Embed Size (px)
Citation preview

Verificando as pressuposições
do modelo estatístico
1
Prof.a Dr.a Simone Daniela Sartorio de Medeiros
DTAiSeR-Ar

As pressuposições do modelo estatístico:
1) os efeitos do modelo estatístico devem ser aditivos;
2) os erros experimentais devem ser independentes;
3) os erros experimentais devem ser normalmente distribuídos;
4) os erros experimentais tem variâncias iguais.
5) Não ter a presença de outliers.
),0(~ 2Neij
2
Assim, se o modelo for apropriado, os resíduos devem refletir as propriedades
impostas pelo termo de erro do modelo.
As técnicas utilizadas para verificar as suposições podem ser informais (como
gráficos) ou formais (como testes). As técnicas gráficas, por serem visuais,
podem ser subjetivas e por isso técnicas formais são mais indicadas para a
tomada de decisão.
O ideal é combinar as técnicas formais e informais para o
diagnóstico de problemas nas suposições do modelo.

Técnicas gráficas
3
a) Análise de resíduos
b) Gráfico quantil-quantil com envelope simulado

a) Análise de resíduos
4
Chamamos de Análise dos Resíduos um conjunto de técnicas
utilizadas para investigar a adequabilidade de um modelo com
base nos resíduos.

Resíduos ordinários
Resíduo padronizado
Resíduo estudentizado
é estimativa da variância residual sem a observação i.
Rsi ~ t (n–p–1) , onde n é o número de observações e p número de parâmetros.
iijij
iijiijijijij
mye
mmmytmyyye
ˆˆ
)ˆˆ(ˆ)ˆˆ(ˆˆ
Valor predito:
s
e
s
e
sQM
ed
ijijij
ij 2Re
)()( iji
ij
i
eV
eRs
)(ˆ)( ii rV
mmt iiˆˆˆ
iij tmy ˆˆˆ
5
Alguns tipos de Resíduos

0
–3
3
dij
ijy
Condição ideal: indica homogeneidade de variâncias (ou
homocedasticidade) e não apresenta outlier(s).
6
Análise de resíduos
A característica do gráfico construído, com os resíduos obtidos, pode fornecer
as orientações ou padrões quanto à identificação de possíveis inadequações do
modelo adotado, quando comparados com os gráficos apresentados a seguir:
Figura 1. Gráfico dos resíduos padronizados valores preditos

b) Gráfico quantil-quantil
7

8
Normal
(proximidade da reta)
Gráfico quantil-quantil com envelope simulado
OBS:
Os erros para seguirem a
distribuição normal com média
zero e variância constante
devem estar próximos a reta
identidade e dentro do envelope
simulado.

Como verificar as
pressuposições do modelo
estatístico?
(DIC)
9

10
1) Modelo aditivo

1) Aditividade do modelo
Condição imposta pelo modelo, em que os diversos efeitos se somam.
A aditividade possibilita que os dados observados sejam sempre combinações
lineares dos efeitos investigados.
11

12
2) Independência das
observações

2) Erros devem ser independentes
Até certo ponto é garantido pela casualização.
Os efeitos de tratamentos sejam independentes, que não haja correlação
entre eles. Que uma parcela não influencie a outra. Isso significa que não se
pode dizer, em função da resposta obtida numa parcela, que a(s) parcela(s)
vizinha(as) terá(ão) respostas mais alta(s) ou mais baixa(s), a priori.
OBS1: Isso não ocorre quando os tratamentos são doses crescentes de proteína, fósforo,
fibra, adubos, inseticidas, fungicidas, herbicidas, etc. ocasião em que a análise de variância
deve ser feita estudando-se a regressão.
OBS2: Isso também não é verdade quando medimos na mesma parcela dados ao longo do
tempo.
OBS3: O simples fato de aleatorizar (sortear) as parcelas que receberão os tratamentos
diminui a dependência entre os erros.
OBS4: O sinal dos desvios no croqui experimental pode indicar dependência dos erros eij.
13

0
–3
0
–3
3 3
dij dij
ijy ijy
a) Os erros não são independentes,
correlação positiva entre os erros.
b) Os erros não são independentes,
correlação negativa entre os erros.
v
v v
14
Análise de resíduos

15
2.1.) Teste de Durbin-Watson
É utilizado para detectar a presença de autocorrelação (dependência) nos
resíduos de uma análise de regressão. Este teste é baseado na suposição de
que os erros no modelo de regressão são gerados por um processo
autoregressivo de primeira ordem.
Tarefa 1.
Pesquise e responda:
a) Quais são as hipóteses desse teste Durbin-Watson?
b) Qual é a estatística do teste?
c) Qual é a distribuição de probabilidade da estatística do teste?
d) Como se faz a decisão do teste?
Teste de independência

