Embed Size (px)
Citation preview

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 90
4. PLANEAMENTO EXPERIMENTAL
4.1. Razões para o planeamento de experiências
Realizam-se experiências em quase todas as áreas do conhecimento, usualmente para
descobrir algo acerca de determinado processo ou sistema. Por experiência entende-se uma
investigação em que o sistema em estudo está sob controlo do investigador. Pelo contrário, em
estudos observacionais, a variável resposta é medida sem que o responsável pelo estudo controle
um ou mais dos aspectos do assunto. O formato dos dados poderá ser similar ou quase idêntico nos
dois contextos. A diferença reside na "firmeza de interpretação" acerca das diferenças aparentes na
variável-resposta resultantes dos diferentes factores. Contudo, na prática, é muitas vezes difícil
distinguir os dois casos.
Os principais elementos de uma experiência são as unidades experimentais (pessoas,
animais, pacientes, matérias-primas, parcelas de terreno, etc.), os factores (que por vezes são
subdivididos em níveis ou tratamentos) e a variável-resposta (que pode ser uma ou várias). Em
esquema, pode-se imaginar uma experiência como um conjunto de diferentes tratamentos aplicados
pelo investigador a cada unidade experimental do sistema em estudo, após o que se mede a resposta
(Figura 4.1).
Figura 4.1 – Modelo geral de um processo ou sistema.
Recomenda-se que o planeamento e análise de experiências sigam alguns passos: 1) antes do
planeamento propriamente dito, deve-se identificar e definir o problema, escolher os factores e
níveis e seleccionar a variável-resposta; 2) escolher o plano experimental; 3) realizar a experiência;
4) analisar estatisticamente os resultados; e 5) elaborar conclusões ou recomendações.
Os requisitos mais importantes para o planeamento duma experiência (ou desenho

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 91
experimental para autores anglófonos) podem resumir-se aos seguintes: evitar os erros sistemáticos
ou enviesamentos; minimizar os erros aleatórios ou "erros naturais"; deve ser possível estimar a
magnitude dos erros aleatórios; os resultados devem ser o mais preciso possível; por fim, deve
aproveitar-se uma eventual estrutura especial dos dados através da combinação de factores. Em
resumo, os três princípios básicos do desenho experimental são: a replicação (ou repetição da
experiência básica, do ensaio, para estimação do erro aleatório), a aleatorização (da alocação de
tratamentos, ou níveis de factores, às unidades experimentais para redução dos erros sistemáticos
durante a experiência e para “garantir” a independência das observações e dos erros) e a utilização
de blocos (técnica destinada a reduzir ou eliminar a variabilidade introduzida por factores
“nuisance”, isto é, factores que podem influenciar a experiência mas que não interessam e/ou não
foram explicitamente incluídos durante o planeamento).
Existe uma relação estreita entre o plano (ou desenho) experimental e a posterior análise dos
resultados da experiência, uma vez que o objectivo do desenho experimental é tornar a análise e
interpretação dos resultados tão simples e clara quanto possível! Uma técnica estatística designada
por Análise de Variância (ou ANOVA, do inglês "ANalysis Of VA riance") é vulgarmente utilizada
para analisar os resultados de experiências.
O planeamento de experiências com o objectivo de optimizar eficientemente a qualidade
dum produto (alimentar) com o mínimo de custos possível pode ser visto como um processo em
duas fases: 1) determinação dos factores críticos dum conjunto alargado de variáveis (condições de
operação e/ou ingredientes) que influenciam o produto (ou “screening”). Nesta fase, os planos
experimentais factoriais 2k (completos ou incompletos) são extremamente úteis e eficazes (secção
4.2); e 2) optimização dos factores de forma a atingir os objectivos pretendidos no que concerne o
comportamento da variável-resposta (ou “optimization”). Podem utilizar-se metodologias de
superfície de resposta (RSM) para desenvolver esta fase (secção 4.3).
4.2. Experiências factoriais
Existem várias estratégias de experimentação para estudar a influência de tratamentos ou
factores sobre determinado sistema (e consequentemente sobre uma dada variável-resposta). A mais
correcta, nos casos que envolvem vários factores, é realizar uma experiência factorial, na qual se
variam simultaneamente todos os (níveis dos) factores em estudo ao invés de ensaiar um factor de
cada vez. Neste caso, estuda-se sucessivamente o efeito sobre a variável-resposta de cada um dos
factores mantendo os restantes constantes. A maior desvantagem da estratégia um-factor-de-cada-

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 92
vez, que é muito comum na prática industrial, é não permitir estudar as possíveis interacções entre
factores. Por outro lado, a estratégia de um-factor-de-cada-vez é sempre menos eficiente do que
uma experiência factorial.
4.2.1. Experiências completas
Considere-se, por exemplo, uma experiência em que se pretende estudar a influência de dois
factores (cada um com dois níveis distintos) sobre determinada variável-resposta. A Figura 4.2
esquematiza essa experiência em que se repetiram duas vezes todas e cada uma das combinações de
factores (isto é, existem duas repetições/réplicas por combinação). A experiência ilustrada na Figura
4.2 designa-se por experiência factorial completa (por vezes designada desenho factorial
completo), uma vez que se "experimentaram" todas as combinações possíveis de níveis de factores.
É possível estender a experiência a mais factores, contudo a partir de determinada dimensão do
desenho experimental já não será possível ilustrar todas as combinações testadas.
Figura 4.2 – Resultados duma experiência realizada para estudar os efeitos destes factores sobre o "handicap" dum jogador de golfe e ilustração dos cálculos necessários para estimar os efeitos de dois dos factores: tipo de taco, O ou R; e tipo de bola, T ou B. Os resultados da experiência (nº de pancadas) estão resumidos em (a) e ilustram-se os cálculos para as comparações (b) entre tipos de tacos (efeito do taco), (c) entre tipos de bola (efeito da bola) e (d) para a interacção entre os tipos de taco e de bola (efeito interacção).

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 93
4.2.2. Experiências incompletas
Noutros casos, por razões de tempo ou de financiamento, não é possível realizar todas as
combinações de factores, por exemplo quando se pretendem estudar quatro, cinco ou mais factores.
Neste contexto, apenas se executam ensaios para uma parte das combinações de factores, o que se
designa por experiência factorial incompleta (ou desenho factorial incompleto) (Figura 4.3).
Figura 4.3 – Experiência factorial incompleta com quatro factores: tipo de taco; tipo de bola; tipo de bebida; e modo de deslocação no campo. Pretende-se estudar os efeitos destes factores sobre o "handicap" do jogador. Os vértices assinalados com um círculo indicam as combinações de factores que foram “ensaiadas”.
4.2.3. Experiências com um factor
Considere-se o caso mais simples: uma experiência em que se pretende estudar a influência
de determinado factor (com a níveis) sobre uma variável-resposta Y (Exemplo 4.1).
Exemplo 4.1
Considere-se o conjunto de resultados como os que se apresentam na Tabela 4.1. Pretendeu-se estudar a
influência da percentagem dum determinado conservante (% p/v) sobre o tempo de armazenagem (em dias)
de um produto alimentar. Realizou-se uma experiência completamente aleatorizada com cinco observações
(réplicas ou repetições) por nível do factor (15, 20, 25, 30 e 35% p/v).■
Níveis do factor (% p/v)
y1 y2 y3 y4 y5 Total Média
15 7 7 15 11 9 49 9,8
20 12 17 12 18 18 77 15,4
25 14 18 18 19 19 88 17,6
30 19 25 22 19 23 108 21,6
35 7 10 11 15 11 54 10,8
376 15,04 Tabela 4.1 – Resultados duma experiência com um factor. Para cada um dos a = 5 níveis do factor em estudo (% conservante, %p/v), obtiveram-se cinco observações yi da variável-resposta (tempo de armazenagem, dias).

