Embed Size (px)
Citation preview

Universidade Técnica de Lisboa
Instituto Superior de Agronomia
MODELAÇÃO DA DISTRIBUIÇÃO E DA ABUNDÂNCIA LOCAL DO CÁGADO-MEDITERRÂNICO (Mauremys leprosa) E DO CÁGADO-DE-CARAPAÇA-ESTRIADA (Emys orbicularis)
EM PORTUGAL
Pedro Segurado
Orientador: Doutor José Miguel Oliveira Cardoso Pereira
Júri
Presidente: Doutor António Manuel Dorotêa Fabião
Professor Associado do Instituto Superior de Agronomia da Universidade Técnica de Lisboa
Vogais: Doutor José Miguel Oliveira Cardoso Pereira
Professor Associado do Instituto Superior de Agronomia da Universidade Técnica de Lisboa Doutor Jorge Manuel Mestre Marques Palmeirim
Professor Auxiliar da Faculdade de Ciências da Universidade de Lisboa
Mestrado em Gestão de Recursos Naturais
Lisboa 2000
Universidade Técnica de Lisboa

Instituto Superior de Agronomia
MODELAÇÃO DA DISTRIBUIÇÃO E DA ABUNDÂNCIA LOCAL DO CÁGADO-MEDITERRÂNICO (Mauremys leprosa) E DO
CÁGADO-DE-CARAPAÇA-ESTRIADA (Emys orbicularis) EM PORTUGAL.
Pedro Segurado
Orientador: Doutor José Miguel Oliveira Cardoso Pereira
Júri
Presidente: Doutor António Manuel Dorotêa Fabião
Professor Associado do Instituto Superior de Agronomia da Universidade Técnica de Lisboa
Vogais: Doutor José Miguel Oliveira Cardoso Pereira
Professor Associado do Instituto Superior de Agronomia da Universidade Técnica de Lisboa Doutor Jorge Manuel Mestre Marques Palmeirim
Professor Auxiliar da Faculdade de Ciências da Universidade de Lisboa
Dissertação apresentada neste Instituto
para efeitos de obtenção de grau de Mestre
Mestrado em Gestão de Recursos Naturais
Lisboa 2000

RESUMO
Dados sobre a presença/ausência de Mauremys leprosa e de Emys orbicularis em
quadrículas UTM decaquilométricas foram utilizados para ajustar modelos preditivos da
distribuição. Recorreu-se a duas técnicas estatísticas: modelos baseados em árvores de
classificação e modelos de regressão logística multivariada. As variáveis preditoras foram
obtidas a partir do Atlas do Ambiente de Portugal e incluíam variáveis macroclimáticas,
geomorfológicas, ecológicas e de cobertura do solo. Por forma a maximizar o leque de
escolhas na selecção do modelo mais adequado, foram ajustados um grande número de
modelos estatisticamente válidos. Os mapas preditivos da distribuição foram obtidos
através de um Sistema de Informação Geográfica. Como complemento a esta informação
estudou-se a influência de variáveis locais na presença ou abundância das espécies.
Ambos os métodos e as variáveis ambientais disponíveis revelaram-se
razoavelmente eficazes na modelação da distribuição, tendo-se obtido precisões totais de
classificação na ordem dos 80% para M. leprosa e de 84% para E. orbicularis. As
variáveis mais importantes na distribuição das espécies foram sobretudo de natureza
climática, como a radiação solar, humidade, escoamento, evapotranspiração, precipitação
e regiões ecológicas. Os resultados apontam para fortes indícios de regressão de E.
orbicularis em Portugal. Os mapas resultantes serão úteis para seleccionar áreas
prioritárias para a conservação das espécies.
Palavras chave: Mauremys leprosa, Emys orbicularis, biogeografia, conservação,
regressão logística, árvores de classificação.

Predictive models of the distribution and local abundance of the mediterranean-
terrapin (Mauremys leprosa) and the stripe-necked-terrapin (Emys orbicularis) in
Portugal.
ABSTRACT
Information on the presence/absence of Mauremys leprosa and Emys orbicularis in UTM
10 x 10 km grid cells was used to build predictive models of their distribution in Portugal.
Two types of statistical models were used: tree-based models and multivariate logistic
regression models. The predictive variables were obtained from the Environment Atlas of
Portugal, which includes climatic, geomorphological, ecological and land cover variables.
A great number of statistically valid models were adjusted in order to maximise the span
of choices in model selection. The predictive maps were obtained using a Geographic
Information System.
Both methods and the available environmental variables provided a reasonable
predictive power of the models. About 80% (M. leprosa) and 84% (E. orbicularis) of the
cells were correctly classified. The variables with stronger predictive power were mainly
climatic: solar radiation, humidity, drainage, evapotranspiration, rainfall and ecological
region. The results suggests strong evidence on the decline of E. orbicularis populations
in Portugal. The predictive maps will be very useful for the future selection of priority
areas for conservation.
Key-words: Mauremys leprosa, Emys orbicularis, biogeography, conservation, logistic
regression, classification trees.

AGRADECIMENTOS
Ao Dr. José Miguel Pereira por ter aceite a orientação científica desta dissertação e pela
disponibilidade que sempre manifestou.
Ao Dr. Octávio Paulo pela co-orientação desta dissertação e ter facultado o acesso ao seu
gabinete e respectivo recheio.
À Dra. Paula Rito de Araújo pelas facilidades concedidas na realização desta tese,
nomeadamente por ter facultado os dados para a sua realização, pelas sugestões sempre oportunas e
sobretudo pela simpatia que demonstrou como patroa durante os três anos em que trabalhei no
serviço.
Ao José Santos, que me acompanhou muitas vezes por esse país fora.
À Constança Camilo-Alves e ao José Carlos Brito, por terem gentilmente cedido a base de dados
e os mapas das variáveis. Muito obrigado.
Aos amigos, conhecidos, amigos de amigos, irmãos de amigos, etc., que amavelmente me
disponibilizaram as suas informações sobre observações de cágados: Francisco Pereira, Francisco
Álvares, António Monteiro, José Carlos Brito, Rui Rebelo, Gonçalo Rosa, Patrícia Brito, Ana Rainho,
Maria João Marques, Humberto Rosa, Filipe Catry e Miguel Lecoq. Desculpa se me esqueci de ti.
Outra vez ao José Carlos pelo arroz com queijo, o mau cheiro, a tenda, o chão duro, as
derrocadas de estradas, os troncos a barrarem caminhos, o jipe atolado, as ribeiras putrefactas, o
acidente, a muita sorte, a ausência de companhia feminina, os copos e as consequentes e inevitáveis
considerações metafísicas à luz das estrelas, etc, etc, que partilhámos durante as amostragens e que
deram origem a alguns dados que usei nesta tese.
Aos amigos de infância Alberto e Henrique, por terem aceite mais uma vez ser meus colegas,
apesar de os ter abandonado antes de o serem. Obrigado por terem feito tanta publicidade ao S-PLUS.
A todos os colegas de Mestrado que partilharam comigo a imensa alegria de voltar a estudar para
os exames.
Aos meus pais, claro.
Só para acabar e agora numa ordem totalmente aleatória e sem qualquer tipo de preferência
tirando algumas excepções, às amigas e aos amigos: Isabel Pinto, Inês&Paulo, Rui Rebelo, e ainda
talvez ao Pedro Moreira, ou não? Sim. E também à Ana Campos e ao Paulo Catry. E à Susana Rosa
que entretanto apareceu e ainda me ajudou a rever o texto. Obrigado por me terem deixado trabalhar
nos minutos em que não estava convosco.

Índice
ÍNDICE 1 Introdução............................................................................................................... 1
1.1 Enquadramento geral........................................................................................ 1
1.2 As espécies em estudo...................................................................................... 8
1.3 Objectivos......................................................................................................... 11
2. Metodologia............................................................................................................ 13
2.1 Recolha de dados.............................................................................................. 13
2.2 Análise da distribuição conhecida das espécies............................................... 13
2.3 Modelação da distribuição................................................................................ 15
2.3.1. Matriz de dados........................................................................................ 15
2.3.2 Análise exploratória dos dados................................................................. 17
2.3.3 Modelos probabilísticos............................................................................ 18
2.3.3.1 Escolha das técnicas.......................................................................... 18
2.3.3.2 Regressão logística multivariada....................................................... 18
2.3.3.3 Árvores de classificação.................................................................... 24
2.3.3.4 Comparação e integração dos modelos............................................. 26
2.3.4 Representação geográfica dos modelos.................................................... 26
2.4 Influência de variáveis locais........................................................................... 27
2.4.1 Matriz de dados......................................................................................... 27
2.4.2 Análise univariada.................................................................................... 29
2.4.3 Análise multivariada................................................................................. 29
3 Resultados............................................................................................................... 31
3.1 Distribuição conhecida das espécies................................................................ 31
3.2 Modelos preditivos da distribuição................................................................... 32
3.2.1 Mauremys leprosa..................................................................................... 32
3.2.1.1 Análise exploratória.......................................................................... 32
3.2.1.2 Regressão logística............................................................................ 39
3.2.1.3 Árvores de classificação.................................................................... 48
3.2.1.4 Comparação e integração dos modelos............................................. 52
3.2.2 Emys orbicularis....................................................................................... 55
3.2.2.1 Análise exploratória.......................................................................... 55
3.2.2.2 Regressão logística............................................................................ 58

Índice
3.2.2.3 Árvores de classificação.................................................................... 65
3.2.2.4 Comparação e integração dos modelos............................................. 67
3.3 Comparação entre a distribuição de Mauremys leprosa e Emys orbicularis.... 70
3.4 Representação geográfica dos modelos............................................................ 73
3.4.1 Mauremys leprosa..................................................................................... 73
3.4.2 Emys orbicularis....................................................................................... 77
3.5 Influência de variáveis locais........................................................................... 81
3.5.1 Mauremys leprosa..................................................................................... 81
3.5.1.1 Análise univariada............................................................................. 81
3.5.1.2 Análise multivariada......................................................................... 84
3.5.2 Emys orbicularis....................................................................................... 92
4 Discussão................................................................................................................. 95
4.1 Interpretação ecológica dos modelos................................................................ 95
4.2 Avaliação e interpretação dos modelos segundo a sua representação geográfica...............................................................................................................
99
4.3 Influência de varáveis locais............................................................................. 102
5 Considerações finais............................................................................................... 105
6 Referências.......................................................................................................... 107

1. Introdução
1. INTRODUÇÃO
1.1 Enquadramento geral
Padrões de distribuição das espécies
Cada espécie tem uma área de distribuição geográfica única que reflecte tanto o seu nicho
ecológico actual como a sua história evolutiva (Brown & Gibson, 1983). Com efeito, os
limites actuais de distribuição das espécies não são apenas condicionados pelas
características ecológicas e fisiológicas destas, mas resultam, em grande medida, do espaço
geográfico onde ocorreu a sua evolução e especiação.
A área ocupada por uma espécie não é homogénea, apresentando uma alternância
de parcelas com diferentes características ambientais, que determinam a ocorrência e a
densidade das populações (Forman, 1995). Por sua vez, a dinâmica de metapopulações
(Gilpin, 1987; Hanski & Gilpin, 1991; Hanski, 1996) mostra que o padrão de distribuição,
a dimensão, a forma e conectividade das parcelas mais adequadas à sobrevivência de uma
espécie determinam a sua subsistência a longo prazo numa dada região, ao actuarem na
dinâmica da extinção e recolonização locais.
Existe no entanto algum determinismo nos padrões de distribuição da abundância
na área geográfica em que a espécie ocorre. A distribuição da abundância ao longo de um
gradiente ambiental é geralmente descrito por uma curva gaussiana (Begon, 1996). Deste
modo, no centro da área de distribuição a abundância é tendencialmente maior do que na
periferia (Lawton et al., 1994), traduzida quer pela densidade populacional a nível local,
quer pelo número de registos de presença a várias escalas. Segundo o modelo de “fluxo de
centrífugo” de Grinnel (Antunez & Mendonza, 1992), muitas populações periféricas
apresentam taxas de mortalidade que superam as de reprodução e são mantidas por um
fluxo de imigrantes das populações centrais. Este fenómeno é essencialmente válido para
espécies com grande capacidade de dispersão como é o caso das aves (Brown & Gibson,
1983), ou para escalas geográficas ao nível dos habitats.
1

1. Introdução
Factores limitantes da distribuição
Em última análise os factores que afectam a distribuição das espécies são aqueles que
actuam directa ou indirectamente na sobrevivência, reprodução e movimento dos
indivíduos nas populações periféricas. Nos animais, em comparação com o que sucede
com a vegetação, o efeito de factores físicos limitantes é menos aparente, em parte porque
é mais difícil de detectar variações na mortalidade e no sucesso reprodutor e em parte
porque têm a capacidade de se refugiar em microclimas com condições mais favoráveis
(Brown & Gibson, 1983). Outra dificuldade surge da interacção entre os factores que
determinam os limites da distribuição de uma espécie (Brown & Gibson, 1983; Begon,
1996).
Os factores limitantes da distribuição mais frequentemente apontados são (Brown
& Gibson, 1983; Wiens, 1989; Antunez & Mendonza, 1992; Cox & Moore, 2000):
(1) factores climáticos (constrangimentos fisiológicos das espécies), (2) disponibilidade de
habitats (recursos alimentares, locais de reprodução e refúgio), (3) factores bióticos
(competição, predação e mutualismo), (4) barreiras topográficas (cadeias montanhosas,
oceanos, etc.), (5) capacidade de dispersão da espécie (mobilidade, tamanho corporal), (6)
distúrbios (muitas espécies dependem de distúrbios regulares do meio ambiente), (7) fluxo
genético (o fluxo genético das populações centrais para as periféricas impede a adaptação
destas a novas condições ambientais) e (8) acção humana (capturas e alteração dos
habitats).
Diferentes factores ecológicos podem limitar a distribuição espacial duma espécie
em diferentes zonas da sua área geográfica (Cox & Moore, 2000), e por isso as conclusões
que se extraem a nível local não são generalizáveis (Antunez & Mendonza, 1992).
A relação entre os factores ambientais e a distribuição de uma espécie pode ser
estudada a várias escalas espaciais. A escala mais apropriada e a resolução a ser empregue
dependem do objectivo do estudo (May, 1994), podendo estudos do mesmo fenómeno,
efectuados a várias escalas, levar a resultados contraditórios (Gaston & Lawton, 1990). A
escolha de escalas erradas pode inclusivamente levar a generalizações que podem ser
perigosas quando aplicadas à conservação (Murphy, 1989).
Por sua vez, a natureza dos factores a ter em consideração depende igualmente da
escala de estudo (Antunez & Ramirez, 1992; Cox & Moore, 2000). Por exemplo, o padrão
de ocorrência de uma espécie a nível local é determinado sobretudo pelas características
dos habitats e por factores bióticos. Já o padrão de ocorrência ao nível regional é sobretudo
2

1. Introdução
influenciado por factores macro-ambientais (que influenciam igualmente as características
dos habitats). A resolução adoptada na escala regional é necessariamente menor do que na
escala local, não só por razões logísticas, mas porque o excesso de resolução pode
obscurecer o padrão geral que se pretende estudar. Por outro lado, suponhamos que se
adopta uma baixa resolução espacial (por exemplo baseada numa rede UTM 10 x 10 km);
é mais difícil associar a cada quadrícula determinada característica de habitat (por
exemplo, profundidade do meio aquático) do que determinada variável macro-ambiental
(por exemplo temperatura média anual), uma vez que apresenta variações (que podem ser
determinantes para a espécie) apenas detectáveis com resoluções espaciais muito finas.
Modelação ambiental e SIG
Os métodos de identificação dos principais factores ambientais envolvidos no padrão de
ocorrência e abundância das espécies bem como da sua modelação geográfica, sofreram
recentemente um grande desenvolvimento associado aos avanços nos domínios da
estatística espacial e do armazenamento e manipulação de dados espaciais por Sistemas de
Informação Geográfica (SIG) (Haslett, 1990; Walker, 1990; Maurer, 1994; Johnston,
1998).
Com um modelo ambiental pretende-se relacionar uma determinada característica
ou fenómeno (variável dependente ou variável resposta) com factores ambientais (variáveis
independentes ou covariáveis) cuja variação no espaço é conhecida, por forma a permitir a
sua extrapolação por toda a área geográfica que se pretende estudar. Os modelos podem ser
dinâmicos ou estáticos consoante integrem ou não uma componente temporal.
Como seria de esperar, a integração de SIG com modelos ambientais tem emergido
como uma área muito significativa do desenvolvimento dos SIG (Johnston, 1998). Podem
distinguir-se três tipos principais de modelos usados em ambiente SIG: modelos
cartográficos, modelos baseados em regras e modelos estatísticos (Johnston, 1998).
Os modelos cartográficos resultam da simples combinação de várias camadas de
informação, recorrendo às capacidades operativas dos SIG (Berry, 1993; Johnston, 1998),
com o objectivo de localizar as áreas com as propriedades ecológicas desejadas. Estes
modelos têm sido frequentemente utilizados para cartografar o grau de adequação dos
habitats, numa perspectiva de gestão do território. Palmeirim (1985), a partir de uma
imagem Landsat TM classificada produziu camadas de informação relevantes para a
avaliação e selecção de habitats para repovoamentos de galinholas no Nordeste do Kansas.
3

1. Introdução
Ormsby (1987) produziu mapas de disponibilidade de alimento do veado-de-cauda-branca
igualmente a partir de camadas de informação resultantes da classificação de uma imagem
Landsat TM. Breininger et al. (1991) usou mapas de solo e vegetação obtidas a partir de
fotografias aéreas para cartografar os habitats primários e secundários do gaio da Florida.
Uma das desvantagens destes modelos é que a relação entre as camadas de informação e as
propriedades que se pretendem mapear tem de ser conhecida à partida, muitas vezes
através da imposição regras subjectivas.
A modelação baseada em regras recorre a sistemas periciais para o estabelecimento
de regras de decisão. O próprio sistema “aprende” a relação entre as camadas de
informação e estabelece uma série de critérios para a modelação ambiental. Uma técnica
relativamente simples para o estabelecimento de regras de decisão baseia-se em árvores de
classificação (para variáveis resposta categoriais) e regressão (para variáveis resposta
contínuas). Esta técnica recorre a partições binárias que vão subdividindo a amostra inicial,
segundo regras de decisão, em subconjuntos de crescente homogeneidade (Clark &
Pregibon, 1992). Por exemplo, Walker (1990) usou árvores de classificação integradas com
uma base de dados e um SIG para gerar modelos de distribuição de três espécies de
cangurus na Austrália.
Nos modelos estatísticos estabelece-se uma relação empírica entre as variáveis
ambientais e determinada propriedade ecológica (variável resposta), através da estimação
de parâmetros cuja validade é estatisticamente testável. Diferentes abordagens estatísticas
são utilizadas caso se pretenda modelar uma variável resposta contínua ou categorial. Para
variáveis resposta contínuas a técnica mais utilizada é a regressão linear múltipla. Quando
as variáveis resposta são categoriais recorre-se frequentemente a modelos de regressão
logística (Hosmer & Lemeshow, 1989; MacCullagh & Neller, 1989; Trexler & Travis,
1993). Esta técnica, ao contrário do que sucede por exemplo com a análise discriminante
linear, apresenta a vantagem das estatísticas não assumirem quer uma distribuição normal
das variáveis quer a homogeneidade de variâncias entre as classes. Por outro lado, permite
a modelação quer de variáveis dicotómicas quer de variáveis politómicas ordinais
(definidas de forma arbitrária ou subjectiva) ou nominais (MacCullagh & Neller, 1989).
Austin et al. (1996) utilizou funções de análise discriminante e regressões logísticas para
prever a distribuição espacial de áreas de nidificação da águia-de-asa-redonda, tendo
obtido com a última técnica modelos mais simples, mais robustos e mais precisos do que
com a primeira. Mais recentemente tem havido uma tendência crescente para a utilização
4

1. Introdução
de métodos estatísticos bayesianos (Ellison, 1996; Hoef, 1996) em detrimento da estatística
frequentista usual.
Outro conjunto de modelos baseia-se em técnicas de interpolação espacial em que a
modelação geográfica duma característica ou fenómeno é baseada exclusivamente em
informação de natureza espacial. Estas técnicas têm vindo a ser aplicadas na análise de
padrões espaciais da abundância das espécies e no desenvolvimento de métodos de
descrição da fragmentação demográfica das populações (Maurer, 1994).
O ajustamento de modelos ambientais estatísticos é na maioria dos casos realizado
em programas de estatística separados dos SIG. No entanto, tem-se verificado uma
tendência para o desenvolvimento de programas específicos que estabelecem a ligação
entre os SIG e programas de estatística e de módulos estatísticos incluídos nos próprios
SIG (Johnston, 1998).
Modelos de distribuição
No caso da modelação da distribuição, a variável resposta é categorial dicotómica
(presença/ausência). A regressão logística multivariada tem sido a técnica mais
frequentemente utilizada na modelação da probabilidade de ocorrência de espécies a
diversas escalas de estudo (Walker, 1990; Hill, 1991; Pereira & Itami, 1991; Buckland &
Elston, 1993; Chandler et al.,1995; Augustin, et al., 1996; Austin et al., 1996, Brito et al.,
1996; Romero & Leal, 1996; Franklin, 1998; Brito et al., 1999). No caso de se dispor de
dados de abundância é possível produzir modelos espaciais da abundância das espécies
através de modelos de regressão logística ordinal, associando a cada unidade espacial uma
probabilidade de possuir determinado nível de abundância (Gates et al., 1994; North &
Reynolds, 1996). Outras técnicas de modelação da distribuição de espécies incluem
funções discriminantes (Rogers & Williams, 1994; Austin, et al., 1996), distâncias de
Mahanalobis (Clark et al., 1993), análises de correlação canónica (Andries et al, 1994),
métodos baseados em critérios de decisão múltiplos (MCDM) (Pereira & Duckstein, 1993)
e árvores de classificação (Walker, 1990; Franklin, 1998; Iverson & Prasad, 1998). Os
modelos probabilísticos de distribuição são também frequentemente utilizados no domínio
da arqueologia, para a selecção de áreas geográficas a prospectar (Parker, 1985; Kvamme,
1990; Kvamme, 1992; Warren, 1990). Descrevem-se de seguida, muito sucintamente,
alguns exemplos de trabalhos de modelação da distribuição de espécies.
5

1. Introdução
Walker (1990) utilizou árvores de classificação e regressão logística para modelar
três espécies de canguru na Austrália com base em variáveis climáticas, tendo obtido
resultados ligeiramente melhores com a primeira técnica.
Franklin (1998) recorreu às mesmas duas técnicas para prever a distribuição de
espécies de arbustos na eco-região do sul da Califórnia em função de variáveis climáticas,
tendo igualmente obtido erros de classificação menores com os modelos baseados em
árvores de classificação.
Gates et al. (1994) modelaram a ocorrência e a abundância de oito espécies de aves
agrícolas da Grã-Bretanha numa rede UTM 10 x 10 km. Obtiveram um máximo de 16
modelos por espécie, tendo sido escolhido aquele que possuía melhores medidas de
qualidade de ajustamento.
Brito et al. (1996; 1999) e Teixeira et al. (1996) recorreram a modelos de regressão
logística para gerar mapas da probabilidade de ocorrência, respectivamente, de lagarto-de-
água e de salamandra-dourada em Portugal, a partir de variáveis ambientais extraídas do
Atlas do Ambiente de Portugal (C.N.A., 1983). A resolução adoptada foi também baseada
na rede UTM 10 x 10 km. Brito et al. (1999) compararam ainda os resultados obtidos com
os modelos de regressão logística, com os mapas originados a partir da simples
combinação de camadas de informação (modelo cartográfico).
Pereira & Itami (1991) geraram dois modelos de regressão logística de presença do
esquilo-vermelho de Mount Graham (Arizona, E.U.A.) - um modelo ambiental e um
modelo baseado unicamente nas coordenadas dos locais de ocorrência (utilizando um
polinómio do 4º grau) - e integraram a informação recorrendo a um modelo bayesiano,
utilizando o segundo modelo para gerar probabilidades a priori.
Aspinall & Veitch (1993) recorreram igualmente a um modelo bayesiano para obter
um mapa de probabilidade de ocorrência de maçarico-real no NE da Escócia. As
probabilidades condicionais foram calculadas com base nos valores espectrais de uma
imagem Landsat TM e de um modelo digital do terreno e foram posteriormente usadas
para classificar a imagem.
Buckland & Elston (1993) efectuaram uma revisão dos modelos empíricos de
distribuição, utilizando dados de ocorrência de pica-pau-verde, de rabirruivo e de veado no
NE da Escócia. Utilizaram, como variáveis independentes, as componentes principais do
espaço das variáveis ambientais, como forma de reduzir a sua dimensionalidade.
Recomendaram a técnica de bootstrap para avaliar a precisão do modelo.
6

1. Introdução
Como forma de contornar os problemas provenientes da autocorrelação espacial,
Augustin et al. (1996) propuseram a adição de um termo designado por autocov à equação
logística. Para testar o procedimento utilizaram os mesmos dados de ocorrência de veado
que Buckland & Elston (1993).
Iverson & Prasad (1998) desenvolveram modelos baseados em árvores de regressão
para avaliar potenciais alterações nos limites de distribuição de 80 espécies arbóreas do
Este dos Estados Unidos face a mudanças climáticas globais.
Biogeografia e conservação
Os limites de distribuição de uma espécie não são estáticos no tempo, estando em
constante mudança em resposta a alterações climáticas e geológicas a longo prazo. Para
muitas espécies estes processos foram acelerados pela actividade humana, de forma que
grandes mudanças na distribuição e abundância ocorreram dentro de escalas de tempo sem
antecedentes na história evolutiva (Brown & Gibson, 1983; Lawton, et al., 1994).
As populações mais vulneráveis à acção humana encontram-se geralmente nas
periferias das respectivas áreas de distribuição, uma vez que estão em geral mais isoladas
(Rapoport, 1982), apresentam densidades menores (segundo os modelos
metapopulacionais) e estão mais susceptíveis a alterações globais de factores limitantes.
Dum simples inventário da distribuição, é possível extrair informações de diversa
natureza (Harding, 1991), como por exemplo: (1) os limites de distribuição das espécies,
(2) informações sobre as preferências de habitat das espécies e (3) variações espaciais da
biologia das espécies. Por outro lado, os estudos biogeográficos contribuem para a gestão
dos recursos naturais e problemas de conservação a grande escala, nomeadamente no que
se refere aos planos de ordenamento territorial (Ramirez & Vargas, 1992) e à
monitorização das populações (Harding, 1991).
Os efeitos a larga escala, como é o caso da possível alteração climática global do
planeta, requerem necessariamente estudos a uma escala suficientemente grande, por forma
a poder relacionar esses efeitos com eventuais alterações na área geográfica de uma
espécie. Para tal, é importante identificar os principais factores que influenciam a
distribuição a larga escala das espécies e construir modelos válidos que permitam prever os
futuros efeitos de alterações globais.
7

1. Introdução
Os modelos ambientais são também importantes para acções de restauro de
populações ou comunidades, uma vez que ajudam a localizar as áreas com maiores
potencialidades para levar a cabo acções de reintroduções de espécies.
A determinação e a modelação de áreas de ocorrência podem ser importantes para a
localização de zonas de maior vulnerabilidade para as espécies. Aplicando a escala e as
resoluções certas é possível determinar o grau e o padrão de fragmentação ou isolamento
das populações. Esta informação pode ser importante para prever a maior ou menor
vulnerabilidade das populações, juntamente com dados demográficos e padrão de
dispersão dos indivíduos, de acordo com modelos metapopulacionais (Harrison, 1994).
Por último, os modelos de distribuição são importantes para a delimitação de áreas
prioritárias para a conservação a nível nacional de uma ou várias espécies. A informação
sobre os limites de distribuição, grau de fragmentação, detecção de populações isoladas,
coincidência na distribuição de diferentes espécies, etc., integrada com outro tipo de
informação (demografia, avaliação de habitats, etc.) pode ser útil na selecção de áreas
potencialmente importantes para a conservação de determinada espécie ou para a
biodiversidade em geral.
1.2 As espécies em estudo
Morfologia
Em Portugal continental ocorrem duas espécies de cágados autóctones: O cágado-
mediterrânico, Mauremys leprosa (Schweigger, 1812) e o cágado-de-carapaça-estriada,
Emys orbicularis (Linnaeus, 1758), ambos pertencentes à família Emydidae (Ernst &
Barbour, 1989). No texto que se segue passar-se-ão a adoptar as respectivas abreviaturas:
Mle e Eor. As duas espécies distinguem-se essencialmente pelo padrão de cores e pela
forma e estrutura da carapaça (Barbadillo, 1987; Ernst & Barbour, 1989).
Mle apresenta uma carapaça com uma tonalidade castanho-esverdeada com uma
quilha longitudinal mais ou menos evidente; os membros interiores e pescoço são
percorridos por listas amarelo-alaranjadas; o plastrão é rígido e possui placa inguinal.
Eor possui uma carapaça mais escura e geralmente com o lado dorsal mais convexo
do que a espécie anterior e não possui quilha dorsal; apresenta uma cor preta ou
acastanhada com pintas e estrias amarelas mais ou menos evidentes; a cabeça, pescoço e
8

1. Introdução
patas são igualmente escuras com pintas amarelas; possuem um plastrão ligeiramente
móvel na sua região anterior através de uma charneira transversal; não possuem placa
inguinal.
Distribuição
As duas espécies apresentam uma distribuição distinta, sendo Eor mais setentrional e
cosmopolita. Vivem em simpatria na Península Ibérica e nalgumas regiões do Norte de
África, como por exemplo no Norte de Marrocos (Bons & Geniez, 1996).
Mle distribui-se por maior parte da Península Ibérica, prolongando-se um pouco
para Norte dos Pirinéus orientais, no Sul de França; a sua distribuição prolonga-se ainda
por todo o Magreb mediterrâneo (Marrocos, Argélia e Tunísia) até à Tripolitânia (Oeste da
Líbia). Ocorrem ainda populações isoladas mais a Sul, próximo das margens meridionais
do Saara (Sul da Mauritânia, Mali e Níger) (Bons & Geniez, 1996).
Eor possui uma distribuição caracteristicamente centroeuropeia. A sua área de
distribuição estende-se desde a Península Ibérica até ao médio-oriente (Mar Cáspio), e
desde o Norte de África (Marrocos, Argélia e Tunísia) até ao Norte da Europa (Alemanha,
Polónia, Países Bálticos e Rússia). Ocorre ainda na Grécia, Itália, França, países do Leste
Europeu e em ilhas mediterrâneas como a Córsega, Sardenha e Baleares (Ernst & Barbour,
1989).
Habitat
As duas espécies ocupam habitats semelhantes, partilhando com frequência o mesmo meio
aquático nas regiões de simpatria. A informação disponível sobre a utilização dos habitats
destas espécies tem essencialmente um carácter descritivo.
Mle vive em praticamente todo tipo de habitats de água doce na sua área de
distribuição (Ernst & Barbour, 1989), incluindo rios, ribeiros, valas agrícolas, tanques,
charcos, lagoas, albufeiras e pauis. É frequentemente encontrado em locais com índices de
poluição relativamente elevados (Barbadillo, 1987; observação própria).
Eor prefere cursos ou massas de água estanque ou de corrente lenta, de fundo
lodoso e uma boa cobertura de vegetação aquática (Arnold & Burton, 1978; Barbadillo,
1987; Ernst & Barbour, 1989). Pode também encontrar-se em rios e ribeiros com alguma
corrente. Os juvenis preferem massas de água de pequenas dimensões, pouco profundas ou
9

1. Introdução
mesmo de carácter temporário (Nečas et al., 1997). Esta espécie pode também encontrar-se
em locais com índices de poluição elevados (Ernst & Barbour, 1989; observação própria).
Da Silva (1993) encontrou núcleos populacionais de Eor na província de Badajoz
apenas nos ribeiros de água limpa e pouco alterados das zonas serranas, ao contrário da
outra espécie, que foi observada em todo tipo de habitats, poluídos ou não. Já na região de
Doñana (SW de Espanha) verifica-se uma certa segregação espacial das espécies: Mle
tende a ocupar sobretudo as massas de água de maiores dimensões e de carácter
permanente e Eor tende a ocupar charcos temporários (Keller et al., 1994).
Estado das populações
Mle é considerado comum na maioria das regiões onde ocorre (Barbadillo, 1987; Crespo &
Oliveira, 1990; Da Silva, 1993; Malkmus, 1995; Bons & Geniez, 1996; Araújo et al.,
1997), havendo no entanto alguns indícios de regressão a nível local.
Pelo contrário Eor é considerado raro e em regressão na grande parte da sua área de
distribuição (Servan & Pieau, 1984; Corbett, 1986; Barbadillo, 1987; Crespo & Oliveira,
1990; Frisenda & Ballasina, 1990; Amo, 1991; Astudillo & Arano, 1995; Malkmus, 1995;
Bons & Geniez, 1996; Nečas et al., 1997; Araújo et al., 1997) e especialmente na Europa
central e do Norte, onde ocorrem populações muito isoladas. Em todos os países europeus
onde se dispõe de informação sobre o estado das populações, a espécie é considerada rara e
em regressão (Araújo et al., 1997.). A alteração e destruição de zonas húmidas (drenagens,
regularização das margens, etc.), a poluição industrial e agrícola , a introdução de espécies
de tartarugas exóticas e a captura para comércio são alguns dos factores mais apontados
para a situação actual desta espécie.
Em termos da situação legal a nível internacional, ambas as espécies estão incluídas
no Anexo II da Convenção de Berna e, mais recentemente, nos anexos II e IV da Directiva
da União Europeia - Directiva Habitats - relativa à “Preservação de Habitats Naturais e
Seminaturais e da Fauna e Flora Selvagens” (Directiva 92/43/CEE).
Situação em Portugal
Em Portugal o estado das populações de Mle não parece preocupante (Araújo et al., 1997),
apesar de haver algumas informações sobre desaparecimentos ou declínios a nível local.
10

1. Introdução
Esta espécie é considerada “Não Ameaçada” pelo Livro Vermelho dos Vertebrados de
Portugal (SNPRCN, 1990).
Eor apresenta alguns indícios de regressão em Portugal. Possui uma distribuição
muito fragmentada e nos locais onde ocorre surge invariavelmente com valores de
abundância muito inferiores aos de Mle (Segurado, 1996; Araújo et al., 1997). Os estudos
efectuados até agora em Portugal nas populações consideradas mais importantes revelam a
quase inexistência de juvenis e recém nascidos e uma taxa de gravidez muito baixa
(Segurado, 1996; Araújo et al., 1997.). Esta espécie possui o estatuto de
“Insuficientemente Conhecida”, apesar de haver fortes motivos (Araújo et al., 1997) para a
incluir, segundo os critérios da IUCN, no estatuto de “Vulnerável”. Em Espanha esta
espécie já possui este estatuto.
Em Portugal estas espécies encontram-se numa região periférica da sua distribuição
(limite Noroeste para Mle e Sudoeste para Eor), o que representa um factor adicional na
vulnerabilidade das populações, sobretudo de Eor.
1.3 Objectivos
Tendo em consideração o que foi exposto pretendeu-se com este trabalho:
1. Obter modelos preditivos da distribuição de Mle e de Eor em Portugal, com base nas
variáveis macro-ambientais disponíveis;
2. Comparar os resultados da aplicação de diferentes modelos de classificação;
3. Determinar quais as variáveis com mais influência na ocorrência das espécies a duas
escalas: a nível nacional (influência de variáveis macro-ambientais) e a nível local
(influência de variáveis locais).
Este trabalho poderá, no futuro, fornecer bases para a gestão das populações destas
espécies, nomeadamente quanto à delimitação de áreas prioritárias para a conservação.
A distribuição a nível nacional foi estudada apenas com base em dados de
presença/ausência das espécies, devido à dificuldade em associar abundâncias a cada
unidade de amostragem (quadrículas UTM 10 x 10 km), e sobretudo à grande margem de
erro que tal procedimento acarretaria. Considerando que os factores a nível local
11

1. Introdução
apresentam uma maior relação com a densidade populacional, os modelos a esta escala
basearam-se em dados de abundância relativa. Devido à escassez de dados de Eor, a
influência de variáveis locais foi estudada com base apenas em análises univariadas.
12

2. Metodologia
2. METODOLOGIA
2.1 Recolha dos dados
A maioria dos dados analisados neste trabalho foram obtidos no âmbito do projecto
“avaliação da situação de Emys orbicularis e de Mauremys leprosa em Portugal” (Araújo
et al., 1997), decorrido entre 1992 e 1997. Neste projecto, os resultados relativos à
distribuição das espécies basearam-se na compilação de informação, quer bibliográfica
quer fornecida por colaboradores, e em amostragens no terreno. Os métodos de
amostragem consistiram essencialmente na realização de transectos ao longo de cursos de
água, em capturas com armadilhas e em observações ad-hoc (Araújo et al., 1997). Os
transectos e as armadilhagens permitiram a obtenção de abundâncias relativas, expressas
respectivamente por um índice horário de abundância (número de observações por unidade
de tempo) e por um índice segundo o número de armadilhas e o número de horas de
armadilhagem (número de indivíduos capturados por armadilha e por hora).
Em 1997 e 1998, já no âmbito do presente estudo, com o objectivo de obter dados
adicionais sobre a distribuição e abundância das espécies, foram realizados transectos em
119 locais onde se dispunha ainda de pouca informação.
2.2 Análise da distribuição conhecida das espécies
Representação da distribuição
A todos os locais de amostragem foram retiradas as respectivas coordenadas UTM com
resolução de 1 Km, com base em cartas 1:25000 do Instituto Cartográfico do Exército. A
distribuição das espécies foi representada segundo a sua ocorrência em quadrículas da rede
UTM 10 x 10 km. Apesar da cartografia de Portugal do Instituto Cartográfico do Exército
basear-se no sistema de projecção Gauss, as coordenadas UTM têm sido utilizadas com
mais frequência nos atlas de distribuição de espécies em Portugal, razão pela qual se optou
por este sistema, apesar dos erros que daí advêm.
13

