Embed Size (px)
Citation preview

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 1
Escola Superior de Educação Profª. Raquel Vieira [email protected]
12 11
Breves Considerações sobre SPSS

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 2
ÍNDICE
1. APRESENTAÇÃO SUCINTA DO AMBIENTE SPSS 3 1.1. PRINCIPAIS MENUS E JANELAS 3 1.2. SPSS PARA ORGANIZAR DADOS 5 1.3. EXPLORAÇÃO DE VARIÁVEIS 10 1.4. A APRESENTAÇÃO GRÁFICA DE DADOS E O TIPO DE VARIÁVEL 11
2. MEDIDAS DE LOCALIZAÇÃO DE TENDÊNCIA CENTRAL REVISÃO DE CONCEITOS E APLICAÇÃO A SPSS 15
3. ASSOCIAÇÃO E CORRELAÇÃO 22 3.1. DIAGRAMA DE DISPERSÃO 22 3.2. COVARIÂNCIA E CORRELAÇÃO 25 3.2.1. COEFICIENTE DE CORRELAÇÃO LINEAR DE PEARSON 26 3.2.2. COEFICIENTE DE CORRELAÇÃO ORDINAL DE SPEARMAN 27 3.2.3. COEFICIENTE DE CORRELAÇÃO BISSERIAL POR PONTOS 27 3.3. ASSOCIAÇÃO: TABELAS DE CONTINGÊNCIA E COEFICIENTE DE ASSOCIAÇÃO 29
4. TESTES PARAMÉTRICOS E NÃO PARAMÉTRICOS 36

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 3
1. Apresentação sucinta do Ambiente SPSS
O SPSS (Statistical Package for Social Sciences) é um software de análise estatística e tratamento de dados vocacionado para as Ciências Sociais que permite, entre muitas outras possibilidades, a manipulação, transformação e criação de tabelas e gráficos que resumam a informação obtida. Mas as suas potencialidades vão mais além do que a simples análise descritiva de um conjunto de dados. É também possível realizar, com este software, procedimentos mais avançados que vão desde a Inferência Estatística, teste de hipóteses e estatísticas multivariadas para dados qualitativos e quantitativos.
1.1. Principais menus e janelas Tal como em outros programas, podemos encontrar na parte superior um conjunto de comandos que permitem a execução de várias operações (File, Edit, View, Data, Transform, Analyze, Graphs, Utilities, Window e Help).
Embora quando de se abre um novo documento de SPSS, a aparência possa ser muito semelhante ao programa Excel, no que se refere à organização em linhas e colunas, a forma de funcionamento apresenta diferenças estruturais. De facto, cada uma das células resulta do cruzamento de várias colunas onde devem constar as variáveis em estudo (Ex. Peso, sexo, idade, etc.) e várias linhas, sendo cada uma destas respeitante a cada um dos sujeitos ou participantes.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 4
Além dos Menus, o SPSS apresenta outro tipo de interfaces, tais como: janelas, barras de ferramentas e de estado e caixas de diálogo que tornam mais acessível o seu manuseamento. No que se refere a janelas, destacamos:
A janela de edição (SPSS Data Editor) que se subdivide em duas janelas:
- Janela de dados - (Data View): Ao abrir o SPSS é a primeira janela que é visualizada e consiste numa matriz (linhas/colunas) onde vão ser inseridos (ou alterados) os dados. Cada coluna representa uma variável e cada linha é um registo, caso ou observação.
- Janela de Variáveis - (Variable View): O SPSS tem uma janela de vista de variáveis onde se definem, ou se modificam, todos os aspectos relativos a cada uma das variáveis.
A Janela de resultados (Output Viewer) – Onde todos os resultados, sob a forma de tabelas ou gráficos são exibidos. O conteúdo pode ser editado e gravado em ficheiro.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 5
1.2. SPSS para organizar dados
1º PASSO: INTRODUÇÃO E DEFINIÇÃO DE VARIÁVEIS A introdução de dados pressupõe que, antecipadamente sejam identificadas e classificadas as variáveis em questão. Para isso, deve ser seleccionada a Janela das Variáveis (Variable View) onde deverão ser preenchidas, nas diferentes colunas as dimensões para a caracterização das variáveis em estudo:
Name: Define-se o nome da variável. Type: Determina-se o tipo de variável em uso:
- Numeric - numéricas - Comma - com vírgulas a separar os milhares - Dot- Com ponto separador nos milhares - Scientific notation - numéricos com notação científica - Date- data-város formatos - DolLar-para moeda dólar - Custom Currency- outros fomatos para valores monetários - String- alfanuméricas - mais usada para posteriormente identificar casos em
apresentação gráfica de resultados, ou seja para variáveis Nominais e Ordinais.1 - Restricted Numeric: número inteiro com zeros à esquerda
Label: etiqueta que, queremos que saia, por exemplo, no Output dos resultados.
1 Mesmo quando as variáveis são qualitativas é possível escolher numeric para que se possam realizar posteriormente análises estatísticas com este tipo de variáveis. Por exemplo, Grau de satisfação ser 1 para muito baixo, 2 para moderado e 3 para muito alto.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 6
Value Labels- atribui etiquetas aos valores da variável
Missing values - Os valores em falta. Note-se que os valores de uma variável- mesmo sendo numéricos- especificados como missing values pelo utilizador são excluídos do tratamento estatístico dos dados e são tratados como um caso especial. Columns - Permite definir/alterar o tamanho da coluna. Align - Permite definir/alterar o alinhamento da coluna. Measure – Permite definir o tipo de variável:
- Scale se são quantitativas - Nominal e Ordinal se são variáveis qualitativas (ambas tratadas como categóricas
nos procedimentos de tabelas e gráficos, mesmo que os valores sejam numéricos). Role – Permite definir o papel que a variável poderá tonar na análise dos dados:
- Input : variável independente - Target: variável depente - Both: ambas - None: sem papel assumido - Partition: será usada para a partição de dados em duas amostras separadas - Split: permite a compatibilidade (nos dois sentidos) com o PASW Modeler
(programa que permite a descoberta de padrões).
A EXPLORAÇÃO DE ALGUMAS FERRAMENTAS: O Menu Transform O SPSS possui um conjunto de ferramentas que permitem transformar as variáveis, alterar os valores a uma variável ou até criar novas variáveis a partir de outras, e se necessário também seleccionar casos a analisar.
Compute- Permite calcular valores, mediante uma expressão matemática.
Por exemplo: Um determinado suplemento alimentar faz aumentar a massa muscular em 5%. A fórmula matemática correspondente será: massa muscular final = 1.05* massa muscular inicial
o SPSS permite, assim, a criação de uma nova variável partindo da anterior, usando Compute Variable, escrevemos o nome da nova variável MMfinal" na caixa de texto e em Target Variable a expressão numérica 1.05*MMinicial (Variável anterior)

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 7
Clicamos OK.
Recode – Este comando permite codificar valores de uma variável em novos valores, sendo útil para conseguir categorizar variáveis ou para agrupar ou transformar valores nominais em numéricos. Por exemplo se temos uma variável que necessitamos agrupar por classes.
Por exemplo: Depois de inserirmos a variável peso, podemos ter necessidade de a codificar em intervalos pela classificação de IMC:
até 19,99 - peso baixo 20 a 24,99 - peso normal
25 a 29,99 - excesso de peso 30 a 35,99 - obesidade
a partir de 36 - obesidade mórbida Acedemos ao menu Transform – Recode – Into different Variables e criamos o nome da nova variável, por exemplo classimc, incluindo um nome mais completo em Label.
