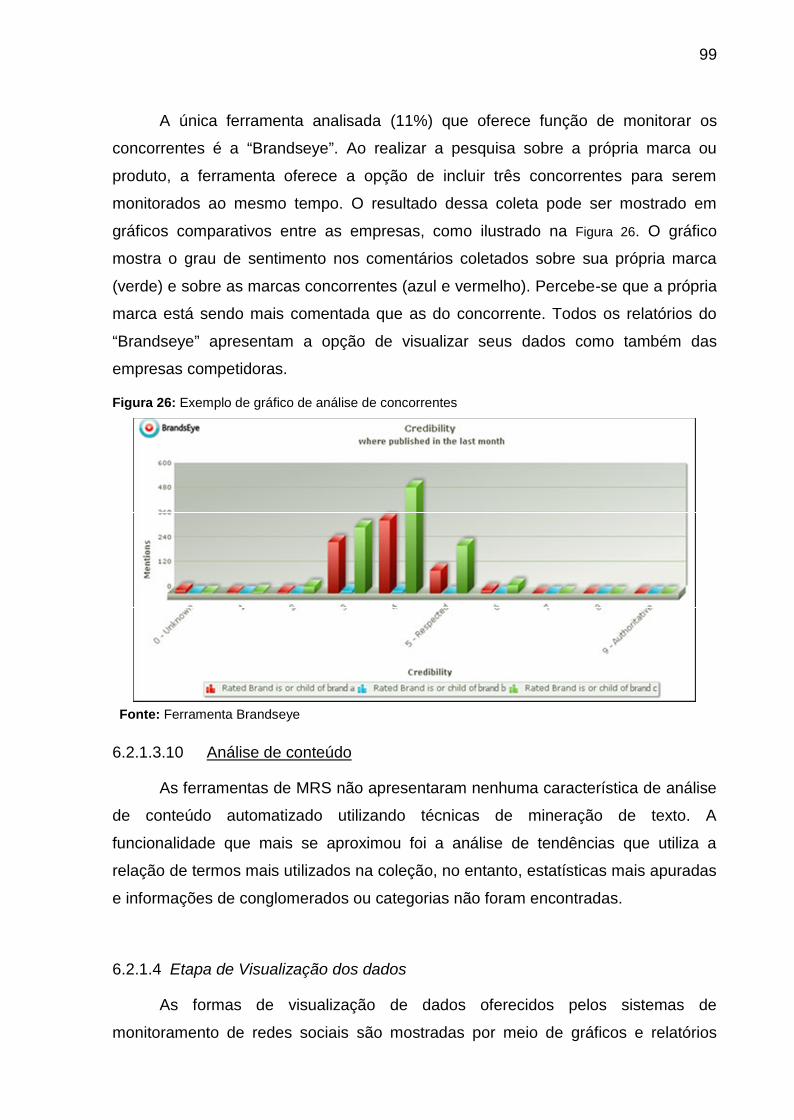
99
A única ferramenta analisada (11%) que oferece função de monitorar os
concorrentes é a “Brandseye”. Ao realizar a pesquisa sobre a própria marca ou
produto, a ferramenta oferece a opção de incluir três concorrentes para serem
monitorados ao mesmo tempo. O resultado dessa coleta pode ser mostrado em
gráficos comparativos entre as empresas, como ilustrado na Figura 26. O gráfico
mostra o grau de sentimento nos comentários coletados sobre sua própria marca
(verde) e sobre as marcas concorrentes (azul e vermelho). Percebe-se que a própria
marca está sendo mais comentada que as do concorrente. Todos os relatórios do
“Brandseye” apresentam a opção de visualizar seus dados como também das
empresas competidoras.
Figura 26: Exemplo de gráfico de análise de concorrentes
6.2.1.3.10 Análise de conteúdo
As ferramentas de MRS não apresentaram nenhuma característica de análise
de conteúdo automatizado utilizando técnicas de mineração de texto. A
funcionalidade que mais se aproximou foi a análise de tendências que utiliza a
relação de termos mais utilizados na coleção, no entanto, estatísticas mais apuradas
e informações de conglomerados ou categorias não foram encontradas.
Etapa de Visualização dos dados6.2.1.4
As formas de visualização de dados oferecidos pelos sistemas de
monitoramento de redes sociais são mostradas por meio de gráficos e relatórios
Fonte: Ferramenta Brandseye
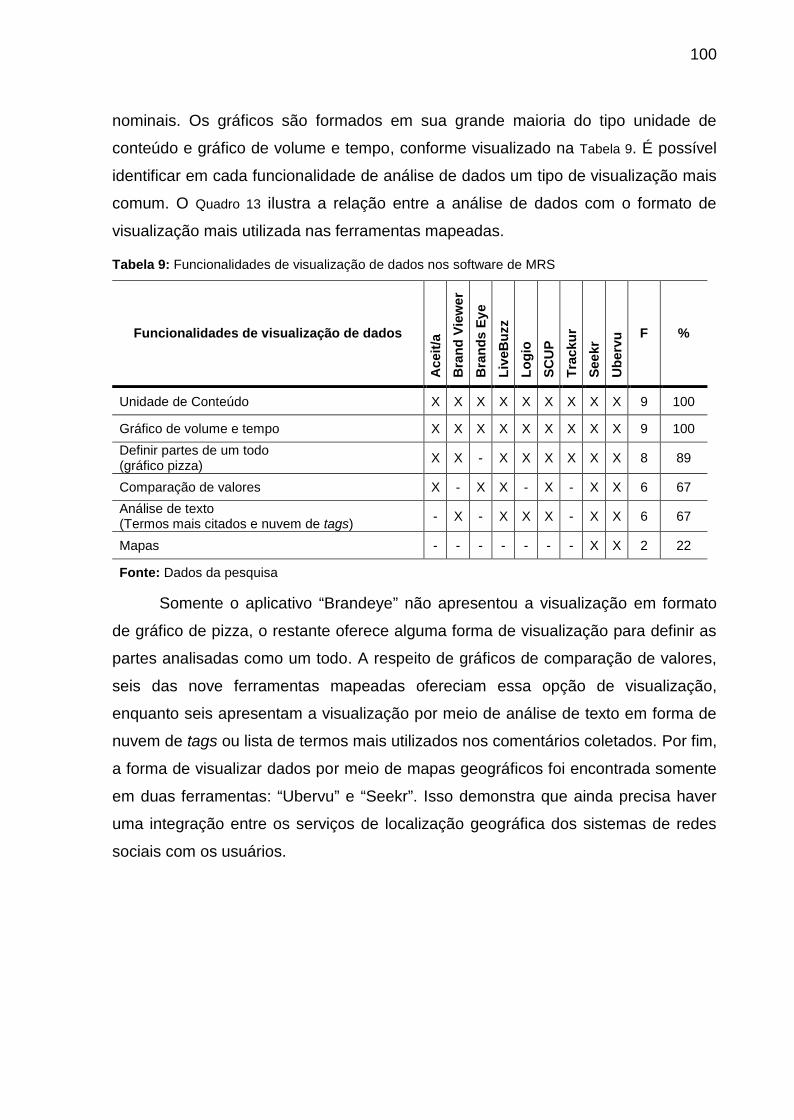
100
nominais. Os gráficos são formados em sua grande maioria do tipo unidade de
conteúdo e gráfico de volume e tempo, conforme visualizado na Tabela 9. É possível
identificar em cada funcionalidade de análise de dados um tipo de visualização mais
comum. O Quadro 13 ilustra a relação entre a análise de dados com o formato de
visualização mais utilizada nas ferramentas mapeadas.
Tabela 9: Funcionalidades de visualização de dados nos software de MRS
Funcionalidades de visualização de dados
Ace
it/a
Bra
nd V
iew
erB
rand
s Ey
eLi
veB
uzz
Logi
oSC
UP
Trac
kur
Seek
rU
berv
u F %
Unidade de Conteúdo X X X X X X X X X 9 100
Gráfico de volume e tempo X X X X X X X X X 9 100Definir partes de um todo(gráfico pizza) X X - X X X X X X 8 89
Comparação de valores X - X X - X - X X 6 67Análise de texto(Termos mais citados e nuvem de tags) - X - X X X - X X 6 67
Mapas - - - - - - - X X 2 22
Fonte: Dados da pesquisa
Somente o aplicativo “Brandeye” não apresentou a visualização em formato
de gráfico de pizza, o restante oferece alguma forma de visualização para definir as
partes analisadas como um todo. A respeito de gráficos de comparação de valores,
seis das nove ferramentas mapeadas ofereciam essa opção de visualização,
enquanto seis apresentam a visualização por meio de análise de texto em forma de
nuvem de tags ou lista de termos mais utilizados nos comentários coletados. Por fim,
a forma de visualizar dados por meio de mapas geográficos foi encontrada somente
em duas ferramentas: “Ubervu” e “Seekr”. Isso demonstra que ainda precisa haver
uma integração entre os serviços de localização geográfica dos sistemas de redes
sociais com os usuários.