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 94
A informação contida na Tabela 4.1 pode ser resumida através de vários tipos de
representações gráficas, nomeadamente através dum diagrama de caixas-de-bigodes ou de dispersão
(Figura 4.4). Com base nessa representação, é possível descrever e examinar os resultados obtidos
mas não é possível retirar conclusões.
Figura 4.4 – Diagramas de caixas-e-bigodes (painel da esquerda) e de dispersão (painel da direita) duma experiência para estudar a influência da percentagem de conservante, em cinco níveis de 15 a 35%, sobre o tempo de armazenagem, em dias (Exemplo 4.1). No diagrama de caixas-e-bigodes (“Boxplot”) representa-se a mediana (traço horizontal), o 1º e 3º quartil (limites da caixa) e os extremos (pontos). No diagrama de dispersão, os resultados são representados pelos ● e as médias dos tratamentos/níveis por ○.
Contudo, se se quiser ser mais objectivo pode-se recorrer a uma técnica estatística mais
elaborada, e também mais apropriada, que permite comparar várias médias (neste caso dos
diferentes níveis do factor em estudo) – ANOVA. A Tabela 4.2 é uma generalização da Tabela 4.1.
Cada entrada na tabela, yij (por exemplo y22), representa a j-ésima observação para o tratamento i, e
existem n observações para um dado tratamento (ou nível) i do factor.
Para descrever a situação resumida na Tabela 4.2, pode-se adoptar o modelo-tipo
ij i ijy µ ε= + (4.1)
em que yij é a ij -ésima observação (i=1, 2, ..., a e j=1, 2, ..., n), µi designa a média (ou valor
esperado) das observações para o nível i (i=1, 2, ..., a) e εij é o erro aleatório (que inclui todas as
fontes de erro da experiência). É conveniente pensar que os erros possuem média igual a zero e que
portanto E(yij)=µi. A equação (4.1) é designada como "modelo das médias". Uma alternativa àquela
formulação é definir αi, ou efeito do tratamento i, e então o modelo será
ij i ijy µ α ε= + + (4.2)

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 95
em que µ será um parâmetro global (alguns autores referem-se à "média geral"). O efeito de
determinado factor corresponde à variação média na variável-resposta em função da variação entre
níveis desse factor. Esta última equação é geralmente designada como "modelo dos efeitos" e é a
mais frequente na bibliografia. As equações (4.1) e (4.2) são modelos estatísticos lineares (i.e. a
variável-resposta é função linear dos parâmetros do modelo). Assume-se, ainda, que a experiência
foi realizada de forma aleatória e com igual número de observações por tratamento, ou seja,
constitui uma experiência completamente aleatorizada (ou casualizada)27.
Níveis i do factor Observações (réplicas) ∑ iy iy
1 11y 12y ... ny1 1y 1y
2 21y 22y ... ny2 2y 2y
... ... ... ... ... ...
... ... ... ... ... ...
a 1ay 2ay ... any ay ay
..y y
Tabela 4.2 – Tabela de resultados duma experiência completamente aleatorizada com um factor (generalização da tabela anterior). Em que ..y e y são a soma e a média de todas as observações, respectivamente.
Os objectivos da análise são testar hipóteses (apropriadas) acerca das médias dos
tratamentos e estimar os seus efeitos utilizando como técnica de eleição a análise de variância
(ANOVA). Para isso, assume-se que os erros são variáveis aleatórias independentes e com
distribuição normal de média igual a zero e variância σ2, εij ~ IN(0, σ2). Considera-se, também, que
a variância σ2 é constante para todos os tratamentos, ou seja yij ~ N(µ+ai, σ2) e que yij são
mutuamente independentes.
A equação (4.2) pode descrever dois tipos de situações. Uma situação em que os tratamentos
(ou níveis) a foram escolhidos arbitrariamente pelo investigador pelo que as conclusões aplicam-se
apenas aos tratamentos definidos. É possível estimar os parâmetros do modelo. Este caso designa-se
como modelo de efeitos fixos. Outra situação, é considerar que os tratamentos a estudados são uma
27 A inexistência de alguns (poucos) resultados não coloca problemas de maior à validade das conclusões da ANOVA (simples). Contudo, no caso das experiências factoriais (vide adiante), se o nº de resultados por tratamento não é igual então a experiência diz-se não-ortogonal. Este facto, pode ser “ultrapassado” descartando, de forma aleatória, alguns resultados (dos factores com maior nº de ensaios) ou usando técnicas estatísticas específicas (Wuensch, Two Way Orthogonal Independent Samples ANOVA: Computations, disponível em http://core.ecu.edu/psyc/wuenschk/ docs30/Factorial-Computations.doc, consultado em 3/10/2007).

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 96
amostra duma população mais vasta de tratamentos e, portanto, pretende-se estender as conclusões
aos tratamentos (ou níveis) não considerados na experiência. Não faz sentido estimar os parâmetros
do modelo mas sim estudar a sua variabilidade. Neste caso estamos a estudar um modelo de efeitos
variáveis. Consideraremos para já um modelo de feitos fixos e o método dos mínimos quadrados
como procedimento óptimo para estimar os parâmetros do modelo na análise de variância.
Nestas condições, com a ANOVA pretende-se testar as seguintes hipóteses:
H0: µ1 = µ2 = ... = µa (ou equivalentemente, os efeitos α1 = α2 = ... = 0)
H1: Nem todos as µi são iguais (ou equivalentemente, algum efeito αi ≠ 0).
A designação ANOVA está relacionada com a subdivisão da variabilidade total (de
determinado problema, conjunto de resultados, etc.) nos seus componentes. De modo similar à
abordagem da ANOVA no contexto de regressão linear (ver secção 1.3.3.1.1, pág. 19 e seg.), a
variabilidade total dos resultados (medida pela soma dos quadrados total SQT) inclui uma parte
devida, neste caso, às diferenças (à variação) entre tratamentos, medida pela SQTratamento, e uma
outra relativa aos erros aleatórios (ou variação dentro dos tratamentos, medida pela SQErro), o que se
poderia escrever simbolicamente como
Total Tratamento ErroSQ SQ SQ= + (4.3)
Podem calcular-se estas medidas através de várias formulações. A SQT obtém-se a partir de
22 2 ..
1 1 1 1
( )a n a n
T ij iji j i j
ySQ y y y
N= = = =
= − = −∑∑ ∑∑ (4.4)
em que y é a média e ..y é a soma de todas as observações yij, respectivamente. Considere-se,
agora, a SQErro e a SQTratam como resultado de
2
1 1
( )a n
Erro ij ii j
SQ y y= =
= −∑∑ (4.5)
22 2 ..
1 1
1( )
a a
Tratam i ii i
ySQ y y y
n N= =
= − = −∑ ∑ (4.6)
em que iy é a média das observações no tratamento/nível i. Podemos “refinar” estas medidas da
variabilidade de modo a obter duas estimativas, separadas, da variância (da variabilidade) da
população. Sabendo que

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 97
Total Tratam Errogl gl gl= + (4.7)
isto é, se iN n=∑ for o número total de observações (ouN n a= ⋅ se n for igual para os vários
tratamentos) então )()1()1( aNaN −+−=− , é possível calcular as “médias quadráticas”:
1Tratam
Tratam
SQMQ
a=
− (4.8)
Erro
Erro
SQMQ
N a=
− (4.9)
que estimam, de forma independente e não-enviesada, a variância da população em estudo. Prova-
se, ainda, que a melhor estimativa da variância, 2σ , é dada pela MQErro, isto é, E{ MQErro}=σ2 (ver
secção 1.3.2).
É possível testar as hipóteses avançadas inicialmente recorrendo à estatística de teste F0, que
no caso de H0 ser verdadeira segue distribuição teórica de F com (a – 1) e (N – a) graus de
liberdade. A e.t. F0 obtém-se da seguinte forma
0
Tratam
Erro
MQF
MQ=
(4.10)
Se f0 > ft = fα [a – 1, N – a], rejeita-se H0 e, portanto, com 100(1 – α)% de confiança existem
diferenças entre tratamentos. Alternativamente, poderia utilizar-se o p-value para a tomada de
decisão. Na Tabela 4.3 resume-se esta informação numa tabela de ANOVA.
Fonte de variação SQ g.l. MQ F0
Tratamentos Equação (4.6) a – 1 Equação (4.8) Equação (4.10)
Erro Equação (4.5) N – a Equação (4.9)
Total Equação (4.4) N – 1 Tabela 4.3 – Tabela da ANOVA para uma experiência completamente aleatorizada com um factor (de efeitos fixos).
É possível estimar os parâmetros do modelo de efeitos fixos (equação 4.2), bem como os
respectivos intervalos de confiança, através de
ˆ yµ = (4.11)
ˆi ia y y= − (4.12)
para os tratamentos i = 1, 2, …, a. Para o i-ésimo tratamento, o intervalo de 100(1 – α)% de