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 8
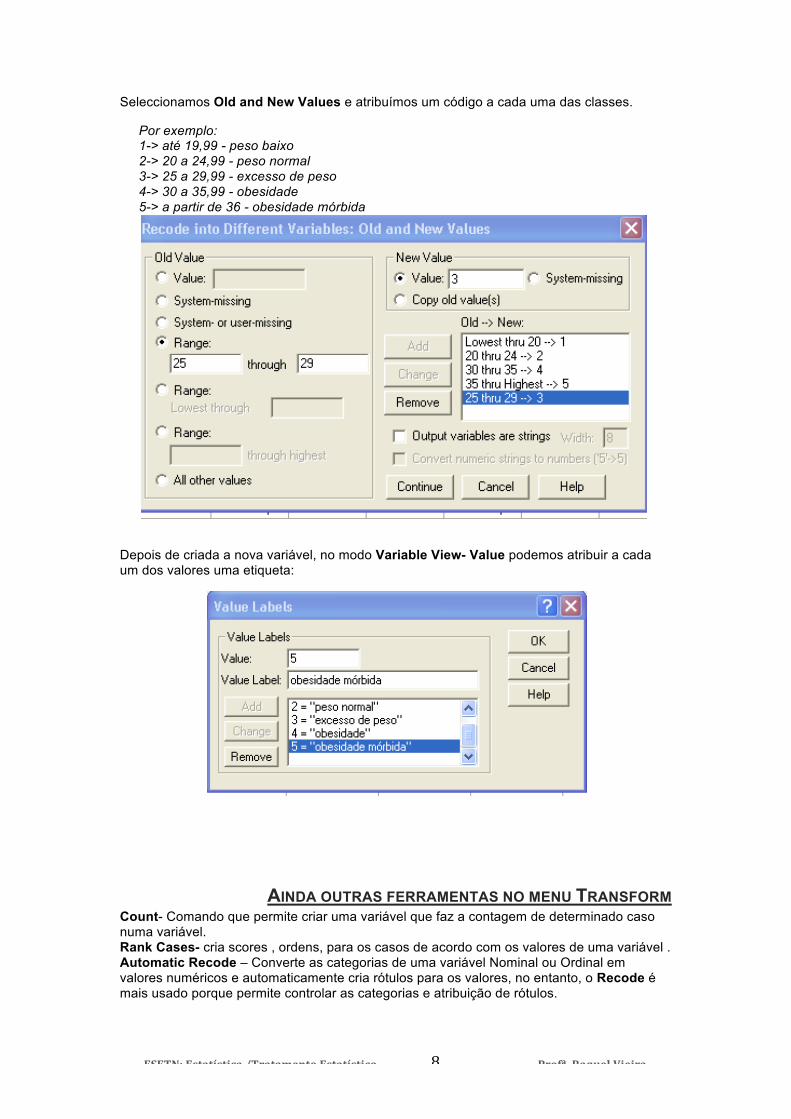
Seleccionamos Old and New Values e atribuímos um código a cada uma das classes.
Por exemplo: 1-> até 19,99 - peso baixo 2-> 20 a 24,99 - peso normal 3-> 25 a 29,99 - excesso de peso 4-> 30 a 35,99 - obesidade 5-> a partir de 36 - obesidade mórbida
Depois de criada a nova variável, no modo Variable View- Value podemos atribuir a cada um dos valores uma etiqueta:
AINDA OUTRAS FERRAMENTAS NO MENU TRANSFORM Count- Comando que permite criar uma variável que faz a contagem de determinado caso numa variável. Rank Cases- cria scores , ordens, para os casos de acordo com os valores de uma variável . Automatic Recode – Converte as categorias de uma variável Nominal ou Ordinal em valores numéricos e automaticamente cria rótulos para os valores, no entanto, o Recode é mais usado porque permite controlar as categorias e atribuição de rótulos.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 9
O Menu Data No menu data estão alguns dos comandos directamente relacionados com os dados, dos quais podemos destacar alguns procedimentos, por enquanto: Sort Cases- Ordena os casos de acordo com uma variável. Neste exemplo os dados estão ordenados a partir da variável peso:
Transpose- Transpõe linhas para colunas o que significa que as variáveis passam a ser casos e as observações variáveis.
Merge files- permite acrescentar valores (casos ou variáveis) de outro ficheiro de dados do SPSS.
Split Files – permite dividir ficheiros de dados em função de categorias de uma variável categórica. Útil quando é necessário compara resultados para dois grupos distintos. Por exemplo: feminino e masculino.
Select Cases- Permite escolher um subconjunto de observações para se fazer várias análises, tendo em consideração esses valores, dependendo de um critério introduzido (if condition is satisfied), aleatoriamente (Random Sample of cases) , num intervalo (time or case range). Por exemplo: seleccionar todos os casos em que a idade seja inferior ou igual a 30 anos:

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 10
Weight Cases- Apresenta os valores “pesados”por uma variável . Ou seja em vez de
cada linha representar uma observação, esta poderá representar tantos casos como os que estarão definidos pela variável definida para pesar os valores (weight). Os valores dessa variável devem indicar o número de observações que verificam conjuntamente as categorias das outras variáveis. Valores nulos, omissos ou negativos serão excluídos.
1.3. Exploração de variáveis Numa análise estatística há a distinguir, em primeiro lugar, dois tipos de estatísticas: a que pretende descrever os dados amostrais - estatística descritiva - e a que pretende extrapolar esses resultados para a população – estatística inferencial. A exploração de variáveis em qualquer um dos contexto remete-nos ao menu Analize
Menu Analyze e a estatística descritiva Mostrar as potencialidades deste menu exige, antes de mais, aprofundar a definição das variáveis, pois esta definição é determinante na saída dos dados. Sabemos que existem os seguintes tipos de variáveis:
Nominal (Nominal): dados classificados por categorias não ordenadas; Ordinal (Ordinal): dados classificados por categorias ordenadas Intervalar (Scale): dados expressos numa escala numérica com origem arbitrária Razão (Scale): dados expressos numa escala numérica com origem fixa
Note-se que, por vezes, há necessidade de categorizar variáveis contínuas.
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 11
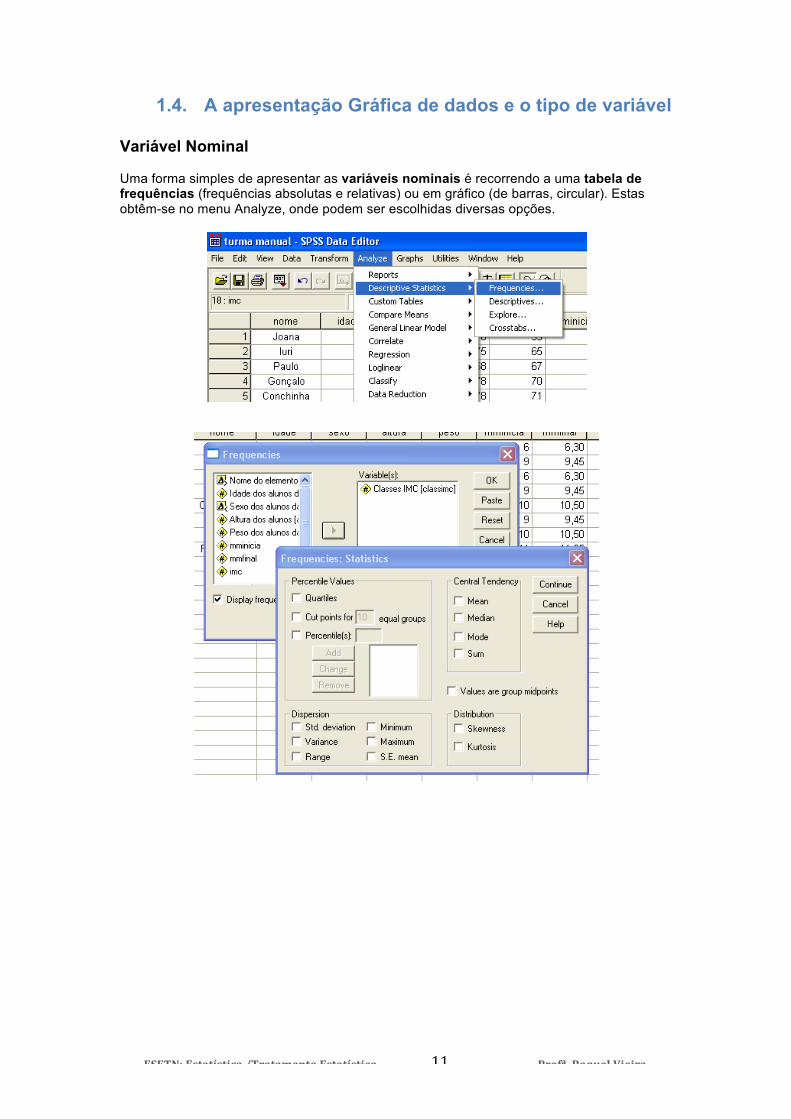
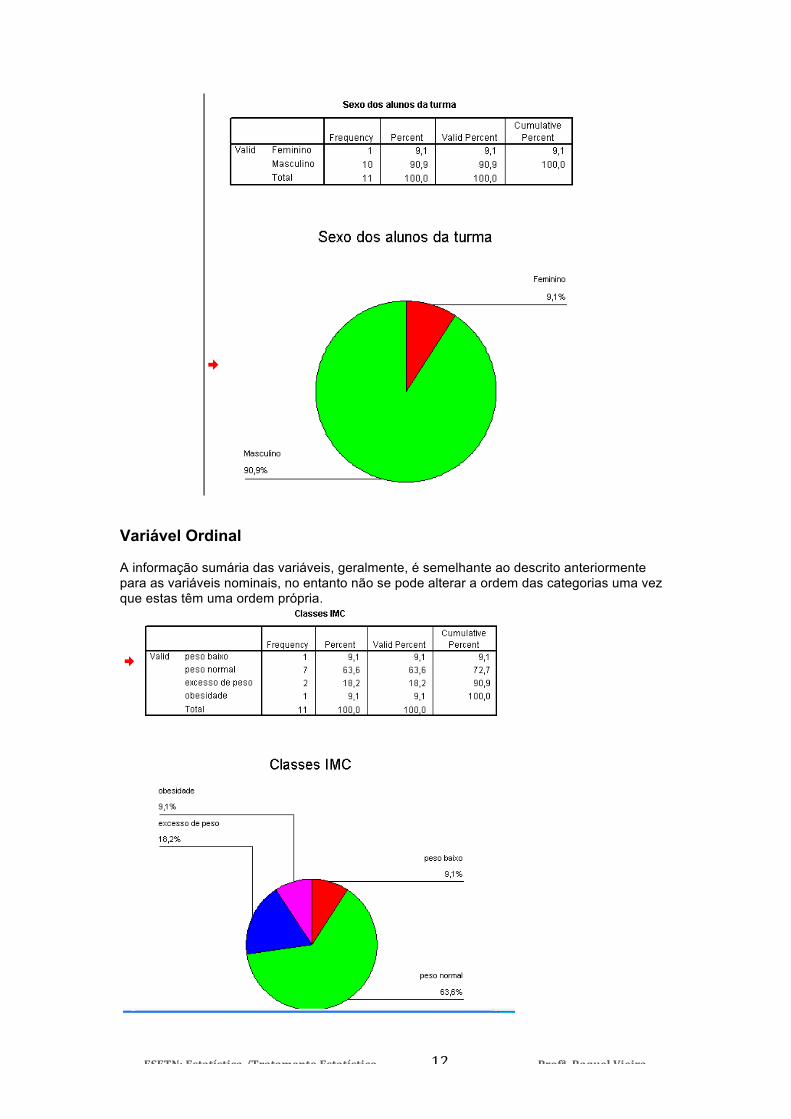
1.4. A apresentação Gráfica de dados e o tipo de variável Variável Nominal Uma forma simples de apresentar as variáveis nominais é recorrendo a uma tabela de frequências (frequências absolutas e relativas) ou em gráfico (de barras, circular). Estas obtêm-se no menu Analyze, onde podem ser escolhidas diversas opções.
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 12
Variável Ordinal A informação sumária das variáveis, geralmente, é semelhante ao descrito anteriormente para as variáveis nominais, no entanto não se pode alterar a ordem das categorias uma vez que estas têm uma ordem própria.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 13
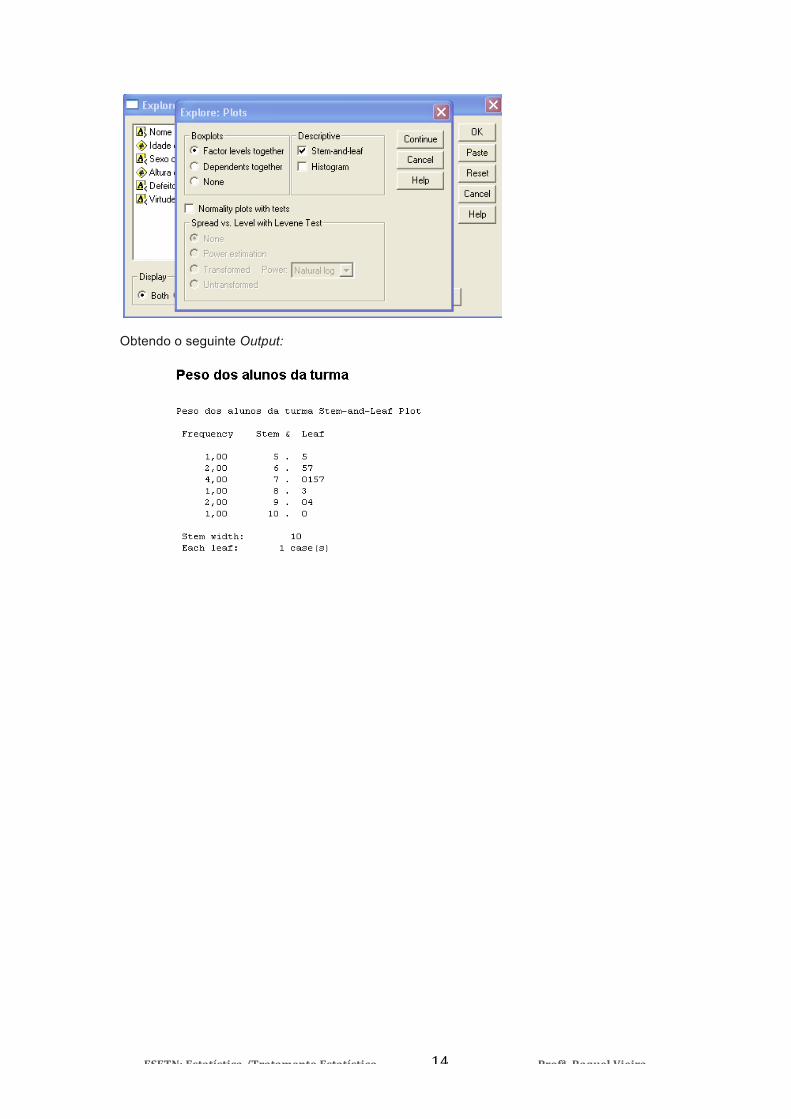
Variável Contínua e Discreta Para descrever variáveis discretas que assumam poucos valores ainda é possível usar uma tabela de frequências e/ou gráficos de barras. Mas para variáveis discretas, que assumam vários valores, ou para variáveis contínuas uma tabela de frequências não é, normalmente, muito útil, pois grande parte dos valores terão frequência muito baixa. A tabela de frequências será uma lista de valores que torna a informação a extrair da variável muito complexa. Da mesma forma um gráfico de barras para dados contínuos seria composto por uma série de pequenas barras. Uma opção que permite uma visualização dos dados melhor que a obtida com um gráfico de barras é o histograma. O histograma é semelhante ao gráfico de barras com a diferença que cada barra representa a frequência de valores num intervalo ou classe (de valores). Cada intervalo de valores tem a continuação no intervalo da barra seguinte. Por isso as barras são representadas todas juntas. Gráfico de Caule-e-folhas O diagrama de caule-e-folha (stem and leaf) consiste numa representação gráfica que apresentar os dados separando em cada dado quantitativo os algarismos de maior ordem (caule) dos de menor ordem (folhas). → Esta tabela tem a particularidade de permitir ao observador uma percepção do aspecto global dos dados sem perda de informação contida na colecção de dados inicial. Para construir um gráfico de caule-e-flores deve proceder aos seguintes passos: Descritive Statistics -> Explore e escolher a variável que pretender e seleccionar Plots -> Stem-and-leaf
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 14
Obtendo o seguinte Output:

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 15
2. Medidas de localização de tendência central Revisão de Conceitos e aplicação a SPSS
Média aritmética
1) Seja x1, x2, x3, .., xn os n valores de uma variável quantitativa. Chama-se média, e
representa-se por , ao valor obtido por
.