2. Metodologia
Índices de raridade
A representação da distribuição com base numa rede quadricular de 10 km tem sido usada
com alguma frequência na quantificação da raridade e na determinação do grau de ameaça
das espécies (Harding, 1991; Spellerberg, 1992). Podem considerar-se dois tipos de
raridade: a distribuição pode estar confinada a uma determinada região restrita e então
considera-se a espécie como rara a nível nacional, ou a distribuição pode ser mais alargada
mas muito fragmentada e então considera-se a espécie como rara a nível local (Spellerberg,
1992).
Para quantificar a raridade foram criados dois índices: um Índice de Raridade
Global (IRG) e um Índice de Raridade Média Local (IRML), calculados da seguinte forma:
IRG = A
A P+
A = nº total de quadrículas de ausência
P = nº total de quadrículas de presença
IRML = IR
P
Lii
P
∑
em que IRL é o Índice de Raridade Local e mede o grau de isolamento de cada quadrícula
de presença, sendo expresso da seguinte forma:
IRL = Av Pv
V−
Av = nº de quadrículas de ausência na vizinhança da quadrícula
Pv = nº de quadrículas de presença na vizinhança da quadrícula
V = nº total de quadrículas na vizinhança da quadrícula
Para determinar o número de quadrículas de cada tipo (ausência, presença, não
amostrada) na vizinhança das quadrículas de presença utilizou-se o módulo “pattern”
(função class frequency) do programa IDRISI (Eastman, 1990), a partir duma imagem com
14

2. Metodologia
informação sobre a presença/ausência, em que cada pixel correspondia a uma quadrícula
UTM 10 x 10 km. Consideraram-se as quadrículas incluídas numa janela de 5 x 5,
excluindo as quadrículas dos cantos (V = 22). Após as operações algébricas entre as
camadas para o cálculo dos IRL calculou-se o valor médio (IRML) através do módulo
“extract”.
O Índice de Raridade Local varia entre -1 (todas as quadrículas da vizinhança são
presenças) e 1 (todas as quadrículas da vizinhança são ausências) e é nulo quando o nº de
quadrículas de cada classe é igual. Quando o IRG é baixo e o IRML é elevado a espécie é
considerada rara a nível nacional; quando ambos os índices são baixos a espécie é
considerada rara a nível local.
2.3 Modelação da distribuição
2.3.1 Matriz de dados
Para cada espécie construiu-se uma matriz de dados com informação sobre a
presença/ausência da espécie por quadrícula UTM 10 x 10 km. A cada quadrícula UTM
10 x 10 km associaram-se variáveis ambientais extraídas do Atlas do Ambiente (C.N.A.,
1983). Para tal, considerou-se a moda das variáveis, ou seja, a classe que ocupava uma área
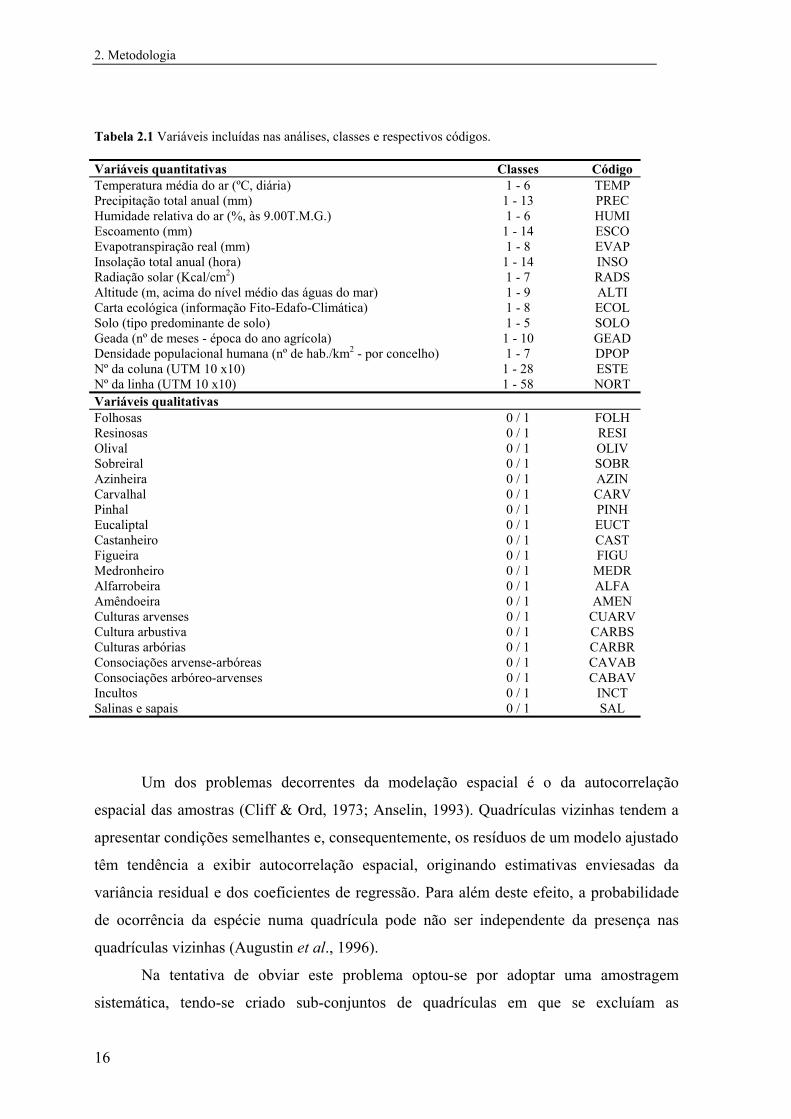
maior na quadrícula. Incluíram-se na matriz um total de 12 variáveis quantitativas e 20
variáveis qualitativas (Tabela 2.1). As variáveis quantitativas consideradas são intervalares
e por isso houve a necessidade de associar um número inteiro a cada classe de variável, por
forma a que as variações se dessem em intervalos unitários (Anexo I). As variáveis
qualitativas são sobretudo de presença/ausência de determinado tipo de cobertura.
Foram ainda incluídas na matriz duas variáveis espaciais (nº da linha e nº da coluna
da quadrícula, no sistema UTM 10 x 10 km), apenas como forma de controlo. No caso
extremo de nenhuma variável ambiental estar relacionada com a distribuição das espécies,
os modelos gerados incluiriam apenas estas duas variáveis.
15
2. Metodologia
Tabela 2.1 Variáveis incluídas nas análises, classes e respectivos códigos. Variáveis quantitativas Classes Código Temperatura média do ar (ºC, diária) 1 - 6 TEMP Precipitação total anual (mm) 1 - 13 PREC Humidade relativa do ar (%, às 9.00T.M.G.) 1 - 6 HUMI Escoamento (mm) 1 - 14 ESCO Evapotranspiração real (mm) 1 - 8 EVAP Insolação total anual (hora) 1 - 14 INSO Radiação solar (Kcal/cm2) 1 - 7 RADS Altitude (m, acima do nível médio das águas do mar) 1 - 9 ALTI Carta ecológica (informação Fito-Edafo-Climática) 1 - 8 ECOL Solo (tipo predominante de solo) 1 - 5 SOLO Geada (nº de meses - época do ano agrícola) 1 - 10 GEAD Densidade populacional humana (nº de hab./km2 - por concelho) 1 - 7 DPOP Nº da coluna (UTM 10 x10) 1 - 28 ESTE Nº da linha (UTM 10 x10) 1 - 58 NORT Variáveis qualitativas Folhosas 0 / 1 FOLH Resinosas 0 / 1 RESI Olival 0 / 1 OLIV Sobreiral 0 / 1 SOBR Azinheira 0 / 1 AZIN Carvalhal 0 / 1 CARV Pinhal 0 / 1 PINH Eucaliptal 0 / 1 EUCT Castanheiro 0 / 1 CAST Figueira 0 / 1 FIGU Medronheiro 0 / 1 MEDR Alfarrobeira 0 / 1 ALFA Amêndoeira 0 / 1 AMEN Culturas arvenses 0 / 1 CUARV Cultura arbustiva 0 / 1 CARBS Culturas arbórias 0 / 1 CARBR Consociações arvense-arbóreas 0 / 1 CAVAB Consociações arbóreo-arvenses 0 / 1 CABAV Incultos 0 / 1 INCT Salinas e sapais 0 / 1 SAL
Um dos problemas decorrentes da modelação espacial é o da autocorrelação
espacial das amostras (Cliff & Ord, 1973; Anselin, 1993). Quadrículas vizinhas tendem a
apresentar condições semelhantes e, consequentemente, os resíduos de um modelo ajustado
têm tendência a exibir autocorrelação espacial, originando estimativas enviesadas da
variância residual e dos coeficientes de regressão. Para além deste efeito, a probabilidade
de ocorrência da espécie numa quadrícula pode não ser independente da presença nas
quadrículas vizinhas (Augustin et al., 1996).
Na tentativa de obviar este problema optou-se por adoptar uma amostragem
sistemática, tendo-se criado sub-conjuntos de quadrículas em que se excluíam as
16

2. Metodologia
quadrículas adjacentes, quer na horizontal e vertical, quer na diagonal. A escolha deste
esquema de subamostragem foi em parte suportado pelo cálculo do valor do Moran´s I
(Cliff & Ord, 1973), através do módulo “autocorr” do programa IDRISI (Eastman, 1990),
para a variável resposta. Com um factor de contracção de segunda ordem o valor do índice
baixou cerca de 50% (de I = 0.482 para I = 0.259). Procedimentos idênticos foram
adoptados por outros autores (Pereira & Itami, 1991; Gates et al., 1994; Brito et al., 1999).
Deste modo, para Mle criaram-se 4 matrizes de dados, com 66, 58, 63 e 60
quadrículas de ausência e, respectivamente, 91, 82, 86 e 80 quadrículas de presença. Estas
matrizes serviram tanto de amostras de treino como de amostras de validação. Para Eor
criaram-se duas matrizes com objectivos diferentes. Uma para discriminar entre
quadrículas de presença e de ausência, com respectivamente 30 e 48 quadrículas, e outra
para discriminar entre quadrículas de presença de ambas as espécies e a presença apenas de
Mle (apenas recorrendo a uma análise univariada), com respectivamente 30 e 56
quadrículas. Como amostra de validação criou-se, para cada abordagem, uma matriz com
19 quadrículas de ausência e 19 de presença. A subamostragem das quadrículas de
ausência para esta espécie foi efectuada com base nas quadrículas de ausência das duas
espécies, por forma a garantir com maior segurança a real ausência da espécie.
2.3.2. Análise exploratória dos dados
Para testar diferenças entre as classes presença e ausência das espécies relativamente a
cada variável quantitativa foram usados testes não paramétricos, uma vez que se
detectaram desvios significativos à normalidade em todas as variáveis. Utilizaram-se o
teste U de Mann-Whitney para testar diferenças nas medianas e o teste de Kolmogorov-
Smirnov de duas amostras para comparar a distribuição de frequências em cada classe
segundo cada variável quantitativa (Zar, 1984). Estes testes foram realizados
separadamente para cada matriz de dados.
Para testar eventuais diferenças entre as distribuições de cada variável nas quatro
matrizes de Mle, separadamente para ausências e presenças, efectuaram-se ainda uma
ANOVA de Kruskal-Wallis e um teste da mediana (Zar, 1984).
17

2. Metodologia
No caso das variáveis qualitativas foram realizados testes de χ2 de modo a testar se
as classes presença e ausência estavam distribuídas aleatoriamente nas categorias das
variáveis.
2.3.3 Modelos probabilísticos
2.3.3.1 Escolha das técnicas
Com o objectivos de conhecer a combinação de variáveis com maior influência na
presença das espécies e de obter um modelo preditivo da distribuição, recorreram-se a duas
técnicas: regressão logística e árvores de classificação.
Como já foi referido anteriormente, a primeira tem sido frequentemente utilizada na
modelação da distribuição de espécies faunísticas. O método das árvores de classificação
não tem sido muito utilizado em problemas biológicos, mas apresenta grandes
potencialidades, sobretudo na área de gestão de recursos naturais, devido à sua
simplicidade de interpretação.
Ambos os métodos apresentam a vantagem das estatísticas não assumirem quer
uma distribuição normal das variáveis, quer a homogeneidade de variâncias entre as
classes, ao contrário do que sucede com outros métodos clássicos como a função
discriminante linear. Por outro lado, permitem ambas uma análise conjunta do efeito de
covariáveis quantitativas e qualitativas.
2.3.3.2 Regressão logística multivariada
O modelo logístico
A regressão logística inclui-se nos designados modelos lineares generalizados, que são
extensões do modelo linear clássico em que o preditor linear η relaciona-se com o valor
esperado µ da variável resposta y por meio de uma função g designada função de ligação
(Hosmer & Lemeshow, 1989; MacCullagh & Neller, 1989). No caso da regressão logística,
na sua versão mais simples em que a variável resposta é binária, a função de ligação é o
logit e toma a seguinte forma:
18

2. Metodologia
( )η µµµ
= =−
g log
1
O valor esperado µ equivale neste caso à probabilidade π(x) de se dar uma das duas
respostas, dado um vector de covariáveis x. A fracção entre parêntesis designa-se por odds.
A expressão pode ser rescrita em função do logit (agora expresso em função de x) do
seguinte modo:
π(x)( )
( )=+e
e
g x
g x1
Esta expressão descreve uma curva logística para π(x) em função do preditor linear g(x),
restringindo os seus valores ao intervalo [0,1]. O logit tem então como finalidade
transformar π(x) numa função com as propriedades desejadas de um modelo de regressão
linear, podendo deste modo tomar a forma clássica:
g(x) = β0 + β1x1 + β2x2 + ...+ βpxp,,
em que β0 é uma constante, β1 ... βp são os coeficientes das x1 ... xp covariáveis ou variáveis
independentes. A principal diferença entre o modelo linear clássico e o modelo logístico é
que a distribuição da variável resposta dado x não segue uma distribuição normal, mas sim
uma distribuição binomial de parâmetro π(x) (Hosmer & Lemeshow, 1989).
Para avaliar a qualidade de ajustamento dos modelos aos dados são geralmente
estimadas duas estatísticas baseadas nos resíduos: A deviance (D) e a estatística X 2 de
Pearson, baseadas respectivamente na soma dos quadrados dos resíduos deviance e de
Pearson. A sua distribuição segue uma distribuição χ2 com J - p + 1 graus de liberdade (J
nº de amostras, p = nº de variáveis no modelo), assumindo o modelo como correcto
(Hosmer & Lemeshow, 1989). São calculadas do seguinte modo:
≈
Deviance: , ( )D d yj
J
j j==∑
1
2, $π
19

2. Metodologia
em que, para yi = 0:
( ) ([ ])d y m mj j j j j, $ ln $π π= − −2 1 ,
e para yi = 1:
( ) ( )d y m mj j j j j, $ ln $π π= 2
X 2 de Pearson: , ( )X r yj
J
j j2
1
2=
=∑ , $π
em que:
( ) ( )( )
r yy m
mj j
j j j
j j j
, $$
$ $π
π
π π=
−
−1
yj = resposta observada para o valor distinto j de x
J = nº de valores distintos de x (J nº de amostras) ≈mj = nº de amostras para cada valor distinto de x (mj ≈ 1)
Após a fixação de uma probabilidade a partir da qual se considera que a espécie
está presente (ponto de corte), torna-se possível a validação do modelo através das
percentagens de classificações correctas em amostras independentes (amostras de
validação) à amostra que lhe deu origem (amostra de treino). Para tal, passam a ser
aplicadas as metodologias usualmente empregues em classificação de imagens (Congalton,
1991).
Ajustamento dos modelos
A cada uma das matrizes de treino foram, em primeiro lugar, ajustados modelos
univariados de modo a seleccionar as covariáveis a incluir na análise multivariada. Assim,
foram incluídas na análise posterior todas as covariáveis com p<0.25 no teste de Wald ou
20

2. Metodologia
cuja importância biológica se considerou relevante, segundo o procedimento recomendado
por Hosmer & Lemeshow (1989). Assim, todas as variáveis quantitativas foram incluídas
na análise multivariada. Verificou-se ainda o efeito de transformações de cada variável
quantitativa ( x 2, x , ln , ln ), bem como de interacções entre variáveis (x x x x i . x j) no
ajustamento univariado.
Seguidamente, foram ajustados para cada matriz de treino modelos multivariados
através de processos de selecção forward e de eliminação backward das covariáveis. As
variáveis incluídas em cada um dos modelos finais, teriam de contribuir significativamente
para a redução da deviance do modelo, estimada pela estatística do quociente de
verosimilhanças (teste G), e o intervalo de confiança do respectivo odds ratio (taxa de
incremento do odds para cada alteração unitária da covariável) não poderia conter o valor
unitário (Hosmer & Lemeshow, 1989). Ajustaram-se ainda oito modelos em que se
“forçavam” cada uma das oito covariáveis com maior significado na análise univariada a
entrar no respectivo modelo final. Os mesmos modelos foram ajustados com e sem as
variáveis de localização espacial (nº da linha e nº da coluna). Após o ajustamento das
variáveis verificava-se ainda o efeito de transformações e de interacções entre covariáveis;
sempre que aumentavam o poder explicativo eram incluídas num novo modelo final.
Este procedimento levou ao ajustamento de um grande número de modelos, por
forma a maximizar o leque de escolhas possíveis do modelo mais adequado. Por outro
lado, a produção de vários modelos preditivos independentes é aconselhável, uma vez que
permite avaliar a importância relativa de cada covariável (Gates et al., 1994). As variáveis
que surgem com mais frequência nos modelos são provavelmente as que mais determinam
a presença ou abundância das espécies.
No processo de ajustamento dos modelos foi utilizado o programa EGRET (1991).
Os mesmos modelos finais foram posteriormente ajustados recorrendo à função glm, do
programa S-PLUS - version 3.3 for Windows (Statistical Science, 1995; Venables &
Ripley, 1997) uma vez que apresenta algumas vantagens na validação e diagnóstico dos
modelos. Em ambos os programas o método de estimação dos parâmetros é o da máxima
verosimilhança, pelo método IRLS (iteratively reweighted least-squares), não se tendo
detectado qualquer diferença no resultado das estimativas.
21

2. Metodologia
Avaliação dos modelos
Na escolha do melhor modelo procurou-se avaliar os modelos através de uma solução de
compromisso entre dois tipos de avaliação: (1) baseadas nas taxas de classificação; (2)
baseadas na quantificação dos desvios reais (resíduos) em relação ao modelo.
Uma vez que o objectivo principal era o de extrapolar o modelo para quadrículas
não amostradas, o primeiro critério na escolha do melhor modelo foi baseado nas taxas de
classificação da amostra de validação (Hosmer & Lemeshow, 1989). Para cada modelo
produzido foram determinadas as percentagens de quadrículas da amostra de treino bem
classificadas, ao longo de sucessivos pontos de corte (Walker, 1990, Pereira & Itami,
1991). Na determinação das taxas de classificação das quadrículas nas amostras de
validação usou-se o ponto de corte em que havia um maior equilíbrio entre a percentagem
de quadrículas de presença e de ausência da amostra de treino bem classificadas. Os
valores de probabilidade para todas as quadrículas, previstos segundo cada modelo, foram
obtidos com a função predict.glm do S-PLUS.
Para cada amostra e para a amostra completa foram construídas matrizes de
classificação (2 x 2) em que as colunas representam as classes de presença e ausência reais
e as linhas representam as classes presença e ausência após a classificação, segundo
determinado ponto de corte. Os valores incluídos representam o número de quadrículas
afectas a determinada classe relativamente à categoria real da quadrícula. A partir destas
tabelas foram calculados os valores de precisão do produtor (fracção de observações
pertencentes a determinada classe que foram correctamente classificadas) e do utilizador
(fracção de observações afectas a uma classe e que na realidade são dessa classe). Em
detecção remota a precisão do produtor (relativa ao erro do tipo I) é uma medida da
probabilidade de um pixel pertencente a determinada classe estar bem classificado, ao
passo que a precisão do utilizador (relativa ao erro do tipo II) indica a probabilidade de
uma quadrícula classificada numa imagem representar na realidade essa classe no terreno
(Congalton, 1991). A precisão do utilizador reflecte assim o grau de fiabilidade do mapa
resultante da extrapolação.
Na modelação da distribuição de Mle, cada modelo ajustado com uma das quatro
matrizes era validado separadamente com as três matrizes restantes. Para Eor foi usada
uma matriz no ajustamento do modelo e outra na sua validação.
Para os dez modelos com as melhores precisões do produtor da amostra de
validação, determinaram-se os respectivos valores de deviance (D) e da estatística de
22

2. Metodologia
Pearson (X 2), quer para as amostras de treino quer para as amostras de validação. Para Mle
determinaram-se os valores médios de D e X 2 entre as três amostras de validação.
Da comparação entre estas estatísticas, ponderadas pelos graus de liberdade, e da
respectiva avaliação do significado biológico, seleccionou-se o modelo mais adequado
para a modelação da distribuição das espécies em Portugal. Optou-se por nunca seleccionar
os modelos que incluíam as variáveis espaciais, uma vez que perdiam o significado
biológico.
Diagnóstico do modelo
Recorreu-se às capacidades gráficas do S-PLUS (funções plot.glm e plot.gam) para efectuar
um diagnóstico informal (MacCullagh & Neller, 1989) do modelo. Para avaliar a
linearidade de cada variável com o logit ajustou-se, com as mesmas variáveis do modelo
seleccionado, um modelo aditivo generalizado (Statistical Sciences, 1995; Venables &
Ripley, 1997) com a função gam (operação de suavização s - cubic B-splines) do S-PLUS.
Um modelo aditivo generalizado é semelhante a um modelo linear generalizado, sendo,
contudo, baseado na combinação linear de diferentes funções de suavização associadas a
cada covariável, e não das próprias covariáveis. A partir da visualização gráfica da
covariável versus a covariável ajustada, decidiu-se quais as transformações de escala das
covariáveis a efectuar no modelo linear (considerando, por exemplo, apenas o intervalo de
valores da variável onde se verificava a linearidade). Se o decréscimo no deviance no
modelo linear era significativo, substituíam-se as variáveis pelas respectivas
transformações.
2.3.3.3 Árvores de Classificação
Os modelos baseados em árvores
As árvores de classificação fornecem uma alternativa aos modelos logísticos lineares e
aditivos em questões de classificação (Clark & Pregibon, 1992). Os modelos baseados em
árvores, segundo os métodos S (Clark & Pregibon, 1992; Statistical Sciences, 1995;
Venables & Ripley, 1997) e a metodologia CART (Walker, 1990), são ajustados através
de regras de decisão, baseadas em partições binárias recursivas, dividindo a matriz de
dados em subconjuntos de crescente homogeneidade. De modo a prever a resposta y dado
23

2. Metodologia
o vector de covariáveis x tem de se seguir o caminho desde a raiz, correspondente à matriz
de dados inicial, até aos nós terminais, ou folhas, às quais estão associadas probabilidades
segundo as regras, ou cisões, no interior dos nós. No caso da função tree do programa S-
PLUS que utiliza a metodologia S, a construção da árvore continua até o número de casos
que chega a cada folha ser inferior a 10, ou a deviance na folha ser inferior a 1% da
deviance no nó da raiz (Clark & Pregibon, 1992; Statistical Sciences, 1995; Venables &
Ripley, 1997). Nas árvores de classificação a variável resposta é nominal - por oposição às
árvores de regressão em que a variável resposta é numérica - e as covariáveis podem ser
contínuas, intervalares ou nominais.
Uma das justificações para o uso da metodologia S é a de que providencia um
modelo probabilístico (Venables & Ripley, 1997). Em cada nó terminal da árvore está
associada uma probabilidade pik (i - nó, k - classe). Cada observação da amostra de treino é
afecta a um nó terminal, cada um incluindo uma amostra aleatória nik de uma distribuição
multinomial especificada por pik. As probabilidades são estimadas a partir das proporções
das classe em cada nó (pik = nik/ni). A deviance da árvore é então definida por:
D ii
= ∑D pik , D ni ikk
= − ∑2 log
e a deviance explicada em cada separação é dada por Di - Di1 - Di2 (i1 e i2 são os dois nós
gerados pelo nó i).
Clark & Pregibon (1992) enumeram algumas vantagens destes modelos
relativamente aos baseados em combinações lineares: (1) a interpretação do modelo é
bastante facilitada, especialmente quando há mistura de variáveis numéricas e nominais;
(2) são invariantes a transformações monotónicas das covariáveis; (3) o tratamento de
valores ausentes é mais satisfatório; (4) a questão da interacção entre variáveis é resolvida
automaticamente. Outra vantagem é a de permitirem hierarquizar as variáveis explicativas
quanto à escala de actuação sobre a variável resposta (Franklin, 1998). As variáveis que
operam a grandes escalas tendem a ser usadas como critério nas primeiras partições do
modelo, ao passo que as variáveis que influenciam a variável resposta a nível mais local
são usadas como regras de decisão perto dos nós terminais. A maior desvantagem desta
técnica prende-se com o facto de ainda não se terem desenvolvido procedimentos formais
para a sua inferência estatística, o que a leva a que seja mais utilizada como uma técnica de
análise exploratória (Clark & Pregibon,1992).
24

2. Metodologia
Ajustamento e avaliação do modelo
Os modelos foram ajustados e avaliados com as mesmas matrizes utilizadas na regressão
logística. Também neste caso os mesmos modelos foram ajustados com e sem as variáveis
de localização espacial (nº da linha e nº da coluna). Uma vez ajustada cada árvore,
procedia-se à sua simplificação de modo a evitar o sobre-ajustamento do modelo às
amostras de treino. Esta simplificação foi realizada através de operações de “poda”
implementadas pelo programa S-PLUS através das funções prune.tree e snip.tree. O número
ideal de nós terminais resultou de uma solução de compromisso entre as taxas de
classificação correcta e os valores de deviance para a amostra de treino e para a amostra de
validação, tendo-se seguido o procedimento do S-PLUS (Clark & Pregibon, 1992;
Statistical Sciences, 1995) com as correcções implementadas pelo módulo Treefix de
Venables & Ripley (1997). Na avaliação da qualidade de ajustamento dos modelos as
probabilidades 1 e 0 foram substituídas respectivamente por 0.999 e 0.001, de acordo com
a recomendação de Venables & Ripley (1997), de modo a possibilitar o cálculo da
deviance.
Resultaram assim dois modelos por matriz, perfazendo um total de oito modelos.
Tal como para a regressão logística, a selecção do modelo final resultou de uma solução de
compromisso entre os valores de deviance ponderados pelos graus de liberdade (número de
observações subtraído pelo número de nós terminais), as taxas de classificação da amostra
de treino e das amostras de validação, a simplicidade do modelo e o seu significado
biológico.
2.3.3.4 Comparação e integração dos modelos
As medidas de qualidade de ajustamento dos modelos finais baseados em árvores e de
regressão logística foram comparadas entre si com base na amostra completa. Por outro
lado, estimaram-se as medidas de qualidade de ajustamento para as quadrículas de
consenso entre os dois modelos (quadrículas afectas à mesma classe por ambos os
modelos), por forma a determinar o aumento de confiança da classificação para estas
quadrículas.
25

2. Metodologia
2.3.4 Representação geográfica dos modelos
Para representar geograficamente os modelos optou-se pela resolução original dos mapas
das covariáveis do Atlas do Ambiente de Portugal. Os mapas, após a sua importação
através de um scanner, foram georeferenciados com base no sistema U.T.M. e, para cada
covariável, os polígonos correspondentes às classes de variável foram digitalizados
recorrendo ao programa TNTMips (Microimages, 1997). Criou-se igualmente uma camada
com informação sobre a presença/ausência das espécies em quadrículas U.T.M. 1 x 1 km.
As camadas assim criadas foram posteriormente convertidas em formato raster e
transferidas para o programa IDRISI. Com este programa procedeu-se à reclassificação das
camadas de acordo com as escalas das respectivas variáveis utilizadas nos modelos, bem
como à posterior representação espacial dos modelos.
Para os modelos de regressão logística aplicaram-se directamente as fórmulas dos
modelos probabilísticos às camadas das variáveis incluídas nos modelos, dando origem a
uma superfície de probabilidade de ocorrência das espécies, a qual foi posteriormente
reclassificada em duas classes - ausência e presença - de acordo com o respectivo ponto de
corte.
No caso dos modelos baseados em árvores, aplicaram-se operações lógicas às
camadas de acordo com as regras de decisão impostas pelos modelos e as probabilidades
associadas aos nós terminais. A camada resultante com informação sobre a probabilidade
de ocorrência da espécie foi reclassificada em duas classes de acordo com a regra de
decisão de Bayes (os pixels eram afectos à classe com maior probabilidade, ou seja,
segundo um ponto de corte de 0.5).
Os mapas preditivos correspondentes aos dois tipos de modelos foram sobrepostos
de modo a determinar as áreas de consenso entre os modelos, onde teoricamente o grau de
confiança da classificação é maior.
26

2. Metodologia
2.4 Influência de variáveis locais
2.4.1 Matriz de dados
A modelação da influência de variáveis locais na presença e abundância de Mle foi baseada
em 249 pontos de amostragem. Apenas se consideraram os pontos situados nas quadrículas
onde os modelos de distribuição previam a ocorrência da espécie, de modo a evitar
”misturar” o efeito das variáveis macro-ambientais. Devido à impossibilidade de se obter
valores de abundância suficientemente precisos em tantos pontos de amostragem, as
abundâncias foram ordenadas em apenas três níveis subjectivos: (1) ausência, (2)
abundância baixa a média e (3) abundância elevada. Considerou-se uma abundância
elevada para locais onde foi obtido um índice horário de abundância superior a 60
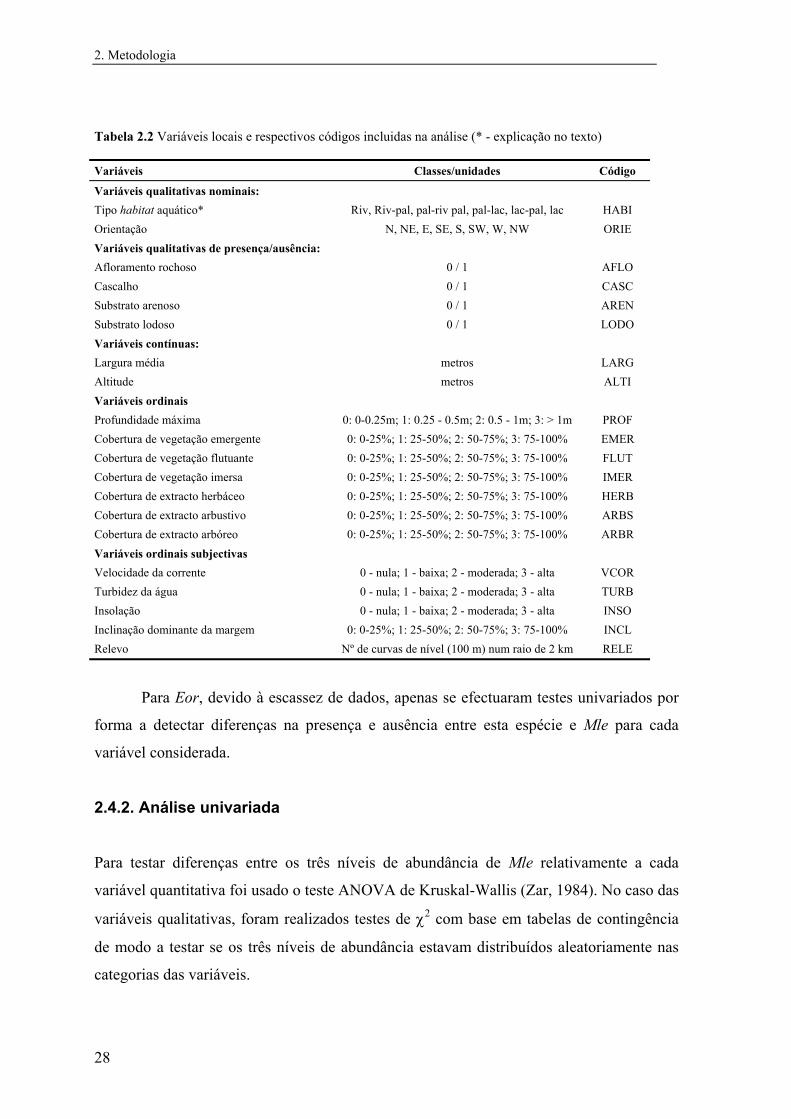
indivíduos/hora. Foram incluídas na análise 7 variáveis qualitativas e 14 variáveis
quantitativas (Tabela 2.2).
As classes da variável Tipo de habitat aquático foram criadas de acordo com a
dominância relativa dos sistemas riverino, palustre e lacustre - segundo definições
semelhantes às adoptadas no programa Medwet (Farinha et al., 1996) - presentes nos
pontos de amostragem. Consideraram-se assim 7 classes:
1. Riverino - cursos de água corrente durante a maior parte do ano, com baixa ou nula
cobertura de vegetação emergente.
2. Riverino-palustre - cursos de água corrente durante a maior parte do ano, com pequenos
troços de água parada (pegos) com características palustres.
3. Palustre-riverino - cursos de água que durante os meses mais secos transformam-se em
poças e charcos com características palustres.
4. Palustre - poças, açudes e charcos com uma área inferior a 8 ha e profundidade máxima
inferior a 2 metros.
5. Palustre-lacustre - lagoas e albufeiras com as margens maioritariamente ocupadas por
ambientes palustres.
6. Lacustre-palustre - lagoas e albufeiras com algumas margens ocupadas por ambientes
palustres.
7. Lacustre - lagoas e albufeiras sem ambientes palustres.
27
2. Metodologia
Tabela 2.2 Variáveis locais e respectivos códigos incluidas na análise (* - explicação no texto) Variáveis Classes/unidades Código
Variáveis qualitativas nominais: Tipo habitat aquático* Riv, Riv-pal, pal-riv pal, pal-lac, lac-pal, lac HABI Orientação N, NE, E, SE, S, SW, W, NW ORIE Variáveis qualitativas de presença/ausência: Afloramento rochoso Cascalho Substrato arenoso Substrato lodoso
0 / 1 0 / 1 0 / 1 0 / 1
AFLO CASC AREN LODO
Variáveis contínuas: Largura média metros LARG Altitude metros ALTI Variáveis ordinais Profundidade máxima 0: 0-0.25m; 1: 0.25 - 0.5m; 2: 0.5 - 1m; 3: > 1m PROF Cobertura de vegetação emergente 0: 0-25%; 1: 25-50%; 2: 50-75%; 3: 75-100% EMER Cobertura de vegetação flutuante 0: 0-25%; 1: 25-50%; 2: 50-75%; 3: 75-100% FLUT Cobertura de vegetação imersa 0: 0-25%; 1: 25-50%; 2: 50-75%; 3: 75-100% IMER Cobertura de extracto herbáceo 0: 0-25%; 1: 25-50%; 2: 50-75%; 3: 75-100% HERB Cobertura de extracto arbustivo 0: 0-25%; 1: 25-50%; 2: 50-75%; 3: 75-100% ARBS Cobertura de extracto arbóreo 0: 0-25%; 1: 25-50%; 2: 50-75%; 3: 75-100% ARBR Variáveis ordinais subjectivas Velocidade da corrente 0 - nula; 1 - baixa; 2 - moderada; 3 - alta VCOR Turbidez da água 0 - nula; 1 - baixa; 2 - moderada; 3 - alta TURB Insolação 0 - nula; 1 - baixa; 2 - moderada; 3 - alta INSO Inclinação dominante da margem 0: 0-25%; 1: 25-50%; 2: 50-75%; 3: 75-100% INCL Relevo Nº de curvas de nível (100 m) num raio de 2 km RELE
Para Eor, devido à escassez de dados, apenas se efectuaram testes univariados por
forma a detectar diferenças na presença e ausência entre esta espécie e Mle para cada
variável considerada.
2.4.2. Análise univariada
Para testar diferenças entre os três níveis de abundância de Mle relativamente a cada
variável quantitativa foi usado o teste ANOVA de Kruskal-Wallis (Zar, 1984). No caso das
variáveis qualitativas, foram realizados testes de χ2 com base em tabelas de contingência
de modo a testar se os três níveis de abundância estavam distribuídos aleatoriamente nas
categorias das variáveis.
28

2. Metodologia
2.4.3 Análise multivariada
Ajustou-se uma árvore de classificação segundo o procedimento descrito na secção 2.3.3.3.
De forma a escolher o grau de simplificação da árvore de classificação recorreu-se às
funções prune.tree, prune.misclass e cv.tree do programa S-PLUS (Clark & Pregibon, 1992;
Statistical Sciences, 1995; Venables & Ripley, 1997). As duas primeiras funções permitem
graficar, respectivamente, a evolução do deviance e do erro de classificação à medida que
se “podam” os ramos terminais da árvore original. A função cv.tree efectua uma validação
cruzada para um grau crescente de simplificação da árvore. Esta função divide a amostra
de treino em 10 subamostras, ajusta uma árvore com base em 9 e testa-a com a décima. O
resultado para cada nível de simplificação é a média das validações das 10 árvores
possíveis, cada uma validada com a amostra que sobra, e pode ser expresso em termos de
deviance ou em termos de erro de classificação (Venables & Ripley, 1997). Esta função
serviu igualmente para validar o modelo final.
Foram ajustadas duas árvores de classificação: uma em que se consideraram todas
as variáveis e outra em que apenas se considerava a influência de características associadas
directamente aos meios aquáticos.
Para cada modelo construíram-se as matrizes de classificação e foram determinadas
as precisões do produtor e do utilizador (Congalton, 1991).
29


3. Resultados
3 RESULTADOS 3.1 Distribuição conhecida das espécies
Na figura 3.1 estão representadas as distribuições de Mle e de Eor em Portugal. Verifica-se
que Mle é muito mais comum do que Eor, possuindo-se informações sobre a sua
ocorrência em 340 quadrículas UTM 10 km x 10 km, correspondendo a cerca de 70% das
quadrículas amostradas. Esta espécie apresenta uma distribuição praticamente contínua a
sul do Rio Tejo. A Norte do Rio Tejo as observações são mais dispersas, excepto na região
de Castelo Branco/Tejo Internacional, e na região da Beira-Alta interior e Nordeste
Transmontano, ou seja, as observações vão-se dispersando no sentido SE para NW do país.
Não foram detectadas populações nem encontradas informações recentes sobre a
ocorrência desta espécie na região entre Douro e Minho.
MG
MF
ME
MD
MC
MB
5
0123456789012345678901234
6789012345678901234567890123
54
6
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 49876543
42
41
43
44
45
46
5 6 7
QG
QF
QE
PGNG
QD
QC
QB
PB
Ausências
Presenças
Mauremys leprosa
MG
MF
ME
MD
MC
MB
5
0123456789012345678901234
6789012345678901234567890123456
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 49876543
42
41
43
44
45
46
5 6 7
QG
QF
QE
PGNG
QD
QC
QB
PB
Emys orbicularis
Figura 3.1 Presença das espécies nas quadrículas UTM decaquilométricas (para Eor
estão representadas apenas as presenças).
31