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 98
confiança da média µi é dado por
[ ] [ ] iaN
iiiaN
i nty
nty
2
2
2
2
ˆˆ σµσαα −−
+≤≤− (4.13)
uma vez que
i
ii
n
ayT
2σ−= (4.14)
tem distribuição t de Student com (N – a) graus de liberdade.
Exemplo 4.1 (cont.)
Considere-se o conjunto de resultados incluídos na Tabela 4.1. Utilizando a ANOVA para testar as
hipóteses H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. H1: Pelo menos uma iµ diferente, temos que
22 2 2 2 2 (376)
(7) (7) (15) ... (15) (11) 636,9625TSQ = + + + + + − =
2
2 21 (376)(49) ... (54) 475,76
5 25TratamentosSQ = + + − = e 636,96 475,76 161,20ErroSQ = − = .
A partir destas quantidades é possível obter as MQ e a estatística de teste pretendida, F0 (Tabela 4.4).
Observe-se que a MQTratam é bastante superior à MQErro, o que indica que é pouco provável que os
tratamentos sejam iguais, isto é, a variabilidade devida aos tratamentos é substancialmente superior aos
erros aleatórios. De facto, f0 = 14,76 > fT = f0,05[4,20] = 2,87, isto é, rejeita-se H0 para um nível de
significância de 0,05. Com (1 – α)100% de confiança existem diferenças entre os tratamentos!
Alternativamente, poderia calcular-se um valor-p para a estatística de teste: neste caso, valor-p = 9,1 x 10-6.
As estimativas dos parâmetros do modelo dos efeitos são 04,15ˆ =µ dias para o efeito global e
24,51ˆ −=α , 36,02ˆ +=α , 56,23ˆ −=α , 56,64ˆ +=α e 24,45ˆ −=α dias, para os efeitos dos cinco
níveis (tratamentos) analisados. O intervalo de 95% de confiança para a média do tratamento 4 (30% p/v),
por exemplo, é dado por 506,8086,260,21 ± , isto é, [18,95 dias; 24,25 dias], sabendo que
60,214 =y dias e que [ ] 086,2202 =αt .■
Para que os resultados da ANOVA sejam válidos, considera-se que: os modelos (4.1) ou
(4.2) se aplicam à experiência em questão; os erros são variáveis aleatórias independentes e com
distribuição normal de média igual a zero e variância σ2; e, ainda, que a variância σ2 é constante
para todos os tratamentos, ou seja yij ~ N(µ+ai, σ2), e que yij são mutuamente independentes.

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 99
Fonte de
variação SQ g.l. MQ F0
Tratamentos 475,76 4 118,94
14,76
Erro 161,20 20 8,06
Total 636,96 24
Tabela 4.4 – Tabela da ANOVA para o Exemplo 4.1.
Na prática, estes pressupostos não se verificam exactamente. Portanto, não se devem utilizar
os resultados da ANOVA até se confirmar a validade daqueles pressupostos. Podem investigar-se as
possíveis violações dos pressupostos básicos analisando os resíduos. O resíduo da observação j do
tratamento i é dado por
ˆij ij ije y y= − (4.15)
sendo que ijy é o valor estimado pelo modelo correspondente à observação yij e que se obtém
através de
ˆij iy y= (4.16)
isto é, o valor estimado duma qualquer observação do tratamento i não é mais do que a média desse
tratamento. O exame dos resíduos deve fazer parte da ANOVA. Se o modelo for adequado, os
resíduos não apresentarão nenhuma estrutura ou padrão! É possível, examinando graficamente os
resíduos, identificar vários tipos de violações aos pressupostos iniciais (cf. secção 2.4.6.2).
A elaboração dum diagrama de dispersão dos valores ordenados dos resíduos (nos xx) contra
a sua frequência relativa acumulada (nos yy), um "normal probability plot of residuals" para os
autores anglófonos, permite avaliar visualmente o pressuposto de que yij ~ N(µ+ai, σ2). Na Figura
4.5 apresenta-se esse diagrama dos resíduos da ANOVA do Exemplo 4.1. Se a distribuição
subjacente aos erros for normal, então a representação dos pontos nesse diagrama deverá
corresponder, aproximadamente, a uma linha recta, aliás como acontece com os dados apresentados
na Figura 4.5.
A representação dos resíduos “contra o tempo”, isto é, ordenados conforme foram obtidos
durante a experiência (pela ordem dos ensaios ou “run order”) permite avaliar o pressuposto de
independência das observações. Se se observar alguma tendência nesse gráfico então é provável que
exista correlação entre resíduos e, logo, que aquele pressuposto foi violado. Os resultados do
Exemplo 4.1 não parecem indicar nenhum problema com a independência entre observações
(Figura 4.6).

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 100
Nor
mal
% p
roba
bilit
y
Studentized Residuals
Normal plot of residuals
-1.50 -0.61 0.28 1.16 2.05
1
5
10
20
30
50
70
80
90
95
99
Figura 4.5. – "Normal probability plot" dos resíduos ("Studentized Residuals") da ANOVA do Exemplo 4.1
conforme é desenhado pelo software Design-Expert 6®.
Stu
dent
ized
Res
idua
ls
Run Number
Residuals vs. Run
-3.00
-1.50
0.00
1.50
3.00
1 4 7 10 13 16 19 22 25
Figura 4.6 – Gráfico dos resíduos vs. tempo ("Run Number") para a ANOVA do Exemplo 4.1 [DX6].
Se se representarem os resíduos contra os valores esperados de y num diagrama de

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 101
dispersão, podemos verificar outro pressuposto da ANOVA, a homocedasticidade (ou
homogeneidade de variâncias entre tratamentos). A Figura 4.7 ilustra os resultados da ANOVA
relativa ao Exemplo 4.1. Também neste aspecto não parece ocorrer violação do pressuposto inicial.
Por outro lado, a forma da "nuvem de pontos" poderá dar informações acerca da adequação do
modelo ajustado (cf. secção 2.4.6.2). A utilização dos resíduos padronizados ije′ (neste caso, usando
( ) 12 11ˆ−
−⋅=′ iijij nee σ para obter os “studentized residuals”) permite, ainda, identificar as
observações demasiado extremas, os “outliers”.
É possível analisar a homogeneidade das variâncias através de testes de hipóteses formais,
por exemplo usando o teste de Bartlett28 ou o teste (modificado) de Levene (que não será abordado
em detalhe aqui). O primeiro recorre a uma estatística de teste, 20χ , derivada dos desvios-padrão
dos tratamentos e dos graus de liberdade, com distribuição qui-quadrado. O segundo examina as
médias dos desvios absolutos entre as observações ijy e a mediana do tratamento i, iijij yyd ~−= ,
usando uma ANOVA.
2222
22
22
22
22
22
Stu
dent
ized
Res
idua
ls
Predicted
Residuals vs. Predicted
-3.00
-1.50
0.00
1.50
3.00
9.80 12.75 15.70 18.65 21.60
Figura 4.7 – Gráfico dos resíduos versus valor esperado da variável-resposta ("Predicted").
28 O teste de Bartlett é bastante sensível a violações do pressuposto de normalidade dos erros, pelo que se deve utilizar nos casos em que aquela condição não é duvidosa.

