Embed Size (px)
Citation preview

Universidade
Estadual de
Londrina
Programa de Mestrado e Doutorado em Ciência Biológicas
Resumo das atividades desenvolvidas em aula
Profa. Dra. Ana Verginia Libos Messetti
LONDRINA
2016

SUMÁRIO
1. Análise exploratória de dados ...........................................................................01
2. Intervalo de confiança e Teste de
Hipótese
...........................................................................13
3. Testes de Hipóteses para duas amostras ...........................................................................16
4. Testes não paramétricos
5. Correlação e regressão
6. Ensaio Inteiramente Casualizado
7. Delineamento em Blocos
8. Ánálise multivariada I
9. Análise multivariada II
10. Referências bibliográficas
.......................................................................... 18
.......................................................................... 22
.......................................................................... 27
.......................................................................... 31
.......................................................................... 34
.......................................................................... 35
...........................................................................39

1
1 – ANÁLISE EXPLORATÓRIA DE DADOS
1.1 Introdução - Em uma pesquisa é importante ter em mente três aspectos: planejamento, execução e
divulgação. O planejamento é a fase inicial que corresponde à definição do tema, os objetivos, a forma de
análise dos dados, ou seja, é o delineamento de todo o projeto de pesquisa. É a fase mais importante dentre
as três fases para se obter um resultado mais preciso.
É importante evidenciar que executarmos uma pesquisa com um planejamento mal feito ou
mesmo se os dados não forem coletados de maneira apropriada, aparecerá um resultado que não
corresponde à realidade ou até mesmo impossível de ser analisada e então esses dados se tornarão inúteis.
Quanto maior tempo gasto no planejamento menor serão os problemas que surgirão na sua execução.
Dependendo do problema a ser analisado e dos objetivos da pesquisa podemos realizar uma pesquisa
observacional ou uma pesquisa experimental:
A pesquisa observacional é aquela em que as características de uma população serão levantadas,
observadas ou medidas, sem a sua manipulação. Como exemplo, tem-se o censo demográfico, pesquisas
eleitorais, inspeção de qualidade.
Nas pesquisas experimentais, grupos de indivíduo, animais ou objetos, serão manipulados para se
avaliar o efeito de diferentes tratamentos. É o caso de se verificar as reações na aplicação de
medicamentos onde existe um grupo controle e o grupo experimental.
A coleta de dados pode ser obtida de várias maneiras. Em alguns casos não se precisa ir até a
população para a obtenção dos dados porque eles já existem em arquivos ou banco de dados e são
chamados dados secundários. Nesta fase da pesquisa, é bom verificar os trabalhos existentes sobre o tema
a ser estudado, pois dados secundários podem reduzir os custos de uma pesquisa.
Dados primários são aqueles em que foram obtidos junto à população ou amostra, mediante um
instrumento, para que sua coleta seja feita de forma organizada.
1.2 Definição e Classificação da Estatística:
Desde a Antigüidade, vários povos já registravam o número de habitantes, de nascimentos, de
óbitos, faziam estimativas das riquezas individual e social, distribuíam eqüitativamente terras ao povo,
cobravam impostos e até realizavam inquéritos quantitativos por processos que, hoje, chamaríamos de
“estatística”. A palavra “estatística” vem do latim e significa o estudo do Estado, pois antigamente se
referia a fatos ou dados coletados por agências ou órgãos governamentais. Mais recentemente se passou a
falar em estatística em várias ciências, tais como Saúde Pública, Antropologia, Meteorologia, Medicina e
outras.
Hoje em dia a estatística envolve toda a elaboração que vai desde o planejamento e a coleta dos dados até
a análise e interpretação dos resultados. Assim, essa elaboração envolve o tratamento dos dados de
diferentes maneiras de torná-los compreensíveis. Para tanto constroem tabelas, gráficos, calculam-se
porcentagens, médias, e outros.
Definição: Estatística é uma parte da matemática aplicada que fornece métodos para coleta, a organização,
a descrição, a análise e a interpretação de dados e a utilização desses dados para a tomada de decisão.
Classificação:
- Estatística descritiva;
- Estatística indutiva.
a. Estatística descritiva: é aquela que tem por objetivo descrever e analisar determinada população ou
amostra, sem pretender tirar conclusões.
Exemplo: taxa de desemprego, índice de mortalidade e natalidade.

2
b. Estatística indutiva: é aquela que consiste em obter e generalizar conclusões para um todo (população)
partindo de resultados particulares (amostra).
Exemplo: pesquisa eleitoral.
1.3 Classificação das Variáveis
Ao fazer um estudo estatístico de um determinado fato ou grupo, tem-se que considerar o tipo de variável.
Pode-se ter variáveis qualitativas e variáveis quantitativas.
As variáveis qualitativas são aquelas que descrevem os atributos de um indivíduo, por exemplo:
sexo, estado civil, grau de instrução, etc. Já as variáveis quantitativas são as provenientes de uma
contagem de mensuração, por exemplo: idade, salário, peso, altura, etc.
As variáveis qualitativas como as quantitativas dividem-se em dois tipos:
Variáveis Tipos Descrição Exemplos
Qualitativas
ou
Categóricas
Nominal Não existe nenhuma
ordenação.
Cor dos olhos, sexo, estado
civil.
Ordinal Existe uma ordenação I, II,
III.
Nível de escolaridade,
estágio da doença.
Quantitativas
Discretas Valor pertence a um
conjunto enumerável.
Número de filhos por casal,
número de eleitores.
Contínuas Quando o valor pertence a
um intervalo real.
Medida de altura e peso,
taxa de glicose.
1.4 População e amostra
População ou Universo: é um conjunto de elementos sobre o qual desejamos pesquisar.
Exemplo: Alunos do curso de Fisioterapia da UEL, número de microrganismos de um lago.
Amostra: e um subconjunto da população, cujos elementos são retirados segundo algum critério.
Exemplo: Alunos do primeiro ano de Fisioterapia da UEL.
Censo e Amostragem
Censo: é o estudo de “todos” os elementos da população.
Exemplo: Altura de todos os alunos de Biologia da UEL
Amostragem: é a parte da estatística que ensina obter amostras representativas de uma população. A
finalidade da amostragem é fazer generalização sobre todo o grupo sem precisar examinar cada um de
seus elementos.
Quando se deseja colher informações sobre um ou mais aspectos de um grupo grande ou
numeroso, verifica-se, muitas vezes, ser praticamente impossível fazer um levantamento do todo. Desse
modo, há a necessidade de investigar apenas uma parte dessa população ou universo.
É compreensível que o estudo de todos os elementos da população possibilita preciso
conhecimento das variáveis que estão sendo pesquisadas; todavia, nem sempre é possível obter as
informações de todos os elementos da população. Torna-se claro que a representatividade da amostra
dependerá do seu tamanho (quanto maior, melhor) e de outras considerações de ordem metodológica. Isto
é, o investigador procurará acercar-se de cuidados, visando à obtenção de uma amostra significativa, ou
seja, que de fato represente “o melhor possível” toda a população.

3
1.5 Conceitos Básicos
Parâmetros - Medidas que descrevem certa característica dos elementos da população.
Estatística - Medidas que descrevem certa característica dos elementos da amostra.
Estimativa – Valor resultante do cálculo de uma estatística.
1.6 Medidas Descritivas - (Comparando População e Amostra)
Média, Variância e Desvio-padrão para valores populacionais e amostrais
Seja a população: P = {X1; X2; X3; ...; XN}, logo:
a) A média aritmética populacional ( ) é: N
xi
N
i 1
onde i=1, 2, ..., N.
A variância populacional (2 ) é:
N
XX
XVouN
N
X
X
XV
N
i
i
N
i
iN
i
i
1
2
2
2
1
1
2
2
)(
)()(
Desvio-padrão populacional ( ) é: = )X(V
i
Seja a amostra: A = {x1; x2; x3; ...; xn}, logo:
A média aritmética amostral ( mx ˆ ) é: n
x
mx
n
i
i 1ˆ
,onde i = 1, 2, ..., n.
A variância amostral (s2) é:
1
)(
1
1
2
2
2
1
1
2
2
n
xx
soun
n
x
x
s
n
i
i
n
i
in
i
i
Desvio-padrão amostral (s) é: s = 2s

4
ESTATÍSTICA DESCRITIVA
1.7 - Tabelas - A apresentação tabular é a forma de se utilizar tabelas para apresentar os dados coletados,
com o objetivo de sintetizar as observações, facilitando sua leitura e compreensão. Refere-se,
conforme seu conteúdo, codificação, processamento, especificações técnicas, conversão de unidades,
descrição de fluxos e apresentação de símbolos.
Elementos componentes das tabelas estatísticas
As tabelas estatísticas são constituídas por elementos essenciais e elementos complementares.
Elementos essenciais da tabela - Os elementos essenciais de uma tabela estatística são: título, corpo,
cabeçalho e coluna indicadora.
Título: O título é a indicação que precede a tabela e que contém a designação do fato observado, o local e
a época em foi registrado.
Corpo: É o conjunto de colunas e linhas que contém, respectivamente, em ordem vertical e horizontal, as
informações referente ao fato observado.
Cabeçalho: É a parte superior da tabela que especifica o conteúdo das colunas.
Coluna indicadora: É a parte da tabela que especifica o conteúdo das linhas. Uma tabela pode ter mais de
uma coluna indicadora.
Elementos complementares da tabela - Os elementos complementares de uma tabela estatística são: fonte,
nota e chamadas, e se situam no rodapé da tabela.
Fonte: A fonte é a indicação da entidade responsável pelo fornecimento dos dados ou pela sua elaboração.
Notas: São as informações de natureza geral, destinadas a conceituar ou esclarecer o conteúdo das tabelas,
ou a indicar a metodologia adotada no levantamento ou na elaboração dos dados.
Chamadas: São as informações de natureza específica referentes às determinadas partes da tabela,
destinadas a conceituar ou esclarecer dados. As chamadas são indicadas no corpo da tabela com
algarismos arábicos, entre parênteses.
Apresentação de tabelas
As tabelas, excluídos os títulos, serão fechadas, no alto e em baixo, por traços horizontais grossos;
Recomenda-se não fechar as tabelas, à direita e à esquerda, por traços verticais;
Será facultativo o emprego de traços verticais para a separação das colunas no corpo da tabela;
Quando uma tabela, por excessiva altura, tiver que ocupar mais de uma página, não será fechado
na parte inferior, repetindo-se o cabeçalho na página seguinte, usando, no alto do cabeçalho ou a
direita da coluna indicadora, a designação continua ou conclusão, conforme o caso.
1.8 Gráficos (Variável qualitativa) - É a representação de dados ou informações através de desenhos,
figuras ou imagens.
Existem diversas formas de apresentação gráfica, ficando a escolha condicionada à natureza do
fenômeno a representar e ao critério do analista. Dar-se-á um maior enfoque àquelas formas gráficas
utilizadas na representação de dados estatísticos. A finalidade principal de apresentar os dados
graficamente é proporcionar ao interessado uma visão rápida do comportamento do fenômeno, poupando
tempo e esforço na compreensão dos dados. A representação gráfica de um fenômeno deve obedecer a
certos requisitos fundamentais como: simplicidade, clareza e veracidade.
Alguns tipos de gráficos