3. Resultados
A informação sobre a ocorrência de Eor é, pelo contrário, muito escassa e dispersa,
possuindo-se informações sobre a sua presença em 49 quadrículas UTM 10 km x 10 km,
correspondendo a cerca de 10% das quadrículas amostradas. O padrão geral de distribuição
é semelhante ao de Mle, tendo uma distribuição predominantemente mediterrânea, tendo-se
no entanto detectado a sua ocorrência na região do Minho. Por outro lado, ao contrário de
Mle, não foram detectadas populações na região da Beira-Alta interior e Nordeste
Transmontano. Excepto numa quadrícula situada no Minho, a espécie ocorre sempre em
quadrículas de ocorrência de Mle.
Na tabela 3.1 apresentam-se os valores das medidas de raridade para as duas
espécies segundo o Índice de Raridade Global (IRG) e o Índice de Raridade Média Local
(IRML). Ambos os índices são consideravelmente mais elevados para Eor, podendo por isso
considerar-se, comparativamente a Mle, como uma espécie localmente rara.
Tabela 3.1 Índices de raridade por espécie (IRG - Índice de Raridade Global; IRML - Índice de Raridade Média Local) Espécie IRG IRML
Mauremys leprosa 0.325 -0.412
Emys orbicularis 0.892 0.276
3.2 Modelos preditivos da distribuição 3.2.1 Mauremys leprosa 3.2.1.1 Análise exploratória
Na tabela 3.2 encontra-se representada a matriz de correlações para as covariáveis
quantitativas da matriz de dados original. Apenas para dois pares de variáveis -
INSO/RADS e PREC/ESCO - os valores de correlação são superiores a 0.8.
32

3. Resultados
Tabela 3.2 Matriz de correlação para as covariáveis quantitativas (valores superiores a 0.80 a bold).
EAST NORT INSO TEMP PREC HUMI ESCO EVAP ALTI ECOL DPOP SOLO GEAD NORT 0.26 INSO 0.22 -0.72 TEMP -0.21 -0.65 0.55 PREC -0.19 0.60 -0.73 -0.55 HUMI -0.39 -0.08 -0.09 -0.07 0.09 ESCO -0.12 0.61 -0.73 -0.56 0.95 0.06 EVAP -0.38 0.55 -0.69 -0.40 0.86 0.08 0.80 ALTI 0.58 0.50 -0.33 -0.59 0.34 -0.31 0.40 0.09 ECOL -0.28 -0.61 0.52 0.67 -0.50 0.05 -0.54 -0.34 -0.66 DPOP -0.51 0.26 -0.39 -0.08 0.40 0.26 0.36 0.49 -0.26 -0.04 SOLO 0.37 0.32 -0.25 -0.39 0.31 -0.11 0.37 0.09 0.58 -0.41 -0.08 GEAD 0.49 0.43 -0.09 -0.33 0.08 -0.23 0.11 0.04 0.45 -0.35 -0.23 0.27 RADS 0.33 -0.72 0.83 0.46 -0.70 -0.06 -0.66 -0.75 -0.17 0.42 -0.44 -0.14 -0.17
Os resultados dos testes não paramétricos (Tabelas 3.3 A a 3.3 B) mostram que o
comportamento das covariáveis quantitativas é semelhante nas quatro matrizes de dados
criadas. Efectivamente, para todas as covariáveis, o teste de ANOVA de Kruskal-Wallis e
o teste da mediana, separadamente para presenças e ausências, não revelaram diferenças
significativas (p<0.05) entre as quatro matrizes. Em todas as matrizes e para a maioria das
variáveis, a classe ausência apresenta maior dispersão dos dados.
Os resultados do teste de Kolmogorov-Smirnov de duas amostras revelam que em
todas as matrizes as distribuições das covariáveis em cada classe da variável resposta não
são significativamente diferentes (p<0.05) para três variáveis: ALT, SOLO e GEAD. Na
primeira (Tabela 3.2 A) e na quarta matriz (Tabela 3.2 D), não ocorrem igualmente
diferenças significativas entre as duas classes, respectivamente para a variável TEMP e
HUMI. Nas matrizes restantes os valores de confiança para estas duas variáveis são sempre
mais baixos do que para as variáveis restantes.
Os testes de Mann-Whitney (Tabelas 3.3 A a 3.3 B) mostram que os locais de
presença de Mle apresentam valores médios significativamente mais elevados (p<0.05)
para as variáveis TEMP, INSO, RADS, ECOL e ESTE, e valores médios
significativamente mais baixos para as variáveis PREC, HUM, ESCO, EVAP, DPOP e
NORT. Os gráficos da figura 3.2 mostram como variam a média e a dispersão dos dados
com a ausência e a presença da espécie para estas variáveis. O mesmo teste mostra a
ausência de diferenças significativas entre os valores médios para as variáveis ALT, SOLO
e GEAD. Para a quarta matriz, tal como o resultado do teste anterior, não se observam
igualmente diferenças significativas entre as médias para a variável HUMI.
33
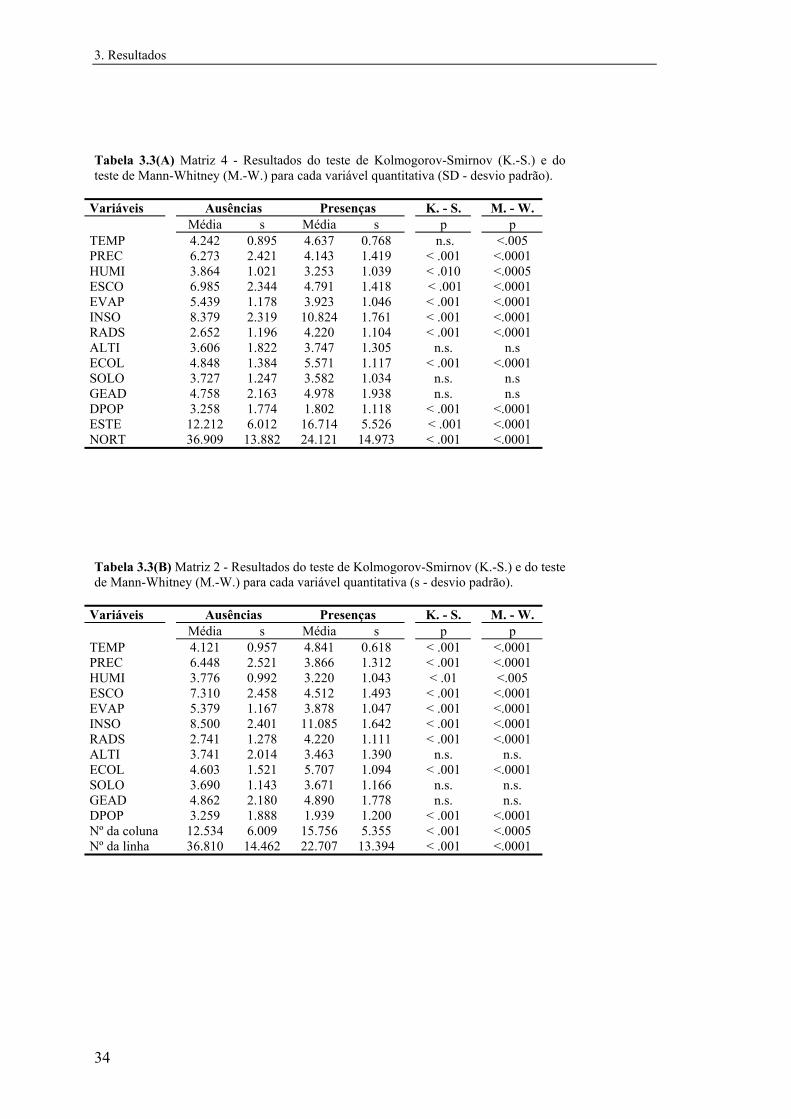
3. Resultados
Tabela 3.3(A) Matriz 4 - Resultados do teste de Kolmogorov-Smirnov (K.-S.) e do teste de Mann-Whitney (M.-W.) para cada variável quantitativa (SD - desvio padrão).
Variáveis Ausências Presenças K. - S. M. - W. Média s Média s p p TEMP 4.242 0.895 4.637 0.768 n.s. <.005 PREC 6.273 2.421 4.143 1.419 < .001 <.0001 HUMI 3.864 1.021 3.253 1.039 < .010 <.0005 ESCO 6.985 2.344 4.791 1.418 < .001 <.0001 EVAP 5.439 1.178 3.923 1.046 < .001 <.0001 INSO 8.379 2.319 10.824 1.761 < .001 <.0001 RADS 2.652 1.196 4.220 1.104 < .001 <.0001 ALTI 3.606 1.822 3.747 1.305 n.s. n.s ECOL 4.848 1.384 5.571 1.117 < .001 <.0001 SOLO 3.727 1.247 3.582 1.034 n.s. n.s GEAD 4.758 2.163 4.978 1.938 n.s. n.s DPOP 3.258 1.774 1.802 1.118 < .001 <.0001 ESTE 12.212 6.012 16.714 5.526 < .001 <.0001 NORT 36.909 13.882 24.121 14.973 < .001 <.0001
Tabela 3.3(B) Matriz 2 - Resultados do teste de Kolmogorov-Smirnov (K.-S.) e do teste de Mann-Whitney (M.-W.) para cada variável quantitativa (s - desvio padrão).
Variáveis Ausências Presenças K. - S. M. - W. Média s Média s p p TEMP 4.121 0.957 4.841 0.618 < .001 <.0001 PREC 6.448 2.521 3.866 1.312 < .001 <.0001 HUMI 3.776 0.992 3.220 1.043 < .01 <.005 ESCO 7.310 2.458 4.512 1.493 < .001 <.0001 EVAP 5.379 1.167 3.878 1.047 < .001 <.0001 INSO 8.500 2.401 11.085 1.642 < .001 <.0001 RADS 2.741 1.278 4.220 1.111 < .001 <.0001 ALTI 3.741 2.014 3.463 1.390 n.s. n.s. ECOL 4.603 1.521 5.707 1.094 < .001 <.0001 SOLO 3.690 1.143 3.671 1.166 n.s. n.s. GEAD 4.862 2.180 4.890 1.778 n.s. n.s. DPOP 3.259 1.888 1.939 1.200 < .001 <.0001 Nº da coluna 12.534 6.009 15.756 5.355 < .001 <.0005 Nº da linha 36.810 14.462 22.707 13.394 < .001 <.0001
34
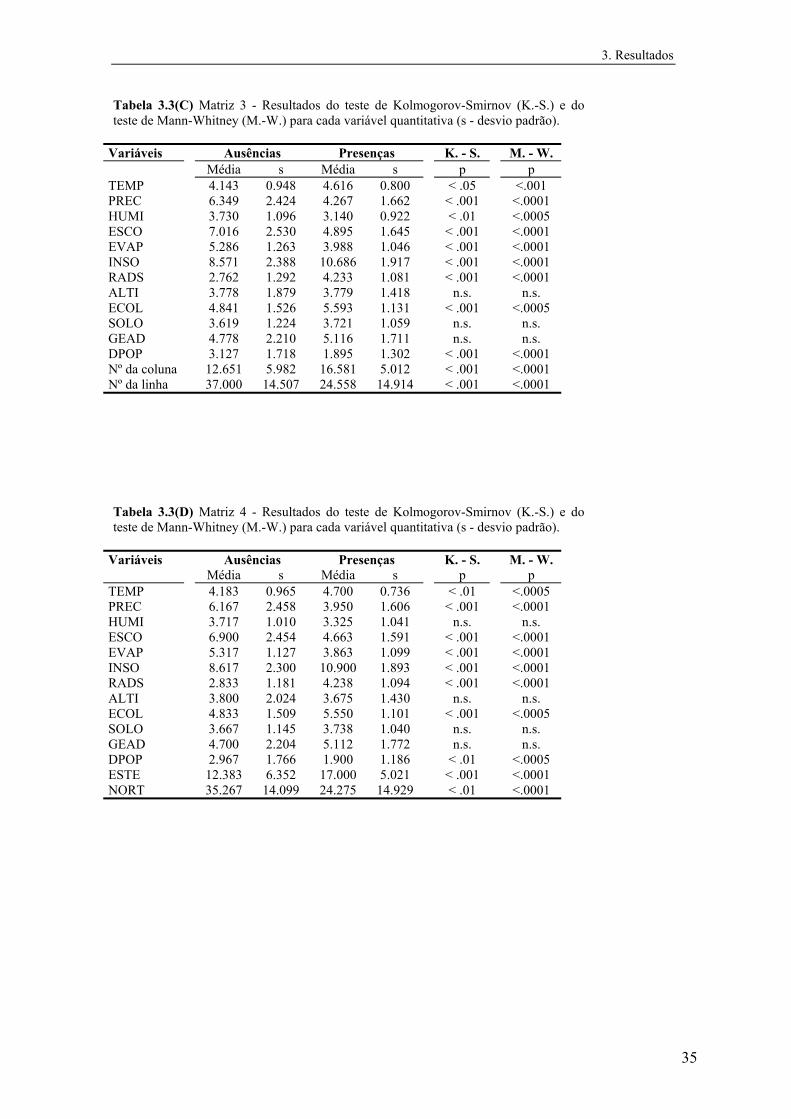
3. Resultados
Tabela 3.3(C) Matriz 3 - Resultados do teste de Kolmogorov-Smirnov (K.-S.) e do teste de Mann-Whitney (M.-W.) para cada variável quantitativa (s - desvio padrão).
Variáveis Ausências Presenças K. - S. M. - W. Média s Média s p p TEMP 4.143 0.948 4.616 0.800 < .05 <.001 PREC 6.349 2.424 4.267 1.662 < .001 <.0001 HUMI 3.730 1.096 3.140 0.922 < .01 <.0005 ESCO 7.016 2.530 4.895 1.645 < .001 <.0001 EVAP 5.286 1.263 3.988 1.046 < .001 <.0001 INSO 8.571 2.388 10.686 1.917 < .001 <.0001 RADS 2.762 1.292 4.233 1.081 < .001 <.0001 ALTI 3.778 1.879 3.779 1.418 n.s. n.s. ECOL 4.841 1.526 5.593 1.131 < .001 <.0005 SOLO 3.619 1.224 3.721 1.059 n.s. n.s. GEAD 4.778 2.210 5.116 1.711 n.s. n.s. DPOP 3.127 1.718 1.895 1.302 < .001 <.0001 Nº da coluna 12.651 5.982 16.581 5.012 < .001 <.0001 Nº da linha 37.000 14.507 24.558 14.914 < .001 <.0001
Tabela 3.3(D) Matriz 4 - Resultados do teste de Kolmogorov-Smirnov (K.-S.) e do teste de Mann-Whitney (M.-W.) para cada variável quantitativa (s - desvio padrão).
Variáveis Ausências Presenças K. - S. M. - W. Média s Média s p p TEMP 4.183 0.965 4.700 0.736 < .01 <.0005 PREC 6.167 2.458 3.950 1.606 < .001 <.0001 HUMI 3.717 1.010 3.325 1.041 n.s. n.s. ESCO 6.900 2.454 4.663 1.591 < .001 <.0001 EVAP 5.317 1.127 3.863 1.099 < .001 <.0001 INSO 8.617 2.300 10.900 1.893 < .001 <.0001 RADS 2.833 1.181 4.238 1.094 < .001 <.0001 ALTI 3.800 2.024 3.675 1.430 n.s. n.s. ECOL 4.833 1.509 5.550 1.101 < .001 <.0005 SOLO 3.667 1.145 3.738 1.040 n.s. n.s. GEAD 4.700 2.204 5.112 1.772 n.s. n.s. DPOP 2.967 1.766 1.900 1.186 < .01 <.0005 ESTE 12.383 6.352 17.000 5.021 < .001 <.0001 NORT 35.267 14.099 24.275 14.929 < .01 <.0001
35
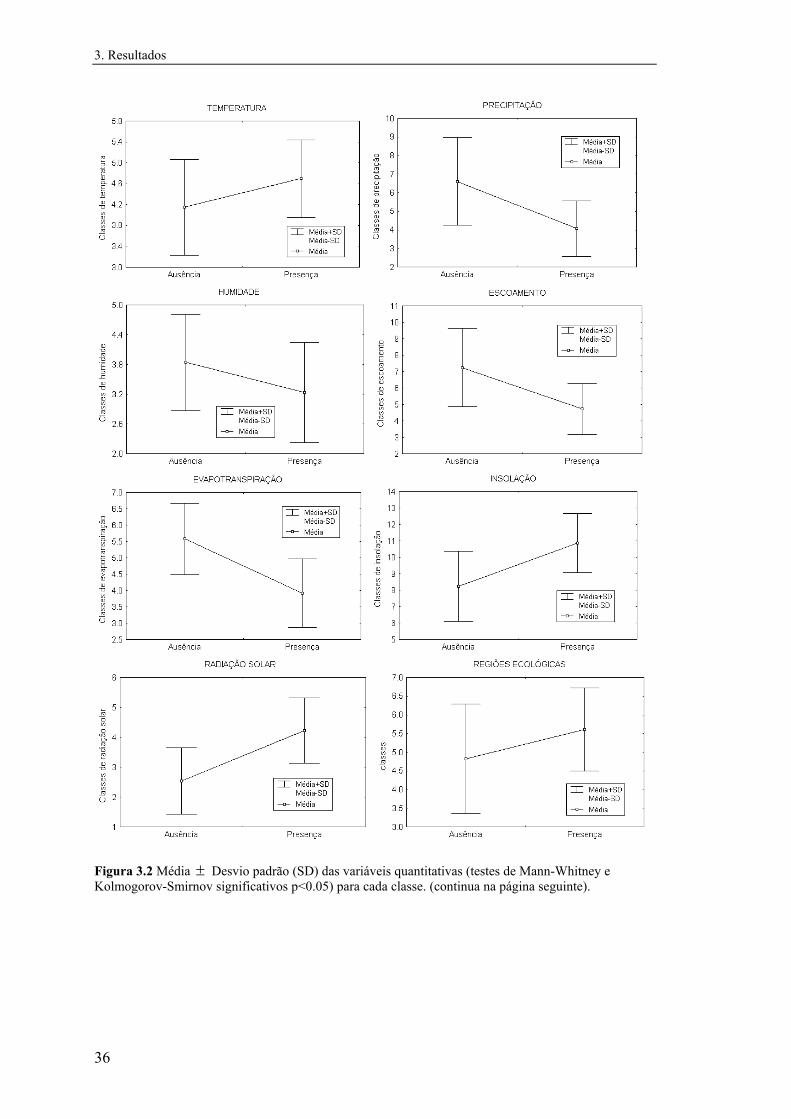
3. Resultados
Figura 3.2 Média Desvio padrão (SD) das variáveis quantitativas (testes de Mann-Whitney e Kolmogorov-Smirnov significativos p<0.05) para cada classe. (continua na página seguinte).
±
36
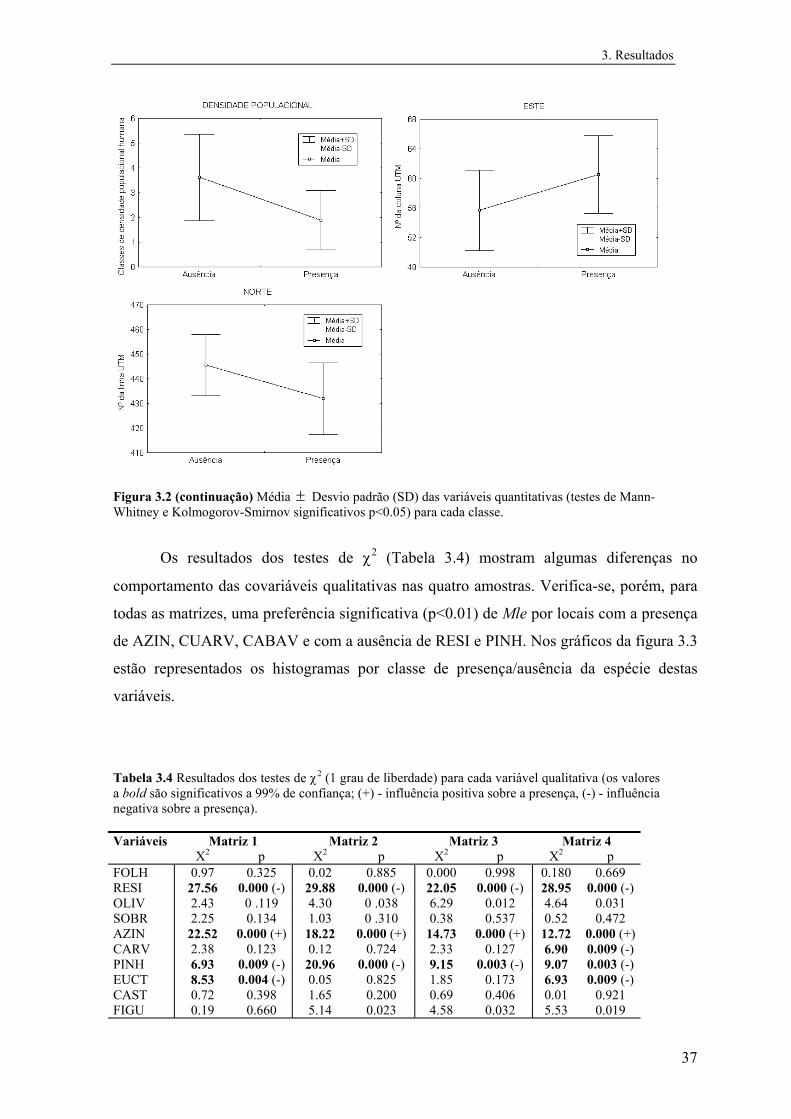
3. Resultados
Figura 3.2 (continuação) Média Desvio padrão (SD) das variáveis quantitativas (testes de Mann-Whitney e Kolmogorov-Smirnov significativos p<0.05) para cada classe.
±
Os resultados dos testes de χ2 (Tabela 3.4) mostram algumas diferenças no
comportamento das covariáveis qualitativas nas quatro amostras. Verifica-se, porém, para
todas as matrizes, uma preferência significativa (p<0.01) de Mle por locais com a presença
de AZIN, CUARV, CABAV e com a ausência de RESI e PINH. Nos gráficos da figura 3.3
estão representados os histogramas por classe de presença/ausência da espécie destas
variáveis.
Tabela 3.4 Resultados dos testes de χ2 (1 grau de liberdade) para cada variável qualitativa (os valores a bold são significativos a 99% de confiança; (+) - influência positiva sobre a presença, (-) - influência negativa sobre a presença). Variáveis Matriz 1 Matriz 2 Matriz 3 Matriz 4 X2 p X2 p X2 p X2 p FOLH 0.97 0.325 0.02 0.885 0.000 0.998 0.180 0.669 RESI 27.56 0.000 (-) 29.88 0.000 (-) 22.05 0.000 (-) 28.95 0.000 (-) OLIV 2.43 0 .119 4.30 0 .038 6.29 0.012 4.64 0.031 SOBR 2.25 0.134 1.03 0 .310 0.38 0.537 0.52 0.472 AZIN 22.52 0.000 (+) 18.22 0.000 (+) 14.73 0.000 (+) 12.72 0.000 (+) CARV 2.38 0.123 0.12 0.724 2.33 0.127 6.90 0.009 (-) PINH 6.93 0.009 (-) 20.96 0.000 (-) 9.15 0.003 (-) 9.07 0.003 (-) EUCT 8.53 0.004 (-) 0.05 0.825 1.85 0.173 6.93 0.009 (-) CAST 0.72 0.398 1.65 0.200 0.69 0.406 0.01 0.921 FIGU 0.19 0.660 5.14 0.023 4.58 0.032 5.53 0.019
37
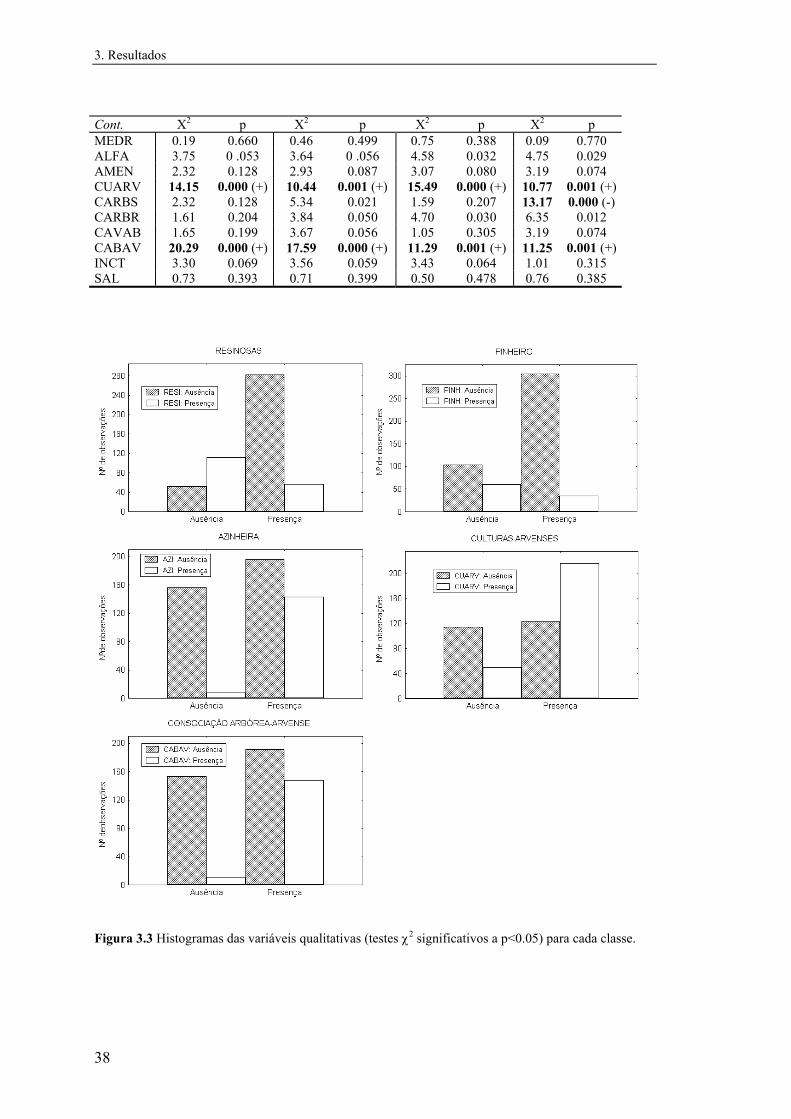
3. Resultados
Cont. X2 p X2 p X2 p X2 p MEDR 0.19 0.660 0.46 0.499 0.75 0.388 0.09 0.770 ALFA 3.75 0 .053 3.64 0 .056 4.58 0.032 4.75 0.029 AMEN 2.32 0.128 2.93 0.087 3.07 0.080 3.19 0.074 CUARV 14.15 0.000 (+) 10.44 0.001 (+) 15.49 0.000 (+) 10.77 0.001 (+) CARBS 2.32 0.128 5.34 0.021 1.59 0.207 13.17 0.000 (-) CARBR 1.61 0.204 3.84 0.050 4.70 0.030 6.35 0.012 CAVAB 1.65 0.199 3.67 0.056 1.05 0.305 3.19 0.074 CABAV 20.29 0.000 (+) 17.59 0.000 (+) 11.29 0.001 (+) 11.25 0.001 (+) INCT 3.30 0.069 3.56 0.059 3.43 0.064 1.01 0.315 SAL 0.73 0.393 0.71 0.399 0.50 0.478 0.76 0.385
Figura 3.3 Histogramas das variáveis qualitativas (testes χ2 significativos a p<0.05) para cada classe.
38
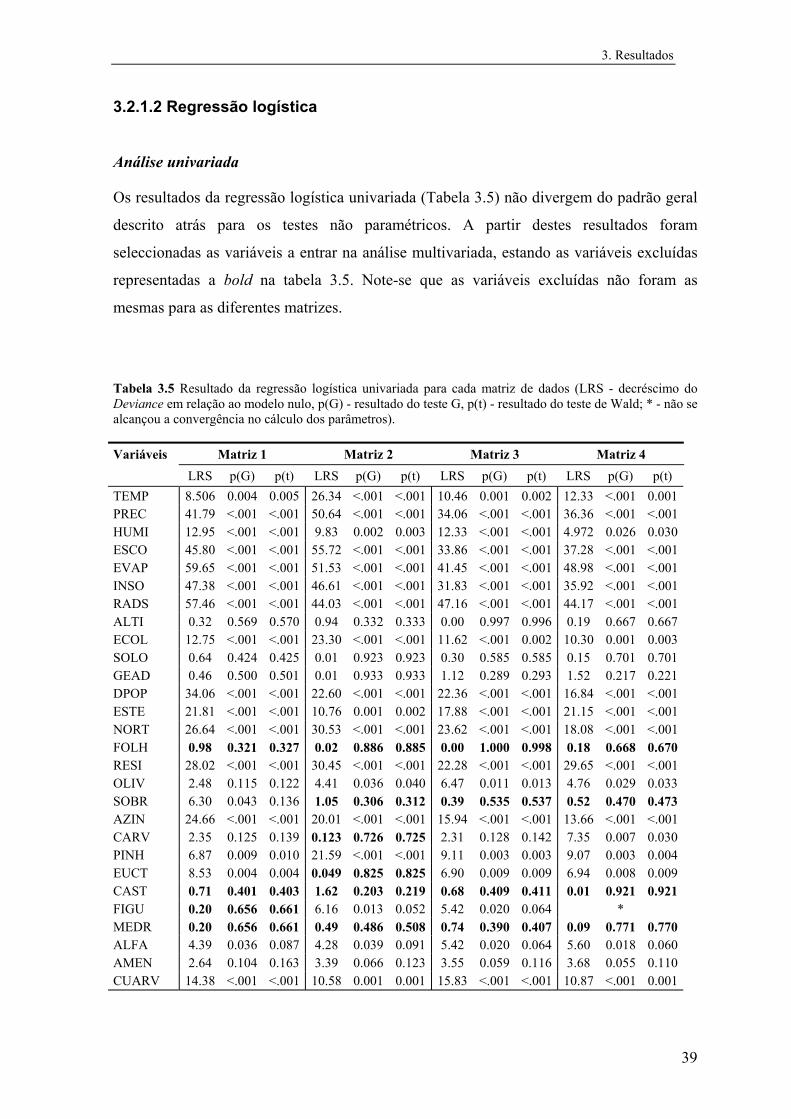
3. Resultados
3.2.1.2 Regressão logística
Análise univariada
Os resultados da regressão logística univariada (Tabela 3.5) não divergem do padrão geral
descrito atrás para os testes não paramétricos. A partir destes resultados foram
seleccionadas as variáveis a entrar na análise multivariada, estando as variáveis excluídas
representadas a bold na tabela 3.5. Note-se que as variáveis excluídas não foram as
mesmas para as diferentes matrizes.
Tabela 3.5 Resultado da regressão logística univariada para cada matriz de dados (LRS - decréscimo do Deviance em relação ao modelo nulo, p(G) - resultado do teste G, p(t) - resultado do teste de Wald; * - não se alcançou a convergência no cálculo dos parâmetros). Variáveis Matriz 1 Matriz 2 Matriz 3 Matriz 4 LRS p(G) p(t) LRS p(G) p(t) LRS p(G) p(t) LRS p(G) p(t) TEMP 8.506 0.004 0.005 26.34 <.001 <.001 10.46 0.001 0.002 12.33 <.001 0.001 PREC 41.79 <.001 <.001 50.64 <.001 <.001 34.06 <.001 <.001 36.36 <.001 <.001 HUMI 12.95 <.001 <.001 9.83 0.002 0.003 12.33 <.001 <.001 4.972 0.026 0.030 ESCO 45.80 <.001 <.001 55.72 <.001 <.001 33.86 <.001 <.001 37.28 <.001 <.001 EVAP 59.65 <.001 <.001 51.53 <.001 <.001 41.45 <.001 <.001 48.98 <.001 <.001 INSO 47.38 <.001 <.001 46.61 <.001 <.001 31.83 <.001 <.001 35.92 <.001 <.001 RADS 57.46 <.001 <.001 44.03 <.001 <.001 47.16 <.001 <.001 44.17 <.001 <.001 ALTI 0.32 0.569 0.570 0.94 0.332 0.333 0.00 0.997 0.996 0.19 0.667 0.667 ECOL 12.75 <.001 <.001 23.30 <.001 <.001 11.62 <.001 0.002 10.30 0.001 0.003 SOLO 0.64 0.424 0.425 0.01 0.923 0.923 0.30 0.585 0.585 0.15 0.701 0.701 GEAD 0.46 0.500 0.501 0.01 0.933 0.933 1.12 0.289 0.293 1.52 0.217 0.221 DPOP 34.06 <.001 <.001 22.60 <.001 <.001 22.36 <.001 <.001 16.84 <.001 <.001 ESTE 21.81 <.001 <.001 10.76 0.001 0.002 17.88 <.001 <.001 21.15 <.001 <.001 NORT 26.64 <.001 <.001 30.53 <.001 <.001 23.62 <.001 <.001 18.08 <.001 <.001 FOLH 0.98 0.321 0.327 0.02 0.886 0.885 0.00 1.000 0.998 0.18 0.668 0.670 RESI 28.02 <.001 <.001 30.45 <.001 <.001 22.28 <.001 <.001 29.65 <.001 <.001 OLIV 2.48 0.115 0.122 4.41 0.036 0.040 6.47 0.011 0.013 4.76 0.029 0.033 SOBR 6.30 0.043 0.136 1.05 0.306 0.312 0.39 0.535 0.537 0.52 0.470 0.473 AZIN 24.66 <.001 <.001 20.01 <.001 <.001 15.94 <.001 <.001 13.66 <.001 <.001 CARV 2.35 0.125 0.139 0.123 0.726 0.725 2.31 0.128 0.142 7.35 0.007 0.030 PINH 6.87 0.009 0.010 21.59 <.001 <.001 9.11 0.003 0.003 9.07 0.003 0.004 EUCT 8.53 0.004 0.004 0.049 0.825 0.825 6.90 0.009 0.009 6.94 0.008 0.009 CAST 0.71 0.401 0.403 1.62 0.203 0.219 0.68 0.409 0.411 0.01 0.921 0.921 FIGU 0.20 0.656 0.661 6.16 0.013 0.052 5.42 0.020 0.064 * MEDR 0.20 0.656 0.661 0.49 0.486 0.508 0.74 0.390 0.407 0.09 0.771 0.770 ALFA 4.39 0.036 0.087 4.28 0.039 0.091 5.42 0.020 0.064 5.60 0.018 0.060 AMEN 2.64 0.104 0.163 3.39 0.066 0.123 3.55 0.059 0.116 3.68 0.055 0.110 CUARV 14.38 <.001 <.001 10.58 0.001 0.001 15.83 <.001 <.001 10.87 <.001 0.001
39
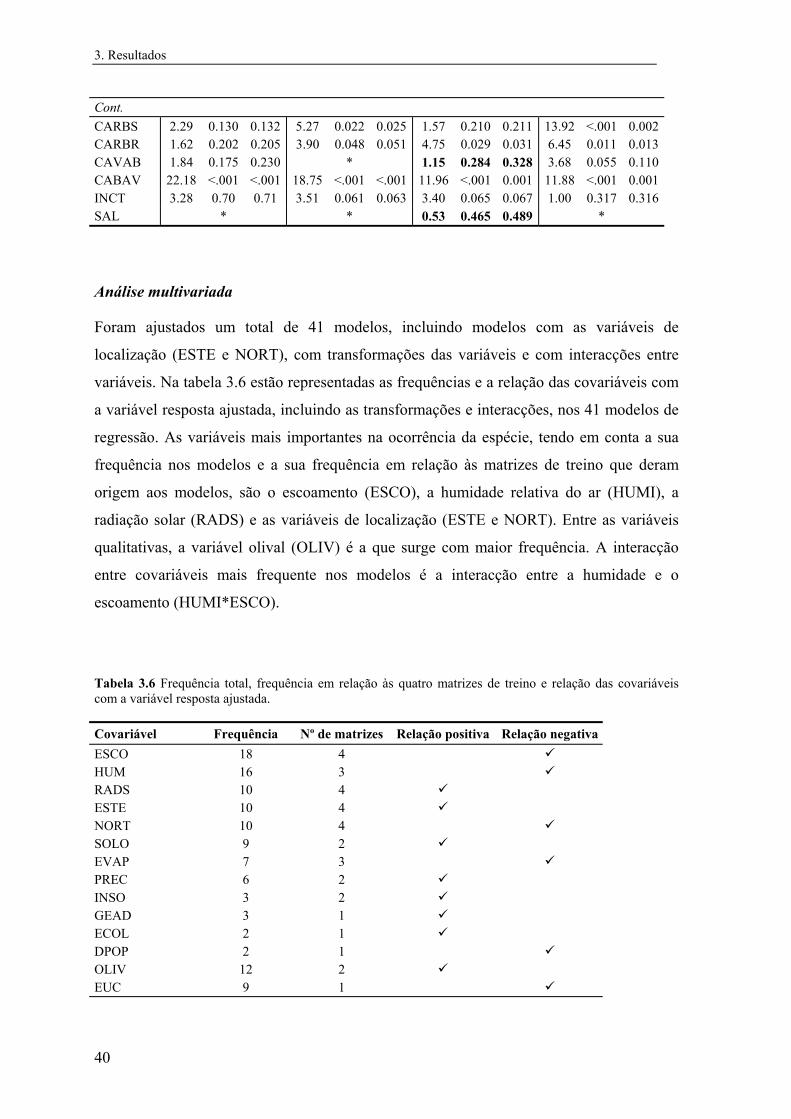
3. Resultados
Cont. CARBS 2.29 0.130 0.132 5.27 0.022 0.025 1.57 0.210 0.211 13.92 <.001 0.002 CARBR 1.62 0.202 0.205 3.90 0.048 0.051 4.75 0.029 0.031 6.45 0.011 0.013 CAVAB 1.84 0.175 0.230 * 1.15 0.284 0.328 3.68 0.055 0.110 CABAV 22.18 <.001 <.001 18.75 <.001 <.001 11.96 <.001 0.001 11.88 <.001 0.001 INCT 3.28 0.70 0.71 3.51 0.061 0.063 3.40 0.065 0.067 1.00 0.317 0.316 SAL * * 0.53 0.465 0.489 *
Análise multivariada
Foram ajustados um total de 41 modelos, incluindo modelos com as variáveis de
localização (ESTE e NORT), com transformações das variáveis e com interacções entre
variáveis. Na tabela 3.6 estão representadas as frequências e a relação das covariáveis com
a variável resposta ajustada, incluindo as transformações e interacções, nos 41 modelos de
regressão. As variáveis mais importantes na ocorrência da espécie, tendo em conta a sua
frequência nos modelos e a sua frequência em relação às matrizes de treino que deram
origem aos modelos, são o escoamento (ESCO), a humidade relativa do ar (HUMI), a
radiação solar (RADS) e as variáveis de localização (ESTE e NORT). Entre as variáveis
qualitativas, a variável olival (OLIV) é a que surge com maior frequência. A interacção
entre covariáveis mais frequente nos modelos é a interacção entre a humidade e o
escoamento (HUMI*ESCO).
Tabela 3.6 Frequência total, frequência em relação às quatro matrizes de treino e relação das covariáveis com a variável resposta ajustada. Covariável Frequência Nº de matrizes Relação positiva Relação negativa ESCO 18 4 HUM 16 3 RADS 10 4 ESTE 10 4 NORT 10 4 SOLO 9 2 EVAP 7 3 PREC 6 2 INSO 3 2 GEAD 3 1 ECOL 2 1 DPOP 2 1 OLIV 12 2 EUC 9 1
40
3. Resultados
Cont. CARBS 7 2 PINH 3 1 FIG 2 1 CARV 1 1 (HUMI)2 9 2 ln(RADS) 7 3 ln(ESCO) 6 2 (EVAP)2 4 2 ln(ESTE) 2 1 (ECOL)2 1 1 HUMI*ESCO 4 3 RADS*GEAD 2 1 ln(RADS)*GEAD 1 1 PREC*RADS 1 1 HUMI*EVAP 1 1 HUMI*SOLO 1 1 INSO*ECOL 1 1 ALT*SOLO 1 1 ESTE*NORT 1 1
Os dez modelos com menores erros de classificação da amostra de validação estão
representados na tabela 3.7, por ordem decrescente da precisão de classificação. Para todos
os modelos o ponto de corte de 0.6 foi o que produziu taxas de classificação da amostra de
treino mais equilibradas, pelo que se utilizou este valor para determinar os valores de
precisão de classificação das amostras de validação. A maioria dos modelos têm origem
nas amostras de treino 3 e 4, excepto o primeiro que tem origem na amostra de treino 1. A
variável ESCO e respectiva transformação é a mais frequente, estando presente em oito dos
dez modelos. Seis dos modelos possuem as variáveis espaciais ESTE e NORT. As
variáveis HUMI e RADS e respectivas transformações surgem em quatro modelos.
41