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 102
Depois de se verificar existirem diferenças entre as médias dos tratamentos (i.e. rejeitar a H0
com determinada confiança) será útil comparar as várias médias com o objectivo de identificar qual
(ou quais) são diferentes. Existem vários métodos para realizar estas comparações múltiplas de
médias.
Suponha-se que estamos interessados em comparar as médias dos níveis i e j, ou seja, testar
as hipóteses H0: µi = µj vs. H1: µi ≠ µj para qualquer i ≠ j. Para as médias iy e jy , calcule-se o erro-
padrão da diferença entre as médias, em que ni e nj são o número de observações para os
tratamentos i e j:
( )112ˆ −−− += jiyy nnse ji σ (4.17).
Então, a estatística de teste é dada por:
i j
i jd
y y
y yT
se −
−= (4.18)
Região de rejeição será: [ ]
2
dN a
t tα −>
Como anteriormente, o valor da prova (ou p-value) ou nível de significância associado ao
valor da estatística de teste constitui uma medida do grau em que os dados amostrais contradizem a
hipótese nula. Se p-value<α (pré-estabelecido) então a H0 deve ser rejeitada. Uma vez conhecido o
p-value, o investigador pode decidir acerca da significância dos dados sem ter predefinido α: a
quantidade 1 – α pode ser interpretada como a confiança para rejeitar H0.
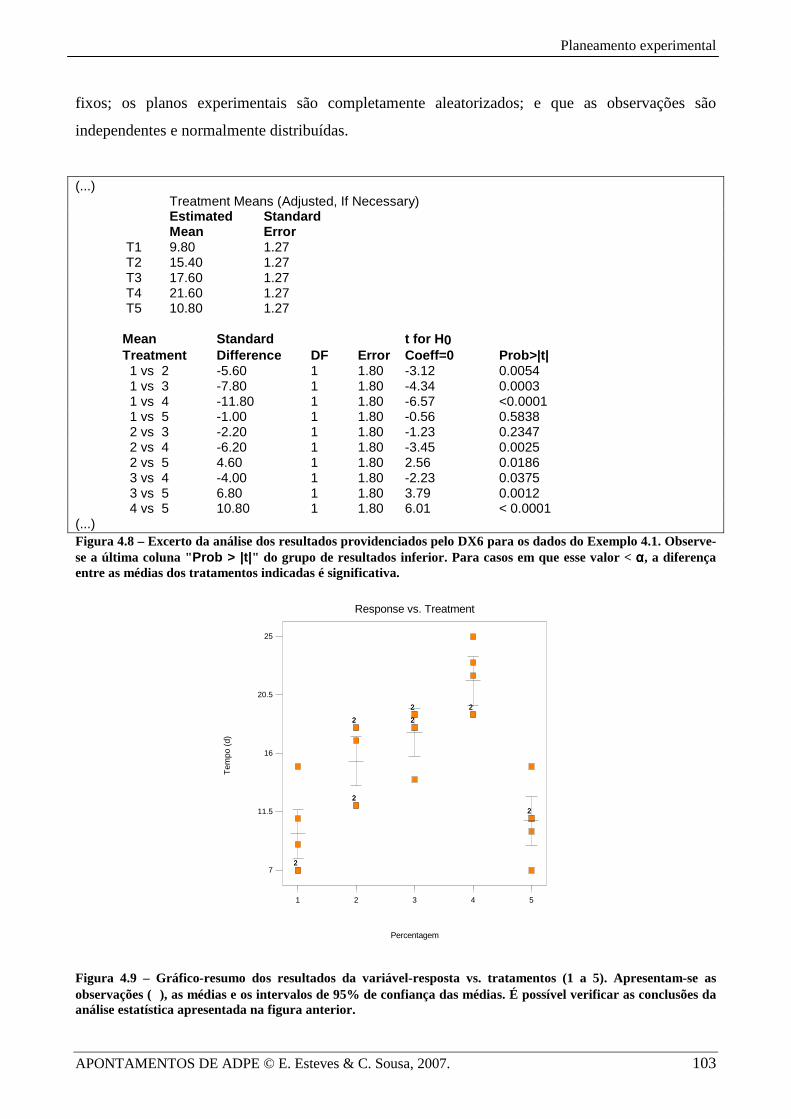
Os resultados dos (múltiplos) testes de comparação entre médias exemplificam-se na Figura
4.8 e ilustram-se na Figura 4.9 (página seguinte), em que se incluem as observações, as médias e os
respectivos limites dos intervalos de confiança. Estes intervalos obtêm-se através da equação (4.13).
Se os intervalos de confiança se sobrepuserem, relativamente ao eixo das ordenadas, então não será
possível distinguir as médias.
4.2.4. Experiências factoriais 2k completas
Muitas experiências envolvem o estudo dos efeitos de dois ou mais factores. Geralmente, os
planos experimentais factoriais são os mais eficientes para estudar este tipo de experiências.
Consideraremos agora os casos que envolvem k factores cada um com dois níveis (ou tratamentos)
– daí a designação desenhos factoriais 2k – por serem os mais utilizados e por constituírem a base
de outros planos experimentais mais complexos. Neste capítulo, assumiremos que: os efeitos são
Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 103
fixos; os planos experimentais são completamente aleatorizados; e que as observações são
independentes e normalmente distribuídas.
(...) Treatment Means (Adjusted, If Necessary) Estimated Standard Mean Error T1 9.80 1.27 T2 15.40 1.27 T3 17.60 1.27 T4 21.60 1.27 T5 10.80 1.27 Mean Standard t for H 0 Treatment Difference DF Error Coeff=0 Prob>|t| 1 vs 2 -5.60 1 1.80 -3.12 0.0054 1 vs 3 -7.80 1 1.80 -4.34 0.0003 1 vs 4 -11.80 1 1.80 -6.57 <0.0001 1 vs 5 -1.00 1 1.80 -0.56 0.5838 2 vs 3 -2.20 1 1.80 -1.23 0.2347 2 vs 4 -6.20 1 1.80 -3.45 0.0025 2 vs 5 4.60 1 1.80 2.56 0.0186 3 vs 4 -4.00 1 1.80 -2.23 0.0375 3 vs 5 6.80 1 1.80 3.79 0.0012 4 vs 5 10.80 1 1.80 6.01 < 0.0001 (...) Figura 4.8 – Excerto da análise dos resultados providenciados pelo DX6 para os dados do Exemplo 4.1. Observe-se a última coluna "Prob > |t| " do grupo de resultados inferior. Para casos em que esse valor < αααα, a diferença entre as médias dos tratamentos indicadas é significativa.
1 2 3 4 5
7
11.5
16
20.5
25
Percentagem
Tem
po (
d)
Response vs. Treatment
22
22
22 22
22 22
22
Figura 4.9 – Gráfico-resumo dos resultados da variável-resposta vs. tratamentos (1 a 5). Apresentam-se as observações (���� ), as médias e os intervalos de 95% de confiança das médias. É possível verificar as conclusões da análise estatística apresentada na figura anterior.

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 104
4.2.4.1. Experiências com dois factores
O caso mais simples de experiências factoriais 2k envolve apenas dois factores, cada um com
dois níveis, um "baixo" e um "alto" – experiência factorial 22. O Exemplo 4.2 descreve e a Figura
4.9 ilustra uma investigação deste tipo com três (observações) réplicas por combinação de níveis de
factores. Consideraremos, no texto que se segue, experiências factoriais com réplicas.
Exemplo 4.2
Numa determinada indústria química pretende-se estudar a influência da concentração dum composto
químico (A) e da quantidade de catalisador (B) sobre a taxa de conversão (Y, %) dum processo químico.
Decidiu realizar-se uma experiência factorial 22, em que se consideraram dois níveis do factor A (15 e 25%)
e do factor B (1 e 2 g) e se obtiveram três resultados (observações, ou réplicas) por combinação de
tratamentos. Os resultados estão incluídos na Figura 4.10.■
Na Figura 4.10, utiliza-se uma das notações possíveis para descrever uma experiência
factorial (Tabela 4.5, página seguinte). A notação adoptada, nomeadamente para o cálculo dos
efeitos, será a de atribuir "rótulos" (notação 3 na Tabela 4.5) às combinações possíveis.
Figura 4.10 – Combinações possíveis numa experiência factorial 22, e respectivos resultados, que envolveu os factores: concentração dum composto (A); e quantidade de catalisador (B).
Os resultados duma experiência factorial podem ser descritos por um modelo dos efeitos do
tipo:
( )ijk i j ij ijky µ α β αβ ε= + + + + (4.19)