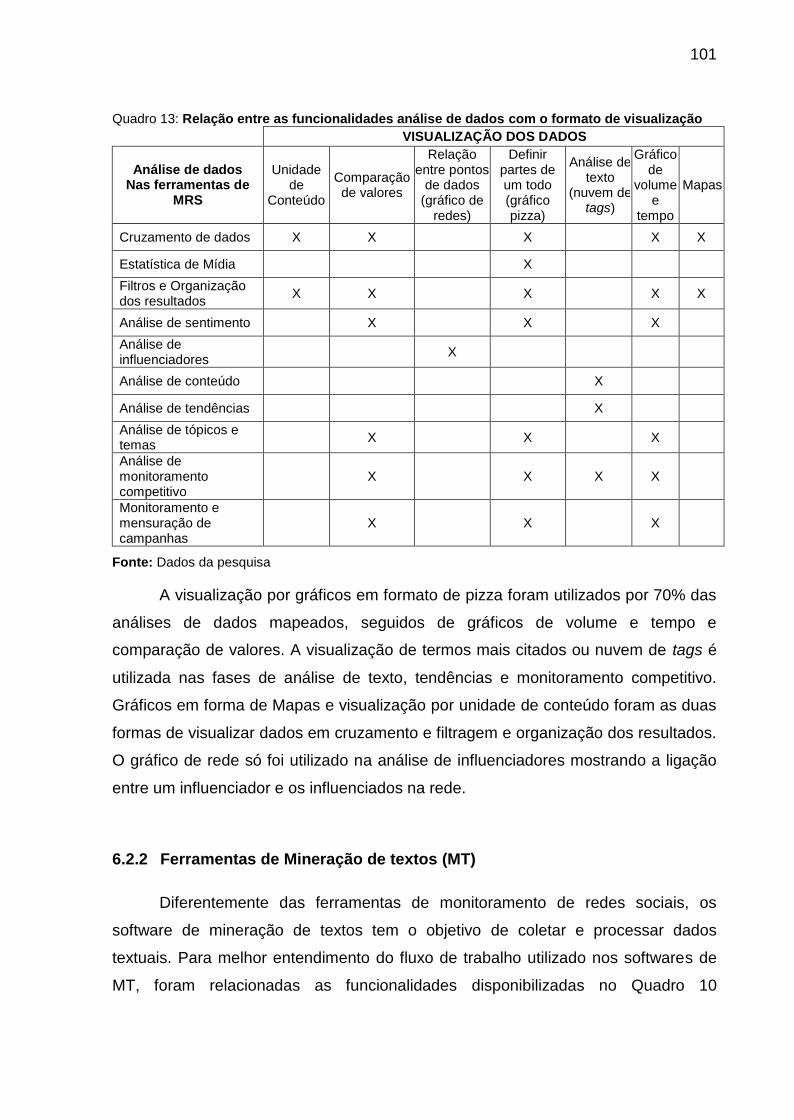
101
Quadro 13: Relação entre as funcionalidades análise de dados com o formato de visualizaçãoVISUALIZAÇÃO DOS DADOS
Análise de dadosNas ferramentas de
MRS
Unidadede
Conteúdo
Comparaçãode valores
Relaçãoentre pontos
de dados(gráfico de
redes)
Definirpartes deum todo(gráficopizza)
Análise detexto
(nuvem detags)
Gráficode
volumee
tempo
Mapas
Cruzamento de dados X X X X X
Estatística de Mídia XFiltros e Organizaçãodos resultados X X X X X
Análise de sentimento X X XAnálise deinfluenciadores X
Análise de conteúdo X
Análise de tendências XAnálise de tópicos etemas X X X
Análise demonitoramentocompetitivo
X X X X
Monitoramento emensuração decampanhas
X X X
Fonte: Dados da pesquisa
A visualização por gráficos em formato de pizza foram utilizados por 70% das
análises de dados mapeados, seguidos de gráficos de volume e tempo e
comparação de valores. A visualização de termos mais citados ou nuvem de tags é
utilizada nas fases de análise de texto, tendências e monitoramento competitivo.
Gráficos em forma de Mapas e visualização por unidade de conteúdo foram as duas
formas de visualizar dados em cruzamento e filtragem e organização dos resultados.
O gráfico de rede só foi utilizado na análise de influenciadores mostrando a ligação
entre um influenciador e os influenciados na rede.
6.2.2 Ferramentas de Mineração de textos (MT)
Diferentemente das ferramentas de monitoramento de redes sociais, os
software de mineração de textos tem o objetivo de coletar e processar dados
textuais. Para melhor entendimento do fluxo de trabalho utilizado nos softwares de
MT, foram relacionadas as funcionalidades disponibilizadas no Quadro 10
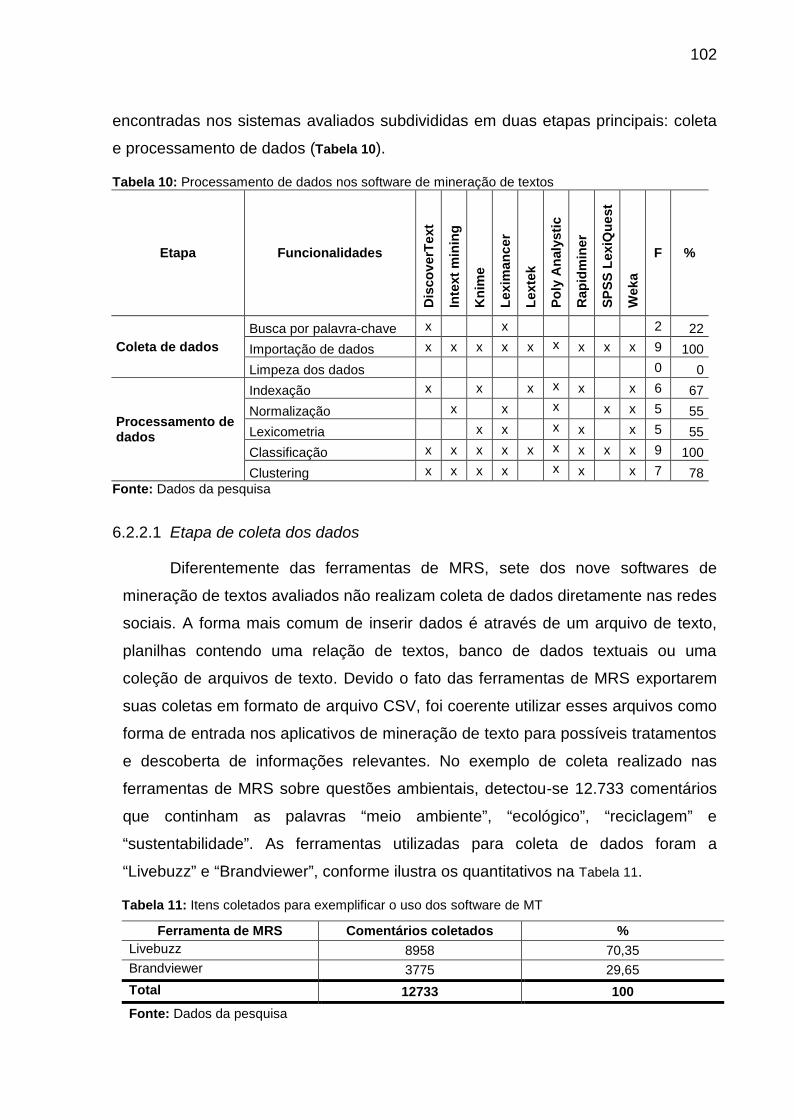
102
encontradas nos sistemas avaliados subdivididas em duas etapas principais: coleta
e processamento de dados (Tabela 10).