5
Gráficos de colunas: São aqueles em que as variações quantitativas de uma ou mais variáveis são
representadas por colunas sucessivas, todas com bases iguais, mas com diferentes alturas, as quais são
proporcionais às freqüências das variáveis confrontadas, dispostos verticalmente.
Gráficos de barras - São semelhantes ao de colunas, onde os retângulos são dispostos horizontalmente.
Gráficos em linhas - Este gráfico representa alterações quantitativas sob a forma de uma linha oligonal
ou curva estatística, que torna mais visível o andamento do fenômeno.
Gráficos em setores - São gráficos que descrevem o fato através de setores em uma circunferência, cuja
finalidade é representar um fato juntamente com todas as partes que o mesmo se subdivide.
Gráficos de colunas múltiplas - São gráficos que permitem comparar diversas variáveis simultaneamente.
Caracteriza-se por apresentar duas ou três colunas representativas de variáveis num mesmo período de
tempo, sem espaço entre si, formando conjuntos de colunas, existindo espaço entre os conjuntos. O
objetivo é fazer comparação.
DISTRIBUIÇÃO DE FREQÜÊNCIAS
1.9 Distribuição de frequência: Distribuição de frequência constitui-se, portanto, nas repetições agrupadas
dos valores da variável. Visa facilitar o trabalho estatístico permitindo melhor compreensão dos
fenômenos. Quando se trabalha com poucos valores, os cálculos podem ser realizados diretamente, sem
maiores dificuldades.
Para se resumir grandes resultados de dados, costumam-se freqüentemente distribuí-los em classes ou
categorias, e determinar o número pertencente a cada uma das classes, denominando a freqüência da
classe (fi).
Dados brutos: é o conjunto de dados numéricos apresentados da maneira que foram coletados.
Rol: é o arranjo dos dados brutos em ordem crescente ou decrescente.
Amplitude total (At): é a diferença entre o maior e o menor valor observado.
At = Xmax – Xmin
Número de classes (K): é a quantidade de classes necessárias para representar os dados.
Regra de Sturges : k = 1 + 3,3 log n, n é o tamanho da amostra
636 nk exemplo se n = 36 for o tamanho da amostra.
Amplitude das classes (ac): é o quociente entre a amplitude total (At) e o número de classes (k), isto é:
ac = At / k
Limites das classes: Li |---- Ls, Li é o limite inferior e o elemento pertence à classe.
Ls é o limite superior e o elemento não pertence à classe.
* Pontos médios das classes (Xi): é a média entre o limite superior e o limite inferior da classe.
xi = (Ls + Li)/2
* Freqüência acumulada crescente (Fac) ou “abaixo de”: é a soma das freqüências dos valores inferiores
ou igual ao valor dado, isto é;
Fac = fi
* Freqüência relativa (fri): é a porcentagem do valor na amostra e é dado por:
fri = fi /n; fr (%) = (fi /n)100

6
Gráficos - Gráfico Estatístico: é uma forma de apresentação dos dados estatísticos, cujo objetivo é o de
produzir, no investigador ou no público em geral, uma impressão mais rápida e viva do fenômeno em
estudo.
Representação Gráfica de uma Distribuição de Freqüência: Uma distribuição de freqüência pode ser
representada graficamente pelo histograma, pelo polígono de frequência.
Histograma: é a representação gráfica de uma distribuição de freqüência por meio de retângulos
justapostos.
Outros Gráficos para variáveis quantitativas
Ramos e folhas O ramo são formados pelos inteiros dos números e as folhas são formados pelos decimais.
Box plot – Gráfico de caixa formado por 5 números: Valor mínimo, primeiro quartil, mediana, terceiro
quartil e valor máximo.
MEDIDAS DESCRITIVAS: Medidas de posição
Introdução: As medidas de posição são denominadas de medidas de tendência central, pois
representam os fenômenos pelos seus valores médios em torno dos quais tendem a concentrarem-se os
dados.
1.10 Medidas de posição: Média aritmética; Moda; Mediana
Média Aritmética - A média aritmética de uma amostra é o conjunto de n valores x1, x2, ..., xn
representado por x é definido por: n
x
n
xxxx
n
in
121
Mediana (Med) - È o valor que divide a amostra ou população em duas partes iguais.
0% 50% 100%
Med
A mediana é o valor que ocupa a posição central da amostra ordenada (crescente ou decrescente). Isto é,
divide a amostra em duas partes iguais de modo que 50% dos valores ficam à sua esquerda e 50% à sua
direita.
Ou A ordem da mediana, indicada pela letra O, será:
a) Se n for ímpar:
2
1nO e Md = X (o)
Exemplo: X = {3 5 5 6 7}; Md = 5.
b) Se n for par, calculam-se duas ordens: 122
21
nOe
nO e Md = [X(O1) + X(O2) ] / 2.
Exemplo: Y={ 3 5 5 6 7 7}; Md = (5 + 6)/2 = 5.5

7
Moda (MO) - Denominamos Moda o valor que ocorre com maior freqüência em uma série de valores.
A moda é classificada da seguinte maneira:
Amodal: quando os dados não apresentam moda;
Modal: apresenta uma moda;
Bimodal: quando os dados apresentam duas modas;
Multimodal: quando os dados apresentam mais de duas modas.
A moda comparada com a média e a mediana, é a menos útil das medidas para representar os dados. A
moda é útil quando um ou dois valores, ou um grupo de valores, ocorrem com freqüência muito maior que
os outros valores.
1.11 Separatrizes - Como vimos, a mediana caracteriza uma série de valores devido a sua posição central.
Porém, ela apresenta uma característica, tão importante quanto à primeira: é que ela separa a série em dois
grupos que apresentam o mesmo número de valores.
Assim, além das medidas de posição que estudamos, há outras que, consideradas individualmente,
não são medidas de tendência central, mas estão ligadas à mediana relativamente à sua Segunda
característica, já que elas se baseiam em sua posição na série. Essas medidas são chamadas de Quartis,
Decis e Percentis que são juntamente com a Mediana, conhecidas pelo nome genérico de Separatrizes.
Quartis Denominamos Quartis os valores de uma série que a dividem em quatro partes iguais.
Q1 = 10 quartil, deixa 25% dos elementos;
Q2 = 20 quartil, coencide com a mediana,deixa 50% dos elementos;
Q3 = 30 quartil, deixa 75% dos elementos;
Decis- Denominamos Decis os valores de uma série que a dividem em 10 partes iguais.
Percentis -Denominamos Percentis os valores de uma série que a dividem em 100 partes iguais.
Forma resumida: Quartis, Decis e Percentis para dados não agrupados.
Para n ímpar - A ordem do quartil “i” (i=1, 2 ou 3) é dada por 4
)1.( ni e o valor é localizado no rol.
Para n par - O quartil será a média dos dois elementos de ordens: 4
.ni e 1
4
.
ni.
Para n ímpar - A ordem do decil “i”( i= 1, 2, ....,9) é dada por 10
)1.( ni e o valor é localizado no rol .
Para n par - O decil será a média dos dois elementos de ordens: 10
.ni e 1
10
.
ni.
Para n ímpar- A ordem do percentil “i”( i= 1, 2, ....,99) é dada por 100
)1.( ni e o valor é localizado no rol.
Para n par- O percentil será a média dos dois elementos de ordens: 100
.ni e 1
100
.
ni.
MEDIDAS DESCRITIVAS – Medidas de Variabilidade
0% 25% 50% 75% 100%
Q1 Q2 Q3

8
Introdução: A sumarização de um conjunto de dados, através de uma única medida representativa
de posição central, esconde toda a informação sobre a variabilidade do conjunto de valores.
1.12 Medidas de variabilidade.
Amplitude Total At = Xmax – Xmin
Variância: Considerando o nosso propósito de medir a dispersão dos valores em torno da média, é
interessante estudarmos o comportamento dos desvios de cada valor em relação à média, isto é,
xxi . Observem que, na determinação de cada desvio xxd
ii , estaremos medindo a dispersão
entre cada xi e a média x . Porém, se somarmos todos os desvios, tem-se
n
1ii
0d ou
n
1ii
0)xx( . Para contornar o problema, resolveu-se considerar o quadrado de cada desvio
2
i)xx( , evitando-se com isso que
n
1ii
0d . Assim, definiu-se a variância (populacional) como:
N
d
N
)xx(
N
N
)x(x
N
1i
2
i
N
1i
2
i
2N
iiiN
1i
2
i2
, se os dados não são agrupados.
Para a variância “amostral”, tem-se:
1n
d
1n
)xx(
1n
n
)x(
x
s
N
1i
2
i
N
1i
2
i
2N
iiiN
1i
2
i2
, se os dados não são agrupados e
Desvio-padrão: 2 , para população e
2ss , para a amostra.
Coeficiente de Variação - Trata-se de uma medida relativa da dispersão, útil para a comparação em termos
relativos do grau de concentração em torno da média de conjuntos de dados distintos. É dado por:
%100...
VC população e %100...
x
sVC amostra.
Alguns analistas consideram:
C.V. < 15% Baixa dispersão e alta representatividade da média aritmética
%30.V.C%15 Média dispersão e média representatividade da média aritmética
%30.V.C Alta dispersão e nenhuma representatividade da média aritmética

9
MEDIDAS DE ASSIMETRIA E CURTOSE
1.13 Assimetria - Definição - Assimetria é o grau de afastamento de uma distribuição em relação ao eixo
simétrico.Uma distribuição pode ser: simétrica; assimétrica positiva ou à direita; assimétrica negativa ou à
esquerda.
Comparação entre as medidas de posição
a- Em uma distribuição simétrica, a média, a mediana e a moda são iguais, isto é,
x = Med = Mo
b- Em uma distribuição assimétrica positiva ou assimétrica à direita, a média é maior que a mediana,
e esta por sua vez, é maior que a moda, isto é,
Mo < Med < x .
c- Em uma distribuição assimétrica negativa ou assimétrica à esquerda, a média é menor que a
mediana, e esta por sua vez, é menor que a moda, isto é, x < Med < Mo.
Coeficiente de assimetria de Pearson - O coeficiente de assimetria de Pearson pode ser determinado
através das seguintes equações: 10 coeficiente de Pearson
s
MedxAs
)(3
s
MoxAs
)(
Obs.: Se As = 0 a distribuição é simétrica
As > 0 a distribuição é assimétrica positiva (à direita)
As < 0 a distribuição é assimétrica negativa (à esquerda).
1.14 Curtose Definição - Curtose é o grau de achatamento de uma distribuição em relação a uma distribuição padrão,
denominada curva normal.
Uma distribuição que não é nem chata e nem delgada é denominada de mesocúrtica. A curva normal, por
exemplo, que é a nossa base referencial, recebe o nome de mesocúrtica. Quando a distribuição apresenta
uma curva de frequência mais fechada que a normal (ou mais aguda em sua parte superior) ela recebe o
nome de leptocúrtica. Quando a distribuição apresenta uma curva de frequência mais aberta que a normal
(ou mais achatada na sua parte superior), ela é chamada de platicúrtica.
Coeficiente de Curtose - Para medir o grau de Curtose pode-se utilizar a seguinte equação;
)PP(
QQC
1090
13
2
onde: P10 e P90 é o décimo e o nonagésimo percentil, respectivamente, Assim:
C = 0,263 curva mesocúrtica
C < 0,263 curva leptocúrtica
C > 0,263 curva platicúrtica
ALICAÇÕES DAS MEDIDAS DESCRITIVAS
GRÁFICO BOX-PLOT - Gráfico Box-Plot – O box - plot mais simples tem base no resumo dos 5
números. (Mínimo, Primeiro quartil, Mediana, Terceiro quartil e Máximo). A distribuição terá outlier se
verificar valores acima (ou abaixo) de 1,5 dq; e outlier extremo se verificar valores acima (ou abaixo 3 dq)
Amplitude Interquartil dq= Q3 – Q1.
Exemplo - os dados abaixo são referentes ao peso de carne de mexilhões, em miligramas,
Pede-se, construir o gráfico box-plot e verificar se há outliers.
PM- [2710, 2755, 2850, 2880, 2880, 2890, 2920, 2940, 2950, 3050, 3130, 3325]
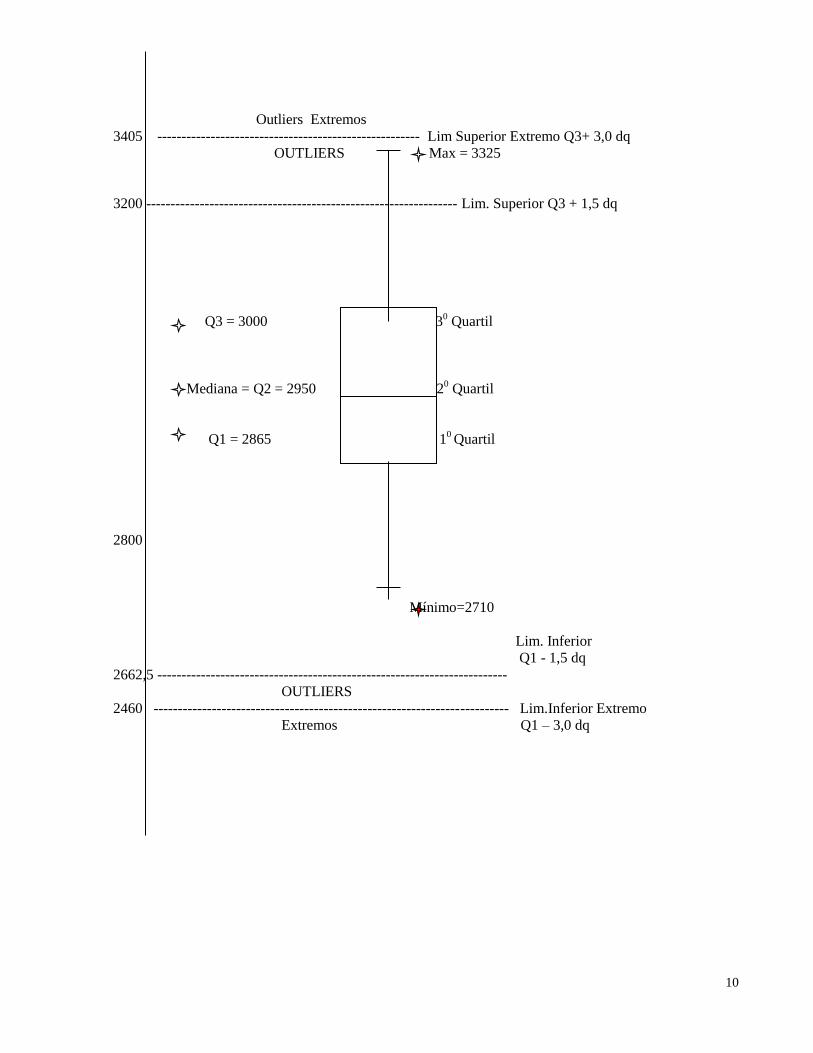
10
Outliers Extremos
3405 ------------------------------------------------------ Lim Superior Extremo Q3+ 3,0 dq
OUTLIERS Max = 3325
3200 ---------------------------------------------------------------- Lim. Superior Q3 + 1,5 dq
Q3 = 3000 30 Quartil
Mediana = Q2 = 2950 20 Quartil
Q1 = 2865 10 Quartil
2800
Mínimo=2710
Lim. Inferior
Q1 - 1,5 dq
2662,5 ------------------------------------------------------------------------
OUTLIERS
2460 ------------------------------------------------------------------------- Lim.Inferior Extremo
Extremos Q1 – 3,0 dq