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 105
em que yijk indica cada uma das observações (i=1, 2; j=1, 2; k=1, 2, ..., n), µ é o efeito médio global,
αi é o efeito do i-ésimo nível do factor A (i=1, 2), βj é o efeito do j-ésimo nível do factor B (j=1, 2),
(αβ)ij é o efeito da interacção entre os factores (i=1, 2; j=1, 2), e εijk é a componente do erro
aleatório.
Notação 1 Notação 2 Notação 3 Notação 4
Unidade experimental A B A B Rótulos A B
1 — — -1 -1 (1) 0 0
2 + — +1 -1 a 1 0
3 — + -1 +1 b 0 1
4 + + +1 +1 ab 1 1 Tabela 4.5 – Possibilidades de notação utilizadas para indicar os diversos níveis duma experiência factorial (neste caso com dois factores A e B). Pode usar-se "—" ou "-1" para nível "baixo" e "+ " ou "+1" para o nível "alto" (primeiras colunas). Ou, então, rótulos em que se utiliza uma letra minúscula para indicar a presença do nível "alto" numa dada combinação e (1) para a combinação que incui os níveis "baixo" dos factores. Ou, finalmente, a indicação através de "0" ou "1" que se referem à ausência ou presença do factor, respectivamente.
Estamos interessados em testar, através duma ANOVA, as seguintes hipóteses acerca do
factor A, do factor B e da interacção entre factores:
H0: α1 = α2 = 0 vs. H1: Algum αi ≠ 0
H0: β1 = β2 = 0 vs. H1: Algum βj ≠ 0
H0: αβij = 0, para todos i, j vs. H1: Algum (αβ)ij ≠ 0.
É possível testar estas hipóteses e estudar o efeito de cada um dos factores, efeitos
principais, e da interacção entre factores, efeito da interacção. Sejam yi a soma das observações
para o nível i do factor A, yj a soma das observações para o nível j do factor B, yij a soma das
observações para a combinação ij dos factores A e B, e y... a soma de todas as observações.
Considerem-se, ainda, iy , jy , ijy e ...y como as correspondentes médias. Assim, a soma dos
quadrados total pode ser escrita como
2 22
...1 1 1
2 2 2 2 2 22 2 2 2
... ... ...1 1 1 1 1 1 1
( )
2 ( ) 2 ( ) ( ) ( )
n
ijki j k
n
i j ij i j ijk iji j i j i j k
y y
n y y n y y n y y y y y y
= = =
= = = = = = =
− =
= − + − + − − + + −
∑∑∑
∑ ∑ ∑∑ ∑∑∑ (4.20)
e que se pode resumir a

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 106
T A B AB ErroSQ SQ SQ SQ SQ= + + + (4.21)
com (4n – 1), (a – 1) = 1, (b – 1) = 1, (a – 1)(b – 1) = 1 e 4(n – 1) graus de liberdade,
respectivamente. A variabilidade total das observações (medida pela SQT) pode ser decomposta na
variabilidade das médias dos níveis do factor A (SQA), na variabilidade correspondente ao factor B
(SQB), nos efeitos dos factores A e B actuando em conjunto e que não são atribuíveis ao factor A
nem ao factor B separadamente (SQAB) e na variabilidade nos dados devida a factores aleatórios (e
não explicada), SQErro.
A partir da divisão de cada umas das somas dos quadrados dos efeitos e do erro pelo
respectivo número de graus de liberdade obtêm-se as médias quadráticas: MQA, MQB, MQAB e
MQErro. É possível, então, testar as hipóteses avançadas inicialmente recorrendo à estatística de teste
F0, que no caso das H0 serem verdadeiras segue distribuição teórica de F com 1 grau de liberdade
no numerador e 4(n – 1) graus de liberdade no denominador. As e.t. F0 para cada efeito obtêm-se da
seguinte forma
0 0 0, e A B AB
Erro Erro Erro
MQ MQ MQF F F
MQ MQ MQ= = = (4.22)
Se f0 > ft = fα [g.l.numerador, g.l.denominador], rejeita-se H0 e, portanto, com 100(1 – α)% de
confiança os efeitos dos factores são significativos. Alternativamente, poderiam utilizar-se os p-
value para a tomada de decisão. A primeira H0 a testar é a que se refere à interacção entre os
factores A e B. A sua rejeição significa que os factores são não-aditivos e, portanto, aqueles factores
interagem. Nesta situação terá pouco interesse testar as H0 referentes aos efeitos principais de A e B.
Será preferível verificar qual a melhor combinação Ai×Bj.
Recorde-se a Figura 4.10. Empiricamente, podem calcular-se os efeitos médios dos factores
A e B e da interacção AB, respectivamente, pelas equações:
[ ]1
(1)2
A ab a bn
= + − − (4.23)
[ ]1(1)
2B ab b a
n= + − − (4.24)
[ ]1(1)
2AB ab a b
n= + − − (4.25)
em que (1), a, b e ab se referem às somas dos resultados para as combinações de factores conforme
se ilustram na Figura 4.10 e n é número total de observações. Os mesmos resultados se obtêm
considerando as equações seguintes:

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 107
ˆ ˆiµ µ− (4.26)
ˆ ˆjµ µ− (4.27)
ˆ ˆ ˆ ˆij i jµ µ µ µ− − + (4.28)
em que i iyµ = , ˆ j jyµ = , ˆ ij ijyµ = e ...ˆ yµ = .
Exemplo 4.2 (cont.)
Os resultados da experiência na indústria química apresentada anteriormente, permitem calcular as várias
quantidades necessárias para a análise de variância e elaborar a Tabela 4.6. Os cálculos envolvidos são
muito facilitados pela utilização de software apropriado (por exemplo, Design-eXpert® da Stat-Ease Inc.).
Na Tabela 4.6 verifica-se que no modelo a interacção entre os factores A e B não é significativa (p=0,1826).
Apresentam-se, na Figura 4.11, excertos da análise estatística dos resultados da experiência
providenciados por aquele software. ■
Fonte de
variação SQ g.l. MQ F0 p-value
A 208,33 1 208,33 53,15 0,0001
B 75,00 1 75,00 19,13 0,0024
AB 8,33 1 8,33 2,13 0,1826
Erro 31,34 8 3,92
Total 323,00 11
Tabela 4.6 – Análise de variância dos resultados da experiência apresentada no Exemplo 4.2.
Facilmente se expressam os resultados duma experiência factorial 2k usando um modelo de
regressão, obtido a partir do modelo dos efeitos (cf. equação 4.19). Neste caso,
εββββ ++++= 21322110 xxxxy , em que x1 e x2 são as variáveis independentes (os factores A e B) e
x1x2 é a correspondente interacção (AB), codificadas de acordo com a notação –1 e +1 (cf. Tabela
4.5), e que têm uma relação linear com as variáveis naturais v do tipo ( ) hmvx −= (em que m é o
valor intermédio e h é a amplitude entre os dois níveis dum dado factor). Os coeficientes βj obtêm-
se a partir das estimativas dos efeitos (equações 4.23 a 4.25), sendo que 21 A=β , 22 B=β e
23 AB=β . A relação 21 A=β , por exemplo, está relacionada com o facto dos coeficientes de
regressão medirem o efeito da variação unitária de x sobre a variação média de y enquanto os
efeitos se baseiam numa variação de duas unidades, de –1 a +1 (ver adiante).

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 108
(...) Analysis of variance table [Partial sum of squares] Sum of Mean F Source Squares DF Square Value Prob > F Model 291.67 3 97.22 24.82 0.0002 significant A 208.33 1 208.33 53.19 <0.0001 B 75.00 1 75.00 19.15 0.0024 AB 8.33 1 8.33 2.13 0.1828 Pure Error 31.33 8 3.92 Cor Total 323.00 11 (...) (…) Std. Dev. 1.98 R-Squared 0.9030 Mean 27.50 Adj R-Squared 0.8666 C.V. 7.20 Pred R-Squared 0.7817 PRESS 70.50 Adeq Precision 11.669 (...) Final Equation in Terms of Coded Factors: Taxa = +27.50 +4.17 * A -2.50 * B +0.83 * A*B Final Equation in Terms of Actual Factors: Taxa = +28.333 +0.333 * Concentração -11.667 * Catalisador +0.333 * Concentração * Catalisador (…) Figura 4.11 – Excertos da análise de variância dos resultados providenciados pelo DX6 para os dados do Exemplo 4.2. Observe-se na tabela da ANOVA que o modelo é significativo ("F value " e " Prob > F ") e que a interacção dos factores em estudo (AB ) não é significativa (painel inferior). Na ANOVA apresentada, a soma dos quadrados do modelo (“Model sum of squares” ) obtém-se considerando que SQModelo = SQA+SQB+SQAB.
É desejável completar a análise do modelo (de regressão) dos efeitos obtido através de
várias estatísticas. Na Figura 4.11 apresentam-se algumas estatísticas complementares,
designadamente a MQErro, o R2 ajustado, o R2 previsto, a PRESS e a Precisão. A média quadrática
do erro, MQErro, estima o erro experimental e obtém-se como se indica na equação (4.9). O
coeficiente de determinação ajustado 2.ajR mede a porção da variabilidade da resposta que é
explicada pelo modelo quando se consideram o número de factores do modelo (ver regressão
múltipla). Complementarmente, o 2previstoR quantifica essa proporção numa “futura” experiência
similar à realizada e obtém-se através de:
cos
2 1BloT
previsto SQSQ
PRESSR
−−= (4.29)
Se a experiência não considerar blocos então SQBlocos=0! Valores similares de 2.ajR e 2
previstoR (por
exemplo, uma diferença <0,02) indicam um ajuste adequado. A PRESS (do inglês “Predicted