Tabela 10: Processamento de dados nos software de mineração de textos
Etapa Funcionalidades
Dis
cove
rTex
t
Inte
xt m
inin
g
Kni
me
Lexi
man
cer
Lext
ek
Poly
Ana
lyst
ic
Rap
idm
iner
SPSS
Lex
iQue
st
Wek
a
F %
Coleta de dadosBusca por palavra-chave x x 2 22Importação de dados x x x x x x x x x 9 100Limpeza dos dados 0 0
Processamento dedados
Indexação x x x x x x 6 67Normalização x x x x x 5 55Lexicometria x x x x x 5 55Classificação x x x x x x x x x 9 100Clustering x x x x x x x 7 78
Fonte: Dados da pesquisa
Etapa de coleta dos dados6.2.2.1
Diferentemente das ferramentas de MRS, sete dos nove softwares de
mineração de textos avaliados não realizam coleta de dados diretamente nas redes
sociais. A forma mais comum de inserir dados é através de um arquivo de texto,
planilhas contendo uma relação de textos, banco de dados textuais ou uma
coleção de arquivos de texto. Devido o fato das ferramentas de MRS exportarem
suas coletas em formato de arquivo CSV, foi coerente utilizar esses arquivos como
forma de entrada nos aplicativos de mineração de texto para possíveis tratamentos
e descoberta de informações relevantes. No exemplo de coleta realizado nas
ferramentas de MRS sobre questões ambientais, detectou-se 12.733 comentários
que continham as palavras “meio ambiente”, “ecológico”, “reciclagem” e
“sustentabilidade”. As ferramentas utilizadas para coleta de dados foram a
“Livebuzz” e “Brandviewer”, conforme ilustra os quantitativos na Tabela 11.
Tabela 11: Itens coletados para exemplificar o uso dos software de MT
Ferramenta de MRS Comentários coletados %Livebuzz 8958 70,35Brandviewer 3775 29,65Total 12733 100Fonte: Dados da pesquisa

103
Etapa de processamento dos dados6.2.2.2
Nessa fase foram verificadas as funcionalidades de processamento de dados
disponibilizado pelas ferramentas avaliadas sob a ótica das técnicas de mineração
de texto apresentados por Wives (2002) que são a indexação, normalização,
lexicometria, classificação, extração e clustering.
As interfaces gráficas dos sistemas mapeados, em sua grande maioria
oferecem o formato de pipeline (tubulação) para facilitar o entendimento do
processo. A Figura 27 esboça um exemplo da apresentação do processo de clustering
e classificação de documentos no software “Rapidminer”. Percebem-se a utilização
de caixas que são os processos e as linhas que indicam o fluxo dos dados. Na caixa
de coleta foram informados os arquivos com os comentários coletados sobre meio
ambiente, na caixa pré-processamento foram utilizadas as técnicas de indexação,
normalização e lexicometria. Após esse procedimento foi realizado o processamento
de clustering e classificação. Esse mesmo tipo de interface pipeline é encontrado
nas ferramentas “Knime” e “SAS text mining”. Apesar da apresentação didática
dessas ferramentas, as terminologias referentes a mineração de texto estão
presentes em todas as ferramentas e é necessário o conhecimento técnico
especializado nesse assunto para manipulação do software pelo analista.
Figura 27: Exemplo de interface pipeline utilizada nos software MT
Fonte: Software “Rapidminer”
6.2.2.2.1 Indexação, normalização e lexicometria
O objetivo da indexação é listar as palavras-chaves mais comuns a cada
documento (comentário). Para isso se utiliza das funções de normalização e
lexicometria para gerar um índice contendo a lista de documentos com seus

104
respectivos termos indexados. Essa funcionalidade foi encontrada em seis softwares
avaliados.
Referente à funcionalidade de normalização de dados cinco dos nove
sistemas verificados apresentaram maneiras para diminuir os ruídos encontrados
nos dados coletados. Nem todo o conteúdo coletado corresponde com o objetivo da
pesquisa, resgatando também além dos dados corretos, muita informação
desnecessária. Para tanto, fez-se necessário realizar um procedimento de
normalização para diminuir essa quantidade de comentários sem ligação com o
objetivo da coleta. Os procedimentos utilizados foram tokenização (tokenize),
transformação de tokens em caracteres minúsculos (case fold), filtrar tokens
desnecessárias (stopwords) e a redução para o menor radical da palavra (stemmin).
Para ilustrar o fluxo utilizado de normalização, a Figura 28 apresenta a lista de tarefas
utilizadas pela ferramenta “Rapidminer”.
Figura 28: Exemplo do fluxo de normalização dos dados
Fonte: Software “Rapidminer”
Das ferramentas de mineração de texto avaliadas, cinco ofereciam o
processamento lexicométrico dos dados por meio da atribuição de pesos. Os pesos
utilizados para gerar a lista de palavras mais frequentes eram o binário, TF (term
frequency) e o TF-IDF (term frequency – Inverse Document Frequency). Esta última
métrica é a mais utilizada nos software mapeados.
Como exemplo, foram selecionados os 12.733 comentários coletados sobre o
meio ambiente e aplicados no software “Rapidminer”, que após a aplicação das
técnicas de normalização (Figura 28) resultou na redução 48,87% dos ruídos. Com a
geração das palavras mais frequentes de acordo com TF-IDF e retirando as menos

105
frequentes, o corpus teve uma redução final de 94%, gerando 6% de termos
relevantes (Tabela 12).
Tabela 12: Redução de termos por técnica de processamento de texto
NormalizaçãoLexicometria
Tokenização Case folding(minúsculo)
RemoverStopwords Stemming
Termos(tokens) 447.350 446.718 239.762 228.710 26.795
Redução determos - 0,14% 46,40% 48,87% 94,01%
Fonte: Dados da pesquisa
6.2.2.2.2 Clustering
A funcionalidade de clustering ou agrupamento de documentos foi encontrada
em 78% dos software investigados. Apesar da presença desse tipo de
processamento na maioria dos sistemas listados, sua execução não ocorre de
maneira trivial. É necessário esforço humano especializado em tratamento
estatístico de dados textuais e poder computacional para gerar informações de
agrupamentos de comentários nas redes sociais.
As técnicas de clustering encontradas foram relacionadas ao agrupamento de
documentos por meio da distância encontrada entre os termos de cada documento.
As ferramentas apresentaram a medida euclidiana e a similaridade por cosseno
como o cálculo da distância entre termos. As técnicas de agrupamento k-means e k-
medoids foram utilizadas para gerar partições disjuntas, colocando os documentos
em grupos distintos e sendo visualizado por meio de gráficos de partição disjunta.
Os agrupamentos hierárquicos que geram a similaridade de clusters, agrupando-os
de acordo com os graus de semelhanças utilizaram-se a visualização em gráficos de
dendogramas ou gráficos de árvores.