2) Quando os dados estão agrupados em classes, x1, x2, x3,..., xn são os valores médios da classe
com k =número de classes; Fi=frequência absoluta classe i; yi é o ponto médio da classe i (representante da classe). O valor que obtemos para a média deixa de ser exacto, passando a ser uma aproximação.
A média aritmética é o valor único que equilibra a distribuição, dado que a soma dos desvios de todas as observações em relação à média é zero. É muitas vezes designada de centro de gravidade da distribuição e depende do valor de todas a observações, sendo objectivamente afectada pelos valores extremos.
• A média é o centro nas distribuições normais
DESVANTAGEM DA MÉDIA: A média é muito sensível a valores muito grandes ou muito pequenos, é por isso uma medida sensível e pouco resistente.
Mediana
Indica o valor central das observações, depois de ordenadas. A mediana é o valor que a divide ao meio, isto é, 50% dos elementos da amostra são menores ou iguais à mediana e os outros 50% são maiores ou iguais.
Depois de ordenada a amostra: • Se n é ímpar – a mediana é o elemento médio.
• Se n é par – a mediana é a semi-soma dos dois elementos médios.
Como medida de localização, a mediana é mais resistente do que a média, pois não é tão
sensível aos dados.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 16
Mediana a partir de dados agrupados:
A fórmula empírica para o cálculo da mediana é:
Sendo:
l – limite inferior da classe; c – amplitude da classe mediana; n – dimensão da população
F – frequência acumulada da classe anterior à classe mediana; f – frequência da classe mediana
Quantil
A designação de quantil encontra-se associada à ideia de que os quantis dividem a distribuição de frequências em quantidades iguais, isto é, com igual número de observações.
Os quantis podem ser:
• Quartis – divide a distribuição de frequências em 4 partes iguais. • Decis – divide a distribuição de frequências em 10 partes iguais • Percentis – divide a distribuição de frequências em 100 partes iguais.
Sejam x1 e xn, respectivamente, o menor e o maior valor da variável considerando o conjunto ordenado.
Q1 Q2 Q3
Q1, Q2 e Q3 representam os quartis da distribuição:
• 1º quartil é o valor da variável tal que o número de observações para valores inferiores a Q1 é 25%, e o nº de observações é superior a 75%.
• 2º quartil coincide com a mediana, o que significa que 50% das observações estão abaixo de Q2 e, pelo menos, 50% estão acima de Q2.
• 3º quartil é o valor da variável tal que o número de observações para valores inferiores a Q3 é 75%, e o nº de observações superiores é 25%.
• As fórmulas de cálculo do Q1 e do Q3 são idênticas à da mediana, substituindo
respectivamente por e (e os valores na fórmula têm de ser adaptados ao
intervalo correspondente ao quartil).
Moda
É o valor mais frequente da distribuição ou o valor que mais observações apresenta no
conjunto de dados. Existem conjuntos de dados que não apresentam moda, porque nenhum
valor se repete maior número de vezes, e existem conjuntos de dados com duas ou mais
modas. Se os dados estão agrupados em classes de igual amplitude, a classe de maior
xn x1 mediana
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 17
frequência chama-se classe modal. Quando as amplitudes são variáveis, a classe modal é
aquela que corresponde ao rectângulo com maior altura do histograma. A moda pode
considerar-se o ponto médio da classe modal.
A moda tem algumas vantagens como medida de estatística descritiva:
• É fácil de calcular e interpretar;
• Não é afectada por valores extremos
Mas apresenta uma clara desvantagem: Não pode ser definida com rigor
Medidas de Assimetria e Curtose
- Assimetria
Este método consiste na comparação das três medidas de tendência central: a média, a
mediana e a moda.
Na maioria dos estudos, o conhecimento de uma única medida pouco adianta para a
compreensão do fenómeno. Vejamos que relação existe entre estas três medidas, quando
temos uma representação através de um polígono de frequências. Para ser mais acessível
esta leitura, imaginemos que limávamos as arestas do polígono de frequências de modo a
obter uma linha curva em vez de uma linha quebrada.
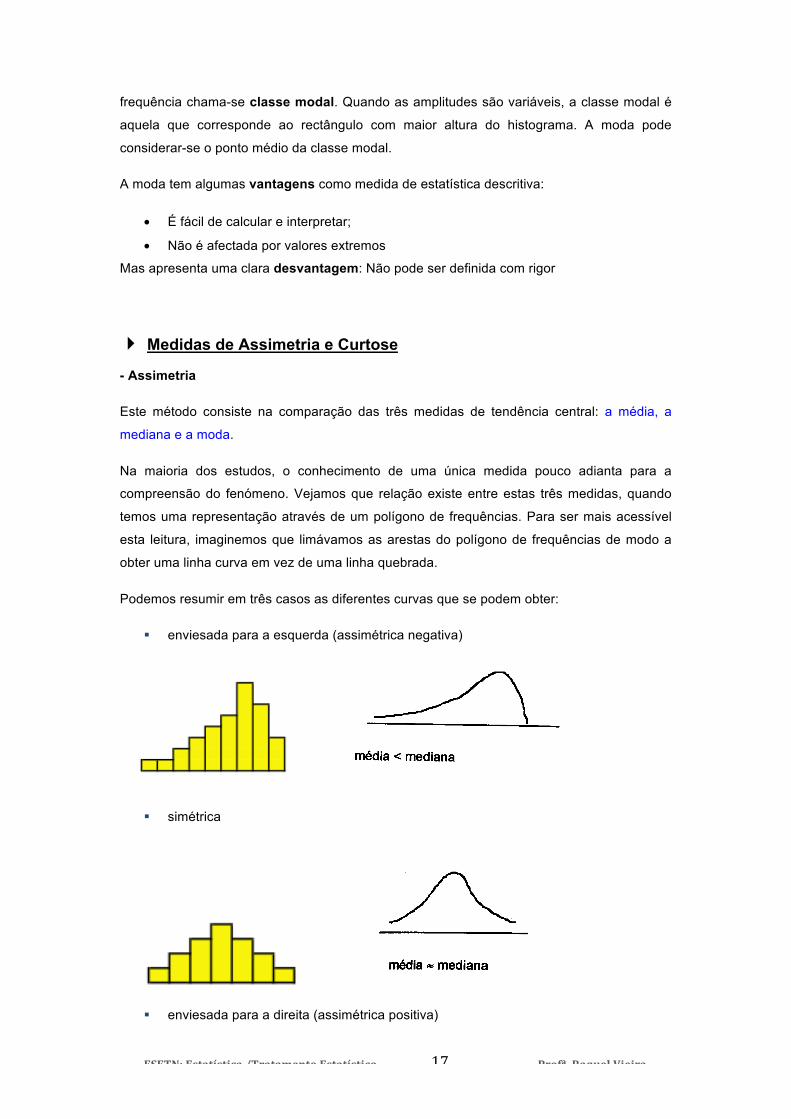
Podemos resumir em três casos as diferentes curvas que se podem obter:
enviesada para a esquerda (assimétrica negativa)
simétrica
enviesada para a direita (assimétrica positiva)

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 18
De um modo geral:
Curva simétrica Curva assimétrica positiva Curva assimétrica negativa
- Achatamento ou Curtose
As medidas de curtose dão-nos uma indicação da intensidade das frequências na vizinhança
dos valores centrais. Como referência ao grau de achatamento podemos ter:
Distribuição Distribuição Distribuição
Leptocúrtica Mesocúrtica Platicúrtica
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 19
Para medir o grau de curtose pode ser utilizada a seguinte medida:
Grau de Curtose
Sendo Q1 e Q3 o primeiro e terceiro quartis e P90 e P10 o 90º e 10º percentis.
• Se K = 0.263 a distribuição é mesocúrtica;
• Se K > 0.263 a distribuição é platicúrtica;
• Se K < 0.263 a distribuição é leptocúrtica.