3. Resultados
Tabela 3.7 Os dez modelos com menores erros de classificação da amostra de validação. Modelo Matriz Fórmula
1 1 β0 +β1(PREC) + β2(HUMI) + β3(ESCO) + β4(EVAP) + β5(RADS)
2 3 β0 + β1(ESTE) + β2(NORT) + β3(OLI) + β4(PINH)
3 4 β0 + β1(NORT*ESTE) + β2(ESTE) + β3(EVAP)
4 4 β0 + β1(ESCO) + β2(ESTE) + β3(NORT) + β4(OLIV)
5 3 β0 + β1(PREC) + β2(HUMI) + β3(ESCO) + β4(RADS) + β5(SOLO) + β6(GEAD) + β7(FIGU)
6 4 β0 + β1(ln(ESCO)) + β2(DPOP) + β3(ln(EAST)) + β4(NORT) + β5 (CARV)
7 3 β0 + β1(PREC) + β2(HUMI)2 + β3(ESCO) + β4(ln(RADS)) + β5(SOLO) + β6(GEAD) + β7(FIGU)
8 4 β0 + β1(ln(ESCO)) + β2(ln(ESTE)) + β3(NORT)
9 3 β0 +β1(ESCO) + β2(HUMI)2 + β3(HUMI*SOLO) + β4(ln(RADS)) + β5(OLIV)
10 4 β0 + β1(ESCO) + β2(ESTE) + β3(NORT)
Selecção do modelo final
Na Figura 3.4 apresentam-se as percentagens de classificações correctas para um ponto de
corte de 0.6 e as estatísticas Deviance, para a amostra de treino e para a amostra de
validação. Os valores de deviance e da estatística de Pearson da amostra de treino, bem
como o valor tabelado de χ2, apresentam-se na tabela 3.8.
O modelo 6 apresenta as precisões de classificação mais elevadas e possui o menor
valor de D para a amostra de treino (Figura 3.4). Porém, a estatística de Pearson não é
significativa (X2 < χ2 0.001; Tabela 3.10) e apresenta os maiores valores médios de D e de
X2 (ponderados pelos respectivos graus de liberdade) para as amostras de validação (Figura
3.6).
O modelo 10 apresenta simultaneamente os valores médios mais baixos de D para
as amostras de validação (Figura 3.4). No entanto, apresenta menores valores médios de
precisão de classificação da amostra de validação, as precisões de classificação da amostra
de treino são também relativamente baixas e o respectivo valor de D ponderado pelos graus
de liberdade é o mais elevado (Figura 3.4).
Os modelos 2, 3 e 4 são os que apresentam valores mais equilibrados entre as
amostras de treino e de validação, no que se refere aos valores de precisão da classificação
e aos valores de D (Figura 3.4). Estes três modelos incluem, no entanto, as variáveis
espaciais (ESTE e NORT), possuindo assim um significado biológico pouco preciso.
O modelo 1, para além de possuir as melhores precisões de classificação das
amostras de validação, apresenta simultaneamente valores de precisão da classificação da
amostra de treino comparativamente elevados e valores de D da amostra de treino e das
42
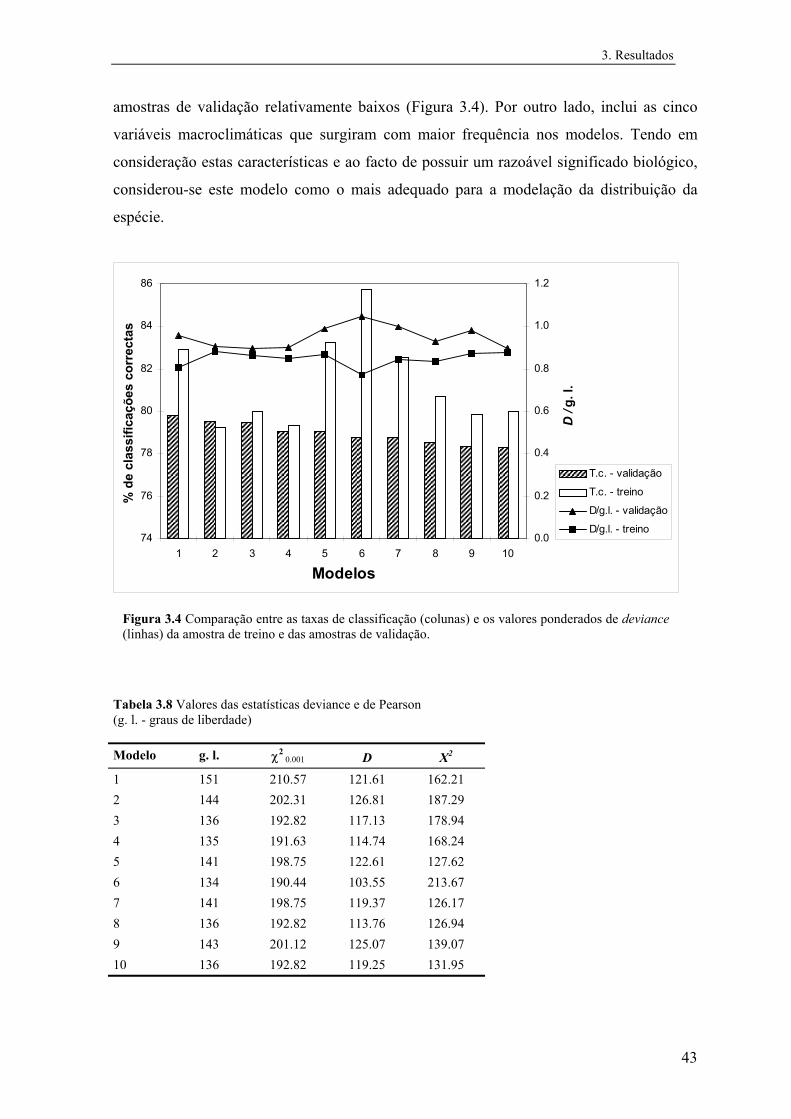
3. Resultados
amostras de validação relativamente baixos (Figura 3.4). Por outro lado, inclui as cinco
variáveis macroclimáticas que surgiram com maior frequência nos modelos. Tendo em
consideração estas características e ao facto de possuir um razoável significado biológico,
considerou-se este modelo como o mais adequado para a modelação da distribuição da
espécie.
���������������������������������������������
���������������������������������������������
���������������������������������������������
����������������������������������������
����������������������������������������
����������������������������������������
����������������������������������������
����������������������������������������
�����������������������������������
�����������������������������������74
76
78
80
82
84
86
1 2 3 4 5 6 7 8 9 10
Modelos
% d
e cl
assi
ficaç
ões
corr
ecta
s
0.0
0.2
0.4
0.6
0.8
1.0
1.2
D /
g. l.
���������������������� T.c. - validação
T.c. - treino
D/g.l. - validação
D/g.l. - treino
Figura 3.4 Comparação entre as taxas de classificação (colunas) e os valores ponderados de deviance (linhas) da amostra de treino e das amostras de validação.
Tabela 3.8 Valores das estatísticas deviance e de Pearson (g. l. - graus de liberdade) Modelo g. l. χ2
0.001 D X2 1 151 210.57 121.61 162.21 2 144 202.31 126.81 187.29 3 136 192.82 117.13 178.94 4 135 191.63 114.74 168.24 5 141 198.75 122.61 127.62 6 134 190.44 103.55 213.67 7 141 198.75 119.37 126.17 8 136 192.82 113.76 126.94 9 143 201.12 125.07 139.07 10 136 192.82 119.25 131.95
43
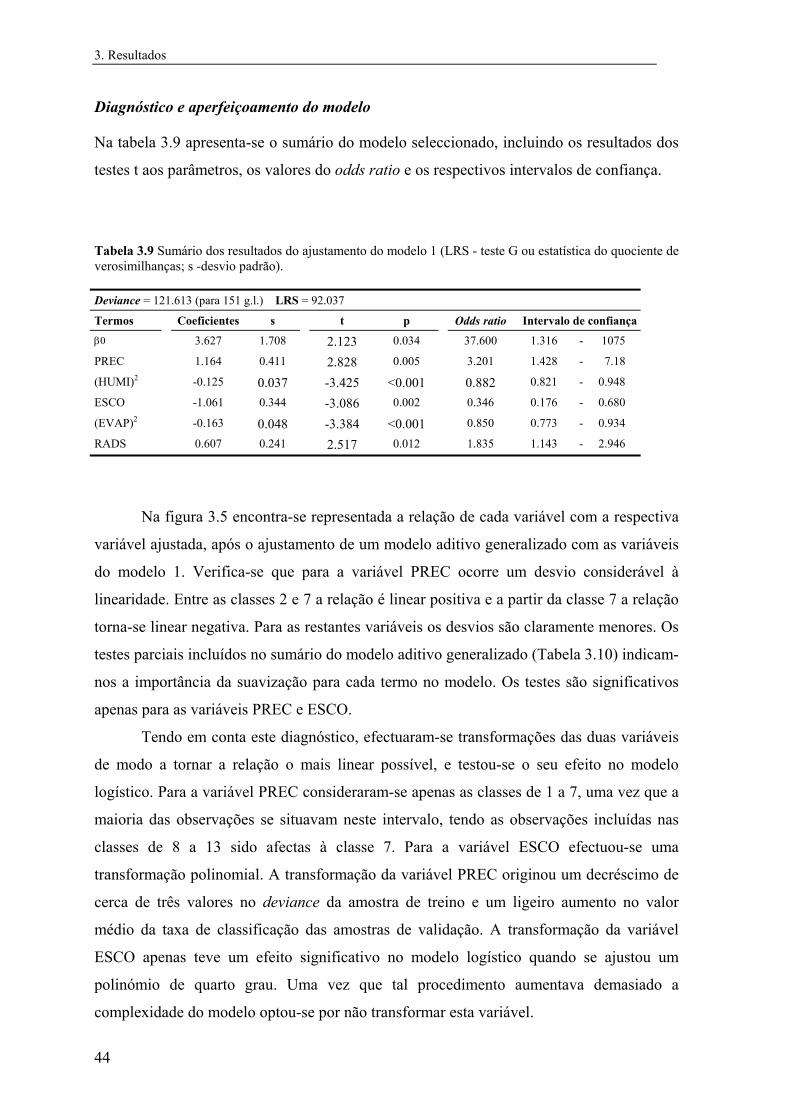
3. Resultados
Diagnóstico e aperfeiçoamento do modelo
Na tabela 3.9 apresenta-se o sumário do modelo seleccionado, incluindo os resultados dos
testes t aos parâmetros, os valores do odds ratio e os respectivos intervalos de confiança.
Tabela 3.9 Sumário dos resultados do ajustamento do modelo 1 (LRS - teste G ou estatística do quociente de verosimilhanças; s -desvio padrão). Deviance = 121.613 (para 151 g.l.) LRS = 92.037
Termos Coeficientes s t p Odds ratio Intervalo de confiança β0 3.627 1.708 2.123 0.034 37.600 1.316 - 1075
PREC 1.164 0.411 2.828 0.005 3.201 1.428 - 7.18
(HUMI)2 -0.125 0.037 -3.425 <0.001 0.882 0.821 - 0.948
ESCO -1.061 0.344 -3.086 0.002 0.346 0.176 - 0.680
(EVAP)2 -0.163 0.048 -3.384 <0.001 0.850 0.773 - 0.934
RADS 0.607 0.241 2.517 0.012 1.835 1.143 - 2.946
Na figura 3.5 encontra-se representada a relação de cada variável com a respectiva
variável ajustada, após o ajustamento de um modelo aditivo generalizado com as variáveis
do modelo 1. Verifica-se que para a variável PREC ocorre um desvio considerável à
linearidade. Entre as classes 2 e 7 a relação é linear positiva e a partir da classe 7 a relação
torna-se linear negativa. Para as restantes variáveis os desvios são claramente menores. Os
testes parciais incluídos no sumário do modelo aditivo generalizado (Tabela 3.10) indicam-
nos a importância da suavização para cada termo no modelo. Os testes são significativos
apenas para as variáveis PREC e ESCO.
Tendo em conta este diagnóstico, efectuaram-se transformações das duas variáveis
de modo a tornar a relação o mais linear possível, e testou-se o seu efeito no modelo
logístico. Para a variável PREC consideraram-se apenas as classes de 1 a 7, uma vez que a
maioria das observações se situavam neste intervalo, tendo as observações incluídas nas
classes de 8 a 13 sido afectas à classe 7. Para a variável ESCO efectuou-se uma
transformação polinomial. A transformação da variável PREC originou um decréscimo de
cerca de três valores no deviance da amostra de treino e um ligeiro aumento no valor
médio da taxa de classificação das amostras de validação. A transformação da variável
ESCO apenas teve um efeito significativo no modelo logístico quando se ajustou um
polinómio de quarto grau. Uma vez que tal procedimento aumentava demasiado a
complexidade do modelo optou-se por não transformar esta variável.
44

3. Resultados
Figura 3.5 Relação entre cada variável incluída no modelo 1 e a respectiva variável ajustada com um modelo aditivo generalizado.
Tabela 3.10 - Sumário do modelo aditivo generalizado (s - função de suavização, g. l. - graus de liberdade, LRS - teste G ou estatística de quociente de verosimilhanças). Deviance = 105.954 (para 136.535 g. l.) LRS = 107.696
Variáveis g. l. Teste χ2 p
s(PREC) 3.0 11.541 0.009 s(HUMID2) 2.9 0.644 0.873 s(ESCOA) 3.0 11.050 0.011 s(EVAP2) 2.7 1.564 0.611 s(RADSOL) 2.9 0.623 0.885
O modelo final
Na tabela 3.11 apresenta-se o sumário do resultado do ajustamento do modelo 1 após o re-
escalonamento da variável. Relativamente ao modelo anterior verifica-se um decréscimo
de 3.22 valores do deviance e um acréscimo de 0.391 no valor de t para a variável PREC.
Os coeficientes e os respectivos valores de t das restantes variáveis mantiveram-se
idênticos.
45
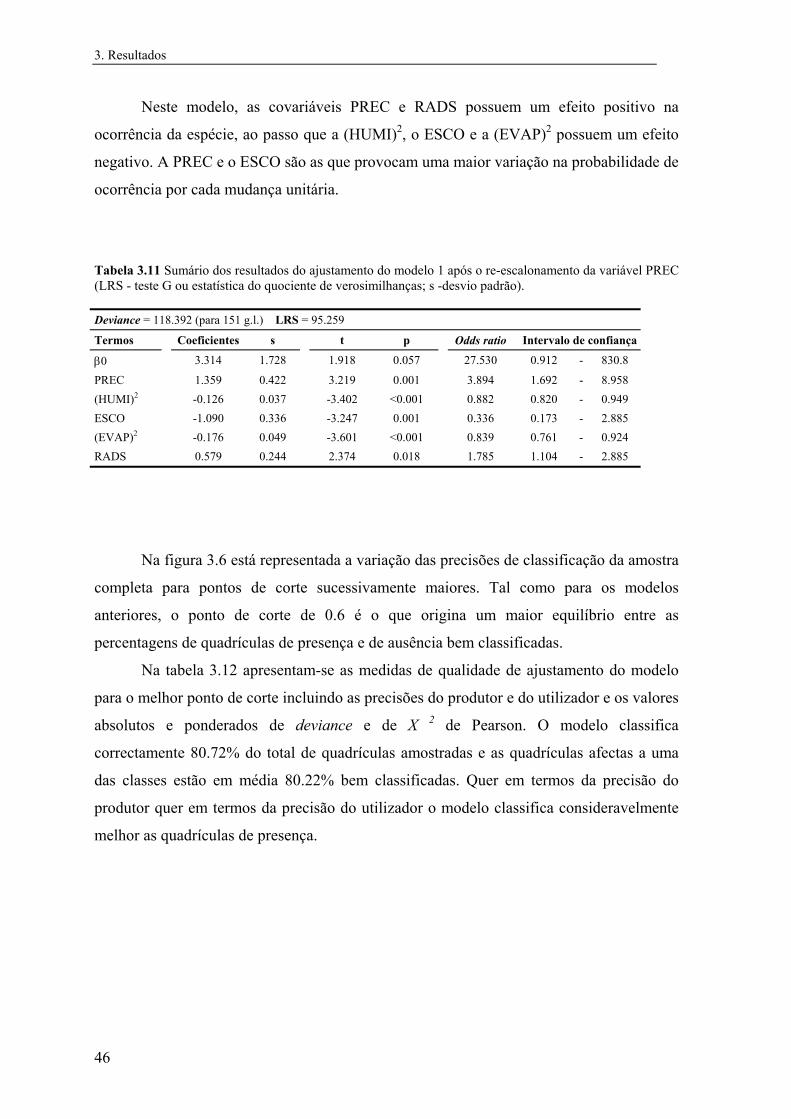
3. Resultados
Neste modelo, as covariáveis PREC e RADS possuem um efeito positivo na
ocorrência da espécie, ao passo que a (HUMI)2, o ESCO e a (EVAP)2 possuem um efeito
negativo. A PREC e o ESCO são as que provocam uma maior variação na probabilidade de
ocorrência por cada mudança unitária.
Tabela 3.11 Sumário dos resultados do ajustamento do modelo 1 após o re-escalonamento da variável PREC (LRS - teste G ou estatística do quociente de verosimilhanças; s -desvio padrão). Deviance = 118.392 (para 151 g.l.) LRS = 95.259
Termos Coeficientes s t p Odds ratio Intervalo de confiança
β0 3.314 1.728 1.918 0.057 27.530 0.912 - 830.8
PREC 1.359 0.422 3.219 0.001 3.894 1.692 - 8.958 (HUMI)2 -0.126 0.037 -3.402 <0.001 0.882 0.820 - 0.949 ESCO -1.090 0.336 -3.247 0.001 0.336 0.173 - 2.885 (EVAP)2 -0.176 0.049 -3.601 <0.001 0.839 0.761 - 0.924 RADS 0.579 0.244 2.374 0.018 1.785 1.104 - 2.885
Na figura 3.6 está representada a variação das precisões de classificação da amostra
completa para pontos de corte sucessivamente maiores. Tal como para os modelos
anteriores, o ponto de corte de 0.6 é o que origina um maior equilíbrio entre as
percentagens de quadrículas de presença e de ausência bem classificadas.
Na tabela 3.12 apresentam-se as medidas de qualidade de ajustamento do modelo
para o melhor ponto de corte incluindo as precisões do produtor e do utilizador e os valores
absolutos e ponderados de deviance e de X 2 de Pearson. O modelo classifica
correctamente 80.72% do total de quadrículas amostradas e as quadrículas afectas a uma
das classes estão em média 80.22% bem classificadas. Quer em termos da precisão do
produtor quer em termos da precisão do utilizador o modelo classifica consideravelmente
melhor as quadrículas de presença.
46
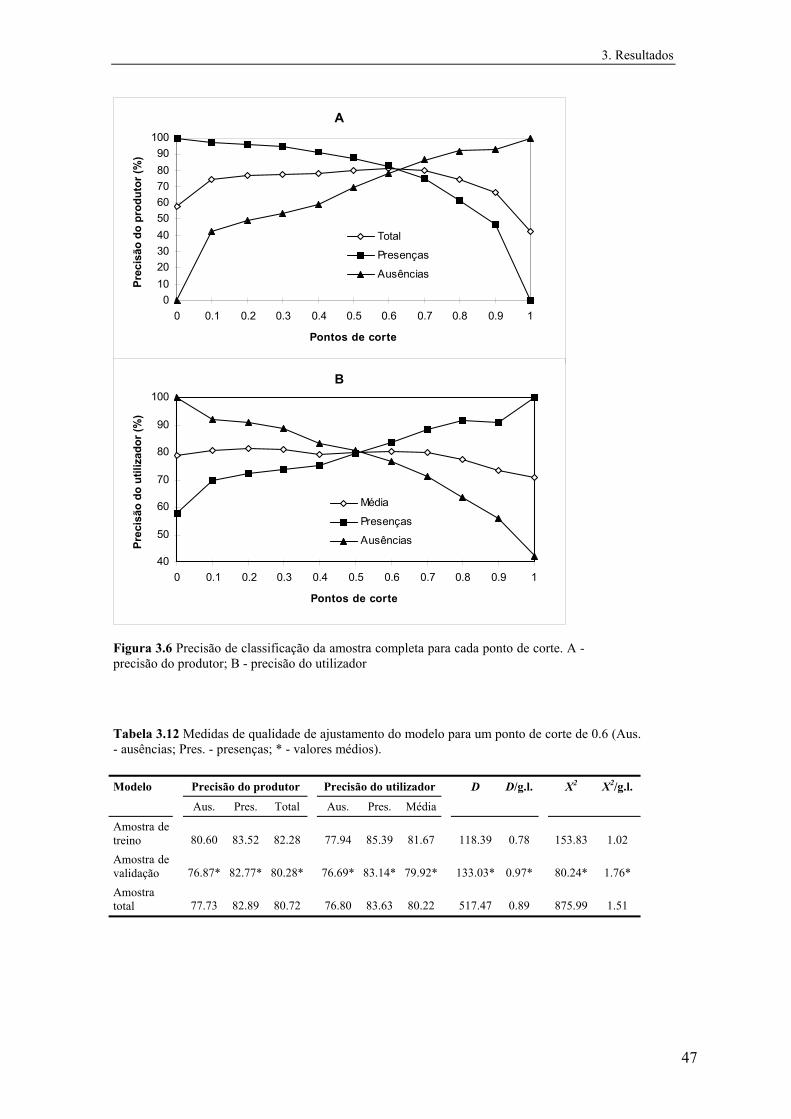
3. Resultados
A
0102030405060708090
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Pontos de corte
Prec
isão
do
prod
utor
(%)
Total
Presenças
Ausências
B
40
50
60
70
80
90
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Pontos de corte
Prec
isão
do
utili
zado
r (%
)
Média
Presenças
Ausências
Figura 3.6 Precisão de classificação da amostra completa para cada ponto de corte. A - precisão do produtor; B - precisão do utilizador
Tabela 3.12 Medidas de qualidade de ajustamento do modelo para um ponto de corte de 0.6 (Aus. - ausências; Pres. - presenças; * - valores médios). Modelo Precisão do produtor Precisão do utilizador D D/g.l. X2 X2/g.l.
Aus. Pres. Total Aus. Pres. Média
Amostra de treino
80.60 83.52 82.28 77.94 85.39 81.67 118.39 0.78 153.83 1.02
Amostra de validação
76.87* 82.77* 80.28* 76.69* 83.14* 79.92* 133.03* 0.97* 80.24* 1.76*
Amostra total
77.73 82.89 80.72 76.80 83.63 80.22 517.47 0.89 875.99 1.51
47

3. Resultados
Os gráficos de diagnóstico do modelo (Figura 3.7), mostram que os outliers mais
importantes correspondem a quadrículas de ausência da espécie, o que justifica os menores
valores de percentagem de quadrículas correctamente classificadas obtidos para esta classe.
Figura 3.7 Gráficos de diagnóstico da regressão logística
3.2.1.3 Árvores de classificação
Na tabela 3.13 apresentam-se as variáveis e o número de nós terminais dos oito modelos
resultantes, numerados por ordem decrescente do valor médio da precisão de classificação
das amostras de validação. Os modelos 3 e 4 são os que apresentam simultaneamente
menor número de variáveis e de nós terminais. As variáveis EVAP e RADS são as mais
frequentes, estando presentes em cinco dos oito modelos. As variáveis HUMI e ESTE
surgem em quatro modelos, a DPOP e a NORT em três, a ESCO, a PREC e a ECOL em
dois..
Tabela 3.13 As oito árvores de classificação resultantes por ordem decrescente do valor médio dos erros de classificação das amostras de validação. Modelo Matriz Nº de nós terminais Variáveis incluídas na árvore 1 2 6 PREC, EVAP, ESTE, NORT 2 1 8 HUMI, EVAP, ESCO, RADS, ALTI, SOLO, CUARV 3 3 5 PREC, HUMI, RADS, ECOL 4 1 5 EVAP, ESTE, NORT 5 4 7 TEMP, EVAP, RADS, GEAD, RESI, CARBR 6 3 8 HUMI, RADS, DPOP, ESTE, OLI, CARBS 7 2 6 HUMI, EVAP, ESCO, ECOL, DPOP 8 4 6 RADS, DPOP, ESTE, NORT, FOL
48
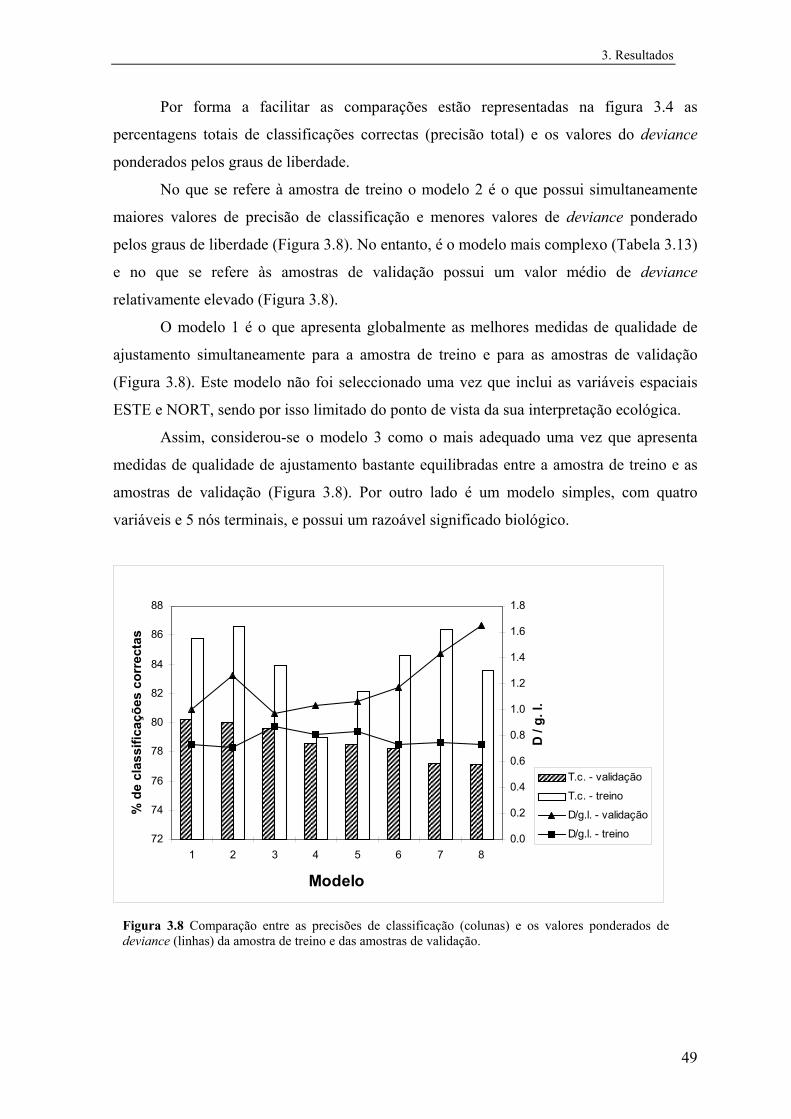
3. Resultados
Por forma a facilitar as comparações estão representadas na figura 3.4 as
percentagens totais de classificações correctas (precisão total) e os valores do deviance
ponderados pelos graus de liberdade.
No que se refere à amostra de treino o modelo 2 é o que possui simultaneamente
maiores valores de precisão de classificação e menores valores de deviance ponderado
pelos graus de liberdade (Figura 3.8). No entanto, é o modelo mais complexo (Tabela 3.13)
e no que se refere às amostras de validação possui um valor médio de deviance
relativamente elevado (Figura 3.8).
O modelo 1 é o que apresenta globalmente as melhores medidas de qualidade de
ajustamento simultaneamente para a amostra de treino e para as amostras de validação
(Figura 3.8). Este modelo não foi seleccionado uma vez que inclui as variáveis espaciais
ESTE e NORT, sendo por isso limitado do ponto de vista da sua interpretação ecológica.
Assim, considerou-se o modelo 3 como o mais adequado uma vez que apresenta
medidas de qualidade de ajustamento bastante equilibradas entre a amostra de treino e as
amostras de validação (Figura 3.8). Por outro lado é um modelo simples, com quatro
variáveis e 5 nós terminais, e possui um razoável significado biológico.
������������������������������������������������������
������������������������������������������������
������������������������������������������������
�����������������������������������
������������������������������������������
������������������������������������������
������������������������������������
������������������������������
72
74
76
78
80
82
84
86
88
1 2 3 4 5 6 7 8
Modelo
% d
e cl
assi
ficaç
ões
corr
ecta
s
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
D /
g. l.
������������T.c. - validação
T.c. - treino
D/g.l. - validação
D/g.l. - treino
Figura 3.8 Comparação entre as precisões de classificação (colunas) e os valores ponderados de deviance (linhas) da amostra de treino e das amostras de validação.
49

3. Resultados
Na figura 3.9 está representada a árvore de classificação referente ao modelo 3 com
a estrutura interna apresentada na tabela 3.14. Segundo o modelo a espécie ocorre para
valores de RADS superiores ou iguais a 3 (145Kcal/km2) e valores de PREC inferiores ou
iguais a 3 (500-600 mm), ou para valores de PREC superiores ou iguais a 4 (600-700mm)
e valores de HUMI inferiores ou iguais a 3 (70-75%) e classes de ECOL superiores ou
iguais a 4 (desde a região Sub-Montano - Termo-Subatlântico à região
Psamo/Eolo/Aluvio/Halo - Mediterrânico).
Note-se que o espaçamento entre os níveis é proporcional à importância do
respectivo nó. Assim, a separação com maior significado é introduzida pela variável
RADS, dando origem ao primeiro nó terminal (“ausência”) com uma probabilidade de erro
apenas de 0.09 (Tabela 3.14). Os nós terminais com maior probabilidade de erro são o
terceiro e o quinto, respectivamente com probabilidades de 0.333 e 0.307, correspondendo
ambos à resposta “ausência”. Os dois nós terminais correspondentes à resposta “presença”
possuem probabilidades de erro relativamente baixas (0.105 e 0.152). Deste modo, as
maiores probabilidades de erro deste modelo resultam da classificação como “ausência”
das quadrículas em que a radiação solar toma valores superiores à classe 2.
Figura 3.9 Árvore de classificação seleccionada.
50