Utilizando-se dos dados obtidos e processados (Tabela 12) foi realizada uma
análise de cluster para gerar uma lista de documentos semelhantes. Para teste
foram utilizados os sistemas “Leximancer” e “Rapidminer”. O processo de clustering
no software “Rapidminer” ofereceu uma lista de palavras mais significativas
separadas por clusters subdivididos pela medida TF-IDF mais significativa (Tabela
13). No primeiro grupo constata-se a presença dos termos: “país”, “polít”,
“desenvolv”, “conferent”, “econôm”, “sustent” e “govern” significando que este grupo
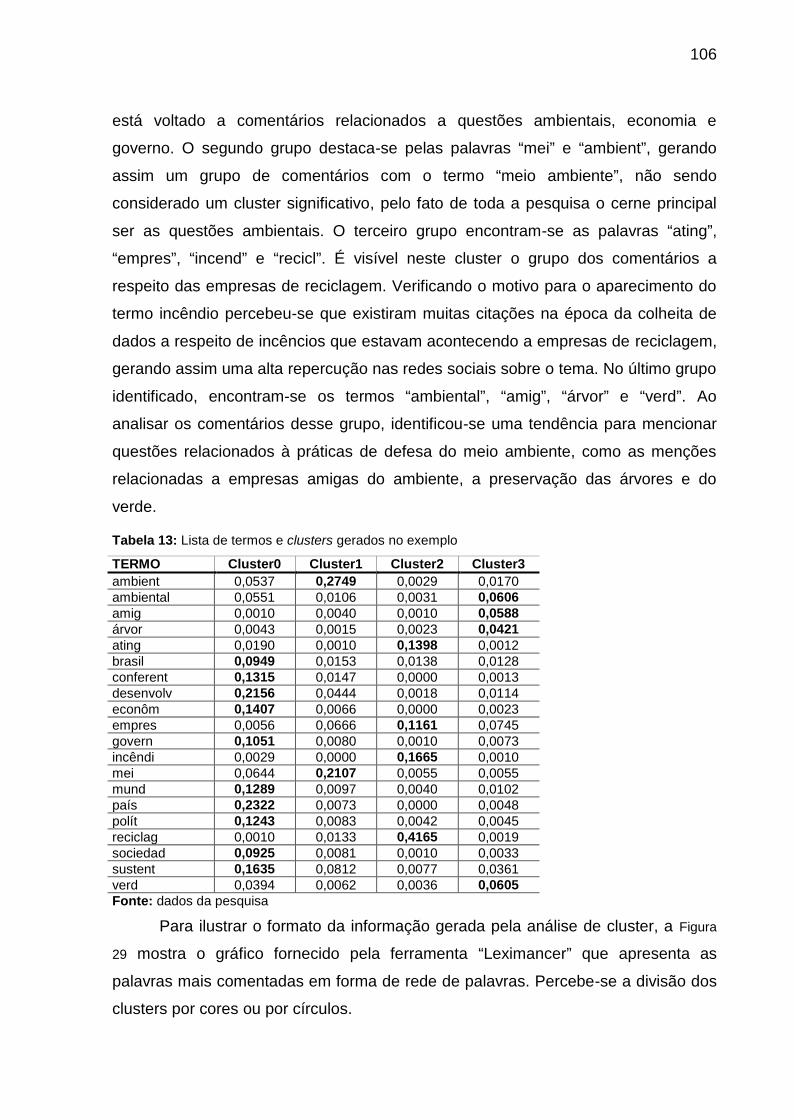
106
está voltado a comentários relacionados a questões ambientais, economia e
governo. O segundo grupo destaca-se pelas palavras “mei” e “ambient”, gerando
assim um grupo de comentários com o termo “meio ambiente”, não sendo
considerado um cluster significativo, pelo fato de toda a pesquisa o cerne principal
ser as questões ambientais. O terceiro grupo encontram-se as palavras “ating”,
“empres”, “incend” e “recicl”. É visível neste cluster o grupo dos comentários a
respeito das empresas de reciclagem. Verificando o motivo para o aparecimento do
termo incêndio percebeu-se que existiram muitas citações na época da colheita de
dados a respeito de incêncios que estavam acontecendo a empresas de reciclagem,
gerando assim uma alta repercução nas redes sociais sobre o tema. No último grupo
identificado, encontram-se os termos “ambiental”, “amig”, “árvor” e “verd”. Ao
analisar os comentários desse grupo, identificou-se uma tendência para mencionar
questões relacionados à práticas de defesa do meio ambiente, como as menções
relacionadas a empresas amigas do ambiente, a preservação das árvores e do
verde.
Tabela 13: Lista de termos e clusters gerados no exemplo
TERMO Cluster0 Cluster1 Cluster2 Cluster3ambient 0,0537 0,2749 0,0029 0,0170ambiental 0,0551 0,0106 0,0031 0,0606amig 0,0010 0,0040 0,0010 0,0588árvor 0,0043 0,0015 0,0023 0,0421ating 0,0190 0,0010 0,1398 0,0012brasil 0,0949 0,0153 0,0138 0,0128conferent 0,1315 0,0147 0,0000 0,0013desenvolv 0,2156 0,0444 0,0018 0,0114econôm 0,1407 0,0066 0,0000 0,0023empres 0,0056 0,0666 0,1161 0,0745govern 0,1051 0,0080 0,0010 0,0073incêndi 0,0029 0,0000 0,1665 0,0010mei 0,0644 0,2107 0,0055 0,0055mund 0,1289 0,0097 0,0040 0,0102país 0,2322 0,0073 0,0000 0,0048polít 0,1243 0,0083 0,0042 0,0045reciclag 0,0010 0,0133 0,4165 0,0019sociedad 0,0925 0,0081 0,0010 0,0033sustent 0,1635 0,0812 0,0077 0,0361verd 0,0394 0,0062 0,0036 0,0605Fonte: dados da pesquisa
Para ilustrar o formato da informação gerada pela análise de cluster, a Figura
29 mostra o gráfico fornecido pela ferramenta “Leximancer” que apresenta as
palavras mais comentadas em forma de rede de palavras. Percebe-se a divisão dos
clusters por cores ou por círculos.
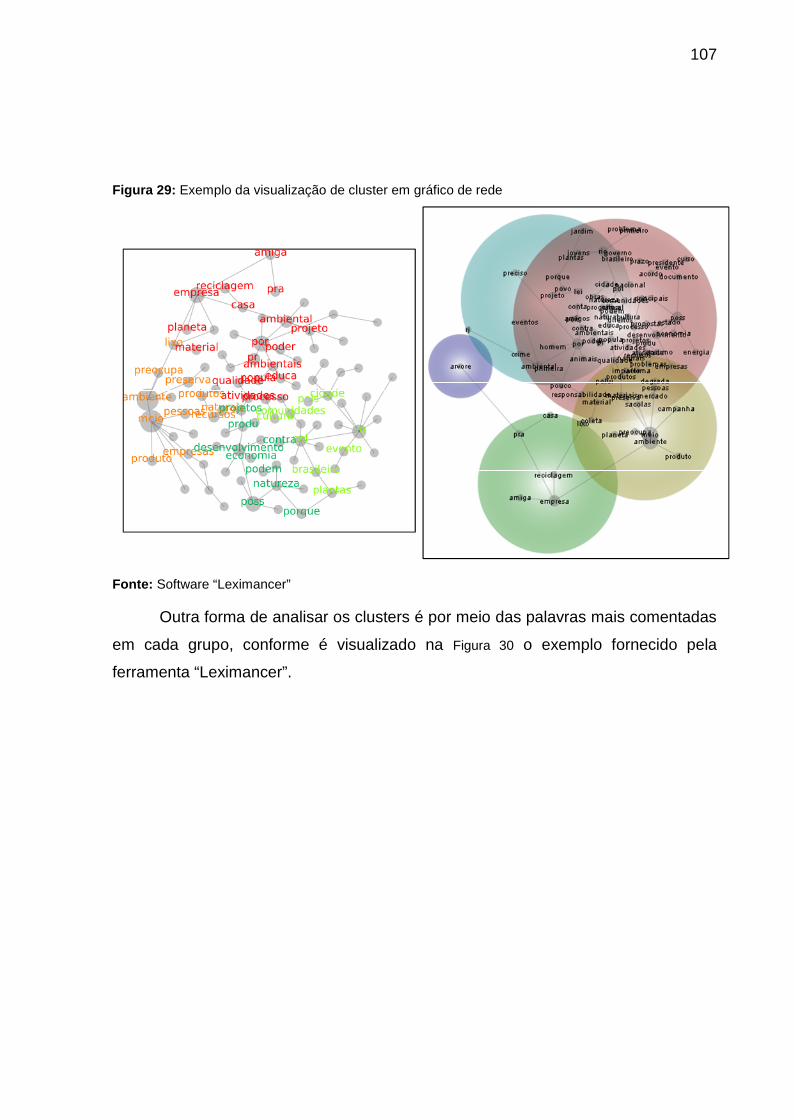
107
Figura 29: Exemplo da visualização de cluster em gráfico de rede
Fonte: Software “Leximancer”
Outra forma de analisar os clusters é por meio das palavras mais comentadas
em cada grupo, conforme é visualizado na Figura 30 o exemplo fornecido pela
ferramenta “Leximancer”.