16
3) Erros com distribuição
normal

3) Erros normais
Os erros (eij) devem ser normalmente distribuídos. Isto implica em que as
observações (yij) se ajustam a uma distribuição normal dentro de cada
tratamento.
Isso pode ser verificado através de um teste de normalidade, como por
exemplo: a) Shapiro-Wilk; b) Lilliefors; c) Kolmogorov-Smirnov; e d) Teste
qui-quadrado, entre outros.
H0: os erros são normais
Ha: os erros não são normais
As hipóteses, em geral, desses testes são:
Decisão pelo valor-p - Regra prática:
Se o valor-p < Rejeita-se H0
Se o valor-p > Aceita-se H0
17

Nos software R avaliamos o valor da probabilidade (valor-p). Se o valor da
probabilidade for menor que o nível de significância (α) rejeitamos a hipótese
H0. Caso contrário, aceitamos H0.
O teste de Shapiro-Wilk é baseado na estatística W (0 < W ≤ 1). Valores
pequenos da estatística W levam a rejeitar a hipótese H0.
Conclusão:
Portanto, como o valor-p é 0,2359 > 0,05,
então, não rejeita-se H0, ou seja, os resíduos
padronizados seguem uma distribuição
Normal ao nível de 5% de significância.
No R:
shapiro.test(rstudent(mod))
Shapiro-Wilk normality test
Data: rstudent(mod)
W = 0.9396, p-value = 0.2359
18
3.1.) Teste de Shapiro-Wilk
Tarefa 2. Pesquise e responda:
a) Quais são as hipóteses desse teste Shapiro-Wilk?
b) Qual é a estatística do teste?
c) Qual é a distribuição de probabilidade da estatística do teste?
d) Como se faz a decisão do teste?
Teste de normalidade

19
3.2.) Teste de Lilliefors
3.3.) Teste Anderson-Darling
3.4.) Teste de Kolmogorov-Smirnov
3.5.) Teste Cramer-von Mises
3.6.) Teste de Shapiro-Francia
3.7.) Teste qui-quadrado para normalidade
Tarefa 3.
Pesquise e responda sobre os testes 3.2.); 3.3.); 3.4.); 3.5.); 3.6.) e 3.7.):
a) Quais são as hipóteses desse teste?
b) Qual é a estatística do teste?
c) Qual é a distribuição de probabilidade da estatística do teste?
d) Como se faz a decisão do teste?
Teste de normalidade

No R:
# Teste de Lilliefors (Kolmogorov-Smirnov)
require(nortest)
lillie.test(rstudent(mod))
# Teste Anderson-Darling
require(nortest)
ad.test(rstudent(mod))
# Teste de Kolmogorov-Smirnov
ks.test(rstudent(mod), "pnorm", mean(rstudent(mod)),
sd(rstudent(mod)))
# Teste Cramer-von Mises
cvm.test(rstudent(mod))
# Teste de Shapiro-Francia
sf.test(rstudent(mod))
20
Teste de normalidade

21
4) Homocedasticidade

Pode ser verificada por um dos seguintes testes, dentre outros:
Teste de Hartley (ou Razão máxima, ou Teste F máximo)
Teste de Cochran
Teste de Bartlett
Teste de Levene
A variabilidade de um tratamento deve ser
semelhante à dos outros.
4) Homogeneidade de variâncias (ou homocedasticidade)
Os erros ou desvios (eij), devem possuir uma variância comum 2. Em outras
palavras,
Todos os
tratamentos
devem ter o
mesmo n.o de
repetições. Usado mesmo quando se tem
n.o diferente de repetições por
tratamento, mas exige
normalidade dos dados.
IiiiiH
H
ii
I
,...,2,1',,',!:
...:
2
'
2
1
22
2
2
10
(Variâncias homogêneas)
(Variâncias heterogêneas)
As hipóteses desses testes são:
22