3. Resultados
Tabela 3.14 Estrutura interna da árvore de classificação seleccionada (n - nº de observações; D - deviance; * - nós terminais; os números dos nós correspondem aos números da árvore original, antes de se proceder à sua simplificação). Nó n D Resposta Probabilidades
1) raiz 149 203.000 presença ( 0.4228, 0.5772 )
2) RADS<2.5 33 20.110 ausência ( 0.9091, 0.0909 ) *
3) RADS>2.5 116 138.500 presença ( 0.2845, 0.7155 )
6) PREC<3.5 38 25.570 presença ( 0.1053, 0.8947 ) *
7) PREC>3.5 78 102.900 presença ( 0.3718, 0.6282 )
14) HUMI<3.5 52 53.660 presença ( 0.2115, 0.7885 )
28) ECOL<3.5 6 7.638 ausência ( 0.6667, 0.3333 ) *
29) ECOL>3.5 46 39.230 presença ( 0.1522, 0.8478 ) *
15) HUMI>3.5 26 32.100 ausência ( 0.6923, 0.3077 ) *
Na tabela 3.15 apresentam-se as medidas de qualidade de ajustamento do modelo
incluindo as precisões do produtor e do utilizador, os valores de deviance e respectivos
valores ponderados pelos graus de liberdade. O modelo classifica correctamente 80.72%
do total de quadrículas amostradas e as quadrículas afectas a uma das classes estão em
média 80.29% bem classificadas. Em termos da precisão do produtor o modelo classifica
ligeiramente melhor as quadrículas de ausência. A precisão do utilizador é no entanto
consideravelmente superior para as quadrículas de presença.
Tabela 3.15 Medidas de qualidade de ajustamento do modelo para um ponto de corte de 0.5 (Aus. - ausências; Pres. - presenças; * - valores médios). Modelo Precisão do produtor Precisão do utilizador D D/g.l.
Aus. Pres. Total Aus. Pres. Média
Amostra de treino
82.54 84.88 83.89 73.31 87.01 80.31 124.65 0.87
Amostra de validação
81.41 78.26 79.58 72.57 85.33 78.95 136.84 0.97
Amostra completa
81.78 79.94 80.72 74.81 85.76 80.29 535.16 0.92
51
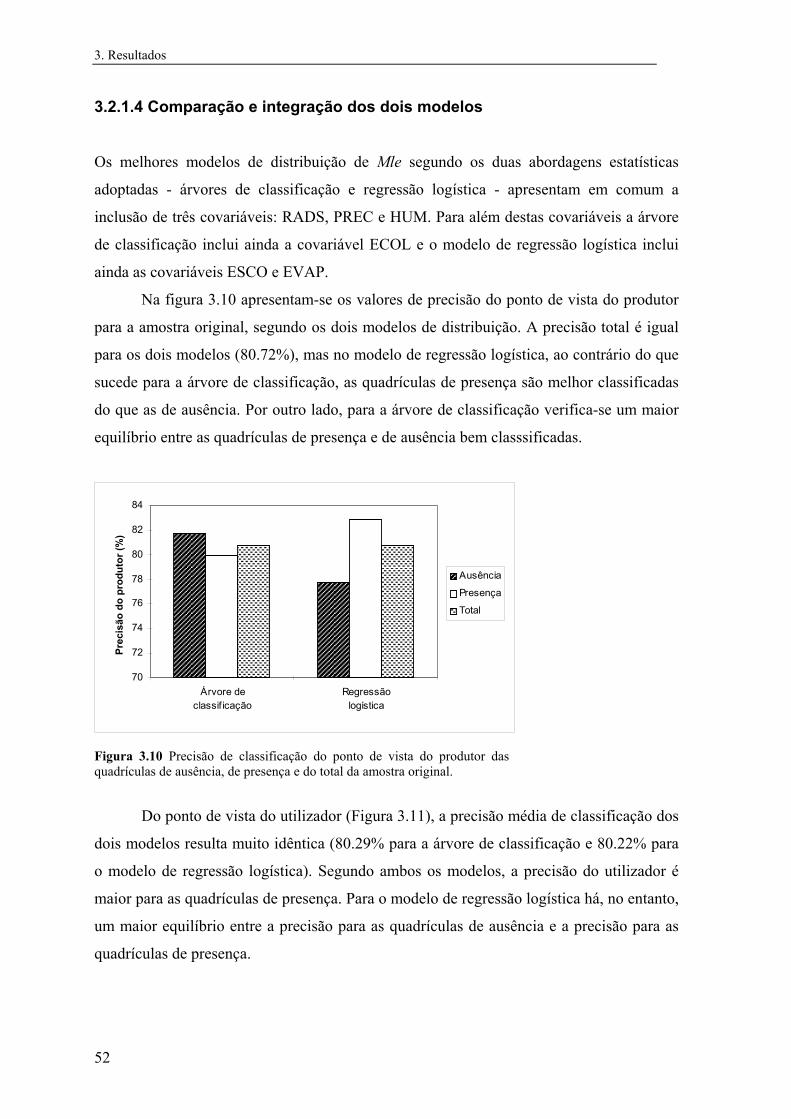
3. Resultados
3.2.1.4 Comparação e integração dos dois modelos
Os melhores modelos de distribuição de Mle segundo os duas abordagens estatísticas
adoptadas - árvores de classificação e regressão logística - apresentam em comum a
inclusão de três covariáveis: RADS, PREC e HUM. Para além destas covariáveis a árvore
de classificação inclui ainda a covariável ECOL e o modelo de regressão logística inclui
ainda as covariáveis ESCO e EVAP.
Na figura 3.10 apresentam-se os valores de precisão do ponto de vista do produtor
para a amostra original, segundo os dois modelos de distribuição. A precisão total é igual
para os dois modelos (80.72%), mas no modelo de regressão logística, ao contrário do que
sucede para a árvore de classificação, as quadrículas de presença são melhor classificadas
do que as de ausência. Por outro lado, para a árvore de classificação verifica-se um maior
equilíbrio entre as quadrículas de presença e de ausência bem classsificadas.
�����������������������������������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
����������������������������������������������������������������������������������������������������������������������������������
����������������������������������������������������������������������������������������������������������������������������������70
72
74
76
78
80
82
84
Árvore declassif icação
Regressãologística
Prec
isão
do
prod
utor
(%)
���Ausência
Presença������ Total
Figura 3.10 Precisão de classificação do ponto de vista do produtor das quadrículas de ausência, de presença e do total da amostra original.
Do ponto de vista do utilizador (Figura 3.11), a precisão média de classificação dos
dois modelos resulta muito idêntica (80.29% para a árvore de classificação e 80.22% para
o modelo de regressão logística). Segundo ambos os modelos, a precisão do utilizador é
maior para as quadrículas de presença. Para o modelo de regressão logística há, no entanto,
um maior equilíbrio entre a precisão para as quadrículas de ausência e a precisão para as
quadrículas de presença.
52
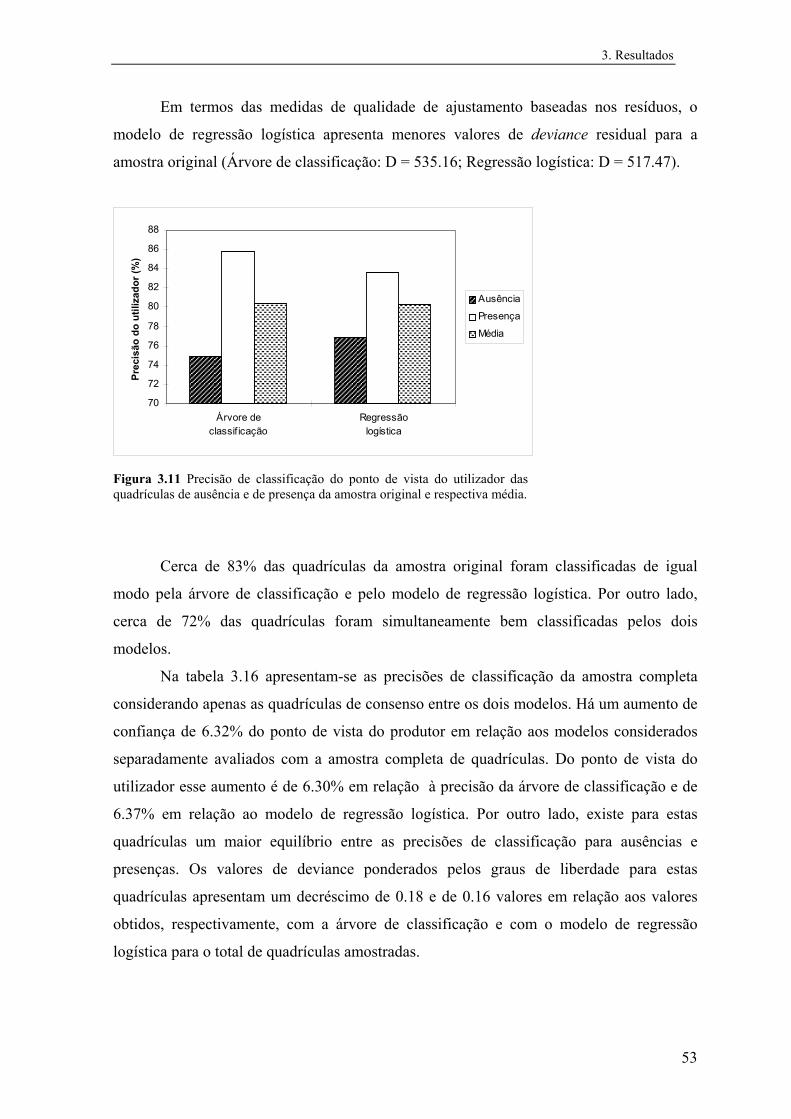
3. Resultados
Em termos das medidas de qualidade de ajustamento baseadas nos resíduos, o
modelo de regressão logística apresenta menores valores de deviance residual para a
amostra original (Árvore de classificação: D = 535.16; Regressão logística: D = 517.47).
����������������������������������������������������
�����������������������������������������������������������������
����������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
70
72
74
76
78
80
82
84
86
88
Árvore declassif icação
Regressãologística
Prec
isão
do
utili
zado
r (%
)
����Ausência
Presença��������Média
Figura 3.11 Precisão de classificação do ponto de vista do utilizador das quadrículas de ausência e de presença da amostra original e respectiva média.
Cerca de 83% das quadrículas da amostra original foram classificadas de igual
modo pela árvore de classificação e pelo modelo de regressão logística. Por outro lado,
cerca de 72% das quadrículas foram simultaneamente bem classificadas pelos dois
modelos.
Na tabela 3.16 apresentam-se as precisões de classificação da amostra completa
considerando apenas as quadrículas de consenso entre os dois modelos. Há um aumento de
confiança de 6.32% do ponto de vista do produtor em relação aos modelos considerados
separadamente avaliados com a amostra completa de quadrículas. Do ponto de vista do
utilizador esse aumento é de 6.30% em relação à precisão da árvore de classificação e de
6.37% em relação ao modelo de regressão logística. Por outro lado, existe para estas
quadrículas um maior equilíbrio entre as precisões de classificação para ausências e
presenças. Os valores de deviance ponderados pelos graus de liberdade para estas
quadrículas apresentam um decréscimo de 0.18 e de 0.16 valores em relação aos valores
obtidos, respectivamente, com a árvore de classificação e com o modelo de regressão
logística para o total de quadrículas amostradas.
53
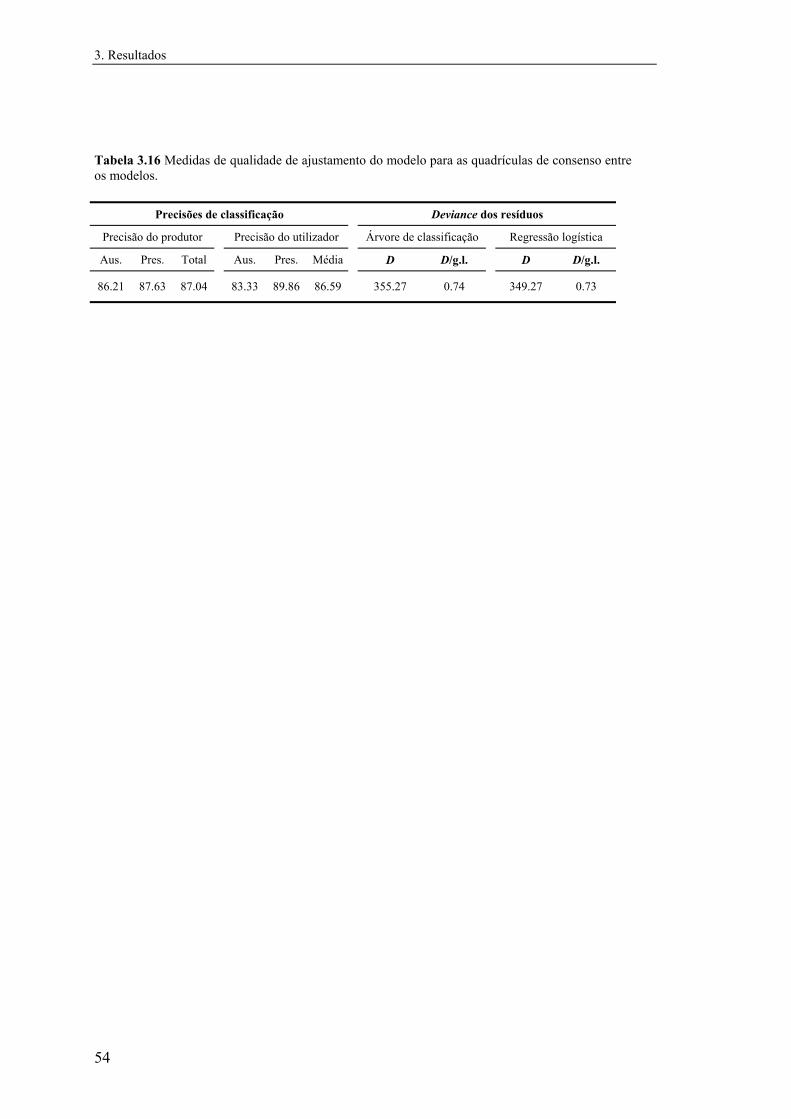
3. Resultados
Tabela 3.16 Medidas de qualidade de ajustamento do modelo para as quadrículas de consenso entre os modelos.
Precisões de classificação Deviance dos resíduos
Precisão do produtor Precisão do utilizador Árvore de classificação Regressão logística
Aus. Pres. Total Aus. Pres. Média D D/g.l. D D/g.l.
86.21 87.63 87.04 83.33 89.86 86.59 355.27 0.74 349.27 0.73
54
3. Resultados
3.2.2 Emys orbicularis 3.2.2.1 Análise exploratória
Os resultados dos testes de Kolmogorov-Smirnov e dos testes de Mann-Whitney (Tabela
3.17) mostram que não ocorrem diferenças significativas (p<0.05) entre as duas classes,
respectivamente, nas distribuições e valores médios das covariáveis HUMI, ALTI, SOLO e
GEAD. Os gráficos da figura 3.12 mostram como variam a média e a dispersão dos dados
com a ausência e a presença da espécie para as variáveis onde se verificaram diferenças
significativas.
Tabela 3.17 Resultados do teste de Kolmogorov-Smirnov (K.-S.) e do teste de Mann-Whitney (M.-W.) para cada variável quantitativa (s - desvio padrão).
Variáveis Ausências Presenças K. - S. M. - W. Média s Média s p p TEMP 4.167 0.930 4.767 0.504 < 0.05 <0.005 PREC 6.208 2.501 3.433 1.569 < 0.001 <0.0001 HUMI 4.000 0.899 3.867 1.008 n.s. n.s. ESCO 6.875 2.481 3.967 1.650 < 0.001 <0.0001 EVAP 5.396 1.267 3.667 1.322 < 0.001 <0.0001 INSO 8.375 2.321 11.433 1.888 < 0.001 <0.0001 RADS 2.604 1.198 4.767 1.278 < 0.001 <0.0001 ALTI 3.542 1.901 2.767 1.382 n.s. n.s. ECOL 4.729 1.469 6.100 1.029 < 0.001 <0.0001 SOLO 3.729 1.216 3.267 1.285 n.s. n.s. GEAD 4.792 2.163 4.167 1.877 n.s. n.s. DPOP 3.208 1.762 1.767 1.501 < 0.01 <0.0005 ESTE 12.250 6.296 15.400 5.506 < 0.01 <0.05 NORT 36.771 14.227 17.367 11.657 < 0.001 <0.0001
Figura 3.12 Média Desvio padrão (SD) das variáveis quantitativas (testes de Mann-Whitney e Kolmogorov-Smirnov significativos p<0.05) para cada classe. (continua na página seguinte).
±
55
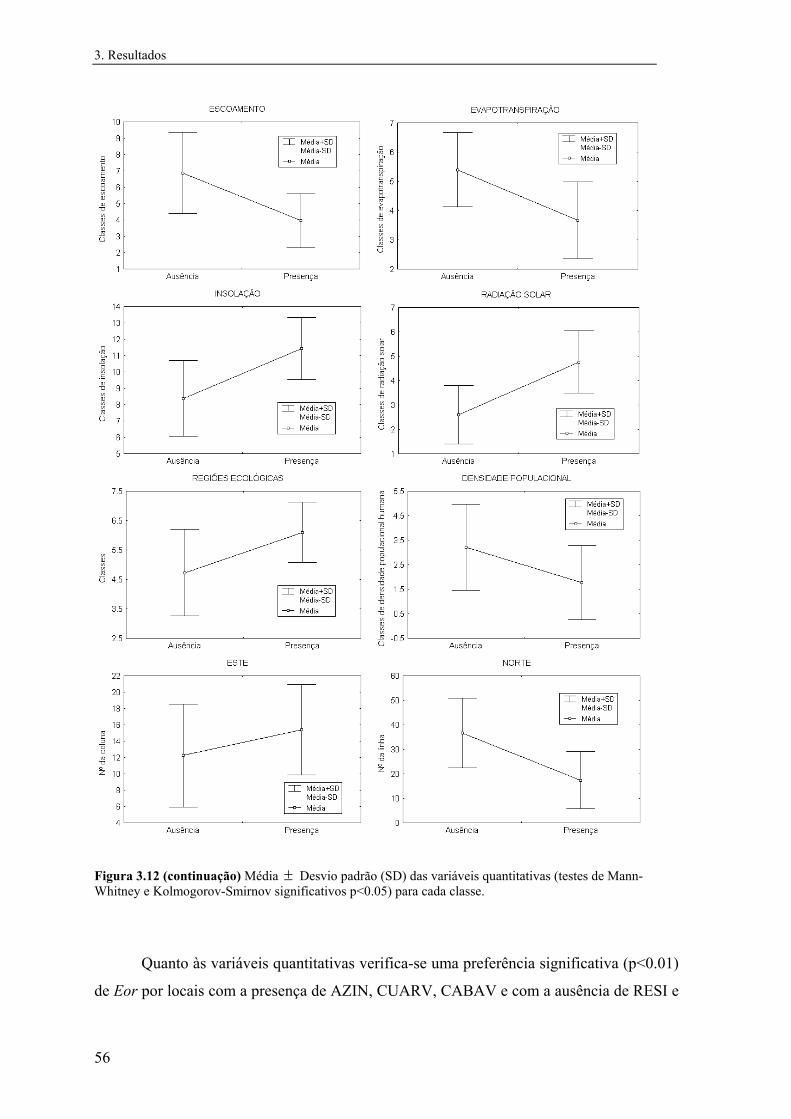
3. Resultados
Figura 3.12 (continuação) Média Desvio padrão (SD) das variáveis quantitativas (testes de Mann-Whitney e Kolmogorov-Smirnov significativos p<0.05) para cada classe.
±
Quanto às variáveis quantitativas verifica-se uma preferência significativa (p<0.01)
de Eor por locais com a presença de AZIN, CUARV, CABAV e com a ausência de RESI e
56
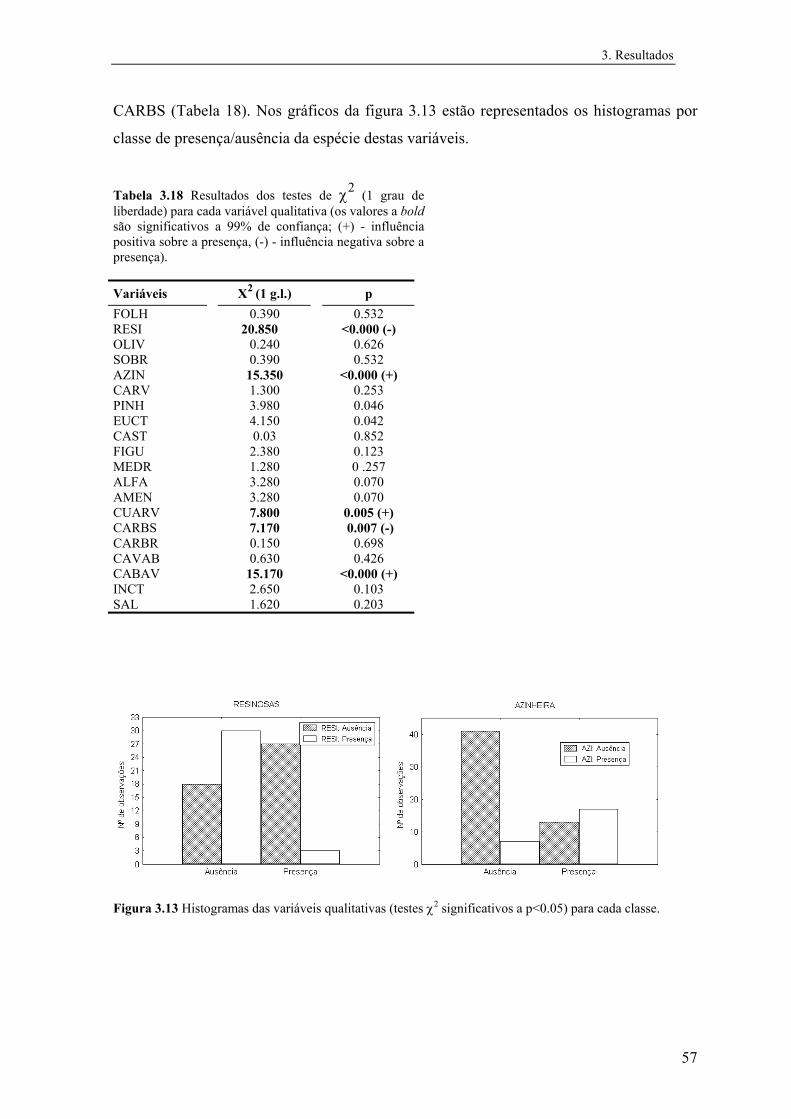
3. Resultados
CARBS (Tabela 18). Nos gráficos da figura 3.13 estão representados os histogramas por
classe de presença/ausência da espécie destas variáveis.
Tabela 3.18 Resultados dos testes de χ2 (1 grau de liberdade) para cada variável qualitativa (os valores a bold são significativos a 99% de confiança; (+) - influência positiva sobre a presença, (-) - influência negativa sobre a presença). Variáveis X2 (1 g.l.) p FOLH 0.390 0.532 RESI 20.850 <0.000 (-) OLIV 0.240 0.626 SOBR 0.390 0.532 AZIN 15.350 <0.000 (+) CARV 1.300 0.253 PINH 3.980 0.046 EUCT 4.150 0.042 CAST 0.03 0.852 FIGU 2.380 0.123 MEDR 1.280 0 .257 ALFA 3.280 0.070 AMEN 3.280 0.070 CUARV 7.800 0.005 (+) CARBS 7.170 0.007 (-) CARBR 0.150 0.698 CAVAB 0.630 0.426 CABAV 15.170 <0.000 (+) INCT 2.650 0.103 SAL 1.620 0.203
Figura 3.13 Histogramas das variáveis qualitativas (testes χ2 significativos a p<0.05) para cada classe.
57
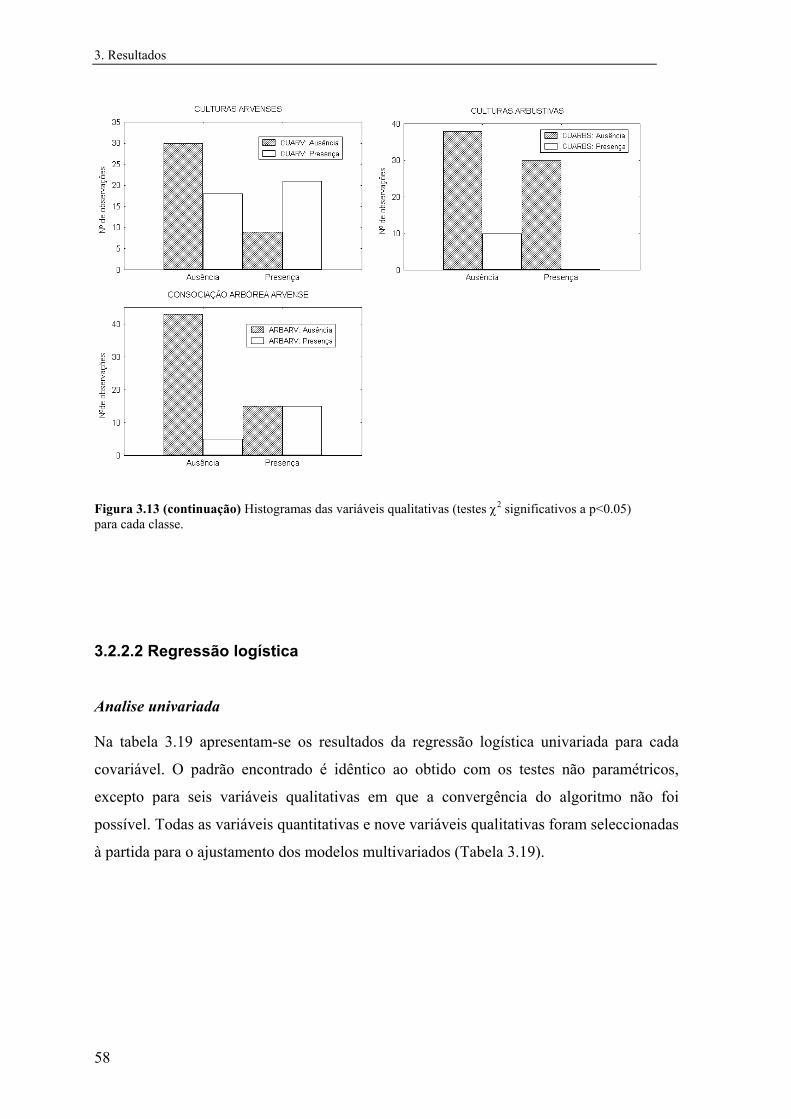
3. Resultados
Figura 3.13 (continuação) Histogramas das variáveis qualitativas (testes χ2 significativos a p<0.05) para cada classe.
3.2.2.2 Regressão logística
Analise univariada
Na tabela 3.19 apresentam-se os resultados da regressão logística univariada para cada
covariável. O padrão encontrado é idêntico ao obtido com os testes não paramétricos,
excepto para seis variáveis qualitativas em que a convergência do algoritmo não foi
possível. Todas as variáveis quantitativas e nove variáveis qualitativas foram seleccionadas
à partida para o ajustamento dos modelos multivariados (Tabela 3.19).
58
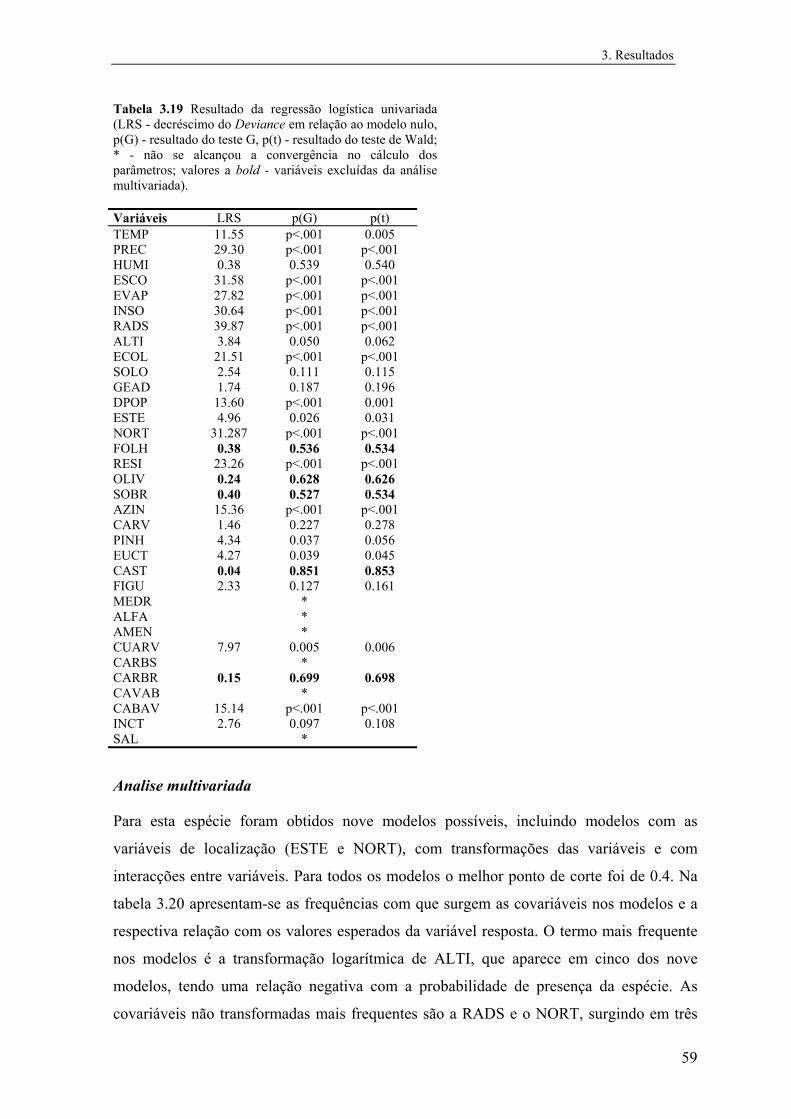
3. Resultados
Tabela 3.19 Resultado da regressão logística univariada (LRS - decréscimo do Deviance em relação ao modelo nulo, p(G) - resultado do teste G, p(t) - resultado do teste de Wald; * - não se alcançou a convergência no cálculo dos parâmetros; valores a bold - variáveis excluídas da análise multivariada). Variáveis LRS p(G) p(t) TEMP 11.55 p<.001 0.005 PREC 29.30 p<.001 p<.001 HUMI 0.38 0.539 0.540 ESCO 31.58 p<.001 p<.001 EVAP 27.82 p<.001 p<.001 INSO 30.64 p<.001 p<.001 RADS 39.87 p<.001 p<.001 ALTI 3.84 0.050 0.062 ECOL 21.51 p<.001 p<.001 SOLO 2.54 0.111 0.115 GEAD 1.74 0.187 0.196 DPOP 13.60 p<.001 0.001 ESTE 4.96 0.026 0.031 NORT 31.287 p<.001 p<.001 FOLH 0.38 0.536 0.534 RESI 23.26 p<.001 p<.001 OLIV 0.24 0.628 0.626 SOBR 0.40 0.527 0.534 AZIN 15.36 p<.001 p<.001 CARV 1.46 0.227 0.278 PINH 4.34 0.037 0.056 EUCT 4.27 0.039 0.045 CAST 0.04 0.851 0.853 FIGU 2.33 0.127 0.161 MEDR * ALFA * AMEN * CUARV 7.97 0.005 0.006 CARBS * CARBR 0.15 0.699 0.698 CAVAB * CABAV 15.14 p<.001 p<.001 INCT 2.76 0.097 0.108 SAL *
Analise multivariada
Para esta espécie foram obtidos nove modelos possíveis, incluindo modelos com as
variáveis de localização (ESTE e NORT), com transformações das variáveis e com
interacções entre variáveis. Para todos os modelos o melhor ponto de corte foi de 0.4. Na
tabela 3.20 apresentam-se as frequências com que surgem as covariáveis nos modelos e a
respectiva relação com os valores esperados da variável resposta. O termo mais frequente
nos modelos é a transformação logarítmica de ALTI, que aparece em cinco dos nove
modelos, tendo uma relação negativa com a probabilidade de presença da espécie. As
covariáveis não transformadas mais frequentes são a RADS e o NORT, surgindo em três
59