11
2 - INTERVALO DE CONFIANÇA E TESTE DE HIPÓTESES
Introdução - Trata-se de uma técnica para se fazer inferência estatística, ou seja, a partir de um intervalo
de confiança, construído com os elementos amostrais, pode-se inferir sobre um parâmetro populacional.
A construção de intervalos de confiança fundamenta-se nas distribuições amostrais. Se a partir de
uma amostra procura-se obter um Intervalo de Confiança 21
ˆˆ 1-α com uma certa
probabilidade de conter o verdadeiro parâmetro populacional.
Quando se diz que o Intervalo de Confiança contém o verdadeiro parâmetro populacional com
uma probabilidade 1 - (nível de confiança), será o nível de significância, ou seja, o erro que está se
cometendo ao afirmar-se que, por exemplo, 95% das vezes o intervalo 1ˆˆ21 contém ,
é de 5%.
Esta técnica diferencia-se da estimação “por ponto” onde se calcula um único valor (estimativa)
para o parâmetro populacional.
2.1 Intervalo de Confiança para Proporção ou Probabilidade P
Quando n > 30. Vimos que, P ~ N (p; pq/n), logo .
n
)p1(p
PpZ
^^
^
Portanto, o intervalo para um
nível será: Então:
1Z
n
)p1(p
PpZP1ZZZP
2^^
^
222
Para obter o intervalo acima é necessário o valor de “p” que é desconhecido. Como estamos
admitindo n > 30 pode-se substituir e encontrar:
1n
)p1(pZp P
n
)p1(pZpP
^^
2
^^^
2
^
resumindo:
IC (P, 1-α ) = [^
p n
)p1(pz
^^
2
]
2.2 Intervalo de Confiança para média populacional (Conhece variância populacional)
Neste caso, não precisa calcular a estimativa da variância a partir da amostra. Trabalha-se então
com a distribuição “z”, isto é:
P [ z
n
xz
] = 1- ;
1]
n.zx
n.zx[P
22
;
IC ( , 1-alfa) = [ x n
z2
]

12
2.3 Intervalo de Confiança para a Média Populacional (Não conhece variância populacional) Neste caso, precisa-se calcular a estimativa da variância a partir da amostra. Trabalha-se então
com a distribuição “t” de Student, com n – 1 graus de liberdade, isto é:
n
s
xt
, com (- t + ); portanto: 1]
n
s.tx
n
s.tx[P
22
Valor do teste t tabelado: 2;1(
2
nt
) logo Resumindo ]n
s.tx[),(IC
2
TESTES DE HIPÓTESES PARA UMA AMOSTRA
Decisões Estatísticas - Na prática somos chamados com muita freqüência a tomar decisões acerca de
populações, baseados nas informações das amostras. Essas decisões são denominadas decisões
estatísticas. Pode-se desejar decidir, com base em dados amostrais, se um novo soro é realmente eficaz na
cura de uma doença, se um processo educacional é melhor do que outro, se uma certa moeda é viciada e
outras.
Hipótese Estatística - A Hipótese Estatística é uma suposição ou afirmação relativa a uma ou mais
populações, que pode ser verdadeira ou falsa.
Testes de Hipótese - Consiste em decidir se a hipótese é verdadeira ou falsa. Assim, através de uma
amostra testaremos a hipótese formulada e concluiremos se ela deve ser rejeitada ou aceita.
As Hipóteses A hipótese lançada para ser rejeitada ou aceita é chamada de hipótese nula, denotada por
Ho. A rejeição de Ho leva a aceitação de uma hipótese alternativa, representada por H1.
Erros do Tipo I e II - Se uma hipótese for rejeitada quando deveriam ser aceita, diz-se que foi cometido
um erro do Tipo I. se, por outro lado, for aceita uma hipótese que deveria ser rejeitada, diz-se que foi
cometido um erro Tipo II. Em ambos os casos ocorreram uma decisão errada ou um erro de julgamento.
Nível de Significância - Ao testar uma hipótese estabelecida, a probabilidade máxima com a qual
estaremos dispostos a correr o risco de um erro Tipo I é denominada nível de significância do teste. Essa
probabilidade, representada freqüentemente por , é geralmente especificada antes da extração de
quaisquer amostras, de modo que os resultados obtidos não influenciem a escolha. Se, por exemplo, é
escolhido um nível de significância 5%, no planejamento de um teste de hipótese, há então cerca de 5
chances em 100, da hipótese ser rejeitada, quando deveria ser aceita, isto é, há uma confiança de cerca de
95% de que se tome uma decisão acertada.
Tipos de Testes de Hipóteses
2.4 Teste para a Média (conhece 2 )
0 (a)
(1a) Formulação das hipóteses
Ho: = 0 vs H1:
2a) Nível de significância - Normalmente adota-se um valor de entre 1% a 10%.
Estabelecer os valores críticos – Tabela Normal padrão
> 0 (b)
< 0 (c)
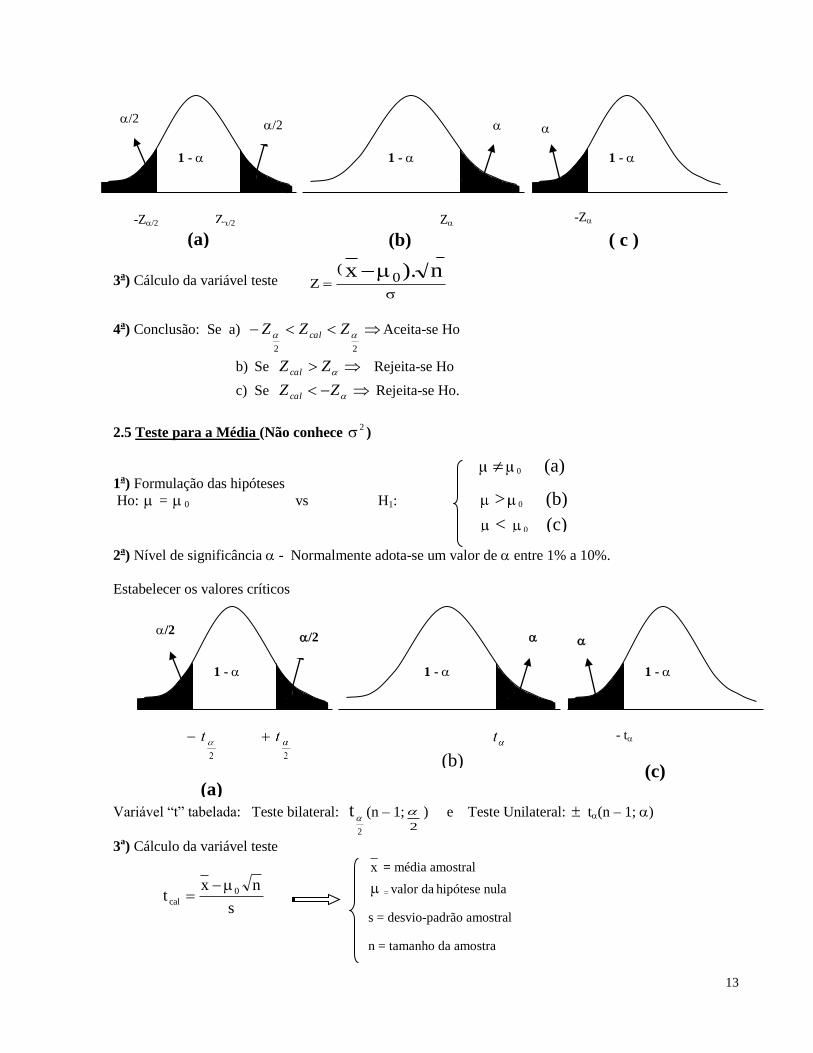
13
3a) Cálculo da variável teste
n).x 0(
Z
4a) Conclusão: Se a)
22
ZZZ cal Aceita-se Ho
b) Se ZZ cal Rejeita-se Ho
c) Se ZZ cal Rejeita-se Ho.
2.5 Teste para a Média (Não conhece 2 )
1a) Formulação das hipóteses
Ho: = 0 vs H1:
2a) Nível de significância - Normalmente adota-se um valor de entre 1% a 10%.
Estabelecer os valores críticos
Variável “t” tabelada: Teste bilateral:
2
t
(n – 1;2
) e Teste Unilateral: t(n – 1; )
3a) Cálculo da variável teste
s
nxt 0
cal
0 (a)
> 0 (b)
< 0 (c)
1 -
(b)
1 -
/2
/2
1 -
- t
(a) (c)
= média amostral
= valor da hipótese nula
s = desvio-padrão amostral
n = tamanho da amostra
1 -
Z
1 -
/2
/2
1 -
-Z/2 Z/2 -Z
(a) (b) ( c )

14
4a) Conclusão: a) Se
22
ttt cal Aceita-se Ho
b) Se ttcal Rejeita-se Ho
c) Se ttcal Rejeita-se Ho.
Abordagem p-valor (ou probabilidade de significância): é a informação sobre a força da evidência
contra Ho obtida a partir dos dados. Isto é, é informado se o valor observado para a estatística de teste que levou à rejeição de Ho está próxima da fronteira da região crítica (RC) (baixa evidência contra H0) ou se está muito afastada da fronteira (alta evidência contra Ho).
Regra: Na prática ficamos com a situação 2, rejeita-se H0 quando o p-valor é menor que o nível de
significância, que representa a probabilidade de rejeição indevida da hipótese nula.
Regra habitual: P > , não rejeita-se H0
P ≤ , rejeita-se H0.
3 -TESTES DE HIPÓTESES PARA DUAS AMOSTRAS
Comparação de 2 médias – Caso com 2 amostras
3.1 Teste t para duas amostras independentes - (Variâncias iguais)
A formação de pares de elementos similares nem sempre é viável. Uma alternativa é considerar
duas amostras independentes. O teste para duas amostras independentes, oriundas de 2 populações com
distribuição normal, com médias ( 21 ) e com variâncias (2
2
2
1 e ) desconhecidas e iguais.
Suposição básica: As observações são independentes;
Os dois grupos provêm de distribuições normais;
Os dois grupos possuem a mesma variância.
1a Hipóteses : H0: 21 vs H1: 21 ; H1: 21 ou H1: 21
2a Nível de significância
Valores críticos: bilateral t(n1+ n2 -2; 2
) e unilateral t (n1 +n2 -2 ; )
3a Variável teste t =
)(
21
21
)(
xxs
xx
onde o estimador do desvio padrão da diferença entre as médias
amostrais é dada:
2121
2
22
2
11
)21(
11
2
)1()1(
nnnn
SnSnS
xx
n1: número observado na amostra 1; n2: número observado na amostra2 2
2
2
1 SeS as variâncias amostrais.
4a Conclusão: A hipótese nula (H0 = 21 ) é rejeitada quando tcalc, o valor da estatística t, em valor
absoluto, é maior do que o valor crítico t(n1 + n2 – 2; ), obtido da tabela da distribuição t de Student
com nível de significância .