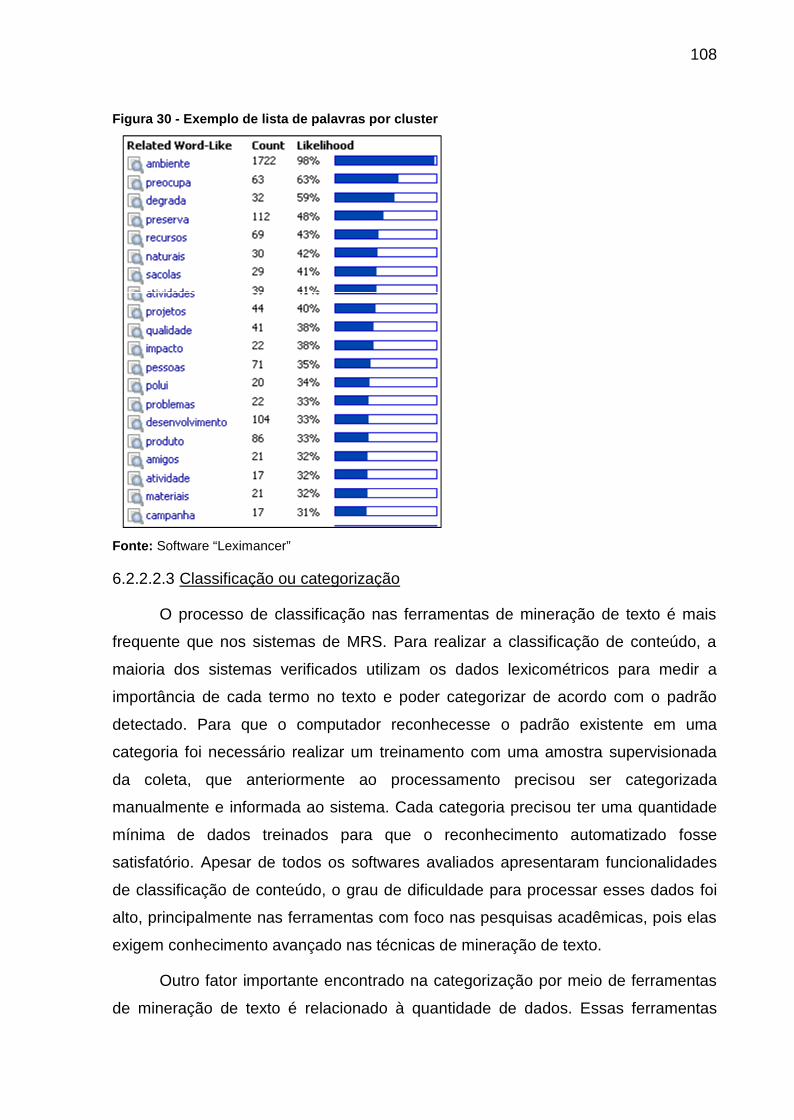
108
Figura 30 - Exemplo de lista de palavras por cluster
Fonte: Software “Leximancer”
6.2.2.2.3 Classificação ou categorização
O processo de classificação nas ferramentas de mineração de texto é mais
frequente que nos sistemas de MRS. Para realizar a classificação de conteúdo, a
maioria dos sistemas verificados utilizam os dados lexicométricos para medir a
importância de cada termo no texto e poder categorizar de acordo com o padrão
detectado. Para que o computador reconhecesse o padrão existente em uma
categoria foi necessário realizar um treinamento com uma amostra supervisionada
da coleta, que anteriormente ao processamento precisou ser categorizada
manualmente e informada ao sistema. Cada categoria precisou ter uma quantidade
mínima de dados treinados para que o reconhecimento automatizado fosse
satisfatório. Apesar de todos os softwares avaliados apresentaram funcionalidades
de classificação de conteúdo, o grau de dificuldade para processar esses dados foi
alto, principalmente nas ferramentas com foco nas pesquisas acadêmicas, pois elas
exigem conhecimento avançado nas técnicas de mineração de texto.
Outro fator importante encontrado na categorização por meio de ferramentas
de mineração de texto é relacionado à quantidade de dados. Essas ferramentas

109
demandam um grau elevado de processamento computacional quando existem
muitos itens para serem analisados, aumentando o tempo de processamento e
exigindo que se utilizem máquinas robustas para realizar esse trabalho. Isso
corrobora com o que foi frisado por Magalhães T. (2009, p. 61). A principal
desvantagem da técnica de categorização de documentos
é o fato de essa abordagem não poder, todavia, ser ajustada para grandesdocumentos e / ou coleções de documentos, tais como a Web, devido aocusto computacional elevado e tempo de processamento. Vale lembrar que,para os fins da pesquisa, pequenos documentos e coleções como sites deopiniões, digitalização direta de texto pode funcionar bem.
No entanto, se forem utilizadas poucas quantidades de dados é possível
recorrer em outro problema: a falta de dados suficientes para encontrar padrões
satisfatórios. Quanto menor o número de dados, menor o grau de confiabilidade na
classificação dos comentários (MORGADO JÚNIOR, 2008).
O procedimento para exemplificar a classificação foi testado na ferramenta
“Rapidminer”. Foi utilizada a técnica supervisionada, no qual são conhecidas
previamente as categorias que se deseja rotular. Foi informada uma lista de
comentários previamente categorizada manualmente de acordo com o sentimento
do texto (positivo, negativo e neutro) para a realização de um treinamento utilizando
o SVM (Support Machine Vector), procedimento este considerado mais rápido e
eficiente para classificação de texto (MAGALHÃES L., 2009). O tempo
computacional para calcular a matriz de distâncias entre os termos dos 12.733
comentários foi maior que 24 horas, necessitando abortar o procedimento e realizar
com um número menor de itens. Morgado Júnior (2008) não recomenda diminuir
muito a quantidade de dados na fase de treinamento do software, visto que a
acurácia dos resultados é afetada negativamente. Portanto, a eficácia do
procedimento de categorização de conteúdo nos software investigados não foi
comprovada devido aos problemas de tempo computacional para processar uma
quantidade satisfatória dos dados.

110
7 CONSIDERAÇÕES FINAIS
Atualmente surgem novas metodologias e instrumentos que possibilitam a
extração das informações de forma automatizada de grandes bases de dados como
as redes sociais. Dentre elas encontram-se as ferramentas de mineração Web que
possibilitam coletar, processar, analisar e visualizar os dados dentre os comentários
disponíveis nas redes sociais.
Este trabalho atingiu seu objetivo geral ao informar quais são as ferramentas
de mineração Web existentes no mercado e mostrar as informações disponibilizadas
por elas aos gestores de marketing para tomada de decisão estratégica em
pequenas e médias empresas. As funcionalidades que as ferramentas de mineração
Web apresentaram podem ser utilizadas para resgatar dados das redes sociais e
disponibilizá-las para auxiliar os gestores nas tomadas de decisões.
Em relação ao objetivo de levantar as principais ferramentas de mineração
Web disponíveis no mercado até junho de 2012 constatou-se a presença de 19
ferramentas de monitoramento de redes sociais e 38 de mineração de textos. Desse
total 18 (9 de MRS e 9 de MT) são direcionadas para o público brasileiro por
oferecerem funcionalidades de processamento de dados na lingua portuguesa do
Brasil.
Para o objetivo de descrever e comparar as características mercadológicas de
cada ferramenta constatou-se a presença de aplicativos de origem nacionais e
internacionais de MRS, mas somente as nacionais puderam realizar buscas mais
precisas no idioma brasileiro com menor custo e com pacotes voltados para
pequenas empresas. Já as principais ferramentas de MT disponíveis para
processamento de textos em português eram voltadas para fins acadêmicos e
exigiam conhecimentos avançados de mineração de texto para utilizá-las. Com
relação ao custo das ferramentas chegou-se a conclusão que apesar da
disponibilidade do material na internet ser de baixo custo, a forma de coletá-lo e
processá-lo pode acarretar em um alto custo. Primeiramente, as ferramentas de
monitoramento de redes sociais oferecem pacotes com valores variando de acordo
com o plano escolhido e com pagamento mensal. Segundo, os softwares de
mineração de textos oferecem licenças anuais e exigem um conhecimento acerca
das técnicas de mineração de textos, exigindo que o gestor realize treinamentos

111
sobre essa tecnologia ou contrate um profissional sabedor das técnicas de
monitoramento de redes sociais e mineração de texto.
Para o objetivo de descrever e comparar as funcionalidades de cada
ferramenta obteve-se como resultado que as ferramentas de MRS se mostraram
mais adequadas para a realização de coleta e análise dos dados, enquanto os
softwares de MT oferecem vantagem somente na etapa de processamento
estatístico dos textos. Sendo necessária a utilização conjunta dos dois tipos de
sistemas para uma quantidade maior de dados para utilizar como informação. As
informações mais disponibilizadas pelas ferramentas de MRS foram relacionadas à
segmentação de usuários ou comentários, tais como a análise de sentimento e a
análise de tópico e temas. Esse tipo de informação propõe oferecer dados
necessários para agrupar os usuários que falam positivamente ou negativamente
sobre sua marca ou mesmo classificando os comentários por categorias de acordo
com a necessidade do gestor. As informações sobre as ações do concorrente foram
pouco satisfatórias, pois as ferramentas não ofereciam funções para que as suas
marcas e as do concorrentes fossem analisadas paralelamente. Para realizar essa
tarefa o gestor precisa monitorar em separado as suas próprias marcas, como
também as marcas do concorrente, gerando um aumento no tempo para conseguir a
informação necessária e no custo, que aumentaria no final do monitoramento.