3. Resultados
dos nove modelos, estando relacionadas, respectivamente, positiva e negativamente com a
probabilidade de ocorrência da espécie.
Tabela 3.20 Frequência nos modelos e relação das covariáveis com o valor esperado da variável resposta. Covariável Frequência Relação positiva Relação negativa RADS 3 NORT 3 ESTE 2 ESCO 1 ALTI 1 RESI 1 AZI 1 Ln(ALT) 5 (RADS)2 1 Ln(ESTE) 1 ESCO*RADS 1 RADS*Ln(ALTI) 1 NORT*ESTE 1
Os modelos obtidos encontram-se esquematizados na tabela 3.21, por ordem
decrescente dos erros de classificação da amostra de validação. Todos os modelos são
muito simples, com duas a três covariáveis. As variáveis espaciais surgem em quatro dos
nove modelos.
Tabela 3.21 Os nove modelos por ordem decrescente dos erros de classificação da amostra de validação. Modelo Fórmula
1 β0 +β1(RADS) + β2(ESCO)
2 β0 + β1(NORT) + β2(AZI)
3 β0 + β1(ESTE) + β2(NORT*ESTE) + β3(ln(ALTI))
4 β0 + β1(RADS) + β2(ESCO*RADS)
5 β0 + β1(ln(ESTE)) + β2(NORT) + β3(ln(ALTI))
6 β0 + β1(ESTE) + β2(NORT) + β3(ALTI)
7 β0 + β1(RADS)2 + β2(ln(ALTI)) + β3(RES)
8 β0 + β1(RADS*ln(ALTI)) + β2(ln(ALTI)) + β3(RES)
9 β0 + β1(RADS) + β2(Ln(ALTI)
60
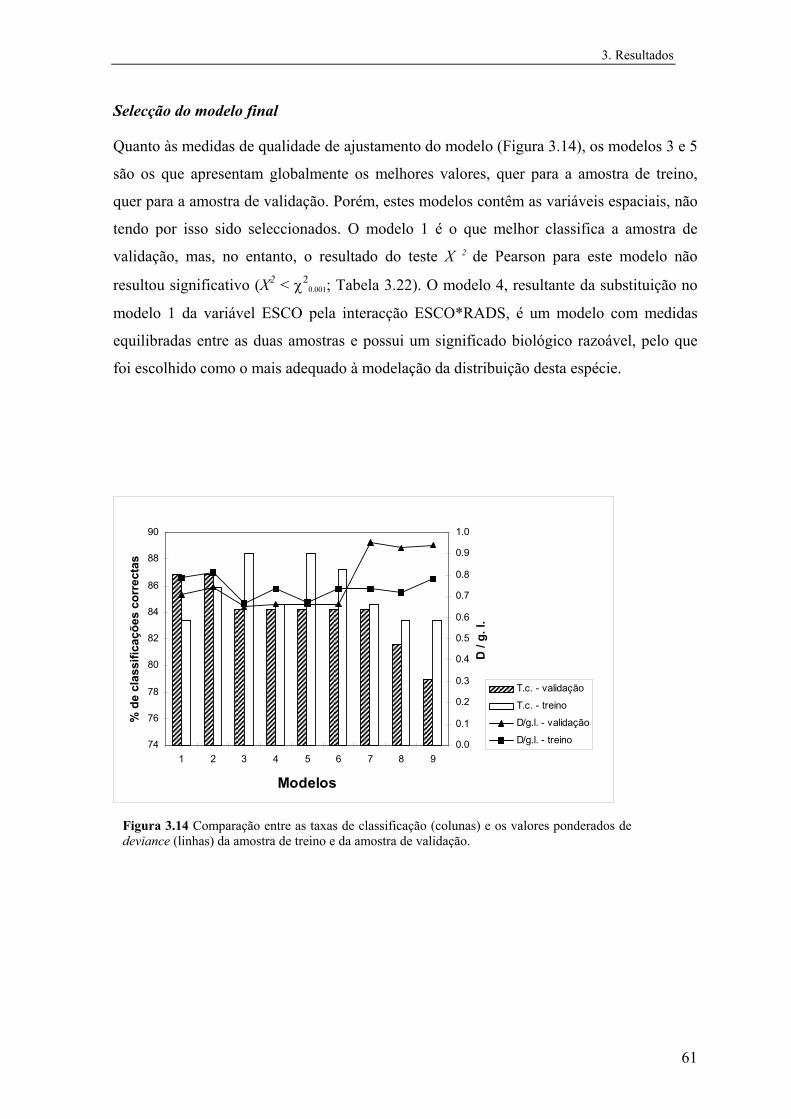
3. Resultados
Selecção do modelo final
Quanto às medidas de qualidade de ajustamento do modelo (Figura 3.14), os modelos 3 e 5
são os que apresentam globalmente os melhores valores, quer para a amostra de treino,
quer para a amostra de validação. Porém, estes modelos contêm as variáveis espaciais, não
tendo por isso sido seleccionados. O modelo 1 é o que melhor classifica a amostra de
validação, mas, no entanto, o resultado do teste X 2 de Pearson para este modelo não
resultou significativo (X2 < χ20.001; Tabela 3.22). O modelo 4, resultante da substituição no
modelo 1 da variável ESCO pela interacção ESCO*RADS, é um modelo com medidas
equilibradas entre as duas amostras e possui um significado biológico razoável, pelo que
foi escolhido como o mais adequado à modelação da distribuição desta espécie.
������������������������������������������������
������������������������������������������������������������
����������������������������������������
��������������������������������������������������
��������������������������������������������������
����������������������������������������
����������������������������������������
�����������������������������������
�������������������������
74
76
78
80
82
84
86
88
90
1 2 3 4 5 6 7 8 9
Modelos
% d
e cl
assi
ficaç
ões
corr
ecta
s
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
D /
g. l.
����������������������T.c. - validação
T.c. - treino
D/g.l. - validação
D/g.l. - treino
Figura 3.14 Comparação entre as taxas de classificação (colunas) e os valores ponderados de deviance (linhas) da amostra de treino e da amostra de validação.
61
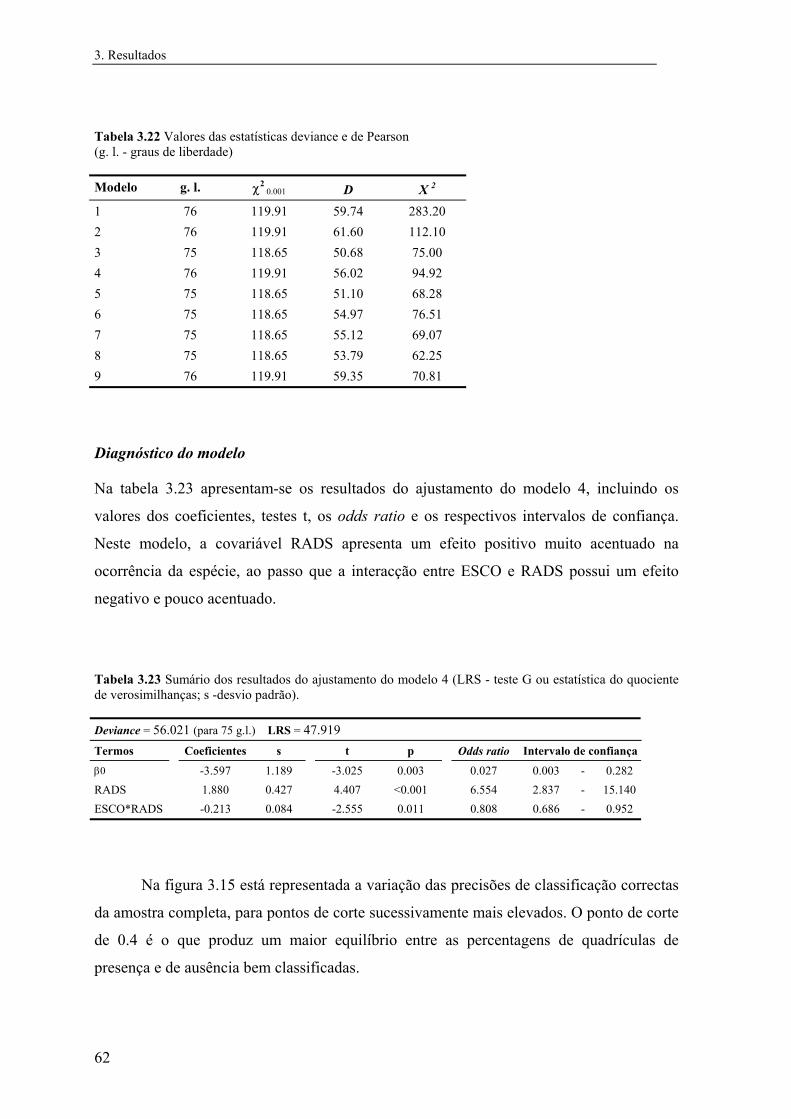
3. Resultados
Tabela 3.22 Valores das estatísticas deviance e de Pearson (g. l. - graus de liberdade) Modelo g. l. χ2
0.001 D X 2 1 76 119.91 59.74 283.20 2 76 119.91 61.60 112.10 3 75 118.65 50.68 75.00 4 76 119.91 56.02 94.92 5 75 118.65 51.10 68.28 6 75 118.65 54.97 76.51 7 75 118.65 55.12 69.07 8 75 118.65 53.79 62.25 9 76 119.91 59.35 70.81
Diagnóstico do modelo
Na tabela 3.23 apresentam-se os resultados do ajustamento do modelo 4, incluindo os
valores dos coeficientes, testes t, os odds ratio e os respectivos intervalos de confiança.
Neste modelo, a covariável RADS apresenta um efeito positivo muito acentuado na
ocorrência da espécie, ao passo que a interacção entre ESCO e RADS possui um efeito
negativo e pouco acentuado.
Tabela 3.23 Sumário dos resultados do ajustamento do modelo 4 (LRS - teste G ou estatística do quociente de verosimilhanças; s -desvio padrão). Deviance = 56.021 (para 75 g.l.) LRS = 47.919
Termos Coeficientes s t p Odds ratio Intervalo de confiança β0 -3.597 1.189 -3.025 0.003 0.027 0.003 - 0.282 RADS 1.880 0.427 4.407 <0.001 6.554 2.837 - 15.140 ESCO*RADS -0.213 0.084 -2.555 0.011 0.808 0.686 - 0.952
Na figura 3.15 está representada a variação das precisões de classificação correctas
da amostra completa, para pontos de corte sucessivamente mais elevados. O ponto de corte
de 0.4 é o que produz um maior equilíbrio entre as percentagens de quadrículas de
presença e de ausência bem classificadas.
62
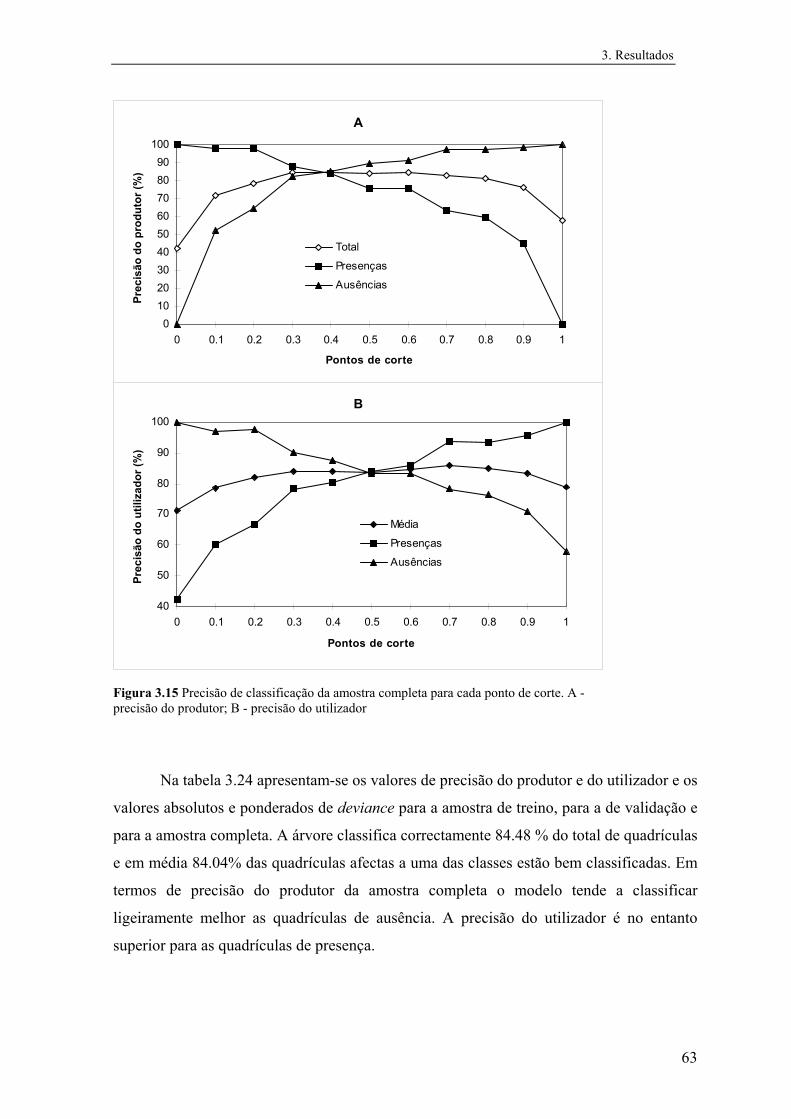
3. Resultados
A
0102030405060708090
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Pontos de corte
Prec
isão
do
prod
utor
(%)
Total
Presenças
Ausências
B
40
50
60
70
80
90
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Pontos de corte
Prec
isão
do
utili
zado
r (%
)
Média
Presenças
Ausências
Figura 3.15 Precisão de classificação da amostra completa para cada ponto de corte. A - precisão do produtor; B - precisão do utilizador
Na tabela 3.24 apresentam-se os valores de precisão do produtor e do utilizador e os
valores absolutos e ponderados de deviance para a amostra de treino, para a de validação e
para a amostra completa. A árvore classifica correctamente 84.48 % do total de quadrículas
e em média 84.04% das quadrículas afectas a uma das classes estão bem classificadas. Em
termos de precisão do produtor da amostra completa o modelo tende a classificar
ligeiramente melhor as quadrículas de ausência. A precisão do utilizador é no entanto
superior para as quadrículas de presença.
63
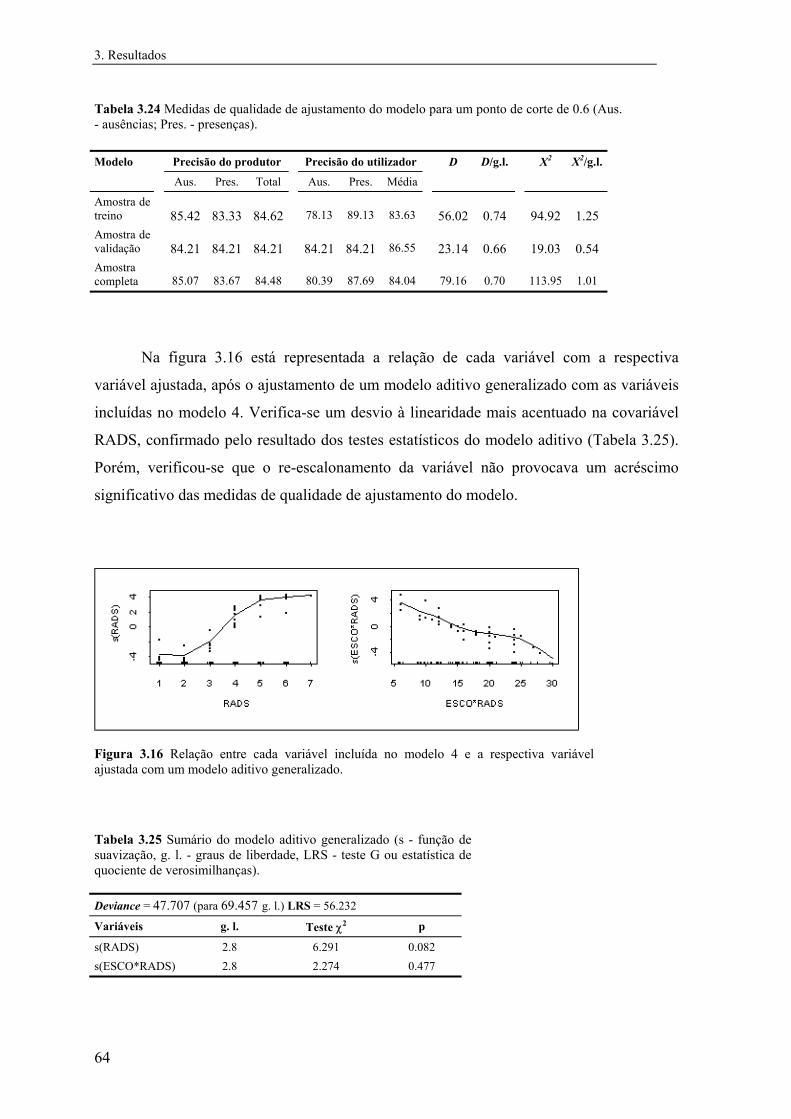
3. Resultados
Tabela 3.24 Medidas de qualidade de ajustamento do modelo para um ponto de corte de 0.6 (Aus. - ausências; Pres. - presenças). Modelo Precisão do produtor Precisão do utilizador D D/g.l. X2 X2/g.l.
Aus. Pres. Total Aus. Pres. Média
Amostra de treino
85.42 83.33 84.62 78.13 89.13 83.63 56.02 0.74 94.92 1.25
Amostra de validação
84.21 84.21 84.21 84.21 84.21 86.55 23.14 0.66 19.03 0.54
Amostra completa
85.07 83.67 84.48 80.39 87.69 84.04 79.16 0.70 113.95 1.01
Na figura 3.16 está representada a relação de cada variável com a respectiva
variável ajustada, após o ajustamento de um modelo aditivo generalizado com as variáveis
incluídas no modelo 4. Verifica-se um desvio à linearidade mais acentuado na covariável
RADS, confirmado pelo resultado dos testes estatísticos do modelo aditivo (Tabela 3.25).
Porém, verificou-se que o re-escalonamento da variável não provocava um acréscimo
significativo das medidas de qualidade de ajustamento do modelo.
Figura 3.16 Relação entre cada variável incluída no modelo 4 e a respectiva variável ajustada com um modelo aditivo generalizado.
Tabela 3.25 Sumário do modelo aditivo generalizado (s - função de suavização, g. l. - graus de liberdade, LRS - teste G ou estatística de quociente de verosimilhanças). Deviance = 47.707 (para 69.457 g. l.) LRS = 56.232
Variáveis g. l. Teste χ2 p
s(RADS) 2.8 6.291 0.082 s(ESCO*RADS) 2.8 2.274 0.477
64
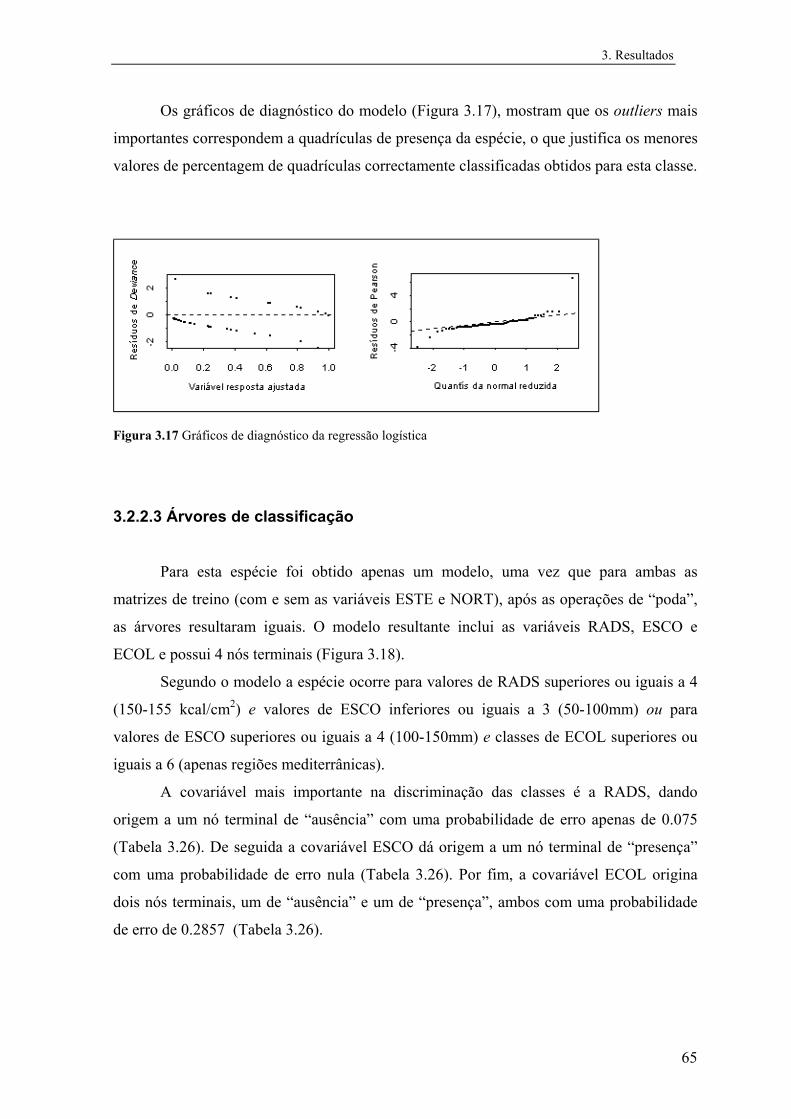
3. Resultados
Os gráficos de diagnóstico do modelo (Figura 3.17), mostram que os outliers mais
importantes correspondem a quadrículas de presença da espécie, o que justifica os menores
valores de percentagem de quadrículas correctamente classificadas obtidos para esta classe.
Figura 3.17 Gráficos de diagnóstico da regressão logística
3.2.2.3 Árvores de classificação
Para esta espécie foi obtido apenas um modelo, uma vez que para ambas as
matrizes de treino (com e sem as variáveis ESTE e NORT), após as operações de “poda”,
as árvores resultaram iguais. O modelo resultante inclui as variáveis RADS, ESCO e
ECOL e possui 4 nós terminais (Figura 3.18).
Segundo o modelo a espécie ocorre para valores de RADS superiores ou iguais a 4
(150-155 kcal/cm2) e valores de ESCO inferiores ou iguais a 3 (50-100mm) ou para
valores de ESCO superiores ou iguais a 4 (100-150mm) e classes de ECOL superiores ou
iguais a 6 (apenas regiões mediterrânicas).
A covariável mais importante na discriminação das classes é a RADS, dando
origem a um nó terminal de “ausência” com uma probabilidade de erro apenas de 0.075
(Tabela 3.26). De seguida a covariável ESCO dá origem a um nó terminal de “presença”
com uma probabilidade de erro nula (Tabela 3.26). Por fim, a covariável ECOL origina
dois nós terminais, um de “ausência” e um de “presença”, ambos com uma probabilidade
de erro de 0.2857 (Tabela 3.26).
65

3. Resultados
Figura 3.18 Árvore de classificação. Tabela 3.26 Estrutura interna da árvore de classificação (n - nº de observações; D - deviance; * - nós terminais; os números dos nós correspondem aos números da árvore original, antes de se proceder à sua simplificação). Nó n D Resposta Probabilidades
1) raiz 78 103.900 ausência ( 0.6154, 0.3846 )
2) RADSOL<3.5 40 21.310 ausência ( 0.9250, 0.0750 ) *
3) RADSOL>3.5 38 45.730 presença ( 0.2895, 0.7105 )
6) ESCOA<3.5 10 0.000 presença ( 0.0000, 1.0000 ) *
7) ESCOA>3.5 28 37.520 presença ( 0.3929, 0.6071 )
14) ECOL<5.5 7 8.376 ausência ( 0.7143, 0.2857 ) *
15) ECOL>5.5 21 25.130 presença ( 0.2857, 0.7143 ) *
Na tabela 3.27 apresentam-se os valores de precisão do produtor e do utilizador e os
valores absolutos e ponderados de deviance, respectivamente, para as amostras de treino,
validação e completa. A árvore classifica correctamente 84.48 % do total de quadrículas e
em média 84.07% das quadrículas afectas a uma das classes estão bem classificadas. Em
termos de precisão do produtor da amostra completa, as quadrículas de presença são
ligeiramente melhor classificadas do que as de ausência. A precisão do utilizador é no
entanto superior para as quadrículas de ausência.
66
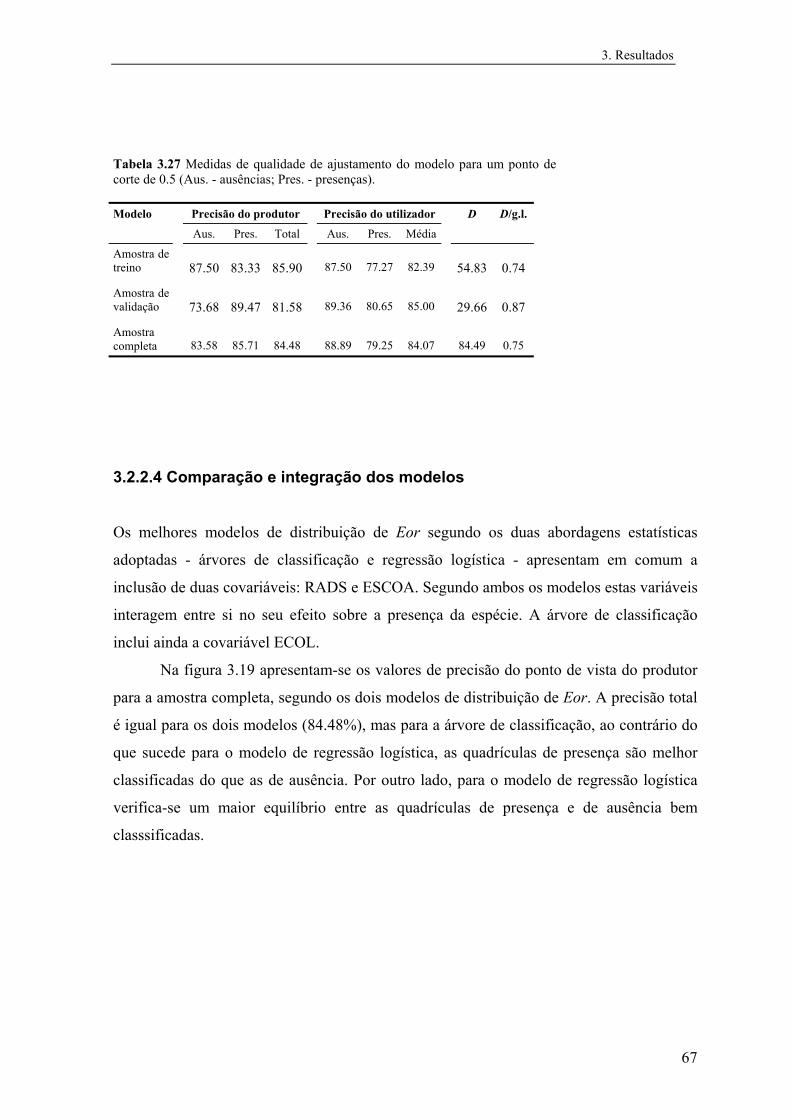
3. Resultados
Tabela 3.27 Medidas de qualidade de ajustamento do modelo para um ponto de corte de 0.5 (Aus. - ausências; Pres. - presenças). Modelo Precisão do produtor Precisão do utilizador D D/g.l.
Aus. Pres. Total Aus. Pres. Média
Amostra de treino
87.50 83.33 85.90 87.50 77.27 82.39 54.83 0.74
Amostra de validação
73.68 89.47 81.58 89.36 80.65 85.00 29.66 0.87
Amostra completa
83.58 85.71 84.48 88.89 79.25 84.07 84.49 0.75
3.2.2.4 Comparação e integração dos modelos
Os melhores modelos de distribuição de Eor segundo os duas abordagens estatísticas
adoptadas - árvores de classificação e regressão logística - apresentam em comum a
inclusão de duas covariáveis: RADS e ESCOA. Segundo ambos os modelos estas variáveis
interagem entre si no seu efeito sobre a presença da espécie. A árvore de classificação
inclui ainda a covariável ECOL.
Na figura 3.19 apresentam-se os valores de precisão do ponto de vista do produtor
para a amostra completa, segundo os dois modelos de distribuição de Eor. A precisão total
é igual para os dois modelos (84.48%), mas para a árvore de classificação, ao contrário do
que sucede para o modelo de regressão logística, as quadrículas de presença são melhor
classificadas do que as de ausência. Por outro lado, para o modelo de regressão logística
verifica-se um maior equilíbrio entre as quadrículas de presença e de ausência bem
classsificadas.
67

3. Resultados
�����������������������������������������������������������������
���������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������
������������������������������������������������������������������������������������
82
82.5
83
83.5
84
84.5
85
85.5
86
Árvore declassif icação
Regressãologística
Prec
isão
do
prod
utor
(%)
���Ausência
Presença���Total
Figura 3.19 Precisão de classificação do ponto de vista do produtor das quadrículas de ausência, de presença e do total da amostra original.
Do ponto de vista do utilizador (Figura 3.20), a precisão média de classificação dos
dois modelos resulta muito idêntica (84.07% para a árvore de classificação e 80.04% para
o modelo de regressão logística). Ao passo que para a árvore de classificação a precisão do
utilizador é mais elevada na classificação das quadrículas de ausência, para a regressão
logística é mais elevada na classificação das quadrículas de presença. Para o modelo de
regressão logística há um maior equilíbrio entre a precisão para as ausências e a precisão
para as presenças.
Em termos das medidas de qualidade de ajustamento baseadas nos resíduos, o
modelo de regressão logística apresenta menores valores de deviance residual para a
amostra original (Árvore de classificação: D = 84.49; Regressão logística: D = 76.16).
�����������������������������������������������������������������������������������������������������������������������������������������������
�����������������������������������������������������������������
�������������������������������������������������������������������������������������������
�������������������������������������������������������������������������������������������
74
76
78
80
82
84
86
88
90
Árvore declassif icação
Regressãologística
Prec
isão
do
utili
zado
r (%
)
���Ausência
Presença���Total
Figura 3.20 Precisão de classificação do ponto de vista do utilizador das quadrículas de ausência e de presença da amostra original e respectiva média.
68

3. Resultados
Cerca de 90% das quadrículas da amostra completa foram classificadas de igual
modo pela árvore de classificação e pelo modelo de regressão logística. Por outro lado,
cerca de 79% das quadrículas foram simultaneamente bem classificadas pelos dois
modelos.
Na tabela 3.28 apresentam-se as precisões de classificação da amostra completa
considerando apenas as quadrículas de consenso entre os dois modelos. Há um aumento de
confiança de 3.98% do ponto de vista do produtor em relação aos modelos considerados
separadamente, avaliados com a amostra completa de quadrículas. Do ponto de vista do
utilizador esse aumento é de 4.39% em relação à precisão da árvore de classificação e de
4.42% em relação ao modelo de regressão logística. Os valores de deviance ponderados
pelos graus de liberdade para estas quadrículas apresentam um decréscimo de 0.12 e de 0.1
valores em relação aos valores obtidos, respectivamente, com a árvore de classificação e
com o modelo de regressão logística para o total de quadrículas amostradas.
Tabela 3.28 Medidas de qualidade de ajustamento do modelo para as quadrículas de consenso entre os modelos.
Precisões de classificação Deviance dos resíduos
Precisão do produtor Precisão do utilizador Árvore de classificação Regressão logística
Aus. Pres. Total Aus. Pres. Média D D/g.l. D D/g.l.
90.32 85.71 88.46 90.32 85.71 88.46 65.42 0.63 62.41 0.60
69
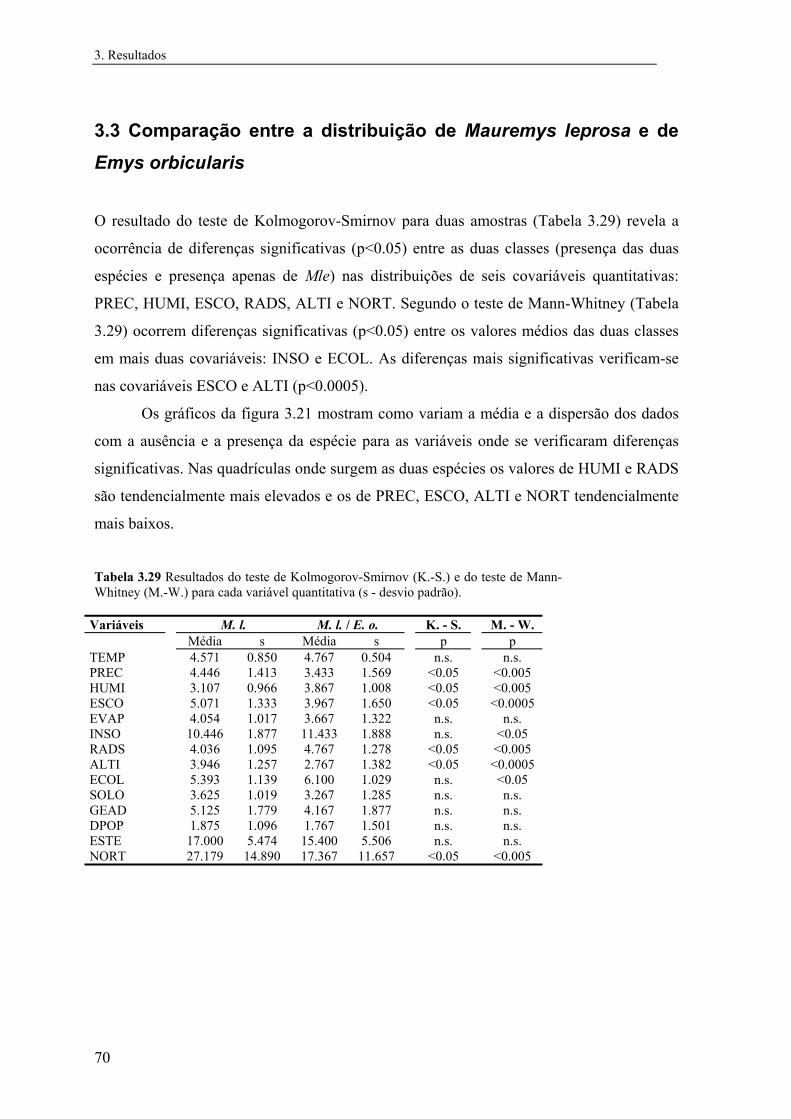
3. Resultados
3.3 Comparação entre a distribuição de Mauremys leprosa e de Emys orbicularis
O resultado do teste de Kolmogorov-Smirnov para duas amostras (Tabela 3.29) revela a
ocorrência de diferenças significativas (p<0.05) entre as duas classes (presença das duas
espécies e presença apenas de Mle) nas distribuições de seis covariáveis quantitativas:
PREC, HUMI, ESCO, RADS, ALTI e NORT. Segundo o teste de Mann-Whitney (Tabela
3.29) ocorrem diferenças significativas (p<0.05) entre os valores médios das duas classes
em mais duas covariáveis: INSO e ECOL. As diferenças mais significativas verificam-se
nas covariáveis ESCO e ALTI (p<0.0005).
Os gráficos da figura 3.21 mostram como variam a média e a dispersão dos dados
com a ausência e a presença da espécie para as variáveis onde se verificaram diferenças
significativas. Nas quadrículas onde surgem as duas espécies os valores de HUMI e RADS
são tendencialmente mais elevados e os de PREC, ESCO, ALTI e NORT tendencialmente
mais baixos.
Tabela 3.29 Resultados do teste de Kolmogorov-Smirnov (K.-S.) e do teste de Mann-Whitney (M.-W.) para cada variável quantitativa (s - desvio padrão).
Variáveis M. l. M. l. / E. o. K. - S. M. - W. Média s Média s p p TEMP 4.571 0.850 4.767 0.504 n.s. n.s. PREC 4.446 1.413 3.433 1.569 <0.05 <0.005 HUMI 3.107 0.966 3.867 1.008 <0.05 <0.005 ESCO 5.071 1.333 3.967 1.650 <0.05 <0.0005 EVAP 4.054 1.017 3.667 1.322 n.s. n.s. INSO 10.446 1.877 11.433 1.888 n.s. <0.05 RADS 4.036 1.095 4.767 1.278 <0.05 <0.005 ALTI 3.946 1.257 2.767 1.382 <0.05 <0.0005 ECOL 5.393 1.139 6.100 1.029 n.s. <0.05 SOLO 3.625 1.019 3.267 1.285 n.s. n.s. GEAD 5.125 1.779 4.167 1.877 n.s. n.s. DPOP 1.875 1.096 1.767 1.501 n.s. n.s. ESTE 17.000 5.474 15.400 5.506 n.s. n.s. NORT 27.179 14.890 17.367 11.657 <0.05 <0.005
70

3. Resultados
Figura 3.21 Média Desvio padrão (SD) das variáveis quantitativas (testes de Mann-Whitney e Kolmogorov-Smirnov significativos p<0.05) para cada classe. (continua na página seguinte).
±
Figura 3.21 (continuação) Média Desvio padrão (SD) das variáveis quantitativas (testes de Mann-Whitney e Kolmogorov-Smirnov significativos p<0.05) para cada classe.
±
71

3. Resultados
No que se refere às covariáveis qualitativas, não se observa uma influência
significativa (p<0.01) de nenhuma das variáveis consideradas (Tabela 3.30).
Tabela 3.30 Resultados dos testes de χ2 (1 grau de liberdade) para cada variável qualitativa (os valores a bold são significativos a 99% de confiança; (+) - influência positiva sobre a presença de ambas as espécies, (-) - influência negativa sobre a presença de ambas as espécies). Variáveis X2 (1 g.l.) p FOLH 0.750 0.385 RESI 1.330 0.248 OLIV 1.790 0.182 SOBR 3.070 0.080 AZIN 2.380 0.123 CARV 0.210 0.650 PINH 1.330 0.248 EUCT 0.480 0.489 CAST 0.520 0.472 FIGU 1.470 0.225 MEDR 1.670 0.197 ALFA 0.060 0.805 AMEN 1.380 0.240 CUARV 2.180 0.140 CARBS 5.380 0.020 CARBR 1.040 0.309 CAVAB 1.670 0 .197 CABAV 0.400 0.526 INCT 0.470 0.494 SAL 1.890 0.169
72

3. Resultados
3.4 Representação geográfica dos modelos
3.4.1 Mauremys leprosa
Modelos probabilísticos
Nas figuras 3.22 A e B estão representadas as superfícies de probabilidade de ocorrência
de Mle em Portugal segundo, respectivamente, o modelo de regressão logística e o modelo
baseado em árvores de classificação. Em ambos os modelos as probabilidades de
ocorrência da espécie mais elevadas situam-se nas regiões do Alentejo, Algarve, Beira
Interior e Nordeste Transmontano. Note-se que modelo baseado em árvores de
classificação (Figura 3.22 B) é bastante mais simples, gerando apenas cinco níveis de
probabilidade, correspondentes ao número de nós terminais da árvore.
A B
Figura 3.22 Superfície de probabilidade de ocorrência de Mle. A - Regressão logística; B - Árvore de classificação.
73

3. Resultados
Para simplificar a representação do modelo de regressão logística (Figura 3.23)
consideraram-se três níveis de acordo com a relação entre as probabilidades (pontos de
corte) e as medidas de precisão do utilizador (ver secção 3.2.1.2, figura 3.6, pág.47): (1)
zona com uma precisão de classificação de ausências superior a 90% (aproximadamente
para probabilidades de ocorrência inferiores a 0.2), (2) zona de “confusão” (precisões
inferiores a 90%) e (3) zona com uma precisão de classificação de presenças superior a
90% (aproximadamente para probabilidades de ocorrência superiores a 0.8)
Figura 3.23 Modelo de regressão logística segundo níveis de precisão do utilizador.
74
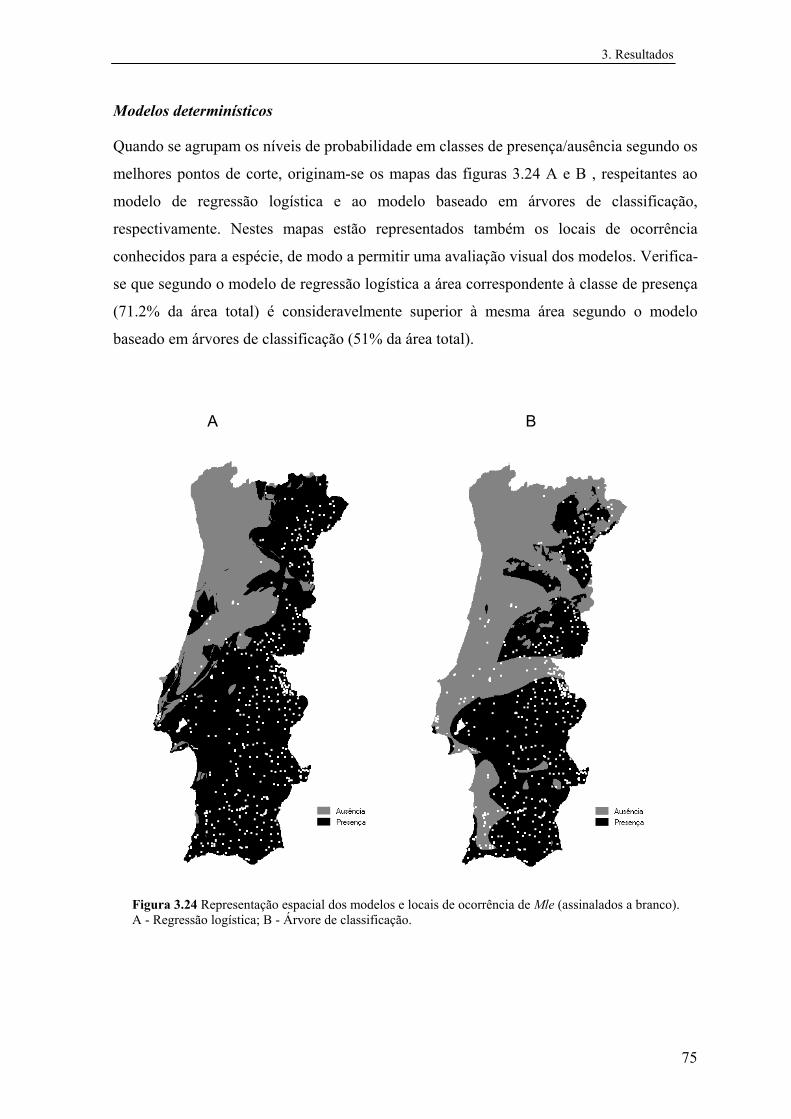
3. Resultados
Modelos determinísticos
Quando se agrupam os níveis de probabilidade em classes de presença/ausência segundo os
melhores pontos de corte, originam-se os mapas das figuras 3.24 A e B , respeitantes ao
modelo de regressão logística e ao modelo baseado em árvores de classificação,
respectivamente. Nestes mapas estão representados também os locais de ocorrência
conhecidos para a espécie, de modo a permitir uma avaliação visual dos modelos. Verifica-
se que segundo o modelo de regressão logística a área correspondente à classe de presença
(71.2% da área total) é consideravelmente superior à mesma área segundo o modelo
baseado em árvores de classificação (51% da área total).
A B
Figura 3.24 Representação espacial dos modelos e locais de ocorrência de Mle (assinalados a branco). A - Regressão logística; B - Árvore de classificação.
75

3. Resultados
Integração dos modelos
A figura 3.25 resulta da sobreposição dos mapas preditivos segundo os dois modelos
originando 3 tipos de áreas: duas áreas classificadas como ausência e como presença por
ambos os modelos (áreas de consenso) e uma área onde os resultados da classificação
foram diferentes para os dois modelos (área de discordância).
Figura 3.25 Sobreposição dos mapas resultantes dos dois modelos (os locais de ocorrência estão assinalados a branco).
76
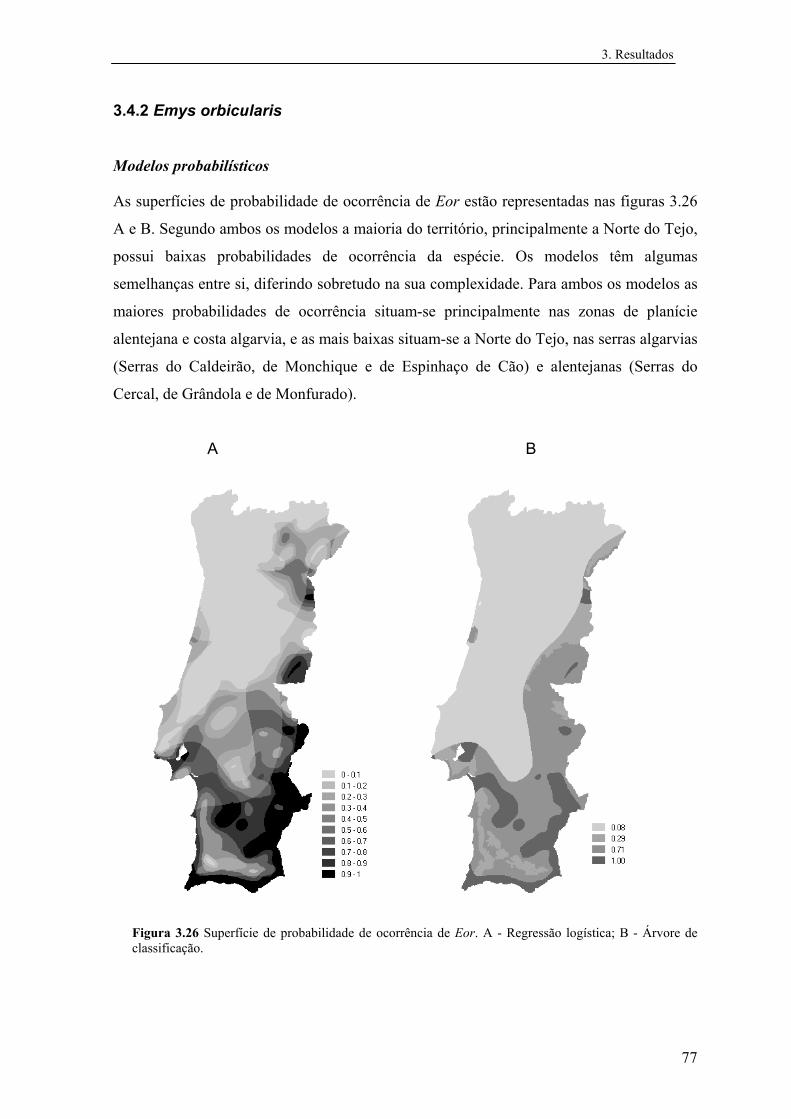
3. Resultados
3.4.2 Emys orbicularis
Modelos probabilísticos
As superfícies de probabilidade de ocorrência de Eor estão representadas nas figuras 3.26
A e B. Segundo ambos os modelos a maioria do território, principalmente a Norte do Tejo,
possui baixas probabilidades de ocorrência da espécie. Os modelos têm algumas
semelhanças entre si, diferindo sobretudo na sua complexidade. Para ambos os modelos as
maiores probabilidades de ocorrência situam-se principalmente nas zonas de planície
alentejana e costa algarvia, e as mais baixas situam-se a Norte do Tejo, nas serras algarvias
(Serras do Caldeirão, de Monchique e de Espinhaço de Cão) e alentejanas (Serras do
Cercal, de Grândola e de Monfurado).
A B
Figura 3.26 Superfície de probabilidade de ocorrência de Eor. A - Regressão logística; B - Árvore de classificação.
77

3. Resultados
Na figura 3.27 está representado o mapa simplificado relativo ao modelo de
regressão logística. Consideraram-se três níveis de acordo com a relação entre as
probabilidades (pontos de corte) e as medidas de precisão do utilizador (ver secção 3.2.2.2,
figura 3.15, pág. 63): (1) zona com uma precisão de classificação de ausências superior a
90% (aproximadamente para probabilidades de ocorrência inferiores a 0.3), (2) zona de
“confusão” (precisões inferiores a 90%) e (3) zona com uma precisão de classificação de
presenças superior a 90% (aproximadamente para probabilidades de ocorrência superiores
a 0.7).
Figura 3.27 Modelo de regressão logística segundo níveis de precisão do utilizador.
78

3. Resultados
Modelos determinísticos
Nas figuras 3.28 A e B estão representados os mapas preditivos da distribuição de Eor
segundo, respectivamente, o modelo de regressão logística e o modelo baseado em árvores
de classificação. Também se encontram assinalados os locais conhecidos de ocorrência. A
área de distribuição potencial da espécie não difere muito entre os dois modelos,
representando 35,7 % da área total para o modelo baseado em árvores de classificação e
34,3% da área total para o modelo de regressão logística. Ambos os modelos classificaram
erradamente como “ausência” alguns locais com populações conhecidas, tais como o Paul
da Tornada (Caldas da Rainha, Estremadura) e as Lagoas do Prado (Vila Verde, Minho).
A B
Figura 3.28 Representação espacial dos modelos e locais de ocorrência de Eor (assinalados a branco). A - Regressão logística; B - Árvore de classificação.
79

3. Resultados
Integração dos modelos
Na figura 3.29 estão representadas as áreas de consenso e de discordância entre os
modelos. Para esta espécie a área de discordância resultou relativamente pequena.
Figura 3.29 Sobreposição dos mapas resultantes dos dois modelos (os locais de ocorrência estão assinalados a branco).
80