15
3.2 Teste t para duas amostras pareadas - O teste t é apropriado para comparar 2 conjuntos de dados
quantitativos, em termos de seus valores médios.
1a Hipóteses : H0: 21 vs H1: 21 ; H1: 21 ou H1: 21
H0: 0D vs H1: 0:H0:H;0 11 DDD
1 - valor esperado da resposta do tratamento 1
2 - valor esperado da resposta do tratamento 2
2a Nível de significância - Valores críticos: bilateral t (n-1;
2
) e unilateral t (n-1; )
3a Variável teste tcalc =
ds
nd onde n: tamanho da amostra;
d : média das diferenças e sd: desvio padrão das diferenças.
4a Conclusão: Região crítica para teste bilateral: RC = {t ϵ R| tcalc <
2
t ou tcalc >+
2
t }.
Região crítica para teste unilateral: RC = {t ϵ R| calct > t }
3.3.Teste F para comparação de duas variâncias populacionais - Comparação de 2 variâncias
Suponha que queremos comparar duas populações, supostamente com distribuições normais, têm
a mesma variância. Formulam-se as hipóteses:
1a Ho:
2
2
2
1 vs H1: 2
2
2
1 (teste bilateral) ou H1: 2
2
2
1
2
2
2
1 :H1 ; (teste unilateral)
onde :2
1 variância da população 1
2populaçãodaiânciavar:2
2 .
20 Nível de significância
Região crítica: Bilateral: Fsup(gl1= n1 -1; gl2= n2 -1; 2
) e
Finf (gl1= n1 -1; gl2= n2 -1;1-2
) = Finf =
)1;2(
1
)2
(glglF
Unilateral: F inf [(1- ) (gl1; gl2)] ou Fsup [ (gl1; gl2)]
30 Estatística teste: f =
2
2
2
1
s
s onde si
2 são as variâncias na condição
2
1s > 2
2s .
40 Conclusão: Rejeita-se Ho: Para teste unilateral à esq: fcalc < F(1- ) (gl1; gl2) e Unil.dir: fcalc > F (gl1; gl2)
Para teste bilateral, fcalc < F(1-
2
) (gl1; gl2) e fcalc > F2
(gl1; gl2)

16
4 – ESTATÍSTICA NÃO PARAMÉTRICA
Nas pesquisas científicas vimos que são muitos usados o teste t de Student, a análise de variância,
o teste de Tukey, a regressão linear, etc.Tais testes exigem, para sua aplicação que a variável em análise
seja numérica e as hipóteses sejam feitas sobre os parâmetros, daí o nome: testes paramétricos. Mas, os
testes paramétricos têm ainda outras exigências.
Os testes paramétricos exigem que os dados tenham uma distribuição normal ou aproximadamente
normal, que seja simétrica, além da pressuposição de homogeneidade de variâncias (homocedasticidade),
O problema existe quando estas exigências não são satisfeitas e as amostras são pequenas. Os
testes não paramétricos são menos exigentes não exigindo normalidade dos dados. Pode-se trabalhar com
variáveis não numéricas, assim como, pode-se trabalhar com os postos ocupados pelas variáveis ou com
suas frequências.
Todos esses aspectos devem ser levados em conta quanto à determinação da prova “ótima” ou
mais adequada para analisar determinado conjunto de dados de pesquisa.
Analisados os aspectos levantados anteriormente fazemos a opção pela aplicação de testes
paramétricos (mais fortes e robustos) ou testes não paramétrico quando certas condições não são
satisfeitas tais como:
As observações não serem independentes
As observações forem extraídas de populações que não possuem uma aproximação com a
distribuição normal.
As populações não possuem variâncias semelhantes (homocedasticidade) e não
apresentam uma relação conhecida entre elas.
As variáveis em estudo não apresentam medidas intervalar de modo a não possibilitar o
emprego de estatísticas como o cálculo de médias e de desvios (parâmetros).
TESTES NÃO PARAMÉTRICOS-CASOS DE DUAS AMOSTRAS INDEPENDENTES
4.1 Teste Qui-quadrado
O teste 2 serve para testar a hipótese de que duas variáveis categóricas independentes ou, o que
matematicamente é o mesmo, testar a hipótese de que duas probabilidades são iguais. Atenção nas
exigências:
1. Independência dos grupos em comparação: os dois grupos em comparação devem ser
independentes como, por exemplo, um grupo controle e outro experimental, ou um grupo é
constituído por portadores de uma doença e outro por não-portadores.
2. Tamanho da amostra: a amostra deve ser de tamanho igual ou maior do que 20. Se a
amostra for menor que 40, as freqüências esperadas devem ser maiores que 5.
ETAPAS
1a Elaboração das hipóteses estatísticas
H0: As variáveis são independentes
H1: As variáveis não são independentes, ou seja, as variáveis apresentam algum
grau de associação entre si.
2a Estabelecer o nível de significância . Neste caso, a variável teste a ser adotada será a “
2 ” com
[(h – 1)(k –1 )] graus de liberdade A região de significância é unilateral.
3a Cálculo da variável teste
Calcular as freqüências esperadas (Fehk) e avaliá-las, caso existam eventos que não satisfaçam à condição
Fe 5, estes devem ser unidos aos eventos adjacentes.

17
F011 Fe11 = n
xCL 11 F012 Fe12 = n
xCL 21 ....
F032 Fe32 = n
xCL 23 F0hk Fe hk = n
xCL kh
Estatística de teste para um teste de independência
h
i
k
j ij
ijij
calFe
FeFo
1 1
2
2)(
hk
hkhk
Fe
FeFo
Fe
FeFo 2
11
2
1111 )(...
)(
4a Conclusão: Se 22
cal Rejeita-se H0 ao nível de significância e conclui-se que as
variáveis são dependentes.
Condições para o Uso do teste Qui-Quadrado:
Utilizar quando n >20. Caso contrário optar pelo exato de Fisher.
Se 20< n <40, aplica o teste somente se todas frequências esperadas são maiores que 5.
Muitos estatísticos recomendam calcular o valor de 2 com correção de continuidade quando o
grau de liberdade for igual a 1. A distribuição empírica do 2 calculado não se aproxima da
distribuição teórica. A estatística conhecida como 2 corrigido de Yates em honra ao estatístico
que a propôs, Frank Yates, é dada por: Fe
FeFo 2
2)5,0(
A correção de continuidade produz um teste mais conservador, isto é, um teste que tem menor
probabilidade de rejeitar a hipótese de nulidade. Se a amostra é pequena, o efeito da correção de
continuidade é ainda maior.
O Coeficiente de Contingência - Quando a hipótese nula é rejeitada, conclui-se que as variáveis
são dependentes e apresentam algum grau de associação que pode ser medida pelo coeficiente de
contingência de Pearson (C), que é dado pela fórmula:
%100.n
C2
cal
2
cal
.
O Coeficiente de Contingência (C) possui intervalo de variação de: 0 < C < 1, que é interpretado
da seguinte forma:
- quanto mais próximo de “1” estiver o valor de C maior será o grau de dependência entre as variáveis.
- quanto mais próximo de “0” estiver o valor de C menor será o grau de dependência entre as variáveis.
4.2 Teste Qui-quadrado para Homogeneidade - O teste de homogeneidade testa a afirmativa de que
populações diferentes têm a mesma proporção de alguma característica. Nas pesquisas, algumas amostras
são retiradas de populações diferentes, e para determinar se essas populações têm a mesma proporção da
característica em consideração, aplica o teste de homogeneidade. A palavra homogêneo significa “tendo a
mesma qualidade”, e neste contexto, testa-se se as proporções são as mesmas.
ETAPAS
1a Elaboração das hipóteses estatísticas
H0: As variáveis são homogêneas
H1: As variáveis não são homogêneas

18
Os requisitos, a estatística teste, o valor crítico têm o mesmo procedimento que o teste de independência
com exceção das hipóteses.
4.3 Teste de Mann-Whitney – 2 amostras independentes
O teste de Mann-Whitney é utilizado para testar a hipótese de que duas populações têm a mesma
distribuição. Esse teste é, portanto, uma alternativa para o teste t no caso de amostras independentes. Mas
só deve aplicar o teste de Mann-Whitney se sua amostra for pequena e/ou as pressuposições exigidas pelo
teste t estiverem seriamente comprometidas.
Procedimento:
a) Considerar n1:o número de casos do grupo com menor observações
n2: o número de casos do grupo com maior observações.
b) Considere todos os dados dos dois grupos e coloque-os em ordem crescente. Atribua o valor dos
postos, primeiro ao escore que algebricamente for menor e prossiga até N = n1 + n2. Às observações
empatadas atribuir à média dos postos correspondentes.
c) Calcular: R1 = soma dos postos do grupo n1. R2 = soma dos postos do grupo n2.
d) Calcular a estatística
ETAPAS:
1a Elaboração das hipóteses estatísticas:
H0: Não há diferença entre os grupos
H1: Há diferença entre os grupos
2a Estabelecer o nível de significância .
Para grandes amostras (n1 >10 e n2 >10, segundo Sidney Siegel; 2006)
Quando H0 é verdadeira, os valores de Z calculado têm distribuição assintoticamente normal com média
zero e variância um. Com auxílio da tabela normal padrão determina-se as regiões críticas.
3a Cálculo do valor da variável. Utilize o menor valor de U;
4a Conclusão: a) Se
22
ZZZ cal não rejeita-se H0
b) Se ZZ cal Rejeita-se H0
c) Se ZZ cal Rejeita-se H0.
TESTES NÃO PARAMÉTRICOS - CASOS DE DUAS AMOSTRAS RELACIONADAS
4.4 Teste de Wilcoxon - O teste dos postos de Wilcoxon deve ser aplicado aos dados pareados. Este
teste é, portanto, uma alternativa ao teste t de Student no caso de amostras dependentes, mas só deve ser
aplicado quando as pressuposições exigidas pelo teste t estiverem seriamente comprometidas (as
diferenças provenham de distribuição normal). Trata-se de uma extensão do teste dos sinais, e é mais
interessante que o teste do sinal, pois leva em consideração a magnitude da diferença para cada par.
2
)1(
2
)1(22
22
11
11
nnRUou
nnRU
;)(
)(
u
uUZcal
12
)1(.)(
2
.)( 212121
nnnn
uenn
u