Para obter as medidas descritivas, basta explorar o menu Analyse:
Analyse -> Descritive Statistics.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 20
Diagrama de caixa de bigodes
Há situações para as quais a avaliação dos extremos é fundamental. Turkey (1977) desenvolveu uma técnica denominada caixa e bigodes (blox plot) que nos fornece uma indicação clara dos valores extremos, da mesma forma que o histograma e o diagrama de caule e folhas informa como os valores estão distribuídos. Da construção deste diagrama depende a determinação das seguintes medidas:
Mediana Quartis Distância entre quartis Valores extremos
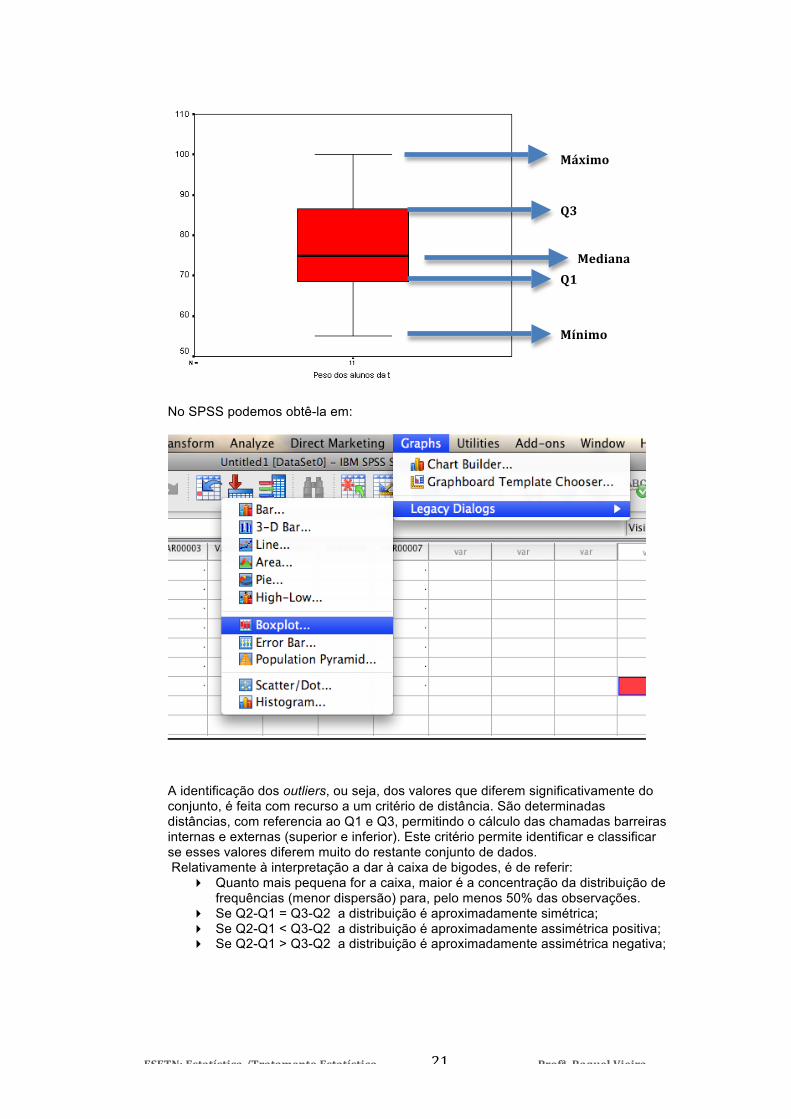
Este diagrama, também denominado por diagrama de extremos e quartis, é uma das representações gráficas mais utilizadas na prática uma vez que é fácil de construir e evidencia uma quantidade de informação dos dados, em suma, medidas de localização, assimetria, curtose e os outliers, como já referimos anteriormente. Este diagrama tanto pode ser apresentado na forma horizontal como vertical. Se o construíssemos manualmente deveríamos seguir os seguintes passos: 1. Determinar máximo e mínimos 2. Determinar os quartis 3. Desenhar uma régua graduada e assinalar os pontos anteriormente assinalados. 4. Construir a caixa de bigodes. Partindo do exemplo dos pesos dos alunos de uma turma em que o peso máximo é 100 kg e o mínimo é 55, seguindo a distribuição ao lado, obtemos a seguinte estatística descritiva e respectivo Diagrama de caixa e bigodes:
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 21
No SPSS podemos obtê-la em:
A identificação dos outliers, ou seja, dos valores que diferem significativamente do conjunto, é feita com recurso a um critério de distância. São determinadas distâncias, com referencia ao Q1 e Q3, permitindo o cálculo das chamadas barreiras internas e externas (superior e inferior). Este critério permite identificar e classificar se esses valores diferem muito do restante conjunto de dados. Relativamente à interpretação a dar à caixa de bigodes, é de referir:
Quanto mais pequena for a caixa, maior é a concentração da distribuição de frequências (menor dispersão) para, pelo menos 50% das observações.
Se Q2-Q1 = Q3-Q2 a distribuição é aproximadamente simétrica; Se Q2-Q1 < Q3-Q2 a distribuição é aproximadamente assimétrica positiva; Se Q2-Q1 > Q3-Q2 a distribuição é aproximadamente assimétrica negativa;
Máximo
Mínimo
Mediana
Q3
Q1
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 22
3. Associação e Correlação
No capítulo anterior vimos como caracterizar dados descrevendo uma variável, no entanto, uma das grandes vantagens na utilização do SPSS consiste na potencialidade comparar o comportamento de várias variáveis entre si. Assim, caso se pretenda estudar a relação existente entre duas variáveis de natureza quantitativa ou qualitativa medida em escala ordinal, recorre-se ao conceito de correlação. Quando as variáveis são de natureza qualitativa e estão medidas através de uma escala nominal, é usual designar-se a relação entre elas por associação. A análise de correlação linear entre duas variáveis X e Y tem por objectivo quantificar a intensidade da relação linear existente entre elas, analisando portanto a sua variação conjunta. Ou seja, a correlação mede o grau de associação linear entre variáveis. Existem vários coeficiente de correlação, que variam em absoluto entre 0 e 1. Quanto mais próximo de 1, mais forte é a associação entre as variáveis. Se assumir valores positivos, as variáveis evoluem no mesmo sentido, enquanto se assumirem valores negativos, variam no sentido inverso. Note-se que a correlação mede apenas o grau de associação entre variáveis não constituindo, isoladamente uma prova de causalidade entre as mesmas. Neste capítulo iremos estudar os aspectos essenciais acerca de Associação de variáveis, e distinguir em que situações devemos usar os coeficientes de correlação respectivos.