3. Resultados
3.5 Influência de variáveis locais
3.5.1 Mauremys leprosa
3.5.1.1 Análise univariada
Os testes ANOVA de Kruskal-Wallis (Tabela 3.31) mostram que ocorrem diferenças
significativas (p<0.01) entre os níveis de abundância para nove variáveis quantitativas:
LARG, PROF, VCOR, INSO, EMER, IMER, HERB, ARBS e ARBR. Os gráficos da
figura 3.30 mostram como variam a média e a dispersão dos dados com os níveis de
abundância para estas variáveis. A abundância de cágados parece assim estar
positivamente relacionada com a profundidade, a insolação, a cobertura de vegetação
emergente e imersa, e negativamente relacionada com a velocidade da corrente, o grau de
cobertura de vegetação herbácea, arbustiva e arbórea da margem. A largura é em média
superior e tem, simultaneamente, maior variação nos pontos onde se observaram níveis
intermédios de abundância.
Tabela 3.31 Resultados dos testes ANOVA de Kruskal-Wallis para cada variável quantitativa. (+) - influência positiva na presença da espécie; (-) - influência negativa sobre a presença da espécie; (n.s.) - resultado não significativo a 99% de confiança. Variáveis “Rank” Teste de Kruskal-Wallis
ausência média alta H p ALTI 8465.5 18828 3831.5 1.611 0.447 (n.s.) RELE 9591.5 17820.5 3713 1.662 0.436 (n.s.) LARG 7222 19359.5 4543.5 12.487 0.002 (+) PROF 6544 19827 4754 25.343 <0.000 (+) VCOR 10961 17582 2582 28.319 <0.000 (-) TURB 8005.5 18896.5 4223 4.079 0.130 (n.s.) INSO 7809 18137 5179 14.163 0.001 (+) INCL 8084 19112.5 3928.5 5.286 0.071 (n.s) EMER 7050.5 18316.5 5758 34.531 <0.000 (+) FLUT 8879 17838.5 4407.5 2.940 0.230 (n.s.) IMER 7462.5 17983.5 5679 27.702 <0.000 (+) HERB 10520 17389.5 3215.5 11.890 0.003 (-) ARBS 10897.5 16169 39.68.5 17.326 <0.000 (-) ARBR 11477 17110 2538 33.182 <0.000 (-)
81

3. Resultados
Figura 3.30 Média Desvio padrão (SD) das variáveis quantitativas (testes de Kruskal-Wallis significativos p<0.05) para cada classe. (continua na página seguinte).
±
82
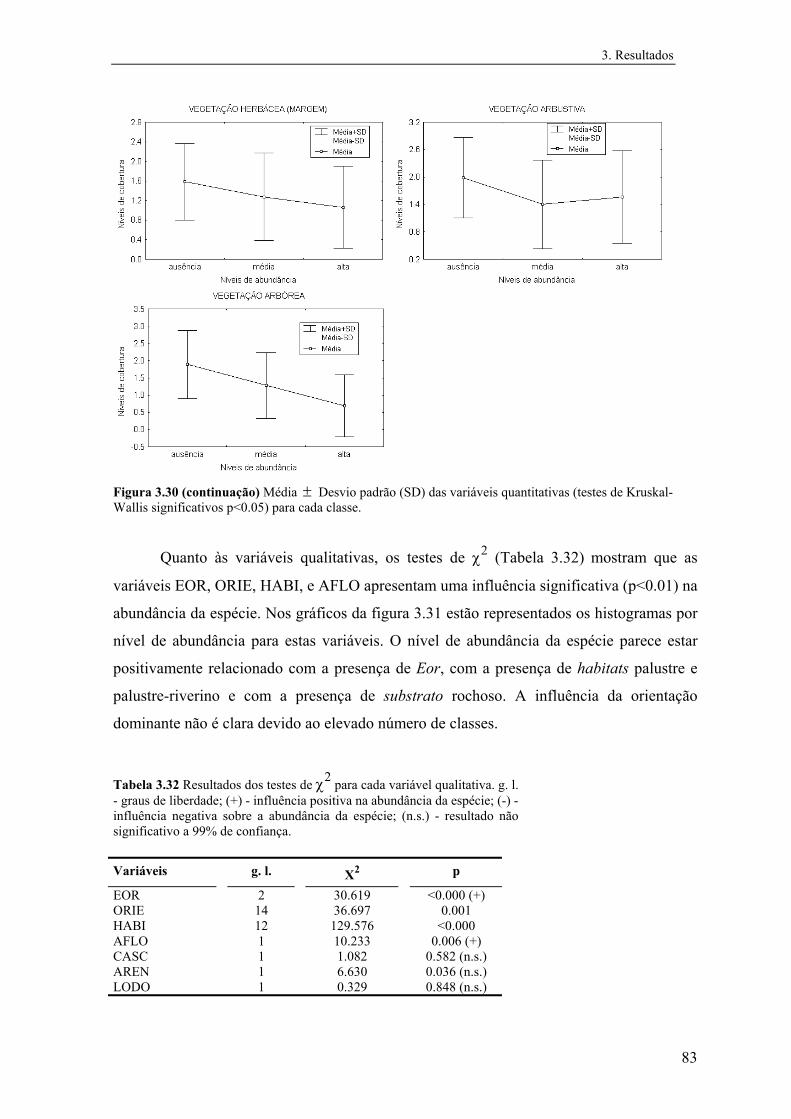
3. Resultados
Figura 3.30 (continuação) Média Desvio padrão (SD) das variáveis quantitativas (testes de Kruskal-Wallis significativos p<0.05) para cada classe.
±
Quanto às variáveis qualitativas, os testes de χ2 (Tabela 3.32) mostram que as
variáveis EOR, ORIE, HABI, e AFLO apresentam uma influência significativa (p<0.01) na
abundância da espécie. Nos gráficos da figura 3.31 estão representados os histogramas por
nível de abundância para estas variáveis. O nível de abundância da espécie parece estar
positivamente relacionado com a presença de Eor, com a presença de habitats palustre e
palustre-riverino e com a presença de substrato rochoso. A influência da orientação
dominante não é clara devido ao elevado número de classes.
Tabela 3.32 Resultados dos testes de χ2 para cada variável qualitativa. g. l. - graus de liberdade; (+) - influência positiva na abundância da espécie; (-) - influência negativa sobre a abundância da espécie; (n.s.) - resultado não significativo a 99% de confiança. Variáveis g. l. X2 p
EOR 2 30.619 <0.000 (+) ORIE 14 36.697 0.001 HABI 12 129.576 <0.000 AFLO 1 10.233 0.006 (+) CASC 1 1.082 0.582 (n.s.) AREN 1 6.630 0.036 (n.s.) LODO 1 0.329 0.848 (n.s.)
83

3. Resultados
Figura 3.31 Histogramas das variáveis qualitativas (testes de χ2 significativos p<0.01) para cada classe.
3.5.1.2 Análise multivariada
Modelo completo
O resultado do ajustamento da árvore de classificação em que todas as variáveis foram
inicialmente consideradas na análise (Figura 3.32) sugere que, para os diferentes tipos de
habitat considerados, diferentes variáveis associadas aos habitats aquáticos influenciam a
abundância das espécies. Com efeito, as duas separações principais são introduzidas pela
variável HABI, dando origem a três grupos de habitats: (1) habitats palustre, palustre-
lacustre e palustre-riverino; (2) habitat riverino; e (3) habitats lacustre, lacustre-palustre e
riverino-palustre.
Segundo este modelo, no primeiro grupo de habitats a abundância das espécie é alta
ou média. Neste grupo as variáveis EMER e PROF são as mais importantes na separação
entre os níveis médio e alto de abundância; as maiores abundâncias verificam-se para
maiores percentagens de cobertura de vegetação emergente (25% a 100%) ou para níveis
de profundidade intermédios (0.5 a 1 m).
84

3. Resultados
Nos habitats riverinos a espécie ou não ocorre ou surge com níveis intermédios de
abundância. As variáveis PROF, IMER e HERB são as que mais determinam a presença ou
ausência da espécie neste tipo de habitats; a espécie ocorre quando o nível de profundidade
é superior a 0.25 m, quando a percentagem de cobertura de vegetação imersa é superior a
50% ou quando a percentagem de cobertura de vegetação herbácea na margem é inferior a
25%.
No terceiro grupo de habitats a espécie surge com abundâncias intermédias ou
altas. Neste grupo as variáveis ARBR e INSO são as mais importantes na separação entre
os níveis médio e alto de abundância; as maiores abundâncias verificam-se para
percentagens de cobertura arbórea superiores a 50% e para níveis de insolação superiores a
2.
Na tabela 3.23 apresenta-se a estrutura interna da árvore de classificação que inclui
o número de casos, os valores de deviance e as probabilidades associadas a cada classe em
cada nó. Cerca de 65% das observações no primeiro grupo de habitats foram classificadas
no nível de abundância alta, 54% das observações do segundo grupo foram classificadas
no nível ausência, e 92% das observações no terceiro grupo foram classificadas no nível
média. A partir das probabilidades associadas aos nós terminais foi possível determinar a
precisão média de classificação da árvore para cada um dos três grupos de habitats. Assim,
para o primeiro grupo de habitats a probabilidade média de classificações correctas é de
81.65%, para o segundo grupo é de 83.02% e para o terceiro grupo é de 67.36%.
Figura 3.32 Árvore de classificação após as operações de poda.
85

3. Resultados
Tabela 3.33 Estrutura interna da árvore de classificação seleccionada (n - nº de observações; D - deviance; * - nós terminais; os números dos nós correspondem aos números da árvore original, antes de se proceder à sua simplificação).
Nó n D Resposta Probabilidades (alta ausência média) 1) raiz 249 466.80 média ( 0.1285 0.2892 0.5823)
2) HABITATS:pal,pal/lac,pal/riv 49 85.99 alta (0.5102 0.0612 0.4286)
4) EMER<1.5 32 53.15 média (0.0625 0.6250 0.3125)
8) PROF<3.5 20 34.23 alta (0.0500 0.4500 0.5000)
16) PROF<2.5 5 5.00 média (0.2000 0.8000 0.0000) *
17) PROF>2.5 15 19.10 alta (0.0000 0.3333 0.6667) *
9) PROF>3.5 12 6.88 média (0.0833 0.9167 0.0000) *
5) EMER>1.5 17 15.09 alta (0.0588 0.0588 0.8824) *
3) HABITATS:lac,lac/pal,riv,riv/pal 200 312.30 média (0.3450 0.6200 0.0350)
6) HABITATS:riv 84 123.20 ausência (0.5833 0.4048 0.0119)
12) PROF<1.5 23 13.59 ausência (0.9130 0.0870 0.0000) *
13) PROF>1.5 61 93.12 média (0.4590 0.5246 0.0164)
26) IMER<1.5 55 84.78 ausência (0.5091 0.4727 0.0182)
52) HERB<0.5 10 6.50 média (0.1000 0.9000 0.0000) *
53) HERB>0.5 45 68.30 ausência (0.6000 0.3778 0.0222)
106) LARG<3.5 22 28.59 ausência (0.7727 0.1818 0.0455) *
107) LARG>3.5 23 31.49 média (0.4348 0.5652 0.0000) *
27) IMER>1.5 6 0.00 média (0.0000 1.0000 0.0000) *
7) HABITATS:lac,lac/pal,riv/pal 116 151.50 média (0.1724 0.7759 0.0517)
14) ARBR<1.5 60 39.42 média (0.0667 0.9167 0.0167) *
15) ARBR>1.5 56 97.15 média (0.2857 0.6250 0.0893)
30) INSOL<2.5 47 67.77 média (0.3191 0.6596 0.0213) *
31) INSOL>2.5 9 17.37 alta (0.1111 0.4444 0.4444) *
As medidas de qualidade de ajustamento do modelo apresentam-se na tabela 3.34.
O modelo classificou correctamente 77.5% dos pontos de amostragem com um valor
ponderado de deviance de 1.1. A validação cruzada resultou numa média de cerca de 70%
de classificações correctas e um valor médio ponderado de deviance de 1.9.
86
3. Resultados
Tabela 3.34 Medidas de qualidade de ajustamento do modelo à amostra de treino e segundo a validação cruzada (D - deviance; g.l. - graus de liberdade = 237). Precisão total (%) D D / g.l.
Amostra de treino 77.51 258.962 1.088
Validação cruzada 69.88 445.436 1.879
Os resultados da matriz de confusão estão representados graficamente na figura
3.33. Do ponto de vista da precisão do produtor (nº de observações pertencentes a
determinada classe que foram correctamente classificadas) cerca de 53% das observações
correspondentes ao nível ausência, 89% correspondentes ao nível média e 91%
correspondentes ao nível alta foram correctamente classificadas. Do ponto de vista da
precisão do utilizador (nº de observações afectas a uma classe e que na realidade são dessa
classe) cerca de 83% das observações classificadas como ausência, 79% classificadas
como média e 73% classificadas como alta, pertenciam realmente a essas classes.
Tanto do ponto de vista do produtor como do utilizador verificou-se um número
maior de trocas entre os níveis de abundância ausência e média e entre os níveis média e
alta do que entre os níveis ausência e alta.
87
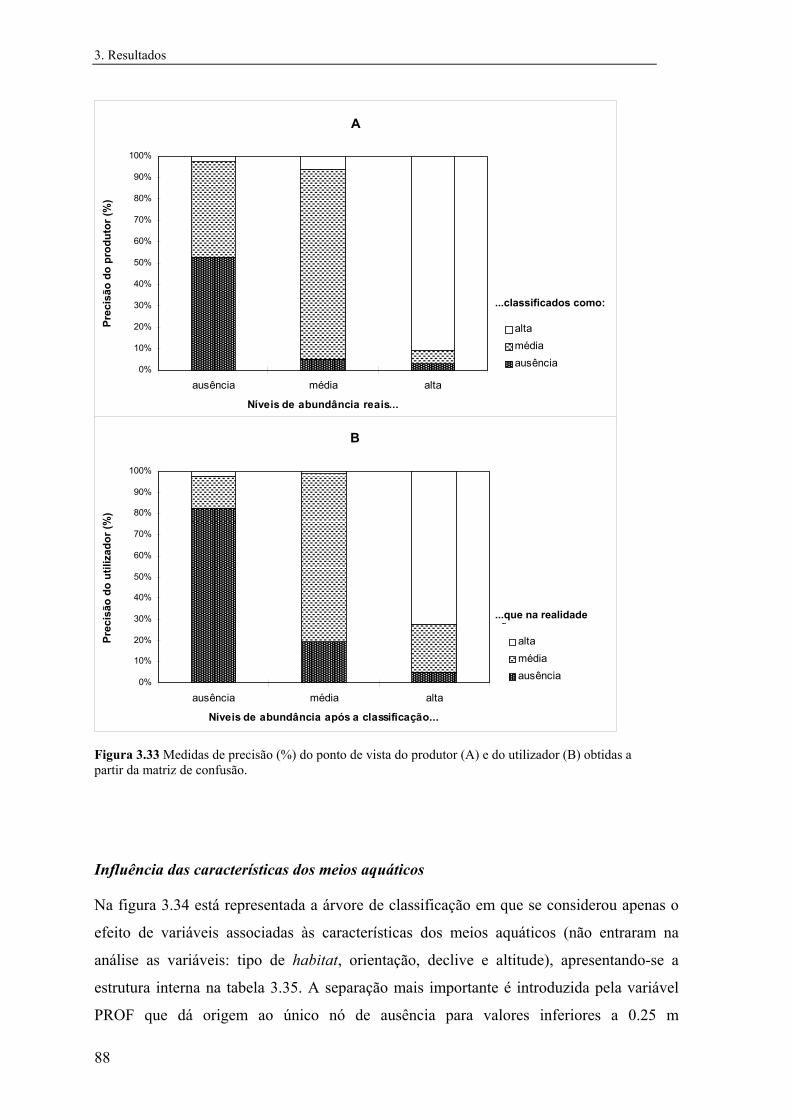
3. Resultados
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������
��������������������������������������
������������������������������������
�������������������������������������������������������������������������������������������������������������������������������������
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������
A
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
ausência média alta
Níveis de abundância reais...
Prec
isão
do
prod
utor
(%)
alta���média���ausência
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������
������������������������������������
���������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������
B
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
ausência média alta
Níveis de abundância após a classificação...
Prec
isão
do
utili
zado
r (%
)
alta������média������ ausência
...classificados como:
...que na realidade ã
Figura 3.33 Medidas de precisão (%) do ponto de vista do produtor (A) e do utilizador (B) obtidas a partir da matriz de confusão.
Influência das características dos meios aquáticos
Na figura 3.34 está representada a árvore de classificação em que se considerou apenas o
efeito de variáveis associadas às características dos meios aquáticos (não entraram na
análise as variáveis: tipo de habitat, orientação, declive e altitude), apresentando-se a
estrutura interna na tabela 3.35. A separação mais importante é introduzida pela variável
PROF que dá origem ao único nó de ausência para valores inferiores a 0.25 m
88

3. Resultados
(probabilidade de 0.77) (Tabela 3.35). A segunda separação mais importante é introduzida
pela variável EMER. Para coberturas de vegetação emergente inferiores a 50%, as
variáveis com maior influência são a ARBR, a INSOL e a TURB na separação entre
abundâncias média e alta; dos quatro nós terminais apenas um corresponde a abundâncias
altas (probabilidade de 0.6) para coberturas de vegetação arbórea superiores a 50%, níveis
de insolação superiores a 2 e níveis de turbidez inferiores a 1. Para valores de cobertura de
vegetação emergente, a variável mais importante na discriminação entre abundâncias
médias e altas é a IMER; para valores de cobertura de vegetação imersa inferiores a 0.25 a
abundância é média (probabilidade de 0.73); para valores superiores a 25% a abundância é
alta (probabilidade de 0.7).
Figura 3.34 Árvore de classificação após as operações de poda.
89

3. Resultados
Tabela 3.35 Estrutura interna da árvore de classificação seleccionada (n - nº de observações; D - deviance; * - nós terminais; os números dos nós correspondem aos números da árvore original, antes de se proceder à sua simplificação).
Nó n D Resposta Probabilidades (alta ausência média) 1) raiz 249 466.80 média ( 0.1285 0.2892 0.5823 )
2) PROF<1.5 35 37.63 ausência ( 0.0000 0.7714 0.2286 ) *
3) PROF>1.5 214 384.20 média ( 0.1495 0.2103 0.6402 )
6) EMER<1.5 176 287.40 média ( 0.0852 0.2386 0.6761 )
12) ARBR<1.5 88 112.10 média ( 0.1364 0.0682 0.7955 ) *
13) ARBR>1.5 88 142.00 média ( 0.0341 0.4091 0.5568 )
26) INSOL<2.5 77 104.50 média ( 0.0000 0.4156 0.5844 ) *
27) INSOL>2.5 11 23.98 ausência ( 0.2727 0.3636 0.3636 )
54) TURB<0.5 5 6.73 alta ( 0.6000 0.4000 0.0000 ) *
55) TURB>0.5 6 7.64 média ( 0.0000 0.3333 0.6667 ) *
7) EMER>1.5 38 69.48 média ( 0.4474 0.0790 0.4737 )
14) IMER<0.5 15 21.90 média ( 0.0667 0.2000 0.7333 ) *
15) IMER>0.5 23 28.27 alta ( 0.6957 0.0000 0.3043 ) *
A classificação obtida com este modelo, segundo as suas medidas da qualidade de
ajustamento (Tabela 3.36), apresenta piores resultados do que o modelo anterior, em que se
incluiu na análise todas as variáveis locais. O modelo classificou correctamente cerca de
70% dos pontos de amostragem, com uma deviance ponderada de 1.317. A validação
cruzada resultou numa média de cerca de 64% de classificações correctas e um valor
médio ponderado de deviance de 2.141.
Tabela 3.36 Medidas de qualidade de ajustamento do modelo à amostra de treino e segundo a validação cruzada (D - deviance; g.l. - graus de liberdade = 242). Precisão total (%) D D / g.l.
Amostra de treino 70.68 318.800 1.317
Validação cruzada 63.86 469.484 2.141
Os resultados da matriz de confusão estão representados graficamente na figura
3.35. Do ponto de vista da precisão do produtor foram correctamente classificadas cerca de
90
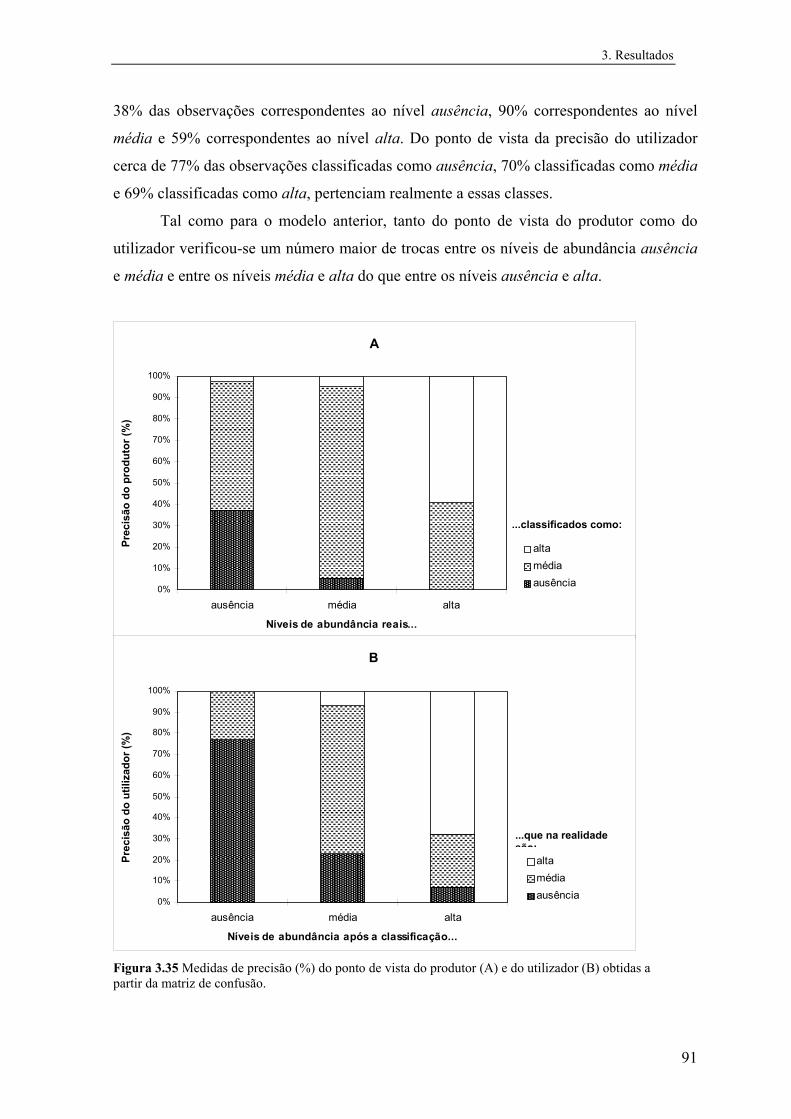
3. Resultados
38% das observações correspondentes ao nível ausência, 90% correspondentes ao nível
média e 59% correspondentes ao nível alta. Do ponto de vista da precisão do utilizador
cerca de 77% das observações classificadas como ausência, 70% classificadas como média
e 69% classificadas como alta, pertenciam realmente a essas classes.
Tal como para o modelo anterior, tanto do ponto de vista do produtor como do
utilizador verificou-se um número maior de trocas entre os níveis de abundância ausência
e média e entre os níveis média e alta do que entre os níveis ausência e alta.
������������������������������������������������������������������������������������������������������������
������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������
A
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
ausência média alta
Níveis de abundância reais...
Prec
isão
do
prod
utor
(%)
alta������média������ ausência
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������
������������������������������������
������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������
B
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
ausência média alta
Níveis de abundância após a classificação...
Prec
isão
do
utili
zado
r (%
)
alta����média
����ausência
...classificados como:
...que na realidade são:
Figura 3.35 Medidas de precisão (%) do ponto de vista do produtor (A) e do utilizador (B) obtidas a partir da matriz de confusão.
91
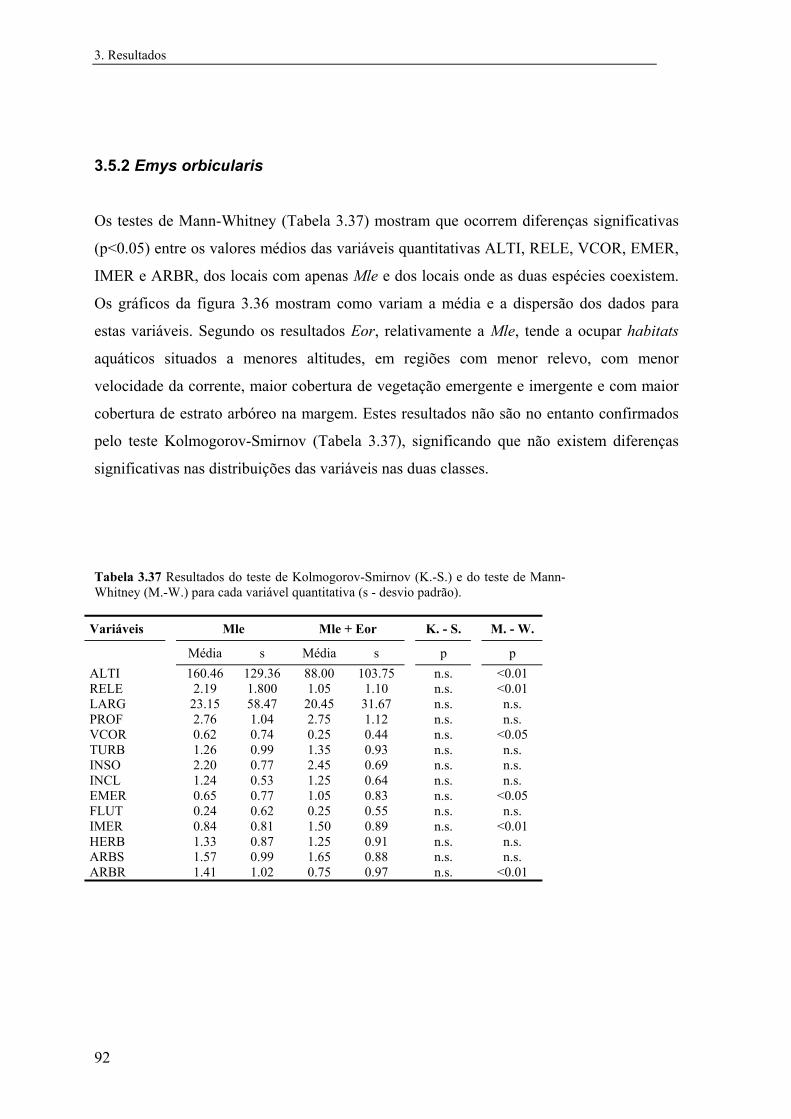
3. Resultados
3.5.2 Emys orbicularis
Os testes de Mann-Whitney (Tabela 3.37) mostram que ocorrem diferenças significativas
(p<0.05) entre os valores médios das variáveis quantitativas ALTI, RELE, VCOR, EMER,
IMER e ARBR, dos locais com apenas Mle e dos locais onde as duas espécies coexistem.
Os gráficos da figura 3.36 mostram como variam a média e a dispersão dos dados para
estas variáveis. Segundo os resultados Eor, relativamente a Mle, tende a ocupar habitats
aquáticos situados a menores altitudes, em regiões com menor relevo, com menor
velocidade da corrente, maior cobertura de vegetação emergente e imergente e com maior
cobertura de estrato arbóreo na margem. Estes resultados não são no entanto confirmados
pelo teste Kolmogorov-Smirnov (Tabela 3.37), significando que não existem diferenças
significativas nas distribuições das variáveis nas duas classes.
Tabela 3.37 Resultados do teste de Kolmogorov-Smirnov (K.-S.) e do teste de Mann-Whitney (M.-W.) para cada variável quantitativa (s - desvio padrão).
Variáveis Mle Mle + Eor K. - S. M. - W.
Média s Média s p p ALTI 160.46 129.36 88.00 103.75 n.s. <0.01 RELE 2.19 1.800 1.05 1.10 n.s. <0.01 LARG 23.15 58.47 20.45 31.67 n.s. n.s. PROF 2.76 1.04 2.75 1.12 n.s. n.s. VCOR 0.62 0.74 0.25 0.44 n.s. <0.05 TURB 1.26 0.99 1.35 0.93 n.s. n.s. INSO 2.20 0.77 2.45 0.69 n.s. n.s. INCL 1.24 0.53 1.25 0.64 n.s. n.s. EMER 0.65 0.77 1.05 0.83 n.s. <0.05 FLUT 0.24 0.62 0.25 0.55 n.s. n.s. IMER 0.84 0.81 1.50 0.89 n.s. <0.01 HERB 1.33 0.87 1.25 0.91 n.s. n.s. ARBS 1.57 0.99 1.65 0.88 n.s. n.s. ARBR 1.41 1.02 0.75 0.97 n.s. <0.01
92

3. Resultados
Figura 3.36 Média Desvio padrão (SD) das variáveis quantitativas (testes deMann-Whitney significativos p<0.05) para cada classe.
±
Quanto às variáveis qualitativas, os testes de χ2 (Tabela 3.38) mostram que as variáveis
MLE, HABI, e CASC apresentam uma influência significativa (p<0.01) na presença de
ambas as espécies relativamente à presença única de Mle. Nos gráficos da figura 3.37 estão
representados os histogramas por nível de abundância para estas variáveis. Segundo os
resultados a espécie apresenta uma maior tendência para ocupar locais com abundâncias
mais elevadas de Mle, surge com maior frequência em habitats palustres e palustres-
riverinos, e tem menor tendência para ocupar habitats com substrato de cascalho.
93
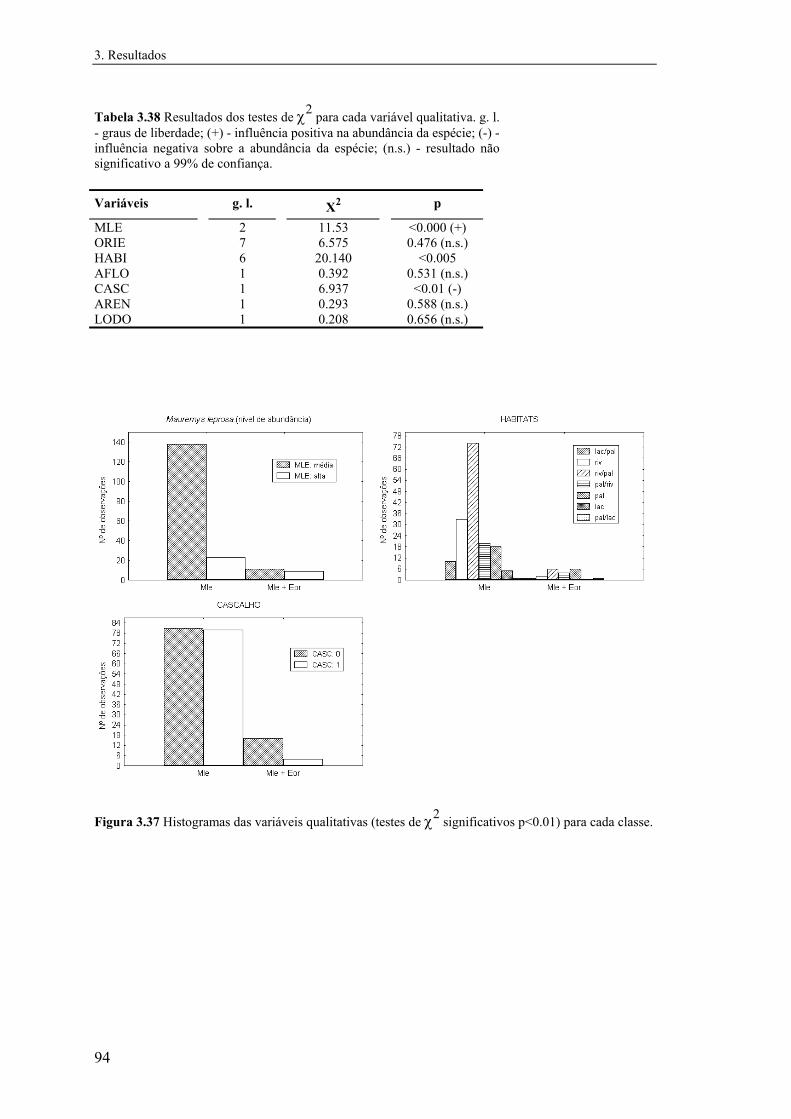
3. Resultados
Tabela 3.38 Resultados dos testes de χ2 para cada variável qualitativa. g. l. - graus de liberdade; (+) - influência positiva na abundância da espécie; (-) - influência negativa sobre a abundância da espécie; (n.s.) - resultado não significativo a 99% de confiança. Variáveis g. l. X2 p
MLE 2 11.53 <0.000 (+) ORIE 7 6.575 0.476 (n.s.) HABI 6 20.140 <0.005 AFLO 1 0.392 0.531 (n.s.) CASC 1 6.937 <0.01 (-) AREN 1 0.293 0.588 (n.s.) LODO 1 0.208 0.656 (n.s.)
Figura 3.37 Histogramas das variáveis qualitativas (testes de χ2 significativos p<0.01) para cada classe.
94

4. Discussão
4. DISCUSSÃO
4.1 Interpretação ecológica dos modelos de distribuição
Os modelos de distribuição que foram produzidos explicaram uma percentagem razoável
(cerca de 80% para Mle e cerca de 84% para Eor) da distribuição observada das espécies à
escala e resolução adoptadas. Estas estimativas de precisão total foram da mesma ordem de
grandeza das obtidas em trabalhos idênticos (Walker, 1996; Pereira & Itami, 1991; Brito et
al., 1996), sendo raros os trabalhos onde os modelos ultrapassam os 90% de precisão (por
exemplo: Austin et al., 1996; Teixeira et al., 1996).
A precisão dos modelos de distribuição depende em grande medida da capacidade
preditiva das variáveis disponíveis e da resolução e robustez dos dados, mas também do
maior ou menor grau de exigência das espécies em relação a determinados factores. Por
exemplo, Teixeira et al. (1996) construiu modelos de regressão logística para uma espécie
com exigências ecológicas muito restritas (salamandra-dourada), tendo estimado uma
precisão total de 94.2%, sendo a sua presença fortemente influenciada pela precipitação e
declive.
A interpretação ecológica dos modelos é geralmente uma tarefa difícil, uma vez que
os factores envolvidos nos modelos podem não actuar directamente na distribuição das
espécies mas antes estar correlacionados ou interactuar com factores não considerados na
análise. Pode até suceder o caso extremo de nenhuma das variáveis incluídas num modelo
actuarem sobre as espécies. Por outro lado, outra dificuldade de interpretação advém do
facto das variáveis macro-ambientais influenciarem não apenas directamente a
distribuição, mas também o tipo de habitats disponíveis.
Numa tentativa de obviar parte do problema, recorde-se que se ajustaram um
grande número de modelos válidos, tendo-se seleccionado aquele que simultaneamente
possuía melhores medidas de qualidade de ajustamento e o maior significado possível à luz
dos conhecimentos sobre a ecologia das espécies. Partiu-se ainda do pressuposto que o
número de vezes que determinada variável entrava em modelos independentes era, de certo
modo, uma indicação da sua importância relativa na distribuição das espécies. Por último,
o número de vezes que as variáveis que eram simultaneamente incluídas nos modelos
segundo as duas técnicas de modelação adoptadas, foi também considerado como uma
medida da sua importância para a ocorrência da espécie.
95

4. Discussão
É importante salientar que as variáveis incluídas no Atlas do Ambiente de Portugal
são muito incompletas, faltando nomeadamente variáveis que reflictam a sua variação
sazonal, o que seria útil por exemplo para avaliar a instabilidade climática (Romero &
Real, 1996). Por outro lado, o grau de detalhe da cartografia das variáveis é muito baixo, o
que pode limitar a sua capacidade preditiva.
Mauremys leprosa
Para Mle as variáveis que surgiram mais do que duas vezes no conjunto dos modelos e
simultaneamente nas duas abordagens estatísticas utilizadas foram a radiação solar, a
evapotranspiração real, a humidade relativa, as variáveis espaciais (nº da linha e nº da
coluna na rede UTM 10 x 10 km), o escoamento, a precipitação e as regiões ecológicas
(informação fito-edafo-climática).
A elevada frequência de ocorrência nos modelos das variáveis espaciais mostra que
provavelmente existem outros factores importantes que estão correlacionados com elas.
Outra hipótese é a distribuição ser também influenciada por factores meramente
biogeográficos, ou seja, mesmo que em determinadas regiões hajam condições para a
ocorrência da espécie, ela não está presente porque outros factores (por exemplo barreiras
naturais) impediram a sua colonização. Estas variáveis nunca foram incluídas nos modelos
seleccionados, uma vez que retiravam o seu significado ecológico. Note-se que as restantes
seis variáveis mais importantes são todas de natureza climática, pelo que se deduz que o
clima é um factor importante na distribuição desta espécie.
O factor mais importante na ecologia dos répteis é a temperatura, uma vez que
dependem de fontes externas de calor para manterem a temperatura ideal à sobrevivência e
reprodução (Spellerberg, 1982; Heatwole & Taylor, 1987). Em última análise dependem da
energia radiante do sol, quer directamente (radiação directa) quer indirectamente (radiação
reflectida ou através de objectos aquecidos por energia radiante) (Heatwole & Taylor,
1987). Segundo os modelos obtidos, a variável temperatura média do ar por si só não se
revelou uma variável importante. Outras medidas de temperatura como os respectivos
máximos e mínimos, ou a temperatura média por estação do ano, contribuiriam certamente
com mais informação. Não obstante este facto e atendendo a que as tartarugas da família
Emydidae em geral controlam a temperatura através da menor ou maior exposição à
radiação solar directa (Crawford et al., 1983), medidas como a radiação solar ou a
insolação são provavelmente mais determinantes do que as medidas de temperatura. Com
96