19
Procedimento:
a) Determinar para cada par a diferença (di) entre os dois escores.
b) Atribuir postos (colocar em ordem crescente) todos os “di”s, desconsiderando-se os sinais.
c) Identificar cada posto pelo sinal “+” ou “-” do “di” que ele representa.
d) Definir a estatística T = menor das somas de postos de mesmo sinal.
T+: soma dos postos dos di’s positivos e T-: soma dos postos dos di’s negativos. A soma dos postos
é igual a n(n+1) /2.
e) Abater do “n” o número de zeros, isto é, di = 0.
ETAPAS - para grandes amostras (N > 15 segundo Sidney Siegel, 2006)
1a Elaboração das hipóteses estatísticas
H0: Não há diferença entre os grupos
H1: Há diferença entre os grupos
2a Estabelecer o nível de significância .
3a Para grandes amostras - Quando H0 é verdadeira, os valores de Z calculado têm distribuição
assintoticamente normal com média zero e variância um. Com auxílio da tabela normal padrão, determina-
se as regiões críticas.
4a Estatistica teste: T = Soma das diferenças dos postos positivos
5a Conclusão: regra habitual da tabela normal padrão
Empates - 10 tipo - Caso os dois escores de algum par são iguais, di = 0 (não houve diferença entre dois
tratamentos), tais pares são retirados da análise e o tamanho n da amostra é reduzido.
20 tipo - Dois ou mais di’s podem ser de mesma magnitude. Atribui-se o empate no mesmo posto. O novo
posto será a média dos postos que teriam sido atribuídos se os di’s tivessem diferido.
TESTES NÃO PARAMÉTRICOS – CASO DE MAIS DE DUAS AMOSTRAS
4.5 Teste de Kruskal-Wallis: Trata-se de um teste extremamente útil para decidir se K amostras (K > 2)
independentes provém de populações com médias iguais. Poderá ser aplicado para variáveis intervalares
ou ordinais.
Procedimento:
a) Dispor, em ordem crescente, as observações de todos os K grupos, atribuindo-lhes postos de 1 a n.
Caso haja empates, atribuir o posto médio.
b) Determinar o valor da soma dos postos para cada um dos K grupos: Ri com i = 1, 2,..., K.
c) Realizar o teste:
1a) As hipóteses : Ho: não há diferença entre os grupos.
H1: há diferença entre os grupos.
2a) Fixar . Escolher uma variável Qui-quadrado (
2 ) com = k – 1.
Com auxílio da tabela Qui-quadrado (2 ), determinam-se as regiões críticas.
3a) Calcula-se a estatística H :
T
Tcal
TZ
4
)1n(nT
24
)1n2)(1n(nT
K
i i
i Nn
R
NNH
1
2
)1(3)(
.)1(
12

20
onde ni = tamanho de cada amostra e N = in
4a) Conclusão. O valor crítico para H( Hα, n1, n2,...) para experimentos com número de grupos (k ≤5),
acima de 5 grupos a distribuição se aproxima da qui-quadrado, e neste caso a variável Qui-quadrado (2 )
com = k – 1. Se houver empates nos postos, corrigir o valor de H obtido nos cálculos. O fator de
correção é: Fc = 1- NN
CE
3 e CE = )( 3 tt logo Hc =
Fc
H
TESTE DUNN – Uma opção para realizar as comparações múltiplas para um teste não paramétrico. O
método é aplicado sobre os postos médios obtidos nas amostras Ri = Ri/ni. Inicialmente ordenam-se do
maior ao menor os postos médios, calculam-se as diferenças entre as médias dos postos. A estatística teste
é dada por:
Considere esse procedimento para o caso sem empates. O valor crítico Q( α; k ) são encontrados na tabela
da distribuição Q para testes de comparações múltiplas não paramétricas.
5 - CORRELAÇÃO E REGRESSÃO LINEAR SIMPLES
A teoria de Regressão teve origem no século XIX com Glaton. Em um de seus trabalhos,
estudou a relação entre a altura dos pais e dos filhos (Xi , Yi), procurando saber como a altura do pai
influenciava a altura do filho. Notou que se o pai fosse muito alto ou muito baixo, o filho teria uma
altura tendendo à média.
Em geral, suponha que haja uma única variável dependente, ou resposta, Y que depende de k
variáveis independentes ou regressora, denominadas X1, X2, ......Xk. A relação entre essas variáveis é
caracterizada por um modelo matemático chamado de equação de regressão. O modelo de regressão é
ajustado a um conjunto de dados amostrais. Em algumas situações, o pesquisador escolhe uma função
apropriada para aproximar f.
1.1 Modelo de Regressão Linear Simples
Na regressão linear objetiva-se determinar relação entre uma única variável regressora X e uma
variável resposta Y. Pode-se assumir que a variável regressora X seja contínua e controlada pelo
pesquisador. Caso o experimento seja planejado, escolhem-se os valores de X e observam-se os
valores correspondentes de Y.
Suponha que a verdadeira relação entre Y e X seja uma linha reta e que a observação Y para cadanível
de X seja uma variável aleatória. O valor esperado de Y para cada valor de X é:
E(Y\X) = X10 .
Em que os parâmetros 10 e são constantes desconhecidas. Assume-se que cada observação Y pode
ser escrita pelo modelo Y = eX 10
)11
()1(1212
)1(
)11
(12
)1(
BA
BA
BA
calc
nnN
CENNEP
ounn
NNEPonde
EP
RRQ

21
Sendo (e) o erro aletório com média zero e variância 2 , o erro e ~ (0,
2 ). Os erros são variáveis
aleatórias não correlacionadas.
O modelo de regressão envolve somente uma variável regressora X e, por isso, é chamado “Modelo de
Regressão Linear Simples”, dado a estimativa dos parâmetros.
n
XX
n
YXYX
n
jjn
jj
n
jj
n
jjn
jjj
1
2
1
2
11
1
1
)(
Os estimadores 10ˆˆ e são os estimadores de mínimos quadrados do intercepto e inclinação,
respectivamente. O modelo de regressão linear simples ajustado é:
jXY 1
^
0
^^
que dá uma estimativa pontual da média de Y para cada valor de X. O denominador é a soma de
quadrados corrigida de Xj e o numerador é a soma dos produtos de Xj e Yj corrigida, que podem ser
escritas de uma forma mais simples:
xxSn
X
X
n
j
jn
j
j
1
2
1
2
)(
n
j
jj XX1
2)( xyS
n
YX
YX
n
j
n
j
jjn
j
jj
1 1
1
.
n
j
jjj XXY1
)( assim,
Coeficiente de Correlação Linear de Pearson-
Tem por objetivo medir o grau de associação entre duas variáveis. O instrumento empregado para
a medida da correlação linear de Pearson, representado pela letra r, e é obtido por:
n
YYSonde
SS
S
n
YY
n
XX
n
YXXY
r YY
YYXX
XY
2
2
2
2
2
2
O Coeficiente de correlação é um número sem dimensão (adimensional) cujo valor se situa entre
(-1; +1). Quando X e Y variam no mesmo sentido, diz-se que a correlação é positiva, assim, o coeficiente
de correlação tem sinal positiva. Quando X e Y variam em sentido contrário, diz-se que a correlação é
negativa, assim, o coeficiente de correlação tem sinal negativo, ou seja,
Se r = 1, a correlação é positiva perfeita;
Se r = -1, a correlação é negativa perfeita;
Se r = 0, a correlação é nula.
O sinal da correlação indica qual tendência da variação conjunta das duas variáveis consideradas,
entretanto, deve-se considerar também a intensidade ou o grau de correlação.

22
Teste de hipóteses para Correlação - Testar a hipótese que o coeficiente de correlação seja igual a zero,
Ho = 0 H1 = 0
o teste estatístico apropriado para esta hipótese é dada por: 20
1
2
r
nrt
, que segue
uma distribuição t com (n-2) graus de liberdade, se H0 for verdadeira. Assim rejeita-se a hipótese nula se
0t > )2(;
2n
t
Estimação de 2 - A diferença entre o valor observado Yj e o correspondente valor ajustado jY é
denominado RESÍDUO. O j-ésimo resíduo é definido por: ej = )ˆˆ(ˆ10 jjjj XYYY
j = 1,2,......,n.
Os resíduos tem papel importante na verificação do ajuste do modelo e nas suposições que são realizadas.
Variância Residual da Amostra - Além de estimar 10 e , uma estimativa de 2 é necessária para
testar a hipóteses e construir intervalos de confiança pertinentes ao modelo de regressão. Esta estimativa
pode ser obtida dos resíduos ej = jj YY ˆ . A soma de quadrado dos resíduos é dada por:
SQRes = 2
1
)ˆ( jj
n
j
j YYe
. Após o desenvolvimento matemático
xyyy SSsSQ 1ˆRe .
A soma de quadrados dos resíduos tem (n-2) graus de liberdade, pois dois graus de liberdade são
associados com as estimativas 10ˆˆ e
envolvidas na estimação de jY . O valor esperado da SQRes é
E(SQRes) = (n-2). 2 , de forma que um estimador não viesado de
2 é:
Testando Hipóteses na Regressão Linear Simples - Para testar hipóteses sobre o intercepto ( )0 e o
coeficiente angular )( 1 do modelo de regressão, deve-se fazer a suposição de que os (ej) são
normalmente distribuídos, ou seja, assume-se que os erros ej ~ NID (0, 2 ).
Teste para o coeficiente angular - Para se testar a hipótese de que o coeficiente angular é igual a um
valor constante, por exemplo, 0,1 . As hipóteses apropriadas são:
H0: 1 = 0,1 vs H1: 1 0,1 em que se especificou uma hipótese alternativa bilateral.
xxSsQMt
/Re
ˆ0,11
1
segue uma distribuição t com (n-2) graus de liberdade sob H0: 1 = 0,1 . A
estatística t1 é usada para testar H0 comparando-se o valor observado de t1 com o valor tabelado da
distribuição t: )2(;
2n
t . A hipótese nula será rejeitada se 1t > )2(;
2n
t .
Teste para o coeficiente angular - Um procedimento similar pose ser usado para testar a hipótese sobre
o intercepto. Para testar: H0 : 0 = 0,0 vs H1: 0 0,0 , usa-se a estatística teste:
)1
(Re
ˆ
2
0,00
0
xxS
x
nsQM
t

23
e rejeita-se a hipótese nula se 0t > )2(;
2n
t . Um caso especial é testar: H0: 1 = 0 vs H1: 1 0., cuja a
hipótese esta relacionada com a significância da regressão. Se H0: 1 = 0 não for rejeitada, isto implica
que não há uma relação linear entre X e Y; logo o melhor estimador de Yj para qualquer valor de Xj é
YY j ˆ .
Análise de Variância na Regressão - A determinação da equação de regressão deve ser precedida de
uma análise de variância, a fim de comprovar estatisticamente, se os dados apresentam a suposta relação
linear entre as variáveis X e Y. Hipóteses a serem testadas pela análise de variância na regressão:
Hipóteses levantadas: H0 : 1 = 0 (não existe a regressão) vs H1: 1 0 ( existe a regressão)
Quadro da Análise de Variância na Regressão
CAUSA DE
VARIAÇÃO
(CV)
GRAUS DE
LIBERDADE
(GL)
SOMA DE
QUADRADOS
(SQ)
QUADRADO
MÉDIO (QM) Fcalculado Ftabelado
Regressão 1 SQRegressão QMRegressão Resíduo
Regressão
QM
QM 1%
Resíduo (n-2) SQResíduo QMResíduo 5%
Total (n-1) SQTotal
Conclusão: se Fcalc Ftab [1, (n-2); 2/ ], rejeita-se H0 ao nível de significância adotado, e conclui-se que
existe a regressão. Como SQTotal = SQReg + SQRes
SQTotal = Syy
SQReg = xyS.ˆ1 ;
SQRes = SQTotal – SQReg
Observe que ao realizar a análise de variância, o procedimento é comparar as variâncias;
n
i
yyi1
2)( = 2
1
)ˆ( i
n
i
yyi
+
n
i
i yy1
2)ˆ(
ou corresponde a SQTotal = SQRes + SQReg.
2: SQTotal é a variação total de Y em torno da média;
2: SQRes é a variação de Y em torno da reta;
2: SQReg é a variação das esperanças específicas de Y, em torno da média.
Coeficiente de Determinação ou Explicação - A Soma de Quadrado Total mede a variação nas
observações Yi, ou a incerteza em predizer Y quando X não é considerado. De forma análoga, Soma de
Quadrado do Resíduo mede a variação em Yi quando um modelo de regressão utilizando a variável X é
empregada. Uma medida natural do efeito de X reduzindo a variação em Yi, ou seja, em reduzir a
incerteza na predição de Y, é expressar a redução da variação como (SQTotal – SQRes = SQReg) como
uma proporção da variação total:
Total
síduo
Total
gressão
SQ
SQou
SQ
SQR ReRe2 1
A medida R2 é chamada de coeficiente de determinação ou explicação e seu compo de variação é:
)10( 2 R e indica a proporção da variação total que é “explicada” pela regressão