4.1.) Teste de Hartley
(ou Razão máxima, ou Teste F máximo)
2
min
2
s
sF máx
calc
Calcula-se as variâncias dentro de cada tratamento e faz-se a razão máxima:
Considerando um nível α de significância, consulta-se a tabela específica do
Teste de Hartley com:
Ftab = H(I,J –1),
onde I é o número de tratamentos e J é número de repetições. Considerando um
nível α de significância, consulta-se a tabela específica com:
Fcalc ≥ Ftab Rejeita H0 ao nível..., concluindo que....
Fcalc < Ftab Aceita H0 ao nível..., concluindo que....
Regra prática:
4 para 1
Ou
7 para 1
OBS: Todos os tratamentos
devem ter o mesmo n.o de
repetições.
23
Tarefa 4:
Faça o teste para o experimento com as 4 variedades de milho (DIC),
feito em sala. Apresente as hipóteses, etc...e conclua o teste.
Teste de homocedasticidade
I
i
i
máxcalc
s
sC
1
2
2
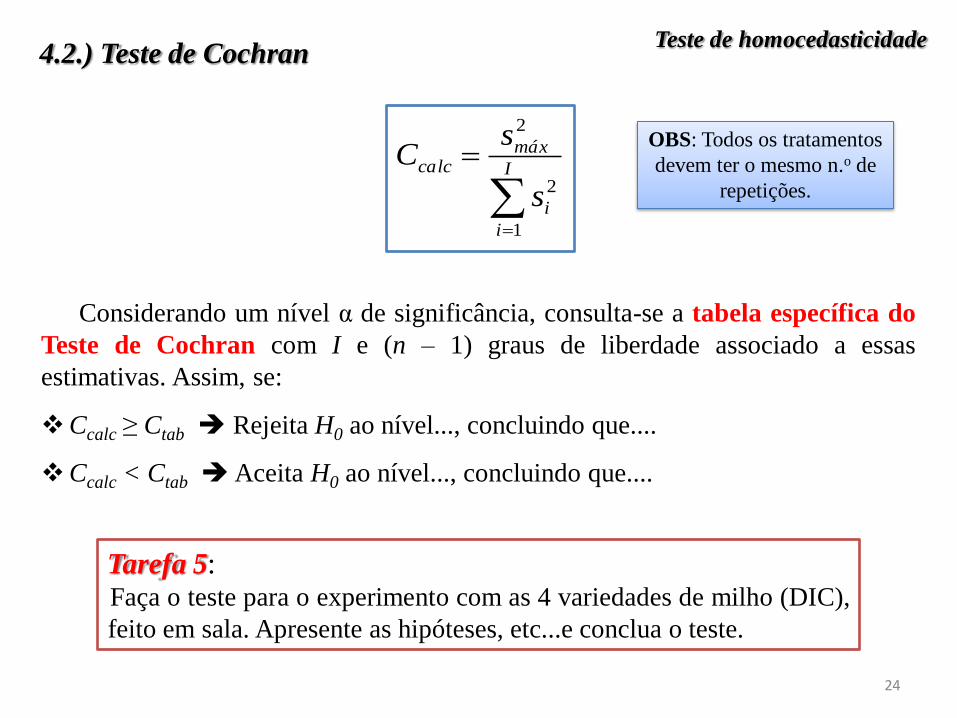
4.2.) Teste de Cochran
Considerando um nível α de significância, consulta-se a tabela específica do
Teste de Cochran com I e (n – 1) graus de liberdade associado a essas
estimativas. Assim, se:
Ccalc ≥ Ctab Rejeita H0 ao nível..., concluindo que....
Ccalc < Ctab Aceita H0 ao nível..., concluindo que....
OBS: Todos os tratamentos
devem ter o mesmo n.o de
repetições.
24
Tarefa 5: Faça o teste para o experimento com as 4 variedades de milho (DIC),
feito em sala. Apresente as hipóteses, etc...e conclua o teste.
Teste de homocedasticidade

2
)1(
1
2
1
2
~1
1
1
)1(3
11
log1log3026,2
II
i i
i
I
i
i
InnI
snsIn
K
4.3.) Teste de Bartlett
Sendo α o nível de significância; I é o número de estimativas de variâncias; é a
média ponderada dos . Temos que a estatística do teste é dada por:
Se Kcalc ≥ Rejeita H0 ao nível..., concluindo que....
Caso, contrárioKcalc < Aceita H0 ao nível..., concluindo que....
OBS: Usado
mesmo quando se
têm n.o diferentes de
repetições por
tratamento, mas
exige normalidade
dos dados.
2
);1( I
2
);1( I
2s2
is
25
Tarefa 6:
Faça o teste para o experimento com as 4 variedades de milho
(DIC), feito em sala. Apresente as hipóteses, etc...e conclua o teste.
No R:
bartlett.test(y ~ trat, data=DIC)
Bartlett test of homogeneity of variances
data: y by trat
Bartlett's K-squared= 6.2881, df= 8, p-value= 0.615