4. Discussão
efeito, segundo os modelos obtidos a radiação solar é das variáveis mais importantes,
senão a mais importante, na distribuição desta espécie. Tal não é de estranhar uma vez que,
ao contrário, por exemplo, da insolação (nº de horas de exposição solar), esta variável é
uma medida da quantidade de energia radiante que chega ao solo. Segundo a árvore de
classificação a espécie ocorre apenas para valores de radiação solar superiores ou iguais a
145 kcal/cm2. Esta variável é provavelmente a que tem um efeito mais directo na presença
de Mle.
Uma vez que os cágados ocorrem em meios aquáticos, a precipitação é um factor
que pode influenciar a sua ocorrência. No entanto, segundo os modelos obtidos o seu efeito
não é muito evidente. De acordo com a árvore de classificação seleccionada, a espécie está
presente quando a precipitação é inferior a 600 mm. Para valores de precipitação
superiores, esta variável interage com as variáveis humidade e regiões ecológicas. No
entanto, o ajustamento do modelo aditivo generalizado baseado no primeiro modelo de
regressão logística seleccionado, mostra que a relação é positiva para valores de
precipitação inferiores a 1200 mm e negativa para valores superiores a este número. Estes
resultados contraditórios poderão estar relacionados com possíveis interacções com outras
variáveis. Porém, a precipitação apresenta certamente uma grande influência ao nível dos
habitats, uma vez que actua directamente na disponibilidade e no tipo predominante de
meios aquáticos. Pode ainda pensar-se que para valores baixos de precipitação o seu efeito
é positivo uma vez que determina a quantidade de água disponível; para valores elevados o
seu efeito é negativo uma vez que provoca um aumento da velocidade da corrente dos
cursos de água. Segundo os resultados do estudo da influência de variáveis locais na
abundância da espécie, a velocidade da corrente apresenta um efeito claramente negativo.
No caso do escoamento, que resulta em grande medida da quantidade de
precipitação e do declive dos terrenos, o seu efeito directo é mais evidente. Segundo os
modelos obtidos, esta variável apresenta um efeito marcadamente negativo sobre a
presença da espécie. A relação directa entre o escoamento e a velocidade da corrente nos
leitos dos cursos de água explica muito provavelmente este comportamento.
Quer a análise univariada quer os modelos obtidos mostram uma influência
considerável da evapotranspiração real na distribuição de Mle. Para todos os modelos a sua
influência na presença da espécie é negativo. Segundo três das oito árvores de classificação
ajustadas a espécie está presente apenas para valores de evapotranspiração inferiores ou
iguais a 700 mm (resultados não apresentados), sendo este o primeiro factor que divide a
raiz. Porém, o seu efeito directo sobre a espécie não é claro. Esta variável depende de
97

4. Discussão
muitos factores como a quantidade de água nos solos, da densidade de cobertura de
vegetação e da temperatura. É provável que este factor actue ao nível dos habitats,
nomeadamente no que se refere ao grau e tipo de cobertura das margens dos meios
aquáticos. Por outro lado, pode estar correlacionado com outras variáveis não disponíveis
que actuam directamente sobre a espécie.
Quanto à humidade, por um lado as análises univariadas não mostram uma
influência muito acentuada na presença da espécie, mas por outro lado surge num grande
número de modelos, incluindo os dois seleccionados. Nas árvores de classificação esta
variável surge principalmente nas separações com menor significado. De acordo com a
árvore de classificação seleccionada, a espécie está ausente para valores iguais ou
superiores a 75% de humidade. Segundo os modelos de regressão logística o seu efeito é
igualmente negativo, sendo a variável que mais vezes está incluída nos modelos. Uma vez
que se trata de uma espécie tipicamente aquática o papel da humidade no balanço hídrico é
muito reduzido, não sendo por isso à partida um factor limitante da sua presença. Tal como
a evapotranspiração, este factor deve actuar ao nível dos habitats ou estar correlacionado
com outra variável importante.
Quanto às regiões ecológicas, a sua categorização é baseada sobretudo nas
comunidades vegetais, resultando assim do efeito de uma gama diversificada de variáveis
climáticas. As regiões ecológicas devem portanto determinar os tipos de habitat aquático
dominantes. Para ambas as abordagens estatísticas, a percentagem de presenças da espécie
é maior para os climas de carácter mais mediterrâneos. Segundo a árvore de classificação a
espécie está presente nas quatro regiões mediterrâneas e ainda na região Sub-Montano -
Termo-Subatlântico.
Emys orbicularis
Quanto a Eor, foram simultaneamente incluídas nos dois modelos seleccionados as
variáveis radiação solar e escoamento. Tal como para a espécie anterior, a radiação solar
parece ser a variável mais importante para esta espécie. Segundo a árvore de classificação
a espécie ocorre apenas para valores de radiação solar superiores ou iguais a 150 kcal/cm2.
As considerações feitas para Mle aplicam-se igualmente a esta espécie.
Segundo as duas abordagens estatísticas, a radiação solar e o escoamento interagem
no efeito sobre a presença da espécie. Na regressão logística a interacção é expressa pelo
98

4. Discussão
produto entre as duas, tendo um efeito negativo na presença. Com a árvore de classificação
a interacção é expressa de uma forma mais simples: o escoamento apenas tem efeito para
valores de radiação solar superiores a 150 kcal/cm2.
Outro factor importante incluído na árvore de classificação é a região ecológica.
Segundo este modelo a espécie está presente, para valores de escoamento superiores a 100
mm, apenas nas três regiões de carácter mais mediterrânico.
Por último, apesar de não estar incluída no modelo de regressão logística
seleccionado, a variável altitude (e respectiva transformação logarítmica) surge em seis dos
nove modelos ajustados. Esta espécie tende a ocupar regiões de menor altitude, o que
também se verificou a nível local. Este efeito pode estar relacionado com uma preferência
mais marcada desta espécie por habitats palustres (confirmada pelo estudo do efeito das
variáveis locais), que dum modo geral são mais frequentes a baixas altitudes. Por outro
lado, se a espécie se encontra em regressão em Portugal, tenderá a ocupar apenas os
habitats de melhor qualidade.
4.2 Avaliação e interpretação dos modelos segundo a sua representação geográfica
As precisões estimadas dos modelos podem ser extrapoladas com algum erro em termos de
área geográfica segundo a sua representação espacial. Assim, por exemplo, do ponto de
vista do produtor do mapa pode afirmar-se que cerca de 83% da área onde Mle está
presente (não esquecendo, porém, que a espécie se limita ao meio aquático) foi bem
classificada pela representação geográfica do modelo de regressão logística. Do ponto de
vista do utilizador do mapa pode afirmar-se que cerca de 84% da área representada como
estando a espécie presente está correctamente classificada.
Mauremys leprosa
As superfícies de probabilidade de ocorrência de Mle são bastante diferentes segundo os
dois métodos de modelação (Figura 3.22, pág. 73). Ao passo que no caso da árvore de
classificação apenas se geram cinco níveis de probabilidade correspondentes ao nós
terminais das árvores, no caso do modelo logístico as áreas possuem uma gama mais
contínua de probabilidades, resultando numa representação aparentemente mais realista.
99

4. Discussão
Quando se reclassifica a imagem correspondente ao modelo de regressão logística
de acordo com a distribuição da precisão do utilizador pelos pontos de corte, verifica-se
que uma grande parte das áreas mal classificadas situam-se na região periférica da
distribuição desta espécie (Figura 3.23, pág. 74), como por exemplo na Beira Litoral e
Estremadura. Esta “zona de confusão” pode ser interpretada como uma zona de maior
fragmentação da distribuição “sentida” pela resolução adoptada, uma vez que ocorre uma
“mistura” maior de quadrículas de presença com quadrículas de ausência. Este padrão
sugere a existência de um limite não “abrupto” da distribuição, estando de acordo com a
ideia de que as populações tendem a fragmentar-se no limite da área de distribuição,
restringindo-se apenas aos habitats mais propícios (Brown & Gibson, 1983). O erro de
classificação pode então em parte ser interpretado como uma medida do grau de
fragmentação da distribuição e, em última análise, da própria abundância das espécies.
Quanto aos mapas resultantes da classificação das imagens segundo os melhores
pontos de corte (Figura 3.24, pág. 75), o mapa relativo ao modelo de regressão logística
está, aparentemente, mais de acordo com a distribuição real da espécie. Tal não é de
estranhar, uma vez que apresenta valores de precisão das quadrículas de presença
superiores aos obtidos com a árvore de classificação. Por outro lado, os pontos de
ocorrência incluídos na área classificada como ausência não se encontram muito
distanciados dos limites da distribuição segundo o modelo de regressão logística.
A árvore de classificação, no entanto, classifica melhor as quadrículas de ausência,
pelo que se considerou importante integrar a informação dos dois modelos de modo a
definir “zonas de consenso” entre os dois modelos. Nestas zonas o grau de certeza da
classificação das áreas aumenta consideravelmente, segundo os resultados da precisão
quando se consideram apenas as quadrículas classificadas de igual modo pelos modelos
(secção 3.2.1.4, pág. 52).
No entanto, uma vez que se tem mais confiança nos dados de presença da espécie,
pensamos que o modelo que melhor reflecte a distribuição real da espécie é o modelo de
regressão logística.
Emys orbicularis
Tal como para a espécie anterior, a superfície de probabilidades resulta mais realista
segundo o modelo de regressão logística (Figura 3.26, pág. 77). Também para esta espécie
a “zona de confusão” situa-se nas regiões periféricas da distribuição, sobretudo no Alto
100

4. Discussão
Alentejo, nas serras do Algarvias e da costa Sudoeste e na região do Alto Douro. A “zona
de confusão” neste caso ocupa uma área substancialmente maior relativamente à área de
presença da espécie (133% da área de presença), do que no caso de Mle (43.7% da área de
presença). Isto deve-se a uma maior fragmentação da distribuição desta espécie, aliás
também confirmada pelo resultado do índice de raridade média local (Tabela 3.1, pág. 32).
Para Eor as precisões de classificação foram consideravelmente superiores do que
para Mle. No entanto, basearam-se numa amostra bastante mais reduzida, não tendo sido
construídos tantos modelos alternativos. Os mapas resultantes da classificação (Figura
3.27, pág. 78) são bastante idênticos entre os dois métodos, embora o mapa referente à
árvore de classificação esteja aparentemente um pouco mais de acordo com a distribuição
da espécie. Isto é confirmado pela precisão do produtor ligeiramente superior da árvore de
classificação para as quadrículas de presença. No entanto, ambos os modelos não
conseguiram prever a ocorrência da espécie em três pontos (situados na zona das Caldas da
Rainha, na zona da Golegã e no Minho, próximo de Vila Verde) que, por serem muito
distantes do limite da distribuição prevista, põem em causa a própria validade dos modelos.
De facto, os modelos revelaram-se muito eficazes na classificação da maioria das
quadrículas de presença uma vez que estas estão concentradas em regiões restritas do país.
A região classificada como ausência deverá ser então interpretada não como uma região de
ausência real das espécies, mas antes como uma região onde ocorre um elevado grau de
fragmentação, resultando em populações extremamente isoladas. Durante a fase terminal
deste trabalho foi-me relatada mais uma nova ocorrência desta espécie situada na região de
Chaves (Francisco Álvares, com. pess.), sendo de esperar que no futuro venham a ser
detectados novos pontos de ocorrência, situados igualmente muito longe dos limites de
distribuição segundo os modelos aqui apresentados.
A distribuição muito dispersa desta espécie e o facto de ser mais setentrional e
cosmopolita faz supor que esta deverá ter apresentado uma distribuição em Portugal
bastante mais alargada no passado, inclusivamente mais alargada do que a de Mle. Com
efeito, Bocage (1863 in Boscá, 1881) no século passado descreveu esta espécie como
sendo comum em Portugal. Estes resultados constituem então uma forte evidência da sua
regressão em Portugal.
101

4. Discussão
4.3 Influência de variáveis locais
A influência de variáveis locais foi estudada com um carácter mais exploratório e de
complemento à informação sobre a distribuição das espécies, sem a pretensão de se
efectuarem extrapolações e interpretações ecológicas muito exaustivas.
Mauremys leprosa
Esta espécie foi encontrada em todos as categorias de habitat aquático consideradas neste
trabalho. No entanto, os resultados da análise estatística univariada e dos modelos baseados
em árvores de classificação mostram uma clara preferência de Mle por habitats com uma
forte componente palustre, ou seja, ambientes de águas paradas, baixa profundidade e com
uma cobertura razoável de vegetação aquática. Segundo a árvore de classificação que
incluiu todas as variáveis consideradas, a espécie apenas está ausente em habitats riverinos
sem qualquer componente palustre, sobretudo em locais com profundidades inferiores a
0.25 m. De acordo com este modelo, verifica-se uma forte interacção entre a variável tipo
de habitat e as características associadas ao meio aquático; ou seja, em diferentes habitats
actuam diferentes factores na abundância, de forma mais ou menos complexa.
Segundo o modelo que entra em consideração apenas com as variáveis associadas
directamente às características dos meios aquáticos, a profundidade é o parâmetro mais
importante na presença desta espécie (ausente para profundidades inferiores a 0.25 m).
Para os locais onde a espécie ocorre, os factores mais importantes na abundância são a
cobertura de vegetação emergente e imersa. As maiores abundâncias verificam-se para
valores simultaneamente elevados destes factores.
A preferência por locais com maior cobertura de vegetação deve-se provavelmente
ao facto de constituir uma importante componente alimentar (Sidis & Gasith, 1985), de
albergar uma maior concentração de fauna aquática consumida por esta espécie e de
desempenhar um papel importante como abrigo. O maior grau de cobertura de vegetação
aquática pode também estar correlacionado com menores velocidades da corrente, que
dificultam a sua movimentação na água.
Para ambos os modelos, tanto do ponto de vista do produtor como do utilizador
verificou-se um número maior de trocas entre os níveis de abundância ausência e média e
entre os níveis média e alta do que entre os níveis ausência e alta. Apesar dos modelos
baseados em árvores de classificação não pressuporem à partida a existência de um
102

4. Discussão
gradiente entre as classes da variável resposta, este resultado sugere um padrão contínuo da
abundância ao longo de um gradiente ambiental.
Emys orbicularis
Esta espécie foi encontrada em todos as categorias de habitat aquático consideradas neste
trabalho, excepto em habitats de carácter lacustre, como por exemplo albufeiras. Alguns
dados estão de acordo com os modelos de distribuição, como é o caso da maior frequência
de presença em locais de menor altitude do que Mle. Um dado curioso é o facto da sua
presença ser mais frequente em locais onde se verificam maiores densidades de Mle. Isto
significa que as exigências ecológicas das duas espécies ao nível do habitat são muito
semelhantes, mas que Eor tende a não ocupar os habitats menos propícios. Este facto pode
ser mais um indício da sua regressão em Portugal, uma vez que, como já foi referido, as
populações sujeitas a uma grande fragmentação tendem a ocupar apenas os habitats de
melhor qualidade.
103


5. Considerações finais
5. CONSIDERAÇÕES FINAIS
Os resultados obtidos neste trabalho mostram que ambas as espécies de cágados
apresentam uma distribuição predominantemente mediterrânea em Portugal. Entre as
variáveis macro-ambientais disponíveis, a radiação solar é aquela que parece ter maior
influência na distribuição de ambas as espécies à escala geográfica. À escala local ambas
as espécies preferem habitats aquáticos de águas paradas, baixa profundidade e com uma
cobertura razoável de vegetação aquática. Para Emys orbicularis essa preferência parece
ser ainda mais marcada do que para Mauremys leprosa.
A distribuição de Emys orbicularis em Portugal contrasta com o seu padrão global
de distribuição; na Europa Emys orbicularis apresenta uma distribuição mais setentrional
do que Mauremys leprosa, estando à partida melhor adaptada a climas mais frios. A maior
frequência desta espécie no sul do país pode dever-se a uma maior disponibilidade de
habitats favoráveis nesta região. Por outro lado, se as suas populações estão em regressão,
a preferência por habitats favoráveis torna-se ainda mais vincada; é o que, de resto,
sugerem os resultados das análises efectuadas a nível local.
As metodologias empregues neste trabalho mostraram ser eficazes na modelação da
distribuição em Portugal das duas espécies de cágados. A regressão logística originou
modelos mais realistas, embora com uma interpretação bastante mais complexa do que as
árvores de classificação. No entanto, as medidas de precisão total dos modelos resultaram
muito semelhantes ou mesmo iguais.
Uma hipótese a considerar futuramente seria a de modelar a distribuição com base
no grau de isolamento de cada quadrícula de presença (utilizando por exemplo o índice de
raridade local - ver pág. 14), entendido como uma medida grosseira da abundância da
espécie. A “zona de confusão” seria certamente mais bem modelada resultando numa
maior precisão de classificação. A regressão logística ordinal e as árvores de regressão ou
classificação constituem dois métodos possíveis para a modelação de variáveis resposta
quantitativas.
Por outro lado, as árvores de classificação revelaram-se bastante úteis na análise
exploratória da influência de variáveis locais na abundância de Mauremys leprosa,
sobretudo atendendo às óbvias limitações da recolha dos dados, que impossibilitaram um
tratamento estatístico mais aprofundado.
105

5. Considerações finais
Os resultados obtidos com este trabalho reflectem razoavelmente bem o estado das
populações a nível nacional das duas espécies. Não se possuem dados históricos
suficientemente precisos para fundamentar uma eventual regressão de Emys orbicularis em
Portugal, embora a sua elevada fragmentação da distribuição e o seu declínio global em
toda a Europa constituam fortes indícios.
A situação das populações de Emys orbicularis em Portugal, comparativamente às
de Mauremys leprosa, nomeadamente em relação à sua raridade e às baixas densidades
observadas, podem ser o resultado de muitos factores, tais como: (1) o resultado da
ocorrência de flutuações naturais das populações, nomeadamente devido a factores
climáticos; (2) fenómenos de competição com Mauremys leprosa; (3) factores intrínsecos à
própria estratégia demográfica da espécie; (4) maior vulnerabilidade desta espécie à
alteração dos habitats e a agentes poluidores; (5) Portugal constituir o limite de distribuição
da espécie, sendo natural a fragmentação observada; (6) a conjugação de todos os factores
atrás mencionados. Apenas estudos mais aprofundados e comparativos da demografia,
genética de populações e biogeografia desta espécie poderão fornecer pistas nesse sentido.
Os dados obtidos com este trabalho, tais como a probabilidade de ocorrência, o
grau de fragmentação, o isolamento das populações e a coexistência das duas espécies,
complementadas com informações sobre a distribuição geográfica do grau de adequação
dos habitats e da abundância, serão úteis para a selecção de áreas prioritárias para a
conservação destas espécies a nível nacional.
106

6. Referências
6. REFERÊNCIAS Amo, O. A. (1991). Estatus y distribuicion del galapago europeu (Emys orbicularis) en
Cataluña. VIII Trabada JuvesNat. Catalunya. 35-39. Araújo, P. R., Segurado, P., & Raimundo, N. (1997). Bases para a conservação das
tartarugas de água doce, Mauremys leprosa e Emys orbicularis. Estudos de Biologia e Conservação da Natureza, 24. Instituto da Conservação da Natureza, Lisboa.
Astudillo, G., & Arano B. (1995). Europa y su Herpetofauna: responsabilidades de cada
pais en lo referente a su conservacion. Bol. Aso. Herpetol. Esp. 6, 14-45 Andries, A.M., Gulinck, H., & Herremans, M. (1994). Spatial modelling of the barn owl
Tyto alba habitat using landscape characteristics derived from SPOT data. Ecography, 17, 278-287.
Antunez, A., & Mendoza, M. (1992). Factores que determinan el área de distribución
geográfica de las espécies: conceptos, modelos y métodos de análisis. In J.M. Vargas, R. Real, & A. Antúnez (Eds.), Objectivos y Métodos Biogeográficos. Aplicaciones en Herpetologia. (pp. 51-72). A.H.E, Madrid.
Anselin, L. (1993). Discrete space autoregressive models. In Goodchild, M.F., Parks, B.O.
& Steyaert, L.T.New (Eds) Environmental Modeling with GIS (pp. 454-469), Oxford University Press, York.
Arnold, E.N., Burton, J.A., & Ovenden, D.W. (1978). A Field Guide to the Reptiles and
Amphibians of Britain and Europe. Collins, London. Aspinall, R., & Veitch, N. (1993). Habitat Mapping from Satelite Imagery and Wildlife
Survey Data Using a Bayesian Modeling Procedure in a GIS. Photogrammetric Engineering & Remote Sensing, 59, 537-543.
Augustin, N.H., Mugglestone, M.A., & Buckland, S.T. (1996). An autologistic model for
the spatial distribution of wildlife. Journal of Applied Ecology, 33, 339-347. Austin, G.E., Thomas, C.J., Houston, D.C., & Thompson, B.A. (1996). Predicting the
spatial distribution of buzzard Buteo buteo nesting areas using Geographical Information System and remote sensing. Journal of Applied Ecology, 33, 1541-1550.
Barbadillo, L.J. (1987). La Guia de INCAFO de los Anfibios Y Reptiles de la Peninsula
Iberica, Islas Baleares y Canarias. INCAFO, Madrid Begon, M., Harper, J.L., & Townsend, C.R. (1996). Ecology. Blackwell Science, Oxford.
107

6. Referências
Berry, J.K. (1993). Cartographic modeling: the analytical capabilities of GIS. In M.F. Goodchild, B.O. Parks, & L.T. Steyaert (Eds.), Environmental Modeling with GIS. (pp. 58-74). Oxford University Press, New York.
Bons, J., & Geniez, P. (1996). Amphibiens et Reptiles du Maroc. Atlas biogeographique.
Asociación Herpetológica Española, Barcelona. Boscá, E. (1881). Catalogue des reptiles et amphibiens de la Peninsule Iberique et des iles
Baléares. Bulletin de la Societé Zoologuique de France: 1-47. Breininger, D.R., Provancha, M.J., & Smith, R.B. (1991). Mapping Florida Scrub Jay
Habitat for Purposes of Land-Use Management. Photogrammetric Engineering & Remote Sensing, 57, 1467-1474.
Brito, J.C., Abreu, F.B., Paulo, O.S., Rosa, H.D., & Crespo, E.G. (1996). Distribution of
Schreiber's lizard (Lacerta Shreiberi) in Portugal: a predictive model. Herpetolical Journal, 6, 43-47.
Brito, J.C., Crespo, E.G., & Paulo, O.S. (1999). Modelling wildlife distributions: logistic
multiple regression vs. overlap analisys. Ecography, 22, 251-260. Brown, J.H., & Gibson, A.C. (1983). Biogeography. Mosby, St Louis. Buckland, S.T., & Elston, D.A. (1993). Empirical models for the spatial distribution of
wildlife. Journal of Applied Ecology, 30, 478-495. Chandler, S.K., Fraser, J.D., Buehler, D.A., & Seegar, J.K.D. (1995). Perch trees and
shoreline development as predictors of bald eagle distribution on Chesapeake Bay. Journal of Wildlife Management, 59, 325-332.
C.N.A. (1983). Atlas do Ambiente. Direcção-Geral do Ambiente. Ministério do Ambiente e
dos Recursos Naturais, Lisboa. Clark, J.D., Dunn, J.E., & Smith, K.G. (1993). A multivariate model of female black bear
habitat use for a geographic information system. Journal of Wildlife Management, 57, 519-526.
Clark L.A., Pregibon, D. (1992). Tree-based Models. in Statistical Models in S. Chambers,
J. M., Hastie, T. J. (eds.). Chapman and Hall, New York. Cliff, A.D. & Ord, J.K. (1998). Spatial autocorrelation, Pion Limited, London. Congalton, R.C. (1991). A review of assessing the accuracy of classification of remotely
sensed data. Remote Sens. Environ. 37, 35-46. Corbett, K. (1989). Conservation of European Reptiles & Amphibians. Cristopher Helm
Ltd, London. Cox, C.B., & Moore, P.D. (2000). Biogeography. An Ecological and evolutionary
approach. Blackwell Science, Oxford.
108

6. Referências
Crawford, K.M., Spotila, J.R., & Standora, E.A. (1983). Operative environmental
temperature and basking behavior of the turtle Pseudemys scripta. Ecology 64(5), 989-999.
Crespo, E.G., & Oliveira, M.E. (1989). Atlas da Distribuição dos Anfíbios e Répteis de
Portugal Continental. Lisboa: S.N.P.R.C.N. Da Silva, E. (1991). Contribucion al conocimiento de la biologia reproductora y dinamica
del crescimento oseo de Mauremys caspica leprosa (Schw. 1812). Resumo da Tese de Doutoramento, Universidade de Extremadura, badajoz.
Eastman, J.R. (1990). IDRISI: AGrid-Based Geographic Information System. Version 3.2.
(Worcester, MA: Clark University Graduate School of Geography) EGRET. (1991). EGRET: Statistical Analysis Package. Seattle: Statistics and
Epidiomological Research Corporation. Ellison, A.M. (1996). An introduction to bayesian inference for ecological research and
environmental decision-making. Ecological Applications, 6, 1036-1046. Ernst, C.H., & Barbour, R.W. (1989). Turtles of the world. Smithsonian Institution Press,
Washington, D.C. Farinha, J.C., Costa, L.T., Zalidis, G., Mantzavelas, A., Fitoka, E., Hecker, N. & Tomàs
Vives, P. (1996). Mediterranean Wetland Inventory: Habitat Description System..Medwet / Instituto da Conservação da Natureza (ICN) / Wetlands International / Greek Biotope/Wetland Centre (EKBY) Publication.Volume III.
Forman, R.T.T. (1995). Land Mosaics. Cambridge University Press, Cambridge. Franklin, J. (1998). Predicting the distribution of shrub species in southern California from
climate and terrain-derived variables. Journal of Vegetation Science, 9, 733-748. Frisenda, S.,& Ballasina, D. (1990). Le Statut des Chéloniens Terrestres et d´Eau Douce en
Italie. Bull. Soc. Herp. Fr. 53,:18-23 Gaston, K.J., & Lawton, J.H. (1990). Effects of scale and habitat on the relationship
between regional distribution and local abundance. Oikos, 58, 329-335. Gates, S., Gibbons, D.W., Lack, P.C., & Fuller, R.J. (1994). Declining farmland bird
species: modelling geographical patterns of abundance in Britain. In P.J. Edwards, R.M. May, & N.R. Webb (Eds.), Large-scale ecology and conservation biology. (pp. 153-177). Blackwell Scientific Publications, London.
Gilpin, M.E. (1987). Spatial structure and population vulnerability. In M.E. Soulé (Ed.),
Viable Populations for Conservation. (pp. 125-139). Cambridge Uinversity Press, Cambridge
109

6. Referências
Hanski, I. (1996). Metapopulation ecology. In O.E. Rhodes, Jr (Ed.), Population dynamics in ecological space and time. (pp. 13-43). University of Chicago Press, Chicago.
Hanski, I., & Gilpin, M.E. (1991). Metapopulation dynamics: brief history and conceptual
domain. Biological Journal of the Linnean Society, 42, 3-16. Harding, P.T. (1991). National species distribution surveys. In F.B. Goldsmith (Ed.),
Monitoring for conservation and ecology. (pp. 133-154). Chapman & Hall, London.
Harrison, S. (1994). Metapopulations and conservation. In P.J. Edwards, R.M. May, &
N.R. Webb (Eds.), Large-scale ecology and conservation biology. (pp. 111-128). Blackwell Scientific Publications, London.
Haslett, J.R. (1990). Geographic information systems: a new approach to habitat definition
and the study of distributions. TREE, 5, 214-218. Heatwole, H., & Taylor, J. (1987). Ecology of Reptiles. Surrey Beatty & Sons, Shipping
Norton. Hill, M.O. (1991). Patterns of species distribution in Britain elucidated by canonical
correspondence analysis. Journal of Biogeography, 18, 247-255. Hoef, J.M.V. (1996). Parametric empirical bayes methods for ecological applications.
Ecological Applications, 6(4), 1047-1055. Hosmer Jr, D.W. & Lemeshow, S. (1989). Applied Logistic Regression. Wiley, New York. Iverson, L.R. & Prasad, A.M. (1998). Predicting abundance of 80 tree species following
climate change in the Eastern United States. Ecological Monographs, 68(4), 465-485.
Johnston, C.A. (1998). Geographic Information Systems in Ecology. Blackwell Science,
Oxford. Keller, C., Díaz-Paniagua C.,& Andreu A.C. (1994). Distribución de Mauremys leprosa y
Emys orbicularis en Doñana (SO de España). III Congresso Luso-español, VII Congresso Español, Badajoz.
Kvamme, K.L. (1990). The fundamental principles and practice of predictive
archaeological modeling. In A. Voorrips (Ed.), Mathematics and information science in archaeology: a flexible framework. (pp. 257-295). Holos-Verlag, Bonn.
Kvamme, K.L. (1992). A predictive site location model on the high plains: an example
with an independent tes. Plains Anthropologist, 37, 19-40. Lawton, J.H., Nee, S., Letcher, A.J., & Harvey, P.H. (1994). Animal distributions: patterns
and processes. In P.J. Edwards, R.M. May, & N.R. Webb (Eds.), Large-scale
110

6. Referências
ecology and conservation biology. (pp. 41-58). Blackwell Scientific Publications, London.
Malkmus R. (1995). Die Amphibien und Reptilien Portugals, Madeiras und Der Azoren.
Westarp Wissenschaften, Magdeburg. 105-109. Maurer, B.A. (1994). Geographical Population Analysis: Tools for the Analysis of
Biodiversity. Blackwell Science, Oxford. May, R.M. (1994). The effects of spatial scale on ecological questions and answers. In P.J.
Edwards, R.M. May, & N.R. Webb (Eds.), Large-scale ecology and conservation biology. (pp. 1-17). Blackwell Scientific Publications, London.
McCullagh, P. & Nelder, J.A. (1989). Generalized Linear Models. Chapman & Hall. MicroImages (1997). The Map and Image Processing System version 5.7. Lincoln, USA. Murphy, D.D. (1989). Conservation and confusion: Wrong species, wrong scale, wrong
conclusions. Conservation Biology, 3 (1), 82-84. Nečas, P.; Modrý, D; Zavadil, V (1997). Czech Recent and Fossil Amphibians and
Reptiles. Edition Cuimaira, Frankfurt. North, M.P., & Reynolds, J.H. (1996). Microhabitat analysis using radiotelemetry locations
and polytomous logistic regression. Journal of Wildlife Management, 60, 639-653.
Ormsby, J.P., & Lunetta, R.S. (1987). Whitetail Deer Food Availability Maps from
Thematic Mapper Data. Photogrammetric Engineering & Remote Sensing, 53, 1585-1589.
Palmeirim, J.M. (1985). Using Landsat TM Imagery and Spatial Modeling in Automatic
Habitat Evaluation and Release Site Selection for the Ruffed Grouse (Gallifomes: Tetraonidae). Proceedings 19th International Symposium of Remote Sensing and Environment.
Parker, S. (1985). Predictive modeling of site settlement systems using multivariate
logistics. In C. Carr (Ed.), For concordance in archaeological analysis. (pp. 173-207). Westport, Kansas City.
Pereira, J.M.C., & Duckstein, L. (1993). A multiple criteria decision-making approach to
GIS-based land suitability evaluation. Int J Gographical Information Systems, 7, 407-424.
Pereira, J.M.C., & Itami, R.M. (1991). GIS-based Habitat Modeling Using Logistic
Multiple Regression: A Study of the Mt. Graham Red Squirrel. Photogrammetric Engineering & Remote Sensing, 57, 1475-1486.
Rapoport, E.H. (1982). Aerography. Geographical strategies of species. Pergamon Press,
Oxford.
111

6. Referências
Rogers, D.J., & Williams, B.G. (1994). Tsetse distribution in Africa: seeing the wood and
the trees. In P.J. Edwards, R.M. May, & N.R. Webb (Eds.), Large-scale ecology and conservation biology. (pp. 247-271). Blackwell Scientific Publications, London.
Romero, J., & Real, R. (1996). Macroenvironmenteal factors as ultimate determinants of
distribution of common toad and natterjack toad in the south of Spain. Ecography, 19, 305-312.
Segurado, P. (1996). Estudo da estrutura das populações e de alguns parâmetros
demográficos de Mauremys leprosa e de Emys orbicularis em Portugal. Actas do IV Congresso Luso-Espanhol, VII Congresso Espanhol de Herpetologia. Porto.
Servan J., & Pieau C. (1984). La cistude d'Europe (Emys orbicularis): Mensuration d'oeufs
et de jeunes individus.Bull. Soc. Herp. Fr. 1984, 31:20-26 S.N.P.R.C.N.(ed.). (1990). Livro Vermelho dos Vertebrados de Portugal. Vol. I -
Mamíferos, Aves, Répteis e Anfíbios. Lisboa: S.N.P.R.C.N. Sidis, I & Gasith, A. (1985). Food Habits of the Caspian Terrapin (Mauremys caspica
rivulata) in Unpolluted and Polluted Habitats in Israel. Journal of Herpetology. 19 (1), 108-115.
Spellerberg, I.F. (1982). Biology of Reptiles. An ecological approach. Blackie & Son Ltd,
London. Spellerberg, I.F. (1992). Evaluation and assessment for conservation Chapman & Hall,
London. Statistical Sciences (1995). S-PLUS Guide to Statistical and Mathematical Analysis,
Version 3.3.StatSci, MathSoft, Inc., Seatle. Teixeira, J., Arntzen, J.W., Ferrand, N., & Alexandrino, J. (1996). Elaboração de um
modelo preditivo da distribuição de Chioglossa lusitanica em Portugal. Actas do IV Congresso Luso-Espanhol, VII Congresso Espanhol de Herpetologia. Porto.
Trexler, J.C., & Travis, J. (1993). Nontraditional regression analysis. Ecology, 74, 1629-
1637. Vernaples W. N., & Ripley, B. D. (1997). Modern Applied Statistics with S-PLUS.
Springer-Verlag, New York. Walker, P.A. (1990). Modelling wildlife distributions using a geographic information
system: Kangaroos in relation to climate. Journal of Biogeography, 17, 279-289. Warren, R.E. (1990). Predictive modelling in archaeology: a primer. In K.M.S. Allen, S.W.
Green, & E.B.W. Zubrow (Eds.), Interpreting space: GIS and archaeology. (pp. 90-111). Taylor & Francis, London.
112

6. Referências
Zar, J.H. (1984). Biostatistical analysis. Prentice-Hall, New Jersey.
113

ANEXO I
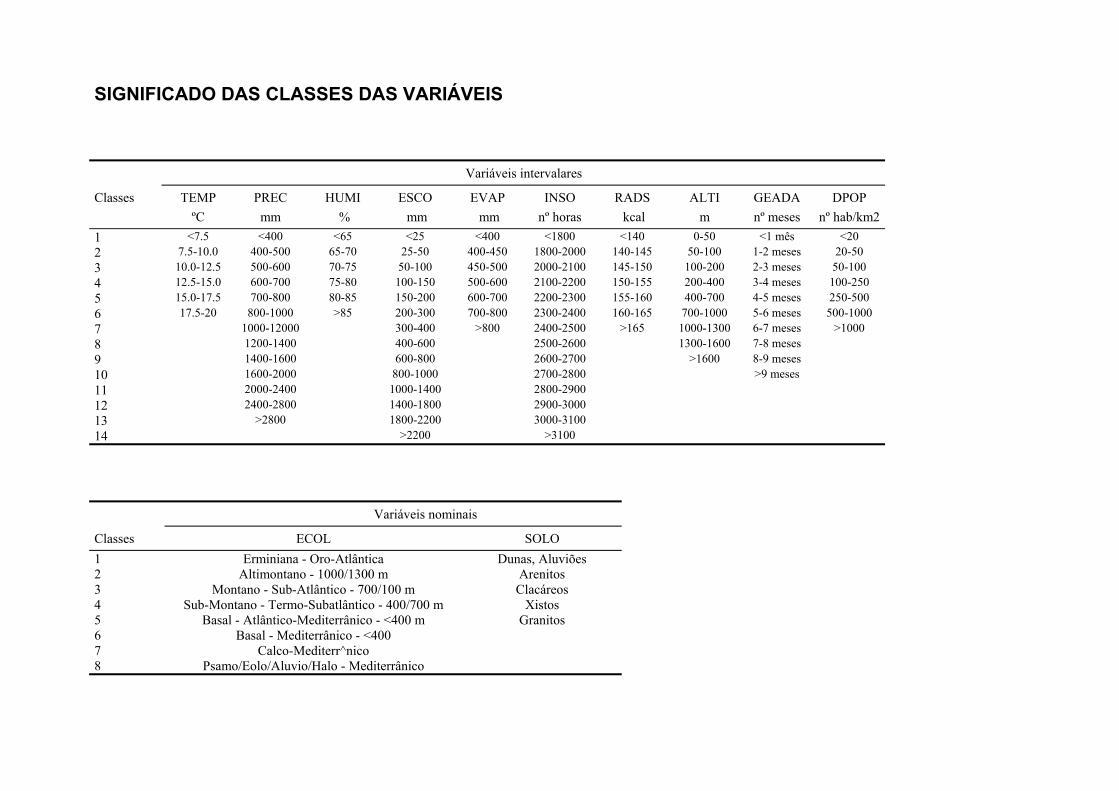
SIGNIFICADO DAS CLASSES DAS VARIÁVEIS
Variáveis intervalares
Classes TEMPºC
PREC mm
HUMI %
ESCO mm
EVAP mm
INSO nº horas
RADS kcal
ALTI m
GEADA nº meses
DPOP nº hab/km2
1 <7.5 <400 <65 <25 <400 <1800 <140 0-50 <1 mês <202 7.5-10.0
400-500 65-70 25-50 400-450 1800-2000 140-145 50-100 1-2 meses 20-503 10.0-12.5 500-600 70-75 50-100 450-500 2000-2100 145-150 100-200 2-3 meses 50-1004 12.5-15.0 600-700 75-80 100-150 500-600 2100-2200 150-155 200-400 3-4 meses 100-2505 15.0-17.5 700-800 80-85 150-200 600-700 2200-2300 155-160 400-700 4-5 meses 250-5006 17.5-20
800-1000 >85 200-300 700-800 2300-2400 160-165 700-1000 5-6 meses 500-1000
7 1000-12000 300-400 >800 2400-2500 >165 1000-1300 6-7 meses >10008 1200-1400 400-600 2500-2600 1300-1600 7-8 meses9 1400-1600 600-800 2600-2700 >1600 8-9 meses10 1600-2000 800-1000 2700-2800 >9 meses
11 2000-2400 1000-1400 2800-290012 2400-2800 1400-1800 2900-300013 >2800 1800-2200 3000-310014 >2200 >3100
Variáveis nominais
Classes ECOL SOLO1 Erminiana - Oro-Atlântica Dunas, Aluviões 2 Altimontano - 1000/1300 m Arenitos 3 Montano - Sub-Atlântico - 700/100 m Clacáreos 4 Sub-Montano - Termo-Subatlântico - 400/700 m Xistos 5 Basal - Atlântico-Mediterrânico - <400 m Granitos 6 Basal - Mediterrânico - <400 7 Calco-Mediterr^nico8 Psamo/Eolo/Aluvio/Halo - Mediterrânico