3.1. Diagrama de Dispersão Na representação de uma amostra de n observações de duas variáveis X e Y utiliza-se muitas vezes um diagrama de dispersão, este consiste na representação das observações (xi, ,yi), i= 1, 2, ... n num referencial cartesiano. A disposição das observações neste gráfico pode alertar para a existência de possíveis relações entre as duas variáveis bem como a existência de eventual valores aberrantes (outliers). Consideremos os seguintes dados acerca das médias de curso e da média horas de estudo respectivas:
Média curso Média de horas de estudo
14,0 2,0 14,5 2,0 12,0 1,5 14,0 2,0 15,0 2,5 15,0 3,0 14,0 2,0 13,0 2,0 16,0 3,5 17,0 4,0 15,0 3,0 16,0 4,0 12,5 1,5
Podemos construir uma tabela que relacione, ordenadamente as duas variáveis:
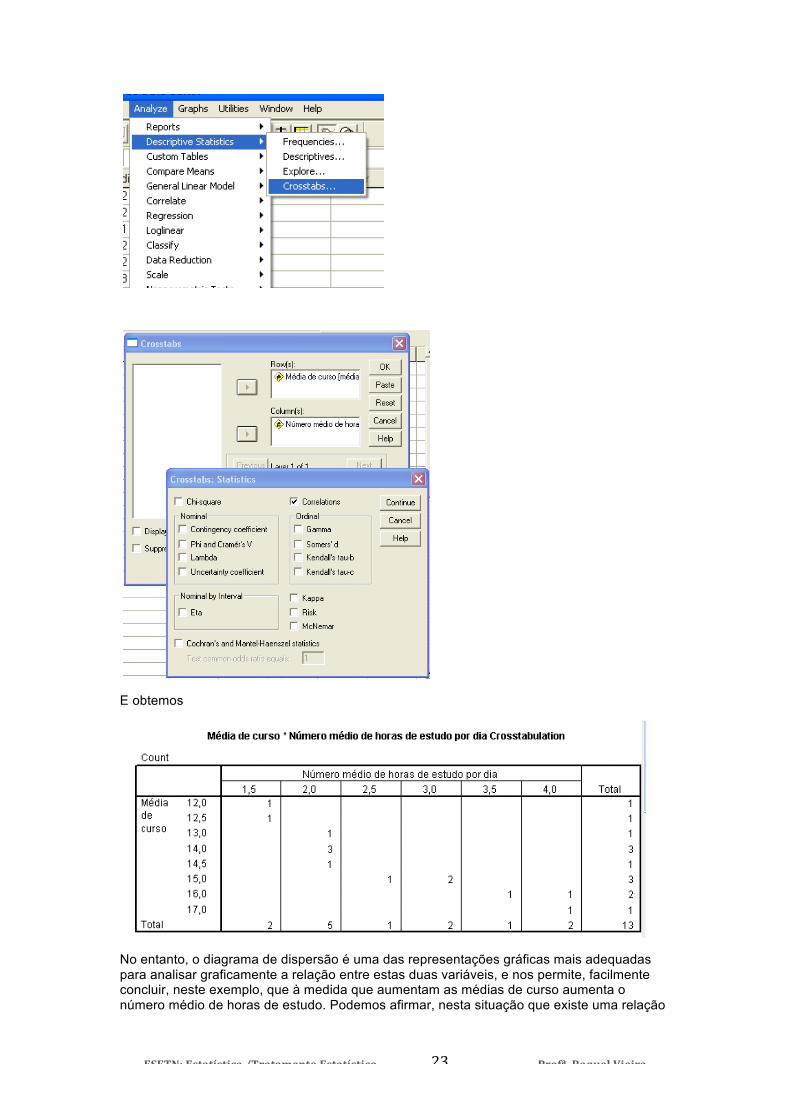
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 23
E obtemos
No entanto, o diagrama de dispersão é uma das representações gráficas mais adequadas para analisar graficamente a relação entre estas duas variáveis, e nos permite, facilmente concluir, neste exemplo, que à medida que aumentam as médias de curso aumenta o número médio de horas de estudo. Podemos afirmar, nesta situação que existe uma relação

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 24
positiva entre as duas variáveis, já que a valores elevados de média estão, em média, associados valores elevados de média de horas de estudo. No entanto, este tipo de diagrama não nos permite quantificar a intensidade desta relação.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 25
3.2. Covariância e Correlação Detectada uma possível relação linear entre as variáveis coloca-se a questão de quantificar a intensidade dessa relação através de medidas adequadas. Uma primeira medida de correlação linear é denominada por covariância e é definida pela média dos produtos dos desvios em relação à média. Assim, para duas variáveis quantitativas X e Y, a covariância entres elas é definida por:
sxy =1n
xi − x( ) yi − y( )i=1
n
∑
Pode fazer-se uma interpretação simples da expressão da covariância a partir do respectivo diagrama de dispersão. O seu sinal depende do quadrante em que o para ordenado se encontra no sistema de eixos cartesianos. Como podemos observar na seguinte tabela:
Quadrantes xi − x( ) yi − y( ) xi − x( ) yi − y( )
1º Quadrante
+ + +
2º Quadrante
- + -
3º Quadrante
- - +
4º Quadrante
+ - -
O sinal da covariância indica se a relação entre X e Y é positiva ou negativa.
Se o sinal for positivo, predominam os produtos dos desvios positivos em relação aos negativos e, por consequência, os desvios tendem a ser ambos positivos ou ambos negativos (Q1 e Q3). Assim, as variáveis variam em média no mesmo sentido, ou seja, quando uma variável aumenta a outra também aumenta, em média, e quando uma variável diminui a outra também diminui, em média.
Se o sinal for negativo, predominam os produtos dos desvios negativos em relação aos positivos e, por consequência, os desvios tendem a ter sinais contrários (Q2 e Q4). Assim, quando uma variável aumenta a outra também diminui, em média, e vice-versa.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 26
Quando a covariância é nula, a magnitude dos desvios positivos e negativos é igual e, por isso, não existe relação linear entre as variáveis.
3.2.1. Coeficiente de Correlação Linear de Pearson Na avaliação do grau de correlação entre duas variáveis, a covariancia apresenta desde logo dois inconvenientes: depende das unidades de medida das variáveis, e assume valores no conjunto dos números reais. Atendendo a que a precisão de qualquer medida é inversamente proporcional à amplitude do intervalo onde a mesma toma valores, podemos concluir que a covariância é uma medida pouco precisa, pois dá-nos pouca informação relativamente à intensidade de correlação existente entre as variáveis. Assim a informação contida na covariância é essencialmente sobre o sinal e não sobre a sua intensidade. Surge assim a necessidade de criar um coeficiente de correlação linear que damos o nome de Pearson, que assume valores no intervalo [-1,1] e não depende das unidades de medida das variáveis e que se calcula fazendo:
rx,y =sxysxsy
=
1n
xi − x( ) yi − y( )i=1
n
∑1n
xi − x( )2i=1
n
∑ 1n
yi − y( )2i=1
n
∑
Em função do sinal e do valor absoluto deste coeficiente pode concluir-se sobre a direcção e a intensidade da relação existente entre duas variáveis quantitativas
Coeficiente de correlação Conclusões Diagrama de
dispersão
rx,y = -1
Os pontos estão inscritos numa recta de declive negativo. A correlação linear entre as variáveis é negativa perfeita.
-1 < rx,y < 0
Os pontos estão inscritos numa recta de declive negativo. A correlação linear entre as variáveis é negativa. Quanto mais próximo de -1 for o valor de rx,y menor é a variabilidade dos pontos em torno da recta.
rx,y = 0
A variável não apresenta relação linear.
0 < rx,y < 1
Os pontos estão inscritos numa recta de declive positivo. A correlação linear entre as variáveis é positiva. Quanto mais próximo de 1 for o valor de rx,y menor é a variabilidade dos pontos em torno da recta.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 27
rx,y = 1
Os pontos estão inscritos numa recta de declive positivo. A correlação linear entre as variáveis é positiva perfeita.
3.2.2. Coeficiente de Correlação Ordinal de Spearman Quando se pretende analisar a correlação entre duas variáveis medidas em escala ordinal deve recorrer-se ao Coeficiente de Correlação Ordinal de Spearman, que mede a intensidade da relação entre variáveis ordinais. Este coeficiente recorre às ordens de observações em detrimento dos seus valores observados. O coeficiente de correlação de Spearman pode ser encarado como um caso particular do coeficiente de correlação de Pearson, entre as ordens de observação.
O coeficiente de correlação de Spearman mede a intensidade da relação existente entre duas variáveis medidas numa escala pelo menos ordinal, e calcula-se da seguinte forma:
rx,y = 1−6 d 2i=1
n
∑n n2 −1( ) em que di = o(xi ) − o(yi ) e
o(xi ) é a ordem da observação xi na amostra o(yi ) é a ordem da observação yi na amostra n é o número total de observações
Este coeficiente assume valor:
1 quando as observações tiverem exactamente a mesma ordem, -1 quando tiverem ordem inversa 0 quando as ordens se dispuserem de uma forma aleatória uma relativamente à
outra.
3.2.3. Coeficiente de Correlação Bisserial por pontos O Coeficiente de Correlação Bisserial por pontos mede a intensidade da relação existente entre uma variável quantitativa y e uma variável qualitativa dicotómica x, e é definido da seguinte forma:
rx,y =yp − yqsy
pq
em que
p =npn
Proporção de casos com 1, em x, e
np é o número de casos de categoria (x=1)
n o número toral de casos

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 28
q =nqn
Proporção de casos com 0, em x, e
np é o número de casos de categoria (x=0)
n o número toral de casos
y média aritmética de todos os valores de Y
yp média, na variável Y, de todos os casos a que correspondem 1’s em X
yq média, na variável Y, de todos os casos a que correspondem 0’s em X
sy desvio padrão dos valores de Y. Este coeficiente, à semelhança do coeficiente de correlação de Spearman, assume os valores:
1 quando as observações tiverem exactamente a mesma ordem, -1 quando tiverem ordem inversa 0 quando as ordens se dispuserem de uma forma aleatória uma relativamente à
outra.
Interpretação:
rbp > 0→ yp > yq existe uma correlação positiva entre Y e a característica medida como 1 em Y.