No R:
require(car)
leveneTest(y ~ trat, data=DIC)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 8 0.2901 0.9604
18
26
4.4.) Teste de Levene
OBS: O teste de Levene é mais eficiente que o teste de Bartlett quando
rejeitamos a hipótese de normalidade dos dados.
Este teste foi proposto por Levene em 1960. O procedimento consiste em fazer uma
transformação dos dados originais e aplicar aos dados transformados o teste da ANOVA.
Tarefa 7. Pesquise e responda:
a) Quais são as hipóteses desse teste de Levene?
b) Qual é a estatística do teste?
c) Qual é a distribuição de probabilidade da estatística do teste?
d) Como se faz a decisão do teste?
e) Considere a saída do software R acima e conclua o teste.
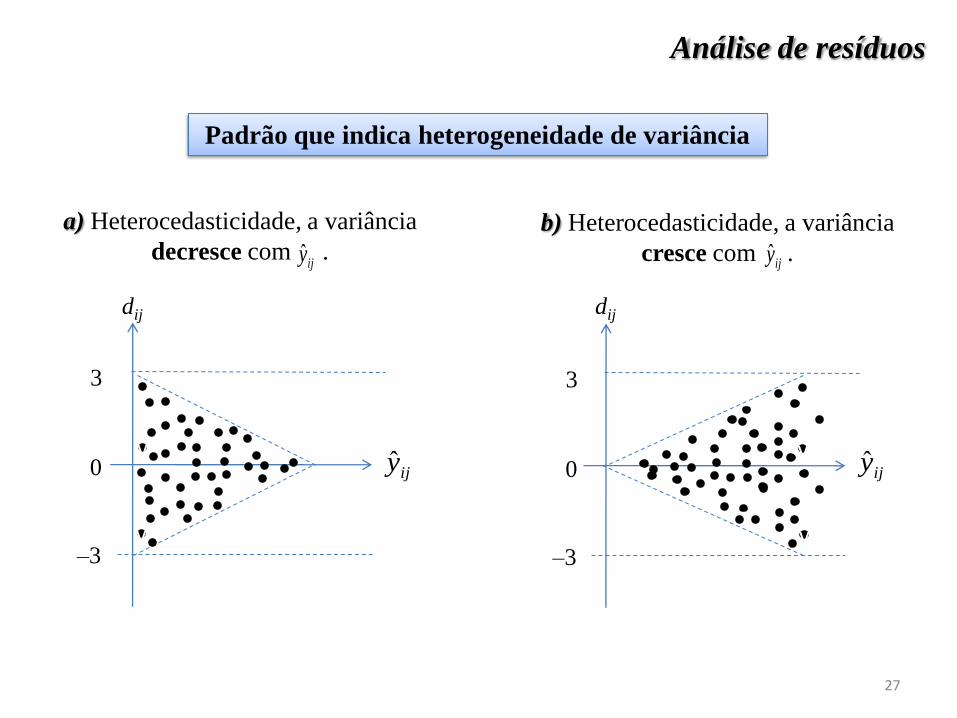
Análise de resíduos
0
–3
0
–3
3 3
dij dij
ijy ijy
a) Heterocedasticidade, a variância
decresce com .
b) Heterocedasticidade, a variância
cresce com .
v
v
v
v
ijy ijy
27
Padrão que indica heterogeneidade de variância
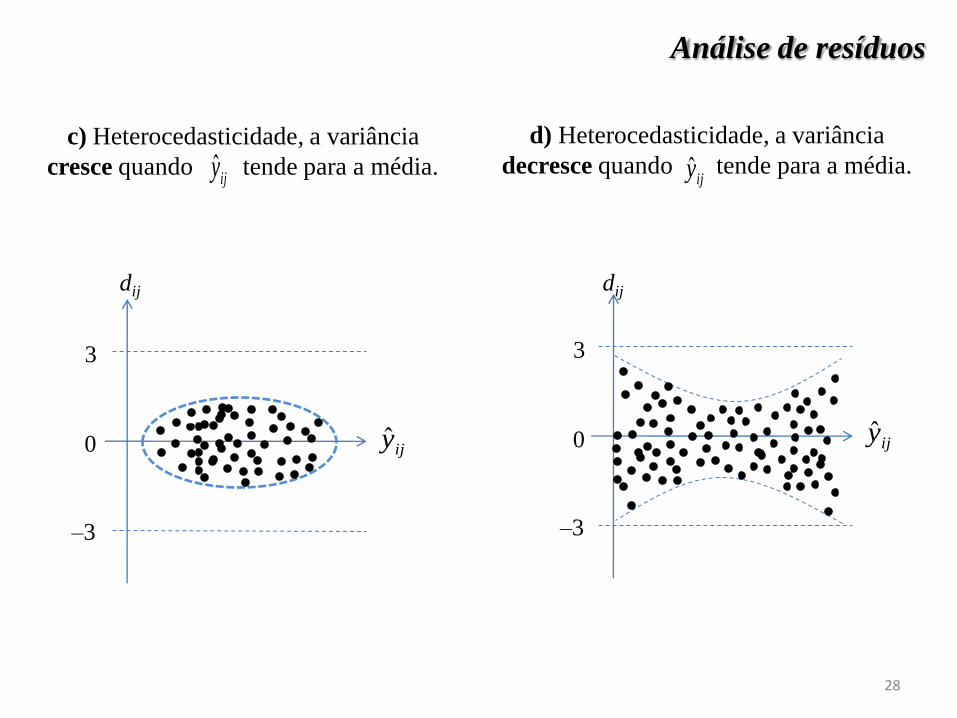
d) Heterocedasticidade, a variância
decresce quando tende para a média.
0
–3
0
–3
3 3
dij dij
ijy ijy
c) Heterocedasticidade, a variância
cresce quando tende para a média. ijy
ijy
28
Análise de resíduos