Com relação ao objetivo de identificar possíveis tratamentos estatísticos a que
os dados coletados possam ser submetidos, percebeu-se que o processamento
oferecido pelas ferramentas de MRS se concentra apenas no cruzamento dos dados
coletados com os elementos informados pelo agente que analisa as informações. Ao
considerar o tratamento estatístico ou mesmo cálculo que exija um alto poder
computacional para gerar inteligência, além dos dados já oferecidos, ainda é
deficiente nesse tipo de sistema. Entretanto, caso seja necessário realizar esse
trabalho, os sistemas oferecem uma forma de exportar as informações coletadas
para arquivos tabulados em planilhas eletrônicas, formato esse que são utilizados
como entradas em sistemas de análise textual, tais como os software de mineração
de textos que realizam tratamentos estatísticos de análise de cluster.
Convém salientar que, apesar de apresentar os software de mineração Web
no mercado, o presente trabalho procurou avaliar somente as ferramentas nacionais
ou que oferecessem possibilidade de tratamento de textos na lingua portuguesa.

112
Além disso, algumas limitações da pesquisa puderam ser detectadas, tal como o
tempo disponibilizado pela maioria das ferramentas ser insuficiente para realizar
uma coleta mais abrangente, e a lentidão dos testes dos software de mineração de
texto, pois utilizou-se um computador laptop resultando em um processamento lento
na realização da análise de cluster e impossibilitando a realização de testes de
categorização com uma quantidade maior de dados.
Esse trabalho procurou contribuir com a área de estratégia de marketing
mostrando a mineração Web como um meio complementar de extrair informações
sobre mercados e consumidores, especificadamente os usuários das redes sociais
digitais. Acredita-se que as informações que circulam nas redes sociais podem se
tornar uma fonte de vantagem competitiva se utilizadas de maneira adequada e a
forma de extraí-la por meio de sistemas de informação podem trazer benefícios aos
médios e pequenos empresários. Para a área da computação, essa pesquisa
demonstrou que existe uma lacuna nas ferramentas de MRS que precisa ser
preenchida, a saber, o uso de tratamento estatístico dentre suas funcionalidades.
A finalização desse estudo leva ao entendimento de que outras pesquisas
podem vir a ser realizadas com o objetivo de analisar novos elementos relacionados
à aplicabilidade de ferramentas de mineração Web nas empresas. Entre eles (1):
realizar uma pesquisa de levantamento em empresas de pequeno e médio porte
para analisar cada funcionalidade das ferramentas de mineração Web apresentada
neste trabalho por meio de uma aplicação prática utilizando uma ferramenta e
confrontá-la com as necessidades dos gestores; (2) estabelecer métricas para
escolha de ferramentas de mineração Web pelas pequenas e médias empresas; (3)
definir quais os tipos de informações eletrônicas são mais utilizadas pelos tomadores
de decisões nas empresas.

113
REFERÊNCIAS
AFONSO, A.S. Uma análise da utilização das redes sociais em ambientescorporativos. 2009, dissertação (mestrado em Tecnologia da Inteligência e DesignDigital), PUC. São Paulo, SP.
AMORIM, F.; FERLA, L.A.; PAIVA, M.; SPYER, J. Tudo o que você precisa sabersobre Twitter, 2009. Disponível em: http://www.talk2.com.br/evento/em-portugues-e-gratis-tudo-o-que-voce-precisa-saber-sobre-twitter/ Acesso em: 1 set. 2012.
ARANHA, C.N. Uma abordagem de pré-processamento automático paramineração de textos em português: sob o enfoque da inteligência computacional,Tese. (Doutorado em Engenharia Elétrica), Departamento de Engenharia Elétrica,PUCRio. 2007.
BARBOSA, R.R. Uso de fontes de informação para a inteligência competitiva: umestudo da influência do porte das empresas sobre o comportamento informacional.Encontros Bibli. p. 91-102. 2006.
BARBOSA, R.R. Inteligência empresarial: uma avaliação de fontes de informaçãosobre o ambiente organizacional externo. Datagrama Zero - Revista de Ciência daInformação v.3 n.6, dez. 2002.
BATTAGLIA, M.G.B. A inteligência competitiva modelando o Sistema de Informaçãode Clientes – FINEP. Ciência da Informação, Brasília, v. 29, n. 2, p. 200-214,maio/ago. 1999.
BLUMMER, H. The nature of symbolic interactionism. In: Conflict, Order andaction: Readings in Sociology. Canada: Canadian Scholar’s Press. p 100-103.2001.
BOYD, D.; ELLISON, N. Social network sites: Definition, history, and scholarship.Journal of Computer-Mediated Communication, v.13. p.1-2. 2007.
BOYD JR., H.W.; WESTFALL, R. Pesquisa mercadológica. Rio de Janeiro:Fundação Getúlio Vargas, 1973.
BOSE, R. Competitive intelligence process and tools for intelligence analysis,Industrial Management & Data Systems, Vol. 108 Iss: 4, pp.510 – 528. 2008.
CAMPOMAR, M.C.; IKEDA, A.A. O planejamento de marketing e a confecção deplanos: dos conceitos a um novo modelo. São Paulo: Saraiva, 2006.
CARENINI, G.; NG, R.T.; ZWART, E. Extracting knowledge from evaluative text.In K-CAP ’05: Proceedings of the 3rd international conference on Knowledgecapture, p. 11–18, Nova Iorque, NY, EUA, 2005.
CAVALCANTI, D.C. “Uma abordagem não supervisionada para classificação deopinião usando o recurso léxico SentiWordNet”, 2011. Dissertação (mestrado emCiência da Computação) – Centro de Informática, Universidade Federal dePernambuco, Recife.
CHIUSOLI, C.L. Dorminhoco ou guerreiro? Perfis e atitudes dos gestores mediante ouso de sistema de inteligência de marketing. Revista Brasileira de Pesquisa deMarketing Opinião e Mídia. V. 5, p. 2-13, set, 2010.

114
CHIUSOLI, C.L. Um estudo exploratório sobre tipologia e sistema deinformação de marketing. São Paulo: Faculdade de Economia, Administração eContabilidade (FEA), 2005. (Tese, Doutorado, Administração de Empresas).
COMBÈS, Y.; KOCERGIN, S. A intermediação na internet: um objeto dequestionamento para as indústrias culturais. Revista Líbero, São Paulo – v. 12,n. 23, p. 43-52, jun. de 2009.
COOLEY, R.W. “Web usage mining: Discovery and application of InterestingPatterns from Web data”. PhD thesis, Dept. of Computer Science, University ofMinesota, 2000.
COSTA, R. A cultura digital. 2. ed. São Paulo: Publifolha, 2003.
COX, D.; GOOD, R. E. How to build a marketing information system. HarvardBusiness Review, Boston, v.45, n.3, Mai/Jun. 1967.
CRESCITELLI, E.; OLIVEIRA, E.C.; BARRETO, I.F. A internet como fonteinformacional para o SIM: os processos de captação e as formas de avaliação.JISTEM J.Inf.Syst. Technol. Manag. (Online) [online], v.3, n.3, p. 347-369. 2006.
CUNHA, J.C. Inteligência competitiva desenvolvida por meio de redes sociais.Dissertação (mestrado em Administração) Faculdade de Economia, Administração,Contabilidade e Ciência da Informação e Documentação. Universidade de Brasilía –UNP, Brasília, DF.
DANIEL, E., WILSON, H. e McDONALD, M. Towards a map of marketing informationsystems: An inductive study. European Journal of Marketing, Bradford, Vol. 37, N°.5/6; p. 821- 851, 2003.
EFE. Empresas usam Twitter como ferramenta de relações públicas e fonte deinformações sobre clientes. O Globo Online, Tecnologia, Caderno Digital, 21 abril.2009. Disponível em: http://oglobo.globo.com/tecnologia/mat/2009/04/21/empresas-usam-twitter-como-ferramenta-de-relacoes-publicas-fonte-de-informacoes-sobre-clientes-755366147.asp. Acesso em: 17 set. 2012.
FACEBOOK. Facebook. [S.l.]: Facebook, 2012. Disponível em:<http://www.facebook.com>. Acesso em 10 setembro 2012.