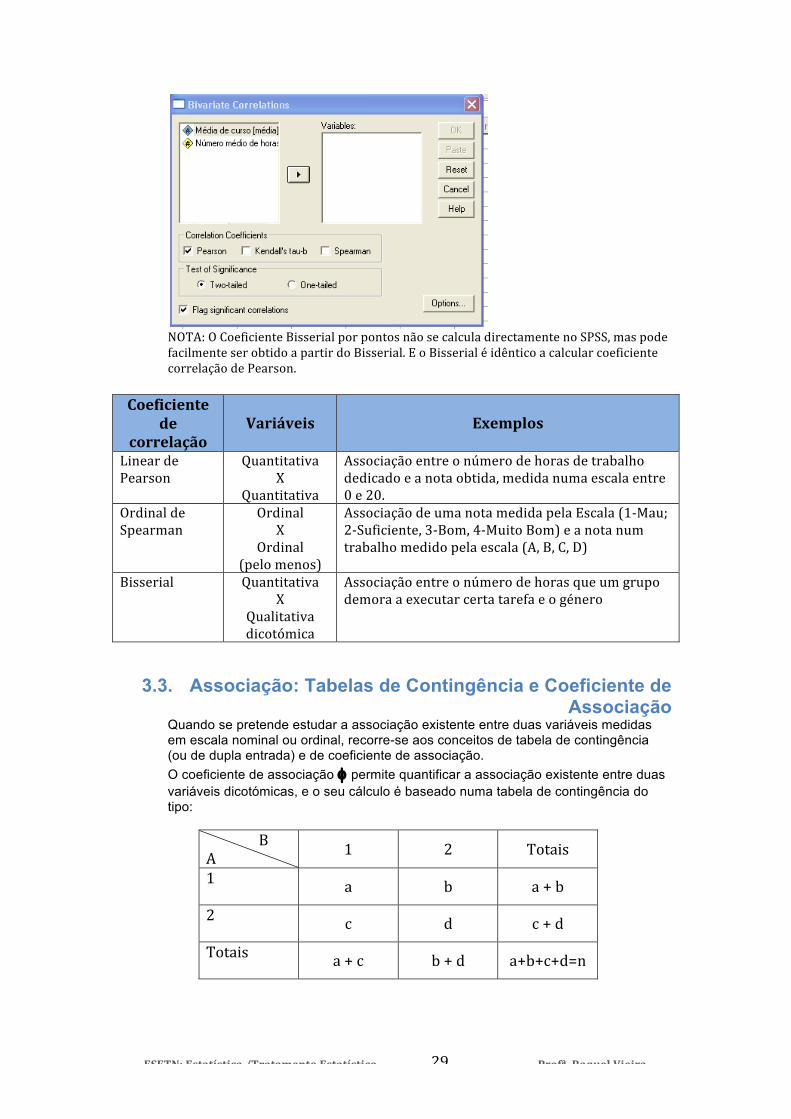
rbp < 0→ yp < yq existe uma correlação negativa entre Y e a característica medida como 1 em Y, ou, uma correlação positiva entre Y e a característica medida como 0 em Y. Para obter estes coeficientes no SPSS, basta fazer:
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 29
NOTA: O Coeficiente Bisserial por pontos não se calcula directamente no SPSS, mas pode facilmente ser obtido a partir do Bisserial. E o Bisserial é idêntico a calcular coeficiente correlação de Pearson.
Coeficiente de
correlação Variáveis Exemplos
Linear de Pearson
Quantitativa X
Quantitativa
Associação entre o número de horas de trabalho dedicado e a nota obtida, medida numa escala entre 0 e 20.
Ordinal de Spearman
Ordinal X
Ordinal (pelo menos)
Associação de uma nota medida pela Escala (1‐Mau; 2‐Suficiente, 3‐Bom, 4‐Muito Bom) e a nota num trabalho medido pela escala (A, B, C, D)
Bisserial Quantitativa X
Qualitativa dicotómica
Associação entre o número de horas que um grupo demora a executar certa tarefa e o género
3.3. Associação: Tabelas de Contingência e Coeficiente de Associação
Quando se pretende estudar a associação existente entre duas variáveis medidas em escala nominal ou ordinal, recorre-se aos conceitos de tabela de contingência (ou de dupla entrada) e de coeficiente de associação. O coeficiente de associação φ permite quantificar a associação existente entre duas variáveis dicotómicas, e o seu cálculo é baseado numa tabela de contingência do tipo:
B A 1 2 Totais
1 a b a + b
2 c d c + d
Totais a + c b + d a+b+c+d=n
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 30
Designam‐se por modalidades concordantes (A1, B1) / (A2, B2) e por modalidades discordantes (A1, B2)/(A2, B1): O coeficiente de associação φ é dado por:
Φ =ad − bc
a + b( ) c + d( ) a + c( ) b + d( )
A interpretação deste coeficiente é feita da seguinte forma:
coeficiente de associação φ -1 < φ < 1 Conclusões
φ > 0 Existe uma associação entre A e B nas modalidades concordantes
φ = 0 Não existe associação entre as variáveis A e B
φ<0 Existe associação entre A e B nas modalidades discordantes
Exemplo: No Ministério da Educação foram inquiridos 500 indivíduos dos quadros técnicos superiores e 700 dos quadros técnicos sobre as normas de segurança dos respectivos locais de trabalho. A opinião dos inquiridos encontra‐se resumida na seguinte tabela:
Opinião São cumpridas
Não são cumpridas Totais
Quadros Superiores 350 150 500
Quadros Técnicos 125 575 700
Totais 475 725 1200
Pretende‐se saber como se relacionam e qual a intensidade da relação entre a duas variáveis consideradas. As variáveis são:
Opinião sobre normas de segurança: variável dicotómica, já que só pode assumir dois valores diferentes (Cumpridas ou não cumpridas)
Quadros: variável dicotómica (Superiores ou técnicos)
Por se tratarem de duas variáveis nominais e dicotómicas, para medir a intensidade da relação entre elas vamos utilizar o coeficiente de associação.
Φ =350 × 575 −150 ×125
350 +150( ) 125 + 575( ) 350 +125( ) 150 + 575( )= 0,526
O valor do coeficiente de associação é 0,526, o que significa que existe uma relação positiva entre a opinião e as normas de segurança e a categoria profissional, ou seja, os quadros superiores têm uma maior tendência em afirmar que as regras de segurança são cumpridas.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 31
Usando o SPSS:
1. Inserir as variáveis e caracterizá‐las convenientemente:
NOTA: para quadros e opinião deve usar a opção Values para indicar as possibilidades das variáveis.