• Possíveis inadequações podem ser identificadas abaixo.
Itens:
a) situação ideal, b) e c) modelo não linear; d) elemento atípico,
e), f) e g) heterocedasticidade e h) não-normalidade 29

30
5) Não ter outlier
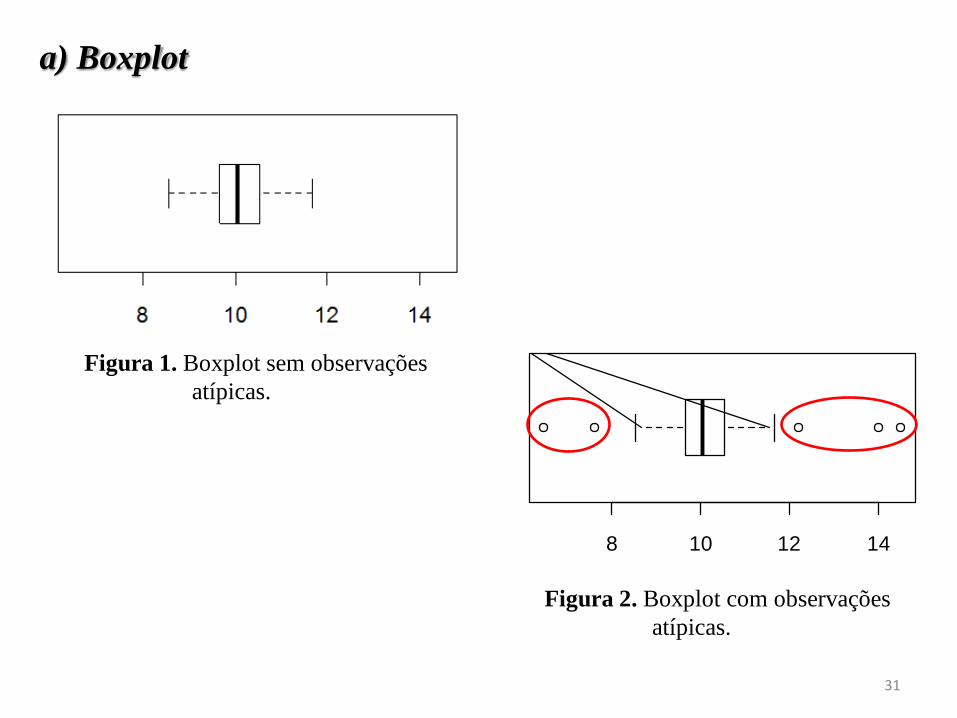
Figura 1. Boxplot sem observações
atípicas.
a) Boxplot
31
8 10 12 14
Figura 2. Boxplot com observações
atípicas.

32
Normal
(proximidade da reta)
b) Gráfico quantil-quantil com
envelope simulado c) Predito Resíduo
Aleatório, sem padrão

33
Outlier?

34
Não Normal
(afastamento da reta)
Outlier?
Outlier?

35
Análise:
• com outlier
e
• sem outlier
Pode mudar os resultados!!!
Exemplo Ana Carolina




















![Circuito Mineiro de Festivais Independentes [CMFI]](https://img.document.onl/doc/110x75/568c52d21a28ab4916b83b5d/circuito-mineiro-de-festivais-independentes-cmfi.jpg)