FERNANDES, M.P. Descoberta de conhecimento em bases de dados eestratégias de relacionamento com clientes: Um estudo no setor de serviços.2007. Dissertação (mestrado em administração de empresas) – UniversidadePresbiteriana Mackenzie, São Paulo, SP.
FLETCHER, K.; WHEELER, C. Marketing intelligence for international markets.Marketing Intelligence & Planning, v. 7, n. 5, 1989.
FREITAS, H.M.R.; LESCA, H.; CUNHA JR., V.M. Como dar um senso útil àsinformações dispersas para facilitar as decisões e ações dos dirigentes: o problemacrucial da inteligência competitiva através da construção de um ‘PUZZLE' (‘quebra-cabeça')®. Revista Eletrônica de Administração, São Paulo, vol 2, no. 2.novembro de 1996.
GOFFMAN, E. Comportamentos em lugares públicos – Nota sobre a organizaçãosocial dos ajuntamentos. Petrópolis: Editora Vozes. 2010.

115
GOOGLE. Orkut. [S.l.]: Google, 2011. Disponível em: <http://www.orkut.com>.Acesso em: 10 setembro 2012.
GOUNARIS, S.P.; PANIGYRAKIS, G.G.; CHATZIPANAGIOTOU, K.C, Measuringthe effectiveness of marketing information systems: An empirically validatedinstrument. 2007
GRISI, C.C.H.; LOURES, C.A.; SAZAKI, C.K.; ALMEIDA, L.O. Sistema deinformação em marketing e a pesquisa de produto: uma nova perspectiva VSEMEAD – seminários em administração São Paulo: FEA – USP, 2001.Disponível em http://www.ead.fea.usp.br/semead/5semead/MKT. Acesso em 12 desetembro de 2012.
GUEDES, R.; AFONSO, D.; MAGALHÃES, L.H. Mineração de opiniões de usuáriosna busca de conhecimento. Revista Vianna Sapiens. v. 1, edição especial, out.2010. Juiz de Fora. MG.
HAIR, I.F.J.; ANDERSON, R.E.; TATHAM, R.L.; BLACK, W.C. Análise Multivariadade Dados. 5ª ed. Porto Alegre: Bookman. 2005.
HASGALL, A.; SHOHAM, S. Digital social network technology and the complexorganizational systems, VINE, Vol. 37 Iss: 2, pp.180 – 191. 2007.
IBOPE NIELSEN, Total de pessoas com acesso à internet atinge 77,8 milhões.Nov. 2011, disponível em http://www.ibope.com.br, acessado em 18/03/2012.
IDEYA, Market Report. Social Media Monitoring Tools and Services. MarketReport. 2012, disponível em http://www.ideya.eu.com
KAUFMAN, D. Processo de tomada de decisão no ciberespaço, o papel dasredes sociais no jogo das escolhas individuais. Tese (mestrado emComunicação e Semiótica, Signo e Significação nas Mídias). Pontifícia universidadeCatólica de São Paulo – PUC-SP. São Paulo, SP, 2010.
KENNEDY, H. Beyond anonymity, or future directions for internet identity research.New Media Society, v.11, n.6, p.943-946, 2009.
KHAUAJA, D.M., CAMPOMAR, M.C. O sistema de informações no planejamento demarketing: uma busca de vantagem competitiva. Revista de Gestão da Tecnologiae Sistemas de Informação/Journal of Information Systems and TechnologyManagement (JISTEM), São Paulo, v. 04, n. 01, p.23-46, jan./abr. 2007.
KOBLITZ, L.F. Ambiente de análise de sentimento baseado em domínio. 2010.Tese (doutorado em Engenharia Civil) – Instituto Alberto Luiz Coimbra de Pós-graduação e pesquisa de engenharia, Universidade Federal do Rio de Janeiro, Riode Janeiro, RJ.
KOSALA R.; BLOCKEEL H. Web mining research: a survey. ACM SIGKDDExplorations, v.2, n.1, p.1-15. Jul, 2000.
KOTLER, P. Administração de marketing: a edição do milênio. Prentice Hall: SãoPaulo, 2000.
KOTLER, P.; ARMSTRONG, G. Princípios de marketing. 9. ed. Tradução de:Arlete Simille Marques e Sabrina Cairo. São Paulo: Prentice Hall, 2003.

116
KRAKAUER, P.V.C. A utilização das informações do ambiente no processo dedecisão estratégica: estudo com empresários brasileiros e americanos depequenas e médais empresas. Dissertação (Mestrado em administração).Departamento de Administração da Faculdade de Economia, Administração econtabilidade, Universidade de São Paulo, São Paulo, 2011.
LAU, K. ; LEE, K. ; HO, Y. ; LAM, P. Mining the web for business intelligence:Homepage analysis in the internet era. Journal of Database Marketing andCustomer Strategy Management. Vol. 12, n. 1, p. 32-54, 2004.
LAUDON, K. C.; LAUDON, J. P. Sistemas de informação gerenciais. 7. ed. SãoPaulo: Pearson Pretince Hall, 2007.
LEMOS, André. A arte da vida: diários pessoais e webcams na Internet. XICOMPÓS. Rio de Janeiro: ECO/UFRJ, 2002.
LEONE, N. M. de C. P. G. As especificidades das pequenas e médias empresas.Revista de Administração, São Paulo, v. 34, n. 2, p. 91-94, abr./jun. 1999.
LOVETT, J.; OWYANG, J. Social Marketing Analytics: A New Framework forMeasuring Results in Social Media. Altimeter Report. Retrieved. Abr., 2010.Disponível em http://www.slideshare.net/jeremiah_owyang/altimeter-report-social-marketing-analytics.
LIU, B. Web Data Mining. Exploring Hiperlinks, Contents, and Usage Data. Springer,Chigago, 2007.
MAGALHÃES L., H. Uma análise de ferramentas para mineração de conteúdo depáginas Web. 2008. Dissertação de Mestrado. Instituto Alberto Luiz Coimbra dePós-graduação e pesquisa de engenharia, Universidade Federal do Rio de Janeiro,Rio de Janeiro, RJ.
MAGALHÃES T., M. Uma metodologia de mineração de opiniões na web. 2009.Tese (doutorado em Engenharia Civil) – Instituto Alberto Luiz Coimbra de Pós-graduação e pesquisa de engenharia, Universidade Federal do Rio de Janeiro, Riode Janeiro.
MALHOTRA, N.K. Introdução a pesquisa de marketing: uma orientaçãoaplicada. Porto Alegre: Bookman, 2001.
MALINI, F. Modelos de colaboração nos meios sociais da internet: Uma análisea partir dos portais de jornalismo participativo. Intercom – Sociedade Brasileirade Estudos Interdisciplinares da Comunicação. XXXI Congresso Brasileiro deCiências da Comunicação, RN, 6 de set. 2008.
MANNING, C.D.; RAGHAVAN, P.; SCHÜTZE; H. Term frequency and weighting. In:______ An Introduction to Information Retrieval. Inglaterra: Cambridge UniversityPress, 2009. p 117-120. Disponível em: http://nlp.stanford.edu/IR-book/pdf/irbookonlinereading.pdf. Acesso em: 17 set. 2011.
MARSHALL, K.P. Marketing information systems: creating competitive advantagein the information age. Danvers: Boyd & Fraser, 1996.
MARTELETO, R.M. Análise de redes sociais: aplicação nos estudos de transferênciada informação. DICI – Diálogo Científico, Rio de Janeiro, v. 30, n. 1, p. 71-81,jan./abr. 2001.

117
MATTAR, F. N. Pesquisa de marketing. São Paulo: Atlas, 2008.
MATTAR, F.N.; SANTOS, D.G. Gerência de produtos: como tornar seu produto umsucesso. São Paulo: Atlas, 1999.
MAYROS, V.; WERNER, D. Marketing information systems: design andapplications for marketers. Radnor: Chilton Book Company, 1982.
McCARTHY, E. J. Marketing essencial: uma abordagem gerencial e global. SãoPaulo: Atlas, 1997.
MILLER, S.H., Competitive Intelligence – An Overview, Society of CompetitiveIntelligence Professionals, Alexandria, VA. 2001.
MIRANDA, R.C.R. O uso da informação na formulação de ações estratégicas pelasempresas. Ciência da Informação, Brasília, v. 28, n. 3, p. 286-292, set./dez. 1999.