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 109
Residual Sum of Squares”) mede o ajuste do modelo a cada uma das observações. Obtém-se da
seguinte forma: calculam-se os valores esperados para cada observação a partir dum modelo em que
essa observação não foi incluída; e somam-se os quadrados dos resíduos dos cálculos anteriores,
isto é:
[ ]2
11
ˆ( )n
i ii
PRESS y y−=
= −∑ (4.30)
em que iy é o valor observado para xi e [ ]1ˆ −iy é o valor esperado que se calcula através dum modelo
que não inclui aquela observação xi. Quanto menor PRESS, melhor “a qualidade do ajuste” do
modelo. Finalmente, considere-se a Precisão P (do inglês “Adequate Precision”), que mede as
diferenças na variável-resposta relacionadas com o erro da experiência. Por outras palavras, é a
razão entre a informação contida no modelo e o “ruído”. Valores desta estatística ≥ 4 são desejáveis.
Calcula-se através de
12)(
)ˆmin()ˆmax(−⋅⋅
−=nMQp
yyP
Erro
(4.31)
em que p é o número de parâmetros (ou coeficientes) do modelo e n é o número de ensaios
realizados.
Em muitas experiências envolvendo desenhos factoriais 2k, examinam-se a magnitude e a
direcção dos efeitos para determinar qual, ou quais, das variáveis são importantes. Assim, no caso
do Exemplo 4.2, o efeito de A é positivo e o efeito de B é negativo, o que indica que a variável-
resposta aumentará quando A aumenta e diminuirá quando B aumenta. Por outro lado, o efeito da
interacção é relativamente pequeno por comparação com os efeitos principais (ver conjunto de
resultados referidos por Final Equation in Terms of Coded Factors na Figura 4.11). O software
apresenta ainda o modelo (de regressão) dos efeitos, considerando as variáveis naturais (ver Final
Equation in Terms of Actual Factors na Figura 4.11) que permite calcular o valor esperado da
variável dependente para “certas e determinadas” condições.
A análise dos resíduos, como meio de verificar os pressupostos iniciais e indicar soluções
para possíveis violações desses pressupostos deve fazer parte da ANOVA de experiências factoriais
(vide secção 2.4.6, pág. 56 e seg.).
4.2.4.2. Experiências com três factores
Suponha-se, agora, que estão envolvidos três factores, cada um com dois níveis – plano
experimental factorial 23 – numa experiência muito semelhante à descrita e abordada na secção

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 110
anterior. As combinações possíveis podem representar-se através dum cubo ou da matriz do
desenho experimental (Figura 4.12).
Figura 4.12 – Experiência factorial 23, numa ilustração geométrica, um cubo (a) e representada por matriz do
desenho experimental (b).
Exemplo 4.3
O responsável pela linha de enchimento duma fábrica de produção de refrigerantes pretende uniformizar a
quantidade de bebida dispensada para cada garrafa, pois verifica-se alguma variação. Com esse objectivo,
realizou uma experiência para estudar, e eventualmente minimizar, os factores que podem influenciar o
enchimento. O engenheiro responsável pode controlar três variáveis: a percentagem de gaseificação (A, %);
a pressão de enchimento (B, psi); e o número de garrafas por minuto ou velocidade de enchimento (C,
gpm). Os níveis escolhidos de cada factor foram, respectivamente, 10 e 14%, 25 e 30 psi, e 200 e 250 gpm.
Realizaram-se duas repetições de cada combinação de factores. Decidiu-se que a variável-resposta seria a
diferença da altura de líquido relativamente ao valor-alvo (Y, mm). Valores de y > 0 indicam alturas
(volumes) maiores do que o pretendido, e y < 0 resultam do contrário. Os resultados desta experiência
apresentam-se na Tabela 4.7.■
As considerações teóricas apresentadas para as experiências factoriais 22 podem estender-se
a estes desenhos factoriais que envolvem três factores, designadamente os factores A, B e C. Para
isso, acrescentam-se ao modelo de efeitos fixos (equação 4.20) os termos necessários,
( ) ( ) ( ) ( )ijk i j k ij ik jk ijk ijkly µ α β γ αβ αγ βγ αβγ ε= + + + + + + + + (4.32)
em que yijkl indica cada uma das observações (i=1, 2; j=1, 2; k=1, 2; l=1, 2, ..., n), µ é o efeito médio
global, αi é o efeito do i-ésimo nível do factor A (i=1, 2), βj é o efeito do j-ésimo nível do factor B
(j=1, 2), γk é o efeito do k-ésimo nível do factor C (k=1, 2), (αβ)ij, (αγ)ik e (βγ)jk são os efeitos das

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 111
interacções entre pares dos factores, (αβγ)ijk é a interacção de todos os factores e εijkl é a
componente do erro aleatório.
Pressão (B)
25 psi 30 psi
Velocidade (C) Velocidade (C)
Percentagem (A) 200 250 200 250
10% -3 -1 -1 0 -1 0 1 1
14% 5 4 7 6 7 9 10 11 Tabela 4.7. Resultados da experiência descrita no Exemplo 4.3. Em cada célula da tabela apresentam-se as duas
réplicas (ensaios) para cada combinação de factores.
As hipóteses em teste são similares às apresentadas anteriormente para os desenhos
factoriais 22, considerando agora os três factores e as várias interacções possíveis. Usualmente, os
cálculos envolvidos na ANOVA deste tipo de experiências são realizados recorrendo a software
apropriado. No entanto, as fórmulas de cálculo das somas dos quadros são ocasionalmente úteis. A
soma dos quadrados total SQT obtém-se através de
22 2 2
2 ....
1 1 1 1 8
n
T ijkli j k l
ySQ y
n= = = =
= −∑∑∑∑ (4.33)
em que ....y é a soma de todas as observações. As somas dos quadrados relativos aos efeitos
principais, SQA, SQB e SQC podem calcular-se da seguinte forma
22
2 ....
1
1
4 8A ii
ySQ y
n n=
= −∑ (4.34)
22
2 ....
1
1
4 8B jj
ySQ y
n n=
= −∑ (4.35)
22
2 ....
1
1
4 8C kk
ySQ y
n n=
= −∑ (4.36)
em que yi, yj e yk são as somas das observações para os níveis i, j e k dos factores A, B e C. No casos
das interacções entre cada dois factores, são necessários os totais das observações por combinação
A x B, A x C e B x C, designadamente yij, yik e yjk. Assim,
22 2
2 ....
1 1
1
2 8AB ij A Bi j
ySQ y SQ SQ
n n= =
= − − −∑∑ (4.37)

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 112
22 2
2 ....
1 1
1
2 8AC ik A Ci k
ySQ y SQ SQ
n n= =
= − − −∑∑ (4.38)
22 2
2 ....
1 1
1
2 8BC jk B Cj k
ySQ y SQ SQ
n n= =
= − − −∑∑ (4.39)
A soma dos quadrados da interacção dos três factores SQABC pode obter-se a partir de
22 2 2
2 ....
1 1 1
1
2 8ABC ijk A B C AB AC BCi j k
ySQ y SQ SQ SQ SQ SQ SQ
n n= = =
= − − − − − − −∑∑∑ (4.40)
considerando que yijk é a soma de todas as observações para a combinação dos três factores.
Finalmente, a soma dos quadrados do erro calcula-se por subtracção
2 2 2
2
1 1 1
1
2Erro T ijki j k
SQ SQ yn = = =
= − ∑∑∑ (4.41)
A partir destas quantidades é possível calcular as respectivas médias quadráticas
considerando que
T A B C AB AC BC ABC ErroSQ SQ SQ SQ SQ SQ SQ SQ SQ= + + + + + + + (4.42)
com (abcn – 1) = (8n – 1), (a – 1) = 1, (b – 1) = 1, (c –1) = 1, (a – 1)(b – 1) = 1, (a – 1)(c – 1) = 1,
(b – 1)(c – 1) = 1, (a – 1)(b – 1)(c – 1) = 1 e abc(n – 1) = 8(n – 1) graus de liberdade,
respectivamente. Por divisão de cada umas das somas dos quadrados dos efeitos e dos erros pelo
respectivo número de graus de liberdade obtêm-se as médias quadráticas: MQA, MQB, MQC, MQAB,
MQAC, MQBC, MQABC e MQErro. É possível, então, testar as hipóteses avançadas inicialmente
recorrendo à estatística de teste F0, que no caso das H0 serem verdadeiras, segue distribuição teórica
de F com 1 grau de liberdade no numerador e 8(n – 1) graus de liberdade no denominador. As e.t.
F0 obtêm-se da seguinte forma para os efeitos principais e para as interacções,
0 0 0, , CA B
Erro Erro Erro
MQMQ MQF F F
MQ MQ MQ= = = (4.43)
0 0 0 0, , ,AC BC ABCAB
Erro Erro Erro Erro
MQ MQ MQMQF F F F
MQ MQ MQ MQ= = = = (4.44)
Se f0 > ft = fα [g.l.numerador, g.l.denominador] rejeita-se H0 e, portanto, com 100(1 – α)% de
confiança os efeitos são significativos. Alternativamente, poderiam utilizar-se os p-value para a
tomada de decisão.