24
Se R2
= 1, todos os pontos observados se situam “exatamente” sobre a reta de regressão, então as
variações de Y são 100% explicados pelas variações de X por meio da função especificada, conforme
figura 1.
Por outro lado, um R2 = 0 pode ou não indicar ausência de correlação entre X e Y, conforme figura 2.
Análise de Resíduo - Resíduos do ajuste de MRLM
A análise de resíduos desempenha papel fundamental na avaliação do ajuste de um MRLs, investiga a
adequação do modelo quanto às suposições básicas do modelo, bem como norrmalidade, independência
dos erros, homocedasticidade, relação linear de X e Y e falta de ajuste do modelo proposto. Além dos
testes de significância e adequação, a análise de resíduo vem complementar o elenco de procedimentos
que devem ser realizados após o ajuste de qualquer modelo.
Propriedades de resíduo - Se o erro: ei = (Y- Y ) com i=1,2,.....,n
P1- E[ei] = 0;.
P2- Var[ei] = ])(1
1[2
2
xx
i
S
xx
n
; considerando
hii = (xx
i
S
xx
n
2)(1 ) e hij =
xx
ji
S
xxxx
n
))((1[
]
Var[ei] = )1(2
iih ;
P3- Cov[ei, ej] = ijh2 com i,j=1,2,.....,n ; i j
No modelo, há a suposição de normalidade dos erros ei, tem-se que Yi tem distribuição normal e os
resíduos não são independentes. Em resumo, os resíduos (e1,e2,....en) não são independentes e possuem
variâncias diferentes que dependem do valor de X correspondente a xi.
Tipos de resíduos - Resíduos padronizados são escalonados para reduzir uma variável aleatória a ter
esperança com média zero e seus desvios padrão seja aproximadamente igual a um. Consequentemente
di > 3 indica outliers. di = 2ˆRe
ii e
sQM
e com i=1,2,....,n
Resíduo na forma de Student (Estudentizado) – os resíduos padronizados e estudentizado são
parecidos, mas em algumas situações os resíduos estudentizado é mais sensível para detectar pontos
influentes. ri = )1(ˆ 2
ii
ii
h
e
com i=1,2,....,n
Gráficos de resíduos - Para o modelo de regressão, os termos dos erros ei são assumidos serem variáveis
aleatórias normais e independentes, com média zero e variância 2 .Se o modelo é adequado para os
dados, os resíduos observados, devem refletir as propriedades assumidas para os erros ei. Esta é a idéia
básica da análise de resíduos, uma maneira útil de examinar a adequação de um modelo estatístico.
Análise gráfico é muito eficiente para verificar a adequação do modelo, e checar violações do modelo (não
independência dos erros, normalidade dos erros, variância constante dos erros).
a- Gráfico dos Zi’s versus variável regressora ou valores estimados.
No gráfico plota-se os resíduos padronizados (zi) no eixo das ordenadas e a variável regressora (xi)
ou o valor estimado da variável resposta no eixo das abscissas. Ambas os gráficos nos dará mesmas
informações. A característica do gráfico é que a faixa de variação dos resíduos ao longo dos valores de X
é constante, ou ainda, os pontos devem estar espalhados aleatoriamente, não demonstrando nenhuma
tendência. Isso indica a não violação do modelo.
b- Presença de Outliers

25
“Outliers” são observações extremas. Outliers residuais podem ser identificados no gráfico de
resíduos versus X, ou ainda, utiliza do gráfico de caixa dos resíduos. O gráfico de resíduos padronizados é
particularmente útil, pois permite distinguir observações afastadas, uma vez que se torna fácil identificar
resíduos que se encontram muitos desvios padrão do zero. Embora a presença de outliers possa criar
dificuldades, só é recomendável retirá-lo da análise se há evidência direta que representa um erro de
coleta, um cálculo mal feito ou circunstância similar.
c- Normal probability Plot Pequenos afastamentos da normalidade não criam sérios problemas, o que não é verdadeiro para
grandes afastamentos. Uma forma de analisar a normalidade dos resíduos é análise gráfica através do
gráfico Normal Probability. Neste caso cada resíduo é plotado contra seu valor esperado de normalidade.
Um gráfico aproximadamente linear sugere concordância com a normalidade, enquanto um gráfico que se
afasta substancialmente da linearidade sugere que a distribuição dos resíduos não seja aproximadamente
normal. Caso seja violada os pressupostos pela análise de resíduo, partir para transformações de dados e
realizar novamente os procedimentos.
AULA 6 – Ensaio Inteiramente Casualizado
1 - Análise de Variância = Comparações de Médias
A análise de variância é uma técnica que pode ser realizada para determinar se a média de duas ou
mais populações são iguais.
O teste se baseia numa amostra extraída de cada população e testa as seguintes hipóteses ao nível
de significância .
H0: As médias das populações são iguais
H1: As médias das populações são diferentes.
SUPOSIÇÕES:
a) O modelo deve ser aditivo, isto é, os efeitos devem se somar; (Teste de não aditividade)
b) Os erros (eij) devem ter distribuição normal; (Teste de Shapiro-Wilk, Lilliefor, Kolmogorov,...)
c) Os erros (eij) devem ser independentes; (garantida pelo princípio da casualização)
d) Os erro (eij) devem ter mesma variância (homocedasticidade: Teste de Bartlett, Hartley..)
1.1 - Princípios básicos da experimentação
A pesquisa científica está constantemente se utilizando de experimentos para provar suas
hipóteses. É claro que os experimentos variam de uma pesquisa para outra, porém, todos eles são regidos
por alguns princípios básicos, necessários para que as conclusões que venham a ser obtidas se tornem
válidas.
1.1.1 - Princípio da repetição Ao compararmos, por exemplo, dois herbicidas (A e B), aplicados em duas parcelas perfeitamente
iguais, apenas o fato do herbicida A ter apresentado maior controle que o B não é suficientemente para
que possamos concluir que o mesmo é mais eficiente, pois esse seu maior controle poderá ter ocorrido por
simples acaso ou ter sido influenciado por fatores estranhos. Porém, se os dois herbicidas forem aplicados
a várias parcelas e, ainda assim, verificarmos que o herbicida, A apresenta, em média, maior controle,
existe já um indício de que ele seja mais eficiente.
Esquematicamente:
A
B
Experimento
básico Repetições
Princípios da
repetição
A A A A A A
B B B B B B

26
1.1.2 - Princípio da casualização
Mesmo reproduzindo o experimento básico, poderá ocorrer que o herbicida A apresentou maior
controle por ter sido favorecido por qualquer fator, como por exemplo, ter todas as suas parcelas
agrupadas numa faixa de menor infestação.
Para evitar que um dos herbicidas seja sistematicamente favorecido por qualquer fator externo,
procedemos à casualização dos herbicidas nas parcelas, isto é, eles são designados às unidades
experimentais de forma totalmente casual.
O princípio da casualização tem por finalidade propiciar a todos os tratamentos a mesma
probabilidade de serem sorteados a qualquer das unidades experimentais. Esquematicamente:
A
B
Experimento
básico Repetições + casualização
Ao fazer um experimento considerando apenas esses dois princípios, temos o delineamento
inteiramente casualizado ou com um fator. As parcelas que receberão cada um dos tratamentos são
determinadas de forma inteiramente casual, através de um sorteio, ou usando a tabela de números
aleatórios para que cada unidade experimental tenha a mesma probabilidade de receber qualquer um dos
tratamentos estudados, sem qualquer restrição no critério de casualização.
As observações de cada grupo ou tratamento são tabeladas para facilitar a análise segundo as
hipóteses lançadas.
Tratamentos ( I )
Repetições ( J ) 1 2 ... I Totais
1 Y11 Y21 ... YI1
2 Y12 Y22 ... YI2
... ... ... ...
J Y1J Y2J ... YIJ
Totais T1 T2 TI G
Médias 1
m 2
m ... I
m m
J
j
JYT1
11 ;
J
j
JYT1
22 ; ...
J
j
IJI YT1
;
I
i ij
iji YTG1
; JxI
Gm ˆ
1.2 – Modelo Matemático: Yi j = m + ti + ei j, onde
m = Média geral do experimento
ti = Efeito do i-ésimo tratamento, i = 1, 2, ...,I
ei j= Erro experimental, com j = 1, 2, ...,J, onde ei j ~ (0; 2).
1.3 – Quando utilizar?
Quando todas as unidades experimentais estiverem sob as mesmas condições.
Princípios da
repetição e casualização
B A A B A B
A B A B B A

27
1.4 – Vantagens
a) Pode-se ter número diferente de repetições por tratamento e qualquer número de tratamento, no
entanto, é preferível o mesmo número de repetições.
b) O número de graus de liberdade do resíduo é o maior possível.
c) Se ocorrer a perda de alguma parcela, esta não acarretará dificuldade na análise.
Deve-se considerar independência entre tratamentos e entre parcelas do mesmo tratamento. Além
disso, as “j” observações por tratamento são normais de média mi e de mesma variância 2, ou seja: Yi j ~
N(mi; 2).
1.5 – Quadro de Análise de Variância e Teste F.
Para testar as hipóteses construiremos o seguinte quadro de análise de variância:
Fonte de
Variação
Graus de
Liberdade
Somas de
Quadrados
Quadrados
Médios
Fcal Ftab
Tratamento(T) I - 1 SQT QMT QMT/QMR [(I – 1), I(J – 1)]
Resíduo (R) I(J – 1) SQR QMR
Total (To) IJ - 1 SQTo
Onde, ij
ijJI
GCsendoCYSQTo
22 ; ;
CJ
T
SQT
I
i
i
1
2
; SQR = SQTo – SQT
1
I
SQTQMT ;
)1(
JI
SQRQMR
QMR
QMTFcal ; )]1();1[( JIIFtab
Assim, se Fcal > Ftab Rejeita-se H0, isto é, as médias das populações são diferentes. Com a
análise de variância descobre-se que existe diferença entre as médias. Para comparar estas diferenças de
médias, pode-se utilizar o teste de Tukey.
1.6 - O Coeficiente de Variação (C.V.)
O coeficiente de variação é dado pela fórmula: %100ˆ
.. xm
QMRVC
Se C.V. < 15% Experimento ótimo e a média representativa;
Se 15% < C.V. < 30% Experimento bom e a média pouco representativa;
Se C.V. > 30% Experimento ruim e a média não representativa.
1-

28
1.7 Testes de comparações múltiplas
Os testes de comparações múltiplas, ou testes de comparações de médias, servem como um
complemento do teste F, para determinar diferenças entre os tratamentos. Para uma melhor compreensão
destes testes são necessárias alguns conceitos, tais como:
Teste de Tukey - Consiste em comparar as médias duas a duas através da sua diferença em valor
absoluto, com a diferença mínima significativa que é dada por:
)ˆ(ˆ2
1. yVq ,
onde q = amplitude total estudentizada, tomada em tabelas ao nível de 5% e 1%, considerando-se número
de tratamentos e graus de liberdade do resíduo.
se os tratamentos tiverem o mesmo número de repetições, porém, se os tratamentos tiverem números de
repetições diferentes, tem-se:
QMRnnn
qI
.)1
...11
(2
1.
21
Teste de Dunnett - Esse teste é quando as únicas comparações que interessam ao experimentador são
aquelas entre um determinado tratamento padrão ou testemunha, e cada um dos demais tratamentos.
calcular a estimativa de cada contraste:
.TestemunhaouPadrãommmY.
mmY
mmY
PPII
P22
P11
Calcular o valor do teste d’ dado por: r
sQMtd d
Re.2.'
onde td é o valor dado na tabela para uso no teste de Dunnett (5% e 1%), em função do número de graus
de liberdade de tratamentos (I – 1) e do número de graus de liberdade do resíduo (n’).
Comparar cada estimativa de contraste, em valor absoluto, com o valor d’.
Se o módulo de Y 'd Rejeita-se Ho, isto é a média da testemunha e a média do tratamento com
ela comparado difere estatisticamente a um nível de probabilidade.
Se o módulo de Y < d’Aceita-se Ho, isto é, a média da testemunha e a média do tratamento com
ela comparado não difere estatisticamente a um nível de probabilidade.