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 32
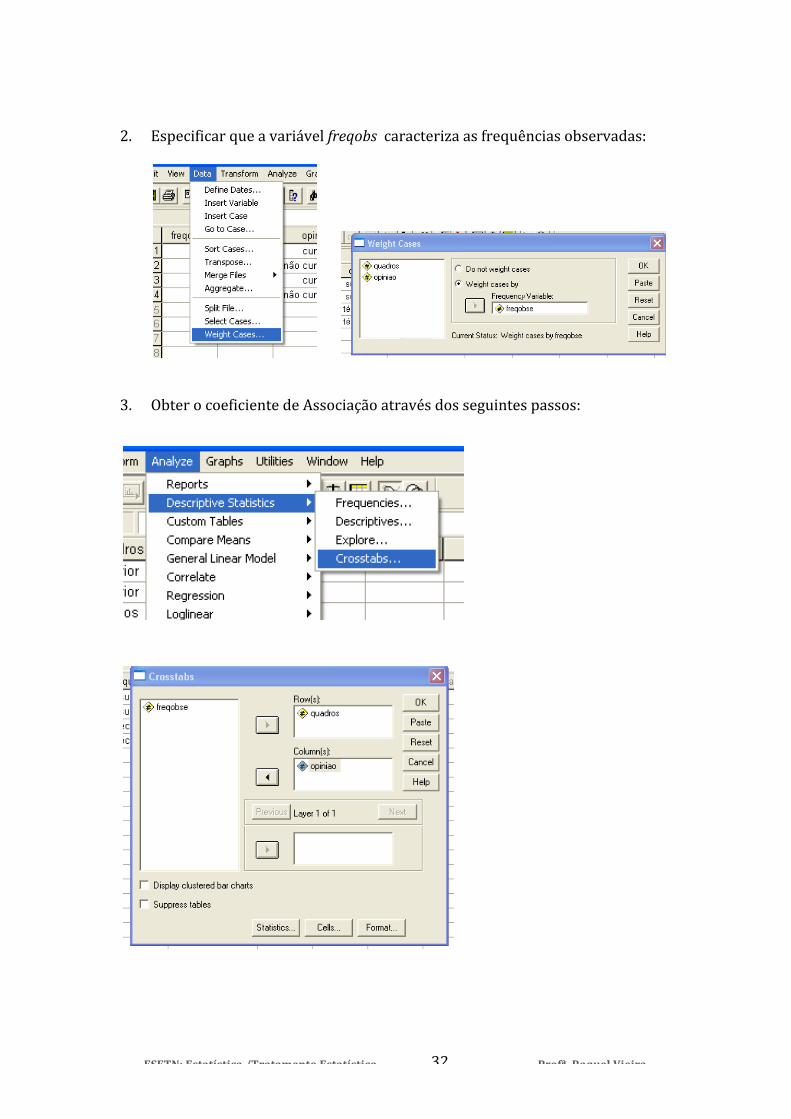
2. Especificar que a variável freqobs caracteriza as frequências observadas:
3. Obter o coeficiente de Associação através dos seguintes passos:

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 33
4. Obtemos assim:
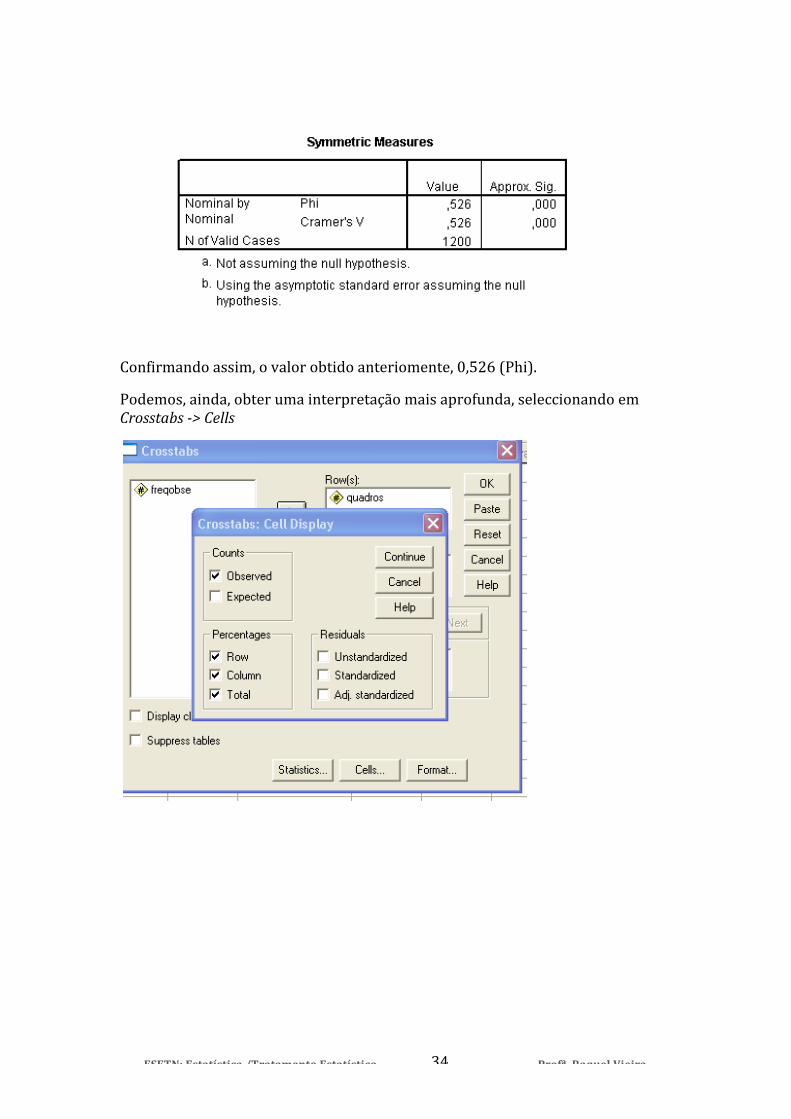
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 34
Confirmando assim, o valor obtido anteriomente, 0,526 (Phi).
Podemos, ainda, obter uma interpretação mais aprofunda, seleccionando em Crosstabs ‐> Cells
ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 35
Para obter:
Podemos retirar algumas conclusões desta tabela:
Dos 475 elementos que afirmaram que as normas de segurança são cumpridas, 350 (73.7%) são dos quadros superiores e os restantes 125 (26,3%) são de quadros técnicos;
Dos 500 elementos de quadros superiores 350 (70%) afirmam que as normas de segurança são cumpridas e 150 (30%) afirmam que não são cumpridas;
Do total dos elementos, 1200, 575 (47,9%) são de quadros técnicos e afirmam que as normas de segurança não são cumpridas;
Do total das elementos, 1200, 500 (41,7%) são de quadros superiores.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 36
4. Testes paramétricos e não paramétricos
Uma ferramenta de extrema utilidade em estatísticas são os testes de hipóteses. São muitos os estudos de investigação que recorrem a esta estratégia e torna-se necessário aprofundar técnicas de tratamento e análise dos dados obtidos. Preferencialmente, e quando estão reunidas diversas condições (ver quadro abaixo), são utilizados métodos paramétricos2. Contudo, quando estas condições não estão reunidas, a opção encontrada é a utilização de testes não paramétricos.
Os testes incidem explicitamente sobre um parâmetro de uma ou mais populações (por exemplo, sobre a média ou valor esperado, ou sobre a variância);
A distribuição de probabilidades da estatística de teste pressupõe uma forma particular das distribuições populacionais de onde as amostras foram recolhidas.
Por exemplo, a distribuição da estatística de teste do teste t-Student para comparar as médias de duas amostras pressupõe que as amostras foram retiradas de uma população que se distribui segundo uma função de probabilidades Normal, e além disso pressupõe também que as variâncias das duas amostras são homogéneas.
Etc. Os testes não paramétricos não estão condicionados por qualquer distribuição de probabilidades dos dados em análise, no entanto, não são tão potentes como os paramétricos. Geralmente utilizam-se quando as variáveis envolvidas são tipicamente qualitativas (nominais ou ordinais) ou, no caso de variáveis quantitativas, se encontram afastadas da normalidade e/ou amostras pequenas. Independentemente do teste utilizado ser, ou não, paramétrico, a questão da aleatoriedade da amostra é fundamental. Para verificar a forma de distribuição das populações, a fim de se decidir pela utilização de um teste paramétrico ou por um teste não paramétrico, podem usar-se os testes de bondade ou qualidade de ajustamento das amostras a funções de distribuição de probabilidades, tais como o teste do qui-quadrado, o teste de Kolmogorov-Smirnov, teste de Shapiro-Wilk. Alguns dos testes não paramétricos baseiam-se em probabilidades ou em frequências (Binomial, Qui-quadrado, McNemar) ou de valores centrais (Mann-Whitney, Wilcoxon, Kruskal-Wallis e Friedman), sendo que estes últimos se baseiam em ordenações, e não em valores absolutos.
2 Estes testes (por exemplo testes t‐student e ANOVA) não serão objecto de estudo desta disciplina.

ESETN: Estatística /Tratamento Estatístico Profª. Raquel Vieira 37
Referências Bibliográficas Bessa, J. (2006). Folha de Apoio - Iniciação ao SPSS. Aveiro: Universidade de Aveiro [Acessível em http://www2.dce.ua.pt/leies/pacgi/Folhaapoio1.pdf]
Cunha, G.; Martins, M. R.; Sousa, R. & Oliveira, F.F. (2007). Estatística Aplicada Às Ciências e Tecnologias da Saúde. Lisboa: Lidel;
Martinez, L. F. & Ferreira, A. I. (2008). Análise de dados com SPSS: Primeiros passos (2ªed.). Lisboa: Escolar Editora.
Pereira, A. (2006). SPSS Guia Prático de Utilização: Análise de dados para ciências sociais e psicologia. (6ª Ed.). Lisboa. Edições Sílabo





