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 113
Exemplo 4.3 (cont.)
A análise de variância da experiência descrita anteriormente permite identificar qual (ou quais) dos factores
considerados influencia a variável-resposta. Na Tabela 4.8 resume-se essa análise. Verifica-se que apenas
os efeitos principais e a interacção entre os factores A e B são significativos (p-value<α = 0,05), pelo que os
restantes efeitos poderiam omitir-se do modelo final sem prejuízo (significativo) para as conclusões do
trabalho. Na Figura 4.13, apresentam-se alguns dos resultados da análise através do software DX6,
considerando-se apenas os efeitos significativos.■
Fonte de variação SQ g.l. MQ F0 p-value
A 248,06 1 248,06 305,31 <10-4
B 27,56 1 27,56 33,92 0,0004
C 14,06 1 14,06 17,31 0,0032
AB 5,06 1 5,06 6,23 0,0372
AC 0,56 1 0,56 0,69 0,4295
BC 0,063 1 0,063 0,077 0,7885
ABC 0,063 1 0,063 0,077 0,7885
Erro 5,00 8 0,63
Total 277,00 15
Tabela 4.8 – Tabela da ANOVA dos resultados da experiência 23 factorial descrita no Exemplo 4.3.
Como anteriormente, podem estimar-se os efeitos principais e das interacções de factores
estudados. Considerando a notação da Figura 4.12 (ver também secção anterior para notação
utilizada), os efeitos dos factores A, B e C obtêm-se a partir de
[ ]1(1)
4A a ab ac abc b c bc
n= + + + − − − − (4.45)
[ ]1(1)
4B b ab bc abc a c ac
n= + + + − − − − (4.46)
[ ]1(1)
4C c ac bc abc a b ab
n= + + + − − − − (4.47)
No caso das interacções, os efeitos podem calcular-se através de
[ ]1(1)
4AB abc bc ab b ac c a
n= − + − − + − + (4.48)
[ ]1(1)
4AC a b ab c ac bc abc
n= − + − − + − + (4.49)

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 114
[ ]1(1)
4BC a b ab c ac bc abc
n= + − − − − + + (4.50)
[ ]1(1)
4ABC abc bc ac c ab b a
n= − − + − + + − (4.51)
(...) Analysis of variance table [Partial sum of squares] Sum of Mean F Source Squares DF Square Value Prob > F Model 294.75 4 73.69 112.77 < 0.0001 significant A 248.06 1 248.06 379.64 < 0.0001 B 27.56 1 27.56 42.18 < 0.0001 C 14.06 1 14.06 21.52 0.0007 AB 5.06 1 5.06 7.75 0.0178 Residual 7.19 11 0.65 Lack of Fit 0.69 3 0.23 0.28 0.8371 not significant Pure Error 6.50 8 0.81 Cor Total 301.94 15 (...) Std. Dev. 0.81 R-Squared 0.9762 Mean 3.44 Adj R-Squared 0.9675
C.V. 23.52 Pred R-Squared 0.9496 PRESS 15.21 Adeq Precision 27.386
(...) Final Equation in Terms of Coded Factors: Altura = +3.44 +3.94 * A +1.31 * B +0.94 * C +0.56 * A * B Final Equation in Terms of Actual Factors: Altura = -5.93750 -1.12500 * Gaseificação -0.82500 * Pressão +0.037500 * Velocidade +0.11250 * Gaseificação * Pressão (...) Figura 4.13 – Excertos da análise de variância dos resultados providenciados pelo DX6 para os dados do Exemplo 4.3. Observe-se que o modelo é significativo ("F value " e " Prob > F ") e quais são os efeitos médios dos vários factores.
A partir destas estimativas é fácil obter o modelo (de regressão) dos efeitos que descreve os
resultados (cf. Equação 4.32). O procedimento é similar àquele apresentado para experiências
factoriais 22. Novamente, interessa examinar a magnitude e a direcção dos efeitos para determinar
qual, ou quais, das variáveis (e interacções) são importantes. Se os factores em estudo forem
quantitativos é possível representar o modelo dos efeitos resultante através duma superfície de
resposta (Figura 4.14a) ou dum gráfico de contorno (Figura 4.14b).

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 115
(a)
(b)
Figura 4.14 – Gráfico de contorno (a) e superfície de resposta (b) da experiência factorial descrita no Exemplo 4.3, para uma velocidade de enchimento intermédia de 225 gpm. O gráfico de contorno obteve-se no DX6 através Analysis > Model Graph > View > Contour , enquanto a superfície de resposta foi desenhada seleccionando nos menus do software Analysis > Model Graph > View > 3D Surface .
Existem outros métodos úteis para determinar (preliminarmente) qual, ou quais, dos factores
em estudo são significativos, designadamente a utilização de normal probability plots (NPP)
(Figura 4.15). Frequentemente, os desenhos factoriais 2k envolvem um número elevado de factores,
o que aumenta o número de ensaios a realizar (por exemplo, um desenho factorial 25 completo e
sem réplicas dá origem a 32 combinações possíveis!). Nesses casos, os recursos disponíveis,
geralmente limitados, permitem obter apenas uma observação para cada combinação (se não se

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 116
omitir nenhum dos factores originais), o que invalida a estimação do erro. O recurso ao NPP das
estimativas dos efeitos permite ultrapassar esta dificuldade. Os efeitos negligenciáveis distribuem-
se normalmente com média igual a zero e variância σ2 e, por isso, a sua representação nesses
diagramas deverá ser aproximadamente uma linha recta, ao contrário dos efeitos importantes
(Figura 4.15). Esta metodologia é geralmente empregue no início dum estudo para identificar o(s)
factor(es) importantes e que devem ser estudados formalmente (através da ANOVA).
Figura 4.15 – Excerto da análise dos resultados do Exemplo 4.3 usando o Normal Probability Plot dos efeitos (obtido, no DX6, através de Analysis > Effects > View > Half Normal plot ). A significância de cada um dos termos do modelo (apenas aqueles que se distanciam horizontalmente da linha diagonal se consideram significativos – pois apresentam maior “efeito”).
Claramente, a inexistência de interacções significativas entre factores simplifica bastante as
conclusões. É, nesse caso, aceitável apresentar e discutir as estimativas dos efeitos dos factores per
se. Contudo, na circunstância das interacções serem relativamente importantes, os efeitos dos
factores principais nelas envolvidos são virtualmente irrelevantes. É possível remover alguns tipos
de interacções através da transformação da variável-resposta. Por outro lado, quando as interacções
significativas envolvem um determinado factor será aconselhável realizar experiências separadas
para os diferentes níveis desse factor.
Novamente, deve completar-se a análise do modelo (de regressão) dos efeitos obtido
recorrendo a estatísticas adequadas, que se apresentaram e explicaram a propósito do Exemplo 4.2,
nomeadamente a MQErro, o R2 ajustado, o R2 previsto, a PRESS e a Precisão. Por outro lado, a
análise dos resíduos, como forma de verificar os pressupostos iniciais e indicar soluções para as