29
7 - Delineamento em Blocos Casualizados
1 – Modelo Matemático : Yi j = m + ti + bj + ei j, onde
m = Média geral do experimento
ti = Efeito do i-ésimo tratamento, i = 1, 2, ...,I
bj = Efeito do j-ésimo bloco, j = 1, 2, ...,J
ei j = Erro experimental, com j = 1, 2, ...,J, onde ei j ~ (0; 2).
Neste delineamento, além dos princípios da repetição e da casualização já visto no capítulo
anterior tem-se também o controle local que é representado pelos blocos, onde cada um deles inclui todos
os tratamentos.
2 - Princípio do controle local - Esse princípio é freqüentemente utilizado, mas não é de uso obrigatório,
pois podemos realizar experimentos sem utilizá-lo. Ele consiste em aplicar os herbicidas sempre em pares
de parcelas o mais homogêneas possível com relação ao ambiente, podendo haver, inclusive, variação
acentuada de um par para outro. A cada par de parcelas denominamos bloco.
Esquematicamente:
10 Bloc. 2
0 Bloc. 3
0 Bloc. 4
0 Bloc. 5
0 Bloc. 6
0 Bloc.
A
B
Experimento Repetições + casualização + contole local
Quando tivermos diversos tratamentos a comparar, cada bloco será constituído por um grupo de
parcelas que deve ser um múltiplo do número de tratamentos.
A finalidade do princípio do controle local é dividir um ambiente heterogêneo em sub-ambientes
homogêneos e tornar o delineamento experimental mais eficiente, pela redução do erro experimental.
O deliamento experimental assim obtido é denominado de delineamento em blocos casualizados
ou em blocos ao acaso e, vemos que, nesse caso, devemos isolar mais uma causa de variação conhecida
(fator controlado), que são os blocos. Como cada bloco deve conter todos os tratamentos, há uma restrição
na casualização, que deve ser feita designando os tratamentos às parcelas dentro de cada bloco como
mostra a Figura 1.
Figura 1 - Disposição do experimento em blocos casualizados.
Princípios da
repetição,
casualização e
controle local
A B B A A B
B A A B B A
1
2 3
4 5
5
4 3
2 1
1
4 3
5 2 4 3
1 2
5
Bloco 1 Bloco 2
Bloco 3 Bloco 4
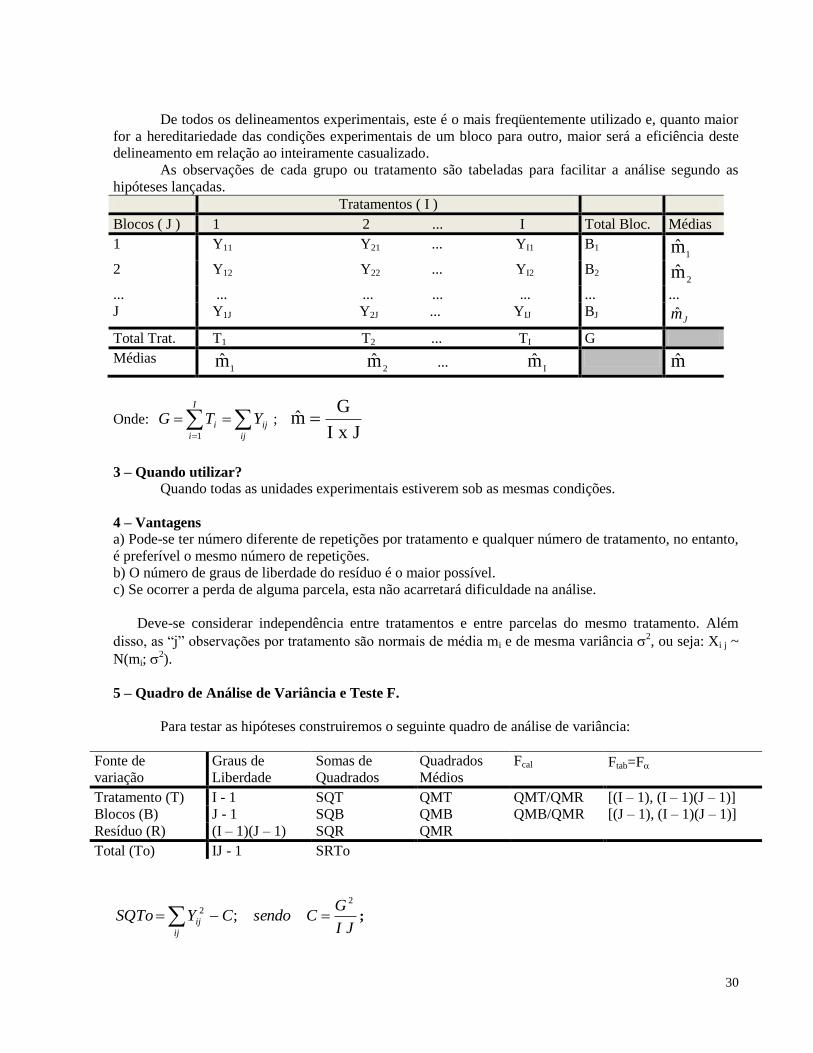
30
De todos os delineamentos experimentais, este é o mais freqüentemente utilizado e, quanto maior
for a hereditariedade das condições experimentais de um bloco para outro, maior será a eficiência deste
delineamento em relação ao inteiramente casualizado.
As observações de cada grupo ou tratamento são tabeladas para facilitar a análise segundo as
hipóteses lançadas.
Tratamentos ( I )
Blocos ( J ) 1 2 ... I Total Bloc. Médias
1 Y11 Y21 ... YI1 B1 1
m
2 Y12 Y22 ... YI2 B2 2
m
... ... ... ... ... ... ...
J Y1J Y2J ... YIJ BJ Jm
Total Trat. T1 T2 ... TI G
Médias 1
m 2
m ... I
m m
Onde:
I
i ij
iji YTG1
; JxI
Gm
3 – Quando utilizar?
Quando todas as unidades experimentais estiverem sob as mesmas condições.
4 – Vantagens
a) Pode-se ter número diferente de repetições por tratamento e qualquer número de tratamento, no entanto,
é preferível o mesmo número de repetições.
b) O número de graus de liberdade do resíduo é o maior possível.
c) Se ocorrer a perda de alguma parcela, esta não acarretará dificuldade na análise.
Deve-se considerar independência entre tratamentos e entre parcelas do mesmo tratamento. Além
disso, as “j” observações por tratamento são normais de média mi e de mesma variância 2, ou seja: Xi j ~
N(mi; 2).
5 – Quadro de Análise de Variância e Teste F.
Para testar as hipóteses construiremos o seguinte quadro de análise de variância:
Fonte de
variação
Graus de
Liberdade
Somas de
Quadrados
Quadrados
Médios
Fcal Ftab=F
Tratamento (T) I - 1 SQT QMT QMT/QMR [(I – 1), (I – 1)(J – 1)]
Blocos (B) J - 1 SQB QMB QMB/QMR [(J – 1), (I – 1)(J – 1)]
Resíduo (R) (I – 1)(J – 1) SQR QMR
Total (To) IJ - 1 SRTo
ij
ijJI
GCsendoCYSQTo
22 ; ;

31
CJ
T
SQT
I
1i
2
i
; CI
B
SQB
J
j
j
1
2
; SQR = SQTo – SQT – SQB
1I
SQTQMT
;
1
J
SQBQMB
)1)(1(
JI
SQRQMR
QMR
QMTFcalT ; )]1)(1();1[( JIIF
Ttab
QMR
QMBFcalB ; )]1)(1();1[( JIJF
Btab
Assim se Fcal > Ftab Rejeita-se Ho, isto é, as médias das populações são diferentes. Com a
análise de variância descobre-se que existe diferença entre pelo menos um par de médias. Para comparar
estas diferenças de médias, pode-se utilizar o teste de Tukey.
6 – Teste de Tukey - Consiste em comparar as médias duas a duas através da sua diferença em valor
absoluto, com a diferença mínima significativa que é dada por: )y(V2
1.q ,
onde q = amplitude total estudentizada, tomada em tabelas ao nível de 5% e 1%, considerando-se número
de tratamentos e graus de liberdade do resíduo. J
QMR.q ,
se os tratamentos tiverem o mesmo número de repetições, porém, se os tratamentos tiverem números de
repetições diferentes, tem-se:
QMR.)n
1
n
1(
2
1.q
21
7 - O Coeficiente de Variação (C.V.)
O coeficiente de variação é dado pela fórmula:
%100xm
QMR.V.C
1-
Se C.V. < 15% Experimento ótimo e a média representativa;
Se 15% < C.V. < 30% Experimento bom e a média pouco representativa;
Se C.V > 30% Experimento ruim e a média não representativa.

32
8 – ANÁLISE DE AGRUPAMENTO
8.1 Introdução – A Análise de agrupamento (cluster) tem como objetivo dividir os elementos da
amostra, ou população, em grupos de forma que os elementos pertencentes a um mesmo grupo sejam
similares entre si com respeito às variáveis (características) que foram medidas nos indivíduos, e os
elementos em grupos diferentes sejam heterogêneos em relação às mesmas características.
Para o desenvolvimento da metodologia, Reis (1997) apresentou cinco etapas:
Seleção de indivíduos e das variáveis das quais será obtida a informação ao agrupamento
Definição de uma medida de semelhança ou distância
Critério de agregação dos indivíduos denominado de algoritmo de partição;
Interpretação e validação dos resultados.
8.2 Coeficientes de dissimilaridades para atributos quantitativos - As medidas de dissimilaridade
significam que quanto menor os seus valores, mais similares serão os elementos amostrados. Existem
diversas métricas que podem ser utilizadas como distâncias entre indivíduos observacionais. As mais
destacadas estão descritas a seguir.
Distância euclideana - A métrica mais conhecida para indicar a proximidade entre dois indivíduos l e k é
à distância euclideana, dada por:
d l,k = [
p
i 1
(Xli - Xki )2 ]
1/2 em linguagem matricial: dl,k = [(
lX~
- kX
~)´(
lX~
e kX
~)]
1/2
onde lX
~e
kX~
são dois vetores de unidades amostrais, comparados nas variáveis observadas.
Distância euclideana Média - O valor da distância euclideana aumenta quando novas variáveis são
incorporadas às originais. Uma maneira de contornar esse problema é dividir esse valor pela raiz
quadrada do número de caracteres, isto é:
klkl dp
,,
1
Essa distância é apenas um reescalonamento da anterior, possuindo as mesmas
propriedades e, portanto, produzindo os mesmos resultados se submetidos às técnicas de análise de
agrupamentos.
Coeficiente de correlação linear simples - Sokal e Sneath (1963) utilizam como coeficiente de
similaridade entre dois indivíduos, para caracterizar as relações entre os caracteres, o coeficiente de
correlação momento produto de Pearson definido por:
ri,i’ =
p
1j
2
kkj
p
1j
2
llj
kkj
p
1j
llj
xxxx
xxxx
, onde
8.3 Algoritmo de agrupamento - Os algoritmos utilizados na formação dos grupos podem ser
classificados em métodos hierárquicos e não hierárquicos.
Os métodos hierárquicos aglomerativos são formados a partir de uma matriz de
distância, onde se identifica o par de indivíduos e mais se parecem. Nesse instante o par é agrupado
formando um único indivíduo. Esse processo requer uma nova matriz de similaridade. Em seguida
identifica-se o par que mais semelhante que formará o novo grupo, e assim sucessivamente até que todos
os indivíduos estejam reunidos num só grupo.