MORGADO JÚNIOR, J.C. Modelo computacional para mineração de texto eanálise de questões de concursos. 2008. Dissertação (mestrado em EngenhariaCivil) – Instituto Alberto Luiz Coimbra de Pós-graduação e pesquisa de engenharia,Universidade Federal do Rio de Janeiro, Rio de Janeiro.
O’BRIEN, J. Sistemas de informações e as decisões gerenciais na era daInternet. São Paulo: Saraiva, 2004.
PANG, B.; LEE, L. Opinion mining and sentiment analysis. Foundations and Trendsin Information Retrieval, v.2, n.1-2, pp. 1-135, 2008.
PAPACHARISSI, Z. (org.). A Networked Self: Identity, community, and culture onSocial Network Sites. Nova York (Estados Unidos): Routledge, 2011.
PEDOTT, P.R. Publicidade na internet: a internet como ferramenta decomunicação de marketing. 2001. Dissertação (Mestrado em administração) –Universidade Federal do Rio Grande do Sul – UFRGS, Porto Alegre, RS.
PERIOTTO, C. Análise e uso da informação em pequenas empresas de basetecnológica incubadas no polo tecnológico de São Carlos-SP. Dissertação(Mestrado em Ciência, Tecnologia e Sociedade) – Universidade Federal de SãoCarlos – UFSCAR, São Carlos, SP, 2010.
PINHEIRO, M.S. Uma abordagem usando sintagmas nominais comodescritores no processo de mineração de opiniões. 2009. Tese (doutorado emEngenharia Civil) – Instituto Alberto Luiz Coimbra de Pós-graduação e pesquisa deengenharia, Universidade Federal do Rio de Janeiro, Rio de Janeiro.
PORTER, M.E. Estratégia competitiva: técnicas para análise de indústrias e daconcorrência. 2. ed. Rio de Janeiro: Campus, 2005.
RECUERO, R.C. Diga-me com quem falas e dir-te-ei quem és: a conversaçãomediada pelo computador e as redes sociais na internet. Revista Famecos, Vol.1, No 38, 2009.
RECUERO, R.C.. Information flows and social capital in weblogs: a case study in thebrazilian blogosphere. In Proceedings of the nineteenth ACM conference onHypertext and hypermedia, p. 97-106, New York, NY, EUA, 2008.
RIBEIRO, J.C. The increase of the experiences of the self through the practice ofmultiple virtual identities. PsychNology Journal, vol. 7, n. 3, p.291-302, 2009.

118
RICCI, G.L. Estudo sobre as especificidades das pequenas e médias empresashoteleiras da região central do estado de São Paulo. XXXI Encontro Nacional deEngenharia de Produção. ENEGEP 2011. Belo Horizonte, MG, out. 2011.
RIOS, N.; SPECK, F. O que você está fazendo? - um estudo da socialidade notwitter. XXXII Congresso Brasileiro de Ciências da Comunicação. SociedadeBrasileira de Estudos Interdisciplinares da Comunicação. Revista Iniciacom. Vol 2.Nº 1. Curitiba, PR. 2010.
ROBIC, A. R. O comportamento informacional nos sistema de informações demarketing: um estudo exploratório no setor do varejo de moda. 2003. Dissertação(Mestrado em Administração) – Faculdade de Economia e Administração,Universidade de São Paulo, São Paulo.
SALZMAN, M.; MATATHIA, I.; O´REILLY, A.. A era do marketing viral: comoaumentar o poder da influência e criar demanda. São Paulo: Editora Cultrix,2003.
SANDHUSSEN, R.L. Marketing básico. São Paulo: Saraiva, 1998.
SARQUIS, A.B. Marketing para pequenas empresas: a indústria da confecção.São Paulo: SENAC, 2003.SCIP. Society of Competitive Intelligence Of Professionals. Disponível em:<http://www.scip.org/>. Acesso em: 22 ago. 2012.
SCOTTO, M.; SILLITTI, A.; VERNAZZA, T.G. “Managing Web-Based Information”,International Conference on Enterprise Information Systems (ICEIS 2004), Porto,Portugal, p. 1-3, Abr, 2004.
SEMENIK, R.J.; BAMOSSY, G. J. Princípios de marketing: uma perspectiva global.São Paulo: Makron Books, 1995.
SHI, Z; MA, H; HE, Q. Web Mining: Extracting Knowledge from the World WideWeb, chapter XIV, p. 197–208. Springer, 2009.
SIMON, B. Identity in Modern Society. A Social Psychological Perspective. Oxford:Blackwell Publishing Ltd, 2004.
SILVA, T.R. Monitoramento de Marcas e Conversações: alguns pontos paradiscussão. In: DOURADO, Danila; SILVA, Tarcízio; CERQUEIRA, Renata; AYRES,Marcel (orgs.). #MidiasSociais: Perspectivas, Tendências e Reflexões.Florianópolis: Bookess, 2010.
SILVA, T.R.. Web 2.0, Vigilância e Monitoramento: entre funções pós-massivas eclassificação social. In: Anais do Congresso Luso Afro Brasileiro de CiênciasSociais, 2011, Salvador (BA).
SILVA, T.R. Aplicativos de análise de informações sociais: mapeamento edinâmicas interacionais. Dissertação (mestrado em Comunicação). UniversidadeFederal da Bahia – UFBA, Salvador, BA, 2012.
SIQUEIRA, H.B.A. WhatMatter: Extração e visualização de características emopiniões sobre serviços. 2010. Dissertação (mestrado em Ciência da Computação) –Centro de Informática, Universidade Federal de Pernambuco, Recife.

119
SOUZA, F.B. Uma análise empírica de interações em redes sociais. Tese(doutorado em Ciência da Computação). Instituto de Ciências Exatas dauniversidade Federal de Minas Gerais – UFMG. Belo Horizonte, MG, 2010.
STAIR, R.M; REYNOLDS, G.W. Princípios de sistemas de informação: umaabordagem gerencial. Trad. Flávio Soares Corrêa da Silva (coord.) Giuliano Mega,Igor Ribeiro Sucupira. 6ª ed. São Paulo: Cengage Learning, 2008.
STANTON, W.J. Fundamentos de marketing. São Paulo: Pioneira, 1980.
STAVRAKANTONAKIS, I.; GAGIU, A.E.; KASPER, H.; TOMA, I.; THALHAMMER, A.An approach for evaluation of social media monitoring tools. In: Common ValueManagement. 1st International Workshop on Common Value ManagementCVM2012. Heraklion, Grécia, p. 52-64. 2012.
TELMA, M.F.P. Uso das ferramentas de Web Analytics no processo deinteligência competitiva das organizações. 2011. Dissertação (mestrado emCiência, Gestão e Tecnologia da Informação). Programa de Pós-Graduação emGestão da Informação. Universidade Federal do Paraná, Paraná.
TICOM, A.A.M. Aplicação de Mineração de Textos e Sistemas Especialistas naLiquidação de Processos Trabalhistas Especialistas. 2007. Dissertação(mestrado em Engenharia Civil) – Instituto Alberto Luiz Coimbra de Pós-graduação epesquisa de engenharia, Universidade Federal do Rio de Janeiro, Rio de Janeiro.
TOMAEL, M.I.; ALCARÁ, A.R.; CHIARA, I.G. Das redes sociais à inovação. Ci. Inf.,Brasília, v. 34, n. 2, p. 93-104, maio/ago. 2005.
TWITTER. Twitter Inc. Disponível em http://www.twitter.com. Acesso em 20 deAgosto de 2011.
VALENTIM, M.L.P. Processo de inteligência competitiva organizacional. In:VALENTIM, M.L.P. (Org.). Informação, conhecimento e inteligênciaorganizacional. Marília: Fundepe Editora, 2006. 282 p. 9-24 p.
WIERENGA, B.; BRUGGEN, G. V. Marketing management support systems:principles, tools and implementation. Boston: Kluwer Academic Publishers, 2000.
WIVES, L.K. Tecnologias de descoberta de conhecimento em textos aplicadasà inteligência competitiva. 2002. Dissetação (Mestrado em Ciência daComputação) – Instituto de Informática, UFRGS, Porto Alegre.
YAMASHITA, S.S. Internet e marketing de relacionamento: impactos emempresas que atuam no mercado consumidor. 2003. Dissertação (mestrado emadministração) – Faculdade de Economia, Administração e Contabilidade,Universidade de São Paulo – USP, São Paulo.





