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 117
possíveis violações, deve integrar qualquer ANOVA (ver secção 4.2.3). Assim, devem observar-se
o "normal probability plot of residuals" e o diagrama de dispersão dos resíduos contra o valor
esperado da variável-resposta, como forma de validar o modelo obtido. Os resultados, ilustrados na
Figura 4.16, não parecem indicar nenhuma irregularidade grave.
Figura 4.16 –"Normal probability plot of residuals" (esq.) e "Residuals vs. Predicted" (dir.) relativos ao dados do Exemplo 4.3. O gráfico (a) obteve-se no DX6 através de Analysis > Diagnostics > Normal Probability (no menu flutuante), enquanto (b) foi desenhado seleccionando Analysis > Diagnostics > Residuals vs Predicted (na caixa de diálogo).
4.2.4.3. Experiências factoriais incompletas 2k – p
Quando o número de factores (k) a considerar numa experiência factorial aumenta, o número
de ensaios necessários para estudar todas as combinações possíveis de (níveis de) factores
rapidamente ultrapassa os recursos disponíveis (por exemplo, numa experiência com 6 factores, A –
F, e sem replicação será necessário realizar 26=64 ensaios). Se for possível assumir que os efeitos
das interacções entre factores de ordem mais elevada (e.g. ABCD, ABCDE e/ou ABCDEF) são
negligenciáveis então é bastante vantajoso o recurso a planos experimentais incompletos (por
exemplo, poderiam realizar-se, apenas, 32 ensaios ou mesmo 16 ensaios). Estes planos são dos mais
usados quando o objectivo é a concepção de produtos ou planificação e optimização de processos.
Outra utilização comum está relacionada com determinação dos factores críticos dum conjunto
alargado de variáveis (condições de operação e/ou ingredientes) que influenciam o produto (ou
“screening”).
A aplicação com sucesso destes planos experimentais baseia-se no facto dos sistemas ou

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 118
processos serem condicionados por um reduzido número de factores e de interacções de ordem
menor de entre os vários que o integram e na possibilidade de (posteriormente) complementar a
experiência com mais ensaios de forma a estimar os efeitos de factores e respectivas interacções.
Numa experiência factorial incompleta 2k – p realizam-se, apenas, p21 dos ensaios e é
possível testar a significância de (2k – p – 1) dos factores (à custa de se “confundirem” o(s) efeito(s)
de algum(ns) factor(es) com interacções complexas entre factores). Existem regras e algoritmos
(relativamente complexos) para a construção e análise destes planos experimentais. No entanto,
quanto menor a fracção dos ensaios a realizar, menor a resolução29 do plano experimental. A
utilização de tabelas apropriadas, que constam da maioria dos manuais dedicados ao tema, ou o
recurso a software especializado (por exemplo, DX®6) facilita muito a preparação dos planos e
análise de resultados (ver Exemplo 4.4).
Exemplo 4.4
Estudaram-se os efeitos de quatro factores, A a D, sobre a pureza do produto num dado processo de
filtração. A pureza foi medida com um instrumento fotoeléctrico e valores maiores correspondem a níveis
superiores de pureza. Apenas foi possível realizar metade dos ensaios necessários a um plano
experimental completo (Tabela 4.9).
Combinação de níveis de factores (a)
Padrão de confounding (b)
Variável-resposta (Pureza)
Efeito (efectivamente) estimado
(1) I=ABCD (c) 107 I + ABCD
ad A=BCD 114 A + BCD
bd B=ACD 122 B + ACD
ab AB=CD 130 AB + CD
cd C=ADB 106 C + ABD
ac AC=BD 121 AC + BD
bc BC=AD 120 BC + AD
abcd D=ABC 132 ABC + D
Tabela 4.9 – Tabela dos resultados da experiência 24 factorial incompleta descrita no Exemplo 4.4. Legenda: (a) utilizando a notação da Tabela 4.5; (b) relações de “confusão” entre os factores; (c) relação geradora deste plano experimental (“defining relation”).
29 A resolução (literalmente traduzido do inglês design resolution) descreve o grau de “confusão” (do inglês confounding) entre os efeitos principais e as interacções de 2º grau, 3º grau, etc. Geralmente, a resolução é igual a um mais a menor ordem (de interacção) com a qual os efeitos principais estão “confundidos”. Se os factores principais estão “confundidos” com as interacções de 2ª ordem então a resolução do plano experimental é III. Nota: Os planos facoriais completos têm resolução infinita pois estimam-se todos os factores e interacções. Na maioria dos casos práticos, uma resolução igual a V é excelente e uma resolução IV poderá ser adequada. Planos experimentais com resolução III são (economicamente) úteis para experiências de screening (NIST/SEMATECH, A Glossary of DOE Terminology, disponível em http://www.itl.nist.gov/div898/handbook/pri/section7/pri7.htm , consultado em 3/10/2007).

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 119
A observação do “half-normal plot” dos efeitos (Figura 4.17), que se obteve recorrendo ao software DX®6,
sugere que apenas os efeitos dos factores A e B (de facto, A+BCD e B+ACD) são significativos. Os
restantes efeitos (■) encontram-se sobre a linha, pelo que não se “distinguem estatisticamente” do “erro
natural” das observações. A tabela da análise de variância (Figura 4.18) confirma aquela suspeição (p-
values de 0,0017 e 0,0005, respectivamente). ■
Figura 4.17 – Excerto da análise estatística dos resultados providenciados pelo DX6 para os dados do Exemplo 4.4. Neste caso, apresenta-se o “diagrama de probabilidades dos efeitos” (obtido através de Analysis > Effects > View > Half Normal plot ) que ilustra a significância de cada um dos termos do modelo (apenas aqueles que se distanciam da linha diagonal se consideram significativos).
Analysis of variance table [Partial sum of squares] Sum of Mean F Source Squares DF Square Value Prob > F Model 612.50 2 306.25 51.91 0.0005 A 220.50 1 220.50 37.37 0.0017 B 392.00 1 392.00 66.44 0.0005 Residual 29.50 5 5.90 Cor Total 642.00 7 (…) Std. Dev. 2.43 R-Squared 0.9540 Mean 119.00 Adj R-Squared 0.9357 C.V. 2.04 Pred R-Squared 0.8824 PRESS 75.52 Adeq Precision 16.471 (…) Final Equation in Terms of Coded Factors: Pureza = +119.00 +5.25 * A +7.00 * B (…) Figura 4.18 – Excertos da análise de variância dos resultados, providenciados pelo DX®6 para os dados do Exemplo 4.4. Observe-se que o modelo e os factores A e B são significativos ("F value " e " Prob > F "). Ver comentários à analise do Exemplo 4.2.

Planeamento experimental
APONTAMENTOS DE ADPE © E. Esteves & C. Sousa, 2007. 120
Da análise de variância é possível obter o modelo (de regressão) que descreve a relação
entre os factores e a variável-resposta (e que permite estimar a pureza em função dos níveis dos
factores). O procedimento é similar àquele apresentado para as experiências factoriais completas.
Na Figura 4.18, apresentam-se os modelos (dos efeitos) obtidos para o Exemplo 4.4.
Genericamente, os passos do procedimento para analisar estatisticamente experiências
factoriais a dois níveis são: 1) Estimar os efeitos dos factores (examinar a “direcção” e a magnitude
dos efeitos); 2) Formular o modelo inicial (integrar os factores num modelo matemático); 3) Testar
a significância do modelo e respectivos coeficientes (através da análise de variância e técnicas
associadas); 4) Aperfeiçoar, “refinar”, o modelo (removendo ou adicionando variáveis); 5) Analisar
os resíduos (para diagnosticar a validade dos pressupostos); e 6) Interpretar os resultados (que é
mais fácil com base na análise gráfica dos resultados).
Bibliografia 30
Box, G.E.P., Hunter, W.G. & Hunter, J.S. (1978). Statistics for Experiments. John Wiley & Sons.
Cabral, J.A.S. & Guimarães, R.C. (1997). Estatística (Edição revista). McGrawHill.
Fonseca, J. (2001) Estatística Matemática. Volumes 1 e 2. Edições Sílabo Lda., Lisboa.
Graybill, F.A. & Iyer, H.K. (1994). Regression Analysis – Concepts and applications. Duxbury
Press.
Hu, R. (1999) Food product design. A computer-aided statistical approach. Technomic Publishing
Company Inc., Lancaster.
Neter, J., Wasserman, W. & Whitmore, G.A. (1988) Applied Statistics. 3rd Edition, Allyn and
Bacon Inc., Boston.
Reis, E.; Melo, P; Andrade, R. & T. Calapez (1999) Estatística aplicada. Volumes I e II. Edições
Sílabo Lda., Lisboa.
Rohlf, F.J. & Sokal, R. (1995). Biometry. W.H. Freeman and company, San Francisco.
Wadsworth, H.M (1990) Handbook of statistical methods for engineers and scientists. McGraw-
Hill Publishing Company, NY.
30 Disponível na biblioteca da EST (Campus da Penha). Ver http://w3.ualg.pt/~eesteves/ para sítios electrónicos com interesse.