33
Para formalizar esta etapa consideram-se os agrupamentos l, k contendo r l , r
k indivíduos. Se os agrupamentos l, k se unem, isto é indicado como (l, k) com r l,k = r l + r k indivíduos.
Single Linkage - (Method SLM - Método do vizinho mais próximo)
Uma população Pj candidata-se a um agrupamento quando apresenta uma
distância a este agrupamento igual à sua menor distância com relação aos membros do agrupamentos. A
distância entre dois agrupamentos L e K será dada por:
k,ld
k,ld min
Kk
Ll
Complete Linkage – (Method CLM- Método do vizinho mais distante)
Uma população Pj candidata-se a um agrupamento quando apresenta uma
distância a este agrupamento igual à sua maior distância com relação aos membros dos agrupamentos. A
distância entre dois agrupamentos L e K será dada por:
kl
KkLl
KL dd ,, max
Unweighted Pair-group Average – (Método UPGMA - Método não ponderado de agrupamento aos
pares por médias aritméticas)
Define-se a distância entre dois agrupamentos como a média entre os valores
individuais de um dos grupos com os de outro grupo.
dl,k =
KkLl
k,l
kl
drr
1
9- COMPONENTES PRINCIPAIS
9.1 Introdução - A análise de componentes principais (ACP) é uma técnica estatística multivariada que
possibilita, em investigações com um grande número de dados disponíveis, a identificação das medidas
responsáveis pelas maiores variações entre os resultados sem perdas significativas de informações.
Geometricamente, a ACP consiste em representar um vetor de parâmetros em um novo sistema de
coordenadas ortogonais, cujos eixos são orientados nas direções de maior variância dos dados originais.
A ACP é uma transformação linear de um espaço p-dimensional para um espaço m-dimensional,
tal que m p. As coordenadas dos dados no novo espaço são não correlacionadas e a maior quantidade de
variância dos dados originais é preservada usando-se somente poucas coordenadas. Um fator importante
da ACP pode ser resumido em: dadas p variáveis x1, x2,..., xp, encontra combinações lineares dessas para
reduzir índices z1, z2, ..., zp que sejam não correlacionados, onde os zi componentes principais são
ordenados de forma que Var (z1) Var (z2) ... Var (zp).
A redução de dimensionalidade se resume no seguinte: se a maioria dos índices apresentarem
variâncias tão pequenas a ponto de serem ignoradas, a variação no conjunto de dados pode ser
apropriadamente descrita pelos poucos índices z que retêm as maiores variâncias. Portanto, a primeira
componente principal é a combinação linear das medidas com variações máximas entre os objetos de

34
estudo. A segunda e a terceira componente, de forma semelhante, são combinações lineares que
representam no conjunto de dados às próximas variações máximas.
O objetivo principal da análise de componentes principais é a obtenção de um pequeno número de
combinações lineares (componentes principais) de um conjunto de variáveis, que retenham o máximo
possível da informação contida nas variáveis originais. Teoricamente o número de componentes é sempre
igual ao número de variáveis. Entretanto, alguns poucos componentes são responsáveis por grande parte
da explicação total.
A análise de componentes principais depende somente da matriz de covariância () ou da matriz
de correlação () de x1, x2,..., xp. Assim, o procedimento para uma ACP se resume em encontrar os
autovalores e os correspondentes autovetores da matriz de covariância às soluções não triviais da equação
característica:
( - . I) v = 0
onde, I é a matriz identidade e são os autovalores associados aos respectivos autovetores v. Cada
autovalor constitui uma medida relativa da fração de variância original que está contida no respectivo
autovetor. Considerando que os autovalores estão ordenados por valores decrescentes, tal que:
1 2 ... p 0
obtém-se os autovetores (componentes principais - CP) os quais representam fração significativa da
variância original. A transformação é concluída com a projeção dos vetores originais sobre cada CP,
obtendo-se então os coeficientes das componentes principais.
9.2 Obtenção das Componentes Principais
Seja x o vetor das p variáveis originais xT = (x1, x2,..., xp), com Cov (X) = . Considere p
combinações lineares de x1, x2,..., xp, tal que:
z1 = 11x1 + 12x2 + ... + 1pxp
z2 = 21x1 + 22x2 + ... + 2pxp
..................................................................
zp = p1x1 + p2x2 + ... + ppxp
As componentes principais são as combinações lineares z1, z2, ..., zp não correlacionadas, cujas
variâncias são as maiores possíveis.
Seja a matriz de covariância associada ao vetor de variáveis aleatórias x. Sejam (1, 1), (2,
2),..., (p, p) os autovalores e os autovetores ortogonais padronizados, associados a , ordenados de
modo que 1 2 ... p 0. A i-ésima componente principal é dada por:
zi = i1x1 + i2x2 + ... + ipxp, i = 1, 2, ..., p onde var (zi) = i, i = 1, 2, ..., p
i1, i2, ..., ip são os elementos do autovetor correspondente
Cov (zi, zj) = iT j = 0 para i j.
Assim, as componentes principais não são correlacionadas e têm variâncias iguais aos autovalores
de . Define-se da seguinte maneira a matriz de dados:

35
Medidas multivariadas
a. Vetor de médias amostrais - Uma vez que está trabalhando com p variáveis aleatórias e n
observações, tem-se uma média amostral para cada uma das p variáveis. Assim o vetor de médias
amostrais é dado por:
p
j
2
1
p
x
x
x
x
x
, onde p,,2,1j,x
n
1x
n
1i
jij
b. Matriz de variâncias e covariâncias amostrais : A estrutura da matriz de variâncias e covariâncias é:
np2n1n
p22221
p11211
sss
sss
sss
onde na diagonal têm-se as variâncias das p variáveis e os elementos fora da diagonal são covariâncias
entre as variáveis.
A diagonal principal da matriz é obtida pela seguinte fórmula:
2jij
n
1i
jj )xx(1n
1s
A outros elementos da matriz obtêm-se usando a seguinte fórmula:
)xx).(xx(1n
1s kkijij
n
1i
kj
c. Matriz de correlação amostral
Considere as componentes principais dadas acima, ou seja, z1 = 1T x, z2 = 2
T x, ..., zp = p
T x,
então a correlação entre a i-ésima componente principal e a j-ésima variável é igual a:
jj
ij
ijj
iji
ij
ij
ji
i
ZVarXVar
ZXCovXZCor
)()(
),(),(
A matriz pode-se ser decomposta em duas matrizes:
1.Autovalores () : A matriz de autovalores é dada definida det[( - . I)] = 0, e

36
2. Autovetores: ( - . I).v = 0. A matriz de autovetores implica em que as componentes principais sejam
dadas por z = Tx, ou seja,
zi = i1x1 + i2x2 + ... + ipxp, i = 1, 2, ..., p
Propriedades das Componentes Principais
Quando a transformação proposta acima é aplicada às variáveis originais, a variância total (soma das
variâncias das variáveis) não modifica, isto é,
2211 + . . . + p21 . . . pp ,
ou seja,
) Z(Var ) X(Varp
1i
i
p
1j
j
Esse resultado implica em que a variância total é a mesma, quer para as variáveis originais quer para
as componentes principais e, portanto a proporção da variância total devida a i–ésima componente
principal é dada por:
p21 . . .
i , i = 1 , 2 , . . . , p.
Então, se uma porcentagem substancial da variabilidade total for explicada pelas primeiras k
componentes principais, por exemplo, 80% ou 90% , pode–se usá–las no lugar das variáveis originais sem
perder muita informação.
Se a matriz de covariância de x tem posto m < p, então a variação total pode ser inteiramente
explicada pelas k primeiras componentes principais, isto é, a primeira e a segunda componente principal
deve explica o máximo da variabilidade total dos dados.
Considere as componentes principais dadas acima, ou seja, Z1= xT
1 , ..., Zp = Tp x, então a
correlação entre a i–ésima componente principal e a j–ésima variável é igual a:
Corr ( Zi, Xj ) =
jj
iij
, i, j = 1 , 2 , . . ., p,
isto é, ij é proporcional à correlação entre Zi e Xj.
Corr (Zi, Xj) =
ijj
iji
ij
ij
) Z(Var )X (Var
) Z, X( Cov
=
jj
iij

37
Referências Bibliográficas
ANDERSON, T.W. (1984). An Introduction to Multivariate Statistical Analysis. 2ed. New York: John
Wiley & Sons.
ANDRADE, D.F.; OGLIARI,P.J. Estatística para as ciências agrárias e biológicas com noções de
experimentação. Florianópolis: Edistora UFSC, 2007.
BARBETTA,P.A.;REIS,M.M.;BORNIA,A.C. Estatística para cursos de engenharia e informática. 20
edição. Editora Atlas, 2008.
BARBIN, D. Planejamento e Análise Estatística de Experimentos Agronômicos, Arapongas, Editora
Midas, 2003.
BANZATTO, D. A. & KRONKA, S. N. Experimentação agrícola. Jaboticabal, São Paulo, FUNEP,
1989, 247p.
BEIGUELMAN, B. Curso prático de Bioestatística. 3ª ed. Ribeirão Preto, Rev. Bras. Genét., 1994.
BERQUIÓ, E. S.; JOSÉ, M. P. S.; SABINA, L. D. G. Bioestatística. 1ª ed. São Paulo: EPU, 1981.
BUSSAB, W. O.; ANDRADE, D. F.; MYAZAKY, E. S. Introdução à análise de agrupamentos. Associação
Brasileira de Estatística, São Paulo: IME/USP, 1990.
CHARNET, R. et. al. Análise de Modelos de Regressão Linear com aplicações. Unicamp. 2ed. 2008.
FONSECA, J.S; MARTINS, G. A. Curso de Estatística. 6ª ed. São Paulo: Atlas, 1996. 320p.
GUEDES, M. L. S. Bioestatística. Rio de Janeiro: Ao livro técnico. Brasília: CNPQ. 1988.
HAIR, J.F.JR., ANDERSON, R.E., TATHAM, R.L. E BLACK, W.C. (1998). Multivariate Data Analysis.
5 ed. Upper Saddle River: Prentice Hall.
JOHNSON, R.A. E WICHERN, D.W. (1988). Applied Multivariate Statistical Analysis. 4ed. Upper
Saddle River: Prentice Hall
MANLY, B.F.J. Métodos Estatísticos Multivariados. 30 ed.Porto Alegre: Bookman, 2008. 229p.
MARCONI, Marina de A, LAKATOS, Eva M. Técnicas de pesquisa. 2ª ed. São Paulo: Atlas, 1982.
MONTGOMERY, D. C. Desgn and analysis of experiments. 3ª ed. New York: J. Wiley & Sons, 1994,
p.649.
MORETTIN, L.G. Estatística Básica. 7ª ed. São Paulo: Makron Books, 1999. 209P.
RODRIGUES, P. C. Bioestatística. EDUFF – 2ª ed. Editora Universitária. UFF. Niterói. 1993.
REIS, E. (1997). Estatística Multivariada Aplicada. Lisboa: Edições Sílabo.

38
SPIEGEL, M.R. Probabilidade Estatística 3ª ed. Coleção Schaum. São Paulo: McGraw-Hill do
Brasil, 1998, 518p.
VIEIRA, S; HOFFMANN, R. Elementos de Estatística. 2ª ed. Atlas, 1990. 159p.